| 编辑推荐: |
| 本文来源简书,介绍了如何开发基于字符的神经网络语言模型,包括:如何针对基于字符的语言建模准备文本,如何使用LSTM开发基于字符的语言模型,如何使用训练过的基于字符的语言模型来生成文本。 |
|
语言模型可根据序列中出现的特定单词来预测下一个单词。可以使用神经网络在字符级别上开发语言模型。基于字符的语言模型有一个最大的优点,就是在处理单词、标点符号和其他文档结构的时候,能保持较小的词汇量和较强的灵活性。但所付出的代价是模型较大、训练较慢。然而,在神经网络语言模型领域,基于字符的模型为语言建模提供了一种通用、灵活和强大的方法。
在本教程中,你将了解到如何开发基于字符的神经网络语言模型。
学习完本教程,你将学会:
1.如何针对基于字符的语言建模准备文本。
2.如何使用LSTM开发基于字符的语言模型。
3.如何使用训练过的基于字符的语言模型来生成文本。
教程概述
本教程分为四个部分:
1.Sing a Song of Sixpence(译者注:一首英文童谣)
2.数据准备
3.训练语言模型
4.生成文本
Sing a Song of Sixpence
童谣“Sing a Song of Sixpence”在西方人人都会唱。我们将用它来开发基于字符的语言模型。
这首童谣很短,所以模型的拟合会很快,但不能太短,那样我们就不会看到任何有意思的东西。下面是这首童谣完整歌词:
| Sing
a song of sixpence,
A pocket full of rye.
Four and twenty blackbirds,
Baked in a pie.
When the pie was opened
The birds began to sing;
Wasn’t that a dainty dish,
To set before the king.
The king was in his counting house,
Counting out his money;
The queen was in the parlour,
Eating bread and honey.
The maid was in the garden,
Hanging out the clothes,
When down came a blackbird
And pecked off her nose. |
复制这段文本,并将其保存到当前工作目录中的一个新文件中,文件名为“rhyme.txt”。
数据准备
第一步是准备文本数据。我们将首先定义语言模型的类型。
语言模型设计
语言模型必须用文本进行训练,在基于字符的语言模型中,输入和输出序列必须是字符。用于输入的字符的个数决定了需要提供给模型以引出第一个预测字符的字符数。在第一个字符生成之后,可以将其添加到输入序列上,作为模型的输入以生成下一个字符。
序列越长,则为模型提供的上下文也越多,同时,模型将耗费更长的时间来进行训练。我们这个模型使用的字符的长度是10。
下面我们将把原始文本转换成模型可以学习的形式。
加载文本
童谣的歌词必须加载到内存之后才能使用。下面是一个名为load_doc()的函数,用于加载指定文件名的文本文件并返回加载的文本。

可以使用这个函数来加载名为“rhyme.txt”的文件,并将内容放入内存中。然后将文件的内容打印到屏幕上进行完整性检查。

净化文本
接下来,需要净化加载的文本。
这里我们不会做太多的事情,只是删除所有的换行符,转换成一段按空格进行分割的长字符序列。

你可能需要探索一下净化数据的其他一些方法,例如将文本转换为小写字母或删除标点符号,以减少最终的词汇量,这样可以开发出更小、更精简的模型。
创建序列
长字符列表有了,下面就可以创建用于训练模型的输入输出序列了。
每个输入序列包含十个字符和一个输出字符,因此,每个序列包含了11个字符。我们可以通过枚举文本中的字符来创建序列,从索引为10也就是第11个字符开始。

运行这段代码,我们可以看到,用来训练语言模型的序列其实只有不到400个字符。

保存序列
最后,将准备好的数据保存到文件中,后面在开发模型的时候再加载。
下面是save_doc()函数,给定字符串列表和文件名,将字符串保存到文件中,每行一个字符串。

调用这个函数,将准备好的序列保存到当前工作目录下的“char_sequences.txt”文件中。

完整的例子
将上面那些代码片段组合到一起,组成下面这份完整的代码:
运行该示例,将生成“char_seqiences.txt”文件,内容如下:

下面准备训练基于字符的神经语言模型。
训练语言模型
本章节将为上面准备好的序列数据开发一个神经语言模型。该模型将读取已经编码的字符,并预测出序列的下一个字符。
加载数据
第一步是从"char_sequences.txt"加载字符序列数据。
我们可以使用上一章节中开发的load_doc()函数。载入后,将文本按换行符进行分割以得到序列列表。

序列编码
字符序列必须编码为整数。也就是说每个字符都会被分配一个指定的整数值,每个字符序列都会被编码为一个整数序列。
我们可以根据原始输入数据来创建映射关系。该映射关系是字符值映射到整数值的字典。

接下来,逐个处理每个字符序列,并使用字典映射来查找每个字符的整数值。

运行的结果是整数序列列表。
字典映射表的大小即词汇表的大小。

运行这段代码,我们可以看到输入数据中的字符剔重后有38个。

分割输入和输出
现在,序列已经被编码成整数了,下面可以将列分割成输入和输出字符序列。可以使用一个简单的数组切片来完成此操作。

接下来,将对每个字符进行独热编码,也就是说,每个字符都会变成一个向量。这为神经网络提供了更精确的输入表示,还为网络预测提供了一个明确的目标。
我们可以使用Keras API中的to_categorical()函数来对输入和输出序列进行独热编码。

现在,我们已经为模型的拟合做好准备了。
模型拟合
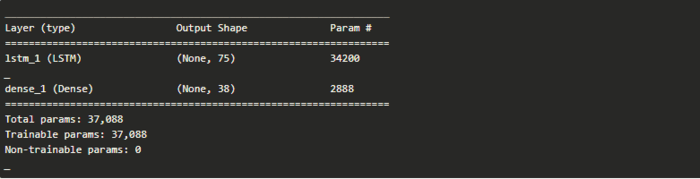
该模型使用了一个针对独热编码输入序列采用10个时间步长和38个特征的输入层进行定义。我们在X输入数据上使用第二和第三个维度,而不是指定这些数字。这是因为当序列的长度或词汇表的大小发生改变的实话,无需改变模型的定义。
该模型有一个包含75个存储器单元的LSTM隐藏层,通过一些试验和错误进行选择。
该模型有一个完全连接的输出层,输出一个词汇表中所有字符概率分布的向量。在输出层上使用softmax激活函数来确保输出具有概率分布的属性。

运行这段代码将打印出网络的概要信息以进行完整性检查。
该模型将执行100次训练迭代来进行拟合。

保存模型
模型拟合完成之后,将其保存到文件以备后面使用。Keras提供了save()函数,可以使用该函数将模型保存到单个文件中,包括权重和拓扑信息。

另外还要保存从字符到整数的映射关系,因为在使用模型的时候,需要对任意的输入进行编码,并对模型的输出进行解码。

完整的例子
将上面那些代码片段组合到一起,组成下面这份基于字符的神经网络语言模型的完整代码:
这个例程的运行时间可能需要一分钟。

运行结束之后,会在当前目录生成两个文件,model.h5和mapping.pkl。
接下来,看一下如何使用这个学习过的模型。
生成文本
我们将使用这个学习过的语言模型来生成具有相同统计特性的新的文本序列。
加载模型
第一步是加载文件“model.h5”中的模型,可以使用Keras
API中的load_model()函数进行加载。

还需要加载文件“mapping.pkl”文件中的字典,用于将字符映射为整数。

下面可以使用这个模型了。
生成字符
为了启动生成过程,必须提供包含10个字符的序列作为模型的输入。
首先,字符序列必须使用加载进来的映射关系编码为整数值。

接下来,使用Keras中的pad_sequences()函数对整数值进行独热编码,并将序列重塑为三个维度。因为我们只有一个序列,而且LSTM需要所有的输入都有三个维度(样本、时间步长、特征)。

下面,就可以使用模型来预测序列中的下一个字符了。

使用predict_classes()而不是predict()来直接选择具有最高概率的字符整数。
可以通过查找映射中的整数-字符关系来对整数进行解码。

这个字符随后可以添加到输入序列中去。然后通过截断输入序列文本中的第一个字符来确保输入序列是10个字符的长度。可以使用Keras
API中的pad_sequences()函数来执行截断操作。
把上面这些放在一起,定义一个名为generate_seq()的新函数来使用模型生成新的文本序列。
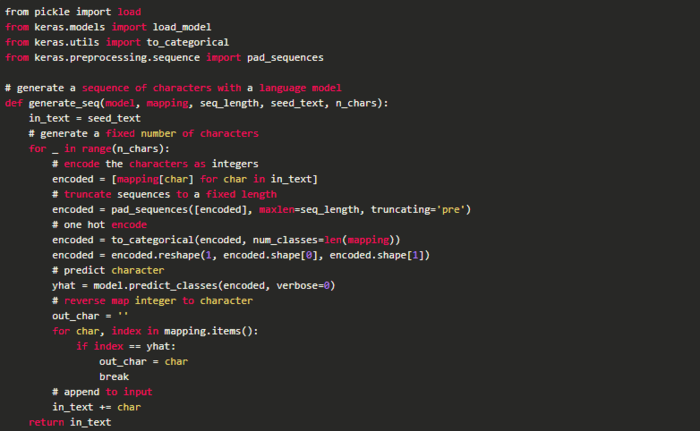

完整的例子
将上面那些代码片段组合到一起,组成下面这份基于字符的神经网络语言模型的完整代码:
运行该示例将生成三个文本序列。
第一个是测试这个模型在从童谣的开头进行预测的话表现如何。第二个是测试从某一行的中间开始预测表现如何。最后是测试模型遇到从未见过的字符序列时表现如何。

我们可以看到,这个模型在前两个例子中的表现得还不错,符合预期。但对于新的文本来说,预测的结果就有点匪夷所思了。
总结
通过阅读本教程,你已经学会了如何开发基于字符的神经网络语言模型,包括:
如何针对基于字符的语言建模准备文本。
如何使用LSTM开发基于字符的语言模型。
如何使用训练过的基于字符的语言模型来生成文本。
|






