| БрМЭЦМі: |
БОЮФЪзЯШЖдИКдиОљКтКЭИпПЩгУЕФМђЕЅНщЩм НгзХНВНтСЫLVSЕФЙЄзїдРэЁЂLVSЕФЫФжжЙЄзїФЃЪННщЩмвдМАLVSЕФЕїЖШЫуЗЈНщЩмЕШЕШЯрЙиЁЃ
РДздгкВЉПЭдАЃЌ,гЩЛ№СњЙћШэМўAnnaБрМЁЂЭЦМіЁЃ |
|
ИКдиОљКтКЭИпПЩгУЕФМђЕЅНщЩм
1.LB(LoadBalancer)ИКдиОљКт,ЛђГЦЮЊЕїЖШЦї гВМўЃКF5 Big-IP ЃЌ Citrix(ЫМНм) Netscaler зюГЃгУЃЌA10 ШэМўЃКLVS(4Ву)ЃКИљОнЬзНгзжРДИКдиОљКтЁЃ ЬзНгзж=IP + ЖЫПк Nginx(7Ву) ЃКИќЪЪКЯhttpЃЌsmtpЃЌpop3ЃЌimapЕФИКдиОљКт Haproxy(7Ву) :ИљОнгУЛЇЧыЧѓЕФФкШнРДЕїЖШЁЃ ЫќжЇГж4ВуКЭ7ВуЕФИКдиОљКтЃЌЦфИќЪЪКЯhttpЃЌtcp(ШчЃКmysqlЃЌsmtp)
LBМЏШКжївЊвдЬсИпВЂЗЂФмСІЮЊИљБО
LBЕФЙІФмЃК 1. МрПижїЗўЮёЦїЕФДцЛюЧщПі 2. ЙЪеЯЧаЛЛЪБЃЌЭъГЩЙвдиДцДЂЃЌЦєЖЏЗўЮёЃЌЧРеМVIP
2. HA(HighAvailability) ИпПЩгУМЏШК дкЯпЪБМф/(дкЯпЪБМф + ЙЪеЯЛжИДЪБМф) RHCS,heartbeat,pacemaker,rose(windows),PowerHA(AIX)ЃКФПЧАетаЉЪЙгУЖМВЛЖрСЫЁЃ жїСїЪЧЃКKeepalived,ФПЧАЙйЗНвВЗЧГЃЛюдО,ИќаТАцБОЮЊ2.xЁЃ
ИпПЩгУжИБъЃК99ЃЅ, 99.9%, 99.99%, 99.999%
#HAМЏШКжївЊНтОіЬсИпЗўЮёдкЯпЪБМфЮЊИљБО
3. HPC(High-Performance Computing):ИпадФмМЦЫуЁОHPCМЏШКжївЊНтОіДѓШЮЮёМЦЫуЕФЮЪЬтЁП MapReduce зЗзйШЮЮёЭъГЩЕФзДЬЌ Hadoop
LVSЕФЙЄзїдРэ:
LVSЕФСНДѓзщМўЃК гУЛЇПеМфЃК ipvsadm ФкКЫПеМфЃК ipvs ЕБгУЛЇЧыЧѓБЛЭјПЈЪеЕНЃЌИУЧыЧѓНЋзюЯШРДЕНPREROUTINGСДЃЌНгзХНјШыINPUTСДЃЌЕБЧыЧѓНјШыINPUTСДКѓЃЌipvsНЋМрЬ§ ЕНетИіСЌНгЧыЧѓЃЌВЂНЋИУСЌНгЧыЧѓжиЖЈЯђЕНздМКЃЌНгзХИљОнФкВПЕїЖШЙцдђНјааЦЅХфЃЌШєУЛгаЦЅХфЕНдђНЋИУЧыЧѓдЗтВЛЖЏЕФ зЊНЛИјINPUTСДЃЌзюжеБЛINPUTСДзЊЗЂИјМрЬ§дкжИЖЈЬзНгзж(IP+Port)ЕФгІгУГЬађЁЃШєЦЅХфЕїЖШЙцдђЃЌдђipvsНЋаоИФИУЧыЧѓ ЕФЯрЙиЕижЗ(NATФЃаЭЃКаоИФVIP-->RIP; DRФЃаЭЃКаоИФФПЕФMACЮЊRealSRVЕФMAC)КѓЃЌжиЖЈЯђЕНPOSTROUTINGСДЩЯЃЌзюже зЊЗЂЕНКѓЖЫЕФReal ServerЩЯЁЃ
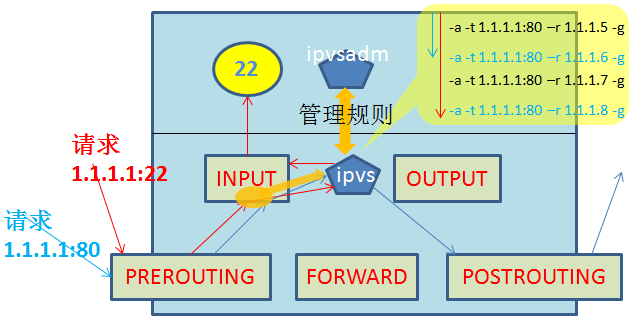
ЪЙгУLVSЫљашвЊЕФМгдиЕФМИИіживЊФкКЫФЃПщ:
- ip_vs
ЁЁЁЁЁЁ- ip_vs_rr
ЁЁЁЁЁЁ- ip_vs_wrr
ЁЁЁЁЁЁ- ip_vs_sh
ЁЁЁЁЁЁ- nf_conntrack_ipv4ЁЁЁЁ # kernel < 4.19
ЁЁЁЁЁЁ- nf_conntrack ЁЁЁЁЁЁЁЁ # kernel >= 4.19 |
LVSЕФЫФжжЙЄзїФЃЪННщЩмЃК 1.Virtual server via NATЃЈVS-NATЃЉ гХЕуЃКМЏШКжаЕФЮяРэЗўЮёЦїПЩвдЪЙгУШЮКЮжЇГжTCP/IPВйзїЯЕЭГЃЌЮяРэЗўЮёЦїПЩвдЗжХфInternetЕФ БЃСєЫНгаЕижЗЃЌжЛгаИКдиОљКтЦїашвЊвЛИіКЯЗЈЕФIPЕижЗЁЃ ШБЕуЃКРЉеЙадгаЯоЁЃЕБЗўЮёЦїНкЕуЃЈЦеЭЈPCЗўЮёЦїЃЉЪ§ОндіГЄЕН20ИіЛђИќЖрЪБ,ИКдиОљКтЦї НЋГЩЮЊећИіЯЕЭГЕФЦПОБЃЌвђЮЊЫљгаЕФЧыЧѓАќКЭгІД№АќЖМашвЊОЙ§ИКдиОљКтЦїЁЃМйЪЙTCPАќЕФ ЦНОљГЄЖШЪЧ536зжНкЕФЛАЃЌЦНОљУПИіАќжиаТЙЙНЈ,бгГйЪБМфДѓдМЮЊ60usЃЈдкPentiumДІРэЦїЩЯМЦЫуЕФЃЌ ВЩгУИќПьЕФДІРэЦїНЋЪЙЕУетИібгГйЪБМфБфЖЬЃЉЃЌИКдиОљКтЦїЕФзюДѓШнаэФмСІЮЊ8.93M/sЃЌМйЖЈУПЬЈ ЮяРэЗўЮёЦїЕФЦНЬЈШнаэФмСІЮЊ400K/sРДМЦЫуЃЌИКдиОљКтЦїФмЮЊ22ЬЈЮяРэЗўЮёЦїЬсЙЉМЦЫуЁЃ
НтОіАьЗЈЃКМДЪЙЪЧЪЧИКдиОљКтЦїГЩЮЊећИіЯЕЭГЕФЦПОБЃЌШчЙћЪЧетбљвВгаСНжжЗНЗЈРДНтОіЫќЁЃ вЛжжЪЧЛьКЯДІРэ: ШчЙћВЩгУЛьКЯДІРэЕФЗНЗЈЃЌНЋашвЊаэЖрЭЌЪєЕЅвЛЕФRR(DNSЕФзЪдДМЧТМ)
DNSгђЁЃ СэвЛжжЪЧВЩгУVirtual Server via IP tunneling(МД:TunlФЃаЭ)ЛђVirtual
Server via direct routing(МД:DRФЃаЭ) : ШєЪЙгУДЫЗНЪНПЩвдЛёЕУИќКУЕФПЩРЉеЙадЃЛвВПЩвдЧЖЬзЪЙгУИКдиОљКтЦїЃЌдкзюЧАЖЫЕФЪЧVS-TunnelingЛђ VS-DRЕФИКдиОљКтЦїЃЌШЛКѓКѓУцВЩгУVS-NATЕФИКдиОљКтЦїЁЃ
2.Virtual server via IP tunnelingЃЈVS-TUNЃЉ ЮвУЧЗЂЯжЃЌаэЖрInternetЗўЮёЃЈР§ШчWEBЗўЮёЦїЃЉЕФЧыЧѓАќКмЖЬаЁЃЌЖјгІД№АќЭЈГЃКмДѓЁЃ гХЕуЃКИКдиОљКтЦїжЛИКд№НЋЧыЧѓАќЗжЗЂИјЮяРэЗўЮёЦїЃЌЖјЮяРэЗўЮёЦїНЋгІД№АќжБНгЗЂИјгУЛЇЁЃЫљвдЃЌ ИКдиОљКтЦїФмДІРэКмОоДѓЕФЧыЧѓСПЃЌетжжЗНЪНЃЌвЛЬЈИКдиОљКтФмЮЊГЌЙ§100ЬЈЕФЮяРэЗўЮёЦїЗўЮёЃЌ ИКдиОљКтЦїВЛдйЪЧЯЕЭГЕФЦПОБЁЃЪЙгУVS-TUNЗНЪНЃЌШчЙћФуЕФИКдиОљКтЦїгЕга100MЕФШЋЫЋЙЄЭјПЈЕФЛАЃЌ ОЭФмЪЙЕУећИіVirtual ServerФмДяЕН1GЕФЭЬЭТСПЁЃ ШБЕуЃКЕЋЪЧЃЌетжжЗНЪНашвЊЫљгаЕФЗўЮёЦїжЇГж"IP Tunneling"(IP
Encapsulation)авщЃЌЮвНідкLinuxЯЕЭГЩЯ ЪЕЯжСЫетИіЃЌФПЧАЦфЫќВйзїЯЕЭГЕФжЇГжЛЙдкЬНЫїжЎжаЁЃ
3.Virtual Server via Direct RoutingЃЈVS-DRЃЉ гХЕуЃККЭVSЃTUNвЛбљЃЌИКдиОљКтЦївВжЛЪЧЗжЗЂЧыЧѓЃЌгІД№АќЭЈЙ§ЕЅЖРЕФТЗгЩЗНЗЈЗЕЛиИјПЭЛЇЖЫЁЃгыVS-TUNЯрБШЃЌ VS-DRетжжЪЕЯжЗНЪНВЛашвЊЫэЕРНсЙЙЃЌвђДЫПЩвдЪЙгУДѓЖрЪ§ВйзїЯЕЭГзіЮЊЮяРэЗўЮёЦїЃЌЦфжаАќРЈЃК LinuxЁЂSolaris ЁЂFreeBSD ЁЂwindowsЁЂIRIX 6.5ЃЛHPUX11ЕШЁЃ ШБЕуЃКвЊЧѓИКдиОљКтЦїЕФЭјПЈБиаыгыЮяРэЭјПЈдквЛИіЮяРэЖЮЩЯЁЃ
4. LVS-FullNAT ЭЈЙ§ЭЌЪБаоИФЧыЧѓБЈЮФЕФдДIPЕижЗКЭФПБъIPЕижЗНјаазЊЗЂЃЈCIP --> DIP, VIP
--> RIP ЃЉ ДЫФЃЪНдкПчЛњЗПЃЌПчЖрИіВЛЭЌЭјТчЪБ,FullNATФЃЪНвВПЩЪЕЯжЕїЖШЁЃ вђЮЊДЫЪБЪЕМЪЪЧНЋIPАќЕФдДКЭФПБъЖМаоИФСЫ,ОЭКУЯѓЕїЖШЦїжБНгШЅЗУЮЪдЖЖЫRealServer,дЖЖЫRealServerжЛашвЊ АДеездМКБОЕиТЗгЩ,евЕНЭјЙи,НЋАќЛигІИјдЖЖЫЕїЖШЦїЃЌдЖЖЫЕїЖШЦїдйДЮНЋЛигІАќЃЌЗЕЛиИјгУЛЇЁЃ
(1) VIPЪЧЙЋЭјЕижЗЃЌRIPКЭDIPЪЧЫНЭјЕижЗЃЌЧвЭЈГЃВЛдкЭЌвЛIPЭјТчЃЛвђДЫЃЌRIPЕФЭјЙивЛАуВЛЛсжИЯђDIP (2) RSЪеЕНЕФЧыЧѓБЈЮФдДЕижЗЪЧDIPЃЌвђДЫЃЌжЛашЯьгІИјDIPЃЛЕЋDirectorЛЙвЊНЋЦфЗЂЭљClient (3) ЧыЧѓКЭЯьгІБЈЮФЖМОгЩDirector (4) жЇГжЖЫПкгГЩф зЂвтЃКДЫРраЭkernelФЌШЯВЛжЇГж ДЫжаЪЙгУГЁОАНЯЩй,НіАЂРядЦФкВПЕФSLBЪЙгУДЫжжФЃЪН.
ЖдЩЯУцШ§жжIPИКдиОљКтММЪѕЕФгХШБЕуБШНЯ:
| дгЯю |
VS/NAT |
VS/TUN |
VS/DR |
| ЗўЮёЦїВйзїЯЕЭГ |
ШЮвтЁЁ |
жЇГжЫэЕРЁЁЁЁЁЁ |
ЖрЪ§(жЇГжNon-arp
) |
| ЗўЮёЦїЭјТчЁЁ |
ЫНгаЭјТч |
ОжгђЭј/ЙугђЭј |
ОжгђЭј |
| ЗўЮёЦїЪ§ФП(100MЭјТч)
|
10-20 |
100ЁЁ |
Жр(100) |
| ЗўЮёЦїЭјЙи |
ИКдиОљКтЦї |
здМКЕФТЗгЩ |
здМКЕФТЗгЩ |
| аЇТЪ |
вЛАу |
ЁЁИп |
зюИп |
LVSЕФЕїЖШЫуЗЈНщЩмЃК 1.ТжНаЕїЖШЃЈRound RobinЃЉ(МђГЦrr) ВЛПМТЧRealServerЪЕМЪСЌНгЪ§,ЯЕЭГИКди,жЛЪЧТжСїИјУПИіRealServerЗжХфЧыЧѓ.
2.МгШЈТжНаЃЈWeighted Round RobinЃЉЃЈМђГЦwrr) ИљОнЪЕМЪRealServerЕФжїЛњХфжУ,НЋжїЛњХфжУЧПЕФRealServerИќДѓЕФШЈжи,ШУЕїЖШЦїЗжХфИќЖрЧыЧѓИјЫќДІРэ, ЭЌЪБЕїЖШЦїПЩздЖЏбЏЮЪRealServerЕФИКдиЧыЧѓ,ВЂЖЏЬЌЕїећЦфШЈжижЕ.
3.зюЩйСДНгЃЈLeast ConnectionsЃЉ(LC) : НЋаТЕФСДНгЧыЧѓЗжХфЕНЕБЧАСДНгЪ§зюаЁЕФЗўЮёЦїЩЯ. ЕїЖШЦїашвЊМЧТМУПИіServerвбОНЈСЂСДНгЕФЪ§ФП,ЕБЕїЖШЦїИјAЕїЖШвЛИіЧыЧѓ,дђНЋAЕФзмСДНгЪ§+1,ЕБСДНгжажЙ/ГЌЪБ, дђзмСДНг-1ЁЃ ШБЯнЃК 1. ServerадФмЯрЭЌЃКПЩЦНЛЌЗжЗЂИКдиЃЌЕЋВЛФмНЋГЄСДНгЕФЧыЧѓЗЂЯђЭЌвЛServer. 2. ServerадФмВЛЭЌЃКИУЫуЗЈВЂВЛРэЛсЁЃ вђЮЊTCPСЌНгДІРэЧыЧѓКѓЛсНјШыTIME_WAITзДЬЌ,TCPЕФTIME_WAITвЛАуЮЊ2Зжжг,ДЫЪБСЌНгЛЙеМгУЗўЮёЦїЕФзЪдД, ЫљвдЛсГіЯжетбљЧщаЮ,адФмИпЕФЗўЮёЦївбДІРэЫљЪеЕНЕФСЌНг,СЌНгДІгкTIME_WAITзДЬЌ,ЖјадФмЕЭЕФЗўЮёЦївбОУІгк ДІРэЫљЪеЕНЕФСЌНг,ЛЙВЛЖЯЕиЪеЕНаТЕФСЌНгЧыЧѓЁЃ
4.МгШЈзюЩйСДНгЃЈWeighted Least ConnectionsЃЉ(WLC) дкМЏШКЯЕЭГжаЕФЗўЮёЦїадФмВювьНЯДѓЕФЧщПіЯТЃЌЕїЖШЦїВЩгУЁАМгШЈзюЩйСДНгЁБЕїЖШЫуЗЈгХЛЏИКдиОљКтадФмЃЌОпгаНЯИпШЈжЕ ЕФЗўЮёЦїНЋГаЪмНЯДѓБШР§ЕФЛюЖЏСЌНгИКдиЁЃЕїЖШЦїПЩвдздЖЏЮЪбЏецЪЕЗўЮёЦїЕФИКдиЧщПіЃЌВЂЖЏЬЌЕиЕїећЦфШЈжЕЁЃ
5.ФПБъЕижЗЩЂСаЃЈDestination HashingЃЉ(DH) ЁАФПБъЕижЗЩЂСаЁБЕїЖШЫуЗЈИљОнЧыЧѓЕФФПБъIPЕижЗЃЌзїЮЊЩЂСаМќЃЈHash KeyЃЉДгОВЬЌЗжХфЕФЩЂСаБэевГіЖдгІЕФЗўЮёЦїЃЌ ШєИУЗўЮёЦїЪЧПЩгУЕФЧвЮДГЌдиЃЌНЋЧыЧѓЗЂЫЭЕНИУЗўЮёЦїЃЌЗёдђЗЕЛиПеЁЃ ВЙГфЃК ФПБъЕижЗЩЂСаЕїЖШ(Destination Hashing Scheduling)ЫуЗЈ,ЪЧеыЖдФПБъIPЕижЗЕФИКдиОљКт,ЫќЪЧвЛжжОВЬЌгГЩфЫуЗЈ, ЭЈЙ§вЛИіЩЂСаКЏЪ§НЋвЛИіФПБъIPЕижЗгГЩфЮЊвЛЬЈЗўЮёЦїЁЃ ФПБъЕижЗЩЂСаЫуЗЈЛсЯШИљОнЧыЧѓЕФФПБъIP,МЦЫуЩЂСаЙўЯЃ(hash key),ДгОВЬЌЗжХфЕФЩЂСаБэевГіЖдгІЕФЗўЮёЦї, ШєИУЗўЮёЦїЪЧПЩгУЧвЮДГЌдиЃЌдђНЋЧыЧѓЗЂИјИУЗўЮёЦїЃЌЗёдђЗЕЛиПе,жиаТЕїЖШЁЃ ЙўЯЃЩЂСаБэПЩРэНтШчЯТЃК
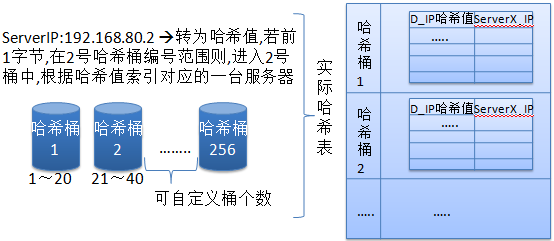
дкДЫЫуЗЈжа,ФЌШЯЫќЪЙгУ256ИіЙўЯЃЭАРДНЋФПБъIPЕФЙўЯЃжЕЧА1ИізжНкЛЎЗж,ЦНОљЗжГЩ256ЗнЃЌУПвЛЗн ОЭЪЧвЛИіЗЖЮЇ,етбљЮвжЛвЊМЦЫуГіФПБъIPЕФЙўЯЃжЕ,ТэЩЯОЭФмШЗЖЈЫќгІИУдкФЧИіЭАжа,ШЛКѓЖЈЮЛЕНИУЭАЃЌ етбљдкзіаЁЗЖЮЇБэЩЈУшЃЌЫйЖШОЭЗЧГЃПьЁЃСэЭтЛЙашвЊзЂвтЃКдкДЫЫуЗЈжаЫќРрЫЦгквЛжТадЙўЯЃЫуЗЈЃЌ ЫќЛсЪТЯШНЋЫљгаПЩгУЗўЮёЦїОљдШбЛЗЗжВМЕНУПИіЭАжаЃЌИќМђЕЅРэНтОЭЪЧБОРДОЭЪЧвЛеХга256ЬѕМЧТМЕФДѓБэ, ИУБэжаЪТЯШНЋЫљгаПЩгУЗўЮёЦїШЋВПЫГађбЛЗВхШыЕНУПвЛааМЧТМжа,ШЛКѓНЋетеХДѓБэВ№ЗжГЩЖрИіаЁБэЃЌ ВЂАДЧАУцЕФЗНЗЈ,НЋвЛИіЗЖЮЇжЕзїЮЊНјШыИУаЁБэЕФЬѕМўЃЌетбљОЭПЩвдзюДѓЯоЖШОљдШУПвЛЬЈЗўЮёЦїЕФИКдиЁЃ
6.дДЕижЗЩЂСаЃЈSource HashingЃЉ(SH) ЁАдДЕижЗЩЂСаЁБЕїЖШЫуЗЈИљОнЧыЧѓЕФдДIPЕижЗЃЌзїЮЊЩЂСаМќЃЈHash KeyЃЉДгОВЬЌЗжХфЕФЩЂСаБэевГіЖдгІЕФЗўЮёЦїЃЌ ШєИУЗўЮёЦїЪЧПЩгУЕФЧвЮДГЌдиЃЌНЋЧыЧѓЗЂЫЭЕНИУЗўЮёЦїЃЌЗёдђЗЕЛиПеЁЃ
7.ЛљгкОжВПадЕФзюЩйСДНгЃЈLocality-Based Least ConnectionsЃЉ(LBLC) ЁАЛљгкОжВПадЕФзюЩйСДНгЁБЕїЖШЫуЗЈЪЧеыЖдФПБъIPЕижЗЕФИКдиОљКтЃЌФПЧАжївЊгУгкCacheМЏШКЯЕЭГЁЃИУЫуЗЈИљОн ЧыЧѓЕФФПБъIPЕижЗевГіИУФПБъIPЕижЗзюНќЪЙгУЕФЗўЮёЦїЃЌШєИУЗўЮёЦїЪЧПЩгУЕФЧвУЛгаГЌдиЃЌНЋЧыЧѓЗЂЫЭЕНИУЗўЮёЦїЃЛ ШєЗўЮёЦїВЛДцдкЃЌЛђепИУЗўЮёЦїГЌдиЧвгаЗўЮёЦїДІгквЛАыЕФЙЄзїИКдиЃЌдђгУЁАзюЩйСДНгЁБ ЕФддђбЁГівЛИіПЩгУЕФЗўЮёЦїЃЌ НЋЧыЧѓЗЂЫЭЕНИУЗўЮёЦїЁЃ
8.ДјИДжЦЕФЛљгкОжВПадзюЩйСДНгЃЈLocality-Based Least Connections
with ReplicationЃЉ(LBLCR)
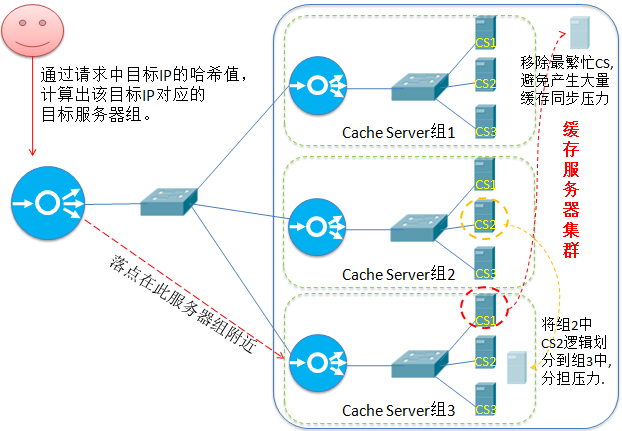
ЁАДјИДжЦЕФЛљгкОжВПадзюЩйСДНгЁБЕїЖШЫуЗЈвВЪЧеыЖдФПБъIPЕижЗЕФИКдиОљКтЃЌФПЧАжївЊгУгкCacheМЏШКЯЕЭГЁЃ ЫќгыLBLCЫуЗЈЕФВЛЭЌжЎДІЪЧЫќвЊЮЌЛЄДгвЛИіФПБъ IPЕижЗЕНвЛзщЗўЮёЦїЕФгГЩфЃЌЖјLBLCЫуЗЈЮЌЛЄДгвЛИіФПБъIP ЕижЗЕНвЛЬЈЗўЮёЦїЕФгГЩфЁЃИУЫуЗЈИљОнЧыЧѓЕФФПБъIPЕижЗевГіИУФПБъIPЕижЗЖдгІЕФЗўЮёЦїзщЃЌАДЁАзюаЁСЌНгЁБддђ ДгЗўЮёЦїзщжабЁГівЛЬЈЗўЮёЦїЃЌШєЗўЮёЦїУЛгаГЌдиЃЌНЋЧыЧѓЗЂЫЭЕНИУЗўЮёЦїЃЛ ШєЫљбЁЗўЮёЦїГЌдиЃЈГЌИКдиЕФБъзМЪЧ:ИУЗўЮёЦїе§дкДІРэЕФСЌНгзмЪ§ > ЦфШЈжижЕЕФ2БЖЃЉЃЌдђАДЁАзюаЁСЌНгЁБддђ ДгетИіМЏШКжабЁГівЛЬЈЗўЮёЦїЃЌНЋИУЗўЮёЦїМгШыЕНЗўЮёЦїзщжаЃЌНЋЧыЧѓЗЂЫЭЕНИУЗўЮёЦїЁЃЭЌЪБЃЌЕБИУЫљбЁЗўЮёЦїзщ гавЛЖЮЪБМфУЛгаБЛаоИФЙ§,дђЫљбЁЗўЮёЦїМгШыаТЛКДцИДжЦзщКѓ,КмПЩФмЕМжТИДжЦСїСПДѓСПдіМгЃЌвђДЫНЋзюУІЕФЗўЮёЦї ДгЗўЮёЦїзщжаЩОГ§ЃЌвдНЕЕЭИДжЦСїСПЕФГЬЖШЁЃ ЮвЕФРэНт: вђЮЊЛКДцЕФШШЕуЪ§ОнПЩФмНіга20%ЪЧгааЇЕФ,зюЗБУІЕФЗўЮёЦїЛКДцЕФЪ§ОнСПКмДѓЃЌЕЋгааЇЕФОГЃБЛЗУЮЪЕФШШЕу Ъ§ОнВЂВЛвЛЖЈКмЖр,вђДЫзмЬхПМТЧ,ИУзщжаЦфЫќЗўЮёЦїЩЯЯжгаЕФЛКДцЪ§ОнПЩгІЖдвЛЖЈСПЕФЧыЧѓ,МДБуЫ№ЪЇзюЗБУІЕФ ЗўЮёЦїЕФЪ§ОнвВВЛЛсдьГЩЬЋДѓгАЯьЃЌЕЋШєСєзХЫќ,аТМгШыЕННкЕу,ПЩФмашвЊИњЫќЭЌВНЛКДцЪ§Он,НЋЛсЕМжТИќДѓЕФЭјТч ДјПэБЛеМгУЃЌКмПЩФмЕМжТећИізщЕФВЛПЩгУ,вђДЫФўдИЫ№ЪЇвЛаЁВПЗжЛКДцЪ§Он,вВВЛФмШУећЬхВЛПЩгУЁЃ ЁОзЂвтЃК вдЩЯРэНтВЛвЛЖЈе§ШЗЃЌНіЙЉВЮПМЁП
9. зюЖЬЕФЦкЭћЕФбгГйЃЈShortest Expected Delay Scheduling
SEDЃЉ(SED) ЛљгкwlcЫуЗЈЁЃетИіБиаыОйР§РДЫЕСЫ ABCШ§ЬЈЛњЦїЗжБ№ШЈжи1ЃЌ2ЃЌ3 ЃЌСЌНгЪ§вВЗжБ№ЪЧ1ЃЌ2ЃЌ3ЁЃФЧУДШчЙћЪЙгУWLCЫуЗЈЕФЛАвЛИіаТЧыЧѓНјШыЪБ ЫќПЩФмЛсЗжИјABCжаЕФШЮвтвЛИіЃЌЪЙгУsedЫуЗЈКѓЛсНјааетбљвЛИідЫЫу AЃК(1+1)/1 = 2 BЃК(1+2)/2 = 1.5 CЃК(1+3)/3 = 1.3334 ИљОндЫЫуНсЙћЃЌАбСЌНгНЛИјCЃЌвђЮЊCЕФДІРэбгЪБзюаЁ ЁЃ
10.зюЩйЖгСаЕїЖШЃЈNever Queue Scheduling NQЃЉ(NQ) ЮоашЖгСаЁЃШчЙћгаЬЈ realserverЕФСЌНгЪ§ЃН0ОЭжБНгЗжХфЙ§ШЅЃЌВЛашвЊдкНјааsedдЫЫуЁЃ
ЯТУцЖдШ§жжФЃЪНзіЪОР§ХфжУЫЕУї:
1. LVS-NATФЃаЭЃК
МђЕЅЕФРДЫЕЃЌLVSЕФNATФЃаЭШчЯТЭМЃК
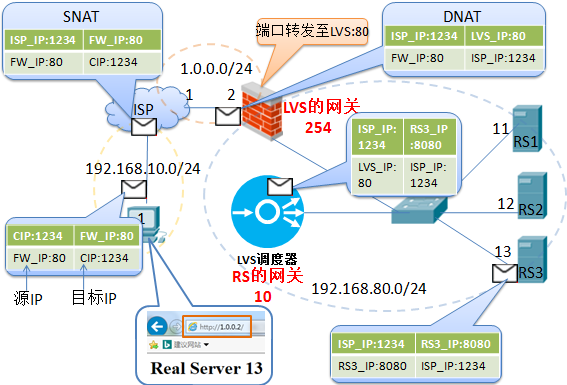
БОжЪЪЧЖрФПБъIPЕФDNATЃЌЭЈЙ§НЋЧыЧѓБЈЮФжаЕФФПБъЕижЗКЭФПБъЖЫПкаоИФЮЊЭЈЙ§ЕїЖШЫуЗЈЬєГі ЕФRSЕФRIPКЭPORTЪЕЯжзЊЗЂЁЃ
LVS-NATФЃаЭ: ЃЈ1ЃЉRealServerКЭЕїЖШЦїгІдкЭЌвЛИіIPЭјТчЃЌЧвгІЪЙгУЫНЭјЕижЗЃЛRealServerЕФЭјЙивЊжИЯђЕїЖШЦїЕФIP ЃЈ2ЃЉЕїЖШЦї(Director)ЪЧRealServerЕФЭјЙи, вђДЫЧыЧѓКЭЯьгІБЈЮФЖМНЋгЩЕїЖШЦїзЊЗЂ,вђДЫЕїЖШЦїШнвзГЩЮЊЯЕЭГЦПОБ. ЃЈ3ЃЉжЇГжЖЫПкгГЩфЃЌПЩаоИФЧыЧѓБЈЮФЕФФПБъPORT ЃЈ4ЃЉLVSБиаыЪЧLinuxЯЕЭГЃЌRSПЩвдЪЧШЮвтOSЯЕЭГ
ЩЯУцЭиЦЫЭМЕФХфжУШчЯТ: Client: ЪЙгУЮвЕФЮяРэЛњ,НЋФЌШЯЭјЙижИЯђISPЃЌЕБШЛЪЙгУVMвВПЩвд.
ISP:
ip addr add dev
eth0 192.168.10.254/24
ip addr add dev eth1 1.0.0.1/24
Systemctl stop firewalld #ЙиБеfirewalld,ЪжЖЏЪЙгУiptablesРДЙмРэЗРЛ№ЧН.
iptables -t nat -A POSTROUTING -s 192.168.10.0/24
!-d 192.168.10.0/24 -j MASQUERADE |
ДЫЪЕбщжаШУClientПЩЗУЮЪЦѓвЕWeb,вВПЩгУМђЕЅЕФЗНЪН: дкISPКЭЦѓвЕЗРЛ№ЧНжБНгЛЅЯрНЋФЌШЯЭјЙижИЯђЖдЗН.
ЦѓвЕFireWallЃК
ip addr add dev
eth0 1.0.0.2/24
ip addr add dev eth1 192.168.80.254/24
systemctl stop firewalld
iptables -t nat -A PREROUTING -d 1.0.0.2 -p tcp
--dport 80 -j DNAT --to-destination 192.168.80.10:80
echo "net.ipv4.ip_forward = 1" >>
/etc/sysctl.conf
sysctl -p |
Director LVS:
ip addr add dev
eth0 192.168.80.10/24
firewall-cmd --add-service=http --permanent ;
firewall-cmd --reload |
yum install -y
ipvsadm
ipvsadm -A -t 192.168.80.10:80 -s wrr
ipvsadm -a -t 192.168.80.10:80 -r 192.168.80.11:8080
-m -w 3
ipvsadm -a -t 192.168.80.10:80 -r 192.168.80.12:8080
-m -w 2
ipvsadm -a -t 192.168.80.10:80 -r 192.168.80.13:8080
-m |
ipvsadm -L -n (КѓРДНиЕФЭМ,ШЈжиВЛЗћ)
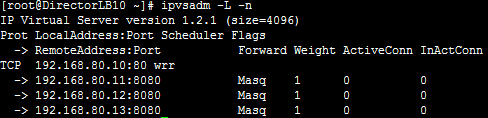
Ш§ЬЈRealServerЩЯжЛашХфжУIP,ВЂАВзАhttpdШэМўЃЌШЛКѓЦєЖЏМДПЩ. firewall-cmd --add-port=8080/tcp --permanent;
firewall-cmd --reload
дкШЮвтвЛЬЈЩЯВщПДhttpdЕФШежО:

ПЩвдПДЕНCIPЪЧISPЩЯЕФIP,МДПЭЛЇЖЫЕФФЌШЯЭјЙиЭтЭјНгПкЕФIP.
2. LVS-DRФЃаЭ
ЪЕбщЭиЦЫЫЕУїЃК етИіЭиЦЫжаБиаыгавЛИіЖРСЂЕФЭјЙиЃЌвђЮЊгУЛЇЧыЧѓЗЂРДЪБЃЌGWНЋЧыЧѓЗЂИјVIPЃЌЖјVIPжЛгаЕїЖШЦїЛсЯьгІЃЌ GWНЋЧыЧѓЗЂИјЕїЖШЦїЃЌЁОзЂвтЃКЕїЖШЦїЕФVIP,ОЁСПЪЙгУ32ЮЛбкТыЃЌетЗЧБиаыЁПЃЌдкDRФЃЪНЯТЃЌЕїЖШЦїЩЯгы GWСЌНгЕФНгПкЩЯгаСНИіIPЃЌвЛИіЪЧVIP(Virtual IP)ЃЌвЛИіЪЧDIP(Director
IP)ЃЛ ЕБЕїЖШЦїЪеЕНРДздGWЕФАќКѓ, ЗЂЯжФПБъЪЧVIP,ВЂЧвЗУЮЪЕФЗўЮёгыздЩэЖЈвхЕФащФтЗўЮёвЛбљЃЌНгзХЕїЖШЦїНЋЪ§ОнАќжаЕФдДMACаоИФЮЊздМКЕФMACЃЌ ЖјФПЕФMACЕФаоИФЪЧ ИљОнЕїЖШЫуЗЈЃЌбЁдёвЛЬЈReal ServerКѓЃЌНЋИУReal ServerЕФMACЬюаДдкФПЕФMACЩЯЃЌ НгзХНЋАќЗЂИјКѓЖЫЗўЮёЦїЃЌШчДЫР§ЮЊReal Server 1ЃЌRIP1ЪеЕНКѓНЋНтАќЗЂЯжЦфIPЪЧБОЕиloopbackЕФНгПкIPЃЌвђДЫRIP1 МЬајНтАќЃЌзюжеНЋАќЫЭИјЩЯВуЗўЮёЃЌШчБОР§ЪЧWebЗўЮёЃЛWebПЊЪМНјааЯьгІЃЌзюжеЗтАќЪБЃЌНЋдДMACаДЮЊздМКЃЌ ФПЕФMACаДЮЊGWЃЌдДIPаДVIPЃЌФПЕФIPаДClient IPЃЌВЂЗЂИјGWГіШЅЯьгІЁЃ
ЃЈ1ЃЉDIP, RIP КЭ VIP : ПЩдкЭЌвЛЭјЖЮЃЌвВПЩВЛдкЭЌвЛЭјЖЮ ЃЌЕЋЫћУЧБиаыдкЭЌвЛИіНЛЛЛЭјТчЁЃ ЃЈ2ЃЉDirector(ЕїЖШЦї)КЭRealServerЫћУЧЕФЭјЙиЖМБиаыжИЯђецЪЕЭјЙи(Firewall)ЃЌВЂЧвЖМвЊХфжУVIP. ЃЈ3ЃЉDirectorПЩвдЯьгІARPВщбЏVIPЕФMACЃЌЕЋRealServerвЛТЩЖМВЛЛигІВщбЏVIPЕФARPЧыЧѓ.
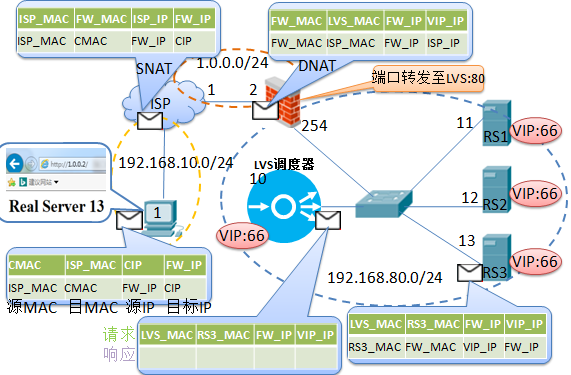
вдЩЯЭиЦЫЭМЕФХфжУШчЯТ:ЁЁЁЁ
Client: НЋФЌШЯЭјЙижИЯђISP
ISP:
ip addr add dev
eth0 192.168.10.254/24
ip addr add dev eth1 1.0.0.1/24
Systemctl stop firewalld #ЙиБеfirewalld,ЪжЖЏЪЙгУiptablesРДЙмРэЗРЛ№ЧН.
iptables -t nat -A POSTROUTING -s 192.168.10.0/24
!-d 192.168.10.0/24 -j MASQUERADE |
ДЫЪЕбщжаШУClientПЩЗУЮЪЦѓвЕWeb,вВПЩгУМђЕЅЕФЗНЪН: дкISPКЭЦѓвЕЗРЛ№ЧНжБНгЛЅЯрНЋФЌШЯЭјЙижИЯђЖдЗН.
ЦѓвЕFireWallЃК
ip addr add dev
eth0 1.0.0.2/24
ip addr add dev eth1 192.168.80.254/24
systemctl stop firewalld
iptables -t nat -A PREROUTING -d 1.0.0.2 -p tcp
--dport 80 -j DNAT --to-destination 192.168.80.10:80
echo "net.ipv4.ip_forward = 1" >>
/etc/sysctl.conf
sysctl -p |
Director LVS:
ip addr add dev
eth0 192.168.80.10/24
ip addr add dev lo 192.168.80.66/32
firewall-cmd --add-service=http --permanent ;
firewall-cmd --reload |
yum install -y
ipvsadm
ipvsadm -A -t 192.168.80.10:80 -s wrr
ipvsadm -a -t 192.168.80.10:80 -r 192.168.80.11:8080
-g -w 3
ipvsadm -a -t 192.168.80.10:80 -r 192.168.80.12:8080
-g -w 2
ipvsadm -a -t 192.168.80.10:80 -r 192.168.80.13:8080
-g |
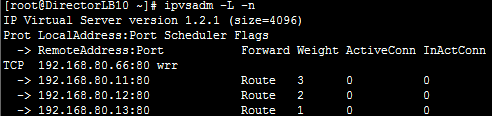
Ш§ЬЈRealServer:
ip addr add dev
eth0 192.168.80.11/24 #Ш§ЬЈЗжБ№ХфжУ11ЃЌ12ЃЌ13
ip addr add dev lo 192.168.80.66/32 #ВЛвЛЖЈЗЧвЊЪЧ32,ПЩвдЪЧ24.
#ЯТУцХфжУЪЕМЪЩЯЪЧжЛдЪаэloНгПкЪеЕНгыloжБНгСЌНгЕФНгПкЗЂРДЕФARPЧыЧѓЪБ,
#ВХЯьгІЙигк192.168.80.66ЕФMACЯьгІ.ЭЌЪБВЛдкЗЂЩњУтЗбARPзіздЮЪздД№.
#ЯђЭјТчжааћИцЮввЊЪЙгУ192.168.80.66етИіIPСЫЁЃ
echo "net.ipv4.conf.all.arp_ignore = 1"
>> /etc/sysctl.conf
echo "net.ipv4.conf.all.arp_announce =
2" >> /etc/sysctl.conf
echo "net.ipv4.conf.lo.arp_ignore = 1"
>> /etc/sysctl.conf
echo "net.ipv4.conf.lo.arp_announce = 2"
>> /etc/sysctl.conf
sysctl -p
firewall-cmd --add-port =80/tcp --permanent;
firewall-cmd --reload |
ВщПДЭЈаХЙ§ГЬЕФЬсЪО: 1. дкЕїЖШЦїЛђRealServerЪЙгУ tcpdump -i НгПк -n -nn port 80 -w director.cap #етбљПЩВЖЛёЭЈаХЙ§ГЬжаЕФЫљгаАќ,АќРЈЕїЖШЦїЪеЕНЕФ,зЊЗЂИјRealServerЕФ, вдМАRealServerЗЂЩњИјFirewallЕФ. #ШєЯђЕЅЖРВщПДЕїЖШЦїЪеЕНКЭЗЂЫЭЕФАќЃЌдкRealServerЩЯВщПДздМКЪеЕНЕФАќКЭЗЂЫЭЕФАќПЩЃК tcpdump -i НгПк -n -nn -p port 80 #-p : НіВЖЛёЗЂИјздМКЕФАќ,ЗЧздМКЕФВЛвЊ.
2. дкFirewallЩЯВщПДЫљгаЕФMAC ip addr show dev eth1 |grep link/ether ip neigh
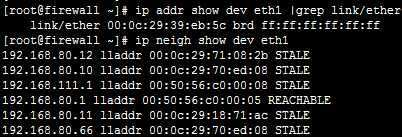
3. ЪЙгУWireshareВщПДЪБ,ЭЈЙ§ЬэМгздЖЈвхСаРДВщПДMACЕФБфЛЏ
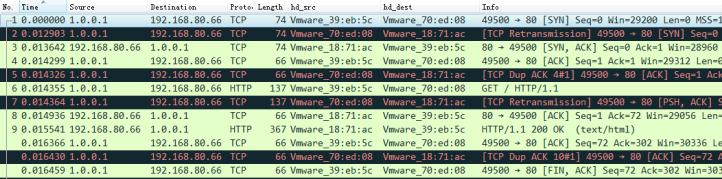
3. LVS TunnelФЃЪН ЭиЦЫЃК
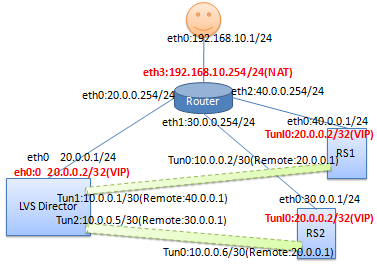
LVS TunnelФЃЪНХфжУвЊЕуЃК (1) LVSЕїЖШНкЕуЁЂRealServerНкЕуЁЂVIPЖМБиаыЪЧЙЋЭјIP (2) LVSЕїЖШНкЕуЁЂRealServerНкЕуЖМБиаыХфжУVIP (3) ЕїЖШНкЕу гы RSМфБиаыДђЭЈвЛЬѕЫэЕР (4) ПЭЛЇЖЫЧыЧѓЗЂЭљЕїЖШНкЕуЃЌЕїЖШНкЕуЭЈЙ§ЫэЕРНЋЧыЧѓБЈЮФЗтзАЦ№РДЗЂИјRS, RSдкЫэЕРСэвЛЖЫШЅЕєGREЗтзА,ЗЂЯжЪЧШЅЭљVIPЕФ,ЫцМДзЊИјtunl0ДІРэ,зюжеTunl0 НЋЯьгІБЈЮФДгRSЕФФЌШЯТЗгЩЗЂГіЁЃ (5) ЕїЖШНкЕувЊдкЫљгаЩшБИЩЯЦєгУ жЛНгЪеЭјЙиЗЂЫЭЕФICMPЕФжиЖЈЯђБЈЮФЁЃ (6) ЕїЖШНкЕу КЭ RSЩЯЖМБиаыЙиБеТЗгЩзЊЗЂ(ip_forward), RSЩЯЙиБеARPЯьгІКЭЗЕЛиТЗОЖЙ§ТЫ (МД:дДЪЧAПк,вЊДгBПкГі,BПкВЛЖЊИУАќ).
LVS TunnelЛЗОГДюНЈ
(1) ТЗгЩЦїФЃФт:
echo 1 > /proc/sys/net/ipv4/ip_forward
ifconfig eth0 20.0.0.254/24 up
ifconfig eth1 30.0.0.254/24 up
ifconfig eth2 40.0.0.254/24 up
ifconfig eth3 192.168.10.254/24 up
iptables -t nat -A POSTROUTING -s 192.168.10.0/24
! -d 192.168.10.0/24 -j SNAT --to 192.168.10.254
|
(2) LVSЕїЖШНкЕу
#ЙиБеТЗгЩзЊЗЂЃЈФЌШЯЪЧЙиБе.ЃЉ echo 0 > /proc/sys/net/ipv4/ip_forward
#дкЫљгаНгПкЁЂФЌШЯНгПкЁЂeth0ЩЯЖМДђПЊ НіНгЪеРДздЭјЙиЕФICMPжиЖЈЯђ. #зЂЃКФЌШЯгІИУЪЧДђПЊЕФ,ДгзЅАќКЭЗжЮіЩЯПД,ICMPжиЖЈЯђЪЧБиаы,вђЮЊПЭЛЇЖЫЗУЮЪЕФЕїЖШЦїЕФзгНгПк, # ЖјЕїЖШЦїЕФжїНгПкIPЪЧ20.0.0.1,зг(ДЮ)НгПкIP20.0.0.2,ЭјЙиЭЈЙ§ARPЗЂЯж,ПЭЛЇЖЫЗУЮЪЕФVIP20.0.0.2 # ЪЧдкЕїЖШЦїНгПкЩЯЃЌвђДЫ,НЋШЅЭљ20.0.0.2ЕФЧыЧѓжиЖЈЯђИјЕїЖШЦїЁЃ
echo 1 > /proc/sys/net/ipv4/conf/all/
send_redirects
echo 1 > /proc/sys/net/ipv4/conf/default/
send_redirects
echo 1 > /proc/sys/net/ipv4/conf/eth0/
send_redirects
#ЯШЙиБеЫљгаНгПк,гУЕНФЧИіМЄЛюФЧИіЁЃ service network stop
ifconfig eth0 20.0.0.1/24 up ifconfig eth0:0 20.0.0.2 broadcast 20.0.0.2
netmask 255.255.255.255 up ip tunnel add tun1 mode gre remote 30.0.0.1
local 20.0.0.1 ifconfig tun1 10.0.0.1/30 up ip tunnel add tun2 mode gre remote 40.0.0.1
local 20.0.0.1 ifconfig tun2 10.0.0.5/30 up #зЂЃК
GRE(ЭЈгУТЗгЩЗтзА) :
МђЕЅРэНт: GREОЭЪЧдкНЋдЪМIPАќ,дйДЮЗтзАдкGREФкВП, НгзХдкдйДЮНЋGREАќЗтзАЕНаТIPАќжа, ШЛКѓдкМгШыШчСДТЗВужЁЭЗ,зюКѓЗЂГіШЅ.ЦфЪЕGRE,VxLAN,NVGRE,IPSecЖМПЩШЯЮЊЪЧвЛжжVPN. MACжЁ[IPЭЗ[GREЭЗЁОIPЭЗ[TCPЭЗ[гІгУавщЪ§Он]]ЁП]] зЂвтЃК GREЗтзАКѓ,ШєКѓЖЫЪЧЕїЖШЦї,дђИУЕїЖШЦїНЋгРдЖжЛФмПДЕНвЛИіIPРДЗУЮЪздМК,вђДЫвЊзЂвтЪЙгУЕїЖШЫуЗЈ.
#ЬэМгФЌШЯТЗгЩ route add default gw 20.0.0.254 #ЬэМгжїЛњТЗгЩ,вдБуLinuxЪеЕНШЅЭљ20.0.0.2ЕФБЈЮФКѓ,жЊЕРзЊЕНФЧИіНгПкЩЯЁЃ route add -host 20.0.0.2 dev eth0:0
yum install ipvsadm ipvsadm -A -t 20.0.0.2:80 -s rr ipvsadm -a -t 20.0.0.2:80 -r 10.0.0.2 -i ЁЁЁЁ #зЂвт:етРяБиаыЪЙгУtunnelФЃЪН,МДЁА-iЁБ ipvsadm -a -t 20.0.0.2:80 -r 10.0.0.6 -i
(2) RealServer1ЕФХфжУ: ifconfig eth0 30.0.0.1/24 up ifconfig tunl0 20.0.0.2 broadcast 20.0.0.2 netmask
255.255.255.255 up #зЂвтЃКвЛЖЈвЊЬэМгвЛЬѕжїЛњТЗгЩ,ЗёдђLinuxЕФtun0НгПкЪеЕНGREЗтАќКѓ, # НтПЊЗЂЯжЪЧвЛИіШЅЭљ20.0.0.2ЕФIPБЈЮФ,ВщБОЛњзЊЗЂБэШєУЛгаевЕН,ОЭПЩФмЖЊЦњИУБЈЮФ. # ФЧУДПЭЛЇЖЫПЩФмОЭДђВЛПЊЭјвГСЫЁЃ route add -host 20.0.0.2 dev tunl0 ip tunnel add tun0 mode gre remote 20.0.0.1 local
30.0.0.1 ifconfig tun0 10.0.0.2/30 up
#ЙиБеТЗгЩзЊЗЂ echo 0 > /proc/sys/net/ipv4/ip_forward
#arp_ignore: ЖЈвхНгЪеЕНARPЧыЧѓЪБЕФЯьгІМЖБ№ЃЛ #ЁЁЁЁ 0ЃКжЛвЊБОЕиХфжУЕФгаЯргІЕижЗЃЌОЭИјгшЯьгІЃЛ #ЁЁЁЁ 1ЃКНіЯьгІФПЕФIPХфжУдкДЫНгПкЩЯЕФARPЙуВЅЧыЧѓ #arp_announce: ЖЈвхНЋздМКЕФЕижЗЯђЭтЭЈИцЪБЕФЭЈИцМЖБ№(ДЫааЮЊНіЗЂЩњдкЭјТчЩшБИИеНгШыЭјТчЪБ) #ЁЁЁЁ 0ЃКНЋБОЕиШЮКЮНгПкЩЯЕФШЮКЮЕижЗЯђЭтЭЈИцЃЛ # ЁЁЁЁ 1ЃКЪдЭМНіЯђФПБъЭјТчЭЈИцгыЦфЭјТчЦЅХфЕФЕижЗЃЛ # ЁЁЁЁ 2ЃКНіЯђгыБОЕиНгПкЩЯЕижЗЦЅХфЕФЭјТчНјааЭЈИцЃЛ echo 1 > /proc/sys/net/ipv4/conf/tunl0/arp_ignore echo 2 > /proc/sys/net/ipv4/conf/tunl0/arp_announce echo 1 > /proc/sys/net/ipv4/conf/all/arp_ignore echo 2 > /proc/sys/net/ipv4/conf/all/arp_announce
#ЙиБеtunl0ЁЂeth0ЩЯЗЕЛиТЗОЖЙ§ТЫ echo 0 > /proc/sys/net/ipv4/conf/tunl0/rp_filter echo 0 > /proc/sys/net/ipv4/conf/eth0/rp_filter echo 0 > /proc/sys/net/ipv4/conf/all/rp_filter
(2) RealServer2ЕФХфжУ: ifconfig eth0 40.0.0.1/24 up ifconfig tunl0 20.0.0.2 broadcast 20.0.0.2 netmask
255.255.255.255 up #зЂвтЃКвЛЖЈвЊЬэМгвЛЬѕжїЛњТЗгЩ,ЗёдђLinuxЕФtun0НгПкЪеЕНGREЗтАќКѓ, # НтПЊЗЂЯжЪЧвЛИіШЅЭљ20.0.0.2ЕФIPБЈЮФ,ВщБОЛњзЊЗЂБэШєУЛгаевЕН,ОЭПЩФмЖЊЦњИУБЈЮФ. # ФЧУДПЭЛЇЖЫПЩФмОЭДђВЛПЊЭјвГСЫЁЃ route add -host 20.0.0.2 dev tunl0 ip tunnel add tun0 mode gre remote 20.0.0.1 local
40.0.0.1 ifconfig tun0 10.0.0.6/30 up
#ЙиБеТЗгЩзЊЗЂ echo 0 > /proc/sys/net/ipv4/ip_forward echo 1 > /proc/sys/net/ipv4/conf/tunl0/arp_ignore echo 2 > /proc/sys/net/ipv4/conf/tunl0/arp_announce echo 1 > /proc/sys/net/ipv4/conf/all/arp_ignore echo 2 > /proc/sys/net/ipv4/conf/all/arp_announce
#ЙиБеtunl0ЁЂeth0ЩЯЗЕЛиТЗОЖЙ§ТЫ echo 0 > /proc/sys/net/ipv4/conf/tunl0/rp_filter echo 0 > /proc/sys/net/ipv4/conf/eth0/rp_filter echo 0 > /proc/sys/net/ipv4/conf/all/rp_filter
LVSЕїЖШЦїЪеЕНРДПЭЛЇЖЫЕФЗУЮЪБЈЮФЃК #ЯШжиЖЈЯђ

#ЕїЖШКѓЗЂЫЭЕФБЈЮФЃЌзЂвтУПИіIPБЈЮФФкВПЕФФкШн,дкИУIPБЈЮФПДРДЖМНіНіЪЧЪ§ОнЖјвбЁЃ

#RealServer2ЪеЕНGREБЈЮФНтЗтзАКѓЃЌНЋИУБЈЮФЗЂИјtun0НгПкКѓЃК

#RealServer2ЕФtun0НгПкШЅЕєIPВуКѓЃЌЗЂЯжЛЙЪЧIPБЈЮФ,ЫцЛњзЊЗЂИјtunl0НгПк:

#ЛигІ

|









