| БрМЭЦМі: |
БОЮФРДздгкjianshuЃЌЮФеТНщЩмСЫRocketmqЁЂkafkaЁЂRabbitmqЕФЯъЯИЖдБШЃЌRocketMQМЏШКВПЪ№ЕШЯрЙиФкШнЁЃ |
|
вЛЁЂ MQБГОА&бЁаЭ
ЯћЯЂЖгСазїЮЊИпВЂЗЂЯЕЭГЕФКЫаФзщМўжЎвЛЃЌФмЙЛАяжњвЕЮёЯЕЭГНтЙЙЬсЩ§ПЊЗЂаЇТЪКЭЯЕЭГЮШЖЈадЁЃжївЊОпгавдЯТгХЪЦЃК
ЯїЗхЬюЙШЃЈжївЊНтОіЫВЪБаДбЙСІДѓгкгІгУЗўЮёФмСІЕМжТЯћЯЂЖЊЪЇЁЂЯЕЭГБМРЃЕШЮЪЬтЃЉ
ЯЕЭГНтёюЃЈНтОіВЛЭЌживЊГЬЖШЁЂВЛЭЌФмСІМЖБ№ЯЕЭГжЎМфвРРЕЕМжТвЛЫРШЋЫРЃЉ
ЬсЩ§адФмЃЈЕБДцдквЛЖдЖрЕїгУЪБЃЌПЩвдЗЂвЛЬѕЯћЯЂИјЯћЯЂЯЕЭГЃЌШУЯћЯЂЯЕЭГЭЈжЊЯрЙиЯЕЭГЃЉ
аюСїбЙВтЃЈЯпЩЯгааЉСДТЗВЛКУбЙВтЃЌПЩвдЭЈЙ§ЖбЛ§вЛЖЈСПЯћЯЂдйЗХПЊРДбЙВтЃЉ
ФПЧАжїСїЕФMQжївЊЪЧRocketmqЁЂkafkaЁЂRabbitmqЃЌRocketmqЯрБШгкRabbitmqЁЂkafkaОпгажївЊгХЪЦЬиадгаЃК
жЇГжЪТЮёаЭЯћЯЂЃЈЯћЯЂЗЂЫЭКЭDBВйзїБЃГжСНЗНЕФзюжевЛжТадЃЌrabbitmqКЭkafkaВЛжЇГжЃЉ
жЇГжНсКЯrocketmqЕФЖрИіЯЕЭГжЎМфЪ§ОнзюжевЛжТадЃЈЖрЗНЪТЮёЃЌЖўЗНЪТЮёЪЧЧАЬсЃЉ
жЇГж18ИіМЖБ№ЕФбгГйЯћЯЂЃЈrabbitmqКЭkafkaВЛжЇГжЃЉ
жЇГжжИЖЈДЮЪ§КЭЪБМфМфИєЕФЪЇАмЯћЯЂжиЗЂЃЈkafkaВЛжЇГжЃЌrabbitmqашвЊЪжЖЏШЗШЯЃЉ
жЇГжconsumerЖЫtagЙ§ТЫЃЌМѕЩйВЛБивЊЕФЭјТчДЋЪфЃЈrabbitmqКЭkafkaВЛжЇГжЃЉ
жЇГжжиИДЯћЗбЃЈrabbitmqВЛжЇГжЃЌkafkaжЇГжЃЉ
RocketmqЁЂkafkaЁЂRabbitmqЕФЯъЯИЖдБШЃЌЧыВЮееЯТБэИёЃК

ЖўЁЂRocketMQМЏШКИХЪі
1. RocketMQМЏШКВПЪ№НсЙЙ
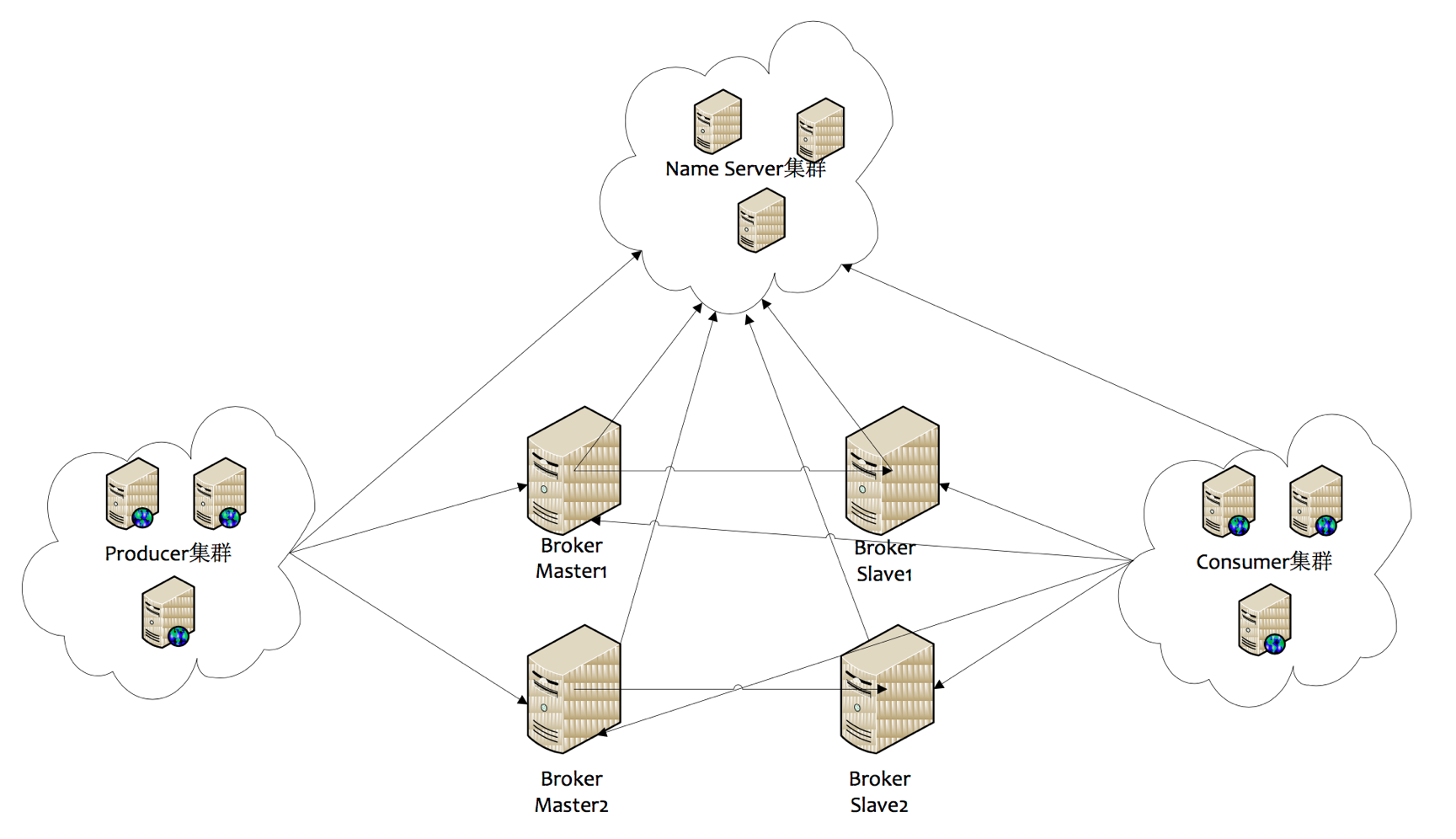
1) Name Server
Name ServerЪЧвЛИіМИКѕЮозДЬЌНкЕуЃЌПЩМЏШКВПЪ№ЃЌНкЕужЎМфЮоШЮКЮаХЯЂЭЌВНЁЃ
2) Broker
BrokerВПЪ№ЯрЖдИДдгЃЌBrokerЗжЮЊMasterгыSlaveЃЌвЛИіMasterПЩвдЖдгІЖрИіSlaveЃЌЕЋЪЧвЛИіSlaveжЛФмЖдгІвЛИіMasterЃЌMasterгыSlaveЕФЖдгІЙиЯЕЭЈЙ§жИЖЈЯрЭЌЕФBroker
NameЃЌВЛЭЌЕФBroker IdРДЖЈвхЃЌBrokerIdЮЊ0БэЪОMasterЃЌЗЧ0БэЪОSlaveЁЃMasterвВПЩвдВПЪ№ЖрИіЁЃ
УПИіBrokerгыName ServerМЏШКжаЕФЫљгаНкЕуНЈСЂГЄСЌНгЃЌЖЈЪБ(УПИє30s)зЂВсTopicаХЯЂЕНЫљгаName
ServerЁЃName ServerЖЈЪБ(УПИє10s)ЩЈУшЫљгаДцЛюbrokerЕФСЌНгЃЌШчЙћName
ServerГЌЙ§2ЗжжгУЛгаЪеЕНаФЬјЃЌдђName ServerЖЯПЊгыBrokerЕФСЌНгЁЃ
3) Producer
ProducerгыName ServerМЏШКжаЕФЦфжавЛИіНкЕу(ЫцЛњбЁдё)НЈСЂГЄСЌНгЃЌЖЈЦкДгName
ServerШЁTopicТЗгЩаХЯЂЃЌВЂЯђЬсЙЉTopicЗўЮёЕФMasterНЈСЂГЄСЌНгЃЌЧвЖЈЪБЯђMasterЗЂЫЭаФЬјЁЃProducerЭъШЋЮозДЬЌЃЌПЩМЏШКВПЪ№ЁЃ
ProducerУПИє30sЃЈгЩClientConfigЕФpollNameServerIntervalЃЉДгName
serverЛёШЁЫљгаtopicЖгСаЕФзюаТЧщПіЃЌетвтЮЖзХШчЙћBrokerВЛПЩгУЃЌProducerзюЖр30sФмЙЛИажЊЃЌдкДЫЦкМфФкЗЂЭљBrokerЕФЫљгаЯћЯЂЖМЛсЪЇАмЁЃ
ProducerУПИє30sЃЈгЩClientConfigжаheartbeatBrokerIntervalОіЖЈЃЉЯђЫљгаЙиСЊЕФbrokerЗЂЫЭаФЬјЃЌBrokerУПИє10sжаЩЈУшЫљгаДцЛюЕФСЌНгЃЌШчЙћBrokerдк2ЗжжгФкУЛгаЪеЕНаФЬјЪ§ОнЃЌдђЙиБегыProducerЕФСЌНгЁЃ
4) Consumer
ConsumerгыName ServerМЏШКжаЕФЦфжавЛИіНкЕу(ЫцЛњбЁдё)НЈСЂГЄСЌНгЃЌЖЈЦкДгName
ServerШЁTopicТЗгЩаХЯЂЃЌВЂЯђЬсЙЉTopicЗўЮёЕФMasterЁЂSlaveНЈСЂГЄСЌНгЃЌЧвЖЈЪБЯђMasterЁЂSlaveЗЂЫЭаФЬјЁЃConsumerМШПЩвдДгMasterЖЉдФЯћЯЂЃЌвВПЩвдДгSlaveЖЉдФЯћЯЂЃЌЖЉдФЙцдђгЩBrokerХфжУОіЖЈЁЃ
ConsumerУПИє30sДгName serverЛёШЁtopicЕФзюаТЖгСаЧщПіЃЌетвтЮЖзХBrokerВЛПЩгУЪБЃЌConsumerзюЖрзюашвЊ30sВХФмИажЊЁЃ
ConsumerУПИє30sЃЈгЩClientConfigжаheartbeatBrokerIntervalОіЖЈЃЉЯђЫљгаЙиСЊЕФbrokerЗЂЫЭаФЬјЃЌBrokerУПИє10sЩЈУшЫљгаДцЛюЕФСЌНгЃЌШєФГИіСЌНг2ЗжжгФкУЛгаЗЂЫЭаФЬјЪ§ОнЃЌдђЙиБеСЌНгЃЛВЂЯђИУConsumer
GroupЕФЫљгаConsumerЗЂГіЭЈжЊЃЌGroupФкЕФConsumerжиаТЗжХфЖгСаЃЌШЛКѓМЬајЯћЗбЁЃ
ЕБConsumerЕУЕНmasterхДЛњЭЈжЊКѓЃЌзЊЯђslaveЯћЗбЃЌslaveВЛФмБЃжЄmasterЕФЯћЯЂ100%ЖМЭЌВНЙ§РДСЫЃЌвђДЫЛсгаЩйСПЕФЯћЯЂЖЊЪЇЁЃЕЋЪЧвЛЕЉmasterЛжИДЃЌЮДЭЌВНЙ§ШЅЕФЯћЯЂЛсБЛзюжеЯћЗбЕєЁЃ
ЯћЗбепЖдСаЪЧЯћЗбепСЌНгжЎКѓЃЈЛђепжЎЧАгаСЌНгЙ§ЃЉВХДДНЈЕФЁЃЮвУЧНЋдЩњЕФЯћЗбепБъЪЖгЩ
{IP}@{ЯћЗбепgroup}РЉеЙЮЊ {IP}@{ЯћЗбепgroup}{topic}{tag}ЃЌЃЈР§Шчxxx.xxx.xxx.xxx@mqtest_producer-group_2m2sTest_tag-zykЃЉЁЃШЮКЮвЛИідЊЫиВЛЭЌЃЌЖМШЯЮЊЪЧВЛЭЌЕФЯћЗбЖЫЃЌУПИіЯћЗбЖЫЛсгЕгавЛЗнздМКЯћЗбЖдСаЃЈФЌШЯЪЧbrokerЖдСаЪ§СП*brokerЪ§СПЃЉЁЃаТЙвдиЕФЯћЗбепЖдСажагЕгаcommitlogжаЕФЫљгаЪ§ОнЁЃ
Ш§ЁЂ RocketmqШчКЮжЇГжЗжВМЪНЪТЮёЯћЯЂ
ГЁОА
AЃЈДцдкDBВйзїЃЉЁЂBЃЈДцдкDBВйзїЃЉСНЗНашвЊБЃжЄЗжВМЪНЪТЮёвЛжТадЃЌЭЈЙ§в§ШыжаМфВуMQЃЌAКЭMQБЃГжЪТЮёвЛжТадЃЈвьГЃЧщПіЯТЭЈЙ§MQЗДВщAНгПкЪЕЯжcheckЃЉЃЌBКЭMQБЃжЄЪТЮёвЛжТЃЈЭЈЙ§жиЪдЃЉЃЌДгЖјДяЕНзюжеЪТЮёвЛжТадЁЃ
дРэЃКДѓЪТЮё = аЁЪТЮё + вьВН
1. MQгыDBвЛжТаддРэЃЈСНЗНЪТЮёЃЉ
СїГЬЭМ

ЩЯЭМЪЧRocketMQЬсЙЉЕФБЃжЄMQЯћЯЂЁЂDBЪТЮёвЛжТадЕФЗНАИЁЃ
MQЯћЯЂЁЂDBВйзївЛжТадЗНАИЃК
1)ЗЂЫЭЯћЯЂЕНMQЗўЮёЦїЃЌДЫЪБЯћЯЂзДЬЌЮЊSEND_OKЁЃДЫЯћЯЂЮЊconsumerВЛПЩМћЁЃ
2)жДааDBВйзїЃЛDBжДааГЩЙІCommit DBВйзїЃЌDBжДааЪЇАмRollback DBВйзїЁЃ
3)ШчЙћDBжДааГЩЙІЃЌЛиИДMQЗўЮёЦїЃЌНЋзДЬЌЮЊCOMMIT_MESSAGEЃЛШчЙћDBжДааЪЇАмЃЌЛиИДMQЗўЮёЦїЃЌНЋзДЬЌИФЮЊROLLBACK_MESSAGEЁЃзЂвтДЫЙ§ГЬгаПЩФмЪЇАмЁЃ
4)MQФкВПЬсЙЉвЛИіУћЮЊЁАЪТЮёзДЬЌЗўЮёЁБЕФЗўЮёЃЌДЫЗўЮёЛсМьВщЪТЮёЯћЯЂЕФзДЬЌЃЌШчЙћЗЂЯжЯћЯЂЮДCOMMITЃЌдђЭЈЙ§ProducerЦєЖЏЪБзЂВсЕФTransactionCheckListenerРДЛиЕївЕЮёЯЕЭГЃЌвЕЮёЯЕЭГдкcheckLocalTransactionStateЗНЗЈжаМьВщDBЪТЮёзДЬЌЃЌШчЙћГЩЙІЃЌдђЛиИДCOMMIT_MESSAGEЃЌЗёдђЛиИДROLLBACK_MESSAGEЁЃ
ЫЕУїЃК
ЩЯУцвдDBЮЊР§ЃЌЦфЪЕДЫДІПЩвдЪЧШЮКЮвЕЮёЛђепЪ§ОндДЁЃ
вдЩЯSEND_OKЁЂCOMMIT_MESSAGEЁЂROLLBACK_MESSAGEОљЪЧclient
jarЬсЙЉЕФзДЬЌЃЌдкMQЗўЮёЦїФкВПЪЧвЛИіЪ§зжЁЃ
TransactionCheckListener ЪЧдкЯћЯЂЕФcommitЛђепrollbackЯћЯЂЖЊЪЇЕФЧщПіЯТВХЛсЛиЕїЃЈЩЯЭМжаЛвЩЋВПЗжЃЉЁЃетжжЯћЯЂЖЊЪЇжЛДцдкгкЖЯЭјЛђепrocketmqМЏШКЙвСЫЕФЧщПіЯТЁЃЕБrocketmqМЏШКЙвСЫЃЌШчЙћВЩгУвьВНЫЂХЬЃЌДцдк1sФкЪ§ОнЖЊЪЇЗчЯеЃЌвьВНЫЂХЬГЁОАЯТБЃеЯЪТЮёУЛгавтвхЁЃЫљвдШчЙћвЊКЫаФвЕЮёгУRocketmqНтОіЗжВМЪНЪТЮёЮЪЬтЃЌНЈвщбЁдёЭЌВНЫЂХЬФЃЪНЁЃ
2. ЖрЯЕЭГжЎМфЪ§ОнвЛжТадЃЈЖрЗНЪТЮёЃЉ
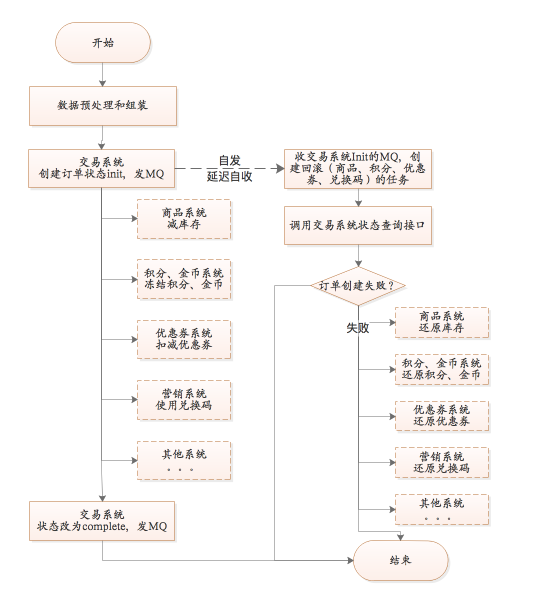
ЕБашвЊБЃжЄЖрЗНЃЈГЌЙ§2ЗНЃЉЕФЗжВМЪНвЛжТадЃЌЩЯУцЕФСНЗНЪТЮёвЛжТадЃЈЭЈЙ§RocketmqЕФЪТЮёадЯћЯЂНтОіЃЉвбОЮоЗЈжЇГжЁЃетИіЪБКђашвЊв§ШыTCCФЃЪНЫМЯыЃЈTry-Confirm-CancelЃЌВЛЧхГўЕФздааАйЖШЃЉЁЃ
вдЩЯЭМНЛвзЯЕЭГЮЊР§ЃК
1ЃЉНЛвзЯЕЭГДДНЈЖЉЕЅЃЈЭљDBВхШывЛЬѕМЧТМЃЉЃЌЭЌЪБЗЂЫЭЖЉЕЅДДНЈЯћЯЂЁЃЭЈЙ§RocketMqЪТЮёадЯћЯЂБЃжЄвЛжТад
2ЃЉНгзХжДааЭъГЩЖЉЕЅЫљашЕФЭЌВНКЫаФRPCЗўЮёЃЈЗЧКЫаФЕФЯЕЭГЭЈЙ§МрЬ§MQЯћЯЂздааДІРэЃЌДІРэНсЙћВЛЛсгАЯьНЛвззДЬЌЃЉЁЃжДааГЩЙІИќИФЖЉЕЅзДЬЌЃЌЭЌЪБЗЂЫЭMQЯћЯЂЁЃ
3ЃЉНЛвзЯЕЭГНгЪмздМКЗЂЫЭЕФЖЉЕЅДДНЈЯћЯЂЃЌЭЈЙ§ЖЈЪБЕїЖШЯЕЭГДДНЈбгЪБЛиЙіШЮЮёЃЈЛђепЪЙгУRocketMqЕФжиЪдЙІФмЃЌЩшжУЕкЖўДЮЗЂЫЭЪБМфЮЊЖЈЪБШЮЮёЕФбгГйДДНЈЪБМфЁЃдкЗЧЯћЯЂЖТШћЕФЧщПіЯТЃЌЯћЯЂЕквЛДЮЕНДябгГйЮЊ1msзѓгвЃЌетЪБПЩФмRPCЛЙЮДжДааЭъЃЌЖЉЕЅзДЬЌЛЙЮДЩшжУЮЊЭъГЩЃЌЕкЖўДЮЯћЗбЪБМфПЩвджИЖЈЃЉЁЃбгГйШЮЮёЯШЭЈЙ§ВщбЏЖЉЕЅзДЬЌХаЖЯЖЉЕЅЪЧЗёЭъГЩЃЌЭъГЩдђВЛДДНЈЛиЙіШЮЮёЃЌЗёдђДДНЈЁЃ
PSЃКЖрИіRPCПЩвдДДНЈвЛИіЛиЙіШЮЮёЃЌЭЈЙ§вЛИіЯћЗбзщНгЪмвЛДЮЯћЯЂОЭПЩвдЃЛвВПЩвдЭЈЙ§ДДНЈЖрИіЯћЗбзщЃЌвЛИіЯћЯЂЯћЗбЖрДЮЃЌУПДЮЯћЗбДДНЈвЛИіRPCЕФЛиЙіШЮЮёЁЃ
ЛиЙіШЮЮёЪЇАмЃЌЭЈЙ§MQЕФжиЗЂРДжиЪдЁЃ
вдЩЯЪЧНЛвзЯЕЭГКЭЦфЫћЯЕЭГжЎМфБЃГжзюжевЛжТадЕФНтОіЗНАИЁЃ
3.АИР§ЗжЮі
1) ЕЅЛњЛЗОГЯТЕФЪТЮёЪОвтЭМ
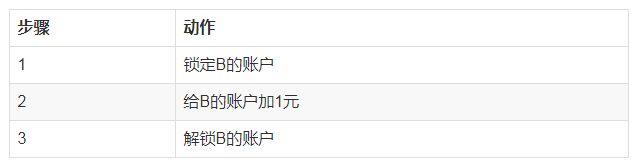
ШчЯТЮЊAИјBзЊеЫЕФР§згЁЃ
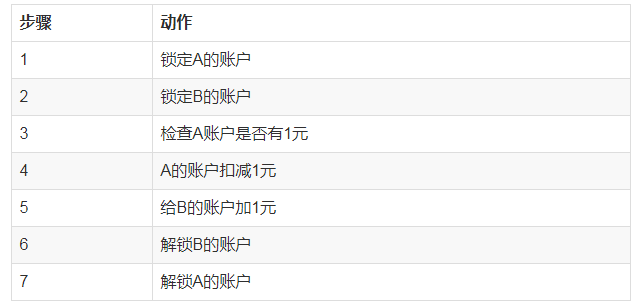
вдЩЯЙ§ГЬдкДњТыВуУцЩѕжСПЩвдМђЛЏЕНдквЛИіЪТЮяжажДааСНЬѕsqlгяОфЁЃ
2) ЗжВМЪНЛЗОГЯТЪТЮё
КЭЕЅЛњЪТЮёВЛЭЌЃЌAЁЂBеЫЛЇПЩФмВЛдкЭЌвЛИіDBжаЃЌДЫЪБЮоЗЈЯёдкЕЅЛњЧщПіЯТЪЙгУЪТЮяРДЪЕЯжЁЃДЫЪБПЩвдЭЈЙ§вЛЯТЗНЪНЪЕЯжЃЌНЋзЊеЫВйзїЗжГЩСНИіВйзїЁЃ
a) AеЫЛЇ
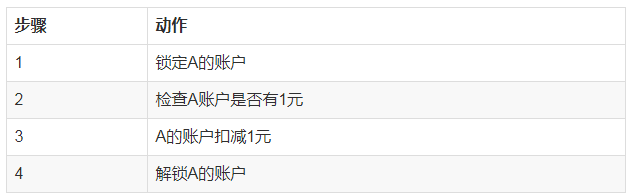
b) MQЯћЯЂ
AеЫЛЇЪ§ОнЗЂЩњБфЛЏЪБЃЌЗЂЫЭMQЯћЯЂЃЌMQЗўЮёЦїНЋЯћЯЂЭЦЫЭИјзЊеЫЯЕЭГЃЌзЊеЫЯЕЭГРДИјBеЫКХМгЧЎЁЃ
c) BеЫЛЇ
ЫФЁЂ ЫГађЯћЯЂ
1. ЫГађЯћЯЂШБЯн
ЗЂЫЭЫГађЯћЯЂЮоЗЈРћгУМЏШКFail OverЬиадЯћЗбЫГађЯћЯЂЕФВЂааЖШвРРЕгкЖгСаЪ§СПЖгСаШШЕуЮЪЬтЃЌИіБ№ЖгСагЩгкЙўЯЃВЛОљЕМжТЯћЯЂЙ§ЖрЃЌЯћЗбЫйЖШИњВЛЩЯЃЌВњЩњЯћЯЂЖбЛ§ЮЪЬтгіЕНЯћЯЂЪЇАмЕФЯћЯЂЃЌЮоЗЈЬјЙ§ЃЌЕБЧАЖгСаЯћЗбднЭЃЁЃ
2. дРэ
produceдкЗЂЫЭЯћЯЂЕФЪБКђЃЌАбЯћЯЂЗЂЕНЭЌвЛИіЖгСаЃЈqueueЃЉжа,ЯћЗбепзЂВсЯћЯЂМрЬ§ЦїЮЊMessageListenerOrderlyЃЌетбљОЭПЩвдБЃжЄЯћЗбЖЫжЛгавЛИіЯпГЬШЅЯћЗбЯћЯЂЁЃ
зЂвтЃКАбЯћЯЂЗЂЕНЭЌвЛИіЖгСаЃЈqueueЃЉЃЌВЛЪЧЭЌвЛИіtopicЃЌФЌШЯЧщПіЯТвЛИіtopicАќРЈ4Иіqueue
3. РЉеЙ
ПЩвдЭЈЙ§ЪЕЯжЗЂЫЭЯћЯЂЕФЖдСабЁдёЦїЗНЗЈЃЌЪЕЯжВПЗжЫГађЯћЯЂЁЃ
ОйР§ЃКБШШчвЛИіЪ§ОнПтЭЈЙ§MQРДЭЌВНЃЌжЛашвЊБЃжЄУПИіБэЕФЪ§ОнЪЧЭЌВНЕФОЭПЩвдЁЃНтЮіbinlogЃЌНЋБэУћзїЮЊЖдСабЁдёЦїЕФВЮЪ§ЃЌетбљОЭПЩвдБЃжЄУПИіБэЕФЪ§ОнЕНЭЌвЛИіЖдСаРяУцЃЌДгЖјБЃжЄБэЪ§ОнЕФЫГађЯћЗб
ЮхЁЂ зюМбЪЕМљ
1. Producer
1) Topic
вЛИігІгУОЁПЩФм .гУвЛИіTopicЃЌЯћЯЂзгРраЭгУtagsРДБъЪЖЃЌtagsПЩвдгЩгІгУздгЩЩшжУЁЃжЛгаЗЂЫЭЯћЯЂЩшжУСЫtagsЃЌЯћЗбЗНдкЖЉдФЯћЯЂЪБЃЌВХПЩвдРћгУtags
дкbrokerзіЯћЯЂЙ§ТЫЁЃ
2) key
УПИіЯћЯЂдквЕЮёВуУцЕФЮЈвЛБъЪЖТыЃЌвЊЩшжУЕН keys зжЖЮЃЌЗНБуНЋРДЖЈЮЛЯћЯЂЖЊЪЇЮЪЬтЁЃЗўЮёЦїЛсЮЊУПИіЯћЯЂДДНЈЫїв§(ЙўЯЃЫїв§)ЃЌгІгУПЩвдЭЈЙ§
topicЃЌkeyРДВщбЏетЬѕЯћЯЂФкШнЃЌвдМАЯћЯЂБЛЫЯћЗбЁЃгЩгкЪЧЙўЯЃЫїв§ЃЌЧыЮёБиБЃжЄkey ОЁПЩФмЮЈвЛЃЌетбљПЩвдБмУтЧБдкЕФЙўЯЃГхЭЛЁЃ
//ЖЉЕЅId
String orderId= "20034568923546";
message.setKeys(orderId);
3) ШежО
ЯћЯЂЗЂЫЭГЩЙІЛђепЪЇАмЃЌвЊДђгЁЯћЯЂШежОЃЌЮёБивЊДђгЁ send result КЭkey зжЖЮЁЃ
4) send
sendЯћЯЂЗНЗЈЃЌжЛвЊВЛХзвьГЃЃЌОЭДњБэЗЂЫЭГЩЙІЁЃЕЋЪЧЗЂЫЭГЩЙІЛсгаЖрИізДЬЌЃЌдкsendResultРяЖЈвхЁЃ
SEND_OKЃКЯћЯЂЗЂЫЭГЩЙІ
FLUSH_DISK_TIMEOUTЃКЯћЯЂЗЂЫЭГЩЙІЃЌЕЋЪЧЗўЮёЦїЫЂХЬГЌЪБЃЌЯћЯЂвбОНјШыЗўЮёЦїЖгСаЃЌжЛгаДЫЪБЗўЮёЦїхДЛњЃЌЯћЯЂВХЛсЖЊЪЇ
FLUSH_SLAVE_TIMEOUTЃКЯћЯЂЗЂЫЭГЩЙІЃЌЕЋЪЧЗўЮёЦїЭЌВНЕНSlaveЪБГЌЪБЃЌЯћЯЂвбОНјШыЗўЮёЦїЖгСаЃЌжЛгаДЫЪБЗўЮёЦїхДЛњЃЌЯћЯЂВХЛсЖЊЪЇ
SLAVE_NOT_AVAILABLEЃКЯћЯЂЗЂЫЭГЩЙІЃЌЕЋЪЧДЫЪБslaveВЛПЩгУЃЌЯћЯЂвбОНјШыЗўЮёЦїЖгСаЃЌжЛгаДЫЪБЗўЮёЦїхДЛњЃЌЯћЯЂВХЛсЖЊЪЇ
2. Consumer
1) УнЕШ
RocketMQЪЙгУЕФЯћЯЂдгяЪЧAt Least OnceЃЌЫљвдconsumerПЩФмЖрДЮЪеЕНЭЌвЛИіЯћЯЂЃЌДЫЪБЮёБизіКУУнЕШЁЃ
2) ШежО
ЯћЗбЪБМЧТМШежОЃЌвдБуКѓајЖЈЮЛЮЪЬтЁЃ
3) ХњСПЯћЗб
ОЁСПЪЙгУХњСПЗНЪНЯћЗбЗНЪНЃЌПЩвдКмДѓГЬЖШЩЯЬсИпЯћЗбЭЬЭТСПЁЃ |









