| БрМЭЦМі: |
БОЮФРДздгкМђЪщЃЌБОЮФНЋМђЕЅЕФНщЩмСЫвЛИіМЏжаЪНКЃСПШежОЪЕЪБДІРэЯЕЭГЁЃ
|
|
БГОАНщЩм
ЫцзХвЕЮёЗўЮёЃЈServer AppЃЉж№НЅдіМгЃЌЪЙЕУЮЪЬтХХВщЗЧГЃРЇФбЃЌКмЖрЪБКђашвЊЙиСЊВщбЏЖрИіЗўЮёЕФШежОЃЌЖјЧвЭГМЦЗжЮіЪЎЗжВЛБуЁЃвђДЫЃЌМБашЩшМЦвЛИіМЏжаЪНКЃСПШежОЪЕЪБДІРэЯЕЭГЁЃашвЊТњзуЙІФмашЧѓЃЈЪЕЪБПДШежОЁЂЭГМЦРњЪЗШежОЁЂЪЕЪБааЮЊЗжЮіЁЂгУЛЇЙьМЃИњзйЕШЃЉЁЂадФмашЧѓЃЈОпгаИпЭЬЭТФмСІЁЂИпРЉеЙадЁЂИпШнДэадЃЉЕШЁЃ
зщМўНщЩм
Kafka ЪЧвЛжжИпЭЬЭТСПЕФЗжВМЪНЗЂВМЖЉдФЯћЯЂЯЕЭГЃЌЫќЪЪКЯДІРэКЃСПШежОЗЂВМЖЉдФЃЌЬсЙЉЯћЯЂДХХЬГжОУЛЏЁЂжЇГжЮяРэЗжЦЌДцДЂЁЂЖрзщЯћЗбЕШЬиадЁЃ
Elasticsearch ЪЧвЛИіПЊдДЪЕЪБЗжВМЪНЫбЫїв§ЧцЃЌОпБИШчЯТЬиеїЃКСуХфжУЃЌЫїв§здЖЏЗжЦЌЃЌЫїв§ИББОЛњжЦЃЌrestfulЗчИёНгПкЃЌЖрЪ§ОндДЃЌздЖЏЫбЫїИКдиЕШЁЃ
Flume ЪЧApacheЛљН№ЛсЕФвЛИіИпПЩгУЕФЃЌИпПЩППЕФЃЌЗжВМЪНЕФКЃСПШежОВЩМЏЁЂОлКЯКЭДЋЪфЕФЯЕЭГЃЌЫќжЇГждкШежОЯЕЭГжаЖЈжЦИїРрЪ§ОнЗЂЫЭЗНЃЌгУгкЪеМЏЪ§ОнЃЛЭЌЪБЬсЙЉЖдЪ§ОнНјааМђЕЅДІРэЃЌВЂаДЕНИїжжЪ§ОнНгЪмЗНЃЈПЩЖЈжЦЃЉЁЃ
ЪЕЯжЫМТЗ
1.ПЊЗЂвЕЮёШежОSDKЃЈЯТЮФЮЊУшЪіЗНБуЃЌГЦжЎЮЊ BizLogSDKЃЉЃЌЧЖгкИївЕЮёAppЃЛ
2.ДгвЕЮёЗўЮёЖЫЪеМЏШежОВЂМЏжаЪфГіЕНKafkaЃЛ
3.ИљОнВЛЭЌашЧѓЃЈВщбЏЁЂЭГМЦЃЉЃЌгЩFlumeЖдЪ§ОндЄДІРэВЂЗжЗЂЃЛ
4.Flume ЕФЯТгЮзщМўЖдШежОФкШнНјааЯћЗбЃЛ
МмЙЙЩшМЦ
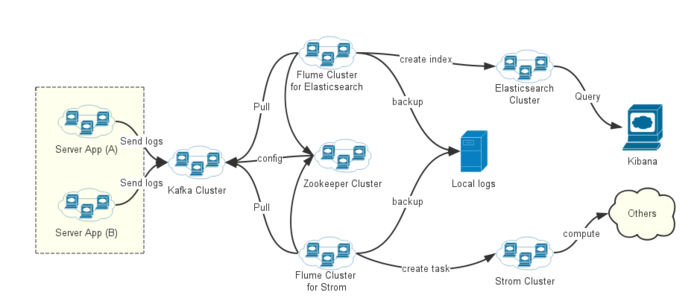
ФПЧАШежОЯћЗбЗНЪНгаСНжжЃК
1.Elasticsearch зіЫїв§ЃЌгУгкВщбЏЁЂЭГМЦЃЛ
2.ЛљгкStormСїЪНМЦЫуЪЕЯжЃЈД§ЭъГЩЃЉЁЃ
в§ШыKafkaЕФФПЕФЃК
ЯпЩЯвЕЮёМЏШКЙцФЃНЯДѓЃЌШежОВњЩњСПОоДѓЃЌШчЙћжБНгЭЌВНШежОЖдЯТгЮЗўЮёИККЩНЯжиЃЌШнвзвђЮЊЙЪеЯЕМжТШежОзшШћбгГйКЭЖЊЪЇЃЌЫљвдв§ШыСЫkafka
ЃЛ
ЯћЯЂПЩвдГжОУЛЏЃЌВЂЧвПЩвдНјааШежОЛиЫнЁЃгаСЫЯћЯЂЖгСаЃЌЩЯгЮЗўЮёКЭЯТгЮЗўЮёЭъШЋНтХКЃЌЭјТчДЋЪфЛсИќЮШЖЈЁЂИќИпаЇЁЂИќОљКтЃЌБмУтМЖСЊаЇгІЁЃ
МмЙЙЫЕУї
1.гЩгквЕЮёШежОСПМЋДѓЃЌЮЊМѕЧсвЕЮёЗўЮёЕФбЙСІЃЌЙЪНЋвЕЮёШежОЪзЯШЪфГіЕН
Kafka МЏШКЃЛ
2.Flume зіЗжЗЂКЭдЄДІРэЁЃДгKafkaжаРШЁД§ДІРэЕФвЕЮёШежОЃЌЯШдкБОЕиБЃСєвЛЗнЃЌШЛКѓзідЄДІРэКЭЗжЗЂЃЛ
3.Elasticsearch зіШежОЫїв§ЁЃЖдвЕЮёШежОАД Prefix-bizType-YYYY.MM.dd
ЕФИёЪНДДНЈЫїв§ЃЛ
4.Kibana зіВщбЏНчУцгыМђЕЅЕФЭГМЦБЈБэЁЃЙЉПЊЗЂЁЂдЫЮЌЁЂдЫгЊШЫдБЪЙгУЃЛ
5.Zookeeper гУгкЮЌЛЄKafkaМЏШКХфжУЁЃFlumeзїЮЊKafkaЕФЯћЗбепЃЌашвЊХфжУZookeeperЕФЯрЙиаХЯЂЃЛ
6.Kibana ЕФБЈБэеЙЪОФмСІгаЯоЃЌПЩвддкElasticsearch
ЯТгЮЖдНг GrafanaЛђЦфЫћЙЄОпЃЈМмЙЙЭМжаЮДзіУшЪіЃЉЃЌЪЕЯжИќьХПсЕФБЈБэЃЛ
7.ПЩвдИљОнвЕЮёРЉеЙашЧѓЃЌдіМгЖдгІЕФ Flume МАДІРэЗўЮёЃЌвдЪЕЯжвЕЮёКсЯђРЉеЙЃЛ
8.ФПЧАЛЙУЛгаЖдвЕЮёШежОзіДѓЪ§ОнЗжЮіЃЌвђДЫМмЙЙжажЛзіСЫНкЕуУшЪіЁЃ
ММЪѕЗНАИ
1.Flume 1.6діМгСЫ KafkaSourceЃЌжЎЧААцБОашвЊздМКЪЕЯжЃЈздЖЈвх
Source ЪЕЯжЪОР§ЃЉЃЛ
2.Flume зідЄДІРэКЭЗжЗЂЃЌашвЊздЖЈвхSinkЃЈздЖЈвхSinkЪЕЯжЪОР§ЃЉЃЛ
3.BizLogSDK ЕФХфжУжаПЩвдЬэМгЖдKafka Producer
ЕФХфжУЃЈProducer ConfigsЃЉЃЌвдгХЛЏадФмЃЛ
4.Elasticsearch ЙйЭјЕФ Java Client БШНЯжиЃЌСЌНгЪ§ЬЋЖрЃЌНЈвщАДееElasticsearch
Reference здМКПЊЗЂвЛИіЛљгкHTTP авщ ЕФ ClientЃЈЪЕЯжCRUDЃЉЃЌЗНБувЕЮёШежОАДее
biztype-date ИёЪННјааЫїв§ЁЃзЂвтЃКHTTP СЌНггІИУИДгУЃЌЃЈПЩвдВЩгУHttpClient
ЕФСЌНгГиЙмРэЗНЪНЃЉЃЌБмУтСЌНгЪ§Й§ЖрЃЛ
5.Flume Sink жаФУЕНвЕЮёШежОКѓЃЌгІИУЗХЕНЯпГЬГиРяДІРэЃЌБмУт
FlumeПЈЫРЃЛ
6.Elasticsearch ФЌШЯЛсНЋ string РраЭзжЖЮЩшЮЊ
_ analyzed _ЃЌЛсдьГЩCPUЙ§ИпЁЃПЩвдЭЈЙ§ Elasticsearch ЬсЙЉЕФ Index
Templates ЗНЪНЃЌдкindex ДДНЈКѓЃЌгІгУ template ЕНЦЅХфЕФindexЃЌНЋЯрЙи
_ string _ аЭзжЖЮЩшЮЊ _ not_analyzed _ЁЃ
BizLogSDK ЃК
вЕЮёAppЭЈЙ§ЕїгУ BizLogSDKЃЌНЋвЕЮёШежОЪфГіЕНKafkaМЏШКЁЃBizLogSDK ашвЊЪЕЯжЩшжУЙЋгУЪєадЁЂРЉеЙЪєадЃЌШежОЗЂЫЭЕШЙІФмЁЃПЩВЮПМ
Log4j ЕФдДТыРДЪЕЯжЁЃ
1.вЕЮёШежОЙЋгУЪєадЃК
_ bizType _ ЃКвЕЮёРраЭ
_ bizAction _ЃКвЕЮёВйзї
_ serverIp _ ЃКЗўЮёЦїIP
_ requestTime _ ЃКЧыЧѓЪБМф
2.ЛљБОХфжУЃК
| #
ЖгСаУћГЦ
topicName = bizlog-server
# ЪЧЗёЭЌВНЗЂЫЭЯћЯЂЃЈвьВНЫйЖШИќПьЃЉ
send.sync = false
# kafka ЯћЯЂЖгСаЗўЮёЦї
bootstrap.servers = 127.0.0.1:9091 |
ЪЕЪБВщбЏ
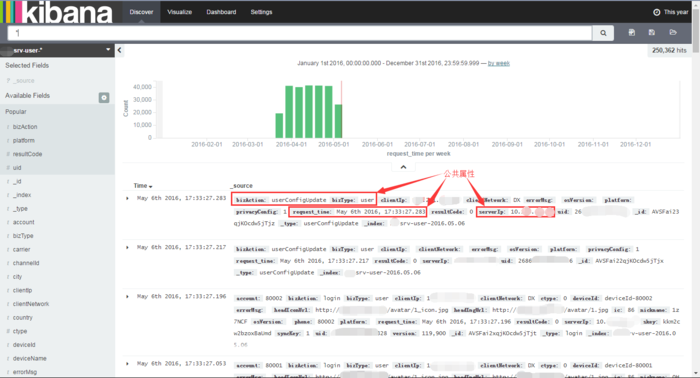
ЪЕЪБЭГМЦ
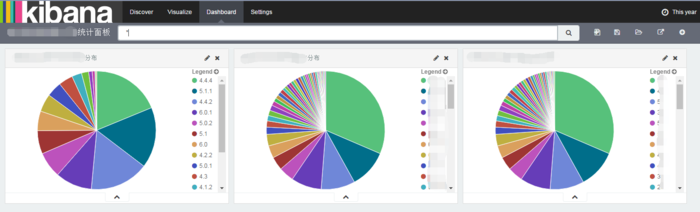
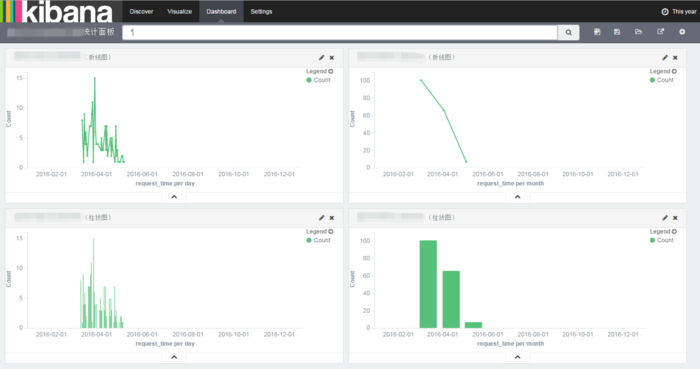
ЯрЙиМрПи
KafkaOffsetMonitor
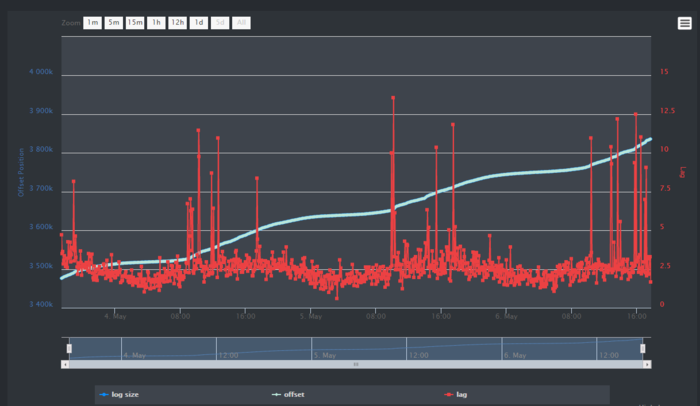
KafkaЖгСаМрПи
Elasticsearch Monitor
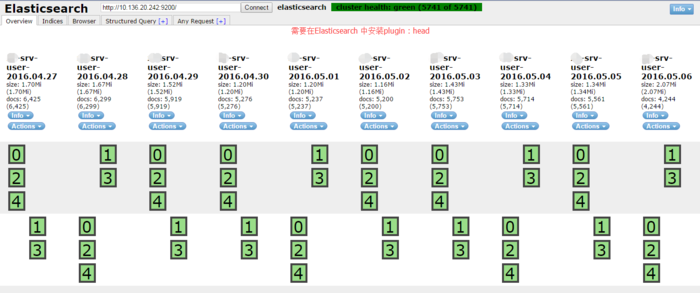
Elasticsearch МрПи
КѓајИФНј
1.BizLogSDK жаашвЊМгШы Log LevelЃЛ
2.вЕЮёШежОашвЊвЛИіЭГвЛЕФНчУцРДЙмРэЃЈЩшжУlevelЁЂЙиБеЁЂЩОГ§ЁЂЖЈЦкЧхРэЕШЃЉЃЛ
|








