|
�Ҳ���һ���˽��������ָо���������Ҫ����ij����Ŀ�������з��ԣ�������֪���Լ��������鷳�С������������5ҳ�Ļõ�Ƭ�������еظо����������ע��������еú�˳������ʹ���������������ϵ�ͨ����ս����ԭ��16ҳ���ݽ�����Ϊ4ҳ��ģ�壬��Ҳ���о����ġ���������֮��ļ����������������κβ��ȶ���˵��������һ��ֽ����һ����Ȼ���������㽫��˵õ�һϵ�ж����ְҵ�������谭�����ϡ���������30�����ڣ���Ŀ�ܼ�����Ĺ����Ŷӽ���һ���������ܹ�ʦû������κ�ʵ�ʵĹ�����
������˴���
�ܹ�ʦ��Ӧ�˽�����ϵͳ�����еĸ���Ԫ��������������һ��ģ��������һ���dz���Ҫ�Ľ�ɫ�������Ŷ�����������ܹ������������ĸ����ԣ��ȵ����������ʱ�������Ѿ�̫���ˡ�
����һ��ͬ��������ʾ�������뱻�����������������ˡ������빲���������Ӱ���API���������Լ�����������ճ������ʽ���б�̡���������Щ����������������������Դ��
�ܹ��������IJ����������ǶԼܹ���Ϣ������ͨ�õ���˵�Ǽܹ�֪ʶ���С�������ʱ�����ġ��������Ǵ�������ϵͳʱ�������ܹ�֪ʶ�Dz��ɱ���ġ����������������кܸߵĸ����ԣ����Ҹ������Բ����
�鷳�ĵط����ڣ����ռܹ��Ķ��壬�����������˼ܹ�Ԫ�أ�������������̻�ʵ��ȵȣ�֮��Ĺ�ϵ�����˿��ܻ�����˵���ܹ���������Ǽܹ������������������ˡ����ǣ�����ܹ��Ĺ�������ʽ�ģ�����˵����������ijЩ�ٶ�����ôΣ�վͻ���֮���������ڴ��ģ����ҵ�������У��������κμٶ������Dz����ܵġ�
������������
����֮ǰ���������ɷù�ij����Ŀ�Ŷӣ����ǵ�ʱ�������滻һ���¾ɵ���ҵ��Ӧ�ó���Ӧ�ó����е�һ����Ĺ����ǿ���Ʊ����������ijɳ����ù�˾����һ�����ҵ��õ�����չ��������չ�����ⲿӦ������IJ�ƷӦ�ó����ƽ��ģ�ԭ���кܶ࣬�����Ե�������֧�֣��Լ���ά���Եȵȡ�
���滻�����У����ڸ���չ��δ�����ϵͳ�еĻ��ҵ���������IJ��ԣ����磬��δ���ÿ�����㲽���е�С����������Ʒ���ļ�����������廯������չ��������ڽ����������Ϸdz�С�Ľ������µ�Ӧ�ó����ڹ����Ϻͼ����϶������������չ�ļ��ݡ����������ڣ��ͻ���Ʊ������������һЩ�����������������
����������ѧ���˺����Ե�һ�ÿΣ������������ϵͳ�Ĺ�����ʽ�����κμ��裬ͨ������ʽ����ƣ����Խ��ⲿ�����Ծ����ܽ�����͡�����һ��������������ȫ�����������⣺
1.�������������ڣ����еļܹ�Ԫ�ض������ij����ʽ�����壬�Լ�ij���������������ڡ������ߺ����ý����ܹ�ģ�ͽ��б����ȴ�Ƿdz���Ҫ�ġ�
2.����ͬ��Ԫ�صĶ���ʵ�֣�һ����Ĺ�˾�����ɹ�ijЩ�ֳɵĴ��Ӧ�ã���������ͳ�Ϊ���ɱ������ʵ�ˡ�
3.�ֶ����ϣ�������Ҫͨ���˹���ʽ��ijЩ���ݴ�ij��ϵͳ��Ǩ������һ��ϵͳ�����������ϻ�ڼܹ�ģ���������Dz��ɼ��ġ������Ŀ�ŶӲ�����Ͷ����������һ�����ӵĽ��棬��ʵ�ֶ�����������ݵ��Զ�ת������ô�������ϻ�ͻ���֡������˹���������������������
������˵��װ�ĸ��������ﲻ�������ˣ���ʵ������Ȼ�ڷ������á���������Dz������������ܹ���ע���������Ӱ�죬Ҳ�������λ��������Щ��������ô����ͻ���֡�
������ʾ���У��йػ�����������IJ��Ծͱ����ܹ�֪ʶ��������ͬ��Ӧ���н����˹�������Ӧ�ó���������չ�еļܹ�Ԫ�ظ���ʵ���˲�ͬ�Ľ�ɫ���ܣ�������չ�����ܵļܹ�ʦ������Ծ�Ӧ�ó����е�����������Խ�����ij�ּ��衣
���仰˵���ܹ�����������ָij��ϵͳ������ϵͳ���У�����������Ԫ�ؼ�����˼ܹ�֪ʶ�Ĺ�������������������һ��Ԫ���ܹ�����ơ����顢�滻����в�����
���ǿ��Խ����ֹ����ģ���ijЩ������Ǽ���ģ�֪ʶ��ģΪһ�ֳ����Ԫ�أ��������ֶ�����ʵ�֣��������֮Ϊ��������Ԫ�ء�����ע�⣬���ֹ�����Ԫ����ӿڵ������Dz�ͬ�ģ���Ȼ����ͬ��Ҳ����Ҫ����Ӧ�õ�ij������ģ�͡�
Ϊʲô������Ԫ�ء����Է��֣�
��ʹ�ô�ͳ�����������ֶ�ʱ�����ǵļ��������ĸ����Ի���������������⣺
֪ʶ������
����ļܹ�ʦ��������֪�����֪ʶ������һ���ܹ�����������ܹ��ύ�������ߣ���ר�ҡ�ҵ������������ܹ�ʦ�ڹ������н�����飬����Ѱ��������ʱ������ȴ�����������鷳��
1.���ڼܹ�ʦ��������ϵͳ��֪ʶ�������ޣ��������ߵĴ����DZ�Ҫ�ģ���������Ƕ����µ�ϵͳ���˽�ͬ��Ҳ�����ġ�Ϊ���ò�������㹻�Ĺ�ʶ�Է���DZ�ڵ���������Ҫ���м��Ķ�����
2.��Ŀ�ķ�Χ����ʹ�üܹ�ʦ���ѱ���һ���������ӽǣ���Ҳ�����˽������������Ƭ���ķ���
���� �μ��۵�1��
3.�ܹ�ʦ����������ϵͳ��ϵͳ���������ֻ�ܹ�ע�ڡ���֪��Χ�ڡ��Ľ�����������Ǻ���Ȼ�ģ�����������֪����Ŀ��Χ������������˵����������һ�����⣬����������ͣ������Ŀ������ķ�Χ��
���� ���ٴβο��۵�1��
������Щ���ض���Ӱ�쵽���Ĺ��̣����յĽ���Ǽܹ�ʦ������ȷ�����ʣ������йص��������������Ӱ���Ƿ�����ȷ��������һ���̶��ϵÿ���������ˡ�
���ݵ�����
������������ͨ��������Դ���������ϸ��ģ�ͣ�UML��ArchiMate�����ƹ��ߣ�����һ�����ʵļ��������У�Ҫ��õ�һ��������ȫ������ģ�ͼ����Dz����ܵġ���������λ�����õ���ij������ϵͳ�ľ�ȷģ�ͣ�����ֿ���������������������Dz����ܴ��ڵġ��Ⲣ����˵��Щ����û�м�ֵ��ֻ��˵�����ڷ�������ϵͳ��ERP��������վ֮�������ʱ��ʲô���ð��ˡ����⣬��Щ���������ڽ���Դ����ṹ���й�ע���������в������������Ӷ�������
��ģ������
��������ڽ��������������ɼ��ģ���ô���ǻ��л������������ȷ�Ĵ������������Щ�������ɼ���������ֻ��������أ�����UML��ArchiMate�����Ľ�ģ�����ܹ���ʹ����ͨ������ģ��Ԫ��֮ǰ����ġ����������ͻ����������ӣ�������������Щ�����������dz�����Ԫ����Ԫ��֮��Ĺ������Ĵ��ڡ����ֹ���ȷʵ�����ã����������ܹ���ȷ�ؽ����������ĵ���������������Щû�м�¼�����������ͽ�����������
���ǣ���Ȼ��Щ����ȷʵ�ܹ���ģ�������ܹ��ϵ�Ԫ��֮��������������Dz����ܹ�����������ϸ���˽��Ԫ�ص���������������һ���֡��������ֻ����ģ���м�˵��Ԫ�ء�X��������Ԫ�ء�Y�����ⲻ�ܹ�������X�����������ڡ�Y���е���һ���֣�����ֻ�ܼ��衰X�������ڡ�Y����ȫ������͵����������ġ��Ŵ���Ϊ��X���������������ڡ�Y���е�ijһ��Ԫ�أ�����˵��Y.A���������Ԫ���ڽ����ϻ����Dz��ɼ��ġ�����������������ڡ�Y.A���ж�Ӧ�������ˣ����仰˵����Y.A���е���Щ��������Ҫ���������н�ģ���أ�
��ʾ����Y.A�����ǡ�������Ԫ�ء���
�����ָ�����Ӧ����һ�����أ�
������ս������α��⡰�ø���Զ�������������������е�̺ʽ���������������Ĵ��ڡ����ǿ��Խ����������
�����ǵ���ϵͳ����������Щ�ⲿԪ�أ����������ʣ��������ǵ���ϵͳ�е���ЩԪ�ز�����ϵͳ�����ܹ��������ģ���
�㿴������ʲô������
��������һ��Сˮ�ӣ�����Ҫ���ǣ�������Сˮ���ܹ����Կ����ˡ�����һ������ʹ��������������Χ���ؼ����ˣ�������ص�֪ʶ�����ݷ�����������ø����������ˡ�
���ǣ�����ΪʲôҪ���Ԫ�صĿ����أ�
ԭ�����ڣ���������ϵͳ�е�ij��Ԫ��ʹ����ijЩ���ݣ�����ʵ����ij���㷨���������ʹ�����ϵͳ����Ϊ��ҵ���ã����֮Ϊ�����ƿ��������Ļ�����ô��˵����Ԫ��������ij��ϵͳ�е�����Ԫ�ء�����һ��������ǡ�����Ԫ�ء���ʵ�֡����Dz���Ҫ֪���Ǹ�������Ԫ�ء��ľ���λ�ã����Ѿ�֪����Ҫ����ij�������ˡ���һ����Ҳ���������ݵ����⣬������ֻ���˽������Լ���ϵͳ���㹻�ˡ�
������Ȼ��Ҫ���������н�ģ���������ܹ�����صĸ�ϵ�˽��������������⡣�����������£����ǿ��Խ�������Ԫ�����Լ��ļܹ��н��н�ģ����Ϊ����Ԫ�ؿ��Գ�Ϊϵͳ�е�ij������Ԫ�أ�������ʵ�ʵ����Ԫ�ء�
����Ҳ��ϣ�����ȶ�����ϵͳ���мܹ���ģ����Ϊ���������������ǵĹ�����������Ҳ�������ǵĽ�����Χ�е�һ���֡���������Ҫ�����������ι������ڹ���ij���ܹ�Ԫ������ɵ�Ӱ��ķ�������ˣ��ܵ���˵��������Ҫһ������ģ�ͣ��Ա����ij���ܹ�������������ɲ��֣�
1.������ϵ��
2.����Ԫ�أ�
3.�Լ���������������IJ��ԣ����磺�������Э������Ԫ������������Ϣ��
Ϊ�˱���������Ϊ���ص����⣬�������������൱��Ҫ�ġ��������Ǹ��Ի��ҽ������������ʾ���У����������Ĵ��ڣ������ҵӦ�ú�������չ֮����������ƾ��ߵ�ͬ������һ�ַ����ǣ����ǿ���ͨ�������µĹ��ܣ�����Э�����ս����������ijЩ�м�ļ�����̣��Ի�����������ɵ�Ӱ�졣�����ַ���������Ч�ģ����ǻ���Ҳ��Ҫ���������й����ͻ��⡣
���²���������һ���ܹ�֧�ָ÷�ʽ�Ľ�ģ��ʾ����
����������ģ
��һ�������ǽ�����ġ�����Ԫ�ء���ϵת��Ϊһ�����ǿ��Խ�ģ��ʵ�塣Ϊ�˸�������˵����һ�㣬�����ǿ���һ���������ʾ����ij����Person��ʵ���롰Company��ʵ���������ģ������������ܹ�����ҹ�˾����ô���Ǿ��ܹ�����һ����ϵ�����а��������е����ԡ����ǿ��Խ����ʵ�彨ģΪ��Staff����
��Staff�������ܹ��������ֺ��壺1) ��Person���͡�Company��֮���һ�ֹ�ϵ���������ֹ�ϵ��Person��Company�����Ľ�ģ���صģ�2)
һϵ���ض��ڸù�ϵ�����ԣ�����employment id�� salary��office location��role�ȵȡ���Щ���Զ��������������������Ƿdz���Ҫ�ġ��ȷ��磬�����Ա�����˽�ʡ������ص��ְλ�����Dz�̫���ܼ�������ҹ�˾�ġ�
��Staff�������������й���Ԫ�صĽ�ɫ
������ϵ
����Callos��������ƪ�����е�������˵�������ļܹ��������������֣����ṹ����������Ϊ���������ṹ��������������������������������͵�API֮������ӣ�����Ϊ�����������˽�����֤�����������ϵ�ʾ������˵�Ļ�������������ԡ����ǿ��Խ����������������������빲��Ԫ�����ϣ�������ͼ��������������
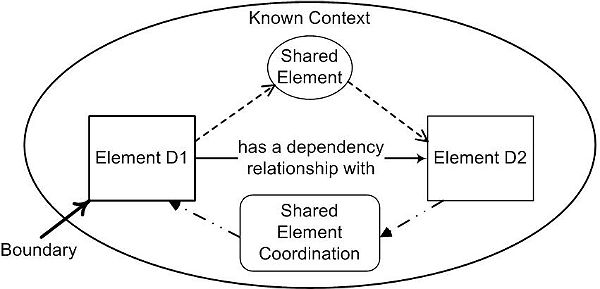
����Ԫ��ͨ����˵�����ݺʹ���Ԫ�صľۺ��壬������������ʽ�У�����Ԫ��Ҳ�ܹ����ǶԼܹ�ģʽ�����Ի��������������á�������������������ʹ�ô����������Ľ�ģ��Ϊ���ܡ�
Ԫ�صı߽�չʾ��ÿ���ܹ���ͼ�����ѡ��Χ��Ԫ����ͼ�ܹ���������ȷ��������й����IJ��֣��������Ĺ���Ԫ��Э������������˵��һ����������ͼ��Ҫ�Թ����������Ϣ����Э������һ�����-��������ͼ����Ҫ��ͨ�����ã�����web
service��Դ�����й���������������˽��йؼܹ���ͼ�ͷ������ݣ�Clements���������������ܗ赵����һ���ܺõ���㡣
һ������Ԫ��Ҳ���ǿɼ��ģ�Ҳ�����ǡ�Ԫ�ء�D1�������ܡ�������Ԫ�ء�D2�����ڹ���Ԫ�صĶ��壨���ⲿ�ġ������������ܣ����ڲ��ġ��������Ǽ���D1���ڿɿ���Ʒ�Χ֮�ڣ���D2���ڷ�Χ֮�⡣������˵��һ�����ݲ�ѯAPI�����ⲿ�ģ��ṹ�ͣ�����������ص�������֤����������ڲ��ģ���Ϊ�ͣ����������ǽṹ�͡���Ϊ�������������ⲿ���ڲ�����Ԫ�ص���ϣ��γ��������ķ��࣬������ͼ��ʾ��
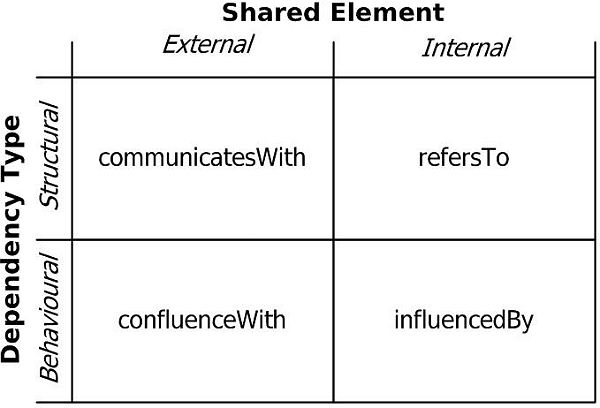
Ϊ��������������ģ�ͣ����ǽ�ʹ�ó�����������͡�dependsOn����Ϊ�������������͵ij��ࡣ
��������
�ܵ���˵��һ������������������ϵ���͵Ĵ��ڣ�SE��ʾ����Ԫ�أ���
1.��dependsOn����D1������D2�����������п�����δ֪�ģ�Ҳ�����Ƕ������͵����������ǽ����ʾΪD1
dependsOn(SE) D2��
2.��communicatesWith����D1�ڽṹ��������D2������������һ�ֿɼ����ⲿԪ�ء����ǽ����ʾΪD1
communicatesWith(SE) D2��
3.��refersTo����D1�ڽṹ��������D2������������һ���������ڲ�Ԫ�ء����ǽ����ʾΪD1
refersTo(SE) D2��
4.��confluenceWith����D1����Ϊ��������D2������������һ�ֿɼ����ⲿԪ�ء����ǽ����ʾΪD1
confluenceWith (SE) D2��
5.��influencedBy����D1����Ϊ��������D2������������һ���������ڲ�Ԫ�ء����ǽ����ʾΪD1
influencedBy (SE) D2��
���������н�ģ
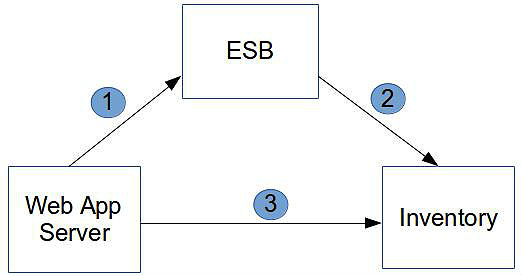
Ϊ�˸�ʵ�ʵر�����������ģ�ͣ����Ǽ�����һ������ļܹ������е�WebӦ�÷�������D1����ͨ����ҵ�������ߣ�ESB��������ͼ��ʾ����ij����棨Inventory��ϵͳ����ͨ�š����Ǽ����webӦ��ʵ���˲�ƷĿ¼���ﳵ���ֹ��ܣ����Ƕ���Ҫʹ�õ�����Ʒ��Product�������ʵ�塣
�ù�˾����ҵ�ܹ�����棨D2��ϵͳ�ƾ�Ϊ���С�Product��ʵ��Ŀ����ߡ����webӦ�þ������ڿ��ϵͳ���ڡ�Product���Ķ��壬Ҳ����˵����Product����Ϊ��һ�ֹ���Ԫ�أ�������ϵͳ�и���һ�ֲ�ͬ��ʵ�֡�
ʹ��ǰ�����ᵽ�ķ��ʽ�����ǿ��Զ�������µ�������
WebӦ�÷�������WAS��dependsOn��1��2��3�����ϵͳ�����У�
1.WAS communicatesWith(Product) ESB
2.ESB communicatesWith(Product) Inventory
3.WAS refersTo(Product) Inventory
��WAS�ܹ�ʦ�ĽǶ���˵��������Ҫ�Թ������-��������ͼ���н�ģ���Ա���ϵͳ�Ľ�������������üܹ�ʦ����Ҫ�˽�WAS��ҵ����������Щҵ��������ʶ���Productʵ����������ԣ�
1.Product Id�ͷ��ࣨcategory��
2.Product������description��
3.��Ʒ�������stock level��
�ܹ�ʦ�������Ŷӽ��н�������ȷ���˿��ϵͳ��������������ȷʵ���������ϼ�����ʶ��������ԡ���Ҳͬʱ���֣���Ʒ�����ͷ������ݶ����µ�webӦ����˵�������ã�����Ҳ��ѡ�������Щ���ݣ���Ϊ��Щ�������²�Ʒ���������һ���֡�����γ���webӦ�õ����ݹ��������е�һ���ؼ���ɲ��֡�
��ƷId�Ϳ�����ǽ��е�����ͨ��ESB���б�¶�IJ�����WebӦ����Ҫ���ֲ�ƷId����ϵͳͬ�����������ݹ�������Ŀ��ǣ��ܹ�ʦѡ���������ݹ�������ȷ����ƷId��ͬ���ԣ�������ʵ��ij���������ܡ�
��ע�⣬��ĿǰΪֹ�����Ƕ�������ϵͳ��˵���dz��١��������Ѿ��˽�������֮��������Ե���Ҫ��Ϣ����������Щ��Ϣ������һ��������ϵͳ����ģ���ˡ�
�ܹ�ʦ���ھ��ܹ����������о����ˣ�������£�
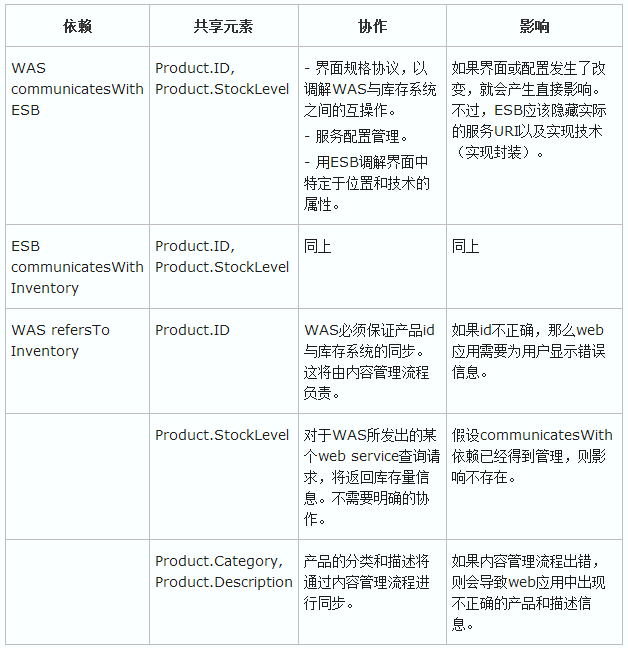
WebӦ�÷�������WAS��dependsOn��1��2��3��Inventory�����У�
1.WAS communicatesWith(Product.ID, Product.StockLevel)
ESB
2.ESB communicatesWith(Product.ID, Product.StockLevel)
Inventory
3.WebӦ�÷�����refersTo(Product.ID, Product.Category,
Product.Description, Product.StockLevel) Inventory
����Ĺؼ����ڣ������Ѿ�������ģ��ת��Ϊһ�����ǿ���ʹ�ô�ͳ�ļܹ���Ƽ������в��ϵؾ����������ˡ�������Ҫ�ĵط����ڣ������ǻ�ȡ���㹻��ϸ����Ϣ֮�Ϳ��������ֹͣ����Щ�����ľ��������ˡ�
��������
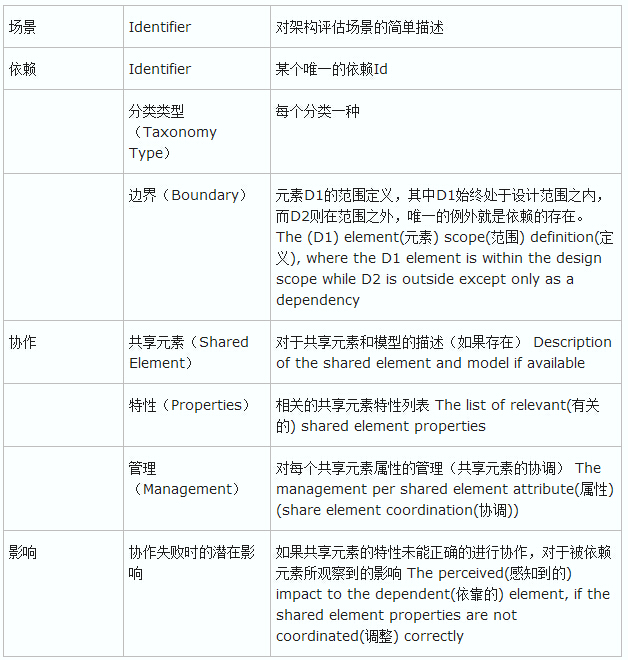
���ǵ�WAS�ܹ�ʦ�Ѿ�ʶ����ܹ������е�������Ҫ���֣���������ϵ����Ԫ���ˡ����ڣ�����Ҫ�Ա���������������������ˡ�����ı����������ʶ�������������ɵļܹ��ϵ�Ӱ�졣
��Ȥ���ǣ����ű��������Ŀ������˵Ҳ�Ǻ��м�ֵ�ģ��ܹ���������ʶ�����Ŀ�����������Դ���Լ���ÿ��ϵͳ����Դ���䡣ÿ����������Ҫ�Ŷӵĺ��������������Э����
�·��ı��������������ij��������һϵ������������һ�ֽ��飬���ݼܹ�����Ŀ��ͨ�������ĵIJ�ͬ������ҲӦ����֮�仯����������Ŀ����Ȼ���ֲ��䣺
1.��صĹ���Ԫ����������Щ��
2.����ÿ������Ԫ�����ԣ�����Ӧ����λ������������������Ԫ��Э������
3.���Э��ʧ�ܣ������ʲô����Ӱ�죿
�����ܽ�
��ϣ�������ܹ�������Ľ������������ж���������ͨ�ñ��Ӱ����������ںܶ�����£���Ŀ�������鷳������Ϊ���ڼ����������������������µġ���ֱ��ĿǰΪֹ���ڶԸ߶ȸ��ӵļ�������������������ʱ�����Ǽ�����ȫ�����ھ���ḻ�����ֵ��������Ȼ��Щ������м�ֵ�����������Ը��ơ���������������ϵͳ��ģ�ijɳ���Ҳ���Խ��Խ���ɿ��ˡ�
����������ģ��һ�����õĹ��ߣ����ܹ�������������Ϊϵͳ�������ظ������Ҹ��ӿɿ�����Ҫ�ĵط�����������ѡ������һ�ּܹ��������������ȷ�ز����˼ܹ�����ι�����������һ�㣡������Ҫ�Բ��������ڼܹ���һ�������ϣ�Ҳ������������Ŀ�ƻ��������ϡ�
������������ģ�������һ�����ڣ�����������������֪�����ݡ�������ոմ���������Ͻ��ѳ�����
|






