| 在LoadRunner里,有两个概念很容易被混淆:pacing和think
time。相关书籍中很难查阅到对pacing的讲解。这两个名词该如何理解,如何应用呢?
它们都出现loadrunner VUGen的run-time settings里,是不同的概念。先引用帮助文档里的解释:
The pacing let you control the time between iterations.
The pace tells the Vuser how long to wait between iterations
of your actions。
Vuser think time emulates the time that a real user
waits between actions. For example, when a user receives
data from a server, the user may wait several seconds
to review the data before responding. This delay is
known as the think time.
为了更好的讲清楚,引入iteration的概念。Iteration,迭代。通过设置,可以指定虚拟用户在同一个Action中重复执行多次,每次重复称之为一个iteration。Iteration可以帮助我们模拟现实世界的重复场景。
Pacing,步调。可以通过设置两次迭代之间的间隔时间,来调整各个action之间的步调(或者称之为节奏)。从定义上来看,Pacing是和iteration绑定在一起的,可以认为是iteration
pacing。
Think time,思考时间。可以通过设置思考时间,来模拟真实用户在操作过程中的等待时间。从定义上来看,think
time是在iteration内部的某个action中各个步骤的间隔时间。
到这里,已经能看出两者之间的区别,但是容易混淆的。接下来通过一个例子来进一步说明,期望能够深入浅出。
淘宝购物车应用,假定每分钟有6000个在线用户浏览(Browser),共10台服务器。用户在浏览过程中,先打开购物车页面,花了1秒钟时间浏览整个页面,然后查看其中的某个宝贝。此时,在性能测试场景中(如果模拟真实场景的话),就会在两个步骤之间设置一个等待时间think
time = 1 秒。如下图1-1所示:

图1-1
假设用户进行一次上述操作会消耗5秒钟的时间,即完成整个迭代需要5秒钟。如果用户不停顿,继续第二次重复操作,则同样耗费约5秒左右的时间。但是真实世界中肯定是有停顿的。一个真正的用户,做完一系列操作后,会间隔一段时间。假定用户停顿了5秒,再第二次重复操作,则一共耗费10秒钟时间。映射到
loadrunner中,就需要在一次iteration中,设置一个think time = 1秒,然后在两个iteration之间,设置一个pacing为5秒。如下图1-2所示:
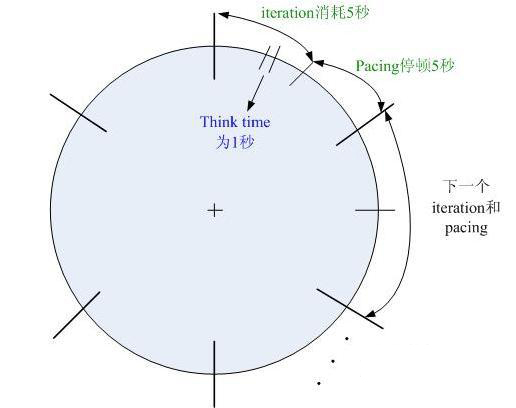
图1-2
一个虚拟用户在1分钟内,就能完成6次的迭代,12次请求。而要达到有6000个用户的浏览量,我们需要6000/12
/10= 50个虚拟用户。
通过上面的例子,相信大家对pacing和think time已经有了相应的理解。至于在loadrunner中符合使用、怎样配置,则可以通过帮助文档来加深认识。在此不一一说明。
尽管性能测试的需求通常都是从客户端角度来定义的,比如“系统需要支撑100个并发用户”、“每分钟有6000个请求量”,但是压力应该以服务器为中心来看待。原因很简单,从loadrunenr端发送出去的请求,需要等待服务器端响应之后才能发送下一个请求。可以说,对于每个虚拟用户,它对服务器发送请求的频率取决于服务器对请求的处理时间。
如果需要模拟真实用户的操作,从而模拟服务器端的真实变动,think time和pacing是两个必不可少的设置项。
评论:
词馨:“讲解很清晰,pacing和think time一目了然。
从以上使用场景来看,pacing和think time都是可以模仿真实世界中的停顿。这是从客户端考虑的。
从服务器端考虑,这两个参数的设置将会更加复杂。
例如,我们需要衡量服务器处理一个请求的平均响应时间。考虑,服务器端能同时并发处理的请求数一定,当性能测试发送的每秒请求数超过它能处理的请求数后,再到达的请求将会在服务器系统中排队等待,这时,整个响应时间的计时已经开始,排队等待时间将会计入响应时间。所以,如果LR仍然持续发送请求,可能造成接下来的请求都在等待。这时,服务器每次处理的事务数在下降,平均响应时间在增大,造成了请求发送越快,处理越少越慢。
对于这种情况,从服务器端出发,来考虑设置请求发送的速度。”
悟石:“从服务器端来看,让每颗CPU都忙碌起来,是件好事。当压力超过CPU能承受范围时,认为是过载,等待队列会越来越长,load不断飙升。
但如果真实情况是存在瞬间超高压,中间会有停顿的话,服务器或许能撑得过去(风险很大)。对于复杂场景,这个停顿要靠pacing来完成。不过,pacing怎么设置才最合适,是需要研究用户行为才能定的。”
|
