| БрМЭЦМі: |
БОЮФРДздгк51ctoЃЌЮФеТНщЩмСЫMapReduceЪЧЪВУДЁЂMapReduceжДааСїГЬвдМАMapReduce1.xМмЙЙКЭMapReduce2.xМмЙЙЕШЯрЙиФкШнЁЃ
|
|
MapReduceИХЪі
MapReduceдДздGoogleЕФMapReduceТлЮФЃЌТлЮФЗЂБэгк2004Фъ12дТЁЃHadoop
MapReduceПЩвдЫЕЪЧGoogle MapReduceЕФвЛИіПЊдДЪЕЯжЁЃMapReduceгХЕудкгкПЩвдНЋКЃСПЕФЪ§ОнНјааРыЯпДІРэЃЌВЂЧвMapReduceвВвзгкПЊЗЂЃЌвђЮЊMapReduceПђМмАяЮвУЧЗтзАКУСЫЗжВМЪНМЦЫуЕФПЊЗЂЁЃЖјЧвЖдгВМўЩшЪЉвЊЧѓВЛИпЃЌПЩвддЫаадкСЎМлЕФЛњЦїЩЯЁЃMapReduceвВгаШБЕуЃЌЫќзюжївЊЕФШБЕуОЭЪЧЮоЗЈЭъГЩЪЕЪБСїЪНМЦЫуЃЌжЛФмРыЯпДІРэЁЃ
MapReduceЪєгквЛжжБрГЬФЃаЭЃЌгУгкДѓЙцФЃЪ§ОнМЏЃЈДѓгк1TBЃЉЕФВЂаадЫЫуЁЃИХФю"MapЃЈгГЩфЃЉ"КЭ"ReduceЃЈЙщдМЃЉ"ЃЌЪЧЫќУЧЕФжївЊЫМЯыЃЌЖМЪЧДгКЏЪ§ЪНБрГЬгябдРяНшРДЕФЃЌЛЙгаДгЪИСПБрГЬгябдРяНшРДЕФЬиадЁЃЫќМЋДѓЕиЗНБуСЫБрГЬШЫдБдкВЛЛсЗжВМЪНВЂааБрГЬЕФЧщПіЯТЃЌНЋздМКЕФГЬађдЫаадкЗжВМЪНЯЕЭГЩЯЁЃ
ЕБЧАЕФШэМўЪЕЯжЪЧжИЖЈвЛИіMapЃЈгГЩфЃЉКЏЪ§ЃЌгУРДАбвЛзщМќжЕЖдгГЩфГЩвЛзщаТЕФМќжЕЖдЃЌжИЖЈВЂЗЂЕФReduceЃЈЙщдМЃЉКЏЪ§ЃЌгУРДБЃжЄЫљгагГЩфЕФМќжЕЖджаЕФУПвЛИіЙВЯэЯрЭЌЕФМќзщЁЃ
MapReduceЙйЗНЮФЕЕЕижЗШчЯТЃК
https://hadoop.apache.org/docs/stable/hadoop-mapreduce-client/hadoop-mapreduce-client-core/MapReduceTutorial.html
дкбЇЯАMapReduceжЎЧАЮвУЧашвЊзМБИКУHadoopЕФЛЗОГЃЌвВОЭЪЧашвЊЯШАВзАКУHDFSвдМАYARN
ДгWordCountАИР§ЫЕЦ№MapReduceБрГЬФЃаЭ
дкАВзАHadoopЪБЃЌЫќОЭздДјгавЛИіWordCountЕФАИР§ЃЌетИіАИР§ЪЧЭГМЦЮФМўжаУПИіЕЅДЪГіЯжЕФДЮЪ§ЃЌвВОЭЪЧДЪЦЕЭГМЦЃЌЮвУЧдкбЇЯАДѓЪ§ОнПЊЗЂЪБЃЌвЛАуЖМвдWordCountзїЮЊШыУХЁЃ
Р§ШчЃЌЮвЯждкгавЛИіtest.txtЃЌЮФМўФкШнШчЯТЃК
hello world
hello hadoop
hello MapReduce |
ЯждкЕФашЧѓЪЧЭГМЦетИіЮФМўжаУПИіЕЅДЪГіЯжЕФДЮЪ§ЁЃМйЩшЮвЯждкаДСЫвЛаЉДњТыЪЕЯжСЫетИіЮФМўЕФДЪЦЕЭГМЦЃЌЭГМЦЕФНсЙћШчЯТЃК
hello 3
world 1
hadoop 1
MapReduce 1 |
вдЩЯетОЭЪЧвЛИіДЪЦЕЭГМЦЕФР§згЁЃ
ДЪЦЕЭГМЦПДЦ№РДУВЫЦКмМђЕЅЕФбљзгЃЌвЛАуВЛашвЊЖрЩйДњТыОЭФмЭъГЩСЫЃЌЖјЧвШчЙћЖдshellНХБОБШНЯЪьЯЄЕФЛАЃЌЩѕжСвЛОфДњТыОЭФмЭъГЩетИіДЪЦЕЭГМЦЕФЙІФмЁЃШЗЪЕДЪЦЕЭГМЦЪЧВЛФбЃЌЕЋЪЧЮЊЪВУДЛЙвЊгУДѓЪ§ОнММЪѕШЅЭъГЩетИіДЪЦЕЭГМЦЕФЙІФмФиЃПетЪЧвђЮЊЪЕЯжаЁЮФМўЕФДЪЦЕЭГМЦЙІФмЛђаэгУМђЕЅЕФДњТыОЭФмЭъГЩЃЌЕЋЪЧШчЙћЪЧМИАйGBЁЂTBЩѕжСЪЧPBМЖЕФДѓЮФМўЛЙФмгУМђЕЅЕФДњТыЭъГЩТ№ЃПетЯдШЛЪЧВЛПЩФмЕФЃЌОЭЫуФмвВашвЊЛЈЗбЯрЕБДѓЕФЪБМфГЩБОЁЃ
ЖјДѓЪ§ОнММЪѕОЭЪЧвЊНтОіетжжДІРэКЃСПЪ§ОнЕФЮЪЬтЃЌMapReduceдкЦфжаОЭЪЧГфЕБвЛИіЗжВМЪНВЂааМЦЫуЕФНЧЩЋЃЌЗжВМЪНВЂааМЦЫуФмДѓЗљЖШЬсИпКЃСПЪ§ОнЕФДІРэЫйЖШЃЌБЯОЙЖрИіШЫИЩЛюПЯЖЈБШвЛИіШЫИЩЛюПьЁЃгжЛиЕНЮвУЧЩЯУцЫљЫЕЕНЕФДЪЦЕЭГМЦЕФР§згЃЌдкЪЕМЪЙЄзїжаКмЖрГЁОАЕФПЊЗЂЖМЪЧдкWordCountЕФЛљДЁЩЯНјааИФдьЕФЁЃР§ШчЃЌвЊДгЫљгаЗўЮёЦїЕФЗУЮЪШежОжаЭГМЦГіБЛЗУЮЪЕУзюЖрЕФurlвдМАЗУЮЪСПзюИпЕФIPЃЌетОЭЪЧвЛИіЕфаЭЕФWordCountгІгУГЁОАЃЌвЊжЊЕРМДБуЪЧаЁЙЋЫОЕФЗўЮёЦїЗУЮЪШежОЭЈГЃвВЖМЪЧGBМЖБ№ЕФЁЃ
ЪЙгУMapReduceжДааWordCountЕФСїГЬЪОвтЭМЃК
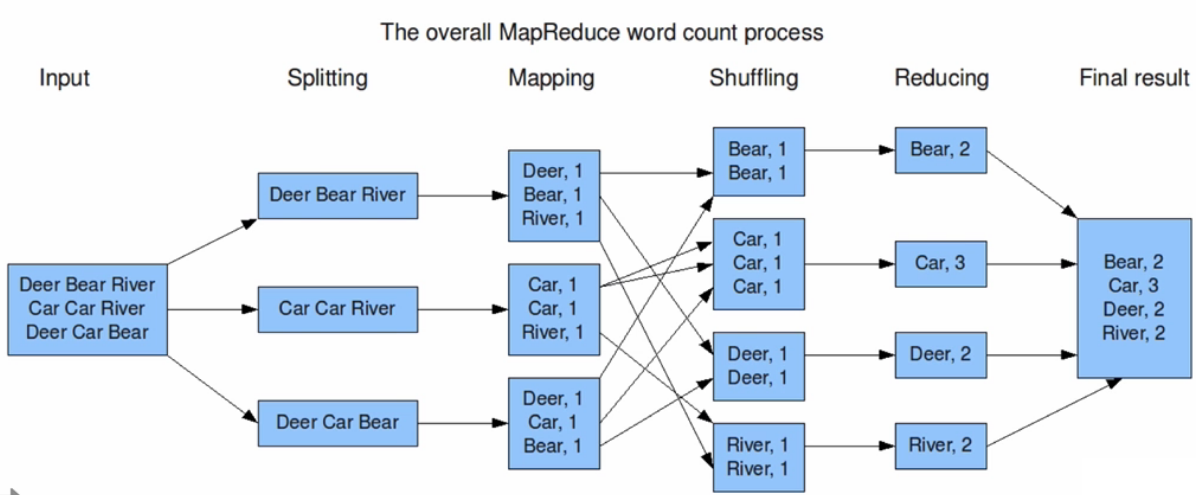
ДгЩЯЭМжаЃЌПЩвдПДЕНЃЌЪфШыЕФЪ§ОнМЏЛсБЛВ№ЗжЮЊЖрИіПщЃЌШЛКѓетаЉПщЖМЛсБЛЗХЕНВЛЭЌЕФНкЕуЩЯНјааВЂааЕФМЦЫуЁЃдкSplittingетвЛЛЗНкЛсАбЕЅДЪАДееЗжИюЗћЛђепЗжИюЙцдђНјааВ№ЗжЃЌВ№ЗжЭъГЩКѓОЭЕНMappingЩЯСЫЃЌЕНMappingетИіЛЗНкКѓЛсАбЯрЭЌЕФЕЅДЪЭЈЙ§ЭјТчНјаагГЩфЛђепЫЕДЋЪфЕНЭЌвЛИіНкЕуЩЯЁЃНгзХетаЉЯрЭЌЕФЕЅДЪОЭЛсдкShufflingЛЗНкЪБНјааЯДХЦвВОЭЪЧКЯВЂЃЌКЯВЂЭъГЩжЎКѓОЭЛсНјШыReducingЛЗНкЃЌетвЛЛЗНкОЭЪЧАбЫљгаНкЕуКЯВЂКѓЕФЕЅДЪдйНјаавЛДЮКЯВЂЃЌвВОЭЪЧЛсЪфГіЕНHDFSЮФМўЯЕЭГжаЕФФГвЛИіЮФМўжаЁЃДѓЬхРДПДОЭЪЧвЛИіВ№ЗжгжКЯВЂЕФЙ§ГЬЃЌЫљвдMapReduceЪЧЗжЮЊmapКЭReduceЕФЁЃзюживЊЕФЪЧЃЌвЊЧхГўетвЛСїГЬЖМЪЧЗжВМЪНВЂааЕФЃЌУПИіНкЕуЖМВЛЛсЛЅЯрвРРЕЃЌЖМЪЧЯрЛЅЖРСЂЕФЁЃ
MapReduceжДааСїГЬ
вдЩЯЮвУЧвВЬсЕНСЫMapReduceЪЧЗжЮЊMapКЭReduceЕФЃЌвВОЭЪЧЫЕвЛИіMapReduceзївЕЛсБЛВ№ЗжГЩMapКЭReduceНзЖЮЁЃMapНзЖЮЖдгІЕФОЭЪЧвЛЖбЕФMap
TasksЃЌЭЌбљЕФReduceНзЖЮвВЪЧЛсЖдгІвЛЖбЕФReduce TasksЁЃ
ЦфЪЕМђЕЅРДЫЕетвВЪЧвЛИіЪфШыЪфГіЕФСїГЬЃЌвЊзЂвтЕФЪЧдкMapReduceПђМмжаЪфШыЕФЪ§ОнМЏЛсБЛађСаЛЏГЩМќ/жЕЖдЃЌmapНзЖЮЭъГЩКѓЛсЖдетаЉМќжЕЖдНјааХХађЃЌзюКѓЕНreduceНзЖЮжаНјааКЯВЂЪфГіЃЌЪфГіЕФвВЪЧМќ/жЕЖдЃЌЙйЭјЮФЕЕаДЕФСїГЬШчЯТЃК
| (input) <k1,
v1> -> map -> <k2, v2> -> combine
-> <k2, v2> -> reduce -> <k3,
v3> (output) |
ЪОвтЭМЃК
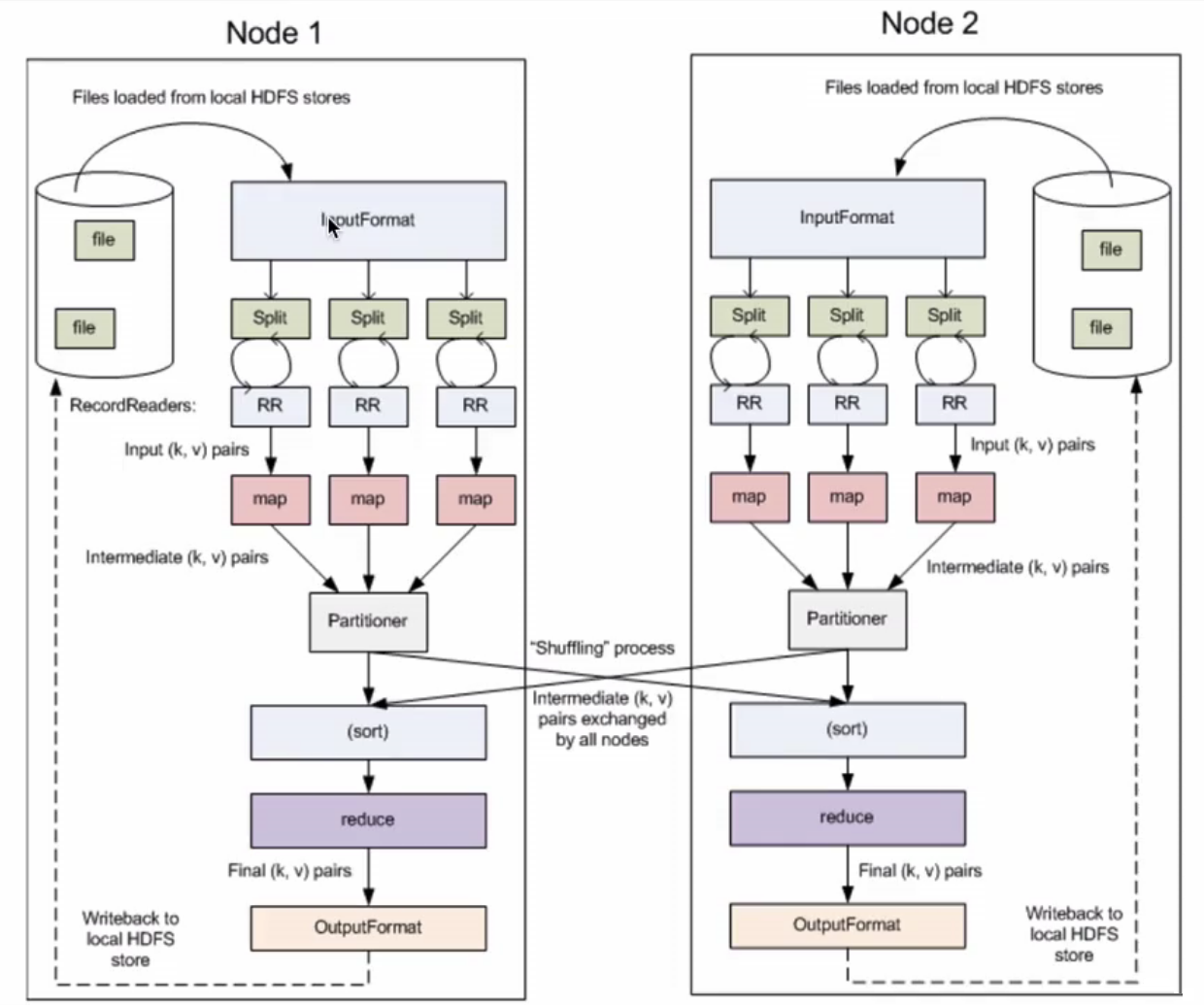
ЮвУЧПЩвдПДЕНгаМИИіжївЊЕФЕуЃК
InputFormatЃКНЋЮвУЧЪфШыЪ§ОнНјааЗжЦЌЃЈsplitЃЉ
SplitЃКНЋЪ§ОнПщНЛMapReduceзївЕРДДІРэЃЌЪ§ОнПщЪЧMapReduceжазюаЁЕФМЦЫуЕЅдЊ
дкHDFSжаЃЌЪ§ОнПщЪЧзюаЁЕФДцДЂЕЅдЊЃЌФЌШЯЮЊ128M
ФЌШЯЧщПіЯТЃЌHDFSгыMapReduceЪЧвЛвЛЖдгІЕФЃЌЕБШЛЮвУЧвВПЩвдЪжЖЏЫљЩшжУЫќУЧжЎМфЕФЙиЯЕЃЈЕЋЪЧВЛНЈвщетУДзіЃЉ
OutputFormatЃКЪфГізюжеЕФДІРэНсЙћ
ЮвУЧПЩвддйРДПДвЛеХЭМЃЌМйЩшЮвУЧЪжЖЏЩшжУСЫblockгыsplitЕФЖдгІЙиЯЕЃЌвЛИіblockЖдгІСНИіsplitЃК

ЩЯЭМжавЛИіblockЖдгІСНИіsplitЃЈФЌШЯЪЧвЛЖдвЛЃЉЃЌвЛИіsplitдђЪЧЖдгІвЛИіMap TaskЁЃMap
TaskНЋЪ§ОнЗжЭъзщжЎКѓЕНShuffleЃЌShuffleЭъГЩКѓОЭЕНReduceЩЯНјааЪфГіЃЌЖјУПвЛИіReduce
TasksЛсЪфГіЕНвЛИіЮФМўЩЯЃЌЩЯЭМжагаШ§ИіReduce TasksЃЌЫљвдЛсЪфГіЕНШ§ИіЮФМўЩЯЁЃ
MapReduce1.xМмЙЙ
MapReduce1.xМмЙЙЭМШчЯТЃК
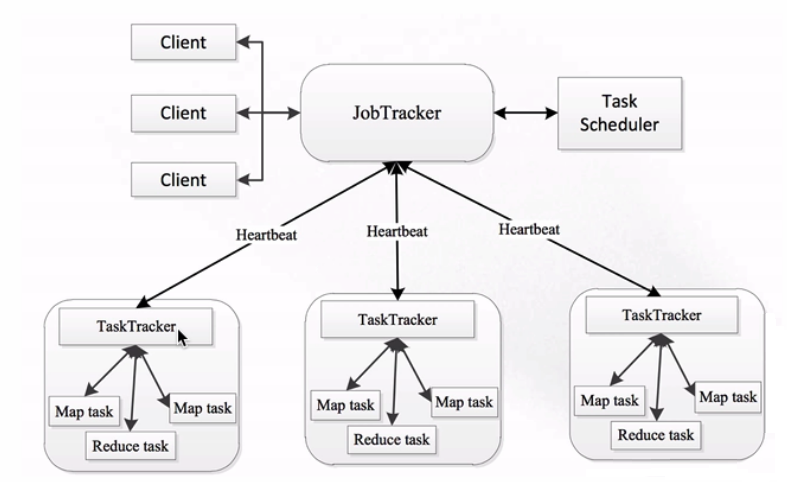
МђЕЅЫЕУївЛЯТЦфжаЕФМИИізщМўЃК
JobTrackerЃКзївЕЕФЙмРэепЃЌЫќЛсНЋзївЕЗжНтГЩвЛЖбЕФШЮЮёЃЌвВОЭЪЧTaskЃЌTaskРяАќКЌMapTaskКЭReduceTaskЁЃЫќЛсНЋЗжНтКѓЕФШЮЮёЗжХЩИјTaskTrackerНјаадЫааЃЌЫќЛЙашвЊЭъГЩзївЕЕФМрПивдМАШнДэДІРэЃЈtaskзївЕЙвЕєСЫЃЌЛсжиЦєtaskЃЉЁЃШчЙћдквЛЖЈЕФЪБМфФкЃЌJobTrackerУЛгаЪеЕНФГИіTaskTrackerЕФаФЬјаХЯЂЕФЛАЃЌОЭЛсХаЖЯИУTaskTrackerЙвЕєСЫЃЌШЛКѓОЭЛсНЋИУTaskTrackerЩЯдЫааЕФШЮЮёжИХЩЕНЦфЫћЕФTaskTrackerЩЯШЅжДааЁЃ
TaskTrackerЃКШЮЮёЕФжДааепЃЌЮвУЧЕФTaskЃЈMapTaskКЭReduceTaskЃЉЖМЪЧдкTaskTrackerЩЯдЫааЕФЃЌTaskTrackerПЩвдгыJobTrackerНјааНЛЛЅЃЌР§ШчжДааЁЂЦєЖЏЛђЭЃжЙзївЕвдМАЗЂЫЭаФЬјаХЯЂИјJobTrackerЕШЁЃ
MapTaskЃКЮвУЧздМКПЊЗЂЕФMapШЮЮёЛсНЛгЩИУTaskЭъГЩЃЌЫќЛсНтЮіУПЬѕМЧТМЕФЪ§ОнЃЌШЛКѓНЛИјздМКБраДЕФMapЗНЗЈНјааДІРэЃЌДІРэЭъГЩжЎКѓЛсНЋMapЕФЪфГіНсЙћаДЕНБОЕиДХХЬЁЃВЛЙ§гааЉзївЕПЩФмжЛгаmapУЛгаreduceЃЌетЪБКђвЛАуЛсНЋНсЙћЪфГіЕНHDFSЮФМўЯЕЭГРяЁЃ
ReduceTaskЃКНЋMapTaskЪфГіЕФЪ§ОнНјааЖСШЁЃЌВЂАДееЪ§ОнЕФЙцдђНјааЗжзщЃЌШЛКѓДЋИјЮвУЧздМКБраДЕФreduceЗНЗЈДІРэЁЃДІРэЭъГЩКѓФЌШЯНЋЪфГіНсЙћаДЕНHDFSЁЃ
MapReduce2.xМмЙЙ
MapReduce2.xМмЙЙЭМШчЯТЃЌПЩвдПДЕНJobTrackerКЭTaskTrackerвбОВЛИДДцдкСЫЃЌШЁЖјДњжЎЕФЪЧResourceManagerКЭNodeManagerЁЃВЛНіМмЙЙБфСЫЃЌЙІФмвВБфСЫЃЌ2.xжЎКѓаТв§ШыСЫYARNЃЌдкYARNжЎЩЯЮвУЧПЩвддЫааВЛЭЌЕФМЦЫуПђМмЃЌВЛдйЪЧ1.xФЧбљжЛФмдЫааMapReduceСЫЃК
JavaАцБОwordcountЙІФмЪЕЯж
1.ДДНЈвЛИіMavenЙЄГЬЃЌХфжУвРРЕШчЯТЃК
<repositories>
<repository>
<id>cloudera</id>
<url>https://repository.cloudera.com/artifactory
/cloudera-repos/</url>
<releases>
<enabled>true</enabled>
</releases>
<snapshots>
<enabled>false</enabled>
</snapshots>
</repository>
</repositories>
<properties>
<project.build.sourceEncoding>UTF-8</project.build.sourceEncoding>
<hadoop.version>2.6.0-cdh5.7.0</hadoop.version>
</properties>
<dependencies>
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-client</artifactId>
<version>${hadoop.version}</version>
</dependency>
<dependency>
<groupId>junit</groupId>
<artifactId>junit</artifactId>
<version>4.10</version>
<scope>test</scope>
</dependency>
</dependencies> |
2.ДДНЈвЛИіРрЃЌПЊЪМБраДЮвУЧwordcountЕФЪЕЯжДњТыЃК
package org.zero01.hadoop.mapreduce;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.Mapper;
import org.apache.hadoop.mapreduce.Reducer;
import org.apache.hadoop.mapreduce.lib.input
.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.output
.FileOutputFormat;
import java.io.IOException;
/**
* @program: hadoop-train
* @description: ЪЙгУMapReduceПЊЗЂWordCountгІгУГЬађ
* @author: 01
* @create: 2018-03-31 14:03
**/
public class WordCountApp {
/**
* Map: ЖСШЁЪфШыЕФЮФМўФкШн
*/
public static class MyMapper extends Mapper<LongWritable,
Text, Text, LongWritable> {
LongWritable one = new LongWritable(1);
protected void map(LongWritable key, Text
value, Context context) throws IOException,
InterruptedException {
// НгЪеЕНЕФУПвЛааЪ§Он
String line = value.toString();
// АДеежИЖЈЕФЗжИюЗћНјааВ№Зж
String[] words = line.split(" ");
for (String word : words) {
// ЭЈЙ§ЩЯЯТЮФАбmapЕФДІРэНсЙћЪфГі
context.write(new Text((word)), one);
}
}
}
/**
* Reduce: ЙщВЂВйзї
*/
public static class MyReducer extends Reducer<Text,
LongWritable, Text, LongWritable> {
protected void reduce(Text key,
Iterable<LongWritable>
values, Context context) throws IOException,
InterruptedException {
long sum = 0;
for (LongWritable value : values) {
// ЧѓkeyГіЯжЕФДЮЪ§змКЭ
sum += value.get();
}
// НЋзюжеЕФЭГМЦНсЙћЪфГі
context.write(key, new LongWritable(sum));
}
}
/**
* ЖЈвхDriverЃКЗтзАСЫMapReduceзївЕЕФЫљгааХЯЂ
*/
public static void main(String[] args) throws
IOException, ClassNotFoundException,
InterruptedException
{
Configuration configuration = new Configuration();
// ДДНЈJobЃЌЭЈЙ§ВЮЪ§ЩшжУJobЕФУћГЦ
Job job = Job.getInstance(configuration,
"wordcount");
// ЩшжУJobЕФДІРэРр
job.setJarByClass(WordCountApp.class);
// ЩшжУзївЕДІРэЕФЪфШыТЗОЖ
FileInputFormat.setInputPaths(job,
new Path(args[0]));
// ЩшжУmapЯрЙиВЮЪ§
job.setMapperClass(MyMapper.class);
job.setMapOutputKeyClass(Text.class);
job.setMapOutputValueClass(LongWritable.class);
// ЩшжУreduceЯрЙиВЮЪ§
job.setReducerClass(MyReducer.class);
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(LongWritable.class);
// ЩшжУзївЕДІРэЭъГЩКѓЕФЪфГіТЗОЖ
FileOutputFormat.setOutputPath(job,
new Path(args[1]));
System.exit(job.waitForCompletion(true) ?
0 : 1);
}
} |
3.БраДЭъГЩжЎКѓЃЌдкIDEAРяЭЈЙ§MavenНјааБрвыДђАќЃК
4.АбДђАќКУЕФjarАќЩЯДЋЕНЗўЮёЦїЩЯЃК
ВтЪдЮФМўФкШнШчЯТЃК
[root@localhost
~]# hdfs dfs -text /test.txt
hello world
hadoop welcome
hadoop hdfs mapreduce
hadoop hdfs
hello hadoop
[root@localhost ~]# |
5.ШЛКѓжДааШчЯТУќСюжДааJobЃК
| [root@localhost
~]# hadoop jar ./hadoop-train-1.0.jar org.zero01.hadoop.mapreduce.WordCountApp
/test.txt /output/wc |
МђЕЅЫЕУївЛЯТетИіУќСюЃК
hadoop jar ЪЧHadoopжДааjarАќЕФУќСю
./hadoop-train-1.0.jar ЪЧjarАќЕФЫљдкТЗОЖ
org.zero01.hadoop.mapreduce.WordCountApp ЪЧjarАќЕФжїРрвВОЭЪЧmainРр
/test.txt ЪЧВтЪдЮФМўвВОЭЪЧЪфШыЮФМўЫљдкТЗОЖЃЈHDFSЩЯЕФТЗОЖЃЉ
/output/wc ЮЊЪфГіЮФМўЕФДцдкТЗОЖ
6.ЕНYARNЩЯВщПДШЮЮёжДааЕФаХЯЂЃК
ЩъЧызЪдДЃК
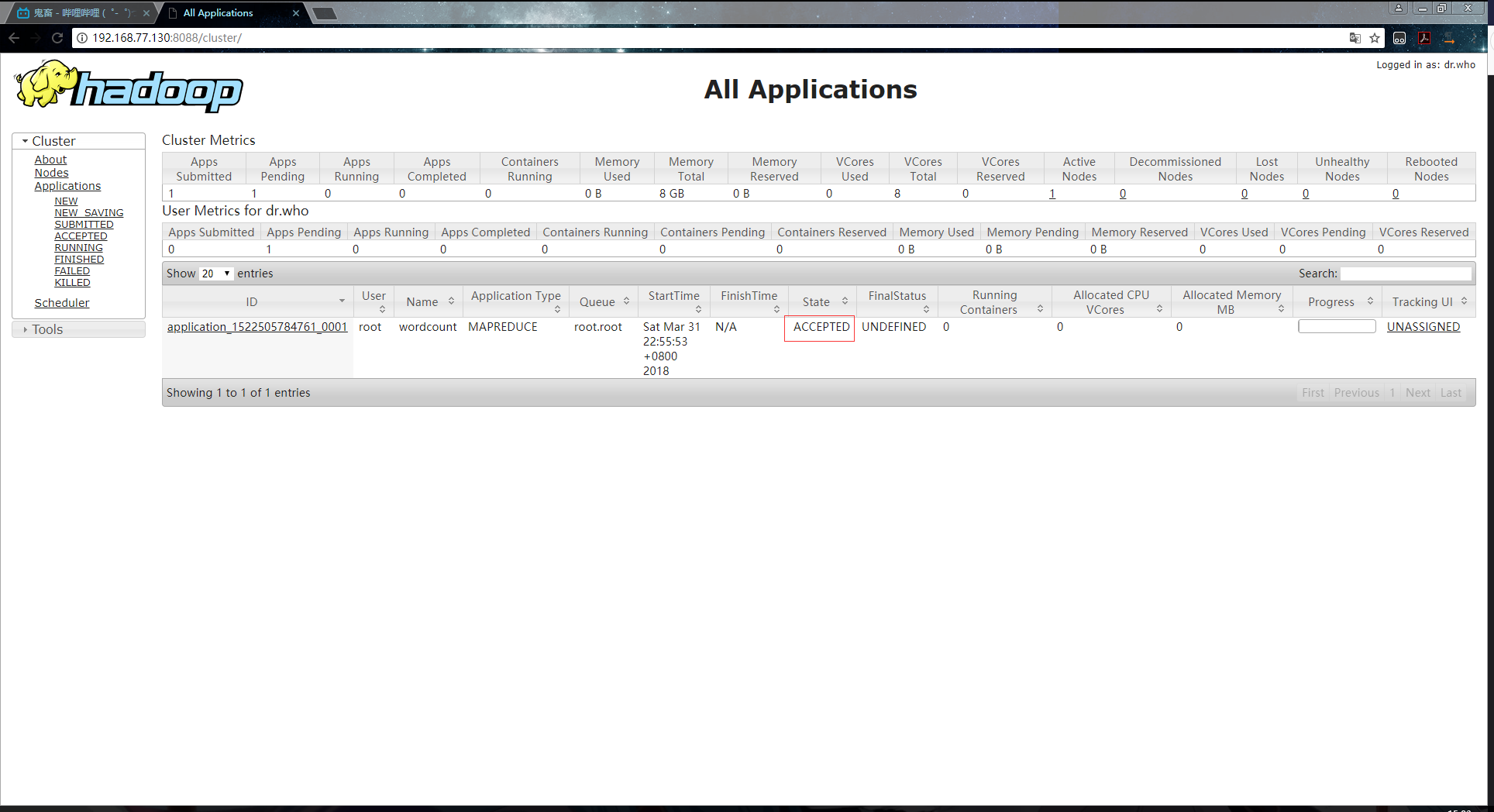
дЫааЃК
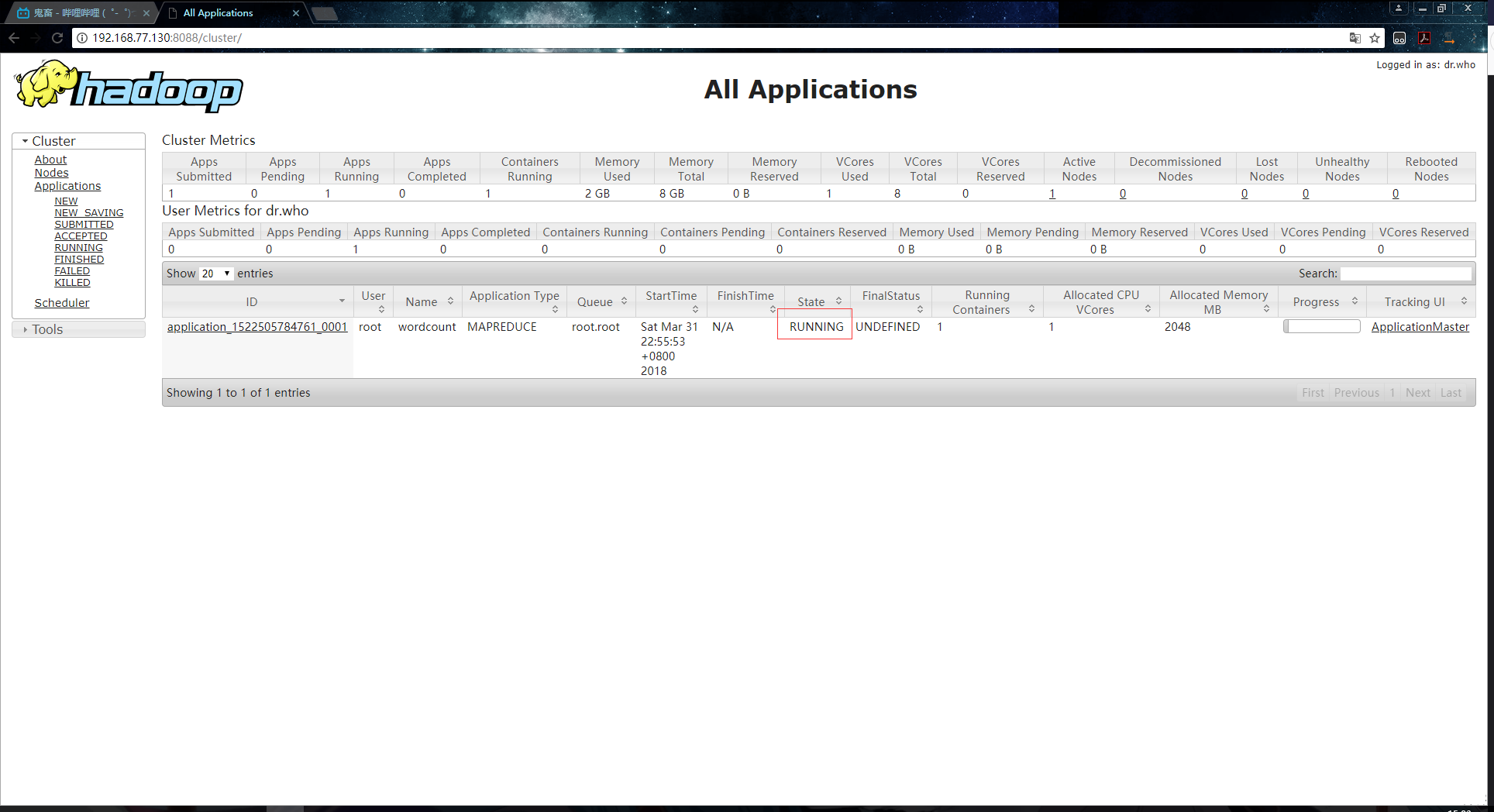
ЭъГЩЃК
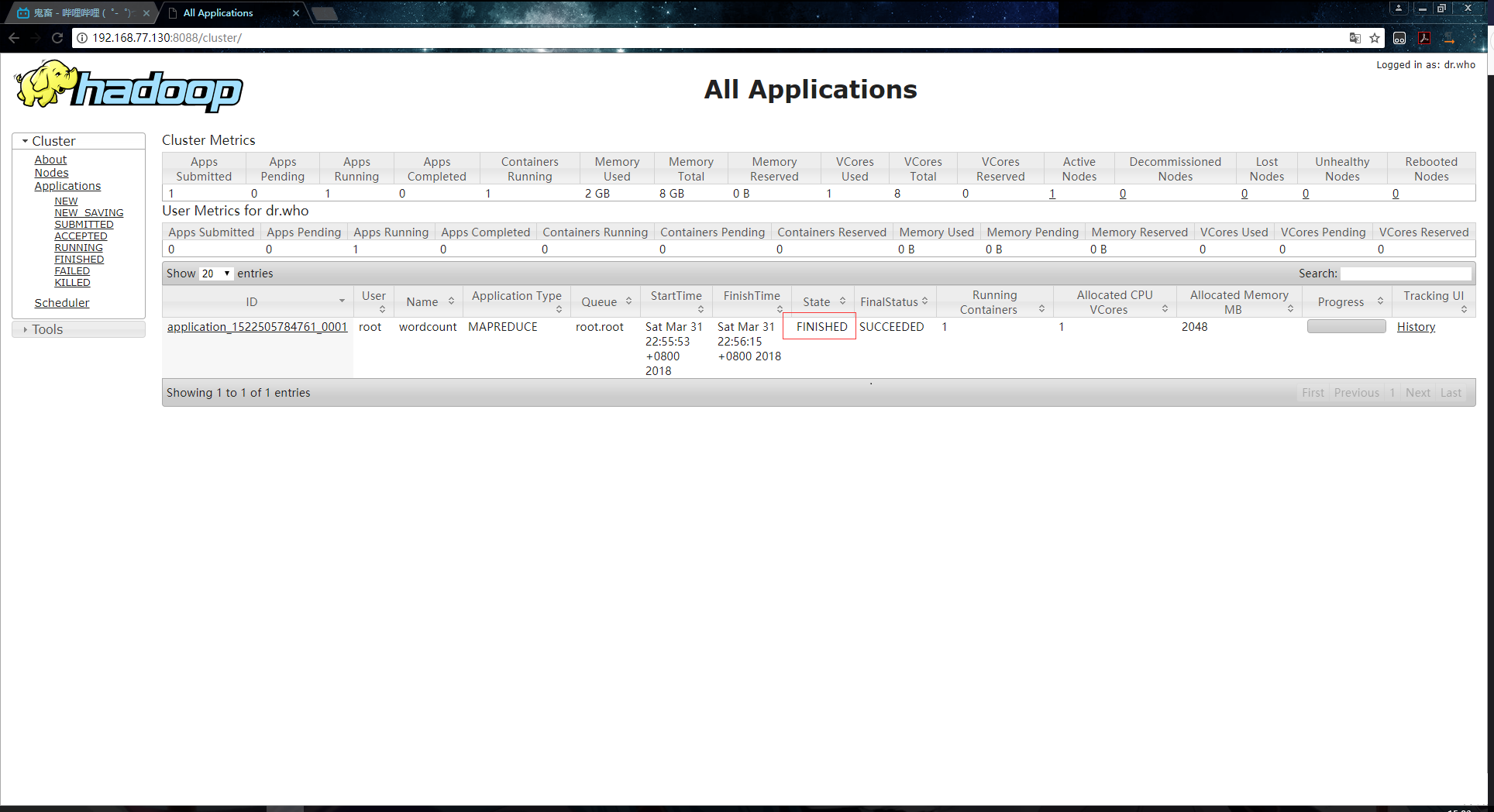
7.ПЩвдПДЕНвбОжДааГЩЙІЃЌУќСюаажеЖЫЕФШежОЪфГіФкШнШчЯТЃК
18/03/31 22:55:51
WARN util.NativeCodeLoader: Unable to load native-hadoop
library for your platform... using builtin-java
classes where applicable
18/03/31 22:55:52 INFO client.RMProxy: Connecting
to ResourceManager at /0.0.0.0:8032
18/03/31 22:55:52 WARN mapreduce.JobResourceUploader:
Hadoop command-line option parsing not performed.
Implement the Tool interface and execute your
application with ToolRunner to remedy this.
18/03/31 22:55:53 INFO input.FileInputFormat:
Total input paths to process : 1
18/03/31 22:55:53 INFO mapreduce.JobSubmitter:
number of splits:1
18/03/31 22:55:53 INFO mapreduce.JobSubmitter:
Submitting tokens for job: job_1522505784761_0001
18/03/31 22:55:54 INFO impl.YarnClientImpl: Submitted
application application_1522505784761_0001
18/03/31 22:55:54 INFO mapreduce.Job: The url
to track the job: http://localhost:8088/proxy/application_
1522505784761_0001/
18/03/31 22:55:54 INFO mapreduce.Job: Running
job: job_1522505784761_0001
18/03/31 22:56:06 INFO mapreduce.Job: Job job_1522505784761_0001
running in uber mode : false
18/03/31 22:56:06 INFO mapreduce.Job: map 0% reduce
0%
18/03/31 22:56:11 INFO mapreduce.Job: map 100%
reduce 0%
18/03/31 22:56:16 INFO mapreduce.Job: map 100%
reduce 100%
18/03/31 22:56:16 INFO mapreduce.Job: Job job_1522505784761_0001
completed successfully
18/03/31 22:56:16 INFO mapreduce.Job: Counters:
49
File System Counters
FILE: Number of bytes read=190
FILE: Number of bytes written=223169
FILE: Number of read operations=0
FILE: Number of large read operations=0
FILE: Number of write operations=0
HDFS: Number of bytes read=174
HDFS: Number of bytes written=54
HDFS: Number of read operations=6
HDFS: Number of large read operations=0
HDFS: Number of write operations=2
Job Counters
Launched map tasks=1
Launched reduce tasks=1
Data-local map tasks=1
Total time spent by all maps in occupied slots
(ms)=3151
Total time spent by all reduces in occupied slots
(ms)=2359
Total time spent by all map tasks (ms)=3151
Total time spent by all reduce tasks (ms)=2359
Total vcore-seconds taken by all map tasks=3151
Total vcore-seconds taken by all reduce tasks=2359
Total megabyte-seconds taken by all map tasks=3226624
Total megabyte-seconds taken by all reduce
tasks=2415616
Map-Reduce Framework
Map input records=5
Map output records=11
Map output bytes=162
Map output materialized bytes=190
Input split bytes=100
Combine input records=0
Combine output records=0
Reduce input groups=6
Reduce shuffle bytes=190
Reduce input records=11
Reduce output records=6
Spilled Records=22
Shuffled Maps =1
Failed Shuffles=0
Merged Map outputs=1
GC time elapsed (ms)=233
CPU time spent (ms)=1860
Physical memory (bytes) snapshot=514777088
Virtual memory (bytes) snapshot=5571788800
Total committed heap usage (bytes)=471859200
Shuffle Errors
BAD_ID=0
CONNECTION=0
IO_ERROR=0
WRONG_LENGTH=0
WRONG_MAP=0
WRONG_REDUCE=0
File Input Format Counters
Bytes Read=74
File Output Format Counters
Bytes Written=54 |
8.ВщПДЪфГіЮФМўЕФФкШнЃК
[root@localhost
~]# hdfs dfs -ls /output/wc/
Found 2 items
-rw-r--r-- 1 root supergroup 0 2018-03-31 22:56
/output/wc/_SUCCESS
-rw-r--r-- 1 root supergroup 54 2018-03-31 22:56
/output/wc/part-r-00000 # жДааНсЙћЕФЪфГіЮФМў
[root@localhost ~]# hdfs dfs -text /output/wc/part-r-00000
# ВщПДЮФМўФкШн
hadoop 4
hdfs 2
hello 2
mapreduce 1
welcome 1
world 1
[root@localhost ~]# |
JavaАцБОwordcountЙІФмжиЙЙ
ЫфШЛЮвУЧвбОГЩЙІЭЈЙ§БраДjavaДњТыЪЕЯжСЫwordcountЙІФмЃЌЕЋЪЧгавЛИіЮЪЬтЃЌШчЙћЮвУЧдйжДааИеИеФЧЬѕУќСюЃЌОЭЛсБЈШчЯТДэЮѓЃК
[root@localhost
~]# hadoop jar ./hadoop-train-1.0.jar
org.zero01.hadoop.mapreduce.WordCountApp
/test.txt /output/wc
18/04/01 00:30:12 WARN util.NativeCodeLoader:
Unable to
load native-hadoop library for your
platform...
using builtin-java classes where applicable
18/04/01 00:30:12 INFO client.RMProxy: Connecting
to ResourceManager at /0.0.0.0:8032
18/04/01 00:30:12 WARN security.UserGroupInformation:
PriviledgedActionException as:root (auth:SIMPLE)
cause:org.apache.hadoop.mapred.
FileAlreadyExistsException:
Output directory
hdfs://192.168.77.130:8020/output/wc
already exists
Exception in thread "main" org.apache.hadoop.mapred.
FileAlreadyExistsException:
Output directory
hdfs://192.168.77.130:8020/output/wc
already exists
at org.apache.hadoop.mapreduce.lib.output.FileOutputFormat.
checkOutputSpecs(FileOutputFormat.java:146)
at org.apache.hadoop.mapreduce.JobSubmitter.checkSpecs
(JobSubmitter.java:270)
at org.apache.hadoop.mapreduce.JobSubmitter.
submitJobInternal(JobSubmitter.java:143)
at org.apache.hadoop.mapreduce.Job$10.run(Job.java:1307)
at org.apache.hadoop.mapreduce.Job$10.run(Job.java:1304)
at java.security.AccessController.doPrivileged(Native
Method)
at javax.security.auth.Subject.doAs(Subject.java:422)
at org.apache.hadoop.security.UserGroupInformation.doAs
(UserGroupInformation.java:1693)
at org.apache.hadoop.mapreduce.Job.submit(Job.java:1304)
at org.apache.hadoop.mapreduce.Job.waitForCompletion
(Job.java:1325)
at org.zero01.hadoop.mapreduce.WordCountApp.main
(WordCountApp.java:86)
at sun.reflect.NativeMethodAccessorImpl.invoke0(Native
Method)
at sun.reflect.NativeMethodAccessorImpl.invoke
(NativeMethodAccessorImpl.java:62)
at sun.reflect.DelegatingMethodAccessorImpl.invoke
(DelegatingMethodAccessorImpl.java:43)
at java.lang.reflect.Method.invoke(Method.java:498)
at org.apache.hadoop.util.RunJar.run(RunJar.java:221)
at org.apache.hadoop.util.RunJar.main(RunJar.java:136)
[root@localhost ~]# |
дкЦНЪБЕФMapReduceОнГЬађПЊЗЂжаЃЌетИівьГЃЗЧГЃЕиГЃМћЃЌетИівьГЃЪЧвђЮЊЪфГіЮФМўЕФДцЗХФПТМвбОДцдкЃКOutput
directory hdfs://192.168.77.130:8020/output/wc already
exists
гаСНжжЗНЪНПЩвдНтОіетИіЮЪЬтЃК
дкжДааMapReduceзївЕЪБЃЌЯШЩОГ§ЛђИќИФЪфГіЮФМўЕФДцЗХФПТМЃЈВЛЭЦМіЃЉ
дкДњТыжаЭъГЩздЖЏЩОГ§ЙІФмЃЈЭЦМіЃЉ
ЮвУЧРДдкДњТыжаЪЕЯжздЖЏЩОГ§ЙІФмЃЌдкИеИеЕФДњТыжаЃЌМгШыШчЯТФкШнЃК
...
/**
* ЖЈвхDriverЃКЗтзАСЫMapReduceзївЕЕФЫљгааХЯЂ
*/
public static void main(String[] args) throws
IOException, ClassNotFoundException, InterruptedException
{
Configuration configuration = new Configuration();
// зМБИЧхРэвбДцдкЕФЪфГіФПТМ
Path outputPath = new Path(args[1]);
FileSystem fileSystem = FileSystem.get(configuration);
if (fileSystem.exists(outputPath)) {
fileSystem.delete(outputPath,true);
System.out.println("output file exists,
but is has deleted");
}
... |
БраДЭъГЩжЎКѓжиаТНЋБрМКѓЕФjarАќЩЯДЋЃЌдйжДааhadoop jar ./hadoop-train-1.0.jar
org.zero01.hadoop.mapreduce.WordCountApp /test.txt
/output/wcУќСюЃЌОЭВЛЛсдйБЈДэСЫЁЃ
CombinerгІгУГЬађПЊЗЂ
CombinerРрЫЦгкБОЕиЕФReduceЃЌЯрЕБгкЪЧдкMapНзЖЮЕФЪБКђОЭзівЛИіReduceЕФВйзїЃЌЫќФмЙЛМѕЩйMap
TaskЪфГіЕФЪ§ОнСПМАЭјТчДЋЪфСПЁЃ
ШчЯТЭМЃК
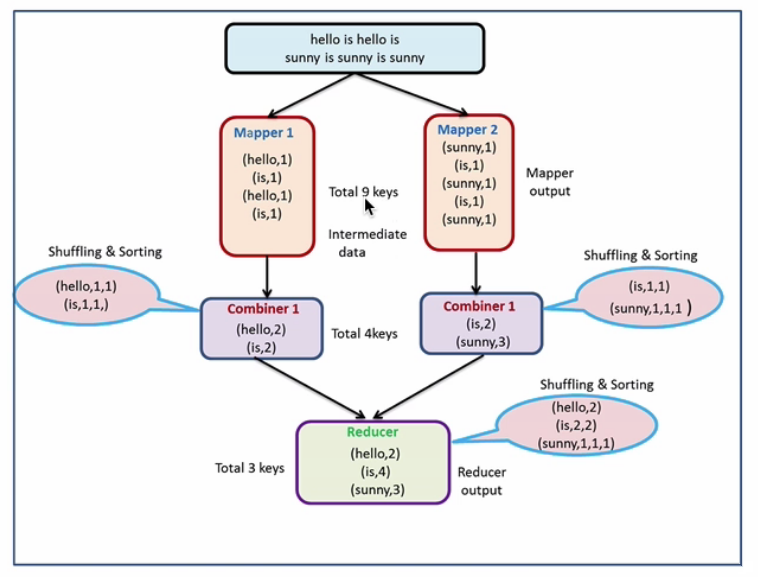
дкЩЯЭМжаЃЌПЩвдПДЕНMapperгыReducerжЎМфгавЛВуCombinerЁЃMapperЯШАбЪ§ОндкБОЕиНјаавЛИіCombinerЃЌвВОЭЪЧЯШзівЛИіБОЕиЪ§ОнЕФКЯВЂЃЌетИіЙ§ГЬРрЫЦгкReduceжЛВЛЙ§ЪЧБОЕиЕФЃЌвВМДЪЧБОНкЕуЁЃЕБCombinerКЯВЂЭъГЩжЎКѓЃЌдйАбЪ§ОнДЋЪфЕНReducerЩЯдйвЛДЮНјаазюжеЕФКЯВЂЁЃетбљMap
TaskЪфГіЕФЪ§ОнСПОЭЛсДѓДѓМѕЩйЃЌадФмвВЛсЯргІЕФЬсИпЃЌетвЛЕуПЩвдДгЩЯЭМжаПДЕНЁЃ
ЮвУЧРДГЂЪдвЛЯТдкИеВХПЊЗЂЕФwordcountГЬађжаЃЌдіМгвЛВуCombinerЁЃдіМгCombinerКмМђЕЅЃЌжЛашвЊдкЩшжУmapКЭreduceВЮЪ§ЕФДњТыжЎМфдіМгвЛааДњТыМДПЩЃЌШчЯТЃК
// ЭЈЙ§JobЖдЯѓРДЩшжУCombinerДІРэРрЃЌдкТпМЩЯКЭreduceЪЧвЛбљЕФ
job.setCombinerClass(MyReducer.class); |
аоИФЭъГЩВЂжиаТЩЯДЋjarАќКѓЃЌетЪБдйжДааwordcountГЬађЃЌдкжеЖЫЕФШежОЪфГіаХЯЂжаЃЌЛсЗЂЯжCombinerЯрЙиЕФзжЖЮЖМгажЕЃЌФЧУДОЭДњБэЮвУЧЕФCombinerвбОГЩЙІЬэМгНјШЅСЫЃК
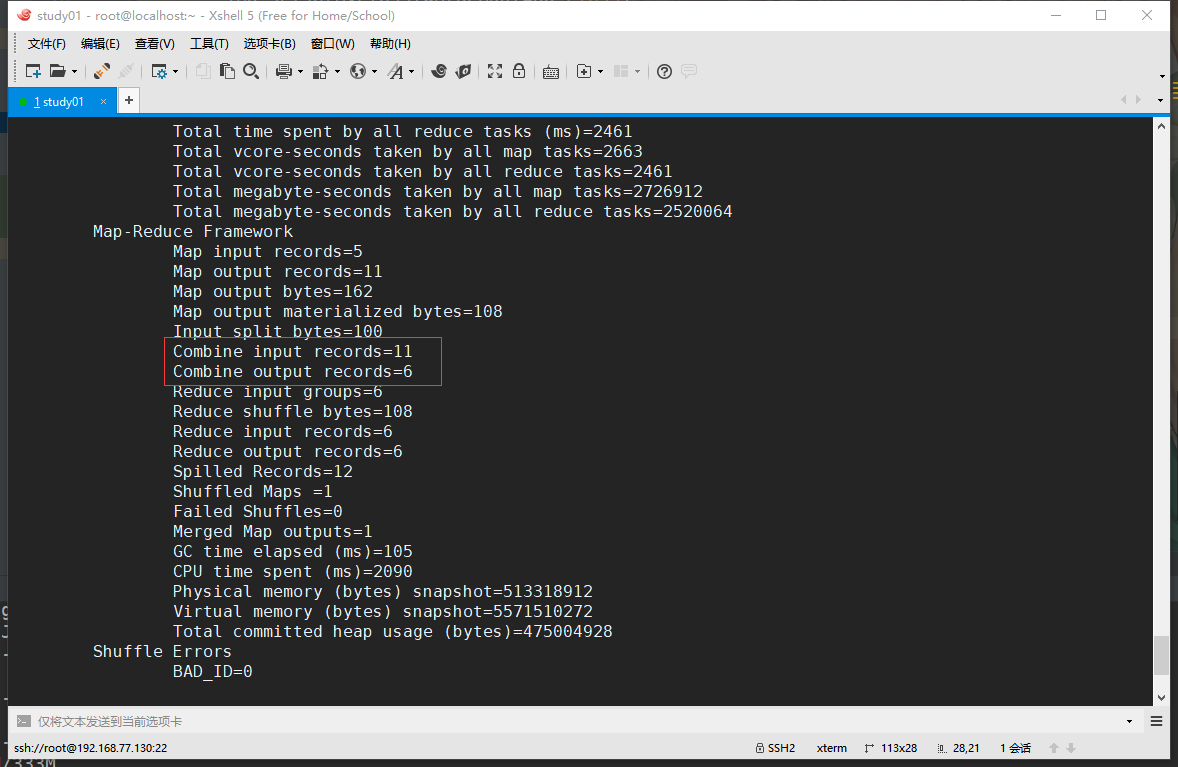
CombinerЕФЪЪгУГЁОАЃК
ЧѓКЭЁЂМЦЪ§ЃЌРлМЦРраЭЕФГЁОАЪЪКЯЪЙгУ
CombinerЕФВЛЪЪгУЕФГЁОАЃК
ЧѓЦНОљЪ§ЁЂЧѓЙЋдМЪ§ЕШРраЭЕФВйзїВЛЪЪКЯЃЌШчЙћетжжГЁОАЯТЪЙгУCombinerЃЌЕУЕНЕФНсЙћОЭЪЧДэЮѓЕФ
PartitionerгІгУГЬађПЊЗЂ
PartitionerОіЖЈMap TaskЪфГіЕФЪ§ОнНЛгЩФФИіReduce TaskДІРэЃЌвВОЭЪЧРрЫЦгкжЦЖЈвЛИіЗжЗЂЙцдђЁЃФЌШЯЧщПіЯТЕФЗжЗЂЙцдђЪЕЯжЃКЗжЗЂЕФkeyЕФhashжЕЖдReduce
TaskИіЪ§ШЁФЃЁЃ
ШчЯТЭМЃК
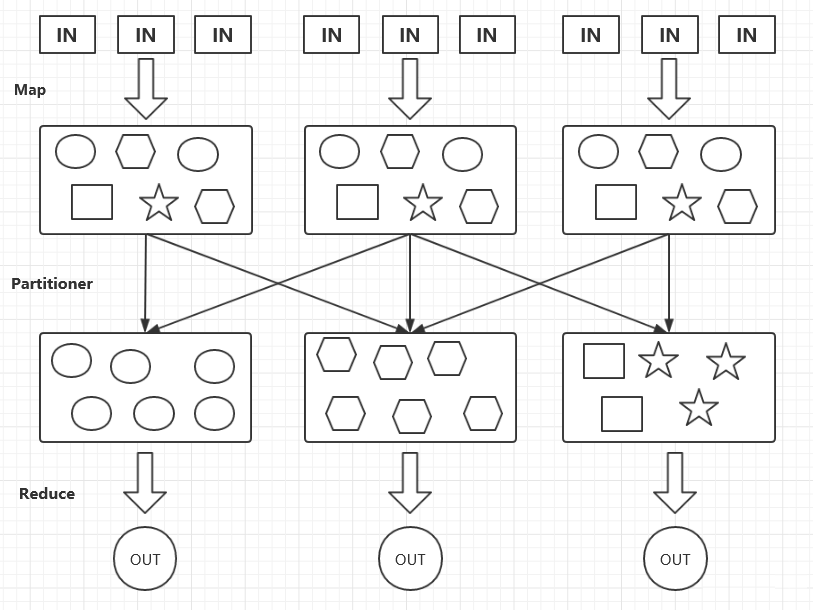
ЩЯЭМжаЃЌАбдВаЮЪ§ОнЗХЕНСЫЭЌвЛИіReduce TaskЩЯЃЌАбСљБпаЮЪ§ОнЗХЕНСЫЭЌвЛИіReduce TaskЩЯЃЌЪЃЯТЕФЭМаЮЪ§ОндђЗХЕНЪЃЯТЕФReduce
TaskЩЯЃЌ етбљЕФвЛИіЗжЗЂЙ§ГЬОЭЪЧPartitionerЁЃ
Р§ШчЃЌЮвЯждкгавЛзщЪ§ОнШчЯТЃЌетЪЧНёШеИїИіЪжЛњЦЗХЦЕФЯњЪлСПЃК
[root@localhost
~]# hdfs dfs -text /partitioner.txt
xiaomi 200
huawei 300
xiaomi 100
iphone7 300
iphone7 500
nokia 100
[root@localhost ~]# |
ЯждкЮвгавЛИіашЧѓЃЌОЭЪЧНЋЯрЭЌЦЗХЦЕФЪжЛњУћГЦЃЌЗжЗЂЕНЭЌвЛИіReduceЩЯНјааДІРэЁЃетОЭашвЊгУЕНPartitionerСЫЃЌдкЮвУЧжЎЧАЕФДњТыжадіМгШчЯТФкШнЃК
public class
WordCountApp {
/**
* Map: ЖСШЁЪфШыЕФЮФМўФкШн
*/
public static class MyMapper extends Mapper<LongWritable,
Text, Text, LongWritable> {
protected void map(LongWritable key, Text
value, Context context) throws IOException,
InterruptedException {
// НгЪеЕНЕФУПвЛааЪ§Он
String line = value.toString();
// АДеежИЖЈЕФЗжИюЗћНјааВ№Зж
String[] words = line.split(" ");
// ЭЈЙ§ЩЯЯТЮФАбmapЕФДІРэНсЙћЪфГі
context.write(new Text((words[0])), new LongWritable(Long.parseLong(words[1])));
}
}
...
/**
* Partitioner: ЩшЖЈMap TaskЪфГіЕФЪ§ОнЕФЗжЗЂЙцдђ
*/
public static class MyPartitioner extends Partitioner<Text,
LongWritable> {
public int getPartition(Text key, LongWritable
value, int numPartitions) {
if(key.toString().equals("xiaomi")){
return 0;
}
if(key.toString().equals("huawei")){
return 1;
}
if(key.toString().equals("iphone7"))
{
return 2;
}
return 3;
}
}
/**
* ЖЈвхDriverЃКЗтзАСЫMapReduceзївЕЕФЫљгааХЯЂ
*/
public static void main(String[] args) throws
IOException, ClassNotFoundException, InterruptedException
{
...
// ЩшжУJobЕФpartition
job.setPartitionerClass(MyPartitioner.class);
// ЩшжУ4ИіreducerЃЌУПИіЗжЧјвЛИі
job.setNumReduceTasks(4);
...
}
} |
ЭЌбљЕФЃЌаоИФСЫДњТыКѓашвЊжиаТБрвыДђАќЃЌАбаТЕФjarЩЯДЋЕНЗўЮёЦїЩЯЁЃШЛКѓжДааУќСюЃК
| [root@localhost
~]# hadoop jar ./hadoop-train-1.0.jar org.zero01.hadoop.mapreduce.WordCountApp
/partitioner.txt /output/wc |
жДааГЩЙІЃЌДЫЪБПЩвдПДЕН/output/wc/ФПТМЯТгаЫФИіНсЙћЮФМўЃЌетЪЧвђЮЊЮвУЧдкДњТыЩЯЩшжУСЫ4ИіreducerЃЌВЂЧвПЩвдПДЕНФкШнЖМЪЧе§ШЗЕФЃК
[root@localhost
~]# hdfs dfs -ls /output/wc/
Found 5 items
-rw-r--r-- 1 root supergroup 0 2018-04-01 04:37
/output/wc/_SUCCESS
-rw-r--r-- 1 root supergroup 11 2018-04-01 04:37
/output/wc/part-r-00000
-rw-r--r-- 1 root supergroup 11 2018-04-01 04:37
/output/wc/part-r-00001
-rw-r--r-- 1 root supergroup 13 2018-04-01 04:37
/output/wc/part-r-00002
-rw-r--r-- 1 root supergroup 10 2018-04-01 04:37
/output/wc/part-r-00003
[root@localhost ~]# for i in `seq 0 3`; do hdfs
dfs -text /output/wc/part-r-0000$i; done
xiaomi 300
huawei 300
iphone7 800
nokia 100
[root@localhost ~]# |
JobHistoryЕФХфжУ
JobHistoryЪЧвЛИіHadoopздДјЕФРњЪЗЗўЮёЦїЃЌЫќгУгкМЧТМвбдЫааЭъЕФMapReduceаХЯЂЕНжИЖЈЕФHDFSФПТМЯТЁЃЮвУЧЖМжЊЕРЃЌжДааСЫMapReduceШЮЮёКѓЃЌПЩвддкYARNЕФЙмРэвГУцЩЯВщПДЕНШЮЮёЕФЯрЙиаХЯЂЃЌЕЋЪЧгЩгкJobHistoryФЌШЯЧщПіЯТЪЧВЛПЊЦєЕФЃЌЫљвдЮвУЧЮоЗЈЭЈЙ§ЕуЛїHistoryВщПДРњЪЗаХЯЂЃК
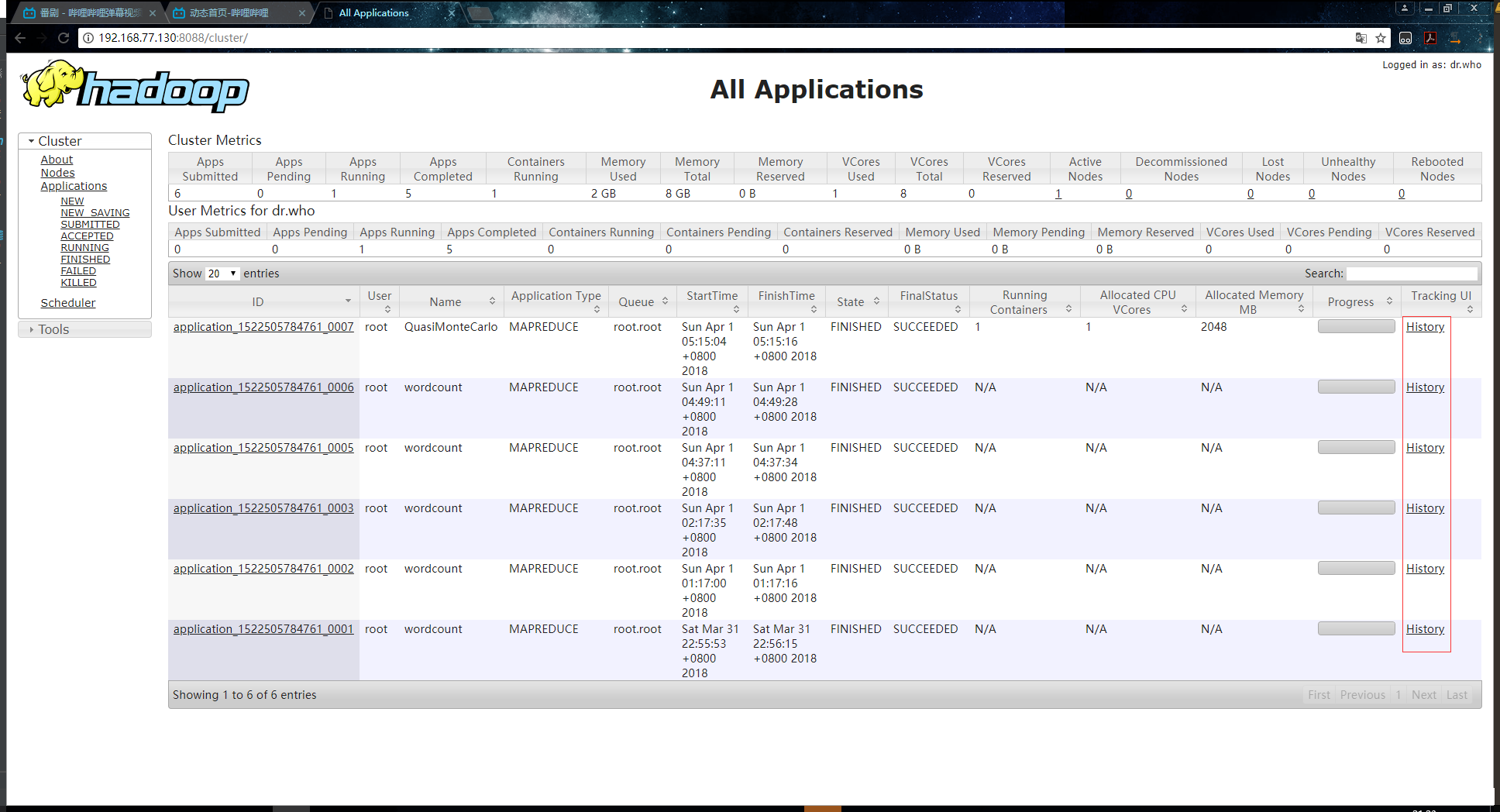
ЫљвдЮвУЧОЭашвЊДђПЊетИіЗўЮёЃЌБрМХфжУЮФМўФкШнЃК
[root@localhost
~]# cd /usr/local/hadoop-2.6.0-cdh5.7.0/etc/hadoop
[root@localhost /usr/local/hadoop-2.6.0-cdh5.7.0/etc/hadoop]#
vim mapred-site.xml # діМгШчЯТФкШн
<!-- jobhistoryЕФЭЈаХЕижЗ -->
<property>
<name>mapreduce.jobhistory.address</name>
<value>192.168.77.130:10020</value>
<description>MapReduce JobHistory Server
IPC host:port</description>
</property>
<!-- jobhistoryЕФwebЗУЮЪЕижЗ -->
<property>
<name>mapreduce.jobhistory.webapp.address</name>
<value>192.168.77.130:19888</value>
<description>MapReduce JobHistory Server
IPC host:port</description>
</property>
<!-- ШЮЮёдЫааЭъГЩКѓЃЌhistoryаХЯЂЫљДцЗХЕФФПТМ -->
<property>
<name>mapreduce.jobhistory.done-dir</name>
<value>/history/done</value>
</property>
<!-- ШЮЮёдЫаажаЃЌhistoryаХЯЂЫљДцЗХЕФФПТМ -->
<property>
<name>mapreduce.jobhistory.intermediate-done-dir</name>
<value>/history/done_intermediate</value>
</property>
[root@localhost /usr/local/hadoop-2.6.0-cdh5.7.0/etc/hadoop]#
vim yarn-site.xml # діМгШчЯТФкШн
<!-- ПЊЦєОлКЯШежО -->
<property>
<name>yarn.log-aggregation-enable</name>
<value>true</value>
</property>
[root@localhost /usr/local/hadoop-2.6.0-cdh5.7.0/etc/hadoop]# |
БрМЭъХфжУЮФМўКѓЃЌжиаТЦєЖЏYARNЗўЮёЃК
[root@localhost
/usr/local/hadoop-2.6.0-cdh5.7.0/sbin]# ./stop-yarn.sh
[root@localhost /usr/local/hadoop-2.6.0-cdh5.7.0/sbin]#
./start-yarn.sh |
ЦєЖЏJobHistoryЗўЮёЃК
[root@localhost
/usr/local/hadoop-2.6.0-cdh5.7.0/sbin]# ./mr-jobhistory-daemon.sh
start historyserver
starting historyserver, logging to /usr/local/hadoop-2.6.0-cdh5.7.0/logs/mapred-root-historyserver-localhost.out
[root@localhost /usr/local/hadoop-2.6.0-cdh5.7.0/sbin]#
|
МьВщНјГЬЃК
[root@localhost
/usr/local/hadoop-2.6.0-cdh5.7.0/sbin]# jps
2945 DataNode
12946 JobHistoryServer
3124 SecondaryNameNode
12569 NodeManager
13001 Jps
2812 NameNode
12463 ResourceManager
[root@localhost /usr/local/hadoop-2.6.0-cdh5.7.0/sbin]# |
ШЛКѓжДаавЛИіАИР§ВтЪдвЛЯТЃК
| [root@localhost
/usr/local/hadoop-2.6.0-cdh5.7.0/share/hadoop/mapreduce]#
hadoop jar ./hadoop-mapreduce-examples-2.6.0-cdh5.7.0.jar
pi 3 4 |
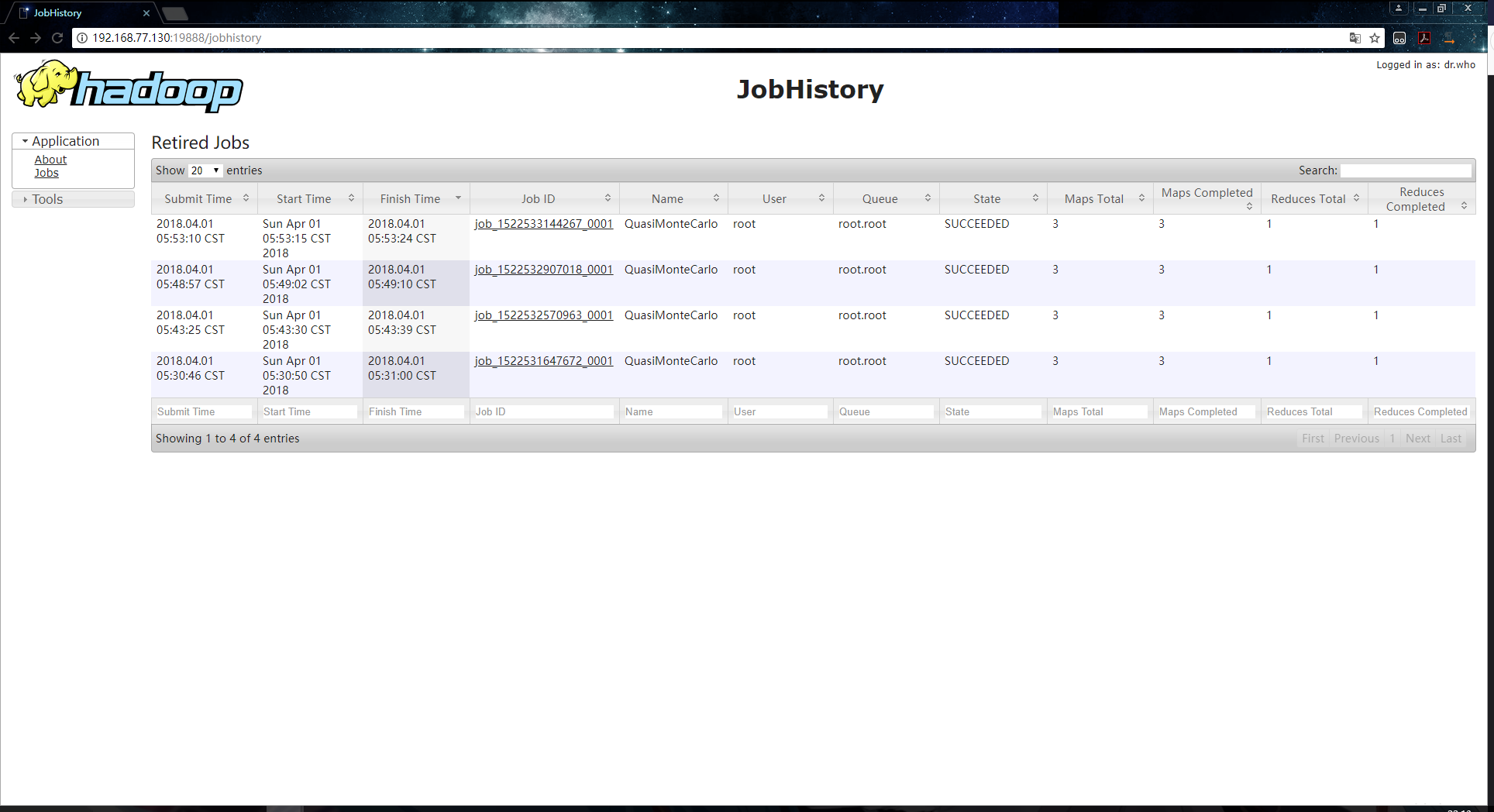
ШЮЮёжДааГЩЙІКѓЃЌетЪБКђЗУЮЪhttp://192.168.77.130:19888ОЭПЩвдНјШыЕНJobHistoryЕФwebвГУцСЫЃК
ФмЙЛе§ГЃЗУЮЪОЭДњБэХфжУвбОГЩЙІСЫЃЌЯждкЫљгаШЮЮёЕФжДааШежОЖМПЩвддкетРяНјааВщПДЃЌгаРћгкЮвУЧШеГЃПЊЗЂжаЕФХХДэЃЌЖјЧвuiНчУцВйзїЦ№РДвВвЊЗНБувЛаЉЁЃ |









