背景介绍
Wonder是基于Open-Falcon二次开发的监控系统,16年4月左右正式上线使用,其中架构和功能设计按照HULK私有云平台需求的而来。
此前HULK使用的是Zabbix和内部开发的另一套监控系统。
首先说下Zabbix,在报警策略配置上是很方便灵活的,我们现在的Mysql实例监控仍然还在继续使用。但当机器数量超过6000台时Zabbix的poller bussy几乎占到了100%,另一方面由于360有上百个机房并且有很多是无光纤会导致queue队列中挤压大量监控项。
关于公司自有的另外一套监控系统架构上和Open-Falcon类似,但由于多年无人维护导致用户大量需求和问题无法解决,急需一套更好用的监控系统。
伴随着HULK自动化越来越成熟,接入公司业务越来越多,几乎接入了85%以上业务,使用成本和自定义的需求远远无法满足现状,所以我们开始开发一套契合HULK的监控系统。下面是我们在开发和设计Wonder监控系统时遇到的一些问题和经验。
为什么选择Open-Falcon?
在选择监控系统前,我们希望是架构简单,二次开发容易。最终,经过一些筛选,我们选择了小米开源的Open-Falcon。下面3点是我们选择Open-Falcon的理由:
- 现代化的设计和良好的架构(良好的设计有助于我们扩展架构);
- 模块化的设计、易于二次开发(模块的解耦也让性能不是瓶颈);
- 采用rrd存储数据,出图非常快;
当然说完优点,就不得不说一些不太方便的地方:
- 文档比较少:我们开始研究Open-Faclon是15年8月份左右,那时候文档还比较少,社区人也不像现在这么多
- 操作界面很多:Portal,Dashboard? 当时就想,为什么没有一个统一的入口呢?
- UIC是Java编写的:当时没有Fe,UIC还是Java编写的,无形中学习成本又加重了一些,还好后面出了Fe。
- 开放的API比较少:管理主机、组和策略都需要手动关联和配置
Open-Falcon使用
我们首先搭建了一套测试环境,测试通过后,部署了一批小规模的集群,然后对其中一些基本功能做了修改。
- 业务树同步:我们开发了API可以定时与HULK的业务树同步,保证了新增的主机可以自动关联策略,因为HULK是三级业务关系,所以我们对每个层级都做了Group和Template绑定,并且设置成继承的关系,这样策略就能一级一级继承,这个缺点就是要讲HULK的业务树转换成Open-Falcon的业务树,需要绑定Group和Template;
- 策略管理:策略管理方面,缺少禁用和加例外,我们也将这个功能集成到Portal了;
- 自定义插件:这个功能使用起来比较麻烦,首先得新建个目录,然后按文件名和周期合并成一个文件名,然后Push到git上,使用成本比较高。后来我们修改Portal,支持在Portal上上传文件,然后添加Step,系统自动将目录和文件名做处理,最后将自定义插件下发;
- 存活监控:Open-Falcon没有提供存活监控组件,但是这个监控非常重要,我们线上主机的ip有30k+,如何在频率一分钟的任务中将这些数据采集完成,而且还需要多机房探测合并,我们当时试了多种方案,但是完成时间和准确度都差强人意,后来我们选用Zabbix存活监控的方案,使用Fping加文件的方式,然后多点多机房部署,最终在20s内可以完成所有数据采集和合并;
- 超过最大报警次数报警:这个是另一种报警类型,当一个报警一直处于未恢复,在报警达到策略设置的MaxStep会将报警丢到指定的队列中,然后在偶数小时将队列中的数据消费合并处理,将报警发出来。超过最大报警我们是新增了一个队列,然后Judge定时消费这个队列,将数据最终丢到Alarm的P0队列;
- 报警处理:Alarm有个Web UI 展示了报警信息,但是这里面的报警看到并不能操作,后来我们加了对报警处理的逻辑;
- Windows Agent:当时我们有准备监控Windows服务器的想法,就开发了一个Windows的Agent采集基础数据;
- 自身组件监控:我们用其他监控系统对Open-Falcon各个组件都做监控
监控系统的设计
经过一段时间的观察和对源码的熟悉,我们决定对Open-Falcon进行更深层次的二次开发,下面几个点是首先需要改的:
- CMDB:CMDB是监控系统业务树的数据来源,我们想法就是监控系统和HULK平台数据一致,这样增加和删除主机,策略也会随之变更;
- 模板:在HULK的层级中,有三级概念,包括主业务、子业务和角色。每个策略是依托于这个层级,策略的继承也就是层级的继承关系。Open-Falcon的模板是将一组的机器的策略进行管理,在设计上,我们将模板和组的机制去除,只保留主机,取而代之的是通过HULK的层级关系来维护策略;
- 人员和报警组:人员都是从HULK同步过来的(包括人员的权限、邮箱和手机号等),报警组也需要结合业务关系;
- 自定义脚本:Open-Falcon的插件功能不够灵活(配置和使用方面),自定义脚本这块我们会细化到主机和文件的概念(同样也需要结合层级关系来自动扩容和继承);
- 公共库:这个功能提供一些经常使用的自定义脚本,可以方便用户使用;
- 日志监控:需要对日志文件进行类似tail -f的操作,然后通过一些规则处理后将数据进行上传和监控,需要支持多Key;
- 策略禁用和加例外:需要支持对策略禁用和主机加例外,策略启用和去掉例外后要重置报警状态(重新开始报警);
- 报警状态标示:通过报警状态标记,帮助用户识别报警,包括未恢复、已恢复和报警终止;
监控系统功能改进
根据预先的设计,我们对Open-Falcon进行了几轮二次开发,终于达到了我们之前预期的一些效果:
- 主机管理:主机信息和HULK保持一致,将Agent默认加到镜像中,实现了主机创建,自动配置Agent、关联和继承策略和自定义脚本等操作;
- 人员信息:实现了和HULK联动,人员信息自动同步;
- 自定义脚本:用户可以手动上传脚本压缩包,配置命令、参数以及主机对数据进行采集,并且支持多Key(多Tags),在Dashboard可以查看脚本执行状态和管理策略等;
- 公共库:公共库依托于自定义脚本,方便使用已提供的脚本;
- 日志监控:日志监控功能类似tail -f的操作,对日志进行分析和过滤,在一定周期内将最终数据进行合并处理并上报,目前支持滚动数目、字符串匹配、正则匹配和数字匹配,支持多文件和日期通配符(例error_%Y%m%d.log)。
- 存活监控:自动对HULK内的主机进行存活探测(采用fping进行探测),多点部署采集端,自动合并数据并上报;
- 策略的操作:支持对报警策略禁用和对主机加例外的功能,操作后报警状态会发生变化,并且在解除后重置报警状态;
- 报警状态:定期对报警状态检查,有未恢复、已恢复和报警终止提示(策略删除、禁用和加例外等);
- 超过最大报警次数报警:这个报警是用来针对未恢复的报警,目前是偶数小时发送;
系统模块优化
1、Agent:
a. cpu.idle粒度平缓:Agent对cpu.idle是取每个周期(60s)当前值和过去一秒的值的对比,这种数据画出图来会导致曲线不是很平缓(对比zabbix和同类监控系统),后来我们按5s取一个值,然后在一个周期内取平均值,这时候图就很平缓了;
b. 采集磁盘分区配置:这个值刚开始调整的比较多(例如memdisk),后来我们就把他放到配置文件中了;
c. Agent自身采集:Agent对自身进程占用资源并没有监控,我们也很关心这个地方,所以我们加了对Agent的CPU、内存和磁盘占用的监控;
d. Listen:我们默认关闭了Agent Http Port,只在本地开启了一个Socket,用来Push数据和Reload 配置;
e. 自动更新:Agent多了,部署和更新是一件很麻烦的事,部署我们用的是Qcmd(很方便),更新的话我们开发自动更新模块,目前很好使;
2、Judge:
a. 报警状态:之前Judge的报警状态(lastevent)存储在各自的内存中,如果Judge重启,会导致报警重发,导致误判。为了修复这个问题,我们将报警状态信息记录到Redis中,这样就避免上述的问题;
b. 报警原始数据:报警原始数据我们也保留到一份到Mongodb中,用来做数据分析;
3、Query:
开放API:提供主机名和Metric,查询所有的Tags的监控数值;根据主机查看所有的Counters等;
4、加密:
Open-Falcon各个组件都是不加密的,为了保证服务安全性,我们对Hbs、Transfer和Agent的Rpc都做了安全加密;
5、 其他组件
我们也做了些小改动,这里就不一一介绍了;
Transfer Socket模式的拒绝服务漏洞?
Transfer的Socket模式默认是开启的,用户可以通过Tcp连接或者Telnet方式进行Push数据,在官方文档中对这个配置有个注释说明“#即将被废弃,请避免使用”,那这个地方有个什么漏洞呢?在源码的receiver/socket/socket_telnet.go的第27行代码处:

这里Socket在接收用户数据时没有设置缓存大小,如果请求中未检测到'\n',则持续使用该缓存接收数据直到‘\n’出现为止,在这之前buffer不会释放,攻击者只要请求足够多不包含'\n'的数据即可使Transfer的CPU和MEM被过度消耗,使得进程崩溃。尝试模拟攻击,可以看到Transfer CPU和MEM的使用都很高。

那如何修复呢?一种方法修改代码,设置接收缓存大小;另一种就是直接关闭Socket模式。我们选择关闭Socket模式,为什么?这个模式应该很少有人用(至少我们在我们这没人用)。
is She with You?
监控系统为什么叫Wonder? 这个是小伙伴们一致讨论的结果,当然是源自DC的超级英雄“Wonder Woman”。
Wonder监控系统:
下面是Wonder监控的一些展示图

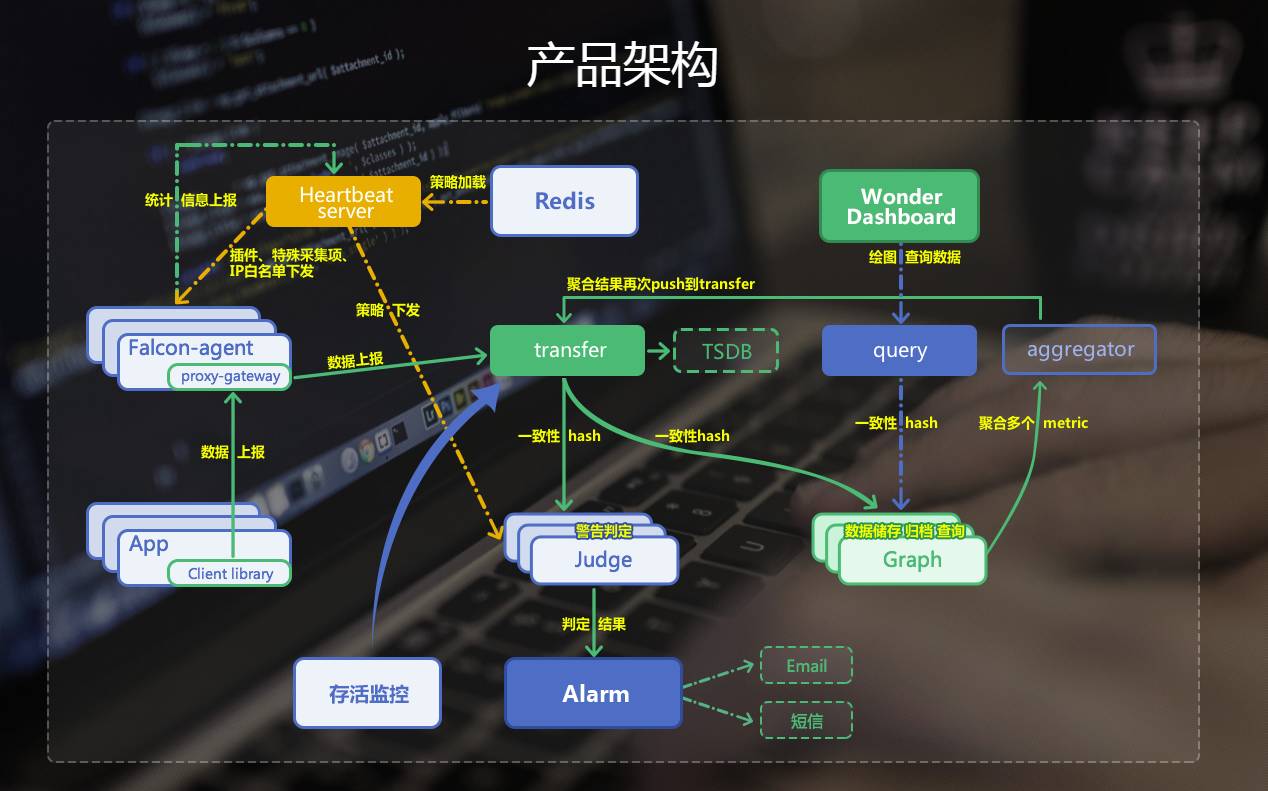

Wonder&智能运维:
有了这些数据,我们就可以针对这些数据做一些数据分析,DoctorStrange(上一期分享中提到的智能数据分析系统)可以对Wonder的数据进行分析,对常见的报警(CPU、磁盘、SWAP等)进行分析,通过监控项的历史数据进行分析,对于历史趋势的增长(或下降)趋势趋于稳定的报警(例如磁盘使用率),或是历史趋势波动的比较厉害,如cpu、网卡流量等,进行提前预测和自识别处理。
Wonder正在做的事情?
- Wonder目前是以主机为维度来做监控,考虑到数据库等其他维度不同,比如数据库是实例为一组(包含多台主机),我们也想展现这个维度,那这个势必要改变现在Endpoint的维度。
- 目前采集的监控项较少,要丰富下数据,目前准备采集包括进程的资源使用信息和网络数据包的定时获取等。
- 联动其他信息对报警进行处理:比如主机报修后,自动过滤报警
- 对报警增加可控性:比如报警可以定期忽略等
- 提供Agent主动抓取数据接口,支持更细粒度的数据维度展示(最小15s的粒度),供其他组件使用
- 支持更为全面的日志监控服务,包括日志采集、分析等。
- 目前Judge报警算法比较简单,我们正在尝试新的算法来判断一些特殊的数据变化(例如突增突减)。混合策略我们也需要,目前已经在开发中。
- 更深层次的监控:目前Wonder提供的监控项都是系统的基础监控项,我们今年的一个目标就是APM监控,用来帮助用户快速定位和发现问题。
- 规划监控原始数据和报警数据存储,支持页面多粒度展示和数据分析
- 数据校验:Open-Falcon是强要求主机名正确,如果主机名错误,会导致各种各样的问题,我们也经常遇到,很典型的问题,网卡进出流量监控项,如果遇到两个主机名相同的主机,一个前1分钟传一个很高的值,另一个又马上传了一个很低的值,这样的话,会导致这台主机的网卡流量一下飙升很高(基本都在几十G上下)。这种无法强要求Agent一致,我们打算在Transfer和Hbs端进行控制。
QA环节
Q1: 如何处理跨机房数据收集的?Agent能作为中转站吗?
A1:跨机房收集应该是考验Agent到Transfer端,我们是联通和电信都有Transfer的点,当然如果数据很多,传输效率低,可以考虑Agent收集和传输分散开(现在Agent是60s收集完一起传输)。Agent可以做为本机的一个中转站,如果不是本机,直接Push到本机房Transfer就可以。
Q2:当初为什么选择Open-Flacon?有做其他考虑吗?
A2:文中我们也提到这一点,之前我们用的Zabbix,这个二次开发成本很高,而且数据库的性能是瓶颈,我们就先排除;公司内部的监控系统数据存放在Hbase中,出图比较慢,我们也是将考虑的优先级放到后面;正好当时Open-Falcon刚开源不久,有大公司背景,模块化后,代码很清晰易读,在尝试了一把后,就决定使用Open-Falcon二次开发。
Q3: 这款监控系统研发多久?最难的是哪个点?
A3:从15年8月底开始接触一直到现在,还有很多功能要做。最难的感觉是将Template和Group去除,再将业务关系融进去(这块保证策略准确与否)。
Q4: Agent和Server见通讯是直接Push等方式,是否有考虑过使用MQ来作为消息中间件传递数据,已解决不同机房,不同网络下,能灵活的汇总收集数据。
A4:360机房非常多,网络情况也非常复杂,我们是尽量在规模比较大的机房部署Transfer,然后将数据Push到Graph(这端我们会加QOS,保证网络情况),这样即便慢一些,只要数据不丢就可以。直接Push的方式从我们自己使用情况上看是没有问题,暂时没考虑换MQ。
Q5:你们三级业务和策略是怎么关联的啊?怎么配置特例的呢?
A5:如果要理解三级业务关系,那么首先要抛开Group和Template,策略和业务绑定,业务和主机绑定,这样将三者联系到一起,如果是继承的话,就是先继承策略,然后落实到主机上。 特例是指例外? 我们会有一个和策略类似的概念:比如给某台机器的某个策略加例外,生成策略的时候会首先去掉该主机的特定策略,然后例外生效后会对相应的LastEvent处理(重置CurrentStep)。
Q6:谢谢分享!监控埋点能否分享一下?
A6:之前我们有个应用监控叫Qalarm,这个是在PHP中埋点采集数据。我们也在做业务的监控,一直想尽量避免埋点,所以我们优先考虑的网络抓包,分析四层和7层数据。我们今年的目标也是会做APM监控,这里面会用埋点,到时候我们会分享一些。
Q7: 对站长开放使用的360网站云监控和这个有区别吗?
A7: 360网站云监控和这个没有关系,功能上重叠的也不多。 |









