ХІдМЪББЈгаКмЖрФкШнЩњГЩЯЕЭГЃЌЮвУЧЪЙгУЕкШ§ЗНЪ§ОнРДБраДЙЪЪТЁЃСэЭтЃЌЮвУЧга161ФъЕФаТЮХаавЕЛ§РлКЭ21ФъЕФдкЯпФкШнЗЂВМОбщЃЌЫљвдДѓСПЕФдкЯпФкШнашвЊБЛЫбЫїЕНЃЌВЂЬсЙЉИјВЛЭЌЕФЗўЮёКЭгІгУЪЙгУЁЃ
СэвЛЗНУцЃЌгаКмЖрЗўЮёКЭгІгУашвЊЗУЮЪЕНетаЉФкШнЁЊЁЊЫбЫїв§ЧцЁЂИіадЛЏЖЈжЦЗўЮёЁЂаТЮХжжзгЩњГЩЦїЃЌвдМАЦфЫћИїжжЧАЖЫгІгУЃЌШчЭјеОКЭвЦЖЏгІгУЁЃвЛЕЉгааТФкШнЗЂВМЃЌОЭвЊдкКмЖЬЕФЪБМфФкШУетаЉЗўЮёЗУЮЪЕНЃЌЖјЧвВЛФмгаЪ§ОнЖЊЪЇЁЊЁЊБЯОЙетаЉФкШнЖМЪЧгаМлжЕЕФаТЮХЁЃ
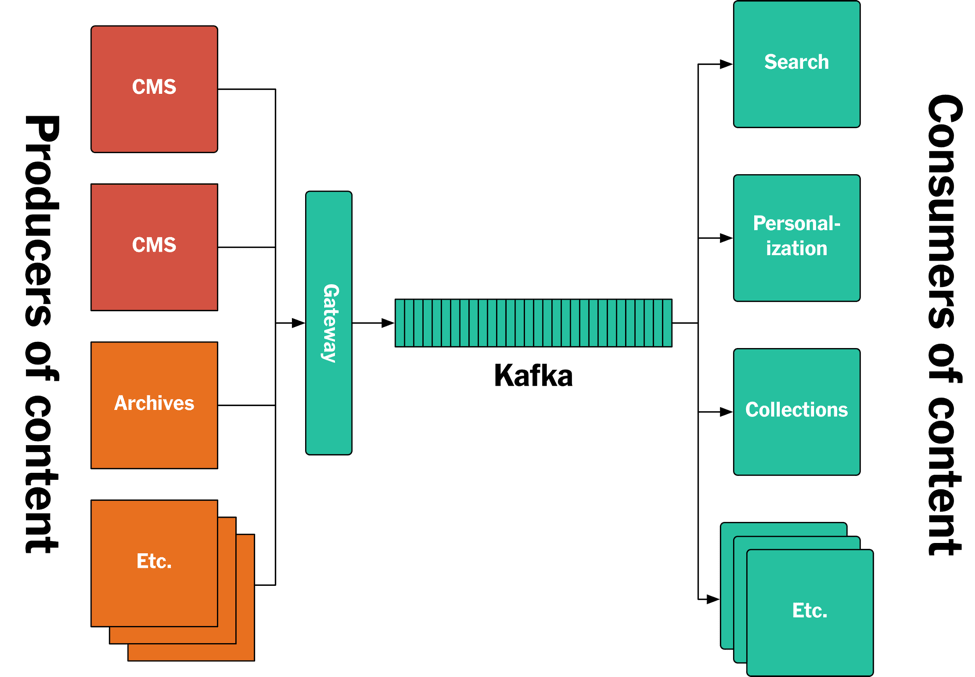
дкетЦЊЮФеТРяЃЌЮвУЧНЋЯъЯИНщЩмЮвУЧЪЧШчКЮЛљгкApache KafkaНтОіЩЯЪіЮЪЬтЕФЁЃЮвУЧАбетИіЯЕЭГНазіЗЂВМЙмЕРЃЈPublishing
PipelineЃЉЁЃетЦЊЮФеТжївЊЙизЂКѓЖЫЕФЯЕЭГЃЌЮвУЧЛсНщЩмШчКЮЪЙгУKafkaБЃДцХІдМЪББЈЕФЮФеТЃЌвдМАШчКЮЪЙгУKafkaКЭSteams
APIНЋЗЂВМЕФФкШнЪЕЪБЭЦЫЭИјИїжжгІгУЁЃЯТУцЪЧзмЬхЕФМмЙЙЭМЃЌОпЬхЯИНкЩдКѓЯъЪіЁЃ
ЛљгкAPIНтОіЗНАИЕФВЛзужЎДІ
ЗУЮЪвбЗЂВМФкШнЕФКѓЖЫЯЕЭГгазХИїжжВЛЭЌЕФашЧѓЁЃ
ЮвУЧгавЛИіЗўЮёзЈУХЮЊЭјеОКЭвЦЖЏгІгУЬсЙЉЪЕЪБФкШнЃЌЫљвддкФкШнЗЂВМжЎКѓЃЌЫќашвЊСЂМДЗУЮЪЕНетаЉФкШнЁЃ
ЮвУЧЛЙгавЛаЉЗўЮёгУгкЬсЙЉФкШнЧхЕЅЁЃгааЉЧхЕЅЪЧЪжЖЏБрМЕФЃЌгааЉдђЪЧЭЈЙ§ВщбЏЛёЕУЕФЁЃЖдгкЭЈЙ§ВщбЏЛёЕУЕФЧхЕЅРДЫЕЃЌвЛЕЉгаЗћКЯВщбЏЬѕМўЕФФкШнЗЂВМЃЌОЭашвЊБЛАќКЌдкЧхЕЅРяЁЃЖјШчЙћвбЗЂВМЕФФкШнОЙ§аоИФКѓВЛдйЗћКЯВщбЏЬѕМўЃЌОЭвЊДгЧхЕЅРявЦГ§ЁЃЮвУЧЛЙвЊжЇГжЖдВщбЏЬѕМўБОЩэНјаааоИФЃЌБШШчДДНЈаТЕФЧхЕЅЃЌЖјвЊаТНЈЧхЕЅОЭашвЊЗУЮЪжЎЧАЗЂВМЕФФкШнЁЃ
ЮвУЧЕФElasticsearchМЏШКЮЊЭјеОЬсЙЉСЫЫбЫїЗўЮёЁЃЮвУЧЖдбгГйУЛгаКмИпЕФвЊЧѓЃЌБШШчдкФкШнЗЂВМКѓЕФвЛСНЗжжгФкЫбЫїВЛЕНаТФкШнВЛЫуЪЧИіДѓЮЪЬтЁЃВЛЙ§ЃЌЫбЫїв§ЧцШдШЛвЊЗУЮЪжЎЧАЗЂВМЕФФкШнЃЌвђЮЊвЛЕЉElasticsearchЕФschemaЖЈвхЗЂЩњБфИќЃЌЛђепаоИФСЫЫбЫїЩуШЁЙмЕРЃЌОЭашвЊЖдЫљгаФкШнНјаажиаТЫїв§ЁЃ
ЮвУЧЛЙгавЛИіИіадЛЏЖЈжЦЯЕЭГЃЌЫќжЛЖдзюаТЕФФкШнИааЫШЄЁЃдкИіадЛЏЖЈжЦЫуЗЈЗЂЩњБфЛЏКѓЃЌашвЊжиаТДІРэетаЉФкШнЁЃ
дквЛПЊЪМЃЌЮвУЧЮЊетаЉгІгУЬсЙЉСЫAPIЃЌШУЫќУЧжБНгЗУЮЪвбЗЂВМЕФФкШнЃЌЛђепШУЫќУЧЖЉдФжжзгЃЌвЛЕЉгааТФкШнЗЂВМЃЌЫќУЧОЭЛсЪеЕНЭЈжЊЁЃ
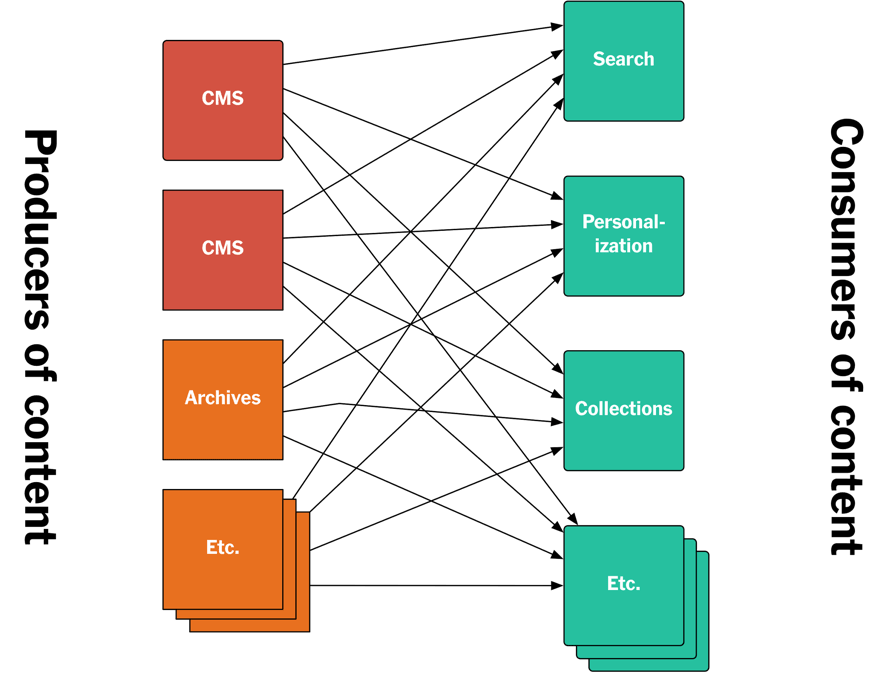
етжжЕфаЭЕФЛљгкAPIЕФНтОіЗНАИДцдкКмЖрЮЪЬтЁЃ
ВЛЭЌЕФAPIЪЧгЩВЛЭЌЕФЭХЖгдкВЛЭЌЕФЪБЦквдВЛЭЌЕФЗНЪНПЊЗЂГіРДЕФЁЃЖЫЕуДцдкВювьЃЌгявхДцдкВювьЃЌЩѕжССЌВЮЪ§вВДцдкВювьЁЃЫфШЛЮвУЧПЩвдЪдзХШЅНтОіетаЉЮЪЬтЃЌЕЋФЧашвЊаЕїИїИіЭХЖгЃЌКФЪБКФСІЁЃ
етаЉЯЕЭГЖМЖЈвхСЫздМКЕФschemaЃЌЭЌвЛзжЖЮдкВЛЭЌЕФЯЕЭГРяНаЗЈВЛвЛбљЃЌЖјЭЌвЛУћзжЕФзжЖЮдкВЛЭЌЕФЯЕЭГРяБэЪОЕФШДЪЧВЛЭЌЕФвтЫМЁЃ
СэвЛИіЮЪЬтЪЧЃЌвЊЗУЮЪЕНжЎЧАЗЂВМЕФФкШнЪЧКмРЇФбЕФЁЃДѓВПЗжЯЕЭГВЂУЛгаЬсЙЉФкШнСїЃЌвђЮЊЫќУЧЪЙгУЕФЪ§ОнПтВЛжЇГжетвЛЬиадЁЃЫфШЛФкШнЖМБЃДцдкЪ§ОнПтРяЃЌЕЋДѓСПЕФAPIЕїгУЯрЕБКФЪБЃЌЖјЧвЛсИјAPIЗўЮёДјРДВЛПЩдЄСЯЕФИКдиЁЃ
ЛљгкШежОЕФМмЙЙ
ЮвУЧМДНЋНщЩмЕФЪЧвЛжжЛљгкШежОЕФМмЙЙЁЃMartin KleppmannдкЁАTurning the database
inside-out with Apache SamzaЁБжаЬсЕНСЫетвЛМмЙЙЗНАИЃЌКѓРДдкЁАDesigning
Data-Intensive ApplicationsЁБжагаСЫИќЮЊЯъЯИЕФУшЪіЁЃЁАLog: What
every software engineer should know about real-time
data's unifying abstractionЁБдђЬсЕНСЫНЋШежОзїЮЊвЛжжЭЈгУЕФЪ§ОнНсЙЙЕФЫЕЗЈЁЃЖдгкЮвУЧРДЫЕЃЌЮвУЧЕФШежООЭЪЧKafkaЃЌЫљгаЗЂВМЕФФкШнАДееЪБМфЫГађЬэМгЕНKafkaжїЬтЩЯЃЌЦфЫћЗўЮёЭЈЙ§ЯћЗбШежОРДЗУЮЪетаЉФкШнЁЃ
ДЋЭГЕФгІгУЪЙгУЪ§ОнПтБЃДцЪ§ОнЃЌОЁЙмЪ§ОнПтвВгаКмЖргХЕуЃЌЕЋДгГЄдЖРДПДЃЌЙмРэЪ§ОнПтЛсГЩЮЊвЛжжИКЕЃЁЃЪзЯШЃЌБфИќЪ§ОнПтschemaОЭКмМЌЪжЁЃдіМгЛђвЦГ§зжЖЮВЂВЛФбЃЌЕЋетаЉБфИќашвЊвдднЭЃЗўЮёЮЊДњМлЁЃЮвУЧвВЮоЗЈздгЩЕиИќЛЛЪ§ОнПтЁЃДѓВПЗжЪ§ОнПтВЛжЇГжСїЪНБфИќЃЌОЁЙмЮвУЧПЩвдЛёЕУЪ§ОнПтПьееЃЌЕЋетаЉПьееКмПьОЭЛсЙ§ЪБЁЃвВОЭЪЧЫЕЃЌЮвУЧФбвдДДНЈбмЩњДцДЂЃЌБШШчЫбЫїв§ЧцЪЙгУЕФЫїв§ЃЌвђЮЊЫїв§РяБиаыАќКЌЫљгаЮФеТФкШнЃЌЖјЧввЛЕЉгааТФкШнЗЂВМОЭвЊжиНЈЫїв§ЁЃЫфЫЕЮвУЧПЩвдШУПЭЛЇЖЫЭЌЪБНЋФкШнЗЂЫЭИјЖрИіДцДЂЯЕЭГЃЌЕЋетбљШдШЛЮоЗЈНтОівЛжТадЮЪЬтЃЌвђЮЊгаЕФаДШыЛсЪЇАмЁЃ
ДгГЄдЖРДПДЃЌЪ§ОнПтзюжеЛсБфГЩвЛИіИДдгЕФЕЅЬхЁЃ
ЛљгкШежОЕФМмЙЙПЩвдНтОіетаЉЮЪЬтЁЃвЛАуРДЫЕЃЌЪ§ОнПтБЃДцЕФЪЧЪТМўЕФНсЙћЛђзДЬЌЃЌЖјШежОБЃДцЕФЪЧЪТМўБОЩэЁЃЮвУЧПЩвдЛљгкШежОДДНЈШЮКЮЮвУЧЯывЊЕФЪ§ОнДцДЂЃЌетаЉЪ§ОнДцДЂОЭЪЧШежОЕФЮяЛЏЪгЭМЃЌЫќУЧАќКЌЕФЪЧХЩЩњЕФФкШнЃЌЖјЗЧдЪМФкШнЁЃШчЙћвЊИќИФЪ§ОнДцДЂЕФschemaЃЌжЛвЊДДНЈвЛИіаТЕФЪ§ОнДцДЂЃЌШЛКѓДгЭЗЕНЮВдйЯћЗбвЛБщЫљгаЕФШежООЭПЩвдСЫЃЌШЛКѓАбОЩЕФЪ§ОнДцДЂШгЕєЁЃ
вЛЕЉЪЙгУШежОзїЮЊЪТЪЕЕФРДдДЃЌОЭУЛгаБивЊдйЪЙгУжааФЪ§ОнПтСЫЁЃУПвЛИіЯЕЭГЖМПЩвдДДНЈЪєгкздМКЕФЪ§ОнДцДЂЃЌЛђепЫЕЮяЛЏЪгЭМЃЌЫќжЛАќКЌИУЯЕЭГЫљБиашЕФЪ§ОнЃЌЖјЧвЮЊИУЯЕЭГЬсЙЉСЫЬиЖЈЕФИёЪНЁЃетОЭМђЛЏСЫЪ§ОнПтдкМмЙЙжаЕФНЧЩЋЃЌИќЬљКЯУПвЛИігІгУЕФашЧѓЁЃ
СэЭтЃЌЛљгкШежОЕФМмЙЙвВМђЛЏСЫЗУЮЪФкШнСїЕФЗНЪНЁЃЖдгкДЋЭГЕФЪ§ОнПтРДЫЕЃЌЗУЮЪећИіЪ§ОнзЊДЂЃЈБШШчПьееЃЉКЭЗУЮЪЁАЪЕЪБЁБЪ§ОнЃЈБШШчжжзгЃЉЪЧСНжжВЛвЛбљЕФВйзїЁЃЖјЖдгкШежОРДЫЕЃЌЫќУЧВЂВЛДцдкВюБ№ЁЃФуПЩвдДгШЮвтЕФЦЋвЦСПДІПЊЪМЯћЗбШежОЃЌДгЦ№ЪМЮЛжУвВКУЃЌДгжаМфПЊЪМвВКУЃЌЩѕжСДгФЉЮВвВПЩвдЁЃвВОЭЪЧЫЕЃЌШчЙћФувЊжиаТДДНЈЪ§ОнДцДЂЃЌжЛвЊИљОнашвЊжиаТЯћЗбШежОМДПЩЁЃ
ЛљгкШежОМмЙЙЕФЯЕЭГдкВПЪ№ЗНУцвВгаКмЖргХЪЦЁЃдкащФтЛњРяНјааЮозДЬЌЗўЮёЕФВЛБфФЃЪНВПЪ№вбОГЩЮЊвЛжжГЃМћЕФЗНЪНЁЃжиаТВПЪ№ећИіЪЕР§ПЩвдБмУтКмЖрЮЪЬтЁЃвђЮЊгаСЫШежОЃЌЮвУЧЯждкПЩвдНјаагазДЬЌЯЕЭГЕФВЛБфФЃЪНВПЪ№ЁЃвђЮЊЮвУЧПЩвдДгШежОжажиаТДДНЈЪ§ОнДцДЂЃЌЫљвдУПДЮдкВПЪ№БфИќЕФЪБКђЖМПЩвдЛёЕУаТЕФЪ§ОнДцДЂЁЃ
ЮЊЪВУДGoogleЕФPubSubЛђAWS SNS/SQS/KinesisЮоЗЈНтОіетаЉЮЪЬт
KafkaвЛАугаСНжжгІгУГЁОАЁЃ
KafkaГЃБЛгУзїЯћЯЂДњРэЃЌгУгкЪ§ОнЗжЮіКЭЪ§ОнМЏГЩЁЃKafkaдкетЗНУцгаКмЖргХЪЦЃЌВЛЙ§Google
PubSubЁЂAWS SNS/SQS/KinesisвВФмНтОіетаЉЕФЮЪЬтЁЃетаЉЗўЮёЖМжЇГжЖрИіЯћЗбепКЭЖрИіЩњВњепЃЌПЩвдИњзйЯћЗбепЕФЯћЗбзДЬЌЃЌЯћЗбепдкхДЛњЕФЪБКђВЛЛсГіЯжЪ§ОнЖЊЪЇЁЃдкетаЉГЁОАРяЃЌШежОжЛЪЧЯћЯЂДњРэЕФвЛжжОпЬхЪЕЯжЖјвбЁЃ
ЕЋдкЛљгкШежОЕФМмЙЙРяЃЌЧщПіОЭВЛвЛбљСЫЁЃетИіЪБКђШежООЭВЛжЛЪЧЕЅДПЕФЪЕЯжЯИНкФЧУДМђЕЅСЫЃЌЖјЪЧБфГЩСЫКЫаФЙІФмЁЃЮвУЧгавдЯТСНЕуашЧѓЃК
ЮвУЧашвЊЭЈЙ§ШежОгРОУЕиБЃСєЫљгаЪТМўЃЌЗёдђОЭЮоЗЈЫцвтДДНЈЮвУЧашвЊЕФЪ§ОнДцДЂЁЃ
ЮвУЧашвЊАДеевЛЖЈЫГађЯћЗбШежОЃЌвђЮЊТвађДІРэЙиСЊадЪТМўЛсЕУЕНДэЮѓЕФНсЙћЁЃ
ФПЧАвВжЛгаKafkaФмЙЛТњзуетСНИіашЧѓЁЃ
Monolog
MonologЪЧЮвУЧЕФаТФкШнЗЂВМдДЃЌЦфЫћЯЕЭГАбДДНЈЕФФкШнвдзЗМгЕФЗНЪНаДЕНMonologЁЃДДНЈЕФФкШндкНјШыMonologЧАЛсОЙ§вЛИіЭјЙиЃЌЭјЙиЛсМьВщСїОЕФФкШнЪЧЗёЗћКЯЮвУЧЖЈвхЕФschemaЁЃ

MonologРяАќКЌСЫзд1851ФъвдРДЗЂааЕФЫљгаФкШнЃЌЫќУЧАДееЗЂааЪБМфНјааХХађЁЃвВОЭЪЧЫЕЃЌЯћЗбепПЩвдДгШЮвтЪБМфЕуПЊЪМЯћЗбетаЉФкШнЁЃШчЙћашвЊЯћЗбЫљгаЕФФкШнЃЌОЭДгЭЗПЊЪМЃЈвВОЭЪЧДг1851ФъПЊЪМЃЉЃЌЛђепИљОнашвЊжЛЯћЗбФЧаЉИќаТЙ§ЕФВПЗжЁЃ
ОйИіР§згЃЌЮвУЧгавЛИіЗўЮёИКд№ЬсЙЉФкШнЧхЕЅЃЌБШШчФГИізїепЗЂВМЙ§ЕФФкШнЁЂгыФГИіПЦбЇжїЬтЯрЙиЕФФкШнЃЌЕШЕШЁЃетИіЗўЮёЛсДгЦ№ЪМЮЛжУПЊЪМЯћЗбMonologЃЌШЛКѓЙЙНЈФкШнЧхЕЅЁЃЮвУЧЛЙгаСэЭтвЛИіЗўЮёЃЌЫќжЛЬсЙЉзюаТЗЂВМЕФФкШнЧхЕЅЃЌЫљвдЫќВЛашвЊгРОУЕФЪ§ОнДцДЂЃЌЫќжЛашвЊЙ§ШЅМИИіаЁЪБЕФШежОЪ§ОнЁЃЫќЛсдкЦєЖЏЕФЪБКђЯћЗбзюНќМИИіаЁЪБЕФШежОЃЌВЂдкФкДцРяЮЌЛЄвЛИізюаТФкШнЕФЧхЕЅЁЃ
ЮвУЧАДееЙцЗЖЛЏаЮЪННЋФкШнЗЂЫЭИјMonologЃЌУПвЛВПЗжФкШнЖМБЛЕБГЩвЛИіЕЅЖРЕФЯћЯЂаДШыKafkaЁЃР§ШчЃЌЭМЦЌКЭЮФеТЪЧЗжПЊЗЂЫЭЕФЃЌвђЮЊЖрЦЊВЛЭЌЕФЮФеТПЩФмАќКЌЭЌвЛеХЭМЦЌЁЃ
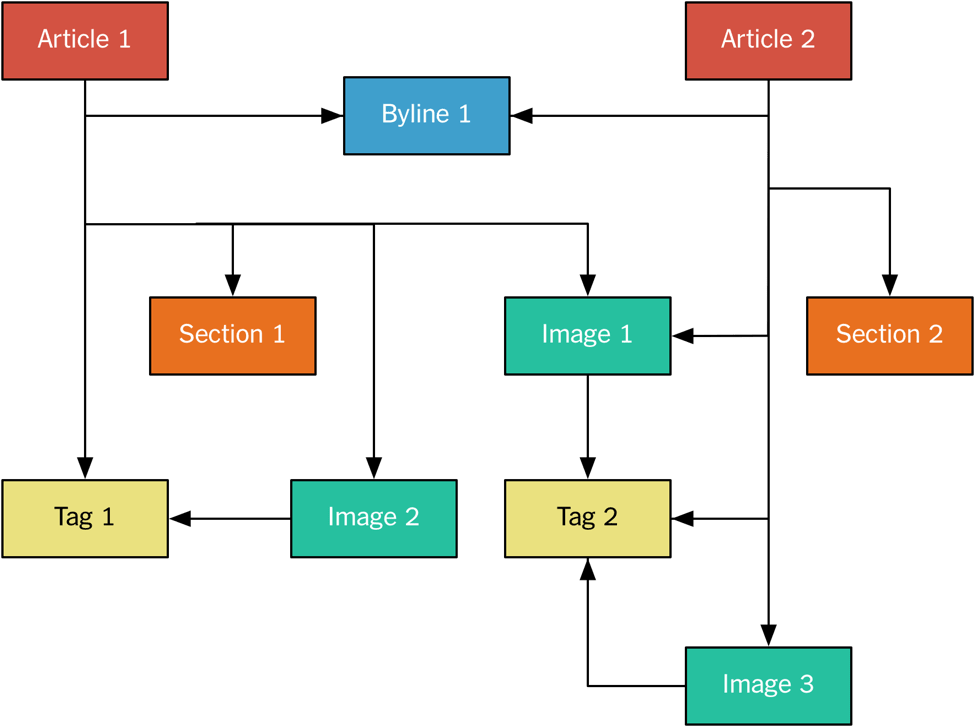
етгыЙиЯЕаЭЪ§ОнПтРяЕФЙцЗЖЛЏФЃаЭКмЯрЫЦЃЌЭМЦЌгыЮФеТжЎМфЪЧЖрЖдЖрЙиЯЕЁЃ
дкЩЯвЛР§згжаЃЌЮвУЧгаСНЦЊЮФеТв§гУСЫЦфЫћФкШнЁЃР§ШчЃЌБъЬтааЪЧЕЅЖРЗЂВМЕФЃЌШЛКѓгжБЛЦфЫћСНЦЊЮФеТв§гУЁЃЫљгаЕФФкШнЖМЪЙгУnyt://article/577d0341-9a0a-46df-b454-ea0718026d30етжжИёЪНЕФURIРДБъЪЖЁЃЮвУЧгавЛИідЩњфЏРРЦїПЩвдВщПДетаЉURIЃЌжЛвЊЕЅЛїетаЉURIОЭПЩвдПДЕНЫќУЧЕФJSONБэЪОЃЌЖјФкШнБОЩэдђвдprotobufИёЪНБЃДцдкMonologЩЯЁЃ
MonologЪЕМЪЩЯЪЧKafkaЩЯЕФвЛИіжїЬтЃЌЫќжЛАќКЌвЛИіЗжЧјЃЌвђЮЊЮвУЧЯывЊБЃГжЯћЯЂЕФШЋОжЫГађЁЃетбљПЩвдБЃжЄЖЅВуФкШнЕФФкВПвЛжТадЁЊЁЊШчЙћЮвУЧдквЛЦЊЮФеТРяЬэМгСЫвЛеХЭМЦЌЃЌЭЌЪБгжЬэМгСЫвЛаЉЮФзжЃЌетаЉЮФзжв§гУСЫетеХЭМЦЌЃЌФЧУДЮвУЧОЭвЊШЗБЃЭМЦЌЕФЮЛжУгІИУдкаТдіЮФзжжЎЧАЁЃ
ЪЕМЪЩЯЃЌФкШнЪЧАДееЭиЦЫЕФЗНЪННјааХХађЕФЃЌШчЯТЭМЫљЪОЁЃ
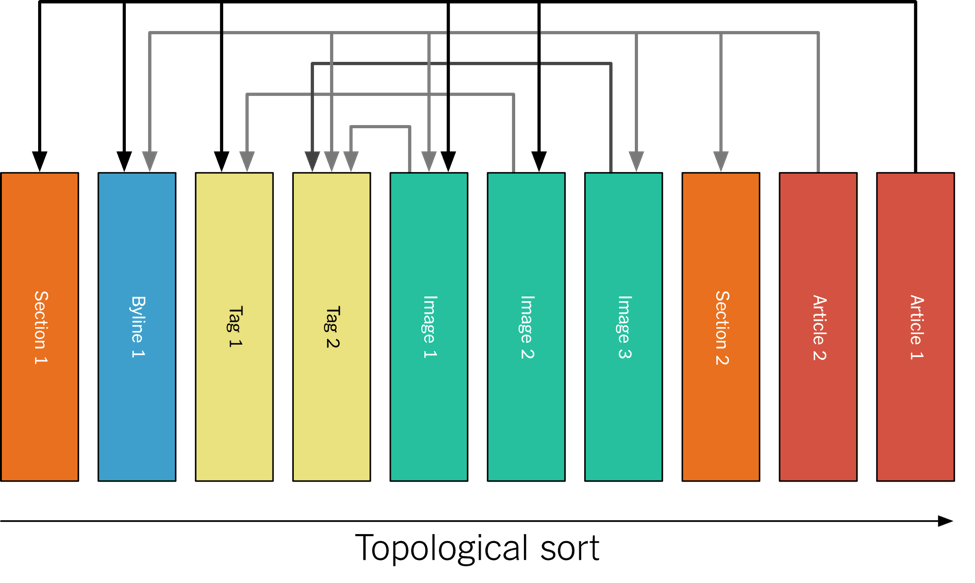
вђЮЊжїЬтжЛАќКЌСЫвЛИіЗжЧјЃЌЫљвдЫљгаФкШнЖМБЃДцдкЭЌвЛИіДХХЬЩЯЃЈKafkaЕФДцДЂЛњжЦОЭЪЧетбљЕФЃЉЁЃВЛЙ§етЖдгкЮвУЧРДЫЕВЛЪЧЮЪЬтЃЌвђЮЊЮвУЧЫљгаЕФФкШнЖМЪЧЮФзжЃЌЕНЯждкзмСПЖМУЛГЌЙ§100GBЁЃ
ЙцЗЖЛЏШежОКЭKafka Streams API
MonologТњзуСЫВПЗжгІгУГЬађЕФашЧѓЃЌетаЉгІгУашвЊЙцЗЖЛЏЕФЪ§ОнЪгЭМЃЌЕЋЖдгкЦфЫћвЛаЉгІгУГЬађРДЫЕОЭВЛЪЧетУДЛиЪТСЫЁЃБШШчЃЌЮЊСЫНЋЪ§ОнЫїв§жСElasticsearchЃЌОЭашвЊЗЧЙцЗЖЛЏЕФЪ§ОнЃЌвђЮЊElasticsearchВЛжЇГжЖрЖдЖрЕФЙиЯЕгГЩфЁЃШчЙћвЊЭЈЙ§ЭМЦЌЫЕУїРДЫбЫїЮФеТЃЌетаЉЭМЦЌЕФЫЕУїадЮФзжОЭБиаыБЛАќКЌдкЮФеТЖдЯѓРяЁЃ
ЮЊСЫжЇГжетжжЪ§ОнЪгЭМЃЌЮвУЧвВзМБИСЫвЛЬзЗЧЙцЗЖЛЏЕФШежОЁЃдкетаЉШежОРяЃЌЖЅВуЕФФкШнМАЦфЫљгавРРЕЯюЖМБЛДђАќЗЂВМЁЃР§ШчЃЌдкЗЂВМArticle
1ЕФЪБКђЃЌШежОЯћЯЂРяВЛНіАќКЌСЫетЦЊЮФеТЃЌвВАќКЌСЫЯрЙиЕФЭМЦЌКЭБъЧЉЁЃ

KafkaЯћЗбепПЭЛЇЖЫДгШежОРяЯћЗбЯћЯЂЃЌдйЬэМгЕНElasticsearchЫїв§РяЁЃдкЗЂВМAriticle
2ЕФЪБКђЃЌетЦЊЮФеТЕФЫљгаЯрЙиФкШнвВЛсБЛДђАќдквЛЦ№ЃЌМДЪЙгааЉЭМЦЌПЩФмвбОдкAriticle 1РяГіЯжЙ§ЁЃ

ШчЙћЮФеТЕФвРРЕЯюЗЂЩњБфЛЏЃЌећЦЊФкШнОЭЛсБЛжиаТЗЂВМЁЃБШШчЃЌШчЙћИќаТСЫImage 2ЃЌФЧУДArticle
1ОЭЛсдйДЮБЛЬэМгЕНШежОРяЁЃ

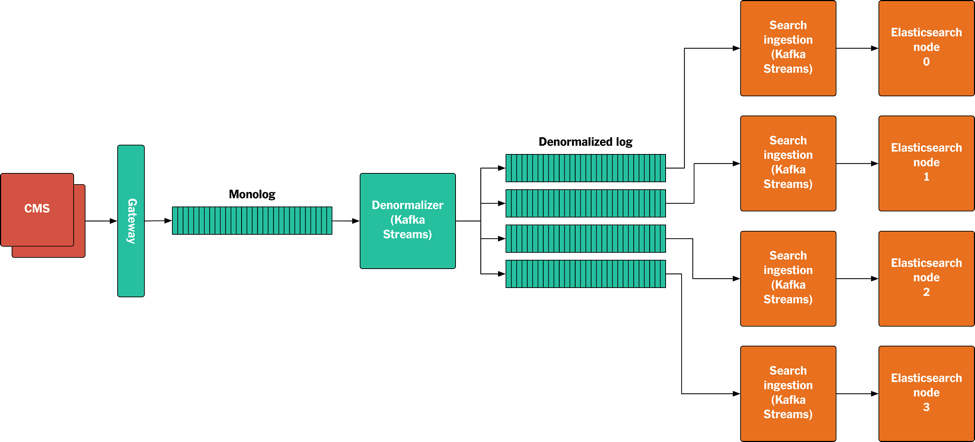
ЮвУЧЪЙгУвЛИіНазїDenormalizerЕФзщМўРДДДНЈЗЧЙцЗЖЛЏШежОЁЃ
DenormalizerЪЧвЛИіЪЙгУСЫKafka Streams APIЕФJavaгІгУГЬађЁЃЫќЯћЗбMonologЕФЯћЯЂЃЌВЂдкБОЕиЮЊУПвЛЦЊЮФеТБЃСєСЫвЛЗнзюаТЕФАцБОЃЌАќРЈЖдЮФеТЕФв§гУЁЃЫцзХФкШнВЛЖЯЕиЗЂВМКЭИќаТЃЌБОЕиДцДЂвВЛсГжајИќаТЁЃвЛЕЉгаЖЅВуФкШнЗЂВМЃЌDenormalizerОЭЛсДгБОЕиДцДЂжаЪеМЏЫљгаЕФвРРЕЯюЃЌАбЫќУЧДђАќаДЕНЗЧЙцЗЖЛЏШежОжаЁЃШчЙћФГИіЖЅВуФкШнЕФвРРЕЯюЗЂЩњСЫБфЛЏЃЌDenormalizerОЭЛсжиаТЗЂВМећИіАќЁЃ
ЗЧЙцЗЖЛЏШежОВЛашвЊШЋОжЕФЫГађБЃжЄЃЌЮвУЧжЛвЊШЗБЃЭЌвЛЦЊЮФеТЕФВЛЭЌАцБОЪЧАДеевЛЖЈЫГађаДШыШежООЭПЩвдСЫЁЃЫљвдЮвУЧПЩвдЪЙгУЗжЧјЃЌШУЖрИіЯћЗбепЭЌЪБЯћЗбетаЉЗжЧјЁЃ
ElasticsearchЪОР§
ЯТЭМеЙЪОСЫЮвУЧЙЙНЈЕФКѓЖЫЫбЫїЗўЮёЃЌЮвУЧЪЙгУСЫElasticsearchЁЃ
ећИіЪ§ОнСїГЬЪЧетбљЕФЁЃ
CMSЗЂВМЛђИќаТФкШнЁЃ
ФкШнвдprotobufЖўНјжЦЕФЗНЪНЗЂЫЭЕНЭјЙиЁЃ
ЭјЙибщжЄФкШнЃЌВЂАбЫќаДШыMonologЁЃ
DenormalizerДгMonologЯћЗбШежОЃЌШчЙћЪЧЖЅВуФкШнЃЌОЭДгБОЕиДцДЂжаЪеМЏЫљгавРРЕЯюЃЌдйДђАќаДШыЗЧЙцЗЖЛЏШежОжаЁЃШчЙћЪЧБЛв§гУЕФФкШнЃЌФЧУДЫљгагыжЎЯрЙиЕФЖЅВуФкШнвВЛсБЛаДШыЗЧЙцЗЖЛЏШежОЁЃ
KafkaЗжЧјЦїИљОнЖЅВуФкШнЕФURIРДЗжЧјЁЃ
ЫљгаЕФЫбЫїНкЕуЭЈЙ§ЕїгУKafka Streams APIРДЗУЮЪЗЧЙцЗЖЛЏШежОЃЌУПИіНкЕуЖСШЁвЛИіЗжЧјЃЌАбЯћЯЂАќзАГЩJSONЖдЯѓЃЌдйЬэМгЕНElasticsearchЫїв§РяЃЌзюКѓдйаДЕНжИЖЈЕФElasticsearchНкЕуЩЯЁЃдкНјааЫїв§жиНЈЕФЪБКђЃЌЮвУЧАбИДжЦЙІФмЙиБеЃЌетбљПЩвдМгПьЫїв§ЫйЖШЃЌдкЙЙНЈКУЫїв§КѓдйАбИДжЦЙІФмДђПЊЁЃ
ЪЕЯж
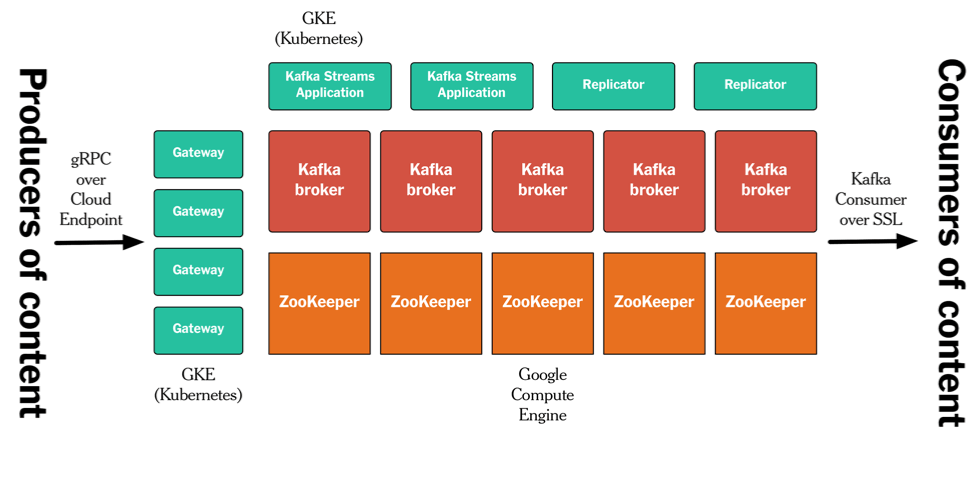
ЮвУЧЕФЗЂВМЙмЕРВПЪ№дкGoogle Cloud PlatformЩЯЁЃЮвВЛДђЫудкетЦЊЮФеТРяУшЪіОпЬхЕФЯИНкЃЌВЛЙ§ЯТЭМИјГіСЫЫќЕФећЬхМмЙЙЧщПіЁЃЮвУЧдкGCP
ComputeЩЯдЫааKafkaКЭZooKeeperЃЌЦфЫћЕФзщМўЁЊЁЊЭјЙиЁЂKafkaИББОНкЕуКЭDenormalizerдђдЫаадкШнЦїРяЁЃЮвУЧЪЙгУСЫЛљгкgRPCКЭCloud
EndpointЕФAPIЃЌВЂЪЙгУSSLШЯжЄКЭЪкШЈШЗБЃKafkaЕФАВШЋЁЃ
НсТл
ЮвУЧЛЈСЫНЋНќвЛФъЪБМфдкЮвУЧЕФаТМмЙЙЩЯЃЌЯждкЫќвбОдЫаадкЩњВњЛЗОГжаЁЃВЛЙ§ЯждкЛЙжЛЪЧИіПЊЪМЃЌЮвУЧЛЙгаКмЖрЦфЫћЯЕЭГвВашвЊЧЈвЦЕНетИіМмЙЙРяЁЃаТМмЙЙгаКмЖргХЪЦЃЌЕЋетЖдгкПЊЗЂепРДЫЕвВЪЧвЛДЮжиДѓЕФЫМЮЌзЊБфЃЌЫћУЧашвЊДгДЋЭГЪ§ОнПтКЭЗЂВМЖЉдФФЃаЭзЊЯђаТЕФЪ§ОнСїФЃаЭЁЃЮЊСЫШУетаЉгХЪЦЗЂбяЙтДѓЃЌЮвУЧашвЊИФБфЮвУЧЕФПЊЗЂЗНЪНЃЌЛЙвЊЛЈКмЖрОЋСІЙЙНЈЙЄОпКЭЛљДЁЩшЪЉЃЌШУПЊЗЂБфЕУИќМђЕЅЁЃ |









