|
1. Memcached���
Memcached����LiveJurnal����Danga Interactive��˾��Bard
FitzpatricΪ�����ĸ����ֲܷ�ʽ�ڴ滺����������䱾���Ͼ���һ���ڴ�key-value���ݿ⣬���Dz�֧�����ݵij־û����������ر�֮����
��ȫ����ʧ��Memcachedʹ��C���Կ������ڴ������Linux��BSD��Solaris��POSIXϵͳ�ϣ�ֻҪ��װ��libevent����ʹ
�á���Windows�£���Ҳ��һ�����õķǹٷ��汾(http://code.jellycan.com/memcached/)
Memcached �Ŀͻ�������ʵ�ַdz��࣬����C/C++, PHP,
Java, Python, Ruby, Perl, Erlang, Lua�ȡ���ǰMemcachedʹ�ù㷺������LiveJournal�����Wikipedia��Flickr��Twitter��Youtube��
WordPress�ȡ�
��Windowϵͳ�£�Memcached�İ�װ�dz����㣬ֻ������ϸ����ĵ�ַ���ؿ�ִ������Ȼ������memcached.exe
�Cd install������ɰ�װ����Linux��ϵͳ�£�����������Ҫ��װlibevent��Ȼ��ӻ�ȡԴ�룬make
&& make install���ɡ�Ĭ������£�Memcached�ķ�������������ᰲװ��/usr/local/binĿ¼�¡�������Memcachedʱ�����ǿ�
��Ϊ�����ò�ͬ������������
1.1 Memcache����
Memcached������������ʱ��Ҫ�Թؼ��IJ����������ã��������ǾͿ�һ��Memcached������ʱ��Ҫ�趨��Щ�ؼ������Լ���Щ���������á�
1��-p Memcached��TCP�����˿ڣ�ȱʡ����Ϊ11211��
2��-U Memcached��UDP�����˿ڣ�ȱʡ����Ϊ11211��Ϊ0ʱ��ʾ�ر�UDP������
3��-s Memcached������UNIX����·����
4��-a ����UNIX���ֵİ˽������룬ȱʡ����Ϊ0700��
5��-l �����ķ�����IP��ַ��Ĭ��Ϊ����������
6��-d ΪMemcached�����������ػ����̣�
7��-r ���core�ļ���С��
8��-u ����Memcached���û��������ǰΪroot�Ļ���Ҫʹ�ô˲���ָ���û���
9��-m �����Memcachedʹ�õ��ڴ���������λ��MB��
10��-M ָʾMemcached���ڴ��ù��ʱ�ش��������ʹ��LRU�㷨�Ƴ����ݼ�¼��
11��-c ���������ȱʡ����Ϊ1024��
12��-v �Cvv �Cvvv �趨�������˴�ӡ����Ϣ����ϸ�̶ȣ�����-v����ӡ����;�����Ϣ��-vv��-v�Ļ����ϻ����ӡ�ͻ��˵��������Ӧ��-vvv��-vv�Ļ����ϻ����ӡ�ڴ�״̬ת����Ϣ��
13��-f ��������chunk��С�ĵ������ӣ�
14��-n ��С��chunk��С��ȱʡ����Ϊ48���ֽڣ�
15��-t Memcached������ʹ�õ��߳�����ȱʡ����Ϊ4����
16��-L ����ʹ�ô��ڴ�ҳ��
17��-R ÿ���¼��������������ȱʡ����Ϊ20����
18��-C ����CAS��CASģʽ�����8���ֽڵ����ࣻ
2. Redis���
Redis��һ����Դ��key-value�洢ϵͳ����Memcached���ƣ�Redis�������ݴ洢���ڴ��У�֧�ֵ��������Ͱ������ַ�
������ϣ�������������ϡ������Լ�������Щ�������͵���ز�����Redisʹ��C���Կ������ڴ������Linux��BSD��Solaris��
POSIXϵͳ�������κ��ⲿ�����Ϳ���ʹ�á�Redis֧�ֵĿͻ�������Ҳ�dz��ḻ�����õļ����������C��C#��C++��Object-C��PHP��
Python�� Java��Perl��Lua��Erlang�Ⱦ��п��õĿͻ���������Redis����������ǰRedis��Ӧ���Ѿ��dz��㷺�����������ˡ��Ա���������
Flickr��Github�Ⱦ���ʹ��Redis�Ļ������
Redis�İ�װ�dz����㣬ֻ���http://redis.io/download��ȡԴ�룬Ȼ��make
&& make install���ɡ�Ĭ������£�Redis�ķ�������������Ϳͻ��˳���ᰲװ��/usr/local/binĿ¼�¡�������Redis������ʱ������
��ҪΪ��ָ��һ�������ļ���ȱʡ����������ļ���Redis��Դ��Ŀ¼�£��ļ���Ϊredis.conf��
2.1 Redis�����ļ�
Ϊ�˶�Redis��ϵͳʵ����һ��ֱ�ӵ���ʶ��������������һ��Redis�������ļ��ж�������Щ��Ҫ�����Լ���Щ���������á�
1��daemonize no Ĭ������£�redis�����ں�̨���еġ������Ҫ�ں�̨���У��Ѹ����ֵ����Ϊyes��
2��pidfile /var/run/redis.pid��Redis�ں�̨���е�ʱ��RedisĬ�ϻ��pid�ļ�����/var/run/redis.pid����������õ�������ַ�������ж��redis����ʱ����Ҫָ����ͬ��pid�ļ��Ͷ˿ڣ�
3��port 6379ָ��redis���еĶ˿ڣ�Ĭ����6379��
4��bind 127.0.0.1 ָ��redisֻ���������ڸ�IP��ַ������������������ã���ô��������������������������������ø��
5��loglevel debug ָ����־��¼��������Redis�ܹ�֧���ĸ�����debug��verbose��notice��warning��Ĭ��Ϊverbose��debug��ʾ
��¼�ܶ���Ϣ�����ڿ����Ͳ��ԡ�verbose��ʾ��¼���õ���Ϣ��������debug���¼��ô�ࡣnotice��ʾ��ͨ��verbose��������������
����warning ��ʾֻ�зdz���Ҫ�������ص���Ϣ���¼����־��
6��logfile /var/log/redis/redis.log ����log�ļ���ַ��Ĭ��ֵΪstdout������̨ģʽ�������/dev/null��
7��databases 16 �������ݿ�����Ĭ��ֵΪ16��Ĭ�����ݿ�Ϊ0�����ݿⷶΧ��0-��database-1��֮�䣻
8��save 900 1�������ݵ����̣���ʽΪsave ��ָ���ڶʱ���ڣ��ж��ٴθ��²������ͽ�����ͬ���������ļ�rdb���൱����������ץȡ���գ�������Զ��������ϡ�
save 900 1�ͱ�ʾ900����������1��key���ı�ͱ������ݵ����̣�
9��rdbcompression yes �洢���������ݿ�ʱ���־û���rdb�ļ����Ƿ�ѹ�����ݣ�Ĭ��Ϊyes��
10��dbfilename dump.rdb���س־û����ݿ��ļ�����Ĭ��ֵΪdump.rdb��
11��dir ./ ����Ŀ¼�����ݿ⾵�ݵ��ļ����õ�·���������·�����ļ���Ҫ�ֿ���������Ϊredis�ڽ��б���ʱ���ȻὫ��ǰ���ݿ��״̬д�뵽һ����ʱ�ļ��У�
�ȱ������ʱ���ٰѸ���ʱ�ļ��滻Ϊ������ָ�����ļ������������ʱ�ļ������������õı����ļ�����������ָ����·�����У�AOF�ļ�Ҳ���������Ŀ
¼���档ע���������ָ��һ��Ŀ¼�������ļ���
12��slaveof ���Ӹ��ƣ����ø����ݿ�Ϊ�������ݿ�Ĵ����ݿ⡣���õ�����Ϊslave����ʱ������master�����IP��ַ���˿ڡ���Redis����ʱ�������Զ���
master��������ͬ����
13��masterauth ��master�������������뱣��ʱ(��requirepass�ƶ�������)slave��������master�����룻
14��slave-serve-stale-data yes ���ӿ�ͬ����ʧȥ���ӻ��߸������ڽ��У��ӻ������������з�ʽ�����slave-serve-stale-data����Ϊyes(Ĭ������)���ӿ�����
��Ӧ�ͻ��˵��������slave-serve-stale-data��ָΪno����ȥINFO��SLAVOF����֮����κ����᷵��һ����
��"SYNC with master in progress"��
15��repl-ping-slave-period 10�ӿ�ᰴ��һ��ʱ���������ⷢ��PING������ͨ��repl-ping-slave-period�������ʱ������Ĭ����10�룻
16��repl-timeout 60 ���������������ݴ���ʱ�����ping�ظ�ʱ������Ĭ��ֵ��60�룬һ��Ҫȷ��repl-timeout����repl-ping-slave-period��
17��requirepass foobared ���ÿͻ������Ӻ�����κ�����ָ��ǰ��Ҫʹ�õ����롣��Ϊredis�ٶ��൱�죬������һ̨�ȽϺõķ������£�һ���ⲿ���û�������һ���ӽ���150K�ε����볢�ԣ�����ζ������Ҫָ���dz�ǿ�����������ֹ�����ƽ⣻
18��rename-command CONFIG "" ��������������һ�����������¿������������Σ�յ���������CONFIG����Ϊһ�������ײ²���ַ���#
rename-command CONFIG b840fc02d524045429941cc15f59e41cb7be6c52�������ɾ��һ�����ֱ�Ӱ���������Ϊһ�����ַ�""��
�ɣ�rename-command CONFIG ""��
19��maxclients 128����ͬһʱ�����ͻ�����������Ĭ�������ơ�Redis����ͬʱ�Ŀͻ���������ΪRedis���̿��Դ�����ļ������������������
maxclients 0����ʾ�������ơ����ͻ�����������������ʱ��Redis��ر��µ����Ӳ���ͻ��˷���max
number of clients reached������Ϣ��
20��maxmemory ָ��Redis����ڴ����ơ�Redis������ʱ������ݼ��ص��ڴ��У��ﵽ����ڴ��Redis���ȳ�������ѵ��ڻ����ڵ�Key��Redisͬ
ʱҲ���Ƴ��յ�list�����˷�����������Ȼ��������ڴ����ã������ٽ���д�����������Ȼ���Խ��ж�ȡ������ע�⣺Redis�µ�vm���ƣ���
��Key����ڴ棬Value������swap����
21��maxmemory-policy volatile-lru ���ڴ�ﵽ���ֵ��ʱ��Redis��ѡ��ɾ����Щ�����أ������ַ�ʽ�ɹ�ѡ��volatile-lru��������LRU�㷨�Ƴ����ù�����ʱ���key
(LRU:���ʹ�� Least Recently Used )��allkeys-lru��������LRU�㷨�Ƴ��κ�key��volatile-random�����Ƴ����ù�����ʱ������
key��allkeys_random�����Ƴ�һ�������key��volatile-ttl�����Ƴ��������ڵ�key(minor
TTL)��noeviction�������Ƴ��κ�key��ֻ�Ƿ���һ��д����
ע�⣺��������IJ��ԣ����û�к��ʵ�key�����Ƴ���д��ʱ��Redis�᷵��һ������
22��appendonly no Ĭ������£�redis���ں�̨�첽�İ����ݿ⾵�ݵ����̣����Ǹñ����Ƿdz���ʱ�ģ����ұ���Ҳ���ܺ�Ƶ�����������������բ�硢�β�ͷ��״������
ô����ɱȽϴ�Χ�����ݶ�ʧ������redis�ṩ������һ�ָ��Ӹ�Ч�����ݿⱸ�ݼ����ѻָ���ʽ������append
onlyģʽ֮��redis��������յ���ÿһ��д���������ӵ�appendonly.aof�ļ��С���redis��������ʱ����Ӹ��ļ��ָ���֮
ǰ��״̬���������������appendonly.aof�ļ���������redis��֧����BGREWRITEAOFָ���appendonly.aof
�������������������ͬʱ����asynchronous dumps �� AOF��
23��appendfilename appendonly.aof AOF�ļ�����,Ĭ��Ϊ"appendonly.aof";
24��appendfsync everysec Redis֧������ͬ��AOF�ļ��IJ���: no����������ͬ����ϵͳȥ������always����ÿ����д����������ͬ����everysec������д���������ۻ���ÿ��ͬ��һ�Σ�Ĭ��
��"everysec"�������ٶȺͰ�ȫ����������õġ�
25��slowlog-log-slower-than 10000 ��¼�����ض�ִ��ʱ������ִ��ʱ�䲻����I/O���㣬�������ӿͻ��ˣ����ؽ���ȣ�ֻ������ִ��ʱ�䡣����ͨ��������������slow
log��һ���Ǹ���Redisִ�г�������ʱ�䱻��¼�IJ���slowlog-log-slower-than(��)����һ����slow
log �ij��ȡ���һ���������¼��ʱ�������������Ӷ������Ƴ��������ʱ��������λ�����1000000����һ���ӡ�ע���ƶ�һ���������ر�����־��
������Ϊ0��ǿ��ÿ��������¼��
26��hash-max-zipmap-entries 512 &&
hash-max-zipmap-value 64 ��hash�а�������ָ��Ԫ�ظ�����������Ԫ��û�г����ٽ�ʱ��hash����һ������ı��뷽ʽ���������ڴ�ʹ�ã����洢��������������������ٽ�
ֵ��Redis Hash��ӦValue�ڲ�ʵ�ʾ���һ��HashMap��ʵ���������2�ֲ�ͬʵ�֡����Hash�ij�Ա�Ƚ���ʱRedisΪ�˽�ʡ�ڴ���������һά��
��ķ�ʽ�����մ洢�����������������HashMap�ṹ����Ӧ��value redisObject��encodingΪzipmap������Ա��������ʱ���Զ�ת��������HashMap����ʱencodingΪht��
27��list-max-ziplist-entries 512 list�������Ͷ��ٽڵ����»����ȥָ��Ľ��մ洢��ʽ��
28��list-max-ziplist-value 64�������ͽڵ�ֵ��СС�ڶ����ֽڻ���ý��մ洢��ʽ��
29��set-max-intset-entries 512 set���������ڲ��������ȫ������ֵ�ͣ��Ұ������ٽڵ����»���ý��ո�ʽ�洢��
30��zset-max-ziplist-entries 128 zsort�������Ͷ��ٽڵ����»����ȥָ��Ľ��մ洢��ʽ��
31��zset-max-ziplist-value 64 zsort�������ͽڵ�ֵ��СС�ڶ����ֽڻ���ý��մ洢��ʽ��
32��activerehashing yes Redis����ÿ100����ʱʹ��1�����CPUʱ������redis��hash����������hash�����Խ����ڴ��ʹ�á������ʹ�ó����У��зdz��ϸ��
ʵʱ����Ҫ�����ܹ�����Redisʱ��ʱ�Ķ�������2������ӳٵĻ�������������Ϊno�����û����ô�ϸ��ʵʱ��Ҫ��������Ϊyes���Ա��ܹ�����
�ܿ���ͷ��ڴ棻
2.2 Redis�ij�����������
��Memcached��֧�ּ�key-value�ṹ�����ݼ�¼��ͬ��Redis֧�ֵ���������Ҫ�ḻ�öࡣ��Ϊ���õ�����������Ҫ����
�֣�String��Hash��List��Set��Sorted Set���ھ��������⼸����������֮ǰ��������ͨ��һ��ͼ���˽���Redis�ڲ��ڴ�����������������Щ��ͬ�������͵ġ�
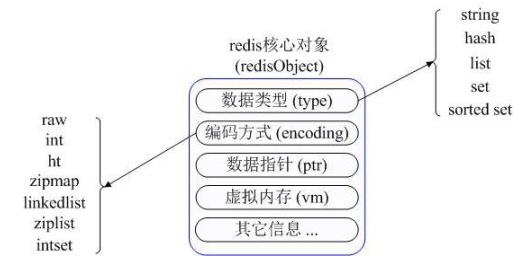
ͼ1 Redis����
Redis�ڲ�ʹ��һ��redisObject��������ʾ���е�key��value��redisObject����Ҫ����Ϣ��ͼ1��ʾ��type����
һ�� value��������Ǻ����������ͣ�encoding�Dz�ͬ����������redis�ڲ��Ĵ洢��ʽ�����磺type=string����value�洢����һ
����ͨ�ַ�������ô��Ӧ��encoding������raw������int�������int�����ʵ��redis�ڲ��ǰ���ֵ����洢�ͱ�ʾ����ַ����ģ���Ȼǰ
��������ַ���������������ֵ��ʾ������:"123" "456"�������ַ�����������Ҫ����˵��һ��vm�ֶΣ�ֻ�д���Redis�������ڴ湦�ܣ����ֶβŻ������ķ����ڴ棬�ù���Ĭ���ǹر�״̬�ġ�ͨ��
Figure1���ǿ��Է���Redisʹ��redisObject����ʾ���е�key/value�����DZȽ��˷��ڴ�ģ���Ȼ��Щ�ڴ�����ɱ��ĸ�����Ҫ
Ҳ��Ϊ�˸�Redis��ͬ���������ṩһ��ͳһ�Ĺ����ӿڣ�ʵ������Ҳ�ṩ�˶��ַ����������Ǿ�����ʡ�ڴ�ʹ�á���������������һ�ķ�������������������
��ʹ�ú��ڲ�ʵ�ַ�ʽ��
1��String
�������set/get/decr/incr/mget�ȣ�
Ӧ�ó�����String����õ�һ���������ͣ���ͨ��key/value�洢�����Թ�Ϊ���ࣻ
ʵ�ַ�ʽ��String��redis�ڲ��洢Ĭ�Ͼ���һ���ַ�������redisObject�����ã�������incr��decr�Ȳ���ʱ��ת����ֵ�ͽ��м��㣬��ʱredisObject��encoding�ֶ�Ϊint��
2��Hash
�������hget/hset/hgetall��
Ӧ�ó���������Ҫ�洢һ���û���Ϣ�������ݣ����а����û�ID���û���������������գ�ͨ���û�ID����ϣ����ȡ���û���������������������գ�
ʵ�ַ�ʽ��Redis��Hashʵ�����ڲ��洢��ValueΪһ��HashMap�����ṩ��ֱ�Ӵ�ȡ���Map��Ա�Ľӿڡ���ͼ2��ʾ��Key����
�� ID, value��һ��Map�����Map��key�dz�Ա����������value������ֵ�����������ݵ��ĺʹ�ȡ������ֱ��ͨ�����ڲ�Map��
Key(Redis����ڲ�Map��keyΪfield), Ҳ����ͨ�� key(�û�ID) + field(���Ա�ǩ)
�Ϳ��Բ�����Ӧ�������ݡ���ǰHashMap��ʵ�������ַ�ʽ����HashMap�ij�Ա�Ƚ���ʱRedisΪ�˽�ʡ�ڴ���������һά����ķ�ʽ�����մ�
�������������������HashMap�ṹ����ʱ��Ӧ��value��redisObject��encodingΪzipmap������Ա��������ʱ���Զ�ת��
������HashMap,��ʱencodingΪht��
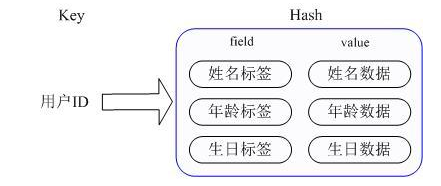
ͼ2 Redis��Hash��������
3��List
�������lpush/rpush/lpop/rpop/lrange�ȣ�
Ӧ�ó�����Redis list��Ӧ�ó����dz��࣬Ҳ��Redis����Ҫ�����ݽṹ֮һ������twitter�Ĺ�ע�б�����˿�б��ȶ�������Redis��list�ṹ��ʵ�֣�
ʵ�ַ�ʽ��Redis list��ʵ��Ϊһ��˫��������������֧�ַ�����Һͱ�������������������������˲��ֶ�����ڴ濪����Redis�ڲ��ĺܶ�ʵ�֣��������ͻ�����е�Ҳ�����õ�������ݽṹ��
4��Set
�������sadd/spop/smembers/sunion�ȣ�
Ӧ�ó�����Redis set�����ṩ�Ĺ�����list������һ���б��Ĺ��ܣ�����֮������set�ǿ����Զ����صģ�������Ҫ�洢һ���б����ݣ��ֲ�ϣ�������ظ�����ʱ��set
��һ���ܺõ�ѡ����set�ṩ���ж�ij����Ա�Ƿ���һ��set�����ڵ���Ҫ�ӿڣ����Ҳ��list�������ṩ�ģ�
ʵ�ַ�ʽ��set ���ڲ�ʵ����һ�� value��ԶΪnull��HashMap��ʵ�ʾ���ͨ������hash�ķ�ʽ���������صģ���Ҳ��set���ṩ�ж�һ����Ա�Ƿ��ڼ����ڵ�ԭ��
5��Sorted Set
�������zadd/zrange/zrem/zcard�ȣ�
Ӧ�ó�����Redis sorted set��ʹ�ó�����set���ƣ�������set�����Զ�����ģ���sorted
set����ͨ���û������ṩһ�����ȼ�(score)�IJ�����Ϊ��Ա�������Dz�������ģ����Զ���������Ҫһ������IJ��Ҳ��ظ��ļ����б�����ô
����ѡ��sorted set���ݽṹ������twitter ��public timeline�����Է���ʱ����Ϊscore���洢��������ȡʱ�����Զ���ʱ���ź���ġ�
ʵ�ַ�ʽ��Redis sorted set���ڲ�ʹ��HashMap����Ծ��(SkipList)����֤���ݵĴ洢������HashMap��ŵ��dz�Ա��score��ӳ�䣬����Ծ�����ŵ�
�����еij�Ա������������HashMap����score,ʹ����Ծ���Ľṹ���Ի�ñȽϸߵIJ���Ч�ʣ�������ʵ���ϱȽϼ�
2.3 Redis�ij־û�
Redis��Ȼ�ǻ����ڴ�Ĵ洢ϵͳ��������������֧���ڴ����ݵij־û��ģ������ṩ������Ҫ�ij־û����ԣ�RDB���պ�AOF��־�����ǻ������ķֱ���������ֲ�ͬ�ij־û����ԡ�
2.3.1 Redis��AOF��־
Redis֧�ֽ���ǰ���ݵĿ��մ��һ�������ļ��ij־û����ƣ���RDB���ա����ַ����Ƿdz�������ģ�����һ������д������ݿ�������ɿ���
�أ�Redis������fork�����copy on write���ơ������ɿ���ʱ������ǰ����fork��һ���ӽ��̣�Ȼ�����ӽ�����ѭ�����е����ݣ�������д��ΪRDB�ļ���
���ǿ���ͨ��Redis��saveָ��������RDB�������ɵ�ʱ����������������õ�10����������100��д������ɿ��գ�Ҳ�������õ�1Сʱ��
�� 1000��д������ɿ��գ�Ҳ���Զ������һ��ʵʩ����Щ����Ķ������Redis�������ļ��У���Ҳ����ͨ��Redis��CONFIG
SET������Redis����ʱ���ù�����Ҫ����Redis��
Redis��RDB�ļ����ỵ������Ϊ��д��������һ���½����н��еģ�������һ���µ�RDB�ļ�ʱ��Redis���ɵ��ӽ��̻��Ƚ�����д��һ����
ʱ�ļ��У�Ȼ��ͨ��ԭ����renameϵͳ���ý���ʱ�ļ�������ΪRDB�ļ����������κ�ʱ����ֹ��ϣ�Redis��RDB�ļ������ǿ��õġ�ͬ
ʱ��Redis ��RDB�ļ�Ҳ��Redis����ͬ���ڲ�ʵ���е�һ����
���ǣ����ǿ��Ժ����ԵĿ�����RDB�����IJ��㣬����һ�����ݿ�������⣬��ô���ǵ�RDB�ļ��б�������ݲ�����ȫ�µģ����ϴ�RDB�ļ����ɵ�
Redisͣ�����ʱ�������ȫ�������ˡ���ijЩҵ���£����ǿ������ܵģ�����Ҳ�Ƽ���Щҵ��ʹ��RDB�ķ�ʽ���г־û�����Ϊ����RDB�Ĵ��۲����ߡ�
���Ƕ�������һЩ�����ݰ�ȫ��Ҫ�ߵ�Ӧ�ã����������ݶ�ʧ��Ӧ�ã�RDB������Ϊ���ˣ�����Redis��������һ����Ҫ�ij־û����ƣ�AOF��־��
2.3.2 Redis��AOF��־
AOF��־��ȫ����append only file�������������Ǿ��ܿ�����������һ����д�����־�ļ�����һ�����ݿ��binlog��ͬ���ǣ�AOF�ļ��ǿ�ʶ��Ĵ��ı����������ݾ���һ����
��Redis�������Ȼ�������Ƿ��ͷ�Redis���������Ҫ��¼��AOF��־���棬ֻ����Щ�ᵼ�����ݷ����ĵ�����Ż��ӵ�AOF�ļ�����ô
ÿһ�������ݵ��������һ����־����ôAOF�ļ��Dz��ǻ�ܴ��ǿ϶��ģ�AOF�ļ���Խ��Խ������Redis���ṩ��һ�����ܣ�����AOF
rewrite���书�ܾ�����������һ��AOF�ļ����µ�AOF�ļ���һ����¼�IJ���ֻ����һ�Σ�������һ�����ļ����������ܼ�¼�˶�ͬһ��ֵ�Ķ�β�
���������ɹ��̺�RDB���ƣ�Ҳ��forkһ�����̣�ֱ�ӱ������ݣ�д���µ�AOF��ʱ�ļ�����д�����ļ��Ĺ����У����е�д������־���ǻ�д��ԭ���ϵ�
AOF�ļ��У�ͬʱ�����¼���ڴ滺�����С������������ɺὫ���л������е���־һ����д�뵽��ʱ�ļ��С�Ȼ�����ԭ���Ե�rename�������µ�
AOF�ļ�ȡ���ϵ�AOF�ļ���
AOF��һ��д�ļ���������Ŀ���ǽ�������־д�������ϣ�������Ҳͬ����������������˵��д������5�����̡���ôдAOF�IJ�����ȫ�����ж���ء�
ʵ�������ǿ������õģ���Redis�ж�AOF����write(2)д���ʱ�ٵ���fsync����д�������ϣ�ͨ��appendfsyncѡ������
�ƣ����� appendfsync�������������ȫǿ����ǿ��
1��appendfsync no
������appendfsyncΪno��ʱ��Redis������������fsyncȥ��AOF��־����ͬ�������̣�������һ�о���ȫ�����ڲ���ϵͳ�ĵ����ˡ��Դ����Linux����ϵͳ����ÿ30�����һ��fsync�����������е�����д�������ϡ�
2��appendfsync everysec
������appendfsyncΪeverysec��ʱ��Redis��Ĭ��ÿ��һ�����һ��fsync���ã����������е�����д�����̡����ǵ���һ
�ε� fsync����ʱ������1��ʱ��Redis���ȡ�ӳ�fsync�IJ��ԣ��ٵ�һ���ӡ�Ҳ������������ٽ���fsync����һ�ε�fsync�Ͳ��ܻ�ִ�ж�
��ʱ�䶼����С���ʱ��������fsyncʱ�ļ��������ᱻ���������Ե�ǰ��д�����ͻ����������Խ��۾��ǣ��ھ����������£�Redis��ÿ��һ�����һ
��fsync�����������£������ӻ����һ��fsync��������һ�����ڴ�������ݿ�ϵͳ�б���Ϊgroup
commit��������϶��д���������ݣ�һ���Խ���־д�����̡�
3��appednfsync always
������appendfsyncΪalwaysʱ��ÿһ��д�����������һ��fsync����ʱ�������ȫ�ģ���Ȼ������ÿ�ζ���ִ��fsync������������Ҳ���ܵ�Ӱ�졣
3. Memcached��Redis�ؼ������Ա�
��Ϊ�ڴ����ݻ���ϵͳ��Memcached��Redis�����кܸߵ����ܣ����������ڹؼ�ʵ�ּ����Ͼ��кܴ���죬���ֲ�����������߾��в�ͬ���ص�Ͳ�ͬ�������������������ǻ�����ߵĹؼ���������һЩ�Աȣ��Դ�����ʾ���ߵIJ��졣
3.1 Memcached��Redis���ڴ�������ƶԱ�
������Redis��Memcached���ֻ����ڴ�����ݿ�ϵͳ��˵���ڴ������Ч�ʸߵ���Ӱ��ϵͳ���ܵĹؼ����ء���ͳC�����е�
malloc/free��������õķ�����ͷ��ڴ�ķ������������ַ��������źܴ��ȱ�ݣ����ȣ����ڿ�����Ա��˵��ƥ���malloc��free����
����ڴ�й¶����Σ�Ƶ�����û���ɴ����ڴ���Ƭ�������������ã������ڴ������ʣ������Ϊϵͳ���ã���ϵͳ����ԶԶ����һ�㺯�����á����ԣ�Ϊ����
���ڴ�Ĺ���Ч�ʣ���Ч���ڴ��������������ֱ��ʹ��malloc/free���á�Redis��Memcached��ʹ����������Ƶ��ڴ�������ƣ�����
ʵ�ַ������ںܴ�IJ��죬���潫������ߵ��ڴ�������Ʒֱ���н��ܡ�
3.1.1 Memcached���ڴ��������
MemcachedĬ��ʹ��Slab Allocation���ƹ����ڴ棬����Ҫ˼���ǰ���Ԥ�ȹ涨�Ĵ�С����������ڴ�ָ���ض����ȵĿ��Դ洢��Ӧ���ȵ�key-value���ݼ�¼������
ȫ����ڴ���Ƭ���⡣Slab Allocation����ֻΪ�洢�ⲿ���ݶ���ƣ�Ҳ����˵���е�key-value���ݶ��洢��Slab
Allocationϵͳ���Memcached�������ڴ�������ͨ����ͨ��malloc/free�����룬��Ϊ��Щ�����������Ƶ�ʾ��������Dz����
����ϵͳ���������Ӱ�졣
Slab Allocation��ԭ���൱����ͼ3��ʾ�������ȴӲ���ϵͳ����һ����ڴ棬������ָ�ɸ��ֳߴ�Ŀ�Chunk�����ѳߴ���ͬ�Ŀ�ֳ���
Slab Class�����У�Chunk���������洢key-value���ݵ���С��λ��ÿ��Slab Class�Ĵ�С��������Memcached������ʱ��ͨ���ƶ�Growth
Factor�����ơ��ٶ�Figure 1��Growth Factor��ȡֵΪ1.25�����������һ��Chunk�Ĵ�СΪ88���ֽڣ��ڶ���Chunk�Ĵ�С��Ϊ112���ֽڣ��������ơ�
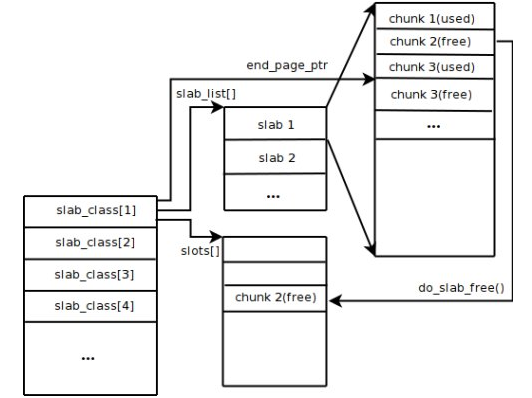
ͼ3 Memcached�ڴ�����ܹ�
��Memcached���յ��ͻ��˷�����������ʱ���Ȼ�����յ����ݵĴ�Сѡ��һ������ʵ�Slab
Class��Ȼ��ͨ����ѯMemcached�����ŵĸ�Slab Class�ڿ���Chunk���б��Ϳ����ҵ�һ�������ڴ洢���ݵ�Chunk����һ�����ݿ���ڻ��߶���ʱ���ü�¼��ռ�õ�Chunk�Ϳ��Ի��գ�������
�ӵ������б��С������Ϲ������ǿ��Կ���Memcached���ڴ������Ч�ʸߣ����Ҳ�������ڴ���Ƭ������������ȱ����ǻᵼ�¿ռ��˷ѡ���Ϊÿ��
Chunk���������ض����ȵ��ڴ�ռ䣬���Ա䳤���������������Щ�ռ䡣��ͼ 4��ʾ����100���ֽڵ����ݻ��浽128���ֽڵ�Chunk�У�ʣ���28���ֽھ��˷ѵ��ˡ�

ͼ4 Memcached�Ĵ洢�ռ��˷�
3.1.2 Redis���ڴ��������
Redis���ڴ������Ҫͨ��Դ����zmalloc.h��zmalloc.c�����ļ���ʵ�ֵġ�RedisΪ�˷����ڴ�Ĺ������ڷ���һ���ڴ�֮
�Ὣ����ڴ�Ĵ�С�����ڴ���ͷ������ͼ 5��ʾ��real_ptr��redis����malloc�ص�ָ�롣redis���ڴ��Ĵ�Сsize����ͷ����size��ռ�ݵ��ڴ��С����֪�ģ�Ϊ
size_t���͵ij��ȣ�Ȼ��ret_ptr������Ҫ�ͷ��ڴ��ʱ��ret_ptr�������ڴ��������ͨ��ret_ptr��������Ժ��������
real_ptr��ֵ��Ȼ��real_ptr����free�ͷ��ڴ档

ͼ5 Redis�����
Redisͨ������һ����������¼���е��ڴ����������������ij���ΪZMALLOC_MAX_ALLOC_STAT�������ÿһ��Ԫ�ش�����ǰ
������������ڴ��ĸ��������ڴ��Ĵ�СΪ��Ԫ�ص��±ꡣ��Դ���У��������Ϊzmalloc_allocations��
zmalloc_allocations[16]�����Ѿ�����ij���Ϊ16bytes���ڴ��ĸ�����zmalloc.c����һ����̬����
used_memory������¼��ǰ������ڴ��ܴ�С�����ԣ��ܵ�������Redis���õ��ǰ�װ��mallc/free�������Memcached���ڴ�
����������˵��Ҫ�ܶࡣ
3.2 Redis��Memcached�ļ�Ⱥʵ�ֻ��ƶԱ�
Memcached��ȫ�ڴ�����ݻ���ϵͳ��Redis��Ȼ֧�����ݵij־û�������ȫ�ڴ�Ͼ�����������ܵı��ʡ���Ϊ�����ڴ�Ĵ洢ϵͳ��˵����
�������ڴ�Ĵ�С����ϵͳ�ܹ����ɵ�����������������Ҫ�����������������˵�̨�����������ڴ��С������Ҫ�����ֲ�ʽ��Ⱥ����չ�洢������
3.2.1 Memcached�ķֲ�ʽ�洢
Memcached��������֧�ֲַ�ʽ�����ֻ���ڿͻ���ͨ����һ���Թ�ϣ�����ķֲ�ʽ�㷨��ʵ��Memcached�ķֲ�ʽ�洢��ͼ6
������Memcached�ķֲ�ʽ�洢ʵ�ּܹ������ͻ�����Memcached��Ⱥ��������֮ǰ�����Ȼ�ͨ�����õķֲ�ʽ�㷨������������ݵ�Ŀ��ڵ㣬
Ȼ�����ݻ�ֱ�ӷ��͵��ýڵ��ϴ洢�����ͻ��˲�ѯ����ʱ��ͬ��Ҫ�������ѯ�������ڵĽڵ㣬Ȼ��ֱ����ýڵ㷢�Ͳ�ѯ�����Ի�ȡ���ݡ�
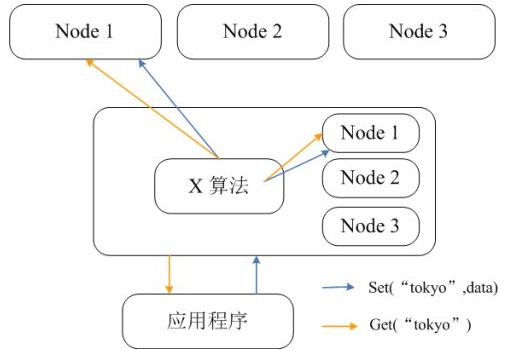
ͼ6 Memcached�ͻ��˷ֲ�ʽ�洢ʵ��
3.2.2 Redis�ķֲ�ʽ�洢
�����Memcachedֻ�ܲ��ÿͻ���ʵ�ֲַ�ʽ�洢��Redis��ƫ�����ڷ������˹����ֲ�ʽ�洢������Redis��ǰ�Ѿ��������ȶ��汾��û
�����ӷֲ�ʽ�洢���ܣ���Redis���������Ѿ��߱���Redis Cluster�Ļ������ܡ�Ԥ����2.6�汾֮��Redis�ͻᷢ����ȫ֧�ֲַ�ʽ���ȶ��汾��ʱ�䲻����2012��ס��������ǻ���ݿ������е�ʵ
�֣�����һ��Redis Cluster�ĺ���˼�롣
Redis Cluster��һ��ʵ���˷ֲ�ʽ������������ϵ�Redis���汾����û�����Ľڵ㣬�������Կ������Ĺ��ܡ�ͼ7����Redis
Cluster�ķֲ�ʽ�洢�ܹ������нڵ���ڵ�֮��ͨ��������Э�����ͨ�ţ��ڵ���ͻ���֮��ͨ��asciiЭ�����ͨ�š������ݵķ��ò���
�ϣ�Redis Cluster������key����ֵ��ֳ�4096����ϣ�ۣ�ÿ���ڵ��Ͽ��Դ洢һ��������ϣ�ۣ�Ҳ����˵��ǰRedis
Cluster֧�ֵ����ڵ�������4096��Redis Clusterʹ�õķֲ�ʽ�㷨Ҳ�ܼ�crc16(
key ) % HASH_SLOTS_NUMBER��
ͼ7 Redis�ֲ�ʽ�ܹ�
Ϊ�˱�֤��������µ����ݿ����ԣ�Redis Cluster������Master�ڵ��Slave�ڵ㡣��ͼ4��ʾ����Redis
Cluster�У�ÿ��Master�ڵ㶼���ж�Ӧ���������������Slave�ڵ㡣������������Ⱥ�У����������ڵ��崻������ᵼ�����ݵIJ����á���
Master�ڵ��˳���Ⱥ���Զ�ѡ��һ��Slave�ڵ��Ϊ�µ�Master�ڵ㡣

ͼ8 Redis Cluster�е�Master�ڵ��Slave�ڵ�
3.3 Redis��Memcached����Ա�
Redis������Salvatore Sanfilippo�����������ֻ����ڴ�����ݴ洢ϵͳ���й��Ƚϣ������������DZȽϿ۵ģ����ܽ����£�
1�����ܶԱȣ�����Redisֻʹ�õ��ˣ���Memcached����ʹ�ö�ˣ�����ƽ��ÿһ������Redis�ڴ洢С����ʱ��Memcached��
�ܸ��ߡ�����100k���ϵ������У�Memcached����Ҫ����Redis����ȻRedis���Ҳ�ڴ洢�����ݵ������Ͻ����Ż������DZ���
Memcached����������ѷɫ��
2���ڴ�ʹ��Ч�ʶԱȣ�ʹ�ü�key-value�洢�Ļ���Memcached���ڴ������ʸ��ߣ������Redis����hash�ṹ����key-value�洢�����������ʽ��ѹ�������ڴ������ʻ����Memcached��
3��Redis֧�ַ������˵����ݲ�����Redis���Memcached��˵��ӵ�и�������ݽṹ�Ͳ�֧�ָ��ḻ�����ݲ�����ͨ����
Memcached �����Ҫ�������õ��ͻ������������Ƶ�����set��ȥ����������������IO�Ĵ����������������Redis�У���Щ���ӵIJ���ͨ����һ���
GET/SETһ����Ч�����ԣ������Ҫ�����ܹ�֧�ָ����ӵĽṹ�Ͳ�������ôRedis���Dz�����ѡ�� |






