| БрМЭЦМі: |
БОЮФРДздгкагШЪММЪѕеОЃЌБОеТжївЊЭЈЙ§вЛИіаЁdemoНщЩмСЫRabbitMQ
зїЮЊжаМфМўЪЕЯжЕФ RPC ФЃЪНЃЌЯЃЭћЖдФњЕФбЇЯАгаЫљАяжњЁЃ
|
|
БГОАжЊЪЖ
RabbitMQ
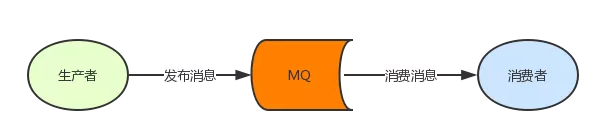
RabbitMQ ЪЧЛљгк AMQP авщЪЕЯжЕФвЛИіЯћЯЂЖгСаЃЈMessage QueueЃЉЃЌMessage
Queue ЪЧвЛИіЕфаЭЕФЩњВњеп/ЯћЗбепФЃЪНЁЃЩњВњепЗЂВМЯћЯЂЃЌЯћЗбепЯћЗбЯћЯЂЃЌЩњВњепКЭЯћЗбепжЎМфЪЧНтёюЕФЃЌЛЅЯрВЛжЊЕРЖдЗНЕФДцдкЁЃ
RPC
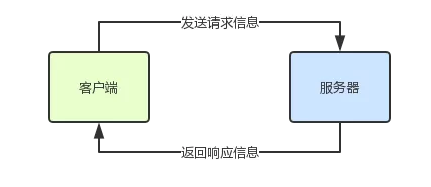
Remote Procedure CallЃКдЖГЬЙ§ГЬЕїгУЃЌвЛДЮдЖГЬЙ§ГЬЕїгУЕФСїГЬМДПЭЛЇЖЫЗЂЫЭвЛИіЧыЧѓЕНЗўЮёЖЫЃЌЗўЮёЖЫИљОнЧыЧѓаХЯЂНјааДІРэКѓЗЕЛиЯьгІаХЯЂЃЌПЭЛЇЖЫЪеЕНЯьгІаХЯЂКѓНсЪјЁЃ
ШчКЮЪЙгУ RabbitMQ ЪЕЯж RPCЃП
ЪЙгУ RabbitMQ ЪЕЯж RPCЃЌЯргІЕФНЧЩЋЪЧгЩЩњВњепРДзїЮЊПЭЛЇЖЫЃЌЯћЗбепзїЮЊЗўЮёЖЫЁЃ
ЕЋ RPC ЕїгУвЛАуЪЧЭЌВНЕФЃЌПЭЛЇЖЫКЭЗўЮёЦївВЪЧНєУмёюКЯЕФЁЃМДПЭЛЇЖЫЭЈЙ§ IP/гђУћКЭЖЫПкСДНгЕНЗўЮёЦїЃЌЯђЗўЮёЦїЗЂЫЭЧыЧѓКѓЕШД§ЗўЮёЦїЗЕЛиЯьгІаХЯЂЁЃ
ЕЋ MQ ЕФЩњВњепКЭЯћЗбепЪЧЭъШЋНтёюЕФЃЌФЧУДШчКЮгУ MQ ЪЕЯж RPC ФиЃПКмУїЯдОЭЪЧАб MQ ЕБзїжаМфМўЪЕЯжвЛДЮЫЋЯђЕФЯћЯЂДЋЕнЃК
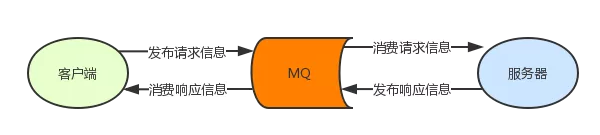
ПЭЛЇЖЫКЭЗўЮёЖЫМДЪЧЩњВњепвВЪЧЯћЗбепЁЃПЭЛЇЖЫЗЂВМЧыЧѓЃЌЯћЗбЯьгІЃЛЗўЮёЖЫЯћЗбЧыЧѓЃЌЗЂВМЯьгІЁЃ
ОпЬхЪЕЯж
MQВПЗжЕФЖЈвх
ЧыЧѓаХЯЂЕФЖгСа
ЮвУЧашвЊвЛИіЖгСаРДДцЗХЧыЧѓаХЯЂЃЌПЭЛЇЖЫЯђетИіЖгСаЗЂВМЧыЧѓаХЯЂЃЌЗўЮёЖЫЯћЗбИУЖгСаДІРэЧыЧѓЁЃИУЖгСаВЛашвЊИДдгЕФТЗгЩЙцдђЃЌжБНгЪЙгУ
RabbitMQ ФЌШЯЕФ direct exchange РДТЗгЩЯћЯЂМДПЩЁЃ
ЯьгІаХЯЂЕФЖгСа
ДцЗХЯьгІаХЯЂЕФЖгСаВЛгІжЛгавЛИіЁЃШчЙћДцдкЖрИіПЭЛЇЖЫЃЌВЛФмБЃжЄЯьгІаХЯЂБЛЗЂВМЧыЧѓЕФФЧИіПЭЛЇЖЫЯћЗбЕНЁЃЫљвдгІЮЊУПвЛИіПЭЛЇЖЫДДНЈвЛИіЯьгІЖгСаЃЌетИіЖгСагІИУгЩПЭЛЇЖЫРДДДНЈЧвжЛФмгЩетИіПЭЛЇЖЫЪЙгУВЂдкЪЙгУЭъБЯКѓЩОГ§ЃЌетРяПЩвдЪЙгУ
RabbitMQ ЬсЙЉЕФХХЫћЖгСаЃЈExclusive QueueЃЉЃК
| channel.queueDeclare(queue:"",
durable:false, exclusive:true, autoDelete:false,
new HashMap<>()) |
ВЂЧввЊБЃжЄЖгСаУћЮЈвЛЃЌЩљУїЖгСаЪБУћГЦЩшЮЊПе RabbitMQ ЛсЩњГЩвЛИіЮЈвЛЕФЖгСаУћЁЃ
exclusiveЩшЮЊtrueБэЪОЩљУївЛИіХХЫћЖгСаЃЌХХЫћЖгСаЕФЬиЕуЪЧжЛФмБЛЕБЧАЕФСЌНгЪЙгУЃЌВЂЧвдкСЌНгЙиБеКѓБЛЩОГ§ЁЃ
вЛИіМђЕЅЕФ demoЃЈЪЙгУ pull ЛњжЦЃЉ
ЮвУЧЪЙгУвЛИіМђЕЅЕФ demo РДСЫНтПЭЛЇЖЫКЭЗўЮёЖЫЕФДІРэСїГЬЁЃ
ЗЂВМЧыЧѓ
БраДДњТыЧАЕФвЛИіаЁЮЪЬт
ЮвУЧдкЩљУїЖгСаЪБЮЊУПвЛИіПЭЛЇЖЫЩљУїСЫЖРгаЕФЯьгІЖгСаЃЌФЧЗўЮёЦїдкЗЂВМЯьгІЪБШчКЮжЊЕРЗЂВМЕНФФИіЖгСаФиЃПЦфЪЕОЭЪЧПЭЛЇЖЫашвЊИцЫпЗўЮёЖЫНЋЯьгІЗЂВМЕНФФИіЖгСаЃЌRabbitMQ
ЬсЙЉСЫетИіжЇГжЃЌЯћЯЂЬхЕФPropertiesжагавЛИіЪєадreply_toОЭЪЧгУРДБъМЧЛиЕїЖгСаЕФУћГЦЃЌЗўЮёЦїашвЊНЋЯьгІЗЂВМЕНreply_toжИЖЈЕФЛиЕїЖгСажаЁЃ
НтОіСЫетИіЮЪЬтжЎКѓЮвУЧОЭПЩвдБраДПЭЛЇЖЫЗЂВМЧыЧѓЕФДњТыСЫЃК
// ЖЈвхЯьгІЛиЕїЖгСа
String replyQueueName = channel.queueDeclare("",
false, true, false, new HashMap<>()).getQueue();
// ЩшжУЛиЕїЖгСаЕН Properties
AMQP.BasicProperties properties = new AMQP.BasicProperties.Builder()
.replyTo(replyQueueName)
.build();
String request = "request";
// ЗЂВМЧыЧѓ
channel.basicPublish("", "rpc_queue",
properties, request.getBytes()); |
RabbitMQ ЬсЙЉСЫвЛжжИќБуНнЕФЛњжЦРДЪЕЯж RPCЃЌВЛашвЊПЭЛЇЖЫУПДЮЖМЖЈвхЛиЕїЖгСаЃЌПЭЛЇЖЫЗЂВМЧыЧѓЪБНЋreplyToЩшЮЊamq.rabbitmq.reply-toЃЌЯћЗбЯьгІЪБвВжИЖЈЯћЗбamq.rabbitmq.reply-toЃЌRabbitMQ
ЛсЮЊПЭЛЇЖЫДДНЈвЛИіФкВПЖгСа
ЯћЗбЧыЧѓ
НгЯТРДЪЧЗўЮёЖЫДІРэЧыЧѓЕФВПЗжЃЌНгЪеЕНЧыЧѓКѓОЙ§ДІРэНЋЯьгІаХЯЂЗЂВМЕНreply_toжИЖЈЕФЛиЕїЖгСаЃК
// ЗўЮёЖЫ Consumer
ЕФЖЈвх
public class RpcServer extends DefaultConsumer
{
public RpcServer(Channel channel) {
super(channel);
}
@Override
public void handleDelivery(String consumerTag,
Envelope envelope, AMQP.BasicProperties properties,
byte[] body) throws IOException {
String msg = new String(body);
String response = (msg + " Received");
// ЛёШЁЛиЕїЖгСаУћ
String replyTo = properties.getReplyTo();
// ЗЂВМЯьгІЯћЯЂЕНЛиЕїЖгСа
this.getChannel().basicPublish("",
replyTo, new AMQP.BasicProperties(), response.getBytes());
}
}
...
// ЦєЖЏЗўЮёЖЫ Consumer
channel.basicConsume("rpc_queue",
true, new RpcServer(channel)); |
НгЪеЯьгІ
ПЭЛЇЖЫШчКЮНгЪеЗўЮёЦїЕФЯьгІФиЃПгаСНжжЗНЪНЃК1.ТжбЏЕФШЅ pull ЛиЕїЖгСажаЕФЯћЯЂЃЌ2.вьВНЕФЯћЗбЛиЕїЖгСажаЕФЯћЯЂЁЃЮвУЧдкетРяМђЕЅЪЕЯжЕквЛжжЗНАИЁЃ
GetResponse getResponse
= null;
while (getResponse == null) {
getResponse = channel.basicGet(replyQueueName,
true);
}
String response = new String(getResponse.getBody());
|
вЛИіМђЕЅЕФЛљгк RabbitMQ ЕФ RPC ФЃаЭвбОЪЕЯжСЫЃЌЕЋетИі demo ВЂВЛЪЕгУЃЌвђЮЊПЭЛЇЖЫУПДЮЗЂЫЭЭъЧыЧѓЖМвЊЭЌВНЕФТжбЏЕШД§ЯьгІЯћЯЂЃЌжЛФмУПДЮДІРэвЛИіЧыЧѓЁЃRabbitMQ
ЕФ pull ФЃЪНаЇТЪвВБШНЯЕЭЁЃ
ЪЕЯжвЛИіЭъБИПЩгУЕФ RPC ФЃЪНашвЊзіЕФЙЄзїЛЙгаКмЖрЃЌвЊДІРэЕФЙиМќЕувВБШНЯИДдгЃЌгаОфЛАНаВЛвЊжиИДдьТжзгЃЌspring
вбОЪЕЯжСЫвЛИіЭъБИПЩгУЕФ RPC ФЃЪНЕФПтЃЌНгЯТРДЮвУЧРДСЫНтвЛЯТЁЃ
Spring Rabbit жаЕФЪЕЯж
КЭЩЯУц demo ЕФ pull ФЃЪНвЛДЮжЛФмДІРэвЛИіЧыЧѓЯрЖдгІЕФЃКШчКЮвьВНЕФНгЪеЯьгІВЂДІРэЖрИіЧыЧѓФиЃПЙиМќЕуОЭдкгкЮвУЧашвЊМЧТМЧыЧѓКЭЯьгІВЂНЋЫќУЧЙиСЊЦ№РДЃЌRabbitMQ
вВЬсЙЉСЫжЇГжЃЌProperties жаЕФСэвЛИіЪєадcorrelation_idгУРДБъЪЖвЛИіЯћЯЂЕФЮЈвЛ
idЁЃ
ВЮПМspring-rabbitжаЕФconvertSendAndReceiveЗНЗЈЕФЪЕЯжЃЌЮЊУПвЛДЮЧыЧѓЩњГЩвЛИіЮЈвЛЕФcorrelation_idЃК
private final
AtomicInteger messageTagProvider = new AtomicInteger();
...
String messageTag = String.valueOf(this.messageTagProvider.
incrementAndGet());
...
message.getMessageProperties().setCorrela
tionId(messageTag); |
ВЂЪЙгУвЛИіConcurrentHashMapРДЮЌЛЄcorrelation_idКЭЯьгІаХЯЂЕФгГЩфЃК
private final
Map<String, PendingReply> replyHolder =
new ConcurrentHashMap<String, PendingReply>();
...
final PendingReply pendingReply = new PendingReply();
this.replyHolder.put(correlationId, pendingReply);
|
PendingReplyжагавЛИіBlockingQueueДцЗХЯьгІаХЯЂЃЌдкЗЂЫЭЭъЧыЧѓаХЯЂКѓЕїгУBlockingQueueЕФpullЗНЗЈВЂЩшжУГЌЪБЪБМфРДЛёШЁЯьгІЃК
private final
BlockingQueue<Object> queue = new ArrayBlockingQueue<Object>(1);
public Message get(long timeout, TimeUnit unit)
throws InterruptedException {
Object reply = this.queue.poll(timeout, unit);
return reply == null ? null : processReply(reply);
} |
дкЛёШЁЯьгІКѓВЛТлНсЙћШчКЮЃЌЖМЛсНЋPendingReplyДгreplyHolderжавЦГ§ЃЌЗРжЙreplyHolderжаЛ§бЙГЌЪБЕФЯьгІЯћЯЂЃК
try {
reply = exchangeMessages(exchange, routingKey,
message, correlationData, channel, pendingReply,messageTag);
} finally {
this.replyHolder.remove(messageTag);
...
} |
ЯьгІаХЯЂЪЧКЮЪБШчКЮБЛЗХЕНетИіBlockingQueueжаЕФФиЃППДвЛЯТRabbitTemplateНгЪеЯћЯЂЕФЕиЗНЃК
public void onMessage(Message
message) {
String messageTag;
if (this.correlationKey == null) { // using standard
correlationId property
messageTag = message.getMessageProperties().getCorrelationId();
} else {
messageTag = (String) message.getMessageProperties()
.getHeaders().get(this.correlationKey);
}
// Дцдк correlation_id ВХШЯЮЊЪЧRPCЕФЯьгІаХЯЂЃЌВЛДцдкЪБВЛДІРэ
if (messageTag == null) {
logger.error("No correlation header in
reply");
return;
}
// Дг replyHolder жаШЁГі correlation_id ЖдгІЕФ PendingReply
PendingReply pendingReply = this.replyHolder.get(messageTag);
if (pendingReply == null) {
if (logger.isWarnEnabled()) {
logger.warn("Reply received after timeout
for " + messageTag);
}
throw new AmqpRejectAndDontRequeueException("Reply
received after timeout");
}
else {
restoreProperties(message, pendingReply);
// НЋЯьгІаХЯЂ add ЕН BlockingQueue жа
pendingReply.reply(message);
}
} |
вдЩЯЕФ spring ДњТывўШЅСЫКмЖрЖюЭтВПЗжЕФДІРэКЭЯИНкЃЌжЛЙизЂЙиМќЕФВПЗжЁЃ
жСДЫвЛИіЭъећПЩгУЕФгЩ RabbitMQ зїЮЊжаМфМўЪЕЯжЕФ RPC ФЃЪНОЭЭъГЩСЫЁЃ
змНс
ЗўЮёЖЫ
ЗўЮёЖЫЕФЪЕЯжБШНЯМђЕЅЃЌКЭвЛАуЕФConsumerЕФЧјБ№жЛдкгкашвЊНЋЧыЧѓЛиИДЕНreplyToжИЖЈЕФ queue
жаВЂДјЩЯЯћЯЂБъЪЖcorrelation_idМДПЩ
ЗўЮёЖЫЕФвЛЕуаЁгХЛЏЃК
ГЌЪБЕФДІРэЪЧгЩПЭЛЇЖЫРДЪЕЯжЕФЃЌФЧЗўЮёЖЫгаУЛгаПЩвдгХЛЏЕФЕиЗНФиЃП
Д№АИЪЧгаЕФЃКШчЙћЮвУЧЕФЗўЮёЖЫДІРэБШНЯКФЪБЃЌШчКЮХаЖЯПЭЛЇЖЫЪЧЗёЛЙдкЕШД§ЯьгІФиЃП
ЮвУЧПЩвдЪЙгУpassiveВЮЪ§ШЅМьВщreplyToЕФ queue ЪЧЗёДцдкЃЌвђЮЊПЭЛЇЖЫЩљУїЕФЪЧФкВПЖгСаЃЌПЭЛЇЖЫШчЙћЖЯЕєСДНгСЫетИі
queue ОЭВЛДцдкСЫЃЌетЪБЗўЮёЖЫОЭЮоашДІРэетИіЯћЯЂСЫЁЃ
ПЭЛЇЖЫ
ПЭЛЇЖЫГаЕЃСЫИќЖрЕФЙЄзїСПЃЌАќРЈЃК
ЩљУїreplyToЖгСаЃЈЪЙгУamq.rabbitmq.reply-toЛсМђЕЅКмЖрЃЉ
ЮЌЛЄЧыЧѓКЭЯьгІЯћЯЂЃЈЪЙгУЮЈвЛЕФcorrelation_idРДЙиСЊЃЉ
ЯћЗбЗўЮёЖЫЕФЗЕЛи
ДІРэГЌЪБЕШвьГЃЧщПіЃЈЪЙгУBlockingQueueРДзшШћЛёШЁЃЉ
КУдк spring вбОЪЕЯжСЫвЛЬзЭъБИПЩППЕФДњТыЃЌЮвУЧдкЧхГўСЫСїГЬКЭЙиМќЕужЎКѓЃЌПЩвджБНгЪЙгУ spring
ЬсЙЉЕФRabbitTemplateЃЌЮоашздМКЪЕЯжЁЃ
ЪЙгУ MQ ЪЕЯж RPC ЕФвтвх
ЭЈЙ§ MQ ЪЕЯж RPC ПДЦ№РДБШПЭЛЇЖЫКЭЗўЮёЦїжБНгЭЈбЖвЊИДдгвЛаЉЃЌФЧЮвУЧЮЊЪВУДвЊетбљзіФиЃПЛђепЫЕетбљзігаЪВУДКУДІЃК
НЋПЭЛЇЖЫКЭЗўЮёЦїНтёюЃКПЭЛЇЖЫжЛЪЧЗЂВМвЛИіЧыЧѓЕН MQ ВЂЯћЗбетИіЧыЧѓЕФЯьгІЁЃВЂВЛЙиаФОпЬхгЩЫРДДІРэетИіЧыЧѓЃЌMQ
СэвЛЖЫЕФЧыЧѓЕФЯћЗбепПЩвдЫцвтЬцЛЛГЩШЮКЮПЩвдДІРэЧыЧѓЕФЗўЮёЦїЃЌВЂВЛгАЯьЕНПЭЛЇЖЫЁЃ
МѕЧсЗўЮёЦїЕФбЙСІЃКДЋЭГЕФ RPC ФЃЪНжаШчЙћПЭЛЇЖЫКЭЧыЧѓЙ§ЖрЃЌЗўЮёЦїЕФбЙСІЛсЙ§ДѓЁЃгЩ MQ зїЮЊжаМфМўЕФЛАЃЌЙ§ЖрЕФЧыЧѓЖјЪЧБЛ
MQ ЯћЛЏЕєЃЌЗўЮёЦїПЩвдПижЦЯћЗбЧыЧѓЕФЦЕДЮЃЌВЂВЛЛсгАЯьЕНЗўЮёЦїЁЃ
ЗўЮёЦїЕФКсЯђРЉеЙИќМгШнвзЃКШчЙћЗўЮёЦїЕФДІРэФмСІВЛФмТњзуЧыЧѓЕФЦЕДЮЃЌжЛашвЊдіМгЗўЮёЦїРДЯћЗб MQ ЕФЯћЯЂМДПЩЃЌMQЛсАяЮвУЧЪЕЯжЯћЯЂЯћЗбЕФИКдиОљКтЁЃ
ПЩвдПДГі RabbitMQ Ждгк RPC ФЃЪНЕФжЇГжвВЪЧБШНЯгбКУЕиЃЌ
amq.rabbitmq.reply-to, reply_to, correlation_idетаЉЬиадЖМЫЕУїСЫетвЛЕуЃЌдйМгЩЯ
spring-rabbit ЕФЪЕЯжЃЌПЩвдШУЮвУЧКмМђЕЅЕФЪЙгУЯћЯЂЖгСаФЃЪНЕФ RPC ЕїгУЁЃ
|









