| ±ајНЖјц: |
±ѕОДАґЧФУЪxybabyЈ¬·ЦІјКЅКВОсКЗЦёКВОсµДІОУлХЯЎўЦ§іЦКВОсµД·юОсЖчЎўЧКФґ·юОсЖчТФј°КВОс№ЬАнЖч·Ц±рО»УЪІ»Н¬µД·ЦІјКЅПµНіµДІ»Н¬ЅЪµгЦ®ЙПЎЈ ЎЈ
|
|
ХэОД
ЛјїјХвёцОКМвµДіхЦФЈ¬КЗУРТ»ґОёшЕуУСЧЄХЛЈ¬Ѕб№ыОТµДЗ®±»їЫБЛЈ¬ЕуУСГ»КХµЅЗ®ЎЈ¶шОТЦ®З°Т»Ц±ИПОЄТшРРЧЄХЛТ»¶ЁКЗУЙКВОс±ЈЦ¤ЗїТ»ЦВРФµДЈ¬УЪКЗС§П°ЎўЧЬЅбБЛТ»ПВ·ЦІјКЅКВОсµДёчЦЦАнВЫЎў·Ѕ·ЁЎЈ
КВОсКЗТ»ёц·ЗіЈ№гТеµДґК»гЈ¬ёчРРёчТµЅв¶Б¶јІ»Т»СщЎЈ¶ФУЪіМРтФ±Ј¬КВОсµИјЫУЪTransactionЈ¬КЗЦёТ»ЧйБ¬РшµДІЩЧчЈ¬ХвР©ІЩЧчЧйєПіЙТ»ёцВЯјµДЎўНкХыµДІЩЧчЎЈјґХвЧйІЩЧчЦґРРЗ°єуЈ¬ПµНіРиТЄґ¦УЪТ»ёцїЙФ¤ЦЄµДЎўТ»ЦВµДЧґМ¬ЎЈТтґЛЈ¬ХвТ»ЧйІЩЧчТЄГґ¶јіЙ№¦ЦґРРЈ¬ТЄГґ¶јІ»ДЬЦґРРЈ»Из№ыІї·ЦіЙ№¦Ј¬Ії·ЦК§°ЬЈ¬іЙ№¦µДІї·ЦРиТЄ»Ш№цЈЁrollbackЈ©ЎЈ
жўГГЖЄЈє ФЩВЫ·ЦІјКЅКВОсЈєґУАнВЫµЅКµјщ
№ШПµРНКэѕЭївКВОс
ґу¶аКэИЛїЙДЬєНОТТ»СщЈ¬µЪТ»ґОМэЛµКВОсКЗФЪС§П°№ШПµРНКэѕЭївЈЁmysqlЎўsql serverЎўOracleЈ©µДК±єтЈ¬ФЪ№ШПµРНКэѕЭївЦРЈ¬Из№ыТ»ЧйІЩЧчВъЧгACIDМШРФЈ¬ДЗГґіЖЦ®ОЄТ»ёцКВОсЎЈ№ШУЪ№ШПµРНКэѕЭївµДACID МШРФЈ¬І»№ЬКЗЅМІД»№КЗНшВзЙП¶јУРґуБїµДЧКБПЈ¬ХвАпЦ»јтµҐЅйЙЬЎЈ
AЈЁAtomicЈ©ЈєФЧУРФЈ¬№№іЙКВОсµДЛщУРІЩЧчЈ¬ТЄГґ¶јЦґРРНкіЙЈ¬ТЄГґИ«ІїІ»ЦґРРЈ¬І»їЙДЬіцПЦІї·ЦіЙ№¦Ії·ЦК§°ЬµДЗйїц
CЈЁConsistencyЈ©ЈєТ»ЦВРФЈ¬ФЪКВОсЦґРРЗ°єуЈ¬КэѕЭївµДТ»ЦВРФФјКшГ»УР±»ЖЖ»µЎЈХвАпµДТ»ЦВРФє¬ТеєуГж»бПкПёЅвКН
IЈЁIsolationЈ©ЈєёфАлРФЈ¬КэѕЭївЦРµДКВОсТ»°г¶јКЗІў·ўµДЈ¬ёфАлРФКЗЦёІў·ўµДБЅёцКВОсµДЦґРР»ҐІ»ёЙИЕЈ¬Т»ёцКВОсІ»ДЬїґµЅЖдЛыКВОсФЛРР№эіМµДЦРјдЧґМ¬
DЈЁDurabilityЈ©ЈєіЦѕГРФЈ¬КВОсНкіЙЦ®єуЈ¬ёГКВОс¶ФКэѕЭµДёьёД»б±»іЦѕГ»ЇµЅКэѕЭївЈ¬ЗТІ»»б±»»Ш№цЎЈ
ОТГЗѕЩТ»ёцјтµҐµДЧЄХЛµДАэЧУЈ¬УГ»§AёшНжјТBЧЄ100їйЗ®Ј¬ДЗГґЙжј°µЅБЅёцІЩЧчЈєНжјТAµДХЛ»§їЫ100ФЄЈ¬НжјТBµДХЛ»§јУ100ФЄЎЈјґ
UserA.account -= 100
UserB.account += 100 |
ФЧУРФєЬєГАнЅвЈ¬ХвБЅёцІЩЧчТЄГґ¶јіЙ№¦Ј¬ТЄГґ¶јІ»ЦґРРЈЁёьЧјИ·µДКЗґУР§№ыЙПАґїґµИјЫУЪ¶јГ»УРЦґРРЈ©ЎЈІ»їЙДЬіцПЦУГ»§AµДЗ®јхЙЩБЛ¶шУГ»§BµДЗ®Г»ФцјУµДЗйїцЈ¬УГ»§КЗІ»ФКРнµДЈ»ёьІ»їЙДЬіцПЦУГ»§BµДЗ®ФцјУ ¶ш УГ»§AµДЗ®Г»УРјхЙЩµДЗйїцЈ¬ТшРРКЗѕш¶ФІ»ёЙµДЎЈ
Т»ЦВРФЛµТ»ЖрАґґујТ¶ј¶®Ј¬µ«КЗЙоѕїЖрАґТІКЗЛЖ¶®·З¶®ЎЈACIDЦРµДТ»ЦВРФЈ¬НшВзЙПµДЅйЙЬ¶јєЬДЈєэЈ¬¶јКЗЛµТЄґ¦УЪТ»ЦВµДЧґМ¬Ј¬ДЗКІГґКЗТ»ЦВµДЧґМ¬ДШЈ¬±ИИзЧЄХЛІЩЧчЦРЈ¬AїЫЗ®Ј¬BјУЗ®Ј¬ABµДЗ®µДЧЫєПКЗТ»¶ЁµДЈ¬ХвёцКЗ·сКфУЪACIDЦРµДConsistencyДШЈїОТѕхµГІ»КЗµДЈ¬ Wiki Transaction_processing єН WikiЈє ACID ·Ц±рКЗХвГґГиКцµД
Consistency: A transaction is a correct transformation of the state. The actions taken as a group do not violate any of the integrity constraints associated with the state.
The consistency property ensures that any transaction will bring the database from one valid state to another. Any data written to the database must be valid according to all defined rules, including constraints, cascades, triggers, and any combination thereof. This does not guarantee correctness of the transaction in all ways the application programmer might have wanted (that is the responsibility of application-level code), but merely that any programming errors cannot result in the violation of any defined rules.
ЙПГжєЪЙ«јУґЦµДІї·ЦЦёіцЈ¬ACIDЦРµДТ»ЦВРФКЗЦёНкХыРФФјКшІ»±»ЖЖ»µЈ¬НкХыРФ°ьє¬КµМеНкХыРФЈЁЦчКфРФІ»ОЄїХЈ©ЎўІОХХНкХыРФЈЁНвјь±ШРлґжФЪФ±нЦРЈ©ЎўУГ»§ЧФ¶ЁТеµДНкХыРФЎЈУГ»§ЧФ¶ЁТеµДНкХыРФ±ИИзБРЦµ·ЗїХЈЁnot nullЈ©ЎўБРЦµОЁТ»ЈЁuniqueЈ©ЎўБРЦµКЗ·сВъЧгТ»ёцbool±нґпКЅЈЁcheckУпѕдЈ¬ИзРФ±рЦ»ДЬУРБЅёцЦµЎўЛкКэКЗТ»¶Ё·¶О§ДЪµДХыКэµИЈ©Ј¬АэИзage smallint CHECK (age >=0 AND age <= 120).КэѕЭїв±ЈЦ¤ageµДЦµФЪ[0, 120]µД·¶О§Ј¬Из№ыІ»ФЪХвёц·¶ОДЈ¬ДЗГґёьРВІЩЧчК§°ЬЈ¬КВОсТІ»бК§°ЬЎЈБнНвЈ¬ПтmysqlЦРµДcascadeЈ¬ТФј°ґҐ·ўЖчЈЁtriggerЈ©¶јКфУЪУГ»§ЧФ¶ЁТеµДНкХыРФФјКшЎЈФЪMongoDB3.2ЦР document validationѕНКЗУГ»§ЧФ¶ЁТеµДНкХыРФФјКшЈ¬ФЪІеИл»тХЯёьРВdocuemntµДК±єтјмІйЈ¬І»№эУГ»§їЙТФЧФРРЙи¶ЁvalidationActionЈ¬И·¶Ёµ±КэѕЭІ»·ыєПФјКшК±µД±нПЦЈ¬Д¬ИПОЄerrorЈ¬јґѕЬѕшКэѕЭРґІЩЧчЎЈ
ТтґЛЈ¬УГ»§AЈ¬BФЪХвґОКВОсІЩЧчЗ°єуЈ¬ХЛ»§µДЧЬєНТ»¶ЁЈ¬КЗУ¦УГІгГжµДТ»ЦВРФЈ¬¶шІ»КЗКэѕЭїв±ЈЦ¤µДТ»ЦВРФЈ¬У¦УГІгГжµДТ»ЦВРФКВКµЙПКЗУЙФЧУРФАґ±ЈЦ¤µДЎЈ
ёфАлРФЛµЖрАґјтµҐЈ¬µ«КВКµЙП±ієуµДКВЗйєЬёґФУЈ¬КэѕЭївµДёфАлРФТААµУЪјУЛш»тХЯ¶а°ж±ѕїШЦЖЎЈјтµҐАґЛµЈ¬Из№ыUserA.accountіхКјЦµОЄ500Ј¬ЦґРРНкµЪТ»МхЦёБоЈЁјґјхИҐ100Ј©Ј¬µ«КВОс»№Г»УРМбЅ»Ј¬ЖдЛыµДКВОсКЗІ»ДЬ¶БµЅХвёцЦРјдЅб№ыЈЁUserA.accountµДЦµОЄ400Ј©µДЎЈХвѕНКЗ±ЬГвБЛФа¶БЈЁDrity ReadЈ©Ј¬¶ФУ¦µДёфАлј¶±рѕНКЗREAD_COMMITTEDЎЈФЪSQL±кЧјЦРЈ¬¶ЁТеБЛЛДёцёфАлј¶±рЈє
READ_UNCOMMITTED
READ_COMMITTED
REPEATABLE_READ
SERIALIZABLE |
АґЅвѕцКВОсІў·ўЦРґшАґµДТ»ПВјёёцОКМвФа¶БЈЁDirty Read)ЎўІ»їЙЦШёґ¶БЈЁNon-repeatable ReadЈ©Ўў»Г¶БЈЁPhantom ReadЈ©
І»Н¬µДКэѕЭїв»тХЯЛµґжґўТэЗжД¬ИПЦ§іЦІ»Н¬µДёфАлј¶±рЈ¬±ИИзInnoDBґжґўТэЗжД¬ИПЦ§іЦREPEATABLE_READЈ¬¶шMongodbЦ»Ц§іЦREAD_UNCOMMITTED
іЦѕГРФРиТЄїјВЗµЅТ»ёцКВОсФЪЦґРР№эіМЦРµДёчЦЦЗйїцµДТміЈЎЈТ»ёцКВОсµДБчіМКЗХвСщµДЈє
їЄЖфТ»ёцКВОс
ЦґРРТ»ЧйІЩЧч
Из№ы¶јЦґРРіЙ№¦Ј¬ДЗГґМбЅ»ІўЅбКшКВОс
Из№ыИОєОІЩЧчК§°ЬЈ¬ДЗГґ»Ш№цТСѕЦґРРµДІЩЧчЈ¬ЅбКшКВОс
ФЪКВОсЦґРР№эіМЦРЈ¬Из№ыіцПЦ№КХПЈ¬±ИИз¶ПµзЎўеґ»ъЈ¬ХвёцК±єтѕНТЄАыУГИХЦѕЈЁredo log»тХЯundo logЈ© јУЙП checkpointАґ±ЈЦ¤КВОсµДНкХыЅбКшЎЈ
·ЦІјКЅКВОс
µ±КэѕЭµД№жДЈФЅАґФЅґуЈ¬і¬іцБЛµҐёц№ШПµРНКэѕЭївµДґ¦АнДЬБ¦Ј¬ХвёцК±єтѕНіцПЦБЛ№ШПµРНКэѕЭµДґ№Ц±·Ц±н»тХЯЛ®ЖЅ·Ц±нЈ¬ТІіцПЦБЛМмИ»Ц§іЦЛ®ЖЅА©Х№ЈЁshardingЈ©µДNoSqlЎЈБнНвЈ¬ґуРННшХѕµД·юОс»ЇЈЁSOAЈ©ТФј°ХвБЅДк·ЗіЈ»рµДОў·юОсЈ¬НщНщЅ«·юОсЅшРРІр·ЦЈ¬µҐ¶АІїКрЈ¬ЧФИ»ТІК№УГ¶АБўµДКэѕЭївЈ¬ЙхЦБКЗТм№№µДКэѕЭївЎЈХвёцК±єтЈ¬№ШПµРНКэѕЭїв±ЈЦ¤КВОсµДКЦ¶ОЈ¬±ИИзјУЛшЎўИХЦѕѕНРРІ»НЁБЛЎЈµ±И»Ј¬±ѕОДМЦВЫµДІ»ЅцЅцКЗКэѕЭївЈ¬ТІ°ьє¬·ЦІјКЅґжґўЎўПыПў¶УБРЈ¬ТФј°ИОєОТЄ±ЈЦ¤ФЧУРФЎўіЦѕГРФµДВЯјЎЈ
·ЦІјКЅКВОсµДЧоґуМфХЅФЪУЪCAPЈ¬ФЪЎ¶CAPАнВЫУлMongoDBТ»ЦВРФЎўїЙУГРФµДТ»Р©ЛјїјЎ·Т»ОДЦРУРПкПёЅйЙЬЎЈјт¶шСФЦ®Ј¬УЙУЪНшВз·ЦёоЈЁPЈє Network PartitionЈ©µДґжФЪЈ¬УГ»§І»µГІ»ФЪТ»ЦВРФЈЁC ConsistencyЈ©УлїЙУГРФЈЁAЈє AvaliableЈ©Ц®З°ЧцИЁєвЎЈИз№ыТЄ±ЈЦ¤ЗїТ»ЦВРФЈЁЦчТЄКЗУ¦УГІгГжµДЗїТ»ЦВРФЈ©Ј¬ДЗГґФЪНшВз·ЦёоµДК±єтЈ¬ПµНіѕНІ»їЙУГЈ»Из№ыТЄ±ЈЦ¤ёЯїЙУГРФЈ¬ДЗГґѕНЦ»ДЬМṩИхТ»ЦВРФЈ¬±ЈЦ¤ЧоЦХТ»ЦВЎЈПВГжМбµЅµДёчЦЦКµПЦ·ЦІјКЅКВОсµД·Ѕ·ЁЎўРТй¶јРиТЄФЪТ»ЦВРФУлїЙУГРФЦ®јдИЁєвЎЈ
2PC
МбµЅ·ЦІјКЅКВОсЈ¬КЧПИПлµЅµДїП¶ЁКЗБЅЅЧ¶ОМбЅ»ЈЁ2pcЈ¬two-phase commit protocolЈ©Ј¬2pcКЗ·ЗіЈѕµдµДЗїТ»ЦВРФЎўЦРРД»ЇµДФЧУМбЅ»РТйЎЈЦРРД»ЇКЗЦёРТйЦРУРБЅАаЅЪµгЈєТ»ёцЦРРД»ЇРµчХЯЅЪµгЈЁcoordinatorЈ©єНNёцІОУлХЯЅЪµгЈЁparticipantЎўcohortЈ©ЎЈ
№ЛГыЛјТеЈ¬БЅЅЧ¶ОМбЅ»РТйµДГїТ»ґОКВОсМбЅ»·ЦОЄБЅёцЅЧ¶ОЈє
ФЪµЪТ»ЅЧ¶ОЈ¬РµчХЯСЇОКЛщУРµДІОУлХЯКЗ·сїЙТФМбЅ»КВОсЈЁЗлІОУлХЯН¶Ж±Ј©Ј¬ЛщУРІОУлХЯПтРµчХЯН¶Ж±ЎЈ
ФЪµЪ¶юЅЧ¶ОЈ¬РµчХЯёщѕЭЛщУРІОУлХЯµДН¶Ж±Ѕб№ыЧціцКЗ·сКВОсїЙТФИ«ѕЦМбЅ»µДѕц¶ЁЈ¬ІўНЁЦЄЛщУРµДІОУлХЯЦґРРёГѕц¶ЁЎЈФЪТ»ёцБЅЅЧ¶ОМбЅ»БчіМЦРЈ¬ІОУлХЯІ»ДЬёД±дЧФјєµДН¶Ж±Ѕб№ыЎЈБЅЅЧ¶ОМбЅ»РТйµДїЙТФИ«ѕЦМбЅ»µДЗ°МбКЗЛщУРµДІОУлХЯ¶јН¬ТвМбЅ»КВОсЈ¬Ц»ТЄУРТ»ёцІОУлХЯН¶Ж±СЎФс·ЕЖъ(abort)КВОсЈ¬ФтКВОс±ШРл±»·ЕЖъЎЈ
wikiЙПёшіцБЛјтТЄБчіМЈє

ЧўТвЈ¬ЙПНјЦРЧоПВГжТ»РРТІ±нГчЈ¬БЅЅЧ¶ОМбЅ»РТйТІТААµУлИХЦѕЈ¬Ц»ТЄґжґўЅйЦКІ»іцОКМвЈ¬БЅЅЧ¶ОРТйѕНДЬЧоЦХґпµЅТ»ЦВµДЧґМ¬ЈЁіЙ№¦»тХЯ»Ш№цЈ©
¶шПВНјЈЁАґЧФslideshareЈ©ПкПёГиКцБЛХыёцБчіМЈє
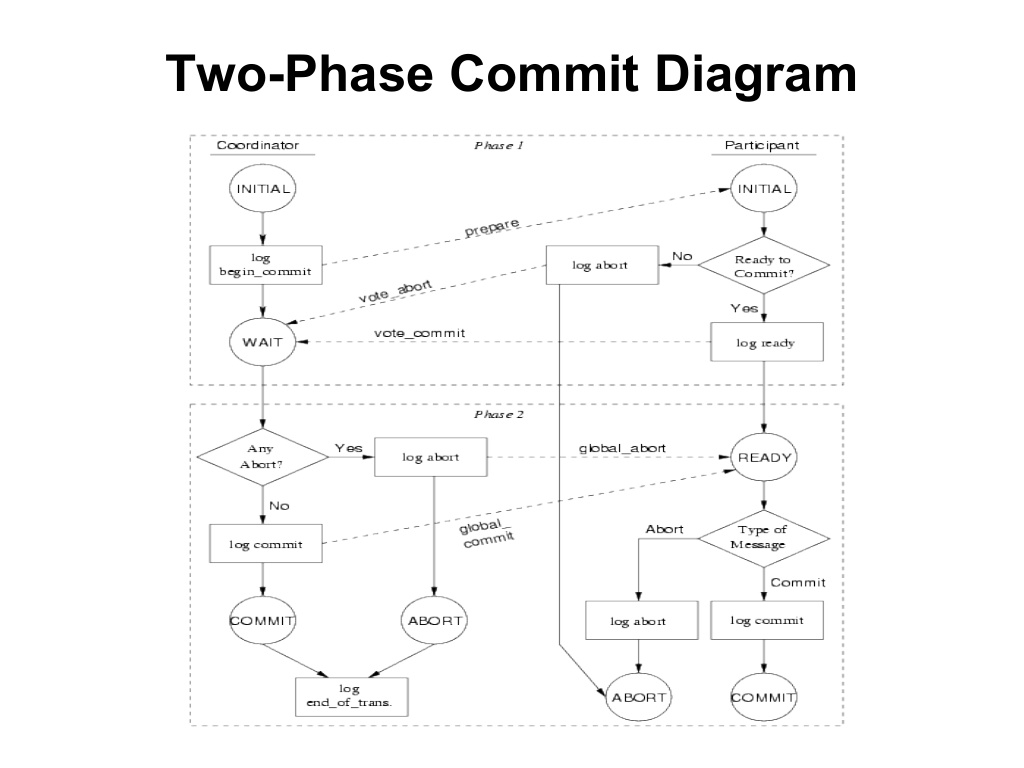
ФЪБхЅЬµДЎ¶·ЦІјКЅФАнЅйЙЬЦРЎ·Ј¬УР·ЗіЈПкПёµДБчіМЅйЙЬЈ¬їЙТФЕдєПЙПНјТ»ЖрїґЈ¬БнНв»№ЅйЙЬБЛФЪёчЦЦТміЈЗйїцПВЈЁ±ИИзCoordinatorЎўParticipantеґ»ъЈ¬НшВз·ЦёоµјЦВµДі¬К±Ј©БЅЅЧ¶ОРТйµД№¤ЧчЗйїцЎў№¤ЧчР§ВКЎЈБнНвЈ¬ФЪХвЖЄОДХВЦРТІУР±ИЅПЗеОъµДБчіМЅйЙЬЎЈФЪХвАпЦ»МЦВЫ2PCµДУЕИ±µгЈє
УЕµгЈєЗїТ»ЦВРФЈ¬Ц»ТЄЅЪµг»тХЯНшВзЧоЦХ»ЦёґХэіЈЈ¬РТйѕНДЬ±ЈЦ¤ЛіАыЅбКшЈ»Ії·Ц№ШПµРНКэѕЭївЈЁOracleЈ©ЎўїтјЬЦ±ЅУЦ§іЦ
И±µгЈєБЅЅЧ¶ОМбЅ»РТйµДИЭґнДЬБ¦ЅПІоЈ¬±ИИзФЪЅЪµгеґ»ъ»тХЯі¬К±µДЗйїцПВЈ¬ОЮ·ЁИ·¶ЁБчіМµДЧґМ¬Ј¬Ц»ДЬІ»¶ПЦШКФЈ»БЅЅЧ¶ОМбЅ»РТйµДРФДЬЅПІоЈ¬ ПыПўЅ»»Ґ¶аЈ¬ЗТКЬЧоВэЅЪµгУ°Пм
ХвЖЄОДХВГиКцБЛОЄКІГґБЅЅЧ¶ОМбЅ»РТйФЪ·ЦІјКЅПµНіЦРІ»ККУГЈє
ПµНіЎ°Л®ЖЅЎ±ЙмЛхµДЛАµРЎЈ»щУЪБЅЅЧ¶ОМбЅ»µД·ЦІјКЅКВОсФЪМбЅ»КВОсК±РиТЄФЪ¶аёцЅЪµгЦ®јдЅшРРРµч,ЧоґуПЮ¶ИµШНЖєуБЛМбЅ»КВОсµДК±јдµгЈ¬їН№ЫЙПСУі¤БЛКВОсµДЦґРРК±јдЈ¬Хв»бµјЦВКВОсФЪ·ГОК№ІПнЧКФґК±·ўЙъіеН»єНЛАЛшµДёЕВКФцёЯЈ¬ЛжЧЕКэѕЭївЅЪµгµДФц¶аЈ¬ХвЦЦЗчКЖ»бФЅАґФЅСПЦШЈ¬ґУ¶шіЙОЄПµНіФЪКэѕЭївІгГжЙПЛ®ЖЅЙмЛхµД"јПЛш"Ј¬ ХвКЗєЬ¶аShardingПµНіІ»ІЙУГ·ЦІјКЅКВОсµДЦчТЄФТтЎЈ
ЛщСФЙхКЗЈЎ
3PC
ИэЅЧ¶ОМбЅ»РТйЈЁ3pc Three-phase_commit_protocolЈ©ЦчТЄКЗОЄБЛЅвѕцБЅЅЧ¶ОМбЅ»РТйµДЧиИыОКМвЈ¬ґУФАґµДБЅёцЅЧ¶ОА©Х№ОЄИэёцЅЧ¶ОЈ¬ІўЗТФцјУБЛі¬К±»ъЦЖЎЈ
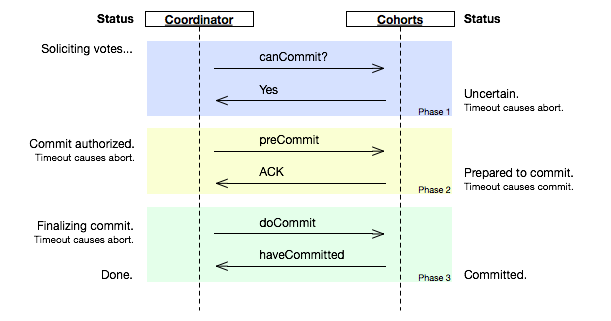
3PCЦ»КЗЅвѕцБЛФЪТміЈЗйїцПВ2PCµДЧиИыОКМвЈ¬µ«µјЦВТ»ґОМбЅ»ТЄґ«µЭ6МхПыПўЈ¬СУК±єЬґуЎЈѕЯМеБчіМГиКцїЙІОјыЎ¶№ШУЪ·ЦІјКЅКВОсЎўБЅЅЧ¶ОМбЅ»РТйЎўИэЅЧМбЅ»РТйЎ·Т»ОДЎЈ
TCC
TCCКЗTryЎўCommitЎўCancelµДЛхРґЈ¬ФЪ№ъДЪУЙУЪЦ§ё¶±¦µДІјµА¶ш№гОЄИЛЦЄЈ¬TCCФЪ±ЈЦ¤ЗїТ»ЦВРФµДН¬К±Ј¬ЧоґуПЮ¶ИМбёЯПµНіµДїЙЙмЛхРФУлїЙУГРФЎЈ
ОТГЗјЩЙиТ»ёцНкХыµДТµОс°ьє¬Т»ЧйЧУТµОсЈ¬TryІЩЧчНкіЙЛщУРµДЧУТµОсјмІйЈ¬Ф¤Бф±ШТЄµДТµОсЧКФґЈ¬КµПЦУлЖдЛыКВОсµДёфАлЈ»ConfirmК№УГTryЅЧ¶ОФ¤БфµДТµОсЧКФґХжХэЦґРРТµОсЈ¬¶шЗТConfirmІЩЧчВъЧгГЭµИРФЈ¬ТФ±йЦ§іЦЦШКФЈ»CancelІЩЧчКН·ЕTryЅЧ¶ОФ¤БфµДТµОсЧКФґЈ¬Н¬СщТІВъЧгГЭµИРФЎЈЎ°Т»ґОНкХыµДЅ»ТЧУЙТ»ПµБРОўЅ»ТЧµДTry ІЩЧчЧйіЙЈ¬Из№ыЛщУРµДTry ІЩЧч¶јіЙ№¦Ј¬ЧоЦХУЙОўЅ»ТЧїтјЬАґНіТ»ConfirmЈ¬·сФтНіТ»CancelЈ¬ґУ¶шКµПЦБЛАаЛЖѕµдБЅЅЧ¶ОМбЅ»РТйЈЁ2PCЈ©µДЗїТ»ЦВРФЎЈЎ±
Ул2PCРТй±ИЅП Ј¬TCCУµУРТФПВМШµгЈє
О»УЪТµОс·юОсІг¶ш·ЗЧКФґІг Ј¬УЙТµОсІг±ЈЦ¤ФЧУРФ
Г»УРµҐ¶АµДЧј±ё(Prepare)ЅЧ¶ОЈ¬ЅµµНБЛМбЅ»РТйµДіЙ±ѕ
TryІЩЧч јж±ёЧКФґІЩЧчУлЧј±ёДЬБ¦
TryІЩЧчїЙТФБй»оСЎФсТµОсЧКФґµДЛш¶ЁБЈ¶ИЈ¬¶шІ»КЗЛшЧЎХыёцЧКФґЈ¬МбёЯБЛІў·ў¶И
µ±И»Ј¬TCCРиТЄЅПёЯµДїЄ·ўіЙ±ѕЈ¬ГїёцЧУТµОс¶јРиТЄУРПмУ¦µДcomfirmЎўCancelІЩЧчЈ¬јґКµПЦПаУ¦µДІ№іҐВЯјЎЈ
»щУЪПыПўµД·ЦІјКЅКВОс
ХвАаКВОс»ъЦЖЅ«·ЦІјКЅКВОс·ЦіЙ¶аёц±ѕµШКВОсЈ¬ХвАпіЖЦ®ОЄЦчКВОсУлґУКВОсЎЈКЧПИЦчКВОс±ѕµШПИРРМбЅ»Ј¬И»єуНЁ№эПыПўНЁЦЄґУКВОсЈ¬ґУКВОсґУПыПўЦР»сИЎРЕПўЅшРР±ѕµШМбЅ»ЎЈїЙТФїґіцХвКЗТ»ЦЦТмІЅКВОс»ъЦЖЎўЦ»ДЬ±ЈЦ¤ЧоЦХТ»ЦВРФЈ»µ«їЙУГРФ·ЗіЈёЯЈ¬І»»бТтОЄ№КХП¶ш·ўЙъЧиИыЎЈБнНвЈ¬ЦчКВОсТСѕПИРРМбЅ»Ј¬Из№ыТтОЄґУКВОсОЮ·ЁМбЅ»Ј¬ТЄ»Ш№цЦчКВОс»№КЗ±ИЅПВй·іЈ¬ЛщТФХвЦЦДЈКЅЦ»ККУГУЪАнВЫЙПґуёЕВКµИіЙ№¦µДТµОсЗйїцЈ¬јґґУКВОсµДМбЅ»К§°ЬїЙДЬКЗУЙУЪ№КХПЈ¬¶шІ»ґуїЙДЬКЗВЯјґнОуЎЈ
»щУЪТмІЅПыПўµДКВОс»ъЦЖЦчТЄУРБЅЦЦ·ЅКЅЈє±ѕµШПыПў±нУлКВОсПыПўЎЈ¶юХЯµДЗш±рФЪУЪЈєФхГґ±ЈЦ¤ЦчКВОсµДМбЅ»УлПыПў·ўЛНХвБЅёцІЩЧчµДФЧУРФЎЈ
Из№ыУГТмІЅПыПўКµПЦЧЄХЛµДАэЧУЈ¬ДЗГґІЩЧч·ЦОЄЛДІїЈєУГ»§AїЫЗ®Ј¬·ўПыПўЈ¬УГ»§BКХПыПўЈ¬УГ»§BїЫЗ®ЎЈЗ°БЅІЅ±ШРл±ЈЦ¤ФЧУРФЈ¬Из№ыAїЫЗ®іЙ№¦µ«КЗГ»УР·ўіцПыПўЈ¬ДЗГґУГ»§AЛрК§БЛЈ»Из№ы·ўПыПўіЙ№¦Ј¬µ«КЗГ»УРїЫЗ®Ј¬ДЗГґУГ»§BѕН¶аµГБЛТ»±КЗ®Ј¬ТшРРїП¶ЁІ»ёЙЎЈ
±ѕµШПыПў±н
»щУЪ±ѕµШПыПў±нµД·Ѕ°ёКЗЦёЅ«ПыПўРґИл±ѕµШКэѕЭївЈ¬НЁ№э±ѕµШКВОс±ЈЦ¤ЦчКВОсУлПыПўРґИлµДФЧУРФЎЈАэИзТшРРЧЄХЛµДАэЧУЈ¬О±ВлИзПВЈє
egin transaction:
update User set account = account - 100 where userId = 'A'
insert into message(userId, amount, status) values('A', 100, 1)
commit transaction |
И»єуНЁ№эpull»тХЯpushДЈКЅЈ¬ґУТµОс»сИЎПыПўІўЦґРРЎЈИз№ыКЗpushДЈКЅЈ¬ДЗГґТ»°гК№УГѕЯУРіЦѕГ»Ї№¦ДЬµДПыПў¶УБРЈ¬ґУКВОсОс¶©ФДПыПўЎЈИз№ыКЗpullДЈКЅЈ¬ДЗГґґУКВОс¶ЁК±ИҐАИЎПыПўЈ¬И»єуЦґРРЎЈ
mongodbµДРґИлѕНєЬПс±ѕµШПыПў±нЈ¬ФЪWriteConcernОЄw:1µДЗйїцПВЈ¬ёьРВІЩЧчЦ»ТЄРґµЅoplogТФј°primaryѕНїЙТФПтїН»§¶Л·µ»ШЎЈsecondaryТмІЅАИЎoplogІў±ѕµШјЗВјЦґРРЎЈ
КВОсПыПўЈє
КВОсПыПўТААµУЪЦ§іЦЎ°КВОсПыПўЎ±µДПыПў¶УБРЈ¬Жд»щ±ѕЛјПлКЗ АыУГПыПўЦРјдјдКµК©БЅЅЧ¶ОМбЅ»Ј¬Ѕ«±ѕµШКВОсєН·ўПыПў·ЕФЪБЛТ»ёц·ЦІјКЅКВОсАпЈ¬±ЈЦ¤ТЄГґ±ѕµШІЩЧчіЙ№¦іЙ№¦ІўЗТ¶ФНв·ўПыПўіЙ№¦Ј¬ТЄГґБЅХЯ¶јК§°ЬЎЈБчіМИзПВЈє
КВОсПтПыПў¶УБР·ўЛНФ¤±ёПыПў
ЦчКВОсКХµЅACKЦ®єу±ѕµШЦґРРЦчКВОс
ѕЭЦґРРµДЅб№ыЈЁіЙ№¦»тК§°ЬЈ©ПтПыПў¶УБР·ўЛНМбЅ»»тХЯ»Ш№цПыПў
ПкПёµДБчіМИзПВНјЈЁНјЖ¬АґФґјыЛ®УЎЈ©ЛщКѕЈє
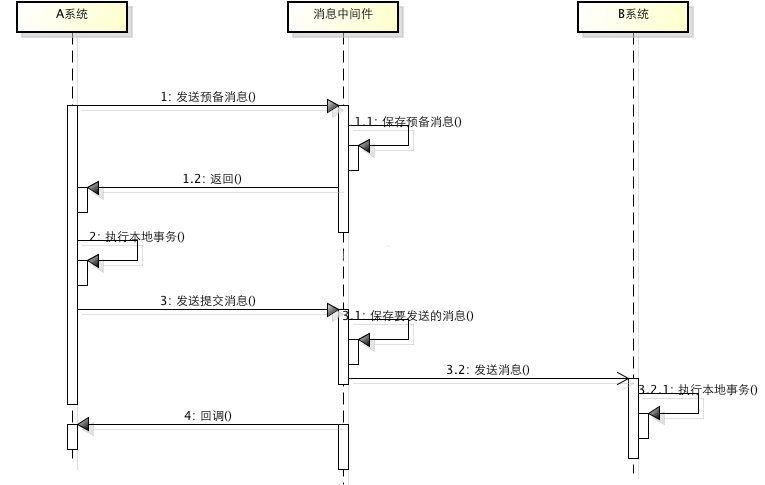
І»ДСїґµЅЈ¬Па±И±ѕµШПыПў±нµД·ЅКЅЈ¬КВОсПыПўУЙПыПўЦРјдјю±ЈЦ¤±ѕµШКВОсУлПыПўµДФЧУРФЈ¬І»ТААµУЪ±ѕµШКэѕЭївґжґўПыПўЎЈµ«КµПЦБЛЎ°КВОсПыПўЎ±µДПыПў¶УБР±ИЅПЙЩЈ¬»№І»№»НЁУГЎЈ
І»№ЬКЗ±ѕµШПыПў±н»№КЗКВОсПыПўЈ¬¶јРиТЄ±ЈЦ¤ґУКВОсЦґРРЗТЅцЅцЦґРРТ»ґОЈ¬exact onceЎЈИз№ыК§°ЬЈ¬РиТЄЦШКФЈ¬µ«ТІІ»їЙДЬОЮПЮґОµДЦШКФЈ¬µ±ґУКВОсЧоЦХК§°ЬµДЗйїцПВЈ¬РиТЄНЁЦЄЦчТµОс»Ш№цВрЈїµ«КЗґЛК±Ј¬ЦчКВОсТСѕМбЅ»Ј¬ТтґЛЦ»ДЬНЁ№эІ№іҐЈ¬КµПЦВЯјЙПµД»Ш№цЈ¬¶шµ±З°К±јдµгѕаЦчКВОсµДМбЅ»ТСѕУРТ»¶ЁК±јдЈ¬»Ш№цТІїЙДЬК§°ЬЎЈТтґЛЈ¬ЧоєГКЗ±ЈЦ¤ґУКВОсВЯјЙПІ»»бК§°ЬЈ¬НтТ»К§°ЬЈ¬јЗВјlogІў±ЁѕЇЈ¬ИЛ№¤ЅйИлЎЈ
1PC
1PCЈЁone phase commitЈ©ХвёцёЕДоЈ¬ОТКЗФЪЎ¶Distributed systems for fun and profitЎ·Т»ОДЦРїґµЅµДЈ¬У¦ёГКЗ¶Ф±к2PCЈ¬3PCЎЈФЪwikiЦРІўГ»УРХэКЅµДґКМхЈ¬ФЪgoogleЙПµДОДХВТІІ»КЗєЬ¶аЎЈФЪОТµДАнЅвЦРЈ¬1PCККУГУЪ·ЦІјКЅґжґўПµНіµДёґЦЖјЇЈ¬јґёґЦЖјЇЦР¶аёцЅЪµгµДКэѕЭМбЅ»Ј¬ЎЈТ»°гАґЛµЈ¬ХвР©ЅЪµгґжґўН¬СщµДКэѕЭЈ¬Ц»ТЄµҐёцЅЪµгДЬМбЅ»Ј¬ЖдЛыЅЪµгАнВЫЙПТІУ¦ёГїЙТФМбЅ»ЎЈФЪЎ¶Distributed systems for fun and profitЎ·ЦРКЗХвГґГиКцµДЈє
Having a second phase in place before the commit is considered permanent is useful, because it allows the system to roll back an update when a node fails. In contrast, in primary/backup ("1PC"), there is no step for rolling back an operation that has failed on some nodes and succeeded on others, and hence the replicas could diverge.
јґ¶ФУЪ·ЦІјКЅґжґўЦРК№УГ·ЗіЈ№г·єµДЦРРД»ЇёґЦЖјЇРТйPrimary SecondaryЈ¬ФЪІї·ЦЅЪµгК§°ЬЎўІї·ЦЅЪµгіЙ№¦µДЗйїцПВГ»УР»Ш№цІЩЧчЈ¬їЙДЬ»бµјЦВІ»Т»ЦВЎЈІ»№эХвР©·ЦІјКЅґжґўПµНі¶јЅЯБ¦±ЈЦ¤Ј¬ХвР©І»Т»ЦВКЗФЭК±µДЈ¬»бНЁ№эЦШКФµИКЦ¶О±ЈЦ¤ЧоЦХµДТ»ЦВЎЈ
1PCµДУЕµгКЗРФДЬ·ЗіЈєГЈ¬¶шЗТЦ»УРФЪіцПЦОпАн№КХПµДК±єтІЕ»біцПЦІ»Т»ЦВЎЈ
±ИИзФЪMongoDBЦРЈ¬ёьРВІЩЧч»бРґИлPrimaryЅЪµгТФј°oplog collectionЈ¬SecondaryЅЪµгґУPrimaryЅЪµгµДoplog collectionАИЎІЩЧчИХЦѕІўЦґРРЈ¬ХвКЗТ»ёцТмІЅµД№эіМЎЈј°К±SecondaryЅЪµгТтОЄ№КХПЦґРРoplogК§°ЬЈ¬PromaryЅЪµгµДКэѕЭТІІ»»б»Ш№цЎЈФЪЎ¶ґшЧЕОКМвС§П°·ЦІјКЅПµНіЦ®ЦРРД»ЇёґЦЖјЇЎ·ЦРТІМбµЅ№эЈ¬ОЄБЛМбёЯКэѕЭїЙїїРФЈЁ±ЬГвј«¶ЛЗйїцПВКэѕЭ±»»Ш№цЈ©Ј¬Йи¶ЁWriteConcernОЄw:MajorityЈ¬ЈЁshardУРТ»ёцPrimary Т»ёцSecondary Т»ёцArbiterЧйіЙЈ©ЎЈИз№ыХвёцК±єтУЙУЪЖдЦРТ»ёцsecondary№ТµфЈ¬РґИлІЩЧчКЗІ»їЙДЬіЙ№¦µДЎЈТтґЛЈ¬ФЪі¬К±К±јдµЅґпЦ®єуЈ¬»бПтїН»§¶Л·µ»ШіцґнРЕПўЎЈµ«КЗФЪХвёцК±єтКэѕЭКЗіЦѕГ»ЇµЅБЛprimaryЅЪµгЈ¬І»»б±»»Ш№цЎЈИз№ыґЛК±SecondaryЦШЖфЈ¬ДЗГґКЗ»бґУPrimaryАИЎИХЦѕІўЦґРРЎЈЛщТФµ±їН»§¶Л·µ»ШµДіцґнРЕПў°ьє¬ WriteResult.writeConcernError К±Ј¬У¦ёГЅчЙчґ¦Ан
¶ФУЪ·ЦІјКЅОДјюПµНіGFSЎўhaystackЈ¬Из№ыSecondaryЅЪµгК§°ЬЈ¬ТІ»бІЙИЎјтµҐґЦ±©µДЦШКФЈ¬ІўНЁ№эТ»Р©»ъЦЖЈЁcheksumЈ¬offsetЈ©Аґ±ЈЦ¤ЧоЦХДЬ¶БµЅХэИ·µДКэѕЭ
ЛјїјУлЧЬЅб
ёь¶аµДК±єтЈ¬·ЦІјКЅКВОсЦ»РиТЄ±ЈЦ¤ФЧУРФЈ¬ХвёцФЧУРФТІ±ЈЦ¤БЛУ¦УГІгГжЙПµДТ»ЦВРФЈ¬¶шУЙ±ѕµШКВОсАґ±ЈЦ¤ёфАлРФЎўіЦѕГРФЎЈ
ФЧУРФХвёц¶«ОчЈ¬јґК№І»КЗ·ЦІјКЅЈ¬ЅцЅцКЗµҐЅшіМµҐПЯіМТІКЗРиТЄїјВЗµДЈ¬ХвѕНКЗC++ЦРµДRAIIЈ¬pythonЦРµДwith statementЈ¬ТФј°ёчЦЦУпСФµДtry...finally...ЎЈµ±Йжј°µЅїзЅшіМЎўТмІЅНЁРЕµДК±єтЈ¬ѕНєЬДСНЁ№эУпСФІгГжµД»ъЦЖ±ЈЦ¤ФЧУРФБЛЎЈ
ФЪ·ЦІјКЅБмУтЈ¬УЙУЪНшВз»тХЯ»ъЖч№КХПЈ¬ѕіЈРиТЄЦШКФЈ¬ТтґЛГЭµИРФ·ЗіЈЦШТЄ
єЬ¶аіЎѕ°Ј¬±ИИзµзЙМЎўНшВз№єЖ±Ј¬КЧПИТЄ±ЈЦ¤µДКЗёЯїЙУГЈ¬І»ґуїЙДЬІЙУГЗїТ»ЦВРФЈ¬ТтґЛОТГЗТІ»бїґµЅЎ®ХэФЪґ¦АнЦР...Ў®ХвЦЦЦРјдЧґМ¬Ј¬єуМЁєЬїЙДЬКЗТмІЅґ¦АнµДЈ¬ФЪ12306Вт№эЖ±µД»°¶јЦЄµАЈ¬ПВµҐіЙ№¦µЅЧоєуКЗ·сДЬіцЖ±УЙєЬі¤Т»¶ОК±јдЎЈ
ФЪ±КХЯµДТµОсБмУтЈ¬ІўГ»УРЙжј°µЅЗїТ»ЦВРФµДіЎѕ°Ј¬Ц»ТЄЧоЦХТ»ЦВРФѕНРРБЛЎЈЙПГжµДМбµЅµДёчЦЦ°м·ЁЈ¬І»№ЬКЗ2PCЎўTCCЎў±ѕµШПыПў±нЎўКВОсПыПўЈ¬¶јРиТЄТэИл¶оНвµДїтјЬ»тХЯЧйјюЎЈЛщТФёь¶аµДК±єтКЗІЙИЎТµОсІ№іҐµД·ЅКЅЈ¬±ИИзТ»ёцЙжј°БЅёцЅшіМµДІЩЧчРиТЄ±ЈЦ¤ФЧУРФЈ¬ЅшіМјдRPCНЁРЕЈ¬ДЗГґТ»°гКЗAЅшіМПИЦґРРЈ¬И»єуRPCµчУГBЅшіМЅУїЪЈ¬ёщѕЭBЅшіМµД·µ»ШЅб№ыЈ¬ѕш¶ФКЗ·с»Ш№цЈЁІ№іҐЈ©Ј»µ«Из№ыЙжј°µЅТмІЅRPCЎў»тХЯ¶аПЯіМЎў»тХЯБЅёцТФЙПЅшіМµДґ®БЄК±Ј¬ДЗГґѕНІ»Т»¶ЁДЬІ№іҐЎўЙхЦБєЬДСІ№іҐБЛЈ¬ХвёцК±єтЦ»јЗВјТ»ёцerror logЈ¬И»єуНЁЦЄИЛ№¤ЕЕІйЎЈТтґЛЈ¬КВОсІ№іҐЦ»ККєПТµОс±ИЅПјтµҐµДіЈјыЈ¬¶шЗТєЬДСРОіЙНЁУГµДїтјЬЈ¬»тХЯЛµКµУГРФІ»ЗїЎЈ
Ц®З°Т»Ц±ТФОЄПсТшРРЧЄХЛХвЦЦіЎѕ°Ј¬Т»¶ЁКЗЗїТ»ЦВРФµДЎЈєуАґЧФјєУцµЅХвГґТ»»ШКВЈ¬ОТёшЕуУСЧЄХЛЈ¬ОТХв±ЯПФКѕЧЄХЛіЙ№¦Ј¬µ«ЕуУСІўГ»УРКХµЅЗ®ЎЈОТТФОЄКЗРиТЄТ»¶ЁК±јдЈ¬Ѕб№ы24РЎК±Ц®єу»№Г»УРКХµЅЎЈОТЧФјєЦШРВ±И¶ФЧЄХЛµҐЈ¬ІЕ·ўПЦКЗ°С¶Ф·ЅµДїЄ»§ТшРРРґґнБЛЎЈТтґЛїЙјыЈ¬ЧЄХЛХвёцІЩЧчїП¶ЁІ»КЗЗїТ»ЦВРФЈ¬ѕЯМеФхГґёгµДФЪНшЙПТІГ»УРІйµЅЎЈёьїУµщµДКЗЈ¬ЧЄХЛК§°ЬЈ¬ОТµДЗ®±»їЫБЛЈ¬ЕуУСТІГ»УРКХµЅЗ®Ј¬µ«КЗОТГ»УРКХµЅИОєОПыПўЈ¬ТІГ»УРёшОТ°СЗ®НЛ»ШАґЈ¬ФЪОТґтµз»°µЅТшРРИҐЧЙСЇЦ®єуІЕНЛ»ШАґЎЈХвёцМеСйХжµДєЬІоЈ¬µ«ТшРРКЗґуТЇЈ¬Г»°м·ЁЈЎ
|









