| (一):什么是Node.js
Node.js从2009年诞生至今,已经发展了两年有余,其成长的速度有目共睹。从在github的访问量超过Rails,到去年底Node.jsS创始人Ryan
Dalh加盟Joyent获得企业资助,再到今年发布Windows移植版本,Node.js的前景获得了技术社区的肯定。InfoQ一直在关注Node.js的发展,在今年的两次Qcon大会(北京站和杭州站)都有专门的讲座。为了更好地促进Node.js在国内的技术推广,我们决定开设“深入浅出Node.js”专栏,邀请来自Node.js领域的布道师、开发人员、技术专家来讲述Node.js的各方面内容,让读者对Node.js有更深入的了解,并且能够积极投入到新技术的讨论和实践中。
专栏的第一篇文章《什么是Node.js》尝试从各个角度来阐述Node.js的基本概念、发展历史、优势等,对该领域不熟悉的开发人员可以通过本文了解Node.js的一些基础知识。
从名字说起
有关Node.js的技术报道越来越多,Node.js的写法也是五花八门,有写成NodeJS的,有写成Nodejs的,到底哪一种写法最标准呢,我们不妨遵循官方的说法。在Node.js的官方网站上,一直将其项目称之为”Node“或者”Node.js“,没有发现其他的说法,”Node“用的最多,考虑到Node这个单词的意思和用途太广泛,容易让开发人员误解,我们采用了第二种称呼――”Node.js“,js的后缀点出了Node项目的本意,其他的名称五花八门,没有确切的出处,我们不推荐使用。
Node.js不是JS应用、而是JS运行平台
看到Node.js这个名字,初学者可能会误以为这是一个Javascript应用,事实上,Node.js采用C++语言编写而成,是一个Javascript的运行环境。为什么采用C++语言呢?据Node.js创始人Ryan
Dahl回忆,他最初希望采用Ruby来写Node.js,但是后来发现Ruby虚拟机的性能不能满足他的要求,后来他尝试采用V8引擎,所以选择了C++语言。既然不是Javascript应用,为何叫.js呢?因为Node.js是一个Javascript的运行环境。提到Javascript,大家首先想到的是日常使用的浏览器,现代浏览器包含了各种组件,包括渲染引擎、Javascript引擎等,其中Javascript引擎负责解释执行网页中的Javascript代码。作为Web前端最重要的语言之一,Javascript一直是前端工程师的专利。不过,Node.js是一个后端的Javascript运行环境(支持的系统包括*nux、Windows),这意味着你可以编写系统级或者服务器端的Javascript代码,交给Node.js来解释执行,简单的命令类似于:
Node.js采用了Google Chrome浏览器的V8引擎,性能很好,同时还提供了很多系统级的API,如文件操作、网络编程等。浏览器端的Javascript代码在运行时会受到各种安全性的限制,对客户系统的操作有限。相比之下,Node.js则是一个全面的后台运行时,为Javascript提供了其他语言能够实现的许多功能。
Node.js采用事件驱动、异步编程,为网络服务而设计
事件驱动这个词并不陌生,在某些传统语言的网络编程中,我们会用到回调函数,比如当socket资源达到某种状态时,注册的回调函数就会执行。Node.js的设计思想中以事件驱动为核心,它提供的绝大多数API都是基于事件的、异步的风格。以Net模块为例,其中的net.Socket对象就有以下事件:connect、data、end、timeout、drain、error、close等,使用Node.js的开发人员需要根据自己的业务逻辑注册相应的回调函数。这些回调函数都是异步执行的,这意味着虽然在代码结构中,这些函数看似是依次注册的,但是它们并不依赖于自身出现的顺序,而是等待相应的事件触发。事件驱动、异步编程的设计(感兴趣的读者可以查阅笔者的另一篇文章《Node.js的异步编程风格》),重要的优势在于,充分利用了系统资源,执行代码无须阻塞等待某种操作完成,有限的资源可以用于其他的任务。此类设计非常适合于后端的网络服务编程,Node.js的目标也在于此。在服务器开发中,并发的请求处理是个大问题,阻塞式的函数会导致资源浪费和时间延迟。通过事件注册、异步函数,开发人员可以提高资源的利用率,性能也会改善。
从Node.js提供的支持模块中,我们可以看到包括文件操作在内的许多函数都是异步执行的,这和传统语言存在区别,而且为了方便服务器开发,Node.js的网络模块特别多,包括HTTP、DNS、NET、UDP、HTTPS、TLS等,开发人员可以在此基础上快速构建Web服务器。以简单的helloworld.js为例:
var http = require('http');
http.createServer(function (req, res) {
res.writeHead(200, {'Content-Type': 'text/plain'});
res.end('Hello World\n');
}).listen(80, "127.0.0.1"); |
上面的代码搭建了一个简单的http服务器(运行示例部署在http://helloworld.cnodejs.net/中,读者可以访问),在本地监听80端口,对于任意的http请求,服务器都返回一个头部状态码为200、Content-Type'值为text/plain'的”Hello
World“文字响应。从这个小例子中,我们可以看出几点:
Node.js的网络编程比较便利,提供的模块(在这里是http)开放了容易上手的API接口,短短几行代码就可以构建服务器。
体现了事件驱动、异步编程,在createServer函数的参数中指定了一个回调函数(采用Javascript的匿名函数实现),当有http请求发送过来时,Node.js就会调用该回调函数来处理请求并响应。当然,这个例子相对简单,没有太多的事件注册,在以后的文章中读者会看到更多的实际例子。
Node.js的特点
下面我们来说说Node.js的特点。事件驱动、异步编程的特点刚才已经详细说过了,这里不再重复。
Node.js的性能不错。按照创始人Ryan Dahl的说法,性能是Node.js考虑的重要因素,选择C++和V8而不是Ruby或者其他的虚拟机也是基于性能的目的。Node.js在设计上也是比较大胆,它以单进程、单线程模式运行(很吃惊,对吧?这和Javascript的运行方式一致),事件驱动机制是Node.js通过内部单线程高效率地维护事件循环队列来实现的,没有多线程的资源占用和上下文切换,这意味着面对大规模的http请求,Node.js凭借事件驱动搞定一切,习惯了传统语言的网络服务开发人员可能对多线程并发和协作非常熟悉,但是面对Node.js,我们需要接受和理解它的特点。由此我们是否可以推测出这样的设计会导致负载的压力集中在CPU(事件循环处理?)而不是内存(还记得Java虚拟机抛出OutOfMemory异常的日子吗?),眼见为实,不如来看看淘宝共享数据平台团队对Node.js的性能测试:
物理机配置:RHEL 5.2、CPU 2.2GHz、内存4G
Node.js应用场景:MemCache代理,每次取100字节数据
连接池大小:50
并发用户数:100
测试结果(socket模式):内存(30M)、QPS(16700)、CPU(95%)
从上面的结果,我们可以看到在这样的测试场景下,qps能够达到16700次,内存仅占用30M(其中V8堆占用22M),CPU则达到95%,可能成为瓶颈。此外,还有不少实践者对Node.js做了性能分析,总的来说,它的性能让人信服,也是受欢迎的重要原因。既然Node.js采用单进程、单线程模式,那么在如今多核硬件流行的环境中,单核性能出色的Node.js如何利用多核CPU呢?创始人Ryan
Dahl建议,运行多个Node.js进程,利用某些通信机制来协调各项任务。目前,已经有不少第三方的Node.js多进程支持模块发布,专栏后面的文章会详细讲述Node.js在多核CPU下的编程。
Node.js的另一个特点是它支持的编程语言是Javascript。关于动态语言和静态语言的优缺点比较在这里不再展开讨论。只说三点:
Javascript作为前端工程师的主力语言,在技术社区中有相当的号召力。而且,随着Web技术的不断发展,特别是前端的重要性增加,不少前端工程师开始试水”后台应用“,在许多采用Node.js的企业中,工程师都表示因为习惯了Javascript,所以选择Node.js。
Javascript的匿名函数和闭包特性非常适合事件驱动、异步编程,从helloworld例子中我们可以看到回调函数采用了匿名函数的形式来实现,很方便。闭包的作用则更大,看下面的代码示例:
var hostRequest = http.request(requestOptions,function(response) {
var responseHTML ='';
response.on('data', function (chunk) {
responseHTML = responseHTML + chunk;
});
response.on('end',function(){
console.log(responseHTML);
// do something useful
});
}); |
在上面的代码中,我们需要在end事件中处理responseHTML变量,由于Javascript的闭包特性,我们可以在两个回调函数之外定义responseHTML变量,然后在data事件对应的回调函数中不断修改其值,并最终在end事件中访问处理。
Javascript在动态语言中性能较好,有开发人员对Javacript、Python、Ruby等动态语言做了性能分析,发现Javascript的性能要好于其他语言,再加上V8引擎也是同类的佼佼者,所以Node.js的性能也受益其中。
Node.js发展简史
2009年2月,Ryan Dahl在博客上宣布准备基于V8创建一个轻量级的Web服务器并提供一套库。
2009年5月,Ryan Dahl在GitHub上发布了最初版本的部分Node.js包,随后几个月里,有人开始使用Node.js开发应用。
2009年11月和2010年4月,两届JSConf大会都安排了Node.js的讲座。
2010年年底,Node.js获得云计算服务商Joyent资助,创始人Ryan
Dahl加入Joyent全职负责Node.js的发展。
2011年7月,Node.js在微软的支持下发布Windows版本。
Node.js应用案例
虽然Node.js诞生刚刚两年多,但是其发展势头逐渐赶超Ruby/Rails,我们在这里列举了部分企业应用Node.js的案例,听听来自客户的声音。
在社交网站LinkedIn最新发布的移动应用中,NodeJS是该移动应用的后台基础。LinkedIn移动开发主管Kiran
Prasad对媒体表示,其整个移动软件平台都由NodeJS构建而成:
LinkedIn内部使用了大量的技术,但是在移动服务器这一块,我们完全基于Node。
(使用它的原因)第一,是因为其灵活性。第二,如果你了解Node,就会发现它最擅长的事情是与其他服务通信。移动应用必须与我们的平台API和数据库交互。我们没有做太多数据分析。相比之前采用的Ruby
on Rails技术,开发团队发现Node在性能方面提高很多。他们在每台物理机上跑了15个虚拟服务器(15个实例),其中4个实例即可处理双倍流量。容量评估基于负载测试的结果。
企业社会化服务网站Yammer则利用Node创建了针对其自身平台的跨域代理服务器,第三方的开发人员可以通过该服务器实现从自身域托管的Javascript代码与Yammer平台API的AJAX通信。Yammer平台技术主管Jim
Patterson对Node的优点和缺点提出了自己的看法:
(优点)因为Node是基于事件驱动和无阻塞的,所以非常适合处理并发请求,因此构建在Node上的代理服务器相比其他技术实现(如Ruby)的服务器表现要好得多。此外,与Node代理服务器交互的客户端代码是由javascript语言编写的,因此客户端和服务器端都用同一种语言编写,这是非常美妙的事情。
(缺点)Node是一个相对新的开源项目,所以不太稳定,它总是一直在变,而且缺少足够多的第三方库支持。看起来,就像是Ruby/Rails当年的样子。
知名项目托管网站GitHub也尝试了Node应用。该Node应用称为NodeLoad,是一个存档下载服务器(每当你下载某个存储分支的tarball或者zip文件时就会用到它)。GitHub之前的存档下载服务器采用Ruby编写。在旧系统中,下载存档的请求会创建一个Resque任务。该任务实际上在存档服务器上运行一个git
archive命令,从某个文件服务器中取出数据。然后,初始的请求分配给你一个小型Ruby Sinatra应用等待该任务。它其实只是在检查memcache
flag是否存在,然后再重定向到最终的下载地址上。旧系统运行大约3个Sinatra实例和3个Resque
worker。GitHub的开发人员觉得这是Node应用的好机会。Node基于事件驱动,相比Ruby的阻塞模型,Node能够更好地处理git存档。在编写新下载服务器过程中,开发人员觉得Node非常适合该功能,此外,他们还里利用了Node库socket.io来监控下载状态。
不仅在国外,Node的优点也同样吸引了国内开发人员的注意,淘宝就实际应用了Node技术:
MyFOX 是一个数据处理中间件,负责从一个MySQL集群中提取数据、计算并输出统计结果。用户提交一段SQL语句,MyFOX根据该SQL命令的语义,生成各个数据库分片所需要执行的查询语句,并发送至各个分片,再将结果进行汇总和计算。
MyFOX的特点是CPU密集,无文件IO,并只处理只读数据。起初MyFOX使用PHP编写,但遇到许多问题。例如PHP是单线程的,MySQL又需要阻塞查询,因此很难并发请求数据,后来的解决方案是使用nginx和dirzzle,并基于HTTP协议实现接口,并通过curl_multi_get命
令进行请求。不过MyFOX项目组最终还是决定使用Node.js来实现MyFOX。
选择Node.js有许多方面的原因,比如考虑了兴趣及社区发展,同时也希望可以提高并发能力,榨干CPU。例如,频繁地打开和关闭连接会让大量端口处于等待状态,当并发数量上去之后,时常会因为端口不够用(处于TIME_WAIT状态)而导致连接失败。之前往往是通过修改系统设置来减少等待时间以绕开这个错误,然而使用连接池便可以很好地解决这个问题。此外,以前MyFOX会在某些缓存失效的情况下出现十分密集的访问压力,使用
Node.js便可以共享查询状态,让某些请求“等待片刻”,以便系统重新填充缓存内容。
小结
本文简要介绍了Node.js的基本知识,包括概念、特点、历史、案例等等。作为一个仅仅2岁的平台,Node.js的发展势头有目共睹,越来越多的企业开始关注并尝试Node.js,前后端开发人员应该了解相关的内容。
(二):Node.js&NPM的安装与配置
Node.js安装与配置
Node.js已经诞生两年有余,由于一直处于快速开发中,过去的一些安装配置介绍多数针对0.4.x版本而言的,并非适合最新的0.6.x的版本情况了,对此,我们将在0.6.x的版本上介绍Node.js的安装和配置。(本文一律以0.6.1为例,0.6的其余版本,只需替换版本号即可。从http://nodejs.org/#download可以查看到最新的二进制版本和源代码)。
Windows平台下的Node.js安装
在过去,Node.js一直不支持在Windows平台下原生编译,需要借助Cygwin或MinGW来模拟POSIX系统,才能编译安装。幸运的是2011年6月微软开始与Joyent合作移植Node.js到Windows平台上(http://www.infoq.com/cn/news/2011/06/node-exe
),这次合作的成果最终呈现在0.6.x的稳定版的发布上。这次的版本发布使得Node.js在Windows平台上的性能大幅度提高,使用方面也更容易和轻巧,完全摆脱掉Cygwin或MinGW等实验室式的环境,并且在某些细节方面,表现出比Linux下更高的性能,细节参见http://www.infoq.com/news/2011/11/Nodejs-Windows。
在Windows(Windows7)平台下,我将介绍二种安装Node.js的方法,即普通和文艺安装方法。
普通的安装方法
普通安装方法其实就是最简单的方法了,对于大多Windows用户而言,都是不太喜欢折腾的人,你可以从这里(http://nodejs.org/dist/v0.6.1/node-v0.6.1.msi
)直接下载到Node.js编译好的msi文件。然后双击即可在程序的引导下完成安装。
在命令行中直接运行:
命令行将打印出:
该引导步骤会将node.exe文件安装到C:\Program Files
(x86)\nodejs\目录下,并将该目录添加进PATH环境变量。
文艺的安装方法
Windows平台下的文艺安装方法主要提供给那些热爱折腾,喜欢编译的同学们。在编译源码之前需要注意的是你的Windows系统是否包含编译源码的工具。Node.js的源码主要由C++代码和JavaScript代码构成,但是却用gyp工具(http://code.google.com/p/gyp/
)来做源码的项目管理,该工具采用Python语言写成的。在Windows平台上,Node.js采用gyp来生成Visual
Studio Solution文件,最终通过VC++的编译器将其编译为二进制文件。所以,你需要满足以下两个条件:
Python(Node.js建议使用2.6或更高版本,不推荐3.0),可以从这里(http://python.org/)获取。
VC++ 编译器,包含在Visual Studio 2010中(VC++
2010 Express亦可),VS2010可以从这里(http://msdn.microsoft.com/en-us/vstudio/hh388567)找到。
下载Node.js的0.6.1版本的源码压缩包(http://nodejs.org/dist/v0.6.1/node-v0.6.1.tar.gz
)并解压之。
通过命令行进入解压的源码目录,执行vcbuild.bat release命令,然后经历了漫长的等待后,编译完成后,在Release目录下可以找到编译好的node.exe文件。通过命令行执行node
-v。
命令行返回结果为:
事实上,如果你的编译环境中存在WiX工具集(http://wix.sourceforge.net/
),执行vcbuild.bat msi release命令,你将会在Relase目录下找到node.msi。
是的,我们回到了一开始的普通安装方法。所谓文艺就是多走一些路,多看一些风景罢了。
Unix/Linux平台下的Node.js安装
由于Node.js尚处于v0.x.x的版本的快速发展中,Unix/Linux平台的发行版都不会预置Node的二进制文件,通过源码进行编译安装是目前最好的选择。而且用Unix/Linux系统的同学们多数都是文艺程序员,本节只介绍如何通过源码进行编译和安装。
安装条件
如同在Windows平台下一样,Node.js依然是采用gyp工具管理生成项目的,不同的是通过make工具进行最终的编译。所以Unix/Linux平台下你需要以下几个必备条件,才能确保编译完成:
Python。用于gyp,可以通过在shell下执行python命令,查看是否已安装python,并确认版本是否符合需求(2.6或更高版本,但不推荐3.0)。
源代码编译器,通常 Unix/Linux平台都自带了C++的编译器(GCC/G++)。如果没有,请通过当前发行版的软件包安装工具安装make,g++这些编译工具。
Debian/Ubuntu下的工具是apt-get
RedHat/centOS下通过yum命令
Mac OS X下你可能需要安装xcode来获得编译器
其次,如果你计划在Node.js中启用网络加密,OpenSSL的加密库也是必须的。该加密库是libssl-dev,可以通过apt-get
install libssl-dev等命令安装。
检查环境并安装
完成以上预备条件后,我们获取源码并进行环境检查吧:
检查环境并安装
wget http://nodejs.org/dist/v0.6.1/node-v0.6.1.tar.gz
tar zxvf node-v0.6.1.tar.gz
cd node-v0.6.1
./configure
上面几行命令是通过wget命令下载最新版本的代码,并解压之。./configure命令将会检查环境是否符合Nodejs的编译需要。
Checking for program g++ or c++ : /usr/bin/g++
Checking for program cpp : /usr/bin/cpp
Checking for program ar : /usr/bin/ar
Checking for program ranlib : /usr/bin/ranlib
Checking for g++ : ok
Checking for program gcc or cc : /usr/bin/gcc
Checking for program ar : /usr/bin/ar
Checking for program ranlib : /usr/bin/ranlib
Checking for gcc : ok
Checking for library dl : yes
Checking for openssl : yes
Checking for library util : yes
Checking for library rt : yes
Checking for fdatasync(2) with c++ : yes
'configure' finished successfully (7.350s) |
如果检查没有通过,请确认上面提到的三个条件是否满足。如果configure命令执行成功,就可以进行编译了:
Nodejs通过make工具进行编译和安装(如果make install不成功,请使用sudo以确保拥有权限)。完成以上两步后,检查一下是否安装成功:
检查是否返回:
至此,Nodejs已经编译并安装完成。如需卸载,可以执行make uninstall进行卸载。
小结
以上介绍了*nix和Windows平台下Nodejs的安装,之后可以如同Nodejs官方网站上介绍的那样,编写example.js文件。
var http = require('http');
http.createServer(function (req, res) {
res.writeHead(200, {'Content-Type': 'text/plain'});
res.end('Hello World\n');
}).listen(1337, "127.0.0.1");
console.log('Server running at http://127.0.0.1:1337/'); |
在命令行中执行它:
你就可以通过浏览器访问http://127.0.0.1:1337得到Hello
World的响应。
安装NPM
NPM的全称是Node Package Manager,如果你熟悉ruby的gem,Python的PyPL、setuptools,PHP的pear,那么你就知道NPM的作用是什么了。没错,它就是Nodejs的包管理器。Nodejs自身提供了基本的模块。但是在这些基本模块上开发实际应用需要较多的工作。所幸的是笔者执笔此文的时候NPM上已经有了5112个Nodejs库或框架,这些库从各个方面可以帮助Nodejs的开发者完成较为复杂的应用。这些库的数量和活跃也从侧面反映出Nodejs社区的发展是十分神速和活跃的。下面我将介绍安装NPM和通过NPM安装Nodejs的第三方库,以及在大陆的网络环境下,如何更好的利用NPM。
Unix/Linux下安装NPM
就像NPM的官网(http://npmjs.org/)上介绍的那样,安装NPM仅仅是一行命令的事情:
curl http://npmjs.org/install.sh | sh |
这里详解一下这句命令的意思,curl http://npmjs.org/install.sh是通过curl命令获取这个安装shell脚本,按后通过管道符|
将获取的脚本交由sh命令来执行。这里如果没有权限会安装不成功,需要加上sudo来确保权限:
curl http://npmjs.org/install.sh | sudo sh |
安装成功后执行npm命令,会得到一下的提示:
Usage: npm <command>
where <command> is one of:
adduser, apihelp, author, bin, bugs, c, cache, completion,
config, deprecate, docs, edit, explore, faq, find, get,
help, help-search, home, i, info, init, install, la, link,
list, ll, ln, ls, outdated, owner, pack, prefix, prune,
publish, r, rb, rebuild, remove, restart, rm, root,
run-script, s, se, search, set, show, star, start, stop,
submodule, tag, test, un, uninstall, unlink, unpublish,
unstar, up, update, version, view, whoami |
我们以underscore为例,来展示下通过npm安装第三方包的过程。
返回:
underscore@1.2.2 ./node_modules/underscore |
由于一些特殊的网络环境,直接通过npm install命令安装第三方库的时候,经常会出现卡死的状态。幸运的是国内CNode社区的@fire9同学利用空余时间搭建了一个镜像的NPM资源库,服务器架设在日本,可以绕过某些不必要的网络问题。你可以通过以下这条命令来安装第三方库:
npm --registry "http://npm.hacknodejs.com/" install underscore |
如果你想将它设为默认的资源库,运行下面这条命令即可:
npm config set registry "http://npm.hacknodejs.com/"
设置之后每次安装时就可以不用带上―registry参数。值得一提的是还有另一个镜像可用,该镜像地址是http://registry.npmjs.vitecho.com,如需使用,替换上面两行命令的地址即可。
Windows下安装NPM
由于Nodejs最初在Linux开发下的历史原因,导致NPM一开始也不支持Windows环境,但是随着Nodejs成功移植到到Windows平台,NPM在Windows下的需求亦是日渐增加。下面开始Windows下的NPM之旅吧。
安装GIT工具
由于github网站不支持直接下载打包了所有submodule的源码包,所以需要通过git工具来签出所有的源码。从http://code.google.com/p/msysgit/downloads/list,可以下载到msysgit这个Windows平台下的git客户端工具(最新版本文件为Git-1.7.7.1-preview20111027.exe)。在下载之后双击安装。
下载NPM源码
打开命令行工具(CMD),执行以下命令,可以通过msysgit签出NPM的所有源码和依赖代码并安装npm。
git clone --recursive git://github.com/isaacs/npm.git
cd npm
node cli.js install npm -gf |
在执行这段代码之前,请确保node.exe是跟通过node.msi的方式安装的,或者在PATH环境变量中。这段命令也会将npm加入到PATH环境变量中去,之后可以随处执行npm命令。如果安装中遇到权限方面的错误,请确保cmd命令行工具是通过管理员身份运行的。安装成功后,执行以下命令:
返回:
underscore@1.2.2 ./node_modules/underscore |
如此,Windows平台下的NPM安装完毕。如果遭遇网络问题无法安装,请参照Linux下的NPM命令,添加镜像地址。
(三):深入Node.js的模块机制
专栏的第三篇文章《深入Node.js的模块机制》。之前介绍了Node.js安装的基础知识,本文将深入Node.js的模块机制。
Node.js模块的实现
之前在网上查阅了许多介绍Node.js的文章,可惜对于Node.js的模块机制大都着墨不多。在后续介绍模块的使用之前,我认为有必要深入一下Node.js的模块机制。
CommonJS规范
早在Netscape诞生不久后,JavaScript就一直在探索本地编程的路,Rhino是其代表产物。无奈那时服务端JavaScript走的路均是参考众多服务器端语言来实现的,在这样的背景之下,一没有特色,二没有实用价值。但是随着JavaScript在前端的应用越来越广泛,以及服务端JavaScript的推动,JavaScript现有的规范十分薄弱,不利于JavaScript大规模的应用。那些以JavaScript为宿主语言的环境中,只有本身的基础原生对象和类型,更多的对象和API都取决于宿主的提供,所以,我们可以看到JavaScript缺少这些功能:
JavaScript没有模块系统。没有原生的支持密闭作用域或依赖管理。
JavaScript没有标准库。除了一些核心库外,没有文件系统的API,没有IO流API等。
JavaScript没有标准接口。没有如Web Server或者数据库的统一接口。
JavaScript没有包管理系统。不能自动加载和安装依赖。
于是便有了CommonJS(http://www.commonjs.org)规范的出现,其目标是为了构建JavaScript在包括Web服务器,桌面,命令行工具,及浏览器方面的生态系统。
CommonJS制定了解决这些问题的一些规范,而Node.js就是这些规范的一种实现。Node.js自身实现了require方法作为其引入模块的方法,同时NPM也基于CommonJS定义的包规范,实现了依赖管理和模块自动安装等功能。这里我们将深入一下Node.js的require机制和NPM基于包规范的应用。
简单模块定义和使用
在Node.js中,定义一个模块十分方便。我们以计算圆形的面积和周长两个方法为例,来表现Node.js中模块的定义方式。
var PI = Math.PI;
exports.area = function (r) {
return PI * r * r;
};
exports.circumference = function (r) {
return 2 * PI * r;
}; |
将这个文件存为circle.js,并新建一个app.js文件,并写入以下代码:
var circle = require('./circle.js');
console.log( 'The area of a circle of radius 4 is ' + circle.area(4)); |
可以看到模块调用也十分方便,只需要require需要调用的文件即可。
在require了这个文件之后,定义在exports对象上的方法便可以随意调用。Node.js将模块的定义和调用都封装得极其简单方便,从API对用户友好这一个角度来说,Node.js的模块机制是非常优秀的。
模块载入策略
Node.js的模块分为两类,一类为原生(核心)模块,一类为文件模块。原生模块在Node.js源代码编译的时候编译进了二进制执行文件,加载的速度最快。另一类文件模块是动态加载的,加载速度比原生模块慢。但是Node.js对原生模块和文件模块都进行了缓存,于是在第二次require时,是不会有重复开销的。其中原生模块都被定义在lib这个目录下面,文件模块则不定性。
由于通过命令行加载启动的文件几乎都为文件模块。我们从Node.js如何加载文件模块开始谈起。加载文件模块的工作,主要由原生模块module来实现和完成,该原生模块在启动时已经被加载,进程直接调用到runMain静态方法。
// bootstrap main module.
Module.runMain = function () {
// Load the main module--the command line argument.
Module._load(process.argv[1], null, true);
}; |
_load静态方法在分析文件名之后执行
var module = new Module(id, parent); |
并根据文件路径缓存当前模块对象,该模块实例对象则根据文件名加载。
实际上在文件模块中,又分为3类模块。这三类文件模块以后缀来区分,Node.js会根据后缀名来决定加载方法。
.js。通过fs模块同步读取js文件并编译执行。
.node。通过C/C++进行编写的Addon。通过dlopen方法进行加载。
.json。读取文件,调用JSON.parse解析加载。
这里我们将详细描述js后缀的编译过程。Node.js在编译js文件的过程中实际完成的步骤有对js文件内容进行头尾包装。以app.js为例,包装之后的app.js将会变成以下形式:
(function (exports, require, module, __filename, __dirname) {
var circle = require('./circle.js');
console.log('The area of a circle of radius 4 is ' + circle.area(4));
}); |
这段代码会通过vm原生模块的runInThisContext方法执行(类似eval,只是具有明确上下文,不污染全局),返回为一个具体的function对象。最后传入module对象的exports,require方法,module,文件名,目录名作为实参并执行。
这就是为什么require并没有定义在app.js 文件中,但是这个方法却存在的原因。从Node.js的API文档中可以看到还有__filename、__dirname、module、exports几个没有定义但是却存在的变量。其中__filename和__dirname在查找文件路径的过程中分析得到后传入的。module变量是这个模块对象自身,exports是在module的构造函数中初始化的一个空对象({},而不是null)。
在这个主文件中,可以通过require方法去引入其余的模块。而其实这个require方法实际调用的就是load方法。
load方法在载入、编译、缓存了module后,返回module的exports对象。这就是circle.js文件中只有定义在exports对象上的方法才能被外部调用的原因。
以上所描述的模块载入机制均定义在lib/module.js中。
require方法中的文件查找策略
由于Node.js中存在4类模块(原生模块和3种文件模块),尽管require方法极其简单,但是内部的加载却是十分复杂的,其加载优先级也各自不同。
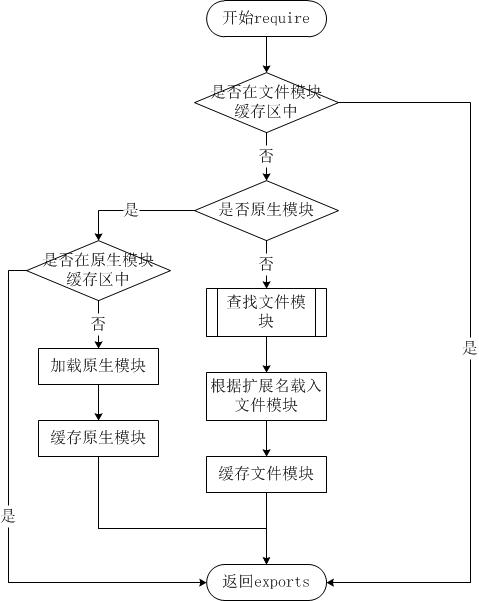
从文件模块缓存中加载
尽管原生模块与文件模块的优先级不同,但是都不会优先于从文件模块的缓存中加载已经存在的模块。
从原生模块加载
原生模块的优先级仅次于文件模块缓存的优先级。require方法在解析文件名之后,优先检查模块是否在原生模块列表中。以http模块为例,尽管在目录下存在一个http/http.js/http.node/http.json文件,require(“http”)都不会从这些文件中加载,而是从原生模块中加载。
原生模块也有一个缓存区,同样也是优先从缓存区加载。如果缓存区没有被加载过,则调用原生模块的加载方式进行加载和执行。
从文件加载
当文件模块缓存中不存在,而且不是原生模块的时候,Node.js会解析require方法传入的参数,并从文件系统中加载实际的文件,加载过程中的包装和编译细节在前一节中已经介绍过,这里我们将详细描述查找文件模块的过程,其中,也有一些细节值得知晓。
require方法接受以下几种参数的传递:
http、fs、path等,原生模块。
./mod或../mod,相对路径的文件模块。
/pathtomodule/mod,绝对路径的文件模块。
mod,非原生模块的文件模块。
在进入路径查找之前有必要描述一下module path这个Node.js中的概念。对于每一个被加载的文件模块,创建这个模块对象的时候,这个模块便会有一个paths属性,其值根据当前文件的路径计算得到。我们创建modulepath.js这样一个文件,其内容为:
console.log(module.paths); |
我们将其放到任意一个目录中执行node modulepath.js命令,将得到以下的输出结果。
[ '/home/jackson/research/node_modules',
'/home/jackson/node_modules',
'/home/node_modules',
'/node_modules' ] |
Windows下:
[ 'c:\\nodejs\\node_modules', 'c:\\node_modules' ] |
可以看出module path的生成规则为:从当前文件目录开始查找node_modules目录;然后依次进入父目录,查找父目录下的node_modules目录;依次迭代,直到根目录下的node_modules目录。
除此之外还有一个全局module path,是当前node执行文件的相对目录(../../lib/node)。如果在环境变量中设置了HOME目录和NODE_PATH目录的话,整个路径还包含NODE_PATH和HOME目录下的.node_libraries与.node_modules。其最终值大致如下:
[NODE_PATH,HOME/.node_modules,HOME/.node_libraries,execPath/../../lib/node] |
下图是笔者从源代码中整理出来的整个文件查找流程:
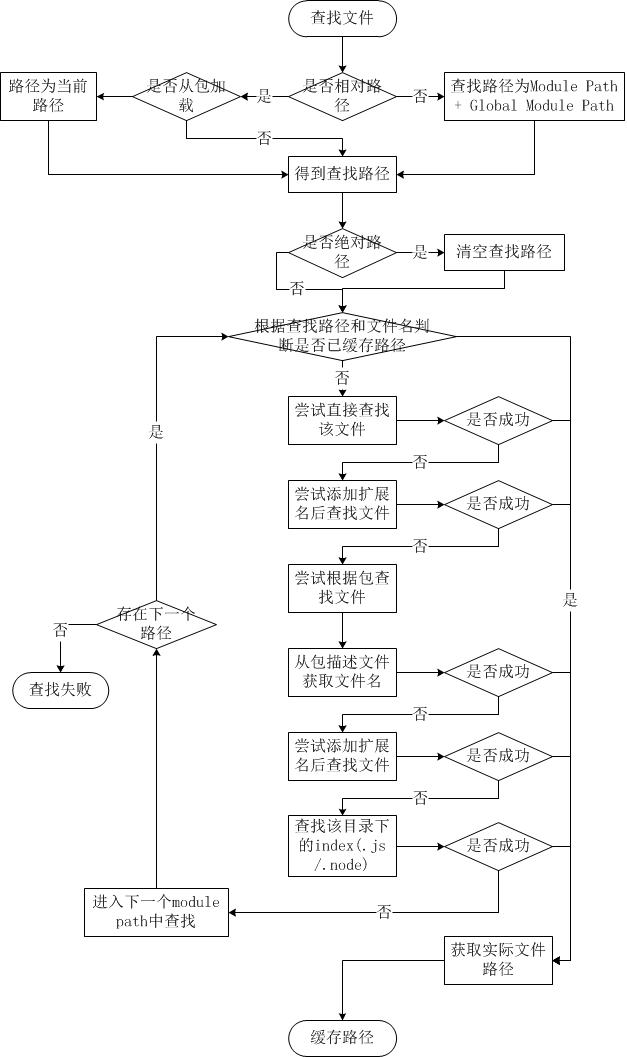
简而言之,如果require绝对路径的文件,查找时不会去遍历每一个node_modules目录,其速度最快。其余流程如下:
从module path数组中取出第一个目录作为查找基准。
直接从目录中查找该文件,如果存在,则结束查找。如果不存在,则进行下一条查找。
尝试添加.js、.json、.node后缀后查找,如果存在文件,则结束查找。如果不存在,则进行下一条。
尝试将require的参数作为一个包来进行查找,读取目录下的package.json文件,取得main参数指定的文件。
尝试查找该文件,如果存在,则结束查找。如果不存在,则进行第3条查找。
如果继续失败,则取出module path数组中的下一个目录作为基准查找,循环第1至5个步骤。
如果继续失败,循环第1至6个步骤,直到module path中的最后一个值。
如果仍然失败,则抛出异常。
整个查找过程十分类似原型链的查找和作用域的查找。所幸Node.js对路径查找实现了缓存机制,否则由于每次判断路径都是同步阻塞式进行,会导致严重的性能消耗。
包结构
前面提到,JavaScript缺少包结构。CommonJS致力于改变这种现状,于是定义了包的结构规范(http://wiki.commonjs.org/wiki/Packages/1.0
)。而NPM的出现则是为了在CommonJS规范的基础上,实现解决包的安装卸载,依赖管理,版本管理等问题。require的查找机制明了之后,我们来看一下包的细节。
一个符合CommonJS规范的包应该是如下这种结构:
一个package.json文件应该存在于包顶级目录下
二进制文件应该包含在bin目录下。
JavaScript代码应该包含在lib目录下。
文档应该在doc目录下。
单元测试应该在test目录下。
由上文的require的查找过程可以知道,Node.js在没有找到目标文件时,会将当前目录当作一个包来尝试加载,所以在package.json文件中最重要的一个字段就是main。而实际上,这一处是Node.js的扩展,标准定义中并不包含此字段,对于require,只需要main属性即可。但是在除此之外包需要接受安装、卸载、依赖管理,版本管理等流程,所以CommonJS为package.json文件定义了如下一些必须的字段:
name。包名,需要在NPM上是唯一的。不能带有空格。
description。包简介。通常会显示在一些列表中。
version。版本号。一个语义化的版本号(http://semver.org/
),通常为x.y.z。该版本号十分重要,常常用于一些版本控制的场合。
keywords。关键字数组。用于NPM中的分类搜索。
maintainers。包维护者的数组。数组元素是一个包含name、email、web三个属性的JSON对象。
contributors。包贡献者的数组。第一个就是包的作者本人。在开源社区,如果提交的patch被merge进master分支的话,就应当加上这个贡献patch的人。格式包含name和email。如:
"contributors": [{
"name": "Jackson Tian",
"email": "mail @gmail.com"
}, {
"name": "fengmk2",
"email": "mail2@gmail.com"
}], |
bugs。一个可以提交bug的URL地址。可以是邮件地址(mailto:mailxx@domain),也可以是网页地址(http://url)。
licenses。包所使用的许可证。例如:
"licenses": [{
"type": "GPLv2",
"url": "http://www.example.com/licenses/gpl.html",
}] |
repositories。托管源代码的地址数组。
dependencies。当前包需要的依赖。这个属性十分重要,NPM会通过这个属性,帮你自动加载依赖的包。
以下是Express框架的package.json文件,值得参考。
{
"name": "express",
"description": "Sinatra inspired web development framework",
"version": "3.0.0alpha1-pre",
"author": "TJ Holowaychuk |
除了前面提到的几个必选字段外,我们还发现了一些额外的字段,如bin、scripts、engines、devDependencies、author。这里可以重点提及一下scripts字段。包管理器(NPM)在对包进行安装或者卸载的时候需要进行一些编译或者清除的工作,scripts字段的对象指明了在进行操作时运行哪个文件,或者执行拿条命令。如下为一个较全面的scripts案例:
"scripts": {
"install": "install.js",
"uninstall": "uninstall.js",
"build": "build.js",
"doc": "make-doc.js",
"test": "test.js",
} |
如果你完善了自己的JavaScript库,使之实现了CommonJS的包规范,那么你可以通过NPM来发布自己的包,为NPM上5000+的基础上再加一个模块。
命令十分简单。但是在这之前你需要通过npm adduser命令在NPM上注册一个帐户,以便后续包的维护。NPM会分析该文件夹下的package.json文件,然后上传目录到NPM的站点上。用户在使用你的包时,也十分简明:
甚至对于NPM无法安装的包(因为某些奇怪的网络原因),可以通过github手动下载其稳定版本,解压之后通过以下命令进行安装:
npm install <package.json folder> |
只需将路径指向package.json存在的目录即可。然后在代码中require('package')即可使用。
Node.js中的require内部流程之复杂,而方法调用之简单,实在值得叹为观止。更多NPM使用技巧可以参见http://www.infoq.com/cn/articles/msh-using-npm-manage-node.js-dependence。
Node.js模块与前端模块的异同
通常有一些模块可以同时适用于前后端,但是在浏览器端通过script标签的载入JavaScript文件的方式与Node.js不同。Node.js在载入到最终的执行中,进行了包装,使得每个文件中的变量天然的形成在一个闭包之中,不会污染全局变量。而浏览器端则通常是裸露的JavaScript代码片段。所以为了解决前后端一致性的问题,类库开发者需要将类库代码包装在一个闭包内。以下代码片段抽取自著名类库underscore的定义方式。
(function () {
// Establish the root object, `window` in the browser, or `global` on the server.
var root = this;
var _ = function (obj) {
return new wrapper(obj);
};
if (typeof exports !== 'undefined') {
if (typeof module !== 'undefined' && module.exports) {
exports = module.exports = _;
}
exports._ = _;
} else if (typeof define === 'function' && define.amd) {
// Register as a named module with AMD.
define('underscore', function () {
return _;
});
} else {
root['_'] = _;
}
}).call(this); |
首先,它通过function定义构建了一个闭包,将this作为上下文对象直接call调用,以避免内部变量污染到全局作用域。续而通过判断exports是否存在来决定将局部变量_绑定给exports,并且根据define变量是否存在,作为处理在实现了AMD规范环境(http://wiki.commonjs.org/wiki/Modules/AsynchronousDefinition)下的使用案例。仅只当处于浏览器的环境中的时候,this指向的是全局对象(window对象),才将_变量赋在全局对象上,作为一个全局对象的方法导出,以供外部调用。
所以在设计前后端通用的JavaScript类库时,都有着以下类似的判断:
if (typeof exports !== "undefined") {
exports.EventProxy = EventProxy;
} else {
this.EventProxy = EventProxy;
} |
即,如果exports对象存在,则将局部变量挂载在exports对象上,如果不存在,则挂载在全局对象上。
对于更多前端的模块实现可以参考国内淘宝玉伯的seajs(http://seajs.com/),或者思科杜欢的oye(http://www.w3cgroup.com/oye/)。
(四):Node.js的事件机制
专栏的第四篇文章《Node.js的事件机制》。之前介绍了Node.js的模块机制,本文将深入Node.js的事件部分。
Node.js的事件机制
Node.js在其Github代码仓库(https://github.com/joyent/node)上有着一句短短的介绍:Evented
I/O for V8 JavaScript。这句近似广告语的句子却道尽了Node.js自身的特色所在:基于V8引擎实现的事件驱动IO。在本文的这部分内容中,我来揭开这Evented这个关键词的一切奥秘吧。
Node.js能够在众多的后端JavaScript技术之中脱颖而出,正是因其基于事件的特点而受到欢迎。拿Rhino来做比较,可以看出Rhino引擎支持的后端JavaScript摆脱不掉其他语言同步执行的影响,导致JavaScript在后端编程与前端编程之间有着十分显著的差别,在编程模型上无法形成统一。在前端编程中,事件的应用十分广泛,DOM上的各种事件。在Ajax大规模应用之后,异步请求更得到广泛的认同,而Ajax亦是基于事件机制的。在Rhino中,文件读取等操作,均是同步操作进行的。在这类单线程的编程模型下,如果采用同步机制,无法与PHP之类的服务端脚本语言的成熟度媲美,性能也没有值得可圈可点的部分。直到Ryan
Dahl在2009年推出Node.js后,后端JavaScript才走出其迷局。Node.js的推出,我觉得该变了两个状况:
统一了前后端JavaScript的编程模型。
利用事件机制充分利用用异步IO突破单线程编程模型的性能瓶颈,使得JavaScript在后端达到实用价值。
有了第二次浏览器大战中的佼佼者V8的适时助力,使得Node.js在短短的两年内达到可观的运行效率,并迅速被大家接受。这一点从Node.js项目在Github上的流行度和NPM上的库的数量可见一斑。
至于Node.js为何会选择Evented I/O for V8 JavaScript的结构和形式来实现,可以参见一下2011年初对作者Ryan
Dahl的一次采访:http://bostinno.com/2011/01/31/node-js-interview-4-questions-with-creator-ryan-dahl/
。
事件机制的实现
Node.js中大部分的模块,都继承自Event模块(http://nodejs.org/docs/latest/api/events.html
)。Event模块(events.EventEmitter)是一个简单的事件监听器模式的实现。具有addListener/on,once,removeListener,removeAllListeners,emit等基本的事件监听模式的方法实现。它与前端DOM树上的事件并不相同,因为它不存在冒泡,逐层捕获等属于DOM的事件行为,也没有preventDefault()、stopPropagation()、
stopImmediatePropagation() 等处理事件传递的方法。
从另一个角度来看,事件侦听器模式也是一种事件钩子(hook)的机制,利用事件钩子导出内部数据或状态给外部调用者。Node.js中的很多对象,大多具有黑盒的特点,功能点较少,如果不通过事件钩子的形式,对象运行期间的中间值或内部状态,是我们无法获取到的。这种通过事件钩子的方式,可以使编程者不用关注组件是如何启动和执行的,只需关注在需要的事件点上即可。
var options = {
host: 'www.google.com',
port: 80,
path: '/upload',
method: 'POST'
};
var req = http.request(options, function (res) {
console.log('STATUS: ' + res.statusCode);
console.log('HEADERS: ' + JSON.stringify(res.headers));
res.setEncoding('utf8');
res.on('data', function (chunk) {
console.log('BODY: ' + chunk);
});
});
req.on('error', function (e) {
console.log('problem with request: ' + e.message);
});
// write data to request body
req.write('data\n');
req.write('data\n');
req.end(); |
在这段HTTP request的代码中,程序员只需要将视线放在error,data这些业务事件点即可,至于内部的流程如何,无需过于关注。
值得一提的是如果对一个事件添加了超过10个侦听器,将会得到一条警告,这一处设计与Node.js自身单线程运行有关,设计者认为侦听器太多,可能导致内存泄漏,所以存在这样一个警告。调用:
emitter.setMaxListeners(0); |
可以将这个限制去掉。
其次,为了提升Node.js的程序的健壮性,EventEmitter对象对error事件进行了特殊对待。如果运行期间的错误触发了error事件。EventEmitter会检查是否有对error事件添加过侦听器,如果添加了,这个错误将会交由该侦听器处理,否则,这个错误将会作为异常抛出。如果外部没有捕获这个异常,将会引起线程的退出。
事件机制的进阶应用
继承event.EventEmitter
实现一个继承了EventEmitter类是十分简单的,以下是Node.js中流对象继承EventEmitter的例子:
function Stream() {
events.EventEmitter.call(this);
}
util.inherits(Stream, events.EventEmitter); |
Node.js在工具模块中封装了继承的方法,所以此处可以很便利地调用。程序员可以通过这样的方式轻松继承EventEmitter对象,利用事件机制,可以帮助你解决一些问题。
多事件之间协作
在略微大一点的应用中,数据与Web服务器之间的分离是必然的,如新浪微博、Facebook、Twitter等。这样的优势在于数据源统一,并且可以为相同数据源制定各种丰富的客户端程序。以Web应用为例,在渲染一张页面的时候,通常需要从多个数据源拉取数据,并最终渲染至客户端。Node.js在这种场景中可以很自然很方便的同时并行发起对多个数据源的请求。
api.getUser("username", function (profile) {
// Got the profile
});
api.getTimeline("username", function (timeline) {
// Got the timeline
});
api.getSkin("username", function (skin) {
// Got the skin
}); |
Node.js通过异步机制使请求之间无阻塞,达到并行请求的目的,有效的调用下层资源。但是,这个场景中的问题是对于多个事件响应结果的协调并非被Node.js原生优雅地支持。为了达到三个请求都得到结果后才进行下一个步骤,程序也许会被变成以下情况:
api.getUser("username", function (profile) {
api.getTimeline("username", function (timeline) {
api.getSkin("username", function (skin) {
// TODO
});
});
}); |
这将导致请求变为串行进行,无法最大化利用底层的API服务器。
为解决这类问题,我曾写作一个模块(EventProxy,https://github.com/JacksonTian/eventproxy)来实现多事件协作,以下为上面代码的改进版:
var proxy = new EventProxy();
proxy.all("profile", "timeline", "skin", function (profile, timeline, skin) {
// TODO
});
api.getUser("username", function (profile) {
proxy.emit("profile", profile);
});
api.getTimeline("username", function (timeline) {
proxy.emit("timeline", timeline);
});
api.getSkin("username", function (skin) {
proxy.emit("skin", skin);
}); |
EventProxy也是一个简单的事件侦听者模式的实现,由于底层实现跟Node.js的EventEmitter不同,无法合并进Node.js中。但是却提供了比EventEmitter更强大的功能,且API保持与EventEmitter一致,与Node.js的思路保持契合,并可以适用在前端中。
这里的all方法是指侦听完profile、timeline、skin三个方法后,执行回调函数,并将侦听接收到的数据传入。
最后还介绍一种解决多事件协作的方案:Jscex(https://github.com/JeffreyZhao/jscex
)。Jscex通过运行时编译的思路(需要时也可在运行前编译),将同步思维的代码转换为最终异步的代码来执行,可以在编写代码的时候通过同步思维来写,可以享受到同步思维的便利写作,异步执行的高效性能。如果通过Jscex编写,将会是以下形式:
var data = $await(Task.whenAll({
profile: api.getUser("username"),
timeline: api.getTimeline("username"),
skin: api.getSkin("username")
}));
// 使用data.profile, data.timeline, data.skin
// TODO |
此节感谢Jscex作者@老赵(http://blog.zhaojie.me/)的指正和帮助。
利用事件队列解决雪崩问题
所谓雪崩问题,是在缓存失效的情景下,大并发高访问量同时涌入数据库中查询,数据库无法同时承受如此大的查询请求,进而往前影响到网站整体响应缓慢。那么在Node.js中如何应付这种情景呢。
var select = function (callback) {
db.select("SQL", function (results) {
callback(results);
});
}; |
以上是一句数据库查询的调用,如果站点刚好启动,这时候缓存中是不存在数据的,而如果访问量巨大,同一句SQL会被发送到数据库中反复查询,影响到服务的整体性能。一个改进是添加一个状态锁。
var status = "ready";
var select = function (callback) {
if (status === "ready") {
status = "pending";
db.select("SQL", function (results) {
callback(results);
status = "ready";
});
}
}; |
但是这种情景,连续的多次调用select发,只有第一次调用是生效的,后续的select是没有数据服务的。所以这个时候引入事件队列吧:
var proxy = new EventProxy();
var status = "ready";
var select = function (callback) {
proxy.once("selected", callback);
if (status === "ready") {
status = "pending";
db.select("SQL", function (results) {
proxy.emit("selected", results);
status = "ready";
});
}
}; |
这里利用了EventProxy对象的once方法,将所有请求的回调都压入事件队列中,并利用其执行一次就会将监视器移除的特点,保证每一个回调只会被执行一次。对于相同的SQL语句,保证在同一个查询开始到结束的时间中永远只有一次,在这查询期间到来的调用,只需在队列中等待数据就绪即可,节省了重复的数据库调用开销。由于Node.js单线程执行的原因,此处无需担心状态问题。这种方式其实也可以应用到其他远程调用的场景中,即使外部没有缓存策略,也能有效节省重复开销。此处也可以用EventEmitter替代EventProxy,不过可能存在侦听器过多,引发警告,需要调用setMaxListeners(0)移除掉警告,或者设更大的警告阀值。
下一篇:深入浅出Node.js(下)
|


