| аЏГЬЪЕЪБгУЛЇааЮЊЗўЮёзїЮЊЛљДЁЗўЮёЃЌФПЧАЦеБщгІгУдкЖрИіГЁОАжаЃЌБШШчВТФуЯВЛЖЃЈаЏГЬЕФЭЦМіЯЕЭГЃЉЃЌЖЏЬЌЙуИцЃЌгУЛЇЛЯёЃЌфЏРРРњЪЗЕШЕШЁЃ
вдВТФуЯВЛЖЮЊР§ЃЌВТФуЯВЛЖЮЊгІгУФкгУЛЇЬсЙЉЧБдкбЁЯюЃЌЬсИпГЩНЛаЇТЪЁЃТУааЪЧвЛЯюзлКЯадЕФашЧѓЃЌгУЛЇЭљЭљашвЊВЛжЙвЛИіВњЦЗЁЃзїЮЊвЛеОЪНЕФТУгЮЗўЮёЦНЬЈЃЌПчвЕЮёЯпЕФЭЦМіЃЌЬиБ№ЪЧЪЕЪБЭЦМіЃЌФмЪЕМЪТњзугУЛЇЕФашЧѓЃЌвђДЫдкЩЯгЮЬсЙЉДђЭЈИївЕЮёЯпжЎМфЕФгУЛЇааЮЊЪ§ОнгаКмДѓЕФБивЊадЁЃ
аЏГЬдгаЕФЪЕЪБгУЛЇааЮЊЯЕЭГДцдквЛаЉЮЪЬтЃЌАќРЈЃК1ЃЉЪ§ОнИВИЧВЛШЋЃЛ2ЃЉЪ§ОнЪфГіУЛгаЭГвЛИёЪНЃЌЖджкЖрЪЙгУЗНЬсИпСЫНгШыГЩБОЃЛ3ЃЉШежОДІРэФЃПщЪЧweb
serviceЃЌБШНЯФбжЇГжЖржжЪ§ОнДІРэВпТдКЭЪЕЯжЗНБуРЉШнгІЖдСїСПКщЗхЕФашЧѓЕШЁЃ
ЖјНќМИФъТУгЮЪаГЁИпЫйдіГЄЃЌЪ§ОнСПдНРДдНДѓЃЌВЂЧвЛсГжајПьЫйдіГЄЁЃгадНРДдНЖрЕФЪЙгУашЧѓЃЌЖдЯЕЭГЕФЪЕЪБадЃЌЮШЖЈадвВЬсГіСЫИќИпЕФвЊЧѓЁЃзмЕФРДЫЕЃЌЕБЧАашЧѓЖдЯЕЭГЕФЪЕЪБад/ПЩгУад/адФм/РЉеЙадЗНУцЖМгаКмИпЕФвЊЧѓЁЃ
вЛЁЂМмЙЙ
етбљЕФБГОАЯТЃЌЮвУЧАДееШчЯТНсЙЙжиаТЩшМЦСЫЯЕЭГЃК
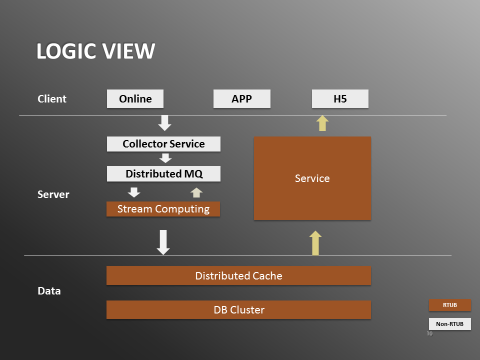
ЭМ1ЃКЪЕЪБгУЛЇааЮЊЯЕЭГТпМЪгЭМ
аТЕФМмЙЙЯТЃЌЪ§ОнгаСНжжСїЯђЃЌЗжБ№ЪЧДІРэСїКЭЪфГіСїЁЃдкДІРэСїЃЌааЮЊШежОЛсДгПЭЛЇЖЫЃЈApp/Online/H5ЃЉЩЯДЋЕНЗўЮёЖЫЕФCollector
ServiceЁЃCollector ServiceНЋЯћЯЂЗЂЫЭЕНЗжВМЪНЖгСаЁЃЪ§ОнДІРэФЃПщгЩСїМЦЫуПђМмЭъГЩЃЌДгЗжВМЪНЖгСаЖСГіЪ§ОнЃЌДІРэжЎКѓАбЪ§ОнаДШыЪ§ОнВуЃЌгЩЗжВМЪНЛКДцКЭЪ§ОнПтМЏШКзщГЩЁЃ
ЪфГіСїЯрЖдМђЕЅЃЌweb serviceЕФКѓЬЈЛсДгЪ§ОнВуРШЁЪ§ОнЃЌВЂЪфГіИјЕїгУЗНЃЌгаЕФЪЧФкВПЗўЮёЕїгУЃЌБШШчЭЦМіЯЕЭГЃЌвВгаЕФЪЧЪфГіЕНЧАЬЈЃЌБШШчфЏРРРњЪЗЁЃЯЕЭГЪЕЯжВЩгУЕФЪЧJava+Kafka+Storm+Redis+Mysql+Tomcat+SpringЕФММЪѕеЛЁЃ
JavaЃКФПЧАЙЋЫОФкВПJavaЛЏЕФЗеЮЇБШНЯХЈКёЃЌВЂЧвJavaгаБШНЯГЩЪьЕФДѓЪ§ОнзщМў
Kafka/StormЃКKafkaзїЮЊЗжВМЪНЯћЯЂЖгСавбОдкЙЋЫОгаБШНЯГЩЪьЕФгІгУЃЌСїМЦЫуПђМмStormвВвбОТфЕиЃЌВЂЧвгаБШНЯКУЕФдЫЮЌжЇГжЛЗОГЁЃ
RedisЃК RedisЕФHAЃЌSortedSetКЭЙ§ЦкЕШЬиадБШНЯКУЕиТњзуСЫЯЕЭГЕФашЧѓЁЃ
MySQL: зїЮЊЛљДЁЯЕЭГЃЌЮШЖЈадКЭадФмвВЪЧЯЕЭГЕФСНДѓжИБъЃЌЖдБШnosqlЕФжївЊбЁЯюЃЌБШШчhbaseКЭelasticsearchЃЌЪЎвкЪ§ОнМЖБ№ЩЯmysqlдкетСНЗНУцгаИќКУЕФБэЯжЃЌВЂЧвОЙ§ЩшМЦФмЙЛгаВЛДэЕФЫЎЦНРЉеЙФмСІЁЃ
ФПЧАЯЕЭГУПЬьДІРэ20вкзѓгвЕФЪ§ОнСПЃЌЪ§ОнДгЩЯЯпЕНПЩгУЕФЪБМфдк300КСУызѓгвЁЃВщбЏЗўЮёУПЬьЗўЮё8000ЭђзѓгвЕФЧыЧѓЃЌЦНОљбгГйдк6КСУызѓгвЁЃЯТУцДгЪЕЪБад/ПЩгУад/адФм/ВПЪ№МИИіЮЌЖШРДЫЕУїЯЕЭГЕФЩшМЦЁЃ
ЖўЁЂЪЕЪБад
зїЮЊвЛИіЪЕЪБЯЕЭГЃЌЪЕЪБадЪЧЪзвЊжИБъЁЃЯпЩЯЯЕЭГУцЖдзХИїжжвьГЃЧщПіЁЃР§ШчШчЯТМИжжЧщПіЃК
ЭЛЗЂСїСПКщЗхЃЌдѕУДгІЖдЃЛ
ГіЯжЪЇАмЪ§ОнЛђЙЪеЯФЃПщЃЌШчКЮБЃжЄЪЇАмЪ§ОнжиЪдВЂЭЌЪББЃжЄаТЪ§ОнЕФДІРэЃЛ
ЛЗОГЮЪЬтЛђbugЕМжТЪ§ОнЛ§бЙЃЌШчКЮПьЫйЯћНтЃЛ
ГЬађbugЃЌОЩЪ§ОнашвЊжиаТДІРэЃЌШчКЮПьЫйДІРэЭЌЪББЃжЄаТЪ§ОнЃЛ
ЯЕЭГДгЩшМЦжЎГѕОЭПМТЧСЫЩЯЪіЧщПіЁЃ
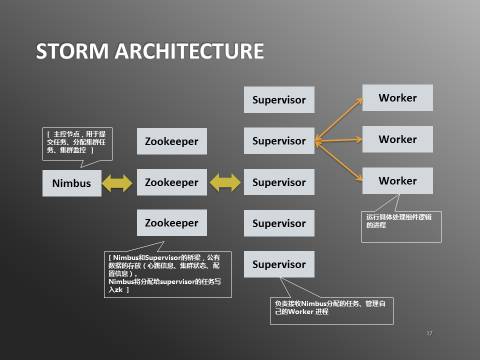
ЪзЯШЪЧгУstormНтОіСЫЭЛЗЂСїСПКщЗхЕФЮЪЬтЁЃstormОпгаШчЯТЬиадЃК

ЭМ2ЃКStormЬиад
зїЮЊвЛИіСїМЦЫуПђМмЃЌКЭдчЦкДѓЪ§ОнДІРэЕФХњДІРэПђМмгаУїЯдЧјБ№ЁЃХњДІРэПђМмЪЧжДааЭъвЛДЮШЮЮёОЭНсЪјдЫааЃЌЖјСїДІРэПђМмдђГжајдЫааЃЌРэТлЩЯгРВЛЭЃжЙЃЌВЂЧвДІРэСЃЖШЪЧЯћЯЂМЖБ№ЃЌвђДЫжЛвЊЯЕЭГЕФМЦЫуФмСІзуЙЛЃЌОЭФмБЃжЄУПЬѕЯћЯЂЖМФмЕквЛЪБМфБЛЗЂЯжВЂДІРэЁЃ
ЖдЕБЧАЯЕЭГРДЫЕЃЌЭЈЙ§stormДІРэПђМмЃЌЯћЯЂФмдкНјШыkafkaжЎКѓКСУыМЖБ№БЛДІРэЁЃДЫЭтЃЌstormОпгаЧПДѓЕФscale
outФмСІЁЃжЛвЊЭЈЙ§КѓЬЈаоИФworkerЪ§СПВЮЪ§ЃЌВЂжиЦєtopologyЃЈstormЕФШЮЮёУћГЦЃЉЃЌПЩвдТэЩЯРЉеЙМЦЫуФмСІЃЌЗНБугІЖдЭЛЗЂЕФСїСПКщЗхЁЃ
ЖдЯћЯЂЕФДІРэstormжЇГжЖржжЪ§ОнБЃжЄВпТдЃЌat least onceЃЌat most onceЃЌexactly
onceЁЃЖдЪЕЪБгУЛЇааЮЊРДЫЕЃЌЪзЯШЪЧБЃжЄЪ§ОнОЁПЩФмЩйЖЊЪЇЃЌСэЭтвЊжЇГжАќРЈжиЪдКЭНЕМЖЕФЖржжЪ§ОнДІРэВпТдЃЌВЂВЛФмЗЂЛгexactly
onceЕФгХЪЦЃЌЗДЖјЛсвђЮЊЪТЮёжЇГжНЕЕЭадФмЃЌЫљвдЪЕЪБгУЛЇааЮЊЯЕЭГВЩгУЕФat least onceЕФВпТдЁЃетжжВпТдЯТЯћЯЂПЩФмЛсжиЗЂЃЌЫљвдГЬађДІРэЪЕЯжСЫУнЕШжЇГжЁЃ
stormЕФЗЂВМБШНЯМђЕЅЃЌЩЯДЋИќаТГЬађjarАќВЂжиЦєШЮЮёМДПЩЭъГЩвЛДЮЗЂВМЃЌвХКЖЕФЪЧУЛгаЖрАцБОЛвЖШЗЂВМЕФжЇГжЁЃ
ЭМ3ЃКStormМмЙЙ
дкВПЗжЧщПіЯТЪ§ОнДІРэашвЊжиЪдЃЌБШШчЪ§ОнПтСЌНгГЌЪБЃЌЛђепЮоЗЈСЌНгЁЃСЌНгГЌЪБПЩФмТэЩЯжиЪдОЭФмЛжИДЃЌЕЋЪЧЮоЗЈСЌНгвЛАуашвЊИќГЄЪБМфЕШД§ЭјТчЛђЪ§ОнПтЕФЛжИДЃЌетжжЧщПіЯТДІРэГЬађВЛФмвЛжБЕШД§ЃЌЗёдђЛсдьГЩЪ§ОнбгГйЁЃЪЕЪБгУЛЇааЮЊЯЕЭГВЩгУСЫЫЋЖгСаЕФЩшМЦРДНтОіетИіЮЪЬтЁЃ
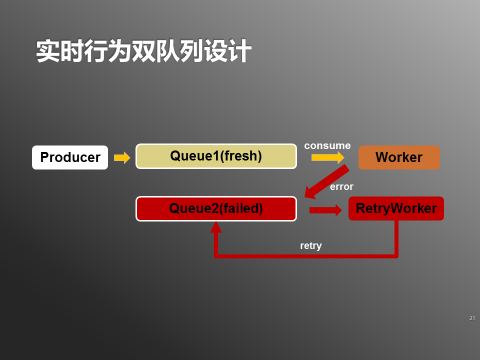
ЭМ4ЃКЫЋЖгСаЩшМЦ
ЩњВњепНЋааЮЊМЭТМаДШыQueue1ЃЈжївЊБЃГжЪ§ОнаТЯЪЃЉЃЌWorkerДгQueue1ЯћЗбаТЯЪЪ§ОнЁЃШчЙћЗЂЩњЩЯЪівьГЃЪ§ОнЃЌдђWorkerНЋвьГЃЪ§ОнаДШыQueue2ЃЈжївЊБЃГжвьГЃЪ§ОнЃЉЁЃ
етбљWorkerЖдQueue1ЕФЯћЗбНјЖШВЛЛсБЛвьГЃЪ§ОнгАЯьЃЌПЩвдБЃГжЯћЗбаТЯЪЪ§ОнЁЃRetryWorkerЛсМрЬ§Queue2ЃЌЯћЗбвьГЃЪ§ОнЃЌШчЙћДІРэЛЙУЛгаГЩЙІЃЌдђАДеевЛЖЈЕФВпТдЃЈШчЯТЭМЃЉЕШД§ЛђепжиаТНЋвьГЃЪ§ОнаДШыQueue2ЁЃ
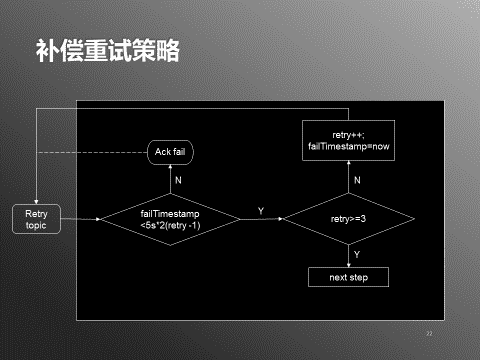
ЭМ5ЃКВЙГЅжиЪдВпТд
СэЭтЃЌЪ§ОнЗЂЩњЛ§бЙЕФЧщПіЯТЃЌПЩвдЕїећWorkerЕФЯћЗбгЮБъЃЌДгзюОнСїГЬвВЫцжЎИФЗбЃЌБЃжЄзюаТЪ§ОнЕУЕНДІРэЁЃжаМфЮДОДІРэЕФвЛЖЮЪ§ОндђЦєЖЏbackupWorkerЃЌжИЖЈЦ№жЙгЮБъЃЌдкЯћЗбЭъжИЖЈЧјМфЕФЪ§ОнжЎКѓЃЌbackupWorkerЛсздЖЏЭЃжЙЁЃЃЈШчЯТЭМЃЉ
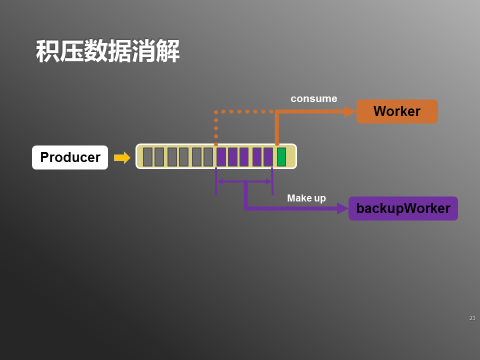
ЭМ6ЃКЛ§бЙЪ§ОнЯћНт
Ш§ЁЂПЩгУад
зїЮЊЛљДЁЗўЮёЃЌЖдПЩгУадЕФвЊЧѓБШвЛАуЕФЗўЮёвЊИпЕУЖрЃЌвђЮЊЯТгЮвРРЕЕФЗўЮёЖрЃЌвЛЕЉГіЯжЙЪеЯЃЌгаПЩФмЛсв§Ц№МЖСЊЗДгІгАЯьДѓСПвЕЮёЁЃЯюФПДгЩшМЦЩЯЖдвдЯТЮЪЬтзіСЫДІРэЃЌБЃеЯЯЕЭГЕФПЩгУадЃК
ЯЕЭГЪЧЗёгаЕЅЕуЃП
DBРЉШн/ЮЌЛЄ/ЙЪеЯдѕУДАьЃП
RedisЮЌЛЄ/Щ§МЖВЙЖЁдѕУДАьЃП
ЗўЮёЭђвЛЙвСЫШчКЮПьЫйЛжИДЃПШчКЮОЁСПВЛгАЯьЯТгЮгІгУЃП
ЪзЯШЪЧЯЕЭГВуУцЩЯзіСЫШЋеЛМЏШКЛЏЁЃkafkaКЭstormБОЩэБШНЯГЩЪьЕижЇГжМЏШКЛЏдЫЮЌЃЛwebЗўЮёжЇГжСЫЮозДЬЌДІРэВЂЧвЭЈЙ§ИКдиОљКтЪЕЯжМЏШКЛЏЃЛRedisКЭDBЗНУцаЏГЬвбОжЇГжжїБИВПЪ№ЃЌЪЙгУЙ§ГЬжаШчЙћжїЛњЗЂЩњЙЪеЯЃЌБИЛњЛсздЖЏНгЙмЗўЮёЃЛЭЈЙ§ШЋеЛМЏШКЛЏБЃеЯЯЕЭГУЛгаЕЅЕуЁЃ
СэЭтЯЕЭГдкВПЗжФЃПщВЛПЩгУЪБЭЈЙ§НЕМЖДІРэБЃеЯећИіЯЕЭГЕФПЩгУадЁЃЯШПДПДе§ГЃЪ§ОнДІРэСїГЬЃКЃЈШчЯТЭМЃЉ
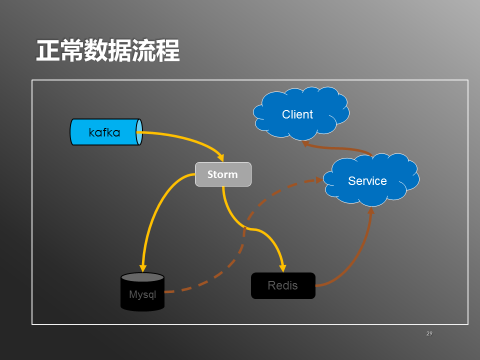
ЭМ7ЃКе§ГЃЪ§ОнСїГЬ
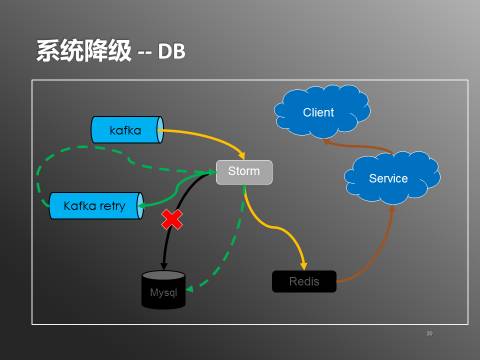
дкЯЕЭГе§ГЃзДЬЌЯТЃЌstormЛсДгkafkaжаЖСШЁЪ§ОнЃЌЗжБ№аДШыЕНredisКЭmysqlжаЁЃЗўЮёДгredisРШЁЃЈШЁВЛЕНЪБДгdbВЙГЅЃЉЃЌЪфГіИјПЭЛЇЖЫЁЃDBНЕМЖЕФЧщПіЯТЃЌЪ§ОнСїГЬвВЫцжЎИФБфЃЈШчЯТЭМЃЉ
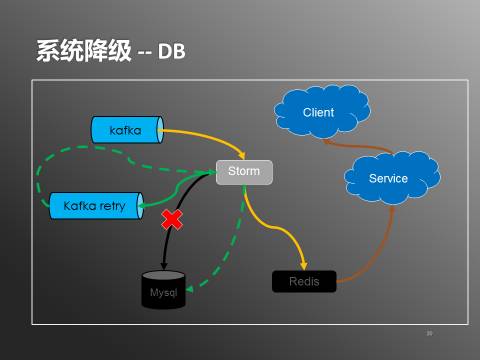
ЭМ8ЃКЯЕЭГНЕМЖ-DB
ЕБmysqlВЛПЩгУЪБЃЌЭЈЙ§ДђПЊdbНЕМЖПЊЙиЃЌstormЛсе§ГЃаДШыredisЃЌЕЋВЛдйЭљmysqlаДШыЪ§ОнЁЃЪ§ОнНјШыreidsОЭПЩвдБЛВщбЏЗўЮёЪЙгУЃЌЬсЙЉИјПЭЛЇЖЫЁЃСэЭтstormЛсАбЪ§ОнаДШывЛЗнЕНkafkaЕФretryЖгСаЃЌдкmysqlе§ГЃЗўЮёжЎКѓЃЌЭЈЙ§ЙиБеdbНЕМЖПЊЙиЃЌstormЛсЯћЗбretryЖгСажаЕФЪ§ОнЃЌДгЖјАбЪ§ОнаДШыЕНmysqlжаЁЃredisКЭmysqlЕФЪ§ОндкНЕМЖЦкМфЛсгаВЛвЛжТЃЌЕЋЯЕЭГЛжИДе§ГЃжЎКѓЛсЭЈЙ§retryБЃжЄЪ§ОнзюжеЕФвЛжТадЁЃredisЕФНЕМЖДІРэвВРрЫЦЃЈШчЯТЭМЃЉ
ЭМ9ЃКЯЕЭГНЕМЖ-Redis
ЮЈвЛгаЕуВЛЭЌЕФЪЧredisЕФЗўЮёФмСІвЊдЖГЌЙ§mysqlЁЃЫљвддкredisНЕМЖЪБЯЕЭГЕФЭЬЭТФмСІЪЧЯТНЕЕФЁЃетЪБЮвУЧЛсМрПиdbбЙСІЃЌШчЙћЗЂЯжmysqlбЙСІНЯДѓЃЌЛсднЪБЭЃжЙЪ§ОнЕФаДШыЃЌНЕЕЭmysqlЕФбЙСІЃЌДгЖјБЃжЄВщбЏЗўЮёЕФЮШЖЈЁЃЮЊСЫНЕЕЭЙЪеЯЧщПіЯТЖдЯТгЮЕФгАЯьЃЌВщбЏЗўЮёЭЈЙ§NetflixЕФHystrixзщМўжЇГжСЫШлЖЯФЃЪНЃЈШчЯТЭМЃЉЁЃ
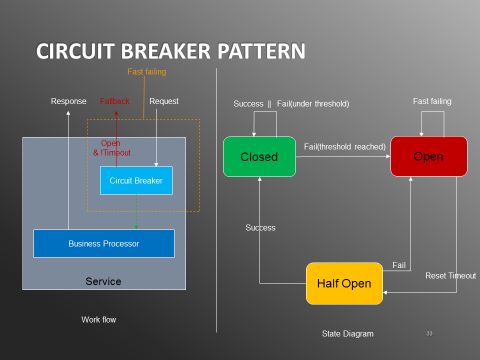
ЭМ10ЃКCircuit Breaker
Pattern
дкИУФЃЪНЯТЃЌвЛЕЉЗўЮёЪЇАмЧыЧѓдкИјЖЈЪБМфФкГЌЙ§вЛИіуажЕЃЌОЭЛсДђПЊШлЖЯПЊЙиЁЃдкПЊЙиПЊЦєЧщПіЯТЃЌЗўЮёЖдКѓајЧыЧѓжБНгЗЕЛиЪЇАмЯьгІЃЌВЛЛсдйШУЧыЧѓОЙ§вЕЮёФЃПщДІРэЃЌДгЖјБмУтЗўЮёЦїНјвЛВНдіМгбЙСІв§Ц№бЉБРЃЌвВВЛЛсвђЮЊЯьгІЪБМфбгГЄЭЯРлЕїгУЗНЁЃ
ПЊЙиДђПЊжЎКѓЛсПЊЪММЦЪБЃЌtimeoutКѓЛсНјШыHalf OpenЕФзДЬЌЃЌдкИУзДЬЌЯТЛсдЪаэвЛИіЧыЧѓЭЈЙ§ЃЌНјШывЕЮёДІРэФЃПщЃЌШчЙћФме§ГЃЗЕЛидђЙиБеПЊЙиЃЌЗёдђМЬајБЃГжПЊЙиДђПЊжБЕНЯТДЮtimeoutЁЃетбљвЕЮёЛжИДжЎКѓОЭФме§ГЃЗўЮёЧыЧѓЁЃСэЭтЃЌЮЊСЫЗРжЙЕЅИіЕїгУЗНЕФЗЧЗЈЕїгУЖдЗўЮёЕФгАЯьЃЌЗўЮёвВжЇГжСЫЖрИіЮЌЖШЯоСїЃЌАќРЈЕїгУЗНAppId/ipЯоСїКЭЗўЮёЯоСїЃЌНгПкЯоСїЕШЁЃ
ЫФЁЂадФм&РЉеЙ
гЩгкдкЯпТУгЮаавЕНќМИФъЕФИпЫйдіГЄЃЌаЏГЬзїЮЊаавЕСьЭЗбђвВХюВЊЗЂеЙЃЌвђДЫЗУЮЪСПКЭЪ§ОнСПвВДѓЗљЬсЩ§ЁЃЙЋЫОЖдвЕЮёЕФвЊЧѓЪЧПЩвджЇГХ10БЖШнСПРЉеЙЃЌРЉеЙзюФбЕФВПЗждкЪ§ОнВуЃЌвђЮЊЩцМАЕНДцСПЪ§ОнЕФЧЈвЦЁЃ
ЪЕЪБгУЛЇааЮЊЯЕЭГЕФЪ§ОнВуАќРЈRedisКЭMysqlЃЌRedisвђЮЊЪЕЯжСЫвЛжТадЙўЯЃЃЌРЉШнЪБжЛвЊМгЛњЦїЃЌВЂЖдЗжХфЕНаТЗжЧјЕФЪ§ОнзїЖСВЙГЅОЭПЩвдЁЃ
MysqlЗНУцЃЌЮвУЧвВзіСЫЫЎЦНЧаЗжзїЮЊРЉеЙЕФзМБИЃЌЗжЦЌЪ§СПЕФбЁдёПМТЧЮЊ2ЕФnДЮЗНЃЌетбљзідкРЉШнЪБгаУїЯдЕФКУДІЁЃвђЮЊаЏГЬЕФmysqlЪ§ОнПтЯждкЦеБщВЩгУЕФЪЧвЛжївЛБИЕФЗНЪНЃЌдкРЉШнЪБПЩвджБНгАбБИЛњРЦНГЩЕкЖўЬЈЃЈзщЃЉжїЛњЁЃМйЩшдРДЗжСЫ2ИіПтЃЌd0КЭd1ЃЌЖМЗХдкЗўЮёЦїs0ЩЯЃЌs0ЭЌЪБгаБИЛњs1ЁЃРЉШнжЛашвЊШчЯТМИВНЃК
ШЗБЃs0 -> s1ЭЌВНЫГРћЃЌУЛгаУїЯдбгГй
s0днЪБЙиБеЖСаДШЈЯо
ШЗШЯs1вбОЭъШЋЭЌВНs0ИќаТ
s1ПЊЗХЖСаДШЈЯо
d1ЕФdnsгЩs0ЧаЛЛЕНs1
s0ПЊЗХЖСаДШЈЯо
ЧЈвЦЙ§ГЬРћгУmysqlЕФИДжЦЗжЗЂЬиадЃЌБмУтСЫЗБЫівзДэЕФШЫЙЄЭЌВНЙ§ГЬЃЌДѓДѓНЕЕЭСЫЧЈвЦГЩБОКЭЪБМфЁЃећИіВйзїЙ§ГЬПЩвддкМИЗжжгЭъГЩЃЌНсКЯDBНЕМЖЕФЙІФмЃЌжЛгадкdnsЧаЛЛЕФМИУыжгЪБМфЛсВњЩњвьГЃЁЃ
ећИіЙ§ГЬБШНЯМђЕЅЗНБуЃЌНЕЕЭСЫдЫЮЌИКЕЃЃЌвЛЖЈГЬЖШвВФмНЕЕЭЙ§ЖрВйзїдьГЩРрЫЦgitlabЪНБЏОчЕФПЩФмадЁЃ
ЮхЁЂВПЪ№
ЧАЮФЬсЕНstormВПЪ№ЪЧБШНЯЗНБуЕФЃЌжЛвЊЩЯДЋжиЦєОЭПЩвдЭъГЩВПЪ№ЁЃВПЪ№жЎКѓгЩгкГЬађжиаТЦєЖЏЩЯЯТЮФЖЊЪЇЃЌПЩвдЭЈЙ§KafkaМЧТМЕФгЮБъевЕНжЎЧАДІРэЮЛжУЃЌЛжИДДІРэЁЃСэЭтгаВПЗжЧщПіЯТГЬађПЩФмашвЊЖрАцБОдЫааЃЌБШШчааЮЊМЭТМднЪБгаЖрИіАцБОЃЌетжжЧщПіЯТЮвУЧЛсаТдівЛИіbackupJobЃЌдкbackupJobжадЫааРњЪЗАцБОЁЃ |









