|
本文试图找到类似Puppet、Chef、Ansible这样自动化配置管理工具的共性,以不至于迷失在杂乱的尘世中。总会有各种人为各种目的造概念,来让世界更复杂。
本文同样适用于没有运维经验的人。因为我就是一个没有运维经验的人。欢迎斧正。
与这仨之间的历史
本人接触自动化运维的时间比较晚,也就一年前才知道Puppet及自动化运维(只限于知道),而Chef、Ansible就更晚了。然而在学习它们之前,我对运维要做哪些事情并没有概念。这就对我学习Puppet,Chef和Ansible造成的障碍。因为不知道这三个工具在运维领域的位置,解决运维过程中的哪些问题。我对这三个工具的最初印象就是有了它们,不用我手工的SSH上服务器,然后一条条命令去执行安装软件,不用SCP
war包上服务器等,对服务器的操作都可以自动化了。
这个最初印象也就是我跟它们的历史。为什么要说这些呢?就是因为这个最初印象,让我觉得它们是有共性。所谓共性就是存在一些共通的概念或原理之类的东西,掌握这些“东西”,我就可以站在一个更高的高度去思考。Puppet,
Chef, Ansible都是工具,对于工具来说,共性指的是它们共同要解决的问题。
但是当我翻了不少文章后依然没有结果。所以,我决定自己去找它们的共性,并记录下来。
自制一个自动化运维工具
但是要从多个相似的东西中找到共性,似乎需要同时很熟悉它们。但是我没有那么多时间。所以,我选择了另一种方法:在大脑中预想自己去实现一套自动化运维工具。但问题是,我都不知道“自动化运维工具要实现哪些功能。
那我就先把目标降低一些,把问题简化一下:将我最初的“印象”实现自动化了。我能想到的就是写一个bash脚本:
ssh ....
apt-get install -y java
apt-get -y nginx
scp ..
好,现在将问题难度加大:对多台服务器进行同样的操作。我能到想就是将所有的服务器的IP放在一个数组里,然后用for循环执行。问题来了,如果我对服务器已经执行了一次命令时可能会失败,我再想执行第二次怎么办呢?这时,我们可以在bash脚本里加上if语句,如果安装了java就不安装第二次了。
显然现实中还会有很多问题,如:
反向配置问题,这时,我们应该另写一个bash脚本来解决这个反向的问题?如果采用这种方案,我们bash脚本数量上升到一定程度,如何管理这些脚本及它们之间的关系,这个方案带来的新的复杂性将会成为我们的新问题;
服务器上操作系统的兼容性问题:不同的操作系统,我们的bash命令会不同;
软件的版本升级或降级问题等等。
面对这些问题,我们是可以每次都用bash解决,但是这样始终不是个办法。因为,bash对于建立一个自动化运维工具过于底层。说到这句话,你应该很容易就想到设计一种DSL。到这个点,我觉得我们的方向已经明朗。Puppet,
Chef和Ansible都分别采用不同的DSL。而这种DSL是需要编译成服务器可执行的东西的。什么东西是可执行的?目前,我们假设这个东西是bash脚本。
但是这个DSL是放在哪里编译呢?放在受控机器端,还是主控机器上?所以,我认为所有的自动化运维工具都会遇到这个问题。什么是受控机器与主控机器?你就理解成一台机器只发命令,另一台机器只执行命令。
我们刚刚谈的是设计DSL。但是,要设计一个完整的自动化运维工具,我们最先应该考虑是主控机器如何与受控机器通信。这个问题让我很长时间感到很无力,因为无从下手。后来醒悟,原来你不能单独考虑这个问题,通信方式还与你设计的DSL及编译DSL的方式有关。同时,受控机器的执行结果这个问题,也影响着我们设计DSL。
上面我们似乎忘记了一个事实:自动化运维工具应对的往往不是一台机器,而是很多台机器。当面对多台机器时,就会产生一个新的问题:如何组织它们?因为不同的机器的职责不同,所对应的配置也就不同。
我想我们已经知道自动化运维工具都要解决的问题了:
1. 如何与受控机器通信
2. 如何组织成百上千台机器
3. DSL的设计与编译
4. 如何得到执行结果
我不确定我们的思路与Puppet,Chef和Ansible的作者一样。也不一定完全正确。但是至少,我们大概知道自动化运维工具要解决哪些问题了。而它们是不是自动化运维工具的共性?我不确定。
但是没有关系,我们假设它们就是所有配置管理工具都要解决的问题,它们的共性,接下来我们来看看它们分别是怎么解决这些问题的。
这仨的背景
在进入学习之前,我们先看看它们的背景:

Puppet
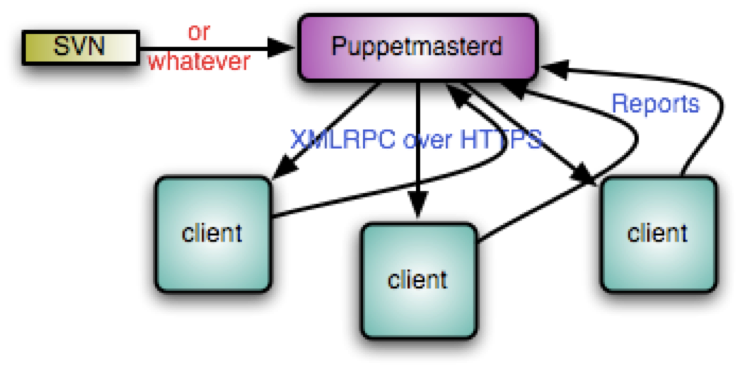
如何与受控机器通信
Puppet的主控机器(Server)称为Puppet master,受控机器(client)称为Puppet
agent。它们使用HTTPS进行通信。在安装puppet之前,需要分别在主控机器和受控上设置的hostname。
因为是C/S架构的,意味着你需要在主控机器上安装Puppet master,(安装的过程或翻阅其它教程的时候,请注意教程所使用的Puppet的版本,Puppet版本之间是有差异的)我们以Ubuntu为例:
sudo apt-get install -y puppetmaster |
在受控机器上安装Puppet agent:
sudo apt-get install -y puppet |
安装完成后,受控机器需要设置在/etc/puppet/puppet.conf文件的[main]节点下加入server=<master’s
hostname>,同时运行sudo puppet agent ―test向主控机器申请认证。主控机器执行sudo
puppet cert sign <agent’s hostname>认证。
在生产环境并不一定采取这样的手工认证。
DSL的设计与编译1
Puppet的DSL称为Manifest ,以.pp为文件扩展名。像其它编程语言一样,它也有一个程序的入口,它默认放在:/etc/puppet/manifests/site.pp
:
#vim /etc/puppet/manifests/site.pp
node 'mysqlserver.example.com' {
$mysql_password = 123456
package {
['mysql-common', 'mysql-client', 'mysql-server']:
ensure => present
}
service {
'mysql':
enable => true,
ensure => running,
require => Package['mysql-server']
}
exec {
'set-root-password':
path => "/usr/bin:/usr/sbin:/bin",
subscribe => [Package['mysql-common'], Package['mysql-client'],
Package['mysql-server']],
refreshonly => true,
unless => "mysqladmin -uroot -p$mysql_password
status",
command => "mysqladmin -uroot password
$mysql_password",
}
file {
'/etc/mysql/my.cnf':
content => template('my.cnf.erb'),
require => Package['mysql-server'],
notify => Service['mysql']
}
}
|
Manifest的基本格式:
node NODENAME{
RESOURCE { NAME:
ATTRIBUTE => VALUE,
...
}
}
|
Nodename实际上就是节点的hostname。这里有个提问:为什么不直接使用IP呢?Resource代表的是资源,也就是Puppet将节点内所有的东西都当作资源。具体细节,我们稍后会讲到。
如何组织成百上千台机器
如果我要控制1000台机器是不是意味着我要在site.pp中写1000个 节点 node NODENAME{…}呢?答案是肯定的。
DSL的设计与编译2
我们注意到`node`节点中所包含的所有内容,本质上都是在描述这个node的状态,如:
service { 'mysql':
enable => true,
ensure => running
} |
指的是`service mysql`这个Resource的状态是可用的且正在运行的。Puppet中内建了不少Resource供给我们使用,如:file,exec,
package等。但是当Puppet内建的Resource不够用了呢?所以,它应该支持resource的扩展。以此类推,所有的自动化运维工具都应该支持此类扩展。
同时,Puppet提供了模板机制。Puppet的模板模式使用的是Ruby的ERB。你将`.erb`的文件放在`/etc/puppet/templates`后,就可以在puppet的代码中使用`template('my.cnf.erb’)`:
#vim /etc/puppet/templates/my.cnf.erb
[mysql]
...
... |
既然有模板,怎么少得了变量?变量的定义:$VAR_NAME = VALUE。有变量的地方,一定会引用作用域概念,不论它是静态作用域还是全局作用域。可以告诉你Puppet是静态作用域。猜猜Puppet的变量的作用域分几级?实际上,Puppet,Chef,Ansible的变量都是静态作用域概念,它们的变量作用域分又都分成几级?多问一句:这也是它们的共性吗?
现在我们了解了Manifest及其基本格式、node、resource概念、模板和变量。同时,我们并不应该把所有的内容都写到一个site.pp文件中,这就像我们不应该把所有的逻辑都写在C语言中的main函数中一样。那Puppet的DSL是如何解决这个问题的:如何让开发者更方便的组织代码?
现在我们来看相对模块化一些的Puppet代码:
#vim /etc/puppet/manifests/site.pp
class mysql($mysql_password = "123456") {
package {
['mysql-common', 'mysql-client', 'mysql-server']:
ensure => present
}
service {
'mysql':
enable => true,
ensure => running,
require => Package['mysql-server']
}
exec {
'set-root-password':
path => "/usr/bin:/usr/sbin:/bin",
subscribe => [Package['mysql-common'], Package['mysql-client'],
Package['mysql-server']],
refreshonly => true,
unless => "mysqladmin -uroot -p$mysql_password
status",
command => "mysqladmin -uroot password
$mysql_password",
}
file {
'/etc/mysql/my.cnf':
content => template('my.cnf.erb'),
require => Package['mysql-server'],
notify => Service['mysql']
}
}
node 'agent' {
include mysql
class { 'mysql':
mysql_password => '456789'
}
} |
这个版本的site.pp我们用到了class概念。你可以定义了一个class,然后将职责相同的逻辑放在其中。最后在其它地方引用。但是引用的时候要分情况,这个class有没有带参数,
将影响使用这个class的方式。
但是就算这样,我们的site.pp的代码可维护性一样不高。所以,Puppet还提供一种module概念。实际上,用了你就知道,puppet就是将class从site.pp移出去了的另一种说法。我们来看使用了module的第三版:
我们将mysql class抽到mysql module中:
#vim /etc/puppet/modules/mysql/manifests/init.pp
class mysql($mysql_password = "123456") {
package {
['mysql-common', 'mysql-client', 'mysql-server']:
ensure => present
}
service {
'mysql':
enable => true,
ensure => running,
require => Package['mysql-server']
}
exec {
'set-root-password':
path => "/usr/bin:/usr/sbin:/bin",
subscribe => [Package['mysql-common'], Package['mysql-client'],
Package['mysql-server']],
refreshonly => true,
unless => "mysqladmin -uroot -p$mysql_password
status",
command => "mysqladmin -uroot password
$mysql_password",
}
file {
'/etc/mysql/my.cnf':
content => template('mysql/my.cnf.erb'),
require => Package['mysql-server'],
notify => Service['mysql']
}
} |
在使用module之前,我们的文件结构是这样的:
|-- auth.conf
|-- environments
|-- files
|-- manifests
| `-- site.pp
|-- puppet.conf
|-- templates
| `―my.cnf.erb |
使用module后:
|-- auth.conf
|-- environments
|-- files
|-- manifests
| `-- site.pp
|-- modules
| `-- mysql
| |-- manifests
| | `-- init.pp
| `-- templates
| `-- my.cnf.erb
|-- puppet.conf
`-- templates |
定义了module,那怎么用呢?
#vim /etc/puppet/manifests/site.pp
node 'agent' {
include mysql
} |
到这里,我相信你知道大概怎么写Puppet,但是我觉得是不够的。我不理解它为什么这样设计。我们为什么不是:
node 'agent_hostname'{
install package [‘mysql’,’mysqlserver’]
start service ‘mysql'
create template mysql.cnf
} |
我的意思是为什么是以名词导向的描述性语言,而不是以动词为导向。然后,我就去找《配置管理最佳实践》。醒悟了,原来配置管理不是一两个工具就可以搞定。它是一个系统,包括六个核心职能:
1. 源代码管理
2. 构建工程
3. 环境配置
4. 变更控制
5. 发布工程
6. 部署
所以,我以前一直不理解自动化运维和自动化配置管理之间的区别。同时我看到了一些文章里:配置管理实际上就是状态管理,不论是服务器状态还是软件状态。
这下终于感觉明白了,也难怪Puppet,Chef,Ansible的DSL都是描述性的语言。
但是,Puppet如何编译,在哪里编译我们写好的manifest呢?在主控机器与受控机器认证成功后,受控机器会每隔一段时间就向主控机器发请求,这个请求将会把自己(受控机器)的信息告诉主控机器。主控机器拿到这些信息后与manifest链接编译,最后生成一份受控机器(puppet客户端)可执行的catalog。受控机器在执行的过程中,将执行情况反馈给主控主机。这就是Puppet中主控机器如何得到受控机器的命令执行结果的。
到此,我们看到了Puppet已经回答了我们之前的四个问题。
小结
1. 如何与受控机器通信
采用C/S架构,使用HTTPS,agent向master申请证书。
2. 如何组织成百上千台机器
在manifest中使用`node`关键字定义。
3. DSL的设计与编译
* 组织代码的方式
Puppet在manifest文件中定义node(受控节点),将所有node中的构件抽象为resource,我们可以给这个resource的attribute设置值。node下可以包含多个resource,这些resource共同构成了这个node的状态。但是不可能将所有的resource都写在一个文件中,再说一个manifest文件通常不止一个node。所以,所以,Puppet提供一种module和class机制,让你能将一些共同起到同一职责的resource打包到一起。class与module有什么不同呢?class可以直接写到manifest文件中,而module必须另外新建一个目录结构。这就是Puppet组织代码的方式。
深入学习:如果处理resource之间的关系问题,它们很有可能有依赖关系。class及module也会有同样的问题。if
else及for呢?
* 变量定义: $VAR_NAME = VALUE。
深入学习:了解变量的作用域
* 模板:使用ruby的erb文件
4. 如何得到执行结果
受控机器主动将执行结果发送给主控机器。
它真的一定要有master才能用吗?不是的。Puppet提供了单机版的使用方法。具体请google:
puppet apply。
Chef
Chef的中文意思是厨师。所以它将所有的受控机器看作“菜肴”。但是如果我们不给告诉它菜谱(Cookbook),它是不会给我们做菜的。菜谱上都写着什么呢?是配方(Recipe)。所以,我们把recipe一个个的写到Cookbook中,最后交给Chef。
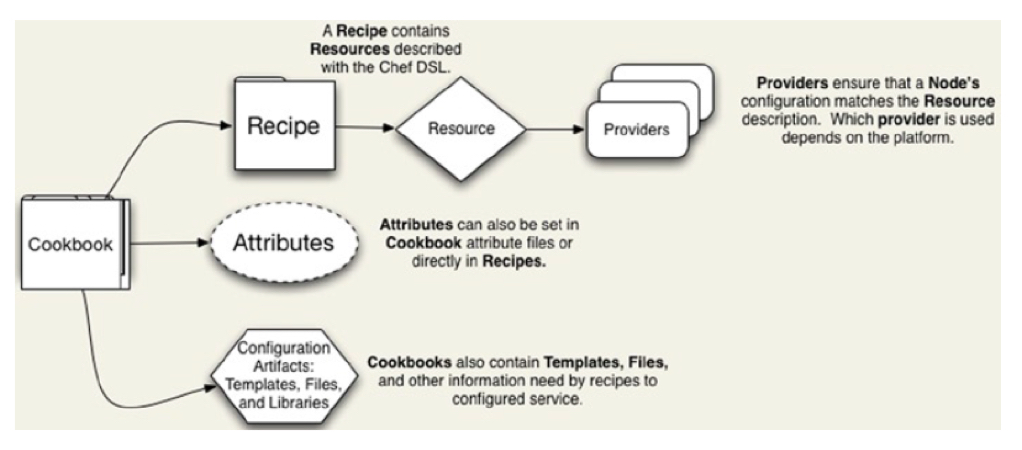
Chef同样是C/S架构,C与S也是使用HTTPS进行通信的。同样的,正因为这样,我们可能重用学习Puppet的pattern来学习Chef。但是因为Chef的C/S模式的投资回报率太低了,所以,我坚持一段时间后,就放弃了。和Puppet一样,Chef也提供了单机版:Chef-solo。
Ansible
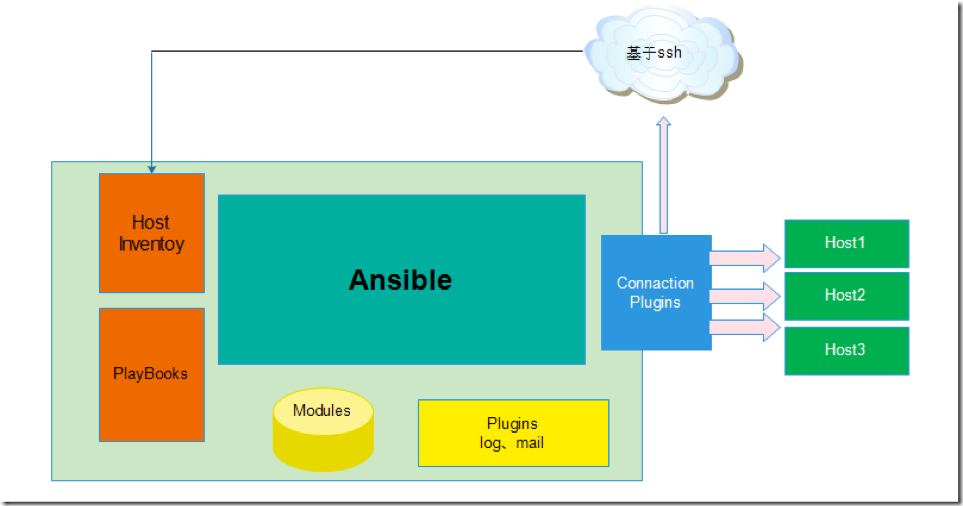
Ansible说是agentles(去客户端)的。但是实际上,它要求受控机器上装有SSH及Python,并且装了python-simplejson包。实际上,我们现在的机器基本上默认都已经安装这些。所以,在使用Ansible时,你不需要特意准备一台机器做为主控服务器。只要你想,任何机器随时都可以变成主控机器。
关于Ansible的安装看文档就好了。与Chef和Puppet不同的是,Ansible组织受控机器的那部分逻辑抽来单独放,叫Inventory。它是一个ini格式的文件,如hosts:
[web]
192.168.33.10
[db]
192.168.33.11 |
文件名和路径都任意,但是建议使用表意的名字及合适的路径。
Puppet和Chef都自己做了一套DSL,然后再自己写编译器,但是Ansible使用的是yaml格式。我觉得这是非常聪明的设计:一是大家都熟悉yaml格式比熟悉自定义的DSL来得简单,二是不需要自己设计DSL了,三是不用自己写编译器了。所以,我个人学习过程中,发现它是相对Puppet,Chef简单很多。
了解yaml文件格式后,接着就是理解Ansible的隐喻了。Ansible是导演,将所有的受控机器理解为演员。而我们开发者则是编剧。我们只要把剧本(playbook)写好,Ansible拿剧本再与Invenstory一对上号,演员只会按照剧本上的如实发挥,不会有任何的个人发挥。
好,我们就来写第一版本的playbook.yml(路径和名字都可自定义):
---
- hosts: web
tasks:
- name: install nginx
apt: name=nginx state=latest
- hosts: db
vars:
mysql_password: '123465'
tasks:
- name: install mysql
yum: name={{item}}
with_items:
- 'mysql-common'
- 'mysql-client'
- 'mysql-server'
- name: configurate mysql-server
template: src=my.cnf.j2 dest=/etc/mysql/my.cnf
- name: start service
service: name=mysql state=started |
#vim templates/my.cnf.j2
[mysql]
...
passowrd={{mysql_password}} |
我们的剧本包括两个演员:web,db。它们都对应哪些受控机器呢?看Invenstory文件就知道了。那这些演员都要做哪些事情呢?看tasks,它下面跟的是一个列表。像`yum`,`apt`,`template`,`service`,被称为module,类似于Puppet的resource和Chef的recipe。Ansible本身提供了不少module,但是想都不用想,一定不能满足所有项目的需求,所以,你可以开发自己的module。
同样的,Ansible提供变量和模板(Jinja2)机制。问题来了,Ansible的作用域分为几级呢?
同样的,我们可以不能容忍把所有的task都写在一个文件里。Ansible是如何组织代码的呢?Ansible提出role的概念。是的,扮演共同职责的task,我们把它们归到同一个role中。所以,我们文件结构也变了,由原来的只有两个文本文件,到现在需要新建目录了:
── hosts
├── playbook.yml
└── roles
└── mysql
├── tasks
│ └── main.yml
└── templcates
└── my.cnf.j2 |
这时,playbook.yml:
--
- hosts: web
tasks:
- name: install nginx
apt: name=nginx state=latest
- hosts: db
var:
mysql_password: '123456'
roles:
- mysql |
而main.yml:
- name: install mysql
yum: name={{item}}
with_items:
- 'mysql-common'
- 'mysql-client'
- 'mysql-server'
- name: configurate mysql-server
template: src=my.cnf.j2 dest=/etc/mysql/my.cnf
- name: start service
service: name=mysql state=started |
就是task和role之间的关系。那task之间的关系,role之间的关系呢?
Ansible的DSL就是这样组织代码的。最后一个问题如何得到执行结果呢?这就要说到Ansible的原理:Ansible将本地的yml文件编译成python代码,然后传到受控机器,受控机器执行结果以Json格式返回。
Ansible的入门非常简单。
小结
1. 如何与受控机器通信
只要主控机器与受控机器双方将有SSH
2. 如何组织成百上千台机器
使用Invenstory管理
3. DSL的设计与编译
* 组织代码的方式
Ansible Language的入口就是playbook。你可以直接在playbook里加`tasks`。很自然,我们想到的这个tasks里是一批小task。事实的确是这样,但是在Ansible中,它叫module。但是,我们不希望所有的task写在同一个文件中,这时,Ansible的role机制就起作用了。你可以把完成同一职责的一批放在一个role中就好了。
深入学习:module之间的依赖问题,if-else问题
* 变量定义:不同的级别有不同的定义方法
深入学习:了解变量的作用域
* 模板:使用Jinja2
4. 如何得到执行结果
受控机器主动将执行结果发送给主控机器。
总结
面对层出不穷的新编程语言、新框架、新概念,我们程序员总是学不完。诚然,我假设大家都爱学习,但是,我们更需要问:学到的这些东西,到底属于解决域还是问题域。所以,来了新东西,我总是要问这东西解决了什么问题?为什么它能解决,依据是什么?我们需要的是问题的本质和问题的解决模型,而不是别人葫芦里的药。
说远了。实际上,除了上述的仨自动化配置管理工具,市面还有很多别的。总的来,我觉得都可以用以上思路去学习。回到我们最开始的问题:Puppet,Chef,Ansible的共性是什么?
我能不能说那四个问题就是它们的共性,答案是我也不知道。 |






