| 编辑推荐: |
本文介绍了如何实现一个简单的解释器。希望对您的学习有所帮助 。
本文来自于博客园,由火龙果软件Alice编辑、推荐。 |
|
“如果你不知道编译器的工作方式,那么你将不知道计算机的工作方式。如果你不能100%确定是否知道编译器的工作方式,那么你将不知道它们的工作方式。”
——史蒂夫·耶格
无论你是新手还是经验丰富的软件开发人员,如果你不知道编译器和解释器的工作方式,那么你也不知道计算机的工作方式,就是这么简单。
那么,你知道编译器和解释器如何工作吗? 你是否100%确定知道它们的工作原理? 如果没有的话:

或者,如果你确实不知道,并且你为此感到不安的话:

别担心。如果你坚持不懈地学习本系列文章,并与我一起实现解释器和编译器,你将最终了解它们是如何工作的。

你为什么要学习解释器和编译器?我会给你三个理由。
1、要编写解释器或编译器,你必须具有很多需要结合使用的技能。编写解释器或编译器将帮助你提高这些技能,并成为更好的软件开发人员。同样,你学到的技能对于编写任何软件(不仅仅是解释器或编译器)都很有用。
2、你想知道计算机如何工作。通常解释器和编译器看起来像魔术,你不应该对这种魔术感到满意。你想揭露实现解释器和编译器的过程的神秘性,了解它们的工作方式并控制一切。
3、你要创建自己的编程语言或特定于某一领域的语言(domain specific language)。如果创建一个,则你还需要为其创建解释器或编译器。最近,人们对新的编程语言重新产生了兴趣。你几乎可以每天看到一种新的编程语言:Elixir,Go和Rust等。
好的,但是解释器和编译器是什么?
解释器或编译器的目标是将某种高级语言的源程序转换为其他形式。很模糊,不是吗?请耐心等待,在本系列的后面部分,你将确切地了解源程序被翻译成什么。
此时,你可能还想知道解释器和编译器之间的区别是什么。就本系列而言,如果我们将源程序翻译成机器语言,则它是编译器。如果我们在不先将其翻译成机器语言的情况下处理和执行源程序,则它就是解释器。看起来像这样:
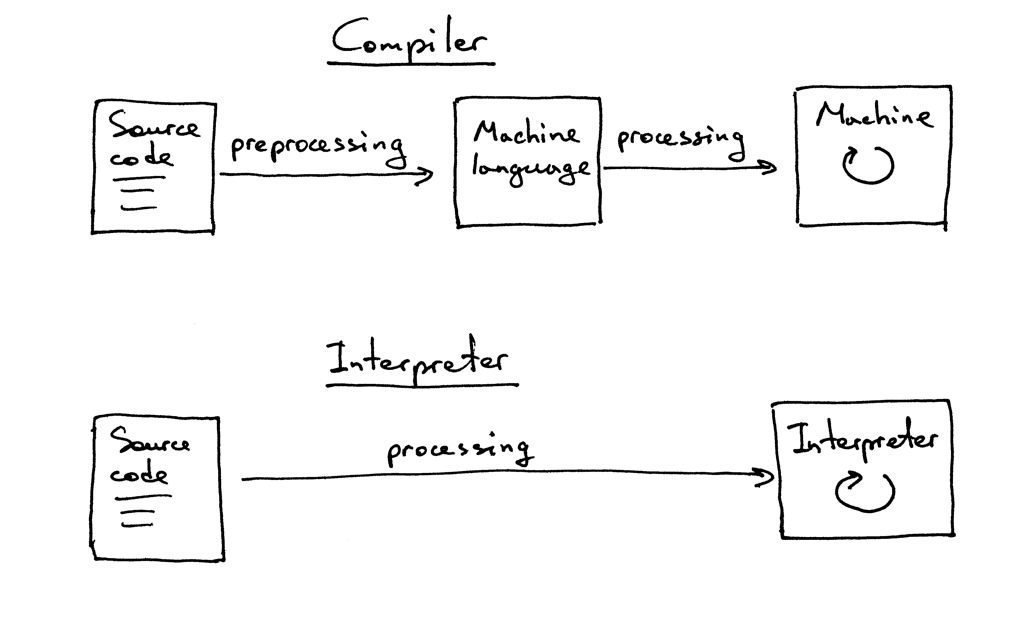
我希望到现在为止,你已经确信要学习并实现解释器和编译器。
你和我将为Pascal这门编程语言的大部分子集实现一个简单的解释器。在本系列的最后,你将拥有一个可运行的Pascal解释器和一个源代码调试器,例如Python的pdb。
你可能会问,为什么是Pascal?一方面,这不是我在本系列中提出的一种组合语言:它是一种真正的编程语言,具有许多重要的语言构造(language
constructs),还有一些古老但有用的CS书籍在其示例中使用Pascal编程语言(我了解,这不是选择我们选择实现Pascal解释器的主要理由,但我认为学习一门非主流(non-mainstream)的编程语言也是很好的:)
这是Pascal中阶乘函数的示例,你将能够使用自己的解释器对这段程序进行解释,并使用我们实现的交互式源代码调试器进行调试:
program factorial;
function factorial(n: integer): longint;
begin
if n = 0 then
factorial := 1
else
factorial := n * factorial(n - 1);
end;
var
n: integer;
begin
for n := 0 to 16 do
writeln(n, '! = ', factorial(n));
end.
|
我们这里将使用Python来实现Pascal解释器,你也可以使用任何所需的语言,因为实现解释器的思路并不局限于任何特定的编程语言。
好吧,让我们开始吧,预备,准备,开始!
我们的首次尝试是编写简单的算术表达式(arithmetic expressions)解释器(也称为计算器),今天的目标很容易:使你的计算器能够处理个位数字的加法,比如3+5。
这是你的解释器的源代码:
# Token types
#
# EOF (end-of-file) token is used to indicate that
# there is no more input left for lexical analysis
INTEGER, PLUS, EOF = 'INTEGER', 'PLUS', 'EOF'
class Token(object):
def __init__(self, type, value):
# token type: INTEGER, PLUS, or EOF
self.type = type
# token value: 0, 1, 2. 3, 4, 5, 6, 7, 8, 9, '+', or None
self.value = value
def __str__(self):
"""String representation of the class instance.
Examples:
Token(INTEGER, 3)
Token(PLUS '+')
"""
return 'Token({type}, {value})'.format(
type=self.type,
value=repr(self.value)
)
def __repr__(self):
return self.__str__()
class Interpreter(object):
def __init__(self, text):
# client string input, e.g. "3+5"
self.text = text
# self.pos is an index into self.text
self.pos = 0
# current token instance
self.current_token = None
def error(self):
raise Exception('Error parsing input')
def get_next_token(self):
"""Lexical analyzer (also known as scanner or tokenizer)
This method is responsible for breaking a sentence
apart into tokens. One token at a time.
"""
text = self.text
# is self.pos index past the end of the self.text ?
# if so, then return EOF token because there is no more
# input left to convert into tokens
if self.pos > len(text) - 1:
return Token(EOF, None)
# get a character at the position self.pos and decide
# what token to create based on the single character
current_char = text[self.pos]
# if the character is a digit then convert it to
# integer, create an INTEGER token, increment self.pos
# index to point to the next character after the digit,
# and return the INTEGER token
if current_char.isdigit():
token = Token(INTEGER, int(current_char))
self.pos += 1
return token
if current_char == '+':
token = Token(PLUS, current_char)
self.pos += 1
return token
self.error()
def eat(self, token_type):
# compare the current token type with the passed token
# type and if they match then "eat" the current token
# and assign the next token to the self.current_token,
# otherwise raise an exception.
if self.current_token.type == token_type:
self.current_token = self.get_next_token()
else:
self.error()
def expr(self):
"""expr -> INTEGER PLUS INTEGER"""
# set current token to the first token taken from the input
self.current_token = self.get_next_token()
# we expect the current token to be a single-digit integer
left = self.current_token
self.eat(INTEGER)
# we expect the current token to be a '+' token
op = self.current_token
self.eat(PLUS)
# we expect the current token to be a single-digit integer
right = self.current_token
self.eat(INTEGER)
# after the above call the self.current_token is set to
# EOF token
# at this point INTEGER PLUS INTEGER sequence of tokens
# has been successfully found and the method can just
# return the result of adding two integers, thus
# effectively interpreting client input
result = left.value + right.value
return result
def main():
while True:
try:
# To run under Python3 replace 'raw_input' call
# with 'input'
text = raw_input('calc> ')
except EOFError:
break
if not text:
continue
interpreter = Interpreter(text)
result = interpreter.expr()
print(result)
if __name__ == '__main__':
main()
|
将以上代码保存为calc1.py,或直接从GitHub下载。 在开始深入地研究代码之前,请在命令行上运行并查看其运行情况。
这是我的笔记本电脑上的一个运行效果(如果你使用的是Python3,则需要用input来替换raw_input):
$ python calc1.py
calc> 3+4
7
calc> 3+5
8
calc> 3+9
12
calc>
|
为了使你的简单计算器正常工作而不会引发异常,你的输入需要遵循某些规则:
1、输入中仅允许一位数(single digit)的整数
2、目前唯一支持的算术运算是加法
3、输入中的任何地方都不允许有空格
这些限制是使计算器简单化所必需的。不用担心,你很快就会使它变得非常复杂。
好的,现在让我们深入了解一下解释器的工作原理以及它如何计算算术表达式。
在命令行上输入表达式3+5时,解释器将获得字符串"3+5"。为了使解释器真正理解如何处理该字符串,首先需要将输入"3+5"分解为Token。Token是具有类型(type)和值(value)的对象(object)。例如,对于字符"3",Token的类型将是INTEGER,而对应的值将是整数3。
将输入字符串分解为Token的过程称为词法分析(lexical analysis)。因此,你的解释器需要做的第一步是读取字输入字符并将其转换为Token流。解释器执行此操作的部分称为词法分析器(lexical
analyzer),简称lexer。你可能还会遇到其他的名称,例如 scanner或者tokenizer,它们的含义都一样:解释器或编译器中将字符输入转换为Token流的部分。
Interpreter类的get_next_token函数是词法分析器。每次调用它时,都会从字符输入中获得下一个Token。让我们仔细看看这个函数,看看它如何完成将字符转换为Token。字符输入存储在text变量中,pos变量是该字符输入的索引(index)(将字符串视为字符数组)。
pos最初设置为0,并指向字符"3"。函数首先检查字符是否为数字,如果是数字,则递增pos并返回类型为INTEGER、值为整数3的Token:
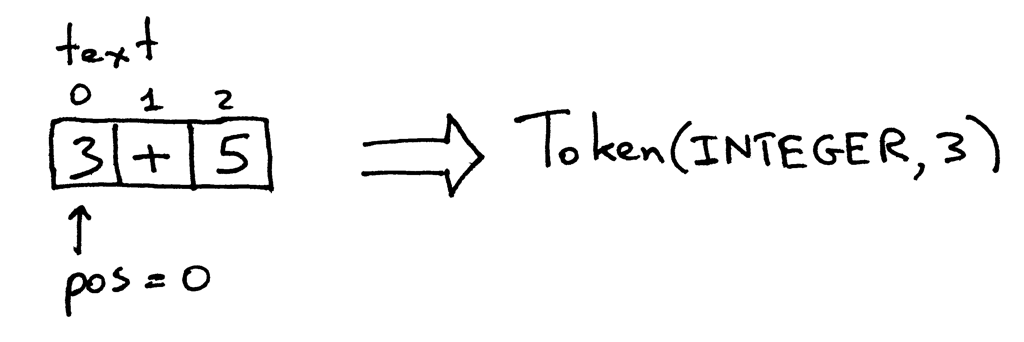
pos现在指向文本中的"+"字符。下次调用该函数时,它将测试pos所指的字符是否为数字,然后测试该字符是否为加号,然后该函数递增pos并返回一个新创建的Token,其类型为PLUS,值为"+":
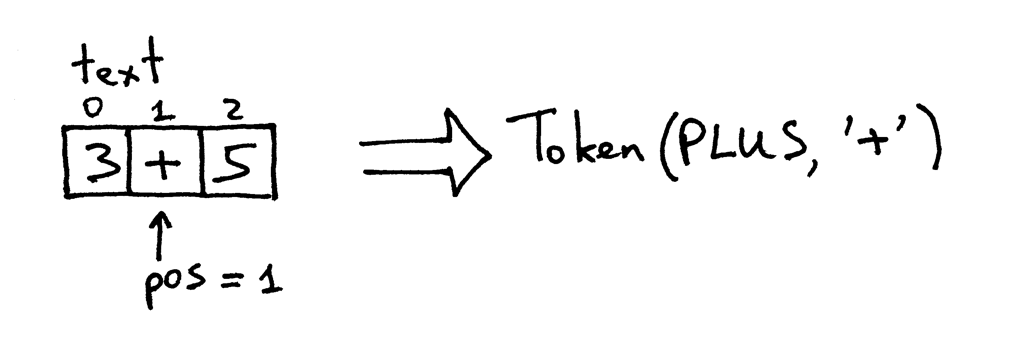
pos现在指向字符"5"。当再次调用get_next_token函数时,将检查它是否为数字,以便递增pos并返回一个新的Token,其类型为INTEGER,值为5:
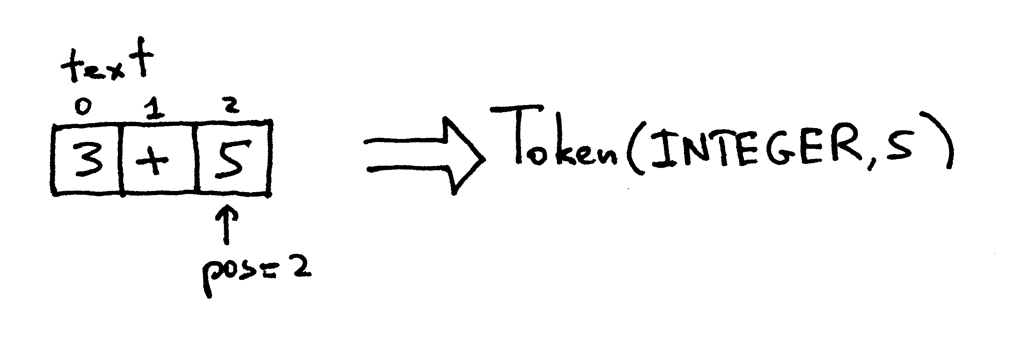
现在pos索引已超过字符串"3+5"的末尾,如果再调用get_next_token函数的话,将返回一个类型为EOF的Token:

试试看,亲自看看计算器的词法分析器如何工作:
>>> from calc1 import Interpreter
>>>
>>> interpreter = Interpreter('3+5')
>>> interpreter.get_next_token()
Token(INTEGER, 3)
>>>
>>> interpreter.get_next_token()
Token(PLUS, '+')
>>>
>>> interpreter.get_next_token()
Token(INTEGER, 5)
>>>
>>> interpreter.get_next_token()
Token(EOF, None)
>>>
|
因此,既然解释器现在可以访问由输入字符组成的Token流,那么解释器就需要对其进行处理:它需要在从Token流中查找结构(structure),解释器希望在Token流中找到以下结构:
INTEGER-> PLUS-> INTEGER
也就是说,它尝试查找Token序列:先是一个整数,后面跟加号,最后再跟一个整数。
负责查找和解释该结构的函数为expr。它验证Token序列是否与预期的Token序列相对应,即INTEGER->
PLUS-> INTEGER。成功确认结构后,它会通过将PLUS左右两侧的Token的值相加来生成结果,从而成功解释了传递给解释器的算术表达式。
expr函数本身使用辅助函数(helper method)eat来验证传递给eat函数的Token类型是否与当前正在处理的Token类型一致(match),在确保类型一致后,eat函数将获取下一个Token并将其分配给current_token变量,从而有效地“消耗”已经验证过的Token并在Token流中推进pos向前,如果Token流中的结构与预期的INTEGER
PLUS INTEGER 序列不对应,那么eat函数将引发异常。
让我们来回顾一下解释器为解析算术表达式所做的事情:
1、解释器接受输入字符串,例如"3+5"
2、解释器调用expr函数以在词法分析器get_next_token返回的Token流中找到预期的结构。它尝试查找的结构的形式为INTEGER
PLUS INTEGER。查找到结构后,它就将输入字符解释为把两个类型为INTEGER的Token的值加起来,也就是将两个整数3和5相加。
恭喜你!刚刚学习了如何构实现你的第一个解释器!
现在该做练习了:

1、修改代码以允许输入中包含多位数(multiple-digit)的整数,例如"12+3"
2、添加一种跳过空格的方法,以便计算器可以处理带有"12 + 3"之类带有空格的字符输入
3、修改代码,使计算器能够处理减法,例如"7-5"
最后再来复习回忆一下:
1、什么是解释器?
2、什么是编译器?
3、解释器和编译器有什么区别?
4、什么是Token?
5、将输入分解为Token的过程的名称是什么?
6、解释器中进行词法分析的部分是什么?
在他们的著作《有效思维的五个要素》(The 5 Elements of Effective Thinking)中,Burger和Starbird分享了一个故事,讲述了他们如何观察国际知名的小号演奏家托尼·普洛(Tony
Plog)为有成就的小号演奏家举办大师班。学生们首先演奏复杂的乐句,他们演奏得很好,但是随后他们被要求演奏非常基本、简单的音符时,与以前演奏的复杂乐句相比,这些音符听起来更幼稚(childish)。他们演奏完毕后,大师老师也演奏了相同的音符,但是当他演奏它们时,它们听起来并不幼稚,区别是惊人的。托尼解释说,掌握简单音符的演奏可以使人在更复杂的控制下演奏复杂的乐曲。该课程很明确:要建立真正的技巧,必须将重点放在掌握简单的基本思想上。
故事中的课程显然不仅适用于音乐,还适用于软件开发。这个故事很好地提醒了我们所有人,即使有时感觉就像是退后一步,也不要忘记深入研究简单,基本概念的重要性。精通所使用的工具或框架很重要,但了解其背后的原理也非常重要。正如Ralph
Waldo Emerson所说:
“如果你只学习方法,那么你将被束缚在方法上。 但是,如果你学习了原理,就可以设计自己的方法。”
关于这一点,让我们再次深入了解解释器和编译器。
今天,我将向您展示第1部分中的计算器的新版本,该版本将能够:
1、在输入字符串中的处理任何地方的空格
2、处理输入中的多位数整数
3、减去两个整数(当前只能加整数)
这是可以执行上述所有操作的新版本计算器的源代码:
# Token types
# EOF (end-of-file) token is used to indicate that
# there is no more input left for lexical analysis
INTEGER, PLUS, MINUS, EOF = 'INTEGER', 'PLUS', 'MINUS', 'EOF'
class Token(object):
def __init__(self, type, value):
# token type: INTEGER, PLUS, MINUS, or EOF
self.type = type
# token value: non-negative integer value, '+', '-', or None
self.value = value
def __str__(self):
"""String representation of the class instance.
Examples:
Token(INTEGER, 3)
Token(PLUS '+')
"""
return 'Token({type}, {value})'.format(
type=self.type,
value=repr(self.value)
)
def __repr__(self):
return self.__str__()
class Interpreter(object):
def __init__(self, text):
# client string input, e.g. "3 + 5", "12 - 5", etc
self.text = text
# self.pos is an index into self.text
self.pos = 0
# current token instance
self.current_token = None
self.current_char = self.text[self.pos]
def error(self):
raise Exception('Error parsing input')
def advance(self):
"""Advance the 'pos' pointer and set the 'current_char' variable."""
self.pos += 1
if self.pos > len(self.text) - 1:
self.current_char = None # Indicates end of input
else:
self.current_char = self.text[self.pos]
def skip_whitespace(self):
while self.current_char is not None and self.current_char.isspace():
self.advance()
def integer(self):
"""Return a (multidigit) integer consumed from the input."""
result = ''
while self.current_char is not None and self.current_char.isdigit():
result += self.current_char
self.advance()
return int(result)
def get_next_token(self):
"""Lexical analyzer (also known as scanner or tokenizer)
This method is responsible for breaking a sentence
apart into tokens.
"""
while self.current_char is not None:
if self.current_char.isspace():
self.skip_whitespace()
continue
if self.current_char.isdigit():
return Token(INTEGER, self.integer())
if self.current_char == '+':
self.advance()
return Token(PLUS, '+')
if self.current_char == '-':
self.advance()
return Token(MINUS, '-')
self.error()
return Token(EOF, None)
def eat(self, token_type):
# compare the current token type with the passed token
# type and if they match then "eat" the current token
# and assign the next token to the self.current_token,
# otherwise raise an exception.
if self.current_token.type == token_type:
self.current_token = self.get_next_token()
else:
self.error()
def expr(self):
"""Parser / Interpreter
expr -> INTEGER PLUS INTEGER
expr -> INTEGER MINUS INTEGER
"""
# set current token to the first token taken from the input
self.current_token = self.get_next_token()
# we expect the current token to be an integer
left = self.current_token
self.eat(INTEGER)
# we expect the current token to be either a '+' or '-'
op = self.current_token
if op.type == PLUS:
self.eat(PLUS)
else:
self.eat(MINUS)
# we expect the current token to be an integer
right = self.current_token
self.eat(INTEGER)
# after the above call the self.current_token is set to
# EOF token
# at this point either the INTEGER PLUS INTEGER or
# the INTEGER MINUS INTEGER sequence of tokens
# has been successfully found and the method can just
# return the result of adding or subtracting two integers,
# thus effectively interpreting client input
if op.type == PLUS:
result = left.value + right.value
else:
result = left.value - right.value
return result
def main():
while True:
try:
# To run under Python3 replace 'raw_input' call
# with 'input'
text = raw_input('calc> ')
except EOFError:
break
if not text:
continue
interpreter = Interpreter(text)
result = interpreter.expr()
print(result)
if __name__ == '__main__':
main()
|
将以上代码保存到calc2.py文件中,或直接从GitHub下载。试试看,了解一下它可以做什么:
它可以处理输入中任何地方的空格;它可以接受多位数整数,也可以减去两个整数,也可以加上两个整数。
这是我在笔记本电脑上的运行效果:
$ python calc2.py
calc> 27 + 3
30
calc> 27 - 7
20
calc>
|
与第1部分中的版本相比,主要的代码更改是:
1、get_next_token函数被重构了一部分,递增pos指针的逻辑单独放入函数advance中。
2、添加了两个函数:skip_whitespace忽略空白字符,integer处理输入中的多位数整数。
3、修改了expr函数,以识别INTEGER-> MINUS-> INTEGER短语,以及INTEGER->
PLUS-> INTEGER短语。现在,函数可以在成功识别(recognize)相应短语之后来解释加法和减法运算。
在第1部分中,你学习了两个重要的概念,即Token和词法分析器(lexical analyzer)的概念。今天,我想谈谈词素(lexemes),解析(parsing)和解析器(parser)。
你已经了解Token,但是,为了使我更完整地讨论Token,我需要提及词素。什么是词素?词素是形成Token的一系列字符,在下图中,你可以看到Token和词素的一些示例,希望可以使它们之间的关系更清晰一点:

现在,还记得expr函数吗?我之前说过,这实际上是对算术表达式进行解释的地方。但是,在解释一个表达式之前,首先需要识别它是哪种短语(phrase),例如,是加还是减,这就是expr函数的本质:它从get_next_token方法获取的Token流中查找结构(structure),然后解释已识别的短语,从而生成算术表达式的结果。
在Token流中查找结构的过程,或者换句话说,在Token流中识别短语的过程称为解析(parsing)。执行该工作的解释器或编译器部分称为解析器(parser)。
因此,现在您知道expr函数是解释器的一部分,解析和解释都会发生在expr函数中,首先尝试在Token流中识别(解析)INTEGER->
PLUS-> INTEGER或INTEGER-> MINUS-> INTEGER短语,并在成功识别(解析)其中一个短语之后,该方法对其进行解释,将两个整数相加或相减的结果返回给调用函数。
现在该做练习了:
1、扩展计算器以处理两个整数的乘法
2、扩展计算器以处理两个整数的除法
3、修改代码以解释包含任意数量的加法和减法的表达式,例如" 9-5 + 3 + 11"
最后再来复习回忆一下:
1、什么是词素?
2、在Token流中找到结构的过程称为什么,或者换句话说,识别该Token流中的特定短语的过程叫什么?
3、解释器(编译器)中负责解析(parsing)的部分叫什么?
| 





 订阅
订阅