|
һ����μ�� NGINX����һƪ��

NGINX ��ʲô?
NGINX (����Ϊ ��engine X��) ��һ�����е� HTTP �ͷ����������������Ϊһ�� HTTP
��������NGINX ����ʹ�ý��ٵ��ڴ�dz���Ч�ɿ����ṩ��̬���ݡ���Ϊ������������������������˷����������ƻ������ƽ������������Ӧ�õĵ�һ���ʿ��Ƶ㡣NGINX
��һ�����ɿ�Դ�IJ�Ʒ������һ���߱���ȫ�Ĺ��ܵĽ��� NGINX Plus ����ҵ�档
NGINX Ҳ���������ʼ�������ͨ�õ� TCP �����������IJ���ֱ������ NGINX ����Щ�����ļ�ء�
NGINX ��Ҫָ��
ͨ����� NGINX ���� �����������⣺NGINX ��������Դ���⣬�ͳ�������Ļ���������ʩ���������⡣�����
NGINX �û����õ�����ָ��ļ�أ�����ÿ�������������ṩ��һ�������������û����ɵ��ϲ���ͼ��������������
���������ķ������Ѿ��û�д���������Ч��������������ʱ�䣬��˵����ķ����������ͻ���������ܹ�ʱ�������ҿ��Կ������ܽ��ͻ�ǰ�������������⣩��
��һ��أ�������������Ҫ��ָ����������ӣ�
�����ָ��
����ָ��
����ָ��
�������ǽ�������ÿ�����������Ҫ�� NGINX ָ�꣬�Լ���һ���൱�ձ鵫��ֵ���ر��ᵽ�İ�����˵����ʹ��
NGINX Plus ��������������ǻ����������ʹ��ͼ�ι����ѡ��ļ�ع�����������е�ָ�ꡣ
��������ָ�������������ǵġ���� 101 ϵ�С�,�����ṩ��һ��ָ���ռ��;����ܡ�
������Ծָ��
�������������������ʹ�� NGINX������������Ҫ���ӷ��������ն��ٿͻ����������δ�����Щ����
NGINX Plus ����Դ NGINX һ�����Ա��������Ծָ�꣬����Ҳ�ṩ�����в�ͬ�ĸ���ģ�顣�����������ۿ�Դ��
NGINX������˵�� NGINX Plus �ṩ������ָ��Ĺ��ܡ�
NGINX
��ͼ��ʾ��һ���ͻ������ӵĹ��̣��Լ���Դ�汾�� NGINX ��������ӹ������ռ�ָ�ꡣ
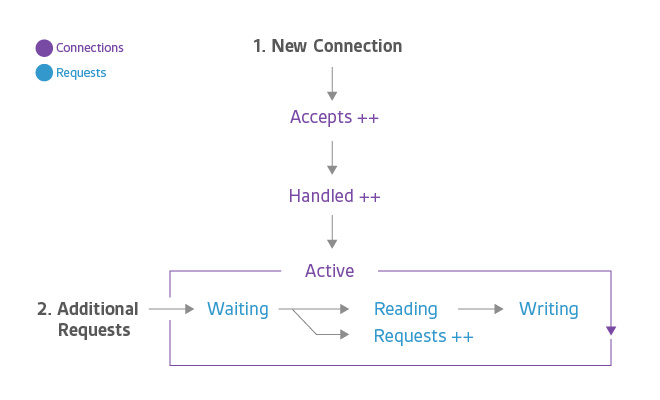
connection, request states
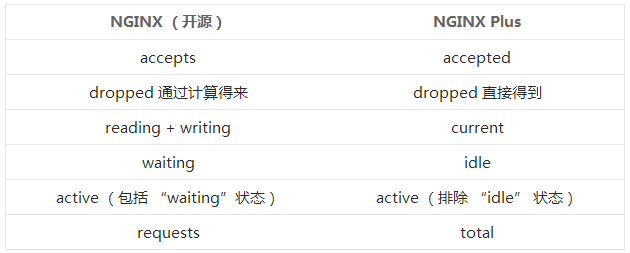
Accepts�����ܣ���Handled���Ѵ�������Requests������������һֱ�����ӵļ�������Active����Ծ����Waiting���ȴ�����Reading��������Writing��д��������������������
*�ϸ����˵�������������� һ����Դ����ָ�꣬������Ϊ���ͻᵼ�� NGINX
ֹͣ���������Ӻ���������ԣ����Ѷ��������� һ������ָ�� �ȽϺ��ʡ�
NGINX worker ���̽��� OS ����������ʱ Accepts ���������ӣ���Handled
�ǵ�ʵ�ʵ�����õ�����ʱ��ͨ������һ���µ����ӻ�����ʹ��һ�����еģ�����������������ֵͨ��������ͬ�ģ���������в����������ӱ�Dropped����������������Դ���ƣ������Ѿ��ﵽ
NGINX ��worker_connections�����ơ�
һ�� NGINX �ɹ�����һ������ʱ�����ӻ��ƶ���Active״̬��������Կͻ���������д�����
Active״̬
Waiting: ��Ծ������Ҳ���Դ��� Waiting ��״̬��������ڴ˿�û�л�Ծ����Ļ��������ӿ����ƹ����״̬��ֱ�ӱ�Ϊ��
Reading ״̬�����������ʹ�á�accept filter�����ܹ��������� �� ��deferred
accept���ӳٽ��ܣ���ʱ������������£�NGINX ������� worker ���̵�֪ͨ��ֱ���������㹻�����ݲſ�ʼ��Ӧ�������������Ϊ
keep-alive ����ô���ڷ�����Ӧ���ڵȴ�״̬��
Reading: �����յ�����ʱ�������뿪 Waiting ״̬�����Ҹ�������ʹ
Reading ״̬�������ӡ�������״̬�� NGINX ���ȡ�ͻ��������ײ��������ײ��DZȽ�С�ģ������ͨ����һ�����ٵIJ�����
Writing: ����ȡ֮����ʹ Writing ״̬�������ӣ��������ڸ�״̬��ֱ����Ӧ���ظ��ͻ��ˡ�����ζ�ţ���������
Writing ״̬ʱ�� һ���� NGINX �ȴ���������ϵͳ�Ľ����ϵͳ���� NGINX �����桱��������һ���棬NGINX
Ҳ��ͬʱ��Ӧ�������������� Writing ״̬���Ѵ�����ʱ�䡣
ͨ����һ��������ͬһʱ��ֻ����һ����������������£�Active ���ӵ���Ŀ
== Waiting ������ + Reading ���� + Writing ��Ȼ�������µ� SPDY ��
HTTP/2 Э�����������������/��Ӧ����һ�����ӣ����� Active ��С�� Waiting �����ӡ�
Reading ����Writing ������ܺ͡� ����д����ʱ��NGINX ��֧�� HTTP/2����Ԥ�Ƶ�2015���ڼ佫��֧�֡���
NGINX Plus
���������ᵽ�ģ����п�Դ NGINX ��ָ���� NGINX Plus ���ǿ��õģ�������Ҳ�ṩ������ָ�ꡣ���ڽ�˵����
NGINX Plus ���õ�ָ�ꡣ
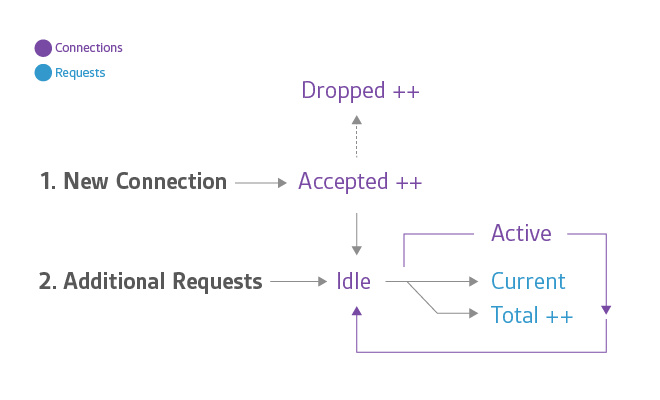
connection, request states
Accepted ���ѽ��ܣ���Dropped�������Dz������ӵļ�������Active��
Idle�����У��ʹ��� Current����ǰ�������εĸ���״̬�µ����ӻ���??��ĵ�ǰ����������������������
*�ϸ����˵�������������� һ����Դ����ָ�꣬������Ϊ���ͻᵼ�� NGINX
ֹͣ���������Ӻ���������ԣ����Ѷ��������� һ������ָ�� �ȽϺ��ʡ�
�� NGINX Plus worker ���̽��� OS ����������ʱ Accepted ���������������
worker ����Ϊ����������ʧ�ܣ�ͨ������һ���µ����ӻ�����ʹ��һ�����У���������ӱ������� Dropped
�������ӡ�ͨ�����ӱ���������Ϊ��Դ���ƣ��� NGINX Plus ��worker_connections�������Ѿ��ﵽ��
Active �� Idle �����������Ŀ�Դ NGINX �ġ�active�� �� ��waiting��״̬����ͬ�ģ�������һ��ؼ��IJ�ͬ���ڿ�Դ
NGINX �ϣ���waiting��״̬�����ڡ�active���У����� NGINX Plus �ϡ�idle�������ӱ��ų��ڡ�active��
�����⡣Current �Ϳ�Դ NGINX ��һ����Ҳ���ɡ�reading + writing�� ״̬��ɡ�
Total Ϊ�ͻ���������ۻ���������ע�⣬�����ͻ������ӿ��漰�����������������ֿ��ܻ�����ӵ��ۼƴ������Դ���ʵ�ϣ���total
/ accepted����ÿ�����ӵ�ƽ������������
��Դ �� Plus ֮��ָ��IJ�ͬ
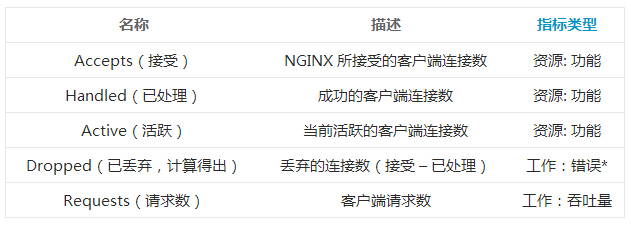
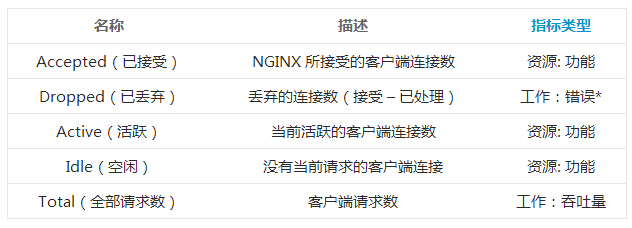
��������������Ŀ���� Accepts �� Handled ֮�NGINX
�У������ǿ�ֱ�ӵõ��ı�ָ�꣨NGINX Plus �У�������������£�����������Ӧ�����㡣�����ÿ����λʱ���ڶ������ӵ��ٶȿ�ʼ��������ôӦ�ÿ����Ƿ���Դ�����ˡ�
Dropped connections
����ָ��: ÿ��������
���̶�ʱ������������������ݣ���Դ NGINX ��requests���� NGINX Plus ��total��
���ṩ���㵥λʱ���ڣ�ͨ���Ƿ��ӻ��룩�����ܵ�����������������ָ����Բ鿴����� Web ������壬�����ǺϷ��Ļ��Ƕ���ģ�����ͻȻ���½�����ͨ���������ų��������⡣ÿ������������������仯����������Ļ������������ˣ���ʹ�����ܸ�����ȷ�������λ�����ڡ���ע�⣬���е�����ͬ������������
URL ��ʲô��

Requests per second
�ռ���Ծָ��
��Դ�� NGINX �ṩ��һ����״̬ҳ������ʾ�����ķ�����ָ�ꡣ��״̬��Ϣ�Ա���ʽ��ʾ��ʵ�����κ�ͼ�λ��ع��߿��Ա�����ȥ������Щ������ݣ������ڷ��������ӻ��������ѡ�NGINX
Plus �ṩһ�� JSON �ӿ���������������ݡ��Ķ�������¡�NGINX ָ���ռ���������ָ���ռ��Ĺ��ܡ�
����ָ��

NGINX ����ָ�������������Ƿ����ش�������������������ͻ��˴���4XX״̬�룬�������˴���5XX״̬�롣
����ָ��: ������������
�����������ʵ����ڵ�λʱ�䣨ͨ��Ϊһ������ӣ���5xx����״̬�������������״̬�루1XX��2XX��3XX��4XX��5XX���������������Ĵ���������ʱ������ƿ�ʼ������������ܵ�ԭ�����ͻȻ���ӣ�������Ҫ��ȡ�����ж�����Ϊ�ͻ��˿����յ�������Ϣ��

Server error rate
���ڿͻ��˴����ע�������Ȼ���4XX�Ǻ����õģ����Ӹ�ָ����������Բ�������Ϣ����Ϊ��ֻ�Ǻ����ͻ�����Ϊ�������κ������
URL�����仰˵��4xx���ֵı仯������һ���źţ���������ɨ��������Ѱ�������վ©��ʱ��
�ռ��������
��Ȼ��Դ NGINX �������ϵõ����ڼ��Ĵ����ʣ������������ַ������Եõ���
ʹ����ҵ֧�ֵ� NGINX Plus �ṩ����չ״̬ģ��
���� NGINX ����־ģ�齫��Ӧ��д�������־
���������ַ��������Ķ�������¡�NGINX ָ���ռ�����
����ָ��

����ָ��: ������ʱ��
������ʱ��ָ���¼�� NGINX ����ÿ�������ʱ�䣬�Ӷ����ͻ��˵ĵ�һ�������ֽڵ�������ϳ�����Ӧʱ��˵�����������Ρ�
�ռ�����ʱ��ָ��
NGINX �� NGINX Plus �û�����ͨ������ $request_time ������������־��ʽ������??����ʱ�����ݡ�����������־��صĸ���ϸ����NGINXָ���ռ���
�������ָ��
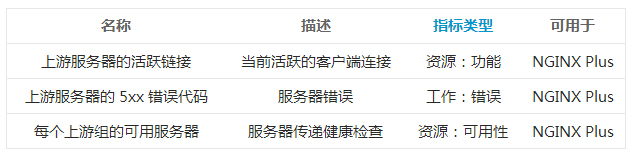
��������� NGINX �����ʹ�÷���֮һ����ҵ֧�ֵ� NGINX Plus
��ʾ�˴����йغ�ˣ������� upstream�����ķ�����ָ�꣬��Щ�뷴�����������صġ������ص�����˼���
NGINX Plus �û����õĹؼ�����ָ�ꡣ
NGINX Plus ���Ƚ���������ָ�갴��ֿ���Ȼ������Ե����������ġ���ˣ����磬��ķ��������������䵽������ε�
Web �������ϣ������һ�ۿ����Ƿ��е���������ѹ������Ҳ���Կ����������з������Ľ���״������ȷ�����õ���Ӧʱ�䡣
��Ծָ��
ÿ���η������Ļ�Ծ���ӵ�������������ȷ�Ϸ�������Ƿ���ȷ�ķ��乤��������������������ϡ����������ʹ��
NGINX ��Ϊ���ؾ��������κ�һ̨������������������������ƫ����ܱ�������������Ŭ��������������������ʹ�õĸ��ؾ���ķ���������round-robin
�� IP hashing���������ʺ�������ģʽ�ġ�
����ָ��
����ָ�꣬������˵�ĸ���5XX������������״̬�룬�Ǽ��ָ�����м�ֵ��һ������������Ӧ�벿�֡� NGINX
Plus ���������ɵ���ȡÿ�����η������� 5xx ���������������Լ���Ӧ�����������Դ���ȷ��ij���ض��������Ĵ����ʡ�
������ָ��
���� web ������������״����������һ�ֽǶȣ�NGINX ����ͨ��ÿ�����е�ǰ���÷������������ܷ��������������Ľ�������һ����ķ�������ϣ�����ܲ���dz���������һ���������ĵ�ǰ״̬��������ֻҪ�п��õķ��������ܹ�������ǰ�ĸ��ؾ����ˡ��������������ڵ����й����ķ�����������Ϊ�ж�
Web �������Ľ���״���ṩһ�����߲�����ӽǡ�
�ռ�����ָ��
NGINX Plus ����ָ����ʾ���ڲ� NGINX Plus �ļ���DZ����ϣ�����Ҳ��ͨ��һ��JSON
�ӿ��������ڸ����ⲿ���ƽ̨�������ǵ�������¡�NGINXָ���ռ������и����ӡ�
����
����ƪ�����У������Ѿ�̸����һЩ���õ�ָ�꣬�����ʹ�ñ�������� NGINX ��������������Ǹտ�ʼʹ��
NGINX����������ṩ�Ĵֻ�ȫ��ָ�꣬��������ܺõ��˽�������������ʩ�Ľ����ͻ�Ծ�̶ȣ�
1.�Ѷ���������
2.ÿ��������
3.������������
4.����������
���գ����ѧ�����࣬��רҵ�ĺ���ָ�꣬�����ǹ������Լ�������ʩ��ʹ������ġ���Ȼ�������һ��ָ�꽫ȡ��������õĹ��ߡ��μ���ص���������ָ�����ָ���ռ���������ʹ��
NGINX ���� NGINX Plus��
�� Datadog �У������Ѿ������� NGINX �� NGINX Plus��������Ϳ��������ٵ��������ռ��ͼ������
Web ��������ָ�ꡣ �ڱ������˽������ NGINX Datadog����أ�����ʼ������� Datadog�ɡ�
��������ռ� NGINX ָ��
��λ�ȡ������Ҫ�� NGINX ָ��
��λ�ȡ��Ҫ��ָ��ȡ����������ʹ�õ� NGINX �汾�Լ���ϣ��������Щָ�ꡣ���μ� ��μ�� NGINX����һƪ��
�������˽�NGINXָ�ꡣ�����ɿ�Դ�� NGINX ����ҵ��� NGINX Plus ���п��Ա���ָ�������״̬ģ�飬NGINX
Ҳ����������־����������ض�ָ�꣺
ָ�������
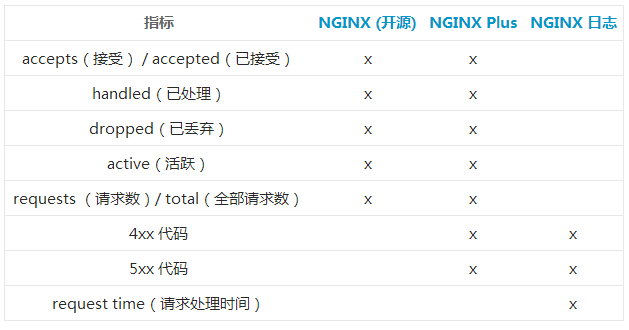
ָ���ռ���NGINX����Դ�棩
��Դ��� NGINX ����һ����״̬ҳ������ʾ�����������״̬�йصĻ���ָ�꣬�����������õ� HTTP
stub status module ���ṩ��Ҫ����ģ���Ƿ������ã������������
nginx -V 2>&1 | grep -o with-http_stub_status_module |
����㿴���ն������ httpstubstatus_module��˵����״̬ģ�������á�
���������û�����������Ҫ���ø�״̬ģ�顣������ڴ�Դ���빹�� NGINX ʱʹ�� �Cwith-http_stub_status_module
����:
./configure \
�� \
--with-http_stub_status_module
make
sudo make install |
����֤��ģ���Ѿ����û����Լ����������㻹��Ҫ�� NGINX �����ļ�������״̬ҳ������һ�����ؿɷ��ʵ�
URL�����磺 /nginx_status����
server {
location /nginx_status {
stub_status on;
access_log off;
allow 127.0.0.1;
deny all;
}
} |
ע��nginx �����е� server ��ͨ�����������������ļ��У����磺/etc/nginx/nginx.conf�������Ƿ��������û���صĸ��������ļ��С�Ҫ�ҵ��������ļ������������������
���г����������ļ������� http ���β�ĸ��������� include ��ͷ���У��磺
include /etc/nginx/conf.d/*.conf; |
������һ�������������ļ��У���Ӧ�û��ҵ��� server �飬�����������ʾ���� NGINX ��ָ������������κ����ú�ͨ��ִ�������������¼��������ļ���
���ڣ���������״̬ҳ�������ָ�꣺
Active connections: 24
server accepts handled requests
1156958 1156958 4491319
Reading: 0 Writing: 18 Waiting : 6 |
��ע�⣬�����ϣ����Զ�̼�������ʸ�״̬ҳ�棬����Ҫ��Զ�̼������ IP ��ַ���ӵ����״̬�����ļ��İ������У�������������ļ��еİ���������
127.0.0.1��
NGINX ��״̬ҳ����һ�ֿ��ٲ鿴ָ��״���ļ����������������ʱ������Ҫ���ձ�����Զ���¼�����ݡ���ع�����
Nagios ���� Datadog���Լ��ռ�ͳ����Ϣ�ķ��� collectD �Ѿ����Խ��� NGINX
��״̬��Ϣ�ˡ�
ָ���ռ�: NGINX Plus
��ҵ��� NGINX Plus ͨ������ ngxhttpstatus_module �ṩ�˱ȿ�Դ�� NGINX
�����ָ�ꡣNGINX Plus ���ֽ����ķ�ʽ�ṩ��Щ�����ָ�꣬�ṩ�˹�������ϵͳ���ٻ������Ϣ��NGINX
Plus Ҳ�ᱨ�����е� HTTP ״̬�����ͣ�1XX��2XX��3XX��4XX��5XX���ļ�����һ�� NGINX
Plus ״̬�������ӿ��ڴ˲鿴��
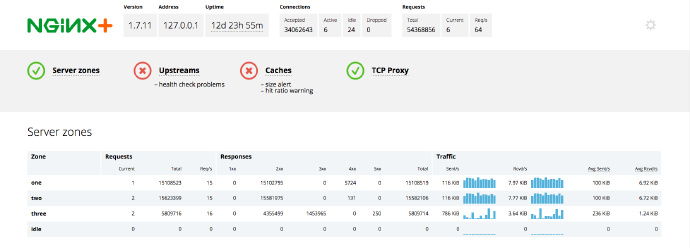
NGINX Plus status board
ע��NGINX Plus ��״̬�DZ����еġ�Active�����ӵĶ���Ϳ�Դ NGINX ͨ�� stubstatusmodule
�ռ��ġ�Active������ָ�����в�ͬ���� NGINX Plus ָ���У���Active�����Ӳ�����Waiting״̬�����ӣ�����Idle�����ӣ���
NGINX Plus Ҳ������� JSON ��ʽ��ָ�꣬�������ڼ��ɵ��������ϵͳ���� NGINX Plus
�У�����Կ��� ���������η��������ָ��ͽ���״�������ش����η������ĵ����������õ���Ӧ����ļ�����
{"1xx":0,"2xx":3483032,"3xx":0,"4xx":23,"5xx":0,"total":3483055} |
Ҫ���� NGINX Plus ָ���DZ��̣�������� NGINX �����ļ��� http ��������״̬ server
�顣 (�μ���һ�ڣ�Ϊ�ռ���Դ�� NGINX ָ�����β�����ص������ļ���˵���������磬Ҫ����һ��״̬�DZ���
��http://your.ip.address:8080/status.html����һ�� JSON �ӿڣ�http://your.ip.address:8080/status����������������
server �����趨��
server {
listen 8080;
root /usr/share/nginx/html;
location /status {
status;
}
location = /status.html {
}
} |
�������¼��� NGINX ���ú�״̬ҳ�Ϳ������ˣ�
�������������չ״̬ģ�飬�ٷ� NGINX Plus �ĵ��� ��ϸ���� ��
ָ���ռ���NGINX ��־
NGINX �� ��־ģ�� ��ѿ��Զ���ķ�����־д�������õ�ָ��λ�á������ͨ�����ӻ��Ƴ��������Զ�����־�ĸ�ʽ�Ͱ��������ݡ�Ҫ�洢��ϸ����־����ķ�������������һ�����������ļ���
server ���У��μ����Ͻڣ�Ϊ�ռ���Դ�� NGINX ָ�����β�����ص������ļ���˵��������
access_log logs/host.access.log combined; |
���� NGINX �����ļ���ִ�������������¼��������ļ���
Ĭ�ϰ����� ��combined�� ����־��ʽ�������һϵ�йؼ������ݣ���ʵ�ʵ� HTTP �������Ӧ����Ӧ���롣�������ʾ����־�У�NGINX
��¼������ /index.html ʱ�� 200���ɹ���״̬��ͷ��ʲ����ڵ������ļ� /fail �� 404��δ�ҵ�������
127.0.0.1 - - [19/Feb/2015:12:10:46 -0500] "GET /index.html HTTP/1.1" 200 612 "-" "Mozilla/5.0
(Macintosh; Intel Mac OS X 10_10_1) AppleWebKit/537.36
(KHTML, like Gecko) Chrome/40.0.2214.111 Safari 537.36"
127.0.0.1 - - [19/Feb/2015:12:11:05 -0500] "GET
/fail HTTP/1.1" 404 570 "-" "Mozilla/5.0 (Macintosh; Intel Mac OS X 10_10_1)
AppleWebKit/537.36 (KHTML, like Gecko) Chrome/40.0.2214.111 Safari/537.36" |
�����ͨ���� NGINX �����ļ��е� http ������һ���µ���־��ʽ����¼������ʱ�䣺
log_format nginx '$remote_addr - $remote_user [$time_local] '
'"$request" $status $body_bytes_sent $request_time '
'"$http_referer" "$http_user_agent"'; |
���������ļ��� server ��� access_log �У�
access_log logs/host.access.log nginx; |
���¼��������ļ������� nginx -s reload������ķ�����־��������Ӧʱ�䣬������ʾ����λΪ�룬���ȵ����롣����������У����������յ�һ����
/big.pdf ������ʱ������ 33973115 �ֽں� 206���ɹ���״̬�롣����������ʱ 0.202
�루202���룩��
127.0.0.1 - - [19/Feb/2015:15:50:36 -0500] "GET /big.pdf HTTP/1.1"
206 33973115 0.202 "-" "Mozilla/5.0 (Macintosh; Intel Mac OS X 10_10_1)
AppleWebKit/537.36 (KHTML, like Gecko) Chrome/40.0.2214.111 Safari/537.36" |
�����ʹ�ø��ֹ��ߺͷ����������ͷ��� NGINX ��־�����磬rsyslog ���Լ��������־�������䴫�ݸ������־����������Ҳ����ʹ�����ɿ�Դ���ߣ�����
logstash ���ռ��ͷ�����־�����������ʹ��һ��ͳһ��־��¼�㣬�� Fluentd ���ռ��ͽ������
NGINX ��־��
����
���� NGINX ����һ��ָ�꽫ȡ��������õĹ��ߣ��Լ����ָ�����ṩ����Ϣ�Ƿ��������ǵ���Ҫ��������˵�������ʵ��ռ��Ƿ��㹻��Ҫ����Ҫ���ǹ���
NGINX Plus �����Ǽ���һ�����Բ���ͷ�����־��ϵͳ���ˣ�
�� Datadog �У������Ѿ������� NGINX �� NGINX Plus��������Ϳ�������С���������ռ��ͼ������
Web ��������ָ�ꡣ�ڱ������˽������ NGINX Datadog ����� ������ʼ Datadog
��������ðɡ�
|






