| БрМЭЦМі: |
БОЮФРДздгкsegmentfault.comЃЌвЛЦ№СЫНтRESTЕФФкдкЃЌШЯЪЖRESTЕФгХЪЦЃЌЖјВЛдйНЋЫќЕБзїЪЧЁАРэЫљЕБШЛЁБ
|
|
в§бд
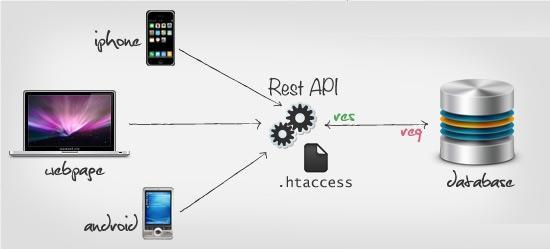
зїЮЊWebПЊЗЂепЃЌФуПЩФмЛђЖрЛђЩйСЫНтвЛаЉRESTЕФжЊЪЖЃЌЩѕжСвбОЗЧГЃЯАЙпгкЫќЃЌвджСгкдке§ЪНЕибЇЯАRESTЕФЪБКђЃЌФуПЩФмаФРяЛсЯыЃКЁАБОРДОЭЪЧетбљзіЕФАЁЃЌВЛШЛЛЙФмдѕУДзіФиЃПЁБ
ШЗЪЕЪЧетбљЃЌRESTвбОГЩЮЊWebЪРНчЕФвЛжжФкдкМмЙЙддђЁЃетжївЊЪЧвђЮЊRESTЕФВњЩњШЗЪЕгыHTTPгазХУмВЛПЩЗжЕФСЊЯЕЁЃRESTЕФЬсГіепRoy
FieldingдкWebНчЪЧвЛЮЛОйзуЧсжиЕФШЫЮяЃЌЫћЪЧHTTPавщЃЈ1.0АцКЭ1.1АцЃЉЕФжївЊЩшМЦепЁЂApacheЗўЮёЦїШэМўЕФзїепжЎвЛЁЂApacheЛљН№ЛсЕФЕквЛШЮжїЯЏЁЁFieldingдкМИФъвдКѓ ЛиЙЫЦ№RESTЕФЩшМЦЙ§ГЬЪБЃЌЫћЫЕЕРЃК
Throughout the HTTP standardization process, I was
called on to defend the design choices of the Web.
That is an extremely difficult thing to do within
a process that accepts proposals from anyone on a
topic that was rapidly becoming the center of an entire
industry. I had comments from well over 500 developers,
many of whom were distinguished engineers with decades
of experience, and I had to explain everything from
the most abstract notions of Web interaction to the
finest details of HTTP syntax. That process honed
my model down to a core set of principles, properties,
and constraints that are now called REST.
дкHTTPБъзМЛЏЕФЙ§ГЬжаЃЌFieldingзїЮЊзїепжЎвЛЃЌИКд№ЯђЭтНчЖдHTTPЕФЩшМЦзїГіНтЪЭКЭБчЛЄЁЃдкетИіЙ§ГЬжаЃЌЫћЕФЫМЮЌФЃаЭЪмЕНВЛЖЯЕиДИСЖЃЌвЛЬззМдђДгжаГСЕэСЫЯТРДЃЌетОЭЪЧRESTЁЃ
REST
RESTЪЧRepresentational State Transfer(дкБэЪОВуЩЯЕФзДЬЌДЋЪф)ЕФЫѕаДЃЌетИіДЪЕФзжУцвтЫМвЊдкЮФеТЕФКѓУцВХФмНтЪЭЧхГўЁЃRESTЪЧвЛжжWEBгІгУЕФМмЙЙЗчИёЃЌЫќБЛЖЈвхЮЊ6ИіЯожЦЃЌТњзует6ИіЯожЦЃЌФмЙЛЛёЕУжюЖргХЪЦЃЈЯъЯИгХЕудкЮФеТзюКѓзмНсЃЉЁЃ
ЯШгУвЛОфЛАРДИХРЈRESTful API(ОпгаRESTЗчИёЕФAPI): гУURLЖЈЮЛзЪдДЃЌгУHTTPЖЏДЪЃЈGET,HEAD,POST,PUT,PATCH,DELETEЃЉУшЪіВйзїЃЌгУЯьгІзДЬЌТыБэЪОВйзїНсЙћЁЃ
ЕЋЪЧRESTдЖдЖВЛНіЪЧжИAPIЕФЗчИёЃЌЫќЪЧвЛжжЭјТчгІгУЕФМмЙЙЗчИёЁЃЮвУЧЕНКѓУцЛсгаЫљЬхЛсЁЃ
СэЭтЃЌашвЊзЂвтЕФЪЧЃЌRESTЕФддђВЛНіНіЪЪгУгкHTTPавщЁЃЕЋЪЧЃЌгЩгкRESTЕФгІгУГЁОАОјДѓВПЗжЪЧWEBгІгУЃЌБОЦЊЮФеТНЋЛљгкHTTPРДЬжТлRESTЁЃ
в§ШыЃКДгСэвЛИіНЧЖШПДД§ЧАКѓЖЫЗжРы
ЮвУЧфЏРРвЛИіЭјеОЃЌЫЕЕНЕзОЭЪЧгыетИіЭјеОжаЕФзЪдДНјааЛЅЖЏЃЈЛёШЁЁЂЬсНЛЁЂИќаТЁЂЩОГ§ЃЉЁЃЧАЖЫЕФЙЄзїЃЌОЭЪЧЮЊгУЛЇДгЗўЮёЖЫЛёШЁзЪдДЁЂеЙЪОзЪдДЁЂЧыЧѓЗўЮёЖЫИФБфзЪдДЁЃ
RESTful APIгажњгкПЭЛЇЖЫКЭЗўЮёЖЫЕФЙІФмЗжРыЃЌЗўЮёЦїЭъШЋАчбнзХвЛИіЁАзЪдДЗўЮёЩЬЁБЕФНЧЩЋЁЃИїжжВЛЭЌЕФПЭЛЇЖЫЖМПЩвдЭЈЙ§вЛжТЕФAPIгыетИіЁАзЪдДЗўЮёЩЬЁБНЛСїЃЌДгЖјгызЪдДНјааЛЅЖЏЁЃ
зЪдД
дкRESTМмЙЙжаЃЌЁАзЪдДЁБАчбнепжївЊНЧЩЋЁЃЫќОпгавдЯТЬиЕуЃК
зЪдДЪЧШЮКЮПЩвдВйзїЃЈЛёШЁЁЂЬсНЛЁЂИќаТЁЂЩОГ§ЃЉЕФЪ§ОнЃЌБШШчвЛИіЮФЕЕЃЈdocumentЃЉЁЂвЛеХЭМЦЌЁЁ
wikipedia: "Web resources" were first defined
on the World Wide Web as documents or files identified
by their URLs. However, today they have a much more
generic and abstract definition that encompasses every
thing or entity that can be identified, named, addressed,
or handled, in any way whatsoever, on the web. ЁАзЪдДЁБАќРЈWebжаШЮКЮПЩвдБЛБъЪЖЁЂУќУћЁЂЖЈЮЛЁЂДІРэЕФЪТЮяЁЃ
зЪдДЕФМЏКЯвВЪЧвЛжжзЪдДЃЌБШШчblogsБэЪОВЉПЭЃЈзЪдДЃЉЕФМЏКЯЁЃ
НјаазЪдДВйзїЕФЪБКђЃЌгУURIРДжИЖЈБЛВйзїЕФзЪдДЁЃШчЙћвЛИіURIВЛНіФмБъЪЖвЛИіЭјТчЩЯЕФзЪдДЃЌЛЙФмЙЛЖЈЮЛетИізЪдДЃЌФЧУДетИіURIвВНаURLЁЃ
зЪдДЪЧвЛИіГщЯѓЕФИХФюЃЌзЪдДЮоЗЈБЛДЋЪфЃЌжЛФмДЋЪфзЪдДЕФБэЪОЃЈrepresentationЃЉЁЃвЛИізЪдДПЩвдгаЖржжБэЪОЃЌБШШчЃЌвЛИізЪдДПЩвдгУHTMLЁЂXMLЁЂJSONРДБэЪОЁЃОпЬхДЋЪфФФжжБэЪОШЁОігкЗўЮёЖЫЕФФмСІКЭПЭЛЇЖЫЕФвЊЧѓЁЃДЋЪфЕФБэЪОЮДБиОЭЪЧЗўЮёЦїДцДЂЪБЪЙгУЕФБэЪОЃЌБШШчЃЌетИізЪдДдкЗўЮёЦїВЛЪЧвдHTMLЛђXMLЛђJSONРДДцДЂЕФЃЌПЩФмЪЧвЛжжИќМгРћгкбЙЫѕЕФБэЪОЁЃзмЕФРДЫЕЃЌЁАБэЪОЁБЪЧЁАзЪдДЁБЕФДцДЂКЭДЋЪфаЮЪНЃЌЁАзЪдДЁБЪЧЁАБэЪОЁБЕФФкШнЃЈГщЯѓИХФюЃЉЁЃВЛЙмгУЪВУДаЮЪНРДБэЪОЃЌЪМжеУшЪіЕФЪЧетИізЪдДЁЃ
ОйвЛИіР§згЃЌЕБЮвУЧЬжТлЁАЮФеТСаБэЁБетИізЪдДЪБЃЌЮвУЧВЂВЛдкКѕЫќЪЧjsonИёЪНЛЙЪЧxmlИёЪНЃЌЮвУЧжИЕФЪЧЫќЕФКЌвхЃКФГИігУЛЇЕФЫљгаЮФеТЁЃЕЋЪЧЕБЮвУЧецЕФвЊдкЗўЮёЦїгыПЭЛЇЖЫжЎМфДЋЪфЪ§ОнЕФЪБКђЃЌВЛФмжБНгЁАДЋЪфзЪдДЁБЃЌвђЮЊзЪдДЬЋГщЯѓСЫЃЌЗЂЫЭЗНБиаывЊвдФГвЛжжБэЪОЃЈrepresentationЃЉРДДЋЕнЫќЃЈБШШчjsonЃЉЃЌНгЪеЗНВХФмКмКУЕиНтЮіКЭДІРэЁЃ
БэЪОЃЈrepresentationЃЉАќРЈЪ§ОнЃЈdataЃЌБэЪОзЪдДБОЩэЃЉКЭдЊЪ§ОнЃЈmetadataЃЌгУгкУшЪіетИіrepresentationЃЉЁЃдкRoy
FieldingЕФТлЮФжагаетИіЖЈвхЃКA representation is a sequence of
bytes, plus representation metadata to describe those
bytes.
дкЧАУцЕФР§згжаЃЌбЯИёРДЫЕЃЌЁАjsonзжЗћДЎЁБВЂВЛЪЧЭъећЕФrepresentationЃЌећИіHTTPЯьгІВХЪЧrepresentationЁЃHTTP
bodyжаЕФЪЧЪ§ОнЃЌHTTP headerжаЕФЪЧдЊЪ§ОнЃЈгШЦфЪЧContent-TypeетжжзжЖЮЃЉЁЃ
ВЮПМhttps://restfulapi.net/
гУURLЖЈЮЛзЪдД
дкRESTfulМмЙЙЗчИёжаЃЌURLгУРДжИЖЈвЛИізЪдДЁЃзЪдДОЭЪЧЗўЮёЦїЩЯПЩВйзїЕФЪЕЬхЃЈПЩвдРэНтЮЊЪ§ОнЃЉЁЃБШШчЫЕURL/api/usersБэЪОЕФЪЧИУЭјеОЕФЫљгагУЛЇЃЌетЪЧвЛжжзЪдДЃЌПЩвдгыжЎЛЅЖЏЃЈЛёШЁЁЂЬсНЛЁЂИќаТЁЂЩОГ§ЃЉЁЃСэЭтЃЌзЪдДЕижЗОпгаВуДЮНсЙЙЃЌБШШч/api/users/csrБэЪОгУЛЇУћЮЊ'csr'ЕФгУЛЇЃЌ/api/users/csr/blogsБэЪО'csr'ЕФЫљгаВЉПЭЃЌ/api/users/csr/blogs/1234567БэЪОЦфжаЕФФГвЛЦЊВЉПЭЁЃетаЉЖМЪЧзЪдДЃЌКѓепЧЖЬздкЧАепжЎжаЁЃ
МШШЛURLБэЪОвЛИізЪдДЃЌздШЛОЭВЛгІИУАќКЌЖЏДЪЃЌЫќгІИУгЩУћДЪзщГЩЁЃвЛИі not RESTful ЕФР§згЪЧЭЈЙ§Яђapi/delete/resourceЗЂЫЭGETЧыЧѓРДЩОГ§вЛИізЪдДЁЃ
ИќЯъЯИЕФURLЩшМЦПЩвдВщПДШювЛЗхЕФ"RESTful API ЩшМЦжИФЯ"ЛђепжЊКѕИпЦБЛиД№ЁЃURLЗчИёжЛЪЧRESTЕФЭтБэЃЌВЛЪЧБОЮФЕФжиЕуЁЃ
ВйзїзЪдД
МШШЛЭЈЙ§URLФмЙЛжИЖЈвЛИіЗўЮёЦїЩЯЕФзЪдДЁЃФЧУДЮвУЧгІИУШчКЮгыетИізЪдДНјааЛЅЖЏФиЃПЮвУЧЖдетИізЪдД(URL)ЪЙгУВЛЭЌЕФHTTPЗНЗЈЃЌОЭДњБэЖдетИізЪдДЕФВЛЭЌВйзїЃК
GETЃЈSELECTЃЉЃКДгЗўЮёЦїЛёШЁзЪдДЃЈвЛИізЪдДЛђзЪдДМЏКЯЃЉЁЃ
POSTЃЈCREATEЃЉЃКдкЗўЮёЦїаТНЈвЛИізЪдДЃЈвВПЩвдгУгкИќаТзЪдДЃЉЁЃ
PUTЃЈUPDATEЃЉЃКдкЗўЮёЦїИќаТзЪдДЃЈПЭЛЇЖЫЬсЙЉИФБфКѓЕФЭъећзЪдДЃЉЁЃ
PATCHЃЈUPDATEЃЉЃКдкЗўЮёЦїИќаТзЪдДЃЈПЭЛЇЖЫЬсЙЉИФБфЕФВПЗжЃЉЁЃ
DELETEЃЈDELETEЃЉЃКДгЗўЮёЦїЩОГ§зЪдДЁЃ
HEADЃКЛёШЁзЪдДЕФдЊЪ§ОнЁЃ
OPTIONSЃКЛёШЁаХЯЂЃЌЙигкзЪдДЕФФФаЉЪєадЪЧПЭЛЇЖЫПЩвдИФБфЕФЁЃ
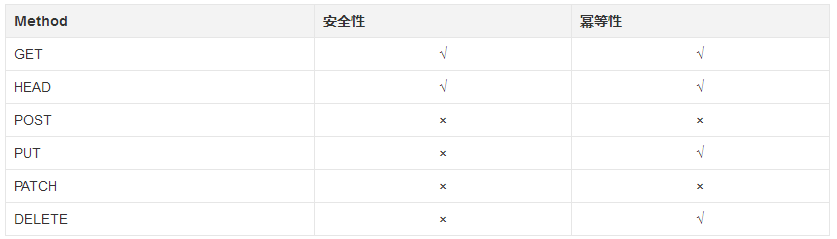
GETЁЂHEADЁЂPUTЁЂDELETEЗНЗЈЪЧУнЕШЗНЗЈ(ЖдгкЭЌвЛИіФкШнЕФЧыЧѓЃЌЗЂГіnДЮЕФаЇЙћгыЗЂГі1ДЮЕФаЇЙћЯрЭЌ)ЁЃ
GETЁЂHEADЗНЗЈЪЧАВШЋЗНЗЈ(ВЛЛсдьГЩЗўЮёЦїЩЯзЪдДЕФИФБф)ЁЃ
PATCHВЛвЛЖЈЪЧУнЕШЕФЁЃPATCHЕФЪЕЯжЗНЪНгаПЩФмЪЧ"ЬсЙЉвЛИігУРДЬцЛЛЕФЪ§Он"ЃЌвВгаПЩФмЪЧ"ЬсЙЉвЛИіИќаТЪ§ОнЕФЗНЗЈ"(БШШчdata++)ЁЃШчЙћЪЧКѓепЃЌФЧУДPATCHВЛЪЧУнЕШЕФЁЃ
ВЮПМЃКHTTP Methods for RESTful Services
ЭЈЙ§HTTPзДЬЌТыБэЪОВйзїЕФНсЙћ
ЫфШЛHTTPзДЬЌТыЩшМЦЕФБОвтОЭЪЧБэЪОВйзїНсЙћЃЌЕЋЪЧгаЪБКђШЫУЧЭљЭљУЛгаКмКУЕФРћгУЫќЃЌRESTful APIвЊЧѓГфЗжРћгУHTTPзДЬЌТы
200 OK - [GET]ЃКЗўЮёЦїГЩЙІЗЕЛигУЛЇЧыЧѓЕФЪ§ОнЃЌИУВйзїЪЧУнЕШЕФЃЈIdempotentЃЉЁЃ
201 CREATED - [POST/PUT/PATCH]ЃКгУЛЇаТНЈЛђаоИФЪ§ОнГЩЙІЁЃ
202 Accepted - [*]ЃКБэЪОвЛИіЧыЧѓвбОНјШыКѓЬЈХХЖгЃЈвьВНШЮЮёЃЉ
204 NO CONTENT - [DELETE]ЃКгУЛЇЩОГ§Ъ§ОнГЩЙІЁЃ
400 INVALID REQUEST - [POST/PUT/PATCH]ЃКгУЛЇЗЂГіЕФЧыЧѓгаДэЮѓЃЌЗўЮёЦїУЛгаНјаааТНЈЛђаоИФЪ§ОнЕФВйзїЃЌИУВйзїЪЧУнЕШЕФЁЃ
401 Unauthorized - [*]ЃКБэЪОгУЛЇУЛгаШЈЯоЃЈСюХЦЁЂгУЛЇУћЁЂУмТыДэЮѓЃЉЁЃ
403 Forbidden - [*] БэЪОгУЛЇЕУЕНЪкШЈЃЈгы401ДэЮѓЯрЖдЃЉЃЌЕЋЪЧЗУЮЪЪЧБЛНћжЙЕФЁЃ
404 NOT FOUND - [*]ЃКгУЛЇЗЂГіЕФЧыЧѓеыЖдЕФЪЧВЛДцдкЕФМЧТМЃЌЗўЮёЦїУЛгаНјааВйзїЃЌИУВйзїЪЧУнЕШЕФЁЃ
406 Not Acceptable - [GET]ЃКгУЛЇЧыЧѓЕФИёЪНВЛПЩЕУЃЈБШШчгУЛЇЧыЧѓJSONИёЪНЃЌЕЋЪЧжЛгаXMLИёЪНЃЉЁЃ
410 Gone -[GET]ЃКгУЛЇЧыЧѓЕФзЪдДБЛгРОУЩОГ§ЃЌЧвВЛЛсдйЕУЕНЕФЁЃ
422 Unprocesable entity - [POST/PUT/PATCH] ЕБДДНЈвЛИіЖдЯѓЪБЃЌЗЂЩњвЛИібщжЄДэЮѓЁЃ
500 INTERNAL SERVER ERROR - [*]ЃКЗўЮёЦїЗЂЩњДэЮѓЃЌгУЛЇНЋЮоЗЈХаЖЯЗЂГіЕФЧыЧѓЪЧЗёГЩЙІЁЃ |
ЭъећзДЬЌТыСаБэ
ШчКЮЩшМЦRESTful API
дкЙ§ШЅВЛЪЙгУRESTfulМмЙЙЗчИёЕФЪБКђЃЌШчЙћЮвУЧвЊЩшМЦвЛИіЯЕЭГЃЌЛсвдЁАВйзїЁБЮЊГіЗЂЕуЃЌШЛКѓЮЇШЦЫќШЅНЈЩшЦфЫћашвЊЕФЖЋЮїЁЃ
ОйИіР§згЃЌЮвУЧвЊЯђЯЕЭГжадіМгвЛИігУЛЇЕЧТНЕФЙІФмЃК
ашвЊвЛИігУЛЇЕЧТНЕФЙІФм(Вйзї)
дМЖЈвЛИігУгкЕЧТМЕФAPI(вВОЭЪЧURL)
дМЖЈетИіAPIЕФЪЙгУЗНЪН(ЗЂЫЭЯьгІЪВУДЪ§ОнЁЂИёЪНЪЧЪВУД)
ЧАКѓЖЫеыЖдетИіAPIНјааПЊЗЂ
етжжЩшМЦЗНЪНгаШчЯТШБЕуЃК
ЕБЮвУЧВЛЖЯЮЊетИіЯЕЭГдіМгВйзїЃЌУПдіМгвЛИіВйзїЖМвЊАДееЩЯУцЕФСїГЬЩшМЦвЛДЮЃЌЕк2КЭ3ЕуЕФЙЄзїЪЕМЪЪЧПЩвдДѓДѓЯїМѕЕФ(ЭЈЙ§REST)ЁЃ
ВйзїжЎМфПЩФмЪЧгавРРЕЕФЃЌвРРЕЖрЦ№РДЃЌЯЕЭГЛсБфЕУКмИДдгЁЃ
ЮвУЧЕФAPIШБЗІвЛжТад(ашвЊвЛЗнХгДѓЕФЮФЕЕРДМЧТМapiЕФЕижЗЁЂЪЙгУЗНЪН)ЁЃ
ВйзїЭЈГЃБЛШЯЮЊЪЧгаИБзїгУЃЈSide EffectЃЉЕФЃЌКмФбЪЙгУЛКДцММЪѕЁЃ
ЖјШчЙћЮвУЧЩшМЦRESTЗчИёЕФЯЕЭГЃЌзЪдДЪЧЕквЛЮЛЕФПМТЧЃЌЪзЯШДгзЪдДЕФНЧЖШНјааЯЕЭГЕФВ№ЗжЁЂЩшМЦЃЌЖјВЛЪЧЯёвдЭљвЛбљвдВйзїЮЊНЧЖШРДНјааЩшМЦЁЃ
гУСНИіР§згРДЫЕУїЃКвјааЕФзЊеЫAPIЃЌМДЪБЭЈбЖШэМўжаЗЂЫЭЯћЯЂЕФAPIЁЃ
етСНИіЙІФмЗЧГЃОпгаЁАЖЏзїадЁБЃЌПДЦ№РДКЭЁАзЪдДЁБСЊЯЕВЛДѓЃЌКмШнвзОЭЛсЩшМЦГЩnot RESTfulЕФAPIЃКPOST
/transfer/${amount}/to/${toUserID}ЁЂPOST /api/sendMessageЁЃ
вЛЕЉдкURLжав§ШыСЫЖЏДЪЃЌетИіURLЕФЙІФмОЭЖЈЫРСЫЃЌЮоЗЈгУгкБ№ЕФгУЭОЃЈБШШчЃЌGET /transfer/${amount}/to/${toUserID}ЛђGET
/api/sendMessageЕФгявхКмЦцЙжЃЌВЛКУЪЙгУЃЉЁЃВЂЧвЃЌВЛЭЌЙІФмЕФAPIгаИїздЕФНсЙЙЃЌвЛжТадКмВюЃЌашвЊвЛЗнЯъЯИЕФAPIЮФЕЕВХФмЪЙгУЁЃ
етжжЧщПіЯТЃЌвЊШчКЮЭЈЙ§RESTfulМмЙЙЗчИёЃЌЩшМЦвЛЬзвЛжТЁЂЖргУЭОЕФURLФиЃП
МђЕЅЕиЫЕЃЌОЭЪЧНЋвЛИіЁАЖЏзїЁБРэНтЮЊЁАВйзївЛИізЪдДЁБЁЃетРяЕФЁАВйзїЁБЪЧжИHTTPЕФЗНЗЈЁЃ
ЖдгкзЊеЫЖЏзїЃЌОЭПЩвдРэНтЮЊЁАаТНЈвЛИізЊеЫЪТЮёЁБЃЈзЊеЫЪТЮёЪЧзЪдДЃЉЃЌвђДЫAPIОЭПЩвдЩшжУГЩетбљ: POST
/transactionsЃЌЧыЧѓЬхЮЊЃКto=632&amount=500ЁЃетбљЕФЩшМЦВЛЕЋМђНрУїСЫЃЌЖјЧвЮвУЧПЩвдНЋетИіURLгУгкБ№ЕФгУЭОЃКЭЈЙ§GET
/transactionsРДЛёШЁИУгУЛЇЕФЫљгазЊеЫЪТЮёЁЃЛЙПЩвдНЋGET /transactions/456828ЖЈвхЮЊЁАЛёШЁФГвЛДЮзЊеЫМЧТМЁБЁЃ
МДЪБЭЈбЖШэМўжаЗЂЫЭЯћЯЂЕФЖЏзїЃЌЮвУЧПЩвдРэНтЮЊЁАВйзїСФЬьМЧТМЃЈСФЬьМЧТМЪЧзЪдДЃЌЫќЪЧгЩЁАЯћЯЂЁБзщГЩЕФМЏКЯЃЌЯћЯЂвВЪЧзЪдДЃЉЁБЃЌЫљвдAPIЩшМЦЮЊ
POST /messages
# ДДНЈаТЕФСФЬьМЧТМЃЈbodyДЋЪфЯћЯЂЕФФкШнЃЉ
GET /messages # ЛёШЁСФЬьМЧТМЃЈЗЕЛивЛИіЪ§зщЃЌЦфжаУПИіЯюЪЧвЛИіЯћЯЂЃЉ
GET /messages/${messageID} # ЛёШЁФГИіЯћЯЂЕФЯъЯИаХЯЂ
PUT /messages/${messageID} # ИќаТФГИіЯћЯЂЃЈbodyДЋЪфЯћЯЂЕФФкШнЃЉ
DELETE /messages/${messageID} # ЩОГ§ФГИіЯћЯЂЕФМЧТМ |
ЭЌРэЃЌТлЬГРргІгУЗЂЬћЁЂЛиЬћЕФAPIвВПЩвдетбљЩшМЦЁЃ
ДгвдЩЯЕФСНИіР§згЮвУЧПЩвдПДГіЃЌЪЙгУRESTfulЗчИёПЩвдПЫЗўДЋЭГМмЙЙЗчИёЕФФЧ4ИіШБЯнЃК
ЩшМЦAPIЙЄзїСПМѕЩйЃЌвђЮЊЙІФмашЧѓвЛЕЉГіРДЃЌашвЊВйзїЕФзЪдДЁЂВйзїЕФЗНЪНСЂПЬОЭФмЗжЮіГіРДЃЌвђДЫзЪдДURLКЭAPIЕФЪЙгУЗНЪН(GET,
POST...)ЖМКмШнвзЕУЕНЁЃ
УЛгаСЫВйзїжЎМфЕФвРРЕЁЃзЪдДжЎМфЫфШЛПЩФмгаЙиСЊЃЌЕЋЪЧаЁЕУЖрЁЃ
ЖдзЪдДЕФВйзївВОЭФЧУДМИжж(ЛёШЁЁЂаТНЈЁЂаоИФЁЂЩОГ§)ЃЌAPIЕФвЛжТадЁЂздЮвУшЪіадКмЧПЃЌВЛашвЊЙ§ЖрНтЪЭЁЃ
ЖдгкGETЧыЧѓЃЌЮвУЧЖМПЩвдПМТЧЪЙгУЛКДцЃЌвђЮЊдкRESTfulЕФМмЙЙжаЃЌGETЧыЧѓДњБэЛёШЁЪ§ОнЃЌБиаыЪЧАВШЋЁЂУнЕШЕФЁЃ
ЗўЮёЦїЮозДЬЌ
ИљОнRESTЕФМмЙЙЯожЦЃЌRESTfulЕФЗўЮёЦїБиаыЪЧЮозДЬЌЕФЃЌетвтЮЖзХРДздПЭЛЇЕФУПвЛИіЧыЧѓБиаыАќКЌЗўЮёЦїДІРэИУЧыЧѓЫљашЕФЫљгааХЯЂЃЌ
ЗўЮёЦїВЛФмРћгУШЮКЮвбОДцДЂЕФЁАЩЯЯТЮФ(contextЃЌдкетРяБэЪОгУЛЇЕФЛсЛАзДЬЌ)ЁБРДДІРэаТЕНРДЕФЧыЧѓЃЌЛсЛАзДЬЌжЛФмгЩПЭЛЇЖЫРДБЃДцЃЌВЂЧвдкЧыЧѓЪБвЛВЂЬсЙЉЁЃ
етРязЂвтСНЕуЁЃ1. ЗўЮёЦїВЛФмДцДЂЁАЩЯЯТЮФЁБВЛДњБэСЌЪ§ОнПтЖМВЛФмгаЃЌЁАЩЯЯТЮФЁБжИФЧаЉдкЗўЮёЦїФкДцжаЕФЁЂЗЧГжОУЛЏЕФЪ§ОнЁЃ2.
ЮозДЬЌВЛДњБэВЛФмгаЛсЛА(sessions)ЃЌЮозДЬЌНіНіжИЗўЮёЦїЮозДЬЌЁЃЗўЮёЦїВЛМЧТМЁЂЮЌЛЄЛсЛАЃЌЕЋЪЧЛсЛАзДЬЌПЩвдгЩПЭЛЇЖЫдкУПДЮЧыЧѓЕФЪБКђЬсЙЉЁЃ
ЮввЛПЊЪМвдЮЊЮозДЬЌгыгУЛЇЕЧТНЪЧГхЭЛЕФЃЌКѓРДдкDo sessions really violate RESTfulness?
- StackOverflowЩЯевЕНСЫвЛИіСюЮвТњвтЕФНтД№ЁЃвдЯТСНЗљЭМеЊТМздетИіД№АИЁЃ
ЮозДЬЌЕФШЯжЄЛњжЦЃК
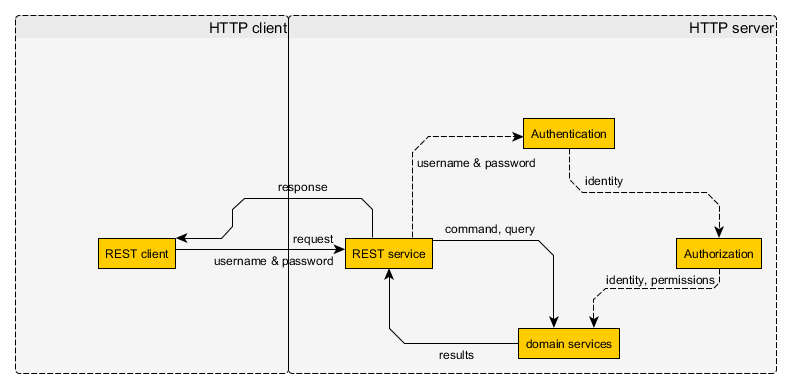
What you need is storing username and password on
the client and send it with every request. You don't
need more to do this than HTTP basic auth and an encrypted
connection.
жЛашвЊНЋгУЛЇУћКЭУмТыДцДЂдкПЭЛЇЖЫЃЌШЛКѓПЭЛЇЖЫУПДЮЗЂЫЭЧыЧѓЖМИНДјЩЯгУЛЇУћКЭУмТыЁЃвЊзіЕНетЕуФужЛашвЊHTTPЛљБОШЯжЄЃЈМђЕЅРДЫЕОЭЪЧНЋгУЛЇУћКЭУмТыЗХдкHTTPЭЗВПЃЉКЭвЛИіМгУмЕФСЌНг(HTTPS)ЁЃ
ШчЙћУПДЮШЯжЄЃЌЖМвЊШЅЪ§ОнПтВщбЏгУЛЇЕФаХЯЂРДКЫЖдЃЌФЧУДЯьгІЛсЗЧГЃТ§ЃЌЖјЧвЗўЮёЦївВЛсгаКмДѓЕФадФмЫ№ЪЇЁЃЮЊСЫМгПьШЯжЄЕФЫйЖШЃЌзюКУдкФкДцжаЪЙгУШЯжЄЛКДцЁЃетВЂВЛЮЅБГЁАЮозДЬЌЁБЕФЯожЦЃЌвђЮЊЛКДцЕФзїгУНіНіЦ№МгЫйЕФзїгУЃЌУЛгаЛКДцеебљФмЙЄзїЁЃ
ЮозДЬЌЕФЕкШ§ЗНМјШЈЛњжЦЃК
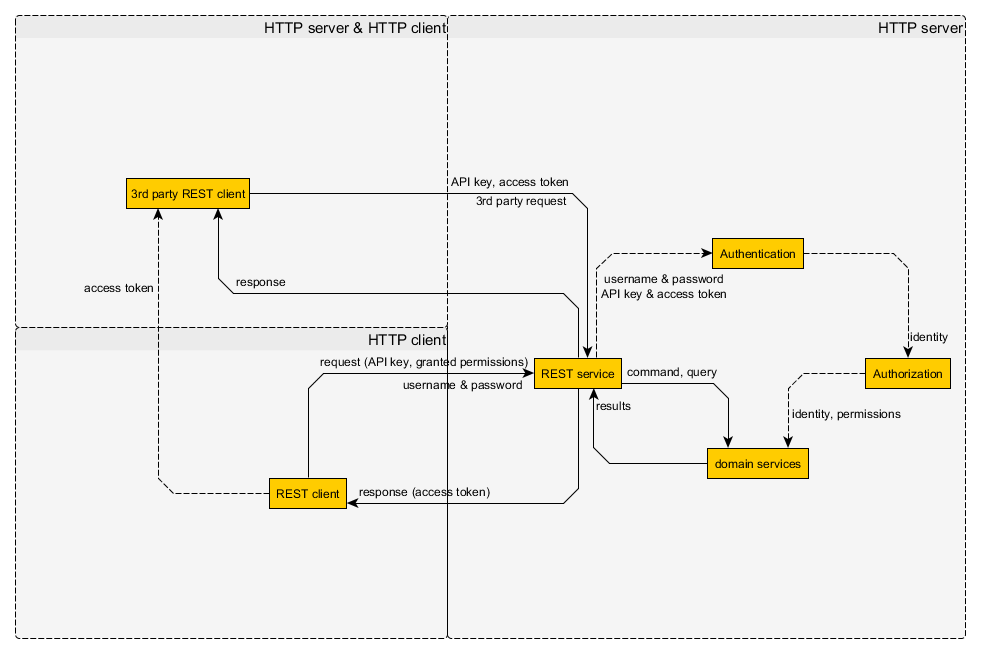
What about 3rd party clients? They cannot have the
username and password and all the permissions of the
users. So you have to store separately what permissions
a 3rd party client can have by a specific user. So
the client developers can register they 3rd party
clients, and get an unique API key and the users can
allow 3rd party clients to access some part of their
permissions. Like reading the name and email address,
or listing their friends, etc... After allowing a
3rd party client the server will generate an access
token. These access token can be used by the 3rd party
client to access the permissions granted by the user.
ЭЈЙ§етИіЗНЪНЃЌгУЛЇПЩвдИјЕкШ§ЗНгІгУЪкШЈЃЌШУЕкШ§ЗНгІгУФУзХгУЛЇЕФЁАСюХЦЁБЗУЮЪЭјеОЕФвЛаЉЗўЮёЁЃ
вдЩЯСНЗљЭМНВЕФЪЧRESTfulЗчИёЕФЩэЗнШЯжЄЛњжЦЁЃдкЪЕМљжазюКУЪЙгУOAuth 2.0ПђМмЁЃ
ЮозДЬЌдіЧПСЫЯЕЭГЕФЙЪеЯЛжИДФмСІЃЌвђЮЊдкЗўЮёЦїЩЯУЛгаБЃДцsessionЕФзДЬЌЃЌЫљвдЛжИДЦ№РДИќШнвзЁЃ
ИќживЊЕФЪЧЃЌЮозДЬЌвтЮЖзХЗжВМЪНЯЕЭГФмЙЛИќКУЕиЙЄзїЃЌИКдиОљКтЦїПЩвдздгЩЕиНЋЧыЧѓЗжЗЂЕНШЮвтЕФЗўЮёЦїЁЃвђЮЊЧыЧѓжаЖМвбОАќКЌСЫЗўЮёЦїЫљашЕФЫљгааХЯЂЃЌШЮКЮЗўЮёЦїЖМПЩвдДІРэЁЃ
ВЛНіНіЪЧЗўЮёЦїЃЌДњРэЁЂЭјЙиЁЂЗРЛ№ЧНвВПЩвдРэНтЯћЯЂЃЌДгЖјПЩвддкВЛаоИФНгПкЕФЧщПіЯТЃЌдіМгИќЖрЧПДѓЕФЙІФмЃЈБШШчДњРэЛКДцЃЉЁЃ
ВЂЧвЃЌЮозДЬЌШУЯЕЭГЕФКсЯђЭиеЙФмСІЧПДѓЁЃвђЮЊВЛашвЊдкВЛЭЌЕФЗўЮёЦїжЎМфЭЌВНsessionзДЬЌЃЌЫљвдЗўЮёЦїжЎМфЕФЙЕЭЈПЊЯњКмЕЭЁЃдіМгЗўЮёЦїЕФЪ§СПВЛЛсДјРДУїЯдЕФадФмЫ№ЪЇЃЈЁА1+1ЁБИќНгНќгкЁА2ЁБСЫЃЉЁЃ
ашвЊзЂвтЕФЪЧЃЌRESTВЛЪЧвЛИіЁАзкНЬЁБЁЃдкФуздМКЕФгІгУжаЃЌзёбRESTЕФЭЌЪБгІИУБЃГжКЯЪЪЕФГпЖШЁЃЭЈЙ§ШЈКтРћБзЃЌбЁдёзмЬхаЇвцзюДѓЕФЗНАИЃЌМДЪЙетИіЗНАИгаПЩФмЁАЩдЮЂЮЅЗДRESTЕФддђЁБЁЃЯъМћ"REST
is not a religion..." - stackoverflow
HATEOAS
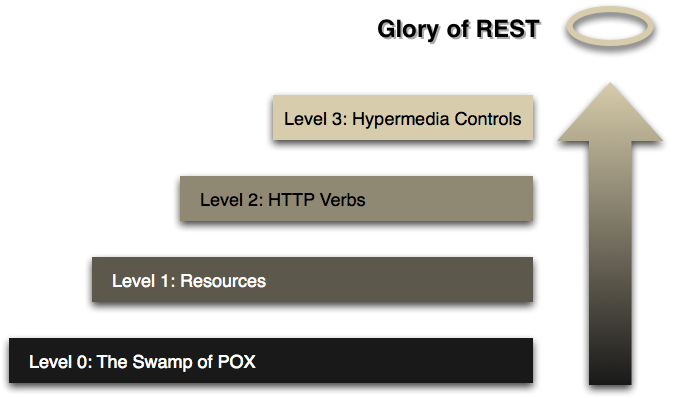
ЭМЦЌРДздsteps toward the glory of RESTЁЃ
ЧАУцвбОЬжТлСЫlevel 1КЭlevel 2ЃЌЪЕМЪЩЯRESTЛЙгавЛИіИќИпЕФВуДЮЃКHATEOAS(Hypermedia
As The Engine Of Application State)ЁЃ
ЖдгкПЭЛЇЖЫЕФзЪдДЧыЧѓЃЌЗўЮёЦїВЛНівЊЗЕЛиЫљЧыЧѓЕФзЪдДЃЌЖјЧввЊЗЕЛиПЭЛЇЖЫЫљДІЕФзДЬЌКЭПЩзЊвЦЕФзДЬЌЁЃЃЈПЭЛЇЖЫгазДЬЌЃЉ
зДЬЌПЩвдМђЕЅЕиРэНтЮЊПЭЛЇЖЫеЙЪОЕФЪ§ОнЁЃПЩвдАбПЭЛЇЖЫБШгїГЩвЛИізДЬЌЛњЃЌФЧУДетИізДЬЌЛњЬјзЊЕНвЛИіаТЕФзДЬЌЃЌОЭЛсЯдЪОаТЕФФкШнЁЃЁАЪзвГЁБЁАЮФеТСаБэЁБЁАФГЦЊЮФеТЁБОЭЪЧШ§жжПЭЛЇЖЫзДЬЌЁЃ
ПЭЛЇЖЫВЛашвЊЬсЧАжЊЕРгІгУгаФФаЉзДЬЌЃЌЖјЪЧИљОнЗўЮёЖЫЯьгІЕФЁАПЩзЊвЦЕФзДЬЌЁБЃЌЬсЙЉИјгУЛЇбЁдёЃЌДгЖјЗЂЩњзДЬЌзЊвЦЁЃ
гУМђЕЅЕФЛАРДЫЕЃЌдкбЯИёЕФRESTfulМмЙЙжаЃЌПЭЛЇЖЫВЛашвЊЬсЧАжЊЕРЗўЮёЖЫЕФAPIгаФФаЉЁЂдѕУДЕїгУЃЌдкПЭЛЇЖЫгыЗўЮёЦїЭЈаХЕФЙ§ГЬжаЃЌЗўЮёЖЫЛсИцЫпПЭЛЇЖЫЃКдкФуЕБЧАЫљДІЕФзДЬЌЯТЃЌгаФФаЉAPIПЩвдЪЙгУЁЂПЩвдзЊвЦЕНФФаЉзДЬЌЁЃ
МШШЛЗўЮёЦїЪЧЮозДЬЌЕФЃЌФЧУДЫќвЊШчКЮжЊЕРЗЂЦ№ЧыЧѓЕФгУЛЇДІгкЪВУДзДЬЌФиЃПетОЭвЊЧѓПЭЛЇЖЫдкЗЂЫЭЧыЧѓЕФЪБКђвЊаЏДјЩЯзуЙЛЕФаХЯЂЃЌШУЗўЮёЦїФмЙЛХаЖЯПЭЛЇЖЫЫљДІЕФзДЬЌЁЃ
етОЭКмЯё10086ЕФЁАЕчЛАздЖЏгявєгІД№ЗўЮёЁБЃКФуЯывЊВщбЏФуЕФЪжЛњСїСПЃЌжЛашвЊЛсВІДђЁА10086ЁБЃЌЖдЗНЛсЬсЪОФуАДЯТФФаЉАДМќОЭФмНјШыФФаЉзДЬЌЁЃНјШыЯТвЛИізДЬЌвдКѓЃЌгжЛсгагявєЬсЪОФуНгЯТРДФмЙЛАДФФаЉАДМќЁЁзюжеЃЌФуФмНјШыЕНФуЯывЊЕФФЧИізДЬЌЃЈСїСПВщбЏЗўЮёЃЉЁЃФуашвЊМЧзЁЕФНіНіЪЧЁА10086ЁБетИіКХТыЖјвбЃЁ
10086ЕФгявєЬсЪОЯрЕБгкHypermediaЃЌЪЧЧ§ЖЏгІгУзДЬЌзЊЛЛЕФЁАв§ЧцЁБЁЃ
дйНјвЛВНЯыЯыЃЌдкRESTfulМмЙЙжаЃЌЫљгаЕФзДЬЌЦфЪЕОЭзщГЩСЫвЛПХЪї(ИќзМШЗЕиЫЕЪЧЭј)ЃКИљНкЕуОЭЪЧЭјеОЕФЛљЕижЗЁЃдкФуЛёШЁвЛИіНкЕужаЕФзЪдДЕФЭЌЪБЃЌЗўЮёЦїЛЙЛсЗЕЛиИјФуетИіНкЕуЕФБпЃКHypermedia(ГЌСДНгОЭЪЧвЛжжHypermedia)ЁЃЭЈЙ§HypermediaЃЌФуФмЙЛжЊЕРЯрСкНкЕуЕФЛљБОаХЯЂЁЂЕижЗЁЃ
НсЙћОЭЪЧЃКФуФмЙЛЗУЮЪЕНетПХЪїЕФЫљгаНкЕуЃЌЖјФуЫљашвЊЬсЧАжЊЕРЕФжЛЪЧЁАШчКЮЕНДяИљНкЕуЁБЖјвбЃЁ
УПИіНкЕуОЭЪЧвЛИізДЬЌЁЃгУЛЇПЩвддкетИізДЬЌЭјжаВЛЖЯЬјзЊЁЃ
етИіР§згЃЈжЊКѕЃЉКЭетИіР§згЃЈstackoverflowЃЉвВЪЧВЛДэЕФНтЪЭЁЃ
wikipediaЕФНтЪЭЃКa REST client should then be able to
use server-provided links dynamically to discover
all the available actions and resources it needs.
As access proceeds, the server responds with text
that includes hyperlinks to other actions that are
currently available. There is no need for the client
to be hard-coded with information regarding the structure
or dynamics of the REST service.
етжжМмЙЙЕФгХЪЦЗЧГЃУїЯдЃКЧАКѓЖЫжЎМфЕФёюКЯИќМгЮЂШѕЁЃ
ЫцзХгІгУЙІФмЕФЩ§МЖИФБфЃЌЁАЪїЁБЕФбљзгЛсДѓДѓИФБфЃЌЕЋЪЧжЛашвЊШУКѓЖЫаоИФЗЕЛиЕФзЪдДФкШнКЭHypermediaЃЌЧАЖЫМИКѕВЛгУИФЖЏЁЃЙІФмЕФбнЛЏИќМгСщЛюСЫЁЃ
ЁАзЪдДЁБКЭЁАзДЬЌЁБЕФЙиЯЕ
ЯждкФугІИУУїАзRepresentational State TransferжаЕФState Transfer(зДЬЌДЋЪф)ЪЧЪВУДвтЫМСЫЃКдкHATEOASжаЃЌЗўЮёЖЫНЋПЭЛЇЖЫЫљДІЕФзДЬЌКЭПЩвдДяЕНЕФзДЬЌДЋЪфИјПЭЛЇЖЫЁЃ
ЕШвЛЯТЃЌдкЧАУцЕФзЪдДаЁНкЃЌЮвУЧВЛЪЧЫЕЙ§ДЋЪфЕФЪЧзЪдДБэЪОЃЈrepresentationЃЉТ№ЃПдѕУДетРягжЫЕДЋЪфЕФЪЧзДЬЌЃП
ЦфЪЕдкRESTМмЙЙЗчИёжаЃЌЁАДЋЪфзДЬЌЁБКЭЁАДЋЪфзЪдДБэЪОЁБЪЧЭЌвЛИівтЫМЁЃПЭЛЇЖЫЫљДІЕФзДЬЌЃЌЪЧгЩЫќНгЪеЕНЕФзЪдДБэЪОРДОіЖЈЕФЁЃБШШчЃЌПЭЛЇЖЫНгЪеЕН/user/csr/blogsзЪдДЃЌФЧУДПЭЛЇЖЫЕФзДЬЌОЭБфГЩ/user/csr/blogs(ЯдЪОcsrЕФЮФеТСаБэ)ЁЃ
ЕШвЛЯТЃЌЮЊЪВУДПЭЛЇЖЫЛсЪеЕНЁА/user/csr/blogsЁБзЪдДЃПвђЮЊПЭЛЇЖЫЧыЧѓЕФОЭЪЧЁА/user/csr/blogsЁБзЪдДЁЃ
МЬајзЗЫнЃЌЮЊЪВУДПЭЛЇЖЫЛсЧыЧѓетИізЪдДЃПвђЮЊгУЛЇЕуЛїСЫЁАВщПДЮФеТСаБэЁБЕФСДНгЃЈетИіСДНгЦфЪЕОЭЪЧвЛИіHypermediaЃЉЁЃ
МЬајзЗЫнЃЌЮЊЪВУДгавЛИіЁАВщПДЮФеТСаБэЁБЕФСДНгЯдЪОИјгУЛЇЕуЛїЃПвђЮЊHATEOASЃКЗўЮёЖЫдкЗЕЛиЩЯвЛИізДЬЌЃЈзЪдДЃЉЕФЪБКђЃЌЛсЗЕЛиЫљгаЯрСкзДЬЌЕФHypermediaЃЌЦфжаОЭАќРЈЁАВщПДЮФеТСаБэЁБетИіHypermediaЁЃПЭЛЇЖЫЛсеЙЪОЫљгаЯрСкзДЬЌЕФHypermediaЙЉгУЛЇбЁдёЁЃ
АДееДгЧАЭљКѓЕФЫГађЪсРэвЛБщЃК
ПЭЛЇЖЫЧыЧѓИљзЪдД
=> ЗўЮёЦїЗЕЛиИљзЪдДЕФБэЪОЃЌвдМАЯрСкзЪдДЕФHypermedia
=> ПЭЛЇЖЫНјШыЁАИљзЪдДЁБзДЬЌЃЈБШШчЫЕЃЌеЙЪОЪзвГЃЉ
=> ПЭЛЇЖЫЯдЪОЫљгаЯрСкзДЬЌЕФHypermediaЙЉгУЛЇбЁдёЃЈБШШчЃЌдкЪзвГгавЛИіЕМКНРИЃЌРяУцгаМИИіСДНгЃЉ
=> гУЛЇбЁдёСЫФГИіHypermediaЃЈБШШчЃЌЕуЛїСЫЁАВщПДЮФеТСаБэЁБЕФСДНгЃЉ
=> ПЭЛЇЖЫЧыЧѓЁАЮФеТСаБэЁБзЪдД
=> ЗўЮёЦїЗЕЛиЁАЮФеТСаБэЁБзЪдДЕФБэЪОЃЌвдМАЯрСкзЪдДЕФHypermedia
=> ПЭЛЇЖЫНјШыЁАЮФеТСаБэЁБзДЬЌ
=> ПЭЛЇЖЫЯдЪОЫљгаЯрСкзДЬЌЕФHypermediaЙЉгУЛЇбЁдёЃЈБШШчЃЌдкЮФеТСаБэРяЃЌЯдЪОЫљгаЮФеТЕФСДНгЃЉ
ЁЁ
ВЛФбЗЂЯжЃЌПЭЛЇЖЫНгЪеЕНвЛИіаТЕФзЪдДБэЪОЃЌОЭЛсЬјзЊЕНаТЕФзДЬЌЃЌетИіЙ§ГЬГЦЮЊзДЬЌДЋЪфЃЈЗўЮёЦїИјПЭЛЇЖЫДЋЪфаТзДЬЌЃЉЁЃвђДЫзДЬЌДЋЪфЪЧЭЈЙ§ДЋЪфзЪдДБэЪОРДЭъГЩЕФЁЃ
RESTЕФзжУцвтЫМ
Representational State TransferЕФгяЗЈНсЙЙЪЧ(Representational
(State Transfer))ЃЌдкетРяЮвУЧгУЕФЪЧrepresentationЕФаЮШнДЪаЮЪНЃЌвтЫМЪЧдкБэЪОВуЩЯЕФзДЬЌДЋЪфЁЃетИіДЪЕФзжУцвтЫМЪЧЭЈЙ§ДЋЪфзЪдДБэЪОРДДЋЪфПЭЛЇЖЫзДЬЌЁЃ
RESTЕФзжУцвтЫМдкЭјТчЩЯгаКмЖржжРэНтЃЌЮвВЮПМСЫФГЮЛД№жїЕФСНИіЛиД№ЃКhttps://stackoverflow.com/a/1...
КЭ https://stackoverflow.com/a/4... ЃЌвђЮЊетЮЛД№жїЕФЛиД№зюЗћКЯwikipediaЕФНтЪЭЃК"The
term is intended to evoke an image of how a well-designed
Web application behaves: it is a network of Web resources
(a virtual state-machine) where the user progresses
through the application by selecting links, such as
/user/tom, and operations such as GET or DELETE (state
transitions), resulting in the next resource (representing
the next state of the application) being transferred
to the user for their use."
змНс
жСДЫЃЌЮвУЧгІИУФмЙЛЬхЛсЕНRESTвбОВЛНіНіЪЧвЛжжAPIЗчИёСЫЃЌЫќЪЧвЛжжШэМўМмЙЙЗчИё(RESTБОЩэВЛЪЧвЛжжМмЙЙ)ЁЃRESTЗчИёЕФШэМўМмЙЙОпгаКмЧПЕФбнЛЏЁЂЭиеЙФмСІЃК
вЛжТЕФURLКЭHTTPЖЏДЪЪЙгУЃКШЗБЃЯЕЭГФмЙЛНгФЩЖрбљЖјгжБъзМЕФПЭЛЇЖЫЃЌБЃжЄПЭЛЇЖЫЕФбнЛЏФмСІЁЃ
ЮозДЬЌЃКБЃжЄСЫЯЕЭГЕФКсЯђЭиеЙФмСІЁЂЗўЮёЖЫЕФбнЛЏФмСІЁЃ
HATEOASЃКБЃжЄСЫгІгУБОЩэЕФбнЛЏФмСІ(ЙІФмдіМгЁЂИФБф)ЁЃ
ет3ЕуЪЧЕЅЕЅЖдбнЛЏЭиеЙгХЪЦЕФЫЕУїЃЌетИіЛиД№змНсСЫRESTЕФ6ИідМЪјЗжБ№ЖдгІЕФгХЕуЁЃ |









