| IT互联网行业有个有趣现象,玩资本的人、玩产品的人、玩技术的人都能很好的在这个行业找到自己的位置并取得成功,而且可以只懂其中一样,不需要懂其余两样。玩技术的人是里面最难做的,也是三者收益最低的,永远都要不停学习,不停把画饼变成煎饼。
在今年5月底,Alphago又战胜了围棋世界冠军柯洁,AI再次呈现燎原之势席卷科技行业,吸引了众多架构师对这个领域技术发展的持续关注和学习,思考AI如何做工程化,如何把我们系统的应用架构、中间件分布式架构、大数据架构跟AI相结合,面向什么样的应用场景落地,对未来做好技术上的规划和布局。
之前发表过一篇文章《如何用70行Java代码实现深度神经网络算法》(点击「阅读原文」获得文章),记录了深度神经网络的计算过程和程序实现,本文再进一步研究一下背后的数学原理。
为了彻底理解深度学习,我们到底需要掌握哪些数学知识呢?经常看到会列出一系列数学科目:微积分、线性代数、概率论、复变函数、数值计算等等。这些数学知识有相关性,但实际上这是一个最大化的知识范围,学习成本会非常久,本文尝试归纳理解深度学习所需要的最小化数学知识和推导过程。
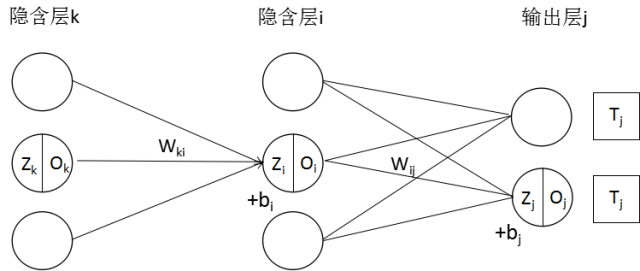
多层神经网络的函数构成关系
多层神经网络从输入层,跨多个隐含层,到最后输出层计算误差,从数学上可以看做一系列函数的嵌套组合而成,上一层函数输出做为下一层函数输入,如下图1所示。
先从误差函数说起,深度学习的误差函数有典型的差平方函数,也有交叉熵函数,本文以差平方函数为例:
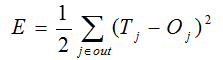
Tj代表每个神经元目标值,Oj代表每个神经元输出值
这里Oj=f(Zj),f是激活函数,一般是s函数:
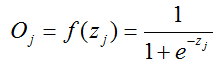
或者relu函数:
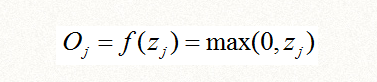
Zj是线性函数(Wij泛指i层和j层节点连接权重,bj泛指j层节点截距):
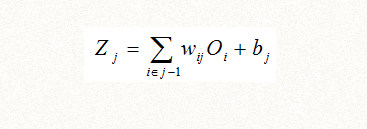
Oi再往前依次类推,整个神经网络都可以由上面的函数嵌套去表达。
现在我们的问题是,如何通过多次调整上面的Wij和bj,能让误差函数E达到最小值?
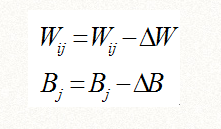
换言之,上面这个变量w和变量b应该怎么取值才能达到效果呢?为了回答这个问题,我们先看看误差函数的几何意义。
误差函数的几何意义及梯度下降
为了方便看懂,我们从二维和三维去理解误差函数,如果输出值Oj只有一项,并设定Tj=1,那么Oj和误差函数E刚好构成X,Y的坐标关系如图2所示:
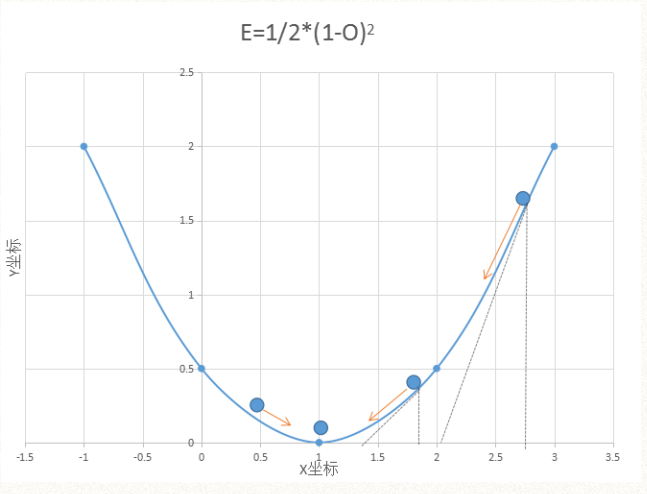
也就是Oj只有一项的时候,误差函数E刚好就是一个简单的抛物线,可以看到它的底部在O=1的时候,这时E=0最小值。
那么,当O不等于1的时候,我们需要一种方法调整O,让O像一个小球一样,把抛物线看做碗,它沿着碗切面向下滚动,越过底部由于重力作用又返回,直到在底部的位置停止不动。什么方法能达到这样神奇的效果呢,就是数学家发明的导数,如果O每次减去一个导数的步长,在离底部远的地方,导数对应的正切值就大,下降就快,离底部近的地方,导数正切值就小,下降就慢,在底部O=1这个点导数为0,不再下降,并且越过底部后,导数的正切值变负数,于是又调整了它的方向,刚好达到重力一样的效果。我们把这种方法取个难懂的名字,叫做梯度下降。
再看看三维的几何意义,假设输出值为O1,O2两项,并设定T1=1,T2=1那么O1,O2和误差函数E刚好构成X,Y,Z的坐标关系如图3所示:
E=1/2(1-O1)2+1/2(1-O2)2
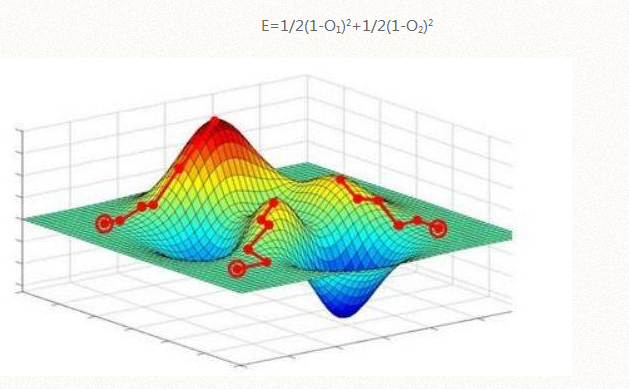
任意给定一个X,Y值,通过函数E计算得到一个Z值,形成一个三维曲面,最小值在谷底。我们继续使用上面的梯度下降方法,会产生一个问题,现在的变量是O1,O2两项,到底使用哪个求导数呢?根据上面的几何图形可以看到,如果O1,O2轴同时往谷底方向下降,那么E能达到最小值,可以试想O2等于一个常数,就相当于一个O1和E构成的二维截面,采用上面的方法减去O1导数的步长就能得到O1的变化量,同样将O1等于一个常数,能得到O2和E构成的二维截面,并求得O2的变化量。这种将其他变量视为常数,而只对当前变量求导的方法叫求偏导。
从上面得知对二元函数z=f(x,y)的梯度下降求法,是对每个X,Y求偏导,那么对于多元函数呢,也是一样的求法,只是多维世界的几何图形就很难表达了,因为我们生活在三维世界,很难想像出克莱因瓶这样的四维世界,瓶底通过第四维空间穿过瓶身去和瓶口相连,人类的眼睛也只能看到三维世界,世界上的三维物体能否通过第四维通道传送到另外一个位置上去呢,看上去像这个物体消失了,在其他地方又突然出现了,跑题了,言归正传。
由于导数的特点是到一个谷底就为0了,也就是不变化了,所以梯度下降求法有可能只到一个山窝里,没有到达最深的谷底,有局部最小值的缺陷,所以我们要不停调整初始参数,和进行多次的训练摸索,争取能碰到一个到达谷底的最好效果。
现在还有个问题,这里是以O为变量来解释梯度下降求法,但是其实我们要求的是Wij和bj的调整值,根据上面的结论,我们可以通过误差函数E对Wij和bj求偏导得到,步长为自己设置的一个常数,如下:
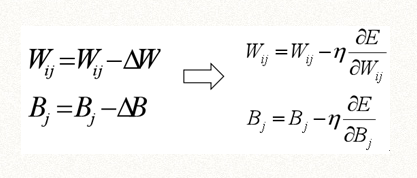
那么如何求呢,通过前面的第一部分的神经网络函数构成关系,Wij和bj到误差函数E是一个多层嵌套的函数关系,这里需要用到复合函数的求偏导方法,截至这里,我们理解了数学原理,再结合下面所用到的数学公式,就构成了推导所需要的最小化数学知识。
推导需要的数学公式
1、复合函数求偏导公式
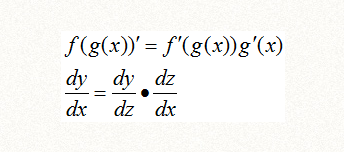
2、导数四则运算公式
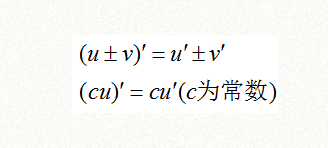
3、导数公式
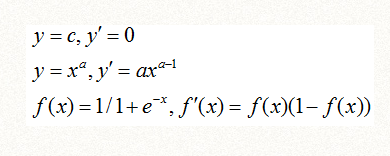
我们只要记住上面3组公式,就可以支持下面完整的推导了。
数学推导过程
先将多层神经网络转成一个数学问题定义,如图4所示:
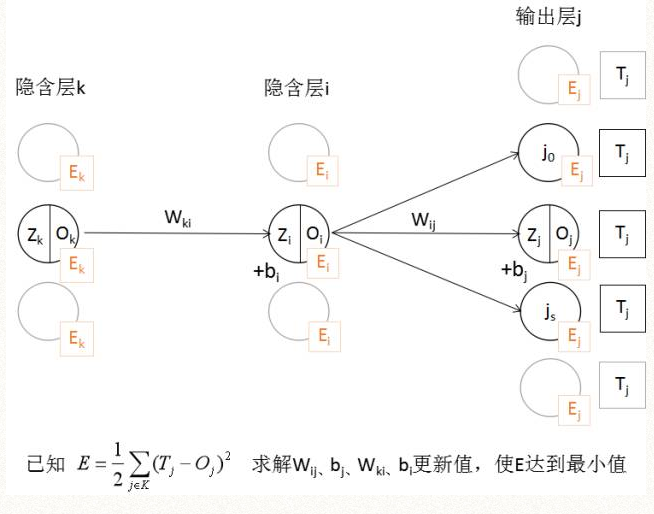
1、对于输出层的权重Wij和截距bj,通过误差函数E对Wij求偏导,由于函数E不能直接由Wij表达,我们根据第1组的复合函数求偏导公式,可以表达成Oj和Zj对Wij求偏导的方式:
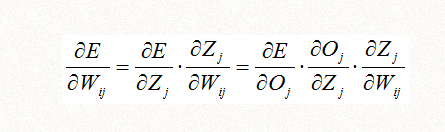
由于Zj是线性函数我们是知道的
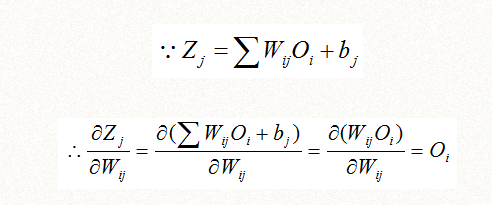
并且Oj是可以直接用Zj表达的:
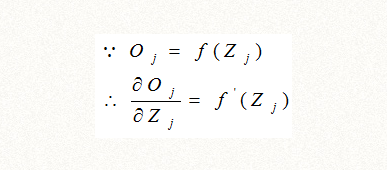
所以E对Wij求偏导可以写成f(Zj)的导数表达,同样对bj求偏导也可以用f(Zj)的导数表达(记做推导公式一)
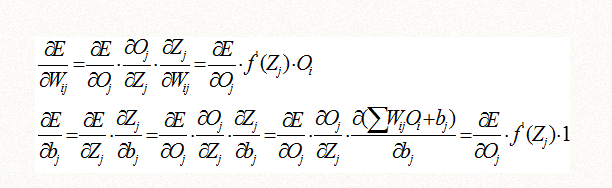
由于误差函数E是可以直接用Oj表达的,我们继续推导如下,根据第2组和第3组导数四则运算公式和导数公式:
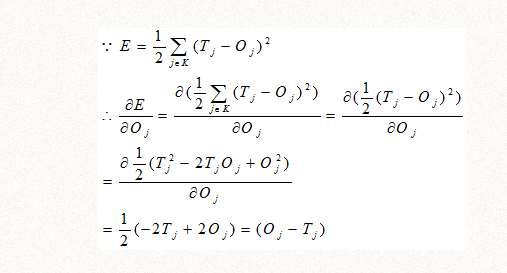
最后得到一个只用f(Zj)的导数表达的通用公式,其中Oj是输出层的输出项,Oi是上一层的输出项:
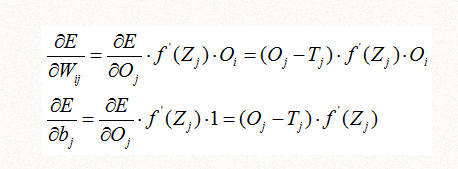
从前面得知,Oj=f(Zj),f是激活函数,一般是s函数或者relu函数,我们继续推导如下:
(1)如果激活函数是s函数,根据它的导数公式:
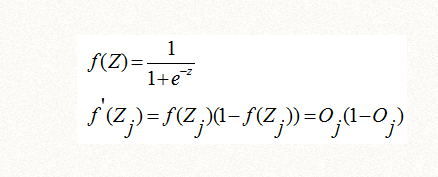
可以得到结论一(1),权重Wij和截距bj,的更新公式为:
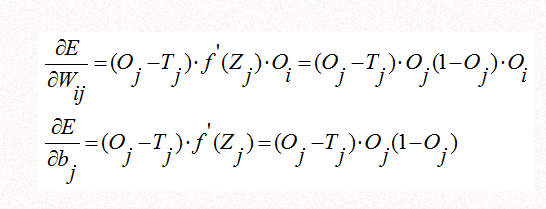
(2)如果激活函数是relu函数,根据它的导数公式:
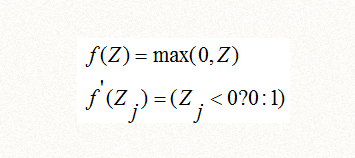
可以得到结论一(2),权重Wij和截距bj,的更新公式为:
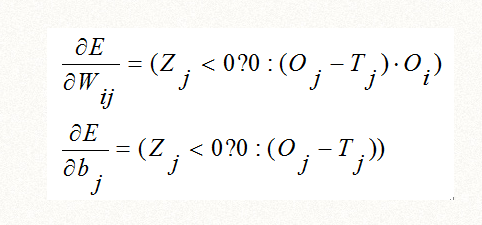
2、除了对输出层的权重Wij和截距bj外,更普遍的隐含层权重Wki和截距bi更新应该如何去求呢?
我们仍然用误差函数E对Wki和bi求偏导,借助前面的推导公式一,可以得到
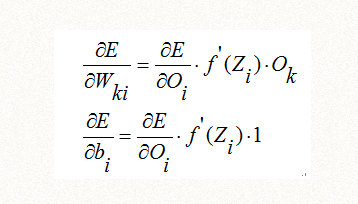
对于输出层来说,误差函数E可以直接用Oj表达,但是对于隐含层,误差函数E并不能直接用Oi表达,根据多层神经网络的函数构成关系,我知道Oj可以通过Oi向前传递进行一系列函数组合得到的。
由于深度学习不一定是全连接,我们假设Oi只和输出层j的s个节点相连接,下标记为j0到js,如上面图四所示,对于Oi来说,只跟和它节点相连接的Oj构成函数关系,跟不相连接的Oj没有函数关系,所以我们根据复合函数求偏导可以把不相连接的Oj视为常数。
并且,根据函数构成关系,Oi可直接构成Zjs,Zjs可直接构成Oj,根据复合函数求偏导公式的链式写法推导如下:
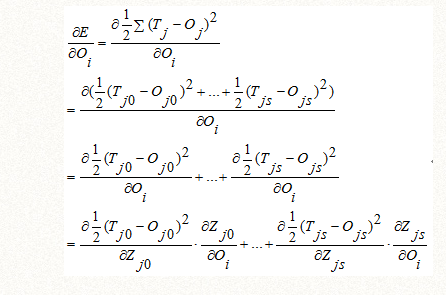
同时,对上式的Zjs来说,误差函数E对它求偏导,其余项可以视为常数:
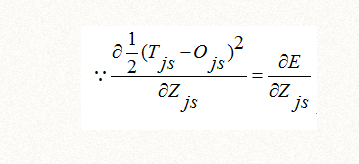
所以,在上式的结果继续推导如下,可以完全用E对Zjs的偏导数来表达:

现在我们将误差函数E对Zjs的偏导数记做输出层相连节点的误差项,根据前面的推导公式一,在计算Wij更新值可以得到:
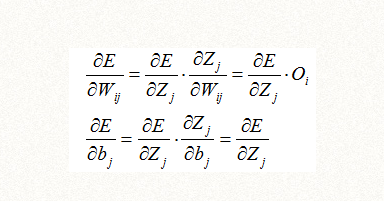
所以,隐含层的权重和截距更新,可以由输出层的误差项得到,同理也适用于其他隐含层,都可以由它的后一层(nextlayer)的误差项得到,下面是结论二,隐含层权重Wki和截距bi的更新公式为:
总结
通过掌握以上数学原理和推导,我们就理解了深度学习为什么要这样计算,接下来利用推导的结论一和结论二,可以完成深度学习的算法程序实现了,剩下的只是架构和工程化的问题。对卷积类的深度学习模型,为了降低训练复杂性,它的权重很多是相同的(权重共享),并且只和下一层部分神经元节点连接(局部连接),数学原理、计算方法、训练方式和上面是一样的,最终的模型结果都是得到一组参数,用该组参数保证误差函数最接近最小值。
|









