| вЛЁЂїШзхДѓЪ§ОнЦНЬЈМмЙЙ
ШчЭМЫљЪОБуЪЧїШзхЕФДѓЪ§ОнЦНЬЈМмЙЙЁЃ
зѓБпЪЧЖрбљадЕФЪ§ОндДНгШыЃЛ
гвЩЯЪЧРыЯпЪ§ОнЕФВЩМЏЃЛ
ЯТУцЪЧСїЦНЬЈЃЈвВЪЧНёЬьЗжЯэЕФжїНЧЃЉЃЛ
жаМфЪЧМЏШКЕФВПЪ№ЃЛ
гвБпЪЧETLЕФЪ§ОнЭкОђЁЂЫуЗЈПтКЭвЛаЉЪ§ОнФЃаЭЃЛ
зѓЩЯНЧЪЧЪ§ОнПЊЗЂЦНЬЈЃЌБШШчwebIDEПЩвдЪЙЕУПЊЗЂШЫдБИќБуНнЕизівЛаЉЪ§ОнВщбЏКЭЙмРэЃЛ
зюгвБпЕФЪЧвЛИіЪ§ОнВњЦЗУХЛЇЃЌАќРЈЮвУЧЕФгУЛЇЛЯёЁЂЭГМЦЯЕЭГЕШЃЌетРяУцАќКЌДѓЪ§ОнЕФКмЖрзщМўЃЌБШШчЪ§ОнВЩМЏЁЂЪ§ОнДІРэЁЂЪ§ОнДцДЂЁЂЪ§ОнЭкОђЕШЃЌзюКѓВњЩњДѓЪ§ОнЕФГћаЮЁЃ
ЖўЁЂСїЦНЬЈНщЩм
СїЦНЬЈЪЧДѓЪ§ОнЦНЬЈвЛИіБШНЯживЊЕФВПЗжЃЌжївЊАќРЈЫФИіВПЗжЃКЪ§ОнВЩМЏЁЂЪ§ОнДІРэЁЂЪ§ОнДцДЂЁЂМЦЫуФмСІЁЃ
Ъ§ОнВЩМЏ
ЁАЫгЕгаСЫећИіЪРНчЕФЪ§ОнЃЌЫћОЭЪЧзюДѓЕФгЎМвЁБЃЌетОфЛАЫфШЛгаЕуПфеХЃЌЕЋЪЧШДБэДяСЫЪ§ОнВЩМЏЕФживЊадЁЃвЛИіДѓЪ§ОнЦНЬЈЪ§ОнЕФЖрбљадЁЂЪ§ОнСПЕФМЖБ№КмДѓГЬЖШЩЯОіЖЈСЫДѓЪ§ОнЕФФмСІКЭЗсИЛГЬЖШЁЃ
Ъ§ОнДІРэ
етРяНВЕФЪ§ОнДІРэВЂВЛЪЧЯёФЉЖЫФЧУДзЈвЕЕФЪ§ОнЧхЯДЃЌИќЖрЕФЪЧЮЊКѓајШыПтзівЛаЉМђЕЅДІРэЃЌвдМАЪЕЪБМЦЫуЁЃ
Ъ§ОнДцДЂ
МЦЫуФмСІЃЌАќРЈРыЯпМЦЫуКЭЪЕЪБМЦЫу
СїЦНЬЈЮЊДѓЪ§ОнЬсЙЉЗЧГЃЧПДѓЕФжЇГХЃЌЪ§ОнЭГМЦЗжЮіЁЂЪ§ОнЭкОђЁЂЩёОЭјТчЕФЭМаЮМЦЫуЕШЖМПЩвдвРППМЦЫуФмСІНјааЁЃ
ЪЕЪБМЦЫуЪЧжИдквЛЖЈЕЅЮЛЕФЪБМфбгГйЗЖЮЇФкЃЌЛљгкдіСПЕФЪ§ОнЭЦЫуГіНсЙћЃЌдйНсКЯРњЪЗЪ§ОнЕУЕНЦкЭћЕФЗжЮіНсЙћЁЃетИіЪБМфЪЧИљОнвЕЮёашЧѓЖјЖЈЁЃ
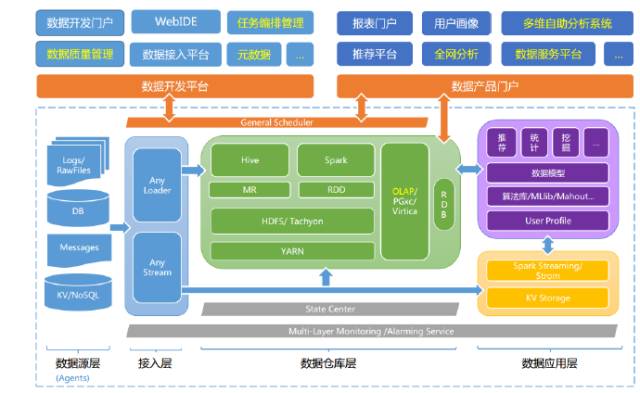
1ЁЂСїЦНЬЈМмЙЙ
ЩЯЭМЪЧЮвУЧЕФСїЦНЬЈМмЙЙЭМ
зѓБпЪЧЪ§ОндДЃЌЯёNoSQLЁЂRDBЁЂЮФМўРраЭЃЛ
зюгвБпЪЧМЏШКЃЌЯТУцЛЙгаЦфЫћЕФвЛаЉHadoopЃЈДцДЂЃЉЃЛ
жаМфЕФПђЪЧКЫаФЃЌвВОЭЪЧСїЦНЬЈЃЛ
зюЩЯУцЕФЪЧAS-ManagerЃЈЮвУЧЕФСїЙмРэЦНЬЈЃЉЃЌГадиСЫЗЧГЃЖрЕФЙмРэЙІФмЃЛ
ЯТУцЪЧZookeeperЃЌетЪЧвЛИіЗЧГЃСїааЕФМЏГЩЙмРэжааФЃЌїШзхЕФвЛаЉМмЙЙЖМЛсгУЕНЫќЃЌСїЦНЬЈвВВЛР§ЭтЃЌZookeeperПЩвдЫЕЙсДЉСЫЮвУЧећИіСїЦНЬЈЕФМмЙЙЃЛ
зюЯТУцЪЧAS-ProtocolЃЌЮвУЧздМКЩшМЦЕФСїЦНЬЈЕФЪ§ОнЖдЯѓавщЃЌДђЭЈСЫећИіСїЦНЬЈЕФЪ§ОнСДТЗЃЛ
жаМфЫФИіПђЪЧКЫаФЕФЫФИіФЃПщЃКВЩМЏФЃПщЁЂЪ§ОнжазЊФЃПщЁЂЛКДцФЃПщЁЂЪЕЪБМЦЫуФЃПщЃЌвВНаКЯВЂВуЁЃ
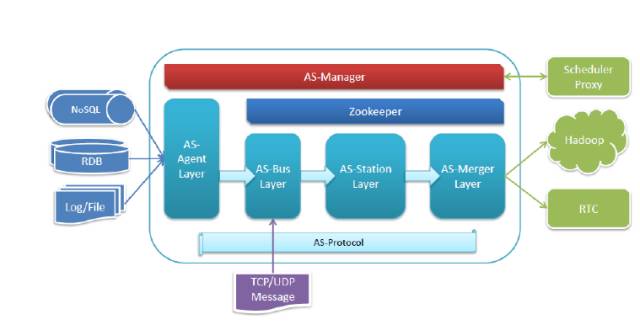
2ЁЂОпЬхМмЙЙНщЩм
етЪЧЮвУЧЕФОпЬхМмЙЙЭМЁЃ
вЕЮёЙцФЃЃКДгетБпВЩМЏЪ§ОнЕНОЙ§СїЦНЬЈзюКѓОЙ§ЪЕЪБМЦЫуЛђШыПтЃЌЫќЕФЪ§ОнСПСПМЖдкЧЇвкМЖБ№ЁЃ
3ЁЂзщМў
Ъ§ОндДЧўЕР
ЧАУцЬсЕНВЩМЏЪ§ОндДЧўЕРЕФЖрбљадОіЖЈСЫДѓЪ§ОнЦНЬЈЕФЯргІФмСІКЭзлКЯГЬЖШЁЃЮвУЧетБпЪзЯШЛсгавЛИіЮФМўРрЕФвЕЮёЪ§ОнЃЌАќРЈвЕЮёШежОЁЂвЕЮёЪ§ОнЁЂЪ§ОнПтЮФМўЃЌетаЉЖМЛсОЙ§ВЩМЏЗўЮёВЩМЏЁЃ
ЯТУцетвЛПщАќРЈвЛаЉЭјеОЕФjsЗУЮЪЁЂЪжЛњИїAPPТёЕуЁЂЬиЕуЕФгІгУШежОЮФМўЃЈЫќЛсЭЈЙ§ЪжЛњЖЫЕФвЛаЉТёЕуЩЯЗУЕНЮвУЧЕФТёЕуЗўЮёЃЉЁЃ
Ъ§ОнВЩМЏ
Ъ§ОнВЩМЏЗжЮЊСНИіВПЗжЃКВЩМЏЗўЮёЁЂЖРСЂВПЪ№ЕФТёЕуЗўЮёЁЃЭМжажЛЯдЪОСЫвЛИіТёЕуЗўЮёЃЌРяУцЛЙЛсгаКмЖрЕФЕкШ§ЗНвЕЮёЃЌЕкШ§ЗНвЕЮёЭЈЙ§етИіКьЩЋЕФВхМўНгШыЮвУЧЕФВЩМЏЁЃ
Ъ§ОнжазЊ
ЭЈЙ§ВЩМЏФЃПщАбЪ§ОнСїзЊЕНжазЊФЃПщЃЌжазЊФЃПщВЩгУЕФЪЧФПЧАБШНЯСїааЕФflumeзщМўЃЌКьЩЋsinkЪЧЮвУЧздМКПЊЗЂЕФЁЃ
Cache
sinkАбЧАУцЕФЪ§ОнзЊИјЛКДцВуЃЌЛКДцВуРягаmetaqКЭKafkaЁЃ
Streaming
ЪЕЪБМЦЫуФЃПщЩЯЯпСЫSparkКЭStormЃЌНЯдчЩЯЯпЕФЪЧSparkЃЌФПЧАСНИіЖМдкгУЕФдвђЪЧЫќЛсЪЪгІВЛЭЌЕФвЕЮёГЁОАЁЃ
Store
зюКѓУцЪЧЮвУЧЬсЙЉИјТфЕиЕФstoreВуЃЌЯёHIVEЁЂHbaseЕШЕШЁЃ
СїЙмРэЦНЬЈ
зюЯТУцЪЧСїЙмРэЦНЬЈЃЌЭМжагаЫФЬѕЯпСЌзХЫФИіКЫаФФЃПщЃЌЖдетЫФИіФЃПщНјааЗЧГЃживЊЧвЗЧГЃЗсИЛЕФТпМЙмРэЃЌАќРЈЪ§ОнЙмРэЁЂЖдИїНкЕуЕФМрПиЁЂжЮРэЁЂЪЕЪБУќСюЕФЯТЗЂЕШЁЃ
Ш§ЁЂСїЦНЬЈЩшМЦ
1ЁЂИХФюНтЖС
MessageЃЌОЭЪЧвЛЬѕЯћЯЂЃЌЪЧзюаЁЕФЪ§ОнЕЅЮЛЁЃвЕЮёЗНИјЕФвЛЬѕЪ§ОнОЭЪЧвЛИіmessageЃЛЮвУЧШЅВЩМЏЮФМўЕФЛАЃЌвЛааЪ§ОнОЭЪЧвЛИіmessageЁЃ
AS-ProtocolЃЌЪЧЮвУЧздМКЩшМЦЕФСїЦНЬЈЪ§ОнЕФЖдЯѓЃЌЫќЛсЖдвЛХњСПЕФmessageНјааДђАќЃЌШЛКѓдйМгЩЯвЛаЉБивЊЕФБфСПзівЛИіЗтзАЁЃ
EvnetЃЌЛсЬсЙЉвЛИіРрЫЦЕФБъзМНгПкЃЌетИіЕиЗНЦфЪЕИќЖрЕФЪЧЮЊСЫДђЭЈВЩМЏЕФСїЦНЬЈЁЃЫќзюживЊЕФвЛИіБфСПЪЧTopicЃЌОЭЪЧЫЕЮвФУЕНСЫЮвЕФAS-ProtocolОЭПЩвдИљОнЖдгІЕФTopicЗЂЕНЯргІЕФЕЧТМШЅЛКДцЬсШЁЃЌвђЮЊЮвУЧЕФAS-ProtocolГ§СЫЦ№ЪМЖЫКЭНсЪјЖЫвдЭтЃЌжаМфВуЪЧВЛгУНтЮіавщЕФЁЃ
TypeЃЌЪ§ОнИёЪНФПЧАЪЧJsonКЭHiveИёЪНЃЌПЩвдИљОнвЕЮёШЅРЉеЙЁЃ
CompressЃЌHiveИёЪНдкПеМфЩЯвВЪЧЗЧГЃгагХЪЦЕФЃЌЗЧГЃЪЪКЯгкЭјТчДЋЪфбЙЫѕЁЃЕБбЙЫѕЪ§ОндДжЪСПУЛгаДяЕНвЛЖЈСПЕФГЬЖШЕФЪБКђЛсдНбЙдНДѓЃЌЫљвдЮвУЧвЊХаЖЯЪЧЗёашвЊбЙЫѕЁЃЮвУЧбЙЫѕВЩгУЕФЪЧвЛИіШЋЯЕЭГ
Data_timestampЃЌЪ§ОнЕФЪБМфЪЧзюЩЯУцЕФmessageЃЌУПвЛИіmessageЛсаЏДјвЛИіЪ§ОнЪБМф.етИіБШНЯКУРэНтЃЌОЭЪЧШыПтжЎКѓЛсгУзіЪ§ОнЭГМЦКЭЗжЮіЕФЁЃ
Send_timestampЃЌЗЂЫЭЪБМфЛсаЏДјдкЮвУЧЕФAS-ProtocolРяЃЌЫќЩљУїСЫУПвЛИіЪ§ОнАќЗЂЫЭЕФЪБМфЁЃ
Unique KeyЃЌУПвЛИіЪ§ОнАќЖМгавЛИіЮЈвЛЕФБъЪЖЃЌетИівВЪЧЗЧГЃживЊЕФЃЌЫќЛсИњзХAS-ProtocolКЭEventзпЭЈећИіЦНЬЈЕФЪ§ОнСДТЗЃЌдкзіЪ§ОнЖЈЮЛЁЂЮЪЬтЖЈЮЛЕФЪБКђЗЧГЃгагУЃЌПЩвдУїШЗВщЕНУПИіЪ§ОнАќдкФФИіСДТЗОРњСЫЪВУДЪТЧщЁЃ
TopicЁЃетИіВЛашЖрбдЁЃ
Data_GroupЃЌЪ§ОнЗжзщЪЧЮвУЧЗЧГЃКЫаФЕФвЛИіЩшМЦЫМЯыЃЌддђЩЯЮвУЧЪЧвЛИівЕЮёЖдгІвЛИіЪ§ОнЗжзщЁЃ
ProtobufађСаЛЏЃЌЮвУЧЛсЖдEventЪ§ОнзівЛИіPTађСаЛЏЃЌШЛКѓдйЭљЩЯУцДЋЃЌетЪЧЮЊСЫНкЪЁЪ§ОнСїСПЁЃ
2ЁЂавщЩшМЦ
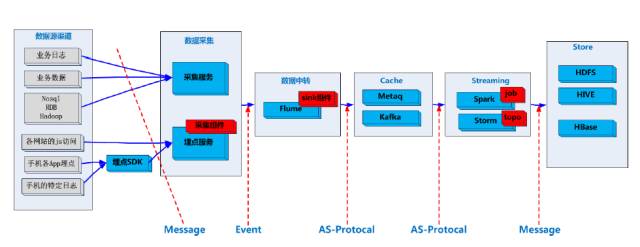
ШчЭМЫљЪОЮЊEventЁЂAs-ProtocolКЭMessageЕФЙиЯЕЁЃ
зюЩЯВуЪЧEventЃЌРяУцгавЛИіUnique KeyКЭTopicАќРЈСЫЮвУЧЕФAs-ProtocolЃЌШЛКѓЪЧЪ§ОнИёЪНЁЂЗЂЖЏЪБМфЪЧЗёбЙЫѕЁЂгУЪВУДЗНЪНбЙЫѕЃЌЛЙаЏДјвЛаЉЖюЭтЕФБфСПЁЃзюКѓУцЪЧвЛИіBodyЃЌBodyЦфЪЕОЭЪЧвЛИіmessageЕФЫожїЃЌвдзжНкСїЕФЗНЪНДцДЂЁЃетИіОЭЪЧЮвУЧвЛИіЪ§ОнЖдЯѓЕФавщЩшМЦЁЃ
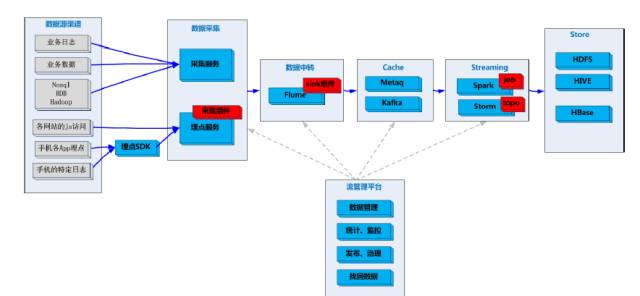
НгЯТРДПДЪ§ОндкећИіМмЙЙРяЪЧШчКЮСїзЊКЭДЋЪфЕФЁЃ
ЪзЯШЪЧЪ§ОндДЧўЕРЃЌзюзѓБпЕФЪЧmessageЃЌШЮКЮвЕЮёЗНЕФЪ§ОнЙ§РДЖМЪЧвЛЬѕmessageЃЌОЙ§Ъ§ОнВЩМЏАбвЛХњmessageДђАќЗтзАГЩEventЃЌдйЗЂИјЪ§ОнжазЊФЃПщЃЌвВНаflumeЁЃАбEventВ№ГіРДЃЌгавЛИіtopicЃЌзюКѓАбAs-protocolЗХЕНЯргІЮЛжУЛКДцЃЌЯћЗбЖдгІЕФTopicЃЌФУЕНЖдгІЕФAs-ProtocolЃЌВЂАбетИіЪ§ОнАќНтЮіГіРДЃЌЕУЕНвЛЬѕвЛЬѕЕФmessageЃЌетЪБОЭПЩвдНјааДІРэЁЂШыПтЛђЪЕЪБМЦЫуЁЃ
ашвЊЬиБ№зЂвтЕФЪЧmessageКЭEventЁЃУПИіMessageЕФвЕЮёСПМЖЪЧВЛвЛбљЕФЃЌгаМИЪЎBЁЂМИАйBЁЂМИЧЇBЕФВюБ№ЃЌДђАќГЩAs-ProtocolЕФЪБКђвЊЪдЪдХњСПЕФЪ§ФПгаЖрЩйЃЌддђЩЯбЙЫѕКѓЕФЪ§ОнгаИіНЈвщжЕЃЌетИіНЈвщжЕЪгвЕЮёЖјЖЈЃЌDataGroupДђАќЕФЪ§СПЪЧПЩвдХфЕФЁЃ
3ЁЂЪ§ОнЗжзщЩшМЦ
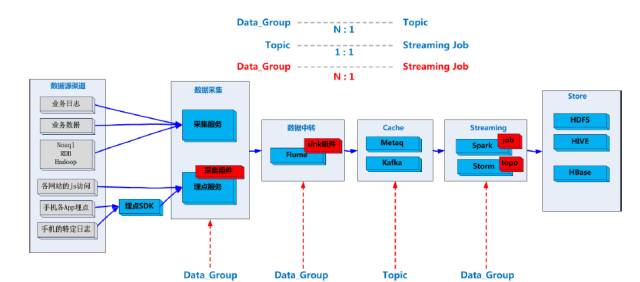
ШчЭМЫљЪОЪЧЮвУЧЕФDataGroupЩшМЦЁЃЪзЯШПДзюЩЯУцЃЌвЛИіTopicПЩвдЖЈвхNИіDataGroupЁЃЭљЯТЪЧTopicКЭstreaming
JobвЛБШвЛЕФЙиЯЕЃЌОЭЪЧЫЕвЛИіЪЕЪБЕФGroupжЛашвЊЖдгІвЛИіTopicЃЌШчЙћСНИівЕЮёВЛЯрЙиОЭЖдгІЕФСНИіTopicЃЌгУСНИіJobШЅДІРэЃЌзюКѓЕУЕНЯывЊЕФЙиЯЕЁЃ
ДгМмЙЙЭМПЩвдПДЕНDataGroupЕФХЄзЊЙиЯЕЁЃзюГѕЪ§ОнВЩМЏУПвЛИіНкЕуЛсЩљУїЫќЪЧЪєгкФФвЛИіDataGroupЃЌЩЯДЋЪ§ОнЛсДІгкетИіDataGroupЃЌОЙ§Ъ§ОнжазЊЗЂИјЮвУЧЕФЗжВМЪНЛКДцвВЖдгІСЫTopicЯТУцВЛЭЌЕФЗжзщЪ§ОнЁЃзюКѓStreamingНЛИјЮвTopicЃЌЮвПЩвдЫЇбЁГідкзюЩЯУцЕФЙиЯЕЃЌШЅХфжУDataGroupЃЌПЩвдЗЧГЃСщЛюЕизщКЯЁЃетОЭЪЧDataGroupЕФЩшМЦЫМЯыЁЃ
ЫФЁЂВЩМЏзщМўAgent
1ЁЂИХЪі
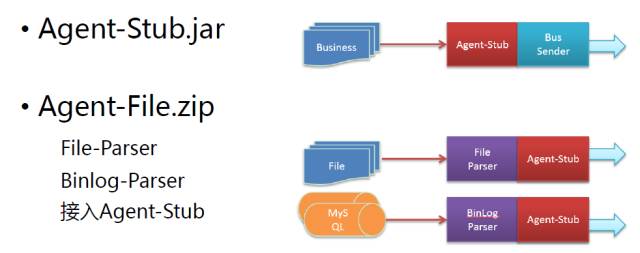
ШчЭМЫљЪОЃЌетЪЧЭъШЋгЩЮвУЧздМКЩшМЦКЭЪЕЯжЕФвЛПюзщМўЁЃгвБпЪЧВЩМЏзщМўЃЌЗжЮЊСНВПЗжЃКвЛИіЪЧЛљгкjavaЛЗОГЕФЖРСЂЙЄзїГЬађЃЛСэвЛИіЪЧjarВхМўЁЃВхМўНаAgen-Stub.jarЃЛЖРСЂВуЪЧAgent-File.zipЃЌAgent-FileгавЛИіparesrжЇГжВЛЭЌЕФЮФМўРраЭЃЌФПЧАжЇГжЕФfileКЭBinlogЃЌПЩРЉеЙЁЃИљОнашвЊПЩвддіМгparserЃЌвВЪЧНгШыAgent-stubЃЌгЕгаAgent-stubЕФвЛаЉЬиадЁЃ
ШчЩЯЭМгвВрЕФЪОвтЭМЃЌAgent-stubНгШыЖрИіBusinessЃЌЧАУцЬсЕНЕФвЛИіТёЕуЗўЮёОЭЪЧвЛИіBusinessЃЌЫќАбЪ§ОнНЛИјAgent-stubЃЌAgent-stubЛсЭљКѓЗЂеЙЃЌгыfileКЭmysQLЯрЖдгІЕФЪЧfile
parserЃЌГіРДЪЧAgent-stubЃЌСїГЬЪЧвЛбљЕФЁЃ
2ЁЂAgent-Stub.jar
НгЯТРДПДAgent-StubЪЧШчКЮЩшМЦЕФЁЃ
ЖрЯпГЬЁЂвьВНЁЃетИіКСЮовЩЮЪЃЌзіВхМўЛЏПЯЖЈЪЧетбљПМТЧЕФЃЌВЛФмзшШћЩЯВувЕЮёЁЃ
ФкДцаЁЖгСа+ДХХЬбЙЫѕЖгСаЁЃетЪЧЮвУЧИФНјзюДѓЕФвЛИіЕиЗНЃЌдчЦкАцБОжаЮвУЧВЩгУЕФЪЧФкДцДѓЖгСаЃЌШчЙћжЛгаФкДцДѓЖгСаШБЕуЗЧГЃУїЯдЃК
ГЬађе§ГЃЦєЖЏЕФЪБКђДѓЖгСаРяЕФЪ§ОндѕУДАьЃПвЊЕШЫћЗЂЭъТ№ЃПЛЙЪЧВЛЗЂЭъЃПЕБДѓЖгСаШћТњЕФЪБКђЃЌЛЙгаЖдЩЯВувЕЮёЕФЧжШыаддѕУДАьЃПГЬађгіЕНЮЪЬтЪБдѕУДАьЃПДѓЖгСаПЩФмЪЧ50ЭђЁЂ100ЭђЩѕжСИќЖрЁЃ
ВЩгУСЫФкДцаЁЖгСа+ДХХЬбЙЫѕЖгСаКѓПЩвдНтОіе§ГЃГЬађЕФЦєЭЃЃЌБЃжЄЪ§ОнУЛгаЮЪЬтЃЌЛЙПЩвдНтОіПеМфЕФеМгУЧхПеадЕФЮЪЬтЃЌвдДЫЭЌЪБЃЌДХХЬбЙЫѕЖгСаЛЙПЩвддкГЬађГіДэЕФЪБКђМгЫйЗЂЫЭЁЃ
НтЪЭвЛЯТДХХЬбЙЫѕЖгСаЃЌ етДЮЮвУЧЩшМЦавщЕФЫМЯыКмМђЕЅЃКбЙЫѕжЎКѓЕУЕНвЛИізжНкЫйЖШЃЌДцдкДХХЬЕФЮФМўРяЃЌетИіЮФМўАДееаЁЪБДцДЂЃЌетЪБЖдгкЖўДЮЗЂЫЭДјРДЕФЫ№КФВЂВЛДѓЃЌВЛашвЊжиаТзшЖЯЪ§ОнвВВЛашвЊНтЮіКЭбЙЫѕЃЌжЛашвЊЖСГіРДЗЂГіШЅЁЃКѓУцЛЙгавЛИіЬсЩ§ОЭЪЧДХХЬЗЂЫЭЖгСаИњФкДцЗЂЫЭЖгСаЪЧЕЅЖРЗжПЊЕФЃЌетбљИќФмЬсЩ§ЖўДЮЪ§ОнЕФЗЂЫЭадФмЁЃ
ЮоЫ№ЦєЭЃЁЃе§ГЃЕФЦєЖЏКЭЭЃжЙЃЌЪ§ОнЪЧВЛЛсЭЃжЙВЛЛсЖЊЪЇЕФЁЃ
AgentЕФАцБОКХздЖЏЩЯБЈЦНЬЈЁЃетИіЗЧГЃживЊЃЌЮвУЧдчЦкЕФАцБОЪЧУЛгаЕФЃЌПЩвдЯыЯѓвЛЯТЕБФуЕФAgentНкЕуЪЧМИЧЇЩЯЭђЃЌШчЙћУЛгавЛИіЦНЬЈжБЙлЕиЙмРэЃЌФЧНЋЪЧвЛИідѕбљПжВРЕФОжУцЁЃЯждкЮвУЧУПвЛИіAgentЦєЖЏЕФЪБКђЖМЛсДДНЈвЛИіnode
pathЃЌАбАцБОКХЗХЕНpathРяЃЌдкЙмРэЦНЬЈНтЮіетИіpathЃЌШЛКѓзіЗжРрЃЌЮвУЧЕФАцБООЭЪЧетбљЩЯБЈЕФЁЃ
здЖЏЪЖБ№НгШыдДЃЌжЧФмЙщРрЁЃетИіЦфЪЕКЭЩЯУцФЧЕуЪЧвЛбљЕФЃЌдкдчЦкАцБОжаЮвУЧзівЛИіAgentЕФБъЪЖЃЌЦфЪЕОЭЪЧвЛИіIP+вЛИіPODЃЌОЭЪЧЫЕФугаМИЧЇИіIP+PODСПБэашвЊШЫЙЄЙмРэЃЌЙЄзїСПЗЧГЃДѓЧвЗІЮЖЁЃЮвУЧгХЛЏСЫвЛИіздЖЏЪЖБ№ЃЌАбDataGroupЗХЕНAgentЕФnode
pathРяЃЌЙмРэЦНЬЈПЩвдзіЕНздЖЏЪЖБ№ЁЃ
AgentЕФШЋУцЪЕЪБМрПиЁЃАќРЈФкДцЖгСаЪ§ЁЂДХХЬЖгСаЪ§ЁЂдЫаазДЬЌЁЂГіДэзДЬЌЁЂqpsЕШЃЌЖМПЩвдAgentЩЯБЈЃЌВЂЧвдкЙмРэЦНЬЈжБЙлЕиПДЕНФФвЛИіНкЕуЪЧЪВУДбљзгЕФЁЃЦфзіЗЈвВвРРЕгкzookeeperЕФЪЕЯжКЭГадиЃЌетРяЦфЪЕОЭЪЧЖдzk
nodeЕФгІгУЃЌЮвУЧгавЛИіЖЈЪБЯпГЬЪеМЏЕБЧАAgentБивЊЕФЪ§ОнЃЌШЛКѓДЋЕНnodeЕФdataЩЯШЅЃЌЙмРэЦНЬЈЛсЛёШЁетаЉdateЃЌзюКѓзівЛИіЦНЬЈЛЏЕФеЙЪОЁЃ
жЇГжЪЕЪБУќСюЁЃАќРЈРЈЯоСїЃЌЛжИДЯоСїЁЂЭЃжЙЁЂЕїећаФЬјжЕЕШЃЌДѓДѓЬсИпСЫдЫЮЌФмСІЁЃЦфЪЕЯждРэвВЪЧвРРЕгкAgentЃЌетРяЮвУЧДДНЈвЛИіData
GroupЃЌЭЈЙ§ЙмРэЦНЬЈВйзїжЎКѓАбЪ§ОнЗХЕНData GroupРяЃЌШЛКѓЛсгавЛИіМрЬ§епШЅМрЬ§ЛёШЁЪ§ОнЕФБфЛЏВЂзїГіЯргІЕФТпМЁЃ
МцШнDockerЁЃФПЧАїШзхдкгУDokerЃЌDokerЖдЮвУЧетБпЕФAgentРДНВЪЧвЛИіЬєеНЃЌЫќЕФЦєЖЏКЭЭЃжЙЪЧЗЧГЃЬЌЛЏЕФЃЌОЭЪЧФуПЩФмШЯЮЊЯрЭЌЕФDockerШнЦїВЛЛсжиЦєЕкЖўДЮЁЃ
3ЁЂAgent-File.zip
НгШыAgent-StubЁЃ Agent-fileЪзЯШЪЧНгШыAgent-stubЃЌгЕгаAgent-stubЕФвЛаЉЬиадЁЃ
МцШнDockerЁЃвђЮЊЦєЖЏКЭЭЃжЙЕФГЃЬЌЃЌМйЩшЮвУЧИеИевЛИівЕЮёНгШыСЫAgent-stubЃЌФЧЭЃжЙЕФЪБКђЫќЛсЭЈжЊЮвЃЌAgent-stubЛсАбаЁЖгСаРяЕФЪ§ОнзЅЕНДХХЬбЙЫѕЖгСаРяШЅЁЃЕЋЪЧетРяашвЊзЂвтЕФЪЧЃКДХХЬбЙЫѕЖгСаВЛФмЗХЕНDockerздМКЕФЮФМўЯЕЭГРяЃЌВЛШЛЫќЭЃСЫжЎКѓЪ§ОнОЭУЛгаШЫФмЙЛЕУЕНСЫЁЃ
ЕБAgent-stubЭЃЕФЪБКђЃЌЛсгавЛИіБъЪЖЫЕДХХЬвЊзіЖгСаЃЌЮвУЧЕФЪ§ОнгаУЛгаЗЂЭъЃЌДХХЬбЙЫѕЖгСаРягавЛИіЦРМЖЕФБъЪЖЮФМўЃЌетЪБвЊгУЕНAgent-fileЃЌAgent-fileгавЛИіЕЅЖРЕФЩЈУшЯпГЬвЛИіИіЕиШЅЩЈУшDockerФПТМЃЌЩЈЕНетИіЮФМўЕФЪБКђХаЖЯЦфЪ§ОнгаУЛгаЗЂЭъЃЌШчЙћУЛЗЂЭъОЭжЛФмЕБзівЛИіЗЂЫЭепЁЃ
жЇГжжиЗЂРњЪЗЪ§ОнЁЃзіДѓЪ§ОнЕФПЩФмЖМжЊЕРетаЉУћДЪЃЌБШШчзђЬьЕФЪ§ОнвбОВЩМЏЭъСЫЃЌЕЋгЩгкФГаЉдвђгаПЩФмЪ§ОнгавХТЉЃЌашвЊдйХмвЛДЮКѓЖЫЕФВЙЬљТпМЃЌЛђепЩЯТэбЕСЗЃЌетЪБОЭвЊзіЪ§ОнжиЗЂЁЃЮвУЧдкЙмРэЦНЬЈЩЯОЭЛсгавЛИіжЇГжетжжЬиЖЈЮФМўЛђЬиЖЈЪБМфЖЮЕФбЁдёЃЌAgentНгЪеЕНетИіУќСюЕФЪБКђЛсАбЯргІЕФЪ§ОнЗЂЩЯШЅЃЌЕБШЛЧАЬсЪЧЪ§ОнВЛвЊБЛЧхСЫЁЃ
ЙмРэЦНЬЈзджњЩ§МЖЁЃетИіПЩвдРэНтГЩШэМўЩ§МЖЃЌAgentПЩвдЫЕЪЧЗЧГЃГЃМћЕФзщМўЃЌЕЋЪЧЮвУЧжиаТЩшМЦЪБАбздЖЏЩ§МЖПМТЧдкФкЃЌетвВЪЧЮвУЧЮЊЪВУДЩшМЦздМКзіЖјВЛЪЧгУПЊдДЕФзщМўЁЃетбљзіДјРДЕФКУДІЪЧЗЧГЃДѓЕФЃЌЮвУЧМИЧЇИіAgentдкЦНЬЈРяжЛашвЊвЛМќОЭПЩвдЭъГЩздЖЏЩ§МЖЁЃ
ЮФМўУће§дђБэДяЪНЦЅХфЁЃЮФМўУћЕФЩЈУшЪЧгУздЖЏБэДяЪНЁЃ
дДФПТМЖЈЪБЩЈУш and JnotifyЁЃжиЕуНщЩмЮФМўЩЈУшЛњжЦЁЃдчЦкЕФАцБОЪЧЛљгкAgent-fireКЭKO-FСНепНсКЯзіЕФЪ§ОнВЩМЏЃКAgent-fileЪЧМгТыРяЖдЮФМўБфИќЕФЪТМўМјЖЈЃЌАќРЈжиУќУћЁЂЩОГ§ЁЂДДНЈЖМгавЛИіЪТМўВњЩњЃЛKO-FЪЧФУЕНЮФМўЯТЕФзюМбЪ§ОнЁЃМйЩшдДФПТМРягавЛЧЇИіЮФМўЃЌKO-FЯжГЁОЭЪЧвЛЧЇИіЃЌAgent-fileЖдгІЕФЮФМўБфИяИГгшЕФзЗМгЁЂжиУќУћЕШЖМПЩФмЛсВњЩњвЛЯЕСаЪТМўЃЌТпМИДдгЁЃ
ЫљвдЮвУЧЩшМЦСЫдДФПТМЖЈЪБЩЈУшЕФЛњжЦЃЌЪзЯШгавЛИіФПБъЃЌОЭЪЧЮвУЧЕФЮФМўЖгСаЃЌАќРЈЮЊЮДЖСЮФМўЁЂвбЖСЮФМўзіЧјБ№ЃЌЧјБ№жЎКѓЩЈУшЃЌЕБШЛЛЙЛсгаЯёЮФМўеЊвЊЕШЕФДцдкетРяВЛЯИНВЃЌЩЈУшжЎКѓИќаТЮДЖСЮФМўЁЂвбЖСЮФМўСаБэЁЃ
жЎЫљвдМгJnotifyЪЧвђЮЊЮвУЧЗЂЯжжЛгУЖЈжЦЩЈУшВЛФмНтОіЫљгавЕЮёГЁОАЕФЮЪЬтЃЌjootifyдкетРяЦ№ЕНВЙГфЖЈжЦЩЈУшЕФзїгУЃЌНтОіЮФМўЗчЯеКЭЮФМўВњГЬЕФЮЪЬтЁЃ
ЕЅЮФМўЖСШЁЁЃдчЦкАцБОжаетвЛЕувРРЕгкЮФМўСаБэЃЌЕБЮФМўЗЧГЃЖрЪБГЬађБфЕУЗЧГЃВЛЮШЖЈЃЌвђЮЊПЩФмвЊПЊМИАйИіЛђМИЧЇИіЯпГЬЁЃКѓРДЮвУЧИФГЩСЫЕЅЮФМўЕФЖСШЁЃЌЩЯЮФЬсЕНЕФЩЈУшЛњжЦЛсВњЩњвЛИіЮФМўЖгСаЃЌШЛКѓДгЮФМўЖгСаРяЖСШЁЃЌетбљвЛИіИіЮФМўЁЂвЛЖЮЖЮЭМЃЌГЬађОЭЗЧГЃЮШЖЈСЫЁЃ
ЮФМўЗНЪНДцДЂoffsetЃЌЮоЫ№ЦєЭЃЁЃдчЦкВЩгУЧаШыЪНPTEзіДцДЂЃЌЯЮНгЗЧГЃжиЃЌКѓРДЮвУЧИФГЩЮФМўЗНЪНДцДЂЃЌЩшМЦЗЧГЃМђЕЅОЭжЛгаСНИіЮФМўЃКвЛИіЪЧФПТМЯТУцЫљгаЮФМўЕФoffsetЃЛвЛИіЪЧе§дкЖСЕФЮФМўЕФoffsetЁЃетРяЩцМАЕНЮоЫ№ЦєЭЃКЭВпТдЕФЮЪЬтЃЌЮвУЧЖЈСЫвЛИі5ДЮЫуЗЈЃКОЭЪЧУПЖССЫ5ДЮОЭЛсЫЂХЬвЛДЮЃЌЕЋжЛЫЂдкЖСЮФМўЃЌБ№ЕФЮФМўВЛЛсБфЛЏЃЌЫљвдПЩвдЯыЯѓЕУЕНЃЌЕБетИіГЬађБЛЬцЛЛзпЕФЪБКђЃЌзюЖрвВОЭЪЧжиИД5ЬѕЪ§ОнЃЌДѓЛсЕМжТЪ§ОнЖЊЪЇЁЃ
4ЁЂAgentЪОвтЭМ
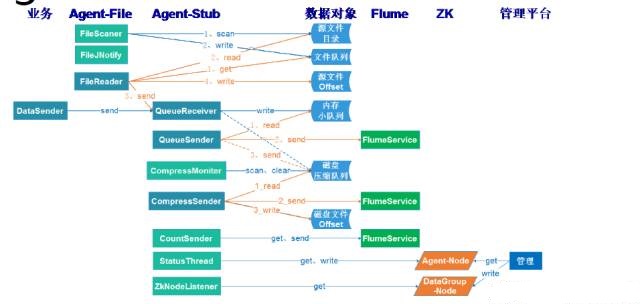
ШчЭМЪЧAgentЪОвтЭМЁЃЩЯУцЪЧAgent-fileКЭЪ§ОнЖдЯѓЁЃAgentЦєЖЏЕФЪБКђвЊАбРяУцЕФoffsetЮФМўШЁРДЃЌОЭЛсВњЩњЮДЖСЮФМўКЭвбЖСЮФМўСаБэЃЌЩЈУшЮФМўФПТМЃЌШЛКѓИќаТЮФМўЖгСаЃЌЛЙгавЛИіfileJNotifyЪЧЯрЖдгІЕФЮФМўЖгСаЁЃШЛКѓгавЛИіБШНЯживЊЕФfileReaderЃЌЮвЛсЯШДгЮФМўЖгСаРяФУЕНдйШЅЖСЪЕМЪЮФМўЃЌЖСЭъЫЂХЬжЎКѓетвЛПщОЭГЩЙІСЫЃЌЮвЛсИљОнЮвЕФЫЂХЬШЅЫЂаТoffsetЁЃ
ЩЯЭМзѓБпгавЛИівЕЮёМгСЫвЛИіAgent-stubЃЌзюКѓБфГЩflumeЃЌетРягавЛИіQueueReceiverЃЈЖгСаНгЪеепЃЉЃЌfilereaderКЭвЕЮёЗНЕФDataSenderЛсАбmessageЗЂЙ§РДЃЌQueueReceiverНгЪмЕФЪ§ОнОЭЪЧвЛЬѕЬѕЕФmessageЃЌШЛКѓЗЂЫЭЕНФкДцаЁЖгСаРяЃЌЕБетБпЕФаЁЖгСаТњСЫдѕУДАьФиЃПжаМфгавЛИіЖюЭтЕФЙЬЖЈДѓаЁЕФадФмЬсЩ§ЕФЕиЗНгУгкmessageЙщРрЃЌЕБетИіfIieReaderЭљетИіФкДцаЁЖгСаЗЂЕФЪБКђЗЂЯжШћВЛНјШЅСЫЃЌОЭЛсдкЙцЖЈДѓаЁЕФЖгСаРяЗЂЃЌЕБвЛИіЙЬЖЈДѓаЁЕФЖгСаТњСЫжЎКѓОЭЛсДђАќбЙЫѕЃЌвдзжНкДІРэЕФЗНЪНДцЕНДХХЬбЙЫѕЖгСаЁЃ
дйРДЫЕЫЕЮвУЧЮЊЪВУДЛсЬсГіЖўДЮЪ§ОнЕФЗЂЫЭЃЌЦфЪЕОЭЪЧЖрСЫвЛИіcountsenderМДбЙЫѕЖгСаЕФЗЂЫЭепЃЌжБНгЕФЪ§ОнРДдДЪЧДХХЬбЙЫѕЖгСаЃЌгыЩЯУцЕФВЂЩњУЛгаШЮКЮГхЭЛЁЃCountsenderЕФЪ§ОнЖдеЫЙІФмЪЧЮвУЧећИіЦНЬЈЕФКЫаФЙІФмжЎвЛЃЌЛљгкетИіЭГМЦЕФЪ§ОнШЗБЃСЫЦфЭъећадЃЌЩйвЛЬѕЪ§ОнЮвУЧЖМжЊЕРЃЌдкВЩМЏВугавЛИіcountsenderЃЌвдСэЭтвЛИіЧўЕРЗЂГіШЅЃЌКЭеце§ЕФЪ§ОндДЧўЕРВЛвЛбљЃЌЛсИќМгЕФЧсСПЛЏИќМгПЩППЃЌЧвЪ§жЕЗЧГЃаЁЁЃ
зюКѓЪЧЧАЮФЬсЕНЕФМрПиКЭУќСюЕФЪЕЯжЃЌвЛБпЪЧAgentnodeЃЌвЛБпЪЧЪ§ОнЙмРэЁЃ
5ЁЂAgentЕФПг
ЖЊЪ§ОнЁЃШчЧАЮФЬсЕНФкДцДѓЖгСаДјРДЕФЮЪЬтЁЃ
АцБОЙмРэЕФЮЪЬтЁЃ
tailf -fЕФЮЪЬтЁЃ
ЭјТчдвђЕМжТzkЩОНкЕуЮЪЬтЁЃЭјТчВЛЮШЖЈЕФЪБКђЃЌZKЛсгавЛИіНкЕуЕФаФЬјМьВтЃЌВЛЮШЖЈЕФЪБКђМрВтЛсвдЮЊНкЕувбОВЛДцдкСЫЖјАбНкЕуЩОЕєЃЌетЛсЕМжТЙмРэЦНЬЈЕФНкЕуМрПиЁЂЮФМўЯТЗЂШЋВПЖМЪЇаЇЁЃНтОіАьЗЈОЭЪЧдкmessageМгвЛВуПижЦМьВщЯпГЬЃЌЗЂЯжНкЕуВЛдкСЫдйДДНЈвЛБщЁЃ
ТвТыЕФЮЪЬтЁЃПЩФмЛсИњвЛаЉдЖГЬЗУЮЪЕФШэМўЯрЙиЃЌддђЩЯЮвУЧМйЩшЕкЖўДЮЦєЖЏЕФЪБКђУЛгаХфжУЮвУЧЕФБрТыЃЌФЌШЯгыЯЕЭГвЛжТЃЌЕЋЕБдЖГЬШэМўЦєЖЏЕФЪБКђПЩФмЛсЗЂЩњВЛвЛбљЕФЕиЗНЃЌЫљвдВЛвЊвРРЕгкФЌШЯжЕЃЌвЛЖЈвЊдкЦєЖЏГЬађРяЩшжУЯЃЭћЕФБрТыЁЃ
ШежОЮЪЬтЃЌдкВхМўЛЏЕФЪБКђПЯЖЈвЊПМТЧЕНвЕЮёЗНЕФШежОЃЌЮвУЧАбвЕЮёЗНЕФШежОЫЂЫРСЫЃЌЕБЭјТчГіЯжЮЪЬтЕФЪБКђУПЗЂЫЭвЛЬѕОЭЪЇАмвЛЬѕЃЌФЧЪЧВЛЪЧЖМвЊДђгЁГіРДЃПЮвУЧЕФПМТЧЪЧЕквЛЬѕВЛДђгЁЃЌКѓУцПЩФмЪЎЬѕДђгЁвЛДЮЃЌвЛАйЬѕДђгЁвЛДЮЃЌвЛЧЇЬѕДђгЁвЛДЮЃЌетИіСПШЁОігквЕЮёЁЃВЙГфвЛЕуЃЌЮвУЧгавЛИіЭГМЦЯпГЬЃЌПЩвдИљОнЭГМЦЯпГЬЙлВьAgentЕФе§ГЃгыЗёЁЃ
ЮхЁЂСїЙмРэЦНЬЈ 
ШчЭМЫљЪОЃЌЮвУЧЕФСїЙмРэЦНЬЈНчУцБШНЯМђЕЅЃЌЕЋЙІФмЗЧГЃЗсИЛЃЌАќРЈЃК
НгШывЕЮёЕФЙмРэЁЂЗЂВМЁЂЩЯЯпЃЛ
ЖдAgentНкЕуНјааЪЕЪБМрВтЁЂЙмРэЁЂУќСюЃЛ
ЖдFlumeНјааМрВтЁЂЙмРэЃЛ
ЖдЪЕЪБМЦЫуЕФjobЕФЙмРэЃЛ
ЖдШЋСДТЗЕФЪ§ОнСїСПЖдеЪЃЌетЪЧЮвУЧздМьЕФЙІФмЃЛ
жЧФмМрПиБЈОЏЃЌЮвУЧгавЛИіЗЧГЃШЫадЛЏЕФБЈОЏЗЇжЕЕФНЈвщЁЃШЁвЛИіЦНОљжЕЃЌБШШчвЛжмЛђвЛЬьЃЌЩшЖЈвЛИіЗЇжЕЃЌБШШчвЛЬьЕФСїСПЗУЮЪДЮЪ§ПЩФмЪЧвЛЧЇДЮЃЌЮвУЧЩшМЦЕФБЈОЏЪЧ2000ДЮЃЌЕБСЌајвЛжмЖМЪЧ2000ДЮЕФЪБКђОЭЕУИФНјЁЃ
СљЁЂЪ§ОнжазЊ
1ЁЂБГОА
вЕЮёЗЂеЙПЩФмДг1ЕН100дйЕН1000ЃЌЛђепЕБЙЋЫОЛЅСЊЭјЗЂеЙЕНвЛЖЈГЬЖШЕФЪБКђвЕЮёПЩФмБщВМЪРНчИїЕиЃЌїШзхЕФдЦЗўЮёЪ§ОнЗжЮЊКЃЭтЗўЮёКЭЙњФкЗўЮёЃЌЮвУЧАбвЕЮёВ№ЗжПЊРДЃЌДѓЪ§ОнВЩМЏПЯЖЈвВвЊИњзХзпЃЌетОЭУцСйзХЪ§ОнжазЊЕФЮЪЬтЁЃ
ШчЭМЫљЪОЪЧЮвУЧСНИіАИР§ЕФЪОвтЭМЁЃКкЩЋЕФЪЧФкЭјЕФЯпЃЌГШЩЋЕФЪЧПчНчадЕФЯпЃЌгаЙЋЭјЕФЁЂдЦЖЫЕФЁЂзЈЯпЕФЃЌИїжжИїбљЕФЭјТчЧщПіЁЃ
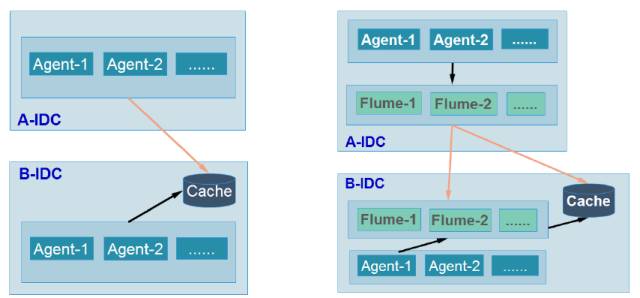
ЩЯУцЕФЪЧAgentМЏШКЃЌB-IDCвВгавЛИіAgentМЏШКЃЌжБНгЗУЮЪЮвУЧЕЧТМЕФМЏШКЁЃ
етРяЕквЛИіЮЪЬтЪЧЮвУЧЕФСЌНгЗЧГЃЖрЃЌЗУЮЪAgentНкЕуЕФЪБКђгаМИЧЇИіAgentНкЕуОЭЕУЗУЮЪМИЧЇИіНкЕуЃЌетЪЧВЛЬЋгбКУЕФЪТЧщЁЃСэвЛИіЮЪЬтЪЧЕБЮвУЧзіЩ§МЖЧЈвЦЕФЪБКђЃЌAgentвЊзіаоИФКЭХфжУЃЌБиаыЕУжиЦєЃЌЕБећИіB-IDCЧЈвЦЕНA-IDCЃЌЮвУЧМгСЫвЛИіFlymeМЏШКЁЃЭЌбљЪЧвЛИіAgentМЏШКЃЌЯТУцгавЛИіFlumeМЏШКЃЌетбљЕФКУДІЃКвЛЪЧРяУцЕФСЌНгЗЧГЃЩйЃЌЯпЩЯЕФFlumeвЛИіIDОЭШ§ЬЈЃЛЖўЪЧетБпГадиСЫЫљгаЕФAgentЃЌГ§СЫAgentЛЙгаЦфЫћЕФВЩМЏЖМдкA-IDCРяжазЊЃЌЕБетИіЦЌЧјвЊзіЩ§МЖЕФЪБКђЩЯУцЕФвЕЮёЪЧЭИУїЕФЃЌСщЛюадЗЧГЃИпЁЃ
2ЁЂFlumeНщЩм
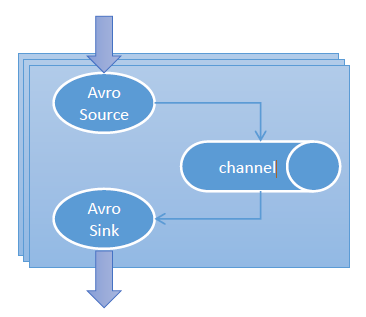
FlumeРягаШ§ИіКЫаФЕФВПЗжЃКSourceЁЂChannelЁЂSinkЃЌSourceЪЧЪ§ОнНсЙЙдДЃЛChannelЯрЕБгкФкДцДѓЖгСаЃЌSinkЪЧЪфГіЕНВЛЭЌЕФФПБъЁЃЙйЗНЬсЙЉСЫКмЖрзщМўЃКAvroЁЂHTTPЁЂThriftЁЂMemoryЁЂFileЁЂSpillable
MemoryЁЂAvroЁЂThriftЁЂHdfsЁЂHiveЁЃ
3ЁЂFlumeЪЕМљ
ЮоGroupЃЌВЩгУZookeeperзіМЏШК
AgentВЩгУLBзіИКдиОљКтЃЌЖЏЬЌИажЊЁЃНсКЯZookeeperПЩвдИажЊЕНAgentСаБэЃЌетЪБЛсВЩгУИКдиОљКтЕФзіЗЈевЕНЕБЧАЕФФЧИіFlumeЃЌЕНКѓЖЫЕФFlumeжБНгБфЛЏЕФЪБКђПЩвдИажЊЕНДгЖјЯТЯпЁЃ
гВХЬЛКДцЁЂЮоЫ№ЦєЭЃЁЃВЩгУmemoryПЩФмЛсДјРДаЉВЛКУЕФЮЪЬтЃЌШчЙћФкДцЖгСаИФГЩЮФМўОЭУЛгаетИіЮЪЬтЁЃвђЮЊФкДцЫйЖШПьЃЌДцДЂЧПжЦЫЂаТЕФЪБКђОЭУЛгаЪ§ОнСЫЃЌЫљвдЮвУЧзіСЫгХЛЏЃКЛЙЪЧВЩгУmemoryЃЌдкFlumeЭЃЕФЪБКђАбЪ§ОнВЩМЏЯТРДЃЌЯТвЛДЮЦєЖЏЕФЪБКђАбЪ§ОнЗЂГіШЅЃЌетЪБОЭПЩвдзіЕНЮоЫ№ЦєЭЃЃЌЕЋЪЧгавЛЕуЧЇЭђвЊзЂвтЃКДХХЬЦфЪЕЪЧЙЬЛЏдкЛњЦїРяУцЃЌЕБетЬЈЛњЦїЭЃЯТВЛдйЦєЖЏЕФЪБКђЃЌБ№ЭќСЫАбЪ§ОнвЦзпЗЂГіШЅЁЃ
ЭЃжЙЫГађгХЛЏЁЃдкзігХЛЏЕФЪБКђгіЕНдДТыЕФаоИФЃЌЦфЪЕОЭЪЧFlumeЭЃжЙЫГађЕФгХЛЏЁЃдЩњРяКУЯёЯШЭЃжЙChannelЃЌШЛКѓЬсИпsinkЃЌетОЭЛсЕМжТЯывЊзіетИіЙІФмЕФЪБКђзіВЛЕНЁЃЮвУЧгІИУЯШАбетИіЪ§ОнИФЕєдйШЅЭЃжЙsinkзюКѓЭЃжЙChannelЃЌетбљОЭБЃжЄChannelРяЕФЪ§ОнПЩвдШЋВПЙЬЛЏЕНгВХЬРяЁЃ
ЖржжзЊЗЂЗНЪНЁЃЮвУЧЯждкЪЧШЋЧђЕФRBCЃЌжЇГжЙЋЭјЁЂФкЭјЁЂПчгђадзЈЯпЃЌЮвУЧЬсЙЉвЛИіЗЧГЃКУЕФЙІФмЃКhttp
sinkЃЌЫќвВЪЧвЛИіАВШЋЕФжЇГжsslЕФзЊЛЛЗНЪНЁЃ
здЖЈвхSinkЃЌЖрЯпГЬЗЂЫЭЃЈchannelЕФgetжЛФмЕЅЯпГЬЃЉЁЃ
4ЁЂЭЃжЙЫГађ
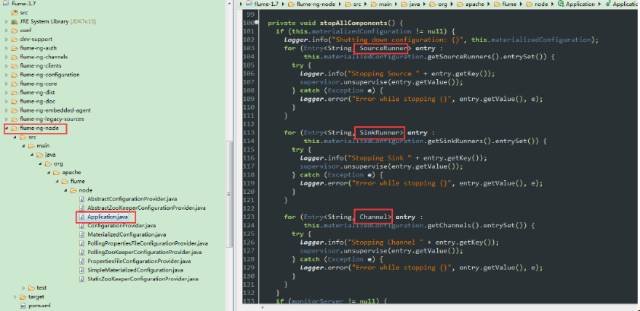
ШчЭМЪЧЭЃжЙЫГађЕФаоИФЁЃетЪЧвЛИіsourceRunnerЁЂsinkЁЂchannelЁЃ
5ЁЂMemoryЕФcapacity
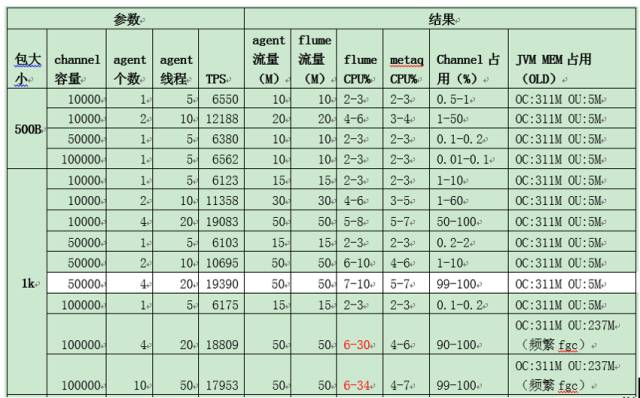
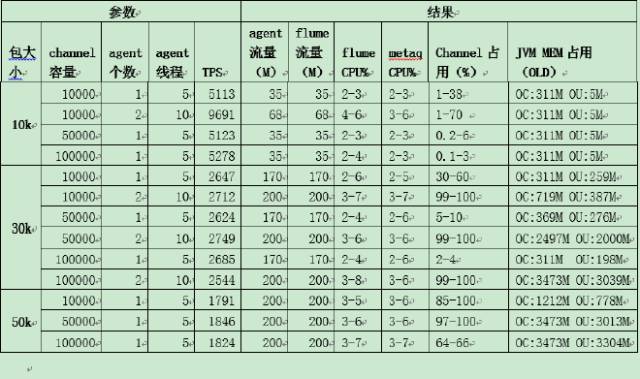
бЁдёФкДцжЎКѓЃЌетИіФкДцДѓаЁЕНЕзЖрЩйБШНЯКЯЪЪЃПШчЭМЫљЪОЃЌзѓБпFlumeЪЧДг500-1000ЃЌchannelШнСПЪЧ5ЭђЁЂ10ЭђЃЌЛЙгаAgentЕФИіЪ§ЁЂЯпГЬЃЌЮвУЧЗЂЯждк10ЭђЕФЪБКђЫќЕФfullGCЪЧЗЧГЃЦЕЗБЕФЃЌЫљвдЮвУЧзюКѓЖЈЕФДѓаЁЪЧ5ЭђЁЃЕБШЛВЛЭЌЕФЛњЦїИљОнВЛЭЌЕФВтЪдЕУЕНздМКЕФжЕЃЌетИіжЕВЛЪЧКуЖЈЕФЁЃ
АќДѓаЁДг10KЕН30KЕН50KгаЪВУДВЛвЛбљФиЃПКмУїЯдTPSДг1ЭђЖрНЕЕНСЫ2000ЖрЃЌвђЮЊАќдНДѓЭјПЈОЭдНТ§СЫЃЌетРяПДЕНЦфЪЕвбОЕНСЫ200езЃЈЫЋЭјПЈЃЉЃЌАбЭјПЈХмТњСЫЁЃЮвУЧзіСїЦНЬЈЩшМЦЕФЪБКђЃЌВЛЯЃЭћСДТЗБЛХмТњЃЌЫљвдЮвУЧИјСЫИіНЈвщжЕЃЌДѓаЁдк5-10KЁЃЕБШЛЃЌЯпЩЯЮвУЧВЩгУЕФЭђезЭјПЈЁЃ
ЦпЁЂЪЕЪБМЦЫу
1ЁЂЪЕЪБМЦЫуМЏШК
дкSparkZKРяжБНгаДHAЃЌПЩвдМѕЩйВЛБивЊЕФMRЬсИпIOЃЌМѕЩйIOЯћКФЁЃ
Kafka+Strom (ZK)
2ЁЂSparkЪЕМљ
жБНгаДHDFSЕзВуЮФМў
здЖЏДДНЈВЛДцдкЕФHiveЗжЧј
ЯргІMetaqЕФШежОЧаИюЃЌетвЛЕуЩЯЯждкЕФKafkaЪЧУЛгаЮЪЬтЕФЃЌЕБЪБЕФШежОЧаИюЛсЕМжТЭјТчСЌНгГЌЪБЃЌЮвУЧВщПДдДДњТыЗЂЯжШЗЪЕЛсЖТШћЃЌЮвУЧЕФНтОіЗНЗЈЪЧАбЧаИюЕїГЩЖрЩЋЛђЗжЧјЕїЖрЁЃ
ВЛвЊЖЈЪБЕФkillJobЁЃдчЦкЕФSparkАцБОвђЮЊДѓХњСПЕФkillJobЕМжТвЛаЉВЛЮШЖЈЕФЧщПіЃЌФГаЉjobЦфЪЕЪЧУЛгаБЛЭъШЋИВИЧЃЌМйЫРдкФЧРяЕФЁЃ |









