|
通俗地讲,云计算就是把基础设施以服务的形式打包对外销售,它是一种商业模式,而其中的云存储是技术难点。可以从两个维度分析云存储系统的特性:功能和可扩展性,这是一个“鱼和熊掌”不容易兼得的问题。不同的数据规模,不同的事务和一致性要求,不同的系统故障容忍度,都可能导致不同的存储系统设计。国外的互联网巨头Amazon、Google、Microsoft、Yahoo都有各自的云存储系统,国内的淘宝也研发了自己的云存储系统Oceanbase,并开始应用到联机事务处理OLTP(On-line
Transaction Processing)和联机分析处理OLAP(On-line Analytical
Processing)业务。
云存储系统数据结构
为了保证存储系统的可靠性,需要将数据复制为多份。当数据规模增加时,我们可能会对传统的数据库分库分表以水平扩展,很多企业还开发了各自的数据库中间层以屏蔽分库分表规则。然而,在传统的分库/分表架构下,每一份数据只能为一组Master-Slave节点服务,这就导致同一组机器节点存放了完全相同的数据,当其中某个节点发生故障时,只能通过所在机器组中的节点进行故障恢复,这样的系统称为同构系统。
云存储系统一般指异构系统,每份数据可以被动态分配到集群中的任意一个节点,当某个节点发生故障时,可以将故障节点原有服务动态迁移到集群中的任何一台机器。只有实现系统异构才能发挥分布式集群的规模优势,减少集群运维成本,适应云存储系统数据量快速增长的需求。
数据结构决定了云存储系统的功能,云存储系统的数据结构主要有两种:分布式Hash表和分布式B+树,如图1所示。分布式Hash表通过比如一致性Hash的方式将数据分布到集群中的不同节点,数据随机分布,不支持范围查询;而分布式B+树的数据连续存放,支持范围查询,但是需要支持分裂和合并,实现相对较为复杂。
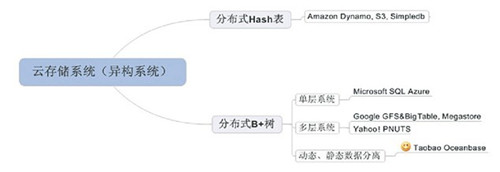
图1 云存储系统分类图
常见的Key-Value系统的数据结构一般为分布式Hash表,只支持基本的Put、Get和Delete操作,比如Amazon的Dynamo和S3系统。而Amazon
Simpledb按照domain进行数据划分,规定同一个domain数据量不能超过10GB,从而可以存放到一个数据节点,用户只允许在同一个domain内部执行范围查询操作。Amazon的云存储系统看起来不完美,但相当实用。
Google的系统设计之初就强调可扩展性。从最初的GFS到BigTable,再到后来的Megastore、Percolator,Google先将系统的可扩展性发挥到极致,以后再逐步加入分布式事务、SQL支持等功能。这样的设计得益于Google强大的工程师团队和公司一直以来崇尚通用系统的文化。Google的云存储分为两层:分布式文件系统GFS和分布式数据库系统BigTable,GFS是一个带有追加功能的分布式文件系统,BigTable将事务的提交日志追加到GFS中做持久化。数据在BigTable内连续存储,逻辑上构成一棵分布式B+树,Megastore、Percolator又在BigTable的基础上加入分布式事务、索引、SQL支持等功能。Google的系统设计比较贵族化,可以远观,但模仿前请三思,比如将系统分成多层可能会增加用户操作的延时,对工程师的设计编码能力提出了更高的要求。
Microsoft SQL Azure是一个传统数据库厂商在云存储系统设计上给出的答案。当数据量增长时,必然要求牺牲部分功能来换取可扩展性,这对于Microsoft是不愿意看到的。Microsoft直接在原有的关系型数据库SQL
Server上进行分布式扩展,尽可能多地支持SQL功能,其功能非常丰富,但系统内部不支持SQL Azure实例的分裂和合并。因此,SQL
Azure内部也限制了单个SQL Azure实例允许的最大数据量,如Business Edition的最大数据量不超过50GB。相比Google的系统,Microsoft系统的扩展性较弱,但功能较强。
云存储系统的难点在于状态数据的迁移和持久化,状态数据也就是系统的事务提交日志。Google
BigTable通过分布式文件系统GFS持久化提交日志,Microsoft SQL Azure直接将提交日志通过网络复制到数据的多个副本,而PNUTS通过Yahoo!内部的分布式消息中间件Yahoo!
Message Broker持久化提交日志。Yahoo!没有对外提供云存储服务,但这样的设计可扩展性也是相当不错的。
淘宝Oceanbase架构设计
淘宝Oceanbase是从2010年5月开始研发的,其定位是解决淘宝内部在线业务的云存储问题。我们在设计系统时,总是考虑现在及今后一段时间的需求。互联网业务大致可以分为OLTP和OLAP两类,对在线存储的需求简单归纳如下。
OLTP:今后数据规模为千亿级,数据量百TB,要求几十万QPS和几万TPS。
OLAP:支持千万级记录的数据集上进行实时计算。
功能:支持范围查询,支持跨行跨表事务。
其他:5个9的可用性、自动故障处理、自动扩容等。
OLTP和OLAP业务对性能的要求使我们必须采用分布式方案。另外,淘宝的业务发展迅猛,传统的分库/分表方法带来的扩容及运维成本太高,必须构建异构的云存储系统。通过进一步分析在线业务,我们发现互联网在线存储业务有一个特点:数据量虽然很大,但新增数据量比较小,每天新增数据量基本在1TB之内。此外,淘宝的业务面临一些其他挑战,比如需要高效支持跨行跨表事务,需要支持两张几亿到几十亿条记录的大表进行联表操作。淘宝的海量数据以及复杂的功能需求对存储系统的设计提出了新的挑战,关系型数据库在数据量上有点儿力不从心,而云存储系统又不能高效地支持复杂的功能要求。因此,需要融合关系型数据库的功能和云存储系统的可扩展性这两个优点。
如何借鉴已有技术满足淘宝未来一段时间内的云存储需求?如果直接模仿国外的互联网巨头,比如模仿GFS
+ BigTable,淘宝的团队确实有一定的经验。然而这样的系统在两年之内很难稳定,并且不能满足跨行跨表事务等复杂的功能需求。既然在线业务新增数据量比较小,那是否可以把最新修改的数据和以前的数据分离呢?
答案是肯定的。淘宝Oceanbase将数据分成动态数据和静态数据两部分:动态数据的数据量较小,侧重TPS和QPS,采用集中式的方法存放到单个节点的高品质存储介质,如内存和SSD;静态数据的数据量很大,侧重存储容量,采用分布式的方法将数据分布到多台普通PC服务器的磁盘或者SSD。由于动态数据的存储介质成本较高,需要不断地将动态数据合并到静态数据中,从而分布到多台机器以实现分布式存储。
淘宝Oceanbase系统架构大致如图2所示。从图2可以看出,系统有以下几个主要模块。
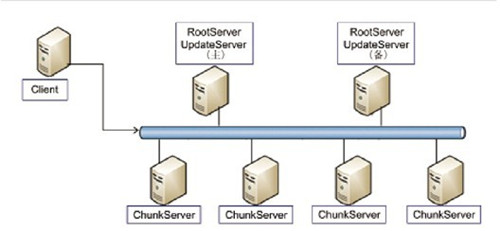
RootServer:负责数据定位、机器管理、负载均衡、全局表Schema信息管理等。
UpdateServer:负责存储动态数据,存储介质为内存和SSD。
ChunkServer:负责存储静态数据,数据存储3份,存储介质为磁盘或者SSD。
Client:Oceanbase提供的胖客户端。
写事务只操作UpdateServer,读事务需要同时读取ChunkServer和UpdateServer。某些操作,比如OLAP分析型操作可能需要涉及多个ChunkServer上的数据,这时将引入一个新的MergeServer模块将请求拆分到不同的ChunkServer,合并每个ChunkServer的返回结果后执行排序、分组、分页等操作。静态数据在ChunkServer中保存三份,UpdateServer通过Linux
HA的方式进行双机热备以保证可靠性。RootServer的访问压力很小,一般可以和UpdateServer部署在相同节点上,并采用相同的Linux
HA方式。Oceanbase的UpdateServer在同一个IDC机房采用实时同步的方式保证强一致性,这意味着写事务只有等到主机和备机都操作成功后才返回客户端。Oceanbase支持跨IDC机房的异步准实时热备,多个机房之间的数据延迟为秒级。
Oceanbase的静态数据和BigTable类似,数据被分为几十到几百MB不等的子表,每个子表的磁盘存储格式为SSTable,通过bloom
filter、block cache、key value cache等方式进行优化。SSTable支持根据column
group按列存储,从而高效地支持OLAP分析。动态数据采用copy-on-write的方式实现了单机内存中的B+树,在单写多读的应用场景下不需要加锁。
Oceanbase静态数据构成一棵分布式B+树,动态数据为单机B+树。与线下MapReduce批处理应用不同,在线存储应用的更新量一般比较小,动态数据服务器不会成为性能瓶颈。这也就意味着,淘宝Oceanbase用一种更为简便的方式在底层实现了和其他互联网巨头类似的B+树数据结构,并且能够高效地支持跨行跨表事务。当然,当数据量增长到万亿级或者数据更新更快时,需要考虑将动态数据服务器的方案由集中式修改为分布式。我们也考虑过多UpdateServer方案的设计,但由于短期内看不到明确的需求,暂时没有实现,目前我们认为可以通过硬件的方法,比如万兆网卡、更好的CPU、更大的内存和SSD来解决。
Oceanbase还实现了一些分布式系统中常见的特性,比如自动负载均衡、在线修改Schema、内置压缩解压缩等。另外,Oceanbase系统里面没有随机写操作,因此天然适应SSD存储介质,很好地弥补了磁盘的IOPS不足这个问题。
Oceanbase应用效果和经验
Oceanbase首先应用在淘宝收藏夹并取得了明显的效果。淘宝收藏夹最初采用MySQL分库/分表的方式实现,通过使用Oceanbase,机器数由原来的16台主加上16台备共32台减少到12台静态数据服务器加上2台动态数据服务器,大大节省了机器资源。另外,目前应用的很多问题在Oceanbase中是通过更好的架构来解决,单机层面基本没做优化,相信后续还有很大的提升空间。在这过程中,我们也积累了一些经验教训。
选择合适的技术。云存储听起来比较神秘,但实际上,对于大多数企业,需要设计好系统可扩展性发展的路线图,当数据规模比较小,可以采用传统的分库分表的方式构建同构系统;当数据规模逐步增加时,可以考虑构建符合企业需求的异构系统。
细节决定成败。云存储更多地是一个工程问题,代码质量、优化细节对系统的表现影响至关重要,淘宝Oceanbase的大多数代码都被两个以上的工程师Review,我们也在减少Cache锁粒度、减少上下文切换、减少内存分配和内存拷贝等方面做了很多细粒度的工作。
展望
Oceanbase目前的主要工作是应用推广,根据应用的需求来逐步完善Oceanbase系统,实现互联网数据库的构想。我们已经开始和淘宝的业务团队开展了千万级数据秒级实时分析的OLAP项目。另外,Oceanbase还在考虑整合分布式Blob存储系统。随着应用推广的深入和Oceanbase系统的优化,希望能在合适的时间进行数据库新基准TPC-E的测试。
另外一个振奋人心的消息是:Oceanbase将在合适的时间点开源。相信通过业界同仁一起努力,一定能够将云存储这个问题解决好! |






