| īůľ“ļ√£¨ő“ «Ľ∂ĺŘ ĪīķĶńłŖ—Ô£¨’‚īőłķīůľ“∑÷ŌŪĶńńŕ»› «…Ó∂»—ßŌį‘ŕ”őŌ∑AI÷–Ķń”¶”√’‚—ý“ĽłŲĽįŐ‚°£

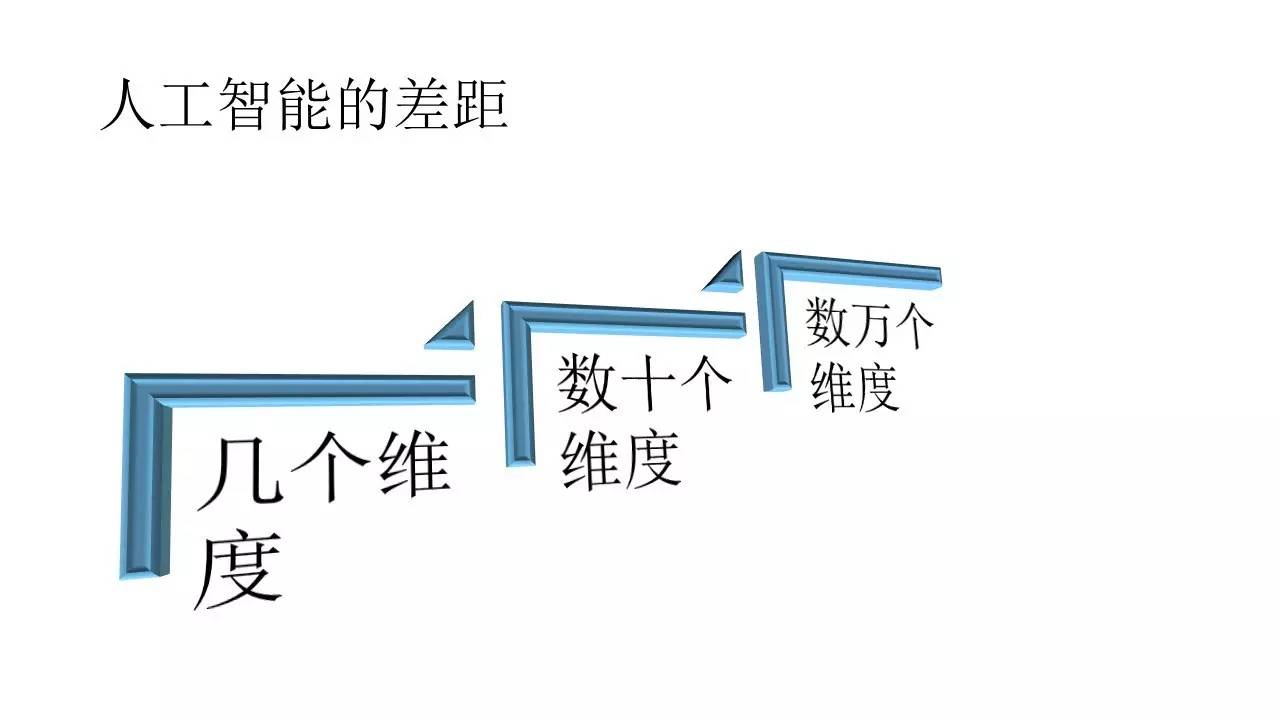
NPCĶń«ż∂Įī÷∑÷Ņ…“‘∑÷≥…ĶÕľ∂°Ę÷–ľ∂°ĘłŖľ∂°ĘŐōłŖľ∂£¨’‚—ýľłłŲņŗĪū°£ĶĪ»Ľ£¨įī’’∆šňŁĶń∑Ĺ Ĺ∑÷“≤őī≥Ę≤ĽŅ…£¨’‚ņÔ÷ų“™ «’Ž∂‘ ĶŌ÷∑Ĺ ĹļÕ”¶”√≥°ĺįĶń“ĽłŲī÷¬‘Ľģ∑÷°£

ĶÕľ∂NPCÕ®≥£ňĶĶń «“Ľ–©”őŌ∑÷–ňýőĹĶń‘”ĪÝ£¨≤Ľ…śľį ≤√ī«ťĹŕ£¨“≤√Ľ”– ≤√īňýőĹĶń≤Ŗ¬‘◊ųő™«ż∂Į°£ĽýĪĺ…ŌĺÕ «įī’’“Ľ∂®Ķń…Ťľ∆ļ√Ķń¬∑ŌŖ––ĹÝ£¨≤Ę÷ĪĹ”Ļ•Ľų”őŌ∑÷ųĹ«°£’‚ņŗ”őŌ∑ļ‹≥£ľŻ£¨”»∆š «ņŌĶńĶ•Ľķ”őŌ∑÷–£¨ĺÝīů≤Ņ∑÷ĺÕ «’‚ņŗNPC°£

÷–ľ∂NPC≥£ľŻ”ŕ”őŌ∑»ļ’Ĺ÷–ĶńŇšļŌ–ÕNPC°£’‚ņŗĽķ∆ų»ňĽŠ”–“Ľ∂®Ķń ¬Ō»ĪŗļŇĶń≤Ŗ¬‘◊ųő™«ż∂Į£¨≤Ę«“”–ľÚĶ•Ķń”¶Īšń‹Ń¶°£ĶĪ»Ľ£¨’‚–©∂ľ «»ňņŗ ¬Ō»…Ť∂®ļ√Ķń≤Ŗ¬‘ńŕ»›°£Ī»»Á”ŇŌ»Ļ•Ľų—™ŃŅĹŌĶÕĶń”őŌ∑÷ųĹ«£¨Ī»»Á‘ŕ◊‘ľļ—™ŃŅĻż…ŔĶń ĪļÚĽŠ”ŇŌ»ĹÝ––Ľō—™Ķ»Ķ»£¨Õ®Ļż’‚–©––ő™ÕÍ≥…“Ľ∂®ĶńĽÓ∂Į–ÚŃ–≤Ó“ž°£Ķę «≥°ĺį∑«≥£Ķ•“Ľ∂Ý«“»∑∂®°£

łŖľ∂NPC «÷łÕÝ”ő÷–ĶńłŖľ∂ÕŇ’Ĺ÷–ĶńŇšļŌ°£ŌŮÕű’Ŗ»Ŕ“ę°ĘĽÚ’Ŗ”Ę–ŘŃ™√ň“ĽņŗĶń”őŌ∑”–◊Ň∑ŠłĽĶń◊ŖőĽ°Ęľ”—™°Ęľ”∑ņ”ý°ĘľűňŔ°≠°≠Ķ»Ķ»łī‘”Ķń”įŌžŇŐ√śĶń“Úňō°£’‚–©“Úňō∂‘”ŕ»ňņīňĶ∂ľ «–Ť“™≥§∆ŕ√ĢňųļÕŃ∑Ōį≤Ňń‹‘ŕ≤ĽÕ¨≥°ĺį÷–Ķ√“‘Ńľļ√ŇšļŌĶń£¨ňý“‘’‚ņŗNPCĶń≤Ŗ¬‘ «Ī»ĹŌń—Īŗ–īĶń£¨÷Ń…Ŕļ‹ń—’“ĶĹ“ĽłŲŌŗ∂‘»∑∂®Ķńń‹ĻĽĪ£÷§ĹŌłŖ §¬ Ķń≤Ŗ¬‘Īŗ–īňľ¬∑°£

ŐōłŖľ∂NPC∑ļ÷łń«–©īÝ”–ĹŌ«ŅĶń≤©řń–‘Ķń∂‘ŅĻ≤Ŗ¬‘°£‘ŕ’‚÷÷NPC–Ť“™∂‘≥§∆ŕĶńŇŐ√ś—›Īš”–ĹŌļ√Ķń»ęĺ÷ń‹Ń¶£¨Õ®≥£łŁń—÷ĪĹ”Īŗ–ī°£»ÁĻŻ≥Ę ‘ Ļ”√«ÓĺŔĶń∑Ĺ Ĺ»•◊Ųň—ňųņī≥šĶĪ≤Ŗ¬‘ĶńĽį£¨∆š Īľšłī‘”∂»Õ®≥£“≤ «∆’Õ®Ķńľ∆ň„Ķ•‘™ń—“‘≥– ‹Ķń°£ňý“‘£¨»ÁĻŻ∆ŕÕŻNPC‘ŕłī‘”Ľ∑ĺ≥÷–”–Ī»ĹŌļ√ĶńĪŪŌ÷ń«√īĺÕ–Ť“™”–łŁļŌ Ķń∑Ĺ Ĺ£¨ņż»Á»√NPC◊‘ľļ‘ŕīůŃŅĶń”őŌ∑Ļż≥Ő÷–◊‘ľļ—ßŌį◊Óļ√Ķń∑Ĺ Ĺ≤Ę÷ū≤ĹĹÝĽĮ°£
’‚÷÷«ťŅŲŌ¬»ňĻ§÷«ń‹‘ŕ”őŌ∑AI÷–Ķń”¶”√ĺÕ‘Ĺņī‘Ĺ ‹ĶĹ»ň√«ĶńĻō◊Ę°£ĶĪ»Ľ£¨»ňĻ§÷«ń‹Ķń≤Óĺŗ÷ų“™ «ŐŚŌ÷‘ŕ”őŌ∑Ľ∑ĺ≥Ķń≤Óĺŗ…Ō°£≤ĽÕ¨Ķń”őŌ∑ĶńNPC—ĶŃ∑∆šń—∂» «≤Ľ“Ľ—ý£¨ĶĪ»Ľ «‘ĹľÚĶ•Ķń≥°ĺį‘Ĺ»›“◊—ĶŃ∑£¨ŐŚŌ÷≥ŲņīĶńĺÕ « š»ŽĶńő¨∂»≤Óĺŗ°£…ŔĶń”őŌ∑÷Ľ”–ľłłŲő¨∂»£¨∂Ý“Ľ–©ĹŌłī‘”Ķń≥°ĺįĺÕ”– żÕÚłŲő¨∂»“÷ĽÚłŁ∂ŗ°£
≥żīň÷ģÕ‚£¨»ňĻ§÷«ń‹Ķń≤ÓĺŗĽĻŐŚŌ÷‘ŕŃŪ“Ľ∑Ĺ√ś£¨ń«ĺÕ «‘ŕ’‚łŲĻż≥Ő÷–£¨»ň∂‘—ĶŃ∑Ļż≥ŐĶń≤ő”Ž≥Ő∂»ĶńłŖĶÕ£¨ő“√«ĶĪ»Ľ «∆ŕÕŻ»ňő™≤ő”Ž≥Ő∂»‘ĹĶÕ‘Ĺļ√°£‘ĹĶÕňĶ√ų’‚÷÷ń£–ÕĽÚ’Ŗ∑Ĺ ĹĶń°į◊‘÷ų–‘°Ī‘Ĺ«Ņ£¨ń«√īőīņī∆š◊‘ľļĹÝĽĮĶń≥°ĺį∑ļĽĮ–‘“≤ĺÕĽŠ‘Ĺīů°£
∂‘”ŕ’‚“Ľņŗ–Ť“™ Ļ”√—ĶŃ∑£®◊‘—ßŌį£©Ķń∑Ĺ ĹņīĹÝĽĮĶńNPCņīňĶ£¨ĽýĪĺŐ◊¬∑ «ĻŐ∂®Ķń°£»ÁĻŻń‹ĻĽ‘ŕ»ęĺ÷∑∂őßńŕ£¨Ĺęń£–Õ◊™ĽĮ≥…ő™“ĽłŲ«ů◊Óīů÷ĶĽÚ’Ŗ◊Ó–°÷ĶĶńő Ő‚ń«√īĺÕŅ…“‘Õ®ĻżÕĻ”ŇĽĮĽÚ’Ŗįľ”ŇĽĮĶń∑Ĺ ĹņīĹ‚ĺŲ°£ń«√ī‘ŕ’‚łŲĹ®ŃĘń£–ÕĶńĻż≥Ő÷–ĺÕ“™…Ť∂®ļ√’ŻłŲń£–ÕĶń∆ņľŘļĮ ż£¨≤Ę‘ŕ≤Ŗ¬‘ĶńĶų’Ż÷– ĻĶ√∆ņľŘļĮ ż»°Ķ√ľę÷Ķ°£

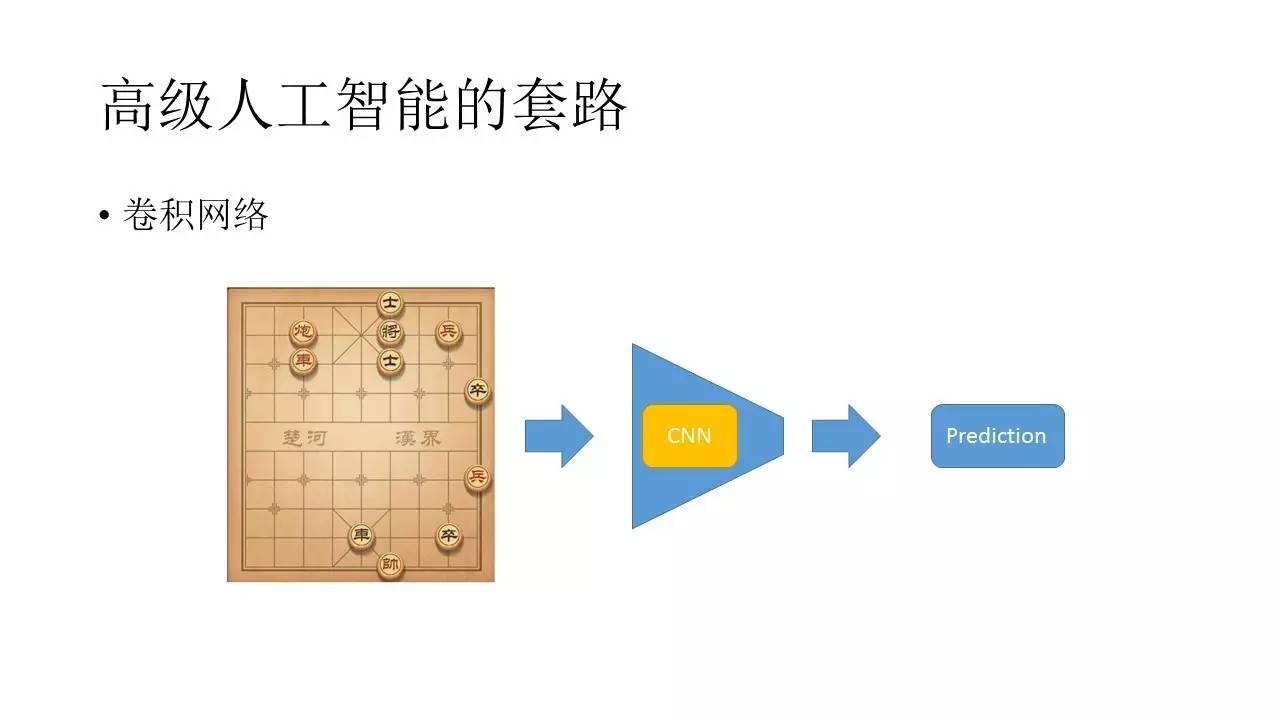
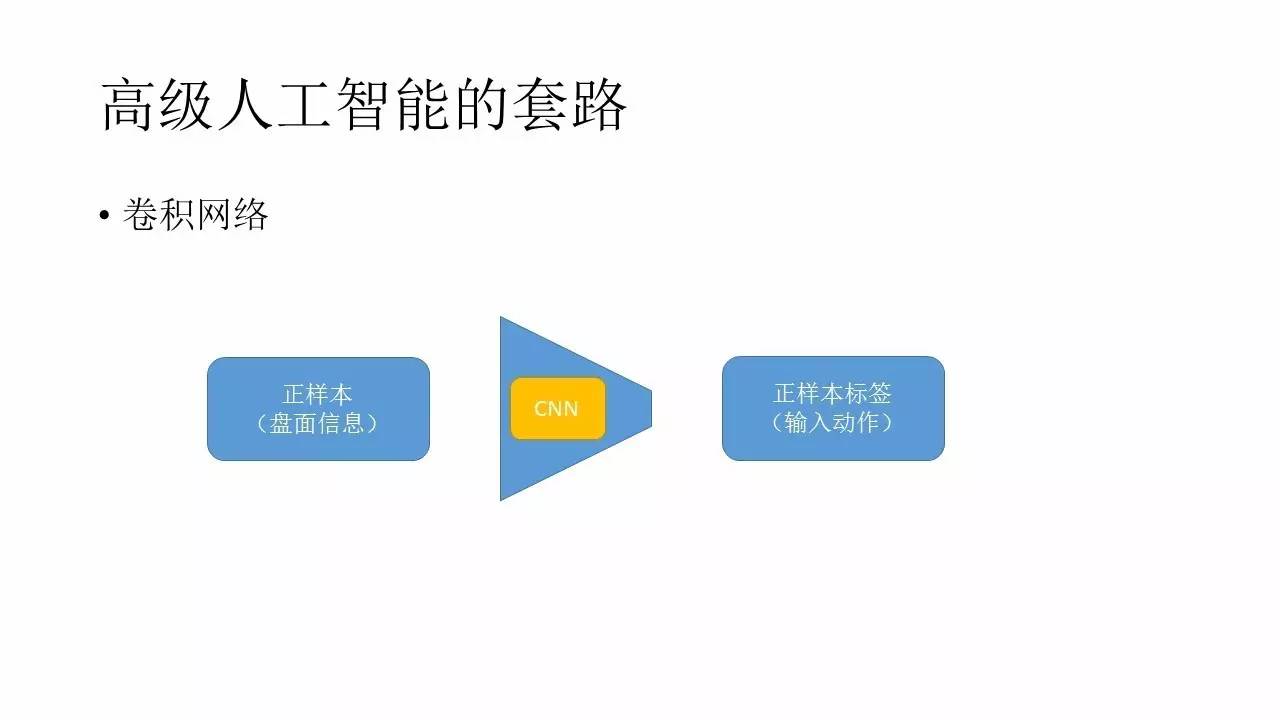
‘ଚĶōĶńĻż≥Ő÷–Ņ…“‘ Ļ”√ĺ≠ĶšĶńÕ≥ľ∆∑Ĺ∑®ņī◊Ų£¨“≤Ņ…“‘”√…Ůĺ≠ÕݬÁņīń‚ļŌ≤Ŗ¬‘£¨ĶĪ»Ľ“≤Ņ…“‘ Ļ”√»ňĻ§÷«ń‹÷–Ī»ĹŌĺ≠ĶšĶń«ŅĽĮ—ßŌįĶńŐ◊¬∑ņī◊Ų ĶŌ÷£¨’‚–©∂ľ «Ņ…“‘—°‘ŮĶń¬∑ĺ∂°£

Ņ…“‘ Ļ”√ĺ≠ĶšĶńÕ≥ľ∆ń£–ÕĶń∂ŗő™łŇ¬ –‘Ķń≤©řń”őŌ∑£¨ņż»ÁĶ¬÷›∆ňŅň°Ę∂Ģ ģ“ĽĶ„Ķ»Ķ»’‚–©°£≤ĽĻż’‚–©ń£–Õ‘ŕĻś‘Ú»∑∂®Ķń«ťŅŲŌ¬ «ľłļű÷Ľń‹įī’’ĺ≤Ő¨łŇ–ÕĶń«ťŅŲÕ®ĻżŇŇŃ–◊ťļŌņī◊Ųľ∆ň„Ķń£¨ňý“‘ĺ÷Ōř–‘“≤Ī»ĹŌ«Ņ°£
»ÁĻŻ Ļ”√…Ůĺ≠ÕݬÁň„∑®£®…Ó∂»—ßŌį£©ņī◊Ų”őŌ∑AI“≤ «Ņ…“‘Ķń£¨”…”ŕ…Ůĺ≠ÕݬÁ”Ķ”–ļ‹łŖĶńVCő¨£¨“≤ĺÕĪĺ…Ū≥¨«ŅĶńń‚ļŌń‹Ń¶£¨ňý“‘ «Ņ…“‘”√ņī”¶∂‘łī‘”≥°ĺįĶń°£ń«√ī‘ŕ’‚∆š÷–◊Ó»›“◊ŌŽĶĹĶńĺÕ « Ļ”√ĺŪĽż…Ůĺ≠ÕݬÁ◊ųő™¬šĶōĻ§ĺŖ°£ĺŪĽż…Ůĺ≠ÕݬÁ”–◊Ňļ‹ļ√ĶńŐō’ųŐŠ»°ĶńŐō–‘£¨ ’Ń≤Ņž£¨ ļŌ š»Žő™īůŃŅŌŮňōĶń«ť–ő°£
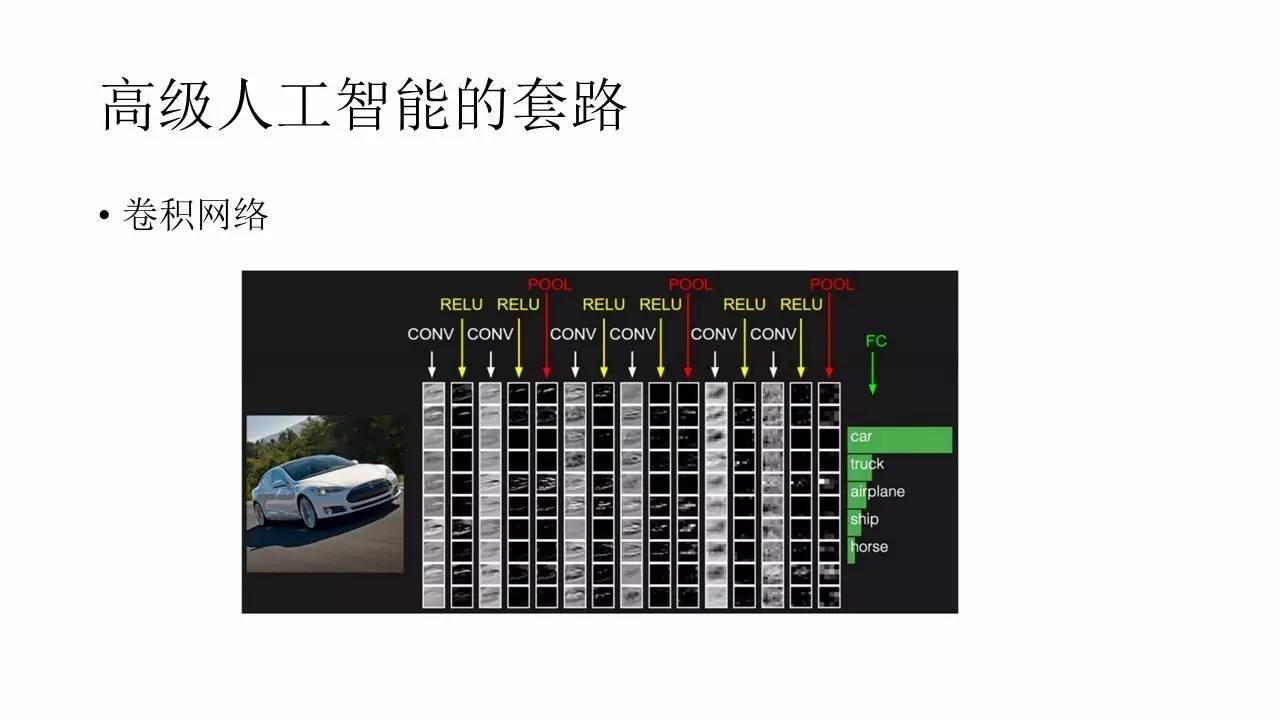
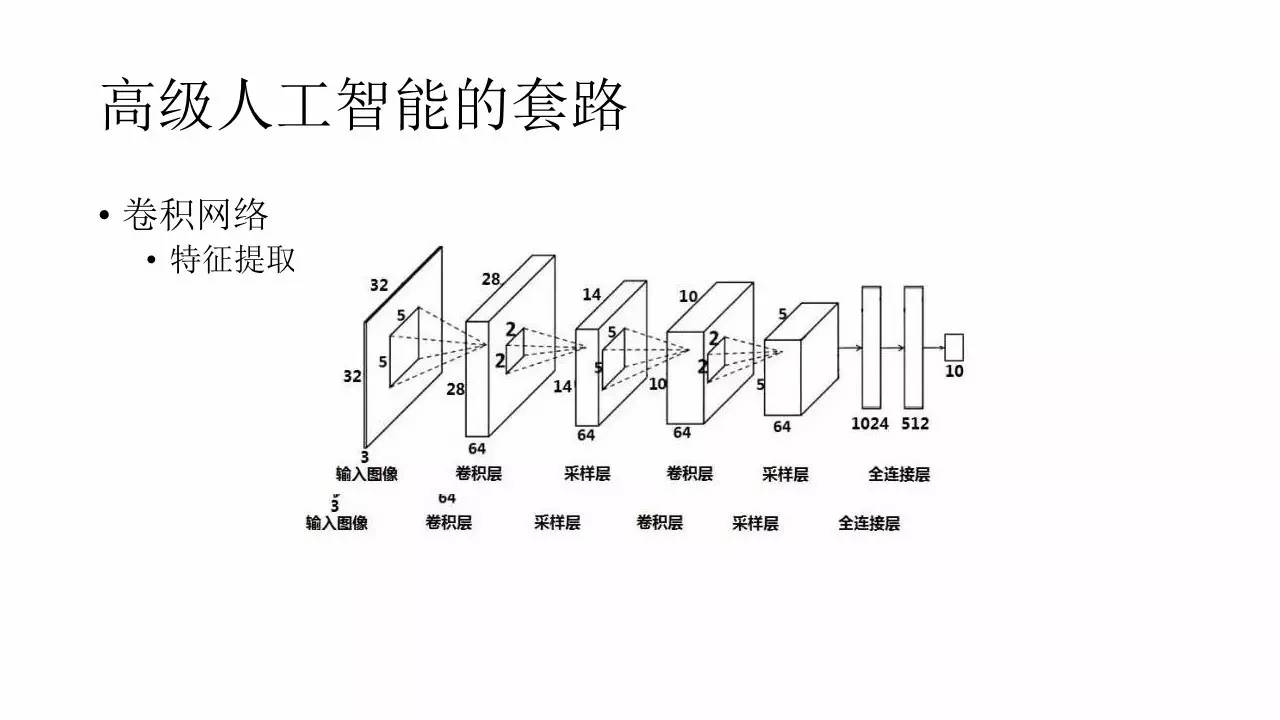
’‚ņÔľÚĶ•Ĺť…‹“ĽŌ¬ĺŪĽżÕݬÁ£¨ĺŪĽżÕݬÁ «“Ľ÷÷ļ‹≥£ľŻĶń…Ó∂»—ßŌįÕݬÁĻĻĹ®∑Ĺ Ĺ°£∆š÷–”Ķ”–ĺŪĽż≤„°Ę≥ōĽĮ≤„ļÕ◊Ó÷’Ķń š≥Ų≤„°£ĺŪĽż≤„”√ņīŐŠ»°Őō’ų£¨≥ōĽĮ≤„”√ņī◊ŲĹĶ≤…—ý£¨ŐŠłŖ∑ļĽĮń‹Ń¶£¨ š≥Ų≤„‘Ú «”√ņī◊Ų∑÷ņŗĽÚ’Ŗ‘§≤‚£¨‘ŕ’‚—ý“ĽłŲ≥°ĺį÷–‘ÚŅ…“‘”√ņīĪŪ ĺNPCĶń š»Ž£¨ĽÚ’Ŗ∂Į◊ų°£“≤ĺÕ «ňĶ£¨≥°ĺį żĺ›ŌÚŃŅ◊ųő™ š»Ž£¨NPC∂Į◊ų◊ųő™ š≥Ų£¨ÕݬÁ‘ŕ—ĶŃ∑ĶńĻż≥Ő÷–ĪĽÕ∂“‘īůŃŅĶń’ż—ýĪĺ°™°™“≤ĺÕ «ń«–©‘ŕ”őŌ∑÷–––ő™’ż»∑Ķń—ýĪĺ°£
ņż»Á‘ŕŌů∆Ś∂‘řń÷–£¨Ōů∆Ś∆ŚŇŐĺÕŅ…“‘√Ť Ų≥…ő™“ĽłŲ9*9ĶńŌÚŃŅ£¨ŌÚŃŅ…ŌĶń√ŅłŲő¨∂»Ņ…“‘”√ŌŖ–‘őřĻōĶńĪŗ¬Ž√Ť Ų”–√Ľ”–∆Ś◊”£¨”–ńńłŲ∆Ś◊”°™°™’‚–©◊ųő™’ŻłŲŇŐ√śĶń√Ť Ų–ŇŌĘ š»ŽłÝĺŪĽżÕݬÁ°£ÕݬÁĶń š»Ž≤Ņ∑÷‘ڳݓĽłŲ°įļ√∆Ś°ĪĶń√Ť Ų£¨ĺÕņŗň∆”ŕ°į≥Ķ»żĹÝ“Ľ°Ī£¨°įŇŕ∂Ģ∆Ĺ∆Ŗ°Ī’‚—ýĶń∂Į◊ųĶńŌÚŃŅĽĮ√Ť Ų°£
«Ž◊Ę“‚£¨‘ŕ’‚łŲĻż≥Ő÷–£¨“Ľ∂®“™łÝĺŪĽżÕݬÁīůŃŅĶń’ż—ýĪĺ£¨“≤ĺÕ «ń«–©Ī»ĹŌŅŅ∆◊Ķń∂Į◊ų£¨’‚—ý≤Ňń‹»√ĺŪĽżÕݬÁ‘ŕ’‚łŲĻż≥Ő÷–—ßĶĹ’ż»∑Ķń∂Į◊ų°£∂Ý»ÁĻŻŌŗ∑ī£¨»ÁĻŻń„łÝĶĹÕݬÁĶń «“Ľ–©≤ĽŐęļ√Ķń––∆Ś∂Į◊ų£¨ń«√īÕݬÁÕ¨—ýĽŠį—’‚–©≥Ű∆Ś∂ľ—ßŌ¬ņī°£Ō‘»Ľ£¨’‚łýĪĺ≤Ľ «ő“√«ŌŽ“™Ķń∂ęőų°£

ĺŪĽżÕݬÁĶń”ŇĶ„ĺÕ»Áł’≤Ňő“√«ňĶĶńń«—ý£¨ ’Ń≤ňŔ∂»Ņž£¨∑ļĽĮń‹Ń¶ļ√£¨”¶”√≥°ĺįĻ„°£’‚ĺÕ ĻĶ√ňŁŅ…“‘‘ŕļ‹∂ŗ÷÷≤ĽÕ¨Ķń”őŌ∑÷–Ķ√“‘”¶”√£¨”√ņīĶĪ◊ŲNPCĶńīůń‘ņī—ĶŃ∑°£

Ķę «Õ¨—ý£¨ĺŪĽżÕݬÁ“≤ «”–◊Ň◊‘ľļĶń»ĪĶ„£¨ňŁ–Ť“™īůŃŅĶń’ż—ýĪĺļÕ»ňĻ§ł…‘§°£ĺÕ“‘ł’≤ŇĶńŌů∆ŚņīňĶ£¨√Ņ“ĽłŲŇŐ√ś‘ŕ š»ŽÕݬÁĶń ĪļÚ£¨∂ľ–Ť“™łÝ∂®∆š“ĽłŲ»ňő™ĪÍ◊ĘĻżĶń°įļ√∆Ś°ĪĶń√Ť Ų°£’‚—ý—ĶŃ∑≥…ĪĺĺÕīůīů‘Ųľ”Ńň£¨ňý“‘’‚“ĽĶ„“≤ĺÕ ĻĶ√őř∑®ĶÕ≥…ĪĺĽŮĶ√’ż—ýĪĺ∆ņľŘĶń≥°ĺį÷–÷ĪĹ”’‚—ý Ļ”√ĺŪĽżÕݬÁ≥…ő™Ńň≤ĽŅ…ń‹°£

◊Ř…Ōňý Ų£¨÷ĪĹ” Ļ”√ĺŪĽżÕݬÁĹŲĹŲ ļŌń«–© š»Ž żĺ›ŃŅ∆ę–°£¨∂Ý«“∂Į◊ųľÚĶ•£¨»›“◊ĽŮĶ√’ż—ýĪĺĶń”őŌ∑°£∂Ý∆šňŁĺ÷ ∆łī‘”Ķń”őŌ∑Õ®≥£∂ľ–Ť“™◊Ų“Ľ–©łńĹÝ≤ŇŅ…“‘°£
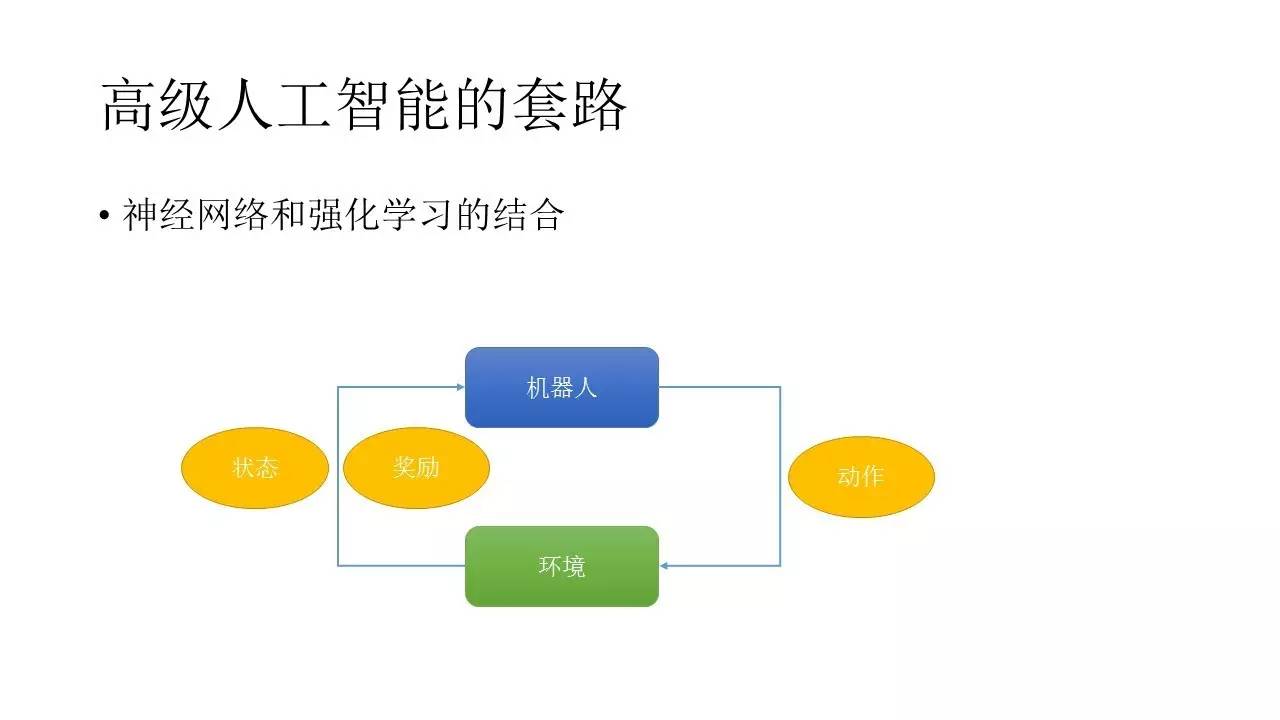
ńŅ«įĪ»ĹŌŌ»ĹÝĶń”őŌ∑AIĶń—ĶŃ∑∑Ĺ Ĺ «“‘2013ńÍNIPS∑ĘĪŪĶńĻō”ŕDQNĶń¬Řőńő™ņŪ¬ŘĽýī°Ķń…Ůĺ≠ÕݬÁļÕ«ŅĽĮ—ßŌįĶńĹŠļŌ∑Ĺ Ĺ°£Ō»Ň◊Ņ™DQN≤ĽĻ‹£¨ő“√«Ō»ņīňĶ«ŅĽĮ—ßŌįĶńĽýĪĺłŇńÓ°£‘ŕ«ŅĽĮ—ßŌįĶń∑∂≥Ž÷–£¨Õ®≥£”–’‚—ýľłłŲ—–ĺŅ∂‘Ōů£¨“ĽłŲ «Ľķ∆ų»ň£¨“≤Ĺ–ĪĺŐŚ£¨ĺÕ «ő“√«“™—ĶŃ∑Ķń∂‘Ōů£Ľ“ĽłŲ «Ľ∑ĺ≥£¨“≤ĺÕ «Ľķ∆ų»ňňýī¶Ķń≥°ĺį£Ľ“ĽłŲ «∂Į◊ų£¨ «Ľķ∆ų»ňňý∑Ę≥ŲĶń––ő™£®Action£©£Ľī”Ľ∑ĺ≥÷–£¨Ľķ∆ų»ňĽŠ≤Ľ∂ŌĶōĶ√ĶĹŃĹ÷÷∂ęőų£¨“ĽłŲ «◊īŐ¨£®State£©£¨“ĽłŲ «ĹĪņÝ£®Reward£©°£
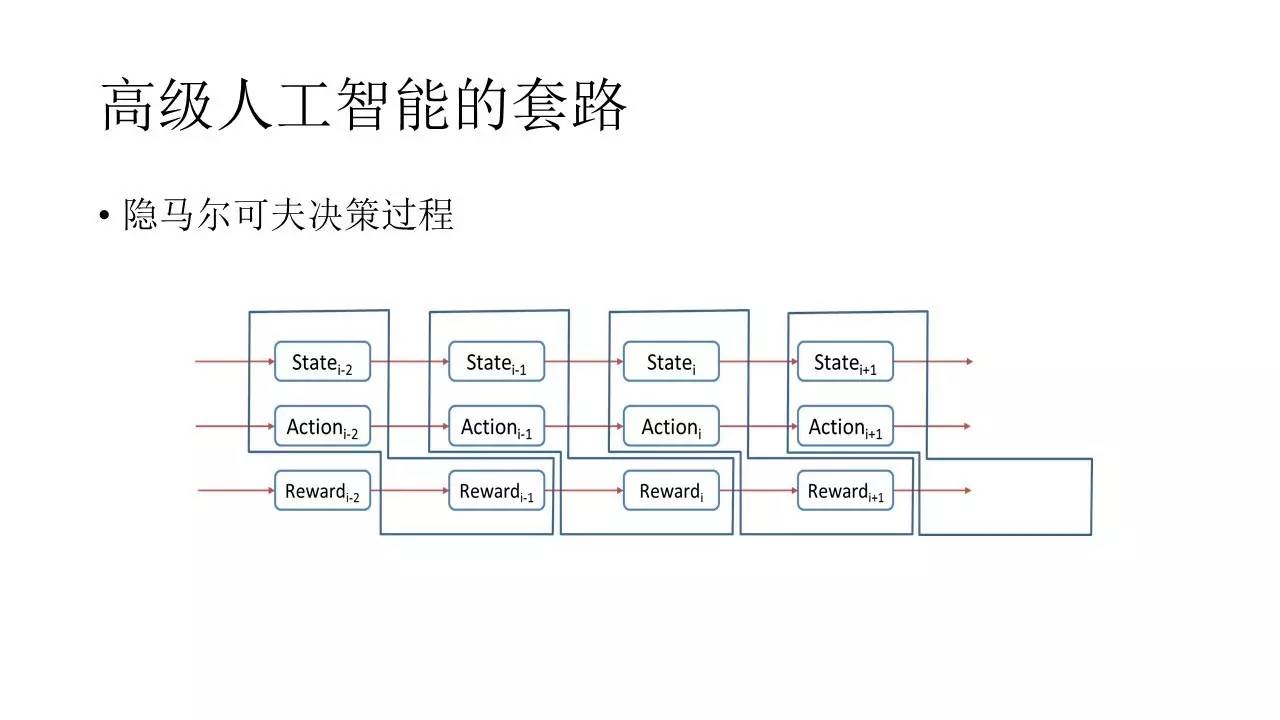
“ĽĶ©’‚łŲ≥°ĺįĹ®ŃĘ÷ģļů£¨∆š ĶĺÕŅ…“‘Ņ™ ľ—ĶŃ∑Ńň£¨◊ųő™Ľķ∆ų»ňő“√«ĹęĽŮĶ√ ≤√īńō£ŅĶĪ»Ľ « Īľš–ÚŃ–…ŌĶń“ĽŌĶŃ–State°ĘAction°ĘļÕReward°£«Ž◊Ę“‚£¨’‚łŲReward≤Ľ“Ľ∂®÷Ľ «ĹĪņÝ£¨»ÁĻŻ «“ĽłŲ’ż ż£¨ń«√īĺÕĪŪ ĺĹĪņÝ£¨»ÁĻŻ «“ĽłŲłļ żĺÕĪŪ ĺ≥Õ∑£°£‘ŕ“ĽłŲ ¬ľĢ–ÚŃ–…Ōő“√«ĹęѨ–Ý≤Ľ∂ŌĶōĽŮĶ√State°ĘActionļÕRewardīģ°£≤ĽĻż’‚ņÔĶńReward≤Ľ «ĪŪ ĺĶĪ«įń„ĶńStateļÕActionĶńĹĪņÝ£¨∂Ý «ĪŪ ĺ‘ŕ«į“ĽłŲStateĶń◊īŐ¨Ō¬£¨”…”ŕń„◊ŲŃň“ĽłŲActionňýīÝņīĶńĹĪņÝ÷Ķ°£
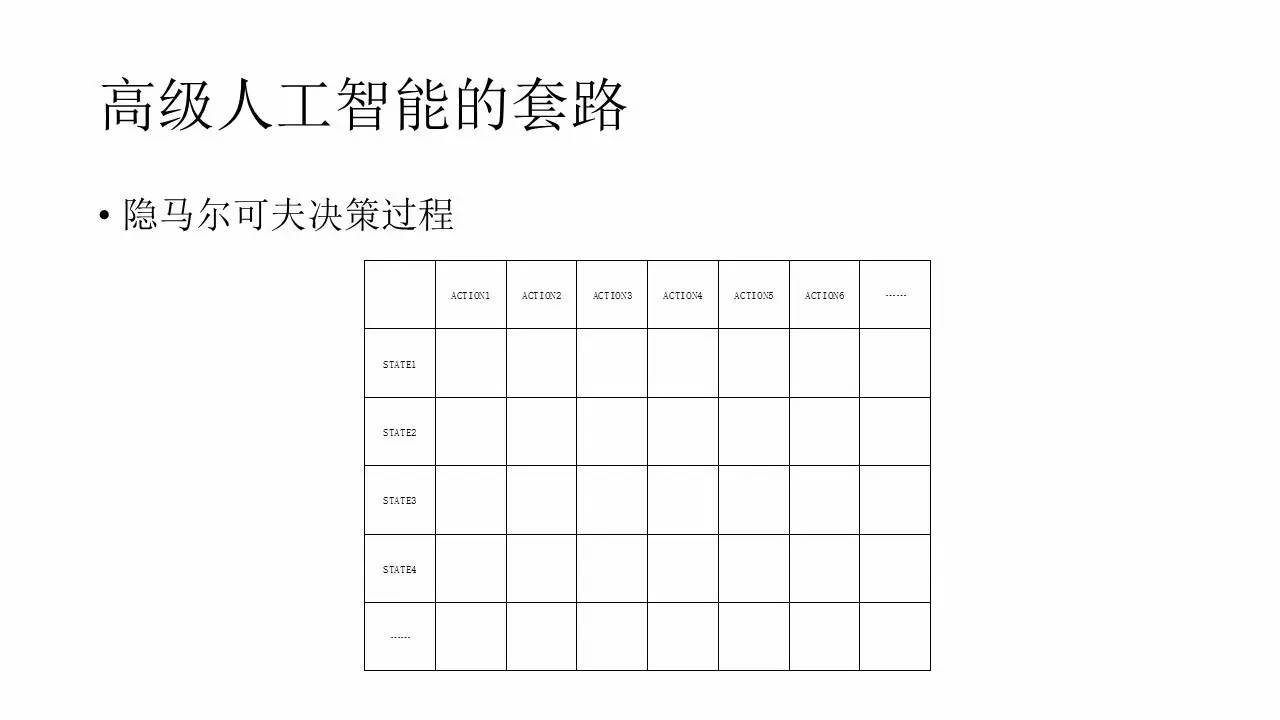
ľ»»Ľ”–Ńň’‚—ý“ĽŌĶŃ–Ķń żĺ›£¨∆š ĶÕ®ĻżľÚĶ•ĶńÕ≥ľ∆ő“√«ĺÕń‹Ķ√ĶĹ’‚—ý“Ľ’ŇĪŪ°£»ÁÕľňý ĺ£¨◊›Ń–∂ľ «State£¨ļŠŃ–∂ľ «Action£¨Õ®ĻżÕ≥ľ∆Ņ…“‘‘ŕĪŪ÷–ŐÓ–ī“ĽłŲReward÷Ķ°£“≤ĺÕ «ĪŪ ĺ‘ŕń≥łŲStateŌ¬£¨∑Ę≥Ųń≥łŲActionļůňýĽŮĶ√ĶńReward÷Ķ£¨’‚ĺÕ «“ĽłŲ»Ō÷™°£ń«√ī‘ŕ Ļ”√Ķń ĪļÚ£¨Ľķ∆ų»ňŅ…“‘Õ®Ļż≤ťĪŪ£¨‘ŕ“ĽłŲStateŌ¬£¨’“ĶĹń«łŲStateŌ¬◊ÓīůĶńReward£¨ļÕňŁ∂‘”¶ĶńAction£¨»Ľļů◊Ų’‚łŲActionĺÕŅ…“‘ĽŮĶ√◊ÓīůĶńĹĪņÝ÷ĶŃň°£
≤ĽĻż’‚—ý“≤”–“ĽłŲŌ‘∂Ý“◊ľŻĶńő Ő‚£¨ń«ĺÕ «∂Ő Īő Ő‚°£“Úő™State «Ń¨–ÝĶń£¨«įļů÷ģľš“≤ «”–◊Ň“Ľ–©«Ī‘ŕ”įŌžĶń°£ĺÕŌŮ‘ŕÕś…≥¬ř¬Ł…Ŗ’‚÷÷”őŌ∑Ķń ĪļÚ£¨»ÁĻŻő™Ńň≥‘łŲ«Ļ∂Ý‘ŕŌ¬“Ľ√Ž◊≤«ĹĶńĽį£¨ń«√ī≥‘«ĻĶń“‚“ŚĺÕ≤Ľīś‘ŕŃň°£ňý“‘£¨ľīĪ„‘ŕĶĪ«įStateŌ¬’“ĶĹ“ĽłŲ◊ÓīůRewardĶńAction≤Ę≤Ľ“‚ő∂◊ŇňŁń‹ĻĽ‘ŕőīņīĪ£÷§≥§∆ŕĶńRewardĪ»ĹŌīů°£
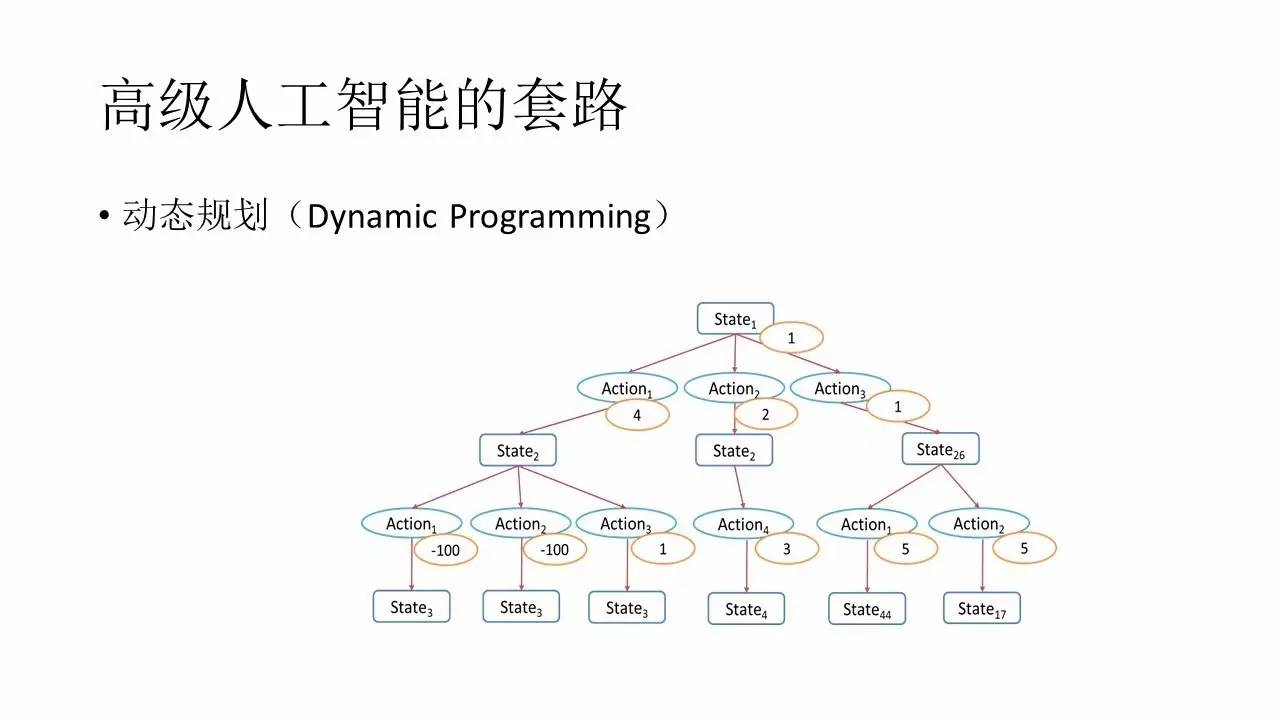
’‚÷÷«ťŅŲő“√«ĺÕ–Ť“™’‚—ýņīŅīŃň£¨∆š ĶĺÕŌŮ’‚—ý“ĽŅŇ ų°£ Ī–Ú…ŌŅŅĹŁ«į√śĶńStateĺÕ « ųłý£¨ Ī–Ú…Ō∆ęļůĶńĺÕ «Ō¬√śĶń ų÷¶ ų“∂ĶńĹŕĶ„°£Ō¬“Ľ≤„…Ōňý”–ĶńAction÷–Reward◊ÓīůĶń∆š Ķ≤Ę≤Ľ“‚ő∂◊Ňń‹“żĶľ“ĽŐű»ęĺ÷Reward◊ÓīůĶń¬∑ĺ∂°£ĽĽĺšĽįňĶ£¨Ō¬“Ľ√Ž–¶Ķ√◊ÓŅ™–ń≤ĽīķĪŪń‹–¶ĶĹ◊Óļů°£ī”’‚łŲÕľ…Ō“≤ń‹Ņī≥Ųņī£¨1-4-1’‚Őű¬∑ĺ∂Ķń◊‹ ’“ś «√Ľ”–”“≤ŗĶń1-1-5łŁļ√Ķń°£

’‚÷÷ ĪļÚĺÕ–Ť“™’‚—ý“Ľ÷÷Ĺ–◊ŲQ-Learningň„∑®Ķń∂ęőų£¨Ļę ĹĺÕ’‚—ý–ī°£Q(s,a)ĪŪ ĺĶńĺÕ ««į√śń«’ŇĪŪĶńńŕ»›£¨aļÕs∑÷Īū «ļŠ◊›◊ÝĪÍ°£“ĽłŲQ(s,a)ĺÕĪŪ ĺ“ĽłŲĺŖŐŚĶń÷Ķ£¨’‚łŲ÷ĶĺÕ «“ĽłŲReward°£‘ŕ’‚łŲň„∑®÷––Ť“™∂‘’ŻłŲĪŪ÷–ĶńQ(s,a)≤Ľ∂ŌłŁ–¬£¨łŁ–¬Ķń‘≠‘ÚĺÕŌŮĻę Ĺ…Ōňý–ī£¨∆š÷–alphaļÕgamma «“ĽłŲ»®÷ōŌĶ ż°£∂®–‘ņīňĶ£¨AlphaīķĪŪ∂‘őīņī ’“śĶń÷ō ”≥Ő∂»£¨0ĺÕĪŪ ĺÕÍ»ę≤ĽŅľ¬«£¨1‘ÚĪŪ ĺĶĪ«įĶń ’“ś»°ĺŲ”ŕŌ¬“ĽłŲŅ…“‘◊™“∆ĶĹĶń◊īŐ¨÷–ń«łŲReward÷Ķ◊ÓīůĶń°£
“≤ĺÕ «Ņ…“‘’‚—ýņŪĹ‚£¨»ÁĻŻį—alphaŇš÷√≥…1ĶńĽį£¨’ŻłŲQ(s,a)ĶńłŁ–¬Ļż≥ŐĺÕ «≤Ľ∂Ōį—ļů“ĽłŲ◊īŐ¨÷–Reward◊ÓłŖĶń÷ĶŌÚ«įł≥”Ť°£“≤ĺÕ «Ņ…“‘Ĺ‚ Õ≥…£¨“ĽłŲ◊īŐ¨ĪĽ∆ņľŘő™°įĪ»ĹŌŅŅ∆◊°Ī «“Úő™ňŁļů“ĽłŲ◊īŐ¨°įĪ»ĹŌŅŅ∆◊°Ī£¨∂Ý’‚ļů“ĽłŲ◊īŐ¨°įĪ»ĹŌŅŅ∆◊°Ī“≤ «”…”ŕňŁĶńļů“ĽłŲ◊īŐ¨°įĪ»ĹŌŅŅ∆◊°Ī°£’‚—ýĹÝ––ŌÚ«įīęĶ›£¨“≤ĺÕ»›“◊Ĺ‚ĺŲ∂Ő ”ő Ő‚Ńň°£
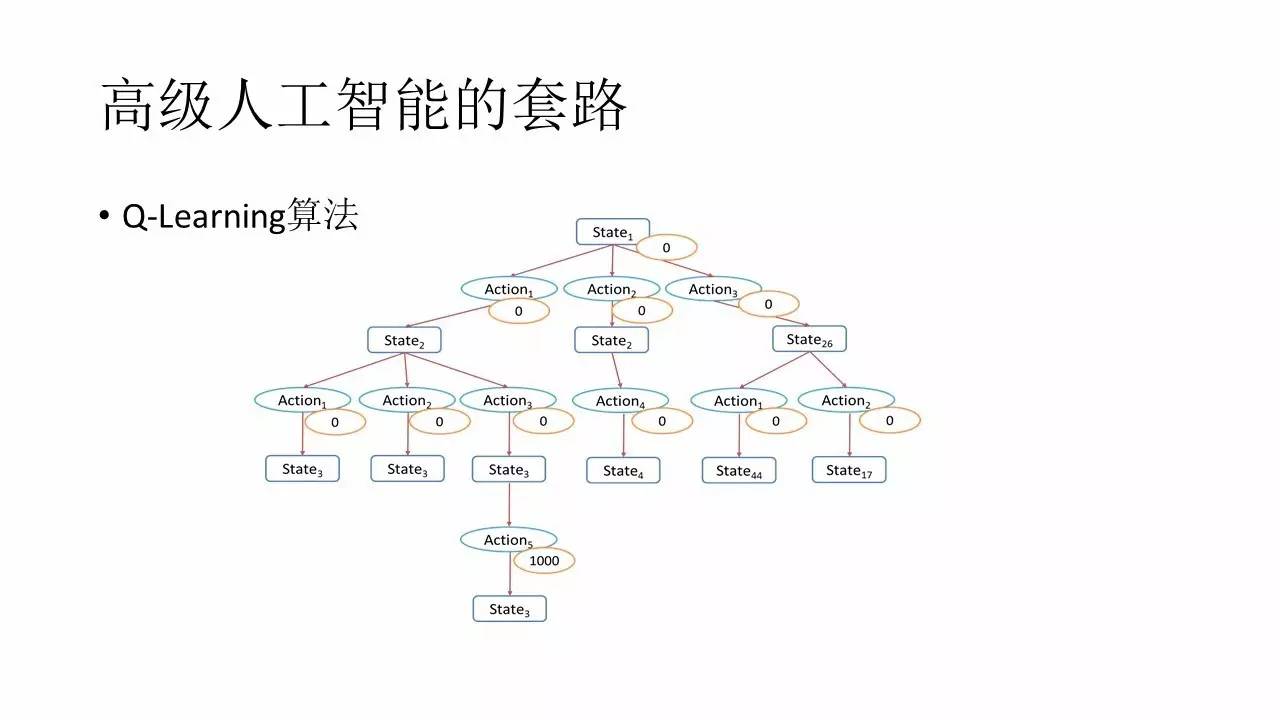
ņīŅī’‚’ŇÕľ£¨‘ŕ’‚÷÷ľŔ…Ť«įŐŠŌ¬£¨ĽýĪĺő“≤Ľń‹ĽŮĶ√√Ņ“ĽłŲStateŌ¬√Ņ“ĽłŲActionĶńĺŖŐŚ∆ņľŘ£¨“≤ń‹ĻĽ‘ŕ’ŻłŲ∆Śĺ÷◊Ó÷’ĹŠ ÝĶń ĪļÚ∂‘ §ņŻ“Ľ∑ųݓĽłŲ’ż÷ĶĶńReward£¨≤ĘÕ®Ļż’‚÷÷∑Ĺ ĹĹÝ––īęĶ›£¨◊Ó÷’į—’ŻłŲ“ĽŐűÕÍ’ŻĶń°įŅŅ∆◊°ĪĶń––ő™Ńī’“ĶĹ°£
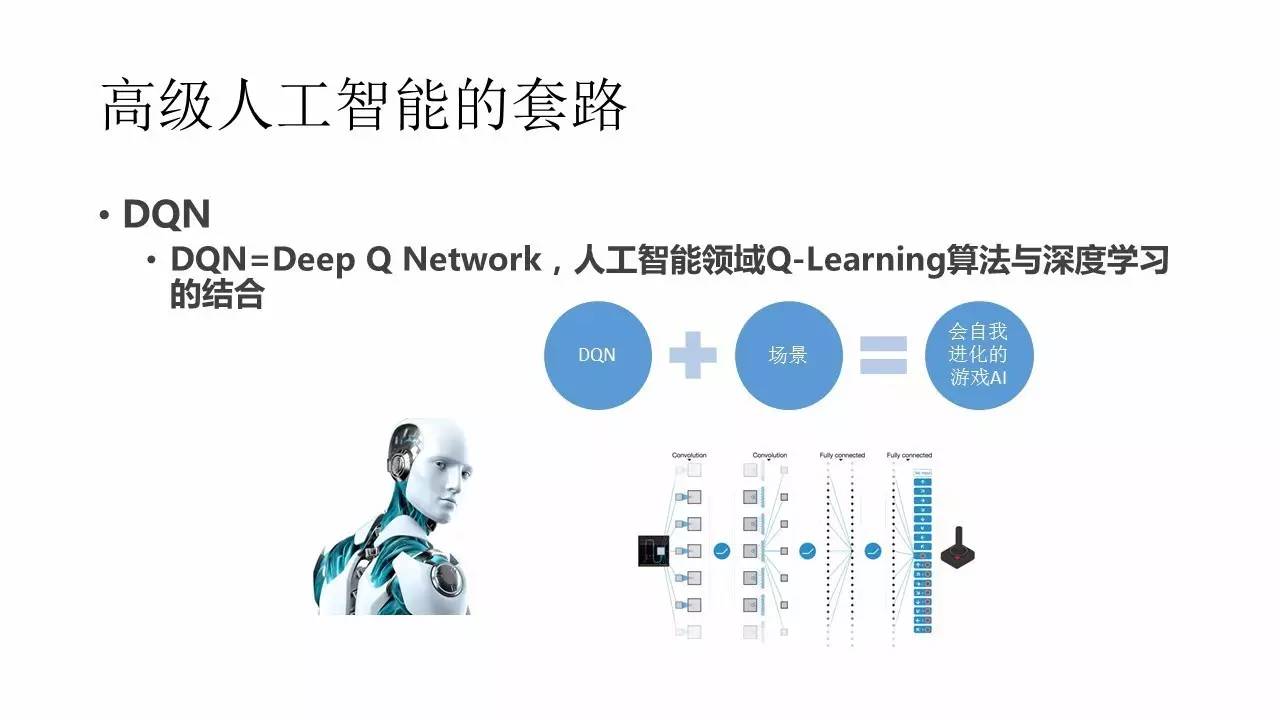
…Ó∂»—ßŌį‘ŕ’‚łŲ≥°ĺį÷–“≤ «”–”¶”√Ķń£¨Ō÷‘ŕ”√ĶńĪ»ĹŌ∂ŗĶń «DQN£¨»ę≥∆Ĺ–◊ŲDeep Q-Network°£’‚ ««ŅĽĮ–ī≥ŲļÕ…Ó∂»—ßŌįĶń“Ľ÷÷ĹŠļŌ£¨ÕݬÁĶń š»Ž «“ĽłŲŇŐ√śĶń–ŇŌĘ£¨÷–ľšÕ®ĻżĺŪĽż≤„ļÕ»ęѨŔ≤„£¨◊Óļů «“ĽłŲSOFTMAXņīń‚ļŌ“ĽłŲQ÷Ķ“≤ĺÕ «ActionļÕ∆š∂‘”¶ĶńReward÷ĶĶń∆ņľŘ°£

DQNĶńňū ßļĮ ż «Ī»ĹŌŐō ‚Ķń°£‘ŕ—ĶŃ∑ĶńĻż≥Ő÷–£¨–Ť“™◊ŲŃĹľĢ ¬£ļ1°Ę≤Ľ∂Ōį—ļů√ś◊īŐ¨ĶńRewardŌÚ«į≤Ņ»•◊ŲłŁ–¬£¨ĺÕŌŮł’≤Ňő“√«–īĶńń«—ý°£2°Ę‘ŕ’‚łŲĻż≥Ő÷–»√“ĽłŲ◊īŐ¨StatetļÕňŁĶńŌ¬“ĽłŲ◊īŐ¨Statet+1Õ®ĻżÕݬÁ£¨»√ňŻ√«≤ķ…ķĶńReward∆ņľŘ≤Ó“ž◊Ó–°°£‘ŕ’ŻłŲň„∑®◊Óļů ’Ń≤Ķń ĪļÚ£¨ĽŠ”–’‚—ý“Ľ÷÷Ō÷Ōů£¨ń«ĺÕ «ń«Őű◊ÓŅŅ∆◊Ķń¬∑ĺ∂…Ōňý”–ĶńStatetļÕStatet+1ĶńReward÷Ķ∂ľ“Ľ—ýīů°£≤Ę«“£¨StatetļÕStatet+1◊īŐ¨Ķń∆ņľŘĻś‘Ú «“Ľ—ýĶń°£“Úīň£¨’‚÷÷«ťŅŲŌ¬£¨»őļő“ĽłŲState š»ŽÕݬÁ£¨∂ľŅ…“‘ň≥◊Ň’‚łŲStateŌ¬√ś◊ÓŅŅ∆◊Ķńń«Őű¬∑ĺ∂◊ŖŌ¬»•°£
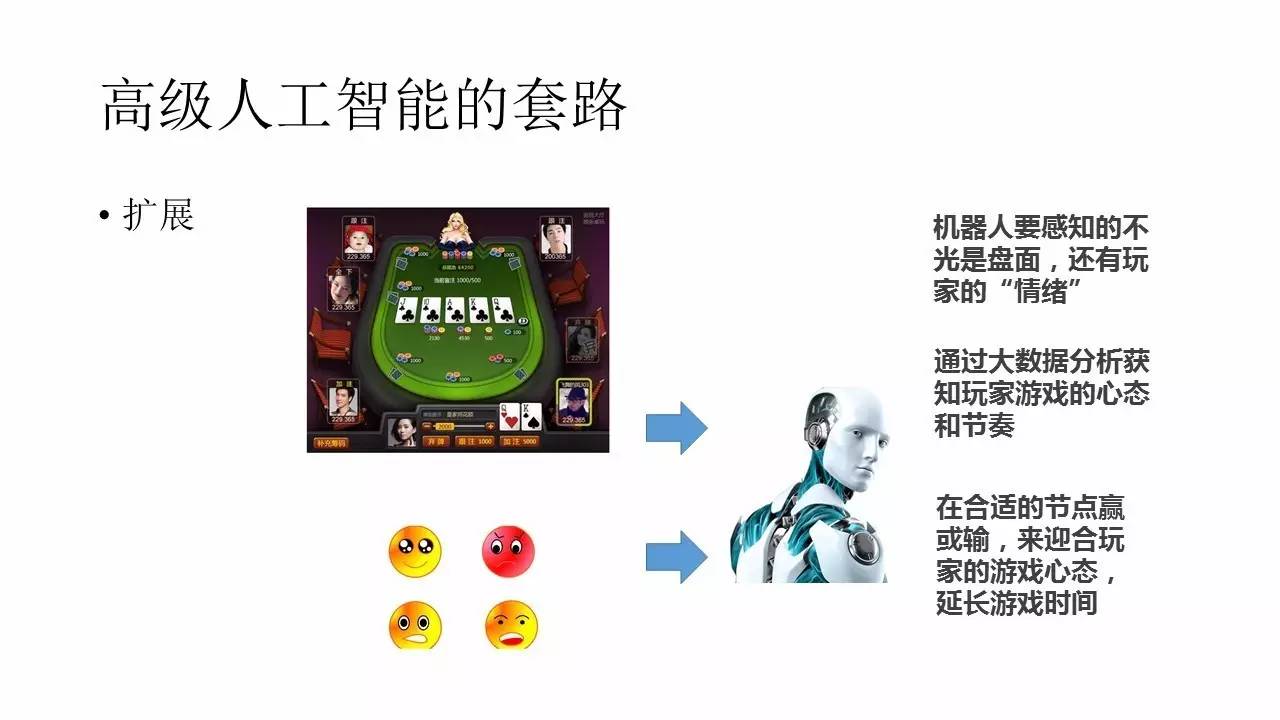
≥żīň÷ģÕ‚£¨∆š Ķ“≤Ņ…“‘∂‘’‚÷÷Ľķ∆ų»ňĹÝ––ņ©’Ļ°£“≤ĺÕ «ňĶ£¨∆ņľŘļĮ ż≤Ľ «»√ňŁ §¬ ◊ÓłŖ£¨∂Ý «»√ňŁ‘ŕłķÕśľ“”őŌ∑ĶńĻż≥Ő÷–£¨ ĻĶ√Õśľ“Ķń”őŌ∑ Ī≥§ľ”īů°£’‚łŲľľ«…ĺÕĪ»ĹŌ∂ŗŃň£¨ «–Ť“™į—Õśľ“Ķń”őŌ∑Ĺŕ◊ŗ“≤◊ųő™—ĶŃ∑ŐűľĢ š»ŽĶń°£
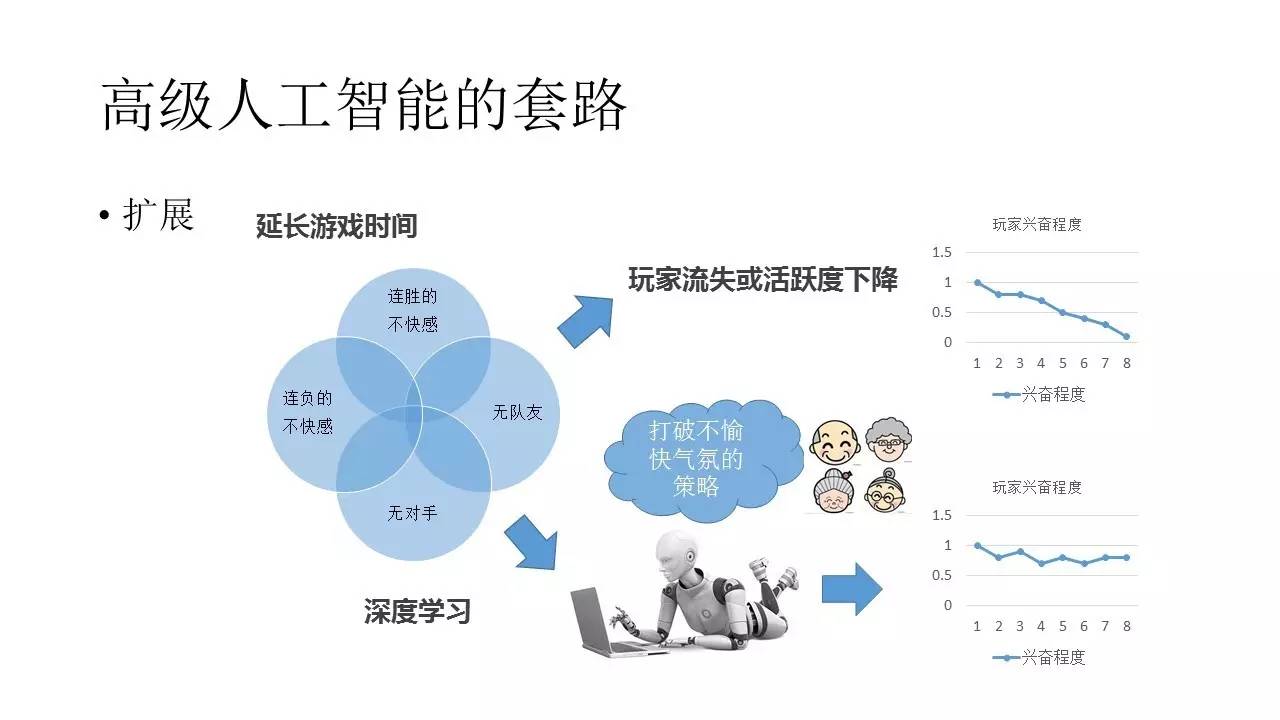
◊‹ŐŚņīňĶ£¨∂‘”ŕļ‹∂ŗŃųŃŅ≤Ľ≥š◊„Ķń”őŌ∑∆ĹŐ®ĽĻ «ĽŠ–Ť“™’‚—ý“Ľ÷÷Ľķ∆ų»ňņīŇ„įťÕśľ“ĹÝ––”őŌ∑Ķń°£≤ĽĻ‹ «Ń¨–Ý”ģ°ĘѨ–Ý š°Ę√Ľ”–∂‘ ÷°Ę√Ľ”–∂””—£¨»őļő“Ľ÷÷“ż∆ūÕśľ“≤Ľ‘√ł–ĺűĶń«ťŅŲ£¨Ľķ∆ų»ňņŪ¬Ř…Ō∂ľ”¶ł√Ņ…“‘∆∆Ĺ‚°£
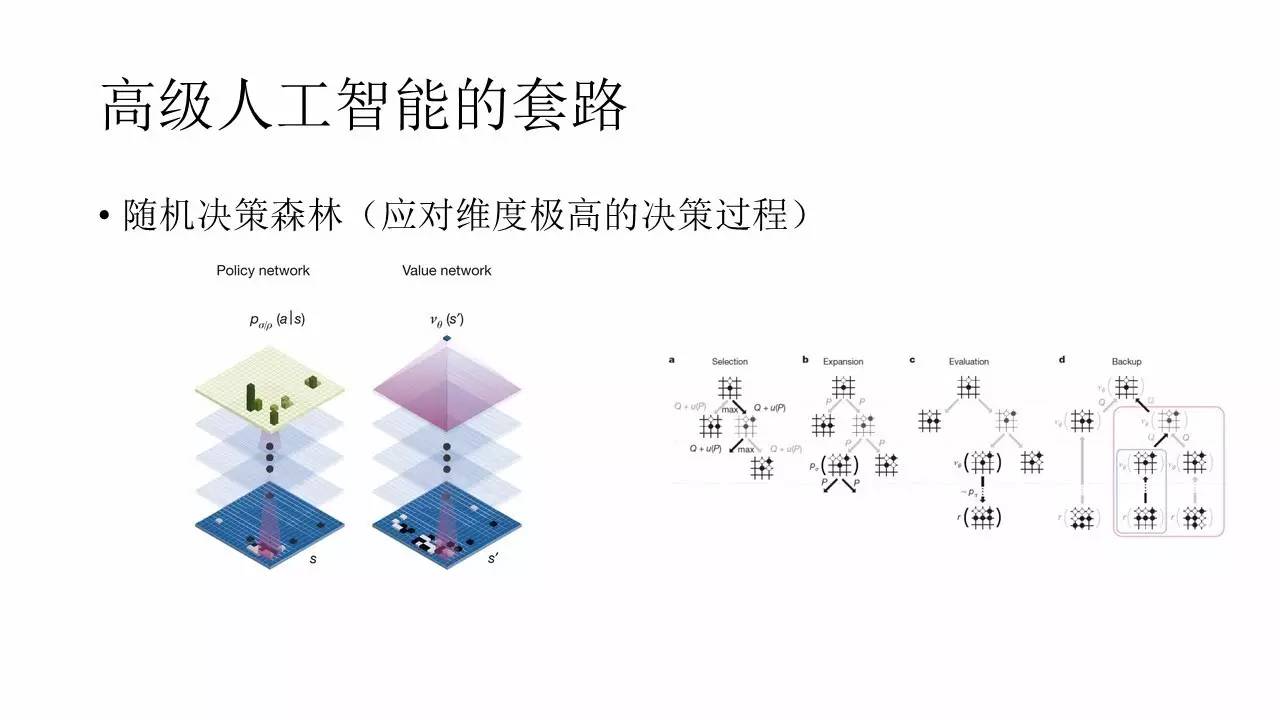
∂‘”ŕ“Ľ–©łŁő™łī‘”Ķńń£–Õ£¨Ķ•īŅ“ņŅŅ∆’Õ®ĶńDQN“—ĺ≠≤Ľń‹ļ‹ļ√ĶōĹ‚ĺŲő Ő‚Ńň°£“Úő™ő¨∂»ĻżłŖ£¨ňý“‘ļ‹Ņ…ń‹Ķľ÷¬ń£–Õ ’Ń≤ňŔ∂»≤ĽņŪŌŽ°£”– ĪļÚŅ…ń‹–Ť“™ĹŤ÷ķ“Ľ–©∆šňŁĶń ÷∂őņīĹÝ––ĺŲ≤Ŗ£¨ņż»ÁňśĽķĺŲ≤Ŗ…≠Ń÷Ķ»°£“≤ĺÕ «ňĶŅ…“‘Ĺ®ŃĘ∂ŗłŲĺę∂»ĹŌ≤ÓĶńń£–Õ£¨»√ňŁ√«łų◊‘łýĺ›◊‘ľļĶńŇ–∂ŌņīĹÝ––≤Ŗ¬‘Õ∂∆Ī£¨◊Ó÷’Õ®ĻżĪŪĺŲĶń∑Ĺ ĹņīĺŲ∂®≤Ŗ¬‘°£∆š ĶĺÕ «“ĽłŲ°į»żłŲ≥Ű∆§Ĺ≥∂•łŲ÷ÓłūŃŃ°ĪĶń”√∑®°£
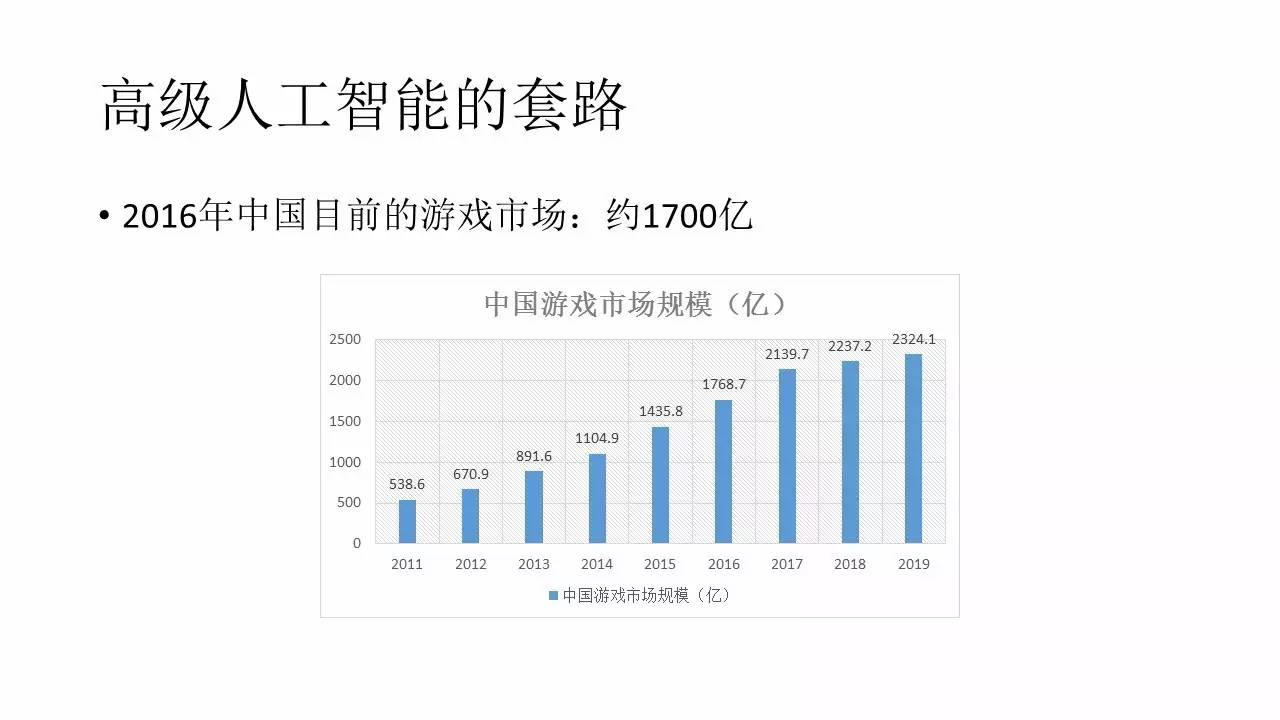
◊ÓļůĹÝ––“ĽŌ¬”őŌ∑ –≥°Ķń’ĻÕŻ£¨2016ńÍ÷–ĻķĶń”őŌ∑ –≥°īů‘ľ1700“ŕĶńŇŐ◊”£¨’‚łŲĻśń£ĽĻ «ļ‹īůĶń°£
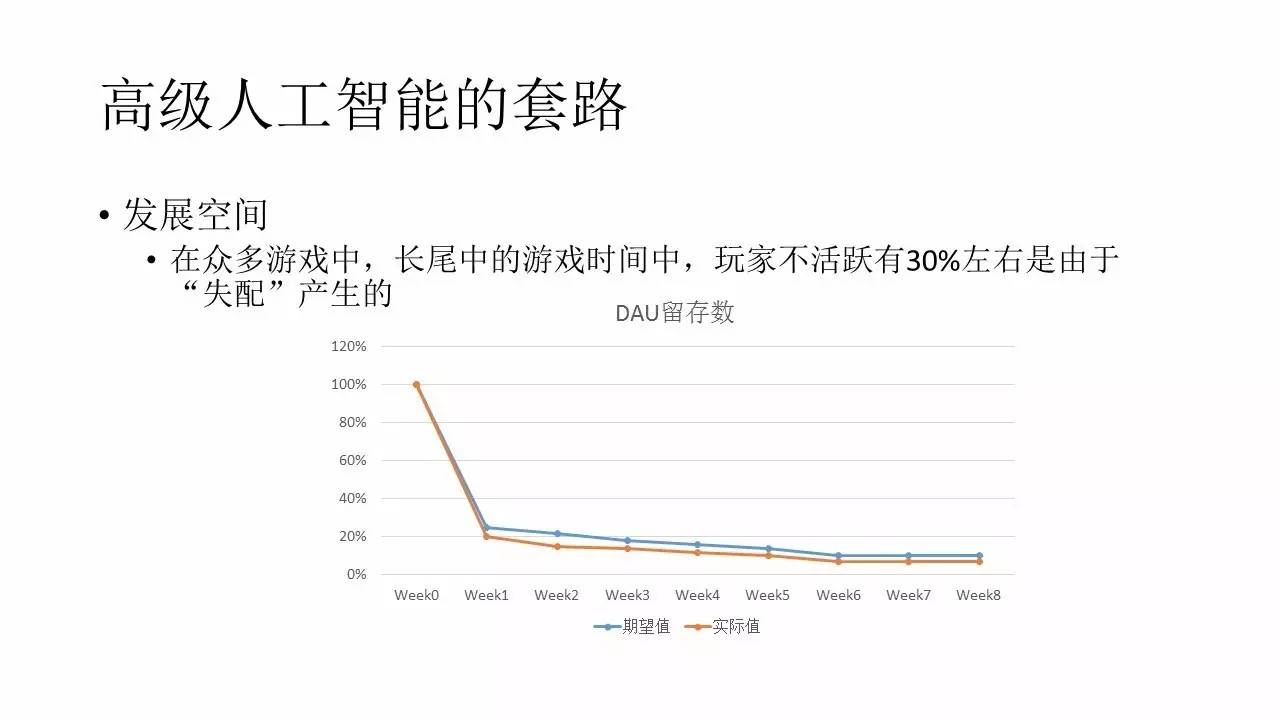
ńŅ«įĺ›ő“√«Ļņň„‘ŕ÷ŕ∂ŗĶń”őŌ∑÷–£¨īůłŇ”–30%‘ŕ≥§ő≤÷–Ķń”√Ľß «”…”ŕ°į ßŇš°ĪĶń‘≠“ÚĶľ÷¬ĶńŃų ߼Ú≤ĽĽÓ‘ĺ°£ń«√īĽķ∆ų»ňĶń◊ų”√ĺÕ∑«≥£√ųŌ‘Ńň£¨ĺÕ «Ō£ÕŻÕ®ĻżňŁ√«”Ž”√ĽßĶńń•ļŌ◊Ó÷’√÷≤Ļ’‚30%Ķń ßŇš«ť–ő£¨◊Óīů≥Ő∂»ŐŠłŖ≥§ő≤”√ĽßĶńĽÓ‘ĺ≥Ő∂»°£
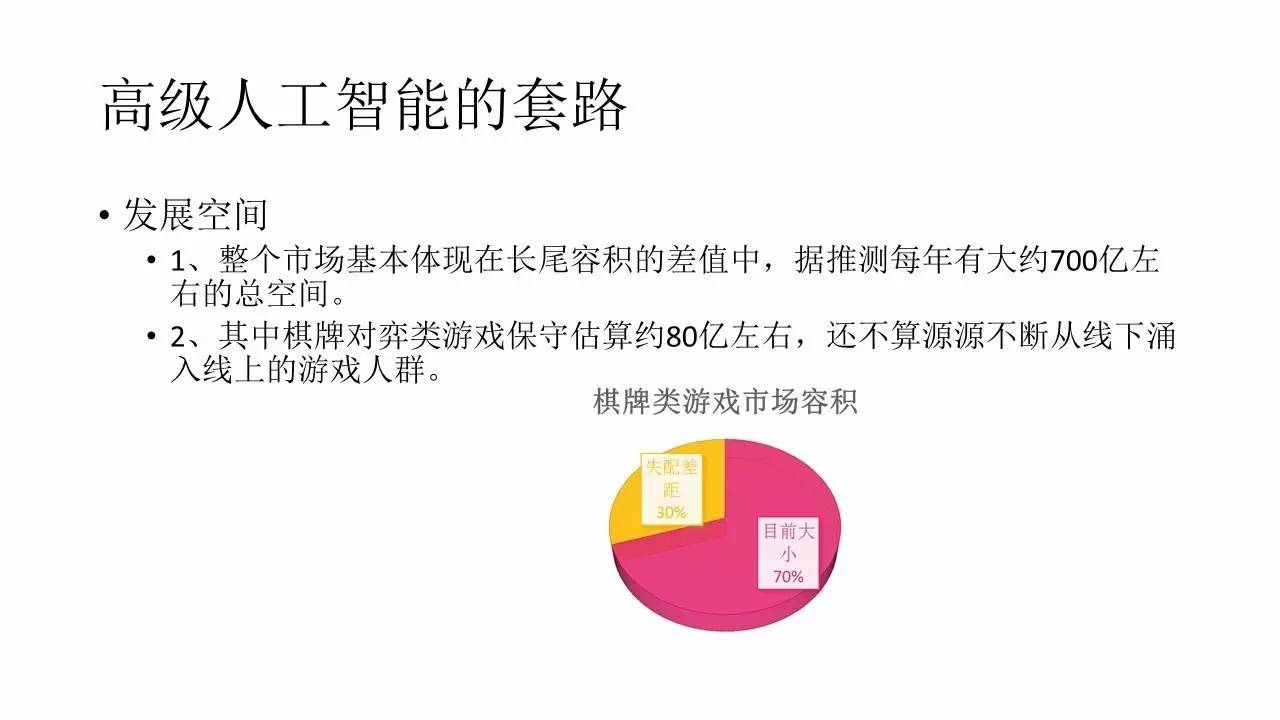
ĺ›Õ∆≤‚‘ŕ’‚≥§ő≤Ķń»›Ľż÷–īůłŇ”–700“ŕ◊ů”“Ķń –≥°Ņ’ľš «Ņ…“‘”…”őŌ∑Ľķ∆ų»ňņī√÷≤ĻĶń£¨“≤ĺÕ «ł’≤ŇĻņň„Ķńń«30%°£∆š÷–∆ŚŇ∆ņŗ”őŌ∑ĶńĪ£ ōĻņň„īů‘ľ80“ŕ£¨ňý“‘ňĶ –≥°Ļśń£ĽĻ «∑«≥£÷ĶĶ√∆ŕīżĶń°£’‚“≤ «ő“√«÷ū≤ĹҨѶĶńńŅĪÍ°£ |









