|
��֮ǰ��һƪ���¡��ź�������� �C ��֥����ڱ�����˵���У�һλ����������������ˡ�������������ٶȱȽ�����¼�������⡱����һ�����ۡ���Ȼ˵�Ҷ����µ���ȷ�Ժ��а��գ���Ҳ����Ҫ��ϸ˼���Ƿ��Լ�����û��˵����������˼�������У���������һ���dz�ֵ��һ˵�Ļ��⣬�Ǿ��Ǹ���ƽ�⡣
����ƪ����������˵����Ҫ��ȫ�ع��������룬���������ϣ��ʹ�õĵ�������Ӧ�þ����ܵشӶ�ʹ�õ��ι�ϣ������ٶȱ䳤�����Ӷ�����Ա�ƽ�������Ѷȡ��������������һ�ٸ��˻���һǧ����ͬʱִ�е�½��������ô��ô�����Ĺ�ϣ���㽫���µ�½������������æ�����������������ʱ���Ǿ���Ҫʹ�ø���ƽ�⽫��½�����ɢ�������½�������ϣ��Խ��͵����������ĸ��ء�
����ƽ����
������Щ������Ȼ�Ը���ƽ��������ʸе�İ������ô���Ǿͻ�һС��ƪ��������һ�µ���ʲô�Ǹ���ƽ�⡣
��һ��������վ�У������û���ʱ�����м�ǧ�����������֮�ࡣ���һ���û���������Ҫ����ʹ��0.02������������ô�÷���ʵ��ÿ���ӽ�ֻ�ܴ���50������������ÿ����Ҳֻ�ܴ���3000��������÷�����һ���û��dz����õĹ��ܣ��������վ�IJ�Ʒ�б�����ô����Ȼ��������ʵ���Ѿ���֧�ָ���վ����Ӫ������������£����Ǿ���Ҫ�Ը÷���������ݡ�
������Ҫ��ΪScale Up��Scale Out���֣��ֱ��Ӧ����ǿ��������ķ��������Լ���ǿ������������ijЩ����£�Scale
Up��һ����Ϊ�IJ���������Ϊ�÷������ڵķ��������Ӹ�����ڴ档��������һ�������������ṩ������ʵ���϶��ܵ�����������Ӳ�����������ƣ������Ǿ���Խ�����ܵķ������䵥λ���������ļ۸�ԽΪ����������Ǿ���Ҫʹ��Scale
Out��ʽ����������̯�����������֮�У�
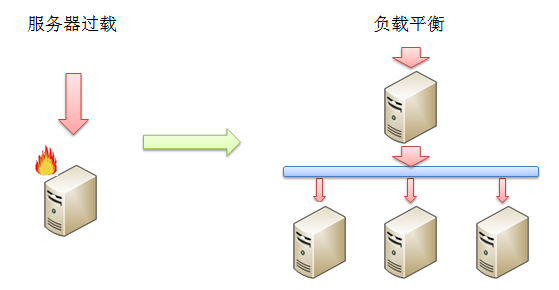
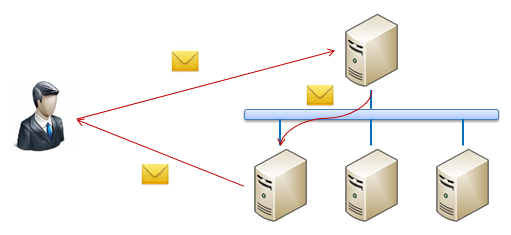
������ͼ����ʾ�����������������ĸ��ع����������������ʱ�������ʹ���һ�ֹ��ص�״̬���ڸ�״̬�ķ����������Ӧ�ٶ�����������Ӧ�����������ִ����Scale
Out֮�����ǽ���ʹ�ö��������ͬʱ�����û��������ڸý�������У�������Ҫʹ��һ̨�ض����豸����Щ����ַ������������������豸��������ڲ�������������ַ�����������ζ���Щ������зַ����Ա�����ֵ������������ص��������Щ������������зַ����豸ʵ���Ͼ��Ǹ���ƽ���������
��Ȼ�����Dz���ȵ����������������˲�ȥ���������⡣�ڷ�����ճ���ά�У������ڷ�������ƽ�����غͷ�ֵ���شﵽij���ض���ֵʱ����Ҫ�����Ƿ���ҪΪ��Ӧ����������ݡ�
һ��һ������ʹ���˸���ƽ��ϵͳ����ô�����ڸ߿������Լ���չ���ϵõ��������ǿ����Ҳ������ʹ�ø���ƽ��������������Ҫԭ���������һ��ӵ����̨�������ĸ���ƽ��ϵͳ���������һ̨�����˹��ϣ���ô����ƽ�����������ͨ������������������ȷ�ʽ��֪���ǵ��쳣��������������������˹��ϵķ������ַ�����
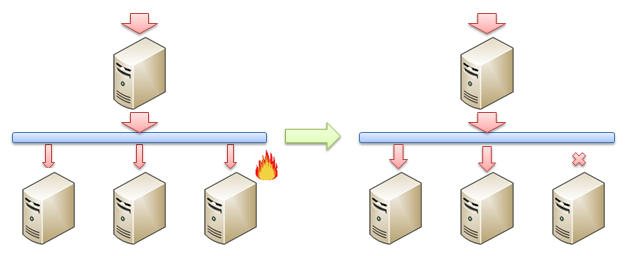
�������ǰ����ƽ��ϵͳ���������ķ��������Ѿ���������ֵ����ô���ǿ��Լ�ͨ���ڸ���ƽ��ϵͳ�����ӷ����������������⣺
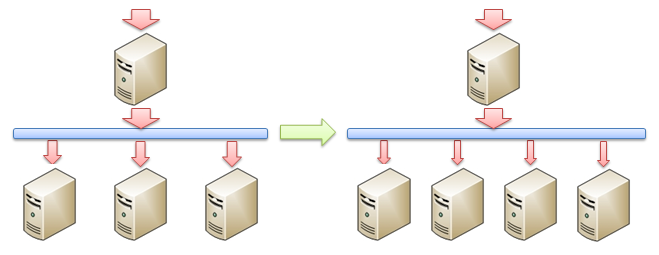
������ÿ������������Ҫ�������������Լ����ˣ��Ӷ������˵����������ĸ�����
����DNS�ĸ���ƽ��
OK�����˽��˸���ƽ��ϵͳ�Ĵ�����ɼ�ʹ�÷�ʽ֮�����Ǿ����������ָ��ؽ��������
��ǰҵ�������ʹ�õĸ���ƽ����������Ҫ��Ϊ���֣�����DNS�ĸ���ƽ�⣬L3/4����ƽ�⣬Ҳ���ǻ��������ĸ���ƽ�⣬�Լ�L7����ƽ�⣬������Ӧ�ò�ĸ���ƽ�⡣����Щ��������У�����DNS�ĸ���ƽ������ģ�Ҳ��������ֵ�һ�ָ���ƽ����������
������ͨ����������ĵ�ַ���м�������������ij����վʱ������������Ȳ��ұ��ص�DNS�����Ƿ�ӵ�и���������Ӧ��IP��ַ������У���ô�����������ֱ��ʹ�ø�IP��ַ���ʸ���վ�����ݡ��������DNS������û�и���������Ӧ��IP��ַ����ô������DNS����һ�������Ի�ø���������Ӧ��IP�����ӵ�����DNS�����С�
����DNS�У�һ���������ܺͶ��IP��ַ������������£�DNS��Ӧ���ᰴ��Round Robin��ʽ������ЩIP��ַ���б��������ڶ��ͨ��nslookup��host���������鿴�ض���������Ӧ��IPʱ������ܵķ������£����������ԭ������ҪFQ�ٽ������飩��
$ host -t a google.com
google.com has address 72.14.207.99
google.com has address 64.233.167.99
google.com has address 64.233.187.99
$ host -t a google.com
google.com has address 64.233.187.99
google.com has address 72.14.207.99
google.com has address 64.233.167.99 |
���Կ�������ͬ��DNS���������صĽ���ᰴ��Round Robin�����ֻ�������ʹ�ò�ͬ���û����ʲ�ͬ��IP��ַ��ƽ������������ĸ��ء�
��Ȼ���ָ���ƽ���������dz�����ʵ�֣���������һ��������ȱ�㣺Ϊ�˼���DNS����Ĵ�������߷���Ч�ʣ����������������DNS��ѯ�Ľ�������һ��IP���ķ���ʧЧ����ô����������Ի����DNS����������¼����Ϣ��ò����õķ���������ͬ������������в�ͬ����Ϊ������Ȼ˵��������ֻ��һ��IP����Ӧ�ķ���ʧЧ�ˣ����Ǵ��û��ĽǶȿ�������վ�Ѿ����ɷ��ʡ���˻���DNS�ĸ���ƽ�ⷽ����������Ϊһ�������ĸ���ƽ�����������ṩ�߿����Եı��ϣ�������Ϊ��������ƽ���������IJ��䷽����ʹ�á�
L3/4 ����ƽ��
��һ�ֽ�Ϊ�����ĸ���ƽ������L3/4����ƽ�⡣�����L3/4ʵ����ָ�ľ��Ǹ���ƽ������������OSIģ���еĵ���������㣨Network
Layer���͵��IJ㴫��㣨Transport Layer�������������������и���ƽ������������ָ���ƽ��������У���Щ������Ҫ�������ݰ���IPͷ��TCP��UDP��Э���Э��ͷ��
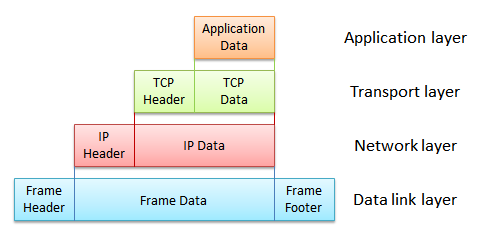
L3/4����ƽ��������Ĺ���ԭ���dz��������ݵ���ʱ������ƽ������������������㷨�Լ�OSIģ�����IJ������������ݾ�����Ҫ���������ݵķ���ʵ��������ת����
��������ƽ������а������������ݣ�����ƽ���������Ҫ֪����ǰ��Ч�ķ���ʵ����������Щ�������������ķ����㷨��������Ҫ�������ݵķ���ʵ�������ݷ����㷨�ļ����������ݷ��͵�Ŀ�����ʵ���ϡ�
��������������ƽ������������ȷ������ʵ������Ч�Եġ�Ϊ���ܹ���֤�Ӹ���ƽ����������ɷ������ݰ��ܱ�������ķ�������Ⱥ��������������ƽ���������Ҫ�����Եط���״̬��ѯ������̽�����Щ����ʵ��������Ч�ع���������״̬��ѯ�����ᳬ���ܶ��˵���֪���������ʵ���������dz������IJ���ϵͳ������������ô�ò���ϵͳ��Ȼ��������Ӧ����ƽ���������������Ping���ֻ�Ǵ�ʱTCP���ӻ�ʧ�ܣ��������ʵ����û�б�������ֻ�ǹ�����ô����Ȼ���Խ���TCP���ӣ�ֻ��������HTTP����
��������״̬��ѯ����ʵ�������ض��ڷ���ʵ���ľ���ʵ�֣���˺ฺܶ��ƽ��������������û������Զ���ű���ִ���ض��ڷ���ʵ���IJ�ѯ����Щ״̬��ѯ���������˺ܶ���ԣ������᳢�Դӷ���ʵ���з������ݡ�
һ������ƽ���������������������ij������ʵ��������Ч����ô���Ͳ����ٽ��κ�����ת�����÷���ʵ����ֱ���÷���ʵ���ع�����״̬������������£�������������ʵ������Ҫ�ֵ�ʧЧ��������ԭ���е��Ĺ�����
������Ҫע���һ���ǣ���ij������ʵ��ʧЧ�Ժ�����ϵͳ��Ӧ�þ����㹻���������Դ������ء�������˵������һ������ƽ�����������������������ͬ�����ķ���ʵ������������������ʵ�����Եĸ��ض���80%���ҡ��������һ������ʵ��ʧЧ����ô���еĸ��ض���Ҫ��������������ʵ������ɡ�ÿ������ʵ������Ҫ�е�120%�ĸ��أ�Զ�������������еĸ������������������ֱ�Ӻ�����ǣ������Ե÷dz����ȶ�����������ϵͳ��ʱ��Ӧ��������������������֡�
OK�� ���ڼ������ǵĸ���ƽ���������һ��������õ�״̬��ѯ������ô���ͻ��������ʹ�õĸ���ƽ���㷨��Ϊ�����ķ���ʵ�����为�ء����ڳ��νӴ�������ƽ��ܵ�����˵�����������������Ϊ����ƽ�����������ݸ�������ʵ������Ӧ�ٶȻ���״��������������Ҫ����ķ���ʵ����
ͨ������£�Round Robin�㷨�����Ҳ�DZ�����õĸ���ƽ���㷨�������������ʵ��������������ͬ����ô����ƽ���������ʹ��Weighted
Round Robin�㷨�������ݸ�������ʵ����ʵ���������������ط��为�ء���ijЩ��ҵ����ƽ��������У����ȷ����ݵ�ǰ����ʵ���ĸ����Լ���Ӧʱ������ض���Щ��������Զ�����С�ص������������Dz����Ǿ����Ե����ء�
���������ʹ��Round Robin�㷨����ô���й�����ϵ�ĸ��������ܱ����䵽��ͬ�ķ���ʵ���ϡ���˺ฺܶ��ƽ������������������ݵ��ض���������Щ���ؽ��з��䣬��ʹ��һ�ֹ�ϣ�㷨�����û����ڵ�IP���м��㣬���Լ�����������Ҫ���䵽�ķ���ʵ����
ͬ���أ�����Ҳ��Ҫ����ij��������ʵ��ʧЧ��������������ƽ��ϵͳ�е�ij��������ʵ��ʧЧ����ô��ϣ�㷨�еĹ�ϣֵ�ռ佫�����仯����������ԭ���ķ���ʵ����������������Ч������������£����е��������·��������ʵ�������⣬��ijЩ����£��û���IPҲ�����ڸ�������֮�䷢���仯����������������Ӧ�ķ���ʵ���������ġ���Ȼ�����õ��ģ������L7����ƽ��������Ľ�������һ�����������
��ȷ�������ݰ���Ŀ���ַ����ƽ�����������Ҫ����������ǽ�����ת����Ŀ��ʵ���ˡ�����ƽ���������ʹ�õ�ת����ʽ��Ҫ��Ϊ���֣�Direct
routing��Tunnelling�Լ�IP address translation��
��ʹ��Direct routing��ʽ��ʱ����ƽ��������Լ���������ʵ��������ͬһ�������ϲ�ʹ��ͬһ��IP���ڽ��յ����ݵ�ʱ����ƽ���������ֱ�Ӷ���Щ���ݰ�����ת��������������ʵ���ڴ��������ݰ�֮����Խ���Ӧ���ظ�����ƽ���������Ҳ����ѡ����Ӧֱ�ӷ����û���������Ҫ�پ�������ƽ�����������һ�ַ��ط�ʽ����ΪDirect
Server Return�������з�ʽ������ʾ��
�ڸù����У�����ƽ���������������ʵ��������Ҫ��IP��Internet Protocol�������ݽ����κθ��ľͿ��Զ������ת����ʹ������ת����ʽ�ĸ���ƽ����������������dz��ߡ���������������֯��ʽҲҪ��Ⱥ�Ĵ��Ա��TCP/IP��Э��ӵ���㹻������⡣
��һ��ת����ʽTunnellingʵ������Direct routing���ơ�Ψһ��һ�㲻ͬ�����ڸ���ƽ���������������֮�佨����һϵ��ͨ��������������Ա��Ȼ����ѡ��ʹ��Direct
Server Return�����Ḻ��ƽ��������ĸ��ء�
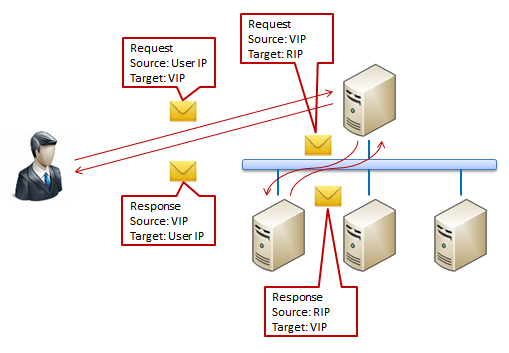
IP Address Translation����ǰ���ַ�ʽ�dz���ͬ���û������ӵ�Ŀ���ַʵ������һ�������ַ��VIP��Virtual
IP����������ƽ��������ڽӵ��������ʱ�Ὣ��Ŀ���ַת��Ϊ����ʵ�����ڵ�ʵ�ʵ�ַ��RIP��Real
IP��������Դ��ַ����ΪLoad Balancer���ڵĵ�ַ�������ڶ���������Ϻ���ʵ���������Ӧ���͵�����ƽ�����������ʱ����ƽ��������ٽ���Ӧ�ĵ�ַ����ΪVIP����������Ӧ���ظ��û���������ת����ʽ�£�������������������ʾ��
��Щϸ�ĵĶ����ʣ�����Ϣ���ݵĹ����У��û����ڵ�User IP�Ѿ�������Ϣ�д����ˣ��Ǹ���ƽ��������ڴ�����Ӧ��ʱ��Ӧ����λָ��û���IP��ַ�أ�ʵ����������ת����ʽ�У�����ƽ���������ά��һϵ�лỰ���Լ�¼ÿ�����ɸ���ƽ������������ڴ����ĸ�������������Ϣ��������Щ�Ự�dz�Σ�ա�������Ự������ʱ�����õñȽϳ�����ô��һ���߲����ĸ���ƽ��������Ͼ���Ҫά������ĻỰ����֮������Ự������ʱ�����õù��̣���ô���п��ܵ���ACK
Storm������
�ȿ��Ự����ʱ��ϳ�����������赱ǰ����ƽ�������ÿ���ӻ���յ�50000�������Ҹø���ƽ��������ĻỰ����ʱ��Ϊ2���ӣ���ô�����Ҫ����6000000���Ự����Щ�Ự��ռ�ø���ƽ��������ĺܴ���Դ�������ڸ��ظ߷��ڣ��������ĵ���Դ���ܻ�ɱ������������������ʩ�Ӹ����ѹ����
���ǽ��Ự����ʱ�����õñȽ϶����Ϊ�鷳����ᵼ���û�����ƽ�������֮�����ACK Storm��ռ���û�����ƽ��������Ĵ�����������һ��TCP�����У��ͻ��˺ͷ������Ҫͨ�����Ե�Sequence
Number�����й�ͨ���������ƽ��������ϵĻỰ���ٵ�ʧЧ����ô����TCP���Ӿ��п������øûỰ�������õĻỰ�пͻ��˺ͷ���˵�Sequence
Number���ᱻ�������ɡ������ʱԭ�е��û��ٴη�����Ϣ����ô����ƽ���������ͨ��һ��ACK��Ϣ֪ͨ�ͻ�����ӵ�е�Sequence
Number���������ڿͻ��˽��ܵ���ACK��Ϣ֮���佫����ƽ�������������һ��ACK��Ϣ֪ͨ�������ӵ�е�Sequence
Number����������˽��ܵ���ACK��Ϣ���ٴη���ACK��Ϣ���ͻ���֪ͨ����ӵ�е�Sequence
Number�������������ͻ��˺ͷ����֮��ͽ������ط��������������ACK��Ϣ��ֱ��ij��ACK��Ϣ�����紫������ж�ʧΪֹ��
���էһ������ʹ��IP Address Translation�ķ����������ģ�����������������ַ�������ȴ����Σ��Ҳ��ά���ɱ���ߵ�һ�ַ�����
L7 ����ƽ��
��һ�ֽ�Ϊ���õĸ���ƽ������������L7����ƽ�⡣����˼�壬����Ҫͨ��OSIģ���еĵ��߲�Ӧ�ò��е����ݾ�����ηַ����ء�
������ʱ��L7����ƽ��������ϵIJ���ϵͳ�Ὣ���յ��ĸ������ݰ���֯��Ϊ�û����������ڸ��������������ĵ��������������ĸ�����ʵ�����Ը�������д���������������ͼ����������ʾ��
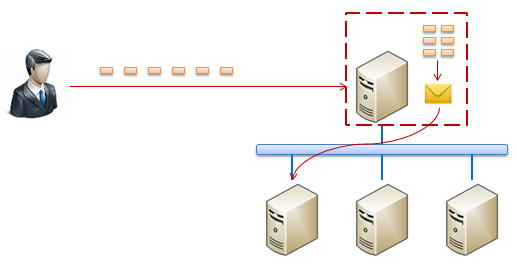
�����L3/4����ƽ�������ʹ�õ����ݣ�L7����ƽ�������ʹ�õ�Ӧ�ò����ݸ��������������������и���ȷ�ĸ���ƽ����Ϊ��
��ǰ���L3/4����ƽ��Ľ����������Ѿ����ܹ�������ijЩ���й�����ϵ�ĸ�������L3/4����ƽ������������ijЩ�㷨�������IP�Ĺ�ϣֵ������������������ķ���ʵ�����������ַ��������Ǻ��ȶ�����һ������ʵ��ʧЧ���û���IP�����仯��ʱ���û������ʵ��֮��Ķ�Ӧ��ϵ�ͽ������ı䡣��ʱ�û�ԭ�еĻỰ�������µķ���ʵ���ϲ������ڣ���������һϵ�����⡣
��ʵ�����������������ԭ������û������ʵ��֮��Ĺ�����ϵ��ͨ��ijЩ�ⲿ���������ģ����������û�/����ʵ����������������������ܵ����ⲿ�����仯�ij�������Ҫ���û��ͷ���ʵ��֮�佨���ȶ��Ĺ�����ϵ����ô����Ҫһ���ȶ������û��ͷ���ʵ��֮�䴫�ݵ����ݡ���Web�����У��������ݾ���Cookie��
��˵������Cookie�ĸ���ƽ�����ʵ���Ͼ��Ƿ����û������е�ij���ض�Cookie��������ֵ������Ҫ�ַ�����Ŀ���ַ������Ҫ��Ϊ���ַ�ʽ��Cookie
Learning�Լ�Cookie Insertion��
Cookie Learning�Dz����������Ե�һ�ֽ����������ͨ�������û������ʵ��ͨѶ�����������ݵ�Cookie��������η��ɸ��أ����û�������һ��ͨѶʱ������ƽ������Ҳ�����Ӧ��Cookie������佫��Ѹ�������ݸ���ƽ���㷨���䵽ij������ʵ���ϡ����ڷ���ʵ�����ص�ʱ����ƽ�����������Ѷ�Ӧ��Cookie�Լ�����ʵ���ĵ�ַ��¼�ڸ���ƽ��������С����û��ٴ������ͨѶʱ������ƽ��������ͻ����Cookie������¼�������ҵ�ǰһ�η�����û��ķ���ʵ������������ת�����÷���ʵ���ϡ�
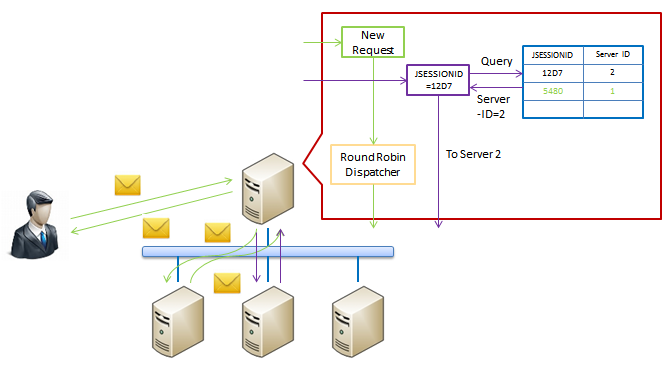
��ô�������ȱ����ǶԸ߿����Ե�֧�ֺܲ���һ������ƽ�������ʧЧ����ô�ڸø���ƽ�����������ά����Cookie�ͷ���ʵ��֮���ƥ���ϵ��ȫ����ʧ�����������ݸ���ƽ�����������֮�����е��û���������������ķ���ʵ����
����һ��������ǻỰά�����ܶ��ڴ�����ġ���L3/4�������ϵĻỰά����ͬ��һ��Cookie��ʧЧʱ����ܷdz�����������һ���û�ʹ���п��ܻ��������Сʱ������һ���������ﵽÿ������ε�ϵͳ���ԣ�����ƽ���������Ҫά���dz���ĻỰ���������ܻὫ���������ڴ����Ĵ����������������������ƽ��������е�Cookie����ʱ�����õ�̫�̣���ô���û����·��ʸ���ƽ���������ʱ���佫������һ������ķ���ʵ����
����Cookie Learning ֮�⣬��һ�ֳ��õķ�������Cookie
Insertion����ͨ������Ӧ������Cookie�Լ�¼�����ɵ��ķ���ʵ����������һ�δ�������ʱ���ݸ�Cookie�������ֵ�������ַ����ķ���ʵ�������û�����������е�һ��ͨѶ��ʱ����ƽ����������Ҳ������ɼ�¼����Ӧ��Cookie����������ݸ���ƽ���㷨Ϊ���������һ������ʵ�����ڽ��յ�����ʵ�������ص�����֮����ƽ���������������Ӧ�в���һ��Cookie���Լ�¼�÷���ʵ����ID�����û��ٴη���������ƽ�������ʱ���佫���ݸ�Cookie������¼�ķ���ʵ����ID�ɷ�������
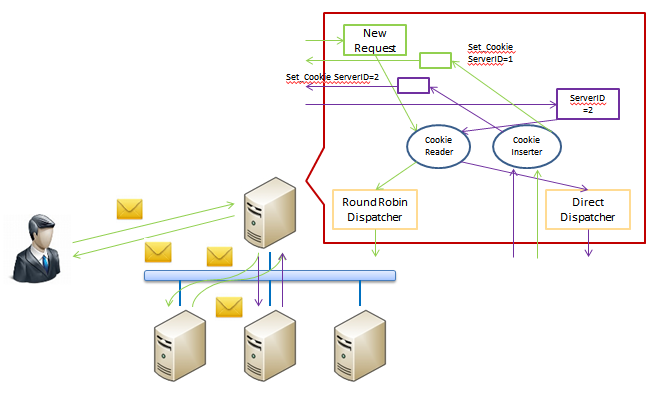
�����Cookie Learning��Cookie Insertion����Ҫ���ڴ���ά��Cookie���������ʵ���Ķ�Ӧ��ϵ�������ڵ�ǰ����ƽ�������ʧЧ��ʱ���ø���ƽ�������Ҳ���Ը���Cookie������¼����Ϣ��ȷ���ɷ���������
��Ȼ��Cookie InsertionҲ��ȱ�ݡ�������������������Լ��û�������Cookie�����ơ���Cookie
Insertion�У�������Ҫ����һ�������Cookie ����¼�������ǰ�û��ķ���ʵ����������ijЩ������У��ر����ƶ�������У�����������Cookie�ĸ���������ֻ��������һ��
Cookie��Ϊ�˽��������⣬����ƽ�������Ҳ��ʹ��һЩ������������Cookie Modification������һ�����е�Cookieʹ���������ʵ����ID��
�����û�������Cookie��ʱ��Cookie Insertion������ȫʧЧ�ġ���ʱ����ƽ������������õĽ�������JSESSIONID����Ϣ�������һ��L7����ƽ��������У�Cookie
Learning��Cookie Insertion����ͬʱʹ�ã�Cookie Learning�����û�����Cookie��ʱ������Ҫ���ã�����Cookie���û����õ��������ʹ��Cookie
Learning������JSESSIONID�������û������ʵ��֮��Ĺ�����ϵ��
���������룺L3/4����ƽ��������ڴ����������������ʱ����ͨ��IP�Ĺ�ϣֵ����������������ķ���ʵ���ġ���Ȼ��Щ����Cookie�Ľ�������ܴﵽ100%��ȷ��Ϊʲô���Dz���L3/4����ƽ���������ʹ�������أ����ǣ�����L3/4����ƽ���������Ҫ��ע�����ݰ������ת������Cookie��Ϣ����������ݰ�֮�У����L3/4����ƽ����������Ѿ�����һ�����ݰ������ת����
������ִ��Cookie Insertion������ʱ��ԭ�����ݰ��е��������ݶ��������ơ���ʱ��Ҫ����ƽ����������յ��������ݰ�֮�������ɣ�
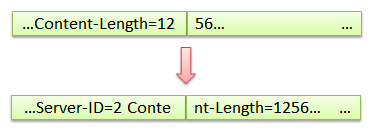
����һ�½����������ݰ������ܷ���������ɡ��������һ�˷��Ͷ�����ݰ���ʱ���������һ�������յ������ݰ���˳�������ԭ�еķ���˳��һ�¡�����������ӵ�µ�ʱ��ijЩ���ݰ����ܻᶪʧ�������ٴμӳ����յ��������ݰ�����Ҫ��ʱ�䡣
�������ڽ����ݰ�ֱ��ת���ķ������ȴ����е����ݰ�����Ȼ���ٲ���Cookie�����ܷdz���ں�����ڽ�������Ľ��������ῴ����L3/4����ƽ��������������ܵ�Ҫ��һ����˵�Ǻܸߵģ���L7����ƽ������������ͨ��һ����Ⱥ������������������⡣����DNS�ĸ���ƽ�⣬L3/4����ƽ��������Լ�L7����ƽ�����������Эͬ�����������һ�����и߿������Լ��߿���չ�Ե�ϵͳ��
SSL Farm
������Ľ����У����Ǻ�����һ�����飬�Ǿ���L7����ƽ�����������SSL��֧�֡���L7����ƽ��������У����dz�����Ҫ��д������Ӧ�е�Cookie���������ͨѶʹ�õ���SSL���ӣ���ôL7����ƽ�������������������Ӧ�����ݽ��ж�д������
���������������ʹ�õ�һ������������ǣ�������ƽ��������Է�������ķ�ʽʹ�á������ַ����У�����ƽ���������ӵ�з����֤�飬������ͨ��֤���е���Կ��������н��ܡ�������ɺ���ƽ��������Ϳ��Կ�ʼ���Զ�ȡCookie�е����ݲ�����������¼����Ϣ��������������Ҫ�ɷ����ķ���ʵ�����ڶԸ���������ɷ���ʱ����ƽ����������Բ���ʹ��SSL���ӣ�����ʹ�ø�������ʵ��������Ҫ�ٴν���������߷���ʵ��������Ч�ʡ�
�����������֮����ʵ����ͨ������ʵ���븺��ƽ��������ķ�SSL���ӷ���һ����Ӧ���ڸ���ƽ����������յ�����Ӧ֮���佫��Ѹ���Ӧ���ܲ�ͨ��SSL���ӷ�����
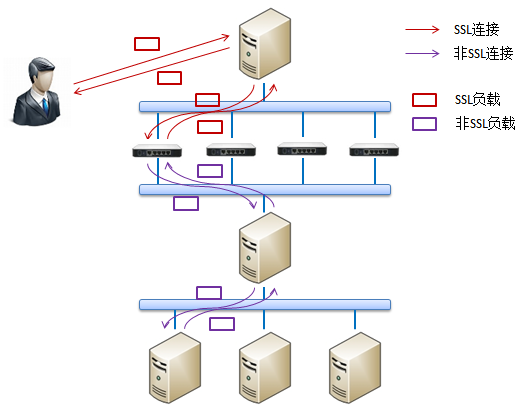
�������������������ڣ�������ж�SSL�Ĵ�����������L7����ƽ��������ϣ���ô��������ϵͳ��ƿ�����ƹ�������ķ���������L7����ƽ�������֮ǰʹ��һϵ�з������������SSL�ı���������
��ʱ����ϵͳ�ļܹ����������µIJ�νṹ��
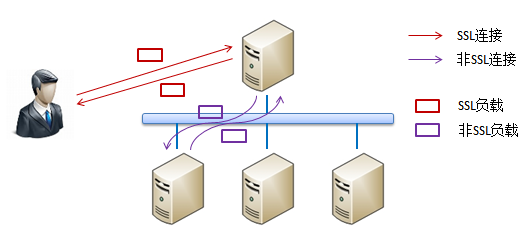
����ͼ�п��Կ������������������Ϊ���IJ㡣���û��������˵�һ��ĸ���ƽ�������ʱ���佫��Ѹ�������������ĸ���ƽ���㷨ת�������ڵڶ����ר�Ÿ���SSL����빤���ķ���������ô����Ὣ�������SSL����������������ɷ�SSL���Ӵ����������������ʱ��L7����ƽ�����������ֱ�ӷ�����Щ������������Cookie��������Cookie�е����ݾ�����Ҫ����������ķ���ʵ����
��ô���ĺô��кܶࡣ���Ⱦ�����Щ��������dz����ˣ�����ֻ�г�������ƽ���������1/20���ҵļ۸�ȴ�ڴ���SSL������ӵ�м�����ͬ��Ч�ʡ�����֮�⣬��Щ����������ṩ�˷dz����õ���չ�Ժ߿����ԡ�һ������ƽ��ϵͳ�ڴ���SSL���ӵ��������Ե���Щ���������Ǿ���ʱ������ϵͳ�������µķ����������һ������һ���������ʧЧ����ô���������������ͨ����е�һЩ��������֤ϵͳ�İ�ȫ���С�
��Ҫ���ǵ�����
���������ĸ���ƽ��������֮ǰ��������Ҫ���Ƚ���һ������Ƹ���ƽ��ϵͳʱ��������Ҫ���ǵ�һЩ���顣
����Ҫ˵�ľ���Ҫ�ڸ���ƽ��ϵͳ���ʱ�������ĸ߿����Լ���չ�ԡ���һ��ʼ�Ľ����У����Ǿ��Ѿ��ᵽ��ͨ��ʹ�ø���ƽ�⣬���ڶ������ʵ������ɵķ�����кܸߵĿ����Լ���չ�ԡ�������һ������ʵ��ʧЧ��ʱ����������ʵ�����������ֵ�һ���ֹ����������ܷ��������Ե���Щ���ŵ�ʱ�����ǿ���������������µķ���ʵ������չ�������������
�����������е����ݴ��䶼��Ҫ��������ƽ�����������˸���ƽ�������һ��ʧЧ����ô����ϵͳ�ͽ���ʹ�á�Ҳ����˵������ƽ��������Ŀ�����Ӱ��������ϵͳ�ĸ߿����ԡ�
����������ķ���Ҫ���ݸ���ƽ������������������ۡ�����L3/4����ƽ����������ԣ�Ϊ���ܹ�������ϵͳ��ʧЧ��ҵ���еij��÷�������ϵͳ��ʹ��һ�Ը���ƽ���������������һ������ƽ�������ʧЧ��ʱ����һ�����ܹ�Ϊ����ϵͳ�ṩ����ƽ�������һ�Ը���ƽ�������������Active-Passiveģʽʹ�ã�Ҳ������Active-Activeģʽʹ�á�
��Active-Passiveģʽ�У�һ������ƽ����������ڰ�����״̬���佫��ͨ��������һ������ƽ�����������������Ϣ��̽��Է��Ŀ����ԡ������ڹ����ĸ���ƽ�������������Ӧ������ʱ����ô����Ӧ�ý���Ѹ���ƽ��������Ӱ�����״̬���ѣ��ӹܸ���ƽ���������IP����ʼִ�и���ƽ��ܡ�
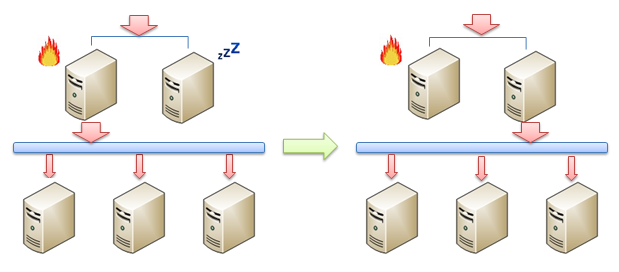
����Active-Activeģʽ�У���̨����ƽ���������ͬʱ�������������һ̨�����������˹��ϣ���ô��һ̨����������е����еĹ�����
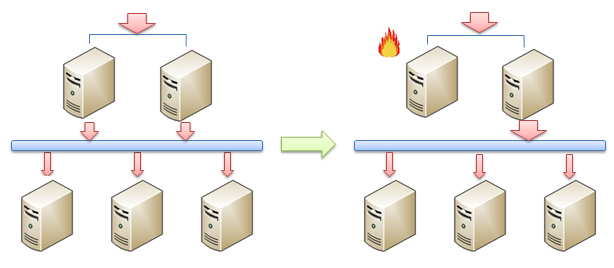
����˵�����߸���ǧ���϶��ԣ�Active-Activeģʽ���нϺõĵֿ���������������������������ͨ������£������������ĸ��ض���30%���ң������ڷ���ʹ�õĸ߷�ʱ�䣬������������ƽʱ����������������������ĸ��ؾͽ��ﵽ60%���ң��Դ���ϵͳ���Դ����ķ�Χ�ڡ��������ʹ�õ���Active-Passiveģʽ����ôƽʱ�ĸ��ؾͽ��ﵽ60%�����ڸ߷�ʱ��ĸ��ؽ��ﵽ����ƽ�������������120%������ʹ�÷������������е��û�����
��������Active-ActiveģʽҲ�в��õĵط����Ǿ��������¹����ϵ������������һ��ʹ����Active-Activeģʽ��ϵͳ�У���������ƽ��������ĸ��س��궼��60%���ҡ���ôһ�����е�һ������ƽ�������ʧЧ�ˣ���ôʣ�µ�Ψһһ��������ͬ�������������е��û�����
���������ʣ�L3/4����ƽ�������һ��Ҫ������ô����ʵ��Ҫ�ɸ�����ƽ���������Ʒ�����������ġ���ǰ�������Ѿ�������ʵ����̽�⸺��ƽ��������Ŀ�����ʵ������Ҫ�ܸ��ӵIJ�������������һ��������һ������ƽ��ϵͳ��ʹ���˹����L3/4����ƽ�����������ô��Щ����ƽ�������֮�������͵ĸ����������Խ����ķdz������Դ��ͬʱ���ںܶ�L3/4����ƽ������������ǻ���Ӳ���ģ�������ܹ��dz����ٵع������������Դﵽ������֧�ֵ����������ƥ��Ĵ��������������һ������£�L3/4����ƽ��������dzɶ�ʹ�õġ�
���L3/4����ƽ���������Ľӽ��为�ؼ��ޣ���ô���ǻ�����ͨ��DNS����ƽ������ɢ����
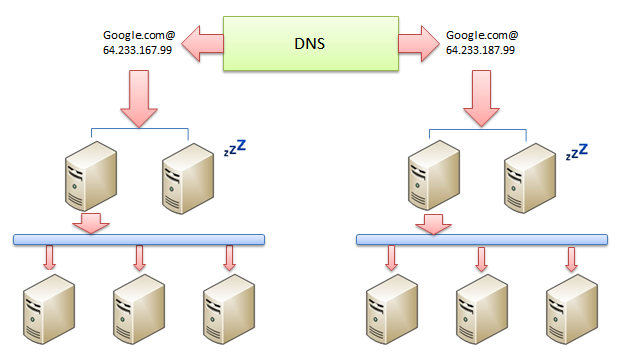
���ַ������������Խ����չ�Ե����⣬����������DNS��һ������������û����飺DNS���Ը����û����ڵ�����ѡ������û�����ķ�����������һ��ȫ���Եķ�������Ϊ��Ч���Ͼ�һ���й��û��������й�����ķ���ʵ��Ҫ�ȷ�������������ķ���ʵ����öࡣ
����������L7����ƽ���������Ҫ�ǻ��������ģ���˺ܶ�L7����ƽ������������û�������Ϊ���ӵĸ���ƽ�������ϵͳ�����綨��һ�������������ö���һ�����õ�һ��L7����ƽ���������
�������˸߿����ԣ����Ǿ�������һ�¸���ƽ�����������չ�ԡ���ʵ���������Ǹոս��ܹ���L3/4����ƽ�������ӵ�кܸߵ����ܣ����һ��ķ�����ʹ�õĸ���ƽ��ϵͳ����������Ҫ��չ�Ե����⡣����һ����������Ҫ��չ���������ôʹ��DNS����ƽ��Ϳ��Դﵽ�Ϻõ���չ�ԡ���L7����ƽ�����Ϊ�������չ�Ը��������⡣
����һ������ƽ��ϵͳ�����ܶ�����L3/4����ƽ���������ɵģ�Ҳ������ֻ��L7����ƽ���������ɵġ�������Ϊ���������ܺͼ۸��϶����зdz���IJ��졣һ��L3/4����ƽ�������ʵ���ϼ۸�dz��������ﵽ������Ԫ����L7����ƽ������������ʹ�����۷��������L3/4����ƽ��������������зdz��ߵ����ܣ���L7����ƽ���������ͨ�����һ����Ⱥ���ﵽ�ϸߵ��������ܡ�
����Ƹ���ƽ��ϵͳʱ������һ����Ҫ���ǵ��Ǿ��Ƿ���Ķ������롣����֪����һ�������ɶ�̬����;�̬����ͬ��ɡ�������������зdz���ͬ���ص㣺һ����̬������Ҫ�����ļ������������ݳ������Ǻܶ࣬��һ����̬��������Ҫ������������ݶ�����Ҫ̫��ļ��㡣��ͬ�ķ�����������Щ����ı��ֲ���ܴ���˺ܶ���������������ķ���ʵ����Ϊ�����֣��ֱ�����������̬����Ͷ�̬����ʹ���ʺϵķ��������ṩ��������������£���̬�����������ض���·���£��硰/static������������ƽ��������Ϳ��Ը������������͵���·��������̬����;�̬��������ʵ���ת����
���Ҫ�ᵽ�ľ���L3/4����ƽ���������һ������ʵ��LVS��Linux Virtual Server���������Ӳ��ʵ�֣�����ʵ����Ҫ���ܶ����Ĺ�������������ݰ��Ľ��룬Ϊ�������ݰ������ڴ�ȵ��ظ�����������ܳ���ֻ�Ǿ�����ͬӲ��������L3/4����ƽ���������1/5��1/10��������ֻ�����������ܵ��Ǵ�����ɱ��ܵͣ����������е���Lab�����õĻ����ȣ�����䳣���ڷ����ģ���Ǻܴ��ʱ����Ϊ��ʱ�������ʹ�á�
����ƽ��������
�����µ�������ǽ�����һϵ�г����ĸ���ƽ�����������Թ���Ҳο���
��һ������£�һ������ĸ��س�����ͨ��ijЩ��ʽ�������ġ���Ӧ�أ���Щ������ӵ�еĸ���ƽ��ϵͳ�����Ǵ�С�������ݻ��ġ��������Ҳ���ᰴ�մ�С����ķ�ʽ��ν�����Щ����ƽ��ϵͳ��
��������İ���һ��L7����ƽ���������ϵͳ��
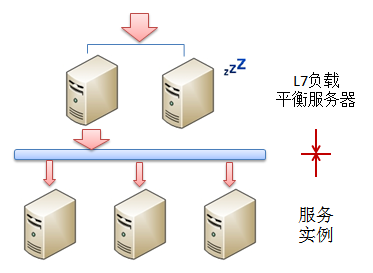
�������ĸ�����������ô��ϵͳ��Ψһ��L7����ƽ������������ױ��ƿ������ʱ���ǿ���ͨ������һ��SSL
Farm�Լ�����LVS�ķ�������������⣺
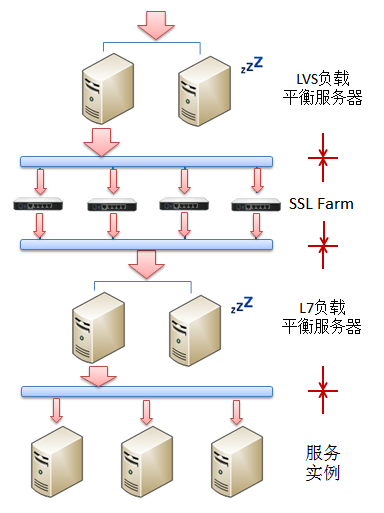
������ǻ�ҪӦ�������ĸ��أ���ô����Ҫʹ�������Ļ���Ӳ����L3/4����ƽ������������LVS�������Ӹ����������
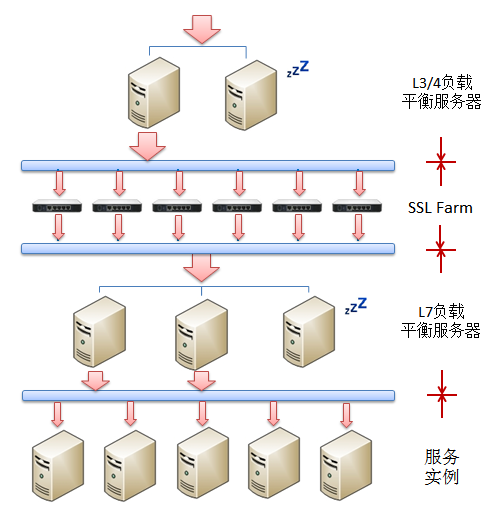
���ڸý�����������������������������������չ�ԣ���������׳��ֹ��صľ����������L3/4����ƽ�������������������£����Ǿ���Ҫʹ��DNS�����为���ˣ�
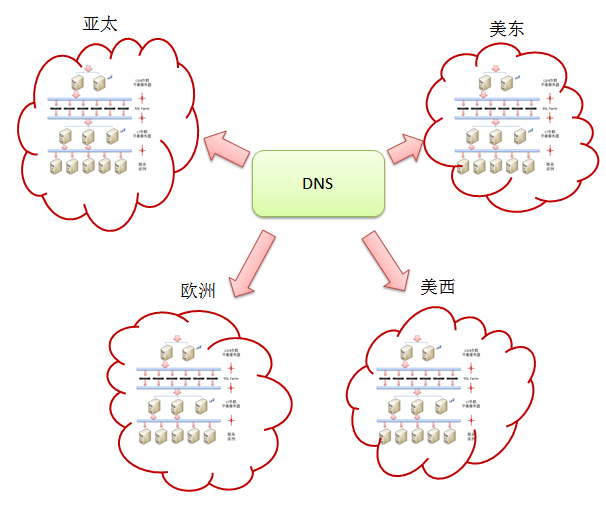
|






