НшжњKerasКЭTensorflowЃЌЪЙгУЩюЖШбЇЯАММЪѕЖдЙКЮяЧхЕЅНјааХХађЁЃ
ШеГЃВЩТђКмТщЗГ
ЩЬЕъКмДѓЃЌЩЬЦЗГТСаКмИДдгЃЌКмШнвзЙфЕНУдЪЇЦфжаЁЃФуЯыТђЕФгЅзьЖЙФрПЩФмАкдкШщЦЗЧјЁЂЪьЪГЧјЃЌЩѕжСЦфЫћФуИљБОЯыВЛЕНЕФЕиЗНЁЃШчКЮдкЩЬЕъРяПьЫйзМШЗЕиевЕНздМКЯыТђЕФЖЋЮїЃЌетЪЧИіКмМшОоЕФШЮЮёЁЃ
InstacartЕФФПБъЪЧАяжњПЭЛЇДгЪ§АйИіСуЪлЩЬКЯзїЛяАщДІЖЉЙКЩЯАйЭђжжВњЦЗЁЃЮвУЧЁАЙКЮяЙЫЮЪЁБЭХЖгжаГЩЧЇЩЯЭђЕФГЩдББиаыФмзМШЗЕидкЪ§ЧЇИіЕъЦЬПьЫйевЕНПЭЛЇЯывЊЙКТђЕФЩЬЦЗЁЃвђДЫБиаыЯыЗНЩшЗЈШУетвЛЙ§ГЬОЁПЩФмПьЫйЁЃ

ЩюЖШбЇЯАММЪѕЁАМгГжЁБЕФЙКЮяЬхбщ
ЩюЖШбЇЯАШыУХ
ЭЈЙ§заЯИЦРЙРЙКЮяЙЫЮЪЮЊЭЈЙ§гІгУЯТЕЅЕФЪ§АйЭђЙЫПЭЬєбЁЩЬЦЗЕФЙ§ГЬЃЌЮвУЧЙЙНЈСЫвЛИіФЃаЭЃЌетИіФЃаЭПЩвддЄВтЙЫЮЪЭЈЙ§дѕбљЕФЫГађРДШЁЛѕПЩвдЪЕЯжзюИпаЇТЪЁЃЫцКѓЕБЙЫЮЪНгЕНаТЖЉЕЅКѓЃЌЮвУЧЛсЪЙгУдЄВтНсЙћЮЊЫћУЧЬсЙЉзюгХЛЏЕФШЁЛѕЫГађЁЃ
етИіЗНЗЈПЩвдШУЙЫЮЪЕФУПДЮШЁЛѕЙ§ГЬНкдМвЛЗжжгЁЃПМТЧЕНвЕЮёЕФХгДѓЙцФЃЃЌУПДЮШЁЛѕНкдМвЛЗжжгЃЌЕШгкУПФъПЩвдНкдМ618ФъЕФЙКЮяЪБМфЁЃ

ФЧУДЕНЕзИУдѕУДзіЃПЪзЯШЃЌЮвУЧУЛгаздМКЕФВжПтЃЌВЛФмОЋШЗСЫНтУПИіЕъЦЬЕФВжДЂЧщПіЛђГТСаВМОжЁЃДЫЭтЃЌгЩгкетИіЮЪЬтдкЫГађЗНУцЕФБОжЪЬиеїЃЌДЋЭГЕФЛњЦїбЇЯАЗНЗЈЃЈЮвУЧ?? XGBoostЃЉвВЬсЙЉВЛСЫЪВУДАяжњЁЃ

гкЪЧЮвУЧгІгУСЫвЛаЉЩюЖШбЇЯАММЪѕЁЃ
НјааЙ§ЕФВтЪд
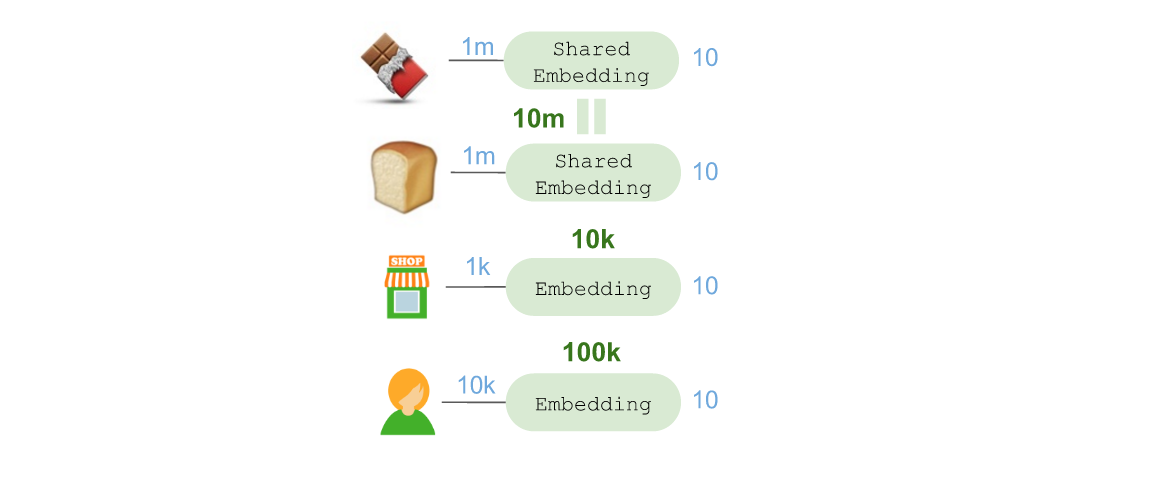
ЮвУЧНјааСЫвЛДЮВтЪдЃЌНЋУПХњЩЬЦЗЃЈвЛЮЛЙЫПЭбЁдёвЊЙКТђЕФвЛЯЕСаЩЬЦЗЃЉЫцЛњЗжХфИјЫФжжЧхЕЅХХађЫуЗЈжЎвЛЃК
- ControlЃЈКьЩЋЃЉЃКАДееВПУХЫцЛњХХађЃЌЭЌВПУХФкЩЬЦЗАДзжФИЫГађХХађЃЛ
- HumanЃЈТЬЩЋЃЉЃКЪЙгУЕъЦЬГТСаВМОжАДееЕъЦЬзпЕРХХађЃЌЭЌзпЕРФкЩЬЦЗАДзжФИЫГађХХађЃЛ
- TSPЃЈЧрЩЋЃЉЃКЪЙгУПчВПУХЩЬЦЗЬєбЁЦНОљЪБМфЙЙНЈЕФЁАбВЛиЭЦЯњдБЁБНтОіЗНАИЃЌЭЌВПУХФкЩЬЦЗАДзжФИЫГађХХађЃЛ
- DeepЃЈзЯЩЋЃЉЃКзюжеЕФЩюЖШбЇЯАМмЙЙЃЌжБНгЖдУПХњжаЕФВЛЭЌЩЬЦЗНјааХХађЁЃ
ЫцКѓЮвУЧбаОПСЫУПжжХХађЗНЪНдкЙКЮяЫйЖШЃЈYжсЃЉКЭУПХњЫљКЌЩЬЦЗЪ§СПЃЈXжсЃЉжЎМфЕФЙиЯЕЃК
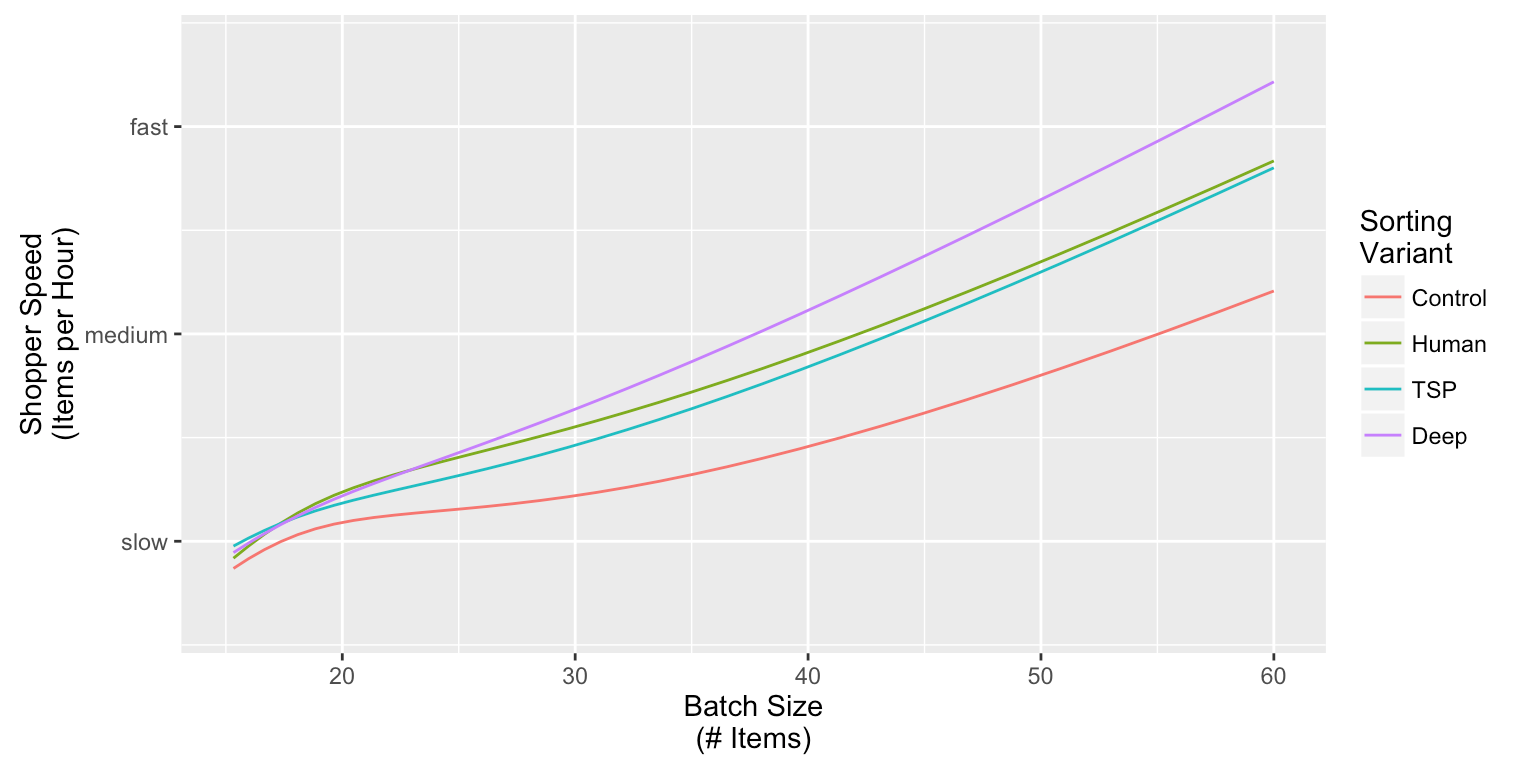
ЧызЂвтЃЌЮвУЧвўВиСЫЪЕМЪЕФЩЬЦЗЬєбЁЫйЖШЃЌвђЮЊЖдInstacartЕФОКељСІРДЫЕетЪЧИіЗЧГЃУєИаЕФKPIЁЃ
ControlХХађЗНЪНБэЯжзюВюЃЈвтСЯжЎжаЃЉЁЃTSPКЭHumanЕФБэЯжКУКмЖрЃЌЕЋДгЭГМЦНсЙћРДПДСНепУЛгаЬЋДѓВювьЁЃ
ЩюЖШбЇЯАФЃаЭдЖдЖЪЄГіЦфЫћХХађЗНЪНЃЌЖдгкАќКЌЩЬЦЗНЯЖрЕФЖЉЕЅЃЌдкЬєбЁЫйЖШЗНУцЃЌДгHumanЕНЩюЖШбЇЯАЗНЪНЕФЬсЩ§ЗљЖШБШДгControlЕНHumanЗНЪНЕФЬсЩ§ЗљЖШГЌЙ§СЫ50%ЁЃ
ЯТЮФНЋНщЩмЮвУЧЫљУцСйЕФЮЪЬтЃЈЕБШЛЛсЪЙгУemojiБэЧщРДНщЩмЃЉЃЌвдМАзюГѕЪЙгУЕФВЂВЛГЩЪьЕФМмЙЙЁЃЯТЮФНЋЯъЯИЗжЮіИУМмЙЙВЂСаОйвЛаЉживЊЕФШБЯнЃЌЫцКѓНщЩмИќИпаЇЃЌаЇЙћвВИќКУЕФзюжеМмЙЙЁЃ
ЭЈЙ§KerasНјааЧхЕЅХХађ
ЮЪЬтЖЈвх
МйЩшФГЮЛЙЫПЭЖЉЙКСЫ10МўЩЬЦЗЃЌЙКЮяЙЫЮЪАДееЯТСаЫГађФУШЁетаЉЩЬЦЗЃК

ЫцзХЙКЮяЙЫЮЪЖдЫљФУШЁЩЬЦЗНјааГЦжиЛђЩЈТыЃЌЮвУЧПЩвдПДЕНЯТУцетбљЕФЫГађЁЃЮЊСЫИќКУЕиСЫНтећИіЫГађЃЌашвЊНЋЦфзЊЛЛГЩвЛжжМрЙмЪНЕФбЇЯАЮЪЬтЁЃМйЩшЩдКѓдйжиаТЩѓЪгетИіЖЉЕЅЃЌВЂдкЙЫЮЪФУШЁСЫ??жЎКѓднЭЃЃК

ЮвУЧЯывЊдЄВтЙЫЮЪНгЯТРДЛсФУШЁЕФЩЬЦЗЃЈБОР§жаЪЧ??ЃЉЃЌПМТЧЕНЙЫЮЪИеИеФУЕН??ЃЌвђДЫдЄВтЙЄзїПЩвддкЪЃгрЕФЮхИіД§ЙКЩЬЦЗЃЈ?????????ЃЉжаНјааЁЃФуЖіСЫТ№ЃП
ЭЈЙ§emojiЪ§бЇЃЈОЭжАгкInstacartЕФКУДІжЎвЛОЭЪЧПЩвдгУemojiНтОіЪ§бЇЮЪЬтЃЉЃЌЮвУЧПЩвдНЋЦфжиаТаДзїЃК

ЧызЂвтЃЌетПЩФмЪЧвЛИіКмживЊЕФМЦЫуЮЪЬтЁЃЕЅЕЅПМТЧФУШЁУцАќжЎКѓдйФУШЁБ§ИЩетжжзіЗЈЕФЦЕТЪЪЧВЛЙЛЕФЁЃБ§ИЩвВаэЬЋЙ§гкЦеЭЈСЫЃЈМИКѕУПМвЖМгаЃЉЃЌвђДЫетИіПДЫЦМђЕЅЕФИХТЪПЩФмЛсБфЕУЯрЕБИпЁЃПМТЧЕННгЯТРДашвЊФУШЁЕФЩЬЦЗЪЧЙЬЖЈВЛБфЕФЃЌЮвУЧЯЃЭћКтСПНгЯТРДбЁдёФУШЁБ§ИЩЕФИХТЪЛсгаЖрИпЁЃ
ГѕЪММмЙЙ
ЮвУЧзюГѕЕФЩюЖШбЇЯАМмЙЙЪЙгУKerasЭЈЙ§TensorflowЪЕЯжЃЌШчЯТЭМЫљЪОЃК

ДгзѓБпПЊЪМЃЌашвЊФУШЁЕФЩЬЦЗЪЧ??ЃЌзюКѓЕНгвБпЃЌдЄВтЕННгЯТРДвЊФУШЁЕФЩЬЦЗЪЧ??ЁЃетвЛЙ§ГЬжаашвЊдЄВтНгЯТРДвЊФУШЁЕФВЛЭЌЩЬЦЗЁЃ
ЪзЯШвЊЬИЬИЁАЧЖШыЁБЃК
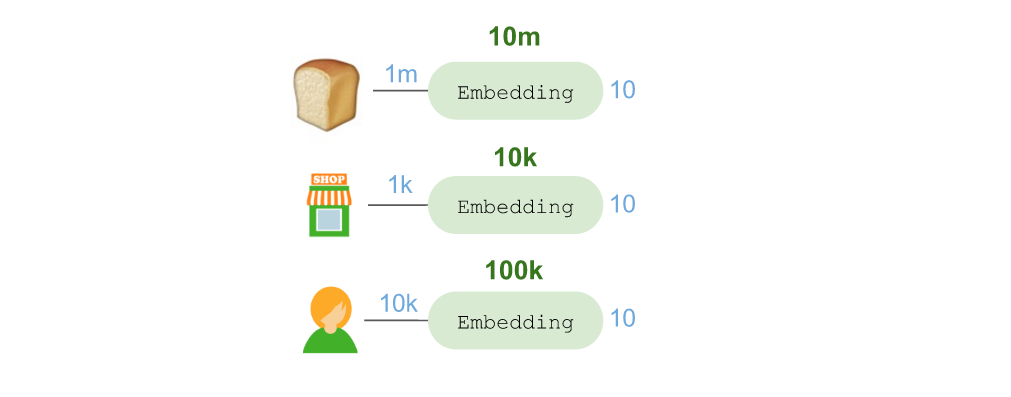
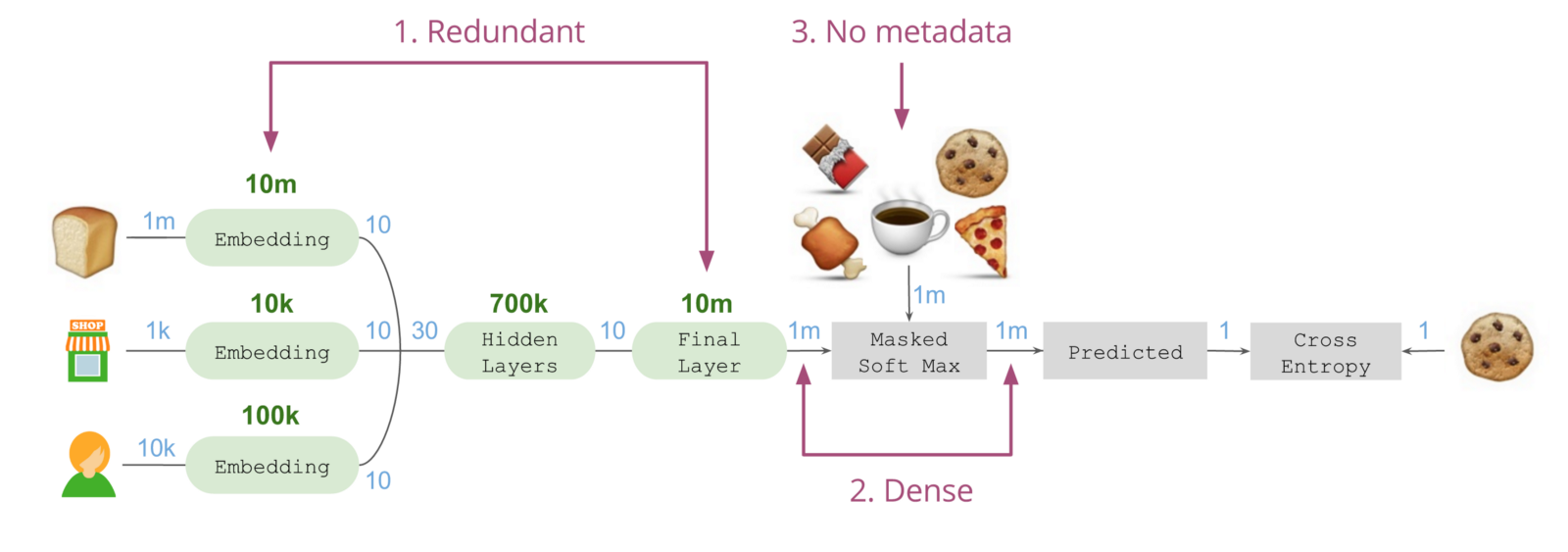
ЭЈЙ§ЪЙгУKerasЕФEmbeddingВуЃЌЮвУЧНЋ??ЧЖШыЕНвЛИі10ЮЌЯђСППеМфЁЃетЦфжаЙВЪЙгУСЫ1ЧЇЭђИіВЮЪ§ЃЌвђЮЊашвЊПМТЧ1АйЭђжжПЩФмашвЊЙКТђЕФЩЬЦЗЁЃЭЌРэЃЌЮвУЧЛЙЧЖШыСЫЕъЦЬЮЛжУЃЈ1ЧЇИіЕъЦЬ = 1ЭђИіВЮЪ§ЃЉКЭЙКЮяЙЫЮЪЃЈ1ЭђИіЙЫЮЪ = 10 ЭђИіВЮЪ§ЃЉЁЃ
ЧЖШыЕФЕъЦЬЮЛжУЪЙЕУетИіФЃаЭПЩвдбЇЯАЕъЦЬВМОжЃЌЖдСуЪлЩЬКЭЮЛжУНјааЙщФЩзмНсгыбЇЯАЁЃЧЖШыЕФЙКЮяЙЫЮЪПЩвдбЇЯАЙЫЮЪдкЕъЦЬФкЫљбЁдёЕФЮхЛЈАЫУХЕФТЗЯпЁЃ
ЫцКѓНЋЧЖШыЕФЫљгаФкШнСЌНгдквЛЦ№зщГЩСЫвЛИі30ЮЌЯђСПЃЌНЋЦфДЋШыЗЧЯпадМЄЛюЃЈreluЃЉЃЌШЋУцЛЅСЊЕФDenseвўВиВуЃЈ70ЭђИіВЮЪ§ЃЉађСаЁЃНшДЫЩњГЩвЛИіГЄЖШЮЊ10ЕФзюжеЯђСПЃЌНјЖјЛёШЁгаЙиЧАађЩЬЦЗЁЂЕъЦЬЮЛжУЃЌвдМАЙКЮяЙЫЮЪЕФЫљгаЯрЙиаХЯЂЃЌВЂШЗЖЈНгЯТРДзюКѓПЩФмвЊФУШЁЕФЩЬЦЗЁЃ
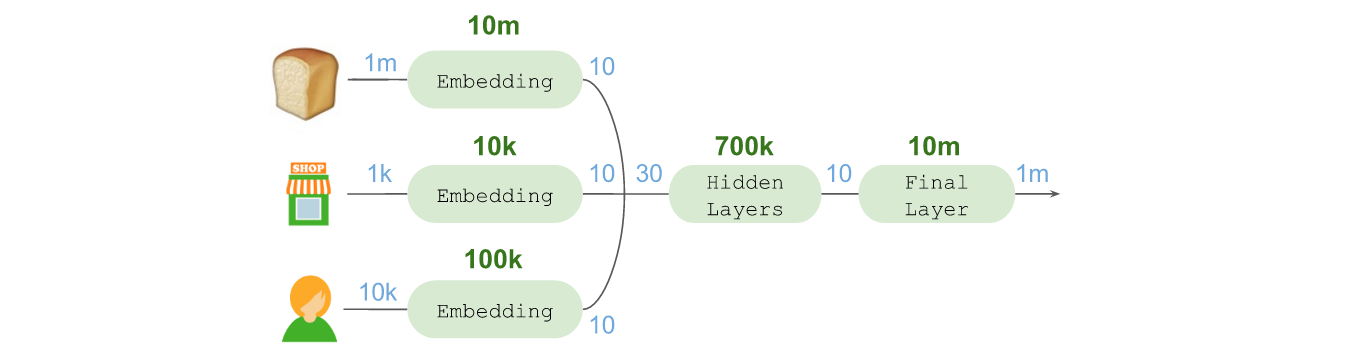
ЮЊСЫНјаадЄВтЃЌЮвУЧЛЙашвЊдкзюжеВуНјааЁАЩШГіЃЈFan outЃЉЁБЃЌетРрЫЦгквЛжжЗДЯђЧЖШыЁЃНшДЫПЩНЋЮвУЧЕФ10ЮЌЯђСПЭЖЩфЕНКѓајПЩФмФУШЁЕФЩЬЦЗЫљдкЕФПеМфжаЁЃетЪЧЭЈЙ§ЪЙгУlinearМЄЛюКЏЪ§ЕФDenseВуЪЕЯжЕФЁЃ
ЫцКѓПЩвдМЦЫуекежЃЈMaskЃЉКѓЕФSoft maxЃЌНшДЫНЋЫљгаЗЧКђбЁЩЬЦЗГЄЖШЩЯАйЭђЕФКђбЁЩЬЦЗЯђСПНЕЕЭжСЁАСуЁБЃЌВЂЙРЫуГі5ИіКђбЁЩЬЦЗЕФе§ЯђИХТЪЁЃетЪЧЭЈЙ§НЋИКд№жИЪ§ЛЏЕФLambdaВуЃЌгыЖдКђбЁЩЬЦЗНјааекежЕФMergeВуНсКЯдквЛЦ№ЃЌВЂСЌНгжССэвЛИіШЗБЃИХТЪзмКЭЕШгк100%ЕФLambdaВуЪЕЯжЕФЁЃ
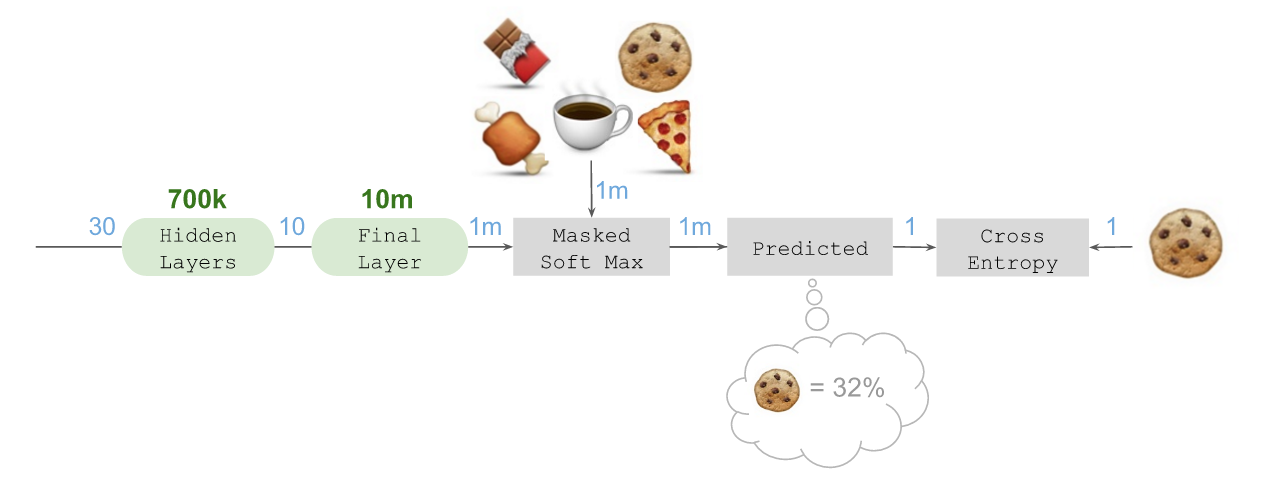
МйЩшБОР§жадЄВтЕННгЯТРДФУШЁ??ЃЈе§ШЗД№АИЃЉЕФИХТЪЮЊ32%ЃЌИУдЄВтЛсЫЭШывЛИіcategorical_crossentropyЫ№ЪЇКЏЪ§ЃЈLoss functionЃЉЃЌЭЌЪБЫЭШыЕФЛЙгаДњБэБОР§жаНгЯТРДЛсбЁдё??зїЮЊД§ФУШЁЕФЯТвЛИіЩЬЦЗЕФжИБъЁЃЫцКѓTensorflowЛсЖдДэЮѓаХЯЂдЫгУЗДЯђДЋВЅЃЈBackpropogateЃЉЫуЗЈЃЌНшДЫЖдвўВиЕФзюжеЧЖШыВуНјаабЕСЗЃЌЮвУЧБуПЩвддкДѓЙцФЃЛЗОГжабЇЯАЁЃ
KerasДњТы
ИУМмЙЙПЩЭЈЙ§ЯТСаДњТыгУKerasЪЕЯжЃК
from keras.models import Model
from keras.layers.core import Dense, Reshape, Lambda
from keras.layers import Input, Embedding, merge
from keras import backend as K
# Number of product IDs available
N_products = 1000000
N_stores = 1000
N_shoppers = 10000
# Integer IDs representing 1-hot encodings
prior_in = Input(shape=(1,))
store_in = Input(shape=(1,))
shopper_in = Input(shape=(1,))
# Dense N-hot encoding for candidate products
candidates_in = Input(shape=(N_products,))
# Embeddings
prior = Embedding(N_products, 10)(prior_in)
store = Embedding(N_stores, 10)(store_in)
shopper = Embedding(N_shoppers, 10)(shopper_in)
# Reshape and merge all embeddings together
reshape = Reshape(target_shape=(10,))
combined = merge([reshape(prior), reshape(store), reshape(shopper)],
mode='concat')
# Hidden layers
hidden_1 = Dense(1024, activation='relu')(combined)
hidden_2 = Dense(512, activation='relu')(hidden_1)
hidden_3 = Dense(256, activation='relu')(hidden_2)
hidden_4 = Dense(10, activation='linear')(hidden_3)
# Final 'fan-out' into the space of future products
final = Dense(N_products, activation='linear')(hidden_4)
# Ensure we do not overflow when we exponentiate
final = Lambda(lambda x: x - K.max(x))(final)
# Masked soft-max using Lambda and merge-multiplication
exponentiate = Lambda(lambda x: K.exp(x))(final)
masked = merge([exponentiate, candidates_in], mode='mul')
predicted = Lambda(lambda x: x / K.sum(x))(masked)
# Compile with categorical crossentropy and adam
mdl = Model(input=[prior_in, store_in, shopper_in, candidates_in],
output=predicted)
mdl.compile(loss='categorical_crossentropy',
optimizer='adam',
metrics=['accuracy']) |
initial_architecture.pyДњТыЭаЙмгк? GitHub
бЕСЗФЃаЭЕФЙ§ГЬжаЃЌзюКѓвЛИіОїЧЯдкгкЪЙгУfit_generatorНЋГЄЖШЩЯАйЭђЕФcandidateЪфШыФкШнМЦЫуЗЖЮЇЯожЦЮЊаЁЙцФЃЕФХњдЫЫуЁЃ
МьВтКЭОжЯо
етИіЭјТчзюгаШЄЕФЕиЗНдкгкзѓВрЫљЧЖШыЕФЩЬЦЗЁЃЮвУЧПЩвдЪЙгУt-SNEНјааЮЌЖШЫѕМѕЃЌНЋЧЖШыЕФФкШнЭЖЩфжСвЛИі2ЮЌПеМфЃК
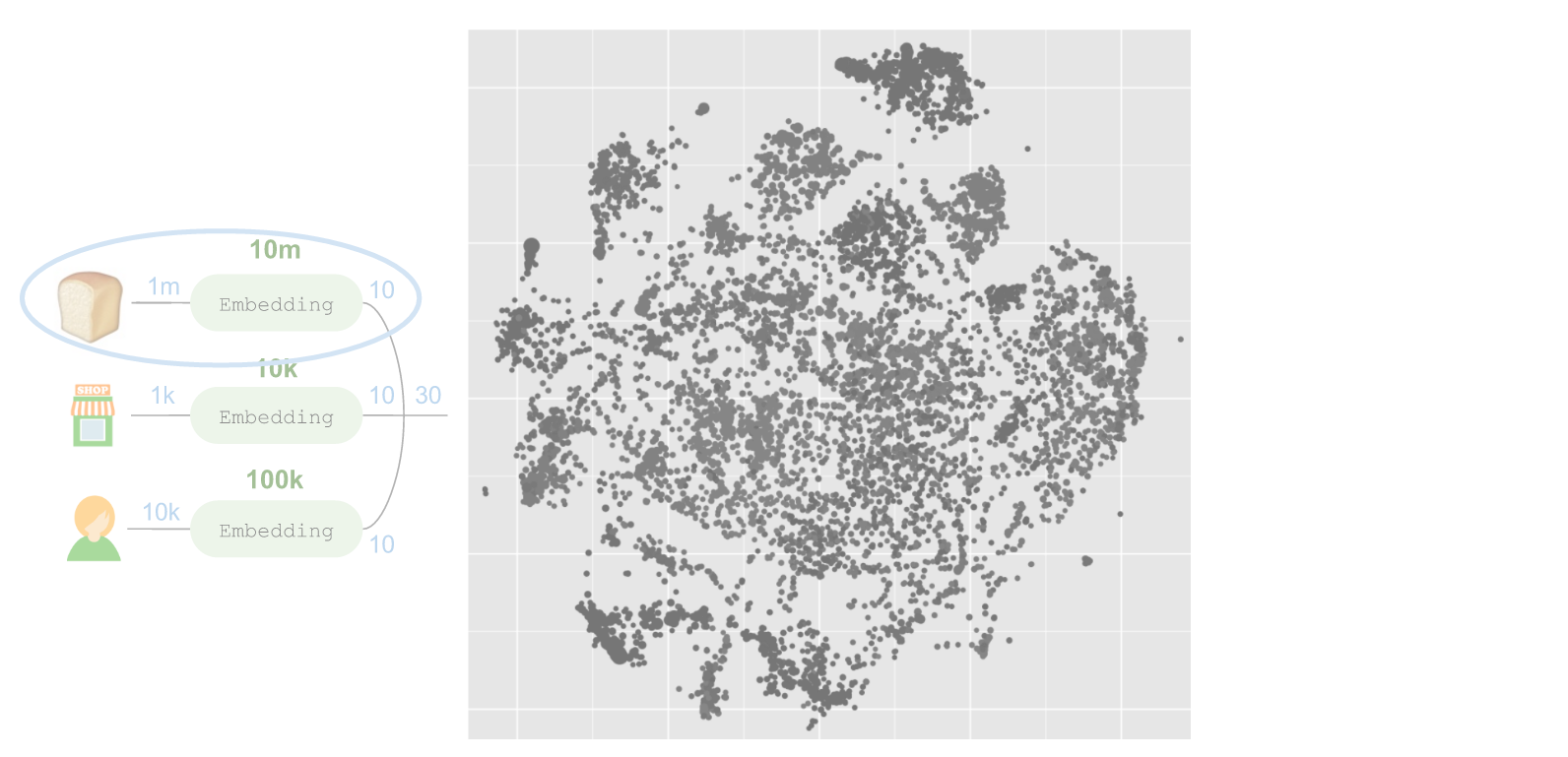
ЩЯЪіУПИідВШІДњБэвЛИіЩЬЦЗЃЌдВШІЕФДѓаЁгыЖдгІЩЬЦЗБЛФУШЁЕФЦЕТЪГЩБШР§ЁЃКмУїЯдЃЌетИіФЃаЭбЇЯАСЫвЛжжМЋЮЊгаШЄЕФНсЙЙЁЃЮвУЧПЩвдЭЈЙ§ЖдУПИіВПУХЕФДњТыгІгУВЛЭЌбеЩЋЕФЗНЪНГЪЯжЦфжаЕФДѓВПЗжНсЙЙЃК
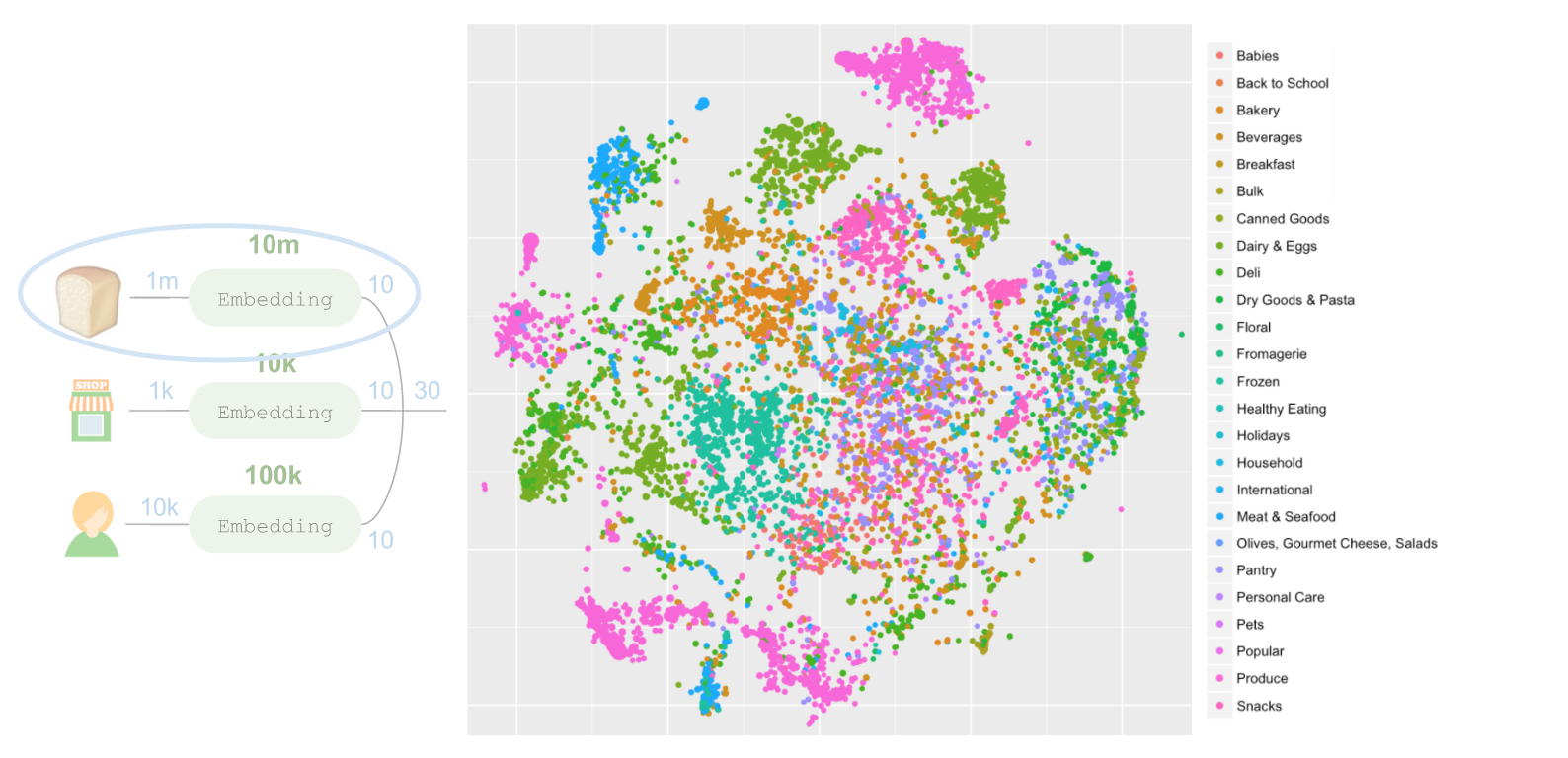
етаЉДижаДѓВПЗжФкШнЖдгІСЫВЛЭЌВПУХЃЌЕЋЭъШЋУЛгаНЋУПИіВПУХЕФЪ§ОнгУгкбЇЯАЧЖШыЁЃДЫЭтЮвУЧПЩвдЗХДѓжСЦфжавЛИіЧјгђЃЌР§ШчзѓЩЯНЧгУРЖЩЋДњБэЕФШтРрКЭКЃВњЦЗВПУХЁЃШтРрКЭКЃВњЦЗВПУХжмЮЇЛЙгаЦфЫћЩЬЦЗЃЌЕЋВЂВЛЪЧШтРрЛђКЃВњЦЗЁЃетаЉВњЦЗЃЈР§ШчРБНЗЁЂЯуСЯКЭЪьЪГЕШЃЉвВЪЧдкШтРрКЭКЃВњЦЗЙёЬЈЩЯЯњЪлЕФЁЃдкЕъФкЩЬЦЗГТСаЙцТЩЕФбЇЯАЗНУцЃЌетИіФЃаЭЕФаЇЙћБШжЎЧАгУЙ§ЕФВПУХХХађКЭзпЕРХХађЫуЗЈИќГіЩЋЁЃ
ЫфШЛетбљЕФМмЙЙвбОПЩвдЭЖШыЪЙгУЃЌЕЋвРШЛДцдкШ§ИіВЛзуЃК
ЪзЯШЃЌЮвУЧдкзѓВрНЋЩЬЦЗЧЖШыЕН10ИіЮЌЖШЃЌЫцКѓЫљЪЕЯжЕФаЇЙћРрЫЦгкдкзюжеВужаЖдетИіЧЖШыНјааФцзЊЃЌНшДЫЭЖЩфжСЁАЯТвЛИіЩЬЦЗЁБПеМфЃЌвђДЫЩЬЦЗЕФЧЖШыКЭзюжеВуЛсЪдзХбЇЯАЯрЫЦЕФЙиЯЕЁЃ
ЦфДЮЃЌжаМфЛЗНкашвЊДІРэЪЎЗжГЄЃЌЪЎЗжУмМЏЕФ1АйЭђГЄЖШЯђСПЃЌЕЋБОР§жаЩЯАйЭђИіжЕжаЃЌжЛга5ИіжЕЪЧгызюжеНсЙћЯрЙиЕФЁЃетвтЮЖзХашвЊЮоЮНЕиКФЗбДѓСПФкДцКЭМЦЫузЪдДЁЃ
зюКѓЃЌЮоЗЈНЋгаЙиКђбЁЩЬЦЗЕФЦфЫћдЊЪ§ОнзЂШыИУМмЙЙЁЃШчЙћЯЃЭћДгВњЦЗЫљЙиСЊЕФзпЕРКЭВПУХаХЯЂжабЇЯАЃЌПЩНЋЦфЗХШыЭјТчжазюаТВњЦЗЃЈУцАќЃЉЕФзѓВрЁЃЕЋШчЙћБ§ИЩвВдкЭЌвЛИізпЕРЩЯЃЌНЋЮоЗЈдкИУМмЙЙжаЬхЯжетИіаХЯЂЁЃКђбЁЩЬЦЗЪЕМЪЩЯЪЧвЛжжгІгУИјЩЯАйЭђГЄЖШМЦЗжЯђСПЕФЖўНјжЦекежЃЈBinary maskЃЉЁЃ
зюжеМмЙЙ
ЮвУЧзюжеЪЙгУЕФМмЙЙНтОіСЫетаЉЮЪЬтЃЌЭЌЪБЛЙдкадФмгыаЇТЪЗНУцгаСЫКмДѓИФНјЁЃ
ЮвУЧЛсДДНЈвЛИіЁАscoring generatorЁБЃЌВЂдкKerasЕФTimeDistributedВуЮЊУПИіКђбЁЩЬЦЗжиИДдЫгУЁЃЮЊСЫбнЪОетвЛзіЗЈЃЌПЩвдгУ??зїЮЊР§згЃЌНЋЦфЗХдкМмЙЙЕФзѓВрЃК
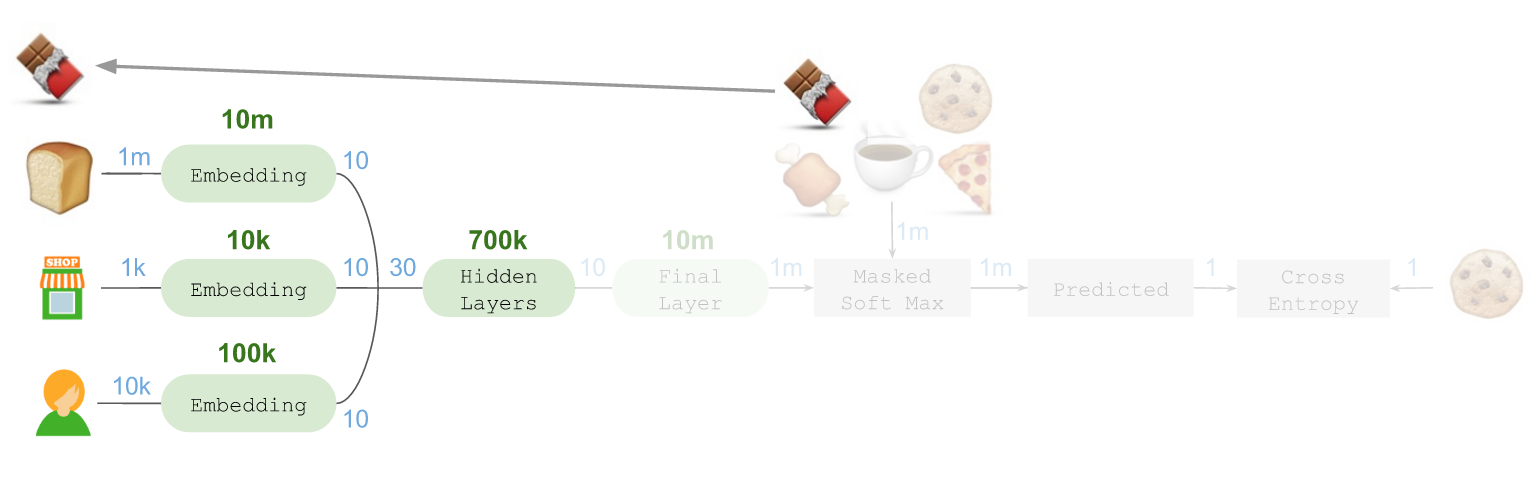
ЫцКѓПЩвдЪЙгУfunctional APIжаЕФKerasЙВЯэВуЃЌЪЙЕУеыЖд??ЕФВњЦЗЧЖШывВФмНЋ??ЭЖЩфжСЯрЭЌЕФ10ЮЌЖШПеМфЃК
етРяашвЊзЂвтЃКетбљзіЪБВЮЪ§ЕФЪ§СПВЂЮДдіМгЃЌвђЮЊЪЕМЪЩЯетЕШгкЪЧНЋетаЉВЮЪ§еыЖдВЛЭЌгУЭОЗДИДЪЙгУЃЈВЂФмНсКЯдквЛЦ№НјаагХЛЏЃЉЁЃЫцКѓЮвУЧПЩвдЪЙгУвЛИіMergeВуНЋЫљгаетаЉЧЖШыЛузмдквЛЦ№ЃЌзщГЩвЛИі40ЮЌЯђСПЃЌВЂНЋЦфЗХШывўВиВуЃЌНјЖјЛёЕУЦРЗжЃК
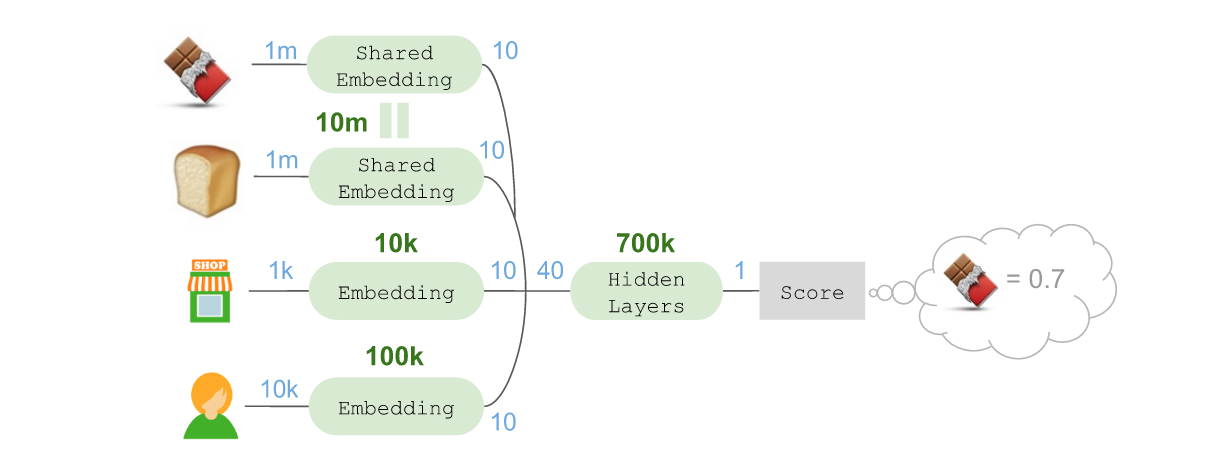
БОР§жаЃЌ??ЕФЗжЪ§ЮЊ0.7ЃЌЮвУЧЛсЖдМмЙЙЕФЦфЫћВПЗжНјааЕїећЃЌЪЙЕУетИіЗжЪ§ПЩвдгУзїДњБэдкФУШЁЙ§??жЎКѓЃЌНгЯТРДФУШЁ??ЕФИХТЪЕНЕзгаЖрДѓЕФЪЕжЕжИБъЃЈReal-valued indicatorЃЉЁЃжЕЮЊе§Ъ§ЕФЩЬЦЗзюгаПЩФмНгЯТРДФУШЁЃЌжЕЮЊИКЪ§ЕФЩЬЦЗНгЯТРДБЛФУШЁЕФИХТЪЗЧГЃаЁЁЃ
ЫцКѓНЋзщМўжаетвЛМмЙЙЕФИДдгадШЋВПгУЁАscore generatorЁБФЃПщбкИЧЦ№РДЃК
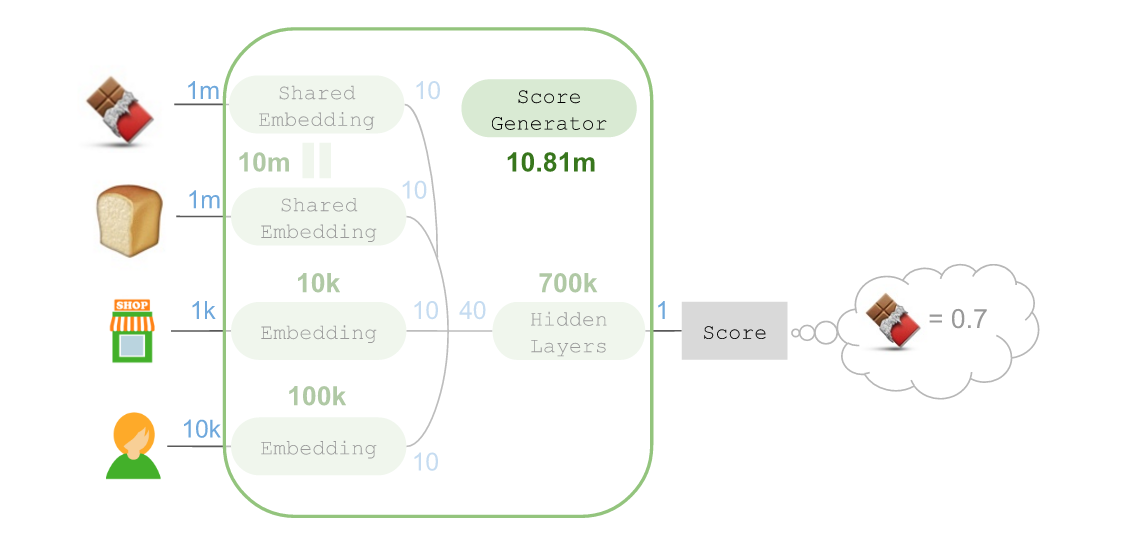
ЫфШЛВЮЪ§змЪ§ИпДя1081ЭђЃЌЕЋвВПЩНЋЦфМђЛЏЮЊЃК
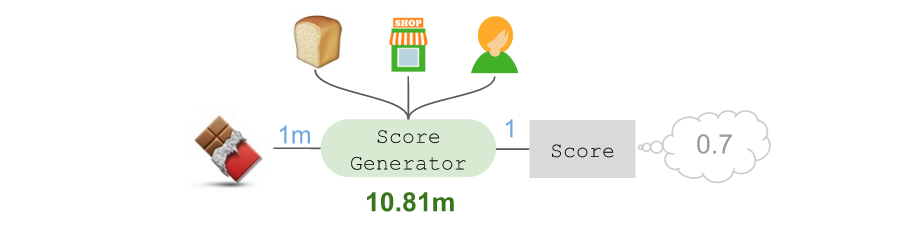
етИіМЦЗжЦїашвЊвРРЕКђбЁЩЬЦЗЃЈ??ЃЉЁЂЧАађЩЬЦЗЃЈ??ЃЉЃЌЕъЦЬЃЌвдМАЙКЮяЙЫЮЪЁЃЮвУЧПЩвдЭЈЙ§етбљЕФЙ§ГЬЖдЦфгрКђбЁЩЬЦЗНјааДђЗжЃК
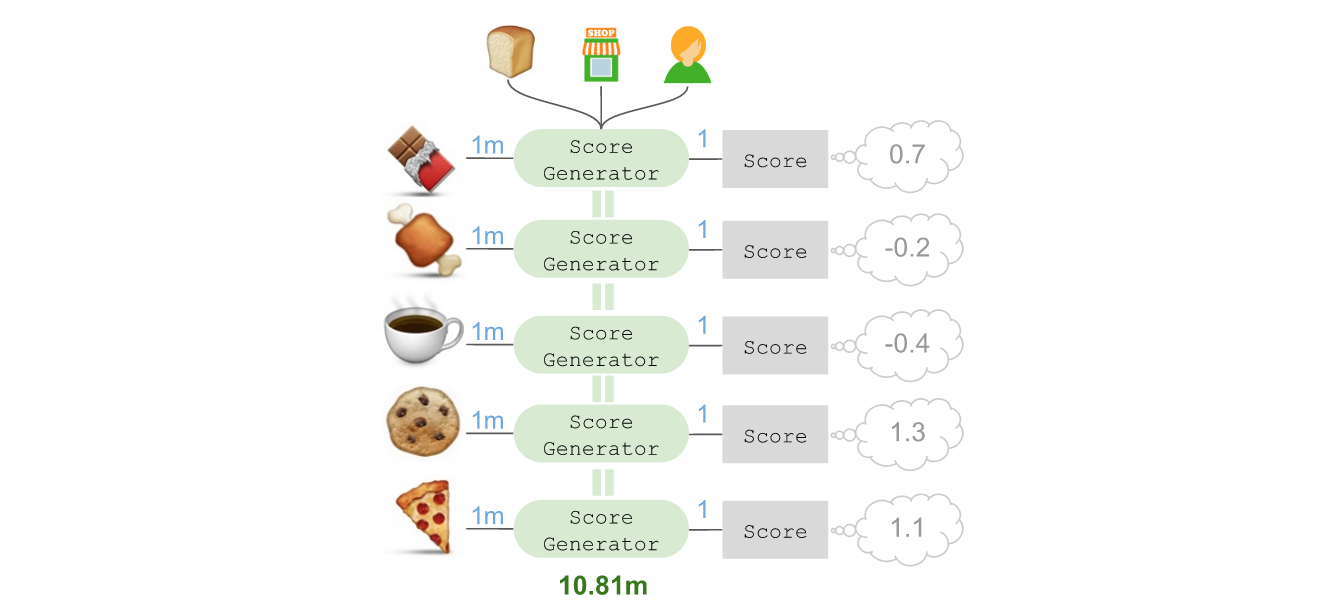
МйЩшЗЂЯжЫцКѓМИКѕВЛПЩФмФУШЁ??ЃЈ-0.2ЃЉЃЌЫцКѓзюВЛПЩФмФУШЁ?ЃЈ-0.4ЃЉЃЌЖјЫцКѓзюгаПЩФмФУШЁ??ЃЈ1.3ЃЉЃЌНгЯТРДЕкЖўгаПЩФмФУШЁЕФЪЧ??ЃЈ1.1ЃЉЁЃ
ЫљгаетаЉЗжЪ§ЖМПЩЗХШывЛИіМђЕЅЕФSoft-maxВуЃЌНшДЫдЄВтГіНгЯТРДФУШЁ??ЕФИХТЪЮЊ36%ЃК
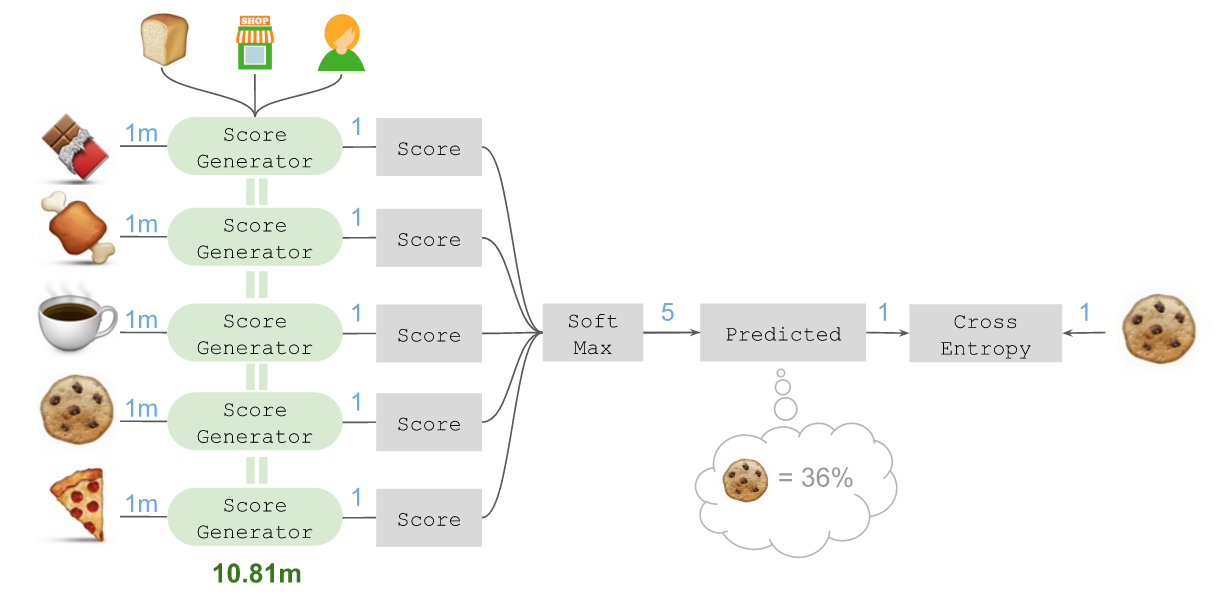
НгЯТРДЃЌНЋетИідЄВтЗХШыНЛВцьиЃЈCross-entropyЃЉЫ№ЪЇКЏЪ§ЃЌВЂХаЖЯЪЕМЪЩЯНгЯТРДашвЊФУШЁЕФе§ЪЧ??ЁЃ
етИіМмЙЙЕФЙиМќдкгкЃЌНшжњKerasжаЕФTimeDistributedВуЃЌПЩвдеыЖдЫљгаКђбЁЩЬЦЗЙВЯэЭЌвЛИіМЦЗжЦїЁЃвђДЫЮвУЧвРШЛЪЙгУСЫ1081ЭђИіВЮЪ§ЃЌЖјTensorFlowвВПЩвдМЦЫуЯрЖдгкЕЅвЛЫГађЮЛжУЃЌЫљгаКђбЁЩЬЦЗЕФМЦЗжЦїећЬхНЛВцьиЫ№ЪЇЕФЦТЖШИќаТЁЃ
жСДЫЃЌЖСепвВПЩвдЭЈЙ§ЮвУЧЬсЙЉЕФетаЉKerasДњТыЪдзХЙЙНЈвЛИізюжеМмЙЙ??ЁЃ
зюжеНсЙћ
ЭЈЙ§етбљЕФМмЙЙЃЌЮвУЧЕФГѕЪММмЙЙдкЖрИіЗНУцЕУвдИФНјЃК

ФЃаЭбЕСЗЫйЖШМгПь10БЖЃЌвђЮЊЃК(a)ЃЌПЩНЋВЮЪ§змЪ§МѕАыЃЛ(b)ЃЌВЛашвЊдйЩнГоЕиЪЙгУ1АйЭђГЄЖШЕФжаМфЯђСПЁЃгЩгкПЩвдзЂШыгаЙивбФУШЁЕФЧАађЩЬЦЗЃЌвдМАЫцКѓашвЊФУШЁЕФЩЬЦЗЕФзпЕРКЭВПУХдЊЪ§ОнЃЌдЄВтЕФзМШЗЖШвВЬсИпСЫ10%ЁЃ
зюКѓЃЌЮЊСЫИјвЛИіАќКЌ20МўЩЬЦЗЕФЖЉЕЅЩњГЩЭъећЕФдЄВтЫГађЃЈашвЊЕїгУpredict20ДЮЃЉЃЌЮвУЧЕФдЄВтЙЄзїЫљашЕФЪБМфбгГЄСЫДѓдМвЛБЖЃЌгЩДѓдМ50msдіМгжС100msЁЃЕЋетЪЧПЩНгЪмЕФЃЌПМТЧЕНОпЬхЕФЩњВњашЧѓЃЌЦфЪЕВЂВЛашвЊЖдЧхЕЅНјааЪЕЪБХХађЁЃ
ОЁЙмдЄВтЫйЖШТ§СЫвЛаЉЃЌЕЋУцЖдбЕСЗЪБМфКЭОЋШЗЖШЗНУцЕФИФНјЃЌЮвУЧвРШЛИаЕНЪЎЗжМЄЖЏЃЁ

Й§ШЅЫФИідТРДЃЌИУЯюФПНјеЙКЭЕќДњЫйЖШЗЩПьЁЃгаКУМИДЮЮвУЧДјзХвЛЬЈдЫааИУФЃаЭдчЦкАцБОЕФJupyterБЪМЧБОЃЌАбЫќЗХдкЙКЮяГЕЩЯЙфWhole FoodsГЌЪаЃЌНшДЫЖдЫљЩњГЩЕФНсЙћНјааВтЪдЁЃХдШЫЖдДЫЭъШЋЮоЖЏгкждЃЌБЯОЙЮвУЧЪЧдкЭхЧјЃЁ
ФПЧАЮвУЧе§дкВтЪдФмЗёеыЖдУПЮЛЙКЮяЙЫЮЪЖдЧхЕЅНјааИіадЛЏЖЈжЦЃЌвдБуШУУПЮЛЙЫЮЪФмЙЛДяЕНБШЫйЖШзюПьЙЫЮЪИќКУЕФГЩМЈЁЃКѓајЮвУЧЛЙМЦЛЎЪЙгУLSTMЧЖШыВњЦЗУшЪіЃЌВЂЪЙгУCNNЧЖШыВњЦЗЭМЦЌЃЌНшДЫЬсИпЕЭЯњСПВњЦЗЕФдЄВтаЇЙћЁЃДЫЭтЮвУЧЛЙМЦЛЎВтЪдЪЙгУLSTMЖдећИіШЁЛѕЫГађНјааНЈФЃЁЃ
дкетРявЊЖдзЈзЂгкИФНјЙКЮягІгУЧхЕЅХХађЙЄзїЕФКЫаФЭХЖгжТвдаЛвтЃК

|









