|
вЛ. Wide&&Deep ФЃаЭ
ЪзЯШИјГіWide && Deep [1] ЭјТчНсЙЙ:
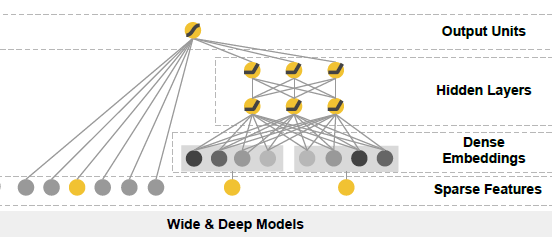
БОжЪЩЯЪЧЯпадФЃаЭ(зѓБпВПЗж, Wide model)КЭDNNЕФШкКЯ(гвБпВПЗж,Deep Model)ЁЃ
ЭЦМіЯЕЭГашвЊНтОіСНИіЮЪЬт:
МЧвфад: БШШчЭЈЙ§РњЪЗЪ§ОнжЊЕРЁБТщШИЛсЗЩЁБЃЌЁБИызгЛсЗЩЁБ
ЗКЛЏад: ЭЦЖЯдкРњЪЗЪ§ОнжаДгЮДМћЙ§ЕФЧщаЮЃЌЁБДјГсАђЕФЖЏЮяЛсЗЩЁБ
WideDeepЪЧдѕУДНтОіетСНИіЮЪЬтФиЃП
WideФЃаЭ:
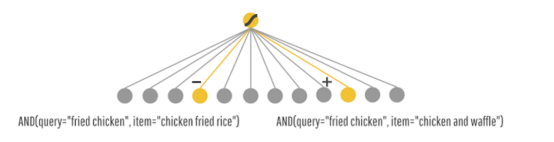
БШШчЯждкгавЛИіЕуВЭЭЦМіAPPЃЌЮвЪфШыеЈМІ(query)ЃЌФЧУДЛсИјЮвНјааЭЦМіЦфЫћЯрЙиЕФЪГЮя(item)ЃЌФЧУДФЃаЭФПЕиОЭЪЧЮЊСЫЯЃЭћжЊЕРИјЖЈСЫquery, ЯћЗбitemЕФИХТЪЃЌ МД: P(ЯћЗб| query, item). ФЧЮвУЧОЭПЩвдЭЈЙ§ЙЙНЈГівЛЯЕСа(query, item)ЕФcross ЬиеїЃЌ ЭЈЙ§LRШЅбЇЯАЕНетаЉВЛЭЌЕФcrossЬиеїгыtarget = ЯћЗб ЕФЯрЙиадЁЃБШШч(query = ЁАеЈМІЁБ, item = ЁАЦЁОЦЁБ) гыtarget = ЯћЗб ,ЭЈЙ§РњЪЗЪ§ОнбЇЯАЕНгаКмЧПЕФЯрЙиадЃЌФЧУДОЭЭЦМіИјеЈМІЁЃ
DeepФЃаЭ:
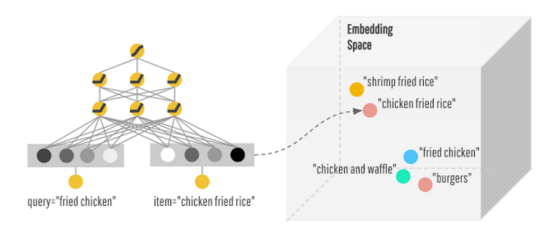
ЯждкЮвбсОыСЫЭЦМіЕФНсЙћЃЌЯЃЭћЭЦвЛаЉШУЮвОЊЯВЕФЪГЮяЃЌЩЯУцЕФwideФЃаЭЃЌЮвУЧЙЙНЈЕФcrossЬиеївВЪЧгаЯоЕФЃЌВЛФмУцУцОуЕНЃЌcrossЬиеїЛђаэПЩвдЪЧШ§ИіРрБ№ЃЌЫФИіРрБ№ЁЃЫљвдЃЌашвЊdeepФЃаЭздЖЏАяЮвУЧзівЛаЉЬиеїЁЃУПИіЬиеїПЩвдгГЩфЕНвЛИіЕЭЮЌПеМфШЅЃЌбЇЯАЕНвЛИіЕЭЮЌdenseЕФБэДя(embedding vector)ЁЃ ФЧУДИјЖЈвЛИіquery, ЮвУЧПЩвддкembedding spaceжаевОрРыЯрНќЕФitemЃЌ ШЯЮЊЪЧЧБдкЯВЛЖЕФitem
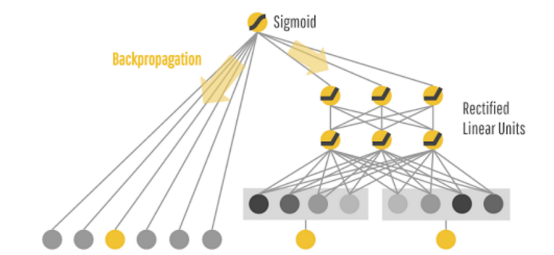
WideФЃаЭгыDeepФЃаЭЕФНсКЯЃЌФПЕФЪЧЮЊСЫЦНКтМЧвфадКЭЗКЛЏадЕФНсЙћ.
Жў. FNNЃЌSNN ФЃаЭ
КЭwide deepГіЗЂЕувЛбљЃЌ вЛаЉЯпадФЃаЭLRКмФббЇЕНЗЧЯпадБэДяЃЌ ЗЧЯпадФЃаЭБШШчFM, GBDTгжКмФббЇЕНЫљгаЕФЬиеїзщКЯЗНЪНЁЃФЧУДЃЌШчКЮРћгУDNNШЅздЖЏбЇЯАЕНЬиеїБэДяЃЌздЖЏШЅбЇЯАЕНЬиеїжЎМфЕФНЛВцФиЃП
FNNФЃаЭНсЙЙ[2]:
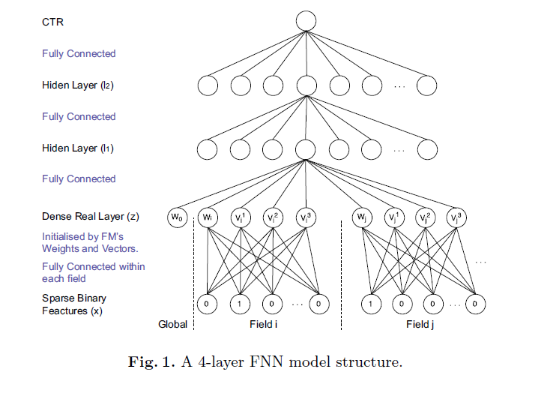
ЪзЯШашвЊЖдcategoryЬиеїНјаавЛИіone-hotБрТыЁЃ
l1, l2ВуЖМЪЧвўВиВуЃЌФЧУДЃЌ dense real layer ОЭПЩвдПДзївЛИіembeddingВуЃЌ УПИіfield ЗжБ№ ЖдгІвЛИіembeddingЕФЙ§ГЬЁЃЭЈГЃЃЌЪЙгУFMШЅГѕЪМЛЏетаЉВЮЪ§ЭљЭљФмЙЛИќПьЕиЪеСВЃЌзюДѓЯожЦБмУтбЕСЗЙ§ГЬжаЯнШыОжВПзюаЁЃЌвдМАЕУЕНИќКУЕФНсЙћЁЃПЩвдПДЕНЃЌFNNЦфЪЕОЭЪЧwidedeepФЃаЭЕФdeepВПЗжЃЌЕЋЪЧFNNгагУFMНјаавЛИіВЮЪ§ГѕЪМЛЏЕФЙ§ГЬЁЃ
SNNФЃаЭНсЙЙ:
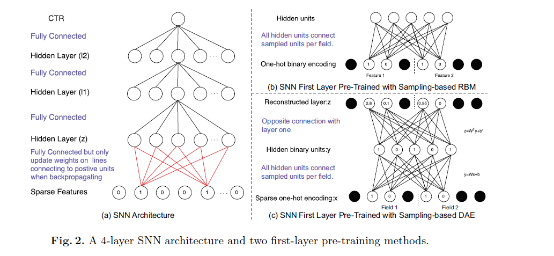
SNNКЭFNNФЃаЭЧјБ№гкзюЕзВуЕФбЕСЗЗНЗЈЃЌ FNNзюЕзВуЯШгУFMГѕЪМЛЏЃЌПЩвдПДЕНЃЌSNNзюЕзВуЪЧШЋСЌНгЕФЃЌВЛЧјЗжВЛЭЌЕФfieldЁЃ ГѕЪМЛЏВЩгУRBM(ЯожЦВЃЖћзШТќЛњ) КЭ DAE(здЖЏБрТыЛњ)ЁЃ
бЕСЗЙ§ГЬжаЃЌУЛгаУПТжЕќДњЖМЛсгУЕНЫљгаЕФЬиеїЃЌЖдЮЊ0ЕФЕЅдЊНјаавЛИіЯТВЩбљВйзїЃЌЭМжаКкЩЋЕФЕЅдЊМДЪЧУЛгаБЛбЁШЁЕНЃЌВЛВЮгыВЮЪ§ЕќДњЁЃМЦЫуИДдгЖШЕУЕНДѓСПЕФМѕЩйЁЃ
ЮФеТдкiPinYouЪ§ОнМЏЩЯНјааЦРВтЃЌПЩвдПДЕНFNNаЇЙћгХгкFMЃЌLRЁЃ
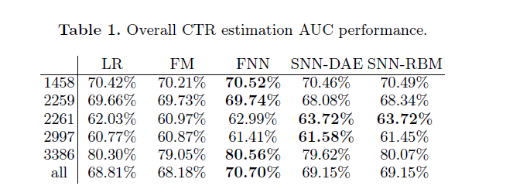
ЮФеТЖдЕїВЮвВИјГіСЫвЛаЉОбщ
- ЭјТчНсЙЙЃЌЭЈГЃЃЌзъЪЏаЭЕФЭјТчНсЙЙЭљЭљгХгкЦфЫћНсЙЙ
- вўВиВуЕЅдЊЪ§ВЛЪЧдНИпдНКУЃЌжаМфгавЛИіСйНчжЕДяЕНзюгХ.
- DropoutдкЪ§ОнСПБОРДОЭКмЯЁЪшЕФЧщПіЯТОЁСПВЛгУЃЌВЛЭЌЕФЪ§ОнМЏdropoutБэЯжВюОрБШНЯДѓЁЃ
Ш§. PNN ФЃаЭ
PNN[3]ЕФЭјТчНсЙЙ:
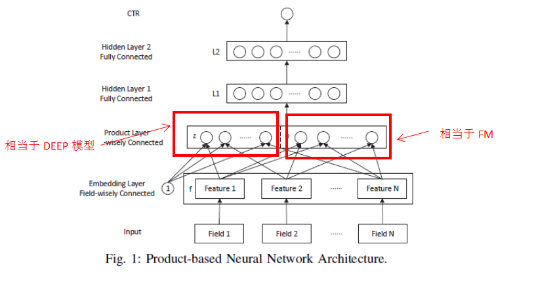
PNNЕФНсЙЙЕФЫМЯыЯрБШгкWideDeepФЃаЭКЫаФИФЖЏЕиЗНдкЖдгкembeddingКѓЕФdense featureЃЌдіМгСЫСНСННЛВцЕФЙІФмЃЌwidedeepЪЧembedding featureШЋВПЪфШыЕНвўВиВуСЫЁЃВЛЭЌfieldОЙ§EmbeddingКѓЕФЬиеїзіЕуЛїдЫЫуЦфЪЕОЭЯрЕБгкFMЃЌФЧУДPNNШЯЮЊЪзЯШашвЊШЗБЃбЇЯАЕНетаЉНЛВцЬиеїЃЌдйШЅЖюЭтНЛИјDNNШЅбЇЯАИќИДдгЕФНЛВцЬиеїЁЃФЧУДPNNНсЙЙЦфЪЕЯрЕБгкFM+DEEPЁЃ
дйЫЕЯТЭјТчЯИНк: Embedding layer КЭWide DeepФЃаЭЪЧвЛбљЕФЃЌ ВЛЭЌfieldЬиеїгГЩфЕНСЫвЛИіembeddingЕФПеМфЩЯЃЌетЪБЃЌВЛЪЧЫљгаЕФЬиеїжБНгЫЭЕНвЛИіNNЭјТчРяУцШЅЃЌетРяЗжГЩСНИіВПЗжz КЭpЁЃ zВПЗжжБНгОЭЪЧдЪМЕФembeddingЬиеїВЛБф; PВПЗжЪЧembeddingЬиеїСНСНзіФкЛ§дЫЫуЃЌДяЕНFMЕФаЇЙћЃЌНгЯТРДzКЭpЦДНгГЩвЛИіvectorЃЌ ЫЭЕНвЛИіNNЭјТчРяУцЃЌзюКѓsoftmaxЪфГіИХТЪжЕЁЃ
ЫФ. DeepFM ФЃаЭ
DeepFM[4]ЕФЭјТчНсЙЙ:
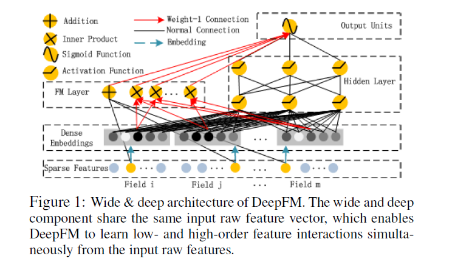
ПЩвдПДЕНЃЌКмЯёPNNНсЙЙЃЌжЛЪЧдкетРяFMУЛгаКЭдЪМЬиеївЛЦ№ЫЭЕНNNжаШЅбЕСЗЃЌЖјЪЧЕЅЖРФУГіРДРрЫЦгкWIDEФЃаЭЁЃЦфЪЕОЭЪЧWideDeepФЃаЭжаWideВрЬцЛЛЮЊFMЁЃ
Юх. NFM ФЃаЭ
NFMФЃаЭ[5]ЕФЭјТчНсЙЙ:
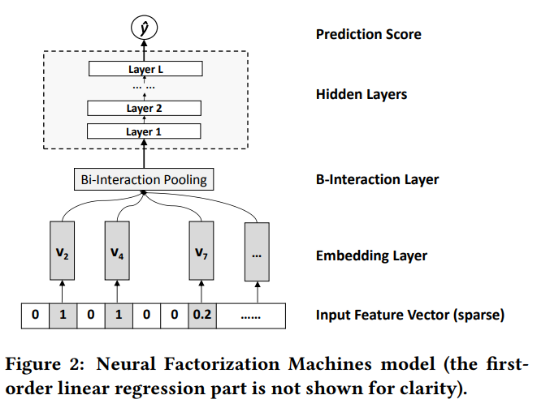
ЪзЯШЃЌвВЪЧОЙ§ШЋСЌНгЕУЕНembeddingВуЃЌЪфШыЪЧ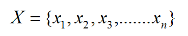
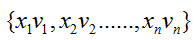 ЗжБ№ЪЧВЛЭЌЬиеїЖдгІЕФЯрЭЌЮЌЪ§ЕФembeddingЯђСПЁЃНгЯТРДЃЌетаЉembeddingЯђСПСНСНзіelement-wiseЕФЯрГЫдЫЫуЕУЕНB-interaction layerЁЃ(element-wideдЫЫуОйР§: (1,2,3)element-wideЯрГЫ(4,5,6)НсЙћЪЧ(4,10,18)ЁЃ) ЗжБ№ЪЧВЛЭЌЬиеїЖдгІЕФЯрЭЌЮЌЪ§ЕФembeddingЯђСПЁЃНгЯТРДЃЌетаЉembeddingЯђСПСНСНзіelement-wiseЕФЯрГЫдЫЫуЕУЕНB-interaction layerЁЃ(element-wideдЫЫуОйР§: (1,2,3)element-wideЯрГЫ(4,5,6)НсЙћЪЧ(4,10,18)ЁЃ)
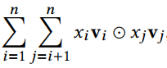
ИУB-interaction Layer ЕУЕНЕФЪЧвЛИіКЭembeddingЮЌЪ§ЯрЭЌЕФЯђСПЁЃШЛКѓКѓУцНгМИИівўВиВуЪфГіНсЙћЁЃ
ЮЊЪВУДетУДзіФиЃПЪзЯШПДШчЙћB-interaction layerКѓУцВЛНгвўВиВуЃЌжБНгАбЯђСПЕФдЊЫиЯрМгЪфГіНсЙћ(ЖдгІЯТУцЕФЙЋЪНh=(1,1,1,...,1)) , ОЭЪЧвЛИіFMЃЌ ОЭКУБШвЛИіЯпадФЃаЭЃЌШЈжиЖМЪЧ1 :
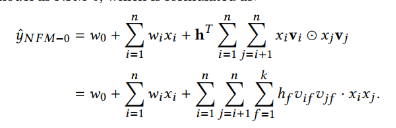
ЯждкКѓУцдіМгСЫвўВиВуЃЌЯрЕБгкзіСЫИќИпНзЕФFMЃЌИќМгдіЧПСЫЗЧЯпадБэДяФмСІЁЃ
Сљ. AFM ФЃаЭ
AFMФЃаЭ[6]ЕФЭјТчНсЙЙ:
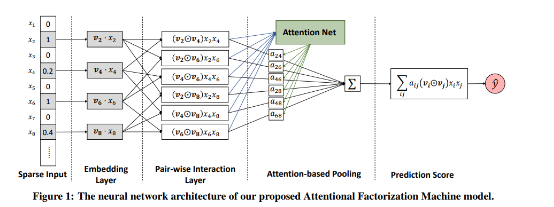
AFMЪЧNFMФЃаЭЕФвЛИіИФНјЃЌ дкДЋЭГFMФЃаЭжаЃЌЪЙгУЖўНзНЛВцЬиеїЕУЕНЗЧЯпадБэДяФмСІЃЌЕЋЪЧВЛЪЧЫљгаЕФЬиеїНЛВцЖМЛсгадЄВтФмСІЃЌКмЖрЮогУЕФЬиеїНЛВцМгШыКѓЗДЖјЛсЯрЕБгкМгШыСЫдыЩљЁЃ
вђДЫЃЌдкетИіФЃаЭжаЃЌМгШыСЫAttention Net ЛњжЦЃЌaijБэЪОЬиеїi,jНЛВцЕФШЈжиЁЃМЦЫуЗНЪНШчЯТ: ОЙ§вЛИіattention netЕФвўВиВуЃЌЕУЕНИУЬиеїНЛВцЕФШЈжи
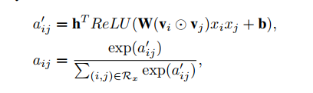
зюКѓЕФдЄВтЗНЪНКЭNFMРрЫЦЃЌ ЕБP=(1,1,1,...,1)ЃЌЪЧМгСЫШЈжиЕФFMЃЌ КѓУцвВПЩвдКЭNFMвЛбљдіМгвўВиВуЃЌЕУЕНИќИпНзЬиеїЕФБэДяФмСІЁЃ
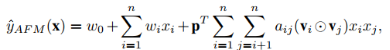
Нсгя: УЛгаЭђФмЕФФЃаЭЃЌеыЖдВЛЭЌЕФвЕЮёПЩФмашвЊбЁдёВЛЭЌЕФФЃаЭЃЌБШШчШчЙћашвЊНтЪЭФмСІЧПЕФЃЌФЧУДВЛЗСбЁдёAFMФЃаЭЃЌ Wide DeepЪЕМЪжагІгУБШНЯЙуЃЌаЇЙћвВПЩвдЃЌЕЋЪЧКмФбЖЈЮЛЮЪЬтЃЌвВФбЗжЮіDeepВрЕФЬиеїживЊадЁЃЭЌЪБЭјТчНсЙЙашвЊВЛЖЯГЂЪдЃЌЛђаэЮвУЧЖМПЩвдembeddingЕНвЛИіЙЬЖЈЕФЮЌЪ§КѓЃЌПЩвдАбетИіembeddingЬиеїЕБзїЭМЯёРДзіЃЌзіОэЛ§ЃЌpooling, ЫЕВЛЖЈгаОЊЯВЃЌДяЕНШЅдыЩљЕФФПЕФЁЃ
|








