| БрМЭЦМі: |
БОЮФжївЊНВНтСЫZooKeeperЪЧЪВУДЃЌЫќЕФНЧЩЋМАМмЙЙЃЌZooKeeperЪ§ОнФЃаЭZnodeЃЌZooKeeperЗўЮёжаВйзїЃЌZookeeperЯТдиАВзАгыХфжУКЭУќСюЯрЙиЁЃ
РДздгкВЉПЭдАЃЌ,гЩЛ№СњЙћШэМўAnnaБрМЁЂЭЦМіЁЃ |
|
ZooKeeperНщЩм ZooKeeperЪЧвЛжжЮЊЗжВМЪНгІгУЫљЩшМЦЕФИпПЩгУЁЂИпадФмЧввЛжТЕФПЊдДаЕїЗўЮё,ЪЧGoogleЕФChubbyвЛИіПЊдДЕФЪЕЯжЁЃ ЬсЙЉЙІФмЃК
УќУћЗўЮё ХфжУЙмРэ МЏШКЙмРэ ЗжВМЪНЫј ЖгСаЙмРэ ЬиадЃК
ЫГађвЛжТадЃКДгЭЌвЛИіПЭЛЇЖЫЗЂЦ№ЕФЪТЮёЧыЧѓЃЌзюжеНЋЛсбЯИёАДееЦфЗЂЦ№ЫГађБЛгІгУЕНZooKeeperжаЁЃ дзгадЃКЫљгаЪТЮёЧыЧѓЕФНсЙћдкМЏШКжаЫљгаЛњЦїЩЯЕФгІгУЧщПіЪЧвЛжТЕФЃЌвВОЭЪЧЫЕвЊУДећИіМЏШКЫљгаМЏШКЖМГЩЙІгІгУСЫФГвЛИіЪТЮёЃЌвЊУДЖМУЛгагІгУЃЌвЛЖЈВЛЛсГіЯжМЏШКжаВПЗжЛњЦїгІгУСЫИУЪТЮёЃЌЖјСэЭтвЛВПЗжУЛгагІгУЕФЧщПіЁЃ ЕЅвЛЪгЭМЃКЮоТлПЭЛЇЖЫСЌНгЕФЪЧФФИіZooKeeperЗўЮёЦїЃЌЦфПДЕНЕФЗўЮёЖЫЪ§ОнФЃаЭЖМЪЧвЛжТЕФЁЃ ПЩППадЃКвЛЕЉЗўЮёЖЫГЩЙІЕигІгУСЫвЛИіЪТЮёЃЌВЂЭъГЩЖдПЭЛЇЖЫЕФЯьгІЃЌФЧУДИУЪТЮёЫљв§Ц№ЕФЗўЮёЖЫзДЬЌБфИќНЋЛсБЛвЛжББЃСєЯТРДЃЌГ§ЗЧгаСэвЛИіЪТЮёгжЖдЦфНјааСЫБфИќЁЃ ЪЕЪБадЃКЭЈГЃШЫУЧПДЕНЪЕЪБадЕФЕквЛЗДгІЪЧЃЌвЛЕЉвЛИіЪТЮёБЛГЩЙІгІгУЃЌФЧУДПЭЛЇЖЫФмЙЛСЂМДДгЗўЮёЖЫЩЯЖСШЁЕНетИіЪТЮёБфИќКѓЕФзюаТЪ§ОнзДЬЌЁЃетРяашвЊзЂвтЕФЪЧЃЌZooKeeperНіНіБЃжЄдквЛЖЈЕФЪБМфЖЮФкЃЌПЭЛЇЖЫзюжевЛЖЈФмЙЛДгЗўЮёЖЫЩЯЖСШЁЕНзюаТЕФЪ§ОнзДЬЌЁЃ
ZookeeperЕФНЧЩЋ СьЕМепЃЈleaderЃЉЃКИКд№НјааЭЖЦБЕФЗЂЦ№КЭОівщ,ИќаТЯЕЭГзДЬЌ,вЛИіZooKeeperМЏШКЭЌвЛЪБПЬжЛЛсгавЛИіLeaderЃЌЦфЫћЖМЪЧFollowerЛђObserverЁЃ бЇЯАепЃЈlearnerЃЉЃКАќРЈИњЫцепЃЈfollowerЃЉКЭЙлВьепЃЈobserverЃЉЁЃ followerгУгкНгЪмПЭЛЇЖЫЧыЧѓВЂЯђПЭЛЇЖЫЗЕЛиНсЙћ,дкбЁжїЙ§ГЬжаВЮгыЭЖЦБЁЃ ObserverПЩвдНгЪмПЭЛЇЖЫСЌНг,НЋаДЧыЧѓзЊЗЂИјleader,ЕЋobserverВЛВЮМгЭЖЦБЙ§ГЬ,жЛЭЌВНleaderЕФзДЬЌ,observerЕФФПЕФЪЧЮЊСЫРЉеЙЯЕЭГ,ЬсИпЖСШЁЫйЖШЁЃ ПЭЛЇЖЫЃЈclientЃЉ,ЧыЧѓЗЂЦ№ЗНЁЃ зЂвтЃКZooKeeperФЌШЯжЛгаLeaderКЭFollowerСНжжНЧЩЋЃЌУЛгаObserverНЧЩЋЁЃЮЊСЫЪЙгУObserverФЃЪНЃЌдкШЮКЮЯыБфГЩObserverЕФНкЕуЕФХфжУЮФМўжаМгШыЃКpeerType=observerЃЌВЂдкЫљгаserverЕФХфжУЮФМўжаЃЌХфжУГЩobserverФЃЪНЕФserverЕФФЧааХфжУзЗМг:observerЃЌР§ШчЃКserver.1:localhost:2888:3888:observer FollowerКЭObserverЧјБ№ЃКFollowerКЭObserverЖМФмЬсЙЉЖСЗўЮёЃЌВЛФмЬсЙЉаДЗўЮёЁЃСНепЮЈвЛЕФЧјБ№дкгкЃЌObserverЛњЦїВЛВЮгыLeaderбЁОйЙ§ГЬЃЌвВВЛВЮгыаДВйзїЕФЁКЙ§АыаДГЩЙІЁЛВпТдЃЌвђДЫObserverПЩвддкВЛгАЯьаДадФмЕФЧщПіЯТЬсЩ§МЏШКЕФЖСадФмЁЃ
ZookeeperМмЙЙ
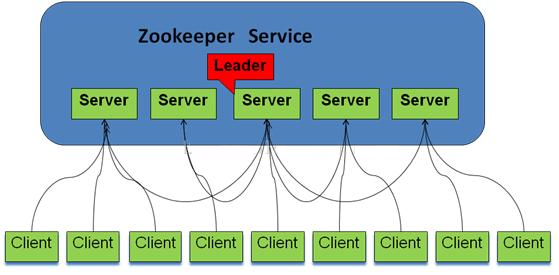
zookeeperЪЧвЛИігЩЖрИіserviceЃЈНкЕуЃЉзщГЩЕФМЏШК,вЛИіleader,ЖрИіfollower,УПИіserverБЃДцвЛЗнЪ§ОнВПЗж,ШЋОжЪ§ОнвЛжТ,ЗжВМЪНЖСаД,ПЭЛЇЖЫИќаТЧыЧѓгЩleaderзЊЗЂЪЕЪЉЁЃ
ИќаТЧыЧѓЫГађНјаа,РДздЭЌвЛИіclientЕФИќаТЧыЧѓАДЦфЗЂЫЭЫГађвРДЮжДаа,Ъ§ОнИќаТдзгад,вЛДЮЪ§ОнИќаТвЊУДГЩЙІ,вЊУДЪЇАм,ШЋОжЮЈвЛЪ§ОнЪдЭМ,clientЮоТлСЌНгЕНФФИіserver,Ъ§ОнЪгЭМЪЧвЛжТЕФЁЃ
zookeeperЕФКЫаФЪЧдзгЙуВЅ,етИіЛњжЦБЃжЄСЫИїИіserverжЎМфЕФЭЌВН,ЪЕЯжетИіЛњжЦЕФавщНазіZabавщ.ZabавщгаСНжжФЃЪН,ЫћУЧЗжБ№ЪЧЛжИДФЃЪНКЭЙуВЅФЃЪНЁЃ
ЃЈ1ЃЉЕБЗўЮёЦєЖЏЛђепдкСьЕМепБРРЃКѓ,ZabОЭНјШыСЫЛжИДФЃЪН,ЕБСьЕМзХБЛбЁОйГіРД,ЧвДѓЖрЪ§serverЖМЭъГЩСЫКЭleaderЕФзДЬЌЭЌВНКѓ,ЛжИДФЃЪНОЭНсЪјСЫ.зДЬЌЭЌВНБЃжЄСЫleaderКЭserverОпгаЯрЭЌЕФЯЕЭГзДЬЌЁЃ
ЃЈ2ЃЉвЛЕЉleaderвбОКЭЖрЪ§ЕФfollowerНјааСЫзДЬЌЭЌВНКѓ,ЫћОЭПЩвдПЊЪМЙуВЅЯћЯЂСЫ,МДНјШыЙуВЅзДЬЌ.етЪБКђЕБвЛИіserverМгШыzookeeperЗўЮёжа,ЫќЛсдкЛжИДФЃЪНЯТЦєЖЏ,ЗЂЯТleader,ВЂКЭleaderНјаазДЬЌЭЌВН,Д§ЕНЭЌВННсЪј,ЫќвВВЮгыЙуВЅЯћЯЂЁЃ
ZooKeeperЪ§ОнФЃаЭZnode (1) НкЕу ЗжВМЪНЕФЪБКђЃЌвЛАуЁКНкЕуЁЛжИЕФЪЧзщГЩМЏШКЕФУПвЛЬЈЛњЦїЁЃЖјZooKeeperжаЕФЪ§ОнНкЕуЪЧжИЪ§ОнФЃаЭжаЕФЪ§ОнЕЅдЊЃЌГЦЮЊZNodeЁЃ
(2) ZooKeeperНкЕуЪєад
ЭЈЙ§ЧАУцЕФНщЩмЃЌЮвУЧПЩвдСЫНтЕНЃЌвЛИіНкЕуздЩэгЕгаБэЪОЦфзДЬЌЕФаэЖрживЊЪєадЃЌШчЯТЭМЫљЪОЁЃ
ZnodeНкЕуЪєадНсЙЙ:
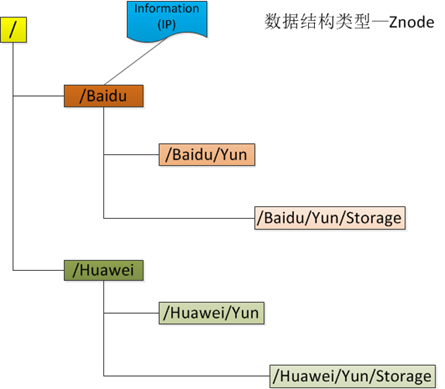
(3) Ъ§ОнФЃаЭНсЙЙ ZooKeeperНЋЫљгаНкЕуЪ§ОнДцДЂдкФкДцжаЃЌЪ§ОнФЃаЭЪЧвЛПУЪїЃЈZNode TreeЃЉЃЌгЩаБИмЃЈ/ЃЉНјааЗжИюЕФТЗОЖЃЌОЭЪЧвЛИіZNodeЃЌШч/hbase/master,ЦфжаhbaseКЭmasterЖМЪЧZNodeЁЃУПИіZNodeЩЯЖМЛсБЃДцздМКЕФЪ§ОнФкШнЃЌЭЌЪБЛсБЃДцвЛЯЕСаЪєадаХЯЂЁЃZooKeeperгЕгавЛИіВуДЮЕФУќУћПеМфЃЌетИіКЭБъзМЕФЮФМўЯЕЭГЗЧГЃЯрЫЦЃЌШчЯТЭМ3.1
ЫљЪОЁЃ
ZooKeeperЪ§ОнФЃаЭгыЮФМўЯЕЭГФПТМЪїЃК
(4) в§гУЗНЪН
ZondeЭЈЙ§ТЗОЖв§гУЃЌШчЭЌUnixжаЕФЮФМўТЗОЖЁЃТЗОЖБиаыЪЧОјЖдЕФЃЌвђДЫЫћУЧБиаыгЩаБИмзжЗћРДПЊЭЗЁЃГ§ДЫвдЭтЃЌЫћУЧБиаыЪЧЮЈвЛЕФЃЌвВОЭЪЧЫЕУПвЛИіТЗОЖжЛгавЛИіБэЪОЃЌвђДЫетаЉТЗОЖВЛФмИФБфЁЃдкZooKeeperжаЃЌТЗОЖгЩUnicodeзжЗћДЎзщГЩЃЌВЂЧвгавЛаЉЯожЦЁЃзжЗћДЎ"/zookeeper"гУвдБЃДцЙмРэаХЯЂЃЌБШШчЙиМќХфЖюаХЯЂЁЃ
(5) ZnodeНсЙЙ
ZooKeeperУќУћПеМфжаЕФZnodeЃЌМцОпЮФМўКЭФПТМСНжжЬиЕуЁЃМШЯёЮФМўвЛбљЮЌЛЄзХЪ§ОнЁЂдЊаХЯЂЁЂACLЁЂЪБМфДСЕШЪ§ОнНсЙЙЃЌгжЯёФПТМвЛбљПЩвдзїЮЊТЗОЖБъЪЖЕФвЛВПЗжЁЃЭМжаЕФУПИіНкЕуГЦЮЊвЛИіZnodeЁЃ
УПИіZnodeгЩ3ВПЗжзщГЩ:
Ђй statЃКДЫЮЊзДЬЌаХЯЂ, УшЪіИУZnodeЕФАцБО, ШЈЯоЕШаХЯЂ
Ђк dataЃКгыИУZnodeЙиСЊЕФЪ§Он
Ђл childrenЃКИУZnodeЯТЕФзгНкЕу
ZooKeeperЫфШЛПЩвдЙиСЊвЛаЉЪ§ОнЃЌЕЋВЂУЛгаБЛЩшМЦЮЊГЃЙцЕФЪ§ОнПтЛђепДѓЪ§ОнДцДЂЃЌЯрЗДЕФЪЧЃЌЫќгУРДЙмРэЕїЖШЪ§ОнЃЌБШШчЗжВМЪНгІгУжаЕФХфжУЮФМўаХЯЂЁЂзДЬЌаХЯЂЁЂЛуМЏЮЛжУЕШЕШЁЃетаЉЪ§ОнЕФЙВЭЌЬиадОЭЪЧЫќУЧЖМЪЧКмаЁЕФЪ§ОнЃЌЭЈГЃвдKBЮЊДѓаЁЕЅЮЛЁЃZooKeeperЕФЗўЮёЦїКЭПЭЛЇЖЫЖМБЛЩшМЦЮЊбЯИёМьВщВЂЯожЦУПИіZnodeЕФЪ§ОнДѓаЁжСЖр1MЃЌЕЋГЃЙцЪЙгУжагІИУдЖаЁгкДЫжЕЁЃ
(6) Ъ§ОнЗУЮЪ
ZooKeeperжаЕФУПИіНкЕуДцДЂЕФЪ§ОнвЊБЛдзгадЕФВйзїЁЃвВОЭЪЧЫЕЖСВйзїНЋЛёШЁгыНкЕуЯрЙиЕФЫљгаЪ§ОнЃЌаДВйзївВНЋЬцЛЛЕєНкЕуЕФЫљгаЪ§ОнЁЃСэЭтЃЌУПвЛИіНкЕуЖМгЕгаздМКЕФACL(ЗУЮЪПижЦСаБэ)ЃЌетИіСаБэЙцЖЈСЫгУЛЇЕФШЈЯоЃЌМДЯоЖЈСЫЬиЖЈгУЛЇЖдФПБъНкЕуПЩвджДааЕФВйзїЁЃ
(7) НкЕуРраЭ
ZooKeeperжаЕФНкЕугаСНжжЃЌЗжБ№ЮЊСйЪБНкЕуКЭгРОУНкЕуЁЃНкЕуЕФРраЭдкДДНЈЪБМДБЛШЗЖЈЃЌВЂЧвВЛФмИФБфЁЃ
Ђй СйЪБНкЕуЃКИУНкЕуЕФЩњУќжмЦквРРЕгкДДНЈЫќУЧЕФЛсЛАЁЃвЛЕЉЛсЛА(Session)НсЪјЃЌСйЪБНкЕуНЋБЛздЖЏЩОГ§ЃЌЕБШЛПЩвдвВПЩвдЪжЖЏЩОГ§ЁЃЫфШЛУПИіСйЪБЕФZnodeЖМЛсАѓЖЈЕНвЛИіПЭЛЇЖЫЛсЛАЃЌЕЋЫћУЧЖдЫљгаЕФПЭЛЇЖЫЛЙЪЧПЩМћЕФЁЃСэЭтЃЌZooKeeperЕФСйЪБНкЕуВЛдЪаэгЕгазгНкЕуЁЃ
Ђк гРОУНкЕуЃКИУНкЕуЕФЩњУќжмЦкВЛвРРЕгкЛсЛАЃЌВЂЧвжЛгадкПЭЛЇЖЫЯдЪОжДааЩОГ§ВйзїЕФЪБКђЃЌЫћУЧВХФмБЛЩОГ§ЁЃ
(8) ЫГађНкЕу
ЕБДДНЈZnodeЕФЪБКђЃЌгУЛЇПЩвдЧыЧѓдкZooKeeperЕФТЗОЖНсЮВЬэМгвЛИіЕндіЕФМЦЪ§ЁЃетИіМЦЪ§ЖдгкДЫНкЕуЕФИИНкЕуРДЫЕЪЧЮЈвЛЕФЃЌЫќЕФИёЪНЮЊ"%10d"(10ЮЛЪ§зжЃЌУЛгаЪ§жЕЕФЪ§ЮЛгУ0ВЙГфЃЌР§Шч"0000000001")ЁЃЕБМЦЪ§жЕДѓгк232-1ЪБЃЌМЦЪ§ЦїНЋвчГіЁЃ
(9) ЙлВь
ПЭЛЇЖЫПЩвддкНкЕуЩЯЩшжУwatchЃЌЮвУЧГЦжЎЮЊМрЪгЦїЁЃЕБНкЕузДЬЌЗЂЩњИФБфЪБ(ZnodeЕФдіЁЂЩОЁЂИФ)НЋЛсДЅЗЂwatchЫљЖдгІЕФВйзїЁЃЕБwatchБЛДЅЗЂЪБЃЌZooKeeperНЋЛсЯђПЭЛЇЖЫЗЂЫЭЧвНіЗЂЫЭвЛЬѕЭЈжЊЃЌвђЮЊwatchжЛФмБЛДЅЗЂвЛДЮЃЌетбљПЩвдМѕЩйЭјТчСїСПЁЃ
ZooKeeperЗўЮёжаВйзї дкZooKeeperжага9ИіЛљБОВйзїЃЌШчЯТЭМЫљЪОЃК
ZooKeeperРрЗНЗЈУшЪі
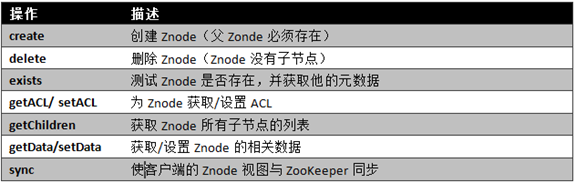
ИќаТZooKeeperВйзїЪЧгаЯожЦЕФЁЃdeleteЛђsetDataБиаыУїШЗвЊИќаТЕФZnodeЕФАцБОКХЃЌЮвУЧПЩвдЕїгУexistsевЕНЁЃШчЙћАцБОКХВЛЦЅХфЃЌИќаТНЋЛсЪЇАмЁЃ
ИќаТZooKeeperВйзїЪЧЗЧзшШћЪНЕФЁЃвђДЫПЭЛЇЖЫШчЙћЪЇШЅСЫвЛИіИќаТ(гЩгкСэвЛИіНјГЬдкЭЌЪБИќаТетИіZnode)ЃЌЫћПЩвддкВЛзшШћЦфЫћНјГЬжДааЕФЧщПіЯТЃЌбЁдёжиаТГЂЪдЛђНјааЦфЫћВйзїЁЃ
ОЁЙмZooKeeperПЩвдБЛПДзіЪЧвЛИіЮФМўЯЕЭГЃЌЕЋЪЧДІгкБуРћЃЌо№ЦњСЫвЛаЉЮФМўЯЕЭГЕиВйзїдгяЁЃвђЮЊЮФМўЗЧГЃЕФаЁВЂЧвЪЙећЬхЖСаДЕФЃЌЫљвдВЛашвЊДђПЊЁЂЙиБеЛђЪЧбАЕиЕФВйзїЁЃ
WatchДЅЗЂЦї (1) watchИХЪі
ZooKeeperПЩвдЮЊЫљгаЕФЖСВйзїЩшжУwatchЃЌетаЉЖСВйзїАќРЈЃКexists()ЁЂgetChildren()МАgetData()ЁЃwatchЪТМўЪЧвЛДЮадЕФДЅЗЂЦїЃЌЕБwatchЕФЖдЯѓзДЬЌЗЂЩњИФБфЪБЃЌНЋЛсДЅЗЂДЫЖдЯѓЩЯwatchЫљЖдгІЕФЪТМўЁЃwatchЪТМўНЋБЛвьВНЕиЗЂЫЭИјПЭЛЇЖЫЃЌВЂЧвZooKeeperЮЊwatchЛњжЦЬсЙЉСЫгаађЕФвЛжТадБЃжЄЁЃРэТлЩЯЃЌПЭЛЇЖЫНгЪеwatchЪТМўЕФЪБМфвЊПьгкЦфПДЕНwatchЖдЯѓзДЬЌБфЛЏЕФЪБМфЁЃ
(2) watchРраЭ
ZooKeeperЫљЙмРэЕФwatchПЩвдЗжЮЊСНРрЃК
Ђй Ъ§Онwatch(data watches)ЃКgetDataКЭexistsИКд№ЩшжУЪ§Онwatch Ђк КЂзгwatch(child watches)ЃКgetChildrenИКд№ЩшжУКЂзгwatch
ЮвУЧПЩвдЭЈЙ§ВйзїЗЕЛиЕФЪ§ОнРДЩшжУВЛЭЌЕФwatchЃК
Ђй getDataКЭexistsЃКЗЕЛиЙигкНкЕуЕФЪ§ОнаХЯЂ Ђк getChildrenЃКЗЕЛиКЂзгСаБэ
вђДЫ
Ђй вЛИіГЩЙІЕФsetDataВйзїНЋДЅЗЂZnodeЕФЪ§Онwatch
Ђк вЛИіГЩЙІЕФcreateВйзїНЋДЅЗЂZnodeЕФЪ§ОнwatchвдМАКЂзгwatch
Ђл вЛИіГЩЙІЕФdeleteВйзїНЋДЅЗЂZnodeЕФЪ§ОнwatchвдМАКЂзгwatch
(3) watchзЂВсгыДІДЅЗЂ
ЭМ 6.1 watchЩшжУВйзїМАЯргІЕФДЅЗЂЦїШчЭМЯТЭМЫљЪОЃК

Ђй existsВйзїЩЯЕФwatchЃЌдкБЛМрЪгЕФZnodeДДНЈЁЂЩОГ§ЛђЪ§ОнИќаТЪББЛДЅЗЂЁЃ Ђк getDataВйзїЩЯЕФwatchЃЌдкБЛМрЪгЕФZnodeЩОГ§ЛђЪ§ОнИќаТЪББЛДЅЗЂЁЃдкБЛДДНЈЪБВЛФмБЛДЅЗЂЃЌвђЮЊжЛгаZnodeвЛЖЈДцдкЃЌgetDataВйзїВХЛсГЩЙІЁЃ Ђл getChildrenВйзїЩЯЕФwatchЃЌдкБЛМрЪгЕФZnodeЕФзгНкЕуДДНЈЛђЩОГ§ЃЌЛђЪЧетИіZnodeздЩэБЛЩОГ§ЪББЛДЅЗЂЁЃПЩвдЭЈЙ§ВщПДwatchЪТМўРраЭРДЧјЗжЪЧZnodeЃЌЛЙЪЧЫћЕФзгНкЕуБЛЩОГ§ЃКNodeDeleteБэЪОZnodeБЛЩОГ§ЃЌNodeDeletedChangedБэЪОзгНкЕуБЛЩОГ§ЁЃ
WatchгЩПЭЛЇЖЫЫљСЌНгЕФZooKeeperЗўЮёЦїдкБОЕиЮЌЛЄЃЌвђДЫwatchПЩвдЗЧГЃШнвзЕиЩшжУЁЂЙмРэКЭЗжХЩЁЃЕБПЭЛЇЖЫСЌНгЕНвЛИіаТЕФЗўЮёЦї
ЪБЃЌШЮКЮЕФЛсЛАЪТМўЖМНЋПЩФмДЅЗЂwatchЁЃСэЭтЃЌЕБДгЗўЮёЦїЖЯПЊСЌНгЕФЪБКђЃЌwatchНЋВЛЛсБЛНгЪеЁЃЕЋЪЧЃЌЕБвЛИіПЭЛЇЖЫжиаТНЈСЂСЌНгЕФЪБКђЃЌШЮКЮЯШЧА
зЂВсЙ§ЕФwatchЖМЛсБЛжиаТзЂВсЁЃ
(4) ашвЊзЂвтЕФМИЕу
ZookeeperЕФwatchЪЕМЪЩЯвЊДІРэСНРрЪТМўЃК
Ђй СЌНгзДЬЌЪТМў(type=None, path=null)
етРрЪТМўВЛашвЊзЂВсЃЌвВВЛашвЊЮвУЧСЌајДЅЗЂЃЌЮвУЧжЛвЊДІРэОЭааСЫЁЃ
Ђк НкЕуЪТМў
НкЕуЕФНЈСЂЃЌЩОГ§ЃЌЪ§ОнЕФаоИФЁЃЫќЪЧone time triggerЃЌЮвУЧашвЊВЛЭЃЕФзЂВсДЅЗЂЃЌЛЙПЩФмЗЂЩњЪТМўЖЊЪЇЕФЧщПіЁЃ
ЩЯУц2РрЪТМўЖМдкWatchжаДІРэЃЌвВОЭЪЧжидиЕФprocess(Event event)
НкЕуЪТМўЕФДЅЗЂЃЌЭЈЙ§КЏЪ§existsЃЌgetDataЛђgetChildrenРДДІРэетРрКЏЪ§ЃЌгаЫЋжизїгУЃК
Ђй зЂВсДЅЗЂЪТМў
Ђк КЏЪ§БОЩэЕФЙІФм
КЏЪ§ЕФБОЩэЕФЙІФмгжПЩвдгУвьВНЕФЛиЕїКЏЪ§РДЪЕЯж,жидиprocessResult()Й§ГЬжаДІРэКЏЪ§БОЩэЕФЕФЙІФмЁЃ
ZookeeperЯТдиАВзАгыХфжУ ZookeeperЯТдиАВзА ДгZooKeeperЙйЭјЯТди
ЯТдиЕижЗ
НтбЙХфжУ
tar -xf /usr/local/src/zookeeper-
3.4.9.tar.gz -C /usr/local/src/
ln -sv /usr/local/src/zookeeper- 3.4.9/ /usr/local/zookeeper
cd /usr/local/zookeeper/ |
3.ХфжУZooKeeper
vim zoo.cfg
# zoo.cfgЮФМўжаФкШнШчЯТ
tickTime=2000
dataDir=/var/lib/zookeeper
clientPort=2181 |
tickTime ЕЅЮЛЮЊЮЂУыЃЌгУгкsessionзЂВсКЭПЭЛЇЖЫКЭZooKeeperЗўЮёЕФаФЬјжмЦкЁЃsessionГЌЪБЪБГЄзюаЁЮЊ
tickTimeЕФСНБЖЁЃ
dataDir ZooKeeperЕФзДЬЌДцДЂЮЛжУЃЌПДУћзжОЭжЊЕРЪщЪ§ОнФПТМЁЃдкФуЕФЯЕЭГжаМьВщетИіФПТМЪЧЗёДцдкЃЌШчЙћВЛДцдкЪжЖЏДДНЈЃЌВЂЧвИјгшПЩаДШЈЯоЁЃ clientPort ПЭЛЇЖЫСЌНгЕФЖЫПкЁЃВЛЭЌЕФЗўЮёЦїПЩвдЩшжУВЛЭЌЕФМрЬ§ЖЫПкЃЌФЌШЯЪЧ2181ЁЃ
4.ЦєЖЏZooKeeper
# етРяУќСюаДЕФГЄЪЧЮЊСЫБугкжЊЕРZooKeeperЪЧШчКЮЪЙгУХфжУЮФМўЕФЁЃ
/usr/local/zookeeper/bin/zkServer.sh start /usr/local/zookeeper/conf/zoo.cfg
# ВщПДZooKeeperЪЧЗёдЫаа
ps ЈCef | grep zookeeper
# вВПЩвдЪЙгУjps ЃЌПЩвдПДЕНjavaНјГЬжагаQuorumPeerMainСаГіРДЁЃ
# ВщПДZooKeeperЕФзДЬЌ
zkServer.sh status
# ГЃгУЕФZooKeeperгУЗЈЃЌетИіЪєгкLinuxЛљДЁЕФВПЗжЃЌОЭВЛЙ§ЖрЫЕУїСЫ
./zkServer.sh {start|start-foreground|stop|restart|status|upgrade|print-cmd} |
5.ЪЙгУzkCliСЌНгZooKeeper
| /usr/local/zookeeper/bin/zkCli.sh
-server localhost:218 |
МЏШКХфжУ
1.ДДНЈХфжУЮФМў
cd /usr/local/zookeeper
touch zoo1.cfg zoo2.cfg zoo3.cfg |
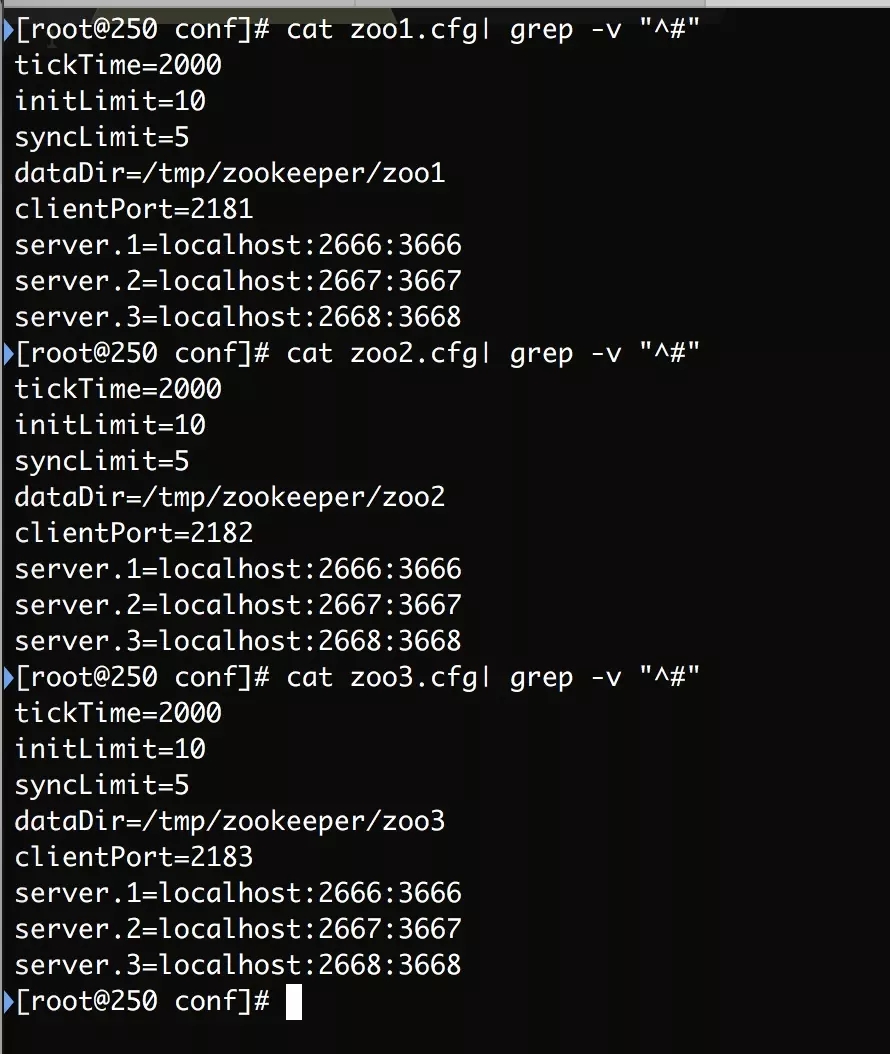
зЂвт ЖЫПкВЛвЊГхЭЛЃЌdataDirВЛвЊЯрЭЌЁЃ
2.ХфжУЪ§ОнФПТМгыЪ§ОнДцЗХФПТМФкШн
mkdir {zoo1,zoo2,zoo3}
echo 1 > zoo1/myid
echo 2 > zoo2/myid
echo 3 > zoo3/myid |
зЂвтЃКетРяЕФmyidЮФМўжавЛЖЈвЊЖдгІЩЯУцХфжУЮФМўжаserver.[id]ЕФЪ§зжЃЌВЛШЛZooKeeperЦєЖЏЛсГіДэЁЃ
3.ЦєЖЏZookeeper
zkServer.sh start
/usr/local/zookeeper/conf/zoo1.cfg
zkServer.sh start /usr/local/zookeeper/conf/zoo2.cfg
zkServer.sh start /usr/local/zookeeper/conf/zoo3.cfg |
4.ВщПДаЇЙћ
ЪЙгУps -ef | grep zooПЩвдПДЕНгаШ§ИіzookeeperЦєЖЏЦ№РДСЫЁЃ
СЌНгZooKeeper
# 192.168.8.250ЪЧZooKeeperЗўЮёЦїЕФЕижЗ
zkCli.sh -server 192.168.8.250:2181, 192.168.8.250:
2182, 192.168.8.250:2183 |
ZookeeperУќСюЦЊ
СЌНгдЖГЬServerЃКzkCli.sh ЈCserver <ip>:<port> БШШчСЌНгЕНБОЕиZoopkerЗўЮёЃК ./zkCli.sh -server localhost:2181 ВщПДНкЕуЪ§ОнЃКls <path>ЃЌБШШчls / дђВщПДИљФПТМНкЕуЪ§Он ВщПДФГИіЗўЮёServiceЕФЬсЙЉеп ls ЗўЮёУћ/providers ВщПДНкЕуЪ§ОнВЂФмПДЕНИќаТДЮЪ§ЕШЪ§ОнЃКls2 <path>ЃЌЪфГізжЖЮКЌвхШчЯТЃК cZxidЃКДДНЈНкЕуЕФЪТЮёid ctimeЃКДДНЈНкЕуЕФЪБМф mZxidЃКаоИФНкЕуЕФЪТЮёid mtimeЃКаоИФНкЕуЕФЪБМф pZxidЃКзгНкЕуСаБэзюКѓвЛДЮаоИФЕФЪТЮёidЁЃЩОГ§ЛђЬэМгзгНкЕуЃЌВЛАќКЌаоИФзгНкЕуЕФЪ§Он cversionЃКзгНкЕуЕФАцБОКХЃЌЩОГ§ЛђЬэМгзгНкЕуЃЌАцБОКХЛсздді dataVersionЃКНкЕуЪ§ОнАцБОКХЃЌЪ§ОнаДШыВйзїЃЌАцБОКХЛсЕнді aclVersionЃКНкЕуACLШЈЯоАцБОЃЌШЈЯоаДШыВйзїЃЌАцБОКХЛсЕнді ephemeralOwnerЃКСйЪБНкЕуДДНЈЪБЕФЪТЮёidЃЌШчЙћНкЕуЪЧгРОУНкЕуЃЌдђЫќЕФжЕЮЊ0 dataLengthЃКНкЕуЪ§ОнГЄЖШЃЈЕЅЮЛЃКbyteЃЉЃЌжаЮФеМ3Иіbyte numChildrenЃКзгНкЕуЪ§СП ДДНЈНкЕуЃКcreate <path> <data> ЛёШЁНкЕуЃЌАќКЌЪ§ОнКЭИќаТДЮЪ§ЕШЪ§ОнЃКget <path> аоИФНкЕуЃКset <path> <data> ЩОГ§НкЕуЃКdelete <path>ЃЌШчЙћгазгНкЕуДцдкдђЩОГ§ЪЇАм
|









