|
1.ұіҫ°
УҰУГҝӘ·ўКұөДіЈ№жЧц·ЁЈ¬КЗөчУГИХЦҫПөНіөДAPIҪшРРИХЦҫөДјЗВјЈ¬ИХЦҫөДҫЯМејЗВј·ҪКҪЈ¬НЁ№эИХЦҫПөНіКөПЦҝв¶ФУҰөДЕдЦГОДјюҪшРРЕдЦГЈ¬ұИИзК№УГlog4j2өД»°Ј¬ҝЙДЬҫНКЗlog4j2.xmlОДјюЈ¬ИХЦҫНЁіЈКЗјЗВјөҪОДјюЦРөДЈ¬Из№ыТӘІйҝҙИХЦҫЈ¬ҫНөГөЗВјёГ·юОсЖчҪшРРКөөШІйҝҙЎЈХвСщИз№ыУҰУГТФјҜИәөД·ҪКҪҪшРРІҝКрЈ¬И»әуУЦІ»ЦӘөАОКМвіцПЦФЪДДМЁ·юОсЖчЈ¬ХвКұҫНРиТӘөЗВјГҝТ»МЁ·юОсЖчЈ¬ХвёшПөНіөДҝӘ·ўЎўІвКФәНФЛО¬ҙшАҙБЛәЬ¶аөДВй·іЎЈ
ө«КЗәНКұПВөД»ҘБӘНш№«ЛҫІ»Н¬Ј¬ЖуТөј¶УҰУГНЁіЈІ»РиТӘ¶ФИХЦҫҪшРР·ЦОцЈ¬НЁ№эХэіЈөДКэҫЭҙжҙўЈ¬ұИИзКэҫЭҝвЈ¬ҫНҝЙТФ»сөГҫшҙуІҝ·ЦПлТӘөДКэҫЭЎЈ
2.Дҝұк
ОКМвКЗұИҪПГчИ·өДЈ¬РиЗуТІұИҪПЗеОъЈ¬ҫНКЗПЈНыДЬЙијЖТ»МЧҪвҫц·Ҫ°ёҪвҫцХвёцОКМвЈ¬ҙуЦВХыАнТ»ПВЈ¬УҰёГ°ьАЁИзПВјјКхөгЈә
¶ФУҰУГНёГчЈә¶ФУҰУГөДҝӘ·ўХЯ¶шСФЈ¬»№КЗПсФӯАҙДЗСщјЗВјИХЦҫЈ¬І»РиТӘ№ШЧўИХЦҫКЗИзәОјЗВјЎўТФКІГҙРОКҪұЈҙжФЪДДАпөДЈ»
УРПаөұөДБй»оРФЈәПЈНыКЗҝЙТФБй»оЕдЦГөДЈ¬іэБЛҝЙТФ°ҙХХ№ШјьЧЦІйСҜНвЈ¬ЧоәГ»№ҝЙТФБй»оөШЧФ¶ЁТеЖдЛыөДО¬¶ИЈ¬·ҪұгёщҫЭҫЯМеөДТөОсіЎҫ°Ј¬ҪшРРУРХл¶ФРФөДІйСҜЈ¬ұИИз°ҙХХКұјд¶ОҪшРРІйСҜЈ¬°ҙХХҫЯМеөДТөОсЦёұкҪшРРІйСҜөИЈ»
УРНіТ»өДІйСҜҪзГжЈәНЁ№эТ»ёцНіТ»өДҪзГжЈ¬ДЬ№»ІйСҜөҪХыёцјҜИә·¶О§ДЪөДИХЦҫЈ¬ұИИзКдИлДіёц№ШјьҙКЈ¬ОЮРи№ШЧўИХЦҫұЈҙжФЪДДМЁ·юОсЖчЙПЈ»
УРҪПёЯөДРФДЬЈәұЈЦӨУРҪПёЯөДІйСҜЛЩ¶ИЈ»
өНЧКФҙХјУГЈәХјУГҪПЙЩөДПөНіЧКФҙЈ¬°ьАЁCPUЎўДЪҙжЈ¬ЙхЦБІ»РиТӘөҘ¶АөД·юОсЖчҪшРРІҝКрЈ»
ІҝКрјтөҘЈәІ»РиТӘёҙФУөДЕдЦГЈ¬ІҝКрјтөҘЎЈ
3.јЬ№№·Ҫ°ё
ФЪЧЫәПҝјВЗБЛЗ°Кцұіҫ°ЎўФјКшТФј°ЙијЖДҝұкЈ¬ЧЫәПҝјВЗБЛПЦУРҝӘФҙЙзЗшөДҪвҫц·Ҫ°ёЦ®әуЈ¬ОТГЗҫц¶ЁІЙУГLucene+Ignite+Log4j2өДјјКх·Ҫ°ёЈ¬ХыМејЬ№№НјИзПВЈә
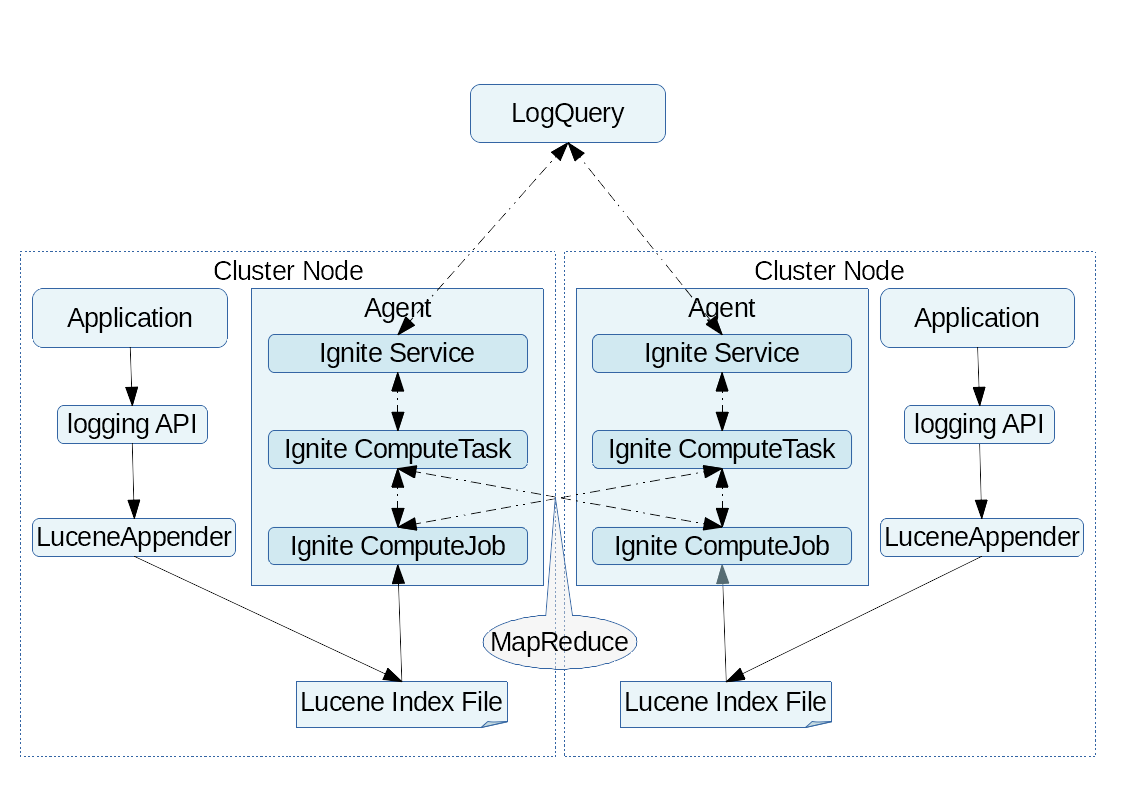
ҙуЦВГиКцПВЙијЖЛјВ·Јә
јјКхСЎРНЈәХыёцјјКх·Ҫ°ёЈ¬Йжј°БЛИэёцБчРРөДҝӘФҙҝвЈ¬·ЦұрКЗЈәLuceneЎўIgniteЎўLog4j2Ј¬ОТГЗК№УГөД°жұҫ·ЦұрКЗ5.5.4Ўў1.9.0әН2.7Ј¬ЛыГЗЖрөДЧчУГИзПВЈә
LuceneЈәУГУЪИХЦҫөДҙжҙўЎўЛчТэәНІйСҜЈ¬ЛьОӘҝӘ·ўХЯМṩБЛјтөҘГчБЛөДAPIЈ¬К№УГ·ЗіЈ·ҪұгЈ¬LuceneФЪХвёцјјКх·Ҫ°ёЦРЈ¬КЗКөПЦДҝұкөД»щҙЎЈ»
IgniteЈәФЪХвёцјјКх·Ҫ°ёЦРК№УГБЛIgniteөД·юОсНшёсәНјЖЛгНшёсјјКхЈ¬ХвАпЈ¬IgniteөД·юОсУГУЪ¶ФІйСҜПөНіұ©В¶ҪУҝЪЈ¬IgniteЦР»щУЪMapReduce·¶КҪөДЗ¶ИлКҪ·ЦІјКҪјЖЛгУГУЪИООсөД·Ц·ўЈ¬ІйСҜҪб№ыөД»гЧЬЎЈIgniteФЪұҫјјКх·Ҫ°ёЦРІў·ЗұШРиЈ¬ө«КЗК№УГIgniteөДјтөҘAPIЈ¬ҝЙТФҙу·щҪөөНұҫјјКх·Ҫ°ёөДКөПЦДС¶ИәНҝӘ·ў№ӨЧчБҝЈ¬ТІК№ұҫјјКх·Ҫ°ёұдөГУЕСЕЈ»
Log4j2ЈәұҫјјКх·Ҫ°ёЦРөДБнТ»ёц№ШјьөгЈ¬ҫНКЗ¶ФLog4j2ҪшРРБЛА©Х№Ј¬ЧФ¶ЁТеБЛТ»МЧ»щУЪLuceneөДAppenderКөПЦТФј°¶ФУҰөДlog4j2.xmlЕдЦГ·Ҫ°ёЈ¬ЛьҪвҫцБЛ¶ФУҰУГНёГчөДОКМвЈ¬»№КЗХыёц·Ҫ°ёҫЯУРБй»оРФөД№ШјьЈ¬ҫНКЗҫЯМе¶ФДЗР©КфРФҪЁБўЛчТэЎўКдіцДЗР©РЕПўТФј°КдіцРЕПўөДёсКҪЎўКэҫЭөДАаРН¶јКЗФЪlog4j2.xmlЦРҪшРРЕдЦГөДЎЈ
ЦҙРРБчіМЈә
log4j2.xmlЕдЦГЈәКЧПИТӘҪшРРlog4j2.xmlОДјюөДЕдЦГЈ¬ЕдЦГ·ҪКҪәуГж»бҪйЙЬЈ»
ИХЦҫөДјЗВјЈәlog4j2.xmlЕдЦГәГЦ®ә󣬶ФУЪУҰУГАҙЛөЈ¬ҫН°ҙХХХэіЈөДИХЦҫјЗВј·ҪКҪРҙҙъВлјҙҝЙЈ¬Г»УРМШұрөДТӘЗуЈ¬ОЁТ»МШұрТӘЧўТвөДКЗЈ¬Из№ыТӘХл¶ФМШұрөДТөОсЦёұкҪЁБўЛчТэЈ¬ТФГыОӘidөДұдБҝОӘАэЈ¬ДЗГҙРиТӘФЪҙъВлЦР¶ФПа№ШөДЙППВОДұдБҝҪшРРёіЦөЈ¬ҙуМеОӘЈәThreadContext.put("id",
id);Ј»
Ignite·юОсөДөчУГЈәУГ»§НЁ№эІйСҜҪзГжКдИл№ШјьҙКЦ®әуЈ¬әуМЁ»бНЁ№эIgnite·юОс·ўІјіцАҙөДҪУҝЪөчУГФ¶іМТөОсПөНіөД·юОсКөПЦҪшРРКөјКИХЦҫөДІйСҜЎЈХвАпIgnite·юОсөДІҝКрЈ¬ҝЙТФКЗјҜИәөҘАэЈ¬ТІҝЙТФКЗГҝҪЪөгөҘАэЈ¬Из№ыКЗГҝҪЪөгөҘАэЈ¬өчУГКұIgnite»бТФёәФШЖҪәвөД·ҪКҪЛж»ъөШСЎФсТ»ёцҪЪөгЈ»
ИООсөД·Ц·ўЈә·юОсөДКөПЦ»бөчУГIgniteјЖЛгНшёсөДИООсЈЁTaskЈ©Ј¬ИООс»б°ҙХХјҜИәҪЪөгөДКэБҝЙъіЙ¶ФУҰКэБҝөДЧчТөЈЁJobЈ©Ј¬Из№ыЧчТөКэәНҪЪөгКэПаөИЈ¬Ignite»бҪ«ХвР©ЧчТөЖҪҫщ·ЦөҪГҝТ»ёцҪЪөгЙПИҘЦҙРРЈ»
ЧчТөөДЦҙРРЈәЧчТөөДЦҙРР№эіМҫНКЗөчУГLuceneөДAPIҪшРРКөјКөДІйСҜБЛЈ¬ХвАпГ»КІГҙМШұрөДЈ¬Из№ыЦ»КЗНЁ№э№ШјьЧЦҪшРРІйСҜЈ¬»бұИҪПјтөҘЈ¬Из№ыПлНЁ№э¶аО¬¶ИҪшРРҫ«И·өШІйСҜЈ¬APIөчУГ·ҪГж»бёҙФУТ»өгЈ¬ө«КЗ¶јІ»КЗДСКВЈ¬І»»бөДҝЙТФ°Щ¶ИЈ»
ИООсөД»гЧЬЈәёчёцҪЪөгІйСҜөДҪб№ыјҜЈ¬РиТӘ»гЧЬәу·ө»ШёшөчУГ¶ЛЈ»
4.№ШјьјјКхөг
4.1.Ignite
Apache IgniteДЪҙжКэҫЭЧйЦҜЖҪМЁКЗТ»ёцёЯРФДЬЎўјҜіЙ»ҜЎў»мәПКҪөДЖуТөј¶·ЦІјКҪјЬ№№Ҫвҫц·Ҫ°ёЈ¬әЛРДјЫЦөФЪУЪҝЙТФ°пЦъОТГЗКөПЦ·ЦІјКҪјЬ№№НёГч»ҜЈ¬ҝӘ·ўИЛФұёщұҫІ»ЦӘөА·ЦІјКҪјјКхөДҙжФЪЈ¬ҝЙТФК№·ЦІјКҪ»әҙжЎўјЖЛгЎўҙжҙўөИТ»ПөБР№ҰДЬЗ¶ИлУҰУГДЪІҝЈ¬әНУҰУГөДЙъГьЦЬЖЪТ»ЦВЈ¬ҙу·щҪөөНБЛ·ЦІјКҪУҰУГҝӘ·ўЎўөчКФЎўІвКФЎўІҝКрөДДС¶ИәНёҙФУ¶ИЎЈ
4.2.Ignite·юОсНшёс
Ignite·юОсНшёсТФТ»ЦЦУЕСЕөД·ҪКҪКөПЦБЛ·ЦІјКҪRPCЈ¬¶ЁТеТ»ёц·юОс·ЗіЈјтөҘЈә
ПВГжНЁ№эТ»ёцјтөҘөДКҫАэСЭКҫПВIgnite·юОсөД¶ЁТеЎўКөПЦЎўІҝКрәНөчУГЈә
4.2.1.·юОс¶ЁТе
public
interface MyCounterService {
int get() throws CacheException;
} |
4.2.2.·юОсКөПЦ
public
class MyCounterServiceImpl implements Service,
MyCounterService {
@Override public int get() {
return 0;
}
} |
4.2.3.·юОсІҝКр
ClusterGroup
cacheGrp = ignite.cluster().forCache("myCounterService");
IgniteServices svcs = ignite.services(cacheGrp);
svcs.deployNodeSingleton("myCounterService",
new MyCounterServiceImpl()); |
4.2.4.·юОсөчУГ
MyCounterService
cntrSvc = ignite.services().
serviceProxy("myCounterService", MyCounterService.class,
/*not-sticky*/false);
System.out.println("value : " + cntrSvc.get()); |
№ШУЪ·юОсНшёсөДПкПёГиКцЈ¬ЗлҝҙХвАпЎЈ
4.3.IgniteјЖЛгНшёс
IgniteөД·ЦІјКҪјЖЛгКЗНЁ№эIgniteComputeҪУҝЪМṩөДЈ¬ЛьМṩБЛФЪјҜИәҪЪөг»тХЯТ»ёцјҜИәЧйЦРФЛРРәЬ¶аЦЦАаРНјЖЛгөД·Ҫ·ЁЈ¬ХвР©·Ҫ·ЁҝЙТФТФТ»ёц·ЦІјКҪөДРОКҪЦҙРРИООс»тХЯұХ°ьЎЈ
ұҫ·Ҫ°ёЦРІЙУГөДКЗComputeTask·ҪКҪЈ¬ЛьКЗIgnite¶ФУЪјт»ҜДЪҙжДЪMapReduceөДійПуЎЈComputeTask¶ЁТеБЛТӘФЪјҜИәДЪЦҙРРөДЧчТөТФј°ХвР©ЧчТөөҪҪЪөгөДУіЙдЈ¬»№¶ЁТеБЛИзәОҙҰАнЧчТөөД·ө»ШЦө(Reduce)ЎЈЛщУРөДIgniteCompute.execute(...)·Ҫ·Ё¶ј»бФЪјҜИәЙПЦҙРРёш¶ЁөДИООсЈ¬УҰУГЦ»РиТӘКөПЦComputeTaskҪУҝЪөДmap(...)әНreduce(...)·Ҫ·ЁјҙҝЙЈ¬Хвјёёц·Ҫ·ЁөДПкПёГиКцІ»ФЪұҫОДМЦВЫөД·¶О§ДЪЎЈ
ПВГжКЗТ»ёцComputeTaskөДјтөҘКҫАэЈә
IgniteCompute compute = ignite.compute();
int cnt = compute.execute(CharacterCountTask.class, "Hello Grid Enabled World!");
System.out.println(">>> Total number of characters in the phrase is '" + cnt + "'.");
private static class CharacterCountTask extends ComputeTaskSplitAdapter<String, Integer> {
@Override
public List<ClusterNode> split(int gridSize, String arg) {
String[] words = arg.split(" ");
List<ComputeJob> jobs = new ArrayList<>(words.length);
for (final String word : arg.split(" ")) {
jobs.add(new ComputeJobAdapter() {
@Override public Object execute() {
System.out.println(">>> Printing '" + word + "' on from compute job.");
return word.length();
}
});
}
return jobs;
}
@Override
public Integer reduce(List<ComputeJobResult> results) {
int sum = 0;
for (ComputeJobResult res : results)
sum += res.<Integer>getData();
return sum;
}
} |
НЁ№эХвСщТ»ёцјтөҘөДАаЈ¬ҫНКөПЦБЛГОГВТФЗуөД·ЦІјКҪјЖЛгЈЎ
№ШУЪјЖЛгНшёсөДПкПёГиКцЈ¬ЗлҝҙХвАпЎЈ
4.4.ЧФ¶ЁТеөДLog4j LuceneAppenderА©Х№
ұҫ·Ҫ°ёөДЧФ¶ЁТеlog4j LuceneAppenderА©Х№Ј¬КЗЧцөҪУҰУГОЮёРЦӘЈ¬ёЯБй»оРФәНёЯРФДЬөД№ШјьЈ¬LuceneAppenderөДҫЯМеКөПЦЈ¬І»ФЪұҫОДөДМЦВЫ·¶О§ДЪЈ¬ө«КЗТӘҪйЙЬПВұҫ·Ҫ°ёөДЕдЦГ·ҪКҪЈ¬ҙуМеЕдЦГ·ҪКҪИзПВЈЁјтВФЈ©Јә
<Lucene name="luceneAppender" ignoreExceptions="true" target="target/lucene/index" expiryTime="1296000">
<IndexField name="logId" pattern="$${ctx:logId}" />
<IndexField name="time" pattern="%d{UNIX_MILLIS}" type = "LongField"/>
<IndexField name="level" pattern="%-5level" />
<IndexField name="content" pattern="%class{36} %L %M - %msg%xEx%n" />
</Lucene> |
ЖдЦРЈәtargetКфРФұнКҫЛчТэОДјюөДО»ЦГЈ¬expiryTimeКфРФұнКҫЛчТэ№эЖЪКұјдЈЁГлЈ©Ј¬IndexFieldұкЗ©ұнКҫҫЯМеөДЛчТэПоЈ¬ЖдЦРnameКфРФКЗЧЦ¶ОГыЈ¬patternКфРФН¬log4jЧФЙнөДpatternКфРФЈ¬typeКфРФұнКҫЧЦ¶ОАаРНЈ¬ДҝЗ°Ц§іЦLongFieldЈ¬TextFieldТФј°StringFieldЎЈ
4.5.Lucene·ЦОцЖч
LuceneAppenderөДКөПЦПёҪЪЛдИ»ұҫОДІ»»бПкПёМЦВЫЈ¬ө«КЗТӘЦШөгЛөПВ·ЦОцЖчөДОКМвЎЈ
4.5.1.РиЗу
ИХЦҫјЗВјөДіЎҫ°ХыМеЙП»№КЗұИҪПГчИ·өДЈ¬УРДДР©РЕПў»бұ»јЗВјөҪИХЦҫЦРПа¶ФұИҪПИЭТЧұ»ФӨјыөҪЈ¬ёщҫЭЗ°КцөДЕдЦГ·Ҫ°ёЈ¬LuceneЦРҫЯМеөДЛчТэПоЈ¬КЗНЁ№эIndexFieldұкЗ©ҪшРРЕдЦГөДЈ¬ХвР©ПоДҝХыМеЙПҝЙ·ЦОӘБҪАаЈ¬Т»АаКЗУРҫЯМеә¬ТеөДЧЦ¶ОЈ¬ұИИзКұјдЈ¬Т»АаКЗДЪИЭІ»И·¶ЁөДЧЦ¶ОЈ¬ұИИзИХЦҫөДДЪИЭЈ¬¶ФУЪУРҫЯМеә¬ТеөДЧЦ¶ОЈ¬УҰёГІ»·ЦҙКЈ¬ІйСҜКұҫ«И·ЖҘЕдЈ¬¶ш¶ФУЪПсДЪИЭХвСщөДДЪИЭІ»ГчИ·ЧЦ¶ОЈ¬ТІУҰёГКЗІ»·ЦҙКЈ¬ө«КЗІйСҜКұІЙУГДЈәэЖҘЕдЈ¬ХвСщөДЙијЖХл¶ФИХЦҫІйСҜХвёціЎҫ°АҙЛөЈ¬»№КЗұИҪПәПАнөДЎЈ
4.5.2.іЈјы·ЦОцЖч¶ФұИ
LuceneДЪЦГБЛәЬ¶аөД·ЦОцЖчЈ¬іЈјыөДұИИзЈәWhitespaceAnalyzerЎўSimpleAnalyzerЎўStopAnalyzerЎўStandardAnalyzerЎўCJKAnalyzerЎўKeywordAnalyzerөИЈ¬ЛьГЗёчЧФМШөгИзПВЈә
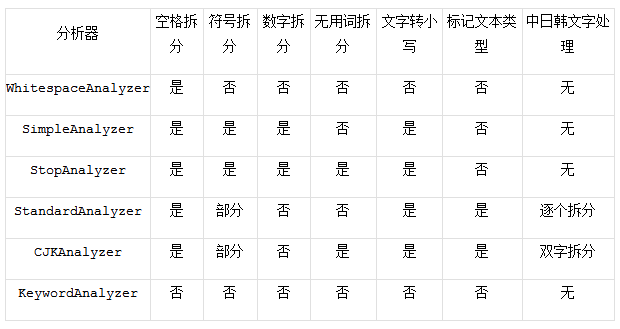
4.5.3.ҪбВЫ
ёщҫЭЙПКцөДРиЗу·ЦОцЈ¬ТФј°¶ФПЦУРөДіЈјы·ЦОцЖч¶ФұИЈ¬KeywordAnalyzer·ЦҙКЖчКЗұИҪПәПККөДЈ¬ө«КЗЈ¬ЛьУРБҪёцФјКшЈ¬Т»ёцКЗЗш·ЦҙуРЎРҙЈ¬Из№ыПЈНыІ»Зш·ЦҙуРЎРҙЈ¬ФтРиТӘҪшРРПаУҰөДА©Х№ҝӘ·ўЈ¬Т»ёцКЗ№ШјьЧЦІ»ДЬ¶аУЪ256ёцЧЦ·ыЈ¬ХвёцФјКшУҰёГОКМвІ»ҙуЎЈ
5.УЕИұөг
5.1.УЕөг
ЧКФҙХјУГЙЩЈәИХЦҫөДјЗВј№эіМЈ¬әНіЈ№жИХЦҫөДјЗВјГ»¶аҙуЗшұрЈ¬Г»УР¶оНвөДCPUәНДЪҙжХјУГЈ¬ОЁТ»УРҪПҙуПыәДөДЈ¬КЗLuceneөДЛчТэОДјюРиТӘХјУГҙЕЕМҝХјдЈ¬Из№ы¶ФХјУГҙЕЕМҝХјдГфёРЈ¬»тХЯ¶ФИХЦҫөДіӨЖЪұЈҙжГ»УРСПёсТӘЗуЈ¬ұҫ·Ҫ°ёЦРҝЙТФЙи¶ЁЛчТэ№эЖЪКұјдЈ¬і¬ЖЪөДЛчТэ»бұ»ЙҫіэЎЈХыёц·Ҫ°ёКЗҝЙТФІ»РиТӘ¶оНвөД·юОсЖчИнУІјюЧКФҙҪшРРІҝКрөДЈ»
ІҝКрјтөҘЈәұҫ·Ҫ°ёЦ»РиТӘҝӘ·ўТ»ёцөҘ¶АөДҙъАнДЈҝйәНУҰУГІҝКрФЪТ»ЖрјҙҝЙЈ¬БнНвҫНКЗІйСҜҪзГжЈ¬ҝЙТФёщҫЭРиТӘјҜіЙФЪПаУҰөДПөНіЦРјҙҝЙЈ¬ұИИзјаҝШПөНіөИЈ»
Бй»оРФЗҝЈәҝЙТФёщҫЭРиТӘЈ¬ФЪИХЦҫЕдЦГОДјюЦРҪшРРБй»оөДЕдЦГЈ¬ҝЙТФЕдЦГјЗВјДДР©ПоДҝЈ¬КІГҙёсКҪөИЈ¬ІйСҜҪзГжТІҝЙТФБй»оөШ¶ЁЦЖЈ¬ёщҫЭРиТӘТФККУҰҫЯМеөДТөОсіЎҫ°Ј»
ҝӘ·ўС§П°јтөҘЈәұҫ·Ҫ°ёЦРРиТӘС§П°өДјјКхІ»¶аЈ¬Ц»РиТӘКмПӨIgniteәНLuceneөДҝӘ·ўјҙҝЙЈ¬ІйСҜҪзГжҝЙТФёщҫЭРиТӘ¶ш¶ЁЈ¬Г»УРСПёсТӘЗуЎЈ
5.2.Иұөг
РиТӘТ»¶ЁөДҝӘ·ўБҝЈәХвІ»КЗТ»МЧҝӘПдјҙУГөДҪвҫц·Ҫ°ёЈ¬°ьАЁІйСҜҪзГжөИЈ¬КЗРиТӘҝӘ·ўөДЈ¬ө«КЗ№ӨЧчБҝІ»ҙуЈ¬Из№ы»№УРЖдЛыөДРиЗуЈ¬ұИИзИХЦҫ·ЦОцөИЈ¬Ц»ДЬЧФРРҝӘ·ўЈ»
ТААөIgniteөДјҜИәІҝКрЈәХвМЧ·Ҫ°ёІйСҜөД·¶О§КЗIgnite№№ҪЁөДјҜИә»тХЯФЪХвёцјҜИә·¶О§ДЪ¶ЁТеөДјҜИәЧйЎЈТтҙЛТ»·ҪГжУҰУГТӘНЁ№эIgnite№№ҪЁјҜИәЈ¬БнНвТ»·ҪГжИз№ыјҜИәДЪУҰУГҪП¶аЈ¬ОӘБЛұЬГвПа»ҘёЙИЕЈ¬¶ФјҜИә·ЦЧйТІКЗұШТӘөДЈ¬Хв·ҪГжҝЙТФЛгЧцТ»ёцЗҝФјКшЎЈ
6.ЖдЛыөДПа№Ш·Ҫ°ё
ҪцҫНҝӘФҙЙзЗш¶шСФЈ¬»№ҙжФЪElastic StackЎўFlumeөИИХЦҫҙҰАнјјКхЈ¬№ҰДЬёчУРІаЦШЈ¬ө«Из№ыҪцҪцПлЧц·ЦІјКҪИХЦҫөДІйСҜөД»°Ј¬ХвР©·Ҫ°ёВФЦШЈ¬Из№ыХвР©·Ҫ°ёІ»ВъЧгРиЗуРиТӘҝӘ·ўЈ¬Фт№ӨЧчБҝВФҙуЈ¬ТФElastic
StackОӘАэЈ¬ХыёцјјКхХ»К№УГөДјјКхҪП¶аЈ¬¶ФҝӘ·ўХЯТӘЗуҪПёЯЈ¬ХыМе¶ЁЦЖіЙұҫҪПёЯЎЈБнНвХвР©·Ҫ°ё¶јРиТӘ¶оНвЈ¬ЙхЦБҪП¶аөД·юОсЖчИнУІјюЧКФҙЈ¬ІҝКріЙұҫҪПёЯЎЈ
7.ККУГБмУт
ХвМЧ·Ҫ°ёХыМеЙПАҙЛөККУГУЪЈ¬»тХЯЛөГжПтөДКЗТФјҜИә·ҪКҪІҝКрөДЖуТөј¶Ҫ»ё¶РНИнјюЈ¬і§ЙМҝЙТФІ»КЬФјКшөДХЖҝШХыёц·Ҫ°ёөД·Ҫ·ҪГжГжЈ¬¶ФҝН»§АҙЛөЈ¬ІҝКріЙұҫТІҪПөНЎЈХвМЧ·Ҫ°ё¶ФУЪИнјюөД№жДЈГ»КІГҙПЮЦЖЈ¬ХыёцјҜИәУРәЬ¶аёцУҰУГТІҝЙТФЎЈХвАаУҰУГ¶ФИХЦҫҙҰАнөДРиЗ󣬹ҰДЬұЯҪз¶ЁТеҝЙТФЧцөҪұИҪПЗеОъЈ¬РиЗуІ»»бА©өДәЬҙуЈ¬ХвСщөД»°Ј¬¶ЁЦЖELKҪвҫц·Ҫ°ёөДҙъјЫҫНПФөГМ«ҙуБЛЎЈ
¶ш¶ФУЪ»ҘБӘНш№«ЛҫАҙЛөЈ¬ДЪІҝУРәГ¶аҙнЧЫёҙФУөДПөНіЈ¬КэБҝҝЙДЬјёК®ЙП°ЩЈ¬ёь¶аөД¶јУРЈ¬ХвКұФЪELKХыёцјјКхХ»өД»щҙЎЙПҪшРР¶ЁЦЖЈ¬ҝЙДЬёь»®ЛгЈ¬ТэИлХвМЧ·Ҫ°ёЙхЦБҝЙДЬ¶јІ»ҝЙРРЎЈ
8.ЧЬҪб
ұҫ·Ҫ°ёБнұЩхиҫ¶Ј¬НЁ№эРВөДјјКхХ»Ј¬ҪПЙЩөДҙъВлҪвҫцБЛіӨЖЪА§ИЕ·ЦІјКҪИХЦҫІйСҜХвёцРРТөНҙөгЈ¬БнНвЈ¬ұҫ·Ҫ°ёТІҝӘА«БЛЛјВ·Ј¬јҙIgniteХвЦЦЗ¶ИлКҪөД·ЦІјКҪјЖЛгјјКхЈ¬MapReduceјЖЛг·ҪКҪЈ¬УР·ЗіЈ¶аөДК№УГіЎҫ°Ј¬І»ҪцҪцҝЙТФУГУЪіЈ№жөДјЖЛгЈ¬»№ҝЙТФУГУЪёчЦЦјҜИә»·ҫіөДКэҫЭКХјҜөИіЎҫ°Ј¬ПлПуҝХјдәЬҙуЎЈ
ұҫ·Ҫ°ёЦРLuceneЧчОӘИ«ОДјмЛчБмУтөДРРТөұкЧјЈ¬өГөҪБЛ№г·әөДУҰУГЈ¬ҙуБҝөДҪвҫц·Ҫ°ё¶ј»щУЪLuceneҪшРР¶ЁЦЖҝӘ·ўЈ¬Elastic
StackөЧІгТІ№№ҪЁУЪLuceneЦ®ЙПЎЈ
Из№ыұҫ·Ҫ°ёДЬіЖОӘЧојСКөјщЈ¬ДЗГҙIgnite№ҰІ»ҝЙГ»ЎЈХвТ»АаөДјјКх»№УРЖдЛыјјКхҝЙСЎЈ¬ұИИзInfinispanөИЈ¬Ц»КЗХвТ»АаөДҝӘФҙЗ¶ИлКҪДЪҙжІўРРјЖЛгјјКхЈ¬»№Г»УРөГөҪТөҪзөД№ШЧў¶шТСЎЈ
|









