| БрМЭЦМі: |
БОЮФРДздгкЭјТчЃЌБОЮФжївЊНщЩмСЫRabbitMQЪЧЪВУДЃЌRabbitMQЮЊКЮЛсГіЯжЃЌRabbitMQЛљДЁИХФюЃЌRabbitMQМЏШКЕШЁЃ
|
|
RabbitMQЪЧЪВУД
ЖЈвх
RabbitMQЪЧвЛИіПЊдДЕФAMQPЪЕЯжЃЌЗўЮёЦїЖЫгУErlangгябдБраДЃЌжЇГжЖржжПЭЛЇЖЫЃЌШчЃКPythonЁЂRubyЁЂ.NETЁЂJavaЁЂJMSЁЂCЁЂPHPЁЂActionScriptЁЂXMPPЁЂSTOMPЕШЃЌжЇГжAJAXЁЃгУгкдкЗжВМЪНЯЕЭГжаДцДЂзЊЗЂЯћЯЂЃЌдквзгУадЁЂРЉеЙадЁЂИпПЩгУадЕШЗНУцБэЯжВЛЫзЁЃ
AMPQ
AMQPЃЌМДAdvanced Message Queuing ProtocolЃЌИпМЖЯћЯЂЖгСаавщЃЌЪЧгІгУВуавщЕФвЛИіПЊЗХБъзМЃЌЮЊУцЯђЯћЯЂЕФжаМфМўЩшМЦЁЃЯћЯЂжаМфМўжївЊгУгкзщМўжЎМфЕФНтёюЃЌЯћЯЂЕФЗЂЫЭепЮоашжЊЕРЯћЯЂЪЙгУепЕФДцдкЃЌЗДжЎврШЛЁЃ
ЫќПЩвдЪЙЖдгІЕФПЭЛЇЖЫЃЈclientЃЉгыЖдгІЕФЯћЯЂжаМфМўЃЈbrokerЃЉНјааНЛЛЅЁЃЯћЯЂжаМфМўДгЗЂВМепЃЈpublisherЃЉФЧРяЪеЕНЯћЯЂЃЈЗЂВМЯћЯЂЕФгІгУЃЌвВГЦЮЊproducerЃЉЃЌШЛКѓНЋЫћУЧзЊЗЂИјЯћЗбепЃЈconsumersЃЌДІРэЯћЯЂЕФгІгУЃЉЁЃгЩгкAMQPЪЧвЛИіЭјТчавщЃЌЫљвдЗЂВМепЁЂЯћЗбепвдМАЯћЯЂжаМфМўПЩвдВПЪ№ЕНВЛЭЌЕФЮяРэЛњЦїЩЯУцЁЃ
ЫфШЛдкЭЌВНЯћЯЂЭЈбЖЕФЪРНчРягаКмЖрЙЋПЊБъзМЃЈШч COBARЕФ IIOP ЃЌЛђепЪЧ SOAP ЕШЃЉЃЌЕЋЪЧдквьВНЯћЯЂДІРэжаШДВЛЪЧетбљЃЌжЛгаДѓЦѓвЕгавЛаЉЩЬвЕЪЕЯжЃЈШчЮЂШэЕФ
MSMQ ЃЌIBM ЕФ Websphere MQ ЕШЃЉЃЌвђДЫЃЌдк 2006 ФъЕФ 6 дТЃЌCisco
ЁЂRedhatЁЂiMatix ЕШСЊКЯжЦЖЈСЫ AMQP ЕФЙЋПЊБъзМЁЃ
RabbitMQЪЧгЩRabbitMQ Technologies LtdПЊЗЂВЂЧвЬсЙЉЩЬвЕжЇГжЕФЁЃИУЙЋЫОдк2010Фъ4дТБЛSpringSourceЃЈVMWareЕФвЛИіВПУХЃЉЪеЙКЁЃдк2013Фъ5дТБЛВЂШыPivotalЁЃЦфЪЕVMWareЃЌPivotalКЭEMCБОжЪЩЯЪЧвЛМвЕФЁЃВЛЭЌЕФЪЧVMWareЪЧЖРСЂЩЯЪазгЙЋЫОЃЌЖјPivotalЪЧећКЯСЫEMCЕФФГаЉзЪдДЃЌЯждкВЂУЛгаЩЯЪаЁЃ
ЭЌРрВњЦЗ
ЯћЯЂжаМфМўЪЧвЛжжгЩЯћЯЂДЋЫЭЛњжЦЛђЯћЯЂЖгСаФЃЪНзщГЩЕФжаМфМўММЪѕЃЌРћгУИпаЇПЩППЕФЯћЯЂДЋЕнЛњжЦНјааЦНЬЈЮоЙиЕФЪ§ОнНЛСїЃЌВЂЛљгкЪ§ОнЭЈаХРДНјааЗжВМЪНЯЕЭГЕФМЏГЩЁЃ
Redis
ЪЧвЛИіKey-ValueЕФNoSQLЪ§ОнПтЃЌПЊЗЂЮЌЛЄКмЛюдОЃЌЫфШЛЫќЪЧвЛИіKey-ValueЪ§ОнПтДцДЂЯЕЭГЃЌЕЋЫќБОЩэжЇГжMQЙІФмЃЌЫљвдЭъГЩПЩвдЕБзівЛИіЧсСПМЖЕФЖгСаЗўЮёРДЪЙгУЁЃЖдгкRabbitMQКЭRedisЕФШыЖгКЭГіЖгВйзїЃЌИїжДаа100ЭђДЮЃЌУП10ЭђДЮМЧТМвЛДЮжДааЪБМфЁЃВтЪдЪ§ОнЗжЮЊ128BytesЁЂ512BytesЁЂ1KКЭ10KЫФИіВЛЭЌДѓаЁЕФЪ§ОнЁЃЪЕбщБэУїЃКШыЖгЪБЃЌЕБЪ§ОнБШНЯаЁЪБЃЌRedisЕФадФмвЊИпгкRabbitMQЃЌЖјШчЗёЪ§ОнДѓаЁГЌЙ§СЫ10KЃЌRedisдђТ§ЕФЮоЗЈШЬЪмЃЛГіЖгЪБЃЌЮоТлЪ§ОнДѓаЁЃЌRedisЖМБэЯжГіЗЧГЃКУЕФадФмЃЌЖјRabbitMQЕФГіЖгадФмдђдЖЕЭгкRedisЁЃ
MemcacheQ
ГжОУЛЏЯћЯЂЖгСаЃЈМђГЦmcqЃЉЪЧвЛИіЧсСПМЖЕФЯћЯЂЖгСаЃЌЬиадШчЯТЃК
МђЕЅвзгУ
ДІРэЫйЖШПь
ЖрЬѕЖгСа
ВЂЗЂадФмКУ
гыmemcacheЕФавщМцШнЁЃвтЮЖзХжЛвЊзАСЫЧАепЕФextensionМДПЩЃЌВЛашвЊЖюЭтЕФВхМў
дкzend frameworkжаЪЙгУКмЗНБу
MSMQ
етЪЧЮЂШэЕФВњЦЗСІЮЈвЛБЛШЯЮЊгаМлжЕЕФЖЋЮїЁЃШчЙћMSMQФмжЄУїПЩвдгІЖдетжжШЮЮёЃЌЫћУЧНЋбЁдёЪЙгУЫќЁЃ
ЙиМќЪЧЫќВЂВЛИДдгЃЌГ§СЫНгЪеКЭЗЂЫЭЃЌУЛгаБ№ЕФЃЛЫќгавЛаЉгВадЯожЦЃЌБШШчзюДѓЯћЯЂЬхЛ§ЪЧ4MBЁЃ
ШЛЖјЃЌЭЈЙ§КЭвЛаЉЯыMassTransitЛђNServiceBusетбљЕФШэМўЕФСЌНгЃЌЫќЭъШЋПЩвдНтОіетаЉЮЪЬтЁЃ

ZeroMQ
ZeroMQЪЧвЛИіЗЧГЃЧсСПМЖЕФЯћЯЂЯЕЭГЃЌКХГЦзюПьЕФЯћЯЂЖгСаЯЕЭГЃЌзЈУХЮЊИпЭЬЭТСП/ЕЭбгГйЕФГЁОАПЊЗЂЃЌдкН№ШкНчЕФгІгУжаОГЃПЩвдЗЂЯжЫќЁЃ
гыRabbitMQЯрБШЃЌZeroMQжЇГжаэЖрИпМЖЯћЯЂГЁОАЃЌФмЙЛЪЕЯжRabbitMQВЛЩУГЄЕФИпМЖ/ИДдгЕФЖгСаЃЌЕЋЪЧФуБиаыЪЕЯжZeroMQПђМмжаЕФИїИіПщЃЈБШШчSocketЛђDeviceЕШЃЉЁЃ
ZeroMQОпгавЛИіЖРЬиЕФЗЧжаМфМўЕФФЃЪНЃЌФуВЛашвЊАВзАКЭдЫаавЛИіЯћЯЂЗўЮёЦїЛђжаМфМўЃЌвђЮЊФуЕФгІгУГЬађНЋАчбнетИіЗўЮёНЧЩЋЁЃФужЛашвЊМђЕЅЕив§гУZeroMQГЬађПтЃЌПЩвдЪЙгУNuGetАВзАЃЌШЛКѓФуОЭПЩвдгфПьЕидкгІгУГЬађжЎМфЗЂЫЭЯћЯЂСЫЁЃ
ЕЋЪЧZeroMQНіЬсЙЉЗЧГжОУадЕФЖгСаЃЌМДУЛгаЕиЗНПЩвдЙлВьЫќЪЧЗёгаЮЪЬтГіЯжЃЌвВОЭЪЧЫЕШчЙћdownЛњЃЌЪ§ОнНЋЛсЖЊЪЇЁЃ
ZeroMQЗЧГЃСщЛюЃЌЕЋЪЧФуБиаыбЇЯАЫќЕФ80вГЕФЪжВсЃЈШчЙћФувЊаДвЛИіЗжВМЪНЯЕЭГЃЌвЛЖЈвЊдФЖСЫќЃЉЁЃ

Jafka/Kafka
KafkaЃЈФмНЋЯћЯЂЗжЩЂЕНВЛЭЌЕФНкЕуЩЯЃЉЪЧLinkedInгк2010Фъ12дТПЊЗЂВЂПЊдДЕФвЛИіЗжВМЪНMQЯЕЭГЃЌЯждкЪЧApacheЕФвЛИіЗѕЛЏЯюФПЃЌЪЧвЛИіИпадФмПчгябдЗжВМЪНPublish/SubscribeЯћЯЂЖгСаЯЕЭГЃЌЖјJafkaЪЧдкKafkaжЎЩЯЗѕЛЏЖјРДЕФЃЌМДKafkaЕФвЛИіЩ§МЖАцЁЃОпгавдЯТЬиадЃК
ПьЫйГжОУЛЏЃЌПЩвддкO(1)ЕФЯЕЭГПЊЯњЯТНјааЯћЯЂГжОУЛЏЃЛ
ИпЭЬЭТЃЌдквЛЬЈЦеЭЈЕФЗўЮёЦїЩЯМШПЩвдДђЕН10W/sЕФЭЬЭТЫйТЪЃЛ
ЭъШЋЕФЗжВМЪНЯЕЭГЃЌBrokerЁЂProducerЁЂConsumerЖМдЩњздЖЏжЇГжЗжВМЪНЃЌздЖЏЪЕЯжИДдгОљКтЃЛ
жЇГжHadoopЪ§ОнВЂааМгдиЃЌЭГвЛСЫдкЯпКЭРыЯпЕФЯћЯЂДІРэЃЌЖдгкЯёHadoopвЛбљЕФШежОЪ§ОнКЭРыЯпЗжЮіЯЕЭГЃЌЕЋгжвЊЧѓЪЕЪБДІРэЕФЯожЦЃЌетЪЧвЛИіПЩааЕФНтОіЗНАИЁЃ
ЯрЖдгкActiveMQЪЧвЛИіЗЧГЃЧсСПМЖЕФЯћЯЂЯЕЭГЃЌГ§СЫадФмЗЧГЃКУжЎЭтЃЌЛЙЪЧвЛИіЙЄзїСМКУЕФЗжВМЪНЯЕЭГЁЃ

Apache ActiveMQ
ActiveMQОггкЃЈRabbitMQ&ZeroMQЃЉжЎМфЃЌРрЫЦгкZemoMQЃЌЫќПЩвдВПЪ№гкДњРэФЃЪНКЭP2PФЃЪНЁЃ
ActiveMQБЛгўЮЊJavaЪРНчЕФжаМсСІСПЁЃЫќгаКмГЄЕФРњЪЗЃЌЧвБЛЙуЗКЪЙгУЁЃЫќЛЙЪЧПчЦНЬЈЕФЃЌИјФЧаЉЗЧЮЂШэЦНЬЈЕФВњЦЗЬсЙЉСЫвЛИіЬьШЛЕФМЏГЩНгШыЕуЁЃ
ШЛЖјЫќжЛгаХмЙ§СЫMSMQВХгаПЩФмБЛПМТЧЁЃШчашХфжУActiveMQдђашвЊдкФПБъЛњЦїЩЯАВзАJavaЛЗОГЁЃ
РрЫЦгкRabbitMQЃЌЫќвзгкЪЕЯжИпМЖГЁОАЃЌЖјЧвжЛашИЖГіЕЭЯћКФЁЃЫќБЛгўЮЊЯћЯЂжаМфМўЕФЁАШ№ЪПОќЕЖЁБЁЃ

RabbitMQ
RabbitMQЪЧЪЙгУErlangБраДЕФвЛИіПЊдДЯћЯЂЖгСаЃЌБОЩэжЇГжКмЖрЕФавщЃКAMQPЃЌ XMPPЃЌ
SMTPЃЌ STONPЃЌвВе§ЪЧШчДЫЃЌЪЙЕФЫќБфЕФЗЧГЃжиСПМЖЃЌИќЪЪКЯгкЦѓвЕМЖЕФПЊЗЂЁЃ
ЫќЪЕЯжСЫДњРэ(Broker)МмЙЙЃЌвтЮЖзХЯћЯЂдкЗЂЫЭЕНПЭЛЇЖЫжЎЧАПЩвддкжабыНкЕуЩЯХХЖгЁЃДЫЬиадЪЙЕУRabbitMQвзгкЪЙгУКЭВПЪ№ЃЌЪЪвЫгкКмЖрГЁОАШчТЗгЩЁЂИКдиОљКтЛђЯћЯЂГжОУЛЏЕШЃЌгУЯћЯЂЖгСажЛашМИааДњТыМДПЩИуЖЈЁЃ
ЕЋЪЧЃЌетЪЙЕУЫќЕФПЩРЉеЙадВюЃЌЫйЖШНЯТ§ЃЌвђЮЊжабыНкЕудіМгСЫбгГйЃЌЯћЯЂЗтзАКѓвВБШНЯДѓЁЃ
ШчашХфжУRabbitMQдђашвЊдкФПБъЛњЦїЩЯАВзАErlangЛЗОГЁЃ

змНс
зюжеЃЌЩЯЪіЭЌРрВњЦЗЃК
1.ЖМгаИїздПЭЛЇЖЫAPIЛђжЇГжЖржжБрГЬгябд
2.ЖМгаДѓСПЕФЮФЕЕ
3.ЖМЬсЙЉСЫЛ§МЋЕФжЇГж
4.ActiveMQЁЂRabbitMQЁЂMSMQЁЂRedisЖМашвЊЦєЖЏЗўЮёНјГЬЃЌетаЉЖМПЩвдМрПиКЭХфжУЃЌЦфЫћМИИіОЭгаЮЪЬтСЫ
5.ЖМЯрЖдЬсЙЉСЫСМКУЕФПЩППадЃЈвЛжТадЃЉЁЂРЉеЙадКЭИКдиОљКтЃЌЕБШЛЛЙгаадФм
ЯТУцЪЧЭјгбЕФЖдЫФжжЯћЯЂЖгСаЕФОпЬхВтЪдНсЙћЃЌЯдЪОЕФЪЧЗЂЫЭКЭНгЪмЕФУПУыжгЕФЯћЯЂЪ§ЃЌећИіЙ§ГЬЙВВњЩњ1АйЭђЬѕ1KЕФЯћЯЂЃЌВтЪдЕФжДааЪЧдкWIndows
VistaЩЯНјааЕФЁЃЃЈгаД§здМКбщжЄЃЉ
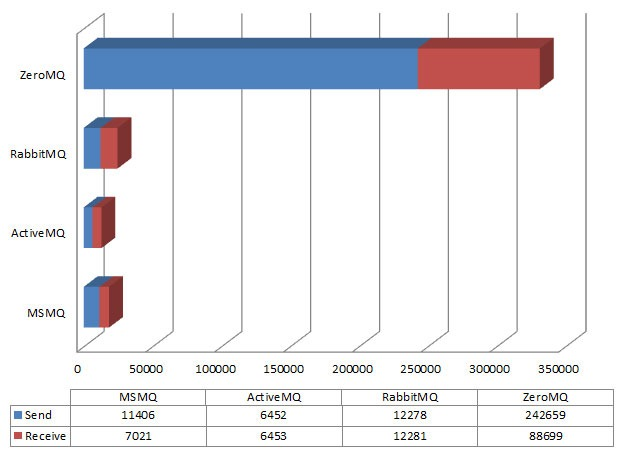
ШчЩЯЭМЫљМћЃЌZeroMQКЭЦфЫћЕФВЛЪЧвЛИіМЖБ№ЃЌЫќЕФадФмОЊШЫЕФИпЁЃНсТлКмЧхГўЃКШчЙћЯЃЭћвЛИігІгУГЬађЗЂЫЭЯћЯЂдНПьдНКУЃЌбЁдёZeroMQЃЌВЂЧвдкФуВЛЬЋдквтХМШЛЛсЖЊЪЇФГаЉЯћЯЂЕФЧщПіЯТИќгаМлжЕЁЃ
RabbitMQЮЊКЮЛсГіЯж
ЛђепЫЕAMPQЮЊКЮЛсГіЯжЃЌЫќЕФгІгУГЁОАгжЪЧЪВУДЃП
НтОіЪВУДЮЪЬт
ФуЪЧЗёгіЕНЙ§СНИіЃЈЖрИіЃЉЯЕЭГМфашвЊЭЈЙ§ЖЈЪБШЮЮёРДЭЌВНФГаЉЪ§ОнЃПФуЪЧЗёдкЮЊвьЙЙЯЕЭГЕФВЛЭЌНјГЬМфЯрЛЅЕїгУЁЂЭЈбЖЕФЮЪЬтЖјПрФеЁЂеѕдњЃП
дкWebгІгУИпВЂЗЂЛЗОГЯТЃЌгЩгкРДВЛМАЭЌВНДІРэЃЌЧыЧѓЭљЭљЛсЗЂЩњЖТШћЁЃБШШчЫЕЃЌДѓСПЕФinsertЁЂupdateЧыЧѓЭЌЪБЕНДяmysqlЃЌЛсДјРДЮоЪ§ЕФааЫјБэЫјЃЌзюКѓЕМжТЧыЧѓЪ§Й§ЖрЃЌДЅЗЂtoo
many connectionsДэЮѓЁЃ
ЯћЯЂЗўЮёЩУГЄгкНтОіЖрЯЕЭГЁЂвьЙЙЯЕЭГМфЕФЪ§ОнНЛЛЛЃЈЯћЯЂЭЈжЊ/ЭЈбЖЃЉЮЪЬтЃЌФувВПЩвдАбЫќгУгкЯЕЭГМфЗўЮёЕФЯрЛЅЕїгУЃЈRPCЃЉЭЈЙ§ЪЙгУЯћЯЂЖгСаЃЌЮвУЧПЩвдвьВНДІРэЧыЧѓЃЌДгЖјЛКНтЯЕЭГЕФбЙСІЁЃ
гІгУГЁОА
ЖдгквЛИіДѓаЭЕФШэМўЯЕЭГРДЫЕЃЌЫќЛсгаКмЖрЕФзщМўЛђепЫЕФЃПщЛђепЫЕзгЯЕЭГЛђепЃЈSubsystem or
Component or SubmoduleЃЉЁЃФЧУДетаЉФЃПщЕФШчКЮЭЈаХЃПетКЭДЋЭГЕФIPCгаКмДѓЕФЧјБ№ЁЃДЋЭГЕФIPCКмЖрЖМЪЧдкЕЅвЛЯЕЭГЩЯЕФЃЌФЃПщёюКЯадКмДѓЃЌВЛЪЪКЯРЉеЙЃЈScalabilityЃЉЃЛШчЙћЪЙгУsocketФЧУДВЛЭЌЕФФЃПщЕФШЗПЩвдВПЪ№ЕНВЛЭЌЕФЛњЦїЩЯЃЌЕЋЪЧЛЙЪЧгаКмЖрЮЪЬташвЊНтОіЁЃБШШчЃК
1.аХЯЂЕФЗЂЫЭепКЭНгЪеепШчКЮЮЌГжетИіСЌНгЃЌШчЙћвЛЗНЕФСЌНгжаЖЯЃЌетЦкМфЕФЪ§ОнШчКЮЗНЪНЖЊЪЇЃП
2.ШчКЮНЕЕЭЗЂЫЭепКЭНгЪеепЕФёюКЯЖШЃП
3.ШчКЮШУPriorityИпЕФНгЪеепЯШНгЕНЪ§ОнЃП
4.ШчКЮзіЕНLoad balanceЃПгааЇОљКтНгЪеепЕФИКдиЃП
5.ШчКЮгааЇЕФНЋЪ§ОнЗЂЫЭЕНЯрЙиЕФНгЪеепЃПвВОЭЪЧЫЕНЋНгЪеепsubscribe
ВЛЭЌЕФЪ§ОнЃЌШчКЮзігааЇЕФfilterЁЃ
6.ШчКЮзіЕНПЩРЉеЙЃЌЩѕжСНЋетИіЭЈаХФЃПщЗЂЕНclusterЩЯЃП
7.ШчКЮБЃжЄНгЪеепНгЪеЕНСЫЭъећЃЌе§ШЗЕФЪ§ОнЃП
AMDQавщНтОіСЫвдЩЯЕФЮЪЬтЃЌЖјRabbitMQЪЕЯжСЫAMQPЁЃ
RabbitMQЛљДЁИХФю
гІгУГЁОАМмЙЙ
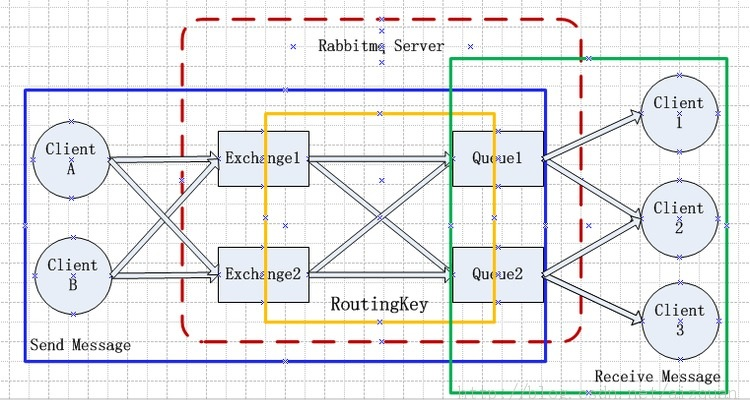
RabbitMQ ServerЃКвВНаbroker serverЃЌЫќВЛЪЧдЫЫЭЪГЮяЕФПЈГЕЃЌЖјЪЧвЛжжДЋЪфЗўЮёЁЃдЛАЪЧRabbitMQ
isnЁЏt a food truck, itЁЏs a delivery service. ЫћЕФНЧЩЋОЭЪЧЮЌЛЄвЛЬѕДгProducerЕНConsumerЕФТЗЯпЃЌБЃжЄЪ§ОнФмЙЛАДеежИЖЈЕФЗНЪННјааДЋЪфЁЃЕЋЪЧетИіБЃжЄвВВЛЪЧ100%ЕФБЃжЄЃЌЕЋЪЧЖдгкЦеЭЈЕФгІгУРДЫЕетвбОзуЙЛСЫЁЃЕБШЛЖдгкЩЬвЕЯЕЭГРДЫЕЃЌПЩвддйзівЛВуЪ§ОнвЛжТадЕФguardЃЌОЭПЩвдГЙЕзБЃжЄЯЕЭГЕФвЛжТадСЫЁЃ
Client A & BЃКвВНаProducerЃЌЪ§ОнЕФЗЂЫЭЗНЁЃCreate messages
and Publish (Send) them to a broker server (RabbitMQ)ЁЃвЛИіMessageгаСНИіВПЗжЃКPayloadЃЈгааЇдиКЩЃЉКЭLabelЃЈБъЧЉЃЉЁЃPayloadЙЫУћЫМвхОЭЪЧДЋЪфЕФЪ§ОнЃЌLabelЪЧExchangeЕФУћзжЛђепЫЕЪЧвЛИіtagЃЌЫќУшЪіСЫpayloadЃЌЖјЧвRabbitMQвВЪЧЭЈЙ§етИіlabelРДОіЖЈАбетИіMessageЗЂИјФФИіConsumerЁЃAMQPНіНіУшЪіСЫlabelЃЌЖјRabbitMQОіЖЈСЫШчКЮЪЙгУетИіlabelЕФЙцдђЁЃ
Client 1ЃЌ2ЃЌ3ЃКвВНаConsumerЃЌЪ§ОнЕФНгЪеЗНЁЃConsumers attach to
a broker server (RabbitMQ) and subscribe to a queueЁЃАбqueueБШзїЪЧвЛИігаУћзжЕФгЪЯфЁЃЕБгаMessageЕНДяФГИігЪЯфКѓЃЌRabbitMQАбЫќЗЂЫЭИјЫќЕФФГИіЖЉдФепМДConsumerЁЃЕБШЛПЩФмЛсАбЭЌвЛИіMessageЗЂЫЭИјКмЖрЕФConsumerЁЃдкетИіMessageжаЃЌжЛгаpayloadЃЌlabelвбОБЛЩОЕєСЫЁЃЖдгкConsumerРДЫЕЃЌЫќЪЧВЛжЊЕРЫЗЂЫЭЕФетИіаХЯЂЕФЁЃОЭЪЧавщБОЩэВЛжЇГжЁЃЕЋЪЧЕБШЛСЫШчЙћProducerЗЂЫЭЕФpayloadАќКЌСЫProducerЕФаХЯЂОЭСэЕББ№ТлСЫЁЃ
ЖдгквЛИіЪ§ОнДгProducerЕНConsumerЕФе§ШЗДЋЕнЃЌЛЙгаШ§ИіИХФюашвЊУїШЗЃКexchanges,
queues and bindingsЁЃ
Exchanges are where producers publish their messages.
ЯћЯЂНЛЛЛЛњЃЌЫќжИЖЈЯћЯЂАДЪВУДЙцдђЃЌТЗгЩЕНФФИіЖгСа
Queues are where the messages end up and are received
by consumers. ЯћЯЂЖгСадиЬхЃЌУПИіЯћЯЂЖМЛсБЛЭЖШыЕНвЛИіЛђЖрИіЖгСа
Bindings are how the messages get routed from the
exchange to particular queues. АѓЖЈЃЌЫќЕФзїгУОЭЪЧАбexchangeКЭqueueАДееТЗгЩЙцдђАѓЖЈЦ№РД
Routing KeyЃКТЗгЩЙиМќзжЃЌexchangeИљОнетИіЙиМќзжНјааЯћЯЂЭЖЕн
ЛЙгаМИИіИХФюЪЧЩЯЪіЭМжаУЛгаБъУїЕФЃЌФЧОЭЪЧConnectionЃЈСЌНгЃЉЃЌChannelЃЈЭЈЕРЃЌЦЕЕРЃЉЃЌVhostЃЈащФтжїЛњЃЉЁЃ
ConnectionЃКОЭЪЧвЛИіTCPЕФСЌНгЁЃProducerКЭConsumerЖМЪЧЭЈЙ§TCPСЌНгЕНRabbitMQ
ServerЕФЁЃвдКѓЮвУЧПЩвдПДЕНЃЌГЬађЕФЦ№ЪМДІОЭЪЧНЈСЂетИіTCPСЌНгЁЃ
ChannelЃКащФтСЌНгЁЃЫќНЈСЂдкЩЯЪіЕФTCPСЌНгжаЁЃЪ§ОнСїЖЏЖМЪЧдкChannelжаНјааЕФЁЃвВОЭЪЧЫЕЃЌвЛАуЧщПіЪЧГЬађЦ№ЪМНЈСЂTCPСЌНгЃЌЕкЖўВНОЭЪЧНЈСЂетИіChannelЁЃ
VhostЃКащФтжїЛњЃЌвЛИіbrokerРяПЩвдПЊЩшЖрИіvhostЃЌгУзїВЛЭЌгУЛЇЕФШЈЯоЗжРыЁЃУПИіvirtual
hostБОжЪЩЯЖМЪЧвЛИіRabbitMQ ServerЃЌгЕгаЫќздМКЕФqueueЃЌexchagneЃЌКЭbings
ruleЕШЕШЁЃетБЃжЄСЫФуПЩвддкЖрИіВЛЭЌЕФapplicationжаЪЙгУRabbitMQЁЃ
ChannelЕФбЁдё
ФЧУДЃЌЮЊЪВУДЪЙгУChannelЃЌЖјВЛЪЧжБНгЪЙгУTCPСЌНгЃП
ЖдгкOSРДЫЕЃЌНЈСЂКЭЙиБеTCPСЌНгЪЧгаДњМлЕФЃЌЦЕЗБЕФНЈСЂЙиБеTCPСЌНгЖдгкЯЕЭГЕФадФмгаКмДѓЕФгАЯьЃЌЖјЧвTCPЕФСЌНгЪ§вВгаЯожЦЃЌетвВЯожЦСЫЯЕЭГДІРэИпВЂЗЂЕФФмСІЁЃЕЋЪЧЃЌдкTCPСЌНгжаНЈСЂChannelЪЧУЛгаЩЯЪіДњМлЕФЁЃЖдгкProducerЛђепConsumerРДЫЕЃЌПЩвдВЂЗЂЕФЪЙгУЖрИіChannelНјааPublishЛђепReceiveЁЃ
гаЪЕбщБэУїЃЌ1sЕФЪ§ОнПЩвдPublish10KЕФЪ§ОнАќЁЃЕБШЛЖдгкВЛЭЌЕФгВМўЛЗОГЃЌВЛЭЌЕФЪ§ОнАќДѓаЁетИіЪ§ОнПЯЖЈВЛвЛбљЃЌЕЋЪЧЮвжЛЯыЫЕУїЃЌЖдгкЦеЭЈЕФConsumerЛђепProducerРДЫЕЃЌетвбОзуЙЛСЫЁЃШчЙћВЛЙЛгУЃЌФуПМТЧЕФгІИУЪЧШчКЮЯИЛЏsplitФуЕФЩшМЦЁЃ
ЯћЯЂЖгСажДааЙ§ГЬ
1.ПЭЛЇЖЫСЌНгЕНЯћЯЂЖгСаЗўЮёЦїЃЌДђПЊвЛИіChannelЁЃ
2.ПЭЛЇЖЫЩљУївЛИіExchangeЃЌВЂЩшжУЯрЙиЪєадЁЃ
3.ПЭЛЇЖЫЩљУївЛИіQueueЃЌВЂЩшжУЯрЙиЪєадЁЃ
4.ПЭЛЇЖЫЪЙгУRouting keyЃЌдкExchangeКЭQueueжЎМфНЈСЂКУАѓЖЈЙиЯЕЁЃ
5.ПЭЛЇЖЫЭЖЕнЯћЯЂЕНExchangeЁЃ
ExchangeНгЪеЕНЯћЯЂКѓЃЌОЭИљОнЯћЯЂЕФkeyКЭвбОЩшжУЕФBindingЃЌНјааЯћЯЂТЗгЩЃЌНЋЯћЯЂЭЖЕнЕНвЛИіЛђЖрИіЖгСаРяЁЃгаШ§жжРраЭЕФExchangesЃКdirectЃЌfanoutЃЌtopicЃЌУПИіЪЕЯжСЫВЛЭЌЕФТЗгЩЫуЗЈЃЈrouting
algorithmЃЉЃК
Direct exchangeЃКЭъШЋИљОнkeyНјааЭЖЕнЕФНазіDirectНЛЛЛЛњЁЃШчЙћRouting
keyЦЅХф, ФЧУДMessageОЭЛсБЛДЋЕнЕНЯргІЕФqueueжаЁЃЦфЪЕдкqueueДДНЈЪБЃЌЫќЛсздЖЏЕФвдqueueЕФУћзжзїЮЊrouting
keyРДАѓЖЈФЧИіexchangeЁЃР§ШчЃЌАѓЖЈЪБЩшжУСЫRouting keyЮЊЁБabcЁБЃЌФЧУДПЭЛЇЖЫЬсНЛЕФЯћЯЂЃЌжЛгаЩшжУСЫkeyЮЊЁБabcЁБЕФВХЛсЭЖЕнЕНЖгСаЁЃ
Fanout exchangeЃКВЛашвЊkeyЕФНазіFanoutНЛЛЛЛњЁЃЫќВЩШЁЙуВЅФЃЪНЃЌвЛИіЯћЯЂНјРДЪБЃЌЭЖЕнЕНгыИУНЛЛЛЛњАѓЖЈЕФЫљгаЖгСаЁЃ
Topic exchangeЃКЖдkeyНјааФЃЪНЦЅХфКѓНјааЭЖЕнЕФНазіTopicНЛЛЛЛњЁЃБШШчЗћКХЁБ#ЁБЦЅХфвЛИіЛђЖрИіДЪЃЌЗћКХЁБЁБЦЅХфе§КУвЛИіДЪЁЃР§ШчЁБabc.#ЁБЦЅХфЁБabc.def.ghiЁБЃЌЁБabc.ЁБжЛЦЅХфЁБabc.defЁБЁЃ
ИќЖрЯћЯЂЖгСаЯрЙиЩшМЦНщЩмЧыВЮПМЃК
RabbitMQЯЕСаЖўЃЈЙЙНЈЯћЯЂЖгСаЃЉ
RabbitMQЯЕСаШ§ ЃЈЩюШыЯћЯЂЖгСаЃЉ
ЯћЯЂЖгСаЕФДДНЈ
ConsumerКЭProcuderЖМПЩвдЭЈЙ§ queue.declare ДДНЈqueueЁЃЖдгкФГИіChannelРДЫЕЃЌConsumerВЛФмdeclareвЛИіqueueЃЌШДЖЉдФЦфЫћЕФqueueЁЃЕБШЛвВПЩвдДДНЈЫНгаЕФqueueЁЃетбљжЛгаappБОЩэВХПЩвдЪЙгУетИіqueueЁЃqueueвВПЩвдздЖЏЩОГ§ЃЌБЛБъЮЊauto-deleteЕФqueueдкзюКѓвЛИіConsumer
unsubscribeКѓОЭЛсБЛздЖЏЩОГ§ЁЃФЧУДШчЙћЪЧДДНЈвЛИівбОДцдкЕФqueueФиЃПФЧУДВЛЛсгаШЮКЮЕФгАЯьЁЃашвЊзЂвтЕФЪЧУЛгаШЮКЮЕФгАЯьЃЌвВОЭЪЧЫЕЕкЖўДЮДДНЈШчЙћВЮЪ§КЭЕквЛДЮВЛвЛбљЃЌФЧУДИУВйзїЫфШЛГЩЙІЃЌЕЋЪЧqueueЕФЪєадВЂВЛЛсБЛаоИФЁЃ
ФЧУДЫгІИУИКд№ДДНЈетИіqueueФиЃПЪЧConsumerЃЌЛЙЪЧProducerЃП
ШчЙћqueueВЛДцдкЃЌЕБШЛConsumerВЛЛсЕУЕНШЮКЮЕФMessageЁЃЕЋЪЧШчЙћqueueВЛДцдкЃЌФЧУДProducer
PublishЕФMessageЛсБЛЖЊЦњЁЃЫљвдЃЌЛЙЪЧЮЊСЫЪ§ОнВЛЖЊЪЇЃЌConsumerКЭProducerЖМtry
to create the queueЃЁЗДе§ВЛЙмдѕУДбљЃЌетИіНгПкЖМВЛЛсГіЮЪЬтЁЃ
QueueЖдload balanceЕФДІРэЪЧЭъУРЕФЁЃЖдгкЖрИіConsumerРДЫЕЃЌRabbitMQ
ЪЙгУбЛЗЕФЗНЪНЃЈround-robinЃЉЕФЗНЪНОљКтЕФЗЂЫЭИјВЛЭЌЕФConsumerЁЃ
ЯћЯЂЕФackЛњжЦ
ФЌШЯЧщПіЯТЃЌШчЙћMessage вбОБЛФГИіConsumerе§ШЗЕФНгЪеЕНСЫЃЌФЧУДИУMessageОЭЛсБЛДгqueueжавЦГ§ЁЃЕБШЛвВПЩвдШУЭЌвЛИіMessageЗЂЫЭЕНКмЖрЕФConsumerЁЃ
ШчЙћвЛИіqueueУЛБЛШЮКЮЕФConsumer SubscribeЃЈЖЉдФЃЉЃЌФЧУДЃЌШчЙћетИіqueueгаЪ§ОнЕНДяЃЌФЧУДетИіЪ§ОнЛсБЛcacheЃЌВЛЛсБЛЖЊЦњЁЃЕБгаConsumerЪБЃЌетИіЪ§ОнЛсБЛСЂМДЗЂЫЭЕНетИіConsumerЃЌетИіЪ§ОнБЛConsumerе§ШЗЪеЕНЪБЃЌетИіЪ§ОнОЭБЛДгqueueжаЩОГ§ЁЃ
ФЧУДЪВУДЪЧе§ШЗЪеЕНФиЃПЭЈЙ§ackЁЃ
УПИіMessageЖМвЊБЛacknowledgedЃЈШЗШЯЃЌackЃЉЁЃЮвУЧПЩвдЯдЪОЕФдкГЬађжаШЅackЃЈConsumerЕФbasic.ackЃЉЃЌвВПЩвдздЖЏЕФackЃЈЖЉдФQueueЪБжИЖЈauto_ackЮЊtrueЃЉЁЃ
ШчЙћгаЪ§ОнУЛгаБЛackЃЌФЧУДRabbitMQ ServerЛсАбетИіаХЯЂЗЂЫЭЕНЯТвЛИіConsumerЁЃ
ШчЙћетИіappгаbugЃЌЭќМЧСЫackЃЌФЧУДRabbitMQ ServerВЛЛсдйЗЂЫЭЪ§ОнИјЫќЃЌвђЮЊServerШЯЮЊетИіConsumerДІРэФмСІгаЯоЁЃ
ЖјЧвackЕФЛњжЦПЩвдЦ№ЕНЯоСїЕФзїгУЃЈBenefit to throttlingЃЉЃКдкConsumerДІРэЭъГЩЪ§ОнКѓЗЂЫЭackЃЌЩѕжСдкЖюЭтЕФбгЪБКѓЗЂЫЭackЃЌНЋгааЇЕФbalance
ConsumerЕФloadЁЃ
ЕБШЛЖдгкЪЕМЪЕФР§згЃЌБШШчЮвУЧПЩФмЛсЖдФГаЉЪ§ОнНјааmergeЃЌБШШчmerge 4sФкЕФЪ§ОнЃЌШЛКѓsleep
4sКѓдйЛёШЁЪ§ОнЁЃЬиБ№ЪЧдкМрЬ§ЯЕЭГЕФstateЃЌЮвУЧВЛЯЃЭћЫљгаЕФstateЪЕЪБЕФДЋЕнЩЯШЅЃЌЖјЪЧЯЃЭћгавЛЖЈЕФбгЪБЁЃетбљПЩвдМѕЩйФГаЉIOЃЌЖјЧвжеЖЫгУЛЇвВВЛЛсИаОѕЕНЁЃ
УЛгае§ШЗЯьгІФиЃП
ШчЙћConsumerНгЪеСЫвЛИіЯћЯЂОЭЛЙУЛгаЗЂЫЭackОЭгыRabbitMQЖЯПЊСЫЃЌRabbitMQЛсШЯЮЊетЬѕЯћЯЂУЛгаЭЖЕнГЩЙІЛсжиаТЭЖЕнЕНБ№ЕФConsumerЁЃ
ШчЙћConsumerБОЩэТпМгаЮЪЬтУЛгаЗЂЫЭackЕФДІРэЃЌRabbitMQВЛЛсдйЯђИУConsumerЗЂЫЭЯћЯЂЁЃRabbitMQЛсШЯЮЊетИіConsumerЛЙУЛгаДІРэЭъЩЯвЛЬѕЯћЯЂЃЌУЛгаФмСІМЬајНгЪеаТЯћЯЂЁЃ
ЮвУЧПЩвдЩЦМгРћгУетвЛЛњжЦЃЌШчЙћашвЊДІРэЙ§ГЬЪЧЯрЕБИДдгЕФЃЌгІгУГЬађПЩвдбгГйЗЂЫЭackжБЕНДІРэЭъГЩЮЊжЙЁЃетПЩвдгааЇПижЦгІгУГЬађетБпЕФИКдиЃЌВЛжТгкБЛДѓСПЯћЯЂГхЛїЁЃ
ЯћЯЂОмОј
гЩгквЊОмОјЯћЯЂЃЌЫљвдackЯьгІЯћЯЂЛЙУЛгаЗЂГіЃЌетРяОмОјЯћЯЂПЩвдгаСНжжбЁдё:
ConsumerжБНгЖЯПЊRabbitMQетбљRabbitMQНЋАбетЬѕЯћЯЂжиаТХХЖгЃЌНЛгЩЦфЫќConsumerДІРэЁЃетИіЗНЗЈдкRabbitMQИїАцБОЖМжЇГжЃЌетбљзіЕФЛЕДІОЭЪЧСЌНгЖЯПЊдіМгСЫRabbitMQЕФЖюЭтИКЕЃЃЌЬиБ№ЪЧconsumerГіЯжвьГЃУПЬѕЯћЯЂЖМЮоЗЈе§ГЃДІРэЕФЪБКђЁЃ
RabbitMQ 2.0.0ПЩвдЪЙгУ basic.reject УќСюЃЌЪеЕНИУУќСюRabbitMQЛсжиаТЭЖЕнЕНЦфЫќЕФConsumerЁЃШчЙћЩшжУrequeueЮЊfalseЃЌRabbitMQЛсжБНгНЋЯћЯЂДгqueueжавЦГ§ЁЃ
ЦфЪЕЛЙгавЛжжбЁдёОЭЪЧжБНгКіТдетЬѕЯћЯЂВЂЗЂЫЭACKЃЌЕБФуУїШЗжЊЕРетЬѕЯћЯЂЪЧвьГЃЕФВЛЛсгаConsumerФмДІРэЃЌПЩвдетбљзіХзЦњвьГЃЪ§ОнЁЃ
ЮЊЪВУДвЊЗЂЫЭbasic.rejectЯћЯЂЖјВЛЪЧACKЃПRabbitMQКѓУцЕФАцБОПЩФмЛсв§ШыЁБdead
letterЁБЖгСаЃЌШчЙћЯыРћгУdead letterзіЕуЮФеТОЭЪЙгУbasic.rejectВЂЩшжУrequeueЮЊfalseЁЃ
ЯћЯЂГжОУЛЏ
RabbitMQжЇГжЯћЯЂЕФГжОУЛЏЃЌвВОЭЪЧЪ§ОнаДдкДХХЬЩЯЃЌЮЊСЫЪ§ОнАВШЋПМТЧЃЌДѓЖрЪ§гУЛЇЖМЛсбЁдёГжОУЛЏЁЃЯћЯЂЖгСаГжОУЛЏАќРЈ3ИіВПЗжЃК
1.ExchangeГжОУЛЏЃЌдкЩљУїЪБжИЖЈdurable =>
1
2.QueueГжОУЛЏЃЌдкЩљУїЪБжИЖЈdurable => 1
3.ЯћЯЂГжОУЛЏЃЌдкЭЖЕнЪБжИЖЈdelivery_mode =>
2ЃЈ1ЪЧЗЧГжОУЛЏЃЉ
ШєExchangeКЭQueueЖМЪЧГжОУЛЏЕФЃЌФЧУДЫќУЧжЎМфЕФBindingвВЪЧГжОУЛЏЕФЃЛЖјExchangeКЭQueueСНепжЎМфгавЛИіГжОУЛЏЃЌвЛИіЗЧГжОУЛЏЃЌОЭВЛдЪаэНЈСЂАѓЖЈЁЃ
ConsumerДгdurable queueжаШЁЛивЛЬѕЯћЯЂжЎКѓВЂЗЂЛиСЫackЯћЯЂЃЌRabbitMQОЭЛсНЋЦфБъМЧЃЌЗНБуКѓајРЌЛјЛиЪеЁЃШчЙћвЛЬѕГжОУЛЏЕФЯћЯЂУЛгаБЛconsumerШЁзпЃЌRabbitMQжиЦєжЎКѓЛсздЖЏжиНЈexchangeКЭqueue(вдМАbingdingЙиЯЕ)ЃЌЯћЯЂЭЈЙ§ГжОУЛЏШежОжиНЈдйДЮНјШыЖдгІЕФqueuesЃЌexchangesЁЃ
RabbitMQМЏШК
гЩгкRabbitMQЪЧгУerlangПЊЗЂЕФЃЌRabbitMQЭъШЋвРРЕerlangЕФClusterЃЌвђЮЊerlangЬьЩњОЭЪЧвЛУХЗжВМЪНгябдЃЌМЏШКЗЧГЃЗНБуЃЌЕЋЦфБОЩэВЂВЛжЇГжИКдиОљКтЁЃErlangЕФМЏШКжаИїНкЕуЪЧОгЩЙ§ГЬвЛИіmagic
cookieРДЪЕЯжЕФЃЌетИіcookieДцЗХдк $home/.erlang.cookieжа(ЯёЮвЕФrootгУЛЇАВзАЕФОЭЪЧЗХдкЮвЕФroot/.erlang.cookieжа)ЃЌЮФМўЪЧ400ЕФШЈЯоЁЃЫљвдБиаыБЃжЄИїНкЕуcookieФкШнвЛжТЃЌВЛШЛНкЕужЎМфОЭЮоЗЈЭЈаХЁЃ
МЏШКЗНЪН
RabbitmqМЏШКДѓИХЗжЮЊЖўжжЗНЪНЃК
1.ЦеЭЈФЃЪНЃКФЌШЯЕФМЏШКФЃЪНЁЃ
ЖдгкQueueРДЫЕЃЌЯћЯЂЪЕЬхжЛДцдкгкЦфжавЛИіНкЕуЃЌAЁЂBСНИіНкЕуНігаЯрЭЌЕФдЊЪ§ОнЃЌМДЖгСаНсЙЙЃЌЕЋЖгСаЕФдЊЪ§ОнНіБЃДцгавЛЗнЃЌМДДДНЈИУЖгСаЕФrabbitmqНкЕуЃЈAНкЕуЃЉЃЌЕБAНкЕухДЛњЃЌФуПЩвдШЅЦфBНкЕуВщПДЃЌ./rabbitmqctl
list_queues ЗЂЯжИУЖгСавбОЖЊЪЇЃЌЕЋЩљУїЕФexchangeЛЙДцдкЁЃ
ЕБЯћЯЂНјШыAНкЕуЕФQueueжаКѓЃЌconsumerДгBНкЕуРШЁЪБЃЌRabbitMQЛсСйЪБдкAЁЂBМфНјааЯћЯЂДЋЪфЃЌАбAжаЕФЯћЯЂЪЕЬхШЁГіВЂОЙ§BЗЂЫЭИјconsumerЃЌЫљвдconsumerгІЦНОљСЌНгУПвЛИіНкЕуЃЌДгжаШЁЯћЯЂЁЃ
ИУФЃЪНДцдквЛИіЮЪЬтОЭЪЧЕБAНкЕуЙЪеЯКѓЃЌBНкЕуЮоЗЈШЁЕНAНкЕужаЛЙЮДЯћЗбЕФЯћЯЂЪЕЬхЁЃШчЙћзіСЫЖгСаГжОУЛЏЛђЯћЯЂГжОУЛЏЃЌФЧУДЕУЕШAНкЕуЛжИДЃЌШЛКѓВХПЩБЛЯћЗбЃЌВЂЧвдкAНкЕуЛжИДжЎЧАЦфЫќНкЕуВЛФмдйДДНЈAНкЕувбОДДНЈЙ§ЕФГжОУЖгСаЃЛШчЙћУЛгаГжОУЛЏЕФЛАЃЌЯћЯЂОЭЛсЪЇЖЊЁЃ
етжжФЃЪНИќЪЪКЯЗЧГжОУЛЏЖгСаЃЌжЛгаИУЖгСаЪЧЗЧГжОУЕФЃЌПЭЛЇЖЫВХФмжиаТСЌНгЕНМЏШКРяЕФЦфЫћНкЕуЃЌВЂжиаТДДНЈЖгСаЁЃМйШчИУЖгСаЪЧГжОУЛЏЕФЃЌФЧУДЮЈвЛАьЗЈЪЧНЋЙЪеЯНкЕуЛжИДЦ№РДЁЃ
2.ОЕЯёФЃЪНЃКАбашвЊЕФЖгСазіГЩОЕЯёЖгСаЃЌДцдкгкЖрИіНкЕуЁЃ
ИУФЃЪННтОіСЫЦеЭЈФЃЪНЕФЮЪЬтЃЌЦфЪЕжЪВЛЭЌжЎДІдкгкЃЌЯћЯЂЪЕЬхЛсжїЖЏдкОЕЯёНкЕуМфЭЌВНЃЌЖјВЛЪЧдкconsumerШЁЪ§ОнЪБСйЪБРШЁЁЃ
ИУФЃЪНДјРДЕФИБзїгУвВКмУїЯдЃЌГ§СЫНЕЕЭЯЕЭГадФмЭтЃЌШчЙћОЕЯёЖгСаЪ§СПЙ§ЖрЃЌМгжЎДѓСПЕФЯћЯЂНјШыЃЌМЏШКФкВПЕФЭјТчДјПэНЋЛсБЛетжжЭЌВНЭЈбЖДѓДѓЯћКФЕєЁЃ
ЫљвддкЖдПЩППадвЊЧѓНЯИпЕФГЁКЯжаЪЪгУЃЌвЛИіЖгСаЯызіГЩОЕЯёЖгСаЃЌашвЊЯШЩшжУpolicyЃЌШЛКѓПЭЛЇЖЫДДНЈЖгСаЕФЪБКђЃЌrabbitmqМЏШКИљОнЁАЖгСаУћГЦЁБздЖЏЩшжУЪЧЦеЭЈМЏШКФЃЪНЛђОЕЯёЖгСаЁЃОпЬхШчЯТЃК
ЖгСаЭЈЙ§ВпТдРДЪЙФмОЕЯёЁЃВпТдФмдкШЮКЮЪБПЬИФБфЃЌrabbitmqЖгСавВНќПЩФмЕФНЋЖгСаЫцзХВпТдБфЛЏЖјБфЛЏЃЛЗЧОЕЯёЖгСаКЭОЕЯёЖгСажЎМфЪЧгаЧјБ№ЕФЃЌЧАепШБЗІЖюЭтЕФОЕЯёЛљДЁЩшЪЉЃЌУЛгаШЮКЮslaveЃЌвђДЫЛсдЫааЕУИќПьЁЃ
ЮЊСЫЪЙЖгСаГЦЮЊОЕЯёЖгСаЃЌФуНЋЛсДДНЈвЛИіВпТдРДЦЅХфЖгСаЃЌЩшжУВпТдгаСНИіМќЁАha-modeКЭ ha-paramsЃЈПЩбЁЃЉЁБЁЃha-paramsИљОнha-modeЩшжУВЛЭЌЕФжЕЃЌЯТУцБэИёЫЕУїетаЉkeyЕФбЁЯюЁЃ

ЮЊЪВУДRabbitMQВЛНЋЖгСаИДжЦЕНМЏШКРяУПИіНкЕуФиЃПетгыЫќЕФМЏШКЕФЩшМЦБОвтЯрГхЭЛЃЌМЏШКЕФЩшМЦФПЕФОЭЪЧдіМгИќЖрНкЕуЪБЃЌФмЯпадЕФдіМгадФмЃЈCPUЁЂФкДцЃЉКЭШнСПЃЈФкДцЁЂДХХЬЃЉЁЃРэгЩШчЯТЃК
Storage Space: If every cluster node had a full
copy of every queue, adding nodes wouldnЁЏt give you
more storage capacity. For example, if one node could
store 1GB of messages, adding two more nodes would
simply give you two more copies of the same 1GB of
messages.ЃЈДцДЂПеМфЃКШчЙћУПИіМЏШКНкЕуУПИіЖгСаЕФвЛИіЭъећИББОЃЌдіМгНкЕуашвЊИќЖрЕФДцДЂШнСПЁЃР§ШчЃЌШчЙћвЛИіНкЕуПЩвдДцДЂ1
gbЕФЯћЯЂЃЌЬэМгСНИіНкЕуашвЊСНЗнЯрЭЌЕФ1gbЕФЯћЯЂЃЉ
Performance: Publishing messages would require replicating
those messages to every cluster node. For durable
messages that would require triggering disk activity
on all nodes for every message. Your network and disk
load would increase every time you added a node, keeping
the performance of the cluster the same (or possibly
worse).ЃЈадФмЃКЗЂВМЯћЯЂашвЊНЋетаЉаХЯЂИДжЦЕНУПИіМЏШКНкЕуЁЃЖдГжОУЯћЯЂЃЌвЊЧѓЮЊУПЬѕЯћЯЂДЅЗЂДХХЬЛюЖЏдкЫљгаНкЕуЩЯЁЃУПДЮЬэМгвЛИіНкЕуЖМЛсДјРД
ЭјТчКЭДХХЬЕФИКдиЁЃЃЉ
ЕБШЛRabbitMQаТАцБОМЏШКвВжЇГжЖгСаИДжЦЃЈгаИібЁЯюПЩвдХфжУЃЉЁЃБШШчдкгаЮхИіНкЕуЕФМЏШКРяЃЌПЩвджИЖЈФГИіЖгСаЕФФкШндк2ИіНкЕуЩЯНјааДцДЂЃЌДгЖјдкадФмгыИпПЩгУаджЎМфШЁЕУвЛИіЦНКтЃЈгІИУОЭЪЧжИОЕЯёФЃЪНЃЉЁЃ
МЏШКНкЕу
RabbitMQЕФМЏШКНкЕуАќРЈФкДцНкЕуЁЂДХХЬНкЕуЁЃЙЫУћЫМвхФкДцНкЕуОЭЪЧНЋЫљгаЪ§ОнЗХдкФкДцЃЌДХХЬНкЕуНЋЪ§ОнЗХдкДХХЬЁЃВЛЙ§ЃЌШчЙћдкЭЖЕнЯћЯЂЪБЃЌДђПЊСЫЯћЯЂЕФГжОУЛЏЃЌФЧУДМДЪЙЪЧФкДцНкЕуЃЌЪ§ОнЛЙЪЧАВШЋЕФЗХдкДХХЬЁЃ
вЛИіrabbitmqМЏ ШКжаПЩвдЙВЯэ userЃЌvhostЃЌqueueЃЌexchangeЕШЃЌЫљгаЕФЪ§ОнКЭзДЬЌЖМЪЧБиаыдкЫљгаНкЕуЩЯИДжЦЕФЃЌвЛИіР§ЭтЪЧЃЌФЧаЉЕБЧАжЛЪєгкДДНЈЫќЕФНкЕуЕФЯћЯЂЖгСаЃЌОЁЙмЫќУЧПЩМћЧвПЩБЛЫљгаНкЕуЖСШЁЁЃrabbitmqНкЕуПЩвдЖЏЬЌЕФМгШыЕНМЏШКжаЃЌвЛИіНкЕуЫќПЩвдМгШыЕНМЏШКжаЃЌвВПЩвдДгМЏШКЛЗМЏШКЛсНјаавЛИіЛљБОЕФИКдиОљКтЁЃ
МЏШКжагаСНжжНкЕуЃК
1.ФкДцНкЕуЃКжЛБЃДцзДЬЌЕНФкДцЃЈвЛИіР§ЭтЕФЧщПіЪЧЃКГжОУЕФqueueЕФГжОУФкШнНЋБЛБЃДцЕНdiskЃЉ
2.ДХХЬНкЕуЃКБЃДцзДЬЌЕНФкДцКЭДХХЬЁЃ
ФкДцНкЕуЫфШЛВЛаДШыДХХЬЃЌЕЋЪЧЫќжДааБШДХХЬНкЕувЊКУЁЃМЏШКжаЃЌжЛашвЊвЛИіДХХЬНкЕуРДБЃДцзДЬЌ ОЭзуЙЛСЫШчЙћМЏШКжажЛгаФкДцНкЕуЃЌФЧУДВЛФмЭЃжЙЫќУЧЃЌЗёдђЫљгаЕФзДЬЌЃЌЯћЯЂЕШЖМЛсЖЊЪЇЁЃ
|









