| БрМЭЦМі: |
БОЮФРДздгкinfoqЃЌЮФеТНщЩмСЫЮЂВЉИпПЩгУзЂВсжааФvintageЕФЩшМЦддђгыЗНАИЃЌвдМАЯпЩЯгІгУЕФзюМбЪЕМљЕШЁЃ
|
|
ЕБЧАЮЂВЉЗўЮёЛЏВЩгУЙЋгадЦЃЋЫНгадЦЕФЛьКЯдЦВПЪ№ЗНЪНЃЌГадиСЫУПЬьАйвкМЖЕФСїСПЃЌvintage
зїЮЊЮЂВЉЮЂЗўЮёЕФзЂВсжааФЃЌЮЊЙмРэ 10w МЖЮЂЗўЮёНкЕувдМАдкСїСПМЄдіЕФЧщПіЯТЕФЗўЮёПьЫйРЉЫѕШнЃЌУцСйСЫМЋДѓЬєеНЁЃР§ШчЃКИДдгЭјТчЬѕМўЯТ
vintage ЗўЮёЕФИпПЩгУБЃеЯЁЂНтОіДѓХњСПНкЕузДЬЌБфИќДЅЗЂЕФЭЈжЊЗчБЉЁЂвьГЃЧщПіЯТ vintage
НкЕуЕФздЪЪгІКЭздЛжИДФмСІЁЂvintage ЖрдЦВПЪ№ГЁОАЯТНкЕуЪ§ОнЭЌВНКЭвЛжТадБЃеЯЕШЁЃ
vintage 3.0 гХбХЕФНтОіСЫЩЯЪіЮЪЬтЃЌОпБИСЫСМКУЕФРЉеЙадЃЌПЩгУадДяЕН
6 Иі 9ЁЃ
вЛЁЂЭЛЗЂШШЕуЖдЮЂВЉзЂВсжааФЕФвЊЧѓгыЬєеН
1.1 ЭЛЗЂШШЕуШШЕуЪТМў
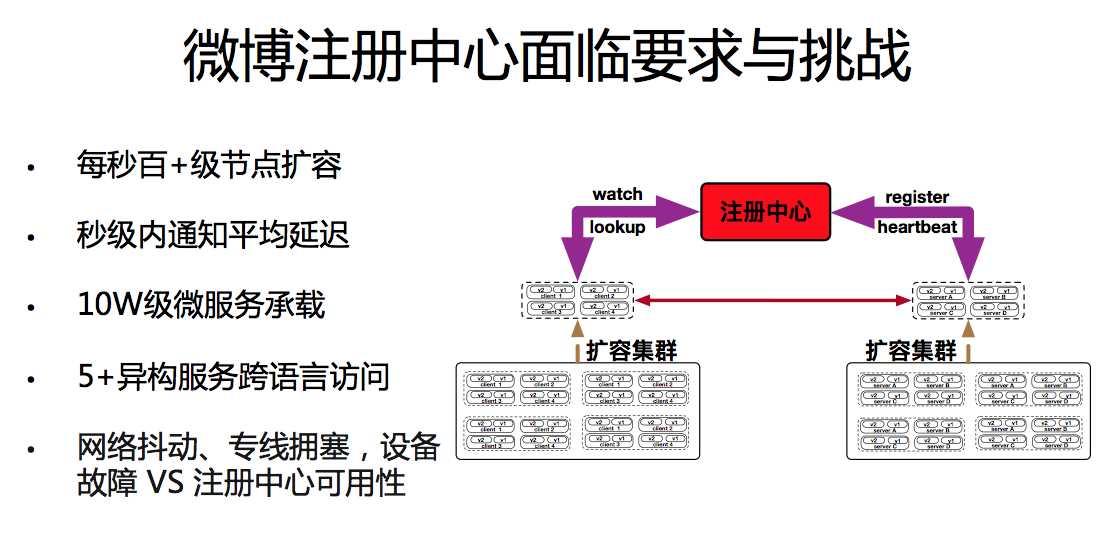
ЭЛЗЂШШЕуЪЧЮЂВЉУцСйЕФзюГЃМћЁЂзюживЊЕФЬєеНЃЌзѓЭМЯдЪОЕФОЭЪЧзюНќЕФвЛИіШШЕуЪТМўЃЌгвЭМЪЧЕБЪБШШЕуЗЂЩњЪБЕФСїСПЭМЃЌЮвУЧПЩвдПДГіШШЕуЪТМўЗЂЩњЪБЃЌдкЖЬЪБМфФкЛсв§ЗЂЮЂВЉСїСПЕФЪ§БЖдіГЄЁЃФЧУДУцЖдШчКЃаЅАуЕФЭЛЗЂСїСПЃЌШчКЮгІЖдОЭЯдЕУгШЮЊживЊЁЃ
ИљОнЗхжЕСїСПФЃаЭВЛЭЌЃЌгІЖдВпТдЖржжЖрбљЃЌЕЋЭЈГЃзмНсЮЊЯТУцШ§жжДыЪЉЃК
ГЃБИГфзуЕФ bufferЃКИУЗНЪНИќМбЪЪгУгкПЩЬсЧАдЄВтЕФСїСПИпЗхЁЃШчЃКЫЋЪЎвЛЙКЮяНкЃЌЮЂВЉЕФДКЭэБЃеЯЕШЁЃЖјМЋШШЪТМўЭљЭљЖМОпБИЭЛЗЂадЃЌКмФбЬсЧАдЄСЯЃЌВЂзіКУГфзуЕФзМБИЁЃЭЌЪБМЋШШЪТМўЗЂЩњЪБЕФСїСПЭљЭљИпгкШеГЃЗхжЕЕФЪ§БЖЃЌЧвВЛЭЌМЋШШЪТМўжЎМфСїСПЗхжЕКЭСїСПФЃаЭВЛОЁЯрЭЌЃЌвђДЫвВКмФбзМШЗЦРЙР
buffer ЕФЪ§СПЁЃ
ВЩгУЗўЮёНЕМЖЕФЗНЪНЃЌБЃеЯКЫаФвЕЮёЃКЭЈЙ§ЖдЯЕЭГНгПкТпМжаЃЌЗЧКЫаФвЕЮёЕФж№ВНМєжІЃЌЛКНтКЫаФНгПкећЬхбЙСІЃЌБЃеЯвЕЮёНгПкЕФЙІФмдЫааМАадФмЮШЖЈЃЌетРрЗНЪНдкКмЖрФъЧАЪЧБШНЯСїааЕФЁЃЕЋДЫРрЗНЪНЭЈГЃЛсАщЫцЯЕЭГЙІФмЪмЯоЃЌвГУцФкШнВЛЭъећЕШЪЧгУЛЇЬхбщЯТНЕЕФЧщПіЗЂЩњЁЃСэЭтШчЙћдкМЋЖЫГЁОАЯТЃЌГіЯжНЕЮоПЩНЕЕФЧщПіЃЌОЭЗЧГЃоЯоЮЁЃвђДЫетжжЗНЗЈвВВЛЪЧЮвУЧФПЧАзюКУЕФбЁдёЁЃ
ЕЏадРЉШн:ЮЊСЫПЫЗўЧАСНжжДыЪЉДјРДЕФВЛзуЃЌОЙ§ЖрФъгІЖдЭЛЗЂСїСПЕФОбщЛ§РлЃЌЮЂВЉФПЧАЪЙгУЛьКЯдЦЕФВПЪ№ЗНЪНЁЃЭЈЙ§ЖдКѓЖЫЮЂЗўЮёзЪдДЕФПьЫйРЉШнЃЌдкЖЬЪБМфФкбИЫйЮЊећИіЯЕЭГЙЙНЈЦ№МсЪЕЕФДѓАгЁЃ
1.2 ЭЛЗЂШШЕуЪТМўЖдЮЂВЉзЂВсжааФЕФвЊЧѓгыЬєеН
жкЫљжмжЊЃЌЮЂЗўЮёЕФдЫааБиаывРРЕзЂВсжааФЕФжЇГжЁЃетОЭЖдЮЂВЉзЂВсжааФЬсГіСЫ 4 ЕувЊЧѓЃК
вЊжЇГжУПУыАйМЖБ№вдЩЯЕФЮЂЗўЮёРЉШн
УыМЖБ№ЕФЮЂЗўЮёБфИќЭЈжЊбгГй
ФмГади 10w+ МЖБ№ЮЂЗўЮёНкЕу
ЙЋЫОМЖЖргябдЮЂЗўЮёзЂВс & ЗўЮёЗЂЯжжЇГж
ШЛЖјМДЪЙЮвУЧТњзуСЫвдЩЯЫФИівЊЧѓЃЌЕЋЪБГЃЛЙЛсгіЕНЭјТчЖЖЖЏЃЌСїСПМЋЖЫЗхжЕЪБзЈЯпДјПэгЕШћЕШЧщПіЁЃФЧУДШчКЮдкЭјТчзДЬЌВЛКУЧщПіЯТЃЌБЃеЯЮЂВЉзЂВсжааФЕФПЩгУадЃЌЪЕЯжЮЂЗўЮёе§ГЃРЉШнОЭГЩЮЊСЫЮЂВЉзЂВсжааФдкЩшМЦЪББиаывЊУцСйЕФЬєеНЁЃ
** ЖўЁЂvintage **ИпПЩгУЩшМЦ & ЪЕМљ
2.1 ЩшМЦФПБъЃК

еыЖдЩЯУцЬсЕНЕФвЊЧѓКЭЬєеНЃЌЩшМЦЮЂВЉзЂВсжааФЪБдкЙІФмЩЯвЊЪЕЯжЙЋЫОМЖБ№ЕФзЂВсжааФМАХфжУЙмРэЦНЬЈЃЌжЇГжЖр
IDCЃЌжЇГжЖргябдЃЌОпБИ 10w+ МЖЮЂЗўЮёГадиФмСІЃЌПЩгУадЩЯашТњзу 6 Иі 9ЁЃдкЗўЮёадФмЗНУцЃЌвЊОпБИУПУыЖдАйМЖБ№вдЩЯЮЂЗўЮёЕФРЉШнФмСІЁЃЭЌЪБвЊЧѓЭЈжЊЦНОљбгГйЕЭгк
500msЁЃЖјдкЩьЫѕадЩЯЃЌЮЂВЉзЂВсжааФздЩэБиаыОпБИЪЎУыМЖНкЕуРЉШнЃЌвдМАЗжжгМЖ IDC зЂВсжааФДюНЈЁЃ
2.2 бЁаЭЖдБШ
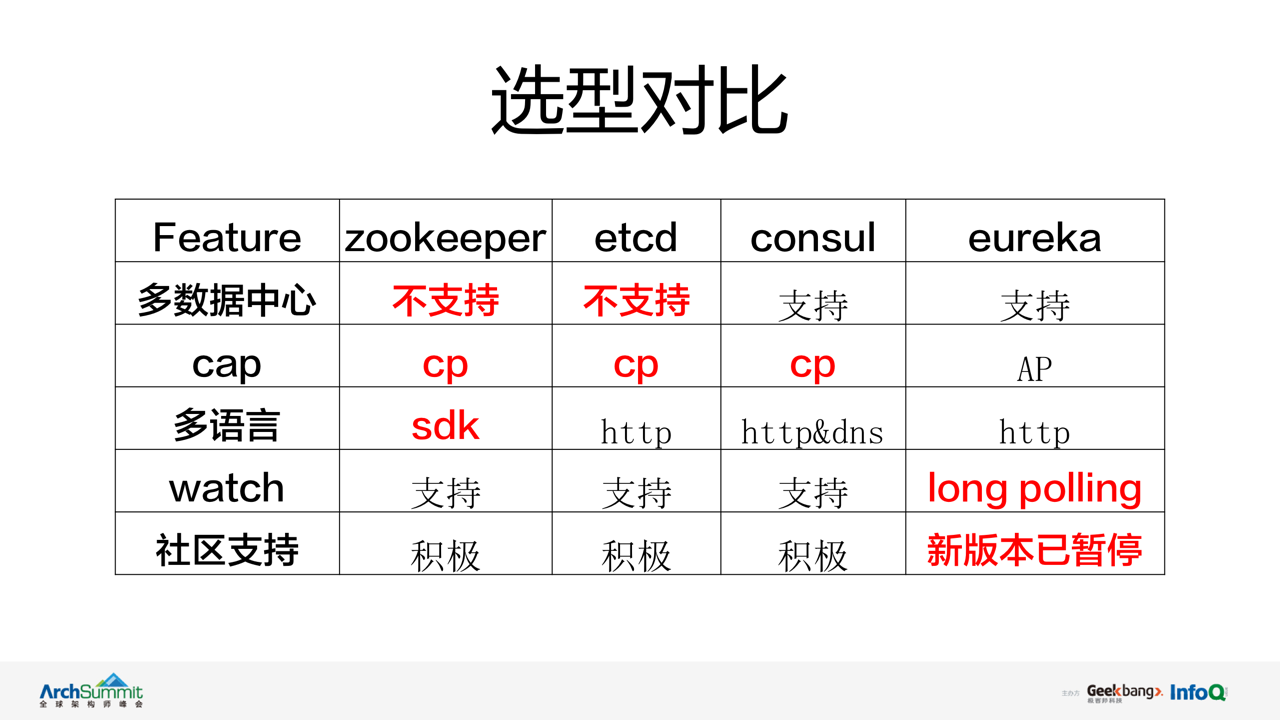
ИљОнЩшМЦФПБъЃЌЖдвЕНчБШНЯСїааЕФзЂВсжааФНјааСЫЕїбаЁЃZooKeeperЃЌEtcd ЮоЗЈНЯКУТњзуЮЂВЉЖдЖрЛњЗПжЇГжвЊЧѓЁЃConsul
ЫфШЛТњзуСЫЖрЛњЗПЕФжЇГжЃЌЕЋдкЭјТч QoS ЗЂЩњЪБгЩгкЦфБОЩэЕФ CP ФЃаЭЩшМЦЃЌдкЗўЮёПЩгУадЗНУцВЛФмЬсЙЉКмКУЕФБЃеЯЁЃЖј
Eureka ЫфШЛдкЖрЛњЗПКЭПЩгУадЗНУцЖМТњзуЮЂВЉЕФвЊЧѓЃЌЕЋ Eureka ФПЧАНіжЇГжвдГЄТжбЏЕФЗНЪНЖЉдФЗўЮёЃЌдкЭЈжЊбгГйЗНУцВЛФмКмКУЕФжЇГжЃЌЭЌЪБ
Eureka дкЩчЧјжЇГжЗНУцвбднЭЃСЫаТАцБОЕФбаЗЂЁЃ
злКЯПМТЧЩЯЪіжИБъ ZooKeeperЃЌEtcdЃЌConsulЃЌEureka ОљЖМЮоЗЈКмКУЕФТњзуЮЂВЉЖдзЂВсжааФЬсГіЕФвЊЧѓЁЃвђДЫЮвУЧОіЖЈдкЯжгаЕФ
vintage ЯЕЭГЛљДЁЩЯНјааЩ§МЖИФдьЃЌРДТњзуОпБИЙЋЫОМЖзЂВсжааФЕФФмСІЁЃ
2.3 vintage МмЙЙЩшМЦ
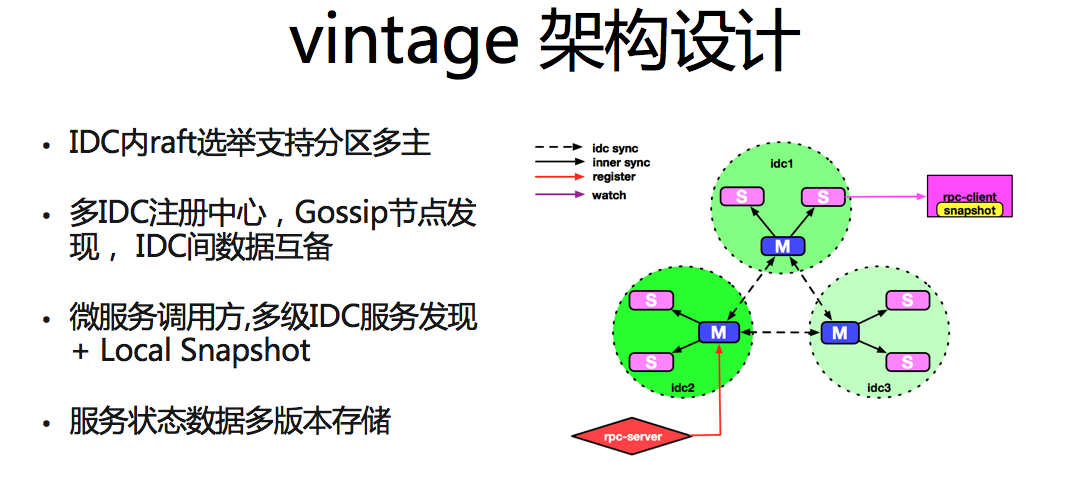
vintage ВПЪ№ЭиЦЫ
ЯШДгЯЕЭГЭиЦЫВПЪ№СЫНтЯТаТАц vintage ЕФећЬхЩшМЦЁЃvintage ЗўЮёВЩгУЖр IDC ЕФВПЪ№ЗНЪНЃЌЭЈЙ§
Gossipe авщЃЌЪЕЯжНкЕуМфЕФздЖЏЗЂЯжЁЃIDC МфжїжїЭЈаХЪЕЯжЖрЛњЗПМфЪ§ОнЭЌВНЁЃIDC ФкВЩгУвЛжїЖрДгЕФВПЪ№ЗНЪНЃЌЛљгк
Raft ЪЕЯжСЫПЩжЇГжЗжЧјЖржїЕФбЁОйавщЃЌжїДгНкЕуНЧЩЋжЎМфЪЕЯжЖСаДЗжРыЁЃ
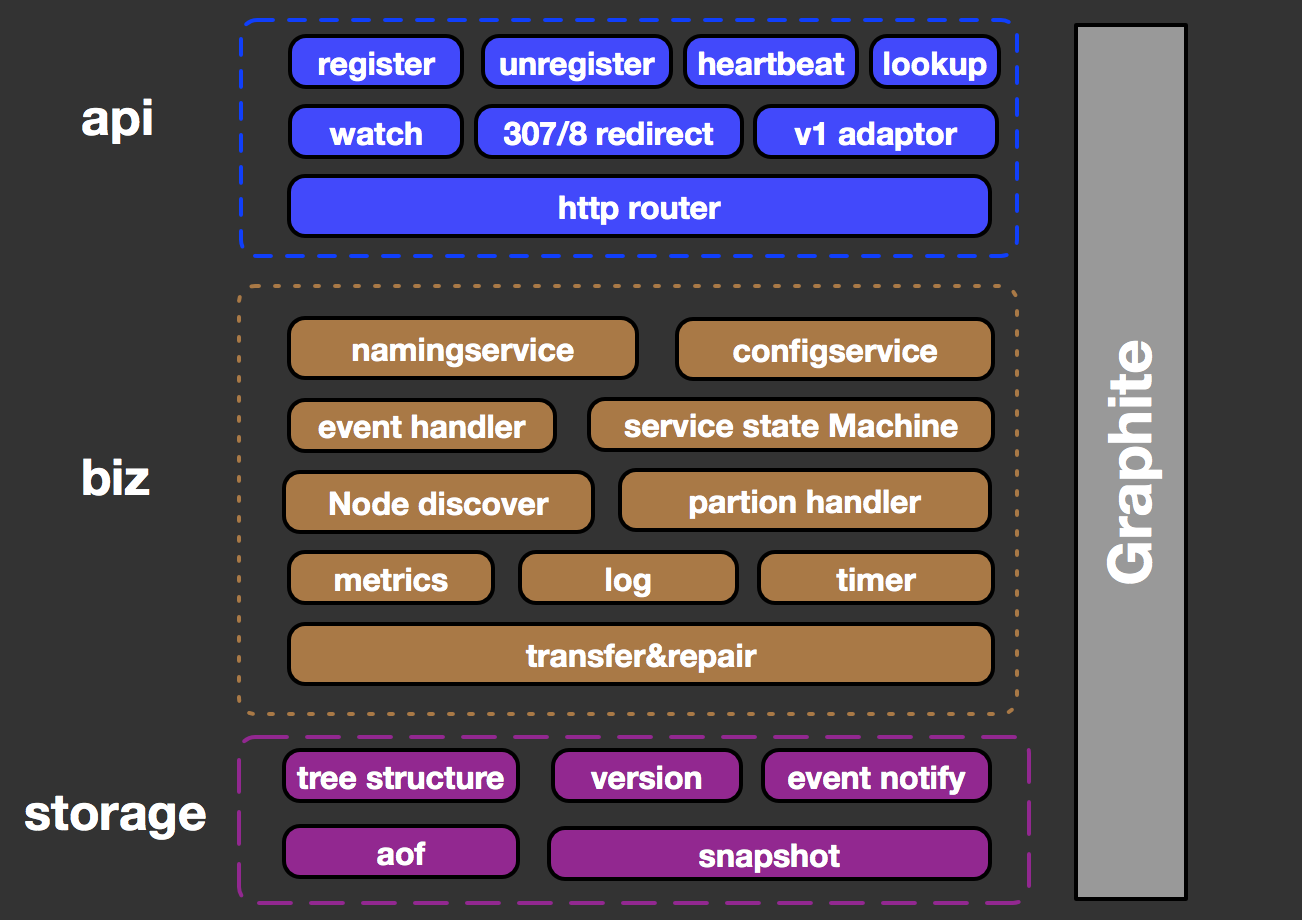
vintage ФЃПщМмЙЙЭМ
vintage ЯЕЭГВЩгУЕфаЭШ§ВуНсЙЙЩшМЦЃЌНЋЭјТчВуЃЌвЕЮёВуЃЌДцДЂВуГщЯѓЗжРыЁЃ
зюЩЯВуЪЧ Restful ЗчИёЪЕЯжЕФ API НгПкЃЌЬсЙЉЮЂЗўЮёзЂВсЃЌЖЉдФМАНЁПЕМьВтЕШЙІФмЁЃЭЌЪБЭЈЙ§
307ЃЌ308 ФЃПщЭъГЩЖдЩЯЯТааСїСПЕФжїЃЌДгНкЕуЗжСїЁЃ
жаМфЕФвЕЮёВуАќРЈУќУћКЭХфжУСНДѓКЫаФвЕЮёЕФЙІФмЪЕЯжЁЃдк vintage ФкВПЙІФмЗНУцЃЌNode discovery
ФЃПщЪЕЯжСЫМЏШКЕФШЋОжНкЕуздЖЏЗЂЯжЃЌtimer КЭ service state MachineЃЈЮЂЗўЮёзДЬЌЛњЃЉЙВЭЌХфКЯЭъГЩЖдЮЂЗўЮёзДЬЌЕФИпаЇЙмРэЁЃЭЌЪБдк
vintage жаЕФШЮКЮзЂВсЃЌзЂЯњМАЮЂЗўЮёдЊЪ§ОнИќаТЃЌНкЕузДЬЌБфИќЕШааЮЊЖМНЋБЛГщЯѓЮЊвЛИіЖРСЂЪТМўВЂНЛгЩ
event handler НјааЭГвЛДІРэЁЃTransfer КЭ repair ФЃПщгУгкећИіМЏШКЕФНкЕуМфЪ§ОнЭЌВНМАвЛжТадаоИДЙІФмЁЃЖјЮЊгІЖдЭјТчЮЪЬтЖдзЂВсжааФМАећИіЮЂЗўЮёЬхЯЕПЩгУадВњЩњЕФгАЯьЃЌvintage
ФкВПЭЈЙ§ partion hanlder ЪЕЯжЭјТчЗжЧјзДЬЌЕФИажЊВЂНсКЯЖрбљЛЏЕФЯЕЭГБЃеЯВпТдгшвдгІЖдЁЃ
зюЯТУцЕФДцДЂВуЃКВЩгУЛљгкЪїаЮНсЙЙЕФЖрАцБОЪ§ОнДцДЂМмЙЙЃЌЪЕЯжСЫЖджкЖрЮЂЗўЮёМАЦфЫљЪєЙиЯЕЕФгааЇЙмРэЃЌжЇГжЮЂЗўЮёЕФЛвЖШЗЂВМЁЃevent
notify ФЃПщНЋЪ§ОнБфИќЪТМўЪЕЪБЭЈжЊЕНвЕЮёВуЃЌХфКЯ watch hub ЭъГЩЖдЯћЯЂЖЉдФепЕФЪЕЪБЭЦЫЭЁЃдкЪ§ОнПЩППадЗНУцЃЌВЩгУ
aof+snapshot ЗНЪНЪЕЯжБОЕиЕФЪ§ОнГжОУЛЏЁЃ
2.4 ИпПЩгУЪЕМљ

СЫНтећИіЯЕЭГКѓЃЌНЋЭЈЙ§ЭјТчЗжЧјЃЌЭЈжЊЗчБЉЃЌЪ§ОнвЛжТадЃЌИпПЩгУВПЪ№ЫФИіЗНУцНщЩм vintage дкИпПЩгУЗНУцЕФЪЕМљЃЌвдМА
AP ФЃаЭзЂВсжааФдкЪ§ОнвЛжТадБЃеЯЗНУцЕФДыЪЉЁЃ
ЭјТчЗжЧј
ГЁОАвЛЃКvintage ФкВПЭјТчЗжЧј
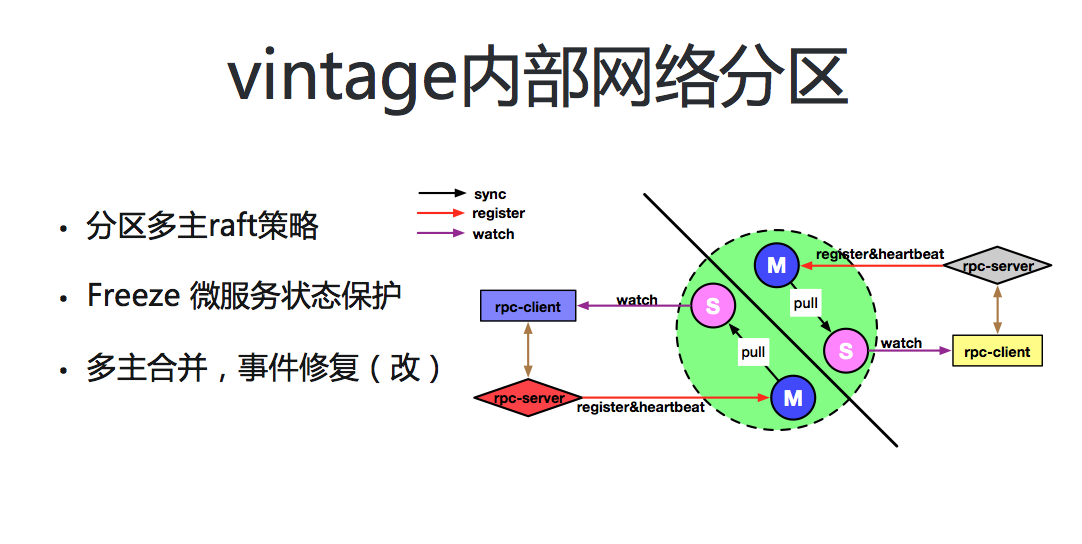
ШчЩЯЭМЃЌЭјТчЗжЧјНЋ vintage МЏШКвЛЗжЮЊЖўЃЌЭЌЪБУПИіЗжЧјжаЕФНкЕуЪ§СПОљЩйгк n/2+1 ИіЃЈn
ЮЊИУ IDC згМЏШК vintage ЗўЮёЕФНкЕузмЪ§ЃЉЁЃдкИУГЁОАЯТЛљгкДЋЭГ Raft авщЕФзЂВсжааФЃЌгЩгкЖдЪ§ОнЧПвЛжТадЕФвЊЧѓЃЌНЋЮоЗЈЬсЙЉе§ГЃЕФЖСаДЗўЮёЁЃЖј
Etcd КЭ Consul дкНтОіетИіЮЪЬтЪБЃЌвВНіЪЧЭЈЙ§ stale read ЕФЗНЪНТњзуСЫЖдЪ§ОнЖСШЁЕФашвЊЃЌЕЋШдШЛЮоЗЈЪЕЯждкИУГЁОАЯТЖдЮЂЗўЮёзЂВсЕФашвЊЁЃ
ЮЂВЉзЂВсжааФЮЊЪЕЯждкЭјТчЗжЧјЯТзЂВсжааФЗўЮёИпПЩгУЃЌЖддга Raft авщбЁОйЛњжЦНјааИФдьЃЌЪЕЯжСЫПЩЖдШЮвтЗжЧјЧщПіЯТЕФЖржїбЁОйжЇГжЃК(1)
НтОіСЫЗжЧјЗЂЩњЪБДІгкЩйЪ§ЗжЧјФк rpc-server гы rpc-client ЕФзЂВсМАЗўЮёЗЂЯжФмСІЁЃЪЕЯжШЮКЮСЃЖШЗжЧјЯТ
vintage ЗўЮёЕФИпПЩгУЁЃ(2) ЖдЙЪеЯНкЕуЕФГаЪмФмСІДѓЗљЬсЩ§ЃЌгЩд Raft авщЕФ n/2-1
ИіНкЕуЃЌЬсЩ§жСзюДѓ n-1 НкЕуЁЃ
ЭЌЪБдкИУГЁОАЯТЭјТчЗжЧјКѓЃЌЮЂЗўЮёЛсНЋздМКЕФаФЬјЛуБЈЕНЫљЪєЗжЧјЕФжїНкЕуЁЃЖјгЩгкЗжЧјДцдкЃЌЗжЧјМфНкЕуЪ§ОнЮоЗЈЭЈаХЁЃЖдгкЃЈvintageЃЉIDC
МЏШКжаЕФЦфЫћжїНкЕуРДЫЕОЭГіЯжСЫЮЂЗўЮёаФЬјЖЊЪЇЕФЯжЯѓЃЌЖјаФЬјЪЧзїЮЊЗўЮёНЁПЕзДЬЌЕФживЊЪЖБ№ЪжЖЮЁЃаФЬјГЌЪБЕФЮЂЗўЮёНкЕуНЋЛсБЛБъЪЖЮЊВЛПЩгУзДЬЌЃЌДгЖјВЛЛсБЛЕїгУЗНЗУЮЪЁЃЭјТчЗжЧјЪБЭљЭљЛсГіЯжДѓХњСПЕФЮЂЗўЮёаФЬјГЌЪБЃЌЮДФмЭзЩЦДІРэНЋжБНггАЯьвЕЮёЯЕЭГЗўЮёЕФЮШЖЈадМА
SLA жИБъЁЃЖјДЫЪБ partion handler ФЃПщНЋЛсгХЯШгкаФЬјГЌЪБИажЊЕНЭјТчЗжЧјЕФЗЂЩњЃЌЦєЖЏ
freeze БЃЛЄЛњжЦЃЈfreezeЃКзЂВсжааФФкВПЖдЮЂЗўЮёзДЬЌЕФБЃЛЄЛњжЦЃЌЛљгкРжЙлВпТдЖГНсЕБЧА vintage
ЯЕЭГжаЕФЮЂЗўЮёНкЕузДЬЌЃЌНћжЙНкЕуВЛПЩгУзДЬЌЕФБфИќЃЌЭЌЪБЖдгкНгЪмЕНаФЬјЕФЮЂЗўЮёНкЕуЃЌжЇГжЦфЛжИДПЩгУзДЬЌЃЉЁЃ
ЗжЧјЛжИДКѓЃЌИїНкЕуМфЭЈаХЛжИДе§ГЃЁЃvintage ЛсНјаадйДЮбЁОйЃЌДгЗжЧјЪБЕФЖрИіжїНкЕужабЁОйГіаТЕФжїНкЕуЁЃvintage
жаЕФЪ§ОнБфИќЖМЛсГщЯѓЮЊвЛИіЖРСЂЪТМўЃЌЯЕЭГЛљгкЯђСПЪБжгЪЕЯжСЫЖдШЋОжЪТМўЕФЫГађПижЦЁЃдкЖржїКЯВЂЙ§ГЬжаЭЈЙ§
repair ФЃПщЭъГЩНкЕуМфЪ§ОнЕФвЛжТадаоИДЃЌБЃеЯ IDC ФкМЏШКзюжевЛжТадЁЃ
ГЁОАЖўЃКclient гы vintage МфЭјТчЗжЧј
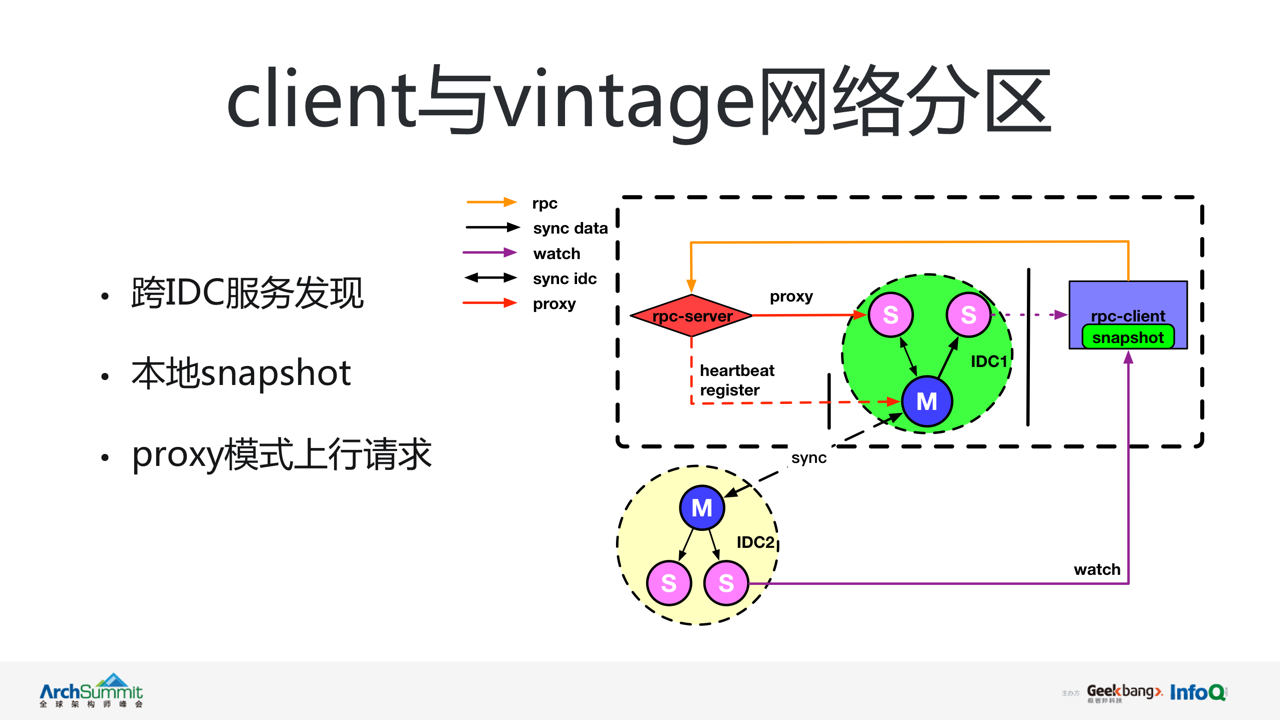
ЭМжаТЬЩЋКЭЛЦЩЋЧјгђЗжБ№ДњБэСНИіВЛЭЌ IDC жаЕФ vintage згМЏШКЁЃКьЩЋКЭзЯЩЋДњБэ IDC1
ФкЕФ rpc-server КЭ rpc-clinetЁЃДЫЪБКьЩЋЕФ rpc-server гы IDC1
жаЕФ vintage жїНкЕуГіЯжСЫЭјТчЗжЧјЃЌЖјзЯЩЋЕФ rpc-client гы IDC1 ЕФ vintage
МЏШКећЬхДцдкЭјТчИєРыЯжЯѓЁЃrpc-server КЭ rpc-client жЎМфЭјТчЭЈаХе§ГЃЁЃЫфШЛетЪЧвЛИіЯрЖдИДдгЧвМЋЖЫЕФЗжЧјГЁОАЃЌЕЋЖдгкЮЂВЉзЂВсжааФЕФИпПЩгУЩшМЦвЊЧѓЪЧБиаывЊНтОіЕФЮЪЬтЁЃЯТУцЮвУЧРДПДПД
vintage ЪЧШчКЮНтОіЕФЁЃ
дкИУГЁОАЯТ rpc-server ПЩЭЈЙ§ DNS ЗЂЯжЕФЗНЪНЛёШЁИУ IDC Фк vintage згМЏШКЕФШЋВПЛњЦїСаБэЃЌВЂЪЙгУ
proxy ФЃЪННЋзЂВсЧыЧѓЗЂЫЭжСзгМЏШКжаШЮвтПЩДяЕФДгНкЕуЁЃВЂЭЈЙ§ДгНкЕуДњРэЃЌНЋзЂВсЧыЧѓзЊЗЂжСжїНкЕуЭъГЩЗўЮёзЂВсЁЃrpc-server
ЛсЖЈЦкМьВтздМКгыжїНкЕуЕФСЌНгзДЬЌЃЌвЛЕЉЗЂЯжСЌНгЛжИДЃЌНЋздЖЏЙиБе proxy ФЃЪНЃЌВЂЭЈЙ§ЯђжїНкЕуЗЂЫЭаФЬјЮЌЛЄздЩэзДЬЌЁЃ
rpc-client ПЩЭЈЙ§Пч IDC ЗўЮёЗЂЯжЗНЪНЃЌдк IDC2 жаЖЉдФЫљЙизЂЕФ rpc-server
ЗўЮёаХЯЂЃЌЦфздЩэЛЙЛсЖЈЦкНЋЛёШЁЕНЕФ rpc-serve ЗўЮёСаБэБЃДцжСБОЕи snapshot ЮФМўЁЃЗРжЙМДЪЙ
rpc-client гыШЋВПЕФ vintage ЗўЮёОљГіЯжЭјТчИєРыЃЌвВПЩБЃжЄздЩэе§ГЃЦєЖЏМАЕїгУЁЃДгЖјЪЕЯжСЫ
client гы vintage ЗўЮёЗжЧјЪБЃЌЮЂЗўЮёзЂВсгыЗўЮёЗЂЯжЕФИпПЩгУЁЃ
зЂЃКvintage ЗўЮёЭЌбљжЇГжПч IDC ЕФЮЂЗўЮёзЂВсЁЃЕЋДгЪЕМЪЗУЮЪМАдЫЮЌФЃаЭПМТЧЃЌвЊЧѓУПИі rpcserver
НкЕудкЭЌвЛЪБПЬНіПЩЪєгквЛИі IDC МЏШКЁЃ
ЭЈжЊЗчБЉЃК

дкЮЂВЉГЁОАЯТЃЌИљОнЕїгУЗНЖдУПжжЮЂЗўЮёЕФЖЉдФЪ§СПЕФВЛЭЌЃЌЭЈГЃЛсГіЯжАйМЖжСЧЇМЖБ№ЕФЭЈжЊЗХДѓЃЌРЯАцБО vintage
ЕФЖЉдФЙІФмЪЧЛљгк signЃЈmd5 КѓЗўЮёСаБэжИЮЦЃЉЖдБШ + ШЋСПЪ§ОнРШЁЕФЗНЪНЃЌИљОнЮЂЗўЮёздЩэЙцФЃЭЌбљЛсГіЯжЪЎМЖжСАйМЖБ№ЕФЯћЯЂЬхЗХДѓЃЈЖўДЮЗХДѓЯжЯѓЃЉЁЃШєДЫЪБГіЯжДѓСПЮЂЗўЮёРЉЫѕШнЃЌЭјТч
QoS ЛђДѓУцЛ§ЮЂЗўЮёЛњЦїЩшБИЕФЙЪеЯЃЌОЙ§СНДЮЗХДѓЕФЭЈжЊЙцФЃПЩДяЕНАйЭђЩѕжСЧЇЭђМЖБ№ЃЌбЯжиеМгУЛњЦїДјПэзЪдДЁЃ
ДјПэПнНпЃЌжБНггАЯьзЂВсжааФвЕЮёЙІФмЪЙгУЃЛ
ДјПэПнНпЛЙНЋЕМжТДѓУцЛ§аФЬјЖЊЪЇЃЌДгЖјДЅЗЂДѓСПЮЂЗўЮёБЛБъЪОЮЊВЛПЩгУзДЬЌЃЌжБНггАЯьЯпЩЯЮЂЗўЮёЕФЕїгУЃЛ
ЭјТчЖЖЖЏМЋПЩФмАщЫцДѓВПЗжЕФаФЬјЖЊЪЇЃЌвзДЅЗЂЦЕЗБЕФЮЂЗўЮёзДЬЌдкЁЎВЛПЩгУЁЏКЭЁЎе§ГЃЁЏжЎМфРДЛиБфЛЏЃЌВњЩњИќДѓСПМЖЕФЭЈжЊБфИќЃЌЗЂЩњЗчБЉЕўМгзшШћЭјТчЃЌЕМжТ
IDC ФкзЂВсжааФЗўЮёВЛПЩгУЁЃ
еыЖдЭЈжЊЗчБЉбЯжиЮЃКІЃЌИФдьКѓЕФ vintage ЯЕЭГЪЙгУСЫЁАЪсЁБКЭЁАБЃЁБСНжжВпТдгІЖдЁЃ
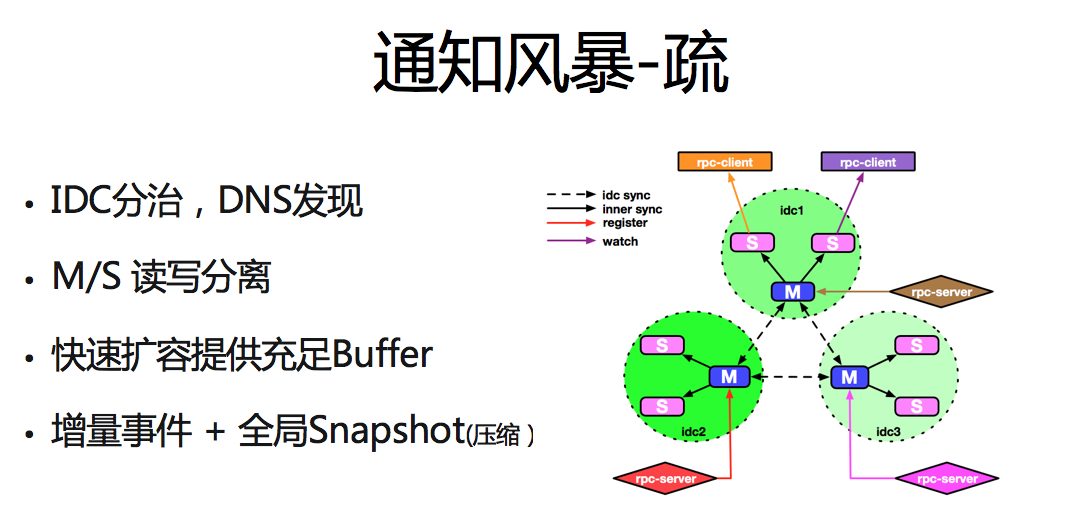
ЁАЪшЁБжївЊВЩгУЕФШ§жжВпТд
ЗжСїМАИКдиОљКтЃКЪзЯШЛЅСЊЭјЙЋЫОЭЈГЃИљОнгУЛЇЕФЕигђКЭдЫгЊЩЬЕШаХЯЂЃЌНЋЧыЧѓЗжСїжСВЛЭЌ IDCЃЌВЂдкКЫаФ
IDC ФкВПВПЪ№ШЋСПЕФКЫаФЗўЮёЃЌБЃеЯ IDC ФкЭъГЩЖдгУЛЇЧыЧѓЕФЯьгІЁЃИљОнЮЂВЉСїСПЗжХфМАвЕЮёЗўЮёЖрЛњЗПВПЪ№ЕФЬиЕуЃЌvintage
дкЙЋЫОМИДѓКЫаФЛњЗПОљгаВПЪ№ЃЌЪЕЯжСЫЖрЛњЗПЮЂЗўЮёЩЯааЧыЧѓЕФСїСПЗжРыЁЃЭЌЪБИљОнзЂВсжааФаДЩйЖСЖрЕФЬиЕудк
IDC ФкВЩгУвЛжїЖрДгЕФВПЪ№НсЙЙЃЌГ§БЃеЯСЫЗўЮёЕФ HA ЭтЃЌвВЖдЯТааСїСПЪЕЯжСЫИКдиОљКтЁЃ
ПьЫйРЉШнЃКЖдгкЭЈжЊЗчБЉдьГЩЕФЯТааСїСПЃЌПЩЭЈЙ§ЖдДгНкЕуПьЫйРЉШнЕФЗНЪНЬсЙЉГфзуЕФЗўЮёЭЬЭТМАДјПэЁЃ
діСПЪТМўЃЌБмУтЯћЯЂЬхЖўДЮЗХДѓЃКvintage ФкВПНЋШЋВПЕФЪ§ОнБфИќЃЌЭГвЛГщЯѓЮЊЖРСЂЪТМўВЂдкМЏШКЪ§ОнЭЌВНЃЌвЛжТадаоИДКЭЗўЮёЗЂЯж
& ЖЉдФЙІФмЩЯОљВЩгУдіСПЭЈжЊЗНЪНЃЌБмУтСЫЯћЯЂЬхЗХДѓЮЪЬтЁЃНЋећЬхЯћЯЂСПгааЇбЙЫѕ 2-3 ИіЪ§СПМЖЃЌНЕЕЭДјПэЕФЪЙгУЁЃЖјЗЂЩњЪТМўвчГіЪБЃЌЯЕЭГвВЛсЯШЖдШЋСПЪ§ОнбЙЫѕКѓдйНјааДЋЕнЁЃ
ЁАБЃЁБЪЧЭЈЙ§ЯЕЭГЖржиЗРЛЄВпТдЃЌБЃеЯЭЈжЊЗчБЉЯТ vintage МАЮЂЗўЮёЕФзДЬЌЮШЖЈЁЃЦфжївЊВЩгУЕФШ§жжВпТдЃК
ЪзЯШЪЙгУ partion handler ЪЕЯжЖд vintage МЏШКФкЗжЧјКЭЮЂЗўЮёгыМЏШКНкЕуЗжЧјЭјТчЮЪЬтЕФзлКЯМрПиЁЃНсКЯ
freeze ЛњжЦгааЇБмУтСЫЮЂЗўЮёНкЕузДЬЌЕФЦЕЗББфИќДгЖјЭЌбљБмУтСЫдкЭјТч QoS в§ЗЂЕФЭЈжЊЗчБЉЁЃ
ЦфДЮЖдгквЕЮёЯЕЭГРДЫЕЃЌЯЕЭГећЬхЗўЮёзДЬЌЯрЖдЮШЖЈЁЃЛљгкетЕу vintage ЮЊЗўЮёдіМгСЫБЃЛЄуажЕЕФЩшМЦЃЈФЌШЯ
60%ЃЉЁЃЭЈЙ§ЩшжУБЃЛЄуажЕЃЌПЩгааЇПижЦЭЈжЊЗчБЉЗЂЩњЪБ vintage ФкВПвьГЃЗўЮёЪ§ОнБфИќЕФЙцФЃЁЃИќБЃеЯвЕЮёЯЕЭГЕФећЬхЮШЖЈЃЌБмУтЗЂЩњЗўЮёбЉБРЁЃ
зюКѓЖдгкДјПэПнНпЮЪЬтЃЌvintage діМгСЫЖдДјПэЪЙгУТЪЕФМьВтКЭЯожЦЁЃЕБГЌЙ§ЛњЦїДјПэЯћКФ >70%ЃЌЛсДЅЗЂЯЕЭГ
304 НЕМЖЃЌднЭЃШЋВПЭЈжЊЭЦЫЭЃЌБмУт vintage НкЕуДјПэПнНпБЃеЯМЏШКНЧЩЋаФЬјЮЌЛЄЃЌНкЕуЗЂЯжЃЌЪ§ОнЭЌВНЕШФкВПЙІФмЖдДјПэЕФЛљБОвЊЧѓЃЌЮЌЛЄећИіМЏШКЕФЮШЖЈдЫааЁЃ
Ъ§ОнвЛжТад
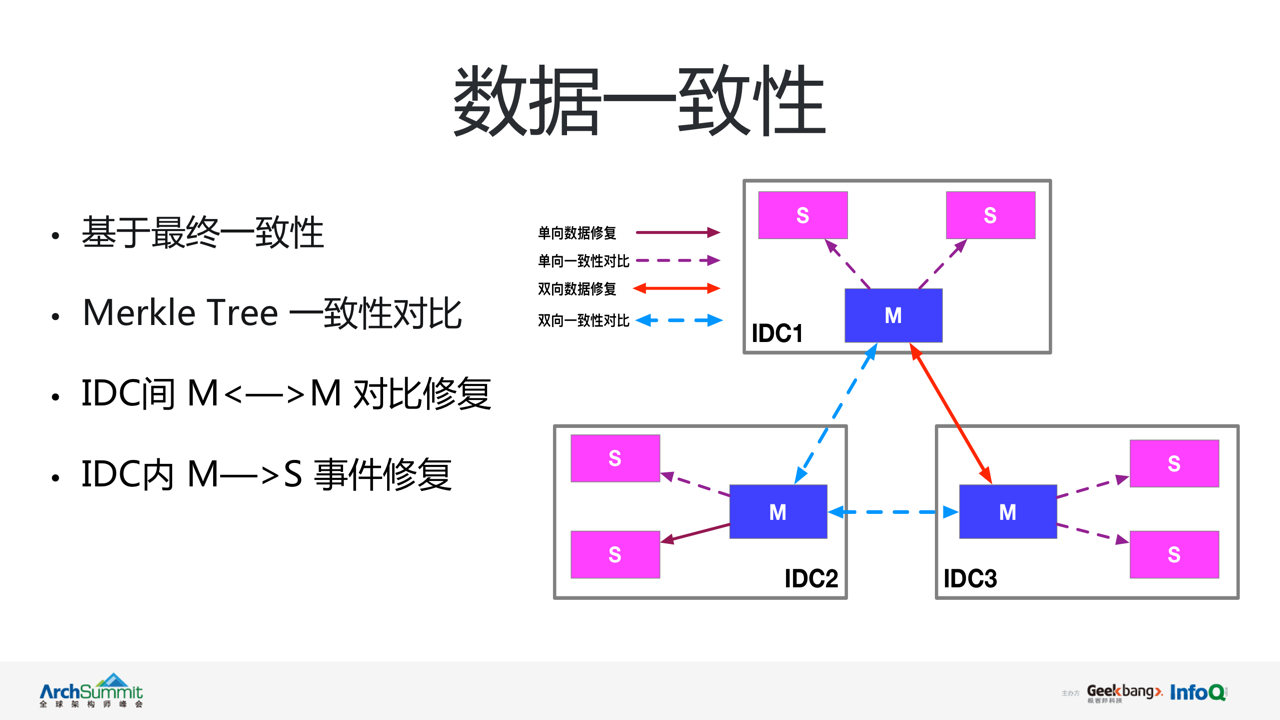
ВЛФбПДГі vintage ЪЧЛљгк AP ФЃаЭЩшМЦЕФзЂВсжааФЁЃИУФЃаЭЯТзЂВсжааФФкНкЕуМфЪ§ОнЕФвЛжТадЮЪЬтЃЌГЩЮЊСЫ
vintage БиаывЊДІРэЕФКЫаФЮЪЬтЁЃvintage бЁдёСЫзюжевЛжТадзїЮЊМЏШКЕФЪ§ОнвЛжТадФЃаЭЁЃ
НгЯТРДНщЩм vintage ЕФзюжевЛжТадЪЕЯжЛњжЦЁЃ
ЪзЯШРДЛиЙЫЯТ vintage МЏШКЕФВПЪ№ЭиЦЫЁЃvintage ВЩгУЖр IDC ВПЪ№ЃЌИї IDC МфЗжжЮЖРСЂЃЌIDC
МфЭЈЙ§жїжїНкЕуЭъГЩЪ§ОнЭЌВНЃЌIDC ФкжїДгНЧЩЋЖСаДЗжРыЁЃдкИУЭиЦЫЯТЃЌvintage ЭЈЙ§МЏШКФкжїДгЃЌМЏШКМфжїжїЕФЪ§ОнЭЌВН
+ ВювьЖдБШаоИДЯрНсКЯЕФЗНЪНЃЌЪЕЯжНкЕуМфЪ§ОнЕФзюжевЛжТадЁЃ(1) Ъ§ОнЭЌВНЃКИї IDC ФкОљгЩжїНкЕуИКд№ЩЯааЧыЧѓДІРэЃЌДгНкЕуЭЈЙ§РШЁжїНкЕуаТдіЕФБфИќЪТМўЭъГЩЪ§ОнЭЌВНЁЃ(2)
ЭЌЪБ vintage ФкВПЖдШЋВПДцДЂЕФЪ§ОнЙЙНЈСЫЖдгІЕФ merkle TreeЃЌВЂЫцЪ§ОнБфЛЏНјааЪЕЪБИќаТЁЃ
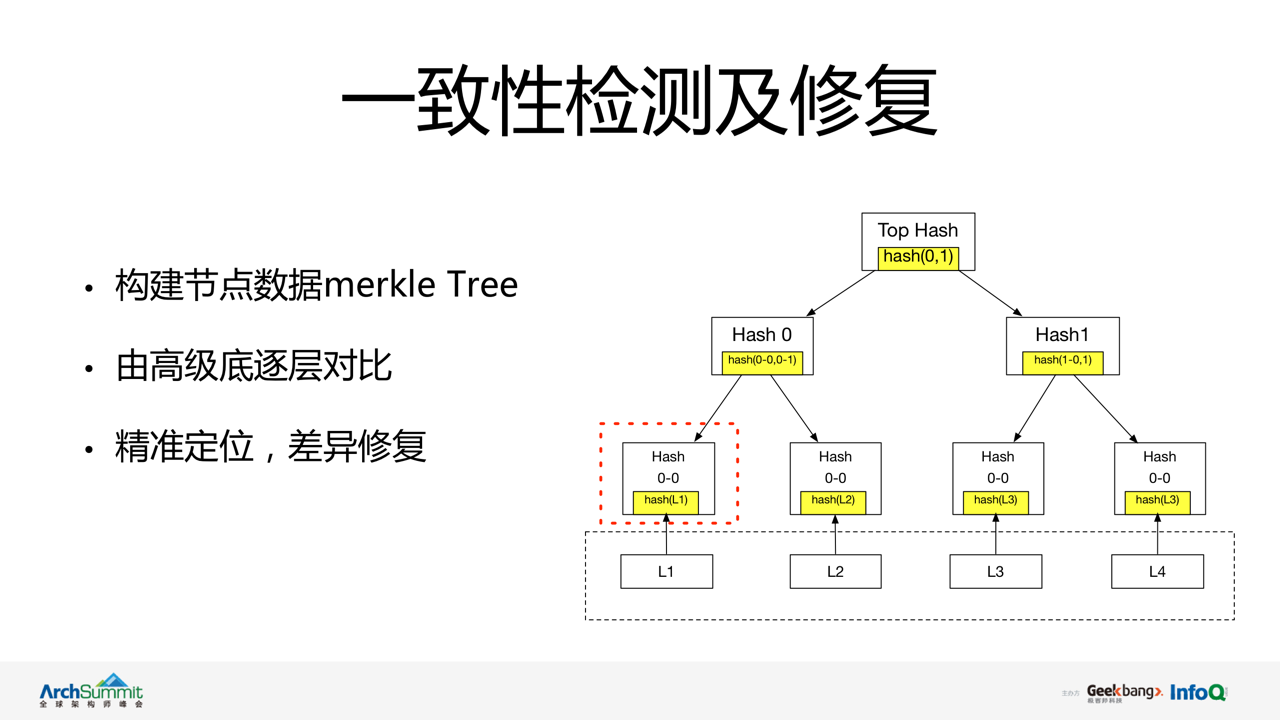
vintage ЛсЖЈЦкДЅЗЂМЏШКвЛжТадМьВтТпМЁЃвджїНкЕужаЪ§ОнЮЊБъзМЃЌIDC ФкВЩгУжїДгЃЌIDC МфдђЪЧжїжїЗНЪНЪЙгУ
merkle tree ЬиЕугЩИљНкЕуж№ВуЖдБШЃЌОЋШЗЖЈЮЛЪ§ОнВювьНкЕуЃЌВЂЭъГЩвЛжТадаоИДЁЃ
зЂЃКЭЈЙ§ЯпЩЯдЫааЭГМЦЃЌЭЈГЃНіга <0.5% ЕФМьВтНсЙћГіЯжЪ§ОнВЛвЛжТЯжЯѓЁЃРћгУ merkle
Tree ЕФЬиЕугааЇгХЛЏСЫЪ§ОнЖдБШМАаоИДЙ§ГЬжаЖдЭјТчДјПэВЛБивЊЕФЯћКФЃК
99.5% вЛжТадМьВтНіашЖдИљНкЕуЪ§ОнЖдБШМДПЩШЗШЯЪ§ОнвЛжТадЁЃ
жЇГжж№ВуНкЕуЖдБШЃЌПЩзМШЗЖЈЮЛВЛвЛжТНкЕуЃЌВЂеыЖдИУНкЕуНјааЪ§ОнаоИДЁЃ
ИпПЩгУВПЪ№ЃК
ЗўЮёЕФИпПЩгУЭЈГЃгыВПЪ№ЗНЪНБиУмВЛПЩЗжЃЌvintage зїЮЊЙЋЫОМЖБ№ЕФзЂВсжааФБОЩэБиаыОпБИМЋИпЕФПЩгУадКЭЙЪеЯЛжИДФмСІЁЃ
vintage дкВПЪ№ЩЯжївЊПМТЧвдЯТ 4 ЕуЃК
ЪЪЖШШпгрЖШВПЪ№ЃКШпгрЖШЗНУцЃЌvintage ЗўЮёВЩгУ 2 БЖШпгрВПЪ№ЃЌШпгрЕФНкЕудкЬсЩ§зЂВсжааФздЩэПЩгУадЕФЭЌЪБЃЌвВЮЊвЕЮёЯЕЭГдкЭЛЗЂЗхжЕСїСПЪБЕФПьЫйРЉШнЗДгІЬсЙЉСЫСМКУЕФЕЏадПеМфЁЃ
гыЭјТчЯћКФаЭвЕЮёИєРыЃКзїЮЊДјПэУєИааЭЗўЮёЃЌvintage дкЛњЦїВПЪ№ЪБЛсгыЭјТчЯћКФРрвЕЮёОЁСПИєРы
ЖрЛњМмВПЪ№ЃЌЭЌЛњМмФкЖрЗўЮёВПЪ№ЃКПМТЧЕНЭјТчЗжЧјКЭЩшБИЙЪеЯЕФвђЫиЃЌvintage ВЩгУЖрЛњМмВПЪ№ЗНЪНЃЌЭЌЛњМмФкЭЈГЃВПЪ№жСЩйСНИіЗўЮёНкЕуЁЃ
Жр IDC МфЪ§ОнЛЅБИЃКvintage ЬьШЛЪЕЯжСЫ IDC МфЕФЪ§ОнЛЅБИЃЌЭЌЪБЭЈЙ§ШпгрвЛЬз IDC
згМЏШКгУгкШЋМЏШКЕФЪ§ОнджБИЁЃМЋЖЫЧщПіЪБПЩдкЗжжгМЖЪЕЯж IDC ЮЌЖШЕФШЮвтзгМЏШКДюНЈЃЌВЂЭЈЙ§ЯЕЭГФкВПНгПкгХЯШДгЪ§ОнджБИЕФзгМЏШКжаЭъГЩЪ§ОнЛжИДЁЃ
2.5 ИпадФмЃК
дкНщЩм vintage ИпПЩгУКѓЃЌдйРДПДПД vintage ЯЕЭГдкИпадФмЗНУцШчКЮЪЕЯж 10w+ НкЕуЕФжЇГХМАЦНОљАйКСУыМЖБ№ЕФЭЈжЊбгГйЁЃ
List+Map Ъ§ОнНсЙЙЪЕЯжСЫжЇГж 10w НкЕуИпадФмЖЈЪБЦїЁЃ
watch БфИќЪЕЪБЭЦЫЭЛњжЦЁЃ
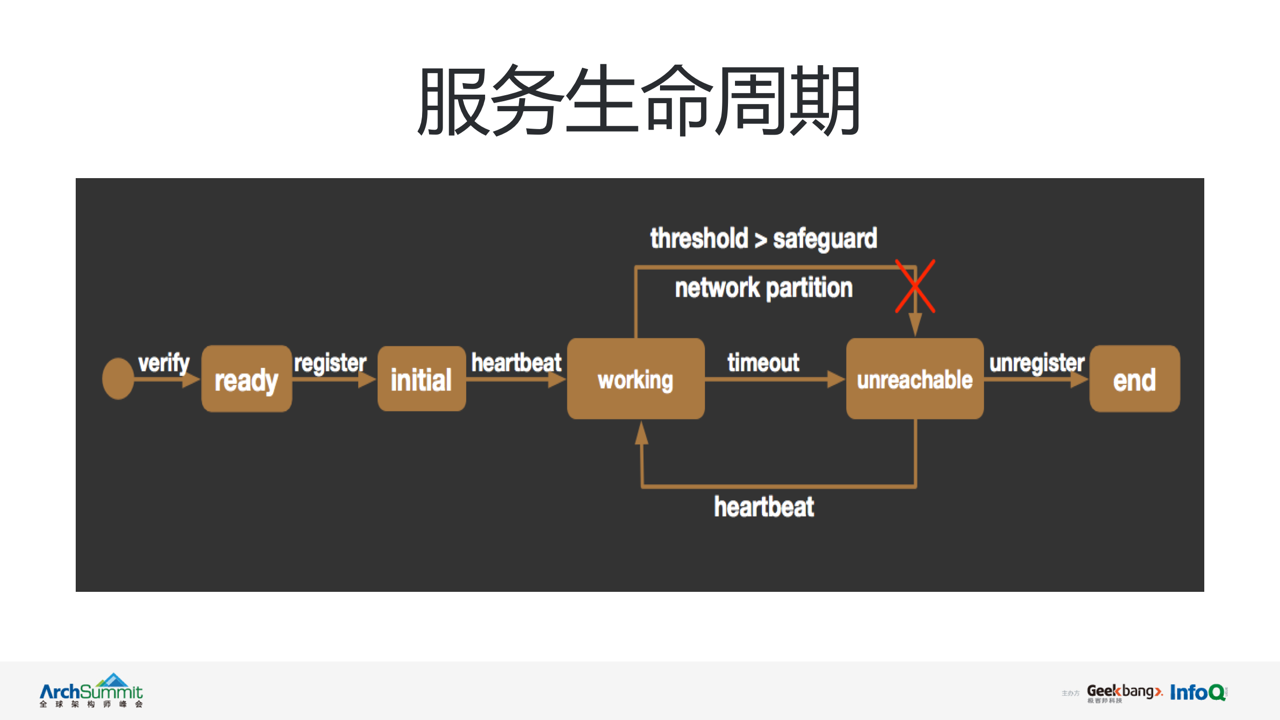
ЪзЯШСЫНтЯТЮЂЗўЮёдк vintage ЯЕЭГжаЕФЩњУќжмЦкЃЌетЪЧвЛеХ vintage ФкВПЮЌЛЄЮЂЗўЮёЩњУќжмЦкЕФзДЬЌЛњЁЃЦфжа
initialЃЌworkingЃЌunreachable ЮЊ vintage ФкВПЖдЙмРэЮЂЗўЮёЕФШ§ИізДЬЌЃЌЗжБ№гУгкЫЕУїНкЕуДІгкГѕЪМзЂВсзДЬЌЃЌПЩгУзДЬЌЃЌвдМАВЛПЩгУзДЬЌЁЃ
ЮЂЗўЮёНкЕуЭЈЙ§ЕїгУ register НгПкЭъГЩзЂВсЃЌvintage ЛсНЋИУНкЕузДЬЌЩшжУЮЊ initialЁЃзЂВсГЩЙІКѓЮЂЗўЮёНкЕуЛсжмЦкадЃЈ5sЃЉЯђ
vintage ЗЂЫЭаФЬјЃЌЛуБЈздЩэНЁПЕзДЬЌЃЌИќаТЗўЮёаФЬјГЌЪБЪБМфЁЃvintage дкЪеЕНЕквЛИіаФЬјЧыЧѓКѓЃЌНЋИУНкЕузДЬЌБЛЮЊ
workingЁЃvintage ЛсжмЦкадДЅЗЂЖдШЋВП working зДЬЌЮЂЗўЮёНкЕуЕФНЁПЕМьВтЃЌЕБЗЂЯжНкЕуаФЬјГЌЪБЃЌИУНкЕузДЬЌНЋБЛБфИќжС
unreachableЃЌВЂЭЈЙ§ watch НгПкНЋБфИќЪБМфЭЦЫЭИјЖЉдФЗНЁЃЖј unreachable
зДЬЌПЩЭЈЙ§дйДЮЗЂЫЭаФЬјЃЌзЊБфЮЊ working зДЬЌЁЃдк working To unreachable
ЕФБфИќЙ§ГЬжаШчЙћДЅЗЂСЫ vintage НкЕузДЬЌБЃЛЄЛњжЦЃЌЛђГіЯжЭјТчЗжЧјЃЌзДЬЌБфИќЛсБЛЖГНсЁЃЮЂЗўЮёНкЕуЯТЯпЪБПЩЭЈЙ§ЕїгУ
unregister НгПкЪЕЯжзЂЯњЃЌЭъГЩећИіЩњУќжмЦкЁЃ
vintage УПИі IDC жаНігЩжїНкЕуИКд№ШЋВПЕФЩЯааЧыЧѓВЂЭЈЙ§аФЬјЗНЪНЮЌЛЄИУ IDC ФкШЋВПЮЂЗўЮёЕФНЁПЕМьВтМАзДЬЌБфИќЁЃЖјаФЬјзїЮЊжмЦкадЕФИпЦЕЧыЧѓЃЌЕБЕЅ
IDC ФкНкЕуЪ§ДяЕНвЛЖЈСПМЖЪБЃЌЖджїНкЕуЕФДІРэФмСІДјРДМЋДѓЕФЬєеНЁЃВЂжБНггАЯьЕНЕЅ IDC МЏШКЕФЭЬЭТКЭЗўЮёНкЕуГадиФмСІЁЃетОЭашвЊвЛИіИпаЇЖЈЪБЦїРДЭъГЩЩЯЪіЕФЬєеНЁЃ
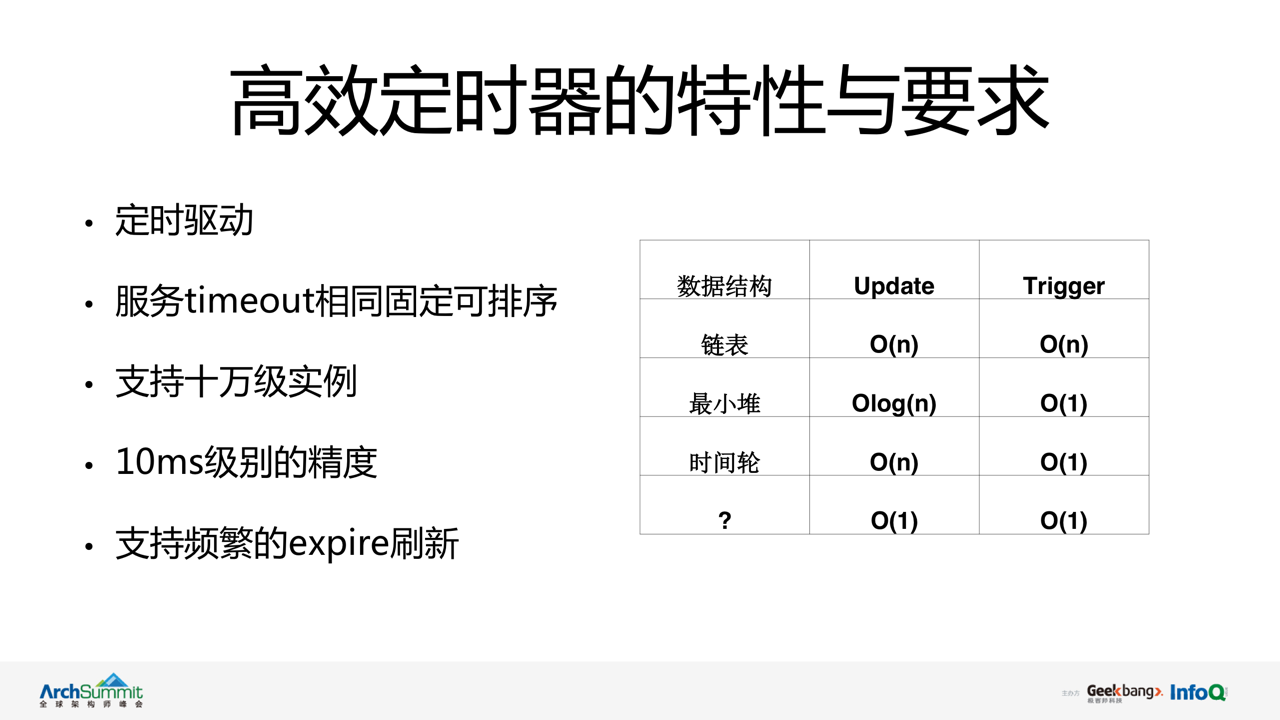
ДгЭМжаПЩвдПДГіЃЌдкЩшМЦЩЯвЊЧѓЕЅ IDC МЏШКЭЌбљПЩГаЕЃ 10w МЖЕФЗўЮёНкЕуЃЌжЇГжЦЕЗБЕФ expire
ИќаТЃЌЭЌЪБвЊЧѓЖдНкЕузДЬЌБфИќОЋЖШДяЕН 10ms МЖБ№ЁЃ
ЪзЯШЖдЯжгаЕФ heartbeat ЛуБЈМАГЌЪБМьВтФЃаЭЗжЮіКѓЃЌЕУГівдЯТМИИіЬиЕуЃК
heartbeat ЛуБЈЧыЧѓЪБМфЃЌЮЊНкЕу expire ЕФајзтЦ№ЪМЪБМфЁЃ
гЩгк heartbeat ајзтЪБМфЙЬЖЈЃЌНкЕуЙ§ЦкЪБМфПЩИљОнајзтЪБМфЙЬЖЈХХађЁЃ
НЁПЕМьВтгыаФЬјЖРСЂДІРэЁЃВЩгУжмЦкадДЅЗЂЛњжЦЪЕЯжЖдвбХХађЪ§Он expire ЕФГЌЪБХаЖЯЁЃ
ЭЈЙ§ЖдЬиЕуЕФЗжЮіЃЌВЂВЮПМСЫФПЧАБШНЯСїааЕФвЛаЉЖЈЪБЦїДІРэЫуЗЈЁЃВЛФбПДГіСДБэЃЌзюаЁЖбвдМАЪБМфТжетаЉжїСїЖЈЪБЦїЕФЪБМфИДдгЖШЩЯОљЛсЪмЕННкЕуЪ§ЕФжБНггАЯьЁЃФЧЪЧЗёгавЛжжЪ§ОнНсЙЙПЩвдзіЕН
update КЭ trigger ЖМЪЧ o(1) ЕФЪБМфИДдгЖШФиЃП
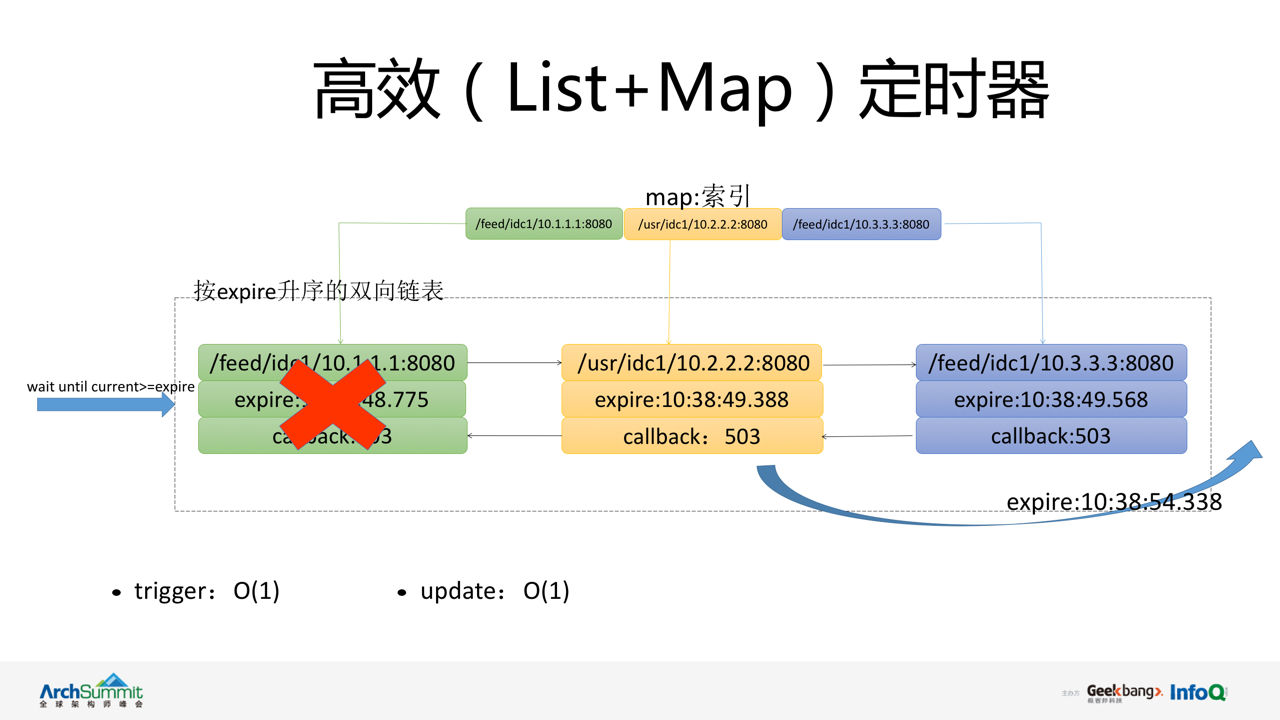
ЖЈЪБЦїЃЈtimerЃЉгЩ List+Map ЙВЭЌзщГЩгУгкЮЌЛЄ vintage ФкВПЫљга working
зДЬЌЕФЮЂЗўЮёНкЕуЕФНЁПЕМрВтКЭаФЬјајзтЁЃ
List ЪЧвЛИіИљОн expire Щ§ађХХСаЕФгаађЫЋЯђСДБэЃЌСДБэжаЕФдЊЫиЮЊЮЂЗўЮёНкЕуЕФзДЬЌЖдЯѓЃЌАќРЈНкЕу
ID КЭГЌЪБЪБМфЁЃMap БЃДцСЫЮЂЗўЮёЕФ ID МАзДЬЌЖдЯѓЕФв§гУЁЃЕБ vintage ЪеЕНФГИіНкЕуЕФаФЬјЧыЧѓЃЌЛсИљОнНкЕу
ID Дг Map жаЛёШЁИУЮЂЗўЮёНкЕузДЬЌЖдЯѓЃЌгЩгкаФЬјајзтЪБМфЙЬЖЈЃЌЭъГЩ expire зжЖЮИќаТКѓЮоашХХађЃЌПЩжБНгНЋНкЕуЖдЯѓВхШыдкСДБэЕФЮВВПЁЃ
timer ЛсЖЈЦкДЅЗЂЮЂЗўЮёЕФГЌЪБМьВтЃЌИљОнСДБэ expire Щ§ађЕФЬиЕуЃЌУПДЮМьВтЕФЫГађЖМЪЧгЩЪзЖМЕНЮВВПЃЌЗЂЯжЪзНкЕу
expire аЁгкЕБЧАЪБМфЃЌДЅЗЂЙ§ЦкВйзїЃЌНЋНкЕуДгСаБэжаЩОГ§ЃЌВЂЕїгУ callback КЏЪ§ЃЌЭЈжЊДцДЂФЃПщНЋНкЕузДЬЌИќаТЮЊ
unreachablЁЃвРДЮЯђКѓМьВщСДБэжаЕФИїНкЕуЃЌжБЕНГіЯжЕквЛИіЮДЙ§ЦкЕФНкЕуЮЊжЙЁЃ
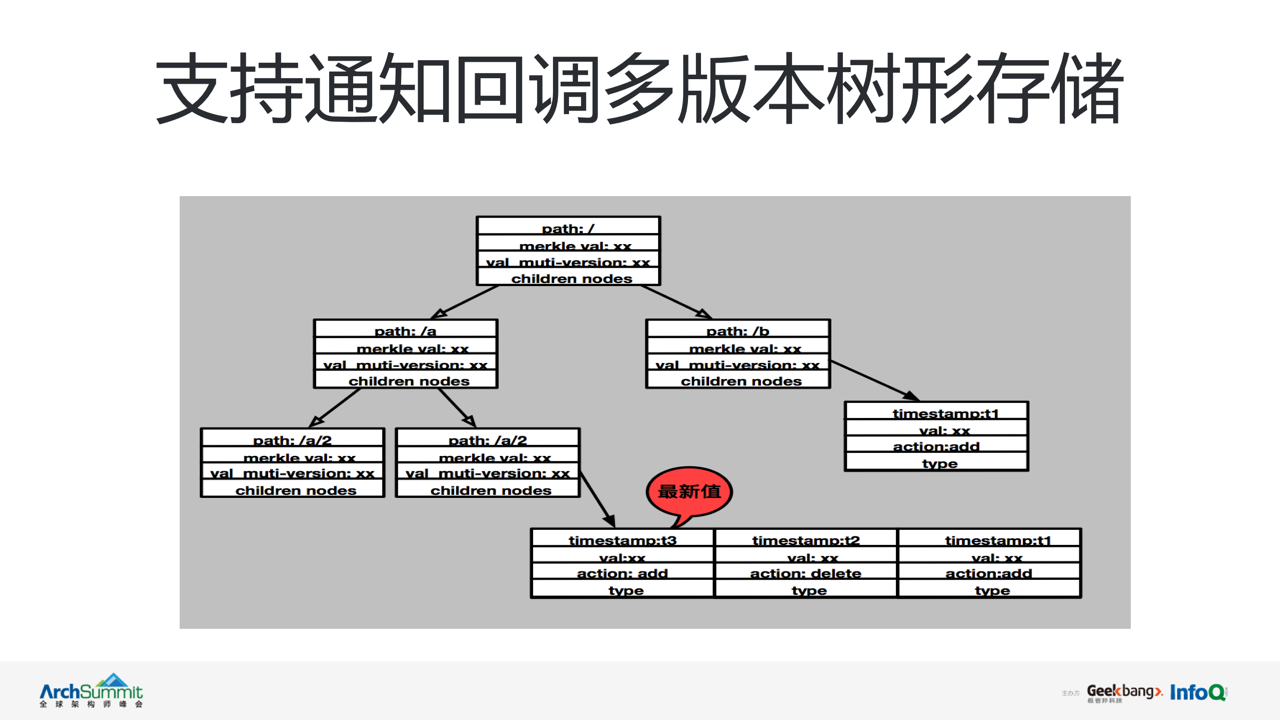
ЕБЗўЮёзДЬЌБфИќЃЌНкЕуЕФзЂВсгызЂЯњЪБЖМЛсНЋЪ§ОнМЧТМЕНДцДЂжаЁЃvintage ЪЕЯжСЫвЛЬзЛљгкЪїаЮНсЙЙЕФЖрАцБОЪ§ОнДцДЂЁЃвРРЕгкЪїаЮДцДЂНсЙЙЃЌvintage
дкЪЕЯжЖдЪ§ОнДцДЂФмСІЭтЃЌЛЙПЩНЋЮЂЗўЮёвРее /IDC/ ВПУХ / вЕЮёЯп / ЗўЮё / МЏШК / ЗўЮёНкЕу
ЕФЗНЪНЗжВуЙмРэЁЃЭЌЪБНшжњгкЖрАцБОЪЕЯжСЫДгЪ§ОнЕНЪТМўЕФзЊЛЛЃЌВЂЭЈЙ§ Event notify ФЃПщНЋБфИќЪТМўЪЕЪБЛиЕїЭЈжЊ
watch hubЃЌЭъГЩЖдаТдіЪТМўЕФЖЉдФЭЦЫЭЁЃ
watch ЭЦЫЭЛњжЦ
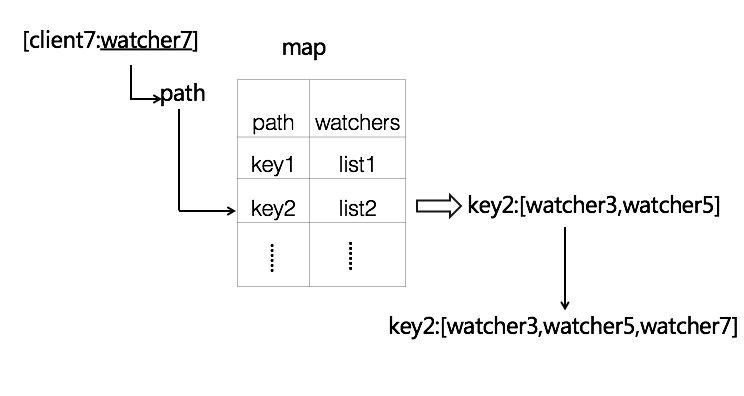
client зЂВс watchhub
client Яђ vintage ЖЉдФЗўЮёБфЛЏЙ§ГЬЁЃЛсЪзЯШЯђ vintage ЕФ watch hub
НјаазЂВсЃЌwatch hub ЛсЮЊУПИіЖЉдФЗНЩњГЩвЛвЛЖдгІЕФ watcher ЖдЯѓЃЌВЂИљОнЖЉдФФПБъЕФ
pathЃЈIDЃЉЃЌНЋЯрЭЌТЗОЖЕФ watcher КЯВЂжСвЛИі watchers СаБэжаЃЌБЃДцдк watch
hub ЕФ map Ыїв§НсЙЙЁЃ
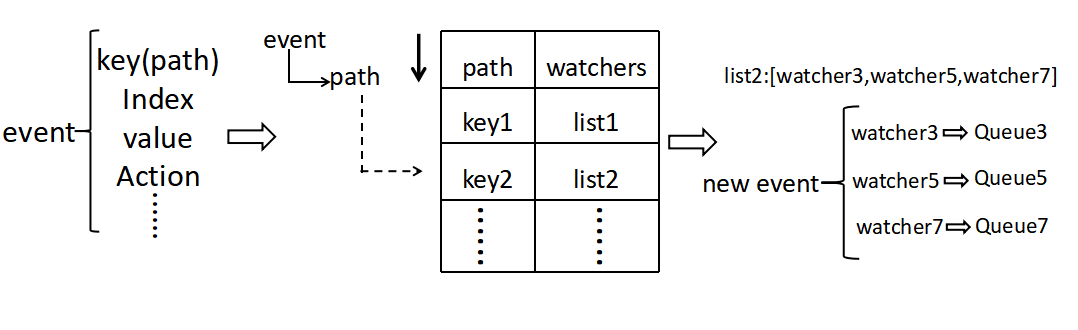
ДцДЂВуЪ§ОнБфИќЭЈжЊ
ЕБ storage ЭъГЩЪ§ОнДцДЂКѓЃЌЛсНЋЪ§ОнБфИќЕФаХЯЂзЊЛЛЮЊаТдіЪТМўЭЈЙ§ Event notify
ФЃПщЛиЕїЭЈжЊ watch hubЁЃwatch hub ЭЈЙ§ИУ event жаЕФ path дк map
Ыїв§евЕНЖЉдФЕФ watchers ЖдЯѓЃЌВЂНЋЪТМўаДШыШЋВП watcher ЕФ event queue
жаЁЃгЩ watch КЏЪ§ЭъГЩЪТЪЕЪ§ОнЭЦЫЭЁЃ
зЂЃКШє path ЪЧЖрВуНсЙЙЪБЃЌwatch hub ЭЈЙ§ФцЯђЕнЙщЕФЗНЪНЃЌНЋИУЪТМўвРДЮВхШыЖрИі event
ЖгСаЃЌЪЕЯж watch hub ЕФ path ЕнЙщЙІФмЁЃ
ЯЕЭГЩьЫѕад
ЮЊБЃеЯЮЂЗўЮёЕФПьЫйРЉШнЃЌvintage ЗўЮёздЩэБиаыОпБИПьЫйЕФРЉШнФмСІ vintage ЛсЭЈЙ§ Docker
ЛЏВПЪ№МА node discovery НкЕуздЖЏЗЂЯжФмСІЃЌЪЕЯжУыМЖБ№ЕФРЉШнЁЃВЂЭЈЙ§ећКЯ Jpool+Dcp
ЬхЯЕЃЌФПЧАПЩЪЕЯжЗжжгМЖ IDC зЂВсжааФДюНЈЁЃ
ЖргябджЇГж
дкЖргябджЇГжЗНУцЃЌvintage ЯЕЭГЭЈЙ§ HTTP Restful API ТњзуСЫЙЋЫОМЖПчгябдзЂВсжааФЕФЗўЮёжЇГжЁЃЭЌЪБвВдкВЛЖЯРЉеЙЖргябдЙйЗН
SDKЃЌФПЧАвбЪЕЯжСЫ JavaЃЌGo ЕФжЇГжЁЃ
Ш§ЁЂзмНс
аТАц vintage ЯЕЭГвбдкЯпЩЯдЫааСЫвЛФъЖрЃЌОРњСЫЮЂВЉДКЭэБЃеЯЃЌЭСГЧЁЂгРЗсКЫаФЛњЗПЭјТчЩ§МЖвдМАЪ§ВЛЪЄЪ§ЕФЭЛЗЂШШЕуЪТМўЁЃ
vintage ЯЕЭГЪЙгУЖр IDC ВПЪ№ЗНЪНжЇГжЙЋЫОЛьКЯдЦеНТдЃЌГаЕЃЪЎЭђМЖБ№ЮЂЗўЮёзЂВсгыЗўЮёЗЂЯжЁЃЭЌЪБЯЕЭГПЩгУадДяЕН
99.9999%ЃЌЭЈжЊБфИќЦНОљбгГй < 200msЃЌp999 бгГйЕЭгк 800msЁЃvintage
зЂВсжааФдкПЩгУадКЭадФмЩЯЃЌвВТњзуСЫвЕЮёдкЭЛЗЂШШЕуЪБЕФгІЖдБЃеЯЃЌНЋГЃБИвЕЮёЛњЦїЕФ buffer гЩ 40%
НЕЕЭжС 25%ЁЃ |









