| БрМЭЦМі: |
БОЮФРДздгкliangzlЃЌЮФеТжївЊЬжТлСЫRocketMQБОЩэЪЧЗёЬсЙЉФГаЉЙиМќаХЯЂПЩвдАяжњЮвУЧШЅжиЃЌКЭвЕЮёЩЯШчКЮжЇГжУнЕШЁЃ |
|
жЎЧАСФЙ§вЛИіЮЪЬтЃЌRocketMQЕФЩшМЦЩЯЃЌЪЧВЛПМТЧЯћЯЂШЅжиЕФЮЪЬтЃЌМДВЛПМТЧЯћЯЂЪЧЗёЛсжиИДЕФЯћЗбЕФЮЪЬтЃЌЖјЪЧНЋетИіЮЪЬтХзИјвЕЮёЖЫздМКШЅДІРэУнЕШЕФЮЪЬтЁЃ
зїЮЊRocketMQЕФЪЙгУепЃЌЯждкШЅЬжТлRocketMQЮЊКЮВЛжЇГжЯћЯЂШЅжиЕФЮЪЬтЃЌМКОЪЧЮоЙиЭДбїЃЌВЂЧввВвтвхВЛДѓЁЃШчЙћеОдкШчКЮЩшМЦвЛИіЯћЯЂЖгСаЕФНЧЖШШЅЫМПМетИіЮЪЬтЃЌетЪЧЩшМЦЩЯЩсгыЕУЃЌЮоЙиЖдДэЁЃЖјЯждквЊПМТЧЕФЪЧЃЌМШШЛЫќВЛжЇГжЯћЯЂШЅжиЃЌФЧУДОЭжЛФмздМКЭЈЙ§ФГаЉЗНЪНШЅБЃжЄЯћЯЂШЅжиЁЃ
RocketMQБОЩэЪЧЗёЬсЙЉФГаЉЙиМќаХЯЂПЩвдАяжњЮвУЧШЅжи
вЕЮёЩЯШчКЮжЇГжУнЕШ
вЕЮёУнЕШ
вЕЮёЩЯжЇГжУнЕШЃЌЪЕЯжЦ№РДЖЈШЛВЛЛсКмИДдгЃЌЕЋЪЧашвЊЖдЯждкЕФКмЖрвЕЮёЖЏЕЖЃЌжЛгаЗЧГЃбЯНїЕФвЕЮёашвЊЩїжиПМТЧШЅжиЮЪЬтЕФЪБКђВХЛсШЅПМТЧИФдьЃЌДгвЕЮёЩЯжЇГжУнЕШЃЌДгЫќећИіЪЕЯжЫМТЗПЩФмЖМВЛЪЧЬиБ№гХбХЃЌвђЮЊвЕЮёЗНгызщМўёюКЯСЫЁЃВЂЧвЃЌRocketMQВЛжЇГжЯћЯЂШЅжиОЭПЩФмВТЕНШчЙћвЊжЇГжШЅжиЃЌећИіЭЬЭТСППЩФмЖМЛсгабЯжиЕФЯТЛЌЁЃ
МйЩшЩшМЦвЛВуdbРДНтОівЕЮёУнЕШ(БШШчЭЈЙ§МЧТМЖЉЕЅid)ЃЌФЧУДвЛЬѕЯћЯЂЛсгаМИжжзДЬЌФиЃП
ЯћЯЂВЛДцдк NONE
ЯћЯЂЯћЗбГЩЙІ SUCCESS
ЯћЯЂЛЙдкДІРэ PROCESS
ЯћЯЂЯћЗбЪЇАм ERROR
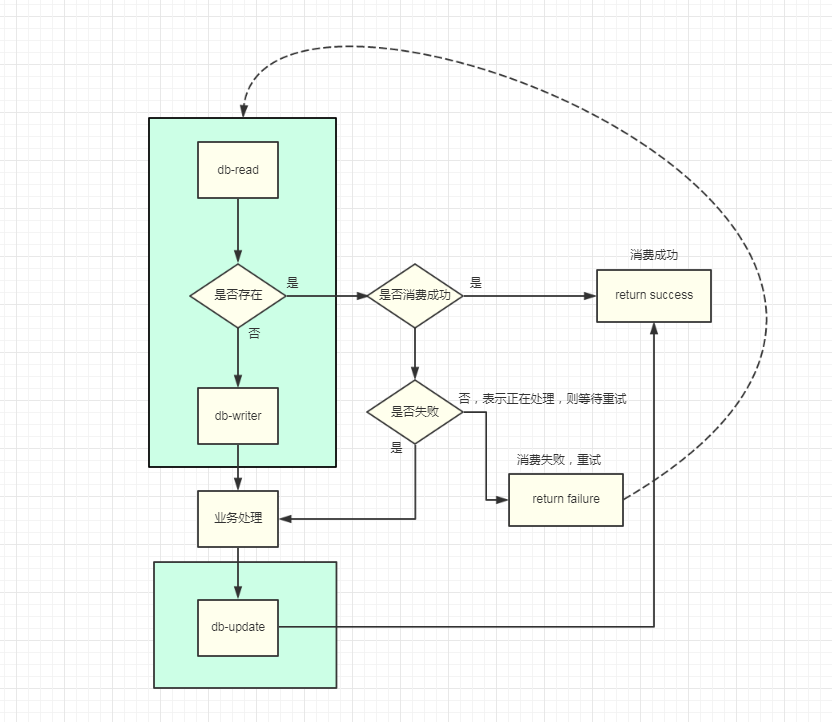
ЛљгквдЩЯМИжжзДЬЌШЅПМТЧЩшМЦвЛИібЯНїЕФвЕЮёУнЕШЕФНтОіЗНАИЃЌећИіЭЬЭТСПЯТНЕСЫЗЧГЃЖрЃЌвЛЬѕЯћЯЂЕФЯћЗбжСЩйЩцМАШ§ДЮdbВйзїЃЌЦфжаСНДЮdb
writerЃЌФЧУДЛиЙ§ЭЗРДЫМПМЯЕЭГМмЙЙв§ШыЯћЯЂЖгСаашвЊШЅНтОіЪВУДбљЕФЮЪЬтЃП
НтёюЃЌЬсИпЯьгІЫйЖШ
СїСПЯїЗхЬюЙШ
Ъ§ОнвьЙЙ
......
дкЯћЯЂЕФЯћЗбЫйЖШдЖдЖЕЭгкЩњВњепЕФЩњВњЫйЖШЃЌжБНгЛсдьГЩДѓСПЕФЯћЯЂЖбЛ§ЃЌДјРДЕФгАЯьЪЧЗЧГЃбЯжиЕФЃЌБШШчКмЖрвЕЮёЕФбгГйДѓЗљЖШЬсИпЃЌећИігУЛЇЬхбщЛсКмВюЃЌвВаэдЯШбгГйНідк1sжЎФкЃЌЭЛШЛЩЯЩ§ЕН1hЩѕжСИќОУЁЃЧАМИЬьАЂРядЦЩњВњЪТЙЪЃЌПЩвдЫЕЪЧвЛЦЌАЇКПЃЌЬиБ№ЪЧЯћЯЂЖгСаЃЌгаЕФШЫЬЉШЛДІжЎЃЌгаЕФШЫгћПоЮоРсЃЌгаЕФШЫзМБИЩОПтХмТЗЁЁ
ЭЈЙ§вдЯТСНИіЗНАИжСЩйПЩвдМѕЧсШчЙћзщМўЗНЭЛШЛГіЪТЙЪЕФЧщПіЫљДјРДЕФЩњВњЪТЙЪЃК
вЛжТадЗНАИ
ЯћЯЂШЅжи
ЦфЫћ
ВЛЭЈЙ§вЕЮёЩЯЕФИїжжЮЈвЛidРДДІРэЯћЯЂШЅжиЮЪЬтЃЌЖјЪЧЛљгкдЯШЖдгкRocketMQЕФСЫНтЃЌЯТвтЪЖШЅПМТЧRocketMQжаЕФMsgIdЪЧЗёПЩвдзїЮЊШЅжиЕФЙиМќЕуЃП
ОпБИШЅжизюНєвЊЕФЪзвЊвђЫиЪЧЁЊЁЊ>ИУжЕПЩвдШЋОжЮЈвЛЕФБъЪЖвЛЬѕЯћЯЂ
ДѓМвЖМжЊЕРЃЌдкЕЅЛњЛЗОГЯТЯывЊЩњГЩЮЈвЛidЪЧвЛМўЗЧГЃШнвзЕФЪТЃЌБШШчЭЈЙ§Ъ§ОнПтжїМќРДЩњГЩвЛИіЮЈвЛЕФidЁЃЕЋЪЧдкЗжВМЪНзївЕЛЗОГЯТЃЌЯывЊЩњГЩвЛИіШЋОжЮЈвЛЕФidЯдШЛЪЧБШНЯРЇФбЕФЃЌВЛЙ§ФПЧАвВгаЗЧГЃЖрЕФГЩЪьЗНАИПЩвдШЅДІРэЃЌетРяВЛзїзИЪіЁЃдкетРяИќЯыЬсЕФЪЧЃЌRocketMQЬсЙЉШЋОжЮЈвЛЕФidЪЧШчКЮзіЕНЕФЃП
ВщПДSendResultРрПЩвдПДЕНЦфжагаСНИіmsgId
public class
SendResult {
private SendStatus sendStatus;
private String msgId;// ПЭЛЇЖЫЩњГЩЕФid
private MessageQueue messageQueue;
private long queueOffset;
private String transactionId;
private String offsetMsgId;//ЗўЮёЖЫЩњГЩЕФid
private String regionId;
private boolean traceOn = true;
.....
} |
ПЭЛЇЖЫЩњГЩЮЈвЛid
ПЭЛЇЖЫMsgIdЪЧдѕУДЩњГЩЕФФиЃПШчЯТдДТы
public class
MessageClientIDSetter {
private static final String TOPIC_KEY_SPLITTER
= "#";
private static final int LEN;
private static final String FIX_STRING;
private static final AtomicInteger COUNTER;
private static long startTime;
private static long nextStartTime;
static {
LEN = 4 + 2 + 4 + 4 + 2;
ByteBuffer tempBuffer = ByteBuffer.allocate(10);
tempBuffer.position(2);
tempBuffer.putInt(UtilAll.getPid());// НјГЬid
tempBuffer.position(0);
try {
tempBuffer.put(UtilAll.getIP());// ipЕижЗ
} catch (Exception e) {
tempBuffer.put(createFakeIP());
}
tempBuffer.position(6);
tempBuffer.putInt(MessageClientIDSetter.class.
getClassLoader().hashCode());//
FIX_STRING = UtilAll.bytes2string(tempBuffer.array());
setStartTime(System.currentTimeMillis());
COUNTER = new AtomicInteger(0);
}
private synchronized static void setStartTime(long
millis) {
Calendar cal = Calendar.getInstance();
cal.setTimeInMillis(millis);
cal.set(Calendar.DAY_OF_MONTH, 1);
cal.set(Calendar.HOUR_OF_DAY, 0);
cal.set(Calendar.MINUTE, 0);
cal.set(Calendar.SECOND, 0);
cal.set(Calendar.MILLISECOND, 0);
startTime = cal.getTimeInMillis();
cal.add(Calendar.MONTH, 1);
nextStartTime = cal.getTimeInMillis();
}
public static Date getNearlyTimeFromID(String
msgID) {
ByteBuffer buf = ByteBuffer.allocate(8);
byte[] bytes = UtilAll.string2bytes(msgID);
buf.put((byte) 0);
buf.put((byte) 0);
buf.put((byte) 0);
buf.put((byte) 0);
buf.put(bytes, 10, 4);
buf.position(0);
long spanMS = buf.getLong();
Calendar cal = Calendar.getInstance();
long now = cal.getTimeInMillis();
cal.set(Calendar.DAY_OF_MONTH, 1);
cal.set(Calendar.HOUR_OF_DAY, 0);
cal.set(Calendar.MINUTE, 0);
cal.set(Calendar.SECOND, 0);
cal.set(Calendar.MILLISECOND, 0);
long monStartTime = cal.getTimeInMillis();
if (monStartTime + spanMS >= now) {
cal.add(Calendar.MONTH, -1);
monStartTime = cal.getTimeInMillis();
}
cal.setTimeInMillis(monStartTime + spanMS);
return cal.getTime();
}
public static String getIPStrFromID(String
msgID) {
byte[] ipBytes = getIPFromID(msgID);
return UtilAll.ipToIPv4Str(ipBytes);
}
public static byte[] getIPFromID(String msgID)
{
byte[] result = new byte[4];
byte[] bytes = UtilAll.string2bytes(msgID);
System.arraycopy(bytes, 0, result, 0, 4);
return result;
}
public static String createUniqID() {
StringBuilder sb = new StringBuilder(LEN * 2);
sb.append(FIX_STRING);
sb.append(UtilAll.bytes2string
(createUniqIDBuffer()));
return sb.toString();
}
private static byte[] createUniqIDBuffer()
{
ByteBuffer buffer = ByteBuffer.allocate(4 +
2);
long current = System.currentTimeMillis();
if (current >= nextStartTime) {
setStartTime(current);
}
buffer.position(0);
buffer.putInt((int) (System.currentTimeMillis()
- startTime));
buffer.putShort((short) COUNTER.getAndIncrement());
return buffer.array();
}
public static void setUniqID(final Message
msg) {
if (msg.getProperty(MessageConst.
PROPERTY_UNIQ_CLIENT_MESSAGE_ID_KEYIDX)
== null) {
msg.putProperty(MessageConst.
PROPERTY_UNIQ_CLIENT_MESSAGE_ID_KEYIDX,
createUniqID());
}
}
public static String getUniqID(final Message
msg) {
return msg.getProperty(MessageConst.
PROPERTY_UNIQ_CLIENT_MESSAGE_ID_KEYIDX);
}
public static byte[] createFakeIP() {
ByteBuffer bb = ByteBuffer.allocate(8);
bb.putLong(System.currentTimeMillis());
bb.position(4);
byte[] fakeIP = new byte[4];
bb.get(fakeIP);
return fakeIP;
}
} |
ДгдДТыжаПЩвдПДЕН
|value|part| |--|--| |FIX_STRING | ipЕижЗ + НјГЬid +
MessageClientIDSetter.class.getClassLoader().hashCode()зщГЩ
| |COUNTER | ЪЧAtomicIntegerжЕЃЌПЩБЃжЄВЂЗЂВйзїЯТЕФАВШЋад| |TIME |
System.currentTimeMillis() - ЕБЧАдТПЊЪМЕФЪБМф|
MsgId = FIX_STRING + bytes2string(TIME + COUNTER)
ipЕижЗОіЖЈСЫЗжВМЪНзївЕЛЗОГЯТЩњВњЕФidжЕЮЈвЛ
НјГЬidОіЖЈСЫЕЅЛњЩЯЖрИіПЭЛЇЖЫЪЕР§МфЩњВњЕФidжЕЮЈвЛ
countзїЮЊдзгIntegerРраЭЃЌОіЖЈСЫЕЅЪЕР§дЫааЪБИпВЂЗЂЯТЩњВњЕФжЕЮЈвЛ
time ФЫЕБЧАЪБМфДС - ЕБдТПЊЪМЪБМфДСЕФlongжЕЃЌБЃжЄгІгУдТФкжиЦєВЛЛсжиИДЁЃ
ЪВУДЧщПіЯТЛсГіЯжidжиИДЃП
гІгУВЛжиЦєЃЌidВЛПЩФмжиИД
дТГѕжиЦєЃЌдкИїИіЬѕМўОљВЛБфЕФЧщПіЯТЃЌЕУЕНЕФжЕПЩФмИњЩЯИідТПЊЪМЕФжЕЯрЕШЁЃЕЋЪЧRocketMQСэЭтЕФвЛИіЛњжЦБЃжЄВЛЛсГіЯжжиИДЕФЪ§ОнЃЌМДФЌШЯЩОГ§Ш§ЬьЧАЕФЪ§ОнЁЃЃЈПЩХфжУЃЉ
ДгетИіРяПЩвдПДЕНЃЌЭЈЙ§ip+НјГЬ+зддіжЕ+ЪБМфДСДяЕНСЫвЛИідТФкЕФЪ§ОнЪБВЛЛсжиИДЕФЃЌгжЭЈЙ§ФЌШЯЧхРэЪ§ОнЕФЛњжЦБЃжЄећИіMQдЫааЪБMsgIdВЛЛсжиИДГіЯжЁЃЕЋЪЧзмЬхРДЫЕЃЌЫуЗЈБОЩэвРРЕСНИіЬѕМўДяЕНЕФЮЈвЛадЃЌвЛИіЪЧЪ§ОндТФкЮЈвЛадЃЌвдМАЪ§ОнЧхРэЛњжЦЁЃетИіЫуЗЈВЛЪЪКЯЫљгаЕФЗжВМЪНЮЈвЛidЩњГЩГЁОАЃЌЕЋЪЧЫќЗЧГЃЪЪКЯЯћЯЂЖгСаетИіГЁОАЃЌМђЕЅВЂЧвадФмКУЃЈБШШчЯрНЯЗжВМЪНЫјЩњГЩidЃЉЁЃ
ЗўЮёЖЫЩњГЩЮЈвЛid
offsetMsgIdЩњГЩЗНЪНИќМгМђЕЅЁЃ
public class
MessageDecoder {
public static String createMessageId(final ByteBuffer
input, final ByteBuffer addr, final long offset)
{
input.flip();
input.limit(MessageDecoder.MSG_ID_LENGTH);//ГЄЖШ16ЮЛ
input.put(addr);// ipЕижЗ
input.putLong(offset);// ЮяРэЗжЧјЕФЦЋвЦСПoffset
return UtilAll.bytes2string(input.array());
}
}
|
ЭЈЙ§ЗўЮёЖЫipЕижЗ+ЗўЮёЖЫЯћЯЂЕФЮяРэЗжЧјЦЋвЦСПРДДяЕНЮЈвЛжЕidЁЃ
ЭЈЙ§MsgIdЛђепoffsetMsgIdШЅжи
дкЦНГЃЕФПЊЗЂЙЄзїжаЃЌЮвУЧГЃГЃЛсЬсабздМКЃЌВЛФмШЅаХШЮЧАЖЫЕФЙиМќЪ§ОнЃЌЮЊКЮЃПвђЮЊЫќДЋЪфЕНЗўЮёЖЫЕФЙ§ГЬЪЧМЋДѓПЩФмБЛаоИФЕФЃЌЫљвдЫќВЛЪЧПЩаХШЮЕФЁЃ
MsgIdЪЧПЭЛЇЖЫЩњГЩЕФidЃЌЫќПЩВЛПЩППЃПЯШВЛЫЕБЛДЎИФетбљЕФЮЪЬтЃЌДгЫуЗЈЕФНЧЖШЗжЮіЫќЪЧПЩППЕФЃЌЕЋЪЧЫќДцдквЛИіжТУќЕФЮЪЬтЃКПЭЛЇЖЫЗЂЫЭжСЗўЮёЖЫЯћЯЂЪБЃЌгаУЛгаПЩФмжиИДЗЂЫЭвЛЬѕЯћЯЂЃПе§ГЃЧщПіЯТВЛПЩФмЃЌЕЋЪЧЕБДцдкЭјТчВЈЖЏЃЌЭјТЗбгЪБЕШжюЖрЮЪЬтЪБЃЌЯћЯЂДгПЭЛЇЖЫЗЂЫЭжСЗўЮёЖЫЙ§ГЬжаЃЌЗўЮёЖЫе§ГЃаДШыСЫcommit-logЃЌПЩдкЯьгІПЭЛЇЖЫЃЈACKЃЉЕФЪБКђЪЇАмСЫЁЁ
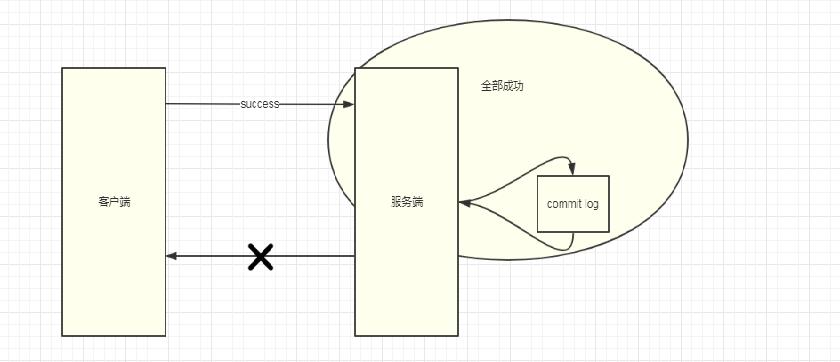
НсЙћШчКЮЃП
ПЩФмЪЧСНЬѕвЛбљЕФЯћЯЂФкШнЃЌШДгаСЫВЛвЛбљЕФMsgIdИњOffsetMsgIdЃЌзюжеЫќЛЙЪЧжиИДЯћЗбСЫЃЈетжжЧщПіМЋЩйГіЯжЃЌЪЪКЯФЧаЉвЕЮёНЯЮЊПэЫЩЕФГЁОАЃЉЃЌЕЋЪЧгЩгкдкЯћЗбЖЫЮоЗЈжБНгШЁЕНMsgIdЕФжЕЃЈврЛђепЮвЛЙУЛПДЕНЃЉЃЌЫљвдШчЙћвЊвджЎзїЮЊШЅжиidЃЌЙ§ГЬашвЊздМКЪЕЯжЁЃ
OffsetMsgIdЪЧЗўЮёЖЫЩњГЩЕФidЃЌЫќПЩВЛПЩППЃПКмУїЯдЫќвВДцдкЧАЮФжаЫЕЕФПЭЛЇЖЫidЕФЧщПіЃЌЕЋЪЧЫќЕФКУДІЪЧЯћЗбЖЫПЩвдЭЈЙ§apiжБНгШЁЕНЁЃДгДњТыЪЕЯжЕФНЧЖШРДНВЃЌвдOffsetMsgIdзїЮЊШЅжиidЪЧИќЮЊгХбХЕФЃЌRocketMQ
зїЮЊЕкШ§ЗНзщМўЧЖШыЯЕЭГЃЌРрЫЦШЅжиетбљЕФЙЄзїШчЙћПЩвдгывЕЮёИєРыПЊЃЌЮовЩЪЧзюКЯЪЪВЛЙ§ЕФЁЃ
СэЃЌШЬВЛзЁЭТВлЃЌдкRocketMQ-ConsoleЕФПЭЛЇЖЫЩЯжиЪдЯћЯЂЕФЪБКђЃЌФУЕНЕФMsgIdИњЯћЯЂе§ГЃЯћЯЂЕФIdОЙШЛВЛЯрЭЌЁЃЧАепЮЊПЭЛЇЖЫIdЃЌКѓЖЫЮЊЗўЮёЖЫIdЁЃ
БШШчПЩвдПМТЧзюМђЕЅЕФЗНАИЃЌШчЯТЃК
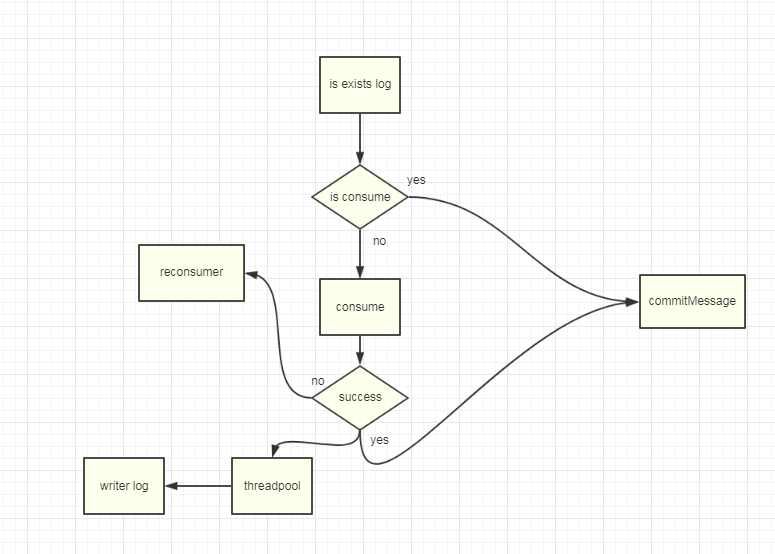
змНс
1ЁЂМЋЮЊбЯНїЕФвЕЮёБиаывЕЮёУнЕШЁЃ 2ЁЂПэЫЩвЕЮёПЩвдПМТЧЪЙгУOffsetMsgIdзїЮЊШЅжиidЁЃ 3ЁЂЮЈвЛidЕФСНжжЗНЪНЗЧГЃжЕЕУНшМјгыЫМПМЃЌМђЕЅЖјЧвгХбХЁЃ
|









