|
Mesos 架构
在官方文档中,Mesos 定义成一个 分布式系统内核 。它使用和 Linux 内核相同的设计原则,只是设计在不同的抽象层级上。它运行在一个机房的所有服务器上并且通过
API 的形式给应用(比如 Hadoop,Spark,Kafka,Elastic Search)提供资源管理、计划任务等功能。
Mesos 是一个在 2009年 由 Benjamin Hindman 等人联合发起的伯克利大学研究项目。随后引入
Twitter,如今已经完美运行在 Twitter,Airbnb 等环境。
Mesos 的架构图如下。
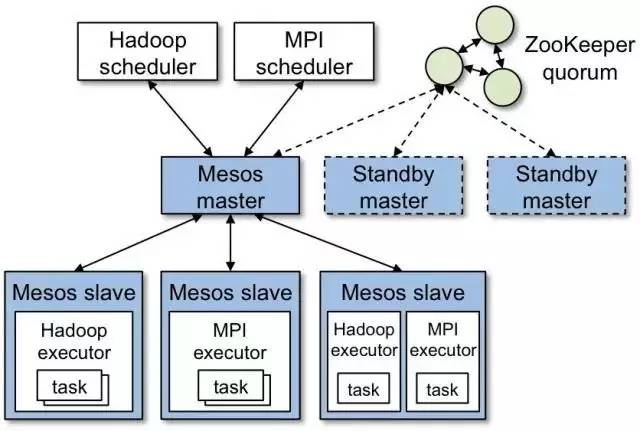
在图中,Master 主要负责 slave 以及 Framework scheduler 的注册,以及资源分配;Slave
主要接受来自 master 的任务。M esos applications ( 也称为 frameworks
)在 slave 上运行 task。
在官方文档中,Mesos 的资源分配流程如图所示。
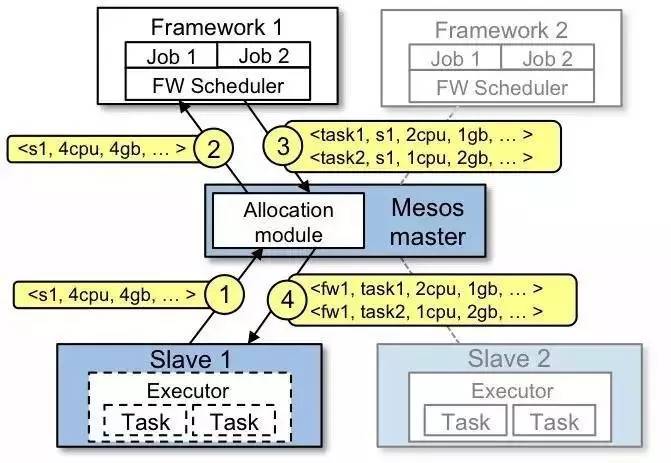
Slave 1 向 Master 汇报其空闲资源:4 CPU、4GB 内存。然后 Master 调用分配策略模块,得到的反馈是
Framework 1 要请求全部可用资源。
Master 向 Framework 1 发送资源 offer,描述了Slave 1上 可用资源。
Framework 的调度器(Scheduler)响应 Master,需要在 Slave 上运行两个任务,第一个任务分配
<2 CPUs, 1 GB RAM> 资源,第二个任务分配 <1 CPUs, 2 GB
RAM> 资源。
最后,Master 向 Slave 下发任务,分配适当的资源给 Framework 的任务执行器(Executor),由执行器启动这两个任务(如图中虚线框所示)。
此时,还有 1 CPU 和 1GB RAM 尚未分配,因此分配模块可以将这些资源供给 Framework
2。
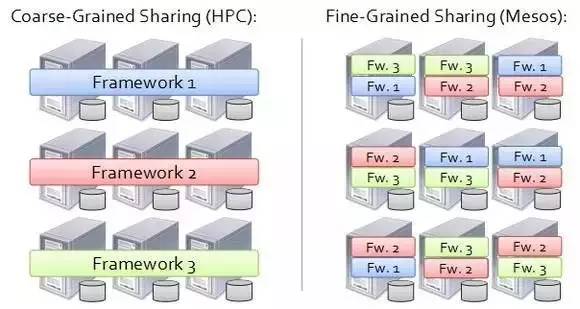
因此也可以看到,Mesos 一个最大的好处是能够对分布式集群做细粒度资源分配。 如下图所示,左边是粗粒的资源分配,右边是细粒的资源分配。
Marathon 是一个 Mesos Framework,能够支持运行长服务,比如 Web 应用等。是集群的分布式
Init.d,能够运行任何 Linux 二进制发布版本,可以统一对集群做多进程管理。也是一种私有的 PaaS,为部署提供
REST API 服务,通过 HAProxy 实现服务发现和负载平衡。后文会详细介绍为什么选择 Marathon
作为统一 framework。

Mesos 在去哪儿的使用
下面给大家分享去哪儿从去年开使用 Mesos 时,在系统实施和扩容阶段,对 Framework 部署和使用上的一些思考,也介绍一下
Framework 迁移的过程。
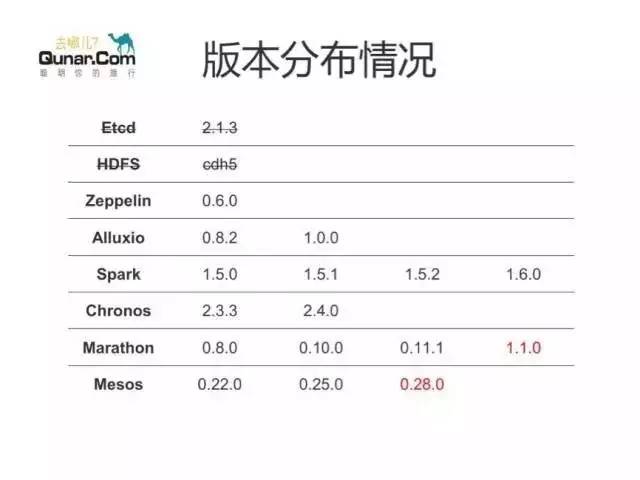
先说一下我们背景和版本使用情况。
Mesos
我们主要还是用 Mesos 做数据分析。Mesos 是从 0.22 开始使用,中间经历了 0.25,现在在调研
0.28。
Marathon
Marathon 从 0.8 开始使用,目前正在用的是 0.11,正在调研 1.1。 从测试来看,暂时不建议大家上
1.0,因为它有一个非常严重的问题,持久化卷处理在机器宕掉重启以后,带有持久化卷的任务恢复不了。1.1.0
修复了 BUG,所以大家如果要上新版建议选择 1.1。
Spark、Alluxio 等
Spark 版本变更比较多,从版本 1.5.0 一直升级到 1.6.0。 Alluxio 是一个开源分布式内存文件系统,也是用作数据加速。Etcd,hdfs
最开始用,用了一半放弃了。因为 Mesos 早期版本对于持久化数据这一块支持不是很好,etcd 和 HDFS
涉及到数据写磁盘重新调度以后恢复问题,当时没有很好的处理办法。因为 Marathon 1.1 版将持久化功能推出,近期会重新再上。
使用场景
我们主要用 Mesos 来做公司的日志处理,把公司业务线数据收集回来做日志分析工作。
举个例子,去哪儿客户端打开酒店后,会有推荐或者猜你喜欢等类似功能,相关数据就是业务线使用平台推送的数据算出来的,相当于平台是公司数据流的集散地,清洗完推到各自系统上。
每天 大致的量有 130 亿,有很多业务线它的日志是重复消费的,比如无线日志有可能酒店度假都在用。
我们容器的量和其他互联网公司相比较小,和十万级和百万级的容器量相差非常大。在实施过程中,在建立平台的过程中,主要会遇到两个问题:
框架 framework 能不能统一?
框架 framework 的嵌套有没有意义,如果做这件事它的性价比是什么样的?
框架统一
第一个问题就是框架 framework 能否统一?现在 Mesos 上跑的软件能不能都用 Marathon
来管理?

Spark on Mesos , 是 Spark 团队用来整合 Mesos 的framework,也是
Spark 团队维护的。 Alluxio 也有自己原生的 framework。
每一个软件在 Mesos 上运行,基本上都会有一个思路,需要提供一个 Framework 来做自己的事情。
Etcd on Mesos 和 HDFS on Mesos 主要是 Mesosphere 公司配套上自己的
DNS 来做。Spark on Mesos 有两种运行模式 batch 和 streaming,它对数据的资源管理比如粗粒度和细粒度,调度方式还不太一样。

这里写的调度逻辑,更多的意义在于针对软件特定的使用场景,会有特定的调度策略混在里面。
一个应用一个 framework 的模式的优势,就是更精确的调度。
调度逻辑这一块 Marathon 提供了一个约束,去控制任务调度到指定的机器上,或者用 group by
的方式来做一个分 rack/region 的部署的功能。
基于特定软件的自定义 framework,总要考虑到特性相关的东西,比如 Alluxio,它优先会使用内存,也会用
SSD,所以它的调度会考虑这到台机器是否安装有 SSD。
如果用在 Marathon 上,可能要打一个 slave 标签,告诉它机器上有 SSD,但是打一个标签就需要把
Mesos slave 重启。在生产过程中,其实相当于已经在破坏集群的稳定性了。
但是在自定义 framework 的时候,调度过程中可以从 DB 里面去抓机器的信息,看它是否配置有
SSD,完成调度,并且不用重启 slave。
异常恢复
在 Marathon 上来讲,task 一旦被标记成 FAILED 或 LOST 状态,它会有一次重新调度,重调度在
Marathon 上认为和重新发布是相同意思。
如果做了一个重调度,任务的启动脚本检测到已经有 ramfs 以后,它会 umount 掉,导致数据丢了。换成自定义
Framework,如果之前已经调过这台机器,重起任务的脚本可以重新换一下,换成直接复用数据方式启动,相当于自己能记录一些信息,然后做恢复控制,控制力能比
Marathon 好一些。
消息控制
然后是消息控制,通过 Mesos 可以发一些消息,Framework 与 Executor 之间做交互。这个用法在
Spark 也用过,这有一个问题就是消息量和消息的大小稍微控制一下,因为 Spark 的早期版本,用 Framework
来做消息的反馈,结果会把 master 打崩。因此需要注意这一点。
服务发现
最后是服务发现,如果自己写一个 Framework,宏观的手段就有很多。用 Marathon,这一块功能是相对缺失的,因为他要考虑照顾不同的方案,只能满足通用性更高的的场景,后面会详细介绍。
自定义 framework 的问题
但是自定义 framework 的劣势也是非常大的,像 Spark on Mesos,提供的 Framework
还是非常简单,基本上不了生产环境,功能只能测一下跑的效果怎么样,导致二次开发的量比较大。
Framework 二次开发里面经常遇到的几个问题,Framework 发完之后任务的状态是否需要保存下来。因为在
HA 情况下,如果原有的 Framework 宕掉了,没有把任务信息记到第三方系统里面(比如 zk),新的
Framework 接管以后,他根本不知道有哪些任务。
比如说任务挂了,Mesos 传递过来一个 statusUpdate 消息,他才会知道原来的 leader
发过这么一个东西。所以需要把 HA 和 state 两个捏在一起来做。就相当于一个应用一个 framework
的情况下,会遇到大量的重复的功能开发,而且这些功能其实都是核心功能。
另外一个劣势就是监控基本没有,以上提到的这些 framework ,对于监控还有报警基本上就是没有的。所以如果在考虑后期维护,没有监控,没有报警,生产环境基本上这是一个黑盒,出了问题基本上不知道怎么回事,从这个角度考虑,自定义
framework 就已经被 Pass 掉了。
统一成 Marathon
遇到这些问题以后,就考虑能不能把所有用过的软件,把他们自己原生的东西废掉。全部先切换到 Marathon,因为
Marathon 本身 framework 功能和监控非常完善,所以切完了以后对后期的运维和基于 API
的二次开发就会变得简单一点。

服务发现
基本上就是两套,四层和七层都支持。四层用 Marathon 的 EventBus,每发一个任务,它把任务信息都发送出来,自己写一个
callback,通过 etcd + confd + haproxy 做服务发现。
如果不想开发,可以选择第二种方式,直接用 Bamboo + Haproxy。七层直接用 OpenResty
+ LUA 写一个。
异常恢复这一块相对差一些,因为异常恢复需要在每一个任务里额外写一些脚本或者小程序,通过这些数据做一个原数据存储,再基于原数据做一个恢复的过程。在这一块有一定开发量,但是开发量和之前讲到的二次开发量比是非常小。
Spark 迁移
我们主要运行 Spark Streaming 任务,只要发一个 spark driver 就可以了,其他
executor 不用 Spark 原生 framework 启动,而是换成 Marathon 启动,把
driver 的 URL 等信息填进去,还有环境变量信息,比如 HADOOP_USER_NAME,把 executor(Spark
非 Mesos)发布以后,就可以从 driver 拿到数据做 streaming 了。这一层相当于我在
Marathon 拆成两次发,第一次发 driver,第二次发 executor。
ElasticSearch
额外提一下 ES 这一块,我们集群有 50 台左右机器,最开始不太关心把 ES 做成一个服务放到 Mesos,也就是不太希望
ES 是混合部署,因为 ES 本身对资源占用率比较大,比如系统文件开销。
但是随着了解 ES 在业务线的使用,发现理解有一些错误,当时把 ES 定位成日志检索、还有针对日志解析后数据出报表的一个工具。后来发现所有人把它当成一个二级索引来用,这种情况下
ES 的集群规模非常小,而且数据量很小,但是他们内存的要求比较大。
因此你会发现 ES 用法完全不一样了,他们的用法是比较倾向于走小集群,把业务线拆分做隔离,所以 ES
变成一个服务的可能性已经出现了。再加上到 Marathon 1.1 以后,基于 Marathon 做 ES
的平台可能性已经有了。
现在已经在 beta 版测试。ES 在业务线实际上还是小集群为主,然后一个集群里就只有几个索引,专门服务于某个业务的集群。
框架嵌套
以上是对框架 framework 统一的思考,下面聊一下 framework 嵌套。

在最开始阶段,集群验证功能的属性更强一点,所以开始时规模非常小,只有一套 Marathon,三个节点的
HA,然后一个 Chronos。
随着 APP 数量增多,Marathon 效率下降比较快,APP 地址超过了 2200,基本上调度等半天才能反应一次,感觉扛不住了。
再加上通过打标签的形式来标记应用是干什么,标签打太多之后管理起来比较麻烦,如果 App Id 超过 24
位会被直接截断。
当时没有好的办法,只能把 Marathon 做一次拆分,拆成了 6 到 8 个不同的 Marathon
跑到 Mesos上,这个缩减 App Id 主要是为了适应 Mesos DNS。
当时在原有的基础上不停的扩容, Framework 多出来一套,就从别的地方要三台机器给它布局,布到最后就发现承载
Framework 的机器越来越多了。我们把好多东西拿到集群用,占用虚拟资源,但是没怎么用。
最后重新思考一下, framework 分散,应用结构就相当于跟着 framework 走,一个 framework
里面应用是一套,另外一个 framework 是另外一套。把应用分摊到 Framework 里,每个 Framework
没什么关联。
独立部署导致这种额外的资源和域名有一些开发量,应用树构建这块是一个问题,应用在上面多了以后,总需要有一个类似于服务治理的功能,需要有地方管理服务,包括树状结构是什么样的,要明确地知道这个东西来自于哪一个部门干什么事情。
因为要把日志的应用分配到每一个业务线对应的一个树结构里面,所以整合时发现树构架集成很高,因为 Marathon
跑在外面,需要每一个 Marathon 抓一个。
多租户
再一个就是多租户,很多时候业务线仅仅是用一下,他就想能不能借用一个 Marathon 做一个测试?这个时候也不好挂靠自己内部资源上,这是当时遇到的一些问题。包括动态分配资源,有时候业务需要
4 核 4G 内存,他就是简单跑一下测试。这两个问题当时都没解决。
我们就决定把所有的 framework 嵌套。只有刚才讲的这些东西还不足以做好。还有一个就是标准化,在运维里面,做一件事情最先考虑的就是能不能标准化,标准化以后意味着后面自动化可以做,Marathon
在标准化这块做得很好,通过 API 就可以把自动化流程串接起来。
面对这些问题,能不能考虑一种相对来讲让所有工作简单一点的事情?
我们调整一下,还是在集群外部署一套 Marathon,叫他 Root Framework,后面所有的
framework 采用 Root framework 去发,如果它挂了,Root framework
会自动切换到其他 standby 节点上,很多运维是 Root framework 完成,以前维护多个
framework ,现在只要盯着 Root framework 就可以了。
用这种方式以后,运维量就开始降低了。包括后面开发量也开降低了,有了 Root Framework 以后,之前讲的七层服务发现,只要基于
Root framework 做一层就够了。
有了 Root framework 以后,就可以拿到二级 framework ,甚至拿到三级、四级的
framework。多级 framework 在 Lua 配合下,直接通过泛域名方式访问所有应用。每一级域名对应着一个
framework ,服务发现与这一级 Framework 绑定,如果他有问题把它的父 framework
直接下掉。
还有应用树的事,因为 framework 一旦形成了父子关系,整个应用树的构建,直接基于 Framework
同步应用树的数据库就可以了,所以就直接和业务树对应。这是选择的另外一个原因。

更多的优化像 HA 或 Failovetimeout,如果 framework 宕掉了,他允许设置一个
failovertimeout 时间,如果超时以后,Framework 还没有注册到 Mesos 集群,它就会默认
framework 所有的 executor 和 task 全杀掉。
还有为 framework 申请动态预留,申请动态保留资源跟上面的 HA 还有 failovertime
是有一定关联的,防止资源不够的时候恰好 framework 出问题重新部署了,但是资源被其他人都耗尽了导致部署不上。
按需求分配任务,分到不同 Marathon,其实变成了按需求去起动,再发一个 framework ,不再担心资源的限制,后面那些功能自然而然就带出来了。 |






