БГОА
ЫцзХвЦЖЏЛЅСЊЭјТ§Т§НјШыКѓАыГЁЃЌдНРДдНЖрЕФЙЋЫОНЋзЂвтСІзЊвЦЕНЮяСЊЭјЃЌЯЃЭћЭЈЙ§дчЦкВМОжРДЦ№ЕНеМСьетИіаавЕЕФжЦИпЕуЃЌБШШчФПЧАСїааЕФФІАнЕЅГЕЃЌOFO ЕЅГЕЖМЪЧЕфаЭЕФЮяСЊЭјгІгУЁЃЮяСЊЭјБОЩэВЂВЛЪЧЪВУДаТИХФюЃЌЫцзХДѓЪ§ОнЃЌAI ЕШММЪѕЕФЗЂеЙЃЌДѓМввтЪЖЕНДЋЭГЕФЮяСЊЭјЭЈЙ§вЛЖЈИФдьЃЌНшжњДѓЪ§ОнвдМА AI ММЪѕПЩвдЛёЕУКмЖрЖюЭтЕФМлжЕЁЃ
етРяжївЊНщЩмЮяСЊЭјЕФНгШыЗўЮёЃЌЮяСЊЭјжїСїНгШыавщЗжЮЊ MQTTЃЌCoaPЃЌHttpЃЌXMPPЕШМИжжЃЌБОЮФжївЊЪЧНщЩм MQTT авщЕФгХШБЕувдМАШчКЮЪЕЯж MQTT ЕФЗжВМЪНПђМмЃЌжСгкИїИіавщжЎМфЕФБШНЯОЭВЛдйетРяЯъЯИНщЩмЃЌДѓМвПЩвдАйЖШЯрЙизЪСЯШЅзіЯъЯИСЫНтЁЃ
MQTT авщжївЊЬиЕу
MQTT авщЪЧЮЊДѓСПМЦЫуФмСІгаЯоЃЌЧвЙЄзїдкЕЭДјПэЁЂВЛПЩППЕФЭјТчЕФдЖГЬДЋИаЦїКЭПижЦЩшБИЭЈбЖЖјЩшМЦЕФавщЃЌЫќОпгавдЯТжївЊЕФМИЯюЬиадЃК
- ЪЙгУЗЂВМ / ЖЉдФЯћЯЂФЃЪНЃЌЬсЙЉвЛЖдЖрЕФЯћЯЂЗЂВМЃЌНтГ§гІгУГЬађёюКЯЃЛ
- ЖдИКдиФкШнЦСБЮЕФЯћЯЂДЋЪфЃЛ
- ЪЙгУ TCP/IP ЬсЙЉЭјТчСЌНгЃЛ
- гаШ§жжЯћЯЂЗЂВМЗўЮёжЪСПЃК
ЁАжСЖрвЛДЮЁБЃЌЯћЯЂЗЂВМЭъШЋвРРЕЕзВу TCP/IP ЭјТчЁЃЛсЗЂЩњЯћЯЂЖЊЪЇЛђжиИДЁЃетвЛМЖБ№ПЩгУгкШчЯТЧщПіЃЌЛЗОГДЋИаЦїЪ§ОнЃЌЖЊЪЇвЛДЮМЧТМЮоЫљЮНЃЌвђЮЊВЛОУКѓЛЙЛсгаЕкЖўДЮЗЂЫЭЁЃ
ЁАжСЩйвЛДЮЁБЃЌШЗБЃЯћЯЂЕНДяЃЌЕЋЯћЯЂжиИДПЩФмЛсЗЂЩњЁЃ
ЁАжЛгавЛДЮЁБЃЌШЗБЃЯћЯЂЕНДявЛДЮЁЃетвЛМЖБ№ПЩгУгкШчЯТЧщПіЃЌдкМЦЗбЯЕЭГжаЃЌЯћЯЂжиИДЛђЖЊЪЇЛсЕМжТВЛе§ШЗЕФНсЙћЁЃ
- аЁаЭДЋЪфЃЌПЊЯњКмаЁЃЈЙЬЖЈГЄЖШЕФЭЗВПЪЧ 2 зжНкЃЉЃЌавщНЛЛЛзюаЁЛЏЃЌвдНЕЕЭЭјТчСїСПЃЛ
- ЪЙгУ Last Will КЭ Testament ЬиадЭЈжЊгаЙиИїЗНПЭЛЇЖЫвьГЃжаЖЯЕФЛњжЦЁЃ
MQTT жївЊгІгУГЁОА
- ГЕСЊЭј
- ЙЄвЕЮяСЊЭј
- жЧФмМвОг
- ЪгЦЕжБВЅЕЏФЛ
- IM ЪЕЪБСФЬь (вЛЖдвЛСФЬьЃЌШКзщСФЬь)
- ЭЦЫЭЗўЮёЃЌБШШчЭЦЫЭЪЕЪБаТЮХ
- Н№ШкНЛвзЪ§ОнЖЉдФЭЦЫЭ
ећЬхМмЙЙ
ЕЅЛњАцБОЕФ MQTT ДцдкВЂЗЂСЌНгЪ§ЩЯЯовдМАДІРэФмСІЕФЯожЦЃЌжїСїЕФЕЅЛњАцБОЕФ MQTT ЗўЮёАќРЈ ActiveMQЃЌ RabbitMQЃЌApolloЃЌMosquittoЃЌЗжВМЪНЕФ MQTT ЗўЮёАќРЈжЊУћЕФ EMQЃЌ VerneMQ ЖМЪЧВЩгУ Erlang ЪЕЯжЕФЁЃ
ЗжВМЪНАцБОЕФ MQTT ЯрЖдгкЕЅЛњАцБОзюДѓЕФФбЕудкгк Session ЕФЙмРэЃЌЬиБ№ЪЧГжОУЛЏ sessionЃЌMQTT авщЖЈвхСЫСНжж SessionЃЌЦфжавЛжжЪЧ transient SessionЃЌСэЭтвЛжжЪЧ Persistent SessionЃЌгУЛЇПЩвдЭЈЙ§дкЗЂЫЭСЌНгавщАќЕФЪБКђЩшжУ clean session етИізДЬЌЮЛРДОіЖЈВЩгУФФжж sessionЁЃСэЭтвЛИіФбЕуОЭЪЧМЏШКЕФЙмРэЃЌетРяЩшМЦЕФПђМмЪЧУПИі broker ЖМЪЧЖдЕШЃЌЫћУЧжЎМфВЛДцдкЪВУДжїДгЙиЯЕЃЌЫљвдЮвУЧжБНг AKKA Cluster етИіПђМмзїЮЊМЏШКЙмРэЃЌУПИі broker ЖМашвЊзЂВсМрЬ§ЕФЪБМфАќРЈ MemberUpЃЌMemberDownЃЌMemberUnreachableЃЌClusterMemberState ЕШЪТМўЃЌетбљУПИі broker ОЭКмПЩвдКмКУЕФИажЊЦфЫћНкЕуЕФзДЬЌЃЌЖдФкВПЕФ session зіЯргІЕФДІРэЃЌbroker КЭ broker жЎМфЕФЯћЯЂЭЈжЊВЩгУ Akka actor РДЪЕЯжЁЃ
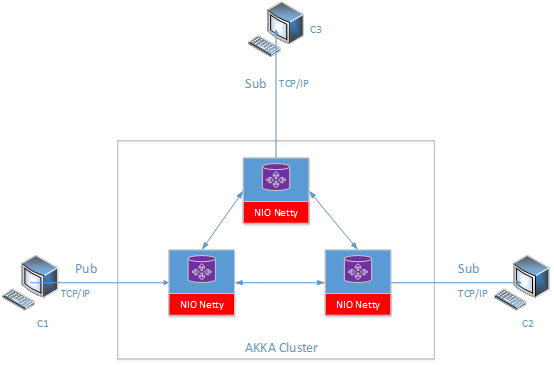
Broker ФкВПЗўЮёПђМм
ЮЊСЫЙмРэЃЌвдМАЩшМЦЗНБуЃЌЮвУЧНЋФкВПЗўЮёГщЯѓГЩЮЊКмЖрЖРСЂЗўЮёЃЌетаЉЗўЮёАќРЈЃК
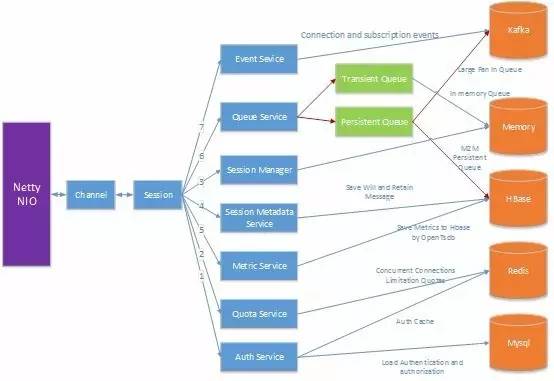
1.Authentication and authorization service
a) ИУЗўЮёИКд№гУЛЇУћЃЌУмТыЕШШЯжЄЗНЪНЕФМјШЈЃЌвдМАУПИі client ЖдгкФЧаЉжїЬтгаШЈЯоНјааЖСКЭаДЃЌКѓЬЈЪ§ОнШЋВПБЃДцдк MysqlЃЌЭЈЙ§ redis зі cache МгЫйЃЌЕБШЛвВзі in memory ЕФ cache МгЫйЃЌcache ЛиЪеЛњжЦВЩгУ LRU ВпТд
2.Session Manager
a) ГжОУЛЏ session ЙмРэЃЌАќРЈ session ЖЉдФЪВУДжїЬтЃЌвдМАЖдгІЕФ persistent queueЃЌИУ session ашвЊдкУПИі broker ЖМЭЌВНвЛЗнЃЌетбљПЩвдгааЇНтОіИпПЩгУадЕФЮЪЬтЃЌБШШч crash жЎКѓЃЌВЛЛсЪмЕНгАЯь
b) ЗЧГжОУЛЏ session ЙмРэЃЌАќРЈ session ЖЉдФЪВУДжїЬтЃЌвдМАЖдгІЕФ transient queueЃЌИУ session жЛашвЊдкСЌНгЛњЦїЩЯБЃГжЃЌВЛашвЊЭЌВНЕНЦфЫћЕФ broker ЩЯЃЌШчЙћЖдгІЕФ client КЭ broker ЪЇШЅСЌНгжЎКѓЃЌЖдгІ session аХЯЂОЭЛсБЛЧхГ§Еє
3.Event Service
a) ИКд№НЋСЌНгЃЌЖЉдФЕШЪТМўЗЂЫЭИјУПИі brokerЃЌЖдгкУПИіСЌНгЪТМўЃЌЮвУЧЖМашвЊНЋИУЯћЯЂЭЦЫЭИј event serviceЃЌЛЙгаОЭЪЧУПИі client ЕФЖЉдФжїЬтЃЌШЁЯћЖЉдФжїЬтЕФЪТМўЃЌФПЧА event service ЕФКѓЖЫЪЕЯжВЩгУ Kafka зіЕФЃЌЕБШЛвВПЩвдЭЈЙ§ Akka БОЩэЬсЙЉЕФЙІФмРДзіЃЌПМТЧЕНашвЊГжОУЛЏЃЌЫљвдВЩгУСЫ KafkaЃЌКѓЦкЮвУЧМѕЩйЖд Kafka ЕФвРРЕ
4.Session State metadata service
a) ИКд№ГжОУЛЏ session metadata Ъ§ОнДцДЂЃЌИУЗўЮёДг Event Service ЖЉдФЪ§ОнЃЌШЛКѓОіЖЈФФаЉЪ§ОнашвЊГжОУЛЏЕНКѓЖЫДцДЂЃЈВЩгУ Hbase зіГжОУЛЏДцДЂЃЉЃЌФПЧАжївЊЪЧДцДЂГжОУЛЏ session ЯрЙиЕФаХЯЂ
5.Queue Service
a) ЙмРэвдМАЗжХф queueЃЌетРяЕФ queue ЗжЮЊСНжжЃЌвЛжжЪЧ transient queueЃЌвЛжжЪЧ persistent queueЃЌtransient queue ЪЧВЩгУ in memory ЕФЗНЪНЪЕЯжЃЌpersistent queue ЪЧВЩгУ Hbase ЪЕЯжЁЃTransient queue ЪЧЮЊ transient session ДДНЈЕФЃЌpersistent queue ЪЧЮЊ persistent session ДДНЈЁЃPersistent session ЕФЬиЕуОЭЪЧМДЪЙИУ session ЖдгІЕФСЌНгЖЯПЊСЫЃЌЮвУЧвВашЮЌЛЄИУ sessionЃЌвдМАИУ session ЖЉдФЕФЪ§ОнЃЌвдБуЯТДЮетИі client жиаТСЌНгЩЯРДжЎКѓЃЌздЖЏЛжИД session ЕФзДЬЌЃЌЛЙгаЯТЗЂУЛгаДІРэЭъЕФЖЉдФЪ§Он
6.Quota Service
a) ЙмРэАќРЈВЂЗЂСЌНгЪ§ЃЌЩЯааДјПэЃЌЯТааДјПэЕФЯожЦ
7.Metric Service
a) МрПиЗўЮёЕФВЂЗЂСЌНгЪ§ЃЌВЂЗЂЯћЯЂЪ§ЃЌЕБЧАСїСПЃЌЗўЮёдЫаажИБъЃЌАќРЈ CPUЃЌmemoryЃЌЭјТчЕШЯрЙижИБъ
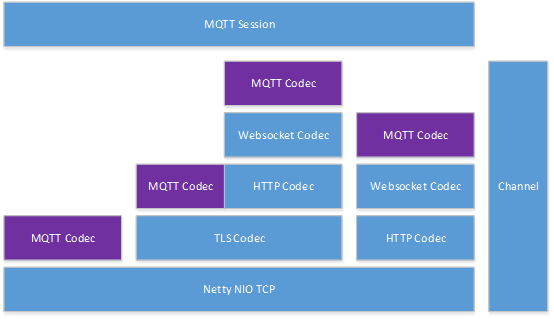
MQTT Codec Stack НсЙЙ
СЌНгВуВЩгУ Netty NIO ПђМмЃЌЙигк Netty NIO ЕФЯъЯИЩшМЦЃЌетРяЮвУЧОЭВЛзіНщЩмСЫЁЃжЇГж 4 жжаЮЪНЕФНгШыЗНЪНЃЌTCPЃЌTLSЃЌwebsocket over TLSЃЌвдМА websocketЃЌИїИіНгШыЗНЪНЕФ codec ВуМЖЙиЯЕПЩвдВЮПМЯТЭМЁЃ
ГжОУЛЏ Session
ЖдгкГжОУЛЏ sessionЃЌашвЊНЋИУ session аХЯЂЭЌВНЕНУПЬЈЛњЦїЃЌУПЬЈЛњЦїЖМгаЫљгаГжОУЛЏ session аХЯЂЕФШЋМЏЃЌетбљзіЕФКУДІОЭЪЧЕБФГЬЈ broker ЮоЗЈЙЄзїСЫЃЌСЌНгдкетИівьГЃ broker ЩЯЕФ client ВЛЛсЖЊЪЇЯћЯЂЃЌУПЬѕ publish ЕФЯћЯЂЖМЪЧжБНгаДШы hbase ЕФЃЌЕБ broker ЛжИДЃЌЛђеп client СЌНгЕНЦфЫћ broker жЎКѓЃЌПЩвдМЬајДг hbase ЛёШЁЪ§ОнЃЌШЛКѓЗЂЫЭИјЖЉдФЕФ clientЁЃ
ЖЉдФЯћЯЂДІРэСїГЬ
ЖЉдФЯћЯЂЛсЗЂЭљ event serviceЃЌУПИі broker ЖМЛсЖЉдФРДзд event service ЕФЪ§ОнЃЌЖдгкГжОУЛЏ sessionЃЌУПИі broker ЖМЛсДДНЈЖдгІ session ЕФЖЉдФаХЯЂвдМА virtual queueЃЌетИі virtual queue ЗжЮЊ client КЭ server СНВПЗжЃЌclient ЖЫЕФ virtual queue ИКд№БЃжЄаДШыЫГађЃЌвдМАХњСПаДШыЃЈЬсЩ§аЇТЪЃЉЃЌserver етБпЕФ queue БЃжЄРДздВЛЭЌ broker ЕФЯћЯЂЕФгаађадЁЃ
ЗЂЫЭЯћЯЂСїГЬ
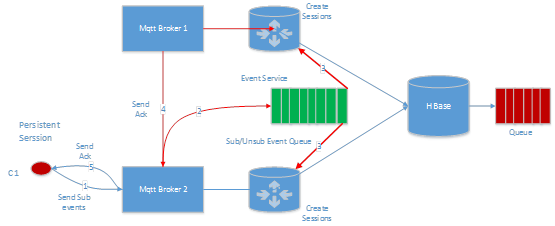
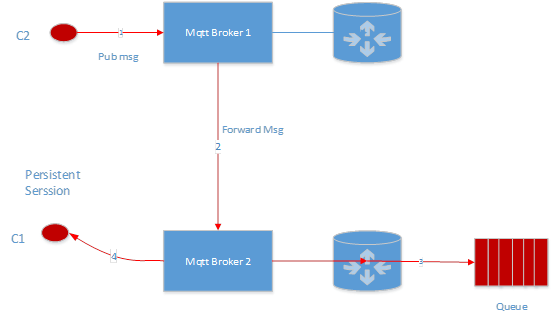
C2 Эљ C1 ЖЉдФЕФжїЬтЗЂЫЭвЛЬѕЪ§ОнЃЌrouter ЛсжБНгНЋЪ§ОнаДШы C1 ЖдгІЕФ hbase queueЃЌШЛКѓЭЈжЊ C1ЃЌИцЫпЫћгааТЕФЪ§ОнПЩвдЯћЗбСЫЃЌетИіЪБКђ broker жБНгДг hbase ЖСШЁЪ§ОнЃЌШЛКѓЗЂЭљ C1ЁЃ
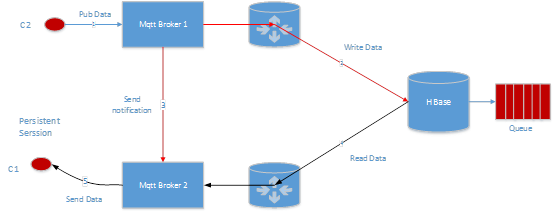
ШчЙћ Mqtt Broker 2 ГіЯж crash СЫЃЌБШШчетИіНјГЬЙвСЫЃЌЛђеп Mqtt Broker 2 ЫљдкЕФЛњЦїЖЯЕчСЫЃЌЛђепЭјТчГіЯжЙЪеЯСЫЃЌC1 БОРДгІИУЪеЕНЕФЪ§ОнВЂВЛЛсМѕЩйЃЌгЩгк Mqtt Broker 1 ЛсМЬајЭљ Hbase аДШыЪ§ОнЃЌЕШ C1 жиаТСЌНгжЎКѓЃЌПЩвдМЬајДг Hbase ЯћЗбЪ§ОнЁЃ
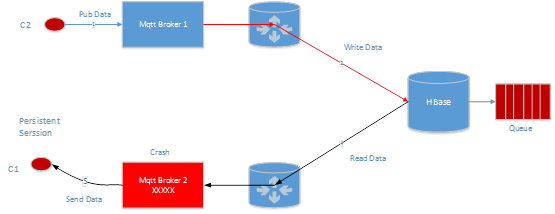
Event service Ъ§ОнЕФ Compaction
ПМТЧГжОУЛЏ session ЯрЙиЕФЪ§ОнЖМЪЧаДШыЕН kafka ЕФЃЌШчЙћвЛИіаТЕФ broker МгШыМЏШКЃЌЪзЯШОЭашвЊНЋГжОУЛЏ session ЕФаХЯЂШЋВПМгдиЃЌШчЙћМгдиЖМЪЧДг kafka жїЬтЕФЭЗВППЊЪМЯћЗбЪ§ОнЕФЛАЃЌПЩФмЛсЛЈЗбКмОУЃЌЮЊДЫЮвУЧашвЊНЋ kafka ЕФЪ§Онзі compactionЃЌетаЉ compaction ЕФЪ§ОнаДШыЕН hbaseЃЌШчКЮМгдиШЋСПаХЯЂСЫЃЌШЋСПаХЯЂОЭЪЧ hbase Ъ§ОнЕФМЏКЯКЭБИЗн checkpoint жЎКѓ kafka Ъ§ОнМЏКЯ merge НсЙћОЭЪЧзюжеЕФШЋСПаХЯЂЁЃ
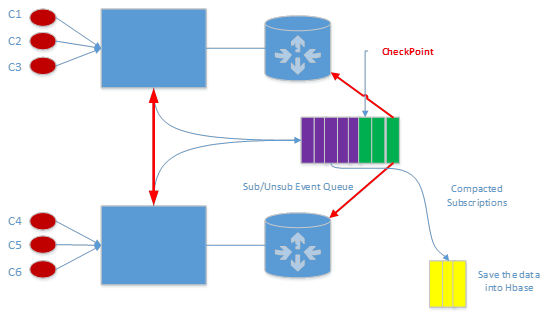
ЗЧГжОУЛЏ Session
ЕБЗЧГжОУЛЏ session ЕФ client СЌНгЩЯРДЕФЪБКђЃЌШчЙћЖЉдФжїЬтЃЌЮвУЧЛсжБНгдкИФ client ЫљдкЛњЦїДДНЈ session вдМА session ЖдгІЕФ queueЁЃ
ЖЉдФЯћЯЂСїГЬЃК
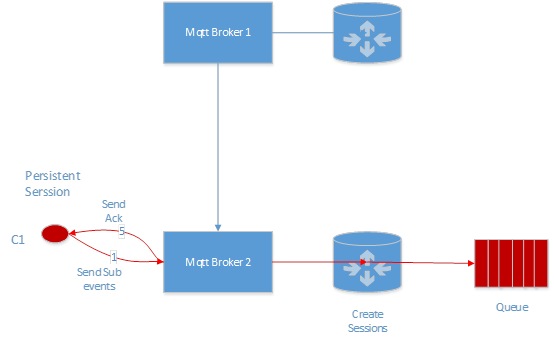
ЗЂЫЭЯћЯЂСїГЬЃК
ЕБ C2 ЗЂЫЭвЛЬѕЯћЯЂЕФЪБКђЃЌbroker 1 ЛсАбЯћЯЂзЊЗЂИј broker 2ЃЌ broker 2 ЛсЯШАбЯћЯЂаДШыЕН C1 ЖдгІЕФ in memory queueЃЌШЛКѓЗЂЫЭвЛИігаЪ§ОнЕФ event Иј C1ЃЌетИіЪБКђ broker 2 ЛсДг queue ЖСШЁЪ§ОнЃЌШЛКѓЗЂЭљИј C1ЁЃ
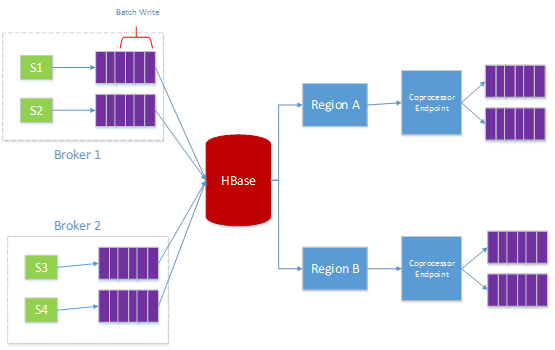
ЛљгкHBase ЕФЗжВМЪНЯћЯЂЖгСа
Hbase БОЩэВЛЬсЙЉ queue етИіЙІФмЃЌЕЋЪЧЮвУЧПЩвдРћгУ hbase ЬиадРДЪЕЯж virtual queue ЕФИХФюЃЌЭЈЙ§ЩшМЦКУ rowkey РДБЃжЄЯћЯЂЕФгаађадЃЌШЛКѓНЋЪ§ОнЕФЖСШЁзЊЛЏЮЊ scan ВйзїЃЌЯТЭМга 4 Иі clientЃЌЮвУЧЮЊУПИі client ЗжХфвЛИі unique ЕФ queue IDЃЌШЛКѓУПИі queue ЕФЪ§ОнЭЈЙ§ queue ID КЭЕЅЕїЕндіЕФ ID РДзщКЯГЩЮЊвЛИі unique ЕФ rowkeyЃЌЮЊСЫБЃжЄаДШыЕФОљдШадЃЌЮвУЧашвЊКЯРэЩшМЦ unique ID ЕФ prefix РДБЃжЄНЋетаЉ rowkey ОљдШЕФЗжВМЕНВЛЭЌЕФ regionЁЃ
ЮЊСЫЪЕЯж queue ЕФЙІФмЃЌЮвУЧдк Hbase ЩЯЖЈвхСЫвЛИіаТЕФ coprocessorЃЌетИі coprocessor гУРДДДНЈ queueЃЌЙмРэ queue ЕФЪ§ОнЃЌвдМАЩОГ§ queueЃЌЭЌЪБЛЙПЩвдаоИФ queue ЕФХфЖюЕШЕШЁЃЯТЭМЪЧЮвУЧЕФвЛИіЪТР§ЃЌЮвУЧга 4 Иі clientЃЌУПИі client ЖМгаздМКЕФ queueЃЌЭЈЙ§ЫуЗЈАбетаЉ queue ОљдШЕФЗжВМЕНВЛЭЌЕФ region ЩЯЪЙгУЖЈжЦ region split ЫуЗЈЁЃ
ЖЈвх queue name ЮЊ reverse{clientId}_tenantIdЃЌетРяЕФ clientID ЪЧЯЕЭГЩњГЩЕФЃЌЪЧ 64bit ЕФ longЃЌЮвУЧЮЊУПИі client ЩњГЩвЛИі IDЃЌетИі ID ЪЧЕЅЕїЕндіЕФЃЌМгШыЮвУЧдЄЦк region ЕФЪ§ФПЮЊ 128 ИіЕФЛАЃЌФЧУДЮвУЧОЭШЁ reverse{clientId}ЕФЭЗ 8bit зїЮЊ region ЗжИюЕФЬѕМўЃЌетбљЮвУЧОЭПЩвдАбВЛЭЌЕФ queue ОљдШЗжВМЕНВЛЭЌЕФ region ЩЯСЫЃЌШЛКѓЖд region зі balanceЁЃ
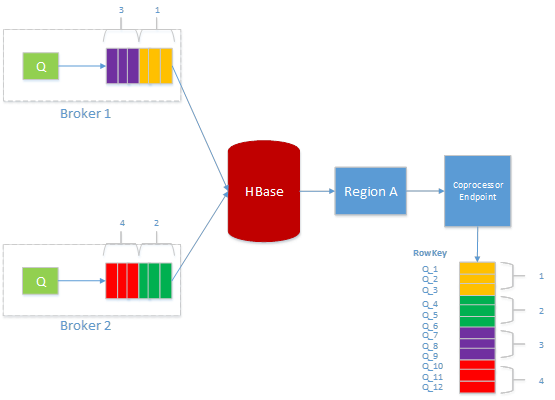
БЃжЄаДШыЯћЯЂЕФгаађад
ЖдгкГжОУЛЏЯћЯЂЖгСаЃЌашвЊдкУПИі broker ЩЯЖМНЈСЂвЛИі virtual queueЃЌИУ virtual queue ЖдгІ hbase ЕФецЪЕ queueЃЌУПДЮ virtual queue ЕФЪ§ОнЖМЪЧ batch аДШы hbaseЃЌМйЩшетИі queue ЕФУћзжЮЊ Q ЕФЛАЃЌЮвУЧЛсЮЊУПИіаДЕН hbase ЕФЯћЯЂЗжХфвЛИі unique ЕФ IDЃЌИУ ID ЪЧ Q_(ID)ЃЌID ЪЧвЛИіЕЅЕїЕндіЕФЪ§зжЃЌВЩгУ 64bit ЕФ long БэЪОЃЌУПИі batch аДШыЕН hbase ЕФ coprocessor жЎКѓЃЌашвЊЯШЛёШЁИУ queue ЕФ lockЃЌШЛКѓЗжХф IDЃЌШЛКѓНЋЪ§ОнаДШы hbaseЃЌзюКѓЪЭЗХ lockЃЌетбљЯТвЛИі request ОЭПЩвдМЬајаДШыЃЌетРя lock ЕФСЃЖШЪЧ queue МЖБ№ЃЌОЭЪЧУПИі queue ЖМЛсгаздМКЕФвЛИі lockЃЌетбљПЩвдБЃжЄВЂЗЂадЁЃ
ЖСШЁ queue ЕФЪ§Он
ЮвУЧЛсЮЊУПИі queue БЃДцИУ queue дк Hbase ЕФзюаЁ IDЃЌвдМАзюДѓ IDЃЌШчЙћИУ queue ЕФзюаЁ ID КЭзюДѓ ID гЩгк cache ЪЇаЇЃЌЕМжТФкДцВЛДцдкЕФЛАЃЌЮвУЧОЭЭЈЙ§ hbase ЕФ scan ВйзїЃЌРДЛёШЁзюаЁЕФ IDЃЌвдМАзюДѓ IDЃЌШЛКѓНЋЪ§ОнБЃСєЕН cache РяУцЃЌетбљПЩвдМгЫйЯТДЮВщевЃЌУПДЮЖСШЁЬиЖЈГЄЖШЕФЪ§ОнЃЌЯТДЮМЦЫуБугкМЬајЖСШЁЃЌЖСЪ§ОнЕФЪБКђВЂВЛашвЊЛёШЁЫјЃЌгЩгкЖСЪ§ОнжЛЛсРДздвЛЬЈЛњЦїЕФвЛИі clientЃЌОЭЪЧШЮКЮЪБПЬжЛгавЛИі client дкЖСЪ§ОнЁЃ
ЩОГ§ queue ЕФЪ§Он
етРяЕФЩОГ§вбОЖСШЁЕФЪ§ОнЃЌгЩгкЮвУЧЕФЪ§ОнЖМЪЧгаађЕФЃЌЫљвдЩОГ§ЕФЪБКђЃЌжЛашвЊИцЫп queue ашвЊЩОГ§ЖрГЄЕФЪ§ОнМДПЩЃЌШЛКѓЮвУЧИљОнзюаЁ IDЃЌвдМА offset ПЩвдЫуГіашвЊЩОГ§ rowkey ЕФ IDЃЌШЛКѓжДаавЛИі batch delete ВйзїЃЌетбљОЭПЩвдНЋЪ§ОнЩОГ§СЫЃЌЩОГ§Ъ§ОнвВВЛЛсашвЊЛёШЁЫјЃЌгЩгкЩОГ§ЧыЧѓжЛЛсРДздвЛЬЈЛњЦїЕФвЛИі clientЃЌОЭЪЧШЮКЮЪБПЬжЛгавЛИі client дкЩОГ§Ъ§ОнЁЃ
Notes
ЭЌЪБгЩгк Hbase ФПЧАВЂВЛДцдкЙйЗНЕФ async ЕФ library РДЭљ hbase аДШыЪ§ОнЃЌЛђепЖСШЁЪ§ОнЃЌФПЧАжЛга opentsdb ЬсЙЉвЛИіАцБОЃЌПМТЧЮвУЧЪЧРћгУ coprocessor діМгСЫвЛИіаТЕФ endpointЃЌЕЋЪЧ opentsdb ЕФ async library ВЂВЛжЇГж coprocessorЃЌЮЊСЫЮвУЧашвЊРЉеЙ async ЕФ libraryЃЌетбљОЭПЩвд async library ЕФ coprocessor ПтРДДІРэЪ§ОнЁЃ
гХЛЏ
ШчКЮРћгУ in memory compaction РДгХЛЏ hbase queue ЕФадФмжИБъЃЌгЩгк mqtt ЕФЯћЯЂаДШы hbase жЎКѓЃЌЛљБОТэЩЯОЭЛсБЛЖСШЁГіРДЃЌШЛКѓЗЂЫЭИј clientЃЌЫљвдЫЕ mqtt ЕФЯћЯЂЖМЪЧЪєгк short lived ЕФЪ§ОнЃЌШчЙћетаЉЪ§ОнЖМдк in memory зі compaction ЕФЛАЃЌФЧОЭвтЮЖЮвУЧВЛашвЊНЋетаЉЪ§ОнаДШы HFileЃЌжЛашвЊаД WAL ШежОЃЌетбљПЩвдМЋДѓЕФНЕЕЭ HDFS ЮФМўЯЕЭГЕФ IOЃЌЖдгкЮвУЧетжжГЁОАЕФЛАЃЌHbase ЕФЦПОБОЭГідк HDFS ЮФМўЯЕЭГЕФЖСаДЩЯЃЌФПЧА in memory compaction вбОдк hbase 2.0 ЩЯЪЕЯжЃЌВЛЙ§УЛгае§ЪН releaseЁЃ
ИќЖр in memory compaction ЕФзЪСЯПЩвдВЮПМЃК
Accordion: HBase Breathes with In-Memory Compaction
https://blogs.apache.org/hbase/entry/accordion-hbase-breathes-with-in
Internal design:
https://blogs.apache.org/hbase/entry/accordion-developer-view-of-in
ИќЖр queue ВхМў
УПжж queue ЖМгаздМКЕФгХШБЕуЃЌЮЊДЫЮвУЧЬсЙЉСЫЖржж queue ПЩвдЙЉгУЛЇбЁдёЃЌЖюЭтЬсЙЉ redis вдМА kafka ЕФ queueЃЌkafka ЕФ queue ЪЧвЛжжКм popular ЕФЗНЪНЃЌжївЊЪЧгУдкДѓЙцФЃЩШШыГЁОАЃЌБШШчЫЕ 100w Иі client ЖМЭљЭЌвЛИіжїЬтЗЂЫЭЯћЯЂЃЌШчЙћВЩгУ in memory ЕФ queue Лђеп hbase ЕФ queueЃЌФЧУДЦПОБОЭЛсГідкЖЉдФЖЫЃЈжЛгавЛИі TCP СЌНгРДДІРэЪ§ОнЃЉЃЌШчЙћВЩгУ kafka queueЃЌПЩвдНЋЪ§ОнЗЂЭљ kafka ЕФжїЬтЃЌШЛКѓЕїгУ kafka ЕФ client РДЯћЗбЪ§ОнЃЌетбљОЭПЩвдЭъУРНтОіДѓЩШШыЕФГЁОАЁЃ
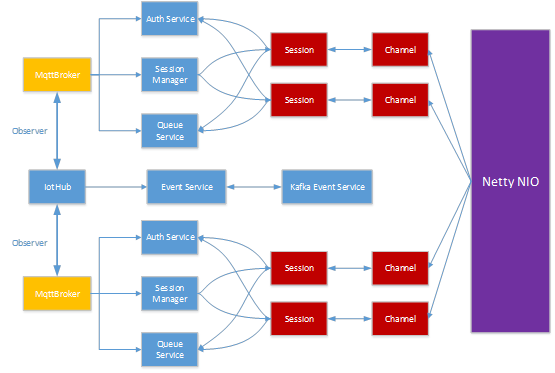
ЖрзтЛЇМмЙЙ
ФПЧА MQTT ЗўЮёЪЧвЛИіЗжВМЪНЖрзтЛЇЕФЗўЮёЃЌвЛИі IotHub ЩЯУцЛсгаКмЖрзтЛЇЕФ MQTT BrokerЃЌУПИі MQTT broker ЖдгІвЛИі tenantЃЌУПИі broker газдМКЕФ authentication service, session manager, Queue serviceЃЌвдМАКмЖрЦфЫћЗўЮёЃЌАќРЈ unique Id generatorЃЌbackend storage serviceЃЌвдМА router ЗўЮёЃЌЕБвЛИі client ЕФЭЈЙ§ TCP КЭЮвУЧЕФЗўЮёНЈСЂСЌНгжЎКѓЃЌЪзЯШЮвУЧЛсЮЊИУ client ДДНЈвЛИі sessionЃЌетИі session ЛсМьВщИУ client ЪЧЗёКЯЗЈЃЌАќРЈ tenant УћзжЃЌгУЛЇУћЃЌУмТыЃЌШчЙћЫљгаЕФЖМКЯЗЈЕФЛАЃЌЮвУЧЛсАбетИі client ЕФ session ЬэМгЕН session managerЃЌШчЙћВЛЪЧКЯЗЈЕФЃЌЮвУЧЛсжБНгАбетИі client ЕФСЌНгИјЖЯПЊЁЃ
MQTT ВЩгУ TCP ЕФЗНЪНКЭдЦЖЫНЈСЂСЌНгЃЌЮвУЧЭЈЙ§гУЛЇУћРДЧјЗжетИі client ЖдгІЕФЪЧФЧИі tenantЃЌЫљвдЮвУЧЖдгУЛЇУћгабЯИёЕФЙцЖЈЃЌгУЛЇУћБиаыЪЧ{tenant Name}/{clientName}ЃЌФУЕНгУЛЇУћКЭУмТыжЎКѓЃЌЮвУЧЯШЫуГіИУ client ЖдгІЕФ tenant nameЃЌШЛКѓЛёШЁИУ tenant ЖдгІ broker ЪЕР§ЃЌКѓШЅИУ broker ЕФ auth ЗўЮёРДШЯжЄгУЛЇУћКЭУмТызщКЯЁЃ
ВтЪдЪ§Он
Baidu IoT Hub vs EMQTT
MPS: message per seconds
ЯћЯЂ payload ДѓаЁ: 1024 bytes
ГЁОАЃКвЛАы pub КЭвЛАы subЃЌУПвЛИі pub ЖдгІвЛИі subЃЌвВОЭЪЧЫЕЭЈЙ§ЮЈвЛжїЬтЙиСЊЦ№РДЃЌетжжГЁОАЪЧЖд MQTT авщзюбЯИёЕФПМбщЃЌЦфЫћГЁОАЯрЖдРДЫЕ CPU ЯћКФЛсЩйвЛаЉ
ВтЪд Queue РраЭЃКIn memory queue
Notes
гЩгк Pub КЭ Sub ЪЧвЛвЛЖдгІЕФЃЌЫљетРяЕФ MPS ЪЧжИ PUB ЕФ QPSЃЌЫљвдЪЕМЪ QPS ЪЧетИіЪ§зжЕФСНБЖЁЃ
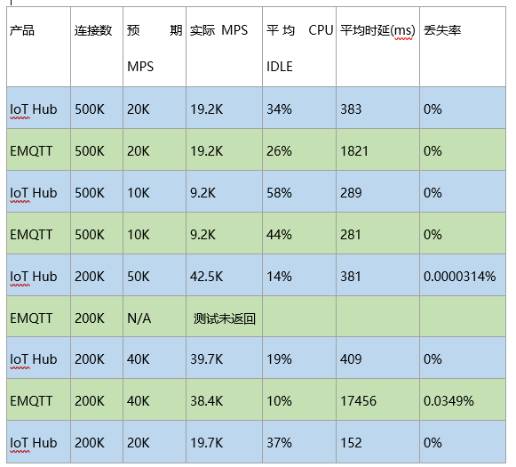
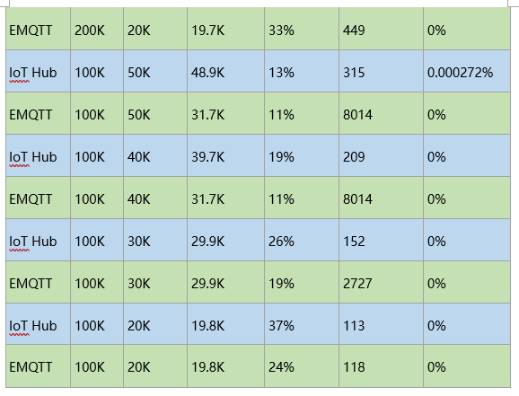
ПЩгУ MPSЃЈЮоЖЊАќЃЌlatency аЁгк 0.5sЃЉЃК
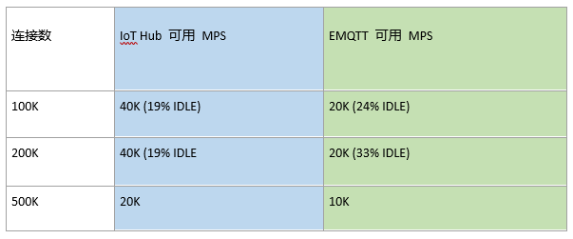
НсТлЃКЭЌЕШСЌНгЪ§ЯТЃЌIoT Hub ЕФПЩгУзюДѓЭЬЭТСПдк EMQTT ЕФ 1~2 БЖжЎМфЁЃ
ВПЪ№ broker ЛњЦїХфжУаХЯЂЃК
vendor_id: GenuineIntel
cpu family: 6
model: 45
model name: Intel(R) Xeon(R) CPU E5-2620 0 @ 2.00GHz
core: 12
Memory:
MemTotal: 132137288 kB
ИќЖрЙигкАйЖШ IoT Hub ЪЙгУаХЯЂПЩвдЗУЮЪЙйЭјЁЃ |









