| БрМЭЦМі: |
| БОЮФРДдДFinleyВЉПЭЃЌБОЮФНЋМђЕЅНщЩмЦфдРэВЂЗжЮіTensorflowЙйЗНЬсЙЉЕФЪОР§ЁЃ |
|
ОэЛ§ЩёОЭјТч(Convolutional Neural Network, CNN)ЪЧвЛжжЧАРЁЩёОЭјТч, дкМЦЫуЛњЪгОѕЕШСьгђБЛЙуЗКгІгУ. БОЮФНЋМђЕЅНщЩмЦфдРэВЂЗжЮіTensorflowЙйЗНЬсЙЉЕФЪОР§.
ЙигкЩёОЭјТчгыЮѓВюЗДЯђДЋВЅЕФдРэПЩвдВЮПМзїепЕФСэвЛЦЊВЉЮФBPЩёОЭјТчгыPythonЪЕЯж.
СЫНтОэЛ§ЩёОЭјТч
ЪВУДЪЧОэЛ§
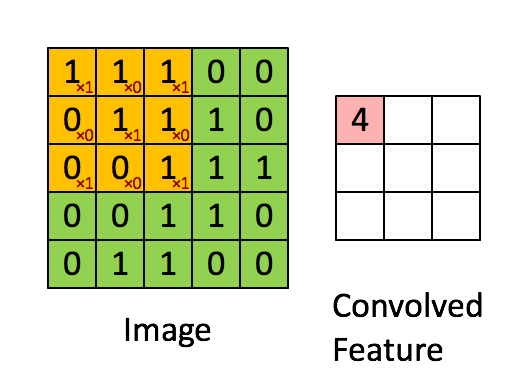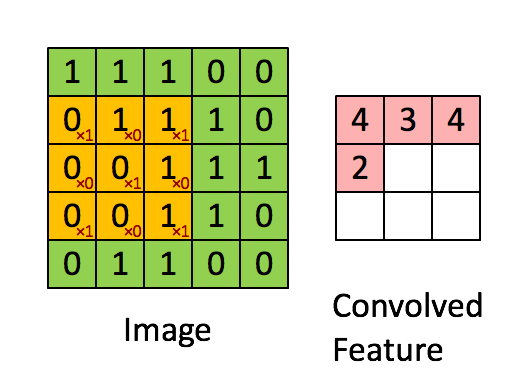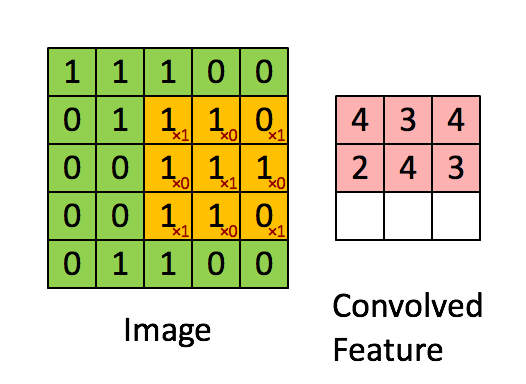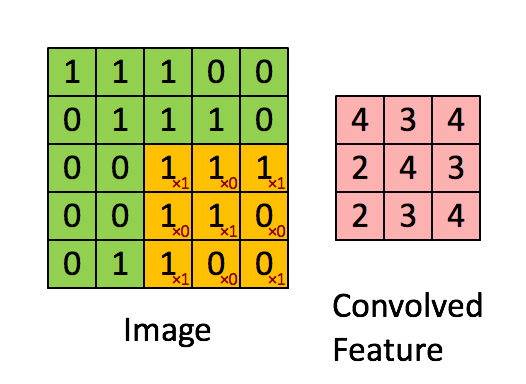
ОэЛ§ЪЧЭМЯёДІРэжавЛжжЛљБОЗНЗЈ. ОэЛ§КЫЪЧвЛИіf*fЕФОиеѓ. ЭЈГЃnШЁЦцЪ§,ЪЙЕУОэЛ§КЫгажааФЕу.
ЖдЭМЯёжаУПИіЕуШЁвдЦфЮЊжааФЕФfНзЗНеѓ, НЋИУЗНеѓжаИїжЕгыОэЛ§КЫжаЖдгІЮЛжУЕФжЕЯрГЫ, ВЂгУЫќУЧЕФКЭзїЮЊНсЙћОиеѓжаЖдгІЕуЕФжЕ.
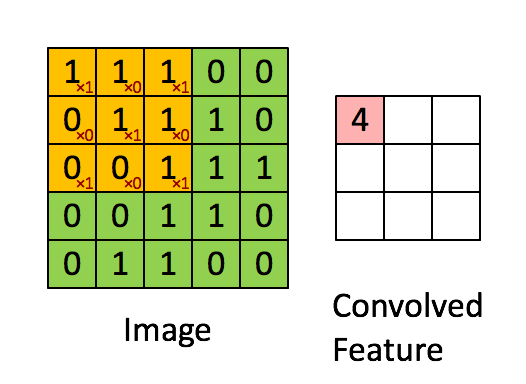
1*1 + 1*0 + 1*1 + 0*0 + 1*1 + 1*0 + 0*1 + 0*0 + 1*1 = 4
ОэЛ§КЫУПДЮЯђгввЦЖЏ1Са, гіааФЉЯђЯТвЦЖЏ1СажБЕНЭъГЩЫљгаМЦЫу. ЮвУЧАбУПДЮвЦЖЏЕФОрРыГЦЮЊВНЗљs.
ЩЯЪіВйзїДІРэЭМЯёЕУЕНаТЭМЯёЕФВйзїГЦЮЊОэЛ§, дкЭМЯёДІРэжаОэЛ§КЫвВБЛГЦЮЊЙ§ТЫЦї(filter).
ОэЛ§ЕУЕНЕФНсЙћОиеѓЭЈГЃгУгкБэЪОдЭМЕФФГжжЬиеї(ШчБпдЕ), вђДЫОэЛ§НсЙћБЛГЦЮЊЬиеїЭМ(Feature Map).
УПИіОэЛ§КЫПЩвдАќКЌвЛИіЦЋжУВЮЪ§b, МДЖдОэЛ§НсЙћЕФУПвЛИідЊЫиЖММгbзїЮЊЪфГіЕФЬиеїЭМ.
БпдЕМьВтЪЧОэЛ§ЕФвЛжжЕфаЭгІгУ, ШЫблЫљМћЕФБпдЕЪЧЭМЯёжаВЛЭЌЧјгђЕФЗжНчЯп. ЗжНчЯпСНВрЕФЩЋВЪЛђЛвЖШЭЈГЃгазХНЯДѓЕФВЛЭЌ.

ЯТУцЮвУЧЪЙгУвЛИіЗЧГЃМђЕЅЕФЪОР§РДеЙЪОБпдЕМьВтЙ§ГЬ. ЕквЛИі6*6ЕФОиеѓЪЧЛвЖШЭМ, ЯдШЛЭМЯёзѓВрНЯССгвВрНЯАЕ, жаМфаЮГЩСЫвЛЬѕУїЯдЕФДЙжББпдЕ.
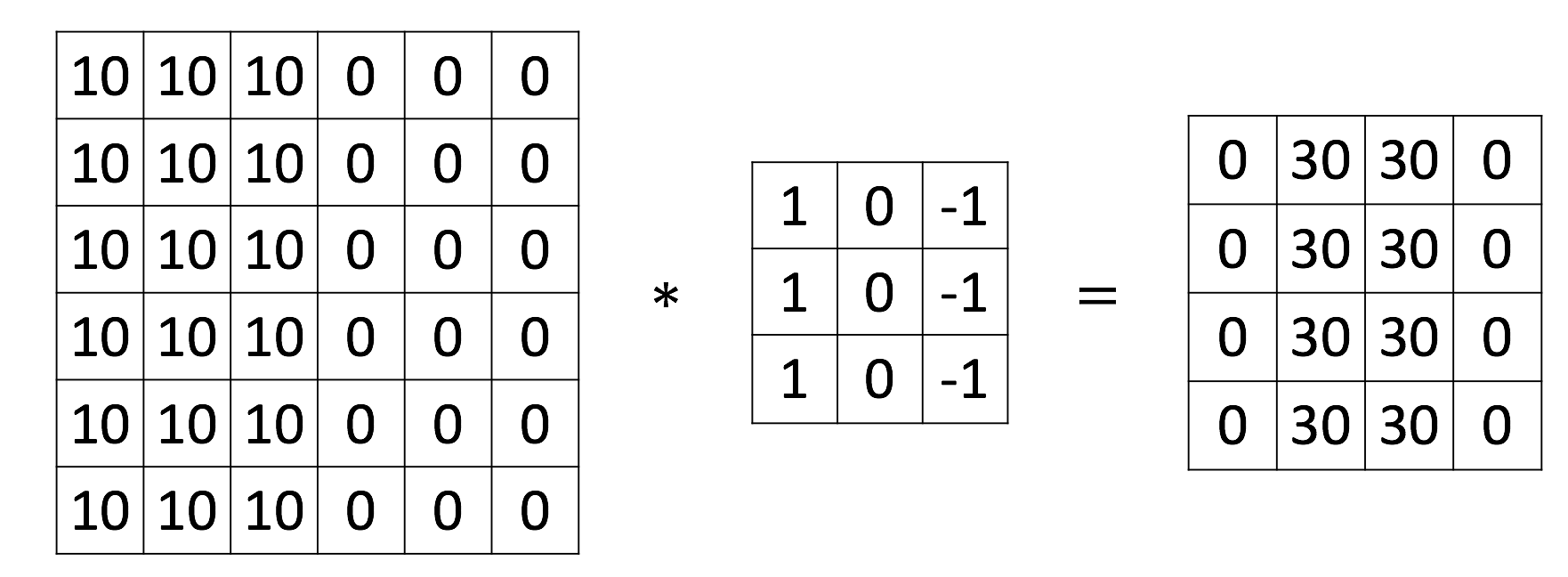
дкЬиеїЭМжабыгавЛЬѕДЙжБССЯп(Ек2,3Са), МДдЭМЕФДЙжББпдЕ. РрЫЦЕФПЩвдМьВтзнЯђБпдЕ:
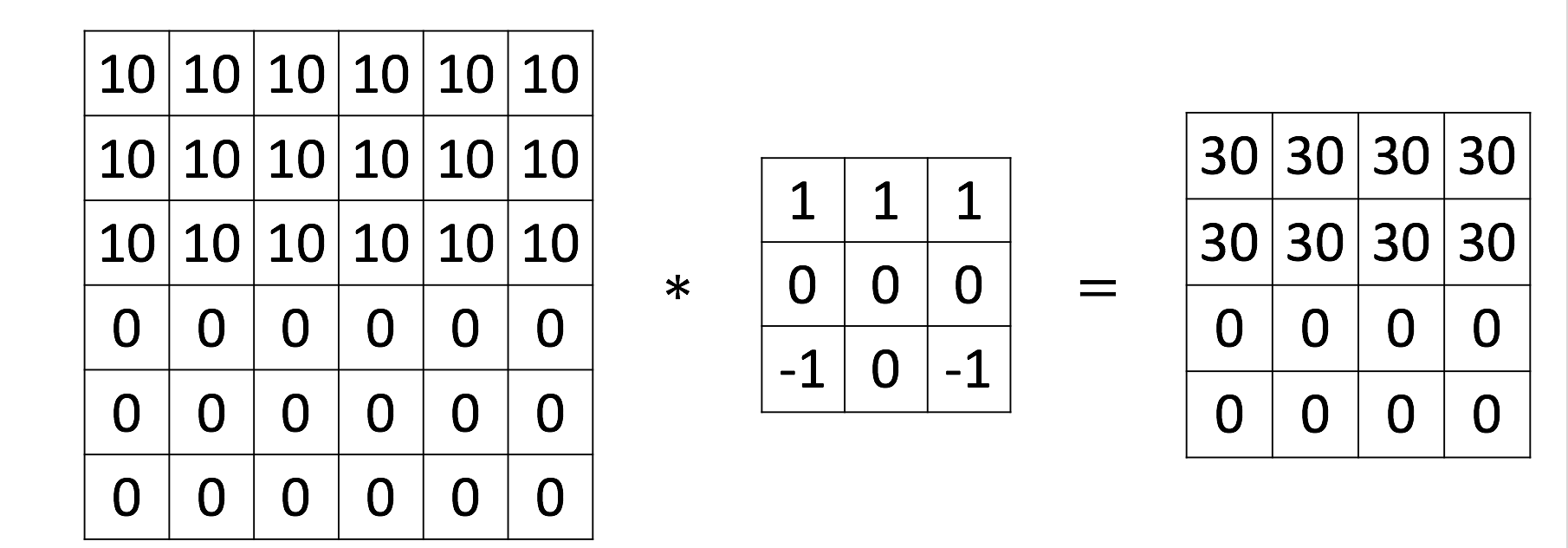
ОэЛ§КЫЕФжааФЮоЗЈЖдзМдЭМЯёжаБпдЕЕФЯёЫиЕу(гыБпдЕОрРыаЁгкОэЛ§КЫАыОЖ), ШєвЊЖдБпдЕЕФЕуНјааМЦЫуБиаыЬюГф(padding)ЭтВПШБЩйЕФЕуЪЙОэЛ§КЫЕФжааФПЩвдЖдзМЫќУЧ. ГЃгУЕФЬюГфВпТдга:
- SAME: ЪЙгУИННќЕуЕФжЕДњЬцШБЪЇЕФЕу, ПЩвдБЃжЄЬиеїЭМВЛЛсБфаЁ
- VALID: жЛЖдПЩгУЕФЮЛжУНјааОэЛ§(ВЛНјааЬюГф), ЕЋЬиеїЭМЛсБфаЁ
ДЫЭтЛЙга0жЕЬюГф, ОљжЕЬюГфЕШЗНЗЈ. ЭЈГЃгУpРДУшЪіЬюГфЕФПэЖШ.
SAMEЬюГфаЇЙћ, 4*4ОиеѓБЛЬюГфЮЊ6*6Оиеѓ, ЬюГфПэЖШp=1:
Ждгкn*nЕФОиеѓ, ЪЙгУf*fЕФКЫНјааОэЛ§, ЬюГфПэЖШЮЊp, ШєзнЯђВНЗљЮЊs1, КсЯђВНЗљЮЊs2дђЬиеїЭМЕФааСаЪ§ЮЊ:
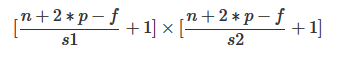
Ш§ЮЌОэЛ§
ЛвЖШЭМЫљФмУшЪіЕФаХЯЂЕФМЋЮЊгаЯо, ЮвУЧИќЖрЕиДІРэRGBЭМЯё. RGBЭМЯёашвЊ3ИіОиеѓВХФмУшЪіЭМЦЌ, ЮвУЧГЦЮЊ3ИіЭЈЕР(channel).
вдЯТЭМ6*6ЕФRGBЭМЮЊР§, 3ИіОиеѓЗжБ№гыЛЦЩЋОэЛ§КЫНјааОэЛ§ЕУЕН3Иі4*4ЬиеїЭМ, НЋ3ИіЬиеїЭМЭЌЮЛжУЕФжЕЕўМгЕУЕНзюжеЕФОэЛ§НсЙћ.
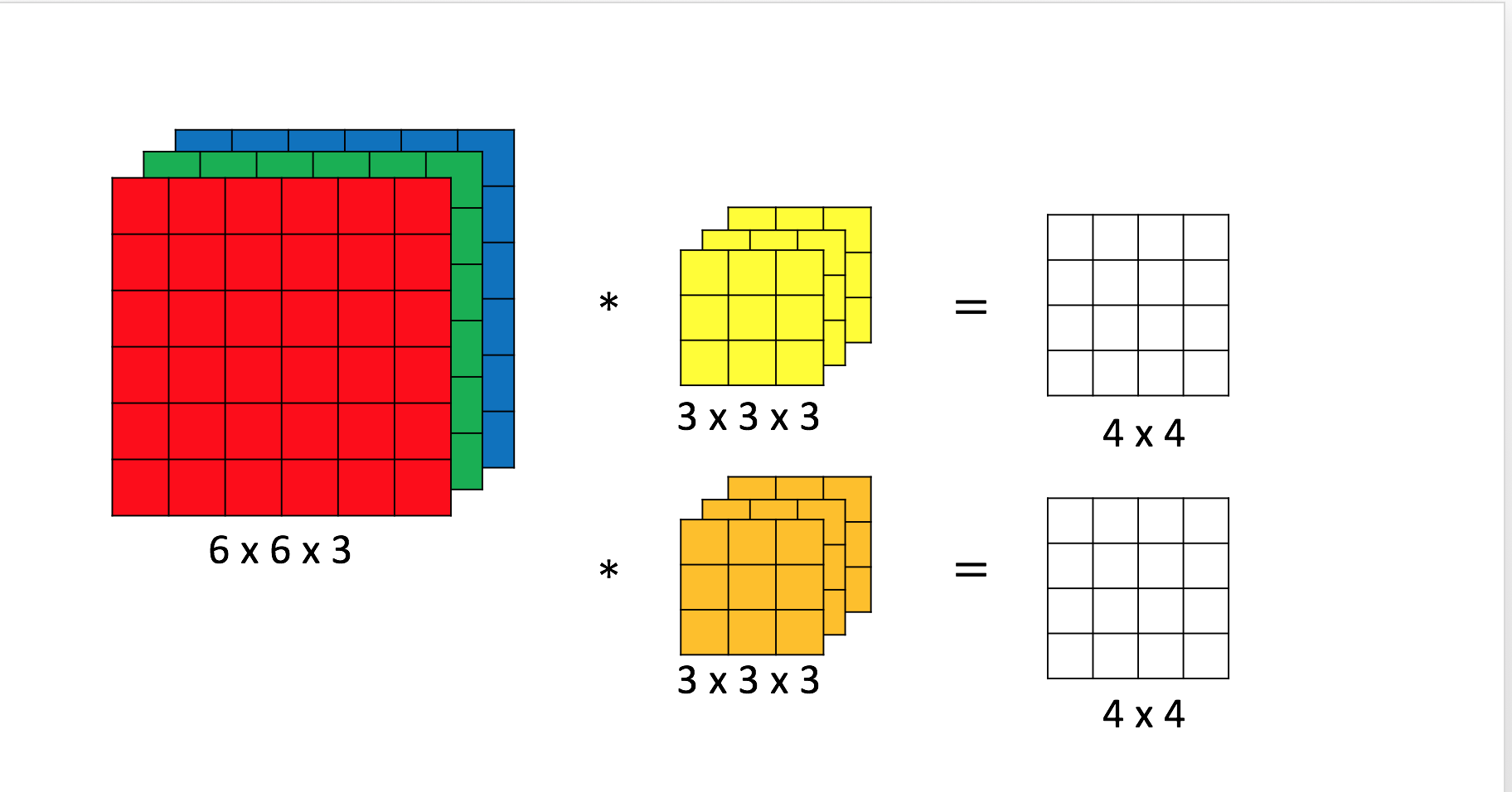
дкБпдЕМьВтжаЮвУЧзЂвтЕН, вЛИіОэЛ§КЫЭЈГЃжЛФмЬсШЁЭМЯёвЛжжЬиеїШчЫЎЦНБпдЕЛђДЙжББпдЕ. ЮЊСЫЬсШЁЭМЯёЕФЖрИіЬиеї, ЮвУЧЭЈГЃЪЙгУЖрИіОэЛ§КЫ.
ЮвУЧЪЙгУИпЮЌОиеѓРДУшЪіетвЛЙ§ГЬ, RGBЭМЯёЮЊ6*6*3Оиеѓ, СНИіОэЛ§КЫЕўМгЮЊ3*3*2Оиеѓ, СНИіЬиеїЭМЕўМгЮЊ4*4*2Оиеѓ. ЪфШы, ЪфГіКЭОэЛ§КЫОљЪЙгУШ§ЮЌОиеѓРДБэЪО, етбљЮвУЧПЩвдЗНБуЕФМЖСЊЖрИіОэЛ§Ву.
ЮЊЪВУДЪЙгУОэЛ§
дкЩЯвЛНкжаЮвУЧвбОНщЩмСЫвЛИіОэЛ§ВуШчКЮЙЄзїЕФ, ЯждкЮвУЧРДЬНЬжЮЊЪВУДЪЙгУОэЛ§ЬсШЁЭМЯёЬиеї.
ЪзЯШЗжЮіОэЛ§ВуЕФЪфШыЪфГі, УПИіОэЛ§ВуЪфШыСЫвЛИіw1 * h1 * c1 ЕФШ§ЮЌОиеѓ, ЪфГіw2 * h2 *c2ЕФШ§ЮЌОиеѓ.
ШєЪЙгУШЋСЌНгВуашвЊ(w1 * h1 * c1) * (w2 * h2 *c2)ИіВЮЪ§, ОэЛ§ВужЛашвЊбЕСЗc2ИіЖўЮЌОэЛ§КЫжаЕФf1 * f1 * c2ИіВЮЪ§КЭc2ИіЦЋжУжЕ, ПЩМћОэЛ§ВуМЋДѓЕиМѕЩйСЫВЮЪ§ЕФЪ§СП.
ИќЩйЕФВЮЪ§ЖдгкбЕСЗЪ§ОнКЭМЦЫузЪдДЖМгаЯоЕФШЮЮёЖјбд, ЭЈГЃвтЮЖзХИќИпЕФОЋЖШКЭИќКУЕФбЕСЗаЇТЪ.
ИќживЊЕФЪЧ, ОэЛ§еыЖдаЁПщЧјгђЖјВЛЪЧЕЅИіЯёЫиНјааДІРэ, ИќКУЕиДгПеМфЗжВМжаЬсШЁЬиеї, етгыШЫРрЪгОѕЪЧРрЫЦЕФ. ЖјШЋСЌНгВубЯжиКіТдСЫПеМфЗжВМЫљАќКЌЕФаХЯЂ.
ЬиеїЭМжавЛИіЯёЫижЛгыЪфШыОиеѓжаf * fИіЯёЫигаЙи, етжжаджЪБЛГЦЮЊОжВПИажЊ. вЛИіОэЛ§КЫгУгкЩњГЩЬиеїЭМжаЫљгаЯёЫи, ИУЬиадБЛГЦЮЊШЈжЕЙВЯэ.
ГиЛЏ
ЭЈЙ§ОэЛ§бЇЯАЕНЕФЭМЯёЬиеїШдШЛЪ§СПОоДѓ, ВЛБужБНгНјааЗжРр. ГиЛЏВуБугУгкМѕЩйЬиеїЪ§СП.
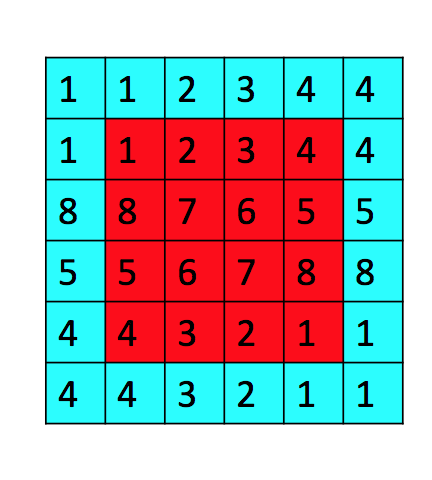
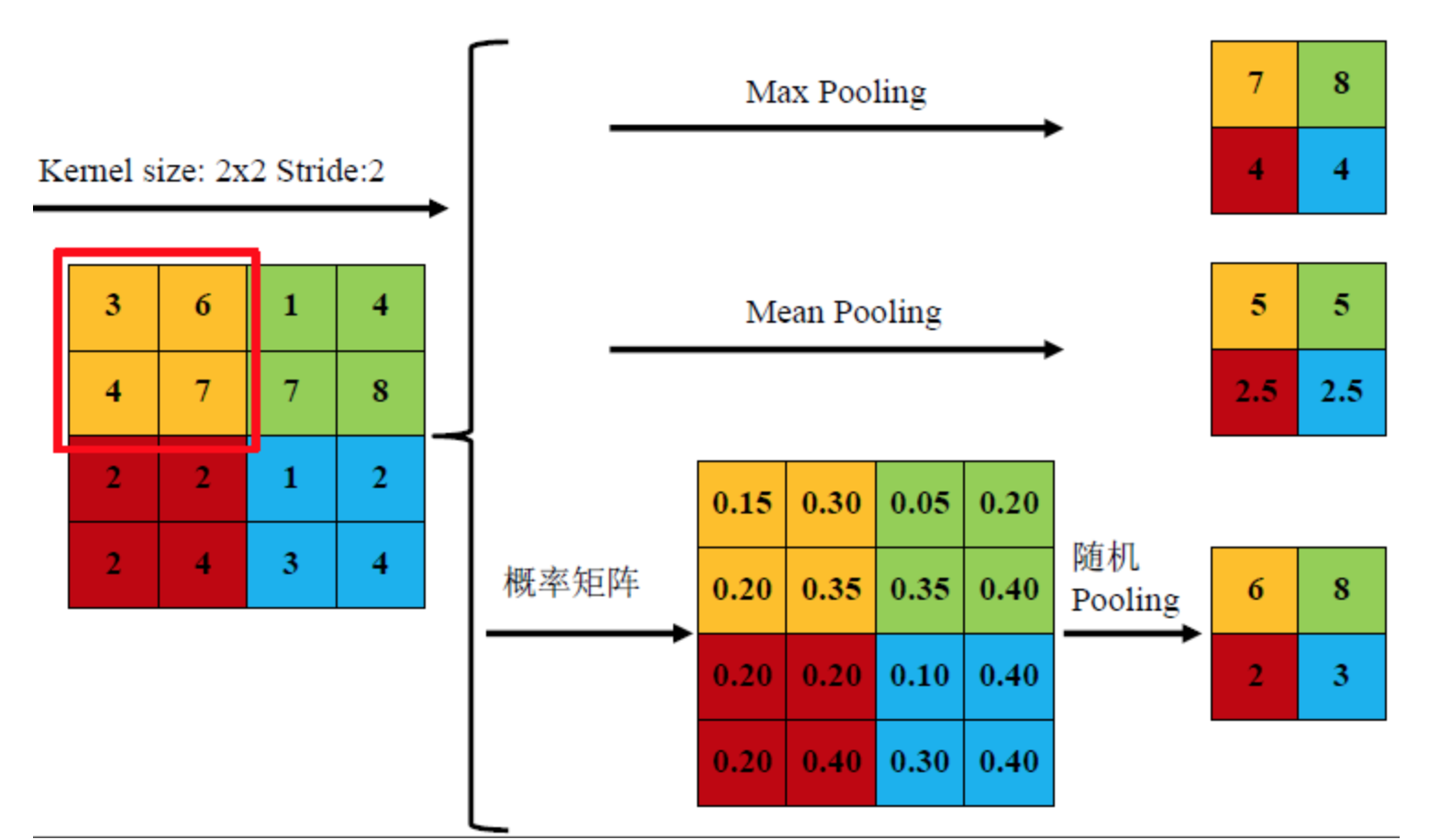
ГиЛЏВйзїЗЧГЃМђЕЅ, БШШчЮвУЧЪЙгУвЛИіОэЛ§КЫЖдвЛеХЭМЦЌНјааЙ§ТЫЕУЕНвЛИі8x8ЕФЗНеѓ, ЮвУЧПЩвдНЋЗНеѓЛЎЗжЮЊ16Иі2x2ЗНеѓ, УПИіаЁЗНеѓГЦЮЊСкгђ.
гУ16ИіаЁЗНеѓЕФОљжЕзщГЩвЛИі4x4ЗНеѓБуЪЧОљжЕГиЛЏ, РрЫЦЕиЛЙгазюДѓжЕГиЛЏЕШВйзї. ОљжЕГиЛЏЖдБЃСєБГОАЕШЬиеїНЯКУ, зюДѓжЕГиЛЏЖдЮЦРэЬсШЁИќКУ.
ЫцЛњГиЛЏдђЪЧИљОнЯёЫиЕуЪ§жЕДѓаЁИГгшИХТЪ(ШЈжЕ), ШЛКѓАДЦфМгШЈЧѓКЭ.
ГиЛЏВйзїгУгкМѕЩйЭМЕФПэЖШКЭИпЖШ, ЕЋВЛФмМѕЩйЭЈЕРЪ§.
гУ1*1*c2ЕФКЫНјааОэЛ§ПЩвдЪЙw1 * h1 * c1ЕФЪфШыОиеѓгГЩфЕНw1 * h1 * c2ЕФЪфГіОиеѓ. МДЖдИїЭЈЕРЪфГіМгШЈЧѓКЭЪЕЯжМѕЩйЭЈЕРЪ§ЕФаЇЙћ.
TensorFlowЪЕЯж
TensorFlowЕФЮФЕЕDeep MNIST for ExpertsНщЩмСЫЪЙгУCNNдкMNISTЪ§ОнМЏЩЯЪЖБ№ЪжаДЪ§зжЕФЗНЗЈ., ИУЪОР§ВЩгУСЫLeNet5ФЃаЭ.
ЭъећДњТыПЩвддкGitHubЩЯевЕН, БОЮФНЋЖдЦфНјааМђЕЅЗжЮі. дДТыРДздtensorflow-1.3.0АцБОЪОР§.
жївЊга3Ьѕв§Шы:
import tempfile
from tensorflow.examples.tutorials.mnist import input_data
import tensorflow as tf |
main(_)КЏЪ§ИКд№ЭјТчЕФЙЙНЈ:
def main(_):
# ЕМШыMNISTЪ§ОнМЏ
# FLAGS.data_dirЪЧБОЕиЪ§ОнЕФТЗОЖ, ПЩвдгУПезжЗћДЎДњЬцвдздЖЏЯТдиЪ§ОнМЏ
mnist = input_data.read_data_sets(FLAGS.data_dir, one_hot=True)
# xЪЧЪфШыВу, УПИі28x28ЕФЭМЯёБЛеЙПЊЮЊ784НзЯђСП
x = tf.placeholder(tf.float32, [None, 784])
# y_ЪЧбЕСЗМЏдЄБъзЂКУЕФНсЙћ, ВЩгУone-hotЕФЗНЗЈБэЪО10жжЗжРр
y_ = tf.placeholder(tf.float32, [None, 10])
# deepnnЗНЗЈЙЙНЈСЫвЛИіcnn, y_convЪЧcnnЕФдЄВтЪфГі
# keep_probЪЧdropoutВуЕФВЮЪ§, ЯТЮФдйНВ
y_conv, keep_prob = deepnn(x)
# МЦЫудЄВтy_convКЭБъЧЉy_ЕФНЛВцьизїЮЊЫ№ЪЇКЏЪ§
with tf.name_scope('loss'):
cross_entropy = tf.nn.softmax_cross_entropy_with_logits(labels=y_,
logits=y_conv)
cross_entropy = tf.reduce_mean(cross_entropy)
# ЪЙгУAdamгХЛЏЫуЗЈ, вдзюаЁЛЏЫ№ЪЇКЏЪ§ЮЊФПБъ
with tf.name_scope('adam_optimizer'):
train_step = tf.train.AdamOptimizer(1e-4).minimize(cross_entropy)
# МЦЫуОЋШЗЖШ(е§ШЗЗжРрЕФбљБОЪ§еМВтЪдбљБОЪ§ЕФБШР§), гУгкЦРЙРФЃаЭаЇЙћ
with tf.name_scope('accuracy'):
correct_prediction = tf.equal(tf.argmax(y_conv, 1), tf.argmax(y_, 1))
correct_prediction = tf.cast(correct_prediction, tf.float32)
accuracy = tf.reduce_mean(correct_prediction)
mainКЏЪ§гыЦфЫќtensorflowЩёОЭјТчВЂЮоЖўжТ, ЙиМќЗжЮіdeepnnЗНЗЈШчКЮЙЙНЈcnn:
def deepnn(x):
# xЕФНсЙЙЮЊ[n, 784], НЋЦфеЙПЊЮЊ[n, 28, 28]
# ЛвЖШЭМжЛгавЛИіЭЈЕР, x_imageЕкЫФЮЌЮЊ1
# x_imageЕФЫФЮЌЗжБ№ЪЧ[n_sample, width, height, channel]
with tf.name_scope('reshape'):
x_image = tf.reshape(x, [-1, 28, 28, 1])
# ЕквЛИіОэЛ§Ву, НЋ28x28*1ЛвЖШЭМЪЙгУ5*5*32КЫНјааОэЛ§
with tf.name_scope('conv1'):
# ГѕЪМЛЏСЌНгШЈжЕ, ЮЊСЫБмУтЬнЖШЯћЪЇШЈжЕЪЙгУе§дђЗжВМНјааГѕЪМЛЏ
W_conv1 = weight_variable([5, 5, 1, 32])
# ГѕЪМЛЏЦЋжУжЕ, етРяЪЙгУЕФЪЧ0.1
b_conv1 = bias_variable([32])
# stridesЪЧОэЛ§КЫвЦЖЏЕФВНЗљ. ВЩгУSAMEВпТдЬюГф, МДЪЙгУЯрЭЌжЕЬюГф
# def conv2d(x, W):
# tf.nn.conv2d(x, W, strides=[1, 1, 1, 1], padding='SAME')
# h_conv1ЕФНсЙЙЮЊ[n, 28, 28, 32]
h_conv1 = tf.nn.relu(conv2d(x_image, W_conv1) + b_conv1)
# ЕквЛИіГиЛЏВу, 2*2зюДѓжЕГиЛЏ, ЕУЕН14*14Оиеѓ
with tf.name_scope('pool1'):
h_pool1 = max_pool_2x2(h_conv1)
# ЕкЖўИіОэЛ§Ву, НЋ28*28*32ЬиеїЭМЪЙгУ5*5*64КЫНјааОэЛ§
with tf.name_scope('conv2'):
W_conv2 = weight_variable([5, 5, 32, 64])
b_conv2 = bias_variable([64])
# h_conv2ЕФНсЙЙЮЊ[n, 14, 14, 64]
h_conv2 = tf.nn.relu(conv2d(h_pool1, W_conv2) + b_conv2)
# ЕкЖўИіГиЛЏВу, 2*2зюДѓжЕГиЛЏ, ЕУЕН7*7Оиеѓ
with tf.name_scope('pool2'):
# h_pool2ЕФНсЙЙЮЊ[n, 7, 7, 64]
h_pool2 = max_pool_2x2(h_conv2)
# ЕквЛИіШЋСЌНгВу, НЋ7*7*64ЬиеїОиеѓгУШЋСЌНгВугГЩфЕН1024ИіЬиеї
with tf.name_scope('fc1'):
W_fc1 = weight_variable([7 * 7 * 64, 1024])
b_fc1 = bias_variable([1024])
h_pool2_flat = tf.reshape(h_pool2, [-1, 7*7*64])
h_fc1 = tf.nn.relu(tf.matmul(h_pool2_flat, W_fc1) + b_fc1)
# ЪЙгУdropoutВуБмУтЙ§ФтКЯ
# МДдкбЕСЗЙ§ГЬжаЕФвЛДЮЕќДњжа, ЫцЛњбЁдёвЛЖЈБШР§ЕФЩёОдЊВЛВЮгыДЫДЮЕќДњ
# ВЮгыЕќДњЕФИХТЪжЕгЩkeep_probжИЖЈ, keep_prob=1.0ЮЊЪЙгУећИіЭјТч
with tf.name_scope('dropout'):
keep_prob = tf.placeholder(tf.float32)
h_fc1_drop = tf.nn.dropout(h_fc1, keep_prob)
# ЕкЖўИіШЋСЌНгВу, НЋ1024ИіЬиеїгГЩфЕН10ИіЬиеї, МД10ИіЗжРрЕФone-hotБрТы
# one-hotБрТыЪЧжИгУ `100`ДњЬц1, `010`ДњЬц2, `001`ДњЬц3... ЕФБрТыЗНЪН
with tf.name_scope('fc2'):
W_fc2 = weight_variable([1024, 10])
b_fc2 = bias_variable([10])
y_conv = tf.matmul(h_fc1_drop, W_fc2) + b_fc2
return y_conv, keep_prob |
mainКЏЪ§гыЦфЫќtensorflowЩёОЭјТчВЂЮоЖўжТ, ЙиМќЗжЮіdeepnnЗНЗЈШчКЮЙЙНЈcnn:
graph_location = tempfile.mkdtemp()
print('Saving graph to: %s' % graph_location)
train_writer = tf.summary.FileWriter(graph_location)
train_writer.add_graph(tf.get_default_graph()) |
ећИіЭјТчБЉТЖЕФНгПкга3Иі:
- ЪфШыВуx[n, 784]
- ЪфГіВуy_conv[n, 10]
- dropoutБЃСєБШР§keep_prob[1]
ЯждкПЩвдМЬајЙизЂmainЗНЗЈСЫ, ЭъГЩЭјТчЙЙНЈжЎКѓmainЯШНЋЭјТчНсЙЙЛКДцЕНгВХЬ:
with tf.Session() as sess:
# ГѕЪМЛЏШЋОжБфСП
sess.run(tf.global_variables_initializer())
for i in range(10000):
# УПДЮШЁбЕСЗЪ§ОнМЏжа50ИібљБО, Зж10000ДЮШЁГі
# batch[0]ЮЊЬиеїМЏ, НсЙЙЮЊ[50, 784]МД50зщ784НзЯђСП
# batch[1]ЮЊБъЧЉМЏ, НсЙЙЮЊ[50, 10]МД50ИіВЩгУone-hotБрТыЕФБъЧЉ
batch = mnist.train.next_batch(50)
# УПНјаа100ДЮЕќДњЦРЙРвЛДЮОЋЖШ
if i % 100 == 0:
train_accuracy = accuracy.eval(feed_dict={
x: batch[0], y_: batch[1], keep_prob: 1.0})
print('step %d, training accuracy %g' % (i, train_accuracy))
# НјаабЕСЗ, dropout keep probЩшЮЊ0.5
train_step.run(feed_dict={x: batch[0], y_: batch[1], keep_prob: 0.5})
# ЦРЙРзюжеОЋЖШ, dropout keep probЩшЮЊ1.0МДЪЙгУШЋВПЭјТч
print('test accuracy %g' % accuracy.eval(feed_dict={
x: mnist.test.images, y_: mnist.test.labels, keep_prob: 1.0})) |
НгЯТРДГѕЪМЛЏtf.Session()НјаабЕСЗ:
if __name__ == '__main__':
parser = argparse.ArgumentParser()
parser.add_argument('--data_dir', type=str,
default='/tmp/tensorflow/mnist/input_data',
help='Directory for storing input data')
FLAGS, unparsed = parser.parse_known_args()
tf.app.run(main=main, argv=[sys.argv[0]] + unparsed) |
Keep working, we will find a way out. This is Finley, welcome to join us.
|







