|
‘⁄2016÷–π˙‘∆º∆À„ºº ı¥Ûª·£®CCTC 2016£¨◊®Ã‚±®µ¿£©…œ£¨∞Ÿ∂»ø™∑≈‘∆ ◊œØºÐππ ¶–Ï¥Æ∑¢±Ì¡ÀÂŒ™°∂∆Û“µITª˘¥°ºÐππ‘⁄‘∆∂À»Á∫Œ±‰∏Ô°∑µƒ÷˜Ã‚—ðΩ≤£¨≤¢Ω” ÐCSDNº«’þ◊®∑√£¨…Ó»Î∑÷œÌ¡ÀÀ˚∂‘ºÐππº∞…˺∆µƒ»œ ∂£¨∂‘ºÐππ ¶π§◊˜∫ÕººƒÐµƒ¿ÌΩ‚£¨“‘º∞∞Ÿ∂»ø™∑≈‘∆ºÐππ¬˙◊„¥Û ˝æð∫Õ»Àπ§÷«ƒÐµ»≤ªÕ¨”¶”√–Ë«Ûµƒ µº˘æ≠—È°£
–Ï¥Æ±Ì æ£¨‘∆º∆À„ª∑æ≥œ¬µƒºÐππ£¨≥˝¡À∏þÕÃÕ¬°¢ø…¿©’π–‘°¢Œ»∂®–‘µƒ–Ë«Û£¨¡ÈªÓ–‘µƒ µœ÷“≤∫Ð÷ÿ“™°£ºÐπ𠶵ƒπ§◊˜æÕ «‘⁄∏˜÷÷√¨∂Ð÷ƺ‰º·≥÷ªÚÕ◊–≠£¨»Á∏þÕÃÕ¬∫ÕµÕ—”≥Ÿµƒ√¨∂У¨”≈—≈ºÐππ∫ÕΩÙ∆»–Ë«Ûµƒ√¨∂а£±£÷§“µŒÒµƒ–Ë«Û£¨ «…˺∆ºÐπ𵃓ª∏ˆª˘±æ‘≠‘Ú£¨“™≥…Œ™”≈–„µƒºÐπ𠶣¨æÕ“™—ߪ·¿ÌΩ‚“µŒÒ£¨∫Õ“ªœþ≤˙∆∑æ≠¿ÌπµÕ®£¨’“≥ˆ◊Ó∫À–ƒµƒÀþ«Û¿¥Ω‚戰£¡Ì“ª∑Ω√Ê£¨ºÐππ ¶≥˝¡À“‘øÌπ„µƒºº ı ”“∞∏˙Ω¯◊Ó–¬µƒºº ı£¨“≤±ÿ–Î…Ó»ÎµΩµΩµ◊≤„¡ÀΩ‚≥Öڑ±µƒπ§◊˜∫ÕÕ¥øý£¨≤≈ƒÐ◊ˆ≥ˆ»√≥Öڑ±¬˙“‚µƒ»°…·°£

∞Ÿ∂»ø™∑≈‘∆ ◊œØºÐππ ¶–Ï¥Æ
ºÐππ…˺∆£∫√¨∂Ðœ¬µƒº·≥÷”ÎÕ◊–≠
◊‘2008ƒÍº”»Î∞Ÿ∂»£¨–ϥƜ»∫Û◊ˆÕ¯“≥À—À˜µ◊≤„µƒ∑÷≤º Ω¥Ê¥¢£¨∫Û¿¥µƒ∑÷≤º Ωº∆À„°¢Hadoopœýπÿµƒ¡Ï”Ú£¨∫Õ’˚õƒµ◊≤„¥Ûπʃ£ºØ»∫πп̜µÕ≥π§◊˜£¨‘⁄µ◊≤„µƒ∑÷≤º ΩœµÕ≥…œ√˛≈¿πˆ¥ÚΩ´Ω¸6ƒÍ£¨µΩ¡À2014ƒÍ∞Ÿ∂»ø™ ºæˆ∂®Õ∂»Îø™∑≈‘∆≤˙∆∑£¨À˚ø™ º…Ê◊„√ÊœÚπ´”–‘∆µƒ∑÷≤º ΩœµÕ≥µƒ…˺∆∫Õ—–∑¢°£
◊Óø™ º◊ˆ∑÷≤º ΩºÐπ𵃠±∫Ú£¨–Ï¥ÆÕ®≥£øº¬«¡Ω∏ˆ“ÚÀÿ£∫
∏þÕÃÕ¬°£“ª∂®“™∞—¥Û¡øµƒ ˝æð¥Ê¥¢∫Õ¥¶¿Ì∆¿¥ £¨”√◊Ó¥ÛµƒÕÃÕ¬¡ø¿¥Ω‚戰£
ø…¿©’π–‘°£∞Ÿ∂»µƒ ˝æð‘ˆ≥§∑«≥£—∏√Õ£¨º∏∫ı√ø“ªƒÍ∂ºª·∑≠±∂‘ˆ≥§£¨“™«ÛœµÕ≥”–◊Ó¥Û≥Ã∂»µƒø…¿©’π–‘°£
ø™ º◊ˆ‘∆≤˙∆∑“‘∫Û£¨–Ï¥Æ∏¸πÿ◊¢µƒ£¨ «‘ı√¥ πºÐππ‘⁄Œ»∂®µƒ«∞÷œ¬±£÷§¡ÈªÓ–‘£¨“ÚŒ™–Ë«Û«ß±‰Õڪأ¨–Ë“™∑·∏ªµƒπ¶ƒÐ◊Ⱥ˛∏¸∫√µÿ÷ß≥≈øÏÀŸµƒ±‰ªØ°£
µ´“≤”–≤ª±‰µƒ∂´Œ˜£¨æÕ «“ª∏ˆ»°…·°£ºÐπ𠶵ƒπ§◊˜£¨ª˘±æ…œæÕ «≤ªÕ£µÿ‘⁄∏˜÷÷∏˜—˘µƒ√¨∂Ð÷–’˝»∑µÿ»°…·£¨±»»Á◊ˆ∑÷≤ºœµÕ≥ ±∏þÕÃÕ¬∫ÕµÕ—”≥Ÿ «“ª∏ˆ√¨∂У¨∫Ѓ—‘⁄∏þÕÃÕ¬µƒ ±∫Ú◊ˆµΩ µ ±œÏ”¶£¨±ÿ–λ°…·µΩµ◊“µŒÒ∏¸œÎ“™ ≤√¥£ª◊ˆπ´”–‘∆µƒ ±∫Ú£¨ µœ÷ºÐππ…˺∆µƒ”≈—≈£¨”ÎÃÿ±ΩÙ∆»µƒ–Ë«Û£¨“≤ «“ª∏ˆ√¨∂У¨‘ı√¥—˘øÿ÷∆Ω⁄◊ý£¨‘⁄ƒ≥–© ±∫Ú◊ˆ“ª–©Õ◊–≠£¨ƒ≥–© ±∫Ú“™º·≥÷£¨‘⁄±£÷§ºÐππ’˚ÃÂ∏…檵ƒ«Èøˆœ¬ƒÐ∏¸∫√µÿ ”¶“µŒÒµƒ∑¢’π°£
πÿ”⁄º·≥÷∫ÕÕ◊–≠µƒæˆ≤þ£¨–Ï¥Æ∑÷œÌ¡ÀÀ˚µƒ∫À–ƒ‘≠‘Ú£∫ ◊œ»“™±£÷§“µŒÒ–Ë«Û“™±ª µœ÷°£
ºÐππ ¶∫Ð∂ý ±∫Úª·±ß‘πÀµ£∫°∞Œ“√«µƒøժߖ˫Ûôπ≈π÷£¨ªÚ’þŒ“√«µƒ≤˙∆∑æ≠¿Ìæ≠≥£∆» πŒ“√«◊ˆ“ª–©∫Ð∞π‘ýµƒ ¬«È°±°£µ´ «–ϥƵƒæ≠—È»œŒ™£¨∫Ð∂ý ±∫Úøժߵƒ–Ë«Û∂º «ø…“‘∏ƒ±‰µƒ£¨πÿº¸ «ºÐπ𠶓ª∂®“™’“≥ˆƒ«–©◊Óª˘±æµƒ–Ë«Û « ≤√¥°™°™øÕªßÕ®≥£ª·Ω≤∫Ð∂ý∂´Œ˜£¨µ´∆‰÷–÷ª”–“ª¡Ωµ„ «À˚◊Ó∫À–ƒµƒÀþ«Û£¨∆‰À˚∂´Œ˜∂º «∏Ωº”µƒ£¨¬˙◊„À˚µƒ∫À–ƒÀþ«Û∆‰ µ≤¢≤ª–Ë“™Ã´∂ý∂´Œ˜°™°™’‚∏ˆ∫À–ƒ‘⁄”⁄◊ˆµ◊≤„ºÐπ𵃻À≤ªƒÐÕ—¿Îø™“µŒÒ£¨±ÿ–ÎµΩµ⁄“ªœþ»•∫Õ≤˙∆∑æ≠¿Ì°¢øժߒʒ˝µÿ…áø£¨∑¢œ÷À˚µƒ∫À–ƒ–Ë«Û£¨¥”∂¯‘⁄¬˙◊„∫À–ƒ–Ë«ÛµƒÕ¨ ±±£≥÷ºÐπ𵃔≈—≈°£
∞Ÿ∂» µº˘£∫ø™‘¥°¢»ð∆˜°¢¥Û ˝æð∫Õ»Àπ§÷«ƒÐµƒ”∞œÏ
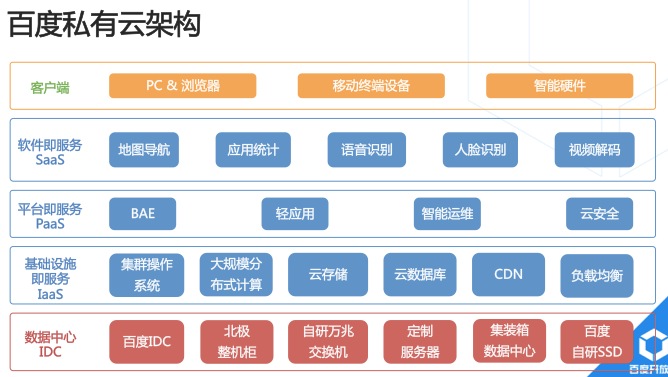
◊˜Œ™ƒ⁄≤øºº ıµƒø™∑≈≤˙∆∑£¨∞Ÿ∂»ø™∑≈‘∆∫Õ∞Ÿ∂»ÀΩ”–‘∆ºÐππ“ª÷¬£¨ «“ª∏ˆ∏¥‘”µƒœµÕ≥°£∞Ÿ∂»ÀΩ”–‘∆◊Óµ◊≤„ «IDCœµÕ≥£¨Ã·π©÷˜“™µƒ”≤º˛ª˘¥°…Ë ©£¨‘⁄…œ√Ê”–“ª≤„ÕÍ’˚µƒºØ»∫≤Ÿ◊˜œµÕ≥£¨”√¿¥πпÌÀ˘”–µƒª˙∆˜∫Õ÷π©’˚õƒ◊ ‘¥µ˜∂»£¨‘⁄’‚…œ√ʪπ”–∑÷≤º ΩœµÕ≥£¨∞¸¿®∏˜÷÷∏˜—˘µƒ∑÷≤º Ω¥Ê¥¢°¢∑÷≤º Ωº∆À„£¨ªπ”– ˝æ𥶿Ì≤„£¨∞¸¿®ƒÐπªπÐ¿Ì¥Û ˝æ𵃠˝æð≤÷ø‚°¢ ˝æðΩ”ø⁄°¢BIµ»£¨‘Ÿ…œ√Ê «”–“ª≤„PaaS£¨Œ™ƒ⁄≤øµƒ∑˛ŒÒ÷π©÷–º‰º˛∏˜÷÷∑˛ŒÒ£¨‘Ÿ’‚÷Æ…œ «∞Ÿ∂»◊‘º∫µƒ”¶”√°£–Ï¥Æ±Ì æ£¨‘⁄√ø∏ˆ“µŒÒ°¢√ø∏ˆ≤˙∆∑∂ºª·—°‘Ò“ªÃ◊◊‘º∫ ”√µƒºº ı’ª£¨µ´ «◊Óµ◊≤„∂º∞¸∫¨’‚∏ˆøںа£µ±»ª£¨∞Ÿ∂»≤¢≤ª «“ªø™ ºæÕ”–’‚√¥∂ý∂´Œ˜µƒ£¨◊Ðÿ¥Àµ£¨æ≠¿˙¡À»˝¥Œ±»Ωœ¥Ûµƒ∏ƒ‘Ï°£
2008ƒÍµƒ ±∫Ú£¨∞Ÿ∂»‘⁄IDC÷Æ…œ÷–º‰÷ª”–∫б°µƒ“ª≤„£¨…œ√ÊæÕ÷±Ω” «∞Ÿ∂»µƒ”¶”√°£‘⁄’‚∏ˆ«Èøˆœ¬£¨∞Ÿ∂»∑¢œ÷◊‘º∫µƒ“µŒÒ‘⁄∑…ÀŸ‘ˆ≥§£¨ ˝æð“≤‘⁄∑…ÀŸµƒ‘ˆ≥§£¨√ª”–¥Û ˝æðœµÕ≥ «≤ªƒÐ÷ß≥≈–Ë«Ûµƒ£¨À˘“‘‘⁄…œ√Ê∑¢√˜¡À∑÷≤º Ω¥Ê¥¢œµÕ≥£®∞¸¿®∑÷≤º ΩŒƒº˛œµÕ≥°¢∑÷≤º Ω±Ì∏ÒœµÕ≥°¢∑÷≤º Ω∂‘œÛ¥Ê¥¢£©∫Õ∑÷≤º Ωº∆À„œµÕ≥£®∞¸¿®∏þÕÃÕ¬¿Îœþº∆À„∆Ωî°¢¥Ûπʃ£ª˙∆˜—ßœ∞∆Ωî°¢ µ ±¡˜ Ωº∆À„∆Ω°£
À‰»ª”–¡À∑÷≤º Ω¥Ê¥¢∫Õ∑÷≤º Ωº∆À„œµÕ≥£¨’˚∏ˆπ´À浃 ˝æð¥¶¿Ìªπ «œ‘µ√‘”¬“ŒÞ’¬£¨√ø∏ˆ≤˙∆∑œþª˘±æ…œ∂º”–◊‘º∫µƒππœÎ£¨’‚∂‘ ˝æðµƒπп̓‘º∞“µŒÒ÷ƺ‰µƒΩªª•°¢¥ÚÕ®–Œ≥…∫Ð¥Ûµƒ’œ∞≠£¨«˝∂Ø∞Ÿ∂»◊ˆ“ª≤„ÕÍ’˚µƒ ˝æ𥶿Ì≤„£¨∞—’˚∏ˆ∞Ÿ∂» ˝æðÕ≥“ªπпÌ∆¿¥£¨Ã·π©“ª∏ˆπÊ∑∂£¨∫Ð∑Ω±„µÿπп̥¶¿Ì∏˜÷÷ ˝æð°£
¡Ω¥Œ¥Ûµ¸¥˙÷Æ∫Û£¨∞Ÿ∂»‘⁄IDCµƒ π”√÷–∑¢œ÷£¨“ÚŒ™ ˝æð¡ø‘⁄∑…ÀŸ‘ˆ≥§£¨»Áπ˚√ª”–“ªÃ◊œµÕ≥ƒÐπª∞—◊ ‘¥≥‰∑÷µÿ¿˚”√∆¿¥Ω¯––µ˜∂»£¨¿À∑— «∫Зœ÷ÿµƒ£¨À˘“‘—–∑¢¡ÀºØ»∫≤Ÿ◊˜œµÕ≥Ω¯––◊ ‘¥µ˜∂»°£
∞Ÿ∂»ÀΩ”–‘∆ºÐππ
»ð∆˜”ÎŒ¢∑˛ŒÒºÐππ
»ð∆˜ºº ıƒø«∞‘⁄ÀΩ”–‘∆¡Ï”Úµƒ”¶”√º´∆‰π„∑∫£¨–Ï¥Æ±Ì æ£¨∞Ÿ∂»∫БÁæÕø™ º◊ˆ»ð∆˜£¨œ÷‘⁄À˘”–µƒ”¶”√∂º «∑≈‘⁄»ð∆˜¿Ô√Ê°£2012ƒÍ£¨»ð∆˜ºº ıªπ√ª”–ƒ«√¥œÒœ÷‘⁄’‚—˘µƒ∑±»Ÿ£¨÷ª”–◊Óª˘±æµƒƒ⁄∫Àºº ıCGroup£¨ºº ıªπ√ª”–≥… Ï£¨∞Ÿ∂»◊ˆ¡À∫Ð∂ýµƒπ§◊˜£¨œ÷‘⁄–Œ≥…¡À◊‘º∫µƒ“ªÃ◊ºº ı£¨∂¯≤ª «≤…”√œ÷‘⁄¡˜––µƒDocker’‚—˘µƒ≥… ϵƒ»ð∆˜Ω‚æˆ∑Ω∞∏£ª»ð∆˜πп̺º ı£¨“ÚŒ™∑¢’π∆‰ µ±»Ωœ‘Á£¨“≤ «◊‘º∫—–∑¢µƒ£¨µ´ «∞Ÿ∂»ª·πÿ◊¢Kubernetes°¢Apache
Mesosµ»“µΩÁµƒ◊Ó–¬∑ΩœÚ£¨œ£Õ˚’“µΩ“ª–©œ»Ω¯µƒÀºœÎø…“‘Ω˺¯£¨“˝»ÎµΩ∞Ÿ∂»»ð∆˜ÃÂœµ¿Ô√Ê£®∞Ÿ∂»ø™∑≈‘∆ƒø«∞ªπ√ª”–ÕÍ’˚ø™∑≈»ð∆˜ºº ı£¨÷ª «ø™∑≈‘∆µ◊≤„ª˘”⁄∞Ÿ∂»◊‘º∫µƒ»ð∆˜ºº ı‘À◊˜£¨∞¸¿®‘∆÷˜ª˙µƒ’˚∏ˆø™∑≈µ◊≤„∂º «ππΩ®‘⁄∞Ÿ∂»»ð∆˜ºº ı÷Æ…œ£¨Œ¥¿¥‘⁄≥… ϵƒ ±∫Ú∞Ÿ∂»“≤ª·∞—»ð∆˜◊˜Œ™“ª∏ˆ∑˛ŒÒø™∑≈≥ˆ¿¥£©°£
∂¯∂‘”⁄ƒø«∞∫л»µƒŒ¢∑˛ŒÒºÐππ£¨–Ï¥Æ±Ì æ£¨Œ¢∑˛ŒÒ∫Ѓ—∂®“£¨∞Ÿ∂»µƒ»∑”–¥Û¡øµƒµ◊≤„∑÷≤º Ω∑˛ŒÒ£¨”…”⁄“µŒÒô∏¥‘”£¨¥”∂•µΩœ¬ø…ƒÐ“™æ≠π˝ŒÂ¡˘≤„£¨’‚∏ˆ∂´Œ˜ƒÐ∑Ò≥∆Œ™Œ¢∑˛ŒÒ÷µµ√…û∂°™°™Œ¢∑˛ŒÒ¿ÌœÎµƒ«Èøˆ£¨ «∞—√ø“ª∏ˆπ§◊˜ƒ£øÈ≤∑÷µΩ◊Ó–°≤¢∑÷±Ω´∆‰∑˛ŒÒªØ£¨µ´ «“ª∞„¿¥Àµ≤µΩ’‚√¥–°¡£∂»µƒ£¨ºÐππ…œª·”–º´¥ÛµƒÃÙ’Ω£¨ ◊œ» «π¶ƒÐ–Ë«Ûµƒ±‰ªØ£¨ø…ƒÐæÕ𷥩µΩ«∞∫Û∫Ð∂ý≤„µƒ±‰ªØ£¨’‚‘⁄∑˛ŒÒ÷–Ω”ø⁄ «“ª∏ˆ÷ÿ¥Ûµƒ ¬«È£¨–Ë“™ÕÍ’˚≤‚ ‘°£»Áπ˚≤∑÷ôœ∏£¨QAª·æ≠≥£Àµª∑æ≥≤ø ô¬È∑≥¡À£¨±æ¿¥÷ª «≤‚ ‘£¨µ´≤ªµ√≤ª≤ø ’˚Ã◊∑˛ŒÒ¿¥◊ˆ’‚∏ˆ ¬«È°£À˘“‘£¨Œ¢∑˛ŒÒµƒ¡£∂»µΩµ◊øÿ÷∆‘⁄ ≤√¥—˘µƒ≥Ã∂»£¨’‚ «“ª∏ˆ÷µµ√…û∂µƒ ¬«È°£
–ϥƻœŒ™£¨“ª∏ˆ∫√µƒºÐπ𠶣¨‘⁄Œ¢∑˛ŒÒ∏≈ƒÓ≥ˆœ÷÷Æ«∞µƒºÐππ…˺∆π§◊˜÷–£¨∆‰ µæÕª·”–“‚ ∂µÿ∑¢œ÷“ª–©∆øæ±£¨ªÚ’þ“ª–©∏þ¿©’πµƒ∂´Œ˜£¨µ´ «“™∞—’‚∏ˆ¡£∂»“™øÿ÷∆◊°£¨“ª∂®≤ªƒÐ‘Ï≥…≤ªø…øÿ÷∆µƒ∏¥‘”–‘°£∞Ÿ∂»µƒƒ£øÈ≤∑÷‘≠‘Ú£¨ «¥”◊ÓºÚµ•µƒø™ ºµ¸¥˙ Ω—ðΩ¯£¨«øµ˜≤ª“™π˝∂»…˺∆°™°™◊Óø™ º «“ª∏ˆ–°∑˛ŒÒµƒ ±∫Ú£¨ø…ƒÐæÕ «“ª∏ˆµ•ª˙œµÕ≥£¨∞—À˘”–µƒ∂´Œ˜∑≈‘⁄“ª∆£¨µ±∑¢œ÷”–≤ø∑÷¥˙¬Îæ≠≥£…˝º∂°¢–Œ≥…∆øæ±£¨æլ̅œ◊ˆ÷ÿππ£¨∞—’‚≤ø∑÷≤∑÷≥ˆ¿¥£¨–Œ≥…“ª∏ˆ∂¿¡¢µƒ∑˛ŒÒ°™°™≤ª «“ªø™ ºæÕ±ª∑˛ŒÒªØªÚ’þSOAµƒ∏≈ƒÓÀ˘¿ß»≈£¨“ª∂®“™—°‘Ò ∫œ“µŒÒ∑¢’πÀÆ∆Ω¿¥µ¸¥˙ Ωµÿ∑¢’π°£
PaaS”ÎDevOps
’˚∏ˆPaaSµƒÕ∆Ω¯‘⁄÷–π˙◊Ó‘Á≤ª «∫Ð≥…𶣨–ϥƻœŒ™◊Óπÿº¸µƒ‘≠“ÚPaaS◊Ó≥ı÷ªƒÐ ∫œµ•“ªµƒºº ı£¨÷ª ∫œ∆≤ΩΩ◊∂Œµƒπ´À棨µ´ «»Œ∫Œ“ª∏ˆπ´À擵ŒÒ∑¢’π∆¿¥“‘∫Û£¨µ•“ªµƒºº ıª˘±æ∂ºŒÞ∑®¬˙◊„–Ë«Û£¨∆Û“µª·µ£”« Ð÷∆”⁄ƒ≥∏ˆPaaS∆Ω“µŒÒ≤ªƒÐ∫Ðøϵÿ∑¢’π£¨À˘“‘º¥ π“ªø™ º—°‘ÒPaaS£¨“≤œ£Õ˚ «◊‘º∫¿¥¥ÓΩ®ª∑æ≥°£À˘“‘£¨∞Ÿ∂»ø™∑≈‘∆µƒPaaSª·Ã·π©PHP°¢Java°¢Python°¢Node.jsµ»µƒ÷ß≥÷£¨Ã·π©MySQL°¢MongoDB°¢Redis°¢Port°¢Cache∑˛ŒÒ£¨Õ¨ ±Œ™∆Û“µ≥…≥§…˺∆¡À“ªÃ◊∑Ω∞∏£¨ø…“‘“ª≤Ω≤Ωµÿ…˝º∂°£
‘ÀŒ¨◊‘∂تؓ≤ «PaaS«øµ˜µƒ“ªµ„°£–Ï¥Æ±Ì æ£¨π˙Õ‚µƒ≥Öڑ±∂‘DevOps¿ÌΩ‚µ√∏¸Õ∏≥𓪖©£¨π˙Õ‚¥Ûπ´À浃«˜ ∆ «Ω≤»´’ª£¨≤ªµ´“™◊ˆø™∑¢£¨“≤“™◊ˆ‘ÀŒ¨≤‚ ‘°£π˙ƒ⁄µƒDevOps≥±¡˜∏’∏’∆¿¥£¨¥´Õ≥ƒ£ Ωœ¬—–∑¢°¢‘ÀŒ¨°¢≤‚ ‘ªπ «∑÷µ√∫ЫŒ˙£¨—–∑¢Õ˘Õ˘»œŒ™‘ÀŒ¨µƒπ§◊˜‘ÀŒ¨æÕƒÐ∏„∂®£¨—–∑¢≤ª”√»•øº¬«°£µ´ «∞Ÿ∂»‘⁄ µº˘÷–ª·∑¢œ÷£¨“ª∏ˆœµÕ≥—–∑¢…œœþ“‘∫Û‘ÀŒ¨“™Õ∂»Î¥Û¡øµƒ»À¡¶£¨“ÚŒ™œµÕ≥‘⁄‘ÀŒ¨…œ…˺∆µƒ≤ªÕÍ…∆£¨±»»Á‘ı√¥◊ˆ…˝º∂£¨‘ı√¥◊ˆ“ª–©–°¡˜¡ø≤‚ ‘£¨’‚–©∂´Œ˜»Áπ˚◊ˆµ√≤ª∫√£¨æ≠≥£ª·∂‘Œ»∂®–‘≤˙…˙ºØ≥…≤˙…˙æÞ¥Ûµƒ”∞œÏ°£À˘“‘∞Ÿ∂»÷Ω•“™«Û‘⁄…˺∆Ω◊∂ŒæÕ“™øº¬«£¨“ª∏ˆœµÕ≥…œœþ“‘∫Û“ª∂®ª·…ʺ∞‘ı√¥…˝º∂£¨“™‘ı√¥—˘‘⁄≤ª”∞œÏ“µŒÒµƒ«Èøˆœ¬◊ˆ’‚–©…˺∆≤Ÿ◊˜£¨‘ı√¥—˘∑Ω±„≤ø £¨‘ı√¥—˘Ã·»°≥ˆ∏¸∂ýµƒ–≈œ¢£¨“™Ã·π©∂‘Õ‚µƒΩ”ø⁄£¨∑Ω±„µÿπ€≤‚µΩƒ⁄≤ø‘À––«Èøˆ£¨»√∫Û∆⁄ƒÐπª∫Ð∑Ω±„µÿ∑¢œ÷œµÕ≥÷–«±‘⁄µƒŒ °£À˘“‘‘⁄’˚ÃÂ…œ¿¥Àµ£¨DevOpsµƒ«˜ ∆æ¯∂‘ «’˝»∑µƒ£¨»Áπ˚≤ªƒÐ‘⁄…˺∆°¢ø™∑¢Ω◊∂ŒæÕ∞—ø…‘ÀŒ¨–‘øº¬«≥‰∑÷«Â≥˛£¨∂‘ø…øø–‘Ω´ «æÞ¥ÛµƒÃÙ’Ω°£
∞Ÿ∂»µƒ◊‘∂تؑÀŒ¨£¨¬˝¬˝µÿ¥”»’≥£“µŒÒ‘ÀŒ¨◊™œÚ◊‘∂تؑÀŒ¨£¨±»»Áºýøÿ°¢≤ø ∂ºø…“‘∆ΩîªØ°¢±Í◊ºªØ£¨»√À˘”–µƒ∆Ωî…˺∆◊€∫œ◊‘∂ØπпÌ∂‘Ω”°£¥”∞—¥˙¬ÎÃ·ΩªµΩ¥˙¬ÎÕ–πÐSVN“‘∫Û£¨∫Û√ʵƒCIºØ≥…°¢…œœþ∑¢≤º°¢–°¡˜¡øøÿ÷∆£¨∂º «“ªÃ◊ÕÍ»´◊‘∂تصƒ»´¡˜≥ð£π§æþ∑Ω√Ê£¨∞Ÿ∂» π”√µƒª˘±æ∂º «ƒ⁄≤ø—–∑¢µƒ£¨∞¸¿®ºýøÿ∆Ωî°¢»’÷æ ’ºØœµÕ≥µ»£¨‘⁄ºØ»∫≤Ÿ◊˜œµÕ≥¿Ô√ÊΩ¯––≤ø ≤Ÿ◊˜£¨Ω¯–––°≈˙¡ø…˝º∂°¢¡˜≥Ãøÿ÷∆µ»£¨’‚–©∂´Œ˜ª·‘À”√ø™‘¥µƒÀºœÎ£¨µ´ «≤ªª·÷±Ω””√ø™‘¥£¨“ÚŒ™∞Ÿ∂»µƒ–Ë«Û“™Ω‚戵ƒ ±∫Ú£¨…Á«¯Õ˘Õ˘ªπ√ª”–≥… ϵƒø™‘¥≤˙∆∑°£
ø™‘¥µƒΩ˺¯
∞Ÿ∂»‘⁄∂ý∏ˆºº ı¡Ï”Ú∂º”–∂‘”⁄ø™‘¥ºº ıµƒΩ˺¯£¨–Ï¥Æ±Ì æ£¨∞Ÿ∂»ª· ±øÃ√Ы–πÿ◊¢ø™‘¥ºº ıµƒ∑¢’π£¨Àºøºø™‘¥ºº ıµΩµ◊∂‘∞Ÿ∂»“µŒÒ”– ≤√¥—˘µƒ◊˜”√£¨ƒƒ–©”¶∏√“˝»Î£¨ƒƒ–©≤ª”¶∏√“˝»Î£¨◊Ó–¬“˝»Îµƒ «‘⁄◊ˆSparkµƒ“ª–©π§◊˜°£
◊Óø™ º «Hadoop£¨’˚∏ˆ∑÷≤º Ω¥Ê¥¢∫Õ∑÷≤º Ωº∆À„∂º «2008ƒÍø™ º¥”Hadoop∑¢’π≥ˆ¿¥µƒ£¨µΩ2009ƒÍ∞Ÿ∂»µƒ–Ë«ÛæÕ≥¨≥ˆ¡À…Á«¯µƒ–Ë«Û£¨…Á«¯÷˜“™√ʜڵƒªπ «“ª–©ª˙∆˜ ˝‘⁄1000î“‘ƒ⁄µƒ÷––°–Õ∆Û“µ£¨∂¯∞Ÿ∂»∫ÐøÏæÕµΩ¡À3000∆øæ±£¨÷ªƒÐ◊‘º∫”≈ªØHadoopƒ⁄∫À£¨‘ŸµΩ“ªÕÚ ±∫Ú£¨∞Ÿ∂»∫Õ…Á«¯Õ¨ ±ø™ º◊ˆ£¨“—æ≠≤˙…˙¡ÀæÞ¥Ûµƒ∑÷∆Á°£
˝æð≤÷ø‚≤„√Ê£¨∞Ÿ∂»Ω˺¯¡Àø™‘¥µƒHive°¢Impala¿¥ππΩ®◊‘º∫µƒ≤˙∆∑∫Õ∑˛ŒÒ£¨∞¸¿®¡– Ω¥Ê¥¢°¢MPPºÐππµ»÷ÿ“™ÀºœÎ°£
»ð∆˜ºØ»∫πпÌ∑Ω√Ê£¨∞Ÿ∂»≤¢≤ª¬‰∫Û”⁄Googleô∂ý£¨ø™ º÷Æ ±ªπ√ª”–ø™‘¥µƒKubenetes°£Kubenetes±»Ωœ∫√µƒ“ªµ„£¨æÕ «À¸∞—“ª–©œ»Ω¯µƒ¿ÌƒÓ±Í◊ºªØ°¢πÊ∑∂ªØ£¨∞Ÿ∂»ª·π€≤ÏKubenetes±Í◊ºªØ∂®“¡À ≤√¥∂´Œ˜£¨ƒÐ∑Ò”√”⁄◊‘º∫µƒ»ð∆˜πп̵˜∂»£¨Œ™∫Û–¯“™ø™∑≈◊‘º∫µƒ»ð∆˜∑˛ŒÒ÷π©≤Œøº°£
¥”¥Û ˝æðµΩ»Àπ§÷«ƒÐ
¥Û ˝æðµƒπ§◊˜∫≠∏« ˝æ𠒺ذ¢¥Ê¥¢°¢Õ≥º∆∑÷Œˆ∫Õ”¶”√£¨∞Ÿ∂»÷˜“™πÿ◊¢∏þ–ß ˝æ𥴠‰°¢∫£¡ø ˝æð¥Ê¥¢°¢∫£¡ø ˝æ𥶿Ì∫Õ ˝æð≤÷ø‚Ω®…Ë”Îπп̣¨ª˘¥°ªπ «∑÷≤º Ω¥Ê¥¢œµÕ≥∫Õ∑÷≤º Ωº∆À„œµÕ≥°£∑÷≤º Ω¥Ê¥¢“≤≤ªÕÍ»´ «◊ˆ¥Û ˝æ𣨓≤ª·÷ß≥÷“ª–©Õº∆¨°¢ ”∆µ°¢ ÷ª˙»Ìº˛µƒ∑÷∑¢£¨»’÷棨ը ±“ª–©◊ˆª˘“ÚºÏ≤‚µƒπ´Àæ“≤ª·∞—“ª–©µÕ≥…±æ¥Ê¥¢–Ë«Û∑≈µΩ∞Ÿ∂»ø™∑≈‘∆£ª‘⁄º∆À„∑Ω√Ê£¨∞Ÿ∂»ø™∑≈¡ÀBMR°™°™“ª∏ˆHadoop°¢Spark‘∆∂ÀÕ–πÐ∑˛ŒÒ£¨∞—œ÷‘⁄ÕÍ»´ø™‘¥µƒ…˙èºØ≥…µΩ∞Ÿ∂»ø™∑≈‘∆∂À¿¥£¨¿˚”√∞Ÿ∂»‘ÀŒ¨°¢πпÌæ≠—È∫Õ∫À–ƒ”≈ªØ£¨Œ™∆Û“µÃ·π©∏¸∫√µƒ∑˛ŒÒ£ª¥ÀÕ‚£¨∞Ÿ∂»¥Û ˝æðªπ◊ˆ¡À“ª∏ˆ◊ˆ±®±Ì∫Õ∂ýŒ¨∑÷ŒˆµƒOLAP“˝«ÊPalo°£
¥Û ˝æðµƒ∏þΩ◊”¶”√ «÷ß≥÷»Àπ§÷«ƒÐºº ı∑¢’𣨻Àπ§÷«ƒÐ∂‘”⁄∞Ÿ∂»ø™∑≈‘∆ºÐπ𵃔∞œÏ∞¸¿®”≤º˛∫ջ̺˛¡Ω∏ˆ≤„√Ê°£
”≤º˛≤„√Ê£¨√ÊœÚÕ®”√º∆À„µƒCPU£¨∆‰–‘ƒÐ≤ªƒÐ∫Ð∫√µÿ¬˙◊„»À◊˜Œ™“ª∏ˆπ§÷«ƒÐ∆Ω–Ë«Û£¨∞Ÿ∂»’˝‘⁄≥¢ ‘¡Ω÷÷∑Ω∞∏£∫
GPUº”ÀŸ°£¥Ûπʃ£ª˙∆˜—ßœ∞–Ë“™µƒ¥Û¡øæÿ’Û°¢œÚ¡ø‘ÀÀ„£¨ «GPUÀ˘…√≥§µƒ£¨”√GPUº”ÀŸ≥…Œ™“µΩÁÕ®––µƒ◊ˆ∑®£¨”»∆‰ «‘⁄∑÷≤º Ω…Ó∂»—ßœ∞—µ¡∑÷–°£∞Ÿ∂»“≤ππΩ®¡À¥Ûπʃ£GPUºØ»∫£¨GPU ˝¡ø‘⁄’‚¡ΩƒÍ”–∑…‘æ Ωµƒ‘ˆ≥§£¨÷ß≥÷∏˜÷÷ª˙∆˜—ßœ∞»ŒŒÒ°£¥Ûπʃ£GPUºØ»∫Õ¨ ±“≤“‚Œ∂◊≈∏þ–‘ƒÐÕ¯¬Á∏ƒ‘ϵƒ–Ë«Û£¨“ÚŒ™µ•ª˙–‘ƒÐ‘ˆ«ø£¨ƒÐ¥¶¿Ìµƒ ˝æð¡ø÷…˝£¨∞Ÿ∂»¥À«∞“—æ≠ÕÍ»´…˝º∂Œ™ÕÚ’◊Õ¯¬Á£¨µ´¥”»Àπ§÷«ƒÐµƒ∑¢’π«Èøˆ¿¥ø¥£¨Ω⁄µ„∫ÕΩ⁄µ„÷ƺ‰µƒΩªª•“≤‘Ω¿¥‘Ω∆µ∑±£¨∞Ÿ∂»“≤‘⁄∏þÀŸÕ¯¬Á∑Ω√Ê ‘µ„◊ˆ“ª–©‘§—ð–‘π§◊˜°£
FPGAº”ÀŸ°£ GPUÀ‰»ªº∆À„–‘ƒÐ∫√£¨µ´∫ƒƒÐ±»Ωœ¥Û£¨ª·”∞œÏIDCµƒ≥…±æ£¨∂¯‘⁄œýÕ¨ƒÐ∫ƒœ¬FPGAƒÐπªÃ·π©±»GPU∏¸∫√µƒ–‘ƒÐ£¨ø…ƒÐΩ´¿¥µƒ»Àπ§÷«ƒÐÀ„∑®ª·”–◊®”√µƒFPGA°£∞Ÿ∂»ƒø«∞“≤‘⁄ÃΩÀ˜FPGAµƒπʃ£”¶”√£¨ª˘±æÀ˘”–÷ß≥÷‘⁄œþπ„∏ʵƒª˙∆˜∂º≤“ªøÈFPGAø®°£◊Ó¥Ûµƒ’œ∞≠£¨ «FPGA±æ…̪πæþ”–“ª–©”≤º˛µƒÃÿ’˜£¨…ʺ∞µΩ≤ºœþ°¢π¶∫ƒ”≈ªØ°¢¡˜∆¨£¨“ª∏ˆFPGA≥Öڵƒµ¸¥˙÷Ð∆⁄“™‘∂±»µ•¥øµƒ≥Öڵ¸¥˙÷Ð∆⁄“™≥§°£»Áπ˚Œ¥¿¥FPGAø™∑¢æþ”–œÒœ÷‘⁄»Ìº˛±ý“Î∆˜“ª—˘µƒπ§æþ£¨ƒÐπª÷«ƒÐªØµÿΩ¯––π¶∫ƒµƒµ˜”≈£¨ºı…Ÿ∂‘–æ∆¨π§≥à ¶±ý–¥¥˙¬ÎµƒƒÐ¡¶µƒ–Ë«Û£¨µ¸¥˙ÀŸ∂»æÕª·¥Û¥Û÷…˝FPGA∆Ωî“≤‘ –ÌøÏÀŸµ¸¥˙£¨∞¸¿®π¶∫ƒ≤‚ ‘°£’‚–Ë“™∫Ð≥§µƒ ±º‰¿¥ µœ÷£¨–Ë“™“µΩÁπ≤Õ¨≈¨¡¶£¨∞Ÿ∂»ƒø«∞ «∏˘æ𓵌ҵƒ«Èøˆ£¨“‘◊‘»ª‘ˆ≥§µƒ∑Ω ΩΩ¯––ÃΩÀ˜°£
»Ìº˛≤„√Ê£¨∞Ÿ∂»‘⁄»Àπ§÷«ƒÐπ§≥ê؅œ∑¢œ÷“ª–©±»Ωœ÷ÿ“™µƒ∂´Œ˜∆‰ µ «Õ®”√µƒ¡˜≥㨻Áµ◊≤„Õ¯¬ÁÕ®–≈µƒ”≈ªØ£¨ø…“‘Àµ∏˙À„∑®≤ªœýπÿ£¨µ´ « µº …œ”¶”√µƒ ±∫Ú≤ªø…±Ð√‚”ˆµΩ’‚–©Œ £¨∞Ÿ∂»ª˘”⁄¥Ûπʃ£µƒª˙∆˜—ßœ∞µƒæ≠—ÈππΩ®“ª∏ˆÕ≥“ªµƒ∆Ω∞¸◊∞≥…BML≤˙∆∑÷π©∑˛ŒÒ£¨»√À„∑®π§≥à ¶÷ª–Ë“™πÿ◊¢◊‘º∫µƒ÷˜“™À„∑®£¨‘ı√¥∏¸∫√µÿ…˺∆»Àπ§÷«ƒÐ≤þ¬‘£¨∂¯≤ª”√πÿ–ƒµ◊≤„¥Ûπʃ£∆Ω…˺∆°£BMLƒø«∞ª˘±æ…œ µœ÷»´¡˜≥ÃÕ–πУ¨∞¸∫¨¡À20∂ý÷÷◊Ó≥£”√µƒª˙∆˜—ßœ∞À„∑®°™°™∞Ÿ∂»∑¢œ÷–Ë“™∂‘œ÷”–æ≠µ‰À„∑®◊ˆ∏ƒ∂صƒ–Ë«Û∫Ð…Ÿ£¨¥Û¡øπ§◊˜ªπ «‘⁄ ˝æ𥶿̰¢Ãÿ’˜Ã·»°…œ°™°™”√ªßø…“‘ª˘”⁄±Í◊º¡˜≥Ã◊‘∂®“Â≥…◊‘º∫µƒ∆Ωî°£
ºÐπ𠶱ÿ–Î «≥Öڑ±
æ°πÐ∞Ÿ∂»‘⁄ª˝º´¿˚”√»Àπ§÷«ƒÐºº ı£¨∞Ÿ∂»ºÐπ𠶓≤‘⁄≈¨¡¶Œ™»Àπ§÷«ƒÐµƒ∑¢’π÷π©∏¸∫√µƒ∆Ωî“‘¥ŸΩ¯∏√ºº ıµƒΩ¯≤Ω£¨µ´±ªŒ º∞»Àπ§÷«ƒÐƒÐ∑ҺڪغÐπ𠶵ƒ“ª–©π§◊˜£¨–ϥƻœŒ™’‚‘⁄ƒø«∞ªπ∫Ѓ—£¨“ÚŒ™ºÐππ ¶√Ê¡Ÿµƒ◊Ó¥ÛŒ  «»°…·£¨’‚ «“ª∏ˆ∫Ð∏¥‘”µƒ ¬«È£¨“™¥”“µŒÒ–Ë«Û≥ˆ∑¢£¨‘⁄»Àπ§÷«ƒÐƒÐπª¿ÌΩ‚’‚∏ˆ“µŒÒµƒ«Èøˆœ¬£¨’‚ª· «“ª∏ˆ«˜ ∆£¨µ´ «’‚ªπ–Ë“™“ª∏ˆ∫Ð≥§ ±º‰°™°™»Áπ˚»Àπ§÷«ƒÐƒÐ◊ˆµΩ’‚—˘£¨»À¿ýœ÷‘⁄¥Û≤ø∑÷π§◊˜∂ºø…“‘”…»Àπ§÷«ƒÐ»°¥˙¡À°£
Ã∏µΩºÐπ𠶵ƒ◊‘Œ“–Þ—¯£¨–Ï¥Æ±Ì æ£¨“ª∏ˆ±»Ωœ∫√µƒºÐπ𠶣¨º»“™”–∫Ðø̵ƒºº ı ”“∞£¨“≤“™ƒÐ¿ÌΩ‚“µŒÒ–Ë«Û°£
1.ºÐπ𠶱ÿ–Î «≥Öڑ±£¨»Áπ˚≤ªƒÐ¿ÌΩ‚≥ÖÚø™∑¢÷–µƒÕ¥£¨æÕ≤ªƒÐ¿ÌΩ‚≥Öڑ±Œ™ ≤√¥∂‘–Ë«Ûµƒ±‰ªØƒ«√¥√Ù∏–£¨øº¬«Œ™ ≤√¥ª·”–’‚–©ºÐπ𵃥˙¬Îµƒ ±∫Ú£¨∫Ѓ—◊˜≥ˆ»√≥Öڑ±¬˙“‚”÷ƒÐ¬˙◊„“µŒÒ–Ë«Ûµƒ»°…·°£À˘“‘ºÐππ ¶ ◊œ»±ÿ–αÿ–Î…Ó»ÎµΩµ◊≤„¡ÀΩ‚≥Öڑ±‘⁄◊ˆ ≤√¥ ¬«È£¨ø™∑¢øںР«‘ı√¥—˘µƒ£¨“™∏˙Ω¯◊Ó–¬µƒºº ı°£
2.≥Öڑ±∫ÕºÐπ𠶵ƒ≤Óæý£¨‘⁄”⁄≤ªƒÐÕ—¿Îµ◊≤„±ý≥õƒπ§◊˜£¨¥”∏¸∏þµƒ∏þ∂»¿¥ø¥¥˝Œ °£‘⁄“ª∏ˆœµÕ≥∏¥‘”µƒ ±∫Ú£¨µ◊≤„≥Öڑ±≥£≥£÷ªø¥µΩ±»Ωœµ◊≤„µƒ“ª≤ø∑÷£¨µ´∏¸÷ÿ“™µƒ «“µŒÒ–Ë«ÛµΩµ◊”¶∏√‘ı√¥≤Ω‚µƒ£¨π˝”⁄∏¥‘”µƒœµÕ≥”¶∏√‘ı√¥∑÷Œˆ£¨À˘“‘ºÐππ ¶–Ë“™Ã·…˝◊‘º∫µƒ∏þ∂»£¨’Ê’˝µÿ»•ø¥“µŒÒ…œ”– ≤√¥—˘µƒ–Ë«Û≤≈–Ë“™◊ˆ’‚∏ˆºÐπ𵃱‰ªØ°£
∂‘”⁄ºÐπ𠶔¶∏√‘ı√¥πÿ◊¢–¬ºº ı£¨–Ï¥ÆÕ∆ºˆ¡À¡Ω÷÷Õææ∂£∫
1.πÿ◊¢“ª–©π˙º ∂•º∂µƒª·“È°£“ÚŒ™◊Ó–¬µƒ“ª–©Àº¬∑°¢—–æø∑ΩœÚ£¨∂ºª·‘⁄“ª–©π˙º ∂•º∂—ß ıª·“È…œ∑¢±Ì¬€Œƒ°£∂¯µ»µΩ ȺÆ≥ˆœ÷µƒ ±∫Ú£¨“‚Œ∂◊≈∏√ºº ı“—æ≠±»Ωœ≥… Ï£¨À˘“‘ È÷ª ∫œ≥Öڑ±£¨À˚√«∏’∏’Ω¯»Î–¬¡Ï”Úµƒ ±∫Ú£¨’““ª–©æ≠µ‰µƒ Ⱥƻ•∫Ðøϵÿ¡ÀΩ‚∏√¡Ï”Ú”– ≤√¥∂´Œ˜°£
2.∏˙Ω¯’˚∏ˆø™‘¥ΩÁ°£œ÷‘⁄ø™‘¥≥…Œ™¥Û«˜ ∆£¨ª˘±æ…œ∫Ð∂ý–¬ºº ı∂ºª·Ω¯––ø™‘¥£¨À˘“‘ºÐπ𠶓™ΩÙ∏˙’‚∏ˆ≥±¡˜£¨Õ¨ ±Ω·∫œ◊‘º∫µƒ“µŒÒæ≠—È¿¥◊ˆ“ª–©≈–∂œ°™°™À‰»ª∫Ð∂ýø™‘¥ºº ı∫Ð∑±»Ÿ£¨µ´“≤”–∫Ð∂ýø™‘¥ºº ı÷ª «Íºª®“ªœ÷£¨À˘“‘ºÐπ𠶓™¿ÌΩ‚ºº ıµƒ±æ÷ £¨µΩµ◊ «‘⁄Ω‚æˆ“ª∏ˆ ≤√¥—˘µƒ“µŒÒŒ £¨≤≈ƒÐ◊ˆ≥ˆ’˝»∑µƒ≈–∂œ°£
|





