| БрМЭЦМі: |
| БОЮФРДзд51ctoЃЌБОЮФеыЖдШчКЮИќИпаЇЕиЪЙгУЛКДцЃЌМѕЩйОВЬЌзЪдДЕФжиИДЯТдиЃЌжиЕуСФСФдіСПИќаТЕФЮЪЬтЁЃ |
|
ЮЊЪВУДвЊзідіСПИќаТ
УРЭХН№ШкЕФвЕЮёдкЙ§ШЅЕФвЛЖЮЪБМфРяЗЂеЙЗЧГЃПьЫйЁЃдквЕЮёдіГЄЕФЭЌЪБЃЌЮвУЧвВзЂвтЕНЃЌКмЖргУЛЇЕФжЇИЖЛЗОГЃЌЦфЪЕЪЧдкШѕЭјЛЗОГжаЕФЁЃ
ДѓМвжЊЕРЃЌЧАЖЫФмЙЛЗўЮёгУЛЇЕФЧАЬсЪЧ JavaScript КЭ CSS ЕШОВЬЌзЪдДФмЙЛе§ШЗМгдиЁЃШчЙћЭјТчЛЗОГЖёСгЃЌФЧУДЮвУЧЕФОВЬЌзЪдДГпДчдНДѓЃЌгУЛЇЯТдиЪЇАмЕФИХТЪОЭдНИпЁЃ
ИљОнЮвУЧЕФЪ§ОнЭГМЦЃЌЮвУЧЕФвЕЮёжага2%ЕФгУЛЇСїЪЇгызЪдДМгдигаЙиЁЃвђДЫУПДЮИќаТЕФДњМлдНаЁЁЂМгдиГЩЙІТЪдНИпЃЌгУЛЇСїЪЇТЪвВОЭЛсдНЕЭЃЌДгЖјОЭФмЙЛБфЯрЬсИпЖЉЕЅЕФзЊЛЏТЪЁЃ
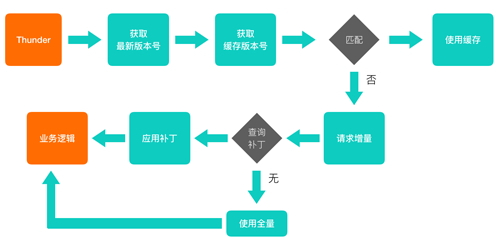
зїЮЊвЛИіЗЂАцЦЕЗБЕФвЕЮёЃЌвЊНЕЕЭЗЂАцЕФгАЯьЃЌПЩвдзіСНЗНУцгХЛЏЃК
ИќИпаЇЕиЪЙгУЛКДцЃЌМѕЩйОВЬЌзЪдДЕФжиИДЯТдиЁЃ
ЪЙгУдіСПИќаТЃЌНЕЕЭЕЅДЮЗЂАцЪБЯТЗЂЕФФкШнГпДчЁЃ
еыЖдЕквЛЕуЃЌЮвУЧгаздМКЕФФЃПщМгдиЦїРДзіЃЌетРяЯШАДЯТВЛБэЃЌЮвУЧРДжиЕуСФСФдіСПИќаТЕФЮЪЬтЁЃ
діСПИќаТЪЧдѕУДвЛИіЙ§ГЬ
ПДЭМЫЕЛАЁЃ
діСПИќаТЕФПЭЛЇЖЫСїГЬЭМ
ЮвУЧЕФдіСПИќаТЭЈЙ§дкфЏРРЦїЖЫВПЪ№вЛИі SDK РДЗЂЦ№ЃЌетИі SDK ЮвУЧГЦжЎЮЊ Thunder.js
ЁЃ
Thunder.js дквГУцМгдиЪБЃЌЛсДгвГУцжаЖСШЁзюаТОВЬЌзЪдДЕФАцБОКХЁЃЭЌЪБЃЌ Thunder.js
вВЛсДгфЏРРЦїЕФЛКДцЃЈЭЈГЃЪЧ localStorageЃЉжаЖСШЁЮвУЧвбОЛКДцЕФАцБОКХЁЃетСНИіАцБОКХНјааЦЅХфЃЌШчЙћЗЂЯжвЛжТЃЌФЧУДЮвУЧПЩвджБНгЪЙгУЛКДцЕБжаЕФАцБОЃЛЗДжЎЃЌЮвУЧЛсЯђдіСПИќаТЗўЮёЗЂЦ№вЛИідіСПВЙЖЁЕФЧыЧѓЁЃ
діСПЗўЮёЪеЕНЧыЧѓКѓЃЌЛсЕїШЁаТОЩСНИіАцБОЕФЮФМўНјааЖдБШЃЌНЋВювьзїЮЊВЙЖЁЗЕЛиЁЃThunder.js ФУЕНЧыЧѓКѓЃЌМДПЩНЋВЙЖЁДђдкРЯЮФМўЩЯЃЌетбљОЭЕУЕНСЫаТЮФМўЁЃ
змжЎвЛОфЛАЃКРЯЮФМў + ВЙЖЁ = аТЮФМўЁЃ
діСПВЙЖЁЕФЩњГЩЃЌжївЊвРРЕгк Myers ЕФ diff ЫуЗЈЁЃЩњГЩдіСПВЙЖЁЕФЙ§ГЬЃЌОЭЪЧбАевСНИізжЗћДЎзюЖЬБрМТЗОЖЕФЙ§ГЬЁЃЫуЗЈБОЩэБШНЯИДдгЃЌДѓМвПЩвддкЭјЩЯеввЛаЉБШНЯЯъЯИЕФЫуЗЈУшЪіЃЌБШШчетЦЊ
ЁЖThe Myers diff algorithmЁЗЃЌетРяОЭВЛЯъЯИНщЩмСЫЁЃ
ВЙЖЁБОЩэЪЧвЛИіЮЂаЭЕФ DSLЃЈDomain Specific LanguageЃЉЁЃетИі DSL вЛЙВгаШ§жжЮЂжИСюЃЌЗжБ№ЖдгІБЃСєЁЂВхШыЁЂЩОГ§Ш§жжзжЗћДЎВйзїЃЌУПжжжИСюЖМгаздМКЕФВйзїЪ§ЁЃ
Р§ШчЃЌЮвУЧвЊЩњГЩДгзжЗћДЎЁАabcdefgЁБЕНЁАacdzЁБЕФдіСПВЙЖЁЃЌФЧУДвЛИіВЙЖЁЕФШЋЮФОЭРрЫЦШчЯТЃК
=1\t-1\t=2\t-3\t+z
етИіВЙЖЁЕБжаЃЌжЦБэЗћ\tЪЧжИСюЕФЗжИєЗћЃЌ=БэЪОБЃСєЃЌ-БэЪОЩОГ§ЃЌ+БэЪОВхШыЁЃећИіВЙЖЁНтЮіГіРДОЭЪЧЃК
БЃСє1ИізжЗћ
ЩОГ§1ИізжЗћ
БЃСє2ИізжЗћ
ЩОГ§3ИізжЗћ
ВхШы1ИізжЗћЃКz
ОпЬхЕФ JavaScript ДњТыОЭВЛдкетРяеГЬљСЫЃЌСїГЬБШНЯМђЕЅЃЌЯраХДѓМвЖМПЩвдздМКаДГіРДЃЌжЛашвЊзЂвтзЊвхКЭзжЗћДЎЯТБъЕФЮЌЛЄМДПЩЁЃ
діСПИќаТЦфЪЕВЛЪЧЧАЖЫЕФаТЯЪММЪѕЃЌдкПЭЛЇЖЫСьгђЃЌдіСПИќаТдчвбОгІгУЖрФъЁЃПДЙ§ЮвУЧЁЖУРЭХН№ШкЩЈТыИЖОВЬЌзЪдДМгдигХЛЏЪЕМљЁЗЕФХѓгбЃЌгІИУжЊЕРЮвУЧЦфЪЕжЎЧАвбгаЪЕМљЃЌдкЕБЪБНіНіППдіСПИќаТЃЌШеОљНкЪЁСїСПДя30ЖрGBЁЃЖјЯждкетИіЪ§зжвбОЫцзХвЕЮёСПБфЕУИќИпСЫЁЃ
ФЧУДЮвУЧЪЧВЛЪЧОЭвбОзіЕНЭђЪТЮогЧСЫФиЃП
ЮвУЧжЎЧАЕФдіСПИќаТЪЕМљгіЕНСЫЪВУДЮЪЬт
ЮвУЧзюжївЊЕФЮЪЬтЪЧдіСПМЦЫуЕФЫйЖШВЛЙЛПьЁЃ
жЎЧАЕФгХЛЏЪЕМљжаЃЌЮвУЧОјДѓВПЗжЕФгХЛЏЦфЪЕЖМЪЧЮЊСЫгХЛЏдіСПМЦЫуЕФЫйЖШЁЃЮФБОдіСПМЦЫуЕФЫйЖШШЗЪЕТ§ЃЌТ§ЕНЪВУДГЬЖШФиЃПвдЧАЖЫБШНЯГЃМћЕФJSзЪдДГпДчЁЊЁЊ200KBЁЊЁЊРДНјаадіСПМЦЫуЃЌНјаавЛДЮдіСПМЦЫуЕФЪБМфвРОнЮФБОВЛЭЌЕФЪ§СПЃЌДгЪ§ЪЎКСУыЕНЪЎМИУыЩѕжСМИЪЎУыЖМгаПЩФмЁЃ
ЖдгкаЁСїСПвЕЮёРДЫЕЃЌМЦЫувЛДЮдіСПВЙЖЁШЛКѓЛКДцЦ№РДЃЌМДЪЙЕквЛДЮМЦЫуКФЪБвЛаЉвВВЛЛсгаЬЋДѓгАЯьЁЃЕЋгУЛЇВрЕФвЕЮёСїСПЖМНЯДѓЃЌУПдТЕФдіСПМЦЫуДЮЪ§ГЌЙ§
10 ЭђДЮЃЌВЂЗЂМЦЫуЗхжЕГЌЙ§ 100 QPS ЁЃ
ФЧУДВЛЙЛПьЕФгАЯьЪЧЪВУДФиЃП
ЮвУЧжЎЧАЕФЩшМЦДѓжТЫМЯыЪЧгУвЛИіЗўЮёРДГаНгСїСПЃЌдйгУСэвЛИіЗўЮёРДНјаадіСПМЦЫуЁЃетСНИіЗўЮёОљгЩ Node.js
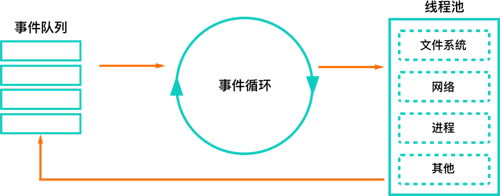
РДЪЕЯжЁЃЖдгкЧАепЃЌ Node.js ЕФЪТМўбЛЗФЃаЭБООЭЪЪКЯНјаа I/O УмМЏаЭвЕЮёЃЛШЛЖјЖдгкКѓепЃЌдђЪЕМЪЮЊ
Node.js ЕФШэРпЁЃ Node.js ЕФЪТМўбЛЗФЃаЭЃЌвЊЧѓ Node.js ЕФЪЙгУБиаыЪБПЬБЃжЄ
Node.js ЕФбЛЗФмЙЛдЫзЊЃЌШчЙћГіЯжЗЧГЃКФЪБЕФКЏЪ§ЃЌФЧУДЪТМўбЛЗОЭЛсЯнШыНјШЅЃЌЮоЗЈМАЪБДІРэЦфЫћЕФШЮЮёЁЃГЃМћЕФЪжЗЈЪЧдкЛњЦїЩЯЖрПЊМИИі
Node.js НјГЬЁЃШЛЖјвЛЬЈЦеЭЈЕФЗўЮёЦївВОЭ8ИіТпМCPUЖјвбЃЌЖдгкдіСПМЦЫуРДЫЕЃЌЕБЮвУЧгіЕНДѓМЦЫуСПЕФШЮЮёЪБЃЌ8ИіВЂЗЂПЩФмОЭЛсШУ
Node.js ЗўЮёКмФбМЬајЯьгІСЫЁЃШчЙћНјвЛВНдіМгНјГЬЪ§СПЃЌдђЛсДјРДЖюЭтЕФНјГЬЧаЛЛГЩБОЃЌетВЂВЛЪЧЮвУЧЕФзюгХбЁдёЁЃ
ИќИпадФмЕФПЩФмЗНАИ
ЁАШУ JavaScript ХмЕФИќПьЁБетИіЮЪЬтЃЌКмЖрЧАБВвбОгаЫљбаОПЁЃдкЮвУЧЫМПМетИіЮЪЬтЪБЃЌПМТЧЙ§Ш§жжЗНАИЁЃ
Node.js Addon
Node.js Addon ЪЧ Node.js ЙйЗНЕФВхМўЗНАИЃЌетИіЗНАИдЪаэПЊЗЂепЪЙгУ C/C++
БраДДњТыЃЌЖјКѓдйгЩ Node.js РДМгдиЕїгУЁЃгЩгкдЩњДњТыЕФадФмБОЩэОЭБШНЯВЛДэЃЌетЪЧвЛжжЗЧГЃжБНгЕФгХЛЏЗНАИЁЃ
ASM.js / WebAssembly
КѓСНжжЗНАИЪЧфЏРРЦїВрЕФЗНАИЁЃ
Цфжа ASM.js гЩ Mozilla ЬсГіЃЌЪЙгУЕФЪЧ JavaScript ЕФвЛИівзгкгХЛЏЕФзгМЏЁЃетИіЗНАИФПЧАвбОБЛЗЯЦњСЫЁЃ
ШЁЖјДњжЎЕФ WebAssembly ЃЌгЩ W3C РДСьЕМЃЌВЩгУЕФЪЧИќМгНєДеЁЂНгНќЛуБрЕФзжНкТыРДЬсЫйЁЃФПЧАдкЪаУцЩЯИеИееИТЖЭЗНЧЃЌЯрЙиЕФЙЄОпСДЛЙдкЭъЩЦжаЁЃ
Mozilla здМКвбОгавЛаЉГЂЪдАИР§СЫЃЌР§ШчНЋ Rust ДњТыБрвыЕН WebAssembly РДЬсЫй
sourcemap ЕФНтЮіЁЃ
ШЛЖјдкПМТЧСЫетШ§жжЗНАИжЎКѓЃЌЮвУЧВЂУЛгаЕУЕНвЛИіКмКУЕФНсТлЁЃетШ§ИіЗНАИЕФЖМПЩвдЬсЩ§ JavaScript
ЕФдЫааадФмЃЌЕЋЪЧЮоТлВЩШЁФФвЛжжЃЌЖМЮоЗЈНЋЕЅИіВЙЖЁЕФМЦЫуКФЪБДгЪ§ЪЎУыНЕЕНКСУыМЖЁЃПіЧвЃЌетШ§жжЗНАИШчЙћВЛМгвдИДдгЕФИФдьЃЌвРШЛЛсдЫаадк
JavaScript ЕФжїЯпГЬжЎжаЃЌетЖд Node.js РДЫЕЃЌвРШЛЛсЗЂЩњбЯжиЕФзшШћЁЃ
гкЪЧЮвУЧПЊЪМПМТЧ Node.js жЎЭтЕФЗНАИЁЃЛЛгябдетвЛЯыЗЈгІдЫЖјЩњЁЃ
ЛЛгябд
ИќЛЛБрГЬгябдЃЌЪЧвЛИіКмЩїжиЕФЪТЧщЃЌвЊПМТЧЕФЕуКмЖрЁЃдкдіСПМЦЫуетМўЪТЩЯЃЌЮвУЧжївЊПМТЧаТгябдвдЯТЗНУцЃК
1.дЫааЫйЖШ
2.ВЂЗЂДІРэ
3.РраЭЯЕЭГ
4.вРРЕЙмРэ
5.ЩчЧј
ЕБШЛЃЌГ§СЫетаЉЕужЎЭтЃЌЮвУЧЛЙПМТЧСЫЕїгХЁЂВПЪ№ЕФФбвзГЬЖШЃЌвдМАгябдБОЩэЪЧЗёФмЙЛПьЫйМндІЕШвђЫиЁЃ
зюжеЃЌЮвУЧОіЖЈЪЙгУ Go гябдНјаадіСПМЦЫуЗўЮёЕФаТЪЕМљЁЃ
бЁдёGoДјРДСЫЪВУД
ИпадФм
діСПВЙЖЁЕФЩњГЩЫуЗЈЃЌдк Node.js ЕФЪЕЯжжаЃЌЖдгІ diff АќЃЛЖјдк Go ЕФЪЕЯжжаЃЌЖдгІ
go-diff АќЁЃ
дкЖЏЪжжЎЧАЃЌЮвУЧЪзЯШгУЪЕМЪЕФСНзщЮФМўЃЌЖд Go КЭ Node.js ЕФдіСПФЃПщНјааСЫадФмЦРВтЃЌвдШЗЖЈЮвУЧЕФЗНЯђЪЧЖдЕФЁЃ
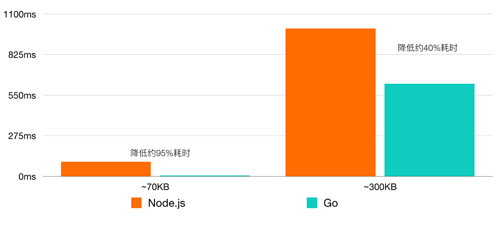
ЯрЭЌЫуЗЈЁЂЯрЭЌЮФМўЕФМЦЫуЪБМфЖдБШ
НсЙћЯдЪОЃЌОЁЙмеыЖдВЛЭЌЕФЮФМўЛсГіЯжВЛЭЌЕФЧщПіЃЌGo ЕФИпадФмвРШЛдкМЦЫуадФмЩЯФыбЙСЫ Node.js
ЁЃетРяашвЊзЂвтЃЌЮФМўГЄЖШВЂВЛЪЧгАЯьМЦЫуКФЪБЕФЮЈвЛвђЫиЃЌСэвЛИіКмживЊЕФвђЫиЪЧЮФМўВювьЕФДѓаЁЁЃ
ВЛвЛбљЕФВЂЗЂФЃаЭ
Go гябдЪЧ Google ЭЦГіЕФвЛУХЯЕЭГБрГЬгябдЁЃЫќгяЗЈМђЕЅЃЌвзгкЕїЪдЃЌадФмгХвьЃЌгаСМКУЕФЩчЧјЩњЬЌЛЗОГЁЃКЭ
Node.js НјааВЂЗЂЕФЗНЪНВЛЭЌЃЌ Go гябдЪЙгУЕФЪЧЧсСПМЖЯпГЬЃЌЛђепНааГЬЃЌРДНјааВЂЗЂЕФЁЃ
зЈзЂгкфЏРРЦїЖЫЕФЧАЖЫЭЌбЇЃЌПЩФмЖдетжжВЂЗЂФЃаЭВЛЬЋСЫНтЁЃетРяЮвИљОнЮвздМКЕФРэНтРДМђвЊНщЩмвЛЯТЫќКЭ Node.js
ЪТМўЧ§ЖЏВЂЗЂЕФЧјБ№ЁЃ
ШчЩЯЮФЫљЫЕЃЌ Node.js ЕФжїЯпГЬШчЙћЯнШыдкФГИіДѓМЦЫуСПЕФКЏЪ§жаЃЌФЧУДећИіЪТМўбЛЗОЭЛсзшШћЁЃаГЬдђгыДЫВЛЭЌЃЌУПИіаГЬжаЖМгаМЦЫуШЮЮёЃЌетаЉМЦЫуШЮЮёЫцзХаГЬЕФЕїЖШЖјЕїЖШЁЃвЛАуРДЫЕЃЌЕїЖШЯЕЭГВЛЛсАбЫљгаЕФ
CPU зЪдДЖМИјЭЌвЛИіаГЬЃЌЖјЪЧЛсаЕїИїИіаГЬЕФзЪдДеМгУЃЌОЁПЩФмЦНЗж CPU зЪдДЁЃ
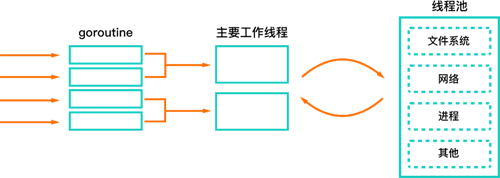
Go ЕФ goroutine
ЯрБШ Node.js ЃЌетжжЗНЪНИќМгЪЪКЯМЦЫуУмМЏгы I/O УмМЏМцгаЕФЗўЮёЁЃ
ЕБШЛетжжЗНЪНвВгаЫќЕФШБЕуЃЌФЧОЭЪЧгЩгкУПИіаГЬЫцЪБЛсБЛднЭЃЃЌвђДЫаГЬжЎМфЛсКЭДЋЭГЕФЯпГЬвЛбљЃЌгаЗЂЩњОКЬЌЕФЗчЯеЁЃЫљавЮвУЧЕФвЕЮёВЂУЛгаЖрЩйашвЊЙВЯэЪ§ОнЕФГЁОАЃЌОКЬЌЕФЧщПіЗЧГЃЩйЁЃ
ЪЕМЪЩЯ Web ЗўЮёРраЭЕФгІгУЃЌЭЈГЃвдЧыЧѓ -> ЗЕЛиЮЊФЃаЭдЫааЃЌУПИіЧыЧѓКмЩйЛсКЭЦфЫћЧыЧѓЗЂЩњСЊЯЕЃЌвђДЫЪЙгУЫјЕФГЁОАКмЩйЁЃвЛаЉЁАМЦЪ§ЦїЁБРрЕФашЧѓЃЌППдзгБфСПвВПЩвдКмШнвзЕиЭъГЩЁЃ
ВЛвЛбљЕФФЃПщЛњжЦ
Go гябдЕФФЃПщвРРЕЙмРэВЂВЛЯё Node.js ФЧУДГЩЪьЁЃОЁЙмЭТВл node_modules ЕФШЫКмЖрЃЌЕЋШДВЛЕУВЛГаШЯЃЌNode.js
ЕФ CMD ЛњжЦЖдгкЮвУЧРДЫЕВЛНівзгкбЇЯАЃЌЭЌЪБУПИіФЃПщЕФжАд№КЭБпНчвВЪЧЗЧГЃЧхЮњЕФЁЃ
ОпЬхРДЫЕЃЌвЛИі Node.js ФЃПщЃЌЫќжЛашЙиаФЫќздМКвРРЕЕФФЃПщЪЧЪВУДЁЂдкФФРяЃЌЖјВЛЙиаФздМКЪЧШчКЮБЛБ№ШЫвРРЕЕФЁЃетвЛЕуЃЌПЩвдДг
require ЕїгУПДГіЃК
етЪЧвЛИіЗЧГЃМђЕЅЕФФЃПщЃЌЫќвРРЕСНИіЦфЫћФЃПщЃЌЦфжа util РДздЮвУЧБОЕиЕФФПТМЃЌЖј http дђРДздгк
Node.js ФкжУЁЃдкетжжЧщаЮЯТЃЌжЛвЊФугаСМКУЕФФЃПщвРРЕЙиЯЕЃЌвЛИіздМКаДКУЕФФЃПщЯывЊИјБ№ШЫИДгУЃЌжЛашвЊАбећИіФПТМЖРСЂЩЯДЋЕН
npm ЩЯМДПЩЁЃ
МђЕЅРДЫЕЃЌ Node.js ЕФФЃПщЬхЯЕЪЧвЛПУЪїЃЌзюжеБОЕиФЃПщОЭЪЧетбљЃК
ЕЋ Go гябдОЭВЛЭЌСЫЁЃдк Go гябджаЃЌУПИіФЃПщВЛНігавЛИіЖЬЕФФЃПщУћЃЌЭЌЪБЛЙгавЛИіЯюФПжаЕФЁАЮЈвЛТЗОЖЁБЁЃШчЙћФуашвЊв§гУвЛИіФЃПщЃЌФЧУДФуашвЊЪЙгУетИіЁАЮЈвЛТЗОЖЁБРДНјаав§гУЁЃБШШчЃК
ЕквЛИівРРЕЕФ fmt ЪЧ Go здДјЕФФЃПщЃЌМђЕЅУїСЫЁЃЕкЖўИіФЃПщЪЧвЛИіЮЛгк Github ЕФПЊдДЕкШ§ЗНФЃПщЃЌПДТЗОЖаЮЪНОЭФмЙЛДѓжТЭЦЖЯГіРДЫќЪЧЕкШ§ЗНЕФЁЃЖјЕкШ§ИіЃЌдђЪЧЮвУЧЯюФПжавЛИіПЩИДгУФЃПщЃЌетОЭгаЕуВЛЬЋКЯЪЪСЫЁЃЦфЪЕШчЙћ
Go жЇГжЧЖЬзЕФФЃПщЙиЯЕЕФЛАЃЌЯрЕБгкУПИівРРЕДгИљФПТМЫуЦ№ОЭПЩвдСЫЃЌФмЙЛБмУтГіЯж ../../../../root/something
етжжоЯоЮЕФЯђЩЯВщевЁЃЕЋЪЧЃЌ Go ЪЧВЛжЇГжБОЕивРРЕжЎМфЕФЮФМўМаЧЖЬзЕФЁЃетбљвЛРДЃЌЫљгаЕФБОЕиФЃПщЃЌЖМЛсЦНЦЬдкЭЌвЛИіФПТМРяЃЌзюжеЛсБфГЩетбљЃК
ЯждкФуВЛЬЋПЩФмжБНгАбФГИіФЃПщАДФПТМВ№ГіШЅСЫЃЌвђЮЊЫќУЧжЎМфЕФЙиЯЕЭъШЋЮоЗЈППФПТМРДЖЯЖЈСЫЁЃ
НЯаТАцБОЕФ Go ЭЦМіНЋЕкШ§ЗНФЃПщЗХдк vendor ФПТМЯТЃЌКЭ src ЪЧЦНМЖЙиЯЕЁЃЖјжЎЧАЃЌетаЉЕкШ§ЗНвРРЕвВЪЧЗХдк
src ЯТУцЃЌЗЧГЃСюШЫРЇЛѓЁЃ
ФПЧАЮвУЧЯюФПЕФДњТыЙцФЃЛЙВЛЫуКмДѓЃЌПЩвдЭЈЙ§УќУћРДНјааЧјЗжЃЌЕЋЕБЯюФПМЬајдіГЄЯТШЅЃЌОЭашвЊИќКУЕФЗНАИСЫЁЃ
Й§гкМђЕЅЕФШЅжааФЛЏЕкШ§ЗНАќЙмРэ
КЭга npm ЕФ Node.js СэвЛИіВЛвЛбљЪЧЃК Go гябдУЛгаздМКЕФАќЙмРэЦНЬЈЁЃЖдгк Go ЕФЙЄОпСДРДЫЕЃЌЫќВЂВЛЙиаФФуЕФЕкШ§ЗНАќЕНЕзЪЧЫРДЭаЙмЕФЁЃ
ЩчЧјРя Go ЕФЕкШ§ЗНАќБщВМИїИі Git ЭаЙмЦНЬЈЃЌетВЛНіШУЮвУЧдкЫбЫїАќЪБЛЈЗбИќЖрЪБМфЃЌИќТщЗГЕФЪЧЃЌЮвУЧЮоЗЈЭЈЙ§дкЦѓвЕФкВПДюНЈвЛИіРрЫЦ
npm ОЕЯёЕФЦНЬЈЃЌРДНЕЕЭДѓМвУПДЮЯТдиЕкШ§ЗНАќЕФКФЪБЃЌЭЌЪБвВФбвддкВЛвРРЕЭтЭјЕФЧщПіЯТЃЌНјааАќЕФздгЩАВзАЁЃ
Go гавЛИіУќСюааЙЄОпЃЌзЈУХИКд№ЯТдиЕкШ§ЗНАќЃЌНазіЁА go-get ЁБЁЃКЭДѓМвЯыЕФВЛвЛбљЃЌетИіЙЄОпУЛгаАцБОУшЪіЮФМўЁЃдк
Go ЕФЪРНчРяВЂУЛга package.json етжжЮФМўЁЃетИјЮвУЧДјРДЕФжБНггАЯьОЭЪЧЮвУЧЕФвРРЕВЛНідкЭтЭјЗХзХЃЌЭЌЪБЛЙЮоЗЈгааЇЕидМЪјАцБОЁЃЭЌвЛИіgo-getУќСюЃЌетИідТЯТдиЕФАцБОЃЌПЩФмЕНЯТИідТОЭвбОЧФЧФЕиБфСЫЁЃ
ФПЧА Go ЩчЧјгаКмЖржжВЛЭЌЕФЕкШ§ЗНЙЄОпРДзіЃЌЮвУЧзюжебЁдёСЫ glide ЁЃетЪЧЮвУЧФмевЕНЕФзюНгНќ
npm ЕФЙЄОпСЫЁЃФПЧАЙйЗНвВдкдаг§вЛИіаТЕФЗНАИРДНјааЭГвЛЃЌЮвУЧЪУФПвдД§АЩЁЃ
Go ЩчЧјЕФИїжжЕкШ§ЗНАќЙмРэЙЄОп
ЖдгкОЕЯёЃЌФПЧАвВУЛгаЬЋКУЕФЗНАИЃЌЮвУЧВЮПМСЫ moby ЃЈОЭЪЧ docker ЃЉЕФзіЗЈЃЌНЋЕкШ§ЗНАќжБНгДцШыЮвУЧздМКЯюФПЕФ
Git ЁЃетбљЫфШЛЯюФПЕФдДДњТыГпДчБфЕУИќДѓСЫЃЌЕЋЮоТлЪЧаТШЫВЮгыЯюФПЃЌЛЙЪЧЩЯЯпЗЂАцЃЌЖМВЛашвЊШЅЭтЭјРШЁвРРЕСЫЁЃ
ибЗІЕФФкВПЛљДЁЩшЪЉжЇГж
Go гябддкУРЭХФкВПЕФгІгУНЯЩйЃЌжБНгНсЙћОЭЪЧЃЌУРЭХФкВПЯрЕБвЛВПЗжЛљДЁЩшЪЉЃЌЪЧШБЩй Go гябд SDK
жЇГжЕФЁЃР§ШчЙЋЫОздНЈЕФ Redis Cluster ЃЌгЩгкИљОнЙЋЫОвЕЮёашЧѓНјааСЫвЛаЉИФЖЏЃЌЕМжТПЊдДЕФ
Redis Cluster SDK ЃЌЪЧЮоЗЈжБНгЪЙгУЕФЁЃдйР§ШчЙЋЫОЪЙгУСЫЬдБІПЊдДГі KV Ъ§ОнПтЁЊЁЊ
Tair ЃЌДѓИХгЩгкПЊдДНЯдчЃЌвВЪЧУЛга Go ЕФ SDK ЕФЁЃ
гЩгкЮвУЧЕФМмЙЙЩшМЦжаЃЌашвЊвРРЕ KV Ъ§ОнПтНјааДцДЂЃЌзюжеЮвУЧЛЙЪЧбЁдёгУ Go гябдЪЕЯжСЫ Tair
ЕФ SDKЁЃЫљЮНЁАЙЄгћЩЦЦфЪТЃЌБиЯШРћЦфЦїЁБЃЌдк SDK ЕФБраДЙ§ГЬжаЃЌЮвУЧж№НЅЪьЯЄСЫ Go ЕФвЛаЉБрГЬЗЖЪНЃЌетЖджЎКѓЮвУЧЯЕЭГЕФЪЕЯжЃЌЦ№ЕНСЫЗЧГЃгавцЕФзїгУЁЃЫљвдгаЪБКђЪжЭЗПЩгУЕФЩшЪЉЩйЃЌВЂВЛвЛЖЈЪЧЛЕЪТЃЌЕЋвВВЛФмУЄФПШЅжЦдьТжзгЃЌЖјЪЧвЊЫМПМздМКдьТжзгЕФвтвхЪЧЪВУДЃЌвдНсЙћРДЦРХаЁЃ
гябджЎЭт
вЊОЪмЩњВњЛЗОГЕФПМбщЃЌжЛППИќЛЛгябдЪЧВЛЙЛЕФЁЃЖдгкЮвУЧРДЫЕЃЌгябдЦфЪЕжЛЪЧвЛИіЙЄОпЃЌЫќАяЮвУЧНтОіЕФЪЧвЛИіОжВПЮЪЬтЃЌЖјдіСПИќаТЗўЮёгаКмЖргябджЎЭтЕФПМСПЁЃ
ШчКЮУцЖдКЃСПЭЛЗЂСїСП
вђЮЊгаЧАГЕжЎМјЃЌЮвУЧКмЧхГўздМКУцЖдЕФСїСПЪЧЪВУДМЖБ№ЕФЁЃвђДЫетвЛДЮДгЯЕЭГЕФМмЙЙЩшМЦЩЯЃЌОЭгХЯШПМТЧСЫШчКЮУцЖдЭЛЗЂЕФКЃСПСїСПЁЃ
ЪзЯШЮвУЧРДСФСФЮЊЪВУДЮвУЧЛсгаЭЛЗЂСїСПЁЃ
ЖдгкЧАЖЫРДЫЕЃЌЭјвГУПДЮИќаТЗЂАцЃЌЦфЪЕОЭЪЧЗЂВМСЫаТЕФОВЬЌзЪдДЃЌКЭгыжЎЖдгІЕФ HTML ЮФМўЁЃЖјЖдгкдіСПИќаТЗўЮёРДЫЕЃЌаТЕФОВЬЌзЪдДвВОЭвтЮЖзХашвЊНјаааТЕФМЦЫуЁЃ
гаОбщЕФЧАЖЫЭЌбЇПЩФмЛсЫЕЃЌЫфШЛаТАцЩЯЯпЛсДДдьаТЕФМЦЫуЃЌЕЋжЛвЊЧАУцЗХвЛВу CDN ЃЌЛКДцзЁМЦЫуНсЙћЃЌОЭПЩвдЧсЫЩЛКНтбЙСІСЫВЛЪЧТ№ЃП
етЪЧгавЛЖЈЕРРэЕФЃЌЕЋВЂВЛЪЧетУДМђЕЅЁЃУцЯђЦеЭЈЯћЗбепЕФ C ЖЫВњЦЗЃЌгавЛИіЬиЕуЃЌФЧОЭЪЧгУЛЇЕФЗУЮЪЦЕЖШЧЇВюЭђБ№ЁЃОпЬхЕНдіСПИќаТЩЯРДЫЕЃЌОЭЪЧЛсГіЯжДѓСПВЛЭЌЕФдіСПЧыЧѓЁЃвђДЫЮвУЧзіСЫИќЖрЕФЩшМЦЃЌРДЛКНтетжжЧщПіЁЃ
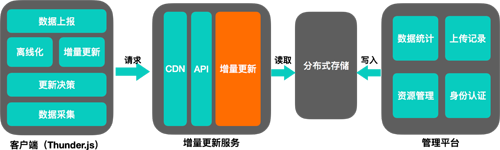
діСПЗўЮёМмЙЙЩшМЦ
етЪЧЮвУЧЖддіСПИќаТЯЕЭГЕФЩшМЦЁЃ
ЗХдкЪзЮЛЕФздШЛЪЧ CDN ЁЃУцЖдКЃСПЧыЧѓЃЌГ§СЫАяжњЮвУЧЯїЗхжЎЭтЃЌвВПЩвдАяжњВЛЭЌЕигђЕФгУЛЇИќПьЕиЛёШЁзЪдДЁЃ
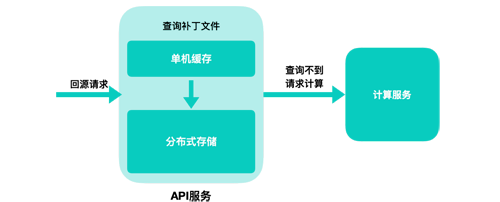
діСПЗўЮё API Ву
дк CDN жЎКѓЃЌЮвУЧНЋдіСПИќаТЯЕЭГЛЎЗжГЩСЫСНИіЖРСЂЕФВуЃЌГЦзї API ВуКЭМЦЫуВуЁЃЮЊЪВУДвЊЛЎЗжПЊФиЃПдкЙ§ЭљЕФЪЕМљЕБжаЃЌЮвУЧЗЂЯжМДЪЙЮвУЧдйаЁаФдйНїЩїЃЌШдШЛЛЙЪЧЛсгаЗИДэЮѓЕФЪБКђЃЌетОЭашвЊЮвУЧдкВПЪ№КЭЩЯЯпЩЯзуЙЛСщЛюЃЛСэвЛЗНУцЃЌЖдгкКЃСПЕФМЦЫуШЮЮёЃЌШчЙћЪЕдкПИВЛзЁЃЌЮвУЧашвЊБЃгазюЛљБОЕФЯьгІФмСІЁЃЛљгкетбљЕФПМТЧЃЌЮвУЧАб
CDN ЕФЛидДЗўЮёЖРСЂГЩвЛИіЗўЮёЁЃетВуЗўЮёгаШ§ИізїгУЃК
1.ЭЈЙ§ЖдДцДЂЯЕЭГЕФЗУЮЪЃЌШчЙћгавбОМЦЫуКУЕФдіСПВЙЖЁЃЌФЧУДПЩвджБНгЗЕЛиЃЌжЛАбзюашвЊМЦЫуЕФШЮЮёДЋЕнИјМЦЫуВуЁЃ
2.ШчЙћМЦЫуВуГіЯжЮЪЬтЃЌAPI ВуБЃгаЯьгІФмСІЃЌФмЙЛНјааЗўЮёНЕМЖЃЌЗЕЛиШЋСПЮФМўФкШнЁЃ
3.НЋЖдЭтЕФНгПкЙмРэЦ№РДЃЌБмУтНгПкБфИќЖдКЫаФЗўЮёЕФгАЯьЁЃдкетИіЛљДЁЩЯПЩвдНјаавЛаЉМђЕЅЕФОлКЯЗўЮёЃЌЬсЙЉжюШчЧыЧѓКЯВЂжЎРрЕФЗўЮёЁЃ
ФЧШчЙћ API ВуУЛФмНЋСїСПРЙНиЯТРДЃЌНјвЛВНДЋЕнЕНСЫМЦЫуВуФиЃП

діСПЗўЮёМЦЫуВу
ЮЊСЫЗРжЙЙ§СПЕФМЦЫуЧыЧѓНјШыЕНМЦЫуЛЗНкЃЌЮвУЧЛЙеыЖдадЕиНјааСЫСїСППижЦЁЃЭЈЙ§бЙВтЃЌЮвУЧевЕНСЫЕЅЛњМЦЫуСПЕФЦПОБЃЌШЛКѓНЋетИіЯожЦХфжУЕНСЫЯЕЭГжаЁЃвЛЕЉМЦЫуСПБЦНќетИіЪ§зжЃЌЯЕЭГОЭЛсЖдГЌСПЕФМЦЫуЧыЧѓНјааНЕМЖЃЌВЛдйНјаадіСПМЦЫуЃЌжБНгЗЕЛиШЋСПЮФМўЁЃ
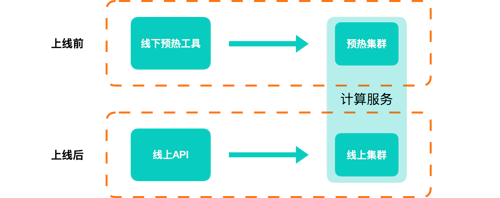
дЄШШЕФЩшМЦ
СэвЛЗНУцЃЌЮвУЧвВгаЯргІЕФЯпЯТдЄШШЛњжЦЁЃЮвУЧЮЊвЕЮёЗНЬсЙЉСЫвЛИідЄШШЙЄОпЃЌвЕЮёЗНдкЩЯЯпЧАЕїгУЮвУЧЕФдЄШШЙЄОпЃЌОЭПЩвддкЩЯЯпЧАдЄЯШЕУЕНдіСПВЙЖЁВЂНЋЦфЛКДцЦ№РДЁЃЮвУЧЕФдЄШШМЏШККЭЯпЩЯМЦЫуМЏШКЪЧЗжРыЕФЃЌжЛЙВЯэЗжВМЪНДцДЂЃЌвђДЫЫЋЗНдкЪЕМЪгІгУжаЛЅВЛгАЯьЁЃ
ШчКЮШндж
1.гаЙиШнджЃЌЮвУЧзмНсСЫвдЭљМћЕНЕФвЛаЉГЃМћЙЪеЯЃЌЗжСЫЫФИіУХРрРДДІРэЁЃ
2.ЯпТЗЙЪеЯЁЃЮвУЧдкУПвЛВуЗўЮёжаЖМФкжУСЫЕЅЛњЛКДцЃЌетИіЛКДцЕФзїгУвЛЗНУцЪЧПЩвдаЙКщЃЌСэвЛЗНУцЃЌШчЙћЯпТЗГіЯжЙЪеЯЃЌЕЅЛњЛКДцвВФмдквЛЖЈГЬЖШЩЯНЕЕЭЖдЯпТЗЕФвРРЕЁЃ
3.ДцДЂЙЪеЯЁЃЖдгкДцДЂЃЌЮвУЧжБНгВЩгУСЫСНжжЙЋЫОФкЗЧГЃГЩЪьЕФЗжВМЪНДцДЂЯЕЭГЃЌЫќУЧЛЅЮЊБИЗнЁЃ
4.CDN ЙЪеЯЁЃзіЧАЖЫЕФЭЌбЇЛђЖрЛђЩйЖМгіЕНЙ§ CDN ГіЙЪеЯЕФЪБКђЃЌЮвУЧвВВЛР§ЭтЁЃвђДЫЮвУЧзМБИСЫСНИіВЛЭЌЕФ
CDN ЃЌгааЇИєРыСЫРДзд CDN ЙЪеЯЕФЗчЯеЁЃ
зюКѓЃЌдкетЬзЗўЮёжЎЭтЃЌЮвУЧфЏРРЦїЖЫЕФ SDK вВгаздМКЕФШнджЛњжЦЁЃЮвУЧдкдіСПИќаТЯЕЭГжЎЭтЃЌЕЅЖРВПЪ№СЫвЛЬз
CDN ЃЌетЬз CDN жЛДцДЂШЋСПЮФМўЁЃвЛЕЉдіСПИќаТЯЕЭГЮоЗЈЙЄзїЃЌ SDK ОЭЛсШЅетЬз CDN ЩЯРШЁШЋСПЮФМўЃЌБЃеЯЧАЖЫЕФПЩгУадЁЃ
ЛиЙЫгызмНс
ЗўЮёЩЯЯпдЫзЊвЛЖЮЪБМфКѓЃЌЮвУЧзмНсСЫаТЪЕМљЫљДјРДЕФаЇЙћЃК

ПМТЧЕНУПИівЕЮёЪЕМЪЕФОВЬЌЮФМўзмСПВЛЭЌЃЌдкетЗнЪ§ОнРяЮвУЧПЬвтАќКЌСЫзмСПКЭШЫОљНкЪЁСїСПСНИіВЛЭЌЕФжЕЁЃдкЪЕМЪвЕЮёЕБжаЃЌвЕЮёЗНздМКвВЛсНЋОВЬЌЮФМўИљОнвГУцНјааВ№ЗжЃЈР§ШчЭЈЙ§
webpack жаЕФ chunk РДЗжЃЉЃЌУПДЮИќаТЪЕМЪВЛЛсашвЊШЋВПИќаТЁЃ
гЩгквЛаЉБпНчЧщПіЃЌдіСПМЦЫуЕФГЩЙІТЪЪмЕНСЫгАЯьЃЌЕЋЫцзХЮЪЬтЕФвЛвЛаое§ЃЌЮДРДдіСПМЦЫуЕФГЩЙІТЪЛсдНРДдНИпЁЃ
ЯждкРДЛиЙЫвЛЯТЃЌдкЮвУЧЕФаТЪЕМљжаЃЌЖМгаФФаЉДѓМвПЩвдеце§НшМјЕФЕуЃК
1.ВЛЭЌЕФгябдКЭЙЄОпгаВЛЭЌЕФгУЮфжЎЕиЃЌВЛвЊЪдЭМгУДИзгШЅОтФОЭЗЁЃИУЛЛгябдОЭЛЛЃЌВЛвЊЯызХвЛИігябдЛђЙЄОпНтОівЛЧаЁЃ
2.ИќЛЛгябдЪЧвЛИіживЊЕФОіЖЈЃЌдкОіЖЈжЎЧАЪзЯШашвЊЫМПМЪЧЗёгІЕБетУДзіЁЃ
3.гябдНтОіИќЖрЕФЪЧОжВПЮЪЬтЃЌМмЙЙНтОіИќЖрЕФЪЧЯЕЭГЮЪЬтЁЃЛЛСЫгябдвВВЛДњБэОЭЭђЪТДѓМЊСЫЁЃ
4.ЙЙНЈвЛИіЯЕЭГЪБЃЌЪзЯШЫМПМЫќЪЧШчКЮПхЕФЁЃЯыЧхГўФуЕФЯЕЭГЧБдкЦПОБЛсГіЯждкФФЃЌШчКЮМгЧПЫќЃЌШчКЮПМТЧЫќЕФБИгУЗНАИЁЃ
Ждгк Go гябдЃЌЮвУЧвВЪЧУўзХЪЏЭЗЙ§КгЃЌЯЃЭћЮвУЧетЕуОбщФмЙЛЖдДѓМвгаЫљАяжњЁЃ
зюКѓЃЌШчЙћДѓМвЖдЮвУЧЫљзіЕФЪТЧщвВгааЫШЄЃЌЯывЊКЭЮвУЧвЛЦ№ЙВНЈДѓЧАЖЫЭХЖгЕФЛАЃЌЛЖгЗЂЫЭМђРњжС liuyanghe02@meituan.com
ЁЃ
|









