| вЊЕу
дкбЁдёЯЕЭГМмЙЙЪБЃЌЩьЫѕадКЭСьгђИДдгадЪЧСНИіживЊЕФПМТЧЕуЁЃ
ФЃПщЛЏЕЅЬхДцдкJARАќЕигќЃЈJAR hellЃЉЮЪЬтЃЌВЛЙ§НшжњвЛаЉЙЄОпПЩвдЛКНтетИіЮЪЬтЁЃ
ЕЅЬхФкЕФФЃПщЃЈЯёЮЂЗўЮёвЛбљЃЉашвЊДІРэздМКЕФЪ§ОнЃЌВЛЙ§ФЃПщЕНRDBMSжЎМфЕФМђЕЅгГЩфЛсЕМжТЪ§ОнПтФбвдЮЌЛЄЁЃгавЛаЉФЃЪНПЩгУгкДІРэетЗНУцЕФЮЪЬтЁЃ
ЖдгкФЃПщЛЏЕЅЬхРДЫЕЃЌЕзВуЕФММЪѕЦНЬЈашвЊОЁСПДІРэКУКсЖЯУцЃЈcross-cuttingЃЉЮЪЬтЃЌШУПЊЗЂШЫдБПЩвдзЈзЂдкИДдгЕФвЕЮёСьгђЩЯЁЃApache
IsisЃЈвдЯТМђГЦIsisЃЉКмЪЪКЯгУРДДІРэетЗНУцЕФЮЪЬтЃЌЫќВЩгУСЫСљБпаЮМмЙЙЃЈhexagonal architectureЃЉЃЌЖјЧвЪЕЯжСЫТуЖдЯѓФЃЪНЃЈnaked
objectes patternЃЉЁЃ
ПЊдДгІгУEstatioЃЈЛљгкIsisЃЉЪЧвЛИіКмКУЕФФЃПщЛЏЕЅЬхЪОР§ЁЃЫќПЩвдАяжњФуХаЖЯФуЕФСьгђЪЧЗёЪЪКЯЪЙгУЕЅЬхЃЈЛђЕЅЬхЯШааЃЉМмЙЙЁЃ
дкЮФеТЕФЕквЛВПЗжЃЌЮвУЧБШНЯСЫЕЅЬхЃЈИќзМШЗЕиЫЕЪЧФЃПщЛЏЕЅЬхЃЉКЭЮЂЗўЮёМмЙЙжЎМфЕФгХШБЕуЁЃЭЌЪБЃЌЮвУЧЛЙЬжТлСЫПЩЮЌЛЄадЁЂЪТЮёадЁЂИДдгадЁЂЩьЫѕадЁЂСщЛюадвдМАПЊЗЂаЇТЪЁЃ
ЮвУЧЕУГіЕФНсТлЪЧЃЌМмЙЙЕФбЁдёШЁОігкЪЕМЪЧщПіЁЃЭМ1СаГіСЫСНИіживЊПМТЧЕуЁЃ
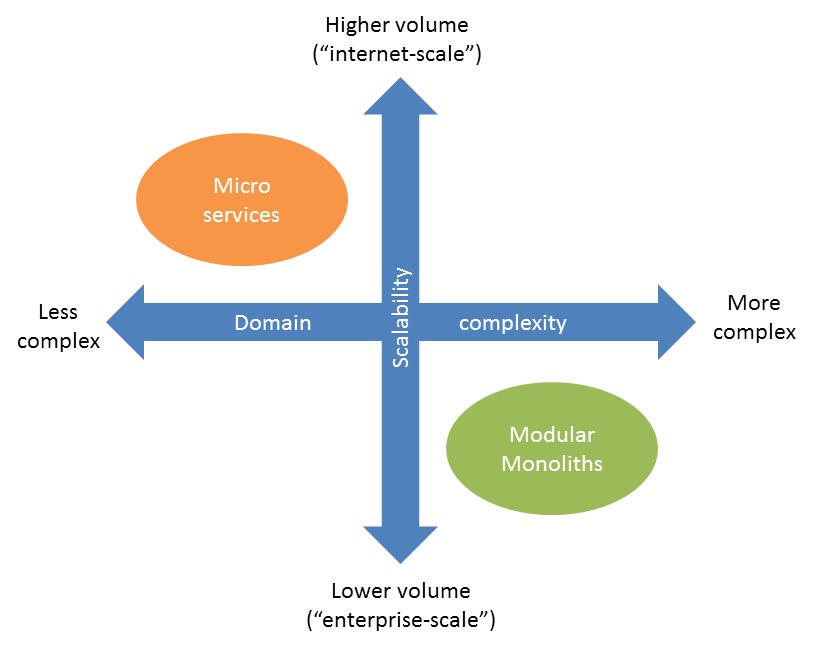
ЭМ1ЃКЩьЫѕадКЭСьгђИДдгад
ШчЙћСьгђЯрЖдМђЕЅЃЌЖјЧввЊДяЕНЁАЛЅСЊЭјЙцФЃЁБЃЌФЧУДВЩгУЮЂЗўЮёМмЙЙЛсБШНЯКЯЪЪЁЃВЛЙ§ШчЙћВЩгУЮЂЗўЮёМмЙЙЃЌашвЊдкЧАЦкЖЈвхКУУПИіЮЂЗўЮёЕФжАд№КЭНгПкЁЃ
ШчЙћСьгђЯрЖдИДдгЃЌЖјЧвЙцФЃгаЯоЃЈБШШчжЛдкЦѓвЕФкЪЙгУЃЉЃЌФЧУДВЩгУФЃПщЛЏЕЅЬхЛсБШНЯКЯЪЪЁЃЫцзХФуЖдСьгђЕФЩюШыСЫНтЃЌЖдЕЅЬхжАд№ЕФжиЙЙЛсЯрЖдМђЕЅЁЃ
ЖдгкИДдгЕФДѓЙцФЃЯЕЭГЃЌЮвШЯЮЊНјааЩьЫѕадгХЛЏВЛЪЧвЛИіУїжЧЕФзіЗЈЁЃЯрЗДЃЌЮвУЧПЩвдЯШЙЙНЈвЛИіФЃПщЛЏЕФЕЅЬхРДНтОіИДдгЕФСьгђЮЪЬтЃЌШЛКѓЫцзХЙцФЃЕФдіГЄЃЌж№ВНЯђЮЂЗўЮёМмЙЙЧЈвЦЁЃетжжЗНЪНБмУтСЫдквЛПЊЪМОЭЪЙгУКмИпЕФГЩБОРДЪЕЯжЮЂЗўЮёМмЙЙЃЌдкЕШЕНЙцФЃдіГЄЕНвЛЖЈГЬЖШЃЈгаСЫвЛЖЈЕФРћШѓЃЉжЎКѓЃЌИљОнвЕЮёЧщПізЗМгЭЖШыЁЃетЪЧвЛжжЛьКЯЕФМмЙЙЗНЪНЃКЯШДгЕЅЬхПЊЪМЃЌдкБивЊЪБдйГщРыГЩЮЂЗўЮёЁЃ
ЪЕЯжЮЂЗўЮёМмЙЙЪЧвЛМўМЋОпЬєеНадЕФЪТЧщЃЌВЛЙ§ЙЙНЈвЛИіФЃПщЛЏЕФЕЅЬхвВВЛФмЕєвдЧсаФЁЃдкЮФеТЕФЕквЛВПЗжЃЌЮвУЧжИГіСЫвЛаЉЧБдкЕФЮЪЬтЁЃ
ФЃПщЛЏЕЅЬхБиаыгЩЩшМЦСМКУЕФФЃПщзщГЩЃЌВЛЙ§вРШЛПЩФмГіЯжбЛЗвРРЕЮЪЬтЁЃЭЌЪБЛЙПЩФмГіЯжJARАќЕигќЮЪЬтЃЌЮвУЧЩдКѓНЋЛсЖдДЫеЙПЊЫЕУїЁЃ
ЫфЫЕУПИіФЃПщгІИУИКд№ДІРэздМКЕФЪ§ОнЃЌЕЋПЩвдДгЁАеНЪѕЁБЩЯНЋЖрИіФЃПщЕФЪ§ОнБЃДцдкЭЌвЛИіЪ§ОнДцДЂв§ЧцРяЃЌЕЋвЊШЗБЃВЛвЊШУЪ§ОнПтГЩЮЊвЛИіЁАДѓФрЧђЁБЁЃ
ФЃПщМфЕФЭЌВННЛЛЅДјРДИќКУЕФгУЛЇЬхбщЁЃВЛЙ§ЃЌетаЉФЃПщБиаыОпБИЖРСЂбнЛЏЕФФмСІЁЃбнЛЏНЯТ§ЕФФЃПщВЛгІИУвРРЕОГЃЗЂЩњБфИќЕФФЃПщЁЃ
ЮЊСЫШУПЊЗЂЭХЖгзЈзЂдкСьгђЮЪЬтЩЯЃЌашвЊШУЦНЬЈЛђПђМмОЁПЩФмЖрЕиДІРэКсЖЯУцЮЪЬтЁЃВЛЙ§ОЁЙмШчДЫЃЌвЕЮёТпМШдШЛПЩФмДгСьгђВуЩјЭИЕНЯрСкЕФГЪЯжВуЛђепГжОУЛЏВуЁЃ
дкЕкЖўВПЗжЃЌЮвУЧНЋНщЩмШчКЮНтОіЩЯЪіЕФМИИіЮЪЬтЃЌЮвУЧЛЙЛсНЋвЛИіецЪЕЕФЛљгкJVMЕФФЃПщЛЏЕЅЬхзїЮЊР§згЃЌЫќЪЙгУСЫвЛИіПЊдДПђМмРДЙмРэКсЖЯУцЮЪЬтЁЃ
ЮобЛЗвРРЕКЭJARАќЕигќЮЪЬт
дкФЃПщЛЏЕЅЬхРяЃЌЮвУЧашвЊЛЎЧхФЃПщЕФБпНчЁЃ
ЕквЛжжЗНЪНЪЧРћгУБрГЬгябдЕФЬиадЖдФЃПщЕФЙІФмНјааЗжзщЃЌБШШчАќЃЈJavaЃЉЛђепУќУћПеМфЃЈ.NETЃЉЁЃВЛЙ§етжжЗНЪНВЂВЛФмНЋФЃПщЭъШЋгыгІгУЕФЦфЫћВПЗжЭъШЋЧјБ№ПЊЃЌЖјЧвВЂВЛФмБЃжЄАќЛђУќУћПеМфВЛЛсГіЯжбЛЗвРРЕЁЃШчЙћжЛЪЙгУетжжЗНЪННјааФЃПщЛЏЃЌзюжеЕУЕНЕФКмПЩФмВЛЪЧвЛИіФЃПщЛЏЕЅЬхЃЌЖјЪЧвЛИіДѓФрЧђЁЃ
ЯрЗДЃЌЮвУЧашвЊИќбЯИёЕФНсЙЙЛЏЃЌВЂЧвПЩвдЪЙгУЙЄОпРДЧПЛЏФЃПщМфЕФЮобЛЗвРРЕЙиЯЕЁЃдкJavaЦНЬЈЩЯЃЌПЩвдЪЙгУMavenРДЙмРэЖрФЃПщЯюФПЃЌЖјдк.NETЦНЬЈЩЯЃЌПЩвдЪЙгУАќКЌСЫЖрИіC#ЯюФПЛђF#ЯюФПЕФЕЅИіVistual
StudioНтОіЗНАИЁЃетаЉДњТыБЛБрвыЕНвЛЦ№ЃЌЙЙНЈЙЄОпЃЈMavenЛђVisual StudioЃЉПЩвдШЗБЃФЃПщМфВЛДцдкбЛЗвРРЕЁЃ
ЕкЖўжжЗНЪНгавЛИіШБЕуЃЌвђЮЊЫљгаЕФДњТыЖМДцдкЭЌвЛИіДњТыПтРяЃЌВЂБЛБрвыЕНвЛЦ№ЃЌЫљвдЫќУЧгЕгаЯрЭЌЕФАцБОКХЃЌВЂЧвашвЊНјааећЬхЕФВтЪдЁЃЕЋдкЪЕМЪЕБжаЃЌВЛЭЌФЃПщЕФбнЛЏЫйЖШЪЧВЛвЛбљЕФЁЃЖдгкБфИќЛКТ§ЕФДњТыРДЫЕЃЌУЛгаБивЊНјааГжајЕФЙЙНЈКЭВтЪдЁЃ
ЕкШ§жжЗНЪНЪЧНЋФЃПщвЦЖЏЕНздМКЕФДњТыПтЃЌВЂгЕгаЖРСЂЕФАцБОКХЁЃдк.NETЦНЬЈЃЌЮвУЧПЩвдНЋУПИіФЃПщДђАќГЩNuGetАќЃЌЖјдкJavaЦНЬЈЃЌЮвУЧПЩвдАбФЃПщДђАќГЩMavenФЃПщЁЃЖдгкЪЙгУетаЉФЃПщЕФжїгІгУРДЫЕЃЌетаЉФЃПщгыЕкШ§ЗНЕФвРРЕАќЪЧВЛвЛбљЕФЁЃ
ВЛЙ§ЃЌЕкШ§жжЗНЪНвВПЩФмГіЯжбЛЗвРРЕЁЃР§ШчЃЌМйЩшcustomers 1.0ФЃПщвРРЕСЫaddresses
1.0ФЃПщЃЌШчЙћПЊЗЂШЫдБДДНЈСЫaddresses 1.1ЃЌВЂЧввРРЕСЫcustomers 1.0ЃЌФЧУДcustomersКЭaddressesжЎМфОЭаЮГЩСЫбЛЗвРРЕЃЌетЕБШЛВЛЪЧвЛМўКУЪТЁЃ
ЮЊСЫНтОіетИіЮЪЬтЃЌЮвУЧвЊШЗЖЈвРРЕЕФЗНЯђадЃКЪЧвЊШУcustomersвРРЕaddressesЃЌЛЙЪЧЗДЙ§РДЃПЮвУЧПЩвдзёбЮШЖЈадвРРЕддђЃКгІИУШУВЛЮШЖЈЃЈОГЃЗЂЩњБфИќЃЉЕФФЃПщвРРЕЮШЖЈЃЈКмЩйЗЂЩњБфИќЃЉЕФФЃПщЁЃдкЮвУЧЫљИјГіЕФР§згРяЃЌЮЪЬтБфГЩЃКФФИіБШНЯВЛЮШЖЈЃЌЪЧcustomersЛЙЪЧaddressesЃПШчЙћИуДэСЫвРРЕЕФЗНЯђЃЌПЩвдЪЙгУвРРЕЗДзЊддђНјаажиЙЙЁЃ
вРРЕЕФЗНЯђадКмШнвзЪЖБ№ЁЃгааЉФЃПщжЛАќКЌСЫв§гУЪ§ОнЃЌБШШчtax rateБэЛђепcurrencyЁЃЦфЫћФЃПщМИКѕВЛАќКЌЛђепжЛАќКЌЩйСПЕФв§гУЪ§ОнЃЌБШШчcounterpartiesКЭfixedassetsЃЌЛђепinstrumentsЁЃСэвЛИіР§згЪЧЁАЮФМўЙёЁБЃЌЫќжЛгУгкДцДЂЮФЕЕЛђепЭЈаХзЪСЯЁЃгІИУШУЦфЫћФЃПщвРРЕЩЯЪіЕФМИИіФЃПщЃЌЖјВЛЪЧЗДЙ§РДЁЃ
ЮвУЧЛЙПЩвдЪЙгУвЛаЉИќМгПЦбЇЕФЗНЪНЃЌЭЈЙ§АцБОПижЦЕФРњЪЗЪ§ОнМЦЫуУПИіФЃПщЕФЯрЖдВЈЖЏЪ§СПЁЃ
ЮвУЧПЩвдНЋЮШЖЈЕФФЃПщвЦЖЏЕНЫќУЧздМКЕФДњТыПтРяЃЌвЛЕЉЫќУЧБЛвЦЕНздМКЕФДњТыПтРяЃЌЦфЫћгІгУОЭПЩвджигУЫќУЧЁЃ
ЪЕМЪЩЯЃЌЮвУЧжЛвЊЧѓФЃПщМфОпгаЮШЖЈЕФНгПкЃЌжСгкНгПкБГКѓЕФЪЕЯжЪЧЗёЮШЖЈВЂВЛживЊЁЃНЋВЛЮШЖЈЕФЪЕЯжДњТывЦГіжїДњТыПтЪЧгаКУДІЕФЃЌвђЮЊетбљПЩвдБмУтГіЯжжїДњТыПтЕФДњТыВЈЖЏЁЃВЛЙ§етвЊЧѓФЃПщМфОпгае§ЪНЖЈвхЕФНгПкЁЃ
ЮЊСЫНѕЩЯЬэЛЈЃЌдкГіЯжбЛЗвРРЕЪБЃЌЮвУЧашвЊЬсЧАЕУЕНИцОЏЃЌзюКУЪЧдкЙЙНЈНзЖЮЛђепГжајМЏГЩЙмЕРРяЁЃетЪЧвЛИіПЩЪЕЯжЕФФПБъЁЃ
ШУЮвУЧЛиЕНжЎЧАЕФР§згЃЌcustomers 1.0вРРЕСЫaddresses 1.0ЃЌЭЌЪБaddresses
1.1вРРЕСЫcustomers 1.0ЁЃвђЮЊгІгУЛсжИЯђУПИіФЃПщЕФзюаТАцБОЃЌЮвУЧОЭЛсжЊЕРcustomers
1.0КЭaddresses 1.1жЎМфДцдкбЛЗвРРЕЁЃ
етИівРРЕОлКЯЮЪЬтЭЈГЃБЛГЦЮЊЁАJARАќЃЈЛђDLLПтЃЉЕигќЁБЁЃЭМ2еЙЪОСЫвЛИіКмГЃМћЕФР§згЃЌвЛИігІгУЪЙгУСЫСНИіПтЃЌетСНИіПтЗДЙ§РДЪЙгУСЫОпгаАцБОГхЭЛЕФЛљДЁПтЁЃ
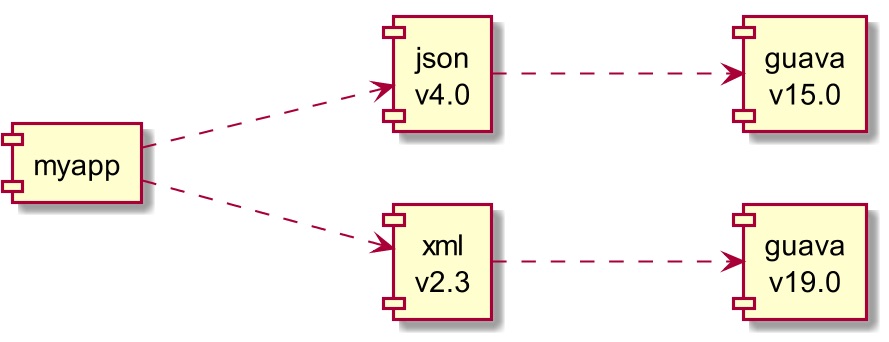
ЭМ2ЃКвРРЕОлКЯГхЭЛ
етИігІгУдкJVMЩЯдЫааЪБЃЌЛсХзГідЫааЪБСДНгДэЮѓЁЃдквЛАуЧщПіЯТЃЌJVMжЛЛсМгдиФГИіАцБОЕФРрвЛДЮЁЃ
ЮЊСЫНтОіетИіЮЪЬтЃЌПЩвдЪЙгУMavenЕФEnforcer PluginБъМЧвРРЕОлКЯЮЪЬтЃЌдкБивЊЧщПіЯТПЩвдШУЙЙНЈЪЇаЇЁЃПЊЗЂШЫдБПЩвддкpom.xmlЮФМўЕФ<dependencyManagement>РяжИЖЈвРРЕАќЕФАцБОЃЈвВПЩвдЪЙгУ<exclusions>ЃЉЁЃПЊдДПтЕФгявхАцБОдНРДдНСїааЃЌЫљвдЃЌШчЙћЭЌвЛИіПтЕФВЛЭЌАцБОКХжЛЪЧдкДЮвЊАцБОКХЃЈР§Шчv2.3гыv2.4ЕФВюБ№ЃЉЩЯДцдкВюБ№ЃЌФЧУДвЛАуОЭбЁдёИќИпЕФАцБОЁЃ
ШчЙћЪЙгУСЫNuGet 3.xЃЌФЧУДЁАОЭНќЁБвРРЕддђПЩвдДяЕНРрЫЦЕФаЇЙћЁЃ
гааЉЯюФПОГЃадЕиЗЂВМжїАцБОВЂЩОГ§ЦњгУAPIЃЌБШШчGuavaЃЌЭМ2жаЫљЪОЕФЕЅЬхвђДЫЮоЗЈе§ГЃдЫааЁЃЖдгкетжжЧщПіЃЌЮвУЧБиаыЭЈЙ§ИќаТЕНзюаТАцБОРДНтОівРРЕГхЭЛЮЪЬтЁЃШчКЮВЛдЪаэетУДзіЃЌЛђаэПЩвдГЂЪдгАзгЛЏЃЈжиаТДђАќЃЉвРРЕЁЃШчЙћЛЙЪЧВЛдЪаэЃЌФЧУДжЛФмжиЙЙДњТыРДНтОіГхЭЛЮЪЬтЃЌЩѕжСПМТЧвЦГ§вРРЕЁЃ
OSGiгІгУЃЈЛљгкJVMЃЉЭЈЙ§ЪЙгУВЛЭЌЕФРрМгдиЦїРДМгдиУПИіФЃПщСДЃЌДгЖјБмУтСЫетИіЮЪЬтЁЃВЛЙ§ЃЌЫфШЛOSGiгавЛЖЈЕФЪаГЁЃЌЕЋЫќжЛЪЧвЛжжР§ЭтЃЌЮвУЧВЛФмНЋЦфЪгзїЙцдђЁЃЖјЧвдкJava
9ЗЂВМJigsawФЃПщЯЕЭГжЎКѓЃЌЛђаэOSGiЛсЪЇШЅЫќЯжгаЕФЕиЮЛЁЃВЛЙ§JigsawвВВЂЗЧвјЕЏЃКЫќВЂУЛгаГЂЪдНтОівРРЕОлКЯЮЪЬтЃЌЖјЪЧАбетИіЮЪЬтСєИјСЫЙЙНЈЙЄОпШЅНтОіЃЈБШШчMavenЃЉЁЃ
змНсвЛЯТЃЌЪЙгУMavenЕФEnforcer PluginНтОівРРЕОлКЯЮЪЬтЃЌШчЙћГіЯжСЫГхЭЛЃЌПЩвддк<dependencyManagement>РяЩљУїНтОіЃЌБивЊЪБЪЙгУ<exclusions>ЁЃЮвАбетаЉМьВщЗХНјвЛИіНазїЁАresolving-conflictsЁБЕФ<profile>РяЃЌетбљПЩвдОГЃадЕиМьВщЕНвРРЕЮЪЬтЃЌВЂМѕЩйвРРЕЮЪЬтЕФГіЯжЁЃ
Ъ§Он
гыЮЂЗўЮёМмЙЙвЛбљЃЌФЃПщЛЏЕЅЬхРяЕФУПИіФЃПщИКд№ГжОУЛЏздМКЕФЪ§ОнЁЃдкДѓЖрЪ§ЧщПіЯТЃЌетаЉФЃПщЛсЪЙгУвЛИіЙиЯЕаЭЪ§ОнПтДцДЂЫќУЧЕФЪЕЬхЃКЙиЯЕаЭЪ§ОнПтдкЦѓвЕWebгІгУСьгђШдШЛеМОнзХживЊЕиЮЛЁЃетаЉБэБЛОлМЏЕНЕЅИіRDBMSРяЃЌДгЖјПЩвдЪЙгУЪТЮёЁЃ
дкФЃПщЪЕЬхЕНЪ§ОнПтЕФгГЩфЗНУцЃЌвђЮЊУПИіФЃПщЖМгаздМКЕФАќЛђУќУћПеМфЃЌЫљвдУПИіФЃПщашвЊБЛгГЩфЕНЪ§ОнПтЕФschemaЩЯЃЈФЃПщЕФЪЕЬхгГЩфГЩschemaЕФБэЃЉЁЃФЃПщЛђschemaЕФУћзжгІИУГЩЮЊИИБэБъЪЖзжЖЮЕФжЕЃЈР§ШчдкгГЩфМЬГаЙиЯЕЪБЃЉЁЃ
СьгђЖдЯѓФЃаЭКЭЙиЯЕаЭЪ§ОнПтжЎМфЕФвЛИіЙиМќЧјБ№дкгкЪЕЬхМфЙиЯЕЕФБэЪОЗНЪНЁЃдкФкДцРяЃЌЭЈЙ§ЖдЯѓжИеыБэЪОЖдЯѓМфЕФЙиЯЕЃЌЖјдкЪ§ОнПтРядђЪЙгУЭтМќЁЃШчЭМ3ЫљЪОЃЌРрЃЈзѓБпЃЉЕНБэЃЈгвБпЃЉжЎМфЕФжБНггГЩфЛсЕМжТЪЕМЪЕФвРРЕЙиЯЕЗНЯђдкЪ§ОнПтРяГіЯжЗДзЊЁЃ
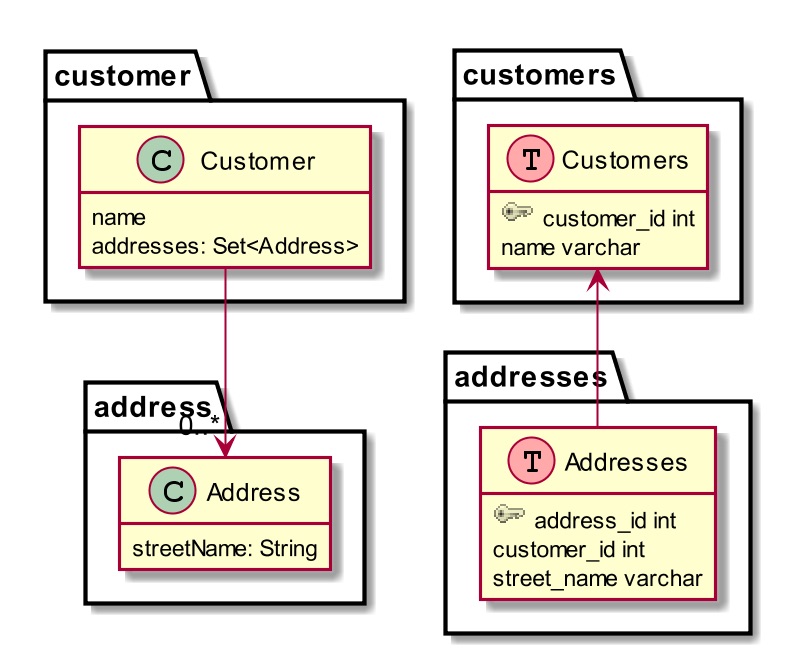
ЭМ3ЃКРрМфЙиЯЕгыБэМфЙиЯЕ
ГжгаCustomerЪЕЬхЕФЪЧCustomersБэКЭAddresses.customer_idзжЖЮЃЈвђЮЊетИіЭтМќгыCustomer.addressesЯрЙиЃЉЁЃМДЪЙдкДњТыРяУЛгабЛЗвРРЕЃЌЕЋЪЧЕНСЫЪ§ОнПтРяЃЌЫќУЧШДБфГЩСЫвЛИіДѓФрЧђЁЃ
ВЛЙ§ЮвУЧПЩвдНтОіетИіЮЪЬтЁЃЮЊСЫНЋCustomerаХЯЂБЃДцдкЯрЭЌЕФschemaРяЃЌЮвУЧвЊАбЭтМќвЦЕНвЛИіСЌНгБэРяЃЌШчЭМ4ЫљЪОЁЃадФмЕФЫ№ЪЇЦфЪЕЪЧЮЂВЛзуЕРЕФЁЃ
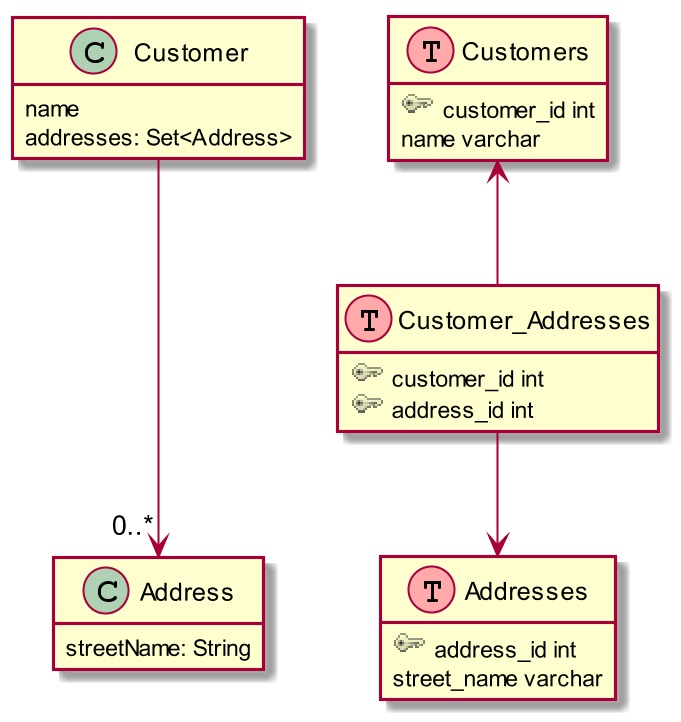
ЭМ4ЃКСЌНгБэ
ЫфШЛЮвШЯЮЊЮвУЧВЛгІИУетбљДІРэЭЌвЛИіФЃПщЪЕЬхЕФБэЙиЯЕЃЌЕЋШчЙћДѓМвМсГжвЊЪЙгУСЌНгБэЃЌФЧЮввВУЛгаЪВУДПЩЫЕЕФЁЃ
ЖдЯѓМфЕФЖрЬЌЙиСЊИќМгИДдгЁЃР§ШчЃЌЮвУЧПЩФмЯЃЭћНЋDocumentsЬэМгЕНЫљгаЕФСьгђЖдЯѓРяЁЃШчЭМ5ЫљЪОЃЌЮвУЧПЩвдв§ШыPaperclipЃЈвЛИіНгПкЃЉЕФИХФюЃЌШЛКѓЪЙгУОпЬхЕФЪЕЯжзїЮЊСЌНгБэЁЃ
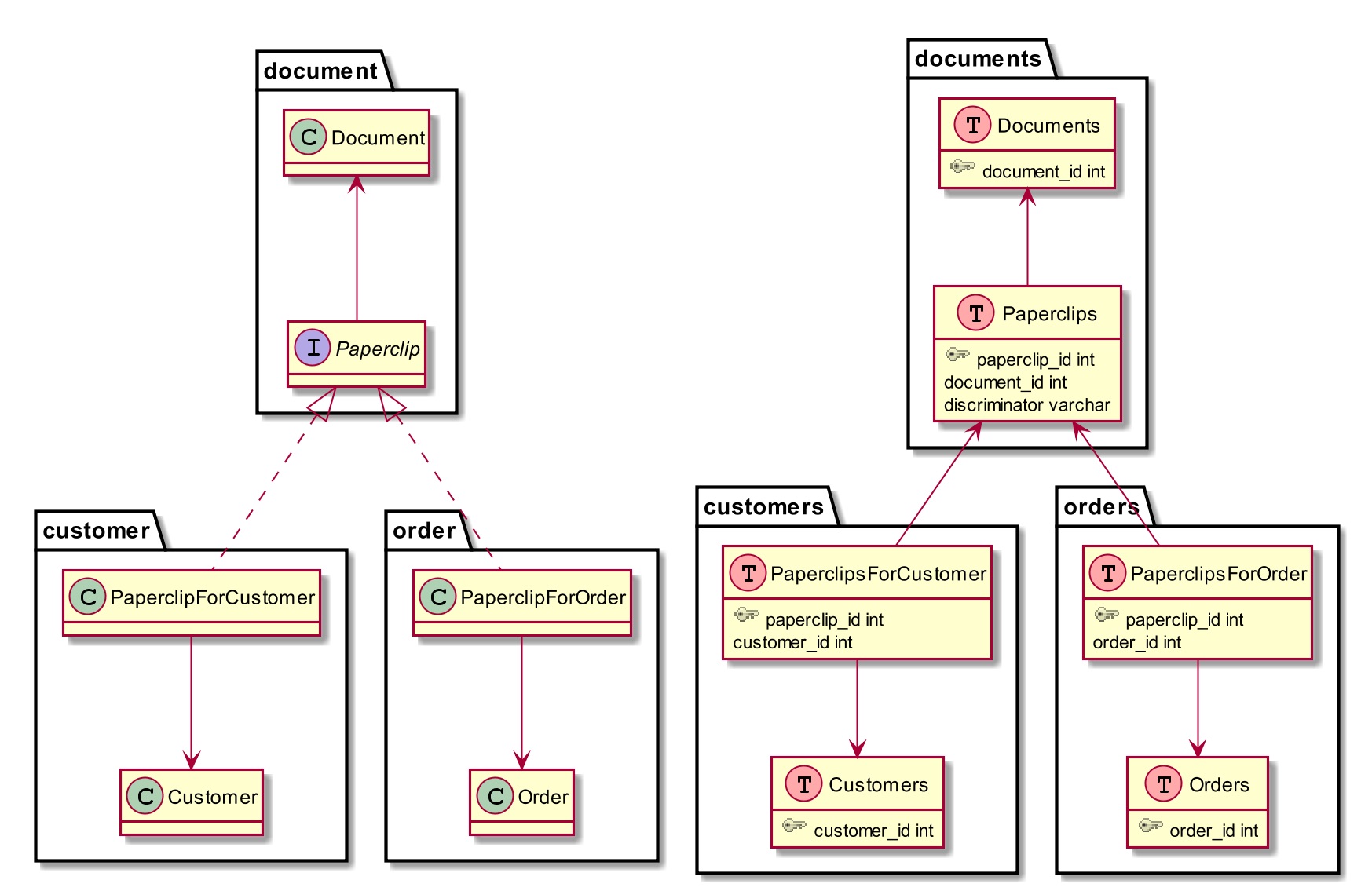
ЭМ5ЃКЖрЬЌЙиСЊ
УПИіPaperclipБЛгГЩфЕНСНеХБэЃЌвЛеХдкdocuments schemaРяЃЌвЛеХдкЫќЕФЪЕЯжschemaРяЃЌБШШчPaperclipsForCustomerЁЃPaperclips.discriminatorзжЖЮжИЖЈСЫОпЬхЕФЪЕЯжРраЭЁЃ
етжжгГЩфЕФКУДІдкгкЃЌдкЪ§ОнПтРяЮвУЧШдШЛПЩвдЮЌЛЄЫљгаБэМфЕФв§гУЭъећадЃЌЭЌЪБЃЌдкДњТыРяЮвУЧПЩвде§ГЃЕиЪЙгУPaperclipНгПкЁЃ
етжжФЃЪННтОіСЫЪ§ОнПтЕФНсЙЙёюКЯЮЪЬтЃЌЕЋВЂВЛвЛЖЈФмНтОіааЮЊёюКЯЮЪЬтЁЃдкЮФеТЕФЕквЛВПЗжЃЌЮвУЧжИГіЃЌПЊЗЂШЫдБПЩвджБНгЪЙгУSELECTгяОфДгФЃПщAРяВщбЏФЃПщBЕФЪ§ОнЁЃФЧУДетИіЮЪЬтИУШчКЮНтОіЃП
дкЮвЫљВЮгыЕФЕЅЬхЯЕЭГРяЃЌЮвУЧМШвЊБЃжЄЪ§ОнПтЕФБэМфНЛЛЅЃЌгжвЊНћжЙСйЪБЕФSELECTВщбЏЁЃдкЮвВЮгыЕФСэвЛИі.NETЕЅЬхЯюФПРяЃЌЮвУЧЪЙгУСЫEntity
FrameworkЃЌУПИіФЃПщЖдгІвЛИіЖРСЂЕФDBЩЯЯТЮФЃЌетбљвВПЩвдНтОіНсЙЙЛЏЮЪЬтЁЃEFжЛЙмРэФЃПщЛђDBЩЯЯТЮФФкЕФЭтМќЃЌЫљвдЮвУЧЪЙгУСЫжЎЧАЬсЕНЕФЖрЬЌСЌНгФЃЪНРДДІРэФЃПщМфЕФЙиЯЕЁЃдкJavaЦНЬЈЃЌЮвУЧЪЙгУСЫDataNucleusЃЈЪЕЯжСЫJDOКЭJPA
APIЃЉЃЌУПИіФЃПщгаздМКЕФГжОУЛЏЩЯЯТЮФЁЃ
ФувВаэЛсЮЪЃКЖдгкВЛФмЪЙгУORMПђМмЕФГЁОАИУШчКЮДІРэЃППЩвдетУДЫЕЃЌЛЈЕуЪБМфбЇЯАШчКЮЪЙгУROMЪЧжЕЕУЕФЃЌЫфШЛПЩФмХЩВЛЩЯгУГЁЁЃдкЮвЫљВЮгыСНИіЕЅЬхЯюФПРяЃЌЮвУЧУцЖдЕФЪЧвЛаЉЬиЪтЕФЧщПіЃЌБШШчДгЖрИіФЃПщЛёШЁДѓСПЕФЪ§ОнЃЌЮвУЧЪЙгУЪгЭМНЋЖрИіЯрЙиФЃПщЕФБэJOINЦ№РДЁЃORMПђМмВЂВЛжЊЕРвВВЛЙиаФЪЕЬхЪЧБЛгГЩфЕНБэЛЙЪЧЪгЭМЩЯЁЃетЪЧЖдадФмЕФгХЛЏЃКЪгЭМПЩвдЭГвЛИпаЇЕиДІРэвЕЮёЪ§ОнЁЃдкДњТыЗЂЩњБфИќЪБЃЌЪгЭМЕФЖЈвхвВФмЙЛБЛзЗзйЕНЃКЕБЮвУЧЮЊСЫТњзуаТЕФашЧѓЖјДђЦЦФЃПщБпНчЪБЃЌЮвУЧПЩвдПДЕНЮвУЧЫљзіЕФБфИќЁЃ
ЪТЮёадЃЈЭЌВНадЃЉ
вЕЮёашЧѓЕМжТЖрИіФЃПщЗЂЩњБфИќЃЌетЪЧКмГЃМћЕФЪТЧщЁЃР§ШчЃЌМйЩшЮвУЧвЊдкЦБОнЯЕЭГРяжДааЦБОнВйзїЃЌвЛАуЧщПіЯТжЛЛсаоИФЦБОнФЃПщЕФзДЬЌЃЌБШШчДДНЈInvoiceКЭInvoiceItemЖдЯѓЁЃВЛЙ§ЃЌШчЙћгааЉПЭЛЇвЊЧѓЪЙгУгЪМўЗЂЫЭЫћУЧЕФЦБОнЃЌФЧУДОЭЛсЩцМАЕНДДНЈDocumentЖдЯѓЃЈЮФЕЕФЃПщЃЉКЭCommunicationЖдЯѓЃЈЭЈаХФЃПщЃЉЁЃ
дкЮЂЗўЮёМмЙЙРяЃЌЗўЮёжЎМфУЛгаЪТЮёЃЌвВОЭЪЧЫЕЃЌЮвУЧБиаыЪЙгУЯћЯЂРДаЕїетаЉБфИќЁЃвђДЫЃЌЯЕЭГжЛгазюжевЛжТадЃЌШчЙћГіЯжСЫЮЪЬтЃЌашвЊЪЙгУВЙГЅВйзїРДЁАЛиЭЫЁББфИќЁЃдкФГаЉЯЕЭГРяЃЌетжжзюжевЛжТадЕФааЮЊШнвзШУгУЛЇКЭПЊЗЂШЫдБИаЕНРЇЛѓЁЃР§ШчЃЌCQRSФЃЪНЖдЖСаДНјааСЫЗжРыЃЌвЛИіЗўЮёаДШыЕФЪ§ОнВЛЛсСЂМДБЛСэвЛИіЗўЮёЖСШЁЕНЁЃ
ЖјЖдгкЕЅЬхРДЫЕЃЌШчЙћЦБОнФЃПщЁЂЮФЕЕФЃПщКЭЭЈаХФЃПщДцдкгкЭЌвЛИіRDBMSРяЃЌФЧУДЮвУЧОЭПЩвдвРРЕRDBMSЕФЪТЮёЛњжЦРДШЗБЃБфИќзДЬЌЕФдзгадЁЃДггУЛЇНЧЖШРДПДЃЌвЛЧаЖМБЃГжвЛжТЃЌВЛДцдкСюШЫРЇЛѓЕФжаМфзДЬЌЃЌЮоашзіГіШЮКЮВЙГЅВйзїЁЃЖдгкПЊЗЂШЫдБРДЫЕЃЌЫћУЧПЩвдСЂМДЖСШЁЕНаДШыЪ§ОнПтЕФЪ§ОнЁЃ
ЭЌВНааЮЊПЩвддкЦфЫћЗНУцЮЊгУЛЇЬхбщДјРДИФНјЁЃМйЩшУПвЛИіCustomerЖМгавЛИіЙиСЊЕФEmailAddressesМЏКЯЃЌВЂЧвЦфжаЕФвЛИігЪМўЕижЗгУгкЗЂЫЭЦБОнЁЃШчЙћгУЛЇЯывЊЩОГ§етИіЕижЗЃЌЦБОнФЃПщвЊЗёОіетИіЩОГ§ВйзїЃЌвђЮЊетИігЪМўЕижЗЁАе§дкЪЙгУжаЁБЁЃвВОЭЪЧЫЕЃЌЮвУЧЯывЊдкФЃПщМфЪЙгУЧПжЦЕФв§гУМьВщдМЪјЁЃ
вЊдкЮЂЗўЮёРяжЇГжетжждМЪјЪЧКмИДдгЕФЃЌЖјдкЕЅЬхРяЮвУЧОЭПЩвдКмЧсЫЩЕизіЕНЁЃЮвУЧПЩвдЪЙгУвЛИіФкВПЪТМўзмЯпЃЌПЭЛЇФЃПщЭЈЙ§ЫќЙуВЅЩОГ§гЪМўЕижЗЕФвтЯђЃЌЦфЫћФЃПщРяЕФЖЉдФепПЩвдЗёОіетИіБфИќЁЃ
public class Customer {
...
@Action(domainEvent = EmailAddressDeletedEvent.class)
public void delete(EmailAddress ea) {
...
}
} |
ЧхЕЅ1ЃКCustomerвЊЩОГ§гЪМўЕижЗЃЌДЅЗЂвЛИіЪТМў
ЖЉдФепДњТыШчЯТЁЃ
public class InvoicingSubscriptions {
@Subscribe
public void on(Customer.EmailAddressDeletedEvent
ev) {
EmailAddress ea = (EmailAddress)ev.getArg(0);
if(inUse(ea)) {
ev.veto(ЁАEmail address in use by invoicingЁБ);
}
}
...
} |
ЧхЕЅ2ЃКЩОГ§ЪТМўЕФЖЉдФеп
ЕзВуЕФЦНЬЈдкжДааЩОГ§жЎЧАЃЌЛсНЋEmailAddressDeletedEventЗЂЫЭЕНФкВПЕФЪТМўзмЯпЩЯЁЃШчЙћетИігЪМўЕижЗдкЪЙгУЕБжаЃЌЖЉдФепПЩвдЗёОіетИіЩОГ§ВйзїЁЃ
СэвЛжжЗНАИЪЧЮЊПЭЛЇФЃПщЩљУївЛИіЗўЮёЬсЙЉепНгПкЃЈSPIЃЉЃЌЦфЫћФЃПщПЩвдЪЕЯжетИіНгПкЁЃ
public class Customer {
...
public void delete(EmailAddress ea) {
...
}
public String validateDelete(EmailAddress ea)
{
return advisors.stream()
.map(advisor -> advisor.cannotDelete(ea))
.filter(reason -> reason != null)
.findFirst().orElse(null);
}
public interface DeleteEmailAddressAdvisor
{
String cannotDelete(EmailAddress ea);
}
@Inject
List<DeleteEmailAddressAdvisor> deleteAdvisors;
} |
ЧхЕЅ3ЃКCustomerЩОГ§гЪМўЕижЗЕФЖЏзїЃЌАќКЌСЫвЛИібщжЄВНжшКЭвЛИіSPI
вЛИіЪЕЯжСЫSPIЕФРрЁЃ
public class Invoicing implements DeleteEmailAddressAdvisor
{
public void cannotDelete(EmailAddress ea) {
if(inUse(ea)) {
return ЁАEmail address in use by invoicingЁБ;
}
return null;
}
...
} |
ЧхЕЅ4ЃКЪЕЯжСЫSPIЕФЦБОнФЃПщ
validateDeleteЪЧвЛИіЪиЛЄЗНЗЈЃЌдкdeleteЗНЗЈжЎМфЕїгУЁЃЫќгУгкХаЖЯгЪМўЕижЗЕФЩОГ§ВйзїЪЧЗёдЪаэБЛжДааЁЃетИіЗНЗЈБщРњЫљгазЂШыЕФSPIЪЕЯжЃЌШчЙћSPIЗЕЛивЛИіЗЧПежЕЃЌЫЕУїСЫВЛФмЩОГ§гЪМўЕижЗЕФдвђЃЌФЧУДОЭВЛФмжДааЩОГ§ВйзїЁЃ
ЛЙгаСэЭтвЛжжЪЙгУГЁОАЁЃДгЭМ5ЮвУЧПЩвдПДЕНЃЌВЛЭЌЕФФЃПщЭЈЙ§Б№еыНЋЮФЕЕИНМгЕНЫќУЧЕФЪЕЬхРяЁЃЛђаэгаШЫШЯЮЊЮФЕЕФЃПщПЩФмЛсЬсЙЉЁАИНМгЁБВйзїЃЌЕЋЪЕМЪЩЯЃЌжЛгаФЧаЉДцдкБ№еыЕФЪЕЬхВХФмжДааетИіВйзїЁЃЮФЕЕФЃПщЭЈЙ§ЯђФкВПЪТМўзмЯпЗЂВМЪТМўЛђепЭЈЙ§SPIРДЗЂЯжФФаЉЪЕЬхБЉТЖСЫЁАИНМгЁБВйзїЁЃ
@Mixin
public class Object_attach {
private final Object context;
public Object_uploadDocument(Object ctx) { this.context
= ctx; }
public Object attach(Blob blob) {
Document doc = asDocument(blob)
paperclipFactory().attach(context, doc);
}
public boolean hideAttach() {
return paperclipFactory() == null;
}
public interface PaperclipFactory {
boolean canAttachTo(Object o)
void attach(Object o, Document d);
}
PaperclipFactory paperclipFactory() {
return paperclipFactories.stream()
.filter(pf -> pf.canAttach(context))
.findFirst().orElse(null);
}
@Inject
List<PaperclipFactory> paperclipFactories;
} |
ЧхЕЅ5ЃКЭЈЙ§MixinНЋЮФЕЕИНМгЕНШЮвтЕФЖдЯѓЩЯ
Object_attachРрГфЕБСЫmixinЛђtraitЕФНЧЩЋЃЌЮЊЫљгаЖдЯѓЬсЙЉСЫИНМгЖЏзїЁЃВЛЙ§ЃЌЃЈЭЈЙ§ЗНЗЈвўВиЃЉетИіЖЏзїВЛЛсдкUIЩЯЯдЪОЃЌГ§ЗЧгаФмЙЛНЋЮФЕЕИНМгЕНЬиЖЈСьгђФЃаЭЖдЯѓЕФPaperclipFactoryРДГфЕБmixinЕФЩЯЯТЮФЁЃ
ЦНЬЈЕФбЁдё
ВЛЙмФубЁдёСЫЕЅЬхЛЙЪЧЮЂЗўЮёЃЌФуЖМашвЊФГжжЦНЬЈЛђепПђМмРДдЫааЫќУЧЁЃ
ЖдгкЮЂЗўЮёМмЙЙРДЫЕЃЌдкбЁдёЦНЬЈЪБжївЊЙизЂЭјТчЗНУцЕФЮЪЬтЃКЫќвЊБЃжЄЗўЮёМфЕФНЛЛЅГЉЭЈЮозшЃЈавщЁЂЯћЯЂБрТыЁЂЭЌВН/вьВНЁЂЗўЮёЗЂЯжЁЂЛиТЗЖЯТЗЦїЁЂТЗгЩЦїЃЌЕШЕШЃЉЃЌЖјЧвФмЙЛШУећИіЯЕЭГдЫааЦ№РДЃЈDocker
ComposeЃЌЕШЕШЃЉЁЃгУгкЪЕЯжУПИіЮЂЗўЮёЕФгябдОЭУЛгаФЧУДживЊСЫЃЌжЛвЊПЊЗЂГіРДЕФгІгУФмЙЛДђГЩПЩВПЪ№ЕФАќЃЌБШШчВПЪ№дкDockerШнЦїРяЃЈЕБШЛЃЌШчЙћбЁдёСЫФГжжПЊЗЂгябдЃЌЯюФПЭХЖгБиаыОпБИЯргІЕФММФмНјааГѕЦкЕФПЊЗЂвдМАКѓЦкЕФЮЌЛЄКЭжЇГжЃЉЁЃ
ЖдгкЕЅЬхМмЙЙРДЫЕЃЌвВашвЊвЛИіЙВЯэЕФЦНЬЈЃЌВЛЙ§ДЫЪБЛсИќЖрЕиЙизЂПЊЗЂгябдКЭЩњЬЌЯЕЭГЁЃжСЩйЃЌашвЊОіЖЈЪЧЪЙгУJavaЦНЬЈЛЙЪЧ.NETЦНЬЈЁЃдкбЁЖЈЦНЬЈжЎКѓЃЌЛђаэЛЙашвЊбЁдёвЛаЉПђМмЃЌБШШчJava
EEЛђепSpringЁЃ
ЕЅЬхЕФгХЪЦдкгкЫќФмДІРэИДдгЕФСьгђТпМЃЌЖјЕзВуЦНЬЈвЊОЁПЩФмЕиДІРэКУММЪѕКЭКсЖЯУцЮЪЬтЃЌБШШчАВШЋЁЂЪТЮёКЭГжОУЛЏЃЈЕБШЛЛЙгаЦфЫћЗНУцЕФЖЋЮїЃЉЁЃСэЭтЃЌвЕЮёФЃПщВЛгІИУвРРЕММЪѕФЃПщЃЌЮвУЧвЊОЁПЩФмЕиНгНќСљБпаЮМмЙЙЁЃ
ЕЅЬхЦНЬЈвВашвЊЬсЙЉЙЄОпЃЌгУгквЕЮёФЃПщжЎМфЕФНтёюЁЃЖдгкЕЅЬхРДЫЕЃЌЫќЕФНтОіЗНАИгыЮЂЗўЮёРрЫЦЃКЪЙгУЪТМўзмЯпЁЃВЛЭЌжЎДІдкгкЃЌЕЅЬхЕФЪТМўзмЯпЪЧдкНјГЬФкВПЃЌЖјЧвОпгаЪТЮёадЁЃ
вЛИіЃЈФЃПщЛЏЃЉЕЅЬхЪОР§
ЮвУЧЪЙгУвЛИіецЪЕЕФАИР§РДЫЕУїФЃПщЛЏЕЅЬхЃЌзїЮЊЮФеТЕФНсЮВЁЃ
етИігІгУГЬађНазїEstatioЃЌЪЧEurocommercial PropertiesЕФвЛИіЦБОнЯЕЭГЁЃEurocommercial
PropertiesЪЧвЛМвЪЕвЕЙЋЫОЃЌФПЧАдкХЗжоЕФ3ИіЙњМвдЫгЊзХ34МвЙКЮяжааФЁЃEstatioЕФдДДњТыПЩвддкGithubЩЯевЕНЁЃ
ЭМ6ЃКEstatioЕФНчУцНиЭМ
EstatioЕФЕзВуЪЙгУСЫIsisПђМмЃЌЫќЪЧвЛИіЛљгкJVMЕФШЋеЛПђМмЃЌгУгкДІРэЫљгаГЃМћЕФКсЖЯУцЮЪЬтЃЌБШШчАВШЋЁЂЪТЮёКЭГжОУЛЏЁЃГ§ДЫжЎЭтЃЌЫќЛЙзёбТуЖдЯѓФЃЪНЃЌЭЈЙ§Web
UIЛђREST APIздЖЏфжШОСьгђЖдЯѓЁЃвЛИіORMПђМмБЛгУгкНЋСьгђЖдЯѓгГЩфЕНвЛИіГжОУЛЏВуЃЌЖјIsisНЋСьгђЖдЯѓгГЩфЕНГЪЯжВуЁЃ
вђЮЊUIЪЧЭЈгУЕФЃЌЫљвддкВЛИФБфСьгђЖдЯѓФЃаЭЕФЧщПіЯТПЩвдГжајЕиЖдUIНјааИФНјКЭдіЧПЁЃР§ШчЃЌЩЯвЛИіАцБОЪЙгУBootstrapЖдIsisЕФЪгЭМНјааСЫИФНјЁЃдкетИіАцБОРяНјааИќаТЕФУПвЛИігІгУЖМЪЙгУСЫетИіИФНјЙ§ЕФЪгЭМЁЃаТАцБОЬэМгСЫЕиЭМЁЂШеРњКЭExcelЕМГіЙІФмЃЌЖјЧвПђМмЛсдкашвЊЫќУЧЕФЕиЗНздЖЏНЋЫќУЧфжШОГіРДЁЃ
гывЕЮёСьгђЖдЯѓЕФНЛЛЅЙсДЉСЫUIКЭећИіКсЖЯУцЃЌIsisНтОіСЫЫљгаЯрЙиЕФЮЪЬтЁЃР§ШчЃЌIsisЮЊУПвЛИіЕїгУВйзїЛђЪєадБфИќДДНЈБИЭќУќСюЃЈађСаЛЏЕНXMLЃЉЃЌдкЪТЮёЭъГЩКѓНЋУќСюЗЂВМЕНЪТМўзмЯпЩЯЃЌБШШчApache
CamelЁЃУќСюРяАќКЌСЫЩѓМЦаХЯЂЃЌЮЊУПИіСьгђЖдЯѓЕФУПвЛИіБфИќЬсЙЉСЫЭъећЕФПЩзЗзйадЁЃ
ПђМмдкФкВПЙЙНЈдЊФЃаЭЃЈmetamodelЃЌРрЫЦORMПђМмЃЉЃЌдЊФЃаЭВЛНіПЩвдгУгкUIКЭREST APIЃЌЫќЛЙгаЦфЫћгУЭОЁЃР§ШчЃЌЭЈЙ§ЕМГівЛИіSwaggerНгПкЮФМўПЩвдЪЕЯжЛљгкREST
APIЕФздЖЈвхUIЃЌЖјвЛИіЧПДѓЕФАВШЋФЃПщЖЈвхСЫгыСьгђЖдЯѓРраЭгаЙиЕФМгЩЋКЭШЈЯоЁЃдЊФЃаЭПЩвдЩњГЩЁА.poЁБЮФМўЃЌШЛКѓгУгкЙњМЪЛЏЁЃЮЊСЫЧПЛЏМмЙЙБъзМЃЌЮвУЧЛЙПЩвдЮЊдЊФЃаЭЖЈвхбщжЄЦїЃЌР§ШчЃЌФЃПщРяЕФУПвЛИіЪЕЬхЖМгІИУБЛе§ШЗЕигГЩфЕНе§ШЗЕФЪ§ОнПтschemaЩЯЁЃ
ПђМмвбОДІРэСЫетУДЖрЮЪЬтЃЌПЊЗЂШЫдБОЭПЩвдзЈзЂдкСьгђЩЯЃЌШЗБЃЖдЫќУЧНјааСЫЪЪЕБЕФФЃПщЛЏЃЌБугкГЄЦкЕФЮЌЛЄЁЃЮЊСЫБмУтФЃПщМфЕФёюКЯЃЌПђМмЬсЙЉСЫЖдmixinЕФжЇГжЃЌвЛИіСьгђЖдЯѓЕФфжШОПЩвдАќКЌРДздЦфЫћЖрИіФЃПщЕФзДЬЌКЭааЮЊЃЌЖјЮоашгыетаЉФЃПщЗЂЩњёюКЯЁЃНЋЮФЕЕИНМгЕНШЮвтвЛИіЖдЯѓОЭЪЧКмКУЕФР§згЃЌЧхЕЅ5ЕФДњТыгыIsisЕФБрГЬФЃаЭКмЯрЫЦЁЃ
ФкВПЕФЪТМўзмЯпвВКмживЊЁЃвЛИіФЃПщЗЂЫЭЪТМўЃЌСэвЛИіФЃПщЖЉдФЪТМўЃЌЖјВЛашвЊЫќУЧжЎМфЗЂЩњжБНгЕФЕїгУЁЃЧхЕЅ1КЭЧхЕЅ2ЕФДњТыНтЪЭСЫIsisЪЧШчКЮжЇГжЪТМўзмЯпЕФЁЃ
жЇГжЖрЬЌЙиСЊЃЈЭМ5ЃЉЕФГжОУЛЏФЃЪНвВКмживЊЁЃетаЉФЃЪНЭЈЙ§ЖржжПЊдДФЃПщЃЈдкIncode CatalogРявбСаГіЃЉЪЕЯжЃЌжЇГж
documentsЁЂnotesЁЂaliasesЁЂclassificationsКЭcommunicationsетаЉзгСьгђЁЃ
IsisЕФВхМўМЏКЯРяЛЙгаКмЖрЦфЫћФЃПщЃЌЫќУЧНтОіСЫАВШЋЁЂЩѓМЦКЭЪТМўЗЂВМЗНУцЕФЮЪЬтЁЃЖдIsisЪгЭМЕФРЉеЙЃЈЕиЭМЁЂШеРњЁЂPDFЃЌЕШЃЉвВЪєгкетаЉВхМўМЏКЯЁЃ
ЮЊСЫШУвЕЮёзгСьгђКЭВхМўИќШнвзБЛРэНтКЭЪЙгУЃЌЫќУЧЛЙЬсЙЉСЫЪОР§КЭМЏГЩВтЪдЁЃетаЉВхМўЕФЧБдкЪЙгУепПЩвдВЮПМетаЉР§згЃЌПДПДЪЧЗёФмТњзуЫћУЧЕФашЧѓЁЃ
IsisгЕгаДѓаЭЕФЩњЬЌЯЕЭГЃЌЪТЪЕЪЄгкалБчЁЃММЪѕЦНЬЈгІИУШУПЊЗЂЭХЖгзЈзЂдкКЫаФСьгђЩЯЃЌВЂНЋСьгђВ№ЗжГЩФЃПщЁЃЫљвдЃЌШчЙћФуШЅМьВщвЛЯТEstatioЕФДњТыЃЌФуОЭЛсЗЂЯжЫќЪЧгЩКмЖрЖРСЂЕФФЃПщзщГЩЕФЁЃЭМ7еЙЪОСЫетаЉФЃПщМфЕФвРРЕЙиЯЕЃЈЙиЯЕЭМЪЙгУStructure
101ЩњГЩЃЉЁЃ
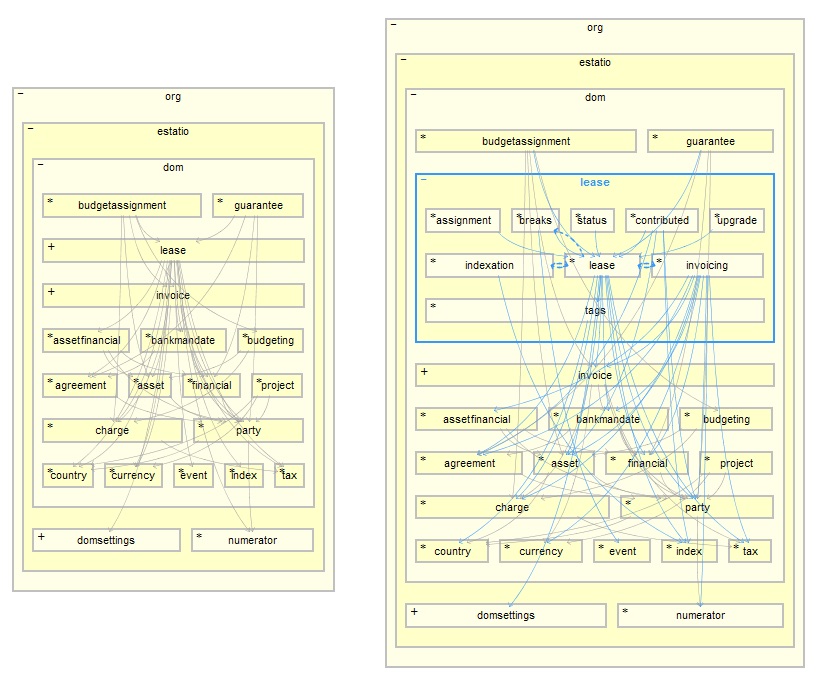
ЭМ7ЃКEstatioЕФФЃПщ
дкЭМ7ЕФзѓБпВПЗжЃЌУПИіЗНПщДњБэСЫвЛИіЖРСЂЕФMavenФЃПщЃЌСЌЯпДњБэСЫФЃПщМфЕФвРРЕЙиЯЕЁЃ
ЕзВПЪЧЙЄОпФЃПщЃЈDOMЩшжУЁЂМЦЫуЦїЃЉЃЌЛђАќКЌСЫв§гУЪ§ОнЕФФЃПщЃЈЙњМвЁЂЛѕБвЁЂЫїв§ЁЂЫАЁЂМЦЗбЃЉЁЃ
дкжаМфЮвУЧПЩвдПДЕНpartyЁЂfinancialЁЂassetЁЂassetfinancialКЭbankmandateФЃПщЃКетаЉФЃПщЕФНсЙЙКЭЫќУЧЕФЪ§ОнЖМВЛЛсОГЃЗЂЩњБфИќЁЃbudgetingЁЂinvoiceКЭleaseЪЧЯЕЭГЕФКЫаФЃЌЫќУЧвРРЕЦфЫћЕФДѓВПЗжзгФЃПщЁЃ
ЭМ7ЕФгвБпвВВюВЛЖрЃЌВЛЙ§leaseФЃПщАќКЌСЫвЛИізгАќЁЃдкетРяЮвУЧПЩвдПДЕНвЛаЉЫЋЯђвРРЕЃЌЫЕУїетРяЕФДњТыашвЊзівЛаЉИФНјЁЃЕБШЛЃЌетРявВгавЛаЉЯђЭтЕФвРРЕЃЌЫЕУїетИіФЃПщзіСЫЬЋЖрЕФЪТЧщЁЃвЊжЊЕРЃЌУЛгавЛИіШэМўЯЕЭГЪЧЭъУРЕФЁЃВЛЙ§ЃЌОЁЙмleaseЪЧЯЕЭГРязюДѓЕФвЛИіФЃПщЃЌЕЋЪЧДгИХФюЩЯРДПДЃЌЫќЖдЮвУЧРДЫЕвбОзуЙЛаЁСЫЃЈЁАleaseОЭЪЧзтЛЇКЭЗПЖЋжЎМфЕФавщЃЌгУгкМЦЫуЦБОнЁБЃЉЁЃ
EstatioвбОга5ФъЕФРњЪЗСЫЃЌЫќШдШЛдкЗЂеЙЃЌвдБужЇГжИќЖрЕФЪЙгУГЁОАЁЃОЁЙмЫќЕФЪЙгУГЁОАдкРЉеЙЃЌЕЋЫќЕФДњТыПтШДдкЪеЫѕЃЌIsisВхМўМЏКЯРяКЭIncode
CatalogРяЕФжївЊФЃПщБЛЧПжЦЗжРыГіEstatioЃЌЖјЧвЮвУЧЯЃЭћдкЮДРДЗжРыГіИќЖрЕФФЃПщЁЃШчЙћФуЯждквЊРШЁДњТыЃЌФуПЩФмЗЂЯжЫќгыжЎЧАЭМЦЌРяИјГіРДЕФНсЙЙгжгаЫљВЛвЛбљСЫЁЃетвВе§ЪЧЮвУЧЫљЦкЭћЕФЃЌетИігІгУНЋЛсГЄЦкДцЛюЯТШЅЃЌВЂБЃГжбнЛЏЁЃ
НсТл
дкЮФеТЕФЕквЛВПЗжЃЌЮвУЧБШНЯСЫФЃПщЛЏЕЅЬхКЭЮЂЗўЮёМмЙЙЃЌЬНЬжСЫСНепЕФгХЪЦКЭВЛзуЁЃ
ЮвУЧЮЪСЫетбљЕФвЛИіЮЪЬтЃКЁАФуНЋЛсбЁдёФФвЛИіМмЙЙЃЌЮЂЗўЮёЛЙЪЧЕЅЬхЃПЁБзїЮЊЛиД№ЃЌЮвУЧЮЪСЫСэЭтвЛИіЮЪЬтЃКЁАФуЯывЊЕФЪЧЪВУДЃПЁБШчЙћСьгђИДдгадЕФЗчЯеИпЙ§ЮоЗЈЩьЫѕЕФЗчЯеЃЌФЧУДОЭгІИУЪЙгУФЃПщЛЏЕЅЬхЁЃЕЋдИЮвУЧдкетРяУшЪіЕФИїжжММЪѕКЭФЃЪНФмЙЛгаЫљАяжњЁЃ
ВЛЙмВЩгУКЮжжМмЙЙЃЌММЪѕЦНЬЈЖМЪЧКмживЊЕФЁЃжиИДЗЂУїТжзгКСЮовтвхЃЌIsisПЩвдШУФузЈзЂгкНтОіСьгђЕФИДдгадЮЪЬтЃЌАяжњФуРэЧхФЃПщБпНчЃЌВЂНтОіМИКѕЫљгаЕФКсЖЯУцЮЪЬтЃЈАќРЈГЪЯжВуЃЉЁЃ
ЮвУЧЛЙНщЩмСЫПЊдДгІгУEstatioЃЌЫќЪЙгУСЫIsisзїЮЊЕзВуЦНЬЈЃЌеЙЪОСЫвЛИіецЪЕЕФФЃПщЛЏЕЅЬхЁЃ
ВЛЙмЪЧЕЅЬхЛЙЪЧЮЂЗўЮёЃЌЫќУЧЖМВЛЪЧвјЕЏЁЃЙигкЁАЮвгІИУбЁдёФФвЛИіЁБетРрЮЪЬтЕФД№АИЭЈГЃЖМЪЧЁАетШЁОігкЁЁЁБЁЃШчЙћгаШЫИвХФаиИЌЃЌФЧУДЫћвЛЖЈЪЧдкЦлЦФуЁЃДгЯЕЭГЕФЩьЫѕадКЭИДдгадГіЗЂЃЌШЛКѓзіГіОіЖЈЁЃ
|









