|
ժҪ�� ����ҵ��Ŀ���������һ�����Ͻ���ϵͳ������ʱ���ڣ�������Ҫά������ϵͳ���ȶ�����Ҫ֧��������Ŀ������������ڼ���֧�Ų�����ʧҵ��չ�ؼ�ʱ�䴰�ڡ����ķ�����һ�δ���ҵ���ܹ����������ܹ�Ǩ�ƵĹ���ʵ����
�����䶯������һ����ƽ̨������Ŀ������Ŀ���ڼ���������ÿ���д�������������ƽ̨��֮ǰ���õ���SpringMVC+Hibernate+FreeMarker+MySql�ܹ�����webǰ�˺ͽӿ�Ϊһ�塣������ҵ���������Ƶ�������Ԥ�ƽ�������֮����֧��ԭ��ҵ���������
��ǰ�ܹ���Ҫ�����������⣺
1����չά������
2������������
����ҵ��Ŀ��������������Ƕ����мܹ������ع������������Ͻ���ϵͳ���������Ǹ����ʱ��dz����ޣ�������Ҫά������ϵͳ���ȶ���Ҫ֧��������Ŀ������������ڼ���֧�Ų�����ʧҵ��չ�ؼ�ʱ�䴰�ڣ�������ʵ��ԭ�������ƶ����²���������졣
һ��ȥhibernateǨ����mybatis
��hibernateǨ����mybatis�� DAO���������Ҫ��дһ�飬������Ҫ������Ϊ����ԭhibernate
DAO�����������sql����Ҫ��ϸ�Ļ������Ҫע�����mybatis��̬�����Ĵ��룬��Ҫ��mapper��statementType������ΪSTATEMENT������SQL�����#{}����Ϊ${}����ʹ��${}���ι����У���Ҫ�ر�ע��SQLע�빥��Σ�ա�һ�����SpringMVC�㽫�����ַ�ת�塣����
">" �á�>����ʾ�������кܶ��װ����������apache common
lang����StringEscapeUtils.escapeHtml()��
����ȡ��sql֮��ı�����
ȥ��sql֮��ı���������ͳ��ϵ�����ݿ������е�����ʽ�ڻ����������ݿ�ģ�����Dz����õģ���Ҫ��ɵ������������зֱ��ֿ⡣���Ҫ������dao�������뱣�ֵ���������
���ֵ�������Ϊ�ֱ�����춨�˸��������
����Service���ԭ��DAOҵ����������װ
��ȡ������������Ҫ��������ʵ��ṹ������ȡ��ʵ��֮���һ��һ�����һ����Զ������ϵ����ʵ��֮������ù�ϵ��Ϊ��ʵ��ID�����á�ͬʱΪ���ϲ㷽��ʹ����Ҫ����ҵ��BO������service����ö��ԭ�ӵ�dao��������װ��ҵ��BO����
�ġ��ֱ�
�ڵ��ű�����2000������¼��mysql�IJ�ѯ���ܿ�ʼ���ͣ�������ֶεȴ�ʱ���������ֱ����������ܺ���չ�Ժ��ִ����������⣺
·�ɲ��Ե�ѡ��
��θ��������������ŵ�·�ɵ���ȷ�ı���
�ֱ����ҳ��ѯ
��α�֤���ߺ�ֱ�����ƽ�����Ͽ���ɵ��¿⡣
1��·�ɲ��Ե�ѡ��
���ȣ����Ƕ����ݿ������еı���¼���з�����ͳ��ÿ�ű�����������С������ͳ�ƺ����Ƿ�������ҵ�������ҵ������Ҳ����ٽ��������ı���ҪΪ��������������ϸ���������ı��ڽ������ڲ���������ҵ�����������������������ֻ��Ҫ�Զ�������������ϸ�����в�֡�
·�ɲ���ѡ�����������������籾��Ҳ�Dz������ģ��ؼ����ں��ʵĽ�ѡ����ʵIJ��ԣ�����������ҵս��ʱ�䴰�ڵ�������������������Ѱ��ƽ��㡣����Ԥ����ҵ���5��ķ�չĿ��Ϊ����ҵ5�������������ְ��½��в�ֿ��Ա�֤ÿ��������������2000������������ʵ��ԭ������ѡ���˰��½��зֱ���·�ɲ��ԡ�
������濼�����ܹ����Ч�ʺͽ����츴�Ӷȵ�˼·����������ϰ취���������°취���������е������������ɣ�������µ����������������ɣ���ǣ�������й������е�ID����Ҫ�����滻�����������Ӹ���ĸ��ӶȺ��������������տ��ǽ������ݰ����µ��������ɲ��Խ������ɡ������·ֱ��Բ�������ҵ��֧��Ҫ��ʱ�������ٴ�������Ϣ�����ϸ���ȵIJ�ֲ��ԣ�����ɰ���Ϊ��λ���б��۷֡�
2��������������ѡ����ȷ�ı�
�����������㷨 ����ID�����ɣ��ο�twitter Snowflake�㷨
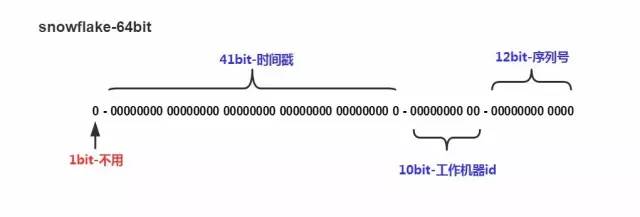
��Java����ϵͳ�У�����ͨ��Long����ʾ������Long���Ͱ���64��λ�����ÿ��Դ洢��ID�� 1��41λ�Ķ�������ֵ������ʾ����ʱ�����43��53λ���Ա�ʾ1024̨���������ǿ���Ϊÿ̨API����������һ����������ID��43��55λ���������߳�Ψһ�����кš�Ԥ���Ĺ�������ID������Ϊ�ϱ�˫�������·���ж���������1,2,3,4�Ź�������ID·�ɵ�������API��������5,6,7,8��������ID·�ɵ��ϻ���API��������
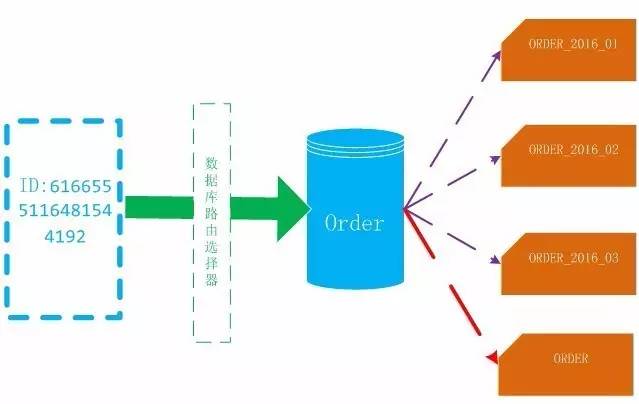
���������Ų�ѯʱϵͳ���ȸ��ݶ����ų��ȵIJ�ͬ����ѡ����·�ɵ��µ��зֶ�����������·�ɵ�ԭ����������Ϊ������ID�����������Ϣ��ϵͳ��������������������Ϣ�������·ݵIJ�ͬ��ѡ������ݿ��Ӧ���·ݱ��������ȡ����������Ϣ�Ϳ����жϳ�Ϊԭ��������
3����α�֤���ߺ�ֱ�����ƽ�����ϱ����ɵ��±�
����ϵͳ����ͳһ�ķֱ��и�ʱ�乫���������ڲ��붩��ʱ���ж��Ƿ��ڷֱ��л�ʱ���֮ǰ������ڷֱ��л�ʱ���֮ǰ�������ݲ��뵽�ϱ������������ݰ���ǰ�·ݲ�ͬ���뵽�µIJ���±���
4���ֱ����ҳ��ѯ
�ڶ����ֱ�����ڵ���Ҫ�ѵ��Ƿֱ������ݵķ�ҳ��ѯ������������2016-07-26 00:00:01 ��ʼ���·ֱ�����ѯ2016-05-01
00:00:01��2016-09-11 12:00:05�ڼ�����ж����ֽ�Ϊ���¼�����
��1��ͨ����ʼʱ�䡢����ʱ�䡢�ֱ�ʱ��������Ҫ��·����Ϣ���ϡ�
a.��ʽ:����|��ʼ����|��������
b.·�ɼ��ϣ�
Order|2016-05-01 00:00:01|2016-07-26 00:00:01
Order_2016_07|2016-07-26 00:00:01|2016-07-01
23:59:59
Order_2016_08|2016-08-01 00:00:01|2016-08-31
23:59:59
Order_2016_09|2016-09-01 00:00:01|2016-09-11
23:59:59 |
��2������ҳ��Ϣ��pageNo,pageSize����·����Ϣ���ϲ�ѯ����������Ϣ���ϡ�
a.����·�ɼ��Ϸ����ܼ�¼������������Ϣ���ϡ�
i. ��������Ϣ���壺��������ʼ��������¼����·����Ϣ��
ii. ��������Ϣ���ϣ�
Order��1��137��Order|2016-05-0100:00:01|2016-07-26 00:00:01
Order_2016_07��137��10��Order_2016_07|2016-07-2600:00:01
|2016-07-01 23:59:59
Order_2016_08��147��32��2016-08-0100:00:01|2016-08-31 23:59:59
Order_2016_09��179��10��2016-09-0100:00:01|2016-09-11 23:59:59 |
iii. ��������:
private RouteTableResult getRouteTableResult
(OrderSearchModel searchModel,List<String> routeTables) {
Integer sumRow = new Integer(0);
Map<String, RouteTable> routeTableCountMap
= new TreeMap<String,RouteTable>();
RouteTableResult routeTableResult = new RouteTableResult();
for (String routeTable : routeTables) {
String[] routeTableArray = routeTable.split("\\|");
if (routeTableArray.length == 3) {
String tableName =getTableByRouteTableAndSetSearchModel(searchModel,
routeTableArray);
Integer orderCount = ticketOrderDao.searchOrderCount(tableName,searchModel);
Integer startIndex = sumRow.intValue();
RouteTable routeInfo = new RouteTable(startIndex,
orderCount, routeTable);
routeTableCountMap.put(tableName, routeInfo);
sumRow += orderCount;
}
}
routeTableResult.setRouteTableCountMap(routeTableCountMap);
routeTableResult.setSumRow(sumRow);
returnrouteTableResult;
} |
b.���ݷ�ҳ��Ϣ����ѯ���÷�ҳ��Ҫ��Խ�ı�·����Ϣ���ϣ������㷨���£�
i. ����������Ϣ����
ii. ����ʼ�кͽ������뵱ǰ·�������н�����˵���������ڸñ��ڲ����ñ��������·�ɼ��ϣ�
iii. ���·�ɱ���Ϣ�������������Ҳ����������������˳���
iv. ������Ҫ��Խ�ı�·����Ϣ���ϣ�
v. ����������
private List<String> getRouteTables
(OrderSearchModel searchModel,Map<String,RouteTable>
routeTableCountMap) {
List<String> routeTableInfoList = new
ArrayList<String>();
Integer startIndex = (searchModel.getPageNo()
- 1) * searchModel.getPageSize();
Integer endIndex = startIndex + searchModel.getPageSize()
-1;
for (Entry<String, RouteTable> entry :
routeTableCountMap.entrySet()) {
RouteTable routeTable = entry.getValue();
//����ʼ�кͽ������뵱��·�����н���
if( !(startIndex > routeTable.getEndIndex())
&& !(endIndex < routeTable.getStartIndex())){
routeTableInfoList.add(routeTable.getRouteInfo());
//���·�ɱ���Ϣ�������������Ҳ����������������˳�
}elseif (routeTableInfoList.size()>0) {
break;
}
}
returnrouteTableInfoList;
} |
c.��ѯ�÷�ҳ�µĶ����б��������㷨���£�
i.�����������һ�α����ı�Ϊ��Ҫ��Խ·����Ϣ���ϵĵ�һ�ű���
ii.���ü�������readCount����0��
iii.������Ҫ��Խ·����Ϣ���ϣ�
iv. ����·����Ϣ���ر�������������������
v. ���ݱ�����ȡ·�ɸ�Ҫ��Ϣ��
vi.���㿪ʼ�кţ������ǰ�������������ı�����ͬ����ʼ�кŵ���(��ǰ��ҳ��-1)*ԭ����ҳ���С(originalPageSize)-��ǰ��·�ɸ�Ҫ��Ϣ��ʼ�У������к�����Ϊ0��
vii. ���㵱ǰҳ���СpageSizeΪԭ����ҳ���С(originalPageSize) �C
��������(readCount)��
viii. ��������������ʼ�кš���ǰҳ���С��
ix.�������һ�α����ı�Ϊ��ǰ����
x.���ݵ�ǰ������������������dao���ض���������Ϣ�б��������붩�����б����ϣ�
xi.���������ӵ�ǰ�����б���С��
xii. ������������ڵ���ԭ����ҳ���С������ѭ�����������ѭ����
xiii.���ض������б����ϣ�
xiv. ����������
private List<Order> getOrderListByRoutePageTable
(OrderSearchModelsearchModel,
Integer originalPageSize, Map<String, RouteTable>
routeTableCountMap,
List<String> routePageTables) {
Integer readCount = 0;
List<Order> orderList = new ArrayList<Order>();
if (routePageTables != null && routePageTables.size()
> 0) {
String[] routeTableArrayFirst = routePageTables.get(0).split("\\|");
String lastTableName = null ;
if (routeTableArrayFirst.length == 3) {
lastTableName = routeTableArrayFirst[0];
}
for (String routeTable : routePageTables) {
String[] routeTableArray = routeTable.split("\\|");
if (routeTableArray.length != 3) {
break;
}
String tableName =
getTableByRouteTableAndSetSearchModel(searchModel,
routeTableArray);
RouteTable routeTableInfo = routeTableCountMap.get(tableName);
Integer startRow = 0;
if( tableName.equals(lastTableName)){
startRow = (searchModel.getPageNo()-1)*originalPageSize
- routeTableInfo.getStartIndex();
}
Integer pageSize = originalPageSize - readCount;
searchModel.setStartRow(startRow);
searchModel.setPageSize(pageSize);
lastTableName = tableName;
List<Order> orderListPage = orderDao.searchOrderList(tableName,searchModel);
orderList.addAll(orderListPage);
readCount += orderListPage.size();
if (readCount.intValue() >= originalPageSize)
{
break;
}
}
}
returnorderList;
} |
��3������Order������װOrderBo����
��4�����ݷ��ص���������ҳ��Ϣ��װ��ҳ���
�塢mysql���ӷ��롢������������
Ϊ��������ܣ���������mysql���ӷ��룬ͨ��Spring������Դ��ʵ�ֶ�̬�л�������������Ҫ��Ϊ����1�����̼߳�����ͬһ�߳�����ʱ���̼߳���������̼߳�ThreadLocal�����ϣ����Խ����̼߳��л���ɵ�ʱ�俪����(2)�����̼������̼�������ͬһjvm�й������棬�����ٿ���̼����翪������3��������̵ļ���ʽ���棺һ��ʹ��redis��memcache�ڴ滺�������Ͷ����ݿ�ϵͳ�ij���������������Ż������ǵĽӿ���Ӧ�ٶ�����˽�5����
����������
���ڷֲ�ʽ��������ϱ�����˫�����������ҵ���պ���ĺʹ�ҷ����� |






