| 基础架构(Infrastructure)相比于大数据、云计算、深度学习,并不是一个很火的概念,甚至很多程序员就业开始就在用
MySQL、Django、Spring、Hadoop 来开发业务逻辑,而没有真正参与过基础架构项目的开发。在机器学习领域也是类似的,借助开源的
Caffe、TensorFlow 或者 AWS、Google CloudML 就可以实现诸多业务应用,但框架或平台可能因行业的发展而流行或者衰退,而追求高可用、高性能、灵活易用的基础架构却几乎是永恒不变的。
Google 的王咏刚老师在《为什么 AI 工程师要懂一点架构》提到,研究院并不能只懂算法,算法实现不等于问题解决,问题解决不等于现场问题解决,架构知识是工程师进行高效团队协作的共同语言。Google
依靠强大的基础架构能力让 AI 研究领先于业界,工业界的发展也让深度学习、Auto Machine
Learning 成为可能,未来将有更多人关注底层的架构与设计。
因此,今天的主题就是介绍机器学习的基础架构,包括以下的几个方面:
1.基础架构的分层设计;
2.机器学习的数值计算;
3.TensorFlow 的重新实现;
4.分布式机器学习平台的设计。
第一部分,基础架构的分层设计
大家想象一下,如果我们在 AWS 上使用编写一个 TensorFlow 应用,究竟经过了多少层应用抽象?首先,物理服务器和网络宽带就不必说了,通过
TCP/IP 等协议的抽象,我们直接在 AWS 虚拟机上操作就和本地操作没有区别。其次,操作系统和编程语言的抽象,让我们可以不感知底层内存物理地址和读写磁盘的
System call,而只需要遵循 Python 规范编写代码即可。然后,我们使用了 TensorFlow
计算库,实际上我们只需调用最上层的 Python API,底层是经过了 Protobuf 序列化和
swig 进行跨语言调研,然后通过 gRPC 或者 RDMA 进行通信,而最底层这是调用 Eigen
或者 CUDA 库进行矩阵运算。
因此,为了实现软件间的解耦和抽象,系统架构常常采用分层架构,通过分层来屏蔽底层实现细节,而每一个底层都相当于上层应用的基础架构。
那么我们如何在一个分层的世界中夹缝生存?
有人可能认为,既然有人实现了操作系统和编程语言,那么我们还需要关注底层的实现细节吗?这个问题没有标准答案,不同的人在不同的时期会有不同的感受,下面我举两个例子。
在《为了 1% 情形,牺牲 99% 情形下的性能:蜗牛般的 Python 深拷贝》这篇文章中,作者介绍了
Python 标准库中 copy.deep_copy() 的实现,1% 的情况是指在深拷贝时对象内部有可能存在引用自身的对象,因此需要在拷贝时记录所有拷贝过的对象信息,而
99% 的场景下对象并不会直接应用自身,为了兼容 100% 的情况这个库损失了 6 倍以上的性能。在深入了解
Python 源码后,我们可以通过实现深拷贝算法来解决上述性能问题,从而优化我们的业务逻辑。
另一个例子是阿里的杨军老师在 Strata Data Conference 分享的《Pluto:
一款分布式异构深度学习框架》,里面介绍到基于 TensorFlow 的 control_dependencies
来实现冷热数据在 GPU 显存上的置入置出,从而在用户几乎不感知的情况下极大降低了显存的使用量。了解源码的人可能发现了,TensorFlow
的 Dynamic computation graph,也就是 tensorflow/fold 项目,也是基于
control_dependencies 实现的,能在声明式机器学习框架中实现动态计算图也是不太容易。这两种实现都不存在
TensorFlow 的官方文档中,只有对源码有足够深入的了解才可能在功能和性能上有巨大的突破,因此如果你是企业内
TensorFlow 框架的基础架构维护者,突破 TensorFlow 的 Python API 抽象层是非常有必要的。
大家在应用机器学习时,不知不觉已经使用了很多基础架构的抽象,其中最重要的莫过于机器学习算法本身的实现,接下来我们将突破抽象,深入了解底层的实现原理。
第二部分,机器学习的数值计算
机器学习,本质上是一系列的数值计算,因此 TensorFlow 定位也不是一个深度学习库,而是一个数值计算库。当我们听到了香农熵、贝叶斯、反向传播这些概念时,并不需要担心,这些都是数学,而且可以通过计算机编程实现的。
接触过机器学习的都知道 LR,一般是指逻辑回归(Logistic regression),也可以指线性回归(Linear
regression),而前者属于分类算法,后者属于回归算法。两种 LR 都有一些可以调优的超参数,例如训练轮数(Epoch
number)、学习率(Learning rate)、优化器(Optimizer)等,通过实现这个算法可以帮忙我们理解其原理和调优技巧。
下面是一个最简单的线性回归 Python 实现,模型是简单的 y = w * x + b。
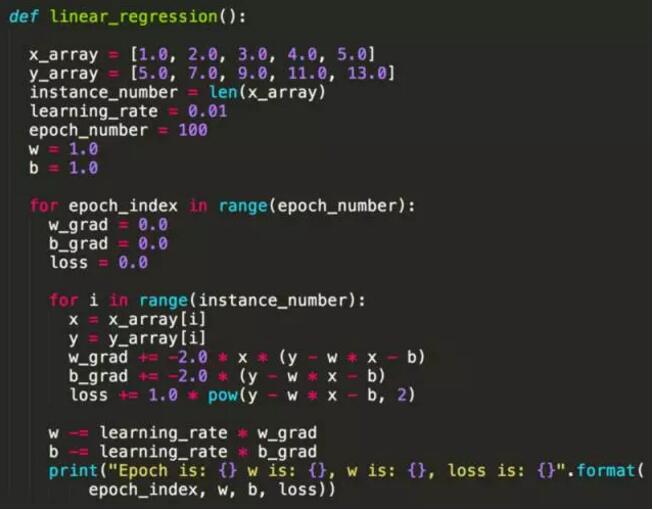
从这个例子大家可以看到,实现一个机器学习算法并不依赖于 Scikit-learn 或者 TensorFlow
等类库,本质上都是数值运算,不同语言实现会有性能差异而已。细心的朋友可能发现,为什么这里 w 的梯度(Gradient)是
-2 * x * (y – x * x –b),而 b 的梯度这是 -2 * (y – w * x
- b),如何保证经过计算后 Loss 下降而准确率上升?这就是数学上保证了,我们定义了 Loss
函数(Mean square error)为 y – w * x - b 的平方,也就是说预测值越接近
y 的话 Loss 越小,目标变成求 Loss 函数在 w 和 b 的任意取值下的最小值,因此对 w
和 b 求偏导后就得到上面两条公式。
如果感兴趣,不妨看一下线性回归下 MSE 求偏导的数学公式证明。

逻辑回归与线性回归类似,当由于是分类问题,因此需要对 w * x + b 的预测结果进行归一化(Normalization),一般使用
Sigmoid 方法,在 Python 中可以通过 1.0 / (1 + numpy.exp(-x))
这种方式实现。由于预测值不同,Loss 函数的定义也不同,求偏导得到的数值计算公式也不同,感兴趣也可以看看我的公式推导。


大家可以看到最终求得的偏导是非常简单的,用任何编程语言都可以轻易实现。但我们自己的实现未必是最高效的,为什么不直接用
Scikit-learn、MXNet 这些开源库已经实现好的算法呢?
我们对这个算法的理解,其实是在工程上使用它的一个很重要的基础。例如在真实的业务场景下,一个样本的特征可能有百亿甚至千亿维,而通过前面的算法我们了解到,LR
模型的大小和样本特征的维度是相同的,也就是说一个接受百亿维特征的模型,本身参数就有百亿个,如果使用标准的双精度浮点数保存模型参数,那么百亿维的模型参数部分至少要超过
40G,那么千亿维的特征更是单机所无法加载的。
因此,虽然 Scikit-learn 通过 native 接口实现了高性能的 LR 算法,但只能满足在单机上训练,而
MXNet 由于原生没有支持 SpareTensor,对于超高维度的稀疏数据训练效率是非常低的,TensorFlow
本身支持 SpareTensor 也支持模型并行,可以支持百亿维特征的模型训练,但没有针对 LR 优化效率也不是很高。在这种场景下,第四范式基于
Parameter server 实现了支持模型并行和数据并行的超高维度、高性能机器学习库,在此基础上的大规模
LR、GBDT 等算法训练效率才能满足工程上的需求。
机器学习还有很多有意思的算法,例如决策树、SVM、神经网络、朴素贝叶斯等等,只需要部分数学理论基础就可以轻易在工程上实现,由于篇幅关系这里就不在赘述了。前面我们介绍的其实是机器学习中的命令式(Imperative)编程接口,我们把求偏导的公式提前推导出来,然后像其他编程脚本一样根据代码那顺序执行,而我们知道
TensorFlow 提供的是一种声明式(Declarative)的编程接口,通过描述计算图的方式来延后和优化执行过程,接下来我们就介绍这方面的内容。
第三部分,TensorFlow 的重新实现
首先大家可能有疑问,我们需要需要重新实现 TensorFlow?TensorFlow 灵活的编程接口、基于
Eigen 和 CUDA 的高性能计算、支持分布式和 Hadoop HDFS 集成,这些都是个人甚至企业很难完全追赶实现的,而且即使需要命令式编程接口我们也可以使用
MXNet,并没有强需求需要一个新的 TensorFlow 框架。
事实上,我个人在学习 TensorFlow 过程中,通过实现一个 TensorFlow-like
的项目,不仅惊叹与其源码和接口的设计精巧,也加深了对声明式编程、DAG 实现、自动求偏导、反向传播等概念的理解。甚至在
Benchmark 测试中发现,纯 Python 实现的项目在线性回归模型训练中比 TensorFlow
快 22 倍,当然这是在特定场景下压测得到的结果,主要原因是 TensorFlow 中存在 Python
与 C++ 跨语言的切换开销。
这个项目就是 MiniFlow,一个实现了链式法则、自动求导、支持命令式编程和声明式编程的数值计算库,并且兼容
TensorFlow Python API。感兴趣可以在这个地址参与开发,下面是两者 API 对比图。
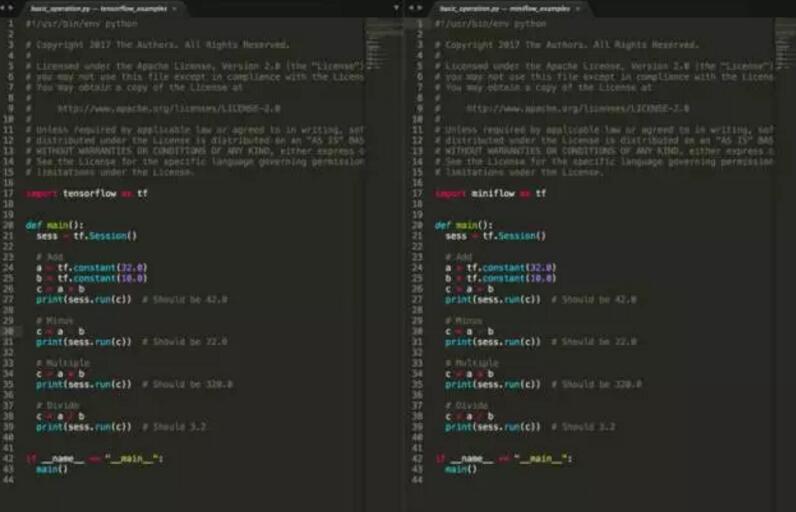
了解 TensorFlow 和 MXNet(或者 NNVM)源码的朋友可能知道,两者都抽象了 Op、Graph、Placeholer、Variable
等概念,通过 DAG 的方式描述模型的计算流图,因此我们也需要实现类似的功能接口。
与前面的 LR 代码不同,基于 Graph 的模型允许用户自定义 Loss 函数,也就是用户可以使用传统的
Mean square error,也可以自定义一个任意的数学公式作为 Loss 函数,这要求框架本身能够实现自动求导的功能,而不是我们根据
Loss 函数预先实现了导数的计算方式。
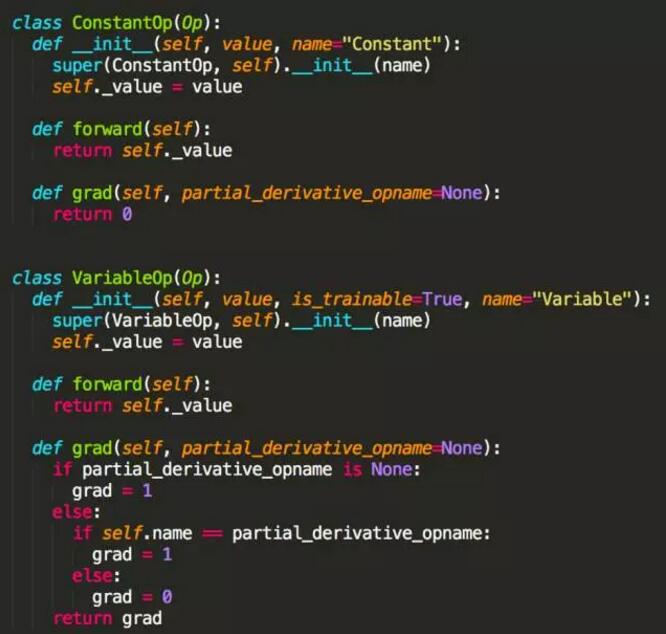
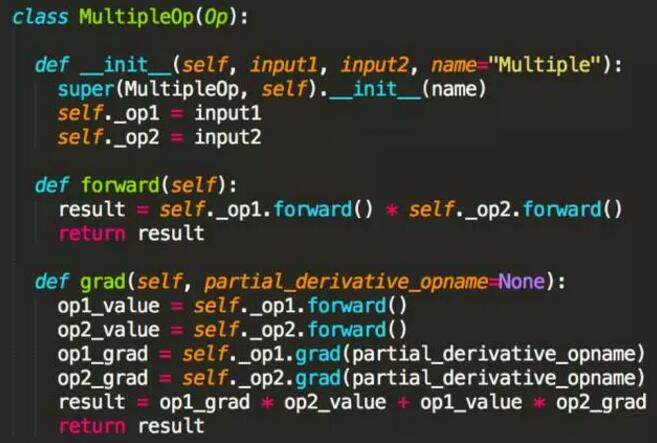
那么用户可以定义的最小操作,也就是 Op,需要平台实现基本的算子,例如 ConstantOp、AddOp、MultipleOp
等,而且用户实现自定义算子时可以加入自动求导的流程中,并不影响框架本身的训练流程。参考 TensorFlow
的 Python 源码,下面我们定义了 Op 的基类,所有的 Op 都应该实现 forward()
和 grad() 以便于模型训练时自动求导,而且通过重载 Python 操作符可以为开发者提供更便利的使用接口。

那么对于常量(ConstantOp)和变量(VariableOp),他们的正向运算就是得到的是本身的值,而求导时常量的导数为
0,求偏导的变量导数为 1,其他变量也为 0,具体代码如下。
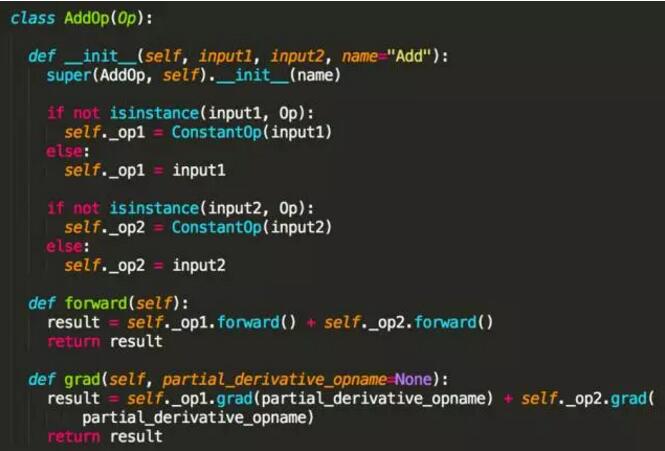
其实更重要的是,我们需要实现加(AddOp)、减(MinusOp)、乘(MultipleOp)、除(DivideOp)、平方(PowerOp)等算子的正向运算和反向运算逻辑,然后根据链式法则,任何复杂的数学公式求导都可以简化成这些基本算子的求导。
例如加法和减法,我们知道两个数加法的导数等于导数的加法,因此根据此数学原理,我们可以很容易实现 AddOp,而
MinusOp 实现类似就不赘述了。
而乘法和除法相对复杂,显然两个数乘法的导数不等于导数的乘法,例如 x 和 x 的平方,先导数后相乘得到
2x,先相乘后导数得到 3 倍 x 的平方。因此这是需要使用乘数法则,基本公式是,而代码实现如下。
除法和平方的求导方式也是类似的,因为数学上已经证明,所以只需要编码实现基本的正向和反向运算即可。由于篇幅有限,这里不再细致介绍
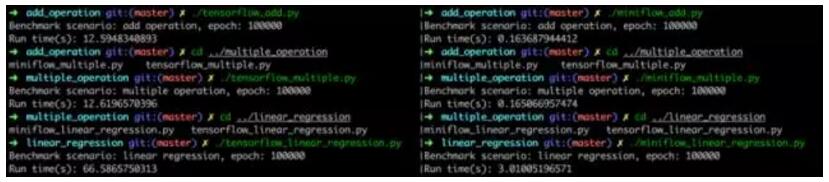
MiniFlow 的源码实现了,感兴趣可以通过上面的 Github 链接找到完整的源码实现,下面再提供使用相同
API 接口实现的模型性能测试结果,对于小批量数据处理、需要频繁切换 Python/C++ 运行环境的场景下
MiniFlow 会有更好的性能表现。
前面介绍了机器学习算法和深度学习类库的实现,并不是所有人都有能力去重写或者优化这部分基础架构的,很多时候我们都只是这些算法的使用者,但从另一个角度,我们就需要维护一个高可用的计算平台来做机器学习的训练和预测,下面将从这方面介绍如何打造分布式机器学习平台。
第四部分,分布式机器学习平台的设计
随着大数据和云计算的发展,实现一个高可用、分布式的机器学习平台成为一个基本需求。无论是 Caffe、TensorFlow,还是我们自研的高性能机器学习库,都只是解决数值计算、算法实现以及模型训练的问题,对于任务的隔离、调度、Failover
都需要上层平台实现。
那么设计一个针对机器学习全流程的基础架构平台,需要涵盖哪些功能呢?
首先,必须实现资源隔离。在一个共享底层计算资源的集群中,用户提交的训练任务不应该受到其他任务的影响,尽可能保证
CPU、内存、GPU 等资源隔离。如果使用 Hadoop 或 Spark 集群,默认就会在任务进程上挂载
cgroups,保证 CPU 和内存的隔离,而随着 Docker 等容器技术的成熟,我们也可以使用
Kubernetes、Mesos 等项目来启动和管理用户实现的模型训练任务。
其次,实现资源调度和共享。随着通用计算的 GPU 流行,目前支持 GPU 调度的编排工具也越来越多,而部分企业内还存在着
GPU 专卡专用的情况,无法实现资源的动态调度和共享,这必然导致计算资源的严重浪费。在设计机器学习平台时,需要尽可能考虑通用的集群共享场景,例如同时支持模型训练、模型存储以及模型服务等功能,可以对标的典例就是
Google Borg 系统。
然后,平台需要有灵活的兼容性。目前机器学习业务发展迅速,针对不同场景的机器学习框架也越来越多,灵活的平台架构可以兼容几乎所有主流的应用框架,避免基础架构因为业务的发展而频繁变化。目前
Docker 是一种非常合适的容器格式规范,通过编写 Dockerfile 就可以描述框架的运行环境和系统依赖,在此基础上我们可以在平台上实现了
TensorFlow、MXNet、Theano、CNTK、Torch、Caffe、Keras、Scikit-learn、XGBoost、PaddlePaddle、Gym、Neon、Chainer、PyTorch、Deeplearning4j、Lasagne、Dsstne、H2O、GraphLab
以及 MiniFlow 等框架的集成。
最后,需要实现机器学习场景下的 API 服务。针对机器学习的模型开发、模型训练和模型服务三个主要流程,我们可以定义提交训练任务、创建开发环境、启动模型服务、提交离线预测任务等
API,用熟悉的编程语言来实现 Web service 接口。要实现一个 Google-like 的云深度学习平台,大家可以参考下面这三个步骤。

当然,要实现一个涵盖数据引入、数据处理、特征工程以及模型评估功能的机器学习平台,我们还需要集成 HDFS、Spark、Hive
等大数据处理工具,实现类似 Azkaban、Oozie 的工作流管理工具,在易用性、低门槛方面做更多的工作。
总结
最后总结一下,机器学习的基础架构包含了机器学习算法、机器学习类库以及机器学习平台等多个层次的内容。根据业务的需求,我们可以选择特定的领域进行深入研究和二次开发,利用轮子和根据需求改造轮子同样重要。
在机器学习与人工智能非常流行的今天,希望大家也可以重视底层基础架构,算法研究员可以 理解更多工程的设计与实现,而研发工程师可以了解更多的算法原理与优化,在合适的基础架构平台上让机器学习发挥更大的效益,真正应用的实际场景中。
今天分享的内容到这里了,非常感谢大家 :)
答疑环节
Q 1:老师您好! 我的问题是 基础架构在具体落地方面 有什么建议?比如在云上部署和虚拟化容器技术的使用?
陈迪豪:基础架构其实包含多层次的内容,如果在云端部署,可以考虑使用 AWS 或者 Google CloudML
等基础服务,也可以基于 Kubernetes、TensorFlow 等开源项目这内部搭建机器学习平台,参考前面图片提到的三个步骤,只需要实现简单的
API 服务和容器调度任务即可。
Q 2:老师好,接触(机器学习)之前需要深入学习 spark 吗?
陈迪豪:机器学习算法本身并依赖 Spark,我们可以自己实现基本的算法,也可以使用 Scikit-learn、TensorFlow
等开源库。当然在大部分业务场景中,我们还是需要 Hadoop、Spark 等大数据框架进行数据处理、特征抽取等功能,因此掌握一定的大数据处理能力也是很有价值的。
Q 3:我有个问题,怎样做到线下模型效果评估的自动化?
陈迪豪:这是个好问题,在线下我们一般会对测试数据集计算 AUC 等离线指标,来预估模型的效果,自动化方面我们有一套自学习的流程,大家也可以使用
Crontab 或者 Azkaban 等任务管理工具,对于新的测试集进行模型评估,这是纯工程的问题了可以结合已有的服务架构来实现。
Q 4:文中介绍的机器学习基础架构平台的搭建思路,是否就是先知平台的架构思路?先知平台是 SaaS
式的服务平台,如果我是想搭建公司内部的机器学习架构平台,思路也是跟文中描述一样还是说有什么差异?
陈迪豪:先知平台的底层也是分布式、高可用的基础架构,也是这个思路,不过在易用性、低门槛方面做了更多的工作。目前先知提供
SaaS 公有云版本可以很方便得注册使用,如果是企业内部搭建,先知平台也有企业版私有云可以单独部署,如果需要自己维护和搭建机器学习平台,可以考虑基于
Kubernetes 的容器调度集群,可以通过管理 CPU、GPU 等异构资源,通过制作 Docker
镜像的方式来支持各种机器学习框架的使用,和前面提到的思路类似。
Q 5:对于一般的公司数据规模没那么大,是不是一个高配的机器 +4 个 GPU 卡,安装一个 tensorflow
就可以了?
陈迪豪:对于规模比较小的公司,可以直接使用单机多卡的方式,包括 BAT 等大企业有的部门也是直接使用裸机的,但裸机带来的问题是没有资源管理和任务调度,使用者之间需要互相约定使用时间和使用的资源,在一定程度上造成资源浪费,如果规模大了建议使用统一的集群调度方式,可以保证任务间的资源隔离和正常执行。
Q 6:正如老师在群里上课提的,在工程上,在真实的业务场景下,一个样本的特征是百亿甚至千亿,在线下的时候,训练好一个模型,部署在服务器端。那么,在线服务阶段,也就是在线服务的预测阶段的时候,由于发起预测请求的样本特征也比较大,那么请问在实际工程中这些数据是怎么存储的?
陈迪豪:在一个百亿甚至是千亿维的模型上,我们一般通过分 shard 的方式来切分,模型本身可以通过多个
Parameter server 实例来保存,而客户端发送预测请求时,由于特征是非常稀疏的,实际有值的数据非常少,因此并不需要把大部分零值数据也请求到服务端,具体格式大家也可以参考下
TensorFlow 中 SparseTensor 的实现。
Q 7:请问先知目前平台的算法是基于开源算法封装还是自己实现的呢?
陈迪豪:目前先知平台主要针对真实的应用场景,自主研发的大规模 LR、GBDT、HE-TreeNet、LFC、SVM、Feature-go
等算法都集成到先知平台上,当然平台也支持 Spark MLlib、TensorFlow 等开源框架的算法实现。
|









