| БрМЭЦМі: |
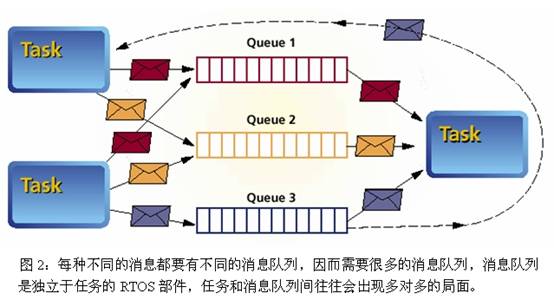
ЮвУЧГЃГЃЛсЬ§ЫЕЃЌФГИіЛЅСЊЭјгІгУЕФЗўЮёЦїЖЫЯЕЭГЖрУДХЃБЦЃЌБШШчQQЁЂЮЂаХЁЂЬдБІЁЃФЧУДЃЌвЛИіЛЅСЊЭјгІгУЕФЗўЮёЦїЖЫЯЕЭГЃЌЕНЕзХЃБЦдкЪВУДЕиЗНЃПЮЊЪВУДКЃСПЕФгУЛЇЗУЮЪЃЌЛсШУвЛИіЗўЮёЦїЖЫЯЕЭГБфЕУИќИДдгЃПБОЮФОЭЪЧЯыДгзюЛљБОЕФЕиЗНПЊЪМЃЌЬНбАЗўЮёЦїЖЫЯЕЭГММЪѕЕФЛљДЁИХФюЁЃ
РДздгкВЉПЭдАЃЌ,гЩЛ№СњЙћШэМўAnnaБрМЁЂЭЦМіЁЃ |
|
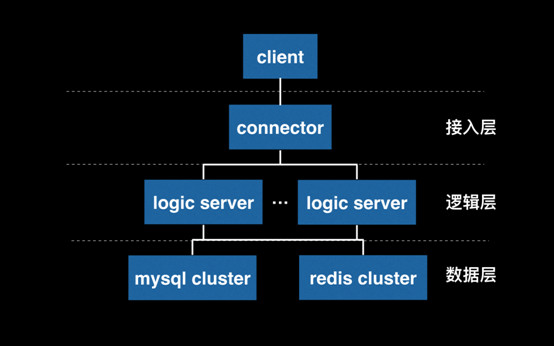
ГадиСПЪЧЗжВМЪНЯЕЭГДцдкЕФдвђ
ЕБвЛИіЛЅСЊЭјвЕЮёЛёЕУДѓжкЛЖгЕФЪБКђЃЌзюЯджјХіЕНЕФММЪѕЮЪЬтЃЌОЭЪЧЗўЮёЦїЗЧГЃЗБУІЁЃЕБУПЬьга1000ЭђИігУЛЇЗУЮЪФуЕФЭјеОЪБЃЌЮоТлФуЪЙгУЪВУДбљЕФЗўЮёЦїгВМўЃЌЖМВЛПЩФмжЛгУвЛЬЈЛњЦїОЭГадиЕФСЫЁЃвђДЫЃЌдкЛЅСЊЭјГЬађдБНтОіЗўЮёЦїЖЫЮЪЬтЕФЪБКђЃЌБиаывЊПМТЧШчКЮЪЙгУЖрЬЈЗўЮёЦїЃЌЮЊЭЌвЛжжЛЅСЊЭјгІгУЬсЙЉЗўЮёЃЌетОЭЪЧЫљЮНЁАЗжВМЪНЯЕЭГЁБЕФРДдДЁЃ
ШЛЖјЃЌДѓСПгУЛЇЗУЮЪЭЌвЛИіЛЅСЊЭјвЕЮёЃЌЫљдьГЩЕФЮЪЬтВЂВЛМђЕЅЁЃДгБэУцЩЯПДЃЌвЊФмТњзуКмЖргУЛЇРДздЛЅСЊЭјЕФЧыЧѓЃЌзюЛљБОЕФашЧѓОЭЪЧЫљЮНадФмашЧѓЃКгУЛЇЗДгІЭјвГДђПЊКмТ§ЃЌЛђепЭјгЮжаЕФЖЏзїКмПЈЕШЕШЁЃЖјетаЉЖдгкЁАЗўЮёЫйЖШЁБЕФвЊЧѓЃЌЪЕМЪЩЯАќКЌЕФВПЗжШДЪЧвдЯТМИИіЃКИпЭЬЭТЁЂИпВЂЗЂЁЂЕЭбгГйКЭИКдиОљКтЁЃ
ИпЭЬЭТЃЌвтЮЖзХФуЕФЯЕЭГЃЌПЩвдЭЌЪБГадиДѓСПЕФгУЛЇЪЙгУЁЃетРяЙизЂЕФећИіЯЕЭГФмЭЌЪБЗўЮёЕФгУЛЇЪ§ЁЃетИіЭЬЭТСППЯЖЈЪЧВЛПЩФмгУЕЅЬЈЗўЮёЦїНтОіЕФЃЌвђДЫашвЊЖрЬЈЗўЮёЦїазїЃЌВХФмДяЕНЫљашвЊЕФЭЬЭТСПЁЃЖјдкЖрЬЈЗўЮёЦїЕФазїжаЃЌШчКЮВХФмгааЇЕФРћгУетаЉЗўЮёЦїЃЌВЛжТгкЦфжаФГвЛВПЗжЗўЮёЦїГЩЮЊЦПОБЃЌДгЖјгАЯьећИіЯЕЭГЕФДІРэФмСІЃЌетОЭЪЧвЛИіЗжВМЪНЯЕЭГЃЌдкМмЙЙЩЯашвЊзаЯИШЈКтЕФЮЪЬтЁЃ
ИпВЂЗЂЪЧИпЭЬЭТЕФвЛИібгЩьашЧѓЁЃЕБЮвУЧдкГадиКЃСПгУЛЇЕФЪБКђЃЌЮвУЧЕБШЛЯЃЭћУПИіЗўЮёЦїЖМФмОЁЦфЫљФмЕФЙЄзїЃЌЖјВЛвЊГіЯжЮоЮНЕФЯћКФКЭЕШД§ЕФЧщПіЁЃШЛЖјЃЌШэМўЯЕЭГВЂВЛЪЧМђЕЅЕФЩшМЦЃЌОЭФмЖдЭЌЪБДІРэЖрИіШЮЮёЃЌзіЕНЁАОЁСПЖрЁБЕФДІРэЁЃКмЖрЪБКђЃЌЮвУЧЕФГЬађЛсвђЮЊвЊбЁдёДІРэФФИіШЮЮёЃЌЖјЕМжТЖюЭтЕФЯћКФЁЃетвВЪЧЗжВМЪНЯЕЭГНтОіЕФЮЪЬтЁЃ
ЕЭбгГйЖдгкШЫЪ§ЯЁЩйЕФЗўЮёРДЫЕВЛЫуЪВУДЮЪЬтЁЃШЛЖјЃЌШчЙћЮвУЧашвЊдкДѓСПгУЛЇЗУЮЪЕФЪБКђЃЌвВФмКмПьЕФЗЕЛиМЦЫуНсЙћЃЌетОЭвЊРЇФбЕФЖрЁЃвђЮЊГ§СЫДѓСПгУЛЇЗУЮЪПЩФмдьГЩЧыЧѓдкХХЖгЭтЃЌЛЙгаПЩФмвђЮЊХХЖгЕФГЄЖШЬЋГЄЃЌЕМжТФкДцКФОЁЁЂДјПэеМТњЕШПеМфадЕФЮЪЬтЁЃШчЙћвђЮЊХХЖгЪЇАмЖјВЩШЁжиЪдЕФВпТдЃЌдђећИібгГйЛсБфЕФИќИпЁЃЫљвдЗжВМЪНЯЕЭГЛсВЩгУКмЖрЧыЧѓЗжМ№КЭЗжЗЂЕФзіЗЈЃЌОЁПьЕФШУИќЖрЕФЗўЮёЦїРДГіРДгУЛЇЕФЧыЧѓЁЃЕЋЪЧЃЌгЩгквЛИіЪ§СПХгДѓЕФЗжВМЪНЯЕЭГЃЌБиШЛашвЊАбгУЛЇЕФЧыЧѓОЙ§ЖрДЮЕФЗжЗЂЃЌећИібгГйПЩФмЛсвђЮЊетаЉЗжЗЂКЭзЊНЛЕФВйзїЃЌБфЕУИќИпЃЌЫљвдЗжВМЪНЯЕЭГГ§СЫЗжЗЂЧыЧѓЭтЃЌЛЙвЊОЁСПЯыАьЗЈМѕЩйЗжЗЂЕФВуДЮЪ§ЃЌвдБуШУЧыЧѓФмОЁПьЕФЕУЕНДІРэЁЃ
гЩгкЛЅСЊЭјвЕЮёЕФгУЛЇРДздШЋЪРНчЃЌвђДЫдкЮяРэПеМфЩЯПЩФмРДздИїжжВЛЭЌбгГйЕФЭјТчКЭЯпТЗЃЌдкЪБМфЩЯвВПЩФмРДздВЛЭЌЕФЪБЧјЃЌЫљвдвЊгааЇЕФгІЖдетжжгУЛЇРДдДЕФИДдгадЃЌОЭашвЊАбЖрИіЗўЮёЦїВПЪ№дкВЛЭЌЕФПеМфРДЬсЙЉЗўЮёЁЃЭЌЪБЃЌЮвУЧвВашвЊШУЭЌЪБЗЂЩњЕФЧыЧѓЃЌгааЇЕФШУЖрИіВЛЭЌЗўЮёЦїГадиЁЃЫљЮНЕФИКдиОљКтЃЌОЭЪЧЗжВМЪНЯЕЭГгыЩњОуРДашвЊЭъГЩЕФЙІПЮЁЃ
гЩгкЗжВМЪНЯЕЭГЃЌМИКѕЪЧНтОіЛЅСЊЭјвЕЮёГадиСПЮЪЬтЃЌЕФзюЛљБОЗНЗЈЃЌЫљвдзїЮЊвЛИіЗўЮёЦїЖЫГЬађдБЃЌеЦЮеЗжВМЪНЯЕЭГММЪѕОЭБфЕУвьГЃживЊСЫЁЃШЛЖјЃЌЗжВМЪНЯЕЭГЕФЮЪЬтЃЌВЂЗЧЪЧбЇЛсгУМИИіПђМмКЭЪЙгУМИИіПтЃЌОЭФмЧсвзНтОіЕФЃЌвђЮЊЕБвЛИіГЬађдквЛИіЕчФдЩЯдЫааЃЌБфГЩСЫгжЮоЪ§ИіЕчФдЩЯЭЌЪБаЭЌдЫааЃЌдкПЊЗЂЁЂдЫЮЌЩЯЖМЛсДјРДКмДѓЕФВюБ№ЁЃ
ЗжВМЪНЯЕЭГЬсИпГадиСПЕФЛљБОЪжЖЮ
ЗжВуФЃаЭЃЈТЗгЩЁЂДњРэЃЉ
ЪЙгУЖрЬЌЗўЮёЦїРДаЭЌЭъГЩМЦЫуШЮЮёЃЌзюМђЕЅЕФЫМТЗОЭЪЧЃЌШУУПИіЗўЮёЦїЖМФмЭъГЩШЋВПЕФЧыЧѓЃЌШЛКѓАбЧыЧѓЫцЛњЕФЗЂИјШЮКЮвЛИіЗўЮёЦїДІРэЁЃзюдчЦкЕФЛЅСЊЭјгІгУжаЃЌDNSТжбЏОЭЪЧетбљЕФзіЗЈЃКЕБгУЛЇЪфШывЛИігђУћЪдЭМЗУЮЪФГИіЭјеОЃЌетИігђУћЛсБЛНтЪЭГЩЖрИіIPЕижЗжаЕФвЛИіЃЌЫцКѓетИіЭјеОЕФЗУЮЪЧыЧѓЃЌОЭБЛЗЂЭљЖдгІIPЕФЗўЮёЦїСЫЃЌетбљЖрИіЗўЮёЦїЃЈЖрИіIPЕижЗЃЉОЭФмвЛЦ№НтОіДІРэДѓСПЕФгУЛЇЧыЧѓЁЃ
ШЛЖјЃЌЕЅДПЕФЧыЧѓЫцЛњзЊЗЂЃЌВЂВЛФмНтОівЛЧаЮЪЬтЁЃБШШчЮвУЧКмЖрЛЅСЊЭјвЕЮёЃЌЖМЪЧашвЊгУЛЇЕЧТМЕФЁЃдкЕЧТМФГвЛИіЗўЮёЦїКѓЃЌгУЛЇЛсЗЂЦ№ЖрИіЧыЧѓЃЌШчЙћЮвУЧАбетаЉЧыЧѓЫцЛњЕФзЊЗЂЕНВЛЭЌЕФЗўЮёЦїЩЯЃЌФЧУДгУЛЇЕЧТМЕФзДЬЌОЭЛсЖЊЪЇЃЌдьГЩвЛаЉЧыЧѓДІРэЪЇАмЁЃМђЕЅЕФвРППвЛВуЗўЮёзЊЗЂЪЧВЛЙЛЕФЃЌЫљвдЮвУЧЛсдіМгвЛХњЗўЮёЦїЃЌетаЉЗўЮёЦїЛсИљОнгУЛЇЕФCookieЃЌЛђепгУЛЇЕФЕЧТМЦООнЃЌРДдйДЮзЊЗЂИјКѓУцОпЬхДІРэвЕЮёЕФЗўЮёЦїЁЃ
Г§СЫЕЧТМЕФашЧѓЭтЃЌЮвУЧЛЙЗЂЯжЃЌКмЖрЪ§ОнЪЧашвЊЪ§ОнПтРДДІРэЕФЃЌЖјЮвУЧЕФетаЉЪ§ОнЭљЭљЖМжЛФмМЏжаЕНвЛИіЪ§ОнПтжаЃЌЗёдђдкВщбЏЕФЪБКђОЭЛсЖЊЪЇЦфЫћЗўЮёЦїЩЯДцЗХЕФЪ§ОнНсЙћЁЃЫљвдЭљЭљЮвУЧЛЙЛсАбЪ§ОнПтЕЅЖРГіРДГЩЮЊвЛХњзЈгУЕФЗўЮёЦїЁЃ
жСДЫЃЌЮвУЧОЭЛсЗЂЯжЃЌвЛИіЕфаЭЕФШ§ВуНсЙЙГіЯжСЫЃКНгШыЁЂТпМЁЂДцДЂЁЃШЛЖјЃЌетжжШ§ВуНсЙћЃЌВЂВЛОЭФмАќвНАйВЁЁЃР§ШчЃЌЕБЮвУЧашвЊШУгУЛЇдкЯпЛЅЖЏЃЈЭјгЮОЭЪЧЕфаЭЃЉ
ЃЌФЧУДЗжИюдкВЛЭЌТпМЗўЮёЦїЩЯЕФдкЯпзДЬЌЪ§ОнЃЌЪЧЮоЗЈжЊЕРЖдЗНЕФЃЌетбљЮвУЧОЭашвЊзЈУХзівЛИіРрЫЦЛЅЖЏЗўЮёЦїЕФзЈУХЯЕЭГЃЌШУгУЛЇЕЧТМЕФЪБКђЃЌвВЭЌЪБМЧТМвЛЗнЪ§ОнЕНЫќФЧРяЃЌБэУїФГИігУЛЇЕЧТМдкФГИіЗўЮёЦїЩЯЃЌЖјЫљгаЕФЛЅЖЏВйзїЃЌвЊЯШОЙ§етИіЛЅЖЏЗўЮёЦїЃЌВХФме§ШЗЕФАбЯћЯЂзЊЗЂЕНФПБъгУЛЇЕФЗўЮёЦїЩЯЁЃ
гжР§ШчЃЌЕБЮвУЧдкЪЙгУЭјЩЯТлЬГЃЈBBSЃЉЯЕЭГЕФЪБКђЃЌЮвУЧЗЂЕФЮФеТЃЌВЛПЩФмжЛаДШывЛИіЪ§ОнПтРяЃЌвђЮЊЬЋЖрШЫЕФдФЖСЧыЧѓЛсЭЯЫРетИіЪ§ОнПтЁЃЮвУЧГЃГЃЛсАДТлЬГАхПщРДаДШыВЛЭЌЕФЪ§ОнПтЃЌгжЛђепЪЧЭЌЪБаДШыЖрИіЪ§ОнПтЁЃетбљАбЮФеТЪ§ОнЗжБ№ДцЗХЕНВЛЭЌЕФЗўЮёЦїЩЯЃЌВХФмгІЖдДѓСПЕФВйзїЧыЧѓЁЃШЛЖјЃЌгУЛЇдкЖСШЁЮФеТЕФЪБКђЃЌОЭашвЊгавЛИізЈУХЕФГЬађЃЌШЅВщевОпЬхЮФеТдкФФвЛИіЗўЮёЦїЩЯЃЌетЪБКђЮвУЧОЭвЊМмЩшвЛИізЈУХЕФДњРэВуЃЌАбЫљгаЕФЮФеТЧыЧѓЯШзЊНЛИјЫќЃЌгЩЫќАДееЮвУЧдЄЩшЕФДцДЂМЦЛЎЃЌШЅевЖдгІЕФЪ§ОнПтЛёШЁЪ§ОнЁЃ
ИљОнЩЯУцЕФР§згРДПДЃЌЗжВМЪНЯЕЭГЫфШЛОпгаШ§ВуЕфаЭЕФНсЙЙЃЌЕЋЪЧЪЕМЪЩЯЭљЭљВЛжЙгаШ§ВуЃЌЖјЪЧИљОнвЕЮёашЧѓЃЌЛсЩшМЦГЩЖрИіВуДЮЕФЁЃЮЊСЫАбЧыЧѓзЊНЛИје§ШЗЕФНјГЬДІРэЃЌЮвУЧЖјЩшМЦКмЖрзЈУХгУгкзЊЗЂЧыЧѓЕФНјГЬКЭЗўЮёЦїЁЃетаЉНјГЬЮвУЧГЃГЃвдProxyЛђепRouterРДУќУћЃЌвЛИіЖрВуНсЙЙГЃГЃЛсОпБИИїжжИїбљЕФProxyНјГЬЁЃетаЉДњРэНјГЬЃЌКмЖрЪБКђЖМЪЧЭЈЙ§TCPРДСЌНгЧАКѓСНЖЫЁЃШЛЖјЃЌTCPЫфШЛМђЕЅЃЌЕЋЪЧШДЛсгаЙЪеЯКѓВЛШнвзЛжИДЕФЮЪЬтЁЃЖјЧвTCPЕФЭјТчБрГЬЃЌвВЪЧгаЕуИДдгЕФЁЃЁЊЁЊЫљвдЃЌШЫУЧЩшМЦГіИќКУНјГЬМфЭЈбЖЛњжЦЃКЯћЯЂЖгСаЁЃ
ОЁЙмЭЈЙ§ИїжжProxyЛђепRouterНјГЬФмзщНЈГіЧПДѓЕФЗжВМЪНЯЕЭГЃЌЕЋЪЧЦфЙмРэЕФИДдгадвВЪЧЗЧГЃИпЕФЁЃЫљвдШЫУЧдкЗжВуФЃЪНЕФЛљДЁЩЯЃЌЯыГіСЫИќЖрЕФЗНЗЈЃЌРДШУетжжЗжВуФЃЪНЕФГЬађБфЕУИќМђЕЅИпаЇЕФЗНЗЈЁЃ
ВЂЗЂФЃаЭЃЈЖрЯпГЬЁЂвьВНЃЉ
ЕБЮвУЧдкБраДЗўЮёЦїЖЫГЬађЪЧЃЌЮвУЧЛсУїШЗЕФжЊЕРЃЌДѓВПЗжЕФГЬађЃЌЖМЪЧЛсДІРэЭЌЪБЕНДяЕФЖрИіЧыЧѓЕФЁЃвђДЫЮвУЧВЛФмКУЯёHelloWorldФЧУДМђЕЅЕФЃЌДгвЛИіМђЕЅЕФЪфШыМЦЫуГіЪфГіРДЁЃвђЮЊЮвУЧЛсЭЌЪБЛёЕУКмЖрИіЪфШыЃЌашвЊЗЕЛиКмЖрИіЪфГіЁЃдкетаЉДІРэЕФЙ§ГЬжаЃЌЭљЭљЮвУЧЛЙЛсХіЕНашвЊЁАЕШД§ЁБЛђЁАзшШћЁБЕФЧщПіЃЌБШШчЮвУЧЕФГЬађвЊЕШД§Ъ§ОнПтДІРэНсЙћЃЌЕШД§ЯђСэЭтвЛИіНјГЬЧыЧѓНсЙћЕШЕШЁЁШчЙћЮвУЧАбЧыЧѓвЛИіАЄзХвЛИіЕФДІРэЃЌФЧУДетаЉПеЯаЕФЕШД§ЪБМфНЋАзАзРЫЗбЃЌдьГЩгУЛЇЕФЯьгІбгЪБдіМгЃЌвдМАећЬхЯЕЭГЕФЭЬЭТСПМЋЖШЯТНЕЁЃ
ЫљвддкШчКЮЭЌЪБДІРэЖрИіЧыЧѓЕФЮЪЬтЩЯЃЌвЕНчга2ИіЕфаЭЕФЗНАИЁЃвЛжжЪЧЖрЯпГЬЃЌвЛжжЪЧвьВНЁЃдкдчЦкЕФЯЕЭГжаЃЌЖрЯпГЬЛђЖрНјГЬЪЧзюГЃгУЕФММЪѕЁЃетжжММЪѕЕФДњТыБраДЦ№РДБШНЯМђЕЅЃЌвђЮЊУПИіЯпГЬжаЕФДњТыЖМПЯЖЈЪЧАДЯШКѓЫГађжДааЕФЁЃЕЋЪЧгЩгкЭЌЪБдЫаазХЖрИіЯпГЬЃЌЫљвдФуЮоЗЈБЃеЯЖрИіЯпГЬжЎМфЕФДњТыЕФЯШКѓЫГађЁЃетЖдгкашвЊДІРэЭЌвЛИіЪ§ОнЕФТпМРДЫЕЃЌЪЧвЛИіЗЧГЃбЯжиЕФЮЪЬтЃЌзюМђЕЅЕФР§згОЭЪЧЯдЪОФГИіаТЮХЕФдФЖССПЁЃСНИі++ВйзїЭЌЪБдЫааЃЌгаПЩФмНсЙћжЛМгСЫ1ЃЌЖјВЛЪЧ2ЁЃЫљвдЖрЯпГЬЯТЃЌЮвУЧГЃГЃвЊМгКмЖрЪ§ОнЕФЫјЃЌЖјетаЉЫјгжЗДЙ§РДПЩФмЕМжТЯпГЬЕФЫРЫјЁЃ
вђДЫвьВНЛиЕїФЃаЭдкЫцКѓБШЖрЯпГЬИќМгСїааЃЌГ§СЫЖрЯпГЬЕФЫРЫјЮЪЬтЭтЃЌвьВНЛЙФмНтОіЖрЯпГЬЯТЃЌЯпГЬЗДИДЧаЛЛЕМжТВЛБивЊЕФПЊЯњЕФЮЪЬтЃКУПИіЯпГЬЖМашвЊвЛИіЖРСЂЕФеЛПеМфЃЌдкЖрЯпГЬВЂаадЫааЕФЪБКђЃЌетаЉеЛЕФЪ§ОнПЩФмашвЊРДЛиЕФПНБДЃЌетЖюЭтЯћКФСЫCPUЁЃЭЌЪБгЩгкУПИіЯпГЬЖМашвЊеМгУеЛПеМфЃЌЫљвддкДѓСПЯпГЬДцдкЕФЪБКђЃЌФкДцЕФЯћКФвВЪЧОоДѓЕФЁЃЖјвьВНЛиЕїФЃаЭдђФмКмКУЕФНтОіетаЉЮЪЬтЃЌВЛЙ§вьВНЛиЕїИќЯёЪЧЁАЪжЙЄАцЁБЕФВЂааДІРэЃЌашвЊПЊЗЂепздМКШЅЪЕЯжШчКЮЁАВЂааЁБЕФЮЪЬтЁЃ
вьВНЛиЕїЛљгкЗЧзшШћЕФI/OВйзїЃЈЭјТчКЭЮФМўЃЉЃЌетбљЮвУЧОЭВЛгУдкЕїгУЖСаДКЏЪ§ЕФЪБКђЁАПЈЁБдкФЧвЛОфКЏЪ§ЕїгУЃЌЖјЪЧСЂПЬЗЕЛиЁАгаЮоЪ§ОнЁБЕФНсЙћЁЃЖјLinuxЕФepollММЪѕЃЌдђРћгУЕзВуФкКЫЕФЛњжЦЃЌШУЮвУЧПЩвдПьЫйЕФЁАВщевЁБЕНгаЪ§ОнПЩвдЖСаДЕФСЌНг\ЮФМўЁЃгЩгкУПИіВйзїЖМЪЧЗЧзшШћЕФЃЌЫљвдЮвУЧЕФГЬађПЩвджЛгУвЛИіНјГЬЃЌОЭДІРэДѓСПВЂЗЂЕФЧыЧѓЁЃвђЮЊжЛгавЛИіНјГЬЃЌЫљвдЫљгаЕФЪ§ОнДІРэЃЌЦфЫГађЖМЪЧЙЬЖЈЕФЃЌВЛПЩФмГіЯжЖрЯпГЬжаЃЌСНИіКЏЪ§ЕФгяОфНЛДэжДааЕФЧщПіЃЌвђДЫвВВЛашвЊИїжжЁАЫјЁБЁЃДгетИіНЧЖШПДЃЌвьВНЗЧзшШћЕФММЪѕЃЌЪЧДѓДѓМђЛЏСЫПЊЗЂЕФЙ§ГЬЁЃгЩгкжЛгавЛИіЯпГЬЃЌвВВЛашвЊгаЯпГЬЧаЛЛжЎРрЕФПЊЯњЃЌЫљвдвьВНЗЧзшШћГЩЮЊКмЖрЖдЭЬЭТСПЁЂВЂЗЂгаНЯИпвЊЧѓЕФЯЕЭГЪзбЁЁЃ
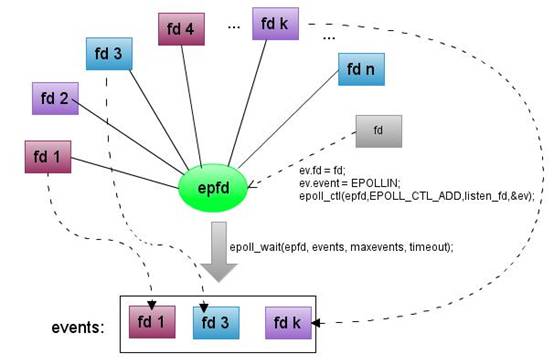
int epoll_create(int size)ЃЛ//ДДНЈвЛИіepollЕФОфБњЃЌsizeгУРДИцЫпФкКЫетИіМрЬ§ЕФЪ§ФПвЛЙВгаЖрДѓ
int epoll_ctl(int epfd, int op, int fd, struct epoll_event
*event)ЃЛ
int epoll_wait(int epfd, struct epoll_event * events,
int maxevents, int timeout);
ЛКГхММЪѕ
дкЛЅСЊЭјЗўЮёжаЃЌДѓВПЗжЕФгУЛЇНЛЛЅЃЌЖМЪЧашвЊСЂПЬЗЕЛиНсЙћЕФЃЌЫљвдЖдгкбгГйгавЛЖЈЕФвЊЧѓЁЃЖјРрЫЦЭјТчгЮЯЗжЎРрЗўЮёЃЌбгГйИќЪЧвЊЧѓЫѕЖЬЕНМИЪЎКСУывдФкЁЃЫљвдЮЊСЫНЕЕЭбгГйЃЌЛКГхЪЧЛЅСЊЭјЗўЮёжазюГЃМћЕФММЪѕжЎвЛЁЃ
дчЦкЕФWEBЯЕЭГжаЃЌШчЙћУПИіHTTPЧыЧѓЕФДІРэЃЌЖМШЅЪ§ОнПтЃЈMySQLЃЉЖСаДвЛДЮЃЌФЧУДЪ§ОнПтКмПьОЭЛсвђЮЊСЌНгЪ§еМТњЖјЭЃжЙЯьгІЁЃвђЮЊвЛАуЕФЪ§ОнПтЃЌжЇГжЕФСЌНгЪ§ЖМжЛгаМИАйЃЌЖјWEBЕФгІгУЕФВЂЗЂЧыЧѓЃЌЧсЫЩФмЕНМИЧЇЁЃетвВЪЧКмЖрЩшМЦВЛСМЕФЭјеОШЫвЛЖрОЭПЈЫРЕФзюжБНгдвђЁЃЮЊСЫОЁСПМѕЩйЖдЪ§ОнПтЕФСЌНгКЭЗУЮЪЃЌШЫУЧЩшМЦСЫКмЖрЛКГхЯЕЭГЁЊЁЊАбДгЪ§ОнПтжаВщбЏЕФНсЙћДцЗХЕНИќПьЕФЩшЪЉЩЯЃЌШчЙћУЛгаЯрЙиСЊЕФаоИФЃЌОЭжБНгДгетРяЖСЁЃ
зюЕфаЭЕФWEBгІгУЛКГхЯЕЭГЪЧMemcacheЁЃгЩгкPHPБОЩэЕФЯпГЬНсЙЙЃЌЪЧВЛДјзДЬЌЕФЁЃдчЦкPHPБОЩэЩѕжССЌВйзїЁАЖбЁБФкДцЕФЗНЗЈЖМУЛгаЃЌЫљвдФЧаЉГжОУЕФзДЬЌЃЌОЭвЛЖЈвЊДцЗХЕНСэЭтвЛИіНјГЬРяЁЃЖјMemcacheОЭЪЧвЛИіМђЕЅПЩППЕФДцЗХСйЪБзДЬЌЕФПЊдДШэМўЁЃКмЖрPHPгІгУЯждкЕФДІРэТпМЃЌЖМЪЧЯШДгЪ§ОнПтЖСШЁЪ§ОнЃЌШЛКѓаДШыMemcacheЃЛЕБЯТДЮЧыЧѓРДЕФЪБКђЃЌЯШГЂЪдДгMemcacheРяУцЖСШЁЪ§ОнЃЌетбљОЭгаПЩФмДѓДѓМѕЩйЖдЪ§ОнПтЕФЗУЮЪЁЃ
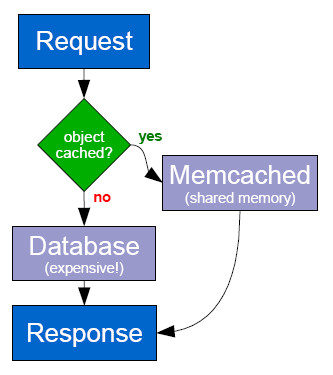
ШЛЖјMemcacheБОЩэЪЧвЛИіЖРСЂЕФЗўЮёЦїНјГЬЃЌетИіНјГЬздЩэВЂВЛДјЬиБ№ЕФМЏШКЙІФмЁЃвВОЭЪЧЫЕетаЉMemcacheНјГЬЃЌВЂВЛФмжБНгзщНЈГЩвЛИіЭГвЛЕФМЏШКЁЃШчЙћвЛИіMemcacheВЛЙЛгУЃЌЮвУЧОЭвЊЪжЙЄгУДњТыШЅЗжХфЃЌФФаЉЪ§ОнгІИУШЅФФИіMemcacheНјГЬЁЃЁЊЁЊетЖдгкеце§ЕФДѓаЭЗжВМЪНЭјеОРДЫЕЃЌЙмРэвЛИіетбљЕФЛКГхЯЕЭГЃЌЪЧвЛИіКмЗБЫіЕФЙЄзїЁЃ
вђДЫШЫУЧПЊЪМПМТЧЩшМЦвЛаЉИќИпаЇЕФЛКГхЯЕЭГЃКДгадФмЩЯРДЫЕЃЌMemcacheЕФУПБЪЧыЧѓЃЌЖМвЊОЙ§ЭјТчДЋЪфЃЌВХФмШЅРШЁФкДцжаЕФЪ§ОнЁЃетЮовЩЪЧгавЛЕуРЫЗбЕФЃЌвђЮЊЧыЧѓепБОЩэЕФФкДцЃЌвВЪЧПЩвдДцЗХЪ§ОнЕФЁЃЁЊЁЊетОЭЪЧДйГЩСЫКмЖрРћгУЧыЧѓЗНФкДцЕФЛКГхЫуЗЈКЭММЪѕЃЌЦфжазюМђЕЅЕФОЭЪЧЪЙгУLRUЫуЗЈЃЌАбЪ§ОнЗХдквЛИіЙўЯЃБэНсЙЙЕФЖбФкДцжаЁЃ
ЖјMemcacheЕФВЛОпБИМЏШКЙІФмЃЌвВЪЧвЛИігУЛЇЕФЭДЕуЁЃгкЪЧКмЖрШЫПЊЪМЩшМЦЃЌШчКЮШУЪ§ОнЛКДцЗжВЛЕНВЛЭЌЕФЛњЦїЩЯЁЃзюМђЕЅЕФЫМТЗЪЧЫљЮНЖСаДЗжРыЃЌвВОЭЪЧЛКДцУПДЮаДЃЌЖМаДЕНЖрИіЛКГхНјГЬЩЯМЧТМЃЌЖјЖСдђПЩвдЫцЛњЖСШЮКЮвЛИіНјГЬЁЃдквЕЮёЪ§ОнгаУїЯдЕФЖСаДВЛЦНКтВюОрЩЯЃЌаЇЙћЪЧЗЧГЃКУЕФЁЃ
ШЛЖјЃЌВЂВЛЪЧЫљгаЕФвЕЮёЖМФмМђЕЅЕФгУЖСаДЗжРыРДНтОіЮЪЬтЃЌБШШчвЛаЉдкЯпЛЅЖЏЕФЛЅСЊЭјвЕЮёЃЌБШШчЩчЧјЁЂгЮЯЗЁЃетаЉвЕЮёЕФЪ§ОнЖСаДЦЕТЪВЂУЛКмДѓЕФВювьЃЌЖјЧввВвЊЧѓКмИпЕФбгГйЁЃвђДЫШЫУЧгждйЯыАьЗЈЃЌАбБОЕиФкДцКЭдЖЖЫНјГЬЕФФкДцЛКДцНсКЯЦ№РДЪЙгУЃЌШУЪ§ОнОпБИСНМЖЛКДцЁЃЭЌЪБЃЌвЛИіЪ§ОнВЛдкЭЌЪБЕФИДжЦДцдкЫљгаЕФЛКДцНјГЬЩЯЃЌЖјЪЧАДвЛЖЈЙцТЩЗжВМдкЖрИіНјГЬЩЯЁЃЁЊЁЊетжжЗжВМЙцТЩЪЙгУЕФЫуЗЈЃЌзюСїааЕФОЭЪЧЫљЮНЁАвЛжТадЙўЯЃЁБЁЃетжжЫуЗЈЕФКУДІЪЧЃЌЕБФГвЛИіНјГЬЪЇаЇЙвЕєЃЌВЛашвЊАбећИіМЏШКжаЫљгаЕФЛКДцЪ§ОнЃЌЖМжиаТаоИФвЛДЮЮЛжУЁЃФуПЩвдЯыЯѓвЛЯТЃЌШчЙћЮвУЧЕФЪ§ОнЛКДцЗжВМЃЌЪЧгУМђЕЅЕФвдЪ§ОнЕФIDЖдНјГЬЪ§ШЁФЃЃЌФЧУДвЛЕЉНјГЬЪ§БфЛЏЃЌУПИіЪ§ОнДцЗХЕФНјГЬЮЛжУЖМПЩФмБфЛЏЃЌетЖдгкЗўЮёЦїЕФЙЪеЯШнШЬЪЧВЛРћЕФЁЃ
OrcaleЙЋЫОЦьЯТгавЛПюНаCoherenceЕФВњЦЗЃЌЪЧдкЛКДцЯЕЭГЩЯЩшМЦБШНЯКУЕФЁЃетИіВњЦЗЪЧвЛИіЩЬвЕВњЦЗЃЌжЇГжРћгУБОЕиФкДцЛКДцКЭдЖГЬНјГЬЛКДцазїЁЃМЏШКНјГЬЪЧЭъШЋздЙмРэЕФЃЌЛЙжЇГждкЪ§ОнЛКДцЫљдкНјГЬЃЌНјаагУЛЇЖЈвхЕФМЦЫуЃЈДІРэЦїЙІФмЃЉЃЌетОЭВЛНіНіЪЧЛКДцСЫЃЌЛЙЪЧвЛИіЗжВМЪНЕФМЦЫуЯЕЭГЁЃ
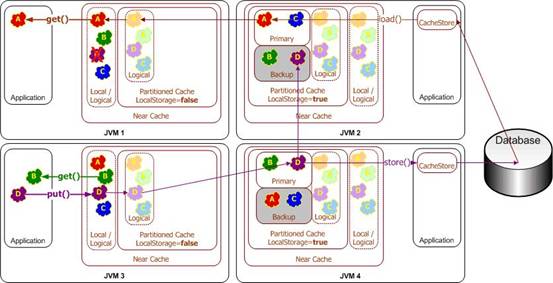
ДцДЂММЪѕЃЈNoSQLЃЉ
ЯраХCAPРэТлДѓМввбОЖњЪьФмЯъЃЌШЛЖјдкЛЅСЊЗЂеЙЕФдчЦкЃЌДѓМвЖМЛЙдкЪЙгУMySQLЕФЪБКђЃЌШчКЮШУЪ§ОнПтДцЗХИќЖрЕФЪ§ОнЃЌГадиИќЖрЕФСЌНгЃЌКмЖрЭХЖгЖМЪЧНЪОЁФджЁЃЩѕжСгкгаКмЖрвЕЮёЃЌжївЊЕФЪ§ОнДцДЂЗНЪНЪЧЮФМўЃЌЪ§ОнПтЗДЖјБфГЩЪЧИЈжњЕФЩшЪЉСЫЁЃ
ШЛЖјЃЌЕБNoSQLаЫЦ№ЃЌДѓМвЭЛШЛЗЂЯжЃЌЦфЪЕКмЖрЛЅСЊЭјвЕЮёЃЌЦфЪ§ОнИёЪНЪЧШчДЫЕФМђЕЅЃЌКмЖрЪБКђИљВПВЛашвЊЙиЯЕаЭЪ§ОнПтФЧжжИДдгЕФБэИёЁЃЖдгкЫїв§ЕФвЊЧѓЭљЭљвВжЛЪЧИљОнжїЫїв§ЫбЫїЁЃЖјИќИДдгЕФШЋЮФЫбЫїЃЌБОЩэЪ§ОнПтвВзіВЛЕНЁЃЫљвдЯждкЯрЕБЖрЕФИпВЂЗЂЕФЛЅСЊЭјвЕЮёЃЌЪзбЁNoSQLРДзіДцДЂЩшЪЉЁЃзюдчЕФNoSQLЪ§ОнПтгаMangoDBЕШЃЌЯждкзюСїааЕФЫЦКѕОЭЪЧRedisСЫЁЃЩѕжСгааЉЭХЖгЃЌАбRedisвВЕБГЩЛКГхЯЕЭГЕФвЛВПЗжЃЌЪЕМЪЩЯвВЪЧШЯПЩRedisЕФадФмгХЪЦЁЃ
NoSQLГ§СЫИќПьЁЂГадиСПИќДѓвдЭтЃЌИќживЊЕФЬиЕуЪЧЃЌетжжЪ§ОнДцДЂЗНЪНЃЌжЛФмАДеевЛЬѕЫїв§РДМьЫїКЭаДШыЁЃетбљЕФашЧѓдМЪјЃЌДјРДСЫЗжВМЩЯЕФКУДІЃЌЮвУЧПЩвдАДетЬѕжїЫїв§ЃЌРДЖЈвхЪ§ОнДцЗХЕФНјГЬЃЈЗўЮёЦїЃЉЁЃетбљвЛИіЪ§ОнПтЕФЪ§ОнЃЌОЭФмКмЗНБуЕФДцЗХдкВЛЭЌЕФЗўЮёЦїЩЯЁЃдкЗжВМЪНЯЕЭГЕФБиШЛЧїЪЦЯТЃЌЪ§ОнДцДЂВужегквВевЕНСЫЗжВМЕФЗНЗЈЁЃ
ЗжВМЪНЯЕЭГдкПЩЙмРэадЩЯдьГЩЕФЮЪЬт
ЗжВМЪНЯЕЭГВЂВЛЪЧМђЕЅЕФАбвЛЖбЗўЮёЦївЛЦ№дЫааЦ№РДОЭФмТњзуашЧѓЕФЁЃЖдБШЕЅЛњЛђЩйСПЗўЮёЦїЕФМЏШКЃЌгавЛаЉЬиБ№ашвЊНтОіЕФЮЪЬтЕШД§зХЮвУЧЁЃ
гВМўЙЪеЯТЪ
ЫљЮНЗжВМЪНЯЕЭГЃЌПЯЖЈОЭВЛЪЧжЛгавЛЬЈЗўЮёЦїЁЃМйЩшвЛЬЈЗўЮёЦїЕФЦНОљЙЪеЯЪБМфЪЧ1%ЃЌФЧУДЕБФуга100ЬЈЗўЮёЦїЕФЪБКђЃЌФЧОЭМИКѕзмгавЛЬЈЪЧдкЙЪеЯЕФЁЃЫфШЛетИіБШЗНВЛвЛЖЈКмзМШЗЃЌЕЋЪЧЃЌЕБФуЕФЯЕЭГЫљЩцМАЕФгВМўдНРДдНЖрЃЌгВМўЕФЙЪеЯвВЛсДгХМШЛЪТМўБфГЩвЛИіБиШЛЪТМўЁЃвЛАуЮвУЧдкаДЙІФмДњТыЕФЪБКђЃЌЪЧВЛЛсПМТЧЕНгВМўЙЪеЯЕФЪБКђгІИУдѕУДАьЕФЁЃЖјШчЙћдкБраДЗжВМЪНЯЕЭГЕФЪБКђЃЌОЭвЛЖЈашвЊУцЖдетИіЮЪЬтСЫЁЃЗёдђЃЌКмПЩФмжЛгавЛЬЈЗўЮёЦїГіЙЪеЯЃЌећИіЪ§АйЬЈЗўЮёЦїЕФМЏШКЖМЙЄзїВЛе§ГЃСЫЁЃ

Г§СЫЗўЮёЦїздМКЕФФкДцЁЂгВХЬЕШЙЪеЯЃЌЗўЮёЦїжЎМфЕФЭјТчЯпТЗЙЪеЯИќМгГЃМћЁЃЖјЧветжжЙЪеЯЛЙгаПЩФмЪЧХМЗЂЕФЃЌЛђепЪЧЛсздЖЏЛжИДЕФЁЃУцЖдетжжЮЪЬтЃЌШчЙћжЛЪЧМђЕЅЕФАбЁАГіЯжЙЪеЯЁБЕФЛњЦїЬоçóؽЃЌФЧЛЙЪЧВЛЙЛЕФЁЃвђЮЊЭјТчПЩФмЙ§вЛЛсЖљОЭгжЛжИДСЫЃЌЖјФуЕФМЏШКПЩФмвђЮЊетвЛЯТЕФСйЪБЙЪеЯЃЌЖЊЪЇСЫЙ§АыЕФДІРэФмСІЁЃ
ШчКЮШУЗжВМЪНЯЕЭГЃЌдкИїжжПЩФмЫцЪБГіЯжЙЪеЯЕФЧщПіЯТЃЌОЁСПЕФздЖЏЮЌЛЄКЭЮЌГжЖдЭтЗўЮёЃЌГЩЮЊСЫБраДГЬађОЭвЊПМТЧЕФЮЪЬтЁЃгЩгквЊПМТЧЕНетжжЙЪеЯЕФЧщПіЃЌЫљвдЮвУЧдкЩшМЦМмЙЙЕФЪБКђЃЌвВвЊгавтЪЖЕФдЄЩшвЛаЉШпгрЁЂздЮвЮЌЛЄЕФЙІФмЁЃетаЉЖМВЛЪЧВњЦЗЩЯЕФвЕЮёашЧѓЃЌЭъШЋОЭЪЧММЪѕЩЯЕФЙІФмашЧѓЁЃФмЗёдкетЗНУцЬсГіЖдЕФашЧѓЃЌШЛКѓе§ШЗЕФЪЕЯжЃЌЪЧЗўЮёЦїЖЫГЬађдБзюживЊЕФжАд№жЎвЛЁЃ
зЪдДРћгУТЪгХЛЏ
дкЗжВМЪНЯЕЭГЕФМЏШКЃЌАќКЌСЫКмЖрИіЗўЮёЦїЃЌЕБетбљвЛИіМЏШКЕФгВМўГадиФмСІЕНДяМЋЯоЕФЪБКђЃЌзюздШЛЕФЯыЗЈОЭЪЧдіМгИќЖрЕФгВМўЁЃШЛЖјЃЌвЛИіШэМўЯЕЭГВЛЪЧФЧУДШнвзОЭПЩвдЭЈЙ§ЁАдіМгЁБгВМўРДЬсИпГадиадФмЕФЁЃвђЮЊШэМўдкЖрИіЗўЮёЦїЩЯЕФЙЄзїЃЌЪЧашвЊгаИДдгЯИжТЕФаЕїЙЄзїЁЃдкЖдвЛИіМЏШКРЉШнЕФЪБКђЃЌЮвУЧЭљЭљЛсвЊЭЃЕєећИіМЏШКЕФЗўЮёЃЌШЛКѓаоИФИїжжХфжУЃЌзюКѓВХФмжиаТЦєЖЏвЛИіМгШыСЫаТЕФЗўЮёЦїЕФМЏШКЁЃ

гЩгкдкУПИіЗўЮёЦїЕФФкДцРяЃЌЖМПЩФмЛсгавЛаЉгУЛЇЪЙгУЕФЪ§ОнЃЌЫљвдШчЙћУАШЛдкдЫааЕФЪБКђЃЌОЭЪдЭМаоИФМЏШКжаЬсЙЉЗўЮёЕФХфжУЃЌКмПЩФмЛсдьГЩФкДцЪ§ОнЕФЖЊЪЇКЭДэЮѓЁЃвђДЫЃЌдЫааЪБРЉШндкЖдЮозДЬЌЕФЗўЮёЩЯЃЌЪЧБШНЯШнвзЕФЃЌБШШчдіМгвЛаЉWebЗўЮёЦїЁЃЕЋШчЙћЪЧдкгазДЬЌЕФЗўЮёЩЯЃЌБШШчЭјТчгЮЯЗЃЌМИКѕЪЧВЛПЩФмНјааМђЕЅЕФдЫааЪБРЉШнЕФЁЃ
ЗжВМЪНМЏШКГ§СЫРЉШнЃЌЛЙгаЫѕШнЕФашЧѓЁЃЕБгУЛЇШЫЪ§ЯТНЕЃЌЗўЮёЦїгВМўзЪдДГіЯжПеЯаЕФЪБКђЃЌЮвУЧЭљЭљашвЊетаЉПеЯаЕФзЪдДФмРћгУЦ№РДЃЌЗХЕНСэЭтвЛаЉаТЕФЗўЮёМЏШКРяШЅЁЃЫѕШнКЭМЏШКжагаЙЪеЯашвЊШнджгавЛЖЈРрЫЦжЎДІЃЌЧјБ№ЪЧЫѕШнЕФЪБМфЕуКЭФПБъЪЧПЩдЄЦкЕФЁЃ
гЩгкЗжВМЪНМЏШКжаЕФРЉШнЁЂЫѕШнЃЌвдМАЯЃЭћОЁСПФмдкЯпВйзїЃЌетЕМжТСЫЗЧГЃИДдгЕФММЪѕЮЪЬташвЊДІРэЃЌБШШчМЏШКжаЛЅЯрЙиСЊЕФХфжУШчКЮе§ШЗИпаЇЕФаоИФЁЂШчКЮЖдгазДЬЌЕФНјГЬНјааВйзїЁЂШчКЮдкРЉШнЫѕШнЕФЙ§ГЬжаБЃжЄМЏШКжаНкЕужЎМфЭЈаХЕФе§ГЃЁЃзїЮЊЗўЮёЦїЖЫГЬађдБЃЌЛсашвЊЛЈЗбДѓСПЕФОРњЃЌРДЖдЖрИіНјГЬЕФМЏШКзДЬЌБфЛЏЃЌдьГЩЕФвЛЯЕСаЮЪЬтНјаазЈУХЕФПЊЗЂЁЃ
ШэМўЗўЮёФкШнИќаТ
ЯждкЖМСїаагУУєНнПЊЗЂФЃЪНжаЕФЁАЕќДњЁБЃЌРДБэЪОвЛИіЗўЮёВЛЖЯЕФИќаТГЬађЃЌТњзуаТЕФашЧѓЃЌаое§BUGЁЃШчЙћЮвУЧНіНіЙмРэвЛЬЈЗўЮёЦїЃЌФЧУДИќаТетвЛЬЈЗўЮёЦїЩЯЕФГЬађЃЌЪЧЗЧГЃМђЕЅЕФЃКжЛвЊАбШэМўАќПНБДЙ§ШЅЃЌШЛКѓаоИФЯТХфжУОЭКУЁЃЕЋЪЧШчЙћФувЊЖдГЩАйЩЯЧЇЕФЗўЮёЦїШЅзіЭЌбљЕФВйзїЃЌОЭВЛПЩФмУПЬЈЗўЮёЦїЕЧТМЩЯШЅДІРэЁЃ
ЗўЮёЦїЖЫЕФГЬађХњСПАВзАВПЪ№ЙЄОпЃЌЪЧУПИіЗжВМЪНЯЕЭГПЊЗЂепЖМашвЊЕФЁЃШЛЖјЃЌЮвУЧЕФАВзАЙЄзїГ§СЫПНБДЖўНјжЦЮФМўКЭХфжУЮФМўЭтЃЌЛЙЛсгаКмЖрЦфЫћЕФВйзїЁЃБШШчДђПЊЗРЛ№ЧНЁЂНЈСЂЙВЯэФкДцЮФМўЁЂаоИФЪ§ОнПтБэНсЙЙЁЂИФаДвЛаЉЪ§ОнЮФМўЕШЕШЁЁЩѕжСгавЛаЉЛЙвЊдкЗўЮёЦїЩЯАВзАаТЕФШэМўЁЃ

ШчЙћЮвУЧдкПЊЗЂЗўЮёЦїЖЫГЬађЕФЪБКђЃЌОЭПМТЧЕНШэМўИќаТЁЂАцБОЩ§МЖЕФЮЪЬтЃЌФЧУДЮвУЧЖдгкХфжУЮФМўЁЂУќСюааВЮЪ§ЁЂЯЕЭГБфСПЕФЪЙгУЃЌОЭЛсдЄЯШзівЛЖЈЕФЙцЛЎЃЌетФмШУАВзАВПЪ№ЕФЙЄОпдЫааИќПьЃЌПЩППадИќИпЁЃ
Г§СЫАВзАВПЪ№ЕФЙ§ГЬЃЌЛЙгавЛИіживЊЕФЮЪЬтЃЌОЭЪЧВЛЭЌАцБОМфЪ§ОнЕФЮЪЬтЁЃЮвУЧдкЩ§МЖАцБОЕФЪБКђЃЌОЩАцБОГЬађЩњГЩЕФвЛаЉГжОУЛЏЪ§ОнЃЌвЛАуЖМЪЧОЩЕФЪ§ОнИёЪНЕФЃЛЖјЮвУЧЩ§МЖАцБОжаШчЙћЩцМАаоИФСЫЪ§ОнИёЪНЃЌБШШчЪ§ОнБэНсЙћЃЌФЧУДетаЉОЩИёЪНЕФЪ§ОнЃЌЖМвЊзЊЛЛИФаДГЩаТАцБОЕФЪ§ОнИёЪНВХааЁЃетЕМжТСЫЮвУЧдкЩшМЦЪ§ОнНсЙЙЕФЪБКђЃЌОЭвЊПМТЧЧхГўетаЉБэИёЕФНсЙЙЃЌЪЧгУзюМђЕЅжБНгЕФБэДяЗНЪНЃЌРДШУНЋРДЕФаоИФИќМђЕЅЃЛЛЙЪЧвЛдчОЭдЄМЦЕНаоИФЕФЗЖЮЇЃЌзЈУХдЄЩшвЛаЉзжЖЮЃЌЛђепЪЙгУЦфЫћаЮЪНДцЗХЪ§ОнЁЃ
Г§СЫГжОУЛЏЪ§ОнвдЭтЃЌШчЙћДцдкПЭЛЇЖЫГЬађЃЈШчЪмЛїAPPЃЉЃЌетаЉПЭЛЇЖЫГЬађЕФЩ§МЖЭљЭљВЛФмКЭЗўЮёЦїЭЌВНЃЌШчЙћЩ§МЖЕФФкШнАќКЌСЫЭЈаХавщЕФаоИФЃЌетОЭдьГЩСЫЮвУЧБиаыЮЊВЛЭЌЕФАцБОВПЪ№ВЛЭЌЕФЗўЮёЦїЖЫЯЕЭГЕФЮЪЬтЁЃЮЊСЫБмУтЭЌЪБЮЌЛЄЖрЬзЗўЮёЦїЃЌЮвУЧдкШэМўПЊЗЂЕФЪБКђЃЌЭљЭљЧуЯђгкЫљЮНЁААцБОМцШнЁБЕФавщЖЈвхЗНЪНЁЃЖјдѕбљЩшМЦЕФавщВХФмгаКмКУЕФМцШнадЃЌгжЪЧЗўЮёЦїЖЫГЬађашвЊзаЯИПМТЧЕФЮЪЬтЁЃ
Ъ§ОнЭГМЦКЭОіВп
вЛАуРДЫЕЃЌЗжВМЪНЯЕЭГЕФШежОЪ§ОнЃЌЖМЪЧБЛМЏжаЕНвЛЦ№ЃЌШЛКѓЭГвЛНјааЭГМЦЕФЁЃШЛЖјЃЌЕБМЏШКЕФЙцФЃЕНвЛЖЈГЬЖШЕФЪБКђЃЌетаЉШежОЕФЪ§ОнСПЛсБфЕУЗЧГЃПжВРЁЃКмЖрЪБКђЃЌЭГМЦвЛЬьЕФШежОСПЃЌвЊЯћКФМЦЫуЛњдЫаавЛЬьвдЩЯЕФЪБМфЁЃЫљвдЃЌШежОЭГМЦетЯюЙЄзїЃЌвВБфГЩвЛУХЗЧГЃзЈвЕЕФЛюЖЏЁЃ
ОЕфЕФЗжВМЪНЭГМЦФЃаЭЃЌгаGoogleЕФMap ReduceФЃаЭЁЃетжжФЃаЭМШгаСщЛюадЃЌвВФмРћгУДѓСПЗўЮёЦїНјааЭГМЦЙЄзїЁЃЕЋЪЧШБЕуЪЧвзгУадЭљЭљВЛЙЛКУЃЌвђЮЊетаЉЪ§ОнЕФЭГМЦКЭЮвУЧГЃМћЕФSQLЪ§ОнБэЭГМЦгаЗЧГЃДѓЕФВювьЃЌЫљвдЮвУЧзюКѓЛЙЪЧГЃГЃАбЪ§ОнЖЊЕНMySQLРяУцШЅзіИќЯИВуУцЕФЭГМЦЁЃ
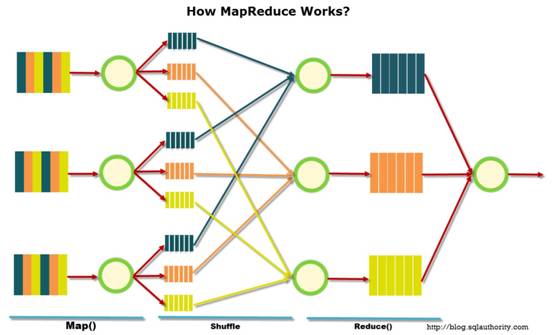
гЩгкЗжВМЪНЯЕЭГШежОЪ§СПЕФХгДѓЃЌвдМАШежОИДдгГЬЖШЕФЬсИпЁЃЮвУЧБфЕУБиаывЊеЦЮеРрЫЦMap ReduceММЪѕЃЌВХФмеце§ЕФЖдЗжВМЪНЯЕЭГНјааЪ§ОнЭГМЦЁЃЖјЧвЮвУЧЛЙашвЊЯыАьЗЈЬсИпЭГМЦЙЄзїЕФЙЄзїаЇТЪЁЃ
НтОіЗжВМЪНЯЕЭГПЩЙмРэадЕФЛљБОЪжЖЮ
ФПТМЗўЮёЃЈZooKeeperЃЉ
ЗжВМЪНЯЕЭГЪЧвЛИігЩКмЖрНјГЬзщГЩЕФећЬхЃЌетИіећЬхжаУПИіГЩдБВПЗжЃЌЖМЛсОпБИвЛаЉзДЬЌЃЌБШШчздМКЕФИКд№ФЃПщЃЌздМКЕФИКдиЧщПіЃЌЖдФГаЉЪ§ОнЕФеЦЮеЕШЕШЁЃЖјетаЉКЭЦфЫћНјГЬЯрЙиЕФЪ§ОнЃЌдкЙЪеЯЛжИДЁЂРЉШнЫѕШнЕФЪБКђБфЕУЗЧГЃживЊЁЃ
МђЕЅЕФЗжВМЪНЯЕЭГЃЌПЩвдЭЈЙ§ОВЬЌЕФХфжУЮФМўЃЌРДМЧТМетаЉЪ§ОнЃКНјГЬжЎМфЕФСЌНгЖдгІЙиЯЕЃЌЫћУЧЕФIPЕижЗКЭЖЫПкЃЌЕШЕШЁЃШЛЖјвЛИіздЖЏЛЏГЬЖШИпЕФЗжВМЪНЯЕЭГЃЌБиШЛвЊЧѓетаЉзДЬЌЪ§ОнЖМЪЧЖЏЬЌБЃДцЕФЁЃетбљВХФмШУГЬађздМКШЅзіШнджКЭИКдиОљКтЕФЙЄзїЁЃ
вЛаЉГЬађдБЛсзЈУХздМКБраДвЛИіDIRЗўЮёЃЈФПТМЗўЮёЃЉЃЌРДМЧТММЏШКжаНјГЬЕФдЫаазДЬЌЁЃМЏШКжаНјГЬЛсКЭетИіDIRЗўЮёВњЩњздЖЏЙиСЊЃЌетбљдкШнджЁЂРЉШнЁЂИКдиОљКтЕФЪБКђЃЌОЭПЩвдздЖЏИљОнетаЉDIRЗўЮёРяЕФЪ§ОнЃЌРДЕїећЧыЧѓЕФЗЂЫЭФПЕиЃЌДгЖјДяЕНШЦПЊЙЪеЯЛњЦїЁЂЛђСЌНгЕНаТЕФЗўЮёЦїЕФВйзїЁЃ
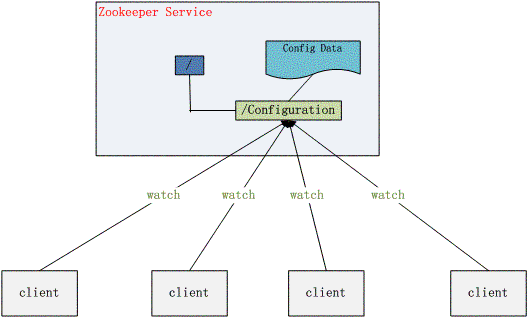
ШЛЖјЃЌШчЙћЮвУЧжЛЪЧгУвЛИіНјГЬРДГфЕБетИіЙЄзїЁЃФЧУДетИіНјГЬОЭГЩЮЊСЫетИіМЏШКЕФЁАЕЅЕуЁБЁЊЁЊвтЫМОЭЪЧЃЌШчЙћетИіНјГЬЙЪеЯСЫЃЌФЧУДећИіМЏШКПЩФмЖМЮоЗЈдЫааЕФЁЃЫљвдДцЗХМЏШКзДЬЌЕФФПТМЗўЮёЃЌвВашвЊЪЧЗжВМЪНЕФЁЃавКУЮвУЧгаZooKeeperетИігХауЕФПЊдДШэМўЃЌЫќе§ЪЧвЛИіЗжВМЪНЕФФПТМЗўЮёЧјЁЃ
ZooKeeperПЩвдМђЕЅЦєЖЏЦцЪ§ИіНјГЬЃЌРДаЮГЩвЛИіаЁЕФФПТМЗўЮёМЏШКЁЃетИіМЏШКЛсЬсЙЉИјЫљгаЦфЫћНјГЬЃЌНјааЖСаДЦфОоДѓЕФЁАХфжУЪїЁБЕФФмСІЁЃетаЉЪ§ОнВЛНіНіЛсДцЗХдквЛИіZooKeeperНјГЬжаЃЌЖјЪЧЛсИљОнвЛЬзЗЧГЃАВШЋЕФЫуЗЈЃЌШУЖрИіНјГЬРДГадиЁЃетШУZooKeeperГЩЮЊвЛИігХауЕФЗжВМЪНЪ§ОнБЃДцЯЕЭГЁЃ
гЩгкZooKeeperЕФЪ§ОнДцДЂНсЙЙЃЌЪЧвЛИіРрЫЦЮФМўФПТМЕФЪїзДЯЕЭГЃЌЫљвдЮвУЧГЃГЃЛсРћгУЫќЕФЙІФмЃЌАбУПИіНјГЬЖМАѓЖЈЕНЦфжавЛИіЁАЗжжІЁБЩЯЃЌШЛКѓЭЈЙ§МьВщетаЉЁАЗжжЇЁБЃЌРДНјааЗўЮёЦїЧыЧѓЕФзЊЗЂЃЌОЭФмМђЕЅЕФНтОіЧыЧѓТЗгЩЃЈгЩЫШЅзіЃЉЕФЮЪЬтЁЃСэЭтЛЙПЩвддкетаЉЁАЗжжЇЁБЩЯБъМЧНјГЬЕФИКдиЕФзДЬЌЃЌетбљИКдиОљКтвВКмШнвззіСЫЁЃ
ФПТМЗўЮёЪЧЗжВМЪНЯЕЭГжазюЙиМќЕФзщМўжЎвЛЁЃЖјZooKeeperЪЧвЛИіКмКУЕФПЊдДШэМўЃЌе§КУЪЧгУРДЭъГЩетИіШЮЮёЁЃ
ЯћЯЂЖгСаЗўЮёЃЈActiveMQЁЂZeroMQЁЂJgroupsЃЉ
СНИіНјГЬМфШчЙћвЊПчЛњЦїЭЈбЖЃЌЮвУЧМИКѕЖМЛсгУTCP/UDPетаЉавщЁЃЕЋЪЧжБНгЪЙгУЭјТчAPIШЅБраДПчНјГЬЭЈбЖЃЌЪЧвЛМўЗЧГЃТщЗГЕФЪТЧщЁЃГ§СЫвЊБраДДѓСПЕФЕзВуsocketДњТыЭтЃЌЮвУЧЛЙвЊДІРэжюШчЃКШчКЮевЕНвЊНЛЛЅЪ§ОнЕФНјГЬЃЌШчКЮБЃеЯЪ§ОнАќЕФЭъећадВЛжСгкЖЊЪЇЃЌШчЙћЭЈбЖЕФЖдЗННјГЬЙвЕєСЫЃЌЛђепНјГЬашвЊжиЦєгІИУдѕбљЕШЕШетвЛЯЕСаЮЪЬтЁЃетаЉЮЪЬтАќКЌСЫШнджРЉШнЁЂИКдиОљКтЕШвЛЯЕСаЕФашЧѓЁЃ
ЮЊСЫНтОіЗжВМЪНЯЕЭГНјГЬМфЭЈбЖЕФЮЪЬтЃЌШЫУЧзмНсГіСЫвЛИігааЇЕФФЃаЭЃЌОЭЪЧЁАЯћЯЂЖгСаЁБФЃаЭЁЃЯћЯЂЖгСаФЃаЭЃЌОЭЪЧАбНјГЬМфЕФНЛЛЅЃЌГщЯѓГЩЖдвЛИіИіЯћЯЂЕФДІРэЃЌЖјЖдгкетаЉЯћЯЂЃЌЮвУЧЖМгавЛаЉЁАЖгСаЁБЃЌвВОЭЪЧЙмЕРЃЌРДЖдЯћЯЂНјааднДцЁЃУПИіНјГЬЖМПЩвдЗУЮЪвЛИіЛђепЖрИіЖгСаЃЌДгРяУцЖСШЁЯћЯЂЃЈЯћЗбЃЉЛђаДШыЯћЯЂЃЈЩњВњЃЉЁЃгЩгкгавЛИіЛКДцЕФЙмЕРЃЌЮвУЧПЩвдЗХаФЕФЖдНјГЬзДЬЌНјааБфЛЏЁЃЕБНјГЬЦ№РДЕФЪБКђЃЌЫќЛсздЖЏШЅЯћЗбЯћЯЂОЭПЩвдСЫЁЃЖјЯћЯЂБОЩэЕФТЗгЩЃЌвВЪЧгЩДцЗХЕФЖгСаОіЖЈЕФЃЌетбљОЭАбИДдгЕФТЗгЩЮЪЬтЃЌБфГЩСЫШчКЮЙмРэОВЬЌЕФЖгСаЕФЮЪЬтЁЃ
вЛАуЕФЯћЯЂЖгСаЗўЮёЃЌЖМЪЧЬсЙЉМђЕЅЕФЁАЭЖЕнЁБКЭЁАЪеШЁЁБСНИіНгПкЃЌЕЋЪЧЯћЯЂЖгСаБОЩэЕФЙмРэЗНЪНШДБШНЯИДдгЃЌвЛАуРДЫЕгаСНжжЁЃвЛВПЗжЕФЯћЯЂЖгСаЗўЮёЃЌЬсГЋЕуЖдЕуЕФЖгСаЙмРэЗНЪНЃКУПЖдЭЈаХНкЕужЎМфЃЌЖМгавЛИіЕЅЖРЕФЯћЯЂЖгСаЁЃетжжзіЗЈЕФКУДІЪЧВЛЭЌРДдДЕФЯћЯЂЃЌПЩвдЛЅВЛгАЯьЃЌВЛЛсвђЮЊФГИіЖгСаЕФЯћЯЂЙ§ЖрЃЌМЗеМСЫЦфЫћЖгСаЕФЯћЯЂЛКДцПеМфЁЃЖјЧвДІРэЯћЯЂЕФГЬађвВПЩвдздМКРДЖЈвхДІРэЕФгХЯШМЖЁЊЁЊЯШЪеШЁЁЂЖрДІРэФГИіЖгСаЃЌЖјЩйДІРэСэЭтвЛаЉЖгСаЁЃ
ЕЋЪЧетжжЕуЖдЕуЕФЯћЯЂЖгСаЃЌЛсЫцзХМЏШКЕФдіГЄЖјдіМгДѓСПЕФЖгСаЃЌетЖдгкФкДцеМгУКЭдЫЮЌЙмРэЖМЪЧвЛИіИДдгЕФЪТЧщЁЃвђДЫИќИпМЖЕФЯћЯЂЖгСаЗўЮёЃЌПЊЪМПЩвдШУВЛЭЌЕФЖгСаЙВЯэФкДцПеМфЃЌЖјЯћЯЂЖгСаЕФЕижЗаХЯЂЁЂНЈСЂКЭЩОГ§ЃЌЖМВЩгУздЖЏЛЏЕФЪжЖЮЁЃЁЊЁЊетаЉздЖЏЛЏЭљЭљашвЊвРРЕЩЯЮФЫљЪіЕФЁАФПТМЗўЮёЁБЃЌРДЕЧМЧЖгСаЕФIDЖдгІЕФЮяРэIPКЭЖЫПкЕШаХЯЂЁЃБШШчКмЖрПЊЗЂепЪЙгУZooKeeperРДГфЕБЯћЯЂЖгСаЗўЮёЕФжабыНкЕуЃЛЖјРрЫЦJgropusетРрШэМўЃЌдђздМКЮЌЛЄвЛИіМЏШКзДЬЌРДДцЗХИїНкЕуНёЮєЁЃ
СэЭтвЛжжЯћЯЂЖгСаЃЌдђРрЫЦвЛИіЙЋЙВЕФгЪЯфЁЃвЛИіЯћЯЂЖгСаЗўЮёОЭЪЧвЛИіНјГЬЃЌШЮКЮЪЙгУепЖМПЩвдЭЖЕнЛђЪеШЁетИіНјГЬжаЕФЯћЯЂЁЃетбљЖдгкЯћЯЂЖгСаЕФЪЙгУИќМђБуЃЌдЫЮЌЙмРэвВБШНЯЗНБуЁЃВЛЙ§етжжгУЗЈЯТЃЌШЮКЮвЛИіЯћЯЂДгЗЂГіЕНДІРэЃЌзюЩйНјЙ§СНДЮНјГЬМфЭЈаХЃЌЦфбгГйЪЧЯрЖдБШНЯИпЕФЁЃВЂЧвгЩгкУЛгадЄЖЈЕФЭЖЕнЁЂЪеШЁдМЪјЃЌЫљвдвВБШНЯШнвзГіBUGЁЃ
ВЛЙмЪЙгУФЧжжЯћЯЂЖгСаЗўЮёЃЌдквЛИіЗжВМЪНЗўЮёЦїЖЫЯЕЭГжаЃЌНјГЬМфЭЈбЖЖМЪЧБиаывЊНтОіЕФЮЪЬтЃЌЫљвдзїЮЊЗўЮёЦїЖЫГЬађдБЃЌдкБраДЗжВМЪНЯЕЭГДњТыЕФЪБКђЃЌЪЙгУЕФзюЖрЕФОЭЪЧЛљгкЯћЯЂЖгСаЧ§ЖЏЕФДњТыЃЌетвВжБНгЕМжТСЫEJB3.0АбЁАЯћЯЂЧ§ЖЏЕФBeanЁБМгШыЕНЙцЗЖжЎжаЁЃ
ЪТЮёЯЕЭГ
дкЗжВМЪНЕФЯЕЭГжаЃЌЪТЮёЪЧзюФбНтОіЕФММЪѕЮЪЬтжЎвЛЁЃгЩгквЛИіДІРэПЩФмЗжВМдкВЛЭЌЕФДІРэНјГЬЩЯЃЌШЮКЮвЛИіНјГЬЖМПЩФмГіЯжЙЪеЯЃЌЖјетИіЙЪеЯЮЪЬтдђашвЊЕМжТвЛДЮЛиЙіЁЃетжжЛиЙіДѓВПЗжгжЩцМАЖрИіЦфЫћЕФНјГЬЁЃетЪЧвЛИіРЉЩЂадЕФЖрНјГЬЭЈбЖЮЪЬтЁЃвЊдкЗжВМЪНЯЕЭГЩЯНтОіЪТЮёЮЪЬтЃЌБиаыОпБИСНИіКЫаФЙЄОпЃКвЛИіЪЧЮШЖЈЕФзДЬЌДцДЂЯЕЭГЃЛСэЭтвЛИіЪЧЗНБуПЩППЕФЙуВЅЯЕЭГЁЃ
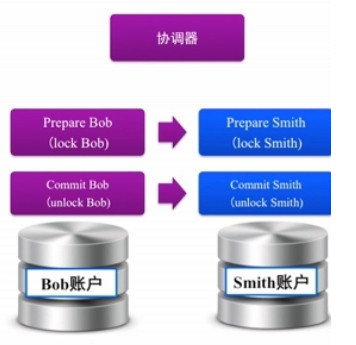
ЪТЮёжаШЮКЮвЛВНЕФзДЬЌЃЌЖМБиаыдкећИіМЏШКжаПЩМћЃЌВЂЧвЛЙвЊгаШнджЕФФмСІЁЃетИіашЧѓЃЌвЛАуЛЙЪЧгЩМЏШКЕФЁАФПТМЗўЮёЁБРДГаЕЃЁЃШчЙћЮвУЧЕФФПТМЗўЮёзуЙЛНЁзГЃЌФЧУДЮвУЧПЩвдАбУПВНЪТЮёЕФДІРэзДЬЌЃЌЖМЭЌВНаДЕНФПТМЗўЮёЩЯШЅЁЃZooKeeperдйДЮдкетИіЕиЗНФмЗЂЛгживЊЕФзїгУЁЃ
ШчЙћЪТЮёЗЂЩњСЫжаЖЯЃЌашвЊЛиЙіЃЌФЧУДетИіЙ§ГЬЛсЩцМАЕНЖрИівбОжДааЙ§ЕФВНжшЁЃвВаэетИіЛиЙіжЛашвЊдкШыПкДІЛиЙіМДПЩЃЈМгШыФЧРягаБЃДцЛиЙіЫљашЕФЪ§ОнЃЉЃЌвВПЩФмашвЊдкИїИіДІРэНкЕуЩЯЛиЙіЁЃШчЙћЪЧКѓепЃЌФЧУДОЭашвЊМЏШКжаГіЯжвьГЃЕФНкЕуЃЌЯђЦфЫћЫљгаЯрЙиЕФНкЕуЙуВЅвЛИіЁАЛиЙіЃЁЪТЮёIDЪЧXXXXЁБетбљЕФЯћЯЂЁЃетИіЙуВЅЕФЕзВувЛАуЛсгЩЯћЯЂЖгСаЗўЮёРДГадиЃЌЖјРрЫЦJgroupsетбљЕФШэМўЃЌжБНгЬсЙЉСЫЙуВЅЗўЮёЁЃ
ЫфШЛЯждкЮвУЧдкЬжТлЪТЮёЯЕЭГЃЌЕЋЪЕМЪЩЯЗжВМЪНЯЕЭГОГЃЫљашЕФЁАЗжВМЪНЫјЁБЙІФмЃЌвВЪЧетИіЯЕЭГПЩвдЭЌЪБЭъГЩЕФЁЃЫљЮНЕФЁАЗжВМЪНЫјЁБЃЌвВОЭЪЧвЛжжФмШУИїИіНкЕуЯШМьВщКѓжДааЕФЯожЦЬѕМўЁЃШчЙћЮвУЧгаИпаЇЖјЕЅзгВйзїЕФФПТМЗўЮёЃЌФЧУДетИіЫјзДЬЌЪЕМЪЩЯОЭЪЧвЛжжЁАЕЅВНЪТЮёЁБЕФзДЬЌМЧТМЃЌЖјЛиЙіВйзїдђФЌШЯЪЧЁАднЭЃВйзїЃЌЩдКѓдйЪдЁБЁЃетжжЁАЫјЁБЕФЗНЪНЃЌБШЪТЮёЕФДІРэИќМђЕЅЃЌвђДЫПЩППадИќИпЃЌЫљвдЯждкдНРДдНЖрЕФПЊЗЂШЫдБЃЌдИвтЪЙгУетжжЁАЫјЁБЗўЮёЃЌЖјВЛЪЧШЅЪЕЯжвЛИіЁАЪТЮёЯЕЭГЁБЁЃ
здЖЏВПЪ№ЙЄОпЃЈDockerЃЉ
гЩгкЗжВМЪНЯЕЭГзюДѓЕФашЧѓЃЌЪЧдкдЫааЪБЃЈгаПЩФмашвЊжаЖЯЗўЮёЃЉРДНјааЗўЮёШнСПЕФБфИќЃКРЉШнЛђепЫѕШнЁЃЖјдкЗжВМЪНЯЕЭГжаФГаЉНкЕуЙЪеЯЕФЪБКђЃЌвВашвЊаТЕФНкЕуРДЛжИДЙЄзїЁЃетаЉШчЙћЛЙЪЧЯёРЯЪНЕФЗўЮёЦїЙмРэЗНЪНЃЌЭЈЙ§ЬюБэЁЂЩъБЈЁЂНјЛњЗПЁЂзАЗўЮёЦїЁЂВПЪ№ШэМўЁЁетвЛЬззіЗЈЃЌФЧаЇТЪПЯЖЈЪЧВЛааЁЃ
дкЗжВМЪНЯЕЭГЕФЛЗОГЯТЃЌЮвУЧвЛАуЖМЪЧВЩгУЁАГиЁБЕФЗНЪНРДЙмРэЗўЮёЁЃЮвУЧдЄЯШЛсЩъЧывЛХњЛњЦїЃЌШЛКѓдкФГаЉЛњЦїЩЯдЫааЗўЮёШэМўЃЌСэЭтвЛаЉдђзїЮЊБИЗнЁЃЯдШЛЮвУЧетвЛХњЗўЮёЦїВЛПЩФмжЛЮЊФГвЛИівЕЮёЗўЮёЃЌЖјЪЧЛсЬсЙЉЖрИіВЛЭЌЕФвЕЮёГадиЁЃФЧаЉБИЗнЕФЗўЮёЦїЃЌдђЛсГЩЮЊЖрИівЕЮёЕФЭЈгУБИЗнЁАГиЁБЁЃЫцзХвЕЮёашЧѓЕФБфЛЏЃЌвЛаЉЗўЮёЦїПЩФмЁАЭЫГіЁБAЗўЮёЖјЁАМгШыЁБBЗўЮёЁЃ
етжжЦЕЗБЕФЗўЮёБфЛЏЃЌвРРЕИпЖШздЖЏЕФШэМўВПЪ№ЙЄОпЁЃЮвУЧЕФдЫЮЌШЫдБЃЌгІИУеЦЮеетПЊЗЂШЫдБЬсЙЉЕФВПЪ№ЙЄОпЃЌЖјВЛЪЧКёКёЕФЪжВсЃЌРДНјааетРрдЫЮЌВйзїЁЃвЛаЉБШНЯгаОбщЕФПЊЗЂЭХЖгЃЌЛсЭГвЛЫљгаЕФвЕЮёЕзВуПђМмЃЌвдЦкДѓВПЗжЕФВПЪ№ЁЂХфжУЙЄОпЃЌЖМФмгУвЛЬзЭЈгУЕФЯЕЭГРДНјааЙмРэЁЃЖјПЊдДНчЃЌвВгаРрЫЦЕФГЂЪдЃЌзюЙуЮЊШЫжЊЕФФЊЙ§гкRPMАВзААќИёЪНЃЌШЛЖјRPMЕФДђАќЗНЪНЛЙЪЧЬЋИДдгЃЌВЛЬЋЗћКЯЗўЮёЦїЖЫГЬађЕФВПЪ№ашЧѓЁЃЫљвдКѓРДгжГіЯжСЫChefЮЊДњБэЕФЃЌПЩБрГЬЕФЭЈгУВПЪ№ЯЕЭГЁЃ
ШЛЖјЃЌЕБNoSQLаЫЦ№ЃЌДѓМвЭЛШЛЗЂЯжЃЌЦфЪЕКмЖрЛЅСЊЭјвЕЮёЃЌЦфЪ§ОнИёЪНЪЧШчДЫЕФМђЕЅЃЌКмЖрЪБКђИљВПВЛашвЊЙиЯЕаЭЪ§ОнПтФЧжжИДдгЕФБэИёЁЃЖдгкЫїв§ЕФвЊЧѓЭљЭљвВжЛЪЧИљОнжїЫїв§ЫбЫїЁЃЖјИќИДдгЕФШЋЮФЫбЫїЃЌБОЩэЪ§ОнПтвВзіВЛЕНЁЃЫљвдЯждкЯрЕБЖрЕФИпВЂЗЂЕФЛЅСЊЭјвЕЮёЃЌЪзбЁNoSQLРДзіДцДЂЩшЪЉЁЃзюдчЕФNoSQLЪ§ОнПтгаMangoDBЕШЃЌЯждкзюСїааЕФЫЦКѕОЭЪЧRedisСЫЁЃЩѕжСгааЉЭХЖгЃЌАбRedisвВЕБГЩЛКГхЯЕЭГЕФвЛВПЗжЃЌЪЕМЪЩЯвВЪЧШЯПЩRedisЕФадФмгХЪЦЁЃ
NoSQLГ§СЫИќПьЁЂГадиСПИќДѓвдЭтЃЌИќживЊЕФЬиЕуЪЧЃЌетжжЪ§ОнДцДЂЗНЪНЃЌжЛФмАДеевЛЬѕЫїв§РДМьЫїКЭаДШыЁЃетбљЕФашЧѓдМЪјЃЌДјРДСЫЗжВМЩЯЕФКУДІЃЌЮвУЧПЩвдАДетЬѕжїЫїв§ЃЌРДЖЈвхЪ§ОнДцЗХЕФНјГЬЃЈЗўЮёЦїЃЉЁЃетбљвЛИіЪ§ОнПтЕФЪ§ОнЃЌОЭФмКмЗНБуЕФДцЗХдкВЛЭЌЕФЗўЮёЦїЩЯЁЃдкЗжВМЪНЯЕЭГЕФБиШЛЧїЪЦЯТЃЌЪ§ОнДцДЂВужегквВевЕНСЫЗжВМЕФЗНЗЈЁЃ
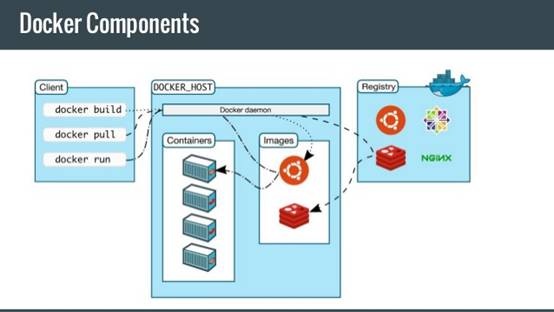
ЮЊСЫЙмРэДѓСПЕФЗжВМЪНЗўЮёЦїЖЫНјГЬЃЌЮвУЧШЗЪЕашвЊЛЈКмЖрЙІЗђЃЌЦфгХЛЏЦфВПЪ№ЙмРэЕФЙЄзїЁЃЭГвЛЗўЮёЦїЖЫНјГЬЕФдЫааЙцЗЖЃЌЪЧЪЕЯжздЖЏЛЏВПЪ№ЙмРэЕФЛљБОЬѕМўЁЃЮвУЧПЩвдИљОнЁАВйзїЯЕЭГЁБзїЮЊЙцЗЖЃЌВЩгУDockerММЪѕЃЛвВПЩвдИљОнЁАWebгІгУЁБзїЮЊЙцЗЖЃЌВЩгУФГаЉPaaSЦНЬЈММЪѕЃЛЛђепздМКЖЈвхвЛаЉИќОпЬхЕФЙцЗЖЃЌздМКПЊЗЂЭъећЕФЗжВМЪНМЦЫуЦНЬЈЁЃ
ШежОЗўЮёЃЈlog4jЃЉ
ЗўЮёЦїЖЫЕФШежОЃЌвЛжБЪЧвЛИіМШживЊгжШнвзБЛКіЪгЕФЮЪЬтЁЃКмЖрЭХЖгдкИеПЊЪМЕФЪБКђЃЌНіНіАбШежОЪгЮЊПЊЗЂЕїЪдЁЂХХГ§BUGЕФИЈжњЙЄОпЁЃЕЋЪЧКмПьЛсЗЂЯжЃЌдкЗўЮёдЫгЊЦ№РДжЎКѓЃЌШежОМИКѕЪЧЗўЮёЦїЖЫЯЕЭГЃЌдкдЫааЪБПЩвдгУРДСЫНтГЬађЧщПіЕФЮЈвЛгааЇЪжЖЮЁЃ
ОЁЙмЮвУЧгаИїжжprofileЙЄОпЃЌЕЋЪЧетаЉЙЄОпДѓВПЗжЖМВЛЪЪКЯдке§ЪНдЫгЊЕФЗўЮёЩЯПЊЦєЃЌвђЮЊЛсбЯжиНЕЕЭЦфдЫааадФмЁЃЫљвдЮвУЧИќЖрЕФЪБКђашвЊИљОнШежОРДЗжЮіЁЃОЁЙмШежОДгБОжЪЩЯЃЌОЭЪЧвЛааааЕФЮФБОаХЯЂЃЌЕЋЪЧгЩгкЦфОпгаКмДѓЕФСщЛюадЃЌЫљвдЛсКмЪмПЊЗЂКЭдЫЮЌШЫдБЕФжиЪгЁЃ
ШежОБОЩэДгИХФюЩЯЃЌЪЧвЛИіКмФЃК§ЕФЖЋЮїЁЃФуПЩвдЫцБуДђПЊвЛИіЮФМўЃЌШЛКѓаДШывЛаЉаХЯЂЁЃЕЋЪЧЯжДњЕФЗўЮёЦїЯЕЭГЃЌвЛАуЖМЛсЖдШежОзівЛаЉБъзМЛЏЕФашЧѓЙцЗЖЃКШежОБиаыЪЧвЛаавЛааЕФЃЌетбљБШНЯЗНБуШеКѓЕФЭГМЦЗжЮіЃЛУПааШежОЮФБОЃЌЖМгІИУгавЛаЉЭГвЛЕФЭЗВПЃЌБШШчШеЦкЪБМфОЭЪЧЛљБОЕФашЧѓЃЛШежОЕФЪфГігІИУЪЧЗжЕШМЖЕФЃЌБШШчfatal/error/warning/info/debug/traceЕШЕШЃЌГЬађПЩвддкдЫааЪБЕїећЪфГіЕФЕШМЖЃЌвдБуПЩвдНкЪЁШежОДђгЁЕФЯћКФЃЛШежОЕФЭЗВПвЛАуЛЙашвЊвЛаЉРрЫЦгУЛЇIDЛђепIPЕижЗжЎРрЕФЭЗаХЯЂЃЌгУгкПьЫйВщевЖЈЮЛЙ§ТЫФГвЛХњШежОМЧТМЃЌЛђепгавЛаЉЦфЫћЕФгУгкЙ§ТЫЫѕаЁШежОВщПДЗЖЮЇЕФзжЖЮЃЌетНазіШОЩЋЙІФмЃЛШежОЮФМўЛЙашвЊгаЁАЛиЙіЁБЙІФмЃЌвВОЭЪЧБЃГжЙЬЖЈДѓаЁЕФЖрИіЮФМўЃЌБмУтГЄЦкдЫааКѓЃЌАбгВХЬаДТњЁЃ

гЩгкгаЩЯЪіЕФИїжжашЧѓЃЌЫљвдПЊдДНчЬсЙЉСЫКмЖргЮЯЗЕФШежОзщМўПтЃЌБШШчДѓУћЖІЖІЕФlog4jЃЌвдМАГЩдБжкЖрЕФlog4XМвзхПтЃЌетаЉЖМЪЧгІгУЙуЗКЖјБЅЪмКУЦРЕФЙЄОпЁЃ
ВЛЙ§ЖдБШШежОЕФДђгЁЙІФмЃЌШежОЕФЫбМЏКЭЭГМЦЙІФмШДЭљЭљБШНЯШнвзБЛКіЪгЁЃзїЮЊЗжВМЪНЯЕЭГЕФГЬађдБЃЌПЯЖЈЪЧЯЃЭћФмДгвЛИіМЏжаНкЕуЃЌФмЫбМЏЭГМЦЕНећИіМЏШКШежОЧщПіЁЃЖјгавЛаЉШежОЕФЭГМЦНсЙћЃЌЩѕжСЯЃЭћФмдкКмЖЬЪБМфФкЗДИДЛёШЁЃЌгУРДМрПиећИіМЏШКЕФНЁПЕЧщПіЁЃвЊзіЕНетвЛЕуЃЌОЭБиаыгавЛИіЗжВМЪНЕФЮФМўЯЕЭГЃЌгУРДДцЗХдДдДВЛЖЯЕНДяЕФШежОЃЈетаЉШежОЭљЭљЭЈЙ§UDPавщЗЂЫЭЙ§РДЃЉЁЃЖјдкетИіЮФМўЯЕЭГЩЯЃЌдђашвЊгавЛИіРрЫЦMap
ReduceМмЙЙЕФЭГМЦЯЕЭГЃЌетбљВХФмЖдКЃСПЕФШежОаХЯЂЃЌНјааПьЫйЕФЭГМЦвдМАБЈОЏЁЃгавЛаЉПЊЗЂепЛсжБНгЪЙгУHadoopЯЕЭГЃЌгавЛаЉдђгУKafkaРДзїЮЊШежОДцДЂЯЕЭГЃЌЩЯУцдйДюНЈздМКЕФЭГМЦГЬађЁЃ
ШежОЗўЮёЪЧЗжВМЪНдЫЮЌЕФвЧБэХЬЁЂЧБЭћОЕЁЃШчЙћУЛгавЛИіПЩППЕФШежОЗўЮёЃЌећИіЯЕЭГЕФдЫаазДПіПЩФмЛсЪЧЪЇПиЕФЁЃЫљвдЮоТлФуЕФЗжВМЪНЯЕЭГНкЕуЪЧЖрЛЙЪЧЩйЃЌБиаыЛЈЗбживЊЕФОЋСІКЭзЈУХЕФПЊЗЂЪБМфЃЌШЅНЈСЂвЛИіЖдШежОНјааздЖЏЛЏЭГМЦЗжЮіЕФЯЕЭГЁЃ
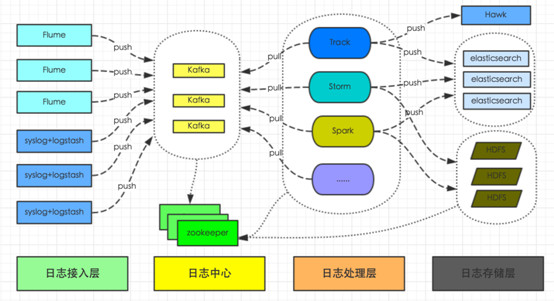
ЗжВМЪНЯЕЭГдкПЊЗЂаЇТЪЩЯдьГЩЕФЮЪЬтКЭНтОіЫМТЗ
ИљОнЩЯЮФЫљЪіЃЌЗжВМЪНЯЕЭГдквЕЮёашЧѓЕФЙІФмвдЮЊЃЌЛЙашвЊдіМгЖюЭтКмЖрЗЧЙІФмЕФашЧѓЁЃетаЉЗЧЙІФмашЧѓЃЌЭљЭљЖМЪЧЮЊСЫвЛИіЖрНјГЬЯЕЭГФмЮШЖЈПЩППдЫааЖјШЅЩшМЦКЭЪЕЯжЕФЁЃетаЉЁАЖюЭтЁБЕФЙЄзїЃЌвЛАуЖМЛсШУФуЕФДњТыИќМгИДдгЃЌШчЙћУЛгаКмКУЕФЙЄОпЃЌОЭЛсШУФуЕФПЊЗЂаЇТЪбЯжиЯТНЕЁЃ
ЮЂЗўЮёПђМмЃКEJBЁЂWebService
ЕБЮвУЧдкЬжТлЗўЮёЦїЖЫШэМўЗжВМЕФЪБКђЃЌЗўЮёНјГЬжЎМфЕФЭЈаХОЭФбУтСЫЁЃШЛЖјЗўЮёНјГЬМфЕФЭЈбЖЃЌВЂВЛЪЧМђЕЅЕФЪеЗЂЯћЯЂОЭФмЭъГЩЕФЁЃетРяЛЙЩцМАСЫЯћЯЂЕФТЗгЩЁЂБрТыНтТыЁЂЗўЮёзДЬЌЕФЖСаДЕШЕШЁЃШчЙћећИіСїГЬЖМгЩздМКПЊЗЂЃЌФЧОЭЬЋРлШЫСЫЁЃ
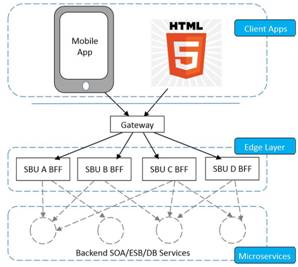
ЫљвдвЕНчКмдчОЭЭЦГіСЫИїжжЗжВМЪНЕФЗўЮёЦїЖЫПЊЗЂПђМмЃЌзюжјУћЕФОЭЪЧЁАEJBЁБЁЊЁЊЦѓвЕJavaBeanЁЃЕЋЗВЙквдЁАЦѓвЕЁБЕФММЪѕЃЌЭљЭљЖМЪЧЗжВМЪНЯТЫљашЕФВПЗжЃЌЖјEJBетжжММЪѕЃЌвВЪЧвЛжжЗжВМЪНЖдЯѓЕїгУЕФММЪѕЁЃЮвУЧШчЙћашвЊШУЖрИіНјГЬКЯзїЭъГЩШЮЮёЃЌдђашвЊАбШЮЮёЗжНтЕНЖрИіЁАРрЁБЩЯЃЌШЛКѓетаЉЁАРрЁБЕФЖдЯѓОЭЛсдкИїИіНјГЬШнЦїжаДцЛюЃЌДгЖјазїЬсЙЉЗўЮёЁЃетИіЙ§ГЬКмЁАУцЯђЖдЯѓЁБЁЃУПИіЖдЯѓЖМЪЧвЛИіЁАЮЂЗўЮёЁБЃЌПЩвдЬсЙЉФГаЉЗжВМЪНЕФЙІФмЁЃ
ЖјСэЭтвЛаЉЯЕЭГЃЌдђзпЯђбЇЯАЛЅСЊЭјЕФЛљБОФЃаЭЃКHTTPЁЃЫљвдОЭгаСЫИїжжЕФWebServiceПђМмЃЌДгПЊдДЕФЕНЩЬвЕШэМўЃЌЖМгаИїздЕФWebServiceЪЕЯжЁЃетжжФЃаЭЃЌАбИДдгЕФТЗгЩЁЂБрНтТыЕШВйзїЃЌМђЛЏГЩГЃМћЕФвЛДЮHTTPВйзїЃЌЪЧвЛжжЗЧГЃгааЇЕФГщЯѓЁЃПЊЗЂШЫдБПЊЗЂКЭВПЪ№ЖрИіWebServiceЕНWebЗўЮёЦїЩЯЃЌОЭЭъГЩСЫЗжВМЪНЯЕЭГЕФДюНЈЁЃ
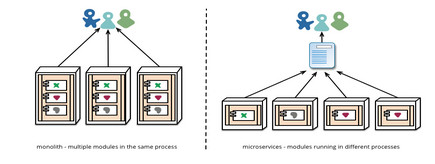
ВЛЙмЮвУЧЪЧбЇЯАEJBЛЙЪЧWebServiceЃЌЪЕМЪЩЯЮвУЧЖМашвЊМђЛЏЗжВМЪНЕїгУЕФИДдгГЬЖШЁЃЖјЗжВМЪНЕїгУЕФИДдгжЎДІЃЌОЭЪЧвђЮЊашвЊАбШнджЁЂРЉШнЁЂИКдиОљКтЕШЙІФмЃЌШкКЯЕНПчНјГЬЕїгУРяЁЃЫљвдЪЙгУвЛЬзЭЈгУЕФДњТыЃЌРДЮЊЫљгаЕФПчНјГЬЭЈбЖЃЈЕїгУЃЉЃЌЭГвЛЕФЪЕЯжШнджЁЂРЉШнЁЂИКдиОљКтЁЂЙ§диБЃЛЄЁЂзДЬЌЛКДцУќжаЕШЕШЗЧЙІФмадашЧѓЃЌФмДѓДѓМђЛЏећИіЗжВМЪНЯЕЭГЕФИДдгадЁЃ
вЛАуЮвУЧЕФЮЂЗўЮёПђМмЃЌЖМЛсдкТЗгЩНзЖЮЃЌЖдећИіМЏШКЫљгаНкЕуЕФзДЬЌНјааЙлВьЃЌШчФФаЉЕижЗЩЯдЫааСЫФФаЉЗўЮёЕФНјГЬЃЌетаЉЗўЮёНјГЬЕФИКдизДПіШчКЮЃЌЪЧЗёПЩгУЃЌШЛКѓЖдгкгазДЬЌЕФЗўЮёЃЌЛЙЛсЪЙгУРрЫЦвЛжТадЙўЯЃЕФЫуЗЈЃЌШЅОЁСПЪдЭМЬсИпЛКДцЕФУќжаТЪЁЃЕБМЏШКжаЕФНкЕузДЬЌЗЂЩњБфЛЏЕФЪБКђЃЌЮЂЗўЮёПђМмЯТЕФЫљгаНкЕуЃЌЖМФмОЁПьЕФЛёЕУетИіБфЛЏЕФЧщПіЃЌДгаТИљОнЕБЧАзДЬЌЃЌжиаТЙцЛЎвдКѓЕФЗўЮёТЗгЩЗНЯђЃЌДгЖјЪЕЯжздЖЏЛЏЕФТЗгЩбЁдёЃЌБмПЊФЧаЉИКдиЙ§ИпЛђепЪЇаЇЕФНкЕуЁЃ
гавЛаЉЮЂЗўЮёПђМмЃЌЛЙЬсЙЉСЫРрЫЦIDLзЊЛЛГЩЁАЙЧМмЁБЁЂЁАзЎЁБДњТыЕФЙЄОпЃЌетбљдкБраДдЖГЬЕїгУГЬађЕФЪБКђЃЌЭъШЋЮоашБраДФЧаЉИДдгЕФЭјТчЯрЙиЕФДњТыЃЌЫљгаЕФДЋЪфВуЁЂБрТыВуДњТыЖМздЖЏЕФБраДКУСЫЁЃетЗНУцEJBЁЂFacebookЕФThriftЃЌGoogle
gRPCЖМОпБИетжжФмСІЁЃдкОпБИДњТыЩњГЩФмСІЕФПђМмЯТЃЌЮвУЧБраДвЛИіЗжВМЪНЯТПЩгУЕФЙІФмФЃПщЃЈПЩФмЪЧвЛИіКЏЪ§ЛђепЪЧвЛИіРрЃЉЃЌОЭКУЯёБраДвЛИіБОЕиЕФКЏЪ§ФЧбљМђЕЅЁЃетОјЖдЪЧЗжВМЪНЯЕЭГЯТЗЧГЃживЊЕФаЇТЪЬсЩ§ЁЃ
вьВНБрГЬЙЄОпЃКаГЬЁЂFutrueЁЂLamda
дкЗжВМЪНЯЕЭГжаБрГЬЃЌФуВЛПЩБмУтЕФЛсХіЕНДѓСПЕФЁАЛиЕїЁБаЭAPIЁЃвђЮЊЗжВМЪНЯЕЭГЩцМАЗЧГЃЖрЕФЭјТчЭЈаХЁЃШЮКЮвЛИівЕЮёУќСюЃЌЖМПЩФмБЛЗжНтЕНЖрИіНјГЬЃЌЭЈЙ§ЖрДЮЭјТчЭЈаХРДзщКЯЭъГЩЁЃгЩгквьВНЗЧзшШћЕФБрГЬФЃаЭДѓааЦфЕРЃЌЫљвдЮвУЧЕФДњТывВЭљЭљЖЏВЛЖЏОЭвЊХіЕНЁАЛиЕїКЏЪ§ЁБЁЃШЛЖјЃЌЛиЕїетжжвьВНБрГЬФЃаЭЃЌЪЧвЛжжЗЧГЃВЛРћгкДњТыдФЖСЕФБрГЬЗНЗЈЁЃвђЮЊФуЮоЗЈДгЭЗЕНЮВЕФдФЖСДњТыЃЌШЅСЫНтвЛИівЕЮёШЮЮёЃЌЪЧдѕбљБЛж№ВНЕФЭъГЩЕФЁЃЪєгквЛИівЕЮёШЮЮёЕФДњТыЃЌгЩгкЖрДЮЕФЗЧзшШћЛиЕїЃЌДгЖјБЛЗжИюГЩКмЖрИіЛиЕїКЏЪ§ЃЌдкДњТыЕФИїДІБЛДЎНгЦ№РДЁЃ
ИќгаЩѕепЃЌЮвУЧгаЪБКђЛсбЁдёЪЙгУЁАЙлВьепФЃЪНЁБЃЌЮвУЧЛсдквЛИіЕиЗНзЂВсДѓСПЕФЁАЪТМў-ЯьгІКЏЪ§ЁБЃЌШЛКѓдкЫљгаашвЊЛиЕїЕФЕиЗНЃЌЖМЗЂГівЛИіЪТМўЁЃЁЊЁЊетбљЕФДњТыЃЌБШЕЅДПЕФзЂВсЛиЕїКЏЪ§ИќФбРэНтЁЃвђЮЊЪТМўЖдгІЕФЯьгІКЏЪ§ЃЌЭЈГЃдкЗЂГіЪТМўДІЪЧЮоЗЈевЕНЕФЁЃетаЉКЏЪ§гРдЖЖМЛсЗХдкСэЭтЕФвЛаЉЮФМўРяЃЌЖјЧвгаЪБКђетаЉКЏЪ§ЛЙЛсдкдЫааЪБИФБфЁЃЖјЪТМўУћзжБОЩэЃЌвВЭљЭљЪЧЗЫвФЫљЫМФбвдРэНтЕФЃЌвђЮЊЕБФуЕФГЬађашвЊГЩЧЇЩЯАйЕФЪТМўЕФЪБКђЃЌЦ№вЛИіШнвзРэНтУћЗћЦфЪЕЕФУћзжЃЌМИКѕЪЧВЛПЩФмЕФЁЃ
ЮЊСЫНтОіЛиЕїКЏЪ§етжжЖдгкДњТыПЩЖСадЕФЦЦЛЕзїгУЃЌШЫУЧЗЂУїСЫКмЖрВЛЭЌЕФИФНјЗНЗЈЁЃЦфжазюжјУћЕФЪЧЁАаГЬЁБЁЃЮвУЧвдЧАГЃГЃЯАЙпгкгУЖрЯпГЬРДНтОіЮЪЬтЃЌЫљвдЗЧГЃЪьЯЄвдЭЌВНЕФЗНЪНШЅаДДњТыЁЃаГЬе§ЪЧбгајСЫЮвУЧЕФетвЛЯАЙпЃЌЕЋВЛЭЌгкЖрЯпГЬЕФЪЧЃЌаГЬВЂВЛЛсЁАЭЌЪБЁБдЫааЃЌЫќжЛЪЧдкашвЊзшШћЕФЕиЗНЃЌгУYield()ЧаЛЛГіШЅжДааЦфЫћаГЬЃЌШЛКѓЕБзшШћНсЪјКѓЃЌгУResume()ЛиЕНИеИеЧаЛЛЕФЮЛжУМЬајЭљЯТжДааЁЃетЯрЕБгкЮвУЧПЩвдАбЛиЕїКЏЪ§ЕФФкШнЃЌНгЕНYield()ЕїгУЕФКѓУцЁЃетжжБраДДњТыЕФЗНЗЈЃЌЗЧГЃРрЫЦгкЭЌВНЕФаДЗЈЃЌШУДњТыБфЕУЗЧГЃвзЖСЁЃЕЋЪЧЮЈвЛЕФШБЕуЪЧЃЌResume()ЕФДњТыЛЙЪЧашвЊдкЫљЮНЁАжїЯпГЬЁБжадЫааЁЃгУЛЇБиаыздМКДгзшШћЛжИДЕФЪБКђЃЌШЅЕїгУResume()ЁЃаГЬСэЭтвЛИіШБЕуЃЌЪЧашвЊзіеЛБЃДцЃЌдкЧаЛЛЕНЦфЫћаГЬжЎКѓЃЌеЛЩЯЕФСйЪББфСПЃЌвВЖМашвЊЖюЭтеМгУПеМфЃЌетЯожЦСЫаГЬДњТыЕФаДЗЈЃЌШУПЊЗЂепВЛФмгУЬЋДѓЕФСйЪББфСПЁЃ
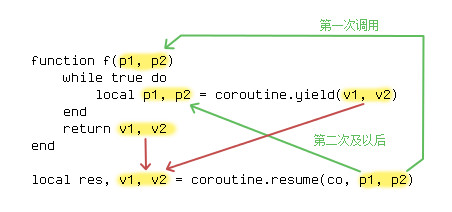
ЖјСэЭтвЛжжИФЩЦЛиЕїКЏЪ§ЕФаДЗЈЃЌЭљЭљНазіFuture/PromiseФЃаЭЁЃетжжаДЗЈЕФЛљБОЫМТЗЃЌОЭЪЧЁАвЛДЮадАбЫљгаЛиЕїаДЕНвЛЦ№ЁБЁЃетЪЧвЛИіЗЧГЃЪЕгУЕФБрГЬФЃаЭЃЌЫќУЛгаШУФуШЅГЙЕзИЩЕєЛиЕїЃЌЖјЪЧШУФуПЩвдАбЛиЕїДгЗжЩЂИїДІЃЌМЏжаЕНвЛИіЕиЗНЁЃдкЭЌвЛЖЮДњТыжаЃЌФуПЩвдЧхЮњЕФПДЕНИїИівьВНЕФВНжшЪЧШчКЮДЎНгЁЂЛђепВЂаажДааЕФЁЃ

зюКѓЫЕвЛЯТlamdaФЃаЭЃЌетжжаДЗЈСїаагкjsгябдЕФЙуЗКгІгУЁЃгЩгкдкЦфЫћгябджаЃЌЖЈвЛИіЛиЕїКЏЪ§ЪЧЗЧГЃЗбЪТЕФЃКJavaгябдвЊЩшМЦвЛИіНгПкШЛКѓзівЛИіЪЕЯжЃЌМђжБЪЧЮхаЧМЖЕФЗбЪТГЬЖШЃЛC/C++жЇГжКЏЪ§жИеыЃЌЫуЪЧБШНЯМђЕЅЃЌЕЋЪЧвВКмШнвзЕМжТДњТыПДВЛЖЎЃЛНХБОгябдЯрЖдКУвЛаЉЃЌвВвЊЖЈвхИіКЏЪ§ЁЃЖјжБНгдкЕїгУЛиЕїЕФЕиЗНЃЌаДЛиЕїКЏЪ§ЕФФкШнЃЌЪЧзюЗНБуПЊЗЂЃЌвВБШНЯРћгкдФЖСЕФЁЃИќживЊЕФЃЌlamdaвЛАувтЮЖзХБеАќЃЌвВОЭЪЧЫЕЃЌетжжЛиЕїКЏЪ§ЕФЕїгУеЛЃЌЪЧБЛЗжБ№БЃДцЕФЃЌКмЖрашвЊдквьВНВйзїжаЃЌашвЊНЈСЂвЛИіРрЫЦЁАЛсЛАГиЁБЕФзДЬЌБЃДцБфСПЃЌдкетРяЖМЪЧВЛашвЊЕФЃЌЖјЪЧПЩвдздШЛЩњаЇЕФЁЃетвЛЕуКЭаГЬгавьЧњЭЌЙЄжЎУюЁЃ

ВЛЙмЪЙгУФФвЛжжвьВНБрГЬЗНЪНЃЌЦфБрТыЕФИДдгЖШЃЌЖМЪЧвЛЖЈБШЭЌВНЕїгУЕФДњТыИпЕФЁЃЫљвдЮвУЧдкБраДЗжВМЪНЗўЮёЦїДњТыЕФЪБКђЃЌвЛЖЈвЊзаЯИЙцЛЎДњТыНсЙЙЃЌБмУтГіЯжЫцвтЬэМгЙІФмДњТыЃЌЕМжТДњТыЕФПЩЖСадБЛЦЦЛЕЕФЧщПіЁЃВЛПЩЖСЕФДњТыЃЌОЭЪЧВЛПЩЮЌЛЄЕФДњТыЃЌЖјДѓСПвьВНЛиЕїЕФЗўЮёЦїЖЫДњТыЃЌЪЧИќШнвзГіЯжетжжЧщПіЕФЁЃ
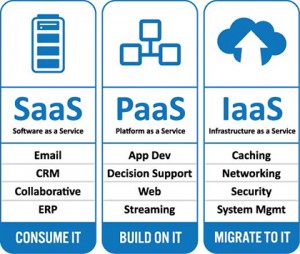
дЦЗўЮёФЃаЭЃКIaaS/PaaS/SaaS
дкИДдгЕФЗжВМЪНЯЕЭГПЊЗЂКЭЪЙгУЙ§ГЬжаЃЌШчКЮЖдДѓСПЗўЮёЦїКЭНјГЬЕФдЫЮЌЃЌвЛжБЪЧвЛИіЙсДЉЦфжаЕФЮЪЬтЁЃВЛЙмЪЧЪЙгУЮЂЗўЮёПђМмЁЂЛЙЪЧЭГвЛЕФВПЪ№ЙЄОпЁЂШежОМрПиЗўЮёЃЌЖМЪЧвђЮЊДѓСПЕФЗўЮёЦїЃЌвЊМЏжаЕФЙмРэЃЌЪЧЗЧГЃВЛШнвзЕФЁЃетРяБГКѓЕФдвђЃЌжївЊЪЧДѓСПЕФгВМўКЭЭјТчЃЌАбТпМЩЯЕФМЦЫуФмСІЃЌЧаИюГЩКмЖраЁПщЁЃ
ЫцзХМЦЫуЛњдЫЫуФмСІЕФЬсЩ§ЃЌГіЯжЕФащФтЛЏММЪѕЃЌШДФмАбБЛЗжИюЕФМЦЫуЕЅдЊЃЌИќжЧФмЕФЭГвЛЦ№РДЁЃЦфжазюГЃМћЕФОЭЪЧIaaSММЪѕЃКЕБЮвУЧПЩвдгУвЛИіЗўЮёЦїгВМўЃЌдЫааЖрИіащФтЕФЗўЮёЦїВйзїЯЕЭГЕФЪБКђЃЌЮвУЧашвЊЮЌЛЄЕФгВМўЪ§СПОЭЛсГЩБЖЕФЯТНЕЁЃЖјPaaSММЪѕЕФСїааЃЌШУЮвУЧПЩвдЮЊФГвЛжжЬиЖЈЕФБрГЬФЃаЭЃЌЭГвЛЕФНјааЯЕЭГдЫааЛЗОГЕФВПЪ№ЮЌЛЄЁЃЖјВЛашвЊдйвЛЬЈЬЈЗўЮёЦїЕФШЅзАВйзїЯЕЭГЁЂХфжУдЫааШнЦїЁЂЩЯДЋдЫааДњТыКЭЪ§ОнЁЃдкУЛгаЭГвЛЕФPaaSжЎЧАЃЌАВзАДѓСПЕФMySQLЪ§ОнПтЃЌдјОЪЧЯћКФДѓСПЪБМф
КЭОЋСІЕФЙЄзїЁЃ
ЕБЮвУЧЕФвЕЮёФЃаЭЃЌГЩЪьЕНПЩвдГщЯѓЮЊвЛаЉЙЬЖЈЕФШэМўЪБЃЌЮвУЧЕФЗжВМЪНЯЕЭГОЭЛсБфЕУИќМгвзгУЁЃЮвУЧЕФМЦЫуФмСІВЛдйЪЧДњТыКЭПтЃЌЖјЪЧвЛИіИіЭЈЙ§ЭјТчЬсЙЉЗўЮёЕФдЦЁЊЁЊSaaSЃЌетбљЪЙгУепИљБОРДЮЌЛЄЁЂВПЪ№ЕФЙЄзїЖМВЛашвЊЃЌжЛвЊЩъЧывЛИіНгПкЃЌЬюЩЯдЄЦкЕФШнСПЖюЖШЃЌОЭФмжБНгЪЙгУСЫЁЃетВЛНіНкЪЁСЫДѓСППЊЗЂЖдгІЙІФмЕФЪТМўЃЌЛЙЕШгкАбДѓСПЕФдЫЮЌЙЄзїЃЌЖМНЛГіШЅИјSaaSЕФЮЌЛЄепЁЊЁЊЖјЫћУЧзіетбљЕФЮЌЛЄЛсИќМгзЈвЕЁЃ
дкдЫЮЌФЃаЭЕФНјЛЏЩЯЃЌДгIaaSЕНPaaSЕНSaaSЃЌЦфгІгУЗЖЮЇвВаэЪЧдНРДдНеЃЌЕЋЪЙгУЕФБуРћадШДГЩБЖЕФЬсИпЁЃетвВжЄУїСЫЃЌШэМўРЭЖЏЕФЙЄзїЃЌвВЪЧПЩвдЭЈЙ§ЗжЙЄЃЌЯђИќзЈвЕЛЏЁЂИќЯИЗжЕФЗНЯђШЅЬсИпаЇТЪЁЃ
змНсЗжВМЪНЯЕЭГЮЪЬтЕФНтОіТЗОЖ
еыЖдЗўЮёЦїГадиФмСІЕФЮЪЬтЃЌЬкбЖWeTestдЫгУСЫГСЕэЪЎЖрФъЕФФкВПЪЕМљОбщзмНсЃЌЭЈЙ§ЛљгкецЪЕвЕЮёГЁОАКЭгУЛЇааЮЊНјаабЙСІВтЪдЃЌАяжњгЮЯЗПЊЗЂепЗЂЯжЗўЮёЦїЖЫЕФадФмЦПОБЃЌНјааеыЖдадЕФадФмЕїгХЃЌНЕЕЭЗўЮёЦїВЩЙККЭЮЌЛЄГЩБОЃЌЬсИпгУЛЇСєДцКЭзЊЛЏТЪЁЃ
|









