| 编辑推荐: |
本文本文将介绍Complier Construction中关于模拟器,汇编以及反汇编的知识,希望对您的学习有所帮助 。
本文来自于AI知识物语,由火龙果软件Alice编辑、推荐。 |
|
前言:
这个秋季,三碗饭会开始更新自己在秋季课程的笔记,主要包括Introduction to ML,可能还会有Complier Construction 以及 Computer Graphics.
本文将介绍Complier Construction中关于模拟器,汇编以及反汇编的知识,在下一章我们会从0写一个简易模拟器,以及汇编,反汇编程序。这门课如果没有兴趣,会非常无聊非常无聊,当然我一开始也觉得挺无聊的,毕竟搞 AI Agent 比这个有意思多,但我还是会尽量以简单的描述(避免复杂的解释),以及有意思的例子去讲这些知识。
前言
在浏览博客的时候看到一个挺有意思的思考,我们什么时候会需要去写编译器,或者反编译程序?
当然我要修学分写作业必须写lol
其他呢?
(1)有一种情况,你从网站下载了一个自动清理桌面的 exe文件 ,通过工具分析,你知道这个文件的是用C写的,你觉得这个exe文件其实功能挺不错,但有些缺点,比如自动扫描磁盘效率低,你也找不到这个文件主人,于是你想修改这个文件,于是你用一个反编译工具把这个程序从EXE反编译为其原来汇编语言的伪代码(无法得到一模一样的源代码),这样你就可以对源代码进行修改和完善,然后再重新编译成EXE。
(2)第2个就比较“刑”,我第一次听到也挺感兴趣。有一些软件你下载了运行需要注册,输入序列号才能使用。因为exe是CPU才能看懂的机器代码,这时候你就可以用到反编译技术,将其翻译为我们能看懂的汇编语言,然后你在代码中寻找判断是否注册的语句,进行修改就可以免费使用。相信大家或多或少在生活学习中有遇到这些情况。
1:编译器和反编译器
(1) 编译器(Compiler) 编译器的核心用途就是把高级语言(C、Java、Haskell 等)翻译成机器可以执行的低级语言(汇编、目标文件、机器码)。典型场景:
我们自己写程序需要执行,所以要编译。
操作系统内核、驱动程序、数据库等系统级软件,都依赖高效的编译器。
(2) 反编译(Decompiler)与反汇编(Disassembler)
反汇编:机器码 → 汇编。工具如 objdump,这是最常见的,因为机器码和汇编是一一对应的。
反编译:机器码 → 高级语言。比如 IDA Pro、Ghidra,结果往往不如源代码整洁,因为编译优化会丢失很多语义。
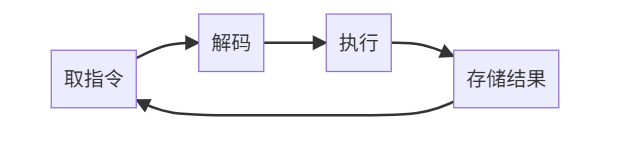
2:一个C++程序是如何运行的?
2.1 总体流程
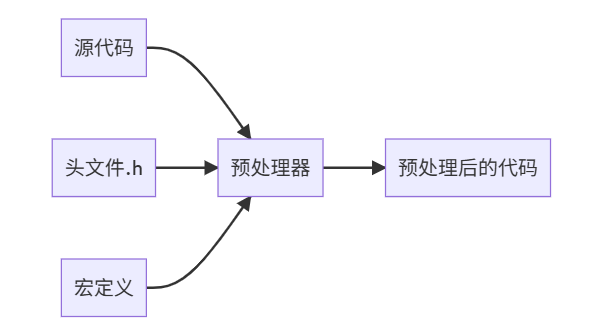
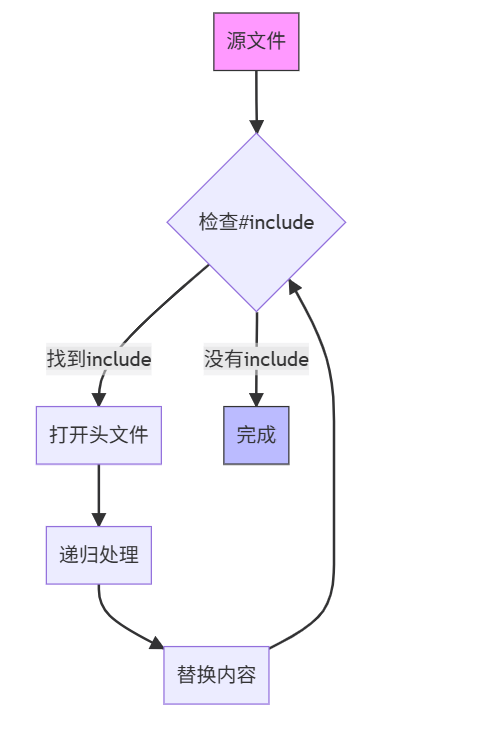
2.2 预处理阶段
示例:
// 输入
#include<iostream>
#define MAX 100
intmain(){ return MAX; }
// 输出
// iostream内容展开
intmain(){ return100; }
|
2.3 编译阶段
示例:
// 输入
intadd(int a, int b){
return a + b;
}
// 输出(汇编代码)
add:
push rbp
mov rbp, rsp
mov eax, edi
add eax, esi
pop rbp
ret
|
2.4 汇编阶段
目标文件内容:
二进制格式:
+-------------+
| ELF头 |
+-------------+
| 代码段 |
+-------------+
| 数据段 |
+-------------+
| 重定位信息 |
+-------------+
|
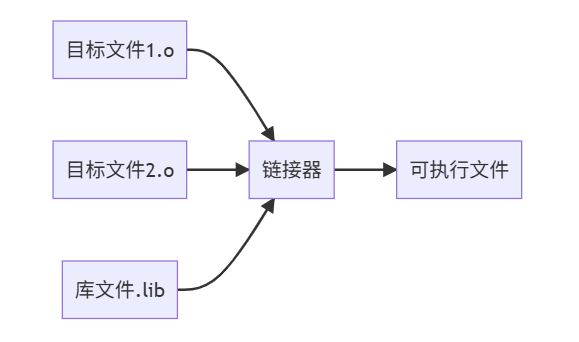
2.5 链接阶段
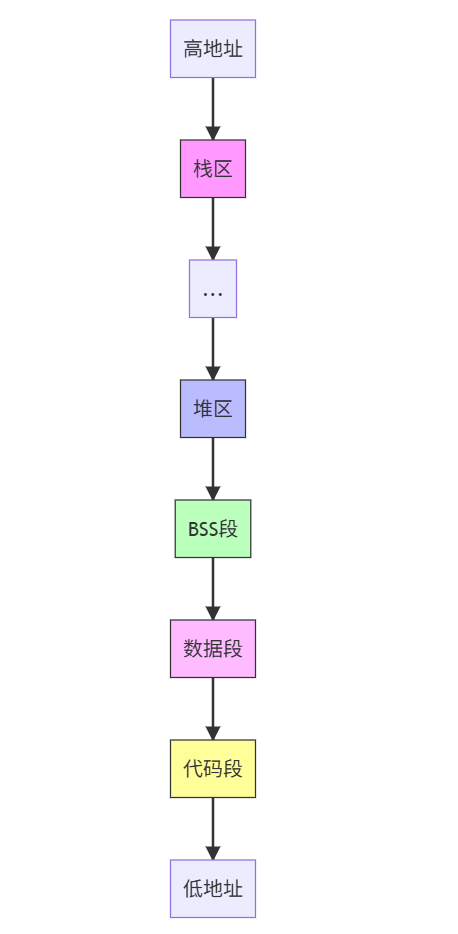
2.6 内存布局
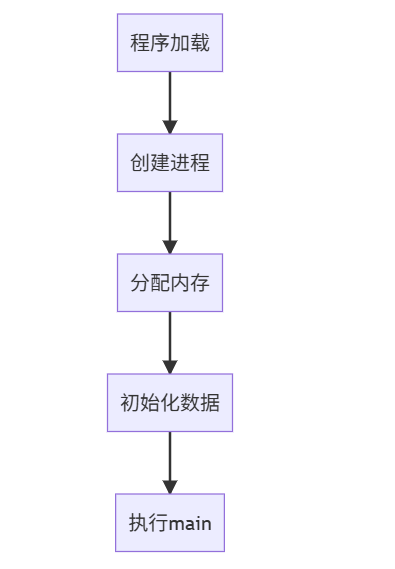
2.7运行时状态
内存使用示例:
intmain(){
int x = 10; // 栈区
int* p = newint; // 堆区
staticint y = 20; // 数据段
return0;
}
|
2.8 执行过程
这就是C++程序从源代码到运行的主要阶段。每个阶段都有其特定的任务和输出,共同协作完成程序的构建和执行。
看不懂也没关系,我们后面将一一来介绍。
这就是C++程序从源代码到运行的主要阶段。每个阶段都有其特定的任务和输出,共同协作完成程序的构建和执行。
看不懂也没关系,我们后面将一一来介绍。
|
3. 预处理
3.1 移除注释
// 输入代码
intmain(){
// 这是一个注释
int x = 1; /* 这也是注释 */
return x;
}
// 预处理后
intmain(){
int x = 1;
return x;
}
|
3.2 头文件处理
示例:
// 输入代码
#include<iostream>
#include"myheader.h"
// 预处理后(展开的头文件内容)
namespacestd { ... } // iostream的内容
classMyClass { ... } // myheader.h的内容
|
3.3 宏定义处理
示例:
// 输入代码
#define MAX 100
#define SQUARE(x) ((x) * (x))
int value = SQUARE(MAX);
// 预处理后
int value = ((100) * (100));
|
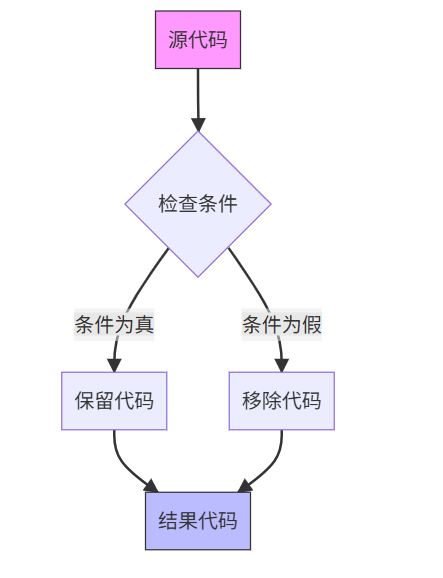
3.4 条件编译
示例:
// 输入代码
#ifdef DEBUG
voidlog(constchar* msg){ printf("%s\n", msg); }
#else
voidlog(constchar* msg){}
#endif
// 预处理后(如果DEBUG未定义)
voidlog(constchar* msg){}
|
4: 编译阶段
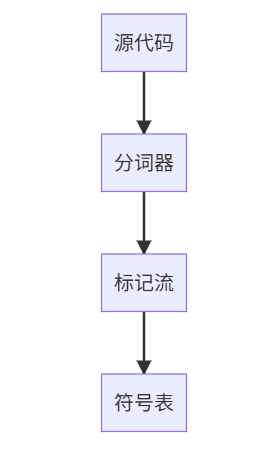
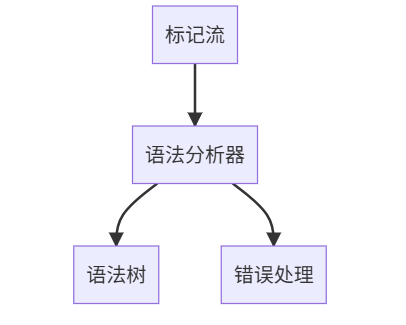
4.1 词法分析(Lexical Analysis)
源代码 → Source Code
分词器 → Lexer
标记流 → Token Stream
符号表 → Symbol Table
示例
intmain(){
int x = 42;
return x;
}
|
对应的Token Stream:
[
Token[0]: {type: KEYWORD, lexeme: "int", line: 1, col: 1}
Token[1]: {type: IDENTIFIER, lexeme: "main", line: 1, col: 5}
Token[2]: {type: SYMBOL, lexeme: "(", line: 1, col: 9}
Token[3]: {type: SYMBOL, lexeme: ")", line: 1, col: 10}
Token[4]: {type: SYMBOL, lexeme: "{", line: 1, col: 12}
Token[5]: {type: KEYWORD, lexeme: "int", line: 2, col: 5}
Token[6]: {type: IDENTIFIER, lexeme: "x", line: 2, col: 9}
Token[7]: {type: OPERATOR, lexeme: "=", line: 2, col: 11}
Token[8]: {type: NUMBER, lexeme: "42", line: 2, col: 13}
Token[9]: {type: SYMBOL, lexeme: ";", line: 2, col: 15}
Token[10]: {type: KEYWORD, lexeme: "return", line: 3, col: 5}
Token[11]: {type: IDENTIFIER, lexeme: "x", line: 3, col: 12}
Token[12]: {type: SYMBOL, lexeme: ";", line: 3, col: 13}
Token[13]: {type: SYMBOL, lexeme: "}", line: 4, col: 1}
]
|
词法分析器(Lexer)会把源代码切分成一连串 Token(记号)。 每个 Token 一般包含:
type:类型(比如关键字、标识符、运算符等)
lexeme:原始文本(代码里具体的字符串)
line/col:出现在源代码里的行号和列号
4.2 语法分析(Syntax Analysis)
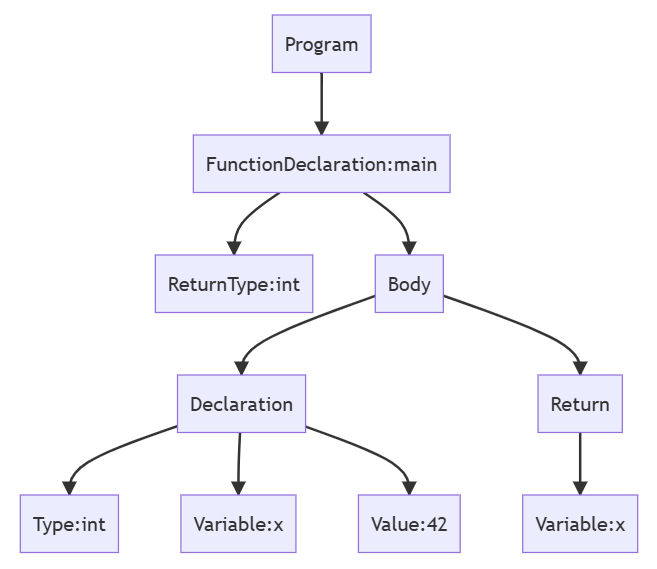
语法树示例
1.函数声明识别 :
Token[0-4]:识别出函数声明的开始
通过Token类型和词素构建FunctionDeclaration节点
2.变量声明识别 :
Token[5-9]:识别出变量声明
构建VariableDeclaration节点及其子节点
3.返回语句识别 :
Token[10-12]:识别出return语句
构建ReturnStatement节点
4.作用域结束识别 :
Token[13]:识别出函数体结束
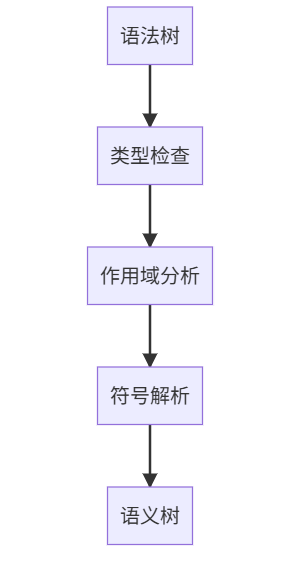
5. 语义分析(Semantic Analysis)
5.1 检查项目
1.类型检查 :
int x = "hello"; // 错误:类型不匹配
int y = 42; // 正确:类型匹配
|
2.作用域检查 :
voidfunc(){
int x = 1;
{
int x = 2; // 合法:新作用域
int y = x; // 使用内层x
}
int y = x; // 使用外层x
}
|
3.符号解析 :
intfunc(){
return x; // 错误:x未定义
}
|
6. 中间代码生成(IR Generation)
工作流程
示例
// 源代码
int x = a + b * c;
// 中间代码
t1 = b * c // 临时变量t1存储b*c的结果
t2 = a + t1 // 临时变量t2存储最终结果
x = t2 // 将结果赋值给x
|
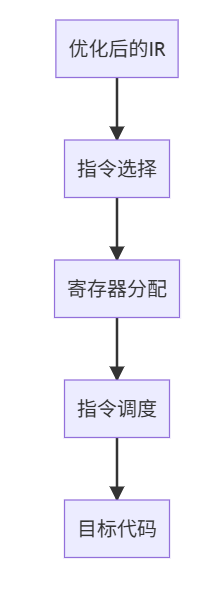
7. 目标代码生成(Code Generation)
示例
t1 = b * c
t2 = a + t1
x = t2
// x86汇编代码
mov eax, [b] ; 加载b到eax
imul eax, [c] ; 乘以c
add eax, [a] ; 加上a
mov [x], eax ; 存储结果到x
|
|






 订阅
订阅