| БрМЭЦМі: |
БОЮФРДздгкcnblogsЃЌЮФеТДггІгУГЁОАМмЙЙНщЩмЃЌАќРЈЪЙгУЙ§ГЬЃЌдѕУДЪЕЯжЕШЯрЙиФкШнЁЃ
|
|
вЛЁЂRabbitMQ
AMQPЃЌМДAdvanced Message Queuing ProtocolЃЌИпМЖЯћЯЂЖгСаавщЃЌЪЧгІгУВуавщЕФвЛИіПЊЗХБъзМЃЌЮЊУцЯђЯћЯЂЕФжаМфМўЩшМЦЁЃЯћЯЂжаМфМўжївЊгУгкзщМўжЎМфЕФНтёюЃЌЯћЯЂЕФЗЂЫЭепЮоашжЊЕРЯћЯЂЪЙгУепЕФДцдкЃЌЗДжЎврШЛЁЃ
AMQPЕФжївЊЬиеїЪЧУцЯђЯћЯЂЁЂЖгСаЁЂТЗгЩЃЈАќРЈЕуЖдЕуКЭЗЂВМ/ЖЉдФЃЉЁЂПЩППадЁЂАВШЋЁЃ
RabbitMQЪЧвЛИіПЊдДЕФAMQPЪЕЯжЃЌЗўЮёЦїЖЫгУErlangгябдБраДЃЌжЇГжЖржжПЭЛЇЖЫЃЌШчЃКPythonЁЂRubyЁЂ.NETЁЂJavaЁЂJMSЁЂCЁЂPHPЁЂActionScriptЁЂXMPPЁЂSTOMPЕШЃЌжЇГжAJAXЁЃгУгкдкЗжВМЪНЯЕЭГжаДцДЂзЊЗЂЯћЯЂЃЌдквзгУадЁЂРЉеЙадЁЂИпПЩгУадЕШЗНУцБэЯжВЛЫзЁЃ
ЖўЁЂRabbitMQЕФЪЙгУГЁОА
ЖдгквЛИіДѓаЭЕФШэМўЯЕЭГРДЫЕЃЌЫќЛсгаКмЖрЕФзщМўЛђепЫЕФЃПщЛђепЫЕзгЯЕЭГЛђепЃЈsubsystem or Component
or submoduleЃЉЁЃФЧУДетаЉФЃПщЕФШчКЮЭЈаХЃПетКЭДЋЭГЕФIPCгаКмДѓЕФЧјБ№ЁЃДЋЭГЕФIPCКмЖрЖМЪЧдкЕЅвЛЯЕЭГЩЯЕФЃЌФЃПщёюКЯадКмДѓЃЌВЛЪЪКЯРЉеЙЃЈScalabilityЃЉЃЛШчЙћЪЙгУsocketФЧУДВЛЭЌЕФФЃПщЕФШЗПЩвдВПЪ№ЕНВЛЭЌЕФЛњЦїЩЯЃЌЕЋЪЧЛЙЪЧгаКмЖрЮЪЬташвЊНтОіЁЃБШШчЃК
1ЃЉаХЯЂЕФЗЂЫЭепКЭНгЪеепШчКЮЮЌГжетИіСЌНгЃЌШчЙћвЛЗНЕФСЌНгжаЖЯЃЌетЦкМфЕФЪ§ОнШчКЮЗНЪНЖЊЪЇЃП
2ЃЉШчКЮНЕЕЭЗЂЫЭепКЭНгЪеепЕФёюКЯЖШЃП
3ЃЉШчКЮШУPriorityИпЕФНгЪеепЯШНгЕНЪ§ОнЃП
4ЃЉШчКЮзіЕНload balanceЃПгааЇОљКтНгЪеепЕФИКдиЃП
5ЃЉШчКЮгааЇЕФНЋЪ§ОнЗЂЫЭЕНЯрЙиЕФНгЪеепЃПвВОЭЪЧЫЕНЋНгЪеепsubscribe ВЛЭЌЕФЪ§ОнЃЌШчКЮзігааЇЕФfilterЁЃ
6ЃЉШчКЮзіЕНПЩРЉеЙЃЌЩѕжСНЋетИіЭЈаХФЃПщЗЂЕНclusterЩЯЃП
7ЃЉШчКЮБЃжЄНгЪеепНгЪеЕНСЫЭъећЃЌе§ШЗЕФЪ§ОнЃП
AMDQавщНтОіСЫвдЩЯЕФЮЪЬтЃЌЖјRabbitMQЪЕЯжСЫAMQPЁЃ
Ш§ЁЂRabbitMQЕФНсЙЙ
RabbitMQЕФгІгУГЁОАМмЙЙЭМШчЯТЃК
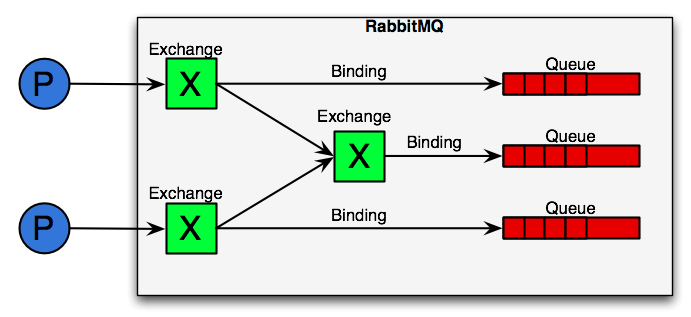
BrokerЃКМђЕЅРДЫЕОЭЪЧЯћЯЂЖгСаЗўЮёЦїЪЕЬхЁЃ
ExchangeЃКЯћЯЂНЛЛЛЛњЃЌЫќжИЖЈЯћЯЂАДЪВУДЙцдђЃЌТЗгЩЕНФФИіЖгСаЁЃ
QueueЃКЯћЯЂЖгСадиЬхЃЌУПИіЯћЯЂЖМЛсБЛЭЖШыЕНвЛИіЛђЖрИіЖгСаЁЃ
BindingЃКАѓЖЈЃЌЫќЕФзїгУОЭЪЧАбexchangeКЭqueueАДееТЗгЩЙцдђАѓЖЈЦ№РДЁЃ
Routing KeyЃКТЗгЩЙиМќзжЃЌexchangeИљОнетИіЙиМќзжНјааЯћЯЂЭЖЕнЁЃ
vhostЃКащФтжїЛњЃЌвЛИіbrokerРяПЩвдПЊЩшЖрИіvhostЃЌгУзїВЛЭЌгУЛЇЕФШЈЯоЗжРыЁЃ
producerЃКЯћЯЂЩњВњепЃЌОЭЪЧЭЖЕнЯћЯЂЕФГЬађЁЃ
consumerЃКЯћЯЂЯћЗбепЃЌОЭЪЧНгЪмЯћЯЂЕФГЬађЁЃ
channelЃКЯћЯЂЭЈЕРЃЌдкПЭЛЇЖЫЕФУПИіСЌНгРяЃЌПЩНЈСЂЖрИіchannelЃЌУПИіchannelДњБэвЛИіЛсЛАШЮЮёЁЃ
ЫФЁЂRabbitMQЕФЪЙгУЙ§ГЬ
AMQPФЃаЭжаЃЌЯћЯЂдкproducerжаВњЩњЃЌЗЂЫЭЕНMQЕФexchangeЩЯЃЌexchangeИљОнХфжУЕФТЗгЩЗНЪНЗЂЕНЯргІЕФQueueЩЯЃЌQueueгжНЋЯћЯЂЗЂЫЭИјconsumerЃЌЯћЯЂДгqueueЕНconsumerгаpushКЭpullСНжжЗНЪНЁЃ
ЯћЯЂЖгСаЕФЪЙгУЙ§ГЬДѓИХШчЯТЃК
ПЭЛЇЖЫСЌНгЕНЯћЯЂЖгСаЗўЮёЦїЃЌДђПЊвЛИіchannelЁЃ
ПЭЛЇЖЫЩљУївЛИіexchangeЃЌВЂЩшжУЯрЙиЪєадЁЃ
ПЭЛЇЖЫЩљУївЛИіqueueЃЌВЂЩшжУЯрЙиЪєадЁЃ
ПЭЛЇЖЫЪЙгУrouting keyЃЌдкexchangeКЭqueueжЎМфНЈСЂКУАѓЖЈЙиЯЕЁЃ
ПЭЛЇЖЫЭЖЕнЯћЯЂЕНexchangeЁЃ
exchangeНгЪеЕНЯћЯЂКѓЃЌОЭИљОнЯћЯЂЕФkeyКЭвбОЩшжУЕФbindingЃЌНјааЯћЯЂТЗгЩЃЌНЋЯћЯЂЭЖЕнЕНвЛИіЛђЖрИіЖгСаРяЁЃ
exchangeвВгаМИИіРраЭЃЌЭъШЋИљОнkeyНјааЭЖЕнЕФНазіDirectНЛЛЛЛњЃЌР§ШчЃЌАѓЖЈЪБЩшжУСЫrouting
keyЮЊЁБabcЁБЃЌФЧУДПЭЛЇЖЫЬсНЛЕФЯћЯЂЃЌжЛгаЩшжУСЫkeyЮЊЁБabcЁБЕФВХЛсЭЖЕнЕНЖгСаЁЃ
4.0 АВзАКЭХфжУ
RabbitMQЪЙгУErlangгябдЪЕЯжЃЌвђДЫдкЪЙгУЪБЪзЯШвЊАВзАКЭХфжУerlangЛЗОГЃЌВЂАВзАЗўЮёЦїКѓНјааЯрЙиХфжУЃЌгЩгкВЛЪЧБОЮФжївЊФкШнЫљвдКіТдЃЌЯъМћRabbitMQМђНщЁЃ
RabbitMQЕФПЭЛЇЖЫЪЙгУЪБашвЊЬэМгЯрЙивРРЕЁЃ
4.1 ЕуЖдЕу
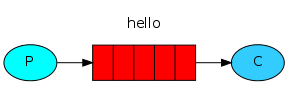
ЯћЯЂЩњВњепЕФДњТыШчЯТЃК
package com.zenhobby.rabbit.demo;
import com.rabbitmq.client.Channel;
import com.rabbitmq.client.Connection;
import com.rabbitmq.client.ConnectionFactory;
public class Send
{
//ЖгСаУћГЦ
private final static String QUEUE_NAME = "hello";
public static void main(String[] argv) throws
java.io.IOException
{
/**
* ДДНЈСЌНгСЌНгЕНMabbitMQ
*/
ConnectionFactory factory = new ConnectionFactory();
//ЩшжУMabbitMQЫљдкжїЛњipЛђепжїЛњУћ
factory.setHost("localhost");
//ДДНЈвЛИіСЌНг
Connection connection = factory.newConnection();
//ДДНЈвЛИіЦЕЕР
Channel channel = connection.createChannel();
//жИЖЈвЛИіЖгСа
channel.queueDeclare(QUEUE_NAME, false, false,
false, null);
//ЗЂЫЭЕФЯћЯЂ
String message = "hello world!";
//ЭљЖгСажаЗЂГівЛЬѕЯћЯЂ
channel.basicPublish("", QUEUE_NAME,
null, message.getBytes());
System.out.println(" [x] Sent '" + message
+ "'");
//ЙиБеЦЕЕРКЭСЌНг
channel.close();
connection.close();
}
} |
ЯћЯЂЯћЗбепЕФДњТыШчЯТЃК
package com.zenhobby.rabbit.demo;
import com.rabbitmq.client.Channel;
import com.rabbitmq.client.Connection;
import com.rabbitmq.client.ConnectionFactory;
import com.rabbitmq.client.QueueingConsumer;
public class Recv
{
//ЖгСаУћГЦ
private final static String QUEUE_NAME = "hello";
public static void main(String[] argv) throws
java.io.IOException,
java.lang.InterruptedException
{
//ДђПЊСЌНгКЭДДНЈЦЕЕРЃЌгыЗЂЫЭЖЫвЛбљ
ConnectionFactory factory = new ConnectionFactory();
factory.setHost("localhost");
Connection connection = factory.newConnection();
Channel channel = connection.createChannel();
//ЩљУїЖгСаЃЌжївЊЮЊСЫЗРжЙЯћЯЂНгЪеепЯШдЫааДЫГЬађЃЌЖгСаЛЙВЛДцдкЪБДДНЈЖгСаЁЃ
channel.queueDeclare(QUEUE_NAME, false, false,
false, null);
System.out.println(" [*] Waiting for messages.
To exit press CTRL+C");
//ДДНЈЖгСаЯћЗбеп
QueueingConsumer consumer = new QueueingConsumer(channel);
//жИЖЈЯћЗбЖгСаЃЌЙиБеФЌШЯЕФЯћЯЂгІД№
channel.basicConsume(QUEUE_NAME, true, consumer);
while (true)
{
//nextDeliveryЪЧвЛИізшШћЗНЗЈЃЈФкВПЪЕЯжЦфЪЕЪЧзшШћЖгСаЕФtakeЗНЗЈЃЉ
QueueingConsumer.Delivery delivery = consumer.nextDelivery();
String message = new String(delivery.getBody());
System.out.println(" [x] Received '"
+ message + "'");
}
}
} |
ЖгСаЗжБ№дкЩњВњепКЭЯћЗбепДІДДНЈЃЌжївЊЪЧЮЊСЫЗРжЙгавЛЖЫЮДНЈСЂЦ№РДЕФЪБКђЖЊЪЇЯћЯЂЁЃ
4.2 ЙЄзїЖгСа
ЙЄзїЖгСаЕФжївЊШЮЮёЪЧЃКБмУтСЂПЬжДаазЪдДУмМЏаЭШЮЮёЃЌШЛКѓБиаыЕШД§ЦфЭъГЩЁЃЯрЗДЕиЃЌЮвУЧНјааШЮЮёЕїЖШЃКЮвУЧАбШЮЮёЗтзАЮЊЯћЯЂЗЂЫЭИјЖгСаЁЃЙЄзїНјаадкКѓЬЈдЫааВЂВЛЖЯЕФДгЖгСажаШЁГіШЮЮёШЛКѓжДааЁЃЕБФудЫааСЫЖрИіЙЄзїНјГЬЪБЃЌШЮЮёЖгСажаЕФШЮЮёНЋЛсБЛЙЄзїНјГЬЙВЯэжДааЁЃетбљЕФИХФюдкwebгІгУжаМЋЦфгагУЃЌЕБдкКмЖЬЕФHTTPЧыЧѓМфашвЊжДааИДдгЕФШЮЮёЁЃ
1.ЯћЯЂЗжЗЂЛњжЦ
ФЌШЯЕФЃЌRabbitMQЛсвЛИівЛИіЕФЗЂЫЭаХЯЂИјЯТвЛИіЯћЗбеп(consumer)ЃЌЖјВЛПМТЧУПИіШЮЮёЕФЪБГЄЕШЕШЃЌЧвЪЧвЛДЮадЗжХфЃЌВЂЗЧвЛИівЛИіЗжХфЁЃЦНОљЕФУПИіЯћЗбепНЋЛсЛёЕУЯрЕШЪ§СПЕФЯћЯЂЁЃетбљЗжЗЂЯћЯЂЕФЗНЪННазіround-robinЁЃ
ФЌШЯЕФШЮЮёЗжЗЂЫфШЛПДЫЦЙЋЦНЕЋДцдкБзЖЫЁЃБШШчЃКЯждкга2ИіЯћЗбепЃЌЫљгаЕФЦцЪ§ЕФЯћЯЂЖМЪЧЗБУІЕФЃЌЖјХМЪ§дђЪЧЧсЫЩЕФЁЃАДееТжбЏЕФЗНЪНЃЌЦцЪ§ЕФШЮЮёНЛИјСЫЕквЛИіЯћЗбепЃЌЫљвдвЛжБдкУІИіВЛЭЃЁЃХМЪ§ЕФШЮЮёНЛИјСэвЛИіЯћЗбепЃЌдђСЂМДЭъГЩШЮЮёЃЌШЛКѓЯаЕУВЛааЁЃЖјRabbitMQдђЪЧВЛСЫНтетаЉЕФЁЃетЪЧвђЮЊЕБЯћЯЂНјШыЖгСаЃЌRabbitMQОЭЛсЗжХЩЯћЯЂЁЃЫќВЛПДЯћЗбепЮЊгІД№ЕФЪ§ФПЃЌжЛЪЧУЄФПЕФНЋЕкnЬѕЯћЯЂЗЂИјЕкnИіЯћЗбепЁЃ
ЮЊСЫНтОіетИіЮЪЬтЃЌЮвУЧЪЙгУbasicQos( prefetchCount = 1)ЗНЗЈЃЌРДЯожЦRabbitMQжЛЗЂВЛГЌЙ§1ЬѕЕФЯћЯЂИјЭЌвЛИіЯћЗбепЁЃЕБЯћЯЂДІРэЭъБЯКѓЃЌгаСЫЗДРЁЃЌВХЛсНјааЕкЖўДЮЗЂЫЭЁЃ
int prefetchCount
= 1;
channel.basicQos(prefetchCount); |
ЪЙгУЙЋЦНЗжЗЂЃЌБиаыЙиБездЖЏгІД№ЃЌИФЮЊЪжЖЏгІД№ЁЃ
2. ЯћЯЂШЗШЯ
УПИіConsumerПЩФмашвЊвЛЖЮЪБМфВХФмДІРэЭъЪеЕНЕФЪ§ОнЁЃШчЙћдкетИіЙ§ГЬжаЃЌConsumerГіДэСЫЃЌвьГЃЭЫГіСЫЃЌЖјЪ§ОнЛЙУЛгаДІРэЭъГЩЃЌФЧУДЗЧГЃВЛавЃЌетЖЮЪ§ОнОЭЖЊЪЇСЫЁЃвђЮЊЮвУЧВЩгУno-ackЕФЗНЪННјааШЗШЯЃЌвВОЭЪЧЫЕЃЌУПДЮConsumerНгЕНЪ§ОнКѓЃЌЖјВЛЙмЪЧЗёДІРэЭъГЩЃЌRabbitMQ
ServerЛсСЂМДАбетИіMessageБъМЧЮЊЭъГЩЃЌШЛКѓДгqueueжаЩОГ§СЫЁЃ
ЮЊСЫБЃжЄЪ§ОнВЛБЛЖЊЪЇЃЌRabbitMQжЇГжЯћЯЂШЗШЯЛњжЦЃЌМДacknowledgmentsЁЃЮЊСЫБЃжЄЪ§ОнФмБЛе§ШЗДІРэЖјВЛНіНіЪЧБЛConsumerЪеЕНЃЌФЧУДЮвУЧВЛФмВЩгУno-ackЁЃЖјгІИУЪЧдкДІРэЭъЪ§ОнКѓЗЂЫЭackЁЃдкДІРэЪ§ОнКѓЗЂЫЭЕФackЃЌОЭЪЧИцЫпRabbitMQЪ§ОнвбОБЛНгЪеЃЌДІРэЭъГЩЃЌRabbitMQПЩвдШЅАВШЋЕФЩОГ§ЫќСЫЁЃШчЙћConsumerЭЫГіСЫЕЋЪЧУЛгаЗЂЫЭackЃЌФЧУДRabbitMQОЭЛсАбетИіMessageЗЂЫЭЕНЯТвЛИіConsumerЁЃетбљОЭБЃжЄСЫдкConsumerвьГЃЭЫГіЕФЧщПіЯТЪ§ОнвВВЛЛсЖЊЪЇЁЃетРяВЂУЛгагУЕНГЌЪБЛњжЦЁЃRabbitMQНіНіЭЈЙ§ConsumerЕФСЌНгжаЖЯРДШЗШЯИУMessageВЂУЛгаБЛе§ШЗДІРэЁЃвВОЭЪЧЫЕЃЌRabbitMQИјСЫConsumerзуЙЛГЄЕФЪБМфРДзіЪ§ОнДІРэЁЃ
ФЌШЯЧщПіЯТЃЌЯћЯЂШЗШЯЪЧДђПЊЕФЃЈenabledЃЉЃК
boolean autoAck
= false;
channel.basicConsume(QUEUE_NAME, autoAck, consumer);
|
аоИФЯћЗбепШчЯТЃК
channel.basicQos(1);//БЃжЄвЛДЮжЛЗжЗЂвЛИі
// ДДНЈЖгСаЯћЗбеп
final Consumer consumer = new DefaultConsumer(channel)
{
@Override
public void handleDelivery(String consumerTag,
Envelope envelope, AMQP.BasicProperties properties,
byte[] body) throws IOException {
String message = new String(body, "UTF-8");
System.out.println(" [x] Received '"
+ message + "'");
System.out.println(" [x] Proccessing... at
" +new Date().toLocaleString());
try {
for (char ch: message.toCharArray()) {
if (ch == '.') {
Thread.sleep(1000);
}
}
} catch (InterruptedException e) {
} finally {
System.out.println(" [x] Done! at "
+new Date().toLocaleString());
channel.basicAck(envelope.getDeliveryTag(), false);
}
}
}; |
ЦфжаЃК
| channel.basicAck(delivery.getEnvelope().getDeliveryTag(),
false); |
гУгкдкЯћЯЂДІРэЭъБЯЪБЗЕЛигІД№зДЬЌЁЃШчЙћMQЗўЮёЦїЮДЪеЕНгІД№дђдкЯћЗбепЙвЕєжЎКѓжиаТАбЯћЯЂЗХШыЕНЖгСажавдЙЉЦфЫћЯћЗбепЪЙгУЁЃШчЙћЙиБеСЫздЖЏЯћЯЂгІД№ЃЌЪжЖЏвВЮДЩшжУгІД№ЃЌетЪЧвЛИіКмМђЕЅЕФДэЮѓЃЌЕЋЪЧКѓЙћШДЪЧМЋЦфбЯжиЕФЁЃЯћЯЂдкЗжЗЂГіШЅвдКѓЃЌЕУВЛЕНЛигІЃЌЫљвдВЛЛсдкФкДцжаЩОГ§ЃЌНсЙћRabbitMQЛсдНРДдНеМгУФкДцЃЌЕМжТЗўЮёЦїЙвЕєЁЃ
3. ЯћЯЂГжОУЛЏ
ЮЊСЫБЃжЄдкRabbitMQЭЫГіЛђепcrashСЫЪ§ОнШдУЛгаЖЊЪЇЃЌашвЊНЋqueueКЭMessageЖМвЊГжОУЛЏЁЃ
queueЕФГжОУЛЏашвЊдкЩљУїЪБжИЖЈdurable=TrueЃК
| channel.queue_declare (queue='hello',
durable=True) |
messageЕФГжОУЛЏашвЊдкЗЂЫЭЪБжИЖЈpropertyЃК
| channel.basicPublish ("",
QUEUE_NAME, MessageProperties.PERSISTENT_TEXT_PLAIN,
message.getBytes()); |
аоИФКѓЕФЩњВњепШчЯТЫљЪОЃК
static void
Main(string[] args)
{
var factory = new ConnectionFactory() { HostName
= "localhost" };
using ( var connection = factory.CreateConnection())
{
using (var channel = connection.CreateModel())
{
bool durable = true;
channel.QueueDeclare ("task_queue", durable,
false, false, null);//queueЕФГжОУЛЏашвЊдкЩљУїЪБжИЖЈdurable=True
var message = GetMessage(args);
var body = Encoding.UTF8.GetBytes(message);
var properties = channel.CreateBasicProperties();
properties.SetPersistent(true);//ашвЊГжОУЛЏMessageЃЌМДдкPublishЕФЪБКђжИЖЈвЛИіpropertiesЃЌ
channel.BasicPublish ("", "task_hello",
properties, body);
}
}
} |
4.3 Publish/Subscribe
1. НЛЛЛЦї
дкЙЄзїЖгСавЛНкжаЪЙгУЕФЗжЗЂШчЯТЃК
| channel.basicPublish ("",
"hello", null, message.getBytes()); |
ЦфжаЕквЛИіШыВЮЮЊПеМДЮЊФЌШЯЕФНЛЛЛЦїЃЌНЛЛЛЦїЪЧRabbitMQжаЕФИХФюЃЌЦфжївЊЙЄзїЪЧНгЪмЩњВњепЗЂГіЕФЯћЯЂЃЌВЂЭЦЫЭЕНЯћЯЂЖгСажаЃЈЩњВњепВЂУЛгажБНгЯђqueueжаЗЂЫЭШЮКЮЯћЯЂЃЌЖјЪЧЗЂИјНЛЛЛЦїгЩНЛЛЛЦїзЊНЛЃЉЁЃ
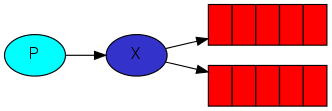
НЛЛЛЦїЕФЙцдђгаЃК
direct ЃЈжБСЌЃЉЃК
topic ЃЈжїЬтЃЉ
headers ЃЈБъЬтЃЉ
fanout ЃЈЗжЗЂЃЉ
Direct Exchange ЈC ДІРэТЗгЩМќЁЃашвЊНЋвЛИіЖгСаАѓЖЈЕННЛЛЛЛњЩЯЃЌвЊЧѓИУЯћЯЂгывЛИіЬиЖЈЕФТЗгЩМќЭъШЋЦЅХфЁЃетЪЧвЛИіЭъећЕФЦЅХфЁЃШчЙћвЛИіЖгСаАѓЖЈЕНИУНЛЛЛЛњЩЯвЊЧѓТЗгЩМќ
ЁАdogЁБЃЌдђжЛгаБЛБъМЧЮЊЁАdogЁБЕФЯћЯЂВХБЛзЊЗЂЃЌВЛЛсзЊЗЂdog.puppyЃЌвВВЛЛсзЊЗЂdog.guardЃЌжЛЛсзЊЗЂdogЁЃ
Channel channel
= connection.createChannel();
channel.exchangeDeclare ("exchangeName",
"direct"); //direct fanout topic
channel.queueDeclare ("queueName");
channel.queueBind ("queueName", "exchangeName",
"routingKey");
byte[] messageBodyBytes = "hello world".getBytes();
//ашвЊАѓЖЈТЗгЩМќ
channel.basicPublish ("exchangeName",
"routingKey", MessageProperties.PERSISTENT_TEXT_PLAIN,
messageBodyBytes); |
Fanout Exchange ЈC ВЛДІРэТЗгЩМќЁЃФужЛашвЊМђЕЅЕФНЋЖгСаАѓЖЈЕННЛЛЛЛњЩЯЁЃвЛИіЗЂЫЭЕННЛЛЛЛњЕФЯћЯЂЖМЛсБЛзЊЗЂЕНгыИУНЛЛЛЛњАѓЖЈЕФЫљгаЖгСаЩЯЁЃКмЯёзгЭјЙуВЅЃЌУПЬЈзгЭјФкЕФжїЛњЖМЛёЕУСЫвЛЗнИДжЦЕФЯћЯЂЁЃFanoutНЛЛЛЛњзЊЗЂЯћЯЂЪЧзюПьЕФЁЃ
Channel channel
= connection.createChannel();
channel.exchangeDeclare ("exchangeName",
"fanout"); //direct fanout topic
channel.queueDeclare ("queueName");
channel.queueBind ("queueName", "exchangeName",
"routingKey");
channel.queueDeclare ("queueName1");
channel.queueBind ("queueName1", " exchangeName",
"routingKey1");
byte[] messageBodyBytes = "hello world".getBytes();
//ТЗгЩМќашвЊЩшжУЮЊПе
channel.basicPublish ("exchangeName",
"", MessageProperties.PERSISTENT_TEXT_PLAIN,
messageBodyBytes); |
Topic Exchange ЈC НЋТЗгЩМќКЭФГФЃЪННјааЦЅХфЁЃДЫЪБЖгСаашвЊАѓЖЈвЊвЛИіФЃЪНЩЯЁЃЗћКХЁА#ЁБЦЅХфвЛИіЛђЖрИіДЪЃЌЗћКХЁА*ЁБЦЅХфВЛЖрВЛЩйвЛИіДЪЁЃвђДЫЁАaudit.#ЁБФмЙЛЦЅХфЕНЁАaudit.irs.corporateЁБЃЌЕЋЪЧЁАaudit.*ЁБ
жЛЛсЦЅХфЕНЁАaudit.irsЁБЁЃ
Channel channel
= connection.createChannel();
channel.exchangeDeclare("exchangeName",
"topic"); //direct fanout topic
channel.queueDeclare("queueName");
channel.queueBind("queueName", "exchangeName",
"routingKey.*");
byte[] messageBodyBytes = "hello world".getBytes();
channel.basicPublish("exchangeName",
"routingKey.one", MessageProperties.PERSISTENT_TEXT_PLAIN,
messageBodyBytes); |
Header Exchange
HeadersРраЭЕФexchangeЪЙгУЕФБШНЯЩйЃЌЫќвВЪЧКіТдroutingKeyЕФвЛжжТЗгЩЗНЪНЁЃЪЧЪЙгУHeadersРДЦЅХфЕФЁЃ
HeadersЪЧвЛИіМќжЕЖдЃЌПЩвдЖЈвхГЩHashtableЁЃЗЂЫЭепдкЗЂЫЭЕФЪБКђЖЈвхвЛаЉМќжЕЖдЃЌНгЪеепвВПЩвддйАѓЖЈЪБКђДЋШывЛаЉМќжЕЖдЃЌСНепЦЅХфЕФЛАЃЌдђЖдгІЕФЖгСаОЭПЩвдЪеЕНЯћЯЂЁЃЦЅХфгаСНжжЗНЪНallКЭanyЁЃетСНжжЗНЪНЪЧдкНгЪеЖЫБиаывЊгУМќжЕ"x-mactch"РДЖЈвхЁЃ
allДњБэЖЈвхЕФЖрИіМќжЕЖдЖМвЊТњзуЃЌЖјanyдђДњТыжЛвЊТњзувЛИіОЭПЩвдСЫЁЃ
fanoutЃЌdirectЃЌtopic exchangeЕФroutingKeyЖМашвЊвЊзжЗћДЎаЮЪНЕФЃЌЖјheaders
exchangeдђУЛгаетИівЊЧѓЃЌвђЮЊМќжЕЖдЕФжЕПЩвдЪЧШЮКЮРраЭЁЃ
ЯћЯЂЩњВњепШчЯТЃК
package cn.slimsmart.rabbitmq.demo.headers;
import java.util.Date;
import java.util.Hashtable;
import java.util.Map;
import org.springframework .amqp.core.ExchangeTypes;
import com.rabbitmq.client.AMQP;
import com.rabbitmq.client .AMQP.BasicProperties;
import com.rabbitmq.client .AMQP.BasicProperties.Builder;
import com.rabbitmq.client.Channel;
import com.rabbitmq.client.Connection;
import com.rabbitmq.client.ConnectionFactory;
public class Producer {
private final static String EXCHANGE_NAME = "header-exchange";
@SuppressWarnings ("deprecation")
public static void main (String[] args) throws
Exception {
// ДДНЈСЌНгКЭЦЕЕР
ConnectionFactory factory = new ConnectionFactory();
factory.setHost ("192.168.36.102");
// жИЖЈгУЛЇ УмТы
factory.setUsername ("admin");
factory.setPassword ("admin");
// жИЖЈЖЫПк
factory.setPort (AMQP.PROTOCOL.PORT);
Connection connection = factory.newConnection();
Channel channel = connection.createChannel();
//ЩљУїзЊЗЂЦїКЭРраЭheaders
channel.exchangeDeclare (EXCHANGE_NAME, ExchangeTypes.HEADERS,false,true,null);
String message = new Date().toLocaleString() +
" : log something";
Map<String,Object> headers = new Hashtable<String,
Object>();
headers.put ("aaa", "01234");
Builder properties = new BasicProperties.Builder();
properties.headers (headers);
// жИЖЈЯћЯЂЗЂЫЭЕНЕФзЊЗЂЦї,АѓЖЈМќжЕЖдheadersМќжЕЖд
channel.basicPublish (EXCHANGE_NAME, "", properties.build(),message.getBytes());
System.out.println("Sent message :'"
+ message + "'");
channel.close();
connection.close();
}
} |
ЯћЯЂЯћЗбепШчЯТЃК
package cn.slimsmart.rabbitmq.demo.headers;
import java.util.Hashtable;
import java.util.Map;
import org.springframework.amqp.core.ExchangeTypes;
import com.rabbitmq.client.AMQP;
import com.rabbitmq.client.Channel;
import com.rabbitmq.client.Connection;
import com.rabbitmq.client.ConnectionFactory;
import com.rabbitmq.client.QueueingConsumer;
public class Consumer {
private final static String EXCHANGE_NAME = "header-exchange";
private final static String QUEUE_NAME = "header-queue";
public static void main(String[] args) throws
Exception {
// ДДНЈСЌНгКЭЦЕЕР
ConnectionFactory factory = new ConnectionFactory();
factory.setHost("192.168.36.102");
// жИЖЈгУЛЇ УмТы
factory.setUsername("admin");
factory.setPassword("admin");
// жИЖЈЖЫПк
factory.setPort(AMQP.PROTOCOL.PORT);
Connection connection = factory.newConnection();
Channel channel = connection.createChannel();
//ЩљУїзЊЗЂЦїКЭРраЭheaders
channel.exchangeDeclare(EXCHANGE_NAME, ExchangeTypes.HEADERS,false,true,null);
channel.queueDeclare(QUEUE_NAME,false, false,
true,null);
Map<String, Object> headers = new Hashtable<String,
Object>();
headers.put("x-match", "any");//all
any
headers.put("aaa", "01234");
headers.put("bbb", "56789");
// ЮЊзЊЗЂЦїжИЖЈЖгСаЃЌЩшжУbinding АѓЖЈheaderМќжЕЖд
channel.queueBind(QUEUE_NAME, EXCHANGE_NAME,"",
headers);
QueueingConsumer consumer = new QueueingConsumer(channel);
// жИЖЈНгЪеепЃЌЕкЖўИіВЮЪ§ЮЊздЖЏгІД№ЃЌЮоашЪжЖЏгІД№
channel.basicConsume(QUEUE_NAME, true, consumer);
while (true) {
QueueingConsumer.Delivery delivery = consumer.nextDelivery();
String message = new String(delivery.getBody());
System.out.println(message);
}
}
} |
Default Exchange
ЦфЪЕГ§СЫЩЯУцЫФжжвдЭтЛЙгавЛжжDefault ExchangeЃЌЫќЪЧвЛжжЬиБ№ЕФDirect ExchangeЁЃ
ЕБФуЪжЖЏДДНЈвЛИіЖгСаЪБЃЌКѓЬЈЛсздЖЏНЋетИіЖгСаАѓЖЈЕНвЛИіУћГЦЮЊПеЕФDirectРраЭНЛЛЛЛњЩЯЃЌАѓЖЈТЗгЩУћГЦгыЖгСаУћГЦЯрЭЌЁЃгаСЫетИіФЌШЯЕФНЛЛЛЛњКЭАѓЖЈЃЌЮвУЧОЭПЩвдЯёЦфЫћЧсСПМЖЕФЖгСаЃЌШчRedisФЧбљЃЌжБНгВйзїЖгСаРДДІРэЯћЯЂЁЃВЛЙ§жЛЪЧПДЦ№РДЪЧЃЌЪЕМЪЩЯдкRabbitMQРяжБНгВйзїЪЧВЛПЩФмЕФЁЃЯћЯЂЪМжеЖМЪЧЯШЗЂЫЭЕННЛЛЛЛњЃЌгЩНЛЛЛМЖОЙ§ТЗгЩДЋЫЭИјЖгСаЃЌЯћЗбепдйДгЖгСажаЛёШЁЯћЯЂЕФЁЃВЛЙ§гЩгкетИіФЌШЯНЛЛЛЛњКЭТЗгЩЕФЙиЯЕЃЌЪЙЮвУЧжЛЙиаФЖгСаетвЛВуМДПЩЃЌетИіБШНЯЪЪКЯзівЛаЉМђЕЅЕФгІгУЃЌБЯОЙУЛгаЗЂЛгRabbitMQЕФзюДѓЙІФмЃЌШчЙћЖМгУетжжЗНЪНШЅЪЙгУЕФЛАОЭецЪЧЩБМІгУдзХЃЕЖСЫЁЃ
2. СйЪБЖгСа
ШчЙћвЊдкЩњВњепКЭЯћЗбепжЎМфДДНЈвЛИіаТЕФЖгСаЃЌгжВЛЯыЪЙгУдРДЕФЖгСаЃЌСйЪБЖгСаОЭЪЧЮЊетИіГЁОАЖјЩњЕФЃК
ЪзЯШЃЌУПЕБЮвУЧСЌНгЕНRabbitMQЃЌЮвУЧашвЊвЛИіаТЕФПеЖгСаЃЌЮвУЧПЩвдгУвЛИіЫцЛњУћГЦРДДДНЈЃЌЛђепЫЕШУЗўЮёЦїбЁдёвЛИіЫцЛњЖгСаУћГЦИјЮвУЧЁЃ
вЛЕЉЮвУЧЖЯПЊЯћЗбепЃЌЖгСагІИУСЂМДБЛЩОГ§ЁЃJavaПЭЛЇЖЫЬсЙЉqueuedeclare()ЮЊЮвУЧДДНЈвЛИіЗЧГжОУЛЏЁЂЖРСЂЁЂздЖЏЩОГ§ЕФЖгСаУћГЦЁЃ
| String queueName
= channel.queueDeclare().getQueue(); |
ЭЈЙ§ЩЯУцЕФДњТыОЭФмЛёШЁЕНвЛИіЫцЛњЖгСаУћГЦЁЃ Р§ШчЃКЫќПЩФмЪЧЃКamq.gen-jzty20brgko-hjmujj0wlgЁЃ
3. АѓЖЈ 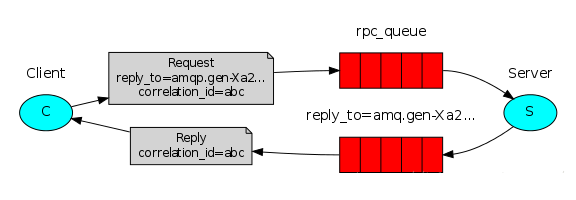
ШчЙћЮвУЧвбОДДНЈСЫвЛИіЗжЗЂНЛЛЛЦїКЭЖгСаЃЌЯждкЮвУЧОЭПЩвдОЭНЋЮвУЧЕФЖгСаИњНЛЛЛЦїНјааАѓЖЈЁЃ
| channel.queueBind(queueName,
"logs", ""); |
жДааЭъетЖЮДњТыКѓЃЌШежОНЛЛЛЦїЛсНЋЯћЯЂЬэМгЕНЮвУЧЕФЖгСажаЁЃ
ЮхЁЂRabbitMQЪЕЯжRPC
RabbitMQПЩвдгУгкЪЕЯжRPCЃЌСНепгаЯрЯёжЎДІЃЌЪЙгУRabbitMQЪЕЯжRPCЗжЮЊШчЯТМИИіВНжшЃК
1. Client interfaceЃЈПЭЛЇЖЫНгПкЃЉ
ЮЊСЫЫЕУїRPCЗўЮёПЩвдЪЙгУЃЌЮвУЧДДНЈвЛИіМђЕЅЕФПЭЛЇЖЫРрЁЃБЉТЖвЛИіЗНЗЈЁЊЁЊЗЂЫЭRPCЧыЧѓЃЌШЛКѓзшШћжБЕНЛёЕУНсЙћЁЃ
FibonacciRpcClient
fibonacciRpc = new FibonacciRpcClient();
String result = fibonacciRpc.call("4");
System.out.println ( "fib(4) is " + result);
|
2. Callback queueЃЈЛиЕїЖгСаЃЉ
вЛАудкRabbitMQжазіRPCЪЧКмМђЕЅЕФЁЃПЭЛЇЖЫЗЂЫЭЧыЧѓЯћЯЂЃЌЗўЮёЦїЛиИДЯьгІЕФЯћЯЂЁЃЮЊСЫНгЪмЯьгІЕФЯћЯЂЃЌЮвУЧашвЊдкЧыЧѓЯћЯЂжаЗЂЫЭвЛИіЛиЕїЖгСаЁЃПЩвдгУФЌШЯЕФЖгСаЃК
BasicProperties
props = new BasicProperties
.Builder()
.replyTo(callbackQueueName)
.build();
channel.basicPublish("", "rpc_queue",
props, message.getBytes());
// ... then code to read a response message from
the callback_queue ... |
3. Message propertiesЃЈЯћЯЂЪєадЃЉ
AMQPавщЮЊЯћЯЂдЄЖЈвхСЫвЛзщ14ИіЪєадЁЃДѓВПЗжЕФЪєадЪЧКмЩйЪЙгУЕФЁЃГ§СЫвЛЯТМИжжЃК
deliveryModeЃКБъМЧЯћЯЂДЋЕнФЃЪНЃЌ2-ЯћЯЂГжОУЛЏЃЌЦфЫћжЕ-ЫВЬЌЁЃдкЕкЖўЦЊЮФеТжаЛЙЬсЕНЙ§ЁЃ
contentTypeЃКФкШнРраЭЃЌгУгкУшЪіБрТыЕФmime-typeЁЃР§ШчОГЃЮЊИУЪєадЩшжУJSONБрТыЁЃ
replyToЃКгІД№ЃЌЭЈгУЕФЛиЕїЖгСаУћГЦ
correlationIdЃКЙиСЊIDЃЌЗНБуRPCЯьгІгыЧыЧѓЙиСЊ
ЮвУЧашвЊЬэМгвЛИіаТЕФЕМШыЃК
| import com.rabbitmq.client.AMQP.BasicProperties;
|
4. Correlation Id
дкЩЯЪіЗНЗЈжаЮЊУПИіRPCЧыЧѓДДНЈвЛИіЛиЕїЖгСаЁЃетЪЧКмЕЭаЇЕФЁЃавдЫЕФЪЧЃЌвЛИіНтОіЗНАИЃКПЩвдЮЊУПИіПЭЛЇЖЫДДНЈвЛИіЕЅвЛЕФЛиЕїЖгСаЁЃ
аТЕФЮЪЬтБЛЬсГіЃЌЖгСаЪеЕНвЛЬѕЛиИДЯћЯЂЃЌЕЋЪЧВЛЧхГўЪЧФЧЬѕЧыЧѓЕФЛиИДЁЃетЪЧОЭашвЊЪЙгУcorrelationIdЪєадСЫЁЃЮвУЧвЊЮЊУПИіЧыЧѓЩшжУЮЈвЛЕФжЕЁЃШЛКѓЃЌдкЛиЕїЖгСажаЛёШЁЯћЯЂЃЌПДПДетИіЪєадЃЌЙиСЊresponseКЭrequestОЭЪЧЛљгкетИіЪєаджЕЕФЁЃШчЙћЮвУЧПДЕНвЛИіЮДжЊЕФcorrelationIdЪєаджЕЕФЯћЯЂЃЌПЩвдЗХаФЕФЮоЪгЫќЁЊЁЊЫќВЛЪЧЮвУЧЗЂЫЭЕФЧыЧѓЁЃ
ФуПЩФмЮЪЕРЃЌЮЊЪВУДвЊКіТдЛиЕїЖгСажаЮДжЊЕФаХЯЂЃЌЖјВЛЪЧЕБзївЛИіЪЇАмЃПетЪЧгЩгкдкЗўЮёЦїЖЫОКељЬѕМўЕФЕМжТЕФЁЃЫфШЛВЛЬЋПЩФмЃЌЕЋЪЧШчЙћRPCЗўЮёЦїдкЗЂЫЭИјЮвУЧНсЙћКѓЃЌЗЂЫЭЧыЧѓЗДРЁЧАОЭЙвЕєСЫЃЌетгаПЩФмЛсЗЂЫЭЮДжЊcorrelationIdЪєаджЕЕФЯћЯЂЁЃШчЙћЗЂЩњСЫетжжЧщПіЃЌжиЦєRPCЗўЮёЦїНЋЛсжиаТДІРэИУЧыЧѓЁЃетОЭЪЧЮЊЪВУДдкПЭЛЇЖЫБиаыКмКУЕФДІРэжиИДЯьгІЃЌRPCгІИУЪЧУнЕШЕФЁЃ
5. ЪЕЯж
ЮвУЧЕФRPCЕФДІРэСїГЬЃК
ЕБПЭЛЇЖЫЦєЖЏЪБЃЌДДНЈвЛИіФфУћЕФЛиЕїЖгСаЁЃ
ПЭЛЇЖЫЮЊRPCЧыЧѓЩшжУ2ИіЪєадЃКreplyToЃКЩшжУЛиЕїЖгСаУћзжЃЛcorrelationIdЃКБъМЧrequestЁЃ
ЧыЧѓБЛЗЂЫЭЕНrpc_queueЖгСажаЁЃ
RPCЗўЮёЦїЖЫМрЬ§rpc_queueЖгСажаЕФЧыЧѓЃЌЕБЧыЧѓЕНРДЪБЃЌЗўЮёЦїЖЫЛсДІРэВЂЧвАбДјгаНсЙћЕФЯћЯЂЗЂЫЭИјПЭЛЇЖЫЁЃНгЪеЕФЖгСаОЭЪЧreplyToЩшЖЈЕФЛиЕїЖгСаЁЃ
ПЭЛЇЖЫМрЬ§ЛиЕїЖгСаЃЌЕБгаЯћЯЂЪБЃЌМьВщcorrelationIdЪєадЃЌШчЙћгыrequestжаЦЅХфЃЌФЧОЭЪЧНсЙћСЫЁЃ
RPCЗўЮёЦїЖЫЃЈRPCServer.javaЃЉ
/**
* RPCЗўЮёЦїЖЫ
*
* @author arron
* @date 2015Фъ9дТ30Ше ЯТЮч3:49:01
* @version 1.0
*/
public class RPCServer {
private static final String RPC_QUEUE_NAME = "rpc_queue";
public static void main( String[] args) throws
Exception {
ConnectionFactory factory = new ConnectionFactory();
// ЩшжУMabbitMQЫљдкжїЛњipЛђепжїЛњУћ
factory.setHost("127.0.0.1");
// ДДНЈвЛИіСЌНг
Connection connection = factory.newConnection();
// ДДНЈвЛИіЦЕЕР
Channel channel = connection.createChannel();
//ЩљУїЖгСа
channel.queueDeclare(RPC_QUEUE_NAME, false, false,
false, null);
//ЯожЦЃКУПДЮзюЖрИјвЛИіЯћЗбепЗЂЫЭ1ЬѕЯћЯЂ
channel.basicQos(1);
//ЮЊrpc_queueЖгСаДДНЈЯћЗбепЃЌгУгкДІРэЧыЧѓ
QueueingConsumer consumer = new QueueingConsumer(channel);
channel.basicConsume(RPC_QUEUE_NAME, false, consumer);
System.out.println(" [x] Awaiting RPC requests");
while (true) {
QueueingConsumer.Delivery delivery = consumer.nextDelivery();
//ЛёШЁЧыЧѓжаЕФcorrelationIdЪєаджЕЃЌВЂНЋЦфЩшжУЕННсЙћЯћЯЂЕФcorrelationIdЪєаджа
BasicProperties props = delivery.getProperties();
BasicProperties replyProps = new BasicProperties.Builder().correlationId (props.getCorrelationId()).build();
//ЛёШЁЛиЕїЖгСаУћзж
String callQueueName = props.getReplyTo();
String message = new String( delivery.getBody(),"UTF-8");
System.out.println(" [.] fib(" + message
+ ")");
//ЛёШЁНсЙћ
String response = "" + fib(Integer.parseInt(message));
//ЯШЗЂЫЭЛиЕїНсЙћ
channel.basicPublish("", callQueueName,
replyProps,response.getBytes());
//КѓЪжЖЏЗЂЫЭЯћЯЂЗДРЁ
channel.basicAck (delivery.getEnvelope( ).getDeliveryTag(),
false);
}
}
/**
* МЦЫуьГВЈСаЦфЪ§СаЕФЕкnЯю
*
* @param n
* @return
* @throws Exception
*/
private static int fib(int n) throws Exception
{
if (n < 0)
throw new Exception("ВЮЪ§ДэЮѓЃЌnБиаыДѓгкЕШгк0");
if (n == 0)
return 0;
if (n == 1)
return 1;
return fib(n - 1) + fib(n - 2);
}
} |
RPCПЭЛЇЖЫЃЈRPCClient.javaЃЉЃК
/**
*
* @author arron
* @date 2015Фъ9дТ30Ше ЯТЮч3:44:43
* @version 1.0
*/
public class RPCClient {
private static final String RPC_QUEUE_NAME = "rpc_queue";
private Connection connection;
private Channel channel;
private String replyQueueName;
private QueueingConsumer consumer;
public RPCClient() throws Exception {
ConnectionFactory factory = new ConnectionFactory();
// ЩшжУMabbitMQЫљдкжїЛњipЛђепжїЛњУћ
factory.setHost("127.0.0.1");
// ДДНЈвЛИіСЌНг
connection = factory.newConnection();
// ДДНЈвЛИіЦЕЕР
channel = connection.createChannel();
//ЩљУїЖгСа
channel.queueDeclare (RPC_QUEUE_NAME, false, false,
false, null);
//ЮЊУПвЛИіПЭЛЇЖЫЛёШЁвЛИіЫцЛњЕФЛиЕїЖгСа
replyQueueName = channel.queueDeclare().getQueue();
//ЮЊУПвЛИіПЭЛЇЖЫДДНЈвЛИіЯћЗбеп ЃЈгУгкМрЬ§ЛиЕїЖгСаЃЌЛёШЁНсЙћЃЉ
consumer = new QueueingConsumer(channel);
//ЯћЗбепгыЖгСаЙиСЊ
channel.basicConsume ( replyQueueName, true, consumer);
}
/**
* ЛёШЁьГВЈСаЦфЪ§СаЕФжЕ
*
* @param message
* @return
* @throws Exception
*/
public String call(String message) throws Exception{
String response = null;
String corrId = java.util.UUID.randomUUID().toString();
//ЩшжУreplyToКЭcorrelationIdЪєаджЕ
BasicProperties props = new BasicProperties.Builder(
).correlationId( corrId).replyTo( replyQueueName
).build();
//ЗЂЫЭЯћЯЂЕНrpc_queueЖгСа
channel.basicPublish("", RPC_QUEUE_NAME,
props, message.getBytes());
while (true) {
QueueingConsumer.Delivery delivery = consumer.nextDelivery();
if (delivery.getProperties( ).getCorrelationId( ).equals(corrId))
{
response = new String( delivery.getBody(),"UTF-8");
break;
}
}
return response;
}
public static void main( String[] args) throws
Exception {
RPCClient fibonacciRpc = new RPCClient();
String result = fibonacciRpc.call("4");
System.out.println ( "fib(4) is " +
result);
}
} |
етРяЕФР§згжЛЪЧRabbitMQжаRPCЗўЮёЕФвЛИіЪЕЯжЃЌФувВПЩвдИљОнвЕЮёашвЊЪЕЯжИќЖрЁЃrpcгавЛИігХЕуЃЌШчЙћвЛИіRPCЗўЮёЦїДІРэВЛРДЃЌПЩвддйдіМгвЛИіЁЂСНИіЁЂШ§ИіЁЃЮвУЧЕФР§згжаЕФДњТыЛЙБШНЯМђЕЅЃЌЛЙгаКмЖрЮЪЬтУЛгаНтОіЃК
ШчЙћУЛгаЗЂЯжЗўЮёЦїЃЌПЭЛЇЖЫШчКЮДІРэЃП
ШчЙћПЭЛЇЖЫЕФRPCЧыЧѓГЌЪБСЫдѕУДАьЃП
ШчЙћЗўЮёЦїГіЯжСЫЙЪеЯЃЌЗЂЩњСЫвьГЃЃЌЪЧЗёНЋвьГЃЗЂЫЭЕНПЭЛЇЖЫ
дкДІРэЯћЯЂЧАЃЌдѕбљЗРжЙЮоаЇЕФЯћЯЂЃПМьВщЗЖЮЇЁЂРраЭЃП
|









