ЬєеН
ИпПЩгУМмЙЙНЈЩшЕФ
СїСПгывЕЮёИДдгад
КЮЮЊИпПЩгУЃПддђгаШ§ЃКЙЪеЯМрВтгыХХГ§ЁЂЯћГ§ДяЕуЙЪеЯЃЌЛЅБИКЭШнджЁЃДѓСїСПЭјеОЕФМмЙЙНЈЩшзюживЊЕФЬєеНРДздЁАСїСПЁБгыЁАвЕЮёИДдгадЁБСНЗНУцЃК
СїСПЁЃИпПЩгУМмЙЙЪзвЊгІЖдЕФЪЧДѓСїСПЧвБфЖЏИДдгГЁОАЯТЕФПЩгУадЮЪЬтЁЃЙЪдкНЈЩшЙ§ГЬжаЃЌМмЙЙашвЊОпБИИпЩьЫѕадЃЌФмЪЕЯжПьЫйРЉеЙЁЃЖСCacheвВЪЧНтОіДѓСїСПДјРДТщЗГЕФЪжЖЮЁЃ
вЕЮёИДдгадЁЃгкЭјеОЖјбдЃЌвЕЮёИДдгадБШСїСПДјРДЕФЬєеНвЊДѓЃЌвђГ§ММЪѕадЮЪЬтЃЌЛЙЩцМАШЫЕФвђЫиЁЃШчећИівЕЮёСїГЬУЛОЙ§КмКУЕФећРэЃЌКѓајЛсДјРДЗБЖрЧвИДдгЕФЮЪЬтЁЃ
дкЭјеОНЈЩшЙ§ГЬжаЃЌвЛЗНУцМмЙЙЩЯвЊзіЕНЗжВМЪНЛЏЃЌвЕЮёЙІФмгђвЊзіЕНЗўЮёЛЏЃЌетбљПЩвдБЃжЄМмЙЙЕФИпПЩгУЁЂИпЩьЫѕадЁЃСэвЛЗНУцвЕЮёМмЙЙгызщжЏМмЙЙвЊЯрЦЅХфЃЌЭјеОСїСПж№НЅдіДѓЕФЭЌЪБзщжЏМмЙЙгывЕЮёМмЙЙвЊЫцжЎБфЛЏЃЌЯрЛЅЦЅХфЁЃ
ЗДжЎЃЌШчдквЕЮёЗЂеЙЙ§ГЬжаЃЌзіЯЕЭГБфИќЛсДјРДвЛЯЕСаЮЪЬтЁЃШчПЊЗЂКЭЗЂВМаЇТЪЛсвђаДТыЗчИёКЭЗЂВМЦЕТЪЃЈМйЩшЫљгавЕЮёаДЕНЭЌвЛЯЕЭГЃЉЪмЕНгАЯьЃЛЮЪЬтХХВщевВЛЕНЖдгІЕФИКд№ШЫЕШЁЃ
ЪЕМљ
ЙЪеЯМьВтгыХХГ§ЁЂЗжВМЪНЗўЮёЛЏИФдьКЭДѓСїСПЯЕЭГИпПЩгУЕќДњ
2011 ФъЃЌЬдБІ PV ДІгкДг 1 вкЕН 10 вкЕФ PV НзЖЮЃЌЯЕЭГадФмГЩЮЊзюДѓЬєеНЁЃеыЖдДѓСїСПЯЕЭГЩшМЦИпПЩгУЕФОВЬЌЛЏЗНАИЃЌгІгУдкЯъЧщЁЂЙКЮяГЕвдМАУыЩБЯЕЭГжаЃЛВЮгыЫЋ11ДѓДйЪБЃЌНЛвзШЋСДТЗНјаагХЛЏЃЌетаЉОбщдкЕЮЕЮвВЕУЕНСЫгІгУЪЕМљЁЃжївЊЮЊвдЯТШ§ЗНУцЃК
еыЖдЙЪеЯМьВтЃЌзіСЫШЋЦНЬЈбЙВт
еыЖдвЕЮёПьЫйдіГЄЧщПіЃЌЖдЯЕЭГзіЗжВМЪНЗўЮёЛЏИФдь
ДѓСїСПЯЕЭГИпПЩгУЕќДњ
ЙЪеЯМьВтгыХХГ§ЁЊЁЊШЋЦНЬЈВтбЙ
бЙВтЪЧШЋвЕЮёЃЌШЋСїГЬЕФбЙВтЁЃдке§ГЃЧщПіЯТжЦдьЯпЩЯЯЕЭГЕФЯпЩЯСїСПЃЌвВОЭЪЧздМКРДЙЅЛїздМКЯЕЭГЃЌСїСППЩздПиЁЃ
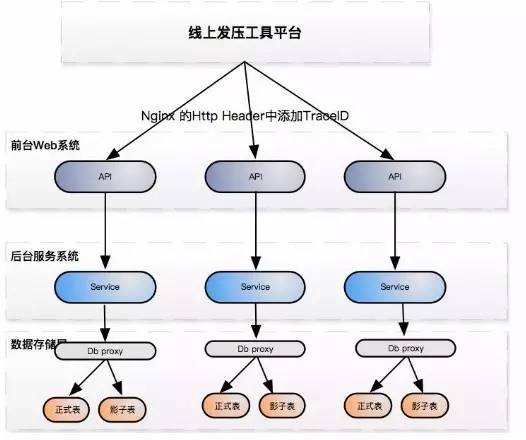
ВњЩњСїСПЕФЯпЩЯЗЂбЙЦНЬЈ
ШчЩЯЭМЃЌЪЧВњЩњСїСПЕФЯпЩЯЗЂбЙЦНЬЈЁЃКЭЬдБІфЏРРФГИіЩЬЦЗааЮЊЯрБШЃЌЕЮЕЮСїСПЗЂЦ№НЯИДдгЃЌЩцМАЪБМфЁЂЕиРэЮЛжУЕШЖрЮЌЖШЁЃ
ЦНЬЈгаЧАЬЈ Web ЯЕЭГЁЂКѓЬЈЗўЮёЯЕЭГКЭЪ§ОнДцДЂШ§ВуЁЃдкВтбЙЙ§ГЬжаЃЌгіЕНвЛаЉЮЪЬтЁЃШчЃК
ВтЪдЪ§ОнКЭЯпЩЯЪ§ОнШчКЮЧјЗжПЊЃП
ддђЩЯЪЧПЩаДдквЛЦ№ЃЌЕЋЮЊБмУтДјРДЮЪЬтЃЌетРязіСЫКЭе§ЪНБэвЛбљЕФгАзгБэЃЌЭЌПтВЛЭЌБэЁЃ
дѕбљЪЖБ№ЪЧдкзібЙВтЃП
гУ Trace РДДЋЕнБъЪЖЃЌЭЈЙ§жаМфМўДЋЕнЃЌжаМфМўВЛЭъЩЦвВПЩЭЈЙ§ВЮЪ§РДзіЁЃ
гЩгкЕЮЕЮЕФЪ§ОнКЭвЛАуЪ§ОнДцдкВювьЃЌШЋЦНЬЈбЙВтЪ§ОнЙЙдьвЊзіЬиЪтДІРэЁЃЗЂЕЅЪБВњЩњЕФЕБЧАЮЛжУЁЂФПЕФЕиЕШЪ§ОнЖМЛсЛиДЋЯЕЭГЁЃетРяЛсГіЯжзјБъЮЪЬтЃЌШчгУецЪЕзјБъЛсИЩШХЯпЩЯФГаЉвђЫиЁЃ
ЙЪАбзјБъЦЋвЦЕНЬЋЦНбѓЃЌФЃФтЖЫЃЌАбОЋЖШЁЂЮГЖШЕШвВзіЦЋвЦЁЃащФтГЫПЭКЭЫОЛњЃЌзі ID ЦЋвЦЁЂЪжЛњКХЬцЛЛЁЃ
ШчЯТЖМЪЧдкзіШЋЦНЬЈВтбЙЪБЃЌЗЂЯжЕФЮЪЬтЃК
вЕЮёЯп
ЫГЗчГЕЃКНгПкКФЪБдіГЄЃЌШчСаБэвГУцЃК100ms => 700ms
ЫГЗчГЕЃКШежОЫбМЏЕФЩЯДЋЗўЮёКЛЫР
зЈПьЃКХЩЕЅЗУЮЪЛКДцГіЯжГЌЪБ
ГізтГЕЃКЛёШЁЫОЛњНгПкДЅЗЂЯоСї
ГізтГЕЃКХЩЕЅЕЅЬѕШежОСПЬЋДѓгАЯьадФм
ЛљДЁЦНЬЈ
NATЃК2ЬЈNATЦєЖЏЮогУЕФФкКЫФЃПщЃЌСїСПДѓЪБДѓСПЖЊАќ
LBSЃКЮЛжУЗўЮёаДШыГЌЪБЃЌВщжмБпНгПкгаГЌЪБ
ЕиЭМЃКТЗОЖЙцЛЎЗўЮёЃЌЕНДяШнСПЦПОБ
бЙВтЙЄОпЕМжТЕФЦфЫћЮЪЬт
зЈПьМЦЫуГЌЪБЃКгЩгкЙЄОпЮЪЬтЃЌЫОЛњКЭЖЉЕЅЖИдіЃЌkmЫуЗЈГЌЪБЃЌжївЊЪЧШежОЙ§ЖрЕМжТЕФЁЃ
ЗжВМЪНИФдь
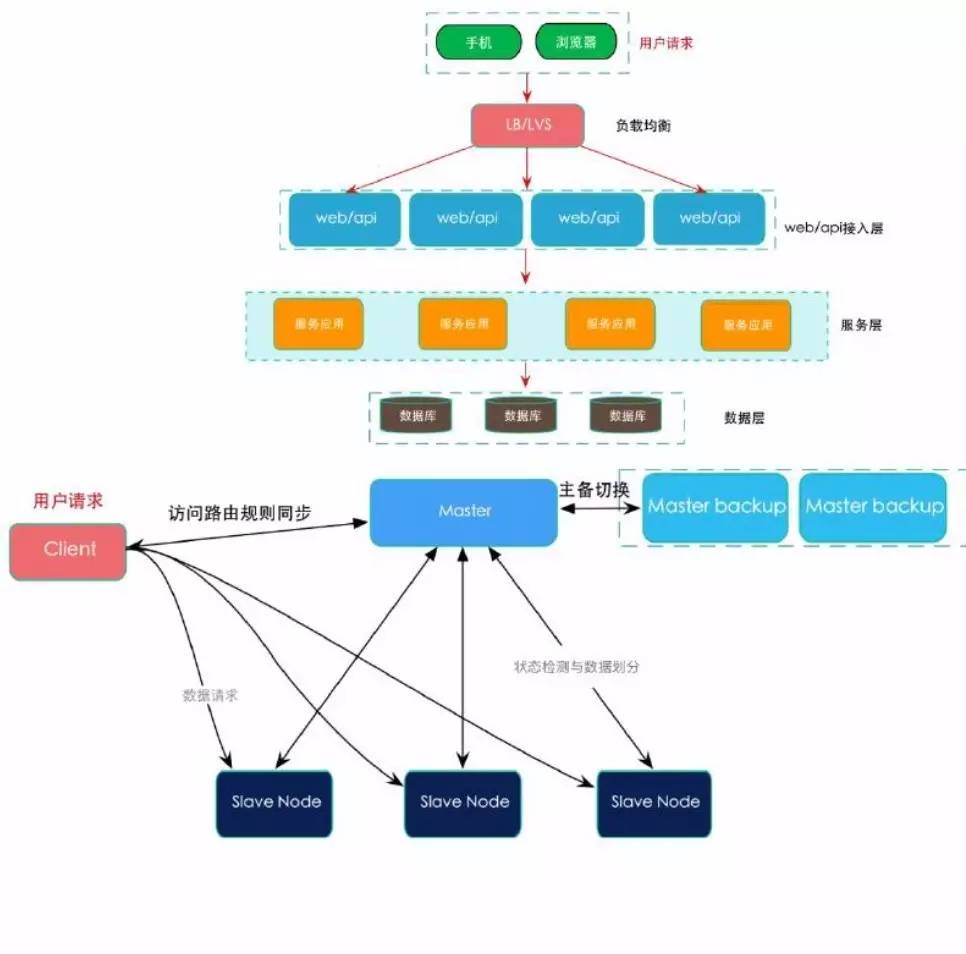
ЕфаЭЕФЗжВМЪНМмЙЙ
ЩЯЭМЪЧЕфаЭЕФЗжВМЪНМмЙЙЁЃзюживЊЕФНгШыВуКЭЗўЮёВувЊзіЕНЗўЮёЕФЮозДЬЌЛЏЃЌУПИіНкЕуЖМашЖдЕШЃЌвђЮЊетСНВужївЊзіЖСЧыЧѓЧвЧыЧѓСПНЯДѓЁЃзіЮозДЬЌЛЏЪЧБугкКсЯђРЉеЙЃЌЕБвЕЮёСПДѓЪБЃЌОЭПЩбИЫйВПЪ№ЛњЦїРДжЇГХСїСПЁЃ
Ъ§ОнВуДѓВПЗжЧщПіЯТЖМЪЧгазДЬЌЕФЃЌашНтОіЕФЪЧШпгрКЭБИЗнЃЌMySQL вЊзіДцПтЃЌФмЖСаДЗжРыЃЌФмзіЙЪеЯЧаЛЛЁЃ
ЗжВМЪНИФдьЙиМќЕФММЪѕЕугаШ§ЃК
ЗжВМЪН RPC ПђМмЃКжївЊНтОіЯЕЭГадЙиСЊЮЪЬтЃЌОЭЪЧЯЕЭГВ№ЗжЃЌБиаывЊНтОіЯЕЭГжЎМфЕФЭЌВНСЌНгЮЪЬтЃЛ
ЗжВМЪНЯћЯЂПђМмЃКжївЊНтОіЯЕЭГМфЕФЪ§ОнЙиСЊадЃЌетЪЧвьВНЕФЃЌгыRPCЭЌВНЕїгУЛЅВЙЃЛ
ЗжВМЪНХфжУПђМмЃКжївЊНтОізДЬЌЮЪЬтЃЌЪЕМЪгІгУжаНгШыВуКЭЗўЮёВувВЪЧгазДЬЌЕФЃЌзюКУзіЕНЮозДЬЌЁЃвђЮЊУПИіЛњЦїПЩФмДцдкВювьЃЌЙЪвЊЭЈЙ§жаМфМўЃЌАбВювьадЗХЕНХфжУПђМмжаНтОіЁЃ
ШЅФъЃЌЕЮЕЮзіСЫЗўЮёжЮРэЯрЙиЕФЪТЁЃШчЯТЭМЃЌЪЧдчЦкЕФЕЮЕЮЯЕЭГМмЙЙЃЌrouter НгЪмВуЃЌЕН inrouter
ЩЯВуЃЌжаМфгав§ШыДњТыЁЃЯТУцЪЧ RedisЃЌБОЩэЪЧИіДњРэЁЃ
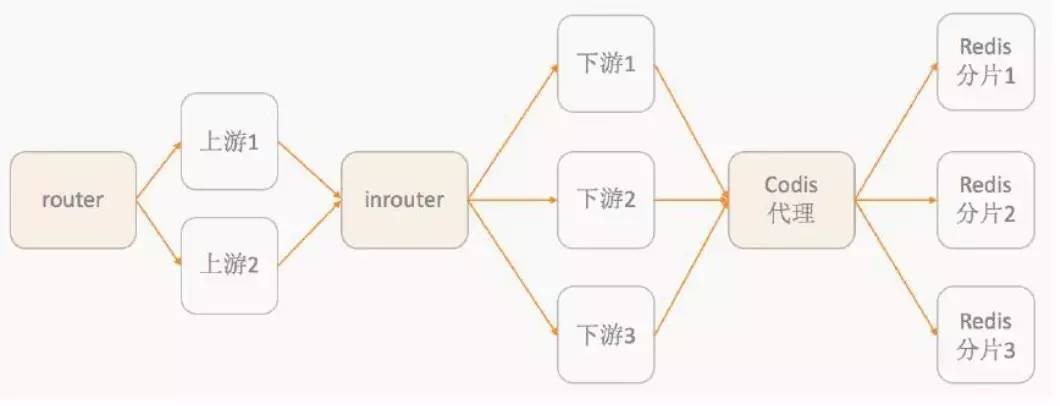
дчЦкЕФЕЮЕЮЯЕЭГМмЙЙ
етРяДцдкЕФЮЪЬтЃК
ЩЯЯТгЮвРРЕгВБрТыдкДњТыРяЃЛ
УЛгаЪЙгУ inrouter/tgw ЕФ ipЃКPortЃЛ
еЊГ§КЭРЉШнашвЊДњТыжиаТЩЯЯпЃЌinrouter гаЭјТчСДТЗЮШЖЈадвўЛМЃЌвдМАаЇТЪЩЯЕФЫ№ЪЇЃЛ
УЛгаЧхЮњЕФЗўЮёФПТМЃЌAPI ЮФЕЕвдМА SLA КЭМрПиЁЃ
ЗжВМЪН RPC ПђМмЭМ
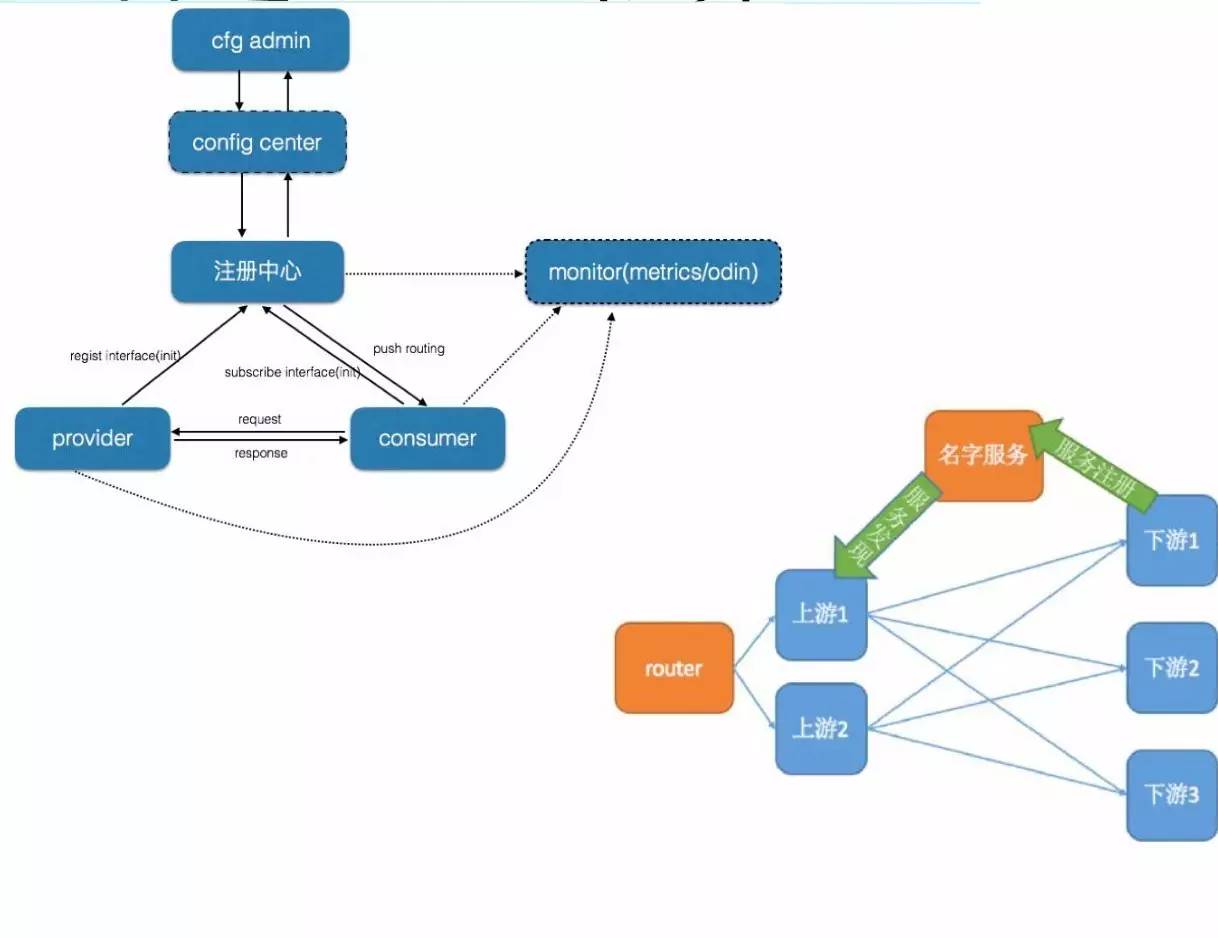
ФПБъЪЧАбвЛаЉЗўЮёжЎМфЕФЕїгУФмЙЛЭЈЙ§ЙцЗЖЛЏЗНЪНДЎСЊЦ№РДЁЃЩЯЯТгЮЭЈЙ§УћзжЗўЮёЃЌДгЩЯгЮКЭЯТгЮЖЫПкНтёюЃЌУћзжЗўЮёашвЊдкШЋЙЋЫОЭГвЛЧвУћзжЮЈвЛЁЃ
Naming ЗўЮёОЭЪЧзіЗўЮёУќУћЃЌЗўЮёзЂВсКЭЗЂЯжЃЌЕНзЂВсжааФ
RPCЭЈЕРЃЌВПЪ№ЫНгаавщЃЌОпБИПЩРЉеЙад
ЗўЮёТЗгЩгыШнджЃЌЖЏЬЌТЗгЩЃЌЙЪеЯНкЕуеЊГ§
етРяашвЊЬсабЕФЪЧЃЌФПЧАЕЮЕЮММЪѕеЛЛЙВЛЭГвЛЃЌЫљвдЕМжТжаМфМўЛсИДдгвЛаЉЃЌгІИУзюдчЦкАбММЪѕеЛЭГвЛЃЌбЁдё Java
Лђеп Go ЕШЃЌПЩвдБмУтКѓајЕФЮЪЬтЁЃ
ЗўЮёУќУћвЊЙцЗЖЃЌЗўЮёУћздУшЪіЃЌвЊЙЙНЈЭГвЛЗўЮёЪїЁЃЮЊСЫаЇТЪКЭЙцЗЖадЃЌавщНЈвщбЁдёЫНга RPC авщЁЃЙЋгаШч
http авщЃЌВтЪдЗНБуЃЌДјРДЗНБуадЕФЭЌЪБвВДјРДЕФЦфЫћЮЪЬтЃЌОЭЪЧШнвзБЛРФгУЁЃ
ЗўЮёТЗгЩНЈвщЪЧШЋОжеЊГ§ЃЌЯёЛњЦївЛЕЉВЛПЩгУОЭЭЈжЊЩЯгЮЃЌМАЪБеЊЕєЃЌЕЋвВгавЛЖЈЕФЗчЯеЁЃШчЭјТчЩСЖЯЃЌЯТУцЛњЦїШЋЙвЃЌЛсЕМжТЫљгаЗўЮёЖМВЛПЩгУЁЃЫљвдашдкШЋдБеђЪиЧщПіЯТзіШЋОжШЗШЯЃЌВЛвЊЭЯзХећИіЗўЮёЃЌвЊДгЩЯгЮзіОіВпЃЌдйЛЛИіIPЃЌжиаТзівЛДЮЁЃ
ЗжВМЪНЗўЮёЛЏИФдьЕФДѓЭХЖгазїЃЌДгЕЅвЕЮёЯЕЭГзіЗжВМЪНИФдьЕФвЛИіГіЗЂЕуОЭЪЧНтОіДѓЭХЖгЗжЙЄКЭазїЮЪЬтЁЃДњТыЕФЗжжЇВ№ЗжЃЌМѕЩйДњТыГхЭЛЃЌЪЙЕУЯЕЭГЖРСЂЃЌДђАќКЭЗЂВМаЇТЪЖМЛсЬсИпЃЛВПЪ№ЖРСЂЃЌЯпЩЯЙЪеЯХХВщКЭд№ШЮШЯЖЈЛсИќМгУїШЗЁЃ
ЭЌЪБЃЌДјРДЕФЮЪЬтЪЧвРРЕЕФВЛШЗЖЈаддіМгЃЌадФмЩЯЕФвЛаЉЫ№КФЁЃЯёвЛДЮЧыЧѓЃЌШчЙћвЛЯТЕїРДЦпАЫИіЧыЧѓЃЌетвВЛсДјРДвЛаЉЮЪЬтЃЌЫљвдетИіЙ§ГЬвЊгавЛЖЈЕФКЯРэадЃЌОЭЪЧЙЋЫОЯждкДІгкЪВУДНзЖЮЃЌЯждкашВЛашвЊВ№ЗжЁЃЫљвдЯЕЭГЁЂаЇТЪЕШЗНУцвЊзівЛИіЦНКтЁЃ
ДѓСїСПЯЕЭГЕФИпПЩгУЕќДњ
ДѓСїСПЯЕЭГЕФМмЙЙЪЕЯжИпПЩгУЕФВпТдВПЪ№ЃЌДјгаЗжзщЙІФмЕФвЛжТад Hash ЕФ CacheЁЂОВЬЌФкШнЧАжУЕН
CDNКЭШШЕуеьВтЕШЁЃ
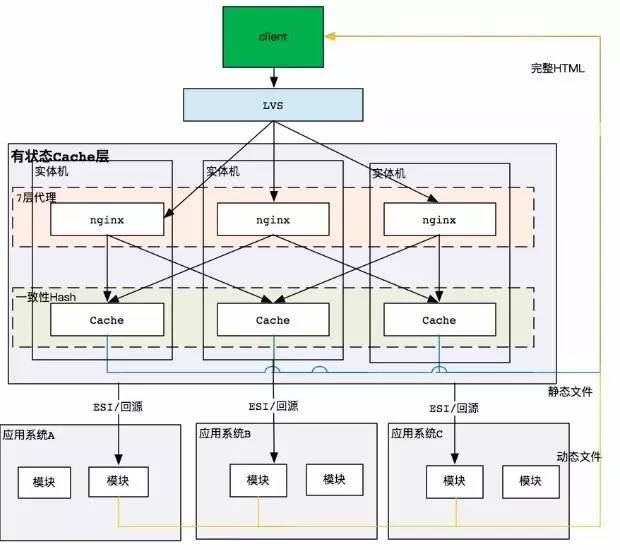
ЯЕЭГ APS КЭЗўЮёВугаЮхВуДњТы
ШчЩЯЭМЃЌвЛИіЯЕЭГ APS КЭЗўЮёВугаЮхВуДњТыЃЌЭЈЙ§ЫЎЦНРЉеЙМгЛњЦївВНтОіВЛСЫЮЪЬтЁЃдквЕЮёВуЃЌУЛАьЗЈзіЫЎЦНРЉеЙЃЌБиаызігазДЬЌЕФБфЛЏЃЌВПЪ№ДјгаЗжзщЙІФмЕФвЛжТад
Hash ЕФ CacheЁЃ
ЮЊСЫОпБИИќДѓЕФЩьЫѕадашвЊАбОВЬЌФкШнЧАжУЕНCDNЁЃ
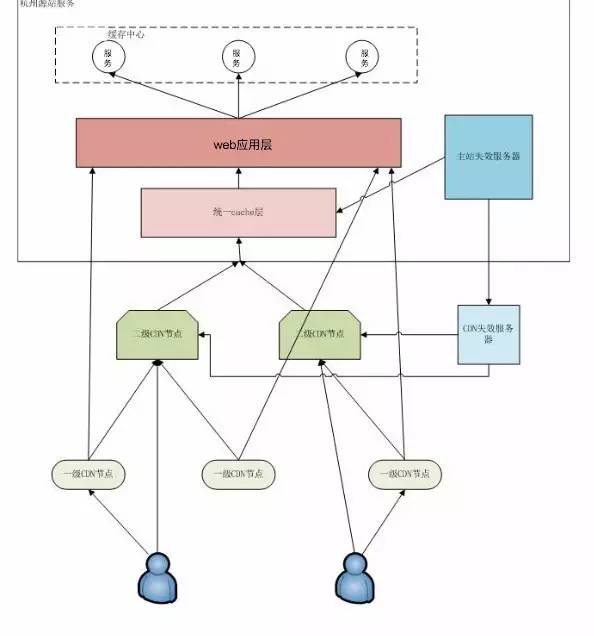
ОВЬЌФкШнЧАжУЕН CDN
дкЗўЮёЖЫМДЪЙзіРЉеЙЃЌСПЛЙЪЧгаЯоЃЌЖСЕФЧыЧѓЃЌЖСЕФЪ§ОнЭљЧАЭЦЃЌзюжеЭЦЕН CDN ЩЯЁЃCDN ЬхЯЕБШНЯЖрЧвгаЕигђадЃЌПЩПЙАйЭђМЖБ№ЕФСїСПЃЌЕЋвЊНтОіШпгрДјРДЕФЪБаЇадЁЂвЛжТадЕФЮЪЬтЁЃетбљзіДјРДЕФКУДІЃЌГ§ЬсИпЩьЫѕадЃЌЛЙНкЪЁДјПэЃЌНкЕуЗжЩЂЃЌПЩгУадИќИпЁЃетРяЬсабЯТЃЌCDN
ПЩгУадашвЊзіЦРЙРЃЌШчВЛЪЧздНЈЃЌашвЊШУЬсЙЉ CDN ЕФЙЉгІЩЬИјГіПЩгУаджИБъЃЌБмУтКѓајЮЌЯЕРЇФбЁЃ
ШШЕуеьВт
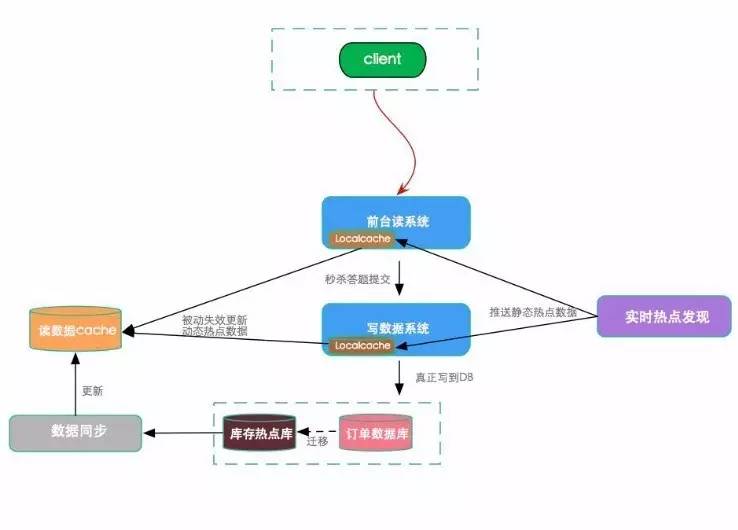
ШШЕуеьВтСїГЬЭМ
ЧАЬЈЯЕЭГЕНКѓЬЈЯЕЭГЃЌећИіЧыЧѓЪЧгаСДТЗЕФЃЌвЛИіЧыЧѓДгЗЂЦ№зюжеЕНЗўЮёЖЫЃЌЕНЪ§ОнПтВужаМфашОРњЖрВуЃЌЙ§ГЬжаДцдкЪБМфВюЁЃЬиЖЈЧщПіЯТЃЌЛсга
1-2 УыбгЪБЁЃРћгУетвЛЕуЃЌЕБЧАЖЫЧыЧѓздЕМЕННгЪмВуЪБЃЌзіЪЕЪБШШЕуеьВтЃЌЕБЗЂЯжНгЪеВуЗЂЩњБфЛЏЃЌПЩМАЪБЭЈЙ§ШЯжЄЕШЪжЖЮЖдетИіЧыЧѓзіБъМЧЃЌАбШШЕуЪ§ОнМЧТМЯТРДЁЃ
жЎКѓЃЌАбШШЕуЪ§ОнЕФаХЯЂЭЈжЊЯТвЛИіЯЕЭГЃЌетбљОЭПЩЦ№ЕНДгЩЯгЮЯЕЭГЗЂЯжЮЪЬтЃЌБЃЛЄЯТгЮЕФФПЕФЁЃЕБЗЂЯжФГИіЧыЧѓЬиБ№ШШЪБЃЌЬсЧАЖдЫќзіРЙНиЁЃШШЕуЪ§ОнЭЈЙ§ЪЕЪБЗЂЯжЃЌШежОВЩМЏЙ§РДЃЌзіЭГМЦЃЌШЛКѓАбетИіШШЕуЪ§ОндйЕМЕНаДЪ§ОнЯЕЭГЕФКѓЖЫЯЕЭГ
cache жаЃЌетбљПЩБЃЛЄКѓЖЫЕФВПЗжШШЕуЯЕЭГЁЃ
1% ЕФШШЕуЛсгАЯь 99% ЕФгУЛЇЃЌетжжЧщПідкЕчЩЬЪЧЬиБ№УїЯдЕФЃЌШчФГИіЩЬЦЗЬиБ№ШШТєЃЌЩЬЦЗЧыЧѓСїСПеМШЋЭјСїСПКмДѓВПЗжЁЃЧвЩЯЦСШнвзВњЩњЕЅЕуЃЌВщЪ§ОнПтЪБНЋЖЈдкЭЌвЛЛњЦїЁЃетбљКмШнвзЕМжТФГИіЩЬЦЗЛсгАЯьећИіЭјеОЕФЫљгаЩЬЦЗЁЃЫљвдвЊдкЪ§ОнПтзіБЃЛЄЃЌШчдкБОЕизі
cacheЁЂЗўЮёВузіБОЕи cacheЁЂЛђепдкЪ§ОнПтВуЕЅЖРзівЛИіШШЕуПтЕШЁЃ
ДѓСїСПЯЕЭГЕФИпПЩгУЕќДњЃЌашвЊзЂвтЕФЕугаЃК
ШШЕуИєРы
ЯШзіЪ§ОнЕФЖЏОВЗжРы
НЋ99%ЕФЪ§ОнЛКДцдкПЭЛЇЖЫфЏРРЦї
НЋЖЏЬЌЧыЧѓЕФЖСЪ§ОнcacheдкwebЖЫ
ЖдЖСЪ§ОнВЛзіЧПвЛжТадаЃбщ
ЖдаДЪ§ОнНјааЛљгкЪБМфЕФКЯРэЗжЦЌ
ЪЕЪБШШЕуЗЂЯж
ЖдаДЧыЧѓзіЯоСїБЃЛЄ
ЖдаДЪ§ОнНјааЧПвЛжТадаЃбщЕШ
Общ
ИпПЩгУМмЙЙНЈЩшЕФ
ЬхЯЕЛЏЁЂЛ§РлКЭГСЕэ
ЭЈЙ§ЖрФъЕФИпПЩгУМмЙЙНЈЩшЃЌетРягавЛаЉОбщжЕЕУЗжЯэЁЃзюДѓЕФЬхЛсОЭЪЧашвЊзіЮШЖЈадЬхЯЕЛЏНЈЩшЃЌАќРЈНЈСЂЙцЗЖКЭд№ШЮЬхЯЕЃЛЦфДЮОЭЪЧЙЄОпвЊЭъЩЦКЭЬхЯЕЛЏЃЌвдМАашвЊХфЬзЕФзщжЏБЃеЯЁЃ
НЈвщдкд№ШЮЬхЯЕЕФНЈЩшЗНУцЃЌЙЋЫОвЛЖЈУПФъЖМвЊжЦЖЈИпПЩгУжИБъЃЈKPIЃЉЁЂЙЪеЯЕШМЖвВвЊУїЮњЃЌгАЯьЖрЩйПЭЛЇЖМвЊзіУшЪіЁЂд№ШЮКЭШйвЋЬхЯЕвВЭЌЕШживЊЃЌетЪЧИіГЄЦкЧвПрБЦЕФЪТЁЃ
ЙЄОпЗНУцЃЌвЊЭъЩЦЧвЬхЯЕЛЏЃЌзіЙцЗЖЃЌзі KPIЃЌзюжевЊзіЕНЙЄОпЛЏЃЌЭЈЙ§ЙЄОпЛЏАбСїГЬЁЂЙцЗЖФмЙЬЖЈЁЃЙЄОпвЊЬхЯЕЛЏЃЌЯёШЋЛњбЙВтЃЌЕЅЛњбЙВтЕШЕШЖМПЩзіЙЄОпЁЃ
вЛИіИпПЩгУМмЙЙЕФНЈЩшЃЌВЛЪЧвЛГЏвЛЯІЃЌашвЊИїЗНУцЛ§РлКЭГСЕэЃЌвЛЖЈвЊзЂвтШ§ЗНУцЕФДІРэСїГЬЁЃ
ЙигкБфИќЃКдкБфИќжЎЧАБиаыжЦЖЈЛиЙіЗНАИЃЌЩцМАЕНЖдБфИќФкШнЩшжУПЊЙиЃЌГіЯжЮЪЬтПЩПьЫйЭЈЙ§ПЊЙиЙиБеаТЙІФмЃЛНгПкБфИќЁЂЪ§ОнНсЙЙБфИќЁЂЛиЙівЊПМТЧЕкШ§ЗНвРРЕЃЌдкБфИќжЎжаГіЯжЮЪЬтЃЌЕквЛЪБМфЛиЙіЁЃ
жИЕМддђЃКНЋЙЪеЯЧхЮњУшЪіКЭБЉТЖГіРДЃЌЛёШЁЕквЛЪжзЪСЯЃЌевЕНЮЪЬтЗДРЁдДЭЗЃЌНтОіЮЪЬтЃЌЯћГ§ЙЪеЯЭЌЪБевЕНЖдгІЯЕЭГКЭвЕЮёЕФжБНгИКд№ШЫЁЃ
ДІРэСїГЬЃКЮЪЬтЗЂЯжКѓЕквЛЪБМфЩЯБЈЕНЁАЯћЗРШКЁЂзщНЈгІМБДІРэаЁзщЁЂПчЭХЖгКЯзїЃЌЭЈжЊЕНЖдЗНЯЕЭГЕФИКд№ШЫЃЌP1ЙЪеЯвЊЭЈжЊЕНПЭЗўгыЙЋЙиНгПкШЫЃЌОЁСПзіЕНМЏжаАьЙЋЃЌЮЪЬтДІРэЭъБЯЃЌСЂМДзмНсКЭжЦЖЈИФНјЗНАИЁЂЯЕЭГTLИКд№ЃЌИФНјЗНАИЕФжДааЧщПіЁЃ |









