| БрМЭЦМі: |
БОЮФРДздгкcnblogsЃЌЮФеТЬжТлСЫетаЉФъЕїЖШМмЙЙЪЧШчКЮЗЂеЙЕФвдМАЮЊЪВУДЛсетбљЗЂеЙЕФЯрЙиФкШнЁЃ |
|
МЏШКЕїЖШЦїЪЧЯждкЪ§ОнжааФжаЗЧГЃживЊЕФвЛИізщМўЃЌВЂЧветЯжФъвбОгаСЫКмДѓЕФЗЂеЙЁЃЫќЕФМмЙЙвВДгжааФЛЏЩшМЦзЊЯђИќМгСщЛюЁЂШЅжааФЛЏКЭЗжВМЪНЩшМЦЁЃШЛЖјаэЖрЯждкПЊдДЕФЕїЖШМмЙЙвРОЩЪЧжааФЛЏЩшМЦЛђепШБЩйКмЖржївЊЕФЬиадЃЌетаЉЬиадЖдгкЪЕМЪЕФгУЛЇРДЫЕЗЧГЃживЊЃЌвђЮЊетаЉКУЕФЬиадПЩвдЪЙЪ§ОнжааФЛёЕУКмИпЕФзЪдДРћгУТЪЁЃ
етЦЊЮФеТЪЧЮвУЧЬНЬжДѓЙцФЃМЏШКзївЕЕїЖШЕФЕквЛЦЊЮФеТЃЌзївЕЕїЖШдкAmazonЁЂGoogleЁЂFacebookЁЂMicrosoftЛђYahooЃЁЕШЛЅСЊЭјЙЋЫОвбОгаСЫКмКУЕФЪЕЯжЃЌВЂЧвЯрЙиЕФашЧѓвВдкВЛЖЯдіГЄЁЃЕїЖШЪЧвЛИіЗЧГЃживЊЕФЮЪЬтЃЌвђЮЊЫќжБНггАЯьЕНдЫааМЏШКЕФПЊЯњЃЌвЛИідуИтЕФЕїЖШПђМмЛсЕМжТМЏШКЕФзЪдДРћгУТЪКмЕЭЃЌФЧаЉАКЙѓЕФЛњЦїзЪдДдђЛсАзАзРЫЗбЁЃШЛЖјЙтППЕїЖШПђМмвВЮоЗЈЪЕЯжКмИпЕФзЪдДРћгУТЪЃЌШчЙћМЏШКУЛгазаЯИХфжУЃЌВЛЭЌзївЕжЎМфЯрЛЅИЩШХвВЛсгАЯьЕНзЪдДЕФРћгУТЪЁЃ
МЏШКЕїЖШМмЙЙЕФбнНјЙ§ГЬ
етЦЊЮФеТЬжТлСЫетаЉФъЕїЖШМмЙЙЪЧШчКЮЗЂеЙЕФвдМАЮЊЪВУДЛсетбљЗЂеЙЁЃЭМвЛеЙЪОСЫМЏШКЕїЖШЕФВЛЭЌЗНЗЈЃКЦфжаЛвЩЋЕФЗНПщЖдгІвЛИіЛњЦїЃЌВЛЭЌбеЩЋЕФдВШІДњБэВЛЭЌЕФШЮЮёЃЌгаЁАSЁББъжОЕФдВНЧОиаЮДњБэЕїЖШЦїЃЈетИіЭММђЛЏСЫвЛаЉЃЌЪЕМЪЩЯЃЌУПЬЈЛњЦїдЫааЖрИіШЮЮёЃЌаэЖрЕїЖШЦїЪЪКЯЖрИізЪдДЮГЖШЕФШЮЮёЃЌЖјВЛЪЧМђЕЅЕФslotsЃЉЃЌМ§ЭЗДњБэЕїЖШЦїОіЖЈЕФзївЕЗХжУЮЛжУЃЌШ§жжбеЩЋДњБэВЛЭЌЕФЙЄзїИКдиЃЈШчЭјеОЗўЮёЁЂХњСПЗжЮіКЭЛњЦїбЇЯАЃЉЁЃ
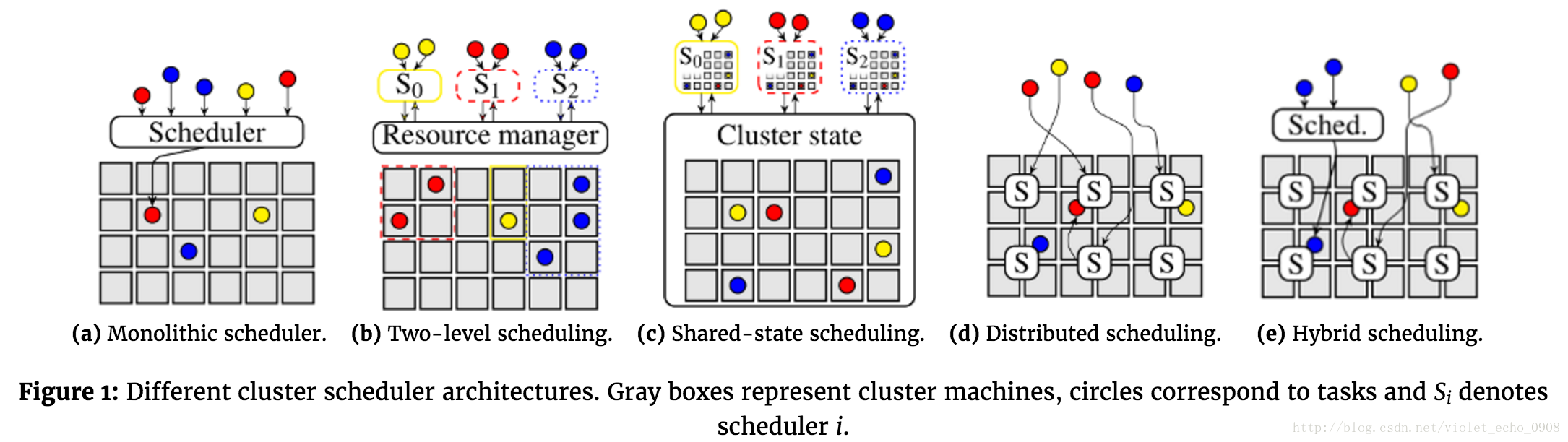
жааФЛЏЕїЖШПђМм
аэЖрМЏШКЕїЖШПђМмЃЌР§ШчДѓСПИпадФмМЦЫуЃЈhigh-performance
computingЃЌHPCЃЉЕїЖШЦїЁЂ Borg ЕїЖШЦїЁЂИїжждчЦкЕФHadoopЕїЖШЦїКЭKubernetesЕїЖШЦїЖМЪЧжааФЛЏЩшМЦЕФЕїЖШПђМмЁЃЕЅвЛЕФЕїЖШНјГЬдквЛЬЈЛњЦїЩЯдЫааЃЈР§ШчHadoop
V1ЕФJobTrackerЁЂKubernetesЕФkube-schedulerЃЉЃЌЕїЖШЦїИКд№НЋШЮЮёжИХЩИјМЏШКФкЕФЛњЦїЁЃдкжааФЛЏЕїЖШПђМмЯТЃЌЫљгаЕФЙЄзїИКдиЖМЪЧгЩвЛИіЕїЖШЦїРДДІРэЃЌЫљгаЕФзївЕЖМЭЈЙ§ЯрЭЌЕФЕїЖШТпМРДДІРэЃЈШчЭМ1aЃЉЁЃетжжМмЙЙКмМђЕЅВЂЧвЭГвЛЃЌдкетИіЛљДЁЩЯЗЂеЙГіСЫаэЖрИДдгЕФЕїЖШЦїЁЃБШШчParagonЕїЖШЦїКЭQuasarЕїЖШЦїЃЌЫќУЧЪЙгУЛњЦїбЇЯАЕФЗНЗЈРДБмУтИКдижЎМфвђЛЅЯрОКељзЪдДЖјВњЩњЕФИЩШХЁЃ
ЯждкДѓВПЗжЕФМЏШКЖМдЫаазХВЛЭЌРраЭЕФгІгУЃЈЯрЗДЃЌШчHadoop MapReduceЕФдчЦкзївЕЃЉЁЃШЛЖјЃЌЮЌЛЄвЛИіДІРэЛьКЯИКдиЕФЕЅвЛЕїЖШЦїЪЧвЛИіКмМЌЪжЕФЮЪЬтЃЌдвђШчЯТЃК
ЯЃЭћЕїЖШЦїФмЧјБ№ДІРэГЄЦкдЫааЕФзївЕКЭХњДІРэзївЕЃЌетЪЧвЛИіКЯРэЕФЧыЧѓЁЃ
вђЮЊВЛЭЌЕФгІгУгаВЛЭЌЕФашЧѓЃЌШєвЊШЋВПТњзуЦфашЧѓдђашвЊВЛЖЯдкЕїЖШЦїжадіМгЬиадЃЌетбљдіМгСЫЫќЕФТпМИДдгЖШКЭВПЪ№ФбЖШЁЃ
ЕїЖШЦїДІРэзївЕЕФЫГађБфГЩСЫвЛИіЮЪЬтЃКЖгСааЇгІЃЈР§ШчЭЗзшШћЃКhead-of-line
blockingЃЉКЭзївЕЛ§бЙЪЧвЛИіЮЪЬтЃЌГ§ЗЧдкЩшМЦЕїЖШЦїЪБЗЧГЃаЁаФЁЃ
змжЎЃЌетаЉЬ§Ц№РДЪЧЙЄГЬЪІЕФиЌУЮЃЌЕїЖШЦїЮЌЛЄепЛсВЛЖЯЪеЕНЭљЕїЖШЦїжаЬэМгЬиадвЊЧѓЕФЧхЕЅЁЃ
СНМЖЕїЖШМмЙЙ
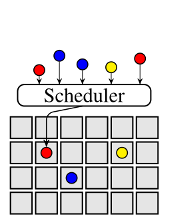
СНМЖЕїЖШПђМмЭЈЙ§НЋзЪдДЕїЖШКЭзївЕЕїЖШЗжПЊЕФЗНЪНРДНтОіетИіЮЪЬтЁЃСНМЖЕїЖШдЪаэИљОнЬиЖЈЕФгІгУРДЖЈзіВЛЭЌЕФзївЕЕїЖШТпМЃЌВЂЭЌЪББЃСєСЫВЛЭЌзївЕжЎМфЙВЯэМЏШКзЪдДЕФЬиадЁЃMesosМЏШКЙмРэЯЕЭГЪзЯШЪЙгУСЫСНМЖЕїЖШЕФЗНЗЈЃЌYarnдђжЇГжЦфгаЯоЕФАцБОЁЃдкMesosжаЃЌзЪдДЪЧжїЖЏБЛЬсЙЉИјгІгУВуЕФЕїЖШЦїРДЪЙгУЕФЃЈЕїЖШЦїПЩвдДгЯТВуЬсЙЉЕФзЪдДжаНјаабЁдёЃЉЃЌЖјYarnдђЪЧгЩгІгУВуРДЧыЧѓзЪдДЃЈВЂЧвНгЪмБЛЗжХфЕФзЪдДЃЉЁЃШчЭМ1bЫљЪОЃЌЪЪгУгкЬиЖЈИКдиЕФЕїЖШЦїЃЈS0-S2ЃЉгызЪдДЙмРэЦїНјааНЛЛЅЃЌзЪдДЙмРэЦїдђЮЊУПИіИКдиЖЏЬЌЛЎЗжМЏШКЕФзЪдДЁЃетЪЧвЛИіЗЧГЃСщЛюЕФЗНЪНЃЌЫќдЪаэеыЖдЬиЖЈЕФИКдиРДздЖЈвхЕїЖШВпТдЁЃ
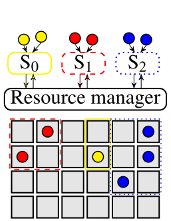
ЕЋЪЧЃЌСНМЖЕїЖШПђМмвВгавЛаЉЮЪЬтЁЃгІгУВуЕїЖШЦїЮоЗЈПДЕНЫљгаЕФзЪдДЃЌвВОЭЪЧЫЕЃЌЫќУЧУЛгаШЋОжЪгНЧЃЌЮоЗЈПДЕНзївЕПЩвдБЛЗХЕНФФаЉЛњЦїЩЯжДааЁЃЯрЗДЃЌЫќУЧжЛФмПДЕНзЪдДЙмРэЦїжїЖЏЬсЙЉЕФзЪдДЃЈMesosЃЉЛђепзЪдДЙмРэЦїЗжХфИјгІгУЃЈYarnЃЉЕФВПЗжзЪдДЁЃетбљЕФЩшМЦгаМИЕуШБЕуЃК
ИпгХЯШМЖЧРеМЃЈИпгХЯШМЖзївЕЛсЬпзпЕЭгХЯШМЖзївЕЃЉЛсБфЕУКмФбЪЕЯжЁЃдкЛљгкofferЕФФЃЪНЯТЃЌБЛдЫаажаЕФзївЕЫљеМгУЕФзЪдДЖдЩЯВуЕїЖШЦїЪЧВЛПЩМћЕФЃЛдкЛљгкrequestЕФФЃЪНЯТЃЌЕзВуЕФзЪдДЙмРэЦїБиаыФмРэНтЧРеМЕФВпТдЃЈетПЩФмгыгІгУГЬађгаЙиЃЉЁЃ
ЕїЖШЦїЮоЗЈПМТЧЕНвђЦфЫћдЫааЕФЙЄзїИКдидьГЩЕФИЩШХПЩФмгАЯьЕНзЪдДЕФжЪСПЃЈБШШчЁАГГФжЕФСкОгЁБеМОнСЫI/OДјПэЃЉЃЌвђЮЊЕїЖШЦїЮоЗЈПДЕНЫќУЧЁЃ
гІгУЬиЖЈЕФЕїЖШЦїЖдЕзВузЪдДЕФКмЖрВЛЭЌЗНУцКмЙиаФЃЌЕЋЪЧЫќУЧЛёЕУзЪдДЕФЮЈвЛЗНЗЈОЭЪЧЭЈЙ§зЪдДЙмРэЦїЬсЙЉЕФoffer/requestНгПкЃЌетИіНгПкКмШнвзБфЕУЗЧГЃИДдгЁЃ
ЙВЯэзДЬЌЕїЖШМмЙЙ
ЙВЯэзДЬЌЕїЖШЭЈЙ§АыЗжВМЪНЕФФЃЪНРДНтОіетИіЮЪЬтЃЌдкетжжФЃЪНЯТгІгУВуЕФУПИіЕїЖШЦїЖМгЕгавЛЗнМЏШКзДЬЌЕФИББОЃЌВЂЧвЕїЖШЦїЛсЖРСЂЕиЖдМЏШКзДЬЌИББОНјааИќаТЃЌШчЭМ1cЫљЪОЁЃвЛЕЉБОЕиЕФзДЬЌИББОВњЩњСЫБфЛЏЃЌЕїЖШЦїЛсЗЂВМвЛИіЪТЮёШЅИќаТећИіМЏШКЕФзДЬЌЃЌгаЪБКђвђСэЭтвЛИіЕїЖШЦїЭЌЪБЗЂВМСЫвЛИіГхЭЛЕФЪТЮёЪБЃЌЪТЮёИќаТгаПЩФмЪЇАмЁЃ
дкЙВЯэзДЬЌЕїЖШЕФПђМмжаЃЌзюжјУћЕФЪЧGoogleЕФOmegaЁЂMicrosoftЕФApolloЃЌвдМАHashicorpЕФNomadШнЦїЕїЖШЦїЁЃЫљгаЕФетаЉЖМЪЧЪЙгУвЛжжЗНЗЈЪЕЯжЙВЯэзДЬЌЕїЖШЃЌОЭЪЧOmegaжаЕФЁАcell
stateЁБЁЂApolloЕФЁАresource monitorЁБвдМАNomadжаЕФЁАplan queueЁБЁЃApolloИњЦфЫћСНИіЕїЖШПђМмВЛЭЌжЎДІдкгкЦфЙВЯэзДЬЌЪЧжЛЖСЕФЃЌЕїЖШЪТЮёЪЧжБНгЬсНЛЕНМЏШКжаЕФЛњЦїЩЯЃЌЛњЦїздМКЛсМьВщГхЭЛЃЌРДОіЖЈЪЧНгЪмЛЙЪЧОмОјетИіБфЛЏЃЌетЪЙЕУApolloМДЪЙдкЙВЯэзДЬЌднЪБВЛПЩгУЕФЧщПіЯТвВПЩвджДааЁЃ
ТпМЩЯЕФЙВЯэзДЬЌЕїЖШМмЙЙвВПЩвдВЛЭЈЙ§НЋећИіМЏШКЕФзДЬЌЗжВМдкЦфЫћЕиЗНРДЪЕЯжЃЌетжжЗНЪНЃЈгаЕуЯёApolloзіЕФЃЉжаЃЌУПЬЈЛњЦїЮЌЛЄЦфздМКЕФзДЬЌВЂЗЂЫЭИќаТЕФЧыЧѓЕНЦфЫћЖдИУНкЕуИааЫШЄЕФДњРэЃЌБШШчЕїЖШЦїЁЂЩшБИНЁПЕМрПиЦїКЭзЪдДМрПиЯЕЭГЕШЁЃУПИіЮяРэЩшБИЕФБОЕизДЬЌЖМГЩЮЊСЫећИіМЏШКЕФЙВЯэзДЬЌЕФЗжЦЌжЎвЛЁЃ
ШЛЖјЃЌЙВЯэзДЬЌЕїЖШМмЙЙвВгавЛаЉШБЕуЃЌЫќБиаыЙЄзїдкгаЮШЖЈаХЯЂЕФЧщПіЯТЃЈетЕуИњжааФЛЏЕїЖШЦїВЛЭЌЃЉЃЌдкМЏШКзЪдДЕФОКељЖШКмИпЕФЧщПіЯТгаПЩФмдьГЩЕїЖШЦїЕФадФмЯТНЕЃЈОЁЙмЦфЫћПђМмвВгаПЩФмГіЯжетжжЧщПіЃЉЁЃ
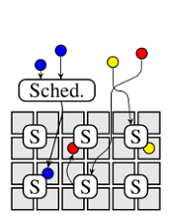
ШЋЗжВМЪНМмЙЙ
ШЋЗжВМЪНМмЙЙИќМгШЅжааФЛЏЃКЕїЖШЦїжЎМфИљБОУЛгаШЮКЮЕФаЕїЃЌВЂЧвЪЙгУКмЖрИїздЖРСЂЕФЕїЖШЦїРДДІРэВЛЭЌЕФИКдиЃЌШчЭМ1dЫљЪОЁЃУПИіЕїЖШЦїЖМзїгУдкздМКБОЕиЃЈВПЗжЛђепОГЃЙ§ЪБЕФЃЉМЏШКзДЬЌаХЯЂЁЃдкЗжВМЪНЕїЖШМмЙЙЯТЃЌзївЕПЩвдЬсНЛИјШЮвтЕФЕїЖШЦїЃЌВЂЧвУПИіЕїЖШЦїПЩвдНЋзївЕЗЂЫЭЕНМЏШКжаШЮКЮЕФНкЕуЩЯжДааЁЃгыСНМЖЕїЖШЕїЖШПђМмВЛЭЌЕФЪЧЃЌУПИіЕїЖШЦїВЂУЛгаИКд№ЕФЗжЧјЃЌЯрЗДЕФЪЧЃЌШЋОжЕїЖШКЭзЪдДЛЎЗжЖМЪЧЗўДгЭГМЦКЭЫцЛњЗжВМЕФЃЌгыЙВЯэзДЬЌЕїЖШМмЙЙгааЉЯрЫЦЃЌЕЋЪЧУЛгажабыПижЦЁЃ
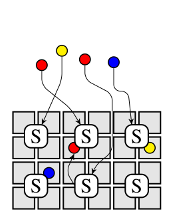
ОЁЙмШЋЗжВМЪНЕїЖШМмЙЙЕФИХФюЃЈЖрИіЫцЛњбЁдёЃЉЪЧДг1996ФъГіЯжЕФЃЌЯжДњвтвхЩЯЕФЗжВМЪНЕїЖШгІИУЪЧДгSparrowТлЮФПЊЪМЕФЁЃSparrowТлЮФЕФЙиМќЪЧЫќМйЩшМЏШКЩЯШЮЮёжмЦкЖМЛсБфЕФдНРДдНЖЬЃЌетЕуЪЧвдЕБЪБвЛИіЬжТлзїЮЊжЇГХЃКЯИСЃЖШЕФШЮЮёгаКмЖрЕФгХЪЦЁЃвђДЫЃЌзїепМйЩшзївЕЛсБфЕУдНРДдНЖрЃЌетвтЮЖзХЕїЖШЦїБиаыжЇГжИќИпОіВпЕФЭЬЭТСПЃЌЖјЕЅвЛЕФЕїЖШЦїВЂВЛФмжЇГжШчДЫИпЕФЭЬЭТСПЃЈМйЩшУПУыгаЩЯАйЭђИіШЮЮёЃЉЃЌвђДЫSparrowНЋетаЉИКдиЗжЩЂЕНКмЖрЕїЖШЦїЩЯЁЃ
етИіЪЕЯжЕФвтвхжиДѓЃКШБЩйжабыПижЦдкРэТлЩЯКмЮќв§ШЫЃЌВЂЧвЗЧГЃКЯЪЪФГаЉИКдиЃЌЮвУЧЛсдкКѓУцЕФСЌдижаНјааЬжТлЁЃФПЧАЃЌЮвУЧзЂвтЕНвђЮЊЗжВМЪНЕїЖШЦїЪЧВЛаЕїЕФЃЌЫќЯрЖдгкжааФЛЏЕїЖШЁЂСНМЖЕїЖШЛђЙВЯэзДЬЌЕїЖШгЕгаИќМђЕЅЕФТпМЃЌР§ШчЃК
ЗжВМЪНЕїЖШЦїЪЧЛљгкМђЕЅЕФЁАslotЁБИХФюЃЌНЋУПЬЈЛњЦїЗжГЩnИіБъзМЕФЁАslotЁБЃЌВЂЗХжУnИіВЂаазївЕЃЌетМђЛЏСЫШЮЮёЕФзЪдДашЧѓВЛЭГвЛЕФЪТЪЕЁЃ
ЫќЪЙгУСЫгЕгаМђЕЅЗўЮёЙцдђЕФworker-sideЖгСаЃЈР§ШчЃЌSparrowжаЕФFIFOЙцдђЃЉЃЌетбљЯожЦСЫЕїЖШЦїЕФСщЛюадЃЌвђЮЊЕїЖШЦїжЛФмбЁдёНЋзївЕЗХжУдкФФЬЈЩшБИЕФЖгСаЩЯЁЃ
ЗжВМЪНЕїЖШЦїКмФбжДааШЋОжВЛБфСПЃЈР§ШчЃЌЙЋЦНВпТдКЭбЯИёЕФгХЯШМЖгХЯШЃЉЃЌвђЮЊЫќУЛгажабыПижЦЁЃ
вђЮЊЗжВМЪНЕїЖШЦїЪЧЛљгкзюЩйжЊЪЖзіГіПьЫйОіВпЖјЩшМЦЃЌЫќЮоЗЈжЇГжЛђГаЕЃИДдгЛђЬиЖЈгІгУЕФЕїЖШВпТдЃЌР§ШчЃЌБмУтШЮЮёжЎМфЕФЯрЛЅИЩШХЖдЗжВМЪНЕїЖШРДЫЕКмРЇФбЁЃ
ЛьКЯЪНЕїЖШМмЙЙ
ЛьКЯЪНЕїЖШМмЙЙЪЧзюНќЃЈбЇЪѕНчЬсГіЕФЃЉЬсГіЕФНтОіЗНЗЈЃЌЫќЕФГіЯжЪЧЮЊСЫНтОіШЋЗжВМЪНМмЙЙЕФШБЕуЃЌЫќНсКЯСЫжааФЛЏЕїЖШКЭЙВЯэзДЬЌЕФЩшМЦЁЃетжжЗНЪНР§ШчTarcilЁЂMercuryКЭHawkвЛАугаСНЬѕЕїЖШТЗОЖЃЌвЛЬѕЪЧЮЊВПЗжИКдиЩшМЦЕФЗжВМЪНЕїЖШЃЈР§ШчЗЧГЃЖЬЕФзївЕЛђепЕЭгХЯШМЖЕФХњзївЕЃЉЃЌСэЭтвЛЬѕЪЧжааФЪНзївЕЕїЖШРДДІРэЪЃЯТЕФИКдиЃЌШчЭМ1eЫљЪОЁЃЛьКЯЕїЖШЦїЕФУПИізщГЩВПЗжЕФааЮЊгыЩЯЪіУшЪіЕФВПЗжМмЙЙЯрЭЌЁЃЪЕМЪЩЯЃЌОнЮвЫљжЊЃЌФПЧАЛЙУЛгаеце§ЕФЛьКЯЕїЖШЦїгІгУгкЩњВњЛЗНкЕБжаЁЃ
ЪЕМЪКЌвх
ЖдВЛЭЌЕїЖШЦїМмЙЙЕФЯрЖдгХШБЕуЕФЬжТлВЂВЛжЛЪЧбЇЪѕЬНЬжЃЌОЁЙмЫќздШЛЮЇШЦзХбаОПТлЮФЁЃДгЙЄвЕНчНЧЖШЖдгкBorgЁЂMesosКЭOmegaТлЮФЕФЩюШыЬжТлПЩвдВЮМћAndrew
WangЕФВЉЮФЁЃДЫЭтЃЌКмЖрвдЩЯЬжТлЕФЯЕЭГЖМвбОВПЪ№ЕНСЫДѓаЭЦѓвЕЕФЩњВњЯЕЭГжаСЫЃЈБШШчMicrosoftЕФApolloЁЂGoogleЕФBorgЁЂAppleЕФMesosЃЉЃЌЗДЙ§РДЃЌетаЉЯЕЭГМЄРјСЫЦфЫћПЩгУгкПЊдДЕФЯюФПЁЃ
ШчНёЃЌКмЖрМЏШКдЫааШнЦїЛЏЕФИКдиЃЌвђДЫгавЛЯЕСаЛљгкШнЦїЕФПђМмЃЈOrchestration
FrameworksЃЉГіЯжСЫЃЌЫќУЧгыGoogleКЭЦфЫћГЦЮЊЁАМЏШКЙмРэЯЕЭГЁБЕФКмЯрЫЦЁЃШЛЖјЃЌКмЩйгаЙигкетаЉЕїЖШЦїЕФПђМмКЭЩшМЦддђЕФЯъЯИЬжТлЃЌЫќУЧИќЖрЕФЪЧМЏжагкУцЯђгУЛЇЕїЖШЕФAPIЃЈР§ШчетЦЊArmand
GrilletЕФБЈЕРЃЌЮФжаБШНЯСЫDocker SwarmЁЂMesos/MarathonКЭKubernetesЕФФЌШЯЕїЖШЦїЃЉЃЌШЛЖјКмЖрПЭЛЇМШВЛЖЎВЛЭЌЕїЖШЦїЕФЧјБ№ЃЌвВВЛжЊЕРФФИіИќЪЪКЯздМКЕФгІгУЁЃ
ЭМ2еЙЪОСЫвЛВПЗжПЊдДПђМмЕФИХПіЃЌАќРЈЫќУЧЕФНсЙЙКЭЕїЖШЦїЫљжЇГжЕФЙІФмЁЃдкЭМБэЕФзюЕЭЖЫЃЌвВАќРЈGoogleКЭMicrosoftУЛгаПЊдДЕФЯЕЭГзїЮЊВЮПМЁЃзЪдДСЃЖШЃЈResource
GranularityЃЉетвЛСаеЙЪОСЫЕїЖШЦїЪЧЗжХфзївЕИјЙЬЖЈДѓаЁЕФslotsЃЌЛЙЪЧАДеезївЕЖрЮЌЖШЕФзЪдДашЧѓРДЗжХфЕФЃЈР§ШчCPUЁЂФкДцЁЂДХХЬIOДјПэЁЂЭјТчДјПэЕШЃЉЁЃ
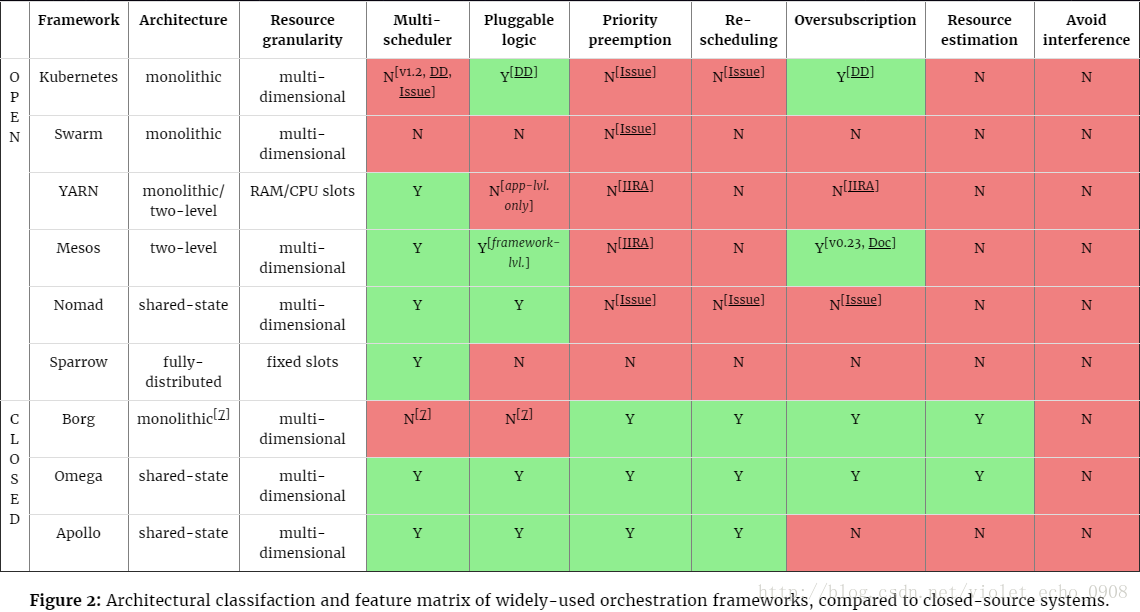
ОіЖЈЪЙгУФФИіЕїЖШПђМмжївЊЕФвЛЕуОЭЪЧПДМЏШКжаЪЧЗёдЫаавЛИівьЙЙЃЈР§ШчЛьКЯЕФЃЉИКдиЁЃР§ШчвЛИіЧАЖЫЗўЮёЃЈР§ШчИКдиОљКтЛђmemcachedЃЉКЭХњСПЪ§ОнЗжЮізївЕЃЈР§ШчMapReduceЛђsparkЃЉЯрНсКЯЕФЩњВњЛЗОГЃЌетжжзщКЯгаРћгкЬсИпЯЕЭГЕФзЪдДРћгУТЪЃЌЕЋЪЧВЛЭЌЕФгІгУЖдЕїЖШЕФашЧѓгаЫљВЛЭЌЁЃдкзївЕЛьВПЕФЧщПіЯТЃЌжааФЛЏЕїЖШПЩФмЕМжТШЮЮёЕФДЮгХЗжХфЃЌвђЮЊВЛФмЛљгкЕЅИігІгУНјааТпМЕФЖрбљЛЏДІРэЃЌвђДЫдкетжжЧщПіЯТЃЌСНМЖЕїЖШКЭЙВЯэзДЬЌЕїЖШПЩФмИќМгКЯЪЪЁЃ
ДѓЖрЪ§УцЯђгУЛЇЗўЮёЕФИКдидЫаадкзЪдДФмТњзуЗхжЕашЧѓЕФШнЦїжаЃЌЕЋЪЧЪЕМЪЩЯетаЉзЪдДЖМЪЧЙ§ЖШЗжХфЕФЃЌдкетжжЧщПіЯТЃЌФмгаЛњЛсНЕЕЭИјЕЭгХЯШМЖИКдиЙ§ЖрЗжХфзЪдДЃЈФмМЬајБЃжЄИКдиЕФQoSЃЉЖдЬсИпМЏШКЕФаЇТЪЪЧЗЧГЃЙиМќЕФЁЃОЁЙмkubernetesгЕгаЯрЖдБШНЯГЩЪьЕФЗНАИЃЌMesosЪЧФПЧАЮЈвЛжЇГжетжжЙ§ЖрЗжХфзЪдДЕФПЊдДЯЕЭГЁЃЮвУЧЦкД§ЮДРДдкетИіЗНУцгаИќЖрЕФЙЄзїЃЌвђЮЊИљОнGoogleЕФBorgМЏШКРДПДКмЖрМЏШКЕФРћгУТЪвРШЛЕЭгк60-70%ЁЃдкКѓајЕФЮФеТжаЃЌЮвУЧНЋЙизЂзЪдДдЄЙРЁЂЙ§ЖШЗжХфКЭгааЇЬсИпЛњЦїЕФзЪдДРћгУТЪЁЃ
зюКѓЃЌЬиЖЈЕФЗжЮіКЭOLAPгІгУЃЈР§ШчDremelЛђепSparkSQL
queriesЃЉЛсДгШЋЗжВМЪНЕїЖШЦїЪмвцЃЌШЛЖјЃЌШЋЗжВМЪНЕїЖШЦїЃЈШчSparrowЃЉгабЯИёЕФЙІФмЩшжУЃЌвђДЫЕБМЏШКЕФИКдиЪЧЭЌЙЙЃЈБШШчЫљгазївЕЕФдЫааЪБМфЪЧДѓИХЯрЭЌЕФЃЉЁЂХфжУЪБМфЖЬЃЈвВОЭЪЧШЮЮёФмБЛЕїЖШЕНГЄЪБМфдЫааЕФworkerЩЯЃЌР§ШчMapReduceзївЕдкYARNжадЫааЃЉЁЂШЮЮёЭЈСПИпЃЈДѓВПЗжЕїЖШЕФОіЖЈБиаыФмдкЖЬЪБМфФкзіГіЃЉЪБЗЧГЃКЯЪЪЁЃЮвУЧНЋдкНгЯТРДЕФЮФеТжаЬжТлетаЉЬѕМўЃЌВЂЧвЬжТлЮЊЪВУДШЋЗжВМЪНЕїЖШЦїКЭЛьКЯЪНЕїЖШЦїжаЕФЗжВМЪНзщМўжЛЖдетаЉгІгУгааЇЁЃЯждкЃЌЮвУЧПЩвджЄУїЗжВМЪНЕїЖШБШЦфЫћЕїЖШПђМмИќМгМђЕЅЃЌЕЋЪЧВЛжЇГжЖрЮЌЖШЕФзЪдДЁЂЙ§ЖШЗжХфКЭжиаТЕїЖШЁЃ
змжЎЃЌЭМ2жаЕФБэИёБэУїЖдгкПЊдДЕФЕїЖШПђМмвРОЩгавЛЖЮТЗвЊзпЃЌжБЕНЫќУЧФмЦЅХфвЛаЉИпМЖЕФХфжУЁЃПЩвдДгвдЯТМИИіЗНУцРДВЩШЁааЖЏЃКЙІФмШБЪЇЁЂзЪдДРћгУТЪЕЭЁЂзївЕЕФадФмВЛПЩВтКЭЁАГГФжЕФСкОгЁБНЕЕЭаЇТЪЃЌВЂЧвашвЊНЋelaborate
hacksМгШыЕНЕїЖШЦїжаРДжЇГжгУЛЇЕФашвЊЁЃ
ШЛЖјЃЌетРягавЛаЉКУЯћЯЂЃКОЁЙмНёЬьЛЙгаКмЖрМЏШКШдШЛЪЙгУжааФЛЏЕїЖШЃЌЕЋЪЧДѓВПЗжвбОПЊЪМЧЈвЦЕНИќСщЛюЕФЩшМЦжаЁЃKubernetesНёЬьвбОПЩвджЇГжЕїЖШЦїВхМўЃЈkube-scheduler
podПЩвдБЛЦфЫћМцШнЕїЖШpodЕФAPIЫљЬцДњЃЉЃЌИќЖрЕїЖШЦїДг1.2АцБОПЊЪМжЇГжЁАРЉеЙЦїЁБРДЬсЙЉЖЈжЦЛЏВпТдЁЃОнЮвСЫНтЃЌDocker
SwarmдкЮДРДПЩФмвВЛсжЇГжЕїЖШЦїВхМўЁЃ
ЯТвЛВН
етвЛЯЕСаЕФЯТвЛЦЊЮФеТНЋЛсЬжТлШЋЗжВМЪНМмЙЙЖдгкПЩРЉеЙЪНМЏШКЕїЖШЪЧЗёЪЧЙиМќЕФММЪѕДДаТЃЈЗДЖдЩљвєЫЕЃКВЛЪЧБиаыЕФЃЉЁЃШЛКѓЃЌЮвУЧЛсЬжТлзЪдДЪЪХфВпТдЃЈЖдЬсИпРћгУТЪКмЙиМќЃЉЃЌзюКѓЬжТлЮвУЧFirmamentЕїЖШЦНЬЈШчКЮМЏГЩЙВЯэзДЬЌЕїЖШПђМмКЭжааФЕїЖШПђМмЕФгХЕуЃЌвдМАШЋЗжВМЪНЕїЖШЦїЕФЫйЖШЮЪЬтЁЃ
|









