дЭМШчЯТЃК
ЫфШЛетаЉНкЕуЭМВЛФмЯдЪОИїИіФЃаЭЕФФкВПЙЄзїЙ§ГЬЃЌЕЋЪЧетаЉНкЕуЭМЕФЛузмПЩвдШУЮвУЧдкЭЌвЛВуУцЩЯЖдБШВЛЭЌЩёОЭјТчЕФНсЙЙЬиЕуЃЌДгЖјЖдВЛЭЌЩёОЭјТчжЎМфЕФЙиЯЕгавЛИіИќЮЊОпЯѓЕФРэНтЁЃ
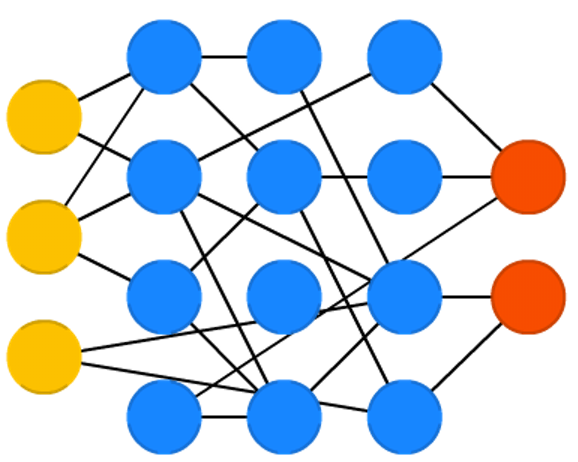
ИажЊЦїЃЈPerceptronsЃЉКЭЧАРЁЩёОЭјТчЃЈFeed Forward Neural NetworksЃЉ

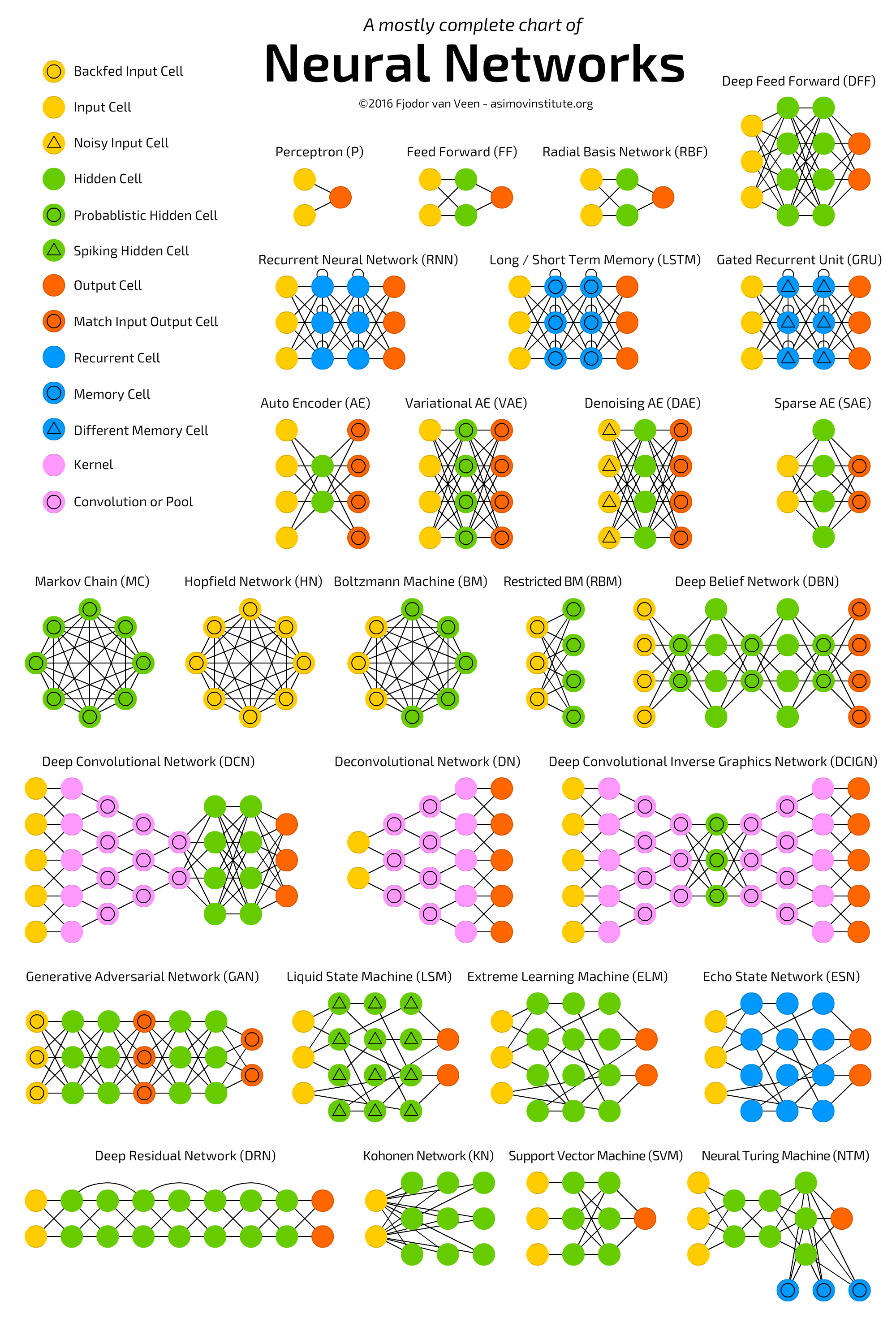
ЕЅВуИажЊЦїЪЧзюМђЕЅЕФЩёОЭјТчЁЃЫќНіАќКЌЪфШыВуКЭЪфГіВуЃЌЖјЪфШыВуКЭЪфГіВуЪЧжБНгЯрСЌЕФЁЃ
ЯрЖдгкЕЅВуИажЊЦїЃЌЧАРЁЩёОЭјТчАќКЌЪфШыВуЁЂвўВиВуКЭЪфГіВуЁЃетвЛРрЭјТчЭЈГЃЪЙгУЗДЯђДЋВЅЫуЗЈЃЈBackpropagationЃЉНјаабЕСЗЃЌгЩгкЭјТчОпгавўВиЩёОдЊЃЌРэТлЩЯПЩвдЖдЪфШыКЭЪфГіжЎМфЕФЙиЯЕНјааНЈФЃЁЃЕЋЪЕМЪЩЯИУЭјТчЕФгІгУЪЧКмгаЯоЕФЃЌЭЈГЃвЊНЋЫќУЧгыЦфЫћЭјТчНсКЯаЮГЩаТЕФЭјТчЁЃ
ОЖЯђЛљКЏЪ§ЭјТчЃЈRadial Basis FunctionЃЌRBFЃЉ
ОЖЯђЛљКЏЪ§ЃЈRBFЃЉЭјТчЪЧвдОЖЯђЛљКЏЪ§зїЮЊМЄЛюКЏЪ§ЕФЧАРЁЩёОЭјТчЁЃОЖЯђЛљКЏЪ§ЭјТчЭЈГЃжЛгаШ§ВуЃЌЪфШыВуЁЂжаМфВуКЭЪфГіВуЁЃжаМфВуМЦЫуЪфШыЪИСПгыбљБОЪИСПХЗЪНОрРыЕФОЖЯђЛљКЏЪ§жЕЃЌЪфГіВуМЦЫуЫќУЧЕФЯпадзщКЯЁЃ
ОЖЯђЛљКЏЪ§ЭјТчЕФЛљБОЫМЯыЪЧЃКгУОЖЯђЛљКЏЪ§зїЮЊвўЕЅдЊЕФЁАЛљЁБЙЙГЩвўКЌВуПеМфЃЌНЋЕЭЮЌПеМфЕФЪфШыЭЈЙ§ЗЧЯпадКЏЪ§гГЩфЕНвЛИіИпЮЌПеМфЃЌЖјЕЭЮЌПеМфВЛПЩЗжЕФЪ§ОнЕНСЫИпЮЌПеМфИќгаПЩФмБфЕУПЩЗжЁЃ
HopfieldЩёОЭјТчЃЈHopfield NetworkЃЌHNЃЉ
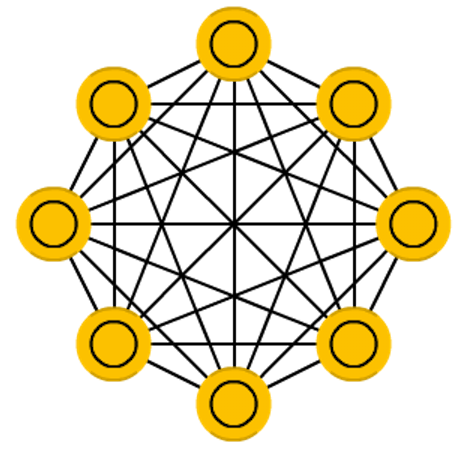
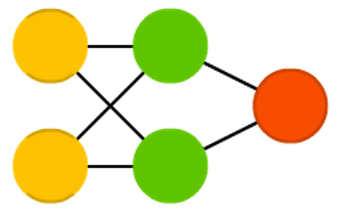
1982ФъЃЌJ.HopfieldЬсГіСЫПЩгУзїСЊЯыДцДЂЦїЕФЛЅСЌЭјТчЃЌетИіЭјТчБЛГЦЮЊHopfieldЭјТчФЃаЭЁЃHopfieldЩёОЭјТчЪЧвЛжжбЛЗЩёОЭјТчЃЌДгЪфГіЕНЪфШыгаЗДРЁСЌНгЁЃЗДРЁЩёОЭјТчгЩгкЦфЪфГіЖЫгжЗДРЁЕНЦфЪфШыЖЫЃЌЫљвдHopfieldЭјТчдкЪфШыЕФМЄРјЯТЃЌЛсВњЩњВЛЖЯЕФзДЬЌБфЛЏЁЃ
ЭјТчЕФУПИіНкЕудкбЕСЗЧАНгЪмЪфШыЃЌШЛКѓдкбЕСЗЦкМфвўВиВЂЪфГіЁЃПЩвдЭЈЙ§НЋЩёОдЊЕФжЕЩшжУЮЊЦкЭћЕФФЃЪНРДбЕСЗЭјТчЃЌДЫКѓШЈжиВЛБфЁЃвЛЕЉбЕСЗСЫвЛИіЛђЖрИіФЃЪНЃЌЭјТчНЋЪеСВЕНвЛИібЇЯАФЃЪНЃЌвђЮЊЭјТчдкетИізДЬЌжаЪЧЮШЖЈЕФЁЃ
ВЈЖћзШТќЛњЃЈBoltzmann MachinesЃЌBMЃЉ
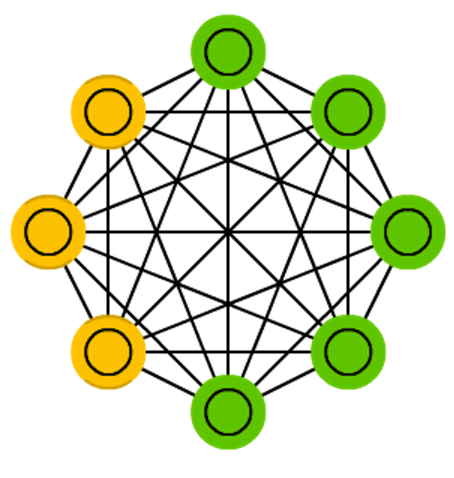
ВЈЖћзШТќЛњЪЧвЛжжЫцЛњЩёОЭјТчЁЃдкетжжЭјТчжаЩёОдЊжЛгаСНжжЪфГізДЬЌЃЌМДЖўНјжЦЕФЃАЛђЃБЁЃзДЬЌЕФШЁжЕИљОнИХТЪЭГМЦЗЈдђОіЖЈЃЌгЩгкетжжИХТЪЭГМЦЗЈдђЕФБэДяаЮЪНгыжјУћЭГМЦСІбЇМвL.BoltzmannЬсГіЕФВЃЖћзШТќЗжВМРрЫЦЃЌЙЪНЋетжжЭјТчШЁУћВЃЖћзШТќЛњЁЃ
ВЈЖћзШТќЛњЃЈBMЃЉКмЯёHopfieldЩёОЭјТчЃЌЧјБ№дкгкЃЌЫќжЛгавЛаЉЩёОдЊБЛБъМЧЮЊЪфШыЩёОдЊЃЌЖјЦфЫћЩёОдЊБЃГжЁАвўВиЁБЁЃЪфШыЩёОдЊдкЭъећЕФЭјТчИќаТНсЪјЪБГЩЮЊЪфГіЩёОдЊЁЃЫќДгЫцЛњШЈжиПЊЪМЃЌЭЈЙ§ЗДЯђДЋВЅЃЈBackpropagationЃЉбЇЯАЛђЭЈЙ§ЖдБШЩЂЖШЃЈContrastive DivergenceЃЉЫуЗЈбЕСЗФЃаЭЁЃ
ЪмЯоВЃЖћзШТќЛњЃЈRestricted Boltzmann MachinesЃЌRBMЃЉ
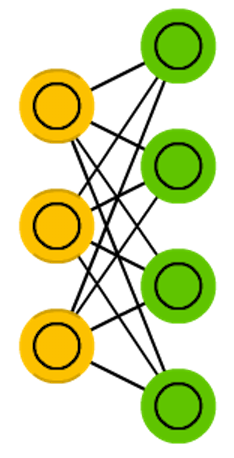
ЪмЯоВЃЖћзШТќЛњЪЧвЛжжПЩЭЈЙ§ЪфШыЪ§ОнМЏбЇЯАИХТЪЗжВМЕФЫцЛњЩњГЩЩёОЭјТчЁЃЪмЯоВЃЖћзШТќЛњгЩвЛИіПЩМћЩёОдЊВуКЭвЛИівўЩёОдЊВузщГЩЁЃгЩгквўВуЩёОдЊжЎМфУЛгаЯрЛЅСЌНгЃЌВЂЧввўВуЩёОдЊЖРСЂгкИјЖЈЕФбЕСЗбљБОЃЌетШУжБНгМЦЫувРРЕЪ§ОнЕФЦкЭћжЕБфЕУИќШнвзЁЃПЩМћВуЩёОдЊжЎМфвВУЛгаЯрЛЅСЌНгЁЃ
ЭјТчЭЈЙ§дкбЕСЗбљБОЕУЕНЕФвўВуЩёОдЊзДЬЌЩЯжДааТэЖћПЩЗђСДГщбљЙ§ГЬРДЙРМЦЖРСЂгкЪ§ОнЕФЦкЭћжЕЃЌВЂааНЛЬцИќаТЫљгаПЩМћВуЩёОдЊКЭвўВуЩёОдЊЕФжЕЁЃ
ТэЖћПЩЗђСДЃЈMarkov ChainsЃЌMCЃЉЛђРыЩЂЪБМфТэЖћПЩЗђСДЃЈDiscrete Time Markov ChainЃЌDTMCЃЉ

ТэЖћПЩЗђСДЪЧжИЪ§бЇжаОпгаТэЖћПЩЗђаджЪЕФРыЩЂЪТМўЫцЛњЙ§ГЬЁЃИУЙ§ГЬжаЃЌдкИјЖЈЕБЧАжЊЪЖЛђаХЯЂЕФЧщПіЯТЃЌЙ§ШЅЃЈРњЪЗзДЬЌЃЉЖдгкдЄВтНЋРДЃЈЮДРДзДЬЌЃЉРДЫЕЪЧУЛгаЙиСЊЕФЁЃТэЖћПЦЗђСДЫфШЛВЛЪЧеце§ЕФЩёОЭјТчЃЌЕЋРрЫЦгкЩёОЭјТчЃЌВЂЧвЙЙГЩСЫВЈЖћзШТќЛњКЭHopfieldЩёОЭјТчЕФРэТлЛљДЁЁЃ
здБрТыЦїЃЈAutoencodersЃЌAEЃЉ
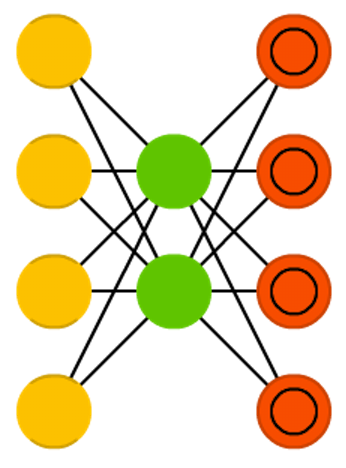
здБрТыЦїЕФЛљБОЫМЯыЪЧздЖЏБрТыаХЯЂЁЃздБрТыЦїЭјТчНсЙЙЯёвЛИіТЉЖЗЃКЫќЕФвўВиВуЕЅдЊБШЪфШыВуКЭЪфГіВуЩйЃЌВЂЧвЙигкжабыВуЖдГЦЁЃзюаЁЕФвўВиВузмЪЧДІдкжабыВуЃЌетвВЪЧаХЯЂбЙЫѕГЬЖШзюИпЕФЕиЗНЁЃДгЪфШыВуЕНжабыВуНазіБрТыВПЗжЃЌДгжабыВуЕНЪфГіВуНазіНтТыВПЗжЃЌжабыВуНазіБрТыЃЈcodeЃЉЁЃ
ПЩвдЪЙгУЗДЯђДЋВЅЫуЗЈРДбЕСЗздБрТыЦїЃЌНЋЪ§ОнЪфШыЭјТчЃЌНЋЮѓВюЩшжУЮЊЪфШыЪ§ОнгыЭјТчЪфГіЪ§ОнжЎМфЕФВювьЁЃздБрТыЦїЕФШЈживВЪЧЖдГЦЕФЃЌМДБрТыШЈжиКЭНтТыШЈжиЪЧвЛбљЕФЁЃ
ЯЁЪшздБрТыЦїЃЈSparse AutoencodersЃЌSAEЃЉ
ЯЁЪшздБрТыЦїдкФГжжГЬЖШЩЯгыздБрТыЦїЯрЗДЁЃВЛЭЌгквдЭљбЕСЗвЛИіЭјТчдкИќЕЭЮЌЕФПеМфКЭНсЕуЩЯШЅБэеїаХЯЂЃЌЫќГЂЪддкИќИпЮЌЕФПеМфЩЯБрТыаХЯЂЁЃЫљвддкжаМфВуЃЌЭјТчВЛЪЧЪеСВЕФЃЌЖјЪЧРЉеХЕФЁЃ
ЯЁЪшздБрТыЦїПЩвдздЖЏДгЮоБъзЂЪ§ОнжабЇЯАЬиеїЃЌПЩвдИјГіБШдЪМЪ§ОнИќКУЕФЬиеїУшЪіЁЃдкЪЕМЪдЫгУЪБПЩвдгУЯЁЪшБрТыЦїЬсШЁЕФЬиеїДњЬцдЪМЪ§ОнЃЌетбљЭљЭљФмДјРДИќКУЕФНсЙћЁЃ
БфЗжздБрТыЦїЃЈVariational AutoencodersЃЌ VAEЃЉ
БфЗжздБрТыЦїКЭздБрТыЦїгаЯрЭЌЕФЭјТчНсЙЙЁЃВЛЭЌЕудкгкЦфвўВиДњТыРДздгкбЕСЗЦкМфбЇЯАЕНЕФИХТЪЗжВМЁЃ
дк90ФъДњЃЌвЛаЉбаОПШЫдБЬсГівЛжжИХТЪНтЪЭЕФЩёОЭјТчФЃаЭЁЃИХТЪНтЪЭЭЈЙ§МйЩшУПИіВЮЪ§ЕФИХТЪЗжВМРДНЕЕЭЭјТчжаУПИіВЮЪ§ЕФИеаддМЪјЃЌНЋЪфШыЁЂвўВиБэЪОвдМАЩёОЭјТчЕФЪфГізЊЛЛЮЊИХТЪЫцЛњБфСПЁЃЭјТчбЇЯАЕФФПБъЪЧевЕНЩЯЪіЗжВМЕФВЮЪ§ЁЃдкБфЗжздЖЏБрТыЦїжаЃЌНідквўВиНкЕуЩЯМйЩшетаЉЗжВМЁЃвђДЫЃЌБрТыЦїБфГЩвЛИіБфЗжЭЦРэЭјТчЃЌЖјвыТыЦїдђБфГЩвЛИіНЋвўВиДњТыгГЩфЛиЪ§ОнЗжВМЕФЩњГЩЭјТчЁЃ
ЭЈЙ§ВЮЪ§ЛЏвўВиЗжВМЃЌПЩвдЗДЯђДЋВЅЬнЖШЕУЕНБрТыЦїЕФВЮЪ§ЃЌВЂгУЫцЛњЬнЖШЯТНЕбЕСЗећИіЭјТчЁЃ
ШЅдыздБрТыЦїЃЈDenoising AutoencodersЃЌDAEЃЉ
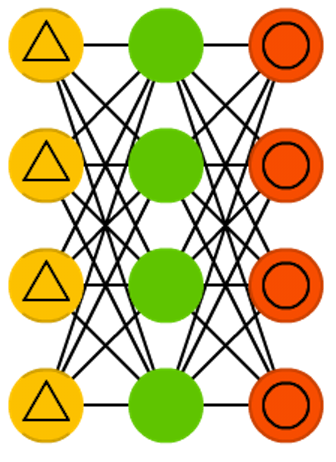
ШЅдыздБрТыЦїЕФбЕСЗЗНЗЈКЭЦфЫћздБрТыЦївЛбљЃЌЕЋЪЧЪфШыВЛЪЧдЪМЪ§ОнЃЌЖјЪЧДјдыЩљЕФЪ§ОнЁЃетбљЕФЭјТчВЛНіФмЙЛбЇЯАЕНЯИНкЃЌЖјЧвФмбЇЯАЕНИќЗКЛЏЕФЬиеїЁЃдвђгаСНЕуЃКвЛЪЧЭЈЙ§гыЗЧЦЦЫ№Ъ§ОнбЕСЗЕФЖдБШЃЌЦЦЫ№Ъ§ОнбЕСЗГіРДЕФШЈжидыЩљБШНЯаЁЃЌЖўЪЧЦЦЫ№Ъ§ОндквЛЖЈГЬЖШЩЯМѕЧсСЫбЕСЗЪ§ОнгыВтЪдЪ§ОнжЎМфЕФДњЙЕЁЃ
ТлЮФзїепвВДгЩњЮяЩёОЭјТчЕФНЧЖШНјааСЫНтЪЭЃКШЫРрОпгаШЯжЊБЛзшЕВЕФЦЦЫ№ЭМЯёФмСІЃЌДЫдДгкЮвУЧЕФИпЕШСЊЯыМЧвфИаЪмЛњФмЁЃЮвУЧФмвдЖржжаЮЪННјааМЧвфЃЈБШШчЭМЯёЁЂЩљвєЃЌЩѕжСШчЩЯЭМЕФДЪИљМЧвфЗЈЃЉЃЌЫљвдМДБуЪЧЪ§ОнЦЦЫ№ЖЊЪЇЃЌЮвУЧвВФмЛиЯыЦ№РДЁЃ
ЩюЖШаХФюЭјТчЃЈDeep Belief NetworksЃЌDBNЃЉ
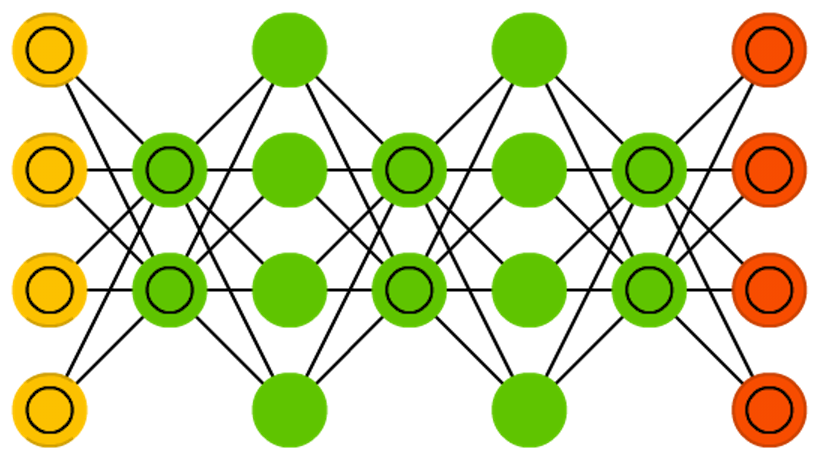
ЩюЖШаХФюЭјТчЪЧЪмЯоВЃЖћзШТќЛњЃЈRBMЃЉЛђепБфЗжздБрТыЦїЃЈVAEЃЉЕФЖбЕўНсЙЙЁЃЩюЖШаХФюЭјТчЪЧвЛжжЩњГЩФЃаЭЃЌЭЈЙ§бЕСЗЦфЩёОдЊМфЕФШЈжиЃЌЮвУЧПЩвдШУећИіЩёОЭјТчАДеезюДѓИХТЪРДЩњГЩЪ§ОнЁЃЩюЖШаХФюЭјТчгЩЖрВуЩёОдЊЙЙГЩЃЌетаЉЩёОдЊгжЗжЮЊЯдадЩёОдЊКЭвўадЩёОдЊЁЃЯддЊгУгкНгЪмЪфШыЃЌвўдЊгУгкЬсШЁЬиеїЁЃ
ЩюЖШаХФюЭјТчФмЙЛЭЈЙ§ЖдБШЩЂЖШЃЈcontrastive divergenceЃЉЛђепЗДЯђДЋВЅРДбЕСЗЃЌВЂЯёГЃЙцЕФЪмЯоВЃЖћзШТќЛњЛђБфЗжздБрТыЦїФЧбљЃЌбЇЯАНЋЪ§ОнБэЪОГЩИХТЪФЃаЭЁЃвЛЕЉФЃаЭЭЈЙ§ЮоМрЖНбЇЯАБЛбЕСЗЛђЪеСВЕНвЛИіЮШЖЈЕФзДЬЌЃЌЫќПЩвдБЛгУгкЩњГЩаТЪ§ОнЁЃ
ОэЛ§ЩёОЭјТчЃЈConvolutional Neural NetworksЃЌCNNЃЉЛђЩюЖШОэЛ§ЩёОЭјТчЃЈDeep Convolutional Neural NetworksЃЌDCNNЃЉ
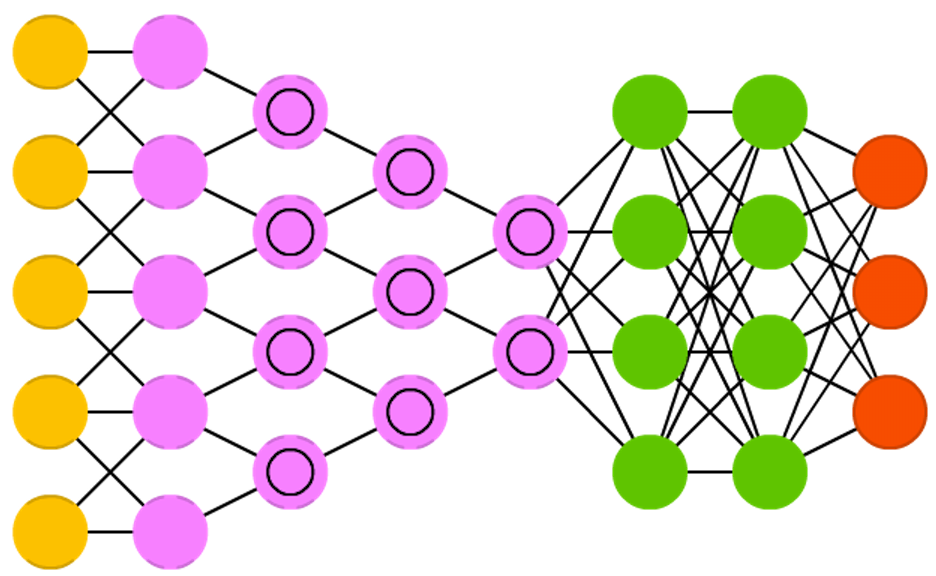
ОэЛ§ЩёОЭјТчгЩШ§ВПЗжЙЙГЩЁЃЕквЛВПЗжЪЧЪфШыВуЁЃЕкЖўВПЗжгЩnИіОэЛ§ВуКЭГиЛЏВуЕФзщКЯЖјзщГЩЕФЁЃЕкШ§ВПЗжгЩвЛИіШЋСЌНсЕФЖрВуИажЊЛњЗжРрЦїЙЙГЩЁЃ
ОэЛ§ЩёОЭјТчжївЊгУгкЭМЯёДІРэЃЌЕЋвВПЩгУгкЦфЫћРраЭЕФЪфШыЃЌШчвєЦЕЁЃЫќЪЧвЛжжЬиЪтЕФЩюВуЩёОЭјТчФЃаЭЃЌЫќЕФЬиЪтадЬхЯждкСНИіЗНУцЃКвЛЗНУцЩёОдЊМфЕФСЌНгЪЧЗЧШЋСЌНгЕФЃЌСэвЛЗНУцЭЌвЛВужаФГаЉЩёОдЊжЎМфЕФСЌНгЕФШЈжиЪЧЙВЯэЕФЁЃЫќЕФЗЧШЋСЌНгКЭШЈжЕЙВЯэЕФЭјТчНсЙЙЪЙжЎИќНгНќгкЩњЮяЩёОЭјТчЃЌНЕЕЭСЫЭјТчФЃаЭЕФИДдгЖШЃЌМѕЩйСЫШЈжЕЕФЪ§СПЁЃ
ОэЛ§ЩёОЭјТчЕФОэЛ§дЫЫуЙ§ГЬШчЯТЃКЪфШыЭМЯёЭЈЙ§ПЩбЕСЗЕФТЫВЈЦїзщНјааЗЧЯпадОэЛ§ЃЌОэЛ§КѓдкУПвЛВуВњЩњЬиеїгГЩфЭМЃЌШЛКѓЬиеїгГЩфЭМжаУПзщЕФЫФИіЯёЫидйНјааЧѓКЭЁЂМгШЈжЕЁЂМгЦЋжУЃЌдкДЫЙ§ГЬжаетаЉЯёЫидкГиЛЏВуБЛГиЛЏЃЌзюжеЕУЕНЪфГіжЕЁЃ
ЗДОэЛ§ЩёОЭјТчЃЈDeconvolutional NetworksЃЌDNЃЉ
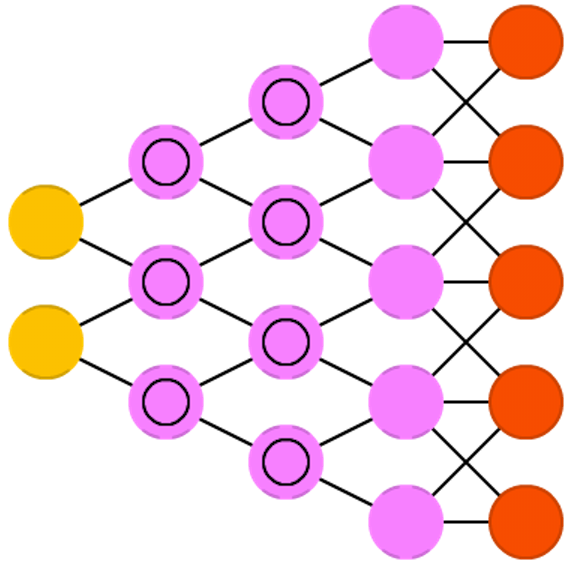
ЗДОэЛ§ЩёОЭјТчЪЧКЭОэЛ§ЩёОЭјТчЖдгІЕФЁЃдкCNNжаЃЌЪЧгЩЪфШыЭМЯёгыЬиеїТЫВЈЦїНјааОэЛ§ЃЌЕУЕНЬиеїЭМЃЌЖјдкЗДОэЛ§ЩёОЭјТчжаЃЌЪЧгЩЬиеїЭМгыЬиеїТЫВЈЦїОэЛ§ЃЌЕУЕНЪфШыЭМЯёЁЃЗДОэЛ§ЩёОЭјТчжївЊгУгкЭМЯёжиЙЙКЭОэЛ§ЭјТчПЩЪгЛЏЁЃ
ДгНсЙЙжаПЩвдПДГіЃЌЭјТчЪзЯШНјааЧАЯђМЦЫуЃЌдкЧАЯђМЦЫужаЪеМЏвЛаЉЪ§ОнЃЌШЛКѓНЋетаЉЪ§ОнЗХШыЗДЯђЭјТчжаНјааЗДЯђМЦЫуЃЌДгЖјЕУЕНзюжеЕФЗДОэЛ§НсЙћЁЃ
ЩюЖШОэЛ§ФцЯђЭМЭјТчЃЈDeep Convolutional Inverse Graphics NetworksЃЌDCIGNЃЉ
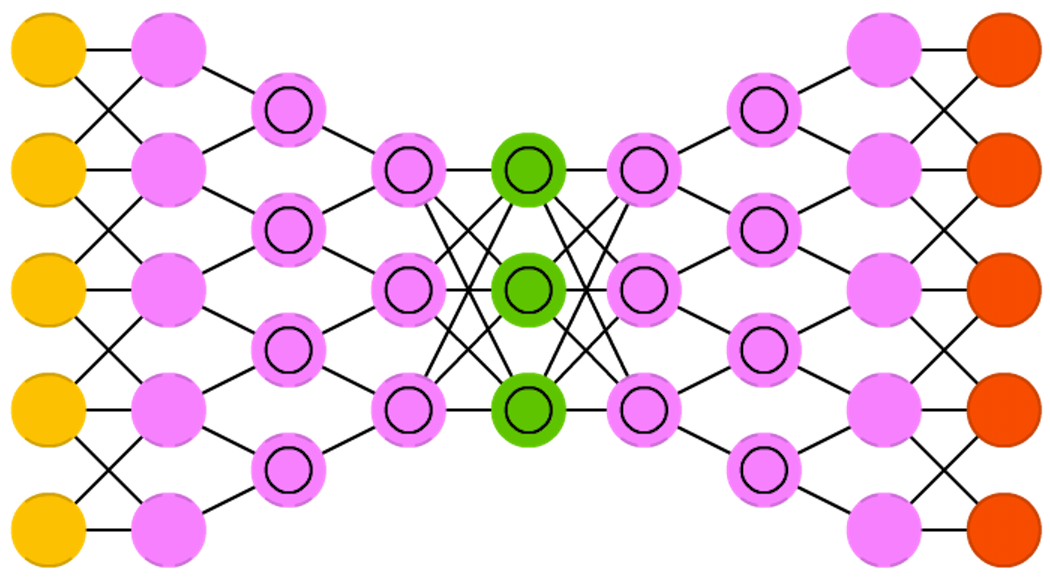
ЩюЖШОэЛ§ФцЯђЭМЭјТчЪЕжЪЩЯЪЧБфЗжздБрТыЦїЃЈVAEЃЉЃЌжЛЪЧдкБрТыЦїКЭНтТыЦїжаЗжБ№ВЩгУОэЛ§ЩёОЭјТчЃЈCNNЃЉКЭЗДОэЛ§ЩёОЭјТчЃЈDNNЃЉНсЙЙЁЃетаЉЭјТчГЂЪддкБрТыЕФЙ§ГЬжаЖдЁАЬиеїЁБНјааИХТЪНЈФЃЁЃИУЭјТчДѓВПЗжгУгкЭМЯёДІРэЁЃЭјТчПЩвдДІРэЮДбЕСЗЕФЭМЯёЃЌвВПЩвдДгЭМЯёжавЦГ§ЮяЬхЁЂжУЛЛФПБъЃЌЛђепНјааЭМЯёЗчИёзЊЛЛЁЃ
ЩњГЩЪНЖдПЙЭјТчЃЈGenerative Adversarial NetworksЃЌGANЃЉ
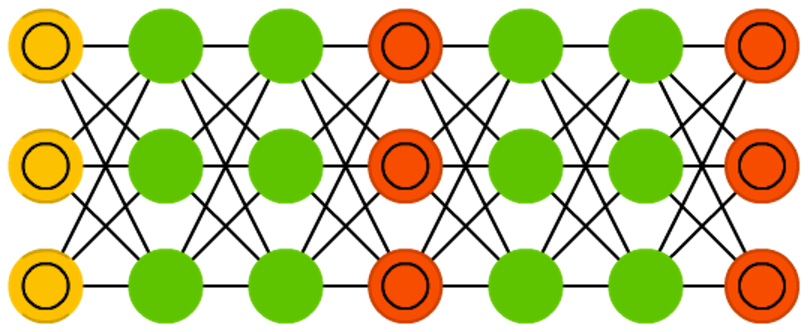
ЩњГЩЪНЖдПЙЭјТчгЩХаБ№ЭјТчКЭЩњГЩЭјТчзщГЩЁЃЩњГЩЭјТчИКд№ЩњГЩФкШнЃЌХаБ№ЭјТчИКд№ЖдФкШнНјааХаБ№ЁЃХаБ№ЭјТчЭЌЪБНгЪебЕСЗЪ§ОнКЭЩњГЩЭјТчЩњГЩЕФЪ§ОнЁЃХаБ№ЭјТчФмЙЛе§ШЗЕидЄВтЪ§ОндДЃЌШЛКѓБЛгУзїЩњГЩЭјТчЕФЮѓВюВПЗжЁЃетаЮГЩСЫвЛжжЖдПЙЃКХаБ№ЦїХЌСІЗжБцецЪЕЪ§ОнгыЩњГЩЪ§ОнЃЌЖјЩњГЩЦїХЌСІЩњГЩХаБ№ЦїФбвдБцЪЖЕФЪ§ОнЁЃ
ЩњГЩЪНЖдПЙЭјТчКмФббЕСЗЃЌвђЮЊВЛНіНівЊбЕСЗСНИіЭјТчЃЌЖјЧвЛЙвЊПМТЧСНИіЭјТчЕФЖЏЬЌЦНКтЁЃШчЙћХаБ№ЛђепЩњГЩЭјТчБфЕУБШСэвЛИіКУЃЌФЧУДЭјТчзюжеВЛЛсЪеСВЁЃ
бЛЗЩёОЭјТчЃЈRecurrent Neural NetworksЃЌRNNЃЉ
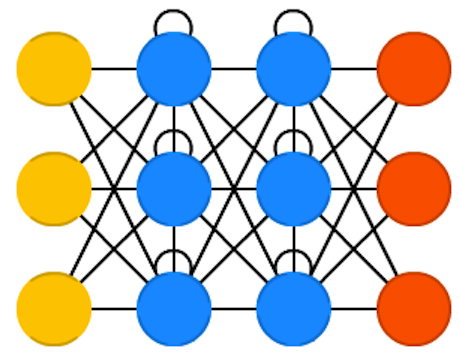
бЛЗЩёОЭјТчЪЧЛљгкЪБМфЕФЧАРЁЩёОЭјТчЃЌбЛЗЩёОЭјТчЕФФПЕФЪЧгУРДДІРэађСаЪ§ОнЁЃдкДЋЭГЕФЩёОЭјТчФЃаЭжаЃЌДгЪфШыВуЕНвўКЌВудйЕНЪфГіВуЃЌВугыВужЎМфЪЧШЋСЌНгЕФЃЌУПВужЎМфЕФНкЕуЪЧЮоСЌНгЕФЁЃЕЋЪЧетжжЦеЭЈЕФЩёОЭјТчЖдгкКмЖрЮЪЬтШДЮоФмЮоСІЁЃР§ШчЃЌФувЊдЄВтОфзгЕФЯТвЛИіЕЅДЪЪЧЪВУДЃЌвЛАуашвЊгУЕНЧАУцЕФЕЅДЪЃЌвђЮЊвЛИіОфзгжаЧАКѓЕЅДЪВЂВЛЪЧЖРСЂЕФЁЃ
дкбЛЗЩёОЭјТЗжаЃЌвЛИіађСаЕБЧАЕФЪфГігыЧАУцЕФЪфГівВгаЙиЁЃОпЬхЕФБэЯжаЮЪНЮЊЭјТчЛсЖдЧАУцЕФаХЯЂНјааМЧвфЃЌВЂгІгУгкЕБЧАЪфГіЕФМЦЫужаЃЌМДвўВиВужЎМфЕФНкЕуВЛдйЪЧЮоСЌНгЕФЃЌЖјЪЧгаСЌНгЕФЁЃВЂЧввўВиВуЕФЪфШыВЛНіАќРЈЪфШыВуЕФЪфГіЃЌЛЙАќРЈЩЯвЛЪБПЬвўВиВуЕФЪфГіЁЃ
бЛЗЩёОЭјТчзюДѓЕФЮЪЬтЪЧЬнЖШЯћЪЇ(ЛђепЬнЖШБЌеЈ)ЃЌетШЁОігкЪЙгУЕФМЄЛюКЏЪ§ЁЃдкетжжЧщПіЯТЃЌЫцзХЪБМфдіМгЃЌЬнЖШЛсПьЫйЯћЪЇЃЌе§ШчЫцзХЧАРЁЩёОЭјТчЕФЩюЖШдіМгЃЌаХЯЂвВЛсЖЊЪЇЁЃ
ГЄЖЬЪБМЧвфЭјТчЃЈLong Short Term MemoryЃЌLSTMЃЉ
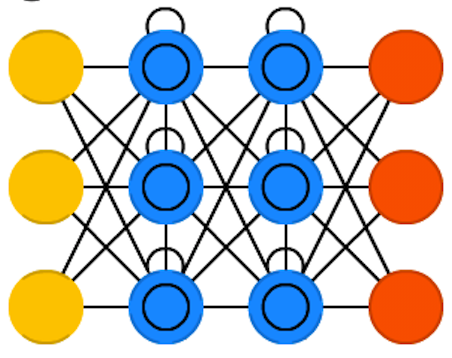
ГЄЖЬЪБМЧвфЭјТчЪЧвЛжжЬиЪтЕФбЛЗЩёОЭјТчЃЌФмЙЛбЇЯАГЄЦквРРЕЙиЯЕЁЃЭјТчЭЈЙ§в§ШыУХНсЙЙ(gate)КЭвЛИіУїШЗЖЈвхЕФМЧвфЕЅдЊ(memory cell)РДГЂЪдПЫЗўЬнЖШЯћЪЇЛђепЬнЖШБЌеЈЕФЮЪЬтЁЃГЄЖЬЪБМЧвфЭјТчгаФмСІЯђЕЅдЊзДЬЌжавЦГ§ЛђЬэМгаХЯЂЃЌЭЈЙ§УХЯоНсЙЙЖдаХЯЂНјааЙмРэЁЃУХЯогабЁдёЕиШУаХЯЂЭЈЙ§ЁЃЫќУЧгЩвЛИіsigmoidЩёОЭјТчВуКЭж№ЕуГЫЗЈдЫЫузщГЩЁЃ
УПИіЩёОдЊгавЛИіМЧвфЕЅдЊКЭШ§ИіУХНсЙЙЃКЪфШыЁЂЪфГіКЭЭќМЧЁЃетаЉУХНсЙЙЕФЙІФмЪЧЭЈЙ§НћжЙЛђдЪаэаХЯЂЕФСїЖЏРДБЃЛЄаХЯЂЁЃЪфШыУХНсЙЙОіЖЈСЫгаЖрЩйРДздЩЯвЛВуЕФаХЯЂДцДЂгкЕБЧАМЧвфЕЅдЊЁЃЪфГіУХНсЙЙГаЕЃСЫСэвЛЖЫЕФЙЄзїЃКОіЖЈЯТвЛВуПЩвдСЫНтЕНЖрЩйетвЛВуЕФаХЯЂЁЃЭќМЧУХНсЙЙГѕПДКмЦцЙжЃЌЕЋЪЧгаЪБКђЭќМЧЪЧБивЊЕФЃКШчЙћЭјТче§дкбЇЯАвЛБОЪщЃЌВЂПЊЪМСЫаТЕФеТНкЃЌФЧУДЭќМЧЧАвЛеТЕФвЛаЉШЫЮяНЧЩЋЪЧгаБивЊЕФЁЃ
УХПибЛЗЕЅдЊЃЈGated Recurrent UnitsЃЌGRUЃЉ
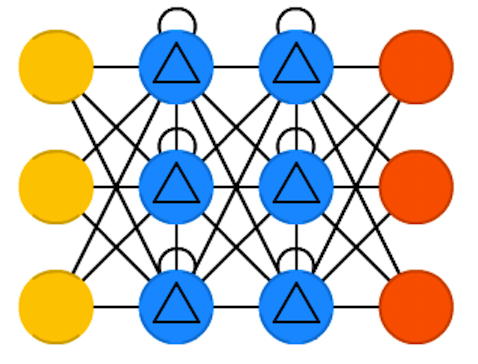
УХПибЛЗЕЅдЊЪЧГЄЖЬЪБМЧвфЭјТчЕФвЛжжБфЬхЁЃВЛЭЌжЎДІдкгкЃЌУЛгаЪфШыУХЁЂЪфГіУХЁЂЭќМЧУХЃЌЫќжЛгавЛИіИќаТУХЁЃИУИќаТУХШЗЖЈСЫДгЩЯвЛИізДЬЌБЃСєЖрЩйаХЯЂЃЌвдМАгаЖрЩйРДздЩЯвЛВуЕФаХЯЂЕУвдБЃСєЁЃдкДѓЖрЪ§ЧщПіЯТЃЌЫќУЧгыLSTMЕФЙІФмЗЧГЃЯрЫЦЃЌзюДѓЕФЧјБ№дкгкGRUЩдПьЃЌдЫааШнвзЃЌЕЋБэДяФмСІИќВюЁЃ
дкЪЕМљжаЃЌетаЉЭљЭљЛсЯрЛЅЕжЯћЃЌвђЮЊЕБЮвУЧашвЊвЛИіИќДѓЕФЭјТчРДЛёЕУИќЧПЕФБэЯжСІЪБЃЌБэЯжСІЭљЭљЛсЕжЯћадФмгХЪЦЁЃдкВЛашвЊЖюЭтБэЯжСІЕФЧщПіЯТЃЌGRUПЩФмгХгкLSTMЁЃ
ЩёОЭМСщЛњЃЈNeural Turing MachinesЃЌNTMЃЉ
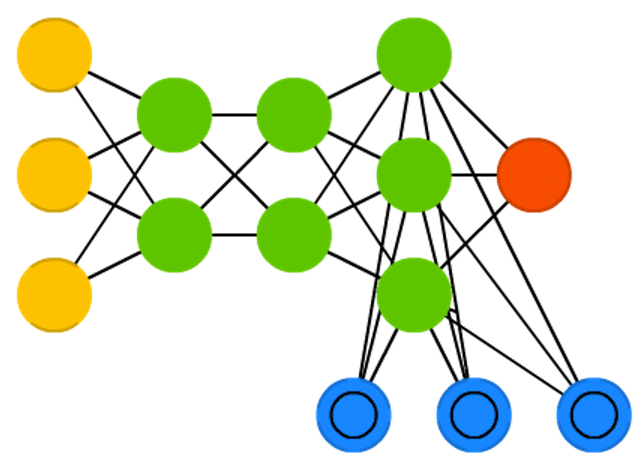
ЩёОЭМСщЛњАќКЌСНИіЛљБОзщГЩВПЗжЃКЩёОЭјТчПижЦЦїКЭМЧвфПтЁЃДЋЭГЕФЩёОЭјТчЪЧвЛИіКкЯфФЃаЭЃЌЖјЩёОЭМСщЛњГЂЪдНтОіетвЛЮЪЬтЁЃ
ЯёДѓЖрЪ§ЩёОЭјТчвЛбљЃЌПижЦЦїЭЈЙ§ЪфШыЪфГіЯђСПгыЭтНчНЛЛЅЃЌЕЋВЛЭЌгкБъзМЭјТчЕФЪЧЃЌЫќЛЙгывЛИіДјгабЁдёадЖСаДВйзїЕФФкДцОиеѓНјааНЛЛЅЁЃЫќЪдЭМНЋГЃЙцЪ§зжДцДЂЕФаЇТЪКЭгРОУадвдМАЩёОЭјТчЕФаЇТЪКЭБэДяСІНсКЯЦ№РДЁЃетжжЯыЗЈЕФЪЕЯжЛљгквЛИігаФкШнбАжЗЕФМЧвфПтЃЌЩёОЭјТчПЩвдДгжаНјааЖСаДЁЃ
ЩюЖШВаВюЭјТчЃЈDeep Residual NetworksЃЌDRNЃЉ
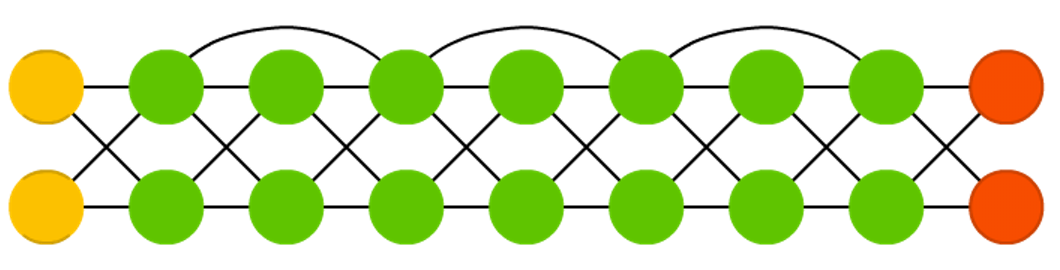
ЩюЖШЭјТчШнвздьГЩЬнЖШдкЗДЯђДЋВЅЕФЙ§ГЬжаЯћЪЇЃЌЕМжТбЕСЗаЇЙћКмВюЃЌЖјЩюЖШВаВюЭјТчНЋЛљБОЕФЕЅдЊИФГЩСЫетбљЃК
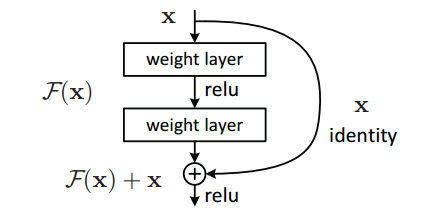
ЫќдкЩёОЭјТчЕФНсЙЙВуУцНтОіСЫетвЛЮЪЬтЃЌОЭЫуЭјТчКмЩюЃЌЬнЖШвВВЛЛсЯћЪЇЁЃ
ЛиЩљзДЬЌЭјТчЃЈEcho State NetworksЃЌESNЃЉ
ЛиЩљзДЬЌЭјТчЪЧСэЭтвЛжжВЛЭЌРраЭЕФбЛЗЭјТчЁЃДЋЭГЕФЖрВуЩёОЭјТчЕФжаМфВуЪЧвЛВувЛВуЕФШЋСЌНгЩёОдЊЃЌЛиЩљзДЬЌЭјТчАбжаМфЕФШЋСЌНгВПЗжБфГЩСЫвЛИіЫцЛњСЌНгЕФДцДЂГиЃЌбЇЯАЙ§ГЬОЭЪЧбЇЯАДцДЂГижаЕФСЌНгЁЃЫќУЧЕФбЕСЗЗНЪНвВВЛвЛбљЁЃ
гыбЛЗЩёОЭјТЗЕФВЛЭЌжЎДІЪЧЭјТчНЋЪфШыЕНвўВиВуЃЌвўВиВуЕНвўВиВуЕФСЌНгШЈжЕЫцЛњГѕЪМЛЏЃЌШЛКѓЙЬЖЈВЛБфЃЌжЛбЕСЗЪфГіСЌНгШЈжЕЁЃгЩгкжЛбЕСЗЪфГіВуЃЌВЛашвЊЗДЯђДЋВЅЮѓВюЃЌбЕСЗЙ§ГЬОЭБфГЩЧѓЯпадЛиЙщЃЌЫйЖШЗЧГЃПьЁЃ
МЋЯобЇЯАЛњЃЈExtreme Learning MachinesЃЌELMЃЉ
МЋЯобЇЯАЛњЪЧвЛжжаТаЭЕФПьЫйбЇЯАЫуЗЈЃЌЫќУЧЫцЛњГѕЪМЛЏШЈжиЃЌВЂЭЈЙ§зюаЁЖўГЫФтКЯвЛВНбЕСЗШЈжиЁЃетЪЙЕУФЃаЭБэЯжСІЩдШѕЃЌЕЋЪЧдкЫйЖШЩЯБШЗДЯђДЋВЅПьКмЖрЁЃ
вКЬхзДЬЌЛњЃЈLiquid State MachinesЃЌLSMЃЉ
вКЬхзДЬЌЛњЪЧвЛжжТіГхЩёОЭјТчЃКsigmoidМЄЛюКЏЪ§БЛуажЕКЏЪ§ЫљШЁДњЃЌУПИіЩёОдЊЪЧвЛИіРлЛ§МЧвфЕЅдЊЃЈmemory cellЃЉЁЃЫљвдЕБИќаТЩёОдЊЕФЪБКђЃЌЦфжЕВЂВЛЪЧСкНќЩёОдЊЕФРлМгЃЌЖјЪЧЫќздЩэЕФРлМгЁЃвЛЕЉДяЕНуажЕЃЌЫќЛсНЋЫќЕФФмСПДЋЕнЕНЦфЫћЩёОдЊЁЃетОЭВњЩњСЫвЛжжРрЫЦТіГхЕФФЃЪНЃЌМДдкЭЛШЛДяЕНуажЕжЎЧАЪВУДвВВЛЛсЗЂЩњЁЃ
жЇГжЯђСПЛњЃЈSupport Vector MachinesЃЌSVMЃЉ
жЇГжЯђСПЛњЪЧЗжРрЮЪЬтЕФзюМбНтОіЗНЪНЁЃжЇГжЯђСПЛњЭЈЙ§КЫКЏЪ§ЃЌНЋЕЭЮЌПеМфВЛПЩЗжЕФЪ§ОнгГЩфЕНИпЮЌПеМфЃЌЪЙЪ§ОнБфЕУЯпадПЩЗжЁЃжЇГжЯђСПЛњФмЙЛбЇЯАГівЛИіЗжРрГЌЦНУцЃЌЖдЪ§ОнНјааЗжРрЃЌЕЋвЛАуВЛШЯЮЊжЇГжЯђСПЛњЪЧЩёОЭјТчЁЃ
KohonenЭјТчЃЈKohonen NetworksЃЌKNЃЉЛђздзщжЏгГЩфЃЈSelf-Organizing MapЃЌSOMЃЉ
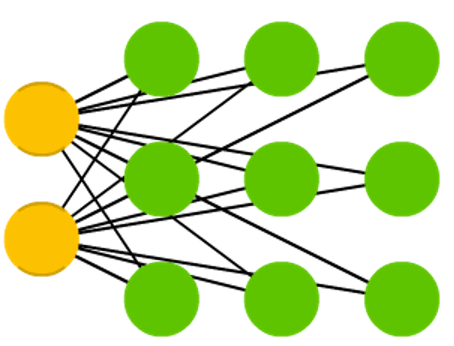
KohonenЭјТчЪЧздзщжЏОКељаЭЩёОЭјТчЕФвЛжжЃЌИУЭјТчЮЊЮоМрЖНбЇЯАЭјТчЃЌФмЙЛЪЖБ№ЛЗОГЬиеїВЂздЖЏОлРрЁЃKohonenЭјТчЩёОдЊЭЈЙ§ЮоМрЖНОКељбЇЯАЃЌСюВЛЭЌЕФЩёОдЊЖдВЛЭЌЕФЪфШыФЃЪНУєИаЃЌДгЖјЬиЖЈЕФЩёОдЊдкФЃЪНЪЖБ№жаПЩвдГфЕБФГвЛЪфШыФЃЪНЕФМьВтЦїЁЃ
KohonenЩёОЭјТчЫуЗЈЙЄзїЛњРэЮЊЃКЭјТчбЇЯАЙ§ГЬжаЃЌЕБбљБОЪфШыЭјТчЪБЃЌОКељВуЩЯЕФЩёОдЊМЦЫуЪфШыбљБОгыОКељВуЩёОдЊШЈжЕжЎМфЕФХЗМИРяЕТОрРыЃЌОрРызюаЁЕФЩёОдЊЮЊЛёЪЄЩёОдЊЁЃЕїећЛёЪЄЩёОдЊКЭЯрСкЩёОдЊШЈжЕЃЌЪЙЛёЕУЩёОдЊМАжмБпШЈжЕППНќИУЪфШыбљБОЁЃ |









