|
Ҳ̸����NodeJS��ȫջʽ����������NodeJS��ǰ��˷��룩
ǰ��
Ϊ�˽����ͳWeb����ģʽ�����ĸ������⣬���ǽ��������ೢ�ԣ�������ǰ/��˵������蹵�����Եķ�������ͬС�졣ʹ��˼ʹ��������������˼���ˡ�ǰ��ˡ��Ķ��壬����ǰ��ͬѧ����Ϥ��NodeJS����ͼ̽��һ��ȫ�µ�ǰ��˷���ģʽ��
���Ų�ͬ�ն�(Pad/Mobile/PC)�����𣬶Կ�����Ա��Ҫ��Խ��Խ�ߣ���������˵���Ӧʽ�Ѿ����������û�����ĸ�Ҫ������������Ҫ��Բ�ͬ���ն˿������Ƶİ汾��Ϊ����������Ч�ʣ�ǰ��˷��������Խ��Խ�����ӣ���˸���ҵ��/���ݽӿڣ�ǰ�˸���չ��/��������ͬһ�����ݽӿڣ����ǿ��Զ��ƿ�������汾��
���������������۵ñȽ϶࣬������ЩBUҲ�ڽ���һЩ���ԡ������˺ܾ�֮�������ŶӾ���̽��һ����NodeJS��ǰ��˷��뷽������������һЩ���ϱ仯����ʶ�Լ�˼������¼�����Ҳϣ��������ͬѧ�������ۣ����������ơ�
һ��ʲô��ǰ��˷��룿
�ʼ�������۵Ĺ������ҷ��֣�ÿ���˶�ǰ��˷�������ⲻһ����Ϊ�˱�֤����ͬһ��Ƶ�����ۣ��Ⱦ�ʲô�ǡ�ǰ��˷��롱���һ�¡�
���һ����ͬ��ǰ��˷�������Ӿ���SPA(Single-page application)�������õ���չ�����ݶ��Ǻ��ͨ���첽�ӿ�(AJAX/JSONP)�ķ�ʽ�ṩ�ģ�ǰ��ֻ��չ�֡�
��ij����������˵��SPAȷʵ������ǰ��˷��룬�����ַ�ʽ�����������⣺
1.WEB�����У�SPA��ռ�ı������١��ܶೡ���»���ͬ��/ͬ��+�첽��ϵ�ģʽ��SPA������Ϊһ��ͨ�õĽ��������
2.�ֽε�SPA����ģʽ���ӿ�ͨ���ǰ���չ�������ṩ�ģ���ʱ��Ϊ�����Ч�ʣ���˻�����Ǵ���һЩչ�����������ζ�ź�˻���������View��Ĺ���������������ǰ��˷��롣
SPAʽ��ǰ��˷��룬�Ǵ������������֣���ΪֻҪ�ǿͻ��˵ľ���ǰ�ˣ��������˵ľ��Ǻ�ˣ������ַַ��Ѿ�����������ǰ��˷��������������Ϊ��ְ���ϻ��ֲ�������Ŀǰ���ǵ�ʹ�ó�����
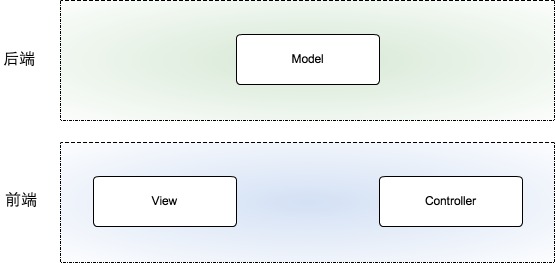
1.ǰ�ˣ�����View��Controller�㡣
2.��ˣ�ֻ����Model�㣬ҵ����/���ݵȡ�
Ϊʲôȥ������ְ��Ļ��֣���������̽�֡�
����ΪʲôҪǰ��˷��룿
����������⣬������Web�з�ģʽ�ݱ��н��͵÷dz�ȫ�棬�����ٴ����һ�£�
2.1 ���п���ģʽ�����ó���
���ᵽ�ļ��ֿ���ģʽ�����и������ó�����û����һ����ȫȡ������һ�֡�
1.������Ϊ����MVC����һЩͬ��չ�ֵ�ҵ��Ч�ʺܸߣ���������ͬ���첽��ϵ�ҳ�棬���˿�����ͨ�����ͻ�Ƚ��鷳��
2.AjaxΪ��SPA�Ϳ���ģʽ���Ƚ��ʺϿ���APP���͵ij���������ֻ�ʺ���APP����ΪSEO�����ⲻ�ý�������ںܶ����͵�ϵͳ�����ֿ�����ʽҲ���ء�
2.2 ǰ���ְ����
��ҵ�������ӵ�ϵͳ���������ά��ǰ��˻�����һ��Ĵ��룬��Ϊû��Լ����M-V-Cÿһ�㶼���ܳ��ֱ�IJ�Ĵ��룬�ջ����ۣ���ȫû��ά���Կ��ԡ�
��Ȼǰ��˷���û�취��ȫ����������⣬���ǿ��Դ�⡣��Ϊ����������ϱ�֤���㲻������ô����
2.3 ����������
�Ա���Web�����϶��ǻ���MVC���webx���ܹ�������ǰ��ֻ��������ˡ�
�������ǵĿ���ģʽ��Ȼ�ǣ�ǰ��д�þ�̬demo����˷����VMģ�棬����ģʽ������Ͳ�˵�ˣ����²��˺ܾá�
ֱ�ӻ��ں�˻�������Ҳ��ʹ�࣬���ð�װʹ�ö����鷳��Ϊ�˽��������⣬���Ƿ����˸��ֹ��ߣ�����VMarket������ǰ�˻���ҪдVM����������������ݣ�Ч����Ȼ���ߡ�
���⣬���Ҳû�����Ѷ�չ�ֵ�ǿ��ע���Ӷ�ר����ҵ������Ŀ�����
2.4 ��ǰ�˷��ӵľ���
�����Ż����ֻ��ǰ�����ռ�dz����ޣ��������Ǿ�����Ҫ��˺���������ײ���������ں�˿�����ƣ����Ǻ���ʹ��Comet��Bigpipe�ȼ����������Ż����ܡ�
Ϊ�˽�������ᵽ��һЩ���⣬���ǽ����˺ܶೢ�ԣ������˸��ֹ��ߣ���ʼ��û��̫����ɫ����Ҫ����Ϊ����ֻ���ں�˸����ǻ��ֵ���һС��ռ�ȥ���ӡ�ֻ����������ǰ��˷��룬���Dz��ܳ�����������⡣
������ô��ǰ��˷��룿
��ô��ǰ��˷��룬��ʵ��һ�����Ѿ����˴𰸣�
1.ǰ�ˣ�����View��Controller�㡣
2.��ˣ�����Model�㣬ҵ����/���ݵȡ�
����һ�£����ǰ��������Controller�����ǿ�����url design�����ǿ��Ը��ݳ��������ڷ����ͬ����Ⱦ�����Ǹ���view���������json���ݣ����ǻ����Ը��ݱ��ֲ������������Bigpipe,Comet,Socket�ȵȣ���ȫ���������ʹ�÷�ʽ��
3.1 ����NodeJS��ȫջ��ʽ����
�����ʵ����ͼ�ķֲ㣬�ͱ�Ȼ��Ҫһ��web���������ʵ����ǰ����������飬���Ǿ����˱����ᵽ�ġ�����NodeJS��ȫջʽ������
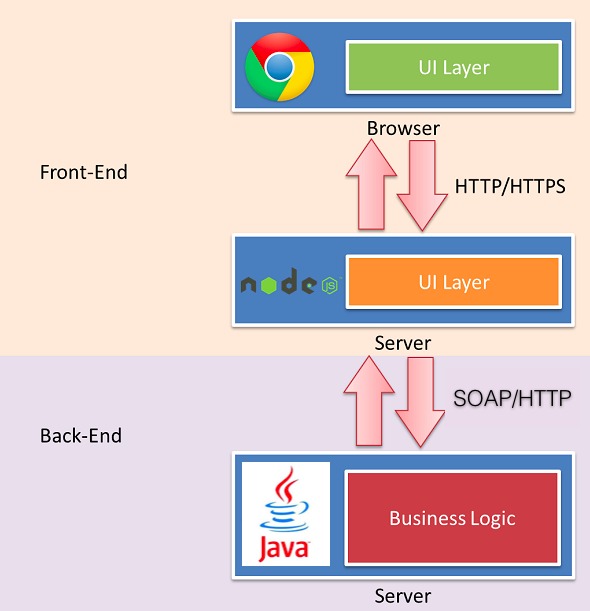
����ͼ���������Һܺ����⣬��û���Թ������кܶ����ʡ�
1.SPAģʽ�У�����ѹ�����������ݽӿڣ�viewǰ���Ѿ����Կ��ƣ�ΪʲôҪ���NodeJS��һ�㣿
2.���һ�㣬������ô����
3.���һ�㣬ǰ�˵Ĺ������Dz��������ˣ�
4.���һ��Ͷ�һ����գ���ô�ƣ�
5.NodeJSʲô��������Ϊʲô��ҪJAVA��
��Щ����Ҫ˵��������ף�����˵���ҵ���ʶ���̡�
3.2 ΪʲôҪ����һ��NodeJS��
�ֽ�������Ҫ�Ժ��MVC��ģʽ���п���������ģʽ�����谭��ǰ�˿���Ч�ʣ�Ҳ�ú�˲���רע��ҵ����
�����������ǰ���ܿ���Controller�㣬������������м�����ϵ�º�����������Ϊ������������ǰ�˶�ѧjava����װ��˵Ŀ���������дVM��
NodeJS���ܺܺõĽ��������⣬��������ѧϰһ���µ����ԣ�����������ǰ�����������������飬һ�ж��Ե���ô��Ȼ��
3.3 ��������
�ֲ���漰ÿ��֮���ͨѶ���϶�����һ����������ġ����Ǻ����ķֲ�����ְ��������Ҳ����Э����������߿���Ч�ʡ��ֲ��������ʧ��һ��������������������ֲ�������
���⣬һ�������ֲ㣬���ǿ���ͨ���Ż�ͨѶ��ʽ��ͨѶЭ�飬�����ܰ���Ľ�����͡�
�ٸ����ӣ�
�Ա���������ҳ��̬��֮�����в�����Ҫʵʱ��ȡ����Ϣ�����������������ȵȣ���Ϊ��Щ��Ϣ�ڲ�ͬҵ��ϵͳ�У�������Ҫǰ�˷���5��6���첽������������Щ���ݡ�
����NodeJS֮��ǰ�˿�����NodeJS��ȥ������5���첽�����ܺ�������Bigpipe,�����Ż�����������ȾЧ�������ܶࡣ
������PC������÷�5,6���첽����Ҳûʲô�����������߶ˣ��ڿͻ��ֻ��Ͻ���һ��HTTP�������ܴ���������Ż�������һ�������ü�����
�Ա��������NodeJS���Ż��������ڽ����У�����֮���һ����һ���Ż��Ĺ��̡�
3.4 ǰ�˵Ĺ������Ƿ������ˣ�
�����ֻ��ҳ��/��demo���϶���������һ�㣬���ǵ�ǰģʽ������������ͨ���ڣ�������̷dz���ʱ�䣬Ҳ���׳�bug��������ά����
���ԣ���Ȼ������������һ�㣬�������忪��Ч�ʻ������ܶࡣ
���⣬���Գɱ����Խ�ʡ�ܶࡣ��ǰ�����Ľӿڶ�����Ա��ֲ�ģ�����д�����������������ǰ��˷��룬�������Զ����Էֿ���һ����ר�Ų��Խӿڣ�һ����רע����UI���ⲿ�ֹ������������ù��ߴ��棩��
3.5 ����Node������ķ�����ô���ƣ�
����Node���ģʹ�ã�ϵͳ/��ά/��ȫ���ŵ�ͬѧҲһ������뵽���������У����ǻ��������ȥ���Ƹ������ڿ��ܳ��ֵ����⣬����ϵ���ȶ��ԡ�
3.6 Nodeʲô��������Ϊʲô��ҪJAVA��
���ǵij�������ǰ��˷��룬����������������е�Υ�����ǵij����ˡ���ʹ��Node���Java������Ҳû�취��֤�����ֽ����������������⣬����ְ���塣���ǵ�Ŀ���Ƿֲ㿪����רҵ���ˣ�רע��רҵ���¡�����JAVA�Ļ����ܹ��Ѿ��dz�ǿ������ȶ������Ҹ��ʺ������ڼܹ������顣
�ġ��Ա�����Node��ǰ��˷���
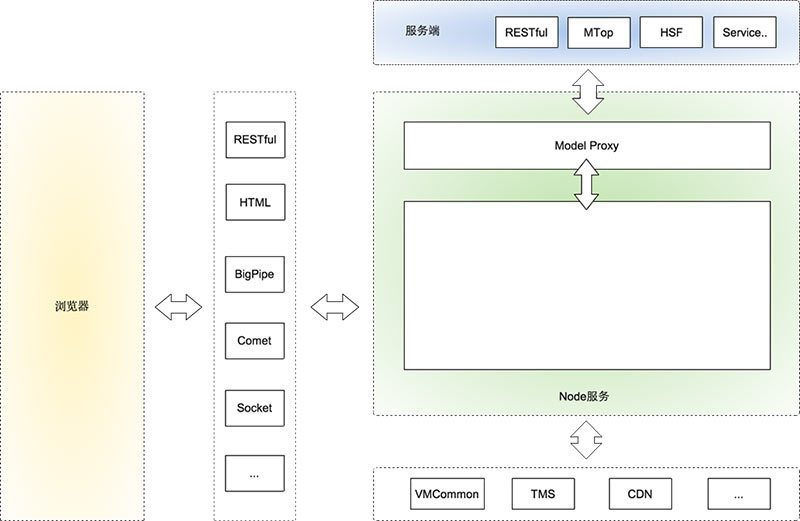
��ͼ����������Ա�����Node��ǰ��˷���ֲ㣬�Լ�Node��ְ��Χ�������£�
1.���϶��Ƿ���ˣ��������dz�˵�ĺ�ˡ���˶���������˵������һ���ӿڵļ��ϣ�������ṩ���ָ����Ľӿڹ�����ʹ�á���Ϊ��Node�㣬Ҳ���þ�����ʲô��ʽ�ķ����ں�˿�����˵������ֻ�ù���ҵ�����Ľӿ�ʵ�֡�
2.�����������NodeӦ�á�
3.NodeӦ������һ��Model Proxy�����˽���ͨѶ����һ����ҪĿǰ��Ĩƽ���ǶԲ�ͬ�ӿڵĵ��÷�ʽ����װһЩview����Ҫ��Model��
4.Node�㻹������ʵ��ԭ��vmcommon,tms�������Ա����ݹ���ϵͳ��������
5.Node��Ҫʹ��ʲô����ɿ������Լ������������Ƽ�ʹ��express+xTemplate����ϣ�xTemplate������ǰ��˹��á�
6.��ô��Node����Լ����������������˷ܵ��ǣ��������ڿ���ʹ��Node����ʵ��������Ҫ�������ʽ:JSON/JSONP/RESTful/HTML/BigPipe/Comet/Socket/ͬ�����첽������ô������ô������ȫ������ij���������
7.�����������������ܹ���û�б仯��Ҳ��ϣ����Ϊ����Node�ı�����ǰ��������п�������֪��
8.����Node��ֻ�ǰѱ��þ�ǰ�˿��ƵIJ��ֽ���ǰ���ƿء�
����ģʽ�����Ѿ���������Ŀ�ڿ����У���Ȼ��û���ߣ������������ڿ���Ч�ʣ������������Ż����棬���Ƕ��Ѿ���������ͷ��
�塢���ǻ���ҪҪ��ʲô��
1.��Node�Ŀ������̼��ɵ��Ա����е�SCM�����С�
2.������ʩ���裬����session,logger��ͨ��ģ�顣
3.��ѿ���ʵ��
4.���ϳɹ�����
5.��Ҷ�Nodeǰ��˷���������ʶ
6.��ȫ
7.����
8.��
�����ϲ�����̫����Ҫȥ���º��о��ģ��Ѿ��зdz����ֳɵĻ��ۡ���ʵ�ؼ���һЩ���̵Ĵ�ͨ��ͨ�ý�������Ļ��ۣ��������Ÿ������Ŀʵ���������������һ���ȶ������̡�
��������;����
��Ȼ������NodeJS��ȫջʽ������ģʽ�������˷ܣ����ǰѻ���Node��ȫջ�������һ���ȶ����ô�Ҷ��ܽ��ܵĶ������кܶ�·Ҫ�ߣ��������ڽ��еġ���;������Ŀ����Ϊ�˽��������⡣��Ȼ�������ã�������Ŀ���Ѿ�Խ��Խ������
����ǰ��˷����ģ��̽��
ǰ��
����ǰ��˷���ʱ����һ����ע����������� ��Ⱦ��Ҳ���� View �������Ĺ�����
�ڴ�ͳ�Ŀ���ģʽ�У��������������������ɲ�ͬ��ǰ��������Ŷӿ���������ģ��ȴ�����������м��ģ���ش������ģ�������ܲ��ɱ����Խ��Խ�ิ��������������ά����
������ѡ����NodeJS����Ϊһ��ǰ��˵��м�㡣��ͼ����NodeJS�������� View ����Ĺ�����
ʹ��ǰ��˷ֹ�����ȷ����ר������ά������ɸ��õ��û����顣
����
��Ⱦ��鹤��������ǰ�˿����ߵ��ճ�������˵�����˷dz���ı�����Ҳ�����������˿��������ĵط���
����ȥǰ�˼�����չ���⼸�꣬ View �������Ĺ���������������εı����ǣ�
1.Form Submit ȫҳˢ�� => AJAX�ֲ�ˢ��
2.�������Ⱦ + MVC => �ͻ�����Ⱦ + MVC
3.��ͳ��ҳ��ת => ��ҳ��Ӧ��
���Թ۲쵽���⼸�꣬��Ҷ����� ��Ⱦ ����£��ӷ������˶�������������ˡ�
������������רע�� ���� ���ṩ���ݽӿڡ�
���������Ⱦ�ĺô�
���������Ⱦ�ĺô������Ƕ������������
1.����ҵ�������������Javaģ�������е��������ҡ�
2.��Զ��ն�Ӧ�ã��������Խӿڻ�����ʽ����������˴��䲻ͬ��ģ�棬���ֲ�ͬ��Ӧ�á�
3.ҳ����ֱ����Ͳ�����html����ǰ�˵���Ⱦ���Ը��������������ʽ
(html + js + css)�ṩ���ܣ�ʹ��ǰ��������������ڷ���˲�����html�ṹ��
4.������ں�˿������������̵�������
5.����������
���������Ⱦ��ɵĻ���
���������ܺô���ͬʱ������ͬ����Ҳ������ ���������Ⱦ �������Ļ��������ǣ�
1.ģ������ڲ�ͬ�Ŀ⡣�е�ģ����ڷ���� (JAVA)�����еķ����������
(JS)��ǰ���ģ�����Բ���ͨ��
2.��Ҫ�ȴ�����ģ����������������������ɺ���ܿ�ʼ��Ⱦ��������������
3.�״ν�����а����ȴ���Ⱦ��ʱ�䣬�������û�����
4.������ҳ��Ӧ��ʱ��ǰ��Route���������Route��ƥ�䣬�����������鷳��
5.��Ҫ���ݶ���ǰ����װ��������SEO
��˼ǰ��˵Ķ���
��ʵ��ͷ���룬�����ǰ���Ⱦ�Ĺ����� �����(Java) ������� �������(JS)
��ʱ�����ǵ�Ŀ��ֻ�� ��ȷ��ǰ���ְ�֣������Ƿ��������Ⱦ���� ��
ֻ����Ϊ�ڴ�ͳ�Ŀ���ģʽ�У����˷������͵��������������ǰ�˵Ĺ�������ֻ�ܱ�������������ˡ�
Ҳ��˺ܶ����϶��� ��� = ����� ǰ�� = ������� ��������������ͼ��
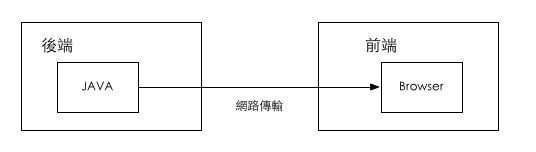
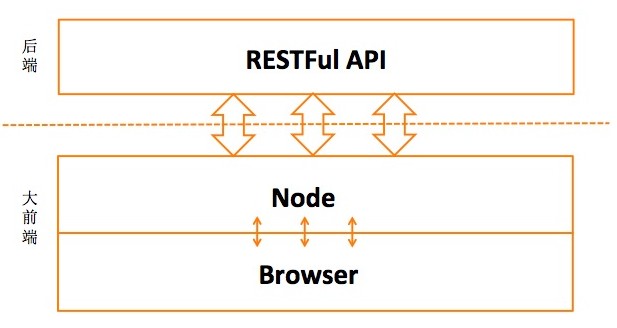
�����Ա�UEDĿǰ���е� ��;��Midway ��Ŀ�У������� JAVA �C Browser�м�һ��NodeJS�м�㣬��ͼ�����ǰ��˵ķָ��ߣ��������
����ְ�� ȥ���֣��������Ӳ�廷��ȥ���֣������� & ���������
��������л�������ģ����·�ɵĹ�����Ҳ��һ��ǰ��˷ֹ����������״̬��
�Ա���;�� Midway
����;����Ŀ�У����ǰ�ǰ��˷ֽ�������ߣ�����������ƻص��˷������ˡ�
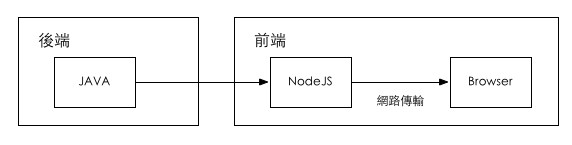
����һ����ǰ�� �����ƿ� �� ���������ͨ ��Nodejs�㣬���Ը������������ǰ��˷��롣
Ҳ������ǰ�˿�����Բ�ͬ����������о��� ���ʵ��Ľ������ ���������������� ����������������� ��
ְ��
��;��������ǰ����ͼ����˷������Ŀ��Ŀ��ֻ�ǰ� ģ�� ���ģ���ش��и������ȡ�ø���ȷ��ְ�֡�
��� (JAVA)��רע��
�����
���ݸ�ʽ�������ȶ�
ҵ����
ǰ�ˣ�רע��
UI��
��ֻ������Ⱦ��
�������û�����
�����پ����ڷ���˻�������˵IJ��졣
ģ�湲��
�ڴ�ͳ�Ŀ���ģʽ�У��������������������ɲ�ͬ��ǰ��������Ŷӿ���������ģ��ȴ�����������м��ģ���ش������ģ�������ܲ��ɱ����Խ��Խ�ิ��������������ά����
����NodeJS�����ͬѧ������JAVA��רע��ҵ���������ݵĿ�������ǰ��ͬѧ��רע�ڿ���������Ⱦ�Ŀ�������������ѡ����Щģ����Ҫ��
����� (NodeJS) ���� ������� ����Ⱦ��
����һ����ģ������ XTemplate ��һ������Ⱦ���� JavaScript
�ڲ�ͬ����Ⱦ��������Server-side��PC Browser��Mobile
Browser��Web View��etc.�� ��Ⱦ�� һ���Ľ�� ��
·�ɹ���
Ҳ��Ϊ����NodeJS��һ�㣬���Ը�ϸ�µĿ���·�ɡ�
������Ҫ��ǰ�����������·��ʱ������ͬʱ���÷������˵�·�ɣ�ʹ���� ������˻�ҳ ���� ����˻�ҳ �������Եõ�һ�µ���ȾЧ����
ͬʱҲ������SEO�����⡣
ģ�湲����ʵ��
ͨ�����������������Ⱦһ��ģ��ʱ�����̲������
1.����������d��ģ������ ��xtmpleate, juicer, handlerbar,
etc.��
2.�������������ģ�浵��������������
1��ʹ�� <script type="js/tpl">
... </script> ӡ��ҳ����
2��ʹ��ģ�����빤�ߣ�����ģ�浵�� ��KISSY, requireJS,
etc.��
3������
ȡ�����ݣ�ʹ��ģ���������html
��html���뵽ָ��λ�á�
�����ϵ����̿����^�쵽��Ҫ��Ҫ����ģ��Ŀ�˹������ص���ʵ�� һ�µ�ģ��ѡ��
����¡�
���������кܶ���ģ��������� KMD��AMD��CommonJS��ֻҪ�ܽ�NodeJS��ģ�浵����һ��ģ��淶�����NodeJS�ˣ��Ϳ�����������ģ�湲���ˡ�
��������ϵ�����»����Model��proxy�빲��������һ����̽�֡�
����̽��
��Ϊ������;�����м�㣬��Թ�����һЩ���ⶼ���˸��õĽ������˵
����һ ���ӽ���Ӧ�� ���繺�ﳵ���µ�ҳ�棩
״����ȫ����HTML������ǰ����Ⱦ��ɣ�����˽��ṩ�ӿڡ�
���⣺����ҳ��ʱ�����ж��ݰ�����
���
�״ν���ҳ�棬��NodeJS�˽��� ȫҳ��Ⱦ �����ڱ���������ص�ģ�档
�������������������������� �ֲ�ˢ��
�õ��� ͬһ��ģ�� �� ���� һ���Ľ��
������ ��ҳ��Ӧ��
״����ʹ��Client Side MVC��ܣ����������ҳ��
���⣺��Ⱦ�뻻ҳ�������������ɣ�ֱ��������ַ�����f5ˢ��ʱ����ֱ�ӳ���ͬ�������ݡ�
���
�����������NodeJS�˹��� ͬ����Route �趨
������˻�ҳʱ����������˽���Route����� ҳ��������Ⱦ
ֱ������ͬ������ַʱ����NodeJS�˽��� ҳ���� + ҳ��������Ⱦ
������������˻�ҳ����ֱ������ͬ������ַ�����������ݶ��� һ���� ��
�����������顢�������}�Ӷ��⡣������� SEO ������
������ �������ҳ��
״����ҳ����ṩ��Ѷ�����ٻ�û�н���
���⣺html�ڷ���˲�����css��js��������һ��λ�ã��˴˼���������
���
��NodeJS��ͳһ����html + css + js
�պ�����Ҫ��չ�ɸ���Ӧ�û��ǵ�ҳ��Ӧ�ã�Ҳ��������ת�ơ�
������ ���ն�ҳ��
״����ͬ����Ӧ��Ҫ�ڲ�ͬ�˵���ֲ�ͬ�Ľ����뽻��
���⣺html�������ף��������ڷ���˲�����һ����html�����������Ҫ����һ���Ĵ���
���
���ն˵�ҳ������Ⱦ�����⣬ͳһ��ǰ����������
��NodeJS�����˷������������������Ӧ�ã������ѵĽ��������
�ܽ�
��ȥ��AJAX��Client-side MVC��SPA��Two-way Data Binding �ȼ����ij��֣�������ͼҪ�����ʱ��ǰ�˿���������ƿ����
��NodeJS�м��ij��֣�Ҳ������ͼ����ֽ�ǰ�˱��I����������˵�һ�����ơ�
�������רע��ǰ���ģ�湲����Ҳϣ������ש��������һ�����������NodeJS�м������ܹ��£����ǿ��������ĸ������ǵĹ������̣������ĸ�
�����ϣ����� ǰ�� ����������ø��á�
Midway-ModelProxy �� �������Ľӿ����ý�ģ���
ǰ��
ʹ��Node��ǰ��˷���Ŀ���ģʽ������һЩ���ܼ����������ϵ�����(����ǰ��˷����˼����ʵ�� һ��),
��ͬʱҲ���ٲ�����ս�����Ա����ӵ�ҵ�����ܹ��£���˱�������Java������ܹ���ͬʱ�ṩ���ҵ��ӿڹ�ǰ��ʹ�á�Node����������������Ҫ
�Ĺ���֮һ���Ǵ�����Щҵ��ӿڣ��Է���ǰ��(Node�˺��������)����������ҳ����Ⱦ��������ô���������ʹ��ǰ��˿�������֮����Ȼ������������
���νӣ���������Ҫ���ǵ����⡣���Ľ������������̽�֣���������������
���ں���ṩ�Ľӿڷ�ʽ���ܶ��ֶ�����ͬʱ������Ա�ڱ�дNode�˴��������Щ�ӿڵķ�ʽҲ�п��ܶ��ֶ�������������ڽӿڷ��ʷ�ʽ��ʹ���ϲ���ͳһ�ܹ�����������������һЩ���⣺
1. ÿһ��������Աʹ�ø��ԵĴ������д�ӿڷ��ʴ��룬��ɹ���Ŀ¼����������ң�ά��������ѡ�
2. ÿһ��������Ա��д�Լ���mock���ݷ�ʽ���������֮����Ҫ�ֹ��Ĵ����Ƴ�mock��
3. ÿһ��������ԱΪ��ʵ�ֽӿڵIJ�ͬ�����л�(�ճ���Ԥ��������)�����ܸ���ά����һЩ�����ļ���
4. ���ݽӿڵ��÷�ʽ��������ҵ��model�dz�����ظ��á�
5. �������ݽӿڵ�����Լ��ɢ���ڴ���ĸ������䣬�п��ܸ������ԱԼ���Ľӿ��ĵ���һ�¡�
6. ������Ŀ���뿪��֮���ڽӿڵ��������߲��Իع�ɱ���Ȼ�ܸߣ���Ҫ�漰��ÿһ���ӿ��ṩ�ߺ�ʹ���ߡ�
��������ϣ��������һ����ܣ�ͨ���ÿ���ṩ�Ļ���ȥ����������Ŀ�������������ⲿ�ӿڣ������ǽ���ͳһ������ͬʱ�ṩ���Ľӿڽ�ģ�����÷�ʽ��
�����ṩ��ݵ����ϻ��������������л�������ʹǰ��˿������ϡ�ModelProxy������������Ҫ�����������ܣ�����Midway
Framework ���Ĺ���֮һ��Ҳ���Ե���ʹ�á�ʹ��ModelProxy���Դ��������ŵ㣺
1. ��ͬ�Ŀ����߶��ڽӿڷ��ʴ����д��ʽͳһ����������������ά���Ѷȡ�
2. ����ڲ����ù���+����ģʽ��ʵ�ֽӿ�һ�����ö�θ��á����ҿ����߿������ⶨ����װ�Լ���ҵ��Model(����ע��)��
3. ���Էdz������ʵ�����ϣ��ճ���Ԥ���������л���
4. ����river-mock��mockjs��mock���棬�ṩmock���ݷdz����㡣
5. ʹ�ýӿ������ļ����Խӿڵ�����������ͳһ�Ĺ���������ɢ���ڸ�������֮�С�
6. ֧��������˹���Model��������˿���ʹ������ǰ��������Ⱦ�������������̶����������
7. �ӿ������ļ������ǽṹ���������ĵ�������ʹ��river�����ϣ��Զ������ĵ���Ҳ��ʹ����������Զ����ӿڲ��ԣ�ʹ�������������γ�һ���ջ���
ModelProxy����ԭ��ͼ����ؿ�������ͼ��
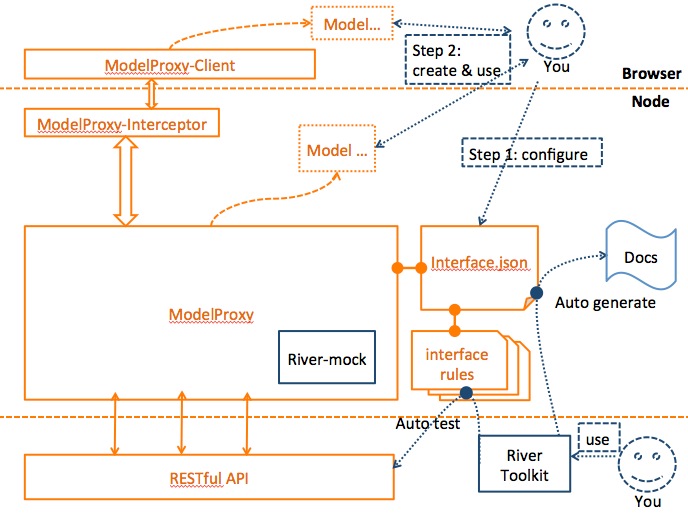
����ͼ�У�������������Ҫ��������Ŀ�����������ĺ�˽ӿ�����������ָ����json��ʽ��д��interface.json�����ļ�����Ҫʱ����Ҫ
��ÿ���ӿڱ�дһ�������ļ���Ҳ��ͼ��interface rules���֡��ù����ļ������ڿ�����mock���ݻ�����������ʹ��River����ȥ��֤�ӿڡ������ļ�������ȡ���ڲ�����һ��mock���棨��
�� mockjs, river-mock �ȵȣ����������֮�����ڴ����а����Լ��������Լ���ҵ��model��
������һ�������ӣ�
����һ��
��һ�� �ڹ���Ŀ¼�д����ӿ������ļ�interface.json, ���������������ѽӿ�json����
{
"title": "pad�Ա���Ŀ���ݽӿڼ��϶���",
"version": "1.0.0",
"engine": "mockjs",
"rulebase": "./interfaceRules/",
"status": "online",
"interfaces": [ {
"name": "�������ӿ�",
"id": "Search.getItems",
"urls": {
"online": "http://s.m.taobao.com/client/search.do"
}
} ]
} |
�ڶ��� �ڴ����д�����ʹ��model
// ����ģ��
var ModelProxy = require( 'modelproxy' );
// ȫ�ֳ�ʼ������ӿ������ļ� ��ע�⣺��ʼ����������ֻ��һ�Σ�
ModelProxy.init( './interface.json' );
// ����model ���ഴ��ģʽ��κ���
var searchModel = new ModelProxy( {
searchItems: 'Search.getItems' // �Զ��巽����: �����ļ��еĶ���Ľӿ�ID
} );
// ʹ��model, ע��: ���÷�������Ҫ�IJ�����Ϊʵ�ʽӿ�����Ҫ�IJ�����
searchModel.searchItems( { q: 'iphone6' } )
// !ע�� ������� done ����ָ���ص���������ȡ�������첽����searchItems��õ�����!
.done( function( data ) {
console.log( data );
} )
.error( function( err ) {
console.log( err );
} ); |
ModelProxy�Ĺ��ܷḻ��������֧�ָ�����ʽ��profile�Դ�����Ҫҵ��model��
ʹ�ýӿ�ID����>���ɵĶ����ȡID���.���ź���ĵ�����Ϊ������
ModelProxy.create( 'Search.getItem' ); |
ʹ�ü�ֵJSON����>�Զ��巽����: �ӿ�ID
ModelProxy.create( {
getName: 'Session.getUserName',
getMyCarts: 'Cart.getCarts'
} ); |
ʹ��������ʽ>ȡ��� . �ź���ĵ�����Ϊ������
���������ɵķ�������������Ϊ: Cart_getItem, getItem,
suggest, getName
ModelProxy.create( [ 'Cart.getItem', 'Search.getItem', 'Search.suggest', 'Session.User.getName' ] ); |
ǰ��ʽ>��������ǰ�Ľӿ�ID�ᱻ�������ȡ���벿����Ϊ������
ModelProxy.create( 'Search.*' ); |
ͬʱ��ʹ����ЩModel������Ժ�����ʵ�ֺϲ���������������������ģ����Ⱦ
�������� �ϲ�����
var model = new ModelProxy( 'Search.*' );
// �ϲ����� (������õ�model������done֮�⣬��Ϊ���ýӿ�idʱָ��)
model.suggest( { q: 'Ů' } )
.list( { keyword: 'iphone6' } )
.getNav( { key: '���з�װ' } )
.done( function( data1, data2, data3 ) {
// ����˳���뷽������˳��һ��
console.log( data1, data2, data3 );
} ); |
�������� ��������
var model = new ModelProxy( {
getUser: 'Session.getUser',
getMyOrderList: 'Order.getOrder'
} );
// �Ȼ���û�id��Ȼ���ٸ���id�Ż�ö����б�
model.getUser( { sid: 'fdkaldjfgsakls0322yf8' } )
.done( function( data ) {
var uid = data.uid;
// ������������������һ��ȡ�õ�id��
this.getMyOrderList( { id: uid } )
.done( function( data ) {
console.log( data );
} );
} ); |
����ModelProxy������Node�˿���ʹ�ã�Ҳ�������������ʹ�á�ֻ��Ҫ��ҳ��������ٷ����ṩ��modelproxy-client.js���ɡ�
�����ġ��������ʹ��ModelProxy
<!-- ����modelproxyģ�飬��ģ�鱾������KISSY��װ�ı�ģ��-->
<script src="modelproxy-client.js" ></script>
<script type="text/javascript">
KISSY.use( "modelproxy", function( S, ModelProxy ) {
// !���û���·������·����ڶ��������õ�����·��һ��!
// ��ȫ����������ֻ��һ�Σ�
ModelProxy.configBase( '/model/' );
// ����model
var searchModel = ModelProxy.create( 'Search.*' );
searchModel
.list( { q: 'ihpone6' } )
.list( { q: '�����' } )
.suggest( { q: 'i' } )
.getNav( { q: '����' } )
.done( function( data1, data2, data3, data4 ) {
console.log( {
"list_ihpone6": data1,
"list_�����": data2,
"suggest_i": data3,
"getNav_����": data4
} );
} );
} );
</script> |
ͬʱ��ModelProxy�������Midway��һ�������Midway-XTPLһ��ʹ�ã�ʵ�����ݺ�ģ���Լ������Ⱦ������������˺ͷ������˵�ȫ����������ModelProxy����ϸ�̳̼��ĵ����Ʋ�https://github.com/purejs/modelproxy
�ܽ�
ModelProxy��һ�����û�����������ܴ��ڣ��ṩ�ѺõĽӿ�model��װ��ʹ�÷�ʽ��ͬʱ�ܺõĽ��ǰ��˿���ģʽ�����еĽӿ�ʹ�ù淶
���⡣��������Ŀ���������У��ӿ�ʼ��ֻ��Ҫ��������һ�Σ�ǰ�˿�����Ա�������ã�ͬʱʹ��River�����Զ������ĵ����γ����˿�����Ա����Լ������
����Զ������ԣ�������Ż��������������̿������̡�
|






