| УПЕБЬсЕНЛњЦїбЇЯАЃЌДѓМвзмЪЧБЛЦфжаЕФИїжжИїбљЕФЫуЗЈКЭЗНЗЈИудЮЃЌОѕЕУЮоДгЯТЪжЁЃШЗЪЕЃЌЛњЦїбЇЯАЕФИїжжЬзТЗШЗЪЕВЛЩйЃЌЕЋЪЧШчЙћеЦЮеСЫе§ШЗЕФТЗОЖКЭЗНЗЈЃЌЦфЪЕЛЙЪЧгаМЃПЩбЕФЃЌетРяЮвЭЦМіSASЕФLi
HuiЕФетЦЊВЉПЭЃЌНВЪіСЫШчКЮбЁдёЛњЦїбЇЯАЕФИїжжЗНЗЈЁЃ
СэЭтЃЌScikit-learn вВЬсЙЉСЫвЛЗљЧхЮњЕФТЗЯпЭМИјДѓМвбЁдёЃК
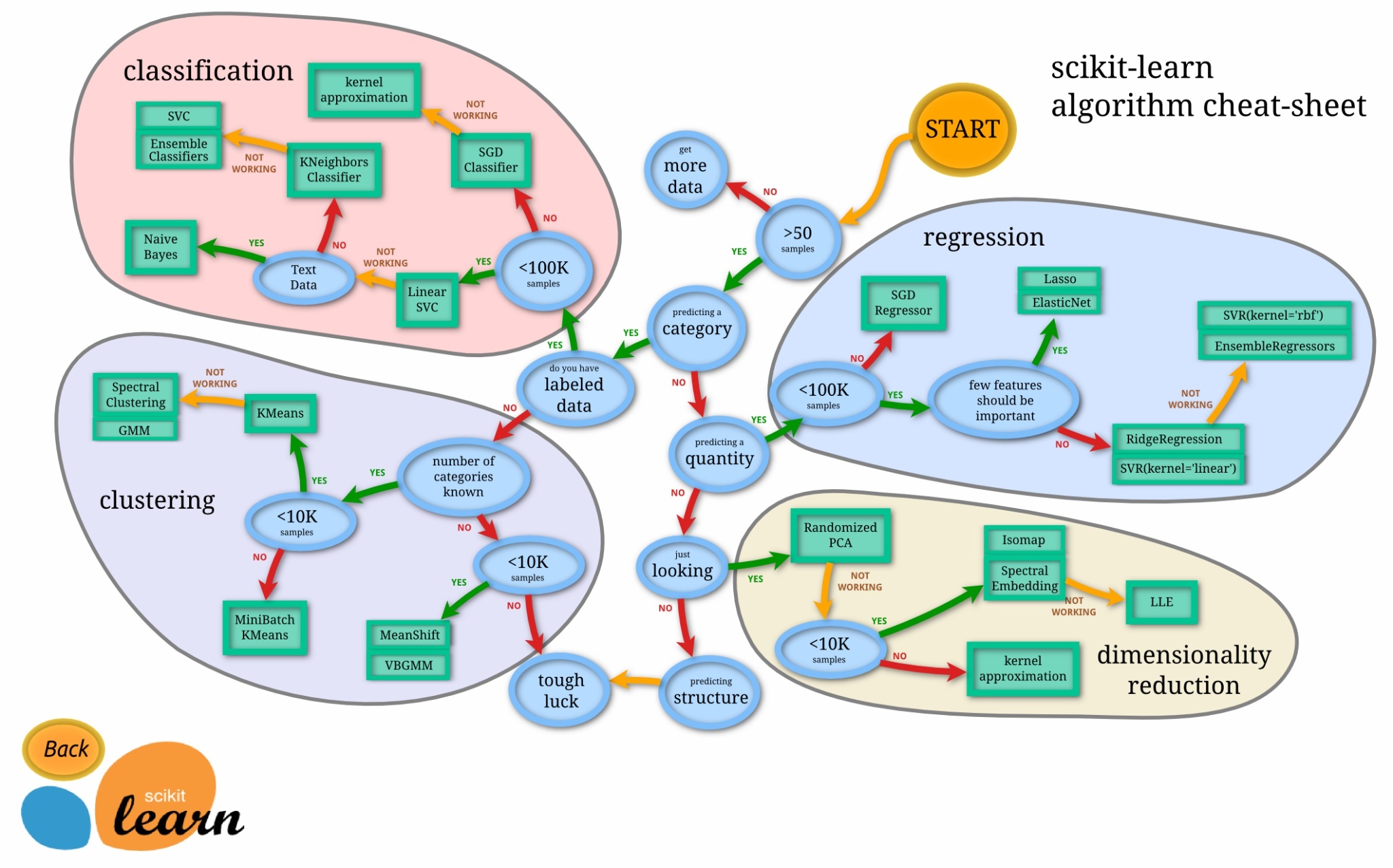
ЦфЪЕЛњЦїбЇЯАЕФЛљБОЫуЗЈЖМКмМђЕЅЃЌЯТУцЮвУЧОЭРћгУЖўЮЌЪ§ОнКЭНЛЛЅЭМаЮРДПДПДЛњЦїбЇЯАжаЕФвЛаЉЛљБОЫуЗЈвдМАЫќУЧЕФдРэЁЃЃЈСэЭтЯђBret
VictorжТОДЃЌЫћЕФ Inventing on principle ЩюЩюЕФгАЯьСЫЮвЃЉ
ЫљгаЕФДњТыМДбнЪОПЩвддкЮвЕФCodepenЕФетИіCollectionжаевЕНЁЃ
ЪзЯШЃЌЛњЦїбЇЯАзюДѓЕФЗжжЇЕФМрЖНбЇЯАКЭЮоМрЖНбЇЯАЃЌМђЕЅЫЕЪ§ОнвбОДђКУБъЧЉЕФЪЧМрЖНбЇЯАЃЌЖјЪ§ОнУЛгаБъЧЉЕФЪЧЮоМрЖНбЇЯАЁЃДгДѓЕФЗжРрЩЯПДЃЌНЕЮЌКЭОлРрБЛЛЎдкЮоМрЖНбЇЯАЃЌЛиЙщКЭЗжРрЪєгкМрЖНбЇЯАЁЃ
ЮоМрЖНбЇЯА
ШчЙћФуЕФЪ§ОнЖМУЛгаБъЧЉЃЌФуПЩвдбЁдёЛЈЧЎЧыШЫРДБъзЂФуЕФЪ§ОнЃЌЛђепЪЙгУЮоМрЖНбЇЯАЕФЗНЗЈЁЃ
ЪзЯШФуПЩвдПМТЧЪЧЗёвЊЖдЪ§ОнНјааНЕЮЌЁЃ
НЕЮЌ
НЕЮЌЙЫУћЫМвхОЭЪЧАбИпЮЌЖШЕФЪ§ОнБфГЩЮЊЕЭЮЌЖШЁЃГЃМћЕФНЕЮЌЗНЗЈгаPCA,
LDA, SVDЕШЁЃ
жїГЩЗжЗжЮі PCA
НЕЮЌРязюОЕфЕФЗНЗЈЪЧжїГЩЗжЗжЮіPCAЃЌвВОЭЪЧевЕНЪ§ОнЕФжївЊзщГЩГЩЗжЃЌХзЦњЕєВЛживЊЕФГЩЗжЁЃ
етРяЮвУЧЯШгУЪѓБъЫцЛњЩњГЩ8ИіЪ§ОнЕуЃЌШЛКѓЛцжЦГіБэЪОжїГЩЗжЕФАзЩЋжБЯпЁЃетИљЯпОЭЪЧЖўЮЌЪ§ОнНЕЮЌКѓЕФжїГЩЗжЃЌРЖЩЋЕФжБЯпЪЧЪ§ОнЕудкаТЕФжїГЩЗжЮЌЖШЩЯЕФЭЖгАЯпЃЌвВОЭЪЧДЙЯпЁЃжїГЩЗжЗжЮіЕФЪ§бЇвтвхПЩвдПДГЩЪЧевЕНетИљАзЩЋжБЯпЃЌЪЙЕУЭЖгАЕФРЖЩЋЯпЖЮЕФГЄЖШЕФКЭЮЊзюаЁжЕЁЃ
ИќЖрPCAЕФЯрЙиР§згЃЌПЩвдВЮПМЃК
1.D3 http://bl.ocks.org/hardbyte/40cd6622cffbe98055d3
2.http://setosa.io/ev/principal-component-analysis/
ОлРр
вђЮЊдкЗЧМрЖНбЇЯАЕФЛЗОГЯТЃЌЪ§ОнУЛгаБъЧЉЃЌФЧУДФмЖдЪ§ОнЫљзіЕФзюКУЕФЗжЮіГ§СЫНЕЮЌЃЌОЭЪЧАбОпгаЯрЭЌЬижЪЕФЪ§ОнЙщВЂдквЛЦ№ЃЌвВОЭЪЧОлРрЁЃ
ВуМЖОлРр Hierachical Cluster
ИУОлРрЗНЗЈгУгкЙЙНЈвЛИігЕгаВуДЮНсЙЙЕФОлРрЃЌ
ШчЩЯЭМЫљЪОЃЌВуМЖОлРрЕФЫуЗЈЗЧГЃЕФМђЕЅЃК
1.ГѕЪМЪБПЬЃЌЫљгаЕуЖМздМКЪЧвЛИіОлРр
2.евЕНОрРызюНќЕФСНИіОлРрЃЈИеПЊЪМвВОЭЪЧСНИіЕуЃЉЃЌаЮГЩвЛИіОлРр
3.СНИіОлРрЕФОрРыжИЕФЪЧОлРржазюНќЕФСНИіЕужЎМфЕФОрРы
4.жиИДЕкЖўВНЃЌжБЕНЫљгаЕФЕуЖМБЛОлМЏЕНОлРржаЁЃ
See the Pen ML Explained Hierarchical Clustering by
gangtao (@gangtao) on CodePen.
KMeans
KMeansжаЮФЗвыKОљжЕЫуЗЈЃЌЪЧзюГЃМћЕФОлРрЫуЗЈЁЃ

1.ЫцЛњдкЭМжаШЁKЃЈетРяK=3ЃЉИіжааФжжзгЕуЁЃ
2.ШЛКѓЖдЭМжаЕФЫљгаЕуЧѓЕНетKИіжааФжжзгЕуЕФОрРыЃЌМйШчЕуPРыжааФЕуSзюНќЃЌФЧУДPЪєгкSЕуЕФОлРрЁЃ
3.НгЯТРДЃЌЮвУЧвЊвЦЖЏжааФЕуЕНЪєгкЫћЕФЁАОлРрЁБЕФжааФЁЃ
4.ШЛКѓжиИДЕк2ЃЉКЭЕк3ЃЉВНЃЌжБЕНЃЌжааФЕуУЛгавЦЖЏЃЌФЧУДЫуЗЈЪеСВЃЌевЕНЫљгаЕФОлРрЁЃ
KMeansЫуЗЈгаМИИіЮЪЬтЃК
1.ШчКЮОіЖЈKжЕЃЌдкЩЯЭМЕФР§згжаЃЌЮвжЊЕРвЊЗжШ§ИіОлРрЃЌЫљвдбЁдёKЕШгк3ЃЌШЛЖјдкЪЕМЪЕФгІгУжаЃЌЭљЭљВЂВЛжЊЕРгІИУЗжГЩМИИіРр
2.гЩгкжааФЕуЕФГѕЪМЮЛжУЪЧЫцЛњЕФЃЌгаПЩФмВЂВЛФме§ШЗЗжРрЃЌДѓМвПЩвддкЮвЕФCodepenжаГЂЪдВЛЭЌЕФЪ§Он
3.ШчЯТЭМЃЌШчЙћЪ§ОнЕФЗжВМдкПеМфЩЯгаЬиЪтадЃЌKMeansЫуЗЈВЂВЛФмгааЇЕФЗжРрЁЃжаМфЕФЕуБЛЗжБ№ЙщЕНСЫГШЩЋКЭРЖЩЋЃЌЦфЪЕЖМгІИУЪЧРЖЩЋЁЃ

DBSCAN
DBSCANЃЈDensity-Based Spatial Clustering of Applications
with NoiseЃЉжаЮФЪЧЛљгкУмЖШЕФОлРрЫуЗЈЁЃ
DBSCANЫуЗЈЛљгквЛИіЪТЪЕЃКвЛИіОлРрПЩвдгЩЦфжаЕФШЮКЮКЫаФЖдЯѓЮЈвЛШЗЖЈЁЃ
ЫуЗЈЕФОпЬхОлРрЙ§ГЬШчЯТЃКЩЈУшећИіЪ§ОнМЏЃЌевЕНШЮвтвЛИіКЫаФЕуЃЌЖдИУКЫаФЕуНјааРЉГфЁЃРЉГфЕФЗНЗЈЪЧбАевДгИУКЫаФЕуГіЗЂЕФЫљгаУмЖШЯрСЌЕФЪ§ОнЕуЃЈзЂвтЪЧУмЖШЯрСЌЃЉЁЃБщРњИУКЫаФЕуЕФСкгђФкЕФЫљгаКЫаФЕуЃЈвђЮЊБпНчЕуЪЧЮоЗЈРЉГфЕФЃЉЃЌбАевгыетаЉЪ§ОнЕуУмЖШЯрСЌЕФЕуЃЌжБЕНУЛгаПЩвдРЉГфЕФЪ§ОнЕуЮЊжЙЁЃзюКѓОлРрГЩЕФДиЕФБпНчНкЕуЖМЪЧЗЧКЫаФЪ§ОнЕуЁЃжЎКѓОЭЪЧжиаТЩЈУшЪ§ОнМЏЃЈВЛАќРЈжЎЧАбАевЕНЕФДижаЕФШЮКЮЪ§ОнЕуЃЉЃЌбАевУЛгаБЛОлРрЕФКЫаФЕуЃЌдйжиИДЩЯУцЕФВНжшЃЌЖдИУКЫаФЕуНјааРЉГфжБЕНЪ§ОнМЏжаУЛгааТЕФКЫаФЕуЮЊжЙЁЃЪ§ОнМЏжаУЛгаАќКЌдкШЮКЮДижаЕФЪ§ОнЕуОЭЙЙГЩвьГЃЕуЁЃ

ШчЩЯЭМЫљЪОЃЌDBSCANПЩвдгааЇЕФНтОіKMeansВЛФме§ШЗЗжРрЕФЪ§ОнМЏЁЃВЂЧвВЛашвЊжЊЕРKжЕЁЃ
ЕБШЛЃЌDBCSANЛЙЪЧвЊОіЖЈСНИіВЮЪ§ЃЌШчКЮОіЖЈетСНИіВЮЪ§ЪЧЗжРраЇЙћЕФЙиМќвђЫиЃК
1.вЛИіВЮЪ§ЪЧАыОЖЃЈEpsЃЉЃЌБэЪОвдИјЖЈЕуPЮЊжааФЕФдВаЮСкгђЕФЗЖЮЇЃЛ
2.СэвЛИіВЮЪ§ЪЧвдЕуPЮЊжааФЕФСкгђФкзюЩйЕуЕФЪ§СПЃЈMinPtsЃЉЁЃШчЙћТњзуЃКвдЕуPЮЊжааФЁЂАыОЖЮЊEpsЕФСкгђФкЕФЕуЕФИіЪ§ВЛЩйгкMinPtsЃЌдђГЦЕуPЮЊКЫаФЕуЁЃ
МрЖНбЇЯА
МрЖНбЇЯАжаЕФЪ§ОнвЊЧѓОпгаБъЧЉЁЃвВОЭЪЧЫЕеыЖдвбгаЕФНсЙћШЅдЄВтаТГіЯжЕФЪ§ОнЁЃШчЙћвЊдЄВтЕФФкШнЪЧЪ§жЕРраЭЃЌЮвУЧГЦзїЛиЙщЃЌШчЙћвЊдЄВтЕФФкШнЪЧРрБ№ЛђепЪЧРыЩЂЕФЃЌЮвУЧГЦзїЗжРрЁЃ
ЦфЪЕЛиЙщКЭЗжРрБОжЪЩЯЪЧРрЫЦЕФЃЌЫљвдКмЖрЕФЫуЗЈМШПЩвдгУзїЗжРрЃЌвВПЩвдгУзїЛиЙщЁЃ
ЛиЙщ
ЯпадЛиЙщ
ЯпадЛиЙщЪЧзюОЕфЕФЛиЙщЫуЗЈЁЃ
дкЭГМЦбЇжаЃЌЯпадЛиЙщЃЈLinear regressionЃЉЪЧРћгУГЦЮЊЯпадЛиЙщЗНГЬЕФзюаЁЖўГЫКЏЪ§ЖдвЛИіЛђЖрИіздБфСПКЭвђБфСПжЎМфЙиЯЕНјааНЈФЃЕФвЛжжЛиЙщЗжЮіЁЃ
етжжКЏЪ§ЪЧвЛИіЛђЖрИіГЦЮЊЛиЙщЯЕЪ§ЕФФЃаЭВЮЪ§ЕФЯпадзщКЯЁЃ жЛгавЛИіздБфСПЕФЧщПіГЦЮЊМђЕЅЛиЙщЃЌДѓгквЛИіздБфСПЧщПіЕФНазіЖрдЊЛиЙщЁЃ

ШчЩЯЭМЫљЪОЃЌЯпадЛиЙщОЭЪЧвЊевЕНвЛЬѕжБЯпЃЌЪЙЕУЫљгаЕФЕудЄВтЕФЪЇЮѓзюаЁЁЃвВОЭЪЧЭМжаЕФРЖЩЋжБЯпЖЮЕФКЭзюаЁЁЃетИіЭМКмЯёЮвУЧЕквЛИіР§згжаЕФPCAЁЃзаЯИЙлВьЃЌЗжБцЫќУЧЕФЧјБ№ЁЃ
ШчЙћЖдгкЫуЗЈЕФЕФзМШЗадвЊЧѓБШНЯИпЃЌЭЦМіЕФЛиЙщЫуЗЈАќРЈЃКЫцЛњЩСжЃЌЩёОЭјТчЛђепGradient Boosting
TreeЁЃ
ШчЙћвЊЧѓЫйЖШгХЯШЃЌНЈвщПМТЧОіВпЪїКЭЯпадЛиЙщЁЃ
ЗжРр
жЇГжЯђСПЛњ SVM
ШчЙћЖдгкЗжРрЕФзМШЗадвЊЧѓБШНЯИпЃЌПЩЪЙгУЕФЫуЗЈАќРЈKernel SVMЃЌЫцЛњЩСжЃЌЩёОЭјТчвдМАGradient
Boosting TreeЁЃ
ИјЖЈвЛзщбЕСЗЪЕР§ЃЌУПИібЕСЗЪЕР§БЛБъМЧЮЊЪєгкСНИіРрБ№жаЕФвЛИіЛђСэвЛИіЃЌSVMбЕСЗЫуЗЈДДНЈвЛИіНЋаТЕФЪЕР§ЗжХфИјСНИіРрБ№жЎвЛЕФФЃаЭЃЌЪЙЦфГЩЮЊЗЧИХТЪЖўдЊЯпадЗжРрЦїЁЃSVMФЃаЭЪЧНЋЪЕР§БэЪОЮЊПеМфжаЕФЕуЃЌетбљгГЩфОЭЪЙЕУЕЅЖРРрБ№ЕФЪЕР§БЛОЁПЩФмПэЕФУїЯдЕФМфИєЗжПЊЁЃШЛКѓЃЌНЋаТЕФЪЕР§гГЩфЕНЭЌвЛПеМфЃЌВЂЛљгкЫќУЧТфдкМфИєЕФФФвЛВрРДдЄВтЫљЪєРрБ№ЁЃ

ЩЯЭМЪОвтСЫВЛЭЌЕФКЫЗНЗЈЕФВЛЭЌЗжРраЇЙћЁЃ
ОіВпЪї
ШчЙћвЊЧѓЗжРрНсЙћЪЧПЩвдНтЪЭЕФЃЌПЩвдПМТЧОіВпЪїЛђепТпМЛиЙщЁЃ
ОіВпЪїЃЈdecision treeЃЉЪЧвЛИіЪїНсЙЙЃЈПЩвдЪЧЖўВцЪїЛђЗЧЖўВцЪїЃЉЁЃ
ЦфУПИіЗЧвЖНкЕуБэЪОвЛИіЬиеїЪєадЩЯЕФВтЪдЃЌУПИіЗжжЇДњБэетИіЬиеїЪєаддкФГИіжЕгђЩЯЕФЪфГіЃЌЖјУПИівЖНкЕуДцЗХвЛИіРрБ№ЁЃ
ЪЙгУОіВпЪїНјааОіВпЕФЙ§ГЬОЭЪЧДгИљНкЕуПЊЪМЃЌВтЪдД§ЗжРрЯюжаЯргІЕФЬиеїЪєадЃЌВЂАДееЦфжЕбЁдёЪфГіЗжжЇЃЌжБЕНЕНДявЖзгНкЕуЃЌНЋвЖзгНкЕуДцЗХЕФРрБ№зїЮЊОіВпНсЙћЁЃ
ОіВпЪїПЩвдгУгкЛиЙщЛђепЗжРрЃЌЯТЭМЪЧвЛИіЗжРрЕФР§згЁЃ

ШчЩЯЭМЫљЪОЃЌОіВпЪїАбПеМфЗжИюГЩВЛЭЌЕФЧјгђЁЃ
ТпМЛиЙщ
ТпМЛиЙщЫфШЛУћзжЪЧЛиЙщЃЌЕЋЪЧШДЪЧИіЗжРрЫуЗЈЁЃвђЮЊЫќКЭSVMРрЫЦЪЧвЛИіЖўЗжРрЃЌЪ§бЇФЃаЭЪЧдЄВт1Лђеп0ЕФИХТЪЁЃЫљвдЮвЫЕЛиЙщКЭЗжРрЦфЪЕБОжЪЩЯЪЧвЛжТЕФЁЃ

етРявЊзЂвтТпМЛиЙщКЭЯпадSVMЗжРрЕФЧјБ№ЃЌПЩвддФЖСЃК
1.https://www.zhihu.com/question/26768865
2.http://blog.jobbole.com/98635/
ЦгЫиБДвЖЫЙ
ЕБЪ§ОнСПЯрЕБДѓЕФЪБКђЃЌЦгЫиБДвЖЫЙЗНЗЈЪЧвЛИіКмКУЕФбЁдёЁЃ
15ФъЮвдкЙЋЫОИјаЁЛяАщУЧЗжЯэЙ§bayersЗНЗЈЃЌПЩЯЇspeaker deckБЛЧНСЫЃЌШчЙћгааЫШЄПЩвдздааЯыАьЗЈЁЃ
ШчЩЯЭМЫљЪОЃЌK=3ЃЌЪѓБъвЦЖЏЕНШЮКЮвЛИіЕуЃЌОЭевЕНОрРыИУЕузюНќЕФKИіЕуЃЌШЛКѓЃЌетKИіЕуЭЖЦБЃЌЖрЪ§БэОіЛёЪЄЁЃОЭЪЧетУДМђЕЅЁЃ
змНс
БОЮФРћгУЖўЮЌНЛЛЅЭМАяжњДѓМвРэНтЛњЦїбЇЯАЕФЛљБОЫуЗЈЃЌЯЃЭћФмдіМгДѓМвЖдЛњЦїбЇЯАЕФИїжжЗНЗЈгаЫљСЫНтЁЃЫљгаЕФДњТыПЩвддкВЮПМжаевЕНЁЃ
|









