使用Apache Kafka在生产环境构建大规模机器学习
智能实时应用为所有行业带来了革命性变化。机器学习及其分支深度学习正蓬勃发展,因为机器学习让计算机能够在无人指引的情况下挖掘深藏的洞见。这种能力正是多种领域所需要的,如非结构化数据分析、图像识别、语音识别和智能决策,这完全不同于传统的编程方式(如Java、.NET或Python)。
机器学习并非新生事物,大数据集的出现和处理能力的进步让每一个企业都具备了构建分析模型的能力。各行各业都在将分析模型应用在企业应用和微服务上,用以增长利润、降低成本,或者改善用户体验。
这篇文章将介绍机器学习在任务关键型实时系统中的应用,将Apache Kafka作为中心化的、可伸缩的任务关键型系统,同时还将介绍使用Kafka Streams API来构建智能流式应用。
可伸缩的任务关键型实时系统
互联网、智能手机和持续在线思维的出现改变了人们的行为方式。其中就包括人们对与设备、产品和服务交互方式的期待:人们希望能够实时地获得信息。这也给企业带来了巨大挑战:如何快速地采取行动才能把握先机。批处理系统已经无法满足需求,取而代之的应该是实时系统。
传统企业可以实现非常强大的实时处理机制来满足日常的业务需求。这通常需要借助领域知识来理解各种应用场景,并构建新的流式分析模型来增加业务价值。流式处理已经存在于各个行业中。
- 欺诈检测。将支付信息与历史数据或已知的模式关联起来,在欺诈发生之前将其检测出来。这对处理速度提出了很高的要求,因为你必须在交易发生之前将其取消掉。
- 交叉销售。利用客户数据为客户提供定制化的销售方案或折扣,争取让客户在离开商店之前成交订单。这种情况下,你需要利用实时数据(比如位置数据、支付数据)和历史数据(来自你的CRM系统或Loyalty平台)为每个客户提供最合适的销售方案。
- 预测性维护。使用机器数据来预测机器故障,在发生故障之前将旧的部件更换掉。从实际情况来看,这可以节省大量的金钱(制造)、增加利润(自动售卖机)或提升用户体验(电信网络故障预测)。
所有这些场景都有一个共同点,那就是在数据产生的同时处理数据。你必须尽快地处理已经发生的事件,是主动处理,而不是被动处理。你的系统需要在欺诈发生之前,或在顾客离开商店之前,或在机器发生故障之前做出决策。
当然,这并不是说一定要求毫秒级别的响应时间。在某些情况下,即使是批处理也是没有问题的。比如,大部分制造行业或物联网场景中,预测性维护可以允许几个小时甚至几天的时间间隔,更换部件可以在当天或当周内完成。这样可以节省大量的金钱,因为你可以在问题发生之前检测出它们,避免造成更大范围的损失。
在智能实时系统中应用机器学习
任务关键型实时应用系统在不使用机器学习的情况下已经存在多年,那为什么说机器学习将给这一领域带来革命性的变化?
如果你读过有关机器学习及其分支深度学习的资料,你经常会看到如下的一些场景。
- 图像识别。上传一张图片到Facebook上,图像中的物体——比如你的朋友、背景或你手中的啤酒——就会被分析出来。
- 语音翻译。机器人因此可以通过生成的文本或声音与人类进行互动。
- 仿人类行为。IBM Watson击败了最强大的Jeopardy选手;Google的AlphaGo战胜了最专业的Go选手。
上述的例子与那些想要构建创新型应用系统并从竞争当中脱颖而出的企业有着越来越紧密的联系。类似的,我们可以将机器学习应用在“传统场景”里,比如欺诈检测、交叉销售或预测性维护,以此来增强业务流程,基于数据驱动做出更好的决策。已有的业务流程可以保持原样,你只需要将业务逻辑和规则替换成分析模型来改进自动化决策即可。
下面将介绍如何将Kafka作为流式平台来构建、运营和监控大规模、任务关键型的分析模型。
机器学习——分析模型的开发生命周期
先让我们了解一下分析模型的开发生命周期:
- 构建:使用机器学习算法(如GLM、Naive Bayes、Random Forest、Gradient Boosting、Neural Networks等)分析历史数据,挖掘洞见。在这一步需要进行数据的收集、准备和转换。
- 验证:使用一些验证技术(如交叉验证)再次确认分析模型能够处理新的输入数据。
- 运营:将分析模型部署到生产环境。
- 监控:观察分析模型的输出。这里包含了两部分内容:在达到某个阈值时发送告警(业务层面的监控);保持结果的准确性和度量指标的质量(分析模型的监控)。
- 持续循环:重复上述步骤来改进分析模型,可以通过手动批次的方式来完成,也可以在线完成,在新事件达到时更新模型。
整个团队在一开始就要在一起工作,并考虑如下问题:
- 它需要在生产环境有怎样的表现?
- 生产环境系统支持哪些技术?
- 如何监控模型的推理和性能?
- 是构建一个完整的机器学习基础设施还是使用已有的框架来分离模型训练和模型推理?
例如,一个数据科学家开发出一个Python程序,创建了一个精确度非常高的模型,但如果你无法将它部署到生产环境(因为它无法伸缩也无法表现得如预期一样),它就毫无用处。这个时候,或许你已经可以意识到为什么Apache Kafka如此适合用在生产环境的分析模型上。下面的章节将介绍使用Apache Kafka作为流式平台以及结合机器学习或深度学习框架来构建、运营和监控分析模型。
机器学习和Apache Kafka架构参考
在了解了机器学习开发生命周期之后,接下来我们来看一个用于构建、营运和监控分析模型的架构参考:
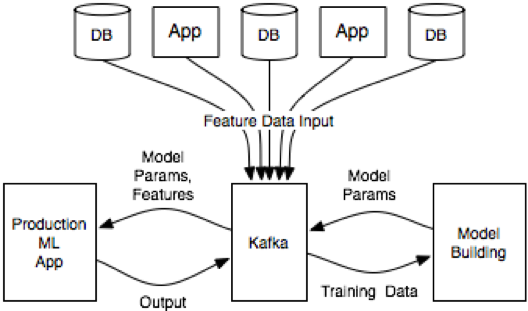
该架构的核心之处在于它使用Kafka作为各种数据源、模型构建环境以及生产环境应用程序之间的媒介。
用于构建模型的特征数据从各个应用程序和数据库流入Kafka。模型构建环境可以是一个数据仓库、一个大数据环境(如Spark或Hadoop)或者一个运行Python脚本的服务器。模型可以被部署在某个地方,只要生产环境的应用程序能够访问到它们,并把它们应用在输入样本数据上。生产环境的应用程序可以从Kafka数据管道接收数据,或者使用Kafka Streams API。
Kafka成为整个系统的中枢神经,这也带来了如下好处:
- 数据管道变得更简单的了。
- 分析模型的构建和服务之间不再耦合。
- 根据具体情况使用实时模式或批处理模式。
- 分析模型可以被部署到高性能、可伸缩的任务关键型环境里。
除了Kafka本身,还可以加入Kafka生态系统的其他开源组件,如Kafka Connect、Kafka Streams、Confluent REST Proxy、Confluent Schema Registry或者KSQL,而不仅仅是使用Kafka Producer和Consumer API。

下面两个章节将介绍如何使用Kafka Steams API来部署分析模型。
机器学习开发生命周期示例
现在我们来深入了解一个围绕Kafka构建的机器学习架构示例:
(点击放大图像)
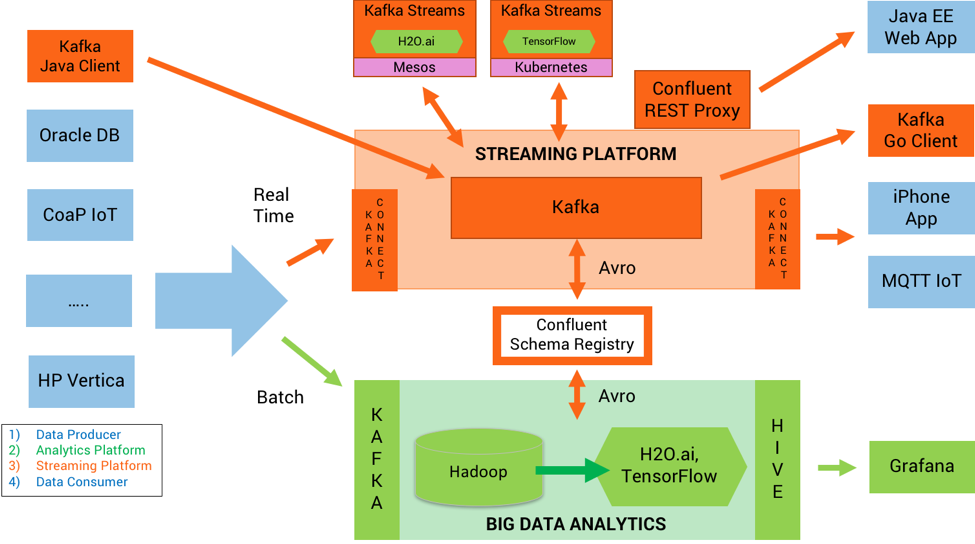
在绿色区域,我们可以看到用于构建和验证分析模型的组件。在橙色区域,我们可以看到流式平台,分析模型就部署在该平台上,用于对新事件做出推理以及执行监控。
数据生产者持续地发送事件,分析平台以批次或实时的方式接收这些数据,然后使用机器学习算法来构建分析模型。分析模型被部署在流式平台上,流式平台将分析模型应用在事件上,从而推理出结果(也就是预测),最后结果被发送给数据消费者。
在这个例子里,我们将模型训练和模型推理分离开,这在当今的大部分机器学习项目中是很常见的做法。
模型训练
数据经由Kafka集中到Hadoop集群上,进而使用H2O.ai分析这些历史数据,构建出神经网络。数据科学家可以使用各种接口来完成这项工作——R语言、Python、Scala、Web UI Notebook等。模型的构建和验证就发生在Hadoop集群上,最后得到一个Java字节码形式的分析模型,接下来就可以将它们部署到生产环境。
模型推理
神经网络被部署到Kafka Streams应用程序里。Streams应用程序可以运行在任何地方,它可以作为单独的Java进程运行,也可以运行在Docker容器里或Kubernetes集群上。模型被实时地应用在每一个新生成的事件上。Kafka Streams借助Kafka集群为我们提供了可伸缩、任务关键型的分析模型操作以及高性能的模型推理。
在线模型训练
除了分离模型训练和模型推理,我们也可以为在线模型训练构建一个完整的基础设施。很多巨头科技公司(比如LinkedIn)在过去就将Apache Kafka作为模型的输入、训练、推理和输出的基础。当然,这种做法存在一些权衡。大部分传统的公司会使用第一种方案,它可以满足现今大部分的使用场景。
模型监控和告警
将分析模型部署到生产环境只是第一步,对模型的准确性、分数、SLA和其他度量指标进行监控并自动实时地发出告警也同样重要。度量指标可以通过Kafka反馈给机器学习工具,用于改进模型。
使用H2O.ai开发分析模型
以下是使用H2O来构建分析模型的例子。H2O是一个开源的机器学习框架,它在内部使用了其他框架,如Apache Spark或TensorFlow。数据科学家可以在上面使用他们喜欢的编程语言,如R语言、Python或Scala。H2O引擎会生成Java字节码,可以很方便地通过Streams进行伸缩。
下面是使用H2O.ai Flow(Web UI或Notebook)和R语言构建分析模型的截图:
(点击放大图像)
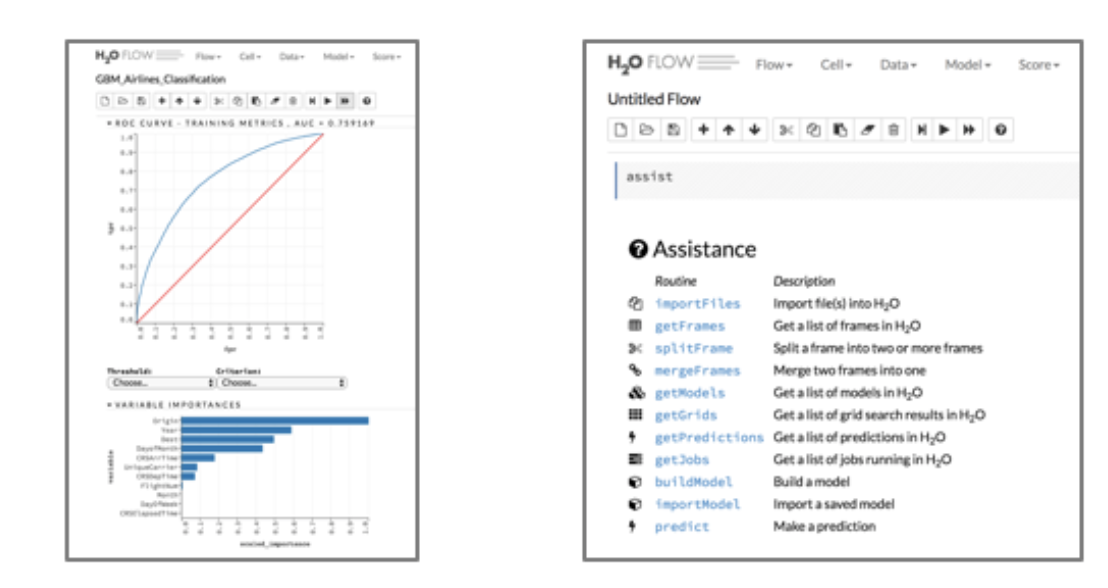

输出的是一个字节码形式的分析模型,它可以直接部署到任务关键型的生产环境里。因此,我们就不再需要花时间去考虑如何将Python或R生成的模型“移植”到基于Java平台的生产系统里。
这个例子使用H2O来产生Java字节码,当然,你也可以使用其他框架(如TensorFlow、Apache MXNet或DeepLearning4J)完成类似的工作。
使用Kafka Steams API部署分析模型
使用Kafka Streams来部署分析模型非常简单,只要将模型添加到基于Streams构建的应用程序里就可以了,然后将其应用在新生成的事件上。
(点击放大图像)
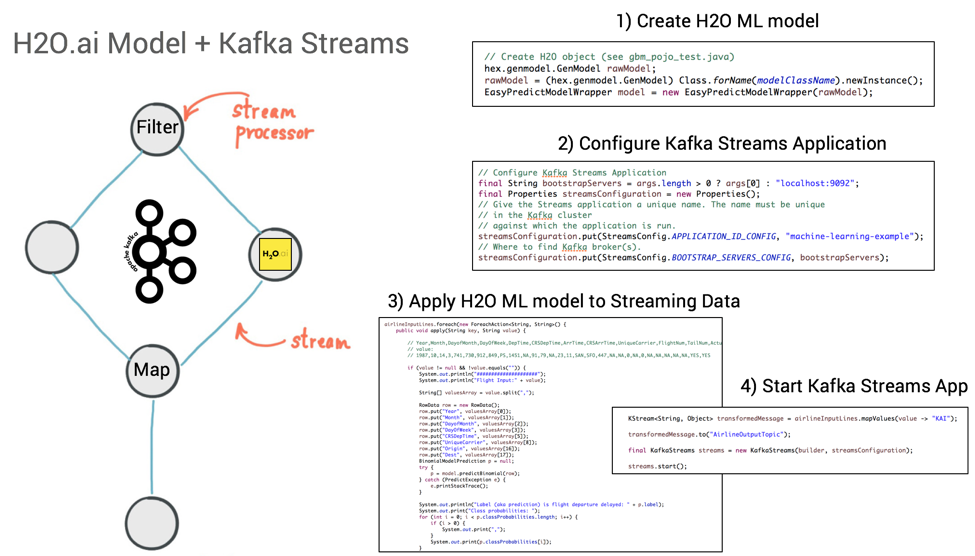
因为Kafka Streams应用程序实际上用到了Kafka的特性,所以已经具备了伸缩性和任务关键型用途,不需要对模型做出任何调整。
例子的代码可以在GitHub上找到:https://github.com/kaiwaehner/ kafka-streams-machine-learning-examples。拉取项目代码,运行maven构建命令,就可以看到H2O模型是如何与Kafka Streams应用集成在一起的。后续我们会不断扩充这个例子,加入更多复杂的应用场景,不仅使用H2O,还会加入TensorFlow和DeepLearning4J。
借助一些CI/CD工具,如Maven、Gradle、Chef、Puppet、Jenkins,机器学习与流式处理相结合的方式可以很容易地被集成到自动化持续集成工作流当中。
使用开放标准在训练和推理之间共享分析模型
以下是其他一些用于在数据科学家之间共享和更新模型以及DevOps团队部署模型的方式。
- 原生模型(Native Model):直接将模型部署到流式处理引擎里,比如通过JNI将Python模型部署到Java应用程序里
- 字节码生成(Generated Code):不管使用哪一种编程语言来构建模型,都可以通过生成二进制库或源代码的方式将它们部署到流式处理应用里。它们经过优化,可以获得更好的性能。例如,数据科学家使用R语言或Python训练的模型可以转成Java字节码的形式。
- 外部服务器(External Server):以请求和响应的方式调用外部的分析服务器。外部调用可以通过SAS、MATLAB、KNIME或H2O这类分析工具来完成,它们一般会提供REST接口。
- PMML(预测模型标记语言):这是一种比较古老的XML标准,尽管还存在一些局限和不足,一些分析工具仍然在支持它。
- PFA(可移植分析格式):一种新标准,可以为模型提供预处理,利用了JSON、Apache Avro,并支持Hadrian。不过大部分分析工具并没有为它提供开箱即用的支持。
以上这些方案之间存在权衡的关系。例如,PFA带来了独立性和可移植性,但同时也存在一些限制。从Kafka角度来看,如果要部署大规模的任务关键型系统,使用Java字节码生成的方式会更加合适,因为这种方式具有更高的性能、更容易伸缩,并且更容易嵌入到Kafka Streams应用中。同时,在进行模型预测时,它免去了与外部REST服务器交互的成本。
结论
机器学习为行业带来了价值,Kafka迅速成为很多企业的中枢神经系统。我们可以借助Kafka来:
- 进行实时的模型推理
- 监控和告警
- 在线训练模型
- 将数据摄取到批次层或分析集群上进行分析模型的训练
|









