| 编辑推荐: |
| 本文来源csdn,在本文中,作者提出了使用k-means算法来对图像进行色彩还原,介绍算法的步骤,同时应用在图像上,通过对比还原前后的图像,来证明k-means算法的有效性。 |
|
k-means是机器学习中最著名、最广泛使用的算法之一。在这篇文章中,将使用k-means算法来减少图像上的颜色(但不减少像素),从而也减少了图像的大小。在这个领域不需要任何基础知识,因为可执行应用程序文件(大小为150MB,这是由于长时间的Spark依赖)已经提供了友好的用户界面。所以你可以很容易地用不同的图像来做实验。在GitHub上有完整可用的执行代码。
K-Means 算法
k-mean算法是一种非监督型学习算法,将相似的数据分成不同的类别或集群。它是无监督型算法,因为数据没有被标记,而且算法不需要对相似数据进行分类的反馈(可能是预期类别的数量——稍后再讨论)。
应用
k- means算法的一些应用包括客户服务、集群计算、社交网络和天文数据分析。
客户服务
假设有大量与客户相关的数据,并且希望更多地了解所拥有的客户类型,从而可以更好地为特定群体服务。也许你要生产牛仔裤和t恤,所以你需要在一个特定的国家将人以身材大小进行分组,这样你就能知道生产什么尺寸更合适。
集群计算
从性能角度来看,将某些计算机分组在一起比较好;例如,从网络的角度来看,交换机适合聚集在一起工作,或者提供相似的计算服务。K-means算法可以将相似功能的计算机分在一组,这样就可以进行更好的布局和优化。
社交网络
在社交网络中,你可以通过客户关系、偏好、相似性等来对他们进行分组,并从营销的角度更好地对客户进行定位。基于提供的数据的输入,k-means算法可以帮助我们从不同的角度对相同的数据进行分类。
天文数据分析
k-means也用于了解星系的形成,以及在天文数据中寻找内聚性。
它是如何工作的
k-means算法有两个步骤。假设把数据分成四组,执行以下步骤。
注意:在开始任何步骤之前,k-means算法会从数据中随机抽取三个样本,称为聚类中心。
1.它检查每一个数据样本,会根据它们与开始随机选择的聚类中心的相似程度,来对它们进行分类。
2.它使聚类中心与相似的同类点更接近(第1步的分组)。
重复这些步骤,直到聚类中心没有显著的移动。下面使用简单数据进行算法执行。
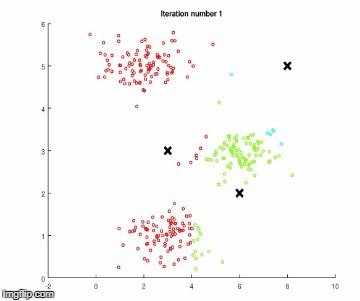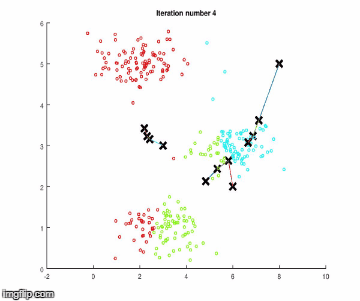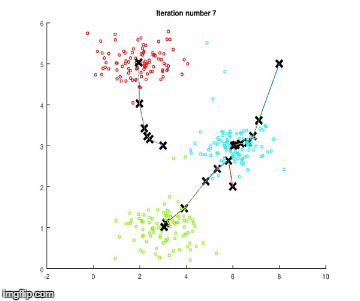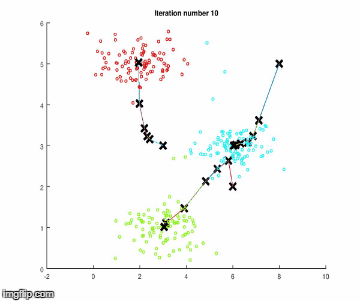
步骤1
现在继续解释步骤1是如何实现的。如果你不熟悉多维特性数据,请参见这里。
首先来介绍一些变量:
k:集群的数量
Xij:示例i的第j个特征值
μij:示例i的第j个特征的聚类中心(类似于X,因为聚类中心是随机选择的)
在这个步骤中,通过迭代,计算它们与聚类中心的相似度,并将它们放入合适的类别中。更确切地说,这是通过一个样本的欧几里得距离来计算的,并从最微小的距离中选取中心。由于中心点是随机选择的,因此将所有特征点与中心点的欧几里德距离相加。
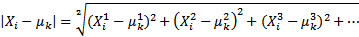
或者,更简化,计算量更少:
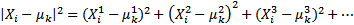
步骤2
从图上看,这一步将中心点向步骤1中相似的分组进行移动。更准确地说,就是取所有与中心点相似或属于该分组的点的平均值(步骤1的分组),来计算每个中心的新位置。
例如,如果有4个集群和第1步骤之后的103个示例,那么有以下结果:
1.μ1 = 20表示标号1-20示例的特征中心是20
2.μ2=10 表示标号21-31示例的特征中心是10
3.μ3=30表示标号32-62示例的特征中心是30
4.μ4=40 表示标号63-103示例的特征中心是40
新的计算方法如下:
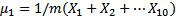
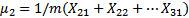
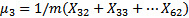
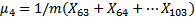
这是所有数据的平均值,类似于一个特定的中心。
重复,重复,重复…何时停止?
重复第1步和第2步,直到如图形上显示的,中心向数据集群移动的越来越近,才会得出新的中心。该算法会一直运行,直到对结果满意时,就需要明确地告诉它,这样它就可以停止了。一种方法是,当迭代时,中心体不会在图中移动,或者它的移动非常少。形式上说,可以计算成本函数,这基本上就是在步骤1中所计算的平均值:
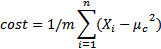
μc是Xi的中心值。每个示例都可以是不同组或中心的一部分。每次迭代成本都会与之前的成本相比较,如果变化真的很低,就停止它。例如,如果改进(成本函数的差异)是0.00001(或者其他认为合适的值),那就可以停止了,因为继续下去就没有意义了。
算法会出错吗?
通常不会出错,但众所周知,k-means算法仅能达到局部最优,而不是全局最优。在这种情况下,k-means算法无法发现更加明显的分组,如下图所示:
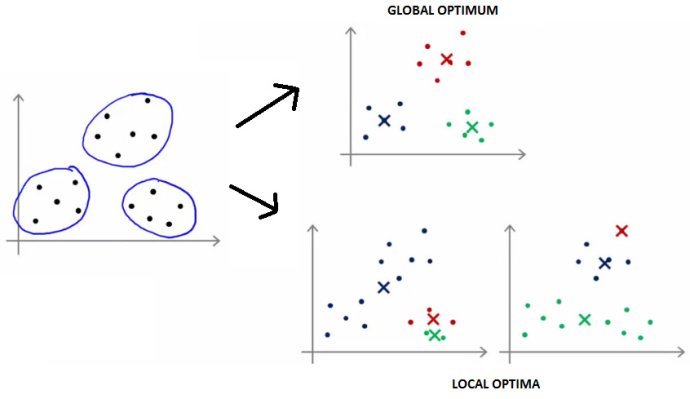
幸运的是,解决方案相当简单——只要用k-means算法多运行几次,然后选择最好的结果就好了。这个解决方案很有帮助,因为在一开始,随机初始化k-means算法,比方说,运行10次,那么会得出局部最优解。当然,这增加了运行时间,因为它运行了很多次,却只需要一个结果。另一方面,完全可以在并行的甚至是不同的集群上运行算法,所以通常可以作为一个工作解决方案。
当然,k-means算法比我所介绍的要多,所以强烈推荐这篇文章,以获得更深入的见解。
算法的执行和结果
在本节中,将运行应用程序(也可以下载代码),并通过一些细节来了解k-means算法如何进行色彩还原。
色彩还原
需要说明的是,k-means算法不是减少图像上的像素,而是通过将相似的颜色组合在一起,以此来减少图像的颜色数量。一个正常的图像通常有几千个甚至更多的颜色,所以减少颜色的数量可以显著减少文件的大小。
为了说明减少颜色的数量有助于减少图像大小,来看一个例子。假设有一个1280x1024像素的图像,对于每个像素,有一个简单的颜色表示(RGB
24位,8位红,8位绿色,8位蓝色)。总而言之,需要1280 * 1024 * 24 = 31457280位或30MB来表示图像。现在,把整体颜色减到16种,这意味着不需要24位像素,而是4位来代表16种颜色。现在,有1280
* 1024 * 4 = 5MB,这也就少占了6倍的内存。当然了,图像看起来不会像之前那样完美(现在只有16种颜色),但肯定能找到一个合适的图像。
执行和结果
执行算法的最简单方法是下载JAR包,并使用自己的图像来执行(需要安装Java)。我的电脑大约需要花一分钟的时间来运行,使颜色减少到16种(高CPU和内存会更好,因为Spark是并行运行的)。在用户界面中,可以选择想要尝试的图像文件,也可以选择减少图像上颜色的数量。下面是一个用户界面和结果的例子:
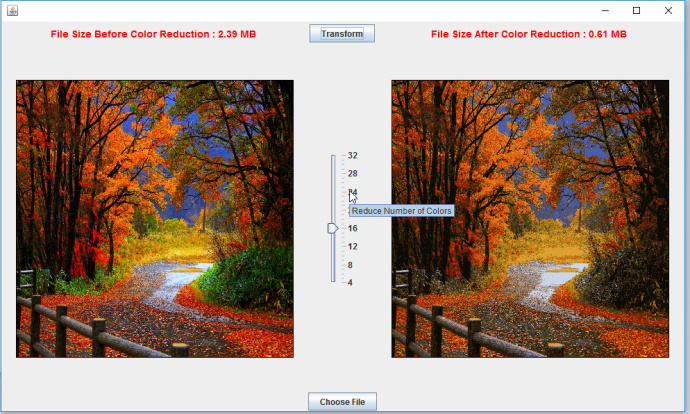
可以注意到,文件大小减少了4倍,但最终的图像看起来并不是那么糟糕。多运行几次它可能会带来更好的效果。再试试24种颜色:
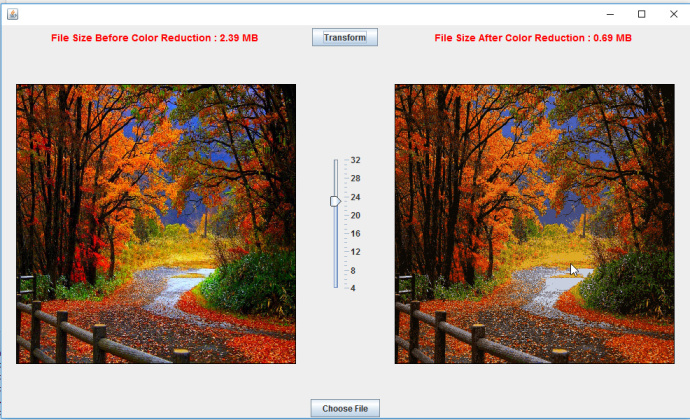
这看起来明显好一些,尺寸也没有增加多少(只有0.08 MB)。似乎在24到28之间是这个图像最好的视觉效果。
尽管结果看起来不错,但选择最佳图像是一项手工任务。毕竟,我们正在执行和挑选最适合视觉的图像。
相信这个问题可以用多种方法来解决。
其中一个解决方案是简单地计算原始图像上的所有颜色,并在此基础上,定义用于图像的颜色数量,同时仍然保持图像看起来不错。这一过程可以通过使用像线性回归这样的机器学习预测算法来完成。通过赋予图像不同的颜色来训练算法,同时,对于每个图像来说,它们看起来仍然很好。在给出了一些重要的示例之后,该算法根据不同的图像学习了如何减少到最佳颜色数量。现在是时候让线性回归算法预测下一个图像的颜色会减少多少了。
|







