|

1
ТэСФ
КІГҙКЗөч¶И?НЁіЈЛщЛөөДөч¶И(schedule)КЗәНКұјдУР№ШөДЈ¬ұИИзОТҪсМмөДscheduleәЬҪф(ИзНј1ЛщКҫ)ЎЈКұјдЧчОӘОЁТ»өДІ»ҝЙДжЧӘөДЧКФҙЈ¬Т»°гКЗ»®·ЦОӘ¶аёцКұјдЖ¬АҙК№УГЎЈҫНјЖЛг»ъ¶шСФЈ¬УЙУЪCPUөДЛЩ¶ИҝмөД¶аЈ¬ЛщТФҫНУРБЛХл¶ФCPUКұјдЖ¬өДөч¶ИЈ¬ИГ¶аёцИООсФЪН¬Т»ёцCPUЙПФЛРРЖрАҙЎЈИ»¶шХвКЗТ»ёцјЩПуЈ¬ДіТ»КұҝМCPU»№КЗөҘИООсФЛРРөДЎЈ
Нј1 КұјдЖ¬өД»®·Ц
ОӘБЛФЪН¬Т»КұјдФЛРРёь¶аөДИООсЈ¬»тХЯ¶аёцҙҰАнЖчТ»Жр№ӨЧчНкіЙТ»ёцИООсДҝұкЈ¬ҫНРиТӘТ»ёцРӯөчХЯЎӘЎӘХвҫНіЙОӘТ»ёц·ЦІјКҪПөНіЈ¬ҫНөҘёцКэҫЭЦРРД»тХЯРЎ·¶О§АҙЛөЈ¬ХвҫНКЗјҜИәЎЈИз№ыИГТ»ёц·ЦІјКҪПөНіФЛРР¶аёцИООсЈ¬ГҝёцИООс¶Ф·ЦІјКҪПөНіЦРөДЧКФҙұШИ»ІъЙъҫәХщЈ¬Кұјдөч¶ИҫН·ўХ№өҪЧКФҙөч¶ИЎЈ
әк№ЫЙПАҙЛөөч¶ИЦчМв°ьАЁБЛөҘ»ъІЩЧчПөНіЎўC/SПөНіЎўB/SПөНіЎўP2PПөНіЎўјҜИәПөНіЎў·ЦІјКҪПөНіөИөИЈ¬ТФј°НшВзРӯТйХ»ЎўҙжҙўРӯТйХ»өДёчЦЦөч¶И»ъЦЖЎЈұҫОДЦчТӘЧЬҪбБЛјҜИәөч¶И·ўХ№өДИэёцҪЧ¶ОЈәәкөч¶ИЎўБҪІгөч¶ИәН№ІПнЧҙМ¬өч¶ИЈ¬ІўұИҪПБЛИэХЯЦ®јдөДУЕИұөгЎЈ
2 јҜИәөч¶И
2.1 әкөч¶И(Monolithic schedulers)
әкөч¶ИЈәФЪН¬Т»ёцҙъВлДЈҝйЦРКөПЦөч¶ИІЯВФЈ¬өҘёцКөАэЈ¬Г»УРІўРРЎЈіЈјыУЪHPC(high-performance
computing)КАҪзЦРЎЈ
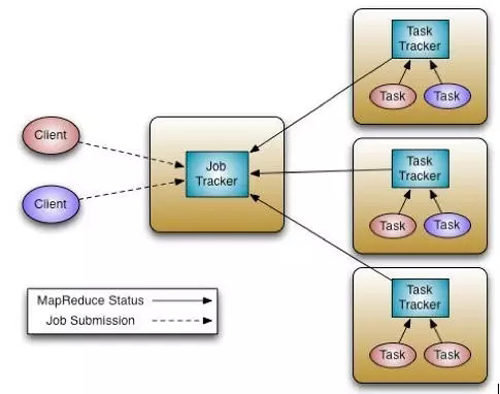
Нј2 Hadoop1әНMapReduce
өДәкөч¶ИјЬ№№
ИзНј2ЛщКҫЈ¬ТФОӘMapReduceОӘАэЈ¬Т»ёціЖЦ®ОӘJobTrackerөДMasterҪшіМКЗЛщУРMapReduceИООсөДЦРРДөч¶ИЖчЎЈГҝТ»ёцҪЪөгЙПГж¶јФЛРРТ»ёцTaskTrackerҪшіМАҙ№ЬАнёчёцҪЪөгЙПөДИООсЎЈёчёцTaskTrackerТӘәНMasterҪЪөгЙПөДJobTrackerНЁРЕІўҪУКЬJobTrackerөДҝШЦЖЎЈәНҙу¶аКэЧКФҙ№ЬАнЖчАаЛЖЈ¬MapReduceөДJobTrackerЦ§іЦБҪЦЦөч¶ИІЯВФЈ¬Capacityөч¶ИІЯВФәНFairөч¶ИІЯВФЎЈ
ФЪJobTrackerЦРЈ¬ЧКФҙөДөч¶ИәНЧчТөөД№ЬАн№ҰДЬИ«Іҝ·ЕөҪТ»ёцҪшіМЦРНкіЙЎЈХвЦЦЙијЖ·ҪКҪөДИұөгКЗА©Х№РФІоЈәКЧПИЈ¬јҜИә№жДЈКЬПЮ;ЖдҙОЈ¬РВөДөч¶ИІЯВФДСТФИЪИлПЦУРҙъВлЦРЈ¬ұИИзЦ®З°ҪцЦ§іЦЕъҙҰАнЧчТөЈ¬ПЦФЪТӘЦ§іЦБчКҪЧчТөЈ¬¶шҪ«БчКҪЧчТөөДөч¶ИІЯВФЗ¶ИлөҪЦРСлКҪөч¶ИЖчЦРКЗТ»ПоәЬДСөД№ӨЧчЎЈ
2.2 ҫІМ¬·ЦЗш(Statically partitioned schedulers)
»щУЪҫІМ¬·ЦЗшөДЧКФҙ»®·ЦәНөч¶ИТІұ»іЖОӘФЖјЖЛгЦРөДөч¶ИЈ¬НЁ№эФЪФЖЖҪМЁЦР·ЦЕдәН¶ЁТеРйДв»ъҪЗЙ«Ј¬КөПЦЧКФҙјҜәПөДИ«ГжҝШЦЖЎЈТөОсПөНіНщНщІҝКрФЪЧЁГЕөДЎўҫІМ¬»®·ЦөДјҜИәөДТ»ёцЧУјҜЙПЎӘЎӘ°СјҜИә»®·ЦОӘІ»Н¬өДІҝ·ЦЈ¬·ЦұрЦ§іЦІ»Н¬өДТөОсЎЈПЦФЪҙу¶аКэЖуТөј¶өДФЖјЖЛг¶јКЗІЙУГХвСщјЖ»®ҫӯјГКҪөДЧКФҙ·ЦЕд·ҪКҪЎӘЎӘФЪПөНіІҝКрЦ®З°ЧцәГИЭБҝ№ж»®әНЧКФҙ·ЦЕд
2.3 БҪІгөч¶И(Two-level scheduling)
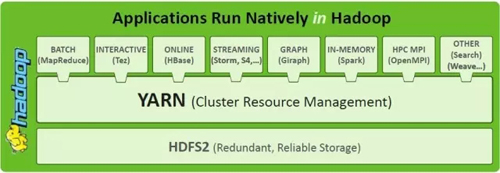
ОӘБЛҙҰАнәкөч¶ИәНјҜИәҫІМ¬·ЦЗшөДЦЦЦЦПЮЦЖЈ¬Т»ёцЦұҪУөДҪвҫц·Ҫ°ёҫНКЗБҪІгөч¶ИЎЈНЁ№эТэИлТ»ёцЦРСлөДРӯөчЧйјюАҙҫц¶ЁГҝТ»ёцЧУјҜИәРиТӘ·ЦЕдөДЧКФҙКэБҝЈ¬ҙУ¶ш¶ҜМ¬өДөчХы·ЦЕдёшГҝТ»ёцөч¶ИЖч(ҝтјЬөч¶ИЖч)өДЧКФҙЎЈБҪІгөч¶ИұҫЦКЙПКЗФЪөч¶ИЦР·ЦАлЧКФҙ·ЦЕдәНИООс·ЦЕдЈ¬ИГ¶ЙТ»Іҝ·ЦҫцІЯИЁБҰёшУҰУГҝтјЬЈ¬ҪвҫцІ»Н¬УҰУГҝтјЬөДРиЗуТм№№ОКМвЎЈИзНј3ЛщКҫЈ¬YARNОӘЙПІгІ»Н¬өДУҰУГҝтјЬМṩБЛНіТ»өДЧКФҙөч¶ИІгЎЈәуОД¶ФMesosөДҪйЙЬТ»ҪЪ»бПкПёҪйЙЬБҪІгөч¶ИөДРиЗуұіҫ°ЎЈ
Нј3 Hadoop1әНMapReduce өДәкөч¶ИјЬ№№
ёчёцҝтјЬөч¶ИЖчІўІ»ЦӘөАХыёцјҜИәЧКФҙК№УГЗйҝцЈ¬Ц»КЗұ»¶ҜөДҪУКХЧКФҙЎЈЦРСлРӯөчЧйјюҪцҪ«ҝЙУГөДЧКФҙНЖЛНёшёчёцҝтјЬЈ¬¶шҝтјЬЧФјәСЎФсК№УГ»№КЗҫЬҫшХвР©ЧКФҙЎЈТ»ө©ҝтјЬ(ұИИзJobTracker)ҪУКХөҪРВЧКФҙәуЈ¬ФЩҪшТ»ІҪҪ«ЧКФҙ·ЦЕдёшЖдДЪІҝөДёчёцУҰУГіМРт(ёчёцMapReduceЧчТө)Ј¬Ҫш¶шКөПЦЛ«Ігөч¶ИЎЈ
Л«Ігөч¶ИЖчУРБҪёцИұөгЈ¬ЖдТ»Ј¬ёчёцҝтјЬОЮ·ЁЦӘөАХыёцјҜИәөДКөКұЧКФҙК№УГЗйҝц;Жд¶юЈ¬ІЙУГұҜ№ЫЛшЈ¬Іў·ўБЈ¶ИРЎЎЈ
2.3.1 YARN
YARNұ»іЖЦ®ОӘApache Hadoop Next Generation Compute PlatformЈ¬КЗhadoop1әНhadoop2Ц®јдЧоҙуөДЗшұрИзНј4ЛщКҫЎЈ
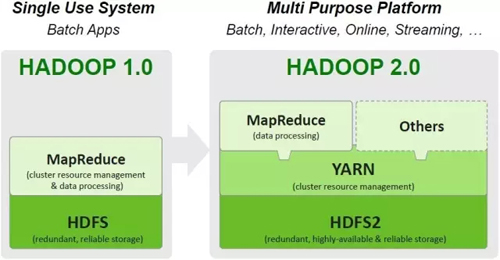
Нј4 ФЪHadoop 2.0ЦРТэИлYARN
Hadoop2(MRv2)өД»щҙЎЛјПлҫНКЗ°СJobTrackerөД№ҰДЬ»®·ЦіЙБҪёц¶АБўөДҪшіМЈәИ«ҫЦөДЧКФҙ№ЬАнResourceManagerәНГҝёцҪшіМөДјаҝШәНөч¶ИApplicationMasterЎЈХвёцҪшіМҝЙТФКЗMap-Reduce
ЦРТ»ёцИООс»тХЯКЗDAGЦРТ»ёцИООсЎЈ
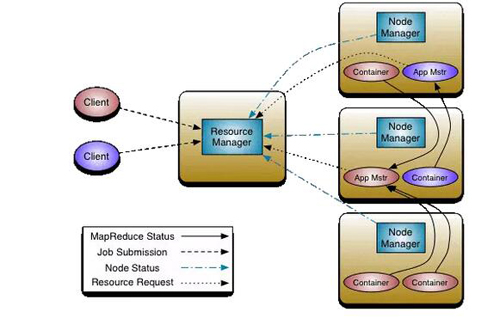
Нј5 ФЪHadoop 2.0ЦРТэИлYARN
ФЪYARNөДЙијЖЦРЈ¬јҜИәЦРҝЙТФУР¶аёцApplicationMastersЈ¬ГҝТ»ёцApplicationMastersҝЙТФУР¶аёцContainers
(АэИзЈ¬Нј5ЦРУРБҪёцApplicationMastersЈ¬әмЙ«әНА¶Й«ЎЈәмЙ«өДУРИэёцContainersЈ¬А¶Й«өДУРТ»ёцContainer)ЎЈ№ШјьөДТ»өгКЗApplicationMasters
І»КЗResourceManagerөДІҝ·ЦЈ¬ХвҫНјхЗбБЛЦРРДөч¶ИЖчөДС№БҰЈ¬ІўЗТЈ¬ГҝТ»ёцApplicationMasters¶јҝЙТФ¶ҜМ¬өДөчХыЧФјәҝШЦЖөДcontainerЎЈ
¶ш ResourceManager КЗТ»ёцҙҝҙвөДөч¶ИЖч(І»јаҝШәНЧ·ЧЩҪшіМөДЦҙРРЧҙМ¬Ј¬ТІІ»ёәФрЦШЖф№КХПөДҪшіМ)Ј¬ЛьОЁТ»өДДҝөДҫНКЗФЪ¶аёцУҰУГЦ®јд№ЬАнҝЙУГөДЧКФҙ(ТФContainersөДБЈ¶И)ЎЈResourceManagerКЗЧКФҙ·ЦЕдөДЦХј«ИЁНюЎЈИз№ыЛөResourceManagerКЗMasterЈ¬NodeManagerҫНКЗЖдslaveЎЈResourceManagerІўЗТЦ§іЦөч¶ИІЯВФөДІејю»ҜЈ¬CapacityScheduler
әН FairSchedulerҫНКЗХвСщөДІејюЎЈ
ApplicationMaster ёәФрИООсМбҪ»Ј¬НЁ№эРӯЙМәНМёЕРҙУResourceManagerДЗАпТФContainersөДРОКҪ»сөГЧКФҙ(ёәФрМёЕР»сөГККәПЖдУҰУГРиТӘөДContainers)ЎЈИ»әуҫНtrackҪшіМөДФЛРРЧҙМ¬ЎЈApplicationMastersКЗМШ¶ЁУЪҫЯМеөДУҰУГЈ¬ҝЙТФёщҫЭІ»Н¬өДУҰУГАҙұаРҙІ»Н¬өДApplicationMastersЎЈАэИзЈ¬Ў°YARN
includes a distributed Shell framework that runs a
shell script on multiple nodes on the cluster. Ўұ БнНвЈ¬ApplicationMaster
МṩЧФ¶ҜЦШЖфөД·юОсЎЈApplicationMasterҝЙТФАнҪвОӘУҰУГіМРтҝЙТФЧФјәКөПЦөДҪУҝЪҝвЎЈ
ApplicationMastersЗлЗуәН№ЬАнContainersЎЈContainersЦё¶ЁБЛТ»ёцУҰУГФЪДіТ»МЁЦч»ъЙПҝЙТФК№УГ¶аЙЩЧКФҙ
(°ьАЁmemory, CPUөИ) Ј¬ХвАаЛЖУЪHPCөч¶ИЦРөДЧКФҙіШЎЈApplicationMasterТ»ө©ҙУ
ResourceManagerДЗАп»сөГЧКФҙЈ¬ЛьҫН»бБӘПөNodeManager АҙЖф¶ҜДіёцМШ¶ЁөДИООсЎЈАэИзИз№ыК№УГ
MapReduce ҝтјЬЈ¬ХвР©ИООсҝЙДЬҫНКЗMapper әН Reducer ҪшіМЎЈІ»Н¬өДҝтјЬ»бУРІ»Н¬өДҪшіМЎЈ
NodeManagerКЗГҝТ»ёц»ъЖчЙПҝтјЬҙъАнЈ¬ёәФрёГ»ъЙПөДContainersЈ¬ІўЗТјаҝШҝЙУГөДЧКФҙ(CPU,
memory, disk, network)ЎЈІўЗТЧКФҙЧҙМ¬ұЁёжёшResourceManagerЎЈ
ұнГжЙПҝҙАҙЈ¬YARNТІКЗТ»ёцБҪІгөч¶ИЎЈФЪYARNЦРЈ¬ЧКФҙЗлЗуҙУApplication Masters·ўіцөҪТ»ёцЦРРДөДИ«ҫЦөч¶ИЖчЙПЈ¬ЦРРДөч¶ИЖчёщҫЭУҰУГөДРиТӘФЪјҜИәЦРөД¶аёцҪЪөгЙП·ЦЕдЧКФҙЎЈө«КЗYARNЦРөДApplication
MastersМṩөДҪцҪцКЗТ»ёцИООс№ЬАн·юОсЈ¬ІўІ»КЗТ»ёцХжХэөД¶юІгөч¶ИЖчЎЈТтҙЛұҫЦКЙПYARNИФҫЙКЗТ»ёцәкөч¶ИјЬ№№ЎЈҪШЦ№ДҝЗ°Ј¬YARNЦ»Ц§іЦЧКФҙАаРН(ДЪҙж)өДөч¶ИЎЈ
Hadoop2(MRv2)өДAPIКЗәуПтјжИЭөДЈ¬Ц§іЦMap-ReduceөДИООсЦ»РиТӘЦШРВұаТлТ»ПВҫНҝЙТФФЛРРФЪHadoop2(MRv2)ЙПЎЈ
2.3.2 Mesos
ҙуБҝ·ЦІјКҪјЖЛгҝтјЬ(Hadoop, Giraph, MPI, etc)өДіцПЦЈ¬ГҝТ»ёцјЖЛгҝтјЬРиТӘ№ЬАнЧФјәөДјЖЛгјҜИәЎЈХвР©јЖЛгҝтјЬНщНщ°СИООс·ЦёоіЙәЬ¶аРЎИООсЈ¬ИГјЖЛгҝҝҪьКэҫЭЈ¬ҙУ¶шҝЙТФМбёЯјҜИәөДАыУГВКЎЈө«КЗХвР©ҝтјЬ¶јКЗ¶АБўҝӘ·ўөДЈ¬І»ҝЙДЬФЪУҰУГҝтјЬЦ®јд№ІПнЧКФҙЎЈРОПуөДұнКҫИзНј6ЛщКҫЎЈ
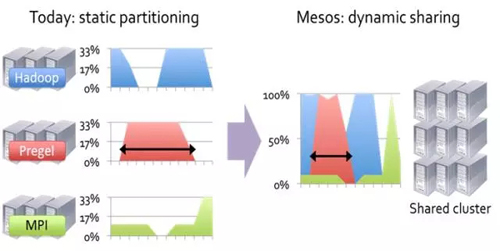
Нј6 јҜИәөДҫІМ¬·ЦЗшәН¶ҜМ¬№ІПн
ОТГЗПЈНыФЪН¬Т»ёцјҜИәЙПҝЙТФФЛРР¶аёцУҰУГҝтјЬЎЈ MesosКЗНЁ№эМṩһёцНЁУГЧКФҙ№ІПнІгЈ¬¶аёцІ»Н¬өДУҰУГҝтјЬҝЙТФФЛРРФЪХвёцЧКФҙ№ІПнІгЦ®ЙПЎЈРОПуөДұнКҫИзНј7ЛщКҫЎЈ

Нј7 MesosОӘІ»Н¬УҰУГҝтјЬМṩͳһөч¶ИҪУҝЪ
ө«ОТГЗІ»ПЈНыК№УГјтөҘөДҫІМ¬·ЦЗшөД·Ҫ·ЁЈ¬ИзНј8ЛщКҫЎЈ
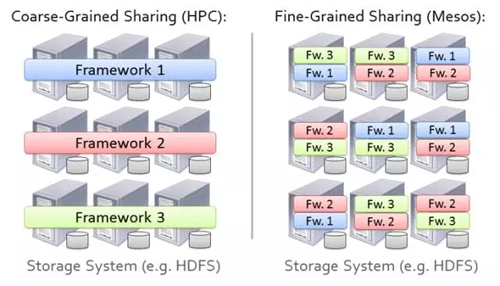
Нј8 јҜИәДЪҫІМ¬·ЦЗш
MesosөДУўОД¶ЁТеОӘЈәЎ° Mesos, which is an open source platform
for fine-grained resource sharing between multiple
diverse cluster computing frameworks.Ўұ
MesosЧоҙуөДәГҙҰҫНКЗМбёЯјҜИәөДАыУГВКЎЈҝЙТФәЬәГөДёфАлІъЖ·»·ҫіәНКөСй»·ҫіЈ¬ҝЙТФН¬КұІў·ўФЛРР¶аёцҝтјЬЎЈЖдҙОЈ¬ҝЙТФФЪ¶аёцјҜИәЦ®јд№ІПнКэҫЭЎЈөЪИэЈ¬ҝЙТФҪөөНО¬»ӨіЙұҫЎЈ
MesosЧоҙуМфХҪКЗИзәОЦ§іЦҙуБҝөДУҰУГҝтјЬЎЈТтОӘГҝТ»ёцҝтјЬ¶јУРІ»Н¬өДөч¶ИРиЗуЈәұаіМДЈРНЎўНЁРЕ·¶РНЎўИООсТААөәНКэҫЭ·ЕЦГЎЈБнНв
MesosөДөч¶ИПөНіРиТӘДЬ№»А©Х№өҪКэЗ§ёцҪЪөгЈ¬ФЛРРКэ°ЩНтёцИООсЎЈУЙУЪјҜИәЦРөДЛщУРИООс¶јТААөУЪ MesosЈ¬өч¶ИПөНіұШРлКЗИЭҙнәНёЯҝЙУГөДЎЈ
MesosөДЙијЖҫцІЯ(ЙијЖХЬС§)ЈәІ»ІЙУГЦРРД»ҜөДЈ¬ЙијЖЦЬИ«өД(УҰУГРиЗуЈ¬ҝЙУГЧКФҙЈ¬ЧйЦҜІЯВФ)Ј¬ККУГУЪЛщУРИООсөДИ«ҫЦөч¶ИІЯВФЎЈ¶шІЙУГОҜЕЙөч¶ИИООсёшУҰУГҝтјЬ(°Сөч¶ИәНЦҙРРөД№ҰДЬҪ»ёшУҰУГҝтјЬ)ЎЈ
MesosЙщіЖЈәХвСщөДЙијЖІЯВФҝЙДЬІ»»бҙпөҪИ«ҫЦЧоУЕөДөч¶ИЈ¬ө«ФЪКөјКФЛРРЦРіцЖжөДәГЈ¬ҝЙТФК№өГУҰУГҝтјЬҪьәхНкГАөДҙпөҪДҝұкЎЈЖдЙщіЖЦРөДУЕөгЦчТӘУРБҪёцЈәУҰУГҝтјЬөДСЭ»Ҝ¶АБўәНұЈіЦ
MesosөДјтҪаЎЈ
MesosөДЦчТӘЧйјю°ьАЁMaster daemonЈ¬Slave daemonsәНФЪslavesЦ®ЙПФЛРРөД
Mesos applications (ТІұ»іЖОӘ frameworks)(ИзНј9ЛщКҫ)ЎЈMasterёщҫЭПаУҰөДІЯВФ(№«ЖҪөч¶ИЈ¬УЕПИј¶өч¶ИөИ)ҫц¶ЁёшГҝТ»ёцУҰУГ·ЦЕд¶аЙЩЧКФҙЎЈДЈҝй»ҜјЬ№№Ц§іЦ¶аЦЦІЯВФЎЈResource
offerКЗЧКФҙөДійПуұнКҫЈ¬»щУЪёГЧКФҙЈ¬УҰУГҝтјЬҝЙТФФЪјҜИәЦРөДДіёцnodeЙПКөАэ»Ҝ·ЦЕдofferЈ¬ІўФЛРРИООсЎЈГҝТ»ёцResource
offer ҫНКЗТ»ёц·ЦІјФЪ¶аёцnodeЙПөДҝХПРЧКФҙБРұнЎЈMesos»щУЪТ»¶ЁөДЛг·ЁІЯВФ(И繫ЖҪөч¶И)ҫц¶ЁУР¶аЙЩЧКФҙҝЙТФ·ЦЕдёшУҰУГҝтјЬЈ¬¶шУҰУГҝтјЬҫц¶ЁК№УГ(ҪУКЬ)ДДР©ЧКФҙЈ¬ФЛРРДДР©ИООсЎЈMesosЙПФЛРРөДУҰУГҝтјЬУЙБҪІҝ·ЦЧйіЙЈәУҰУГөч¶ИЖчәНslaveЙПФЛРРҙъАнЎЈУҰУГөч¶ИЖчПт
MesosЧўІбЎЈMasterҫц¶ЁПтЧўІбөДҝтјЬМṩ¶аЙЩЧКФҙЈ¬УҰУГөч¶ИЖчҫц¶ЁMaster·ЦЕдөДЧКФҙЦРДДР©АҙК№УГЎЈөч¶ИНкіЙЦ®әуЈ¬УҰУГөч¶ИЖч°СҪУКЬөДЧКФҙ·ўЛНёш
MesosЈ¬ҙУ¶шҫц¶ЁБЛК№УГДДР©slaveЎЈИ»әуУҰУГҝтјЬЦРөДИООсөДЦҙРРҝЙТФФЪslaveЙПФЛРРЎЈөұИООсәЬРЎІўЗТКЗ¶МЖЪИООс(ГҝёцИООс¶јЖө·ұөДИГ¶ЙЧФјәОХЧЕөДЧКФҙөДКұ)Ј¬Mesos№ӨЧчөДәЬәГЎЈ
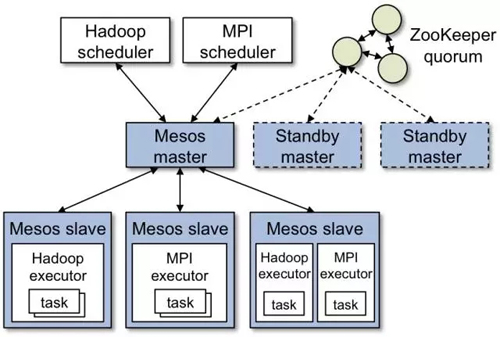
Нј9 Mesosөч¶ИҝтјЬ
ФЪ MesosЦРЈ¬Т»ёцЦРСлЧКФҙ·ЦЕдЖч¶ҜМ¬өД»®·ЦјҜИәЈ¬·ЦЕдЧКФҙёшІ»Н¬өДөч¶ИҝтјЬ(scheduler frameworks)ЎЈЧКФҙҝЙТФФЪІ»Н¬өДөч¶ИҝтјЬЦ®јдТФЎ°offersЎұөДРОКҪИОТв·ЦЕдЈ¬offersұнКҫБЛөұЗ°ҝЙУГөДЧКФҙЎЈЧКФҙ·ЦЕдЖчОӘБЛұЬГвІ»Н¬өч¶ИҝтјЬ¶ФН¬Т»ЧКФҙіеН»ЙкЗлЈ¬Ц»ФКРнТ»ҙОЦ»ДЬ·ЦЕдёшТ»ёцөч¶ИҝтјЬЎЈФЪөч¶ИҫцІЯөД№эіМЦРЈ¬ЧКФҙ·ЦЕдЖчКөЦКЙПЖрөҪБЛЛшөДЧчУГЎЈТтҙЛ
MesosЦРөДІў·ўөч¶ИКЗұҜ№ЫІЯВФөДЎЈ
MasterК№УГresource offer»ъЦЖФЪ¶аёцҝтјЬЦ®јдПёБЈ¶ИөД№ІПнЧКФҙЎЈГҝТ»ёцresource
offerҝХПРЧКФҙБРұнЈ¬·ЦІјФЪ¶аёцslaveЙПЎЈMasterҫц¶ЁёшГҝТ»ёцУҰУГҝтјЬМṩ¶аЙЩЧКФҙЈ¬ТАҫЭКЗ№«ЖҪ·Ҫ·Ё»тХЯУЕПИј¶·Ҫ·ЁЎЈөЪИэ·ўҝЙТФТФҝЙІе°ОДЈҝйөД·ҪКҪ¶ЁЦЖІЯВФЎЈ
Reject»ъЦЖЈәІө»Ш MesosМṩөДЧКФҙ·Ҫ°ёЎЈОӘБЛұЈіЦҪУҝЪөДјтөҘРФЈ¬ MesosІ»ФКРнУҰУГҝтјЬЦё¶ЁЧКФҙРиЗуөДПЮЦЖРЕПўЈ¬¶шКЗФКРнУҰУГҝтјЬҫЬҫш
MesosМṩөДЧКФҙ·Ҫ°ёЎЈУҰУГҝтјЬИз№ыУцөҪГ»УРВъЧгЖдРиЗуөДЧКФҙМṩ·Ҫ°ёЈ¬Фт»бҫЬҫшөИҙэЎЈ MesosЙщіЖҫЬҫш»ъЦЖҝЙТФЦ§іЦИОТвёҙФУөДЧКФҙПЮЦЖЈ¬Н¬КұұЈіЦА©Х№РФәНјтөҘЎЈ
Reject»ъЦЖҙшАҙөДТ»ёцОКМвКЗФЪУҰУГҝтјЬКХөҪТ»ёцВъЧгЖдРиЗуөД·Ҫ°ёЦ®З°ҝЙДЬРиТӘөИҙэәЬіӨКұјдЎЈУЙУЪІ»ЦӘөАУҰУГҝтјЬөДРиЗуЈ¬
MesosҝЙДЬ»б°СН¬Т»ёцЧКФҙ·Ҫ°ё·ўёш¶аёцУҰУГҝтјЬЎЈТтҙЛЈ¬ТэИлfliter»ъЦЖЈә MesosЦРөДТ»ёцөч¶ИҝтјЬК№УГfilterАҙГиКцЛьЖЪНыұ»·юОсөДЧКФҙАаРН(ФКРнУҰУГҝтјЬЙиЦГТ»ёцfilterұнКҫёГУҰУГҝтјЬ»бУАФ¶өДҫЬҫшДіАаЧКФҙ)ЎЈТтҙЛЈ¬ЛьІ»РиТӘ·ГОКХыёцјҜИәЈ¬ЛьЦ»РиТӘ·ГОКЛьұ»offerөДҪЪөгјҙҝЙЎЈХвЦЦІЯВФҙшАҙөДИұөгКЗІ»ДЬЦ§іЦ»щУЪХыёцјҜИәЧҙМ¬өДЗАХјәНІЯВФЈәТ»ёцөч¶ИҝтјЬІ»ЦӘөА·ЦЕдёшЖдЛыөч¶ИҝтјЬөДЧКФҙЎЈ
MesosМṩБЛТ»ЦЦЧКФҙҙўҙжөДІЯВФАҙЦ§іЦGangөч¶ИЎЈАэИзЈ¬УҰУГҝтјЬҝЙТФЦё¶ЁТ»ёцЖдҝЙТФФЛРРnode°ЧГыөҘБРұнЎЈХвІ»КЗ¶ҜМ¬өДјҜИә·ЦЗшВр?
MesosҪшТ»ІҪҪвКНfilter»ъЦЖЈәfilterЦ»КЗТ»ёцЧКФҙ·ЦЕдДЈРНөДРФДЬУЕ»Ҝ·Ҫ°ёЈ¬УҰУГҝтјЬУРДДР©ИООсФЛРРФЪДДР©nodeЙПЧоЦХҫц¶ЁИЁЎЈ
Нј10 Mesosөч¶ИБчіМ
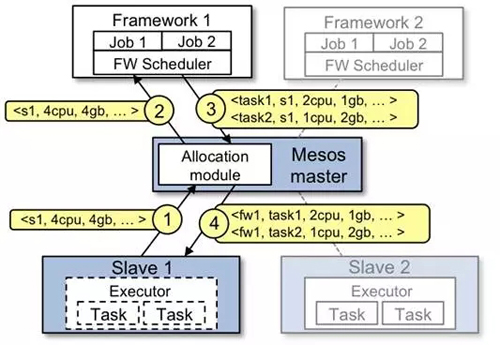
MesosИООсөч¶И№эіМИзНј10ЛщКҫЈ¬ҫЯМеБчіМИзПВЈә
Slave 1 ПтMaster»гұЁЛьУР4ёцCPUs әН 4 GBөДҝХПРДЪҙжЈ¬Master өДallocationДЈҝй»бёщҫЭПаУҰөД·ЦЕдІЯВФНЁЦӘframework
1 ҝЙТФК№УГЛщУРҝЙУГЧКФҙЎЈ
Master°Сslave 1ЙПөДҝЙУГЧКФҙ·ўЛНёшframework 1(ТФresource offerөД·ҪКҪ)ЎЈ
frameworkөДөч¶ИЖчПмУҰMasterөч¶ИЖчЈәЧјұёФЪslaveЙПФЛРРБҪёцИООсЈ¬К№УГөДЧКФҙ·ЦұрКЗЈәөЪТ»ёцИООс<2
CPUs, 1 GB RAM> Ј¬өЪ¶юёцИООс <1 CPUs, 2 GB RAM>
ЎЈ
ЧоәуЈ¬Master°СИООс·ўЛНёшslaveЈ¬И»әу°СПаУҰөДЧКФҙ·ЦЕдёшframeworkөДЦҙРРЖчЎЈИ»әуЦҙРРЖчЖф¶ҜБҪёцИООсЎЈУЙУЪslave1ЙП»№УР1
CPU әН1 GBөДДЪҙжГ»УР·ЦЕдЈ¬·ЦЕдДЈҝйҝЙТФ°СЧКФҙ·ЦЕдёшframework 2ЎЈ
БнНвЈ¬Mesos MasterөДAllocation moduleКЗpluggableЎЈК№УГZooKeeper
АҙКөПЦ Mesos MasterөДFailoverЎЈ
2.4 ЧҙМ¬№ІПнөч¶И(Shared-state scheduling)
ФЪЧҙМ¬№ІПнөч¶ИЦРЈ¬ГҝТ»ёцөч¶ИЖч¶јҝЙТФ·ГОКХыёцјҜИәЧҙМ¬ЎЈөұ¶аёцөч¶ИЖчН¬КұёьРВјҜИәЧҙМ¬КұК№УГАЦ№ЫІў·ўҝШЦЖЎЈShared-stateөч¶ИҝЙТФҪвҫцБҪІгөч¶ИөДБҪёцОКМвЈәұҜ№ЫІў·ўҝШЦЖЛщҙшАҙөДІўРРПЮЦЖәНөч¶ИҝтјЬ¶ФХыёцјҜИәЧКФҙөДҝЙјыРФЎЈАЦ№ЫІў·ўҝШЦЖЛщҙшАҙөДОКМвКЗөұАЦ№ЫјЩЙиІ»іЙБўКұЈ¬РиТӘЦШРВөч¶ИЎЈ
ОӘБЛҝЛ·юЛ«Ігөч¶ИЖчөДТФЙПБҪёцИұөг(Omega paperЦчТӘ№ШЧўБЛХвёцОКМв)Ј¬GoogleҝӘ·ўБЛПВТ»ҙъЧКФҙ№ЬАнПөНіOmegaЈ¬OmegaКЗТ»ЦЦ»щУЪ№ІПнЧҙМ¬өДөч¶ИЖчЈ¬ёГөч¶ИЖчҪ«Л«Ігөч¶ИЖчЦРөДјҜЦРКҪЧКФҙөч¶ИДЈҝйјт»ҜіЙБЛТ»Р©іЦҫГ»ҜөД№ІПнКэҫЭ(ЧҙМ¬)әНХл¶ФХвР©КэҫЭөДСйЦӨҙъВлЈ¬¶шХвАпөДЎ°№ІПнКэҫЭЎұКөјКЙПҫНКЗХыёцјҜИәөДКөКұЧКФҙК№УГРЕПўЎЈТ»ө©ТэИл№ІПнКэҫЭә󣬹ІПнКэҫЭөДІў·ў·ГОК·ҪКҪҫНіЙОӘёГПөНіЙијЖөДәЛРДЈ¬¶шOmegaФтІЙУГБЛҙ«НіКэҫЭҝвЦР»щУЪ¶а°жұҫөДІў·ў·ГОКҝШЦЖ·ҪКҪ(ТІіЖОӘЎ°АЦ№ЫЛшЎұ,
MVCC, Multi-Version Concurrency Control)Ј¬ХвҙуҙуМбЙэБЛOmegaөДІў·ўРФЎЈФЪOmegaЦРГ»УРЦРРДөДЧКФҙ·ЦЕдЖчЈ¬өч¶ИЖчЧФјәЧціцЧКФҙ·ЦЕдөДҫцІЯЎЈ
2.4.1 Omega
әкөч¶ИөДИұөгКЗДСТФФцјУөч¶ИІЯВФәНЧЁГЕөДКөПЦЈ¬ІўЗТІ»ДЬЛжЧЕјҜИәөДА©Х№¶шА©Х№ЎЈБҪІгөч¶ИИ·КөҝЙТФМṩБй»оРФәНІўРРРФЈ¬ө«КЗФЪКөјщЦРЛыГЗөДЧКФҙҝЙјыРФИҙКЗұЈКШөДЈ¬ДСТФККУҰТ»Р©МфМЮРНөДИООсәНТ»Р©РиТӘ·ГОКХыёцјҜИәЧКФҙөДИООсЎЈOmegaөДҪвҫц·Ҫ°ёКЗМбіцБЛТ»ёцРВөДІўРРөч¶ИҝтјЬЈә»щУЪ№ІПнЧҙМ¬өДЎўОЮЛшөДЎўАЦ№ЫІў·ўҝШЦЖЈ¬ҝЙА©Х№өДЎЈ
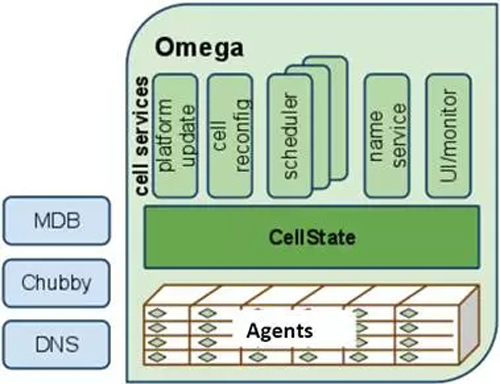
ИзНј11ЛщКҫЈ¬OmegaЦРГ»УРЦРРДөДЧКФҙ·ЦЕдЖчЈ¬ЛщУРөДЧКФҙ·ЦЕдҫцІЯ¶јКЗУЙУҰУГөДөч¶ИЖчЧФјәНкіЙөДЎЈOmegaО¬»ӨБЛТ»ёціЙОӘcell
stateөДЧКФҙ·ЦЕдЧҙМ¬РЕПўЦчҝҪұҙЎЈГҝТ»ёцУҰУГөДөч¶ИЖч¶јО¬»ӨБЛТ»ёцұҫөШЛҪУРөДЈ¬Жө·ұёьРВөДcell stateҝҪұҙЈ¬УГАҙЧцөч¶ИҫцІЯЎЈөч¶ИЖчҝЙТФҝҙөҪИ«ҫЦөДЛщУРЧКФҙЈ¬ІўёщҫЭИЁПЮәНУЕПИј¶АҙЧФТФОӘКЗөДТӘЗуРиТӘөДЧКФҙЎЈөұөч¶ИЖчҫц¶ЁЧКФҙ·Ҫ°ёКұЈ¬ТФФӯЧУөД·ҪКҪёьРВ№ІПнөДcell
stateЈәҙу¶аКэКұәтХвСщcommitҪ«»біЙ№Ұ(ХвҫНКЗАЦ№Ы·Ҫ·Ё)ЎЈөұіеН»·ўЙъКұЈ¬өч¶ИҫцІЯҪ«»бТФКВОсөД·ҪКҪК§°ЬЎЈОЮВЫөч¶ИіЙ№Ұ»№КЗК§°ЬЈ¬өч¶ИЖч¶ј»бЦШРВН¬ІҪұҫөШөДcell
stateәН№ІПнөДcell stateЎЈИ»әуЈ¬Из№ыРиТӘЈ¬ЦШЖфөч¶И№эіМЎЈ
OmegaөДөч¶ИЖчНкИ«КЗІўРРөДЈ¬І»РиТӘөИҙэЖдЛыөч¶ИЖчЎЈОӘБЛұЬГвіеН»ФміЙөДјў¶цЈ¬Omegaөч¶ИЖчК№УГФцБҝөч¶ИЎӘЎӘAccept
all but the conflict thingsЈ¬ХвСщҝЙТФұЬГвЧКФҙ¶Ъ»эЎЈИз№ыК№УГall or
nothing өДІЯВФҝЙТФК№УГGangөч¶И(Either all tasks of a job are
scheduled together, or none are, and the scheduler
must try to schedule the entire job again.)ЎЈGangөч¶ИТӘөИҙэЛщУРЧКФҙҫНРчЈ¬ІЕcommitХыёцИООсЈ¬ҫНФміЙБЛЧКФҙ¶Ъ»эЎЈ
ГҝТ»ёцУҰУГөч¶ИЖч¶јҝЙТФКөПЦЧФјәөДөч¶ИІЯВФЎЈө«КЗЛьГЗұШРлҫНЧКФҙ·ЦЕдәНИООсөДУЕПИј¶ҙпіЙТ»ЦВЎЈБҪІгөч¶ИөДЦРРДЧКФҙ№ЬАнЖчҝЙТФЗбЛЙКөПЦХвТ»өгЎЈХвКЗТ»ёцҝӘ·ЕөД»°МвЈ¬ҝЙТФҪшТ»ІҪМЦВЫЈәGoogleИПОӘ№«ЖҪРФІ»КЗТ»ёц№ШјьРиЗуЈ¬ёчёцөч¶ИЖчЦ»КЗВъЧгЧФјәөДТөОсРиЗуЎЈТтҙЛЈ¬ПЮЦЖГҝТ»ёцУҰУГөч¶ИЖчөДЧКФҙЙППЮәНИООсМбҪ»ЙППЮЎЈ
Нј11 Omegaөч¶ИҝтјЬ
2.4 ¶ФұИ·ЦОц
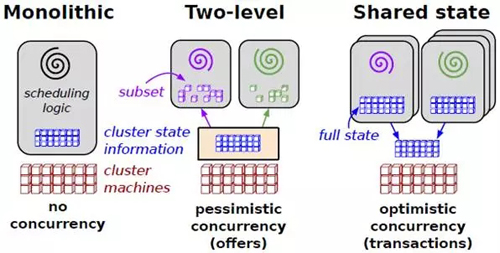
јҜИәөч¶ИөДЦчТӘДҝұкКЗМбёЯјҜИәөДАыУГВКәНК№УГР§ВКЎЈИзНј12ЛщКҫОӘИэЦЦөч¶И·ҪКҪЎЈИзНј13ЛщКҫОӘИэЦЦөч¶И·ҪКҪЎЈ
Нј12 ИэЦЦөч¶И·ҪКҪөД¶ФұИ
әкөч¶И(Monolithic schedulers)ОӘЛщУРИООс¶јК№УГТ»ёцЦРРДөч¶ИЛг·ЁЎЈЖдИұөгКЗІ»ТЧФцјУРВөДөч¶ИІЯВФЈ¬ТІІ»ДЬЛжЧЕјҜИәөДА©Х№¶шА©Х№ЎЈ
БҪІгөч¶И(Two-level schedulers)ұҫЦКЙПКЗФЪөч¶ИЦР·ЦАлЧКФҙ·ЦЕдәНИООс·ЦЕдЎЈК№УГТ»ёц¶ҜМ¬ЧКФҙ№ЬАнЖчМṩјЖЛгЧКФҙ»тХЯҙжҙўЧКФҙёш¶аёцІўРРөДөч¶ИҝтјЬЎЈГҝТ»ёцөч¶ИҝтјЬЛщУөУРөД¶јКЗТ»ёцХыёцЧКФҙөДТ»ёцЧУјҜЎЈОӘКІГҙКЗТ»ёц¶ҜМ¬ЧКФҙ№ЬАнЖчДШ?КЗПа¶ФУЪҫІМ¬өДјҜИә·ЦЗшАҙЛөөДЎЈОТГЗҝЙТФҫІМ¬өД°СјҜИә·ЦОӘјёёцЗшЈ¬·Цұр·юОсУЪІ»Н¬өДУҰУГЎЈЙПГжөД¶ҜМ¬ЧКФҙ№ЬАнЖчНкіЙ№ӨЧчҫНКЗ°СҫІМ¬өД·ЦЗш№ӨЧч¶ҜМ¬»ҜЎЈУЙУЪБҪІгөч¶ИОЮ·ЁҙҰАнДСТФөч¶ИөДМфМЮИООсЈ¬ЗТІ»ДЬёщҫЭХыёцјҜИәөДЧҙМ¬ЧціцҫцІЯЈ¬GoogleТэИл№ІПнЧҙМ¬өч¶ИјЬ№№ЎЈ
№ІПнЧҙМ¬өч¶И(Shared state schedulers)К№УГОЮЛшөДАЦ№ЫІў·ўҝШЦЖЛг·ЁЎЈOmega,GoogleөДПВТ»ҙъөч¶ИПөНіЦРК№УГБЛёГјЬ№№ЎЈДЗГҙ¶ФұИЖрАҙЈ¬БҪІгөч¶И(Two-level
schedulers)ұҫЦКЙПКЗұҜ№Ыөч¶ИЛг·ЁЎЈ
ФЪOmegaҝҙАҙЈ¬ MesosөДoffer өД»ъЦЖұҫЦКЙПКЗТ»ёц¶ҜМ¬өД№эВЛ»ъЦЖЈ¬ХвСщ Mesos MasterПтУҰУГҝтјЬМṩөДЦ»КЗТ»ёцЧКФҙіШөДЧУјҜЎЈөұИ»ҝЙТФ°СХвёцЧУјҜА©ҙуОӘТ»ёцИ«јҜЈ¬ТІҫНКЗShare
stateөДЈ¬ө«ЖдҪУҝЪТАИ»КЗұҜ№ЫІЯВФөДЎЈ
ФЪOmegaҝҙАҙЈ¬YARNЦРөДApplication MastersМṩөДҪцҪцКЗТ»ёцИООс№ЬАн·юОсЈ¬ІўІ»КЗТ»ёцХжХэөД¶юІгөч¶ИЖчЎЈЖдҙОЈ¬өҪДҝЗ°ОӘЦ№Ј¬YARNЦ»Ц§іЦТ»ЦЦЧКФҙАаРНЎЈБнНвЈ¬ҫЎ№ЬYARNЦРөДApplication
MastersҝЙТФЗлЗуТ»ёцМШ¶ЁҪЪөгөДЧКФҙЈ¬ө«КЗЖдҫЯМеІЯВФКЗІ»ЗеОъөДЎЈ
Нј13ЛщКҫјёЦЦөч¶ИІЯВФөД¶ФұИЈә

Нј13 өч¶ИІЯВФөД¶ФұИ(°ьә¬ҫІМ¬·ЦЗш)
3ПВТ»ІҪ№ӨЧч
јҜИәөч¶ИјјКхИФФЪ·ўХ№Ц®ЦРЈ¬OSDI 16Ҫ«»б·ўІјТ»Р©ЧоРВөД№ШУЪөч¶ИөДОДХВЈ¬°ьАЁGoogleөДRapid:Fast,
Centralized Cluster Scheduling at ScaleЈ¬әуГж»бЦ§іЦ№ШЧўЎЈЧКФҙёРЦӘөч¶ИЎЈАыУГ»ъЖчС§П°ҙУАъК·ёәФШұд»ҜЦРФӨІвЧКФҙРиЗуДЈРНЈ¬ОӘөч¶ИҫцІЯМṩТАҫЭЎЈ |









