|
初探nginx架构(100%)
众所周知,nginx性能高,而nginx的高性能与其架构是分不开的。那么nginx究竟是怎么样的呢?这一节我们先来初识一下nginx框架吧。
nginx在启动后,在unix系统中会以daemon的方式在后台运行,后台进程包含一个master进程和多个worker进程。我们也可以手动地关掉后台模式,让nginx在前台运行,并且通过配置让nginx取消master进程,从而可以使nginx以单进程方式运行。很显然,生产环境下我们肯定不会这么做,所以关闭后台模式,一般是用来调试用的,在后面的章节里面,我们会详细地讲解如何调试nginx。所以,我们可以看到,nginx是以多进程的方式来工作的,当然nginx也是支持多线程的方式的,只是我们主流的方式还是多进程的方式,也是nginx的默认方式。nginx采用多进程的方式有诸多好处,所以我就主要讲解nginx的多进程模式吧。
刚才讲到,nginx在启动后,会有一个master进程和多个worker进程。master进程主要用来管理worker进程,包含:接收来自外界的信号,向各worker进程发送信号,监控worker进程的运行状态,当worker进程退出后(异常情况下),会自动重新启动新的worker进程。而基本的网络事件,则是放在worker进程中来处理了。多个worker进程之间是对等的,他们同等竞争来自客户端的请求,各进程互相之间是独立的。一个请求,只可能在一个worker进程中处理,一个worker进程,不可能处理其它进程的请求。worker进程的个数是可以设置的,一般我们会设置与机器cpu核数一致,这里面的原因与nginx的进程模型以及事件处理模型是分不开的。nginx的进程模型,可以由下图来表示:

在nginx启动后,如果我们要操作nginx,要怎么做呢?从上文中我们可以看到,master来管理worker进程,所以我们只需要与master进程通信就行了。master进程会接收来自外界发来的信号,再根据信号做不同的事情。所以我们要控制nginx,只需要通过kill向master进程发送信号就行了。比如kill -HUP pid,则是告诉nginx,从容地重启nginx,我们一般用这个信号来重启nginx,或重新加载配置,因为是从容地重启,因此服务是不中断的。master进程在接收到HUP信号后是怎么做的呢?首先master进程在接到信号后,会先重新加载配置文件,然后再启动新的worker进程,并向所有老的worker进程发送信号,告诉他们可以光荣退休了。新的worker在启动后,就开始接收新的请求,而老的worker在收到来自master的信号后,就不再接收新的请求,并且在当前进程中的所有未处理完的请求处理完成后,再退出。当然,直接给master进程发送信号,这是比较老的操作方式,nginx在0.8版本之后,引入了一系列命令行参数,来方便我们管理。比如,./nginx -s reload,就是来重启nginx,./nginx -s stop,就是来停止nginx的运行。如何做到的呢?我们还是拿reload来说,我们看到,执行命令时,我们是启动一个新的nginx进程,而新的nginx进程在解析到reload参数后,就知道我们的目的是控制nginx来重新加载配置文件了,它会向master进程发送信号,然后接下来的动作,就和我们直接向master进程发送信号一样了。
现在,我们知道了当我们在操作nginx的时候,nginx内部做了些什么事情,那么,worker进程又是如何处理请求的呢?我们前面有提到,worker进程之间是平等的,每个进程,处理请求的机会也是一样的。当我们提供80端口的http服务时,一个连接请求过来,每个进程都有可能处理这个连接,怎么做到的呢?首先,每个worker进程都是从master进程fork过来,在master进程里面,先建立好需要listen的socket(listenfd)之后,然后再fork出多个worker进程。所有worker进程的listenfd会在新连接到来时变得可读,为保证只有一个进程处理该连接,所有worker进程在注册listenfd读事件前抢accept_mutex,抢到互斥锁的那个进程注册listenfd读事件,在读事件里调用accept接受该连接。当一个worker进程在accept这个连接之后,就开始读取请求,解析请求,处理请求,产生数据后,再返回给客户端,最后才断开连接,这样一个完整的请求就是这样的了。我们可以看到,一个请求,完全由worker进程来处理,而且只在一个worker进程中处理。
那么,nginx采用这种进程模型有什么好处呢?当然,好处肯定会很多了。首先,对于每个worker进程来说,独立的进程,不需要加锁,所以省掉了锁带来的开销,同时在编程以及问题查找时,也会方便很多。其次,采用独立的进程,可以让互相之间不会影响,一个进程退出后,其它进程还在工作,服务不会中断,master进程则很快启动新的worker进程。当然,worker进程的异常退出,肯定是程序有bug了,异常退出,会导致当前worker上的所有请求失败,不过不会影响到所有请求,所以降低了风险。当然,好处还有很多,大家可以慢慢体会。
上面讲了很多关于nginx的进程模型,接下来,我们来看看nginx是如何处理事件的。
有人可能要问了,nginx采用多worker的方式来处理请求,每个worker里面只有一个主线程,那能够处理的并发数很有限啊,多少个worker就能处理多少个并发,何来高并发呢?非也,这就是nginx的高明之处,nginx采用了异步非阻塞的方式来处理请求,也就是说,nginx是可以同时处理成千上万个请求的。想想apache的常用工作方式(apache也有异步非阻塞版本,但因其与自带某些模块冲突,所以不常用),每个请求会独占一个工作线程,当并发数上到几千时,就同时有几千的线程在处理请求了。这对操作系统来说,是个不小的挑战,线程带来的内存占用非常大,线程的上下文切换带来的cpu开销很大,自然性能就上不去了,而这些开销完全是没有意义的。
为什么nginx可以采用异步非阻塞的方式来处理呢,或者异步非阻塞到底是怎么回事呢?我们先回到原点,看看一个请求的完整过程。首先,请求过来,要建立连接,然后再接收数据,接收数据后,再发送数据。具体到系统底层,就是读写事件,而当读写事件没有准备好时,必然不可操作,如果不用非阻塞的方式来调用,那就得阻塞调用了,事件没有准备好,那就只能等了,等事件准备好了,你再继续吧。阻塞调用会进入内核等待,cpu就会让出去给别人用了,对单线程的worker来说,显然不合适,当网络事件越多时,大家都在等待呢,cpu空闲下来没人用,cpu利用率自然上不去了,更别谈高并发了。好吧,你说加进程数,这跟apache的线程模型有什么区别,注意,别增加无谓的上下文切换。所以,在nginx里面,最忌讳阻塞的系统调用了。不要阻塞,那就非阻塞喽。非阻塞就是,事件没有准备好,马上返回EAGAIN,告诉你,事件还没准备好呢,你慌什么,过会再来吧。好吧,你过一会,再来检查一下事件,直到事件准备好了为止,在这期间,你就可以先去做其它事情,然后再来看看事件好了没。虽然不阻塞了,但你得不时地过来检查一下事件的状态,你可以做更多的事情了,但带来的开销也是不小的。所以,才会有了异步非阻塞的事件处理机制,具体到系统调用就是像select/poll/epoll/kqueue这样的系统调用。它们提供了一种机制,让你可以同时监控多个事件,调用他们是阻塞的,但可以设置超时时间,在超时时间之内,如果有事件准备好了,就返回。这种机制正好解决了我们上面的两个问题,拿epoll为例(在后面的例子中,我们多以epoll为例子,以代表这一类函数),当事件没准备好时,放到epoll里面,事件准备好了,我们就去读写,当读写返回EAGAIN时,我们将它再次加入到epoll里面。这样,只要有事件准备好了,我们就去处理它,只有当所有事件都没准备好时,才在epoll里面等着。这样,我们就可以并发处理大量的并发了,当然,这里的并发请求,是指未处理完的请求,线程只有一个,所以同时能处理的请求当然只有一个了,只是在请求间进行不断地切换而已,切换也是因为异步事件未准备好,而主动让出的。这里的切换是没有任何代价,你可以理解为循环处理多个准备好的事件,事实上就是这样的。与多线程相比,这种事件处理方式是有很大的优势的,不需要创建线程,每个请求占用的内存也很少,没有上下文切换,事件处理非常的轻量级。并发数再多也不会导致无谓的资源浪费(上下文切换)。更多的并发数,只是会占用更多的内存而已。 我之前有对连接数进行过测试,在24G内存的机器上,处理的并发请求数达到过200万。现在的网络服务器基本都采用这种方式,这也是nginx性能高效的主要原因。
我们之前说过,推荐设置worker的个数为cpu的核数,在这里就很容易理解了,更多的worker数,只会导致进程来竞争cpu资源了,从而带来不必要的上下文切换。而且,nginx为了更好的利用多核特性,提供了cpu亲缘性的绑定选项,我们可以将某一个进程绑定在某一个核上,这样就不会因为进程的切换带来cache的失效。像这种小的优化在nginx中非常常见,同时也说明了nginx作者的苦心孤诣。比如,nginx在做4个字节的字符串比较时,会将4个字符转换成一个int型,再作比较,以减少cpu的指令数等等。
现在,知道了nginx为什么会选择这样的进程模型与事件模型了。对于一个基本的web服务器来说,事件通常有三种类型,网络事件、信号、定时器。从上面的讲解中知道,网络事件通过异步非阻塞可以很好的解决掉。如何处理信号与定时器?
首先,信号的处理。对nginx来说,有一些特定的信号,代表着特定的意义。信号会中断掉程序当前的运行,在改变状态后,继续执行。如果是系统调用,则可能会导致系统调用的失败,需要重入。关于信号的处理,大家可以学习一些专业书籍,这里不多说。对于nginx来说,如果nginx正在等待事件(epoll_wait时),如果程序收到信号,在信号处理函数处理完后,epoll_wait会返回错误,然后程序可再次进入epoll_wait调用。
另外,再来看看定时器。由于epoll_wait等函数在调用的时候是可以设置一个超时时间的,所以nginx借助这个超时时间来实现定时器。nginx里面的定时器事件是放在一颗维护定时器的红黑树里面,每次在进入epoll_wait前,先从该红黑树里面拿到所有定时器事件的最小时间,在计算出epoll_wait的超时时间后进入epoll_wait。所以,当没有事件产生,也没有中断信号时,epoll_wait会超时,也就是说,定时器事件到了。这时,nginx会检查所有的超时事件,将他们的状态设置为超时,然后再去处理网络事件。由此可以看出,当我们写nginx代码时,在处理网络事件的回调函数时,通常做的第一个事情就是判断超时,然后再去处理网络事件。
我们可以用一段伪代码来总结一下nginx的事件处理模型:
while (true) {
for t in run_tasks:
t.handler();
update_time(&now);
timeout = ETERNITY;
for t in wait_tasks: /* sorted already */
if (t.time <= now) {
t.timeout_handler();
} else {
timeout = t.time - now;
break;
}
nevents = poll_function(events, timeout);
for i in nevents:
task t;
if (events[i].type == READ) {
t.handler = read_handler;
} else { /* events[i].type == WRITE */
t.handler = write_handler;
}
run_tasks_add(t);
} |
好,本节我们讲了进程模型,事件模型,包括网络事件,信号,定时器事件。
nginx基础概念(100%)
connection
在nginx中connection就是对tcp连接的封装,其中包括连接的socket,读事件,写事件。利用nginx封装的connection,我们可以很方便的使用nginx来处理与连接相关的事情,比如,建立连接,发送与接受数据等。而nginx中的http请求的处理就是建立在connection之上的,所以nginx不仅可以作为一个web服务器,也可以作为邮件服务器。当然,利用nginx提供的connection,我们可以与任何后端服务打交道。
结合一个tcp连接的生命周期,我们看看nginx是如何处理一个连接的。首先,nginx在启动时,会解析配置文件,得到需要监听的端口与ip地址,然后在nginx的master进程里面,先初始化好这个监控的socket(创建socket,设置addrreuse等选项,绑定到指定的ip地址端口,再listen),然后再fork出多个子进程出来,然后子进程会竞争accept新的连接。此时,客户端就可以向nginx发起连接了。当客户端与服务端通过三次握手建立好一个连接后,nginx的某一个子进程会accept成功,得到这个建立好的连接的socket,然后创建nginx对连接的封装,即ngx_connection_t结构体。接着,设置读写事件处理函数并添加读写事件来与客户端进行数据的交换。最后,nginx或客户端来主动关掉连接,到此,一个连接就寿终正寝了。
当然,nginx也是可以作为客户端来请求其它server的数据的(如upstream模块),此时,与其它server创建的连接,也封装在ngx_connection_t中。作为客户端,nginx先获取一个ngx_connection_t结构体,然后创建socket,并设置socket的属性(
比如非阻塞)。然后再通过添加读写事件,调用connect/read/write来调用连接,最后关掉连接,并释放ngx_connection_t。
在nginx中,每个进程会有一个连接数的最大上限,这个上限与系统对fd的限制不一样。在操作系统中,通过ulimit
-n,我们可以得到一个进程所能够打开的fd的最大数,即nofile,因为每个socket连接会占用掉一个fd,所以这也会限制我们进程的最大连接数,当然也会直接影响到我们程序所能支持的最大并发数,当fd用完后,再创建socket时,就会失败。nginx通过设置worker_connectons来设置每个进程支持的最大连接数。如果该值大于nofile,那么实际的最大连接数是nofile,nginx会有警告。nginx在实现时,是通过一个连接池来管理的,每个worker进程都有一个独立的连接池,连接池的大小是worker_connections。这里的连接池里面保存的其实不是真实的连接,它只是一个worker_connections大小的一个ngx_connection_t结构的数组。并且,nginx会通过一个链表free_connections来保存所有的空闲ngx_connection_t,每次获取一个连接时,就从空闲连接链表中获取一个,用完后,再放回空闲连接链表里面。
在这里,很多人会误解worker_connections这个参数的意思,认为这个值就是nginx所能建立连接的最大值。其实不然,这个值是表示每个worker进程所能建立连接的最大值,所以,一个nginx能建立的最大连接数,应该是worker_connections
* worker_processes。当然,这里说的是最大连接数,对于HTTP请求本地资源来说,能够支持的最大并发数量是worker_connections
* worker_processes,而如果是HTTP作为反向代理来说,最大并发数量应该是worker_connections
* worker_processes/2。因为作为反向代理服务器,每个并发会建立与客户端的连接和与后端服务的连接,会占用两个连接。
那么,我们前面有说过一个客户端连接过来后,多个空闲的进程,会竞争这个连接,很容易看到,这种竞争会导致不公平,如果某个进程得到accept的机会比较多,它的空闲连接很快就用完了,如果不提前做一些控制,当accept到一个新的tcp连接后,因为无法得到空闲连接,而且无法将此连接转交给其它进程,最终会导致此tcp连接得不到处理,就中止掉了。很显然,这是不公平的,有的进程有空余连接,却没有处理机会,有的进程因为没有空余连接,却人为地丢弃连接。那么,如何解决这个问题呢?首先,nginx的处理得先打开accept_mutex选项,此时,只有获得了accept_mutex的进程才会去添加accept事件,也就是说,nginx会控制进程是否添加accept事件。nginx使用一个叫ngx_accept_disabled的变量来控制是否去竞争accept_mutex锁。在第一段代码中,计算ngx_accept_disabled的值,这个值是nginx单进程的所有连接总数的八分之一,减去剩下的空闲连接数量,得到的这个ngx_accept_disabled有一个规律,当剩余连接数小于总连接数的八分之一时,其值才大于0,而且剩余的连接数越小,这个值越大。再看第二段代码,当ngx_accept_disabled大于0时,不会去尝试获取accept_mutex锁,并且将ngx_accept_disabled减1,于是,每次执行到此处时,都会去减1,直到小于0。不去获取accept_mutex锁,就是等于让出获取连接的机会,很显然可以看出,当空余连接越少时,ngx_accept_disable越大,于是让出的机会就越多,这样其它进程获取锁的机会也就越大。不去accept,自己的连接就控制下来了,其它进程的连接池就会得到利用,这样,nginx就控制了多进程间连接的平衡了。
ngx_accept_disabled = ngx_cycle->connection_n / 8
- ngx_cycle->free_connection_n;
if (ngx_accept_disabled > 0) {
ngx_accept_disabled--;} else {
if (ngx_trylock_accept_mutex(cycle) == NGX_ERROR) {
return;
}
if (ngx_accept_mutex_held) {
flags |= NGX_POST_EVENTS;
} else {
if (timer == NGX_TIMER_INFINITE
|| timer > ngx_accept_mutex_delay)
{
timer = ngx_accept_mutex_delay;
}
}
}
|
好了,连接就先介绍到这,本章的目的是介绍基本概念,知道在nginx中连接是个什么东西就行了,而且连接是属于比较高级的用法,在后面的模块开发高级篇会有专门的章节来讲解连接与事件的实现及使用。
request
这节我们讲request,在nginx中我们指的是http请求,具体到nginx中的数据结构是ngx_http_request_t。ngx_http_request_t是对一个http请求的封装。
我们知道,一个http请求,包含请求行、请求头、请求体、响应行、响应头、响应体。
http请求是典型的请求-响应类型的的网络协议,而http是文件协议,所以我们在分析请求行与请求头,以及输出响应行与响应头,往往是一行一行的进行处理。如果我们自己来写一个http服务器,通常在一个连接建立好后,客户端会发送请求过来。然后我们读取一行数据,分析出请求行中包含的method、uri、http_version信息。然后再一行一行处理请求头,并根据请求method与请求头的信息来决定是否有请求体以及请求体的长度,然后再去读取请求体。得到请求后,我们处理请求产生需要输出的数据,然后再生成响应行,响应头以及响应体。在将响应发送给客户端之后,一个完整的请求就处理完了。当然这是最简单的webserver的处理方式,其实nginx也是这样做的,只是有一些小小的区别,比如,当请求头读取完成后,就开始进行请求的处理了。nginx通过ngx_http_request_t来保存解析请求与输出响应相关的数据。
那接下来,简要讲讲nginx是如何处理一个完整的请求的。对于nginx来说,一个请求是从ngx_http_init_request开始的,在这个函数中,会设置读事件为ngx_http_process_request_line,也就是说,接下来的网络事件,会由ngx_http_process_request_line来执行。从ngx_http_process_request_line的函数名,我们可以看到,这就是来处理请求行的,正好与之前讲的,处理请求的第一件事就是处理请求行是一致的。通过ngx_http_read_request_header来读取请求数据。然后调用ngx_http_parse_request_line函数来解析请求行。nginx为提高效率,采用状态机来解析请求行,而且在进行method的比较时,没有直接使用字符串比较,而是将四个字符转换成一个整型,然后一次比较以减少cpu的指令数,这个前面有说过。很多人可能很清楚一个请求行包含请求的方法,uri,版本,却不知道其实在请求行中,也是可以包含有host的。比如一个请求GET
http://www.taobao.com/uri HTTP/1.0这样一个请求行也是合法的,而且host是www.taobao.com,这个时候,nginx会忽略请求头中的host域,而以请求行中的这个为准来查找虚拟主机。另外,对于对于http0.9版来说,是不支持请求头的,所以这里也是要特别的处理。所以,在后面解析请求头时,协议版本都是1.0或1.1。整个请求行解析到的参数,会保存到ngx_http_request_t结构当中。
在解析完请求行后,nginx会设置读事件的handler为ngx_http_process_request_headers,然后后续的请求就在ngx_http_process_request_headers中进行读取与解析。ngx_http_process_request_headers函数用来读取请求头,跟请求行一样,还是调用ngx_http_read_request_header来读取请求头,调用ngx_http_parse_header_line来解析一行请求头,解析到的请求头会保存到ngx_http_request_t的域headers_in中,headers_in是一个链表结构,保存所有的请求头。而HTTP中有些请求是需要特别处理的,这些请求头与请求处理函数存放在一个映射表里面,即ngx_http_headers_in,在初始化时,会生成一个hash表,当每解析到一个请求头后,就会先在这个hash表中查找,如果有找到,则调用相应的处理函数来处理这个请求头。比如:Host头的处理函数是ngx_http_process_host。
当nginx解析到两个回车换行符时,就表示请求头的结束,此时就会调用ngx_http_process_request来处理请求了。ngx_http_process_request会设置当前的连接的读写事件处理函数为ngx_http_request_handler,然后再调用ngx_http_handler来真正开始处理一个完整的http请求。这里可能比较奇怪,读写事件处理函数都是ngx_http_request_handler,其实在这个函数中,会根据当前事件是读事件还是写事件,分别调用ngx_http_request_t中的read_event_handler或者是write_event_handler。由于此时,我们的请求头已经读取完成了,之前有说过,nginx的做法是先不读取请求body,所以这里面我们设置read_event_handler为ngx_http_block_reading,即不读取数据了。刚才说到,真正开始处理数据,是在ngx_http_handler这个函数里面,这个函数会设置write_event_handler为ngx_http_core_run_phases,并执行ngx_http_core_run_phases函数。ngx_http_core_run_phases这个函数将执行多阶段请求处理,nginx将一个http请求的处理分为多个阶段,那么这个函数就是执行这些阶段来产生数据。因为ngx_http_core_run_phases最后会产生数据,所以我们就很容易理解,为什么设置写事件的处理函数为ngx_http_core_run_phases了。在这里,我简要说明了一下函数的调用逻辑,我们需要明白最终是调用ngx_http_core_run_phases来处理请求,产生的响应头会放在ngx_http_request_t的headers_out中,这一部分内容,我会放在请求处理流程里面去讲。nginx的各种阶段会对请求进行处理,最后会调用filter来过滤数据,对数据进行加工,如truncked传输、gzip压缩等。这里的filter包括header
filter与body filter,即对响应头或响应体进行处理。filter是一个链表结构,分别有header
filter与body filter,先执行header filter中的所有filter,然后再执行body
filter中的所有filter。在header filter中的最后一个filter,即ngx_http_header_filter,这个filter将会遍历所有的响应头,最后需要输出的响应头在一个连续的内存,然后调用ngx_http_write_filter进行输出。ngx_http_write_filter是body
filter中的最后一个,所以nginx首先的body信息,在经过一系列的body filter之后,最后也会调用ngx_http_write_filter来进行输出(有图来说明)。
这里要注意的是,nginx会将整个请求头都放在一个buffer里面,这个buffer的大小通过配置项client_header_buffer_size来设置,如果用户的请求头太大,这个buffer装不下,那nginx就会重新分配一个新的更大的buffer来装请求头,这个大buffer可以通过large_client_header_buffers来设置,这个large_buffer这一组buffer,比如配置4
8k,就是表示有四个8k大小的buffer可以用。注意,为了保存请求行或请求头的完整性,一个完整的请求行或请求头,需要放在一个连续的内存里面,所以,一个完整的请求行或请求头,只会保存在一个buffer里面。这样,如果请求行大于一个buffer的大小,就会返回414错误,如果一个请求头大小大于一个buffer大小,就会返回400错误。在了解了这些参数的值,以及nginx实际的做法之后,在应用场景,我们就需要根据实际的需求来调整这些参数,来优化我们的程序了。
处理流程图:
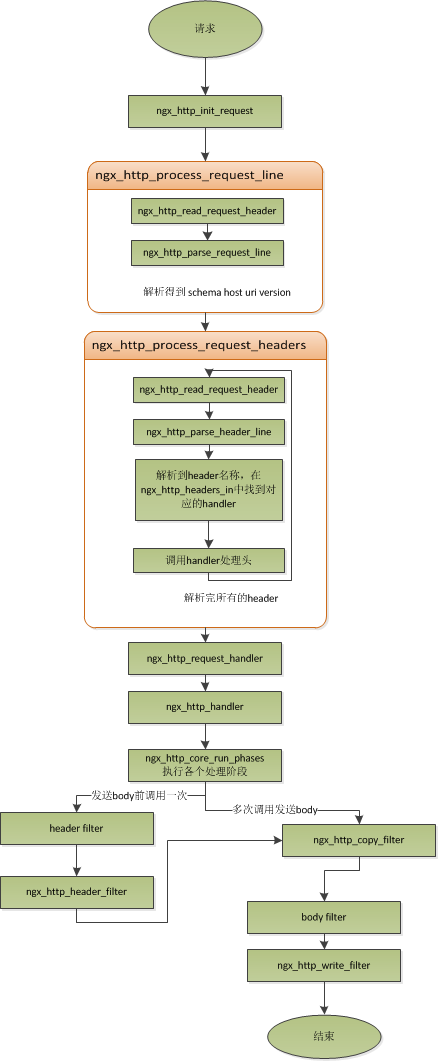
以上这些,就是nginx中一个http请求的生命周期了。我们再看看与请求相关的一些概念吧。
keepalive
当然,在nginx中,对于http1.0与http1.1也是支持长连接的。什么是长连接呢?我们知道,http请求是基于TCP协议之上的,那么,当客户端在发起请求前,需要先与服务端建立TCP连接,而每一次的TCP连接是需要三次握手来确定的,如果客户端与服务端之间网络差一点,这三次交互消费的时间会比较多,而且三次交互也会带来网络流量。当然,当连接断开后,也会有四次的交互,当然对用户体验来说就不重要了。而http请求是请求应答式的,如果我们能知道每个请求头与响应体的长度,那么我们是可以在一个连接上面执行多个请求的,这就是所谓的长连接,但前提条件是我们先得确定请求头与响应体的长度。对于请求来说,如果当前请求需要有body,如POST请求,那么nginx就需要客户端在请求头中指定content-length来表明body的大小,否则返回400错误。也就是说,请求体的长度是确定的,那么响应体的长度呢?先来看看http协议中关于响应body长度的确定:
1.对于http1.0协议来说,如果响应头中有content-length头,则以content-length的长度就可以知道body的长度了,客户端在接收body时,就可以依照这个长度来接收数据,接收完后,就表示这个请求完成了。而如果没有content-length头,则客户端会一直接收数据,直到服务端主动断开连接,才表示body接收完了。
2.而对于http1.1协议来说,如果响应头中的Transfer-encoding为chunked传输,则表示body是流式输出,body会被分成多个块,每块的开始会标识出当前块的长度,此时,body不需要通过长度来指定。如果是非chunked传输,而且有content-length,则按照content-length来接收数据。否则,如果是非chunked,并且没有content-length,则客户端接收数据,直到服务端主动断开连接。
从上面,我们可以看到,除了http1.0不带content-length以及http1.1非chunked不带content-length外,body的长度是可知的。此时,当服务端在输出完body之后,会可以考虑使用长连接。能否使用长连接,也是有条件限制的。如果客户端的请求头中的connection为close,则表示客户端需要关掉长连接,如果为keep-alive,则客户端需要打开长连接,如果客户端的请求中没有connection这个头,那么根据协议,如果是http1.0,则默认为close,如果是http1.1,则默认为keep-alive。如果结果为keepalive,那么,nginx在输出完响应体后,会设置当前连接的keepalive属性,然后等待客户端下一次请求。当然,nginx不可能一直等待下去,如果客户端一直不发数据过来,岂不是一直占用这个连接?所以当nginx设置了keepalive等待下一次的请求时,同时也会设置一个最大等待时间,这个时间是通过选项keepalive_timeout来配置的,如果配置为0,则表示关掉keepalive,此时,http版本无论是1.1还是1.0,客户端的connection不管是close还是keepalive,都会强制为close。
如果服务端最后的决定是keepalive打开,那么在响应的http头里面,也会包含有connection头域,其值是”Keep-Alive”,否则就是”Close”。如果connection值为close,那么在nginx响应完数据后,会主动关掉连接。所以,对于请求量比较大的nginx来说,关掉keepalive最后会产生比较多的time-wait状态的socket。一般来说,当客户端的一次访问,需要多次访问同一个server时,打开keepalive的优势非常大,比如图片服务器,通常一个网页会包含很多个图片。打开keepalive也会大量减少time-wait的数量。
pipe
在http1.1中,引入了一种新的特性,即pipeline。那么什么是pipeline呢?pipeline其实就是流水线作业,它可以看作为keepalive的一种升华,因为pipeline也是基于长连接的,目的就是利用一个连接做多次请求。如果客户端要提交多个请求,对于keepalive来说,那么第二个请求,必须要等到第一个请求的响应接收完全后,才能发起,这和TCP的停止等待协议是一样的,得到两个响应的时间至少为2*RTT。而对pipeline来说,客户端不必等到第一个请求处理完后,就可以马上发起第二个请求。得到两个响应的时间可能能够达到1*RTT。nginx是直接支持pipeline的,但是,nginx对pipeline中的多个请求的处理却不是并行的,依然是一个请求接一个请求的处理,只是在处理第一个请求的时候,客户端就可以发起第二个请求。这样,nginx利用pipeline减少了处理完一个请求后,等待第二个请求的请求头数据的时间。其实nginx的做法很简单,前面说到,nginx在读取数据时,会将读取的数据放到一个buffer里面,所以,如果nginx在处理完前一个请求后,如果发现buffer里面还有数据,就认为剩下的数据是下一个请求的开始,然后就接下来处理下一个请求,否则就设置keepalive。
lingering_close
lingering_close,字面意思就是延迟关闭,也就是说,当nginx要关闭连接时,并非立即关闭连接,而是先关闭tcp连接的写,再等待一段时间后再关掉连接的读。为什么要这样呢?我们先来看看这样一个场景。nginx在接收客户端的请求时,可能由于客户端或服务端出错了,要立即响应错误信息给客户端,而nginx在响应错误信息后,大分部情况下是需要关闭当前连接。nginx执行完write()系统调用把错误信息发送给客户端,write()系统调用返回成功并不表示数据已经发送到客户端,有可能还在tcp连接的write
buffer里。接着如果直接执行close()系统调用关闭tcp连接,内核会首先检查tcp的read buffer里有没有客户端发送过来的数据留在内核态没有被用户态进程读取,如果有则发送给客户端RST报文来关闭tcp连接丢弃write
buffer里的数据,如果没有则等待write buffer里的数据发送完毕,然后再经过正常的4次分手报文断开连接。所以,当在某些场景下出现tcp
write buffer里的数据在write()系统调用之后到close()系统调用执行之前没有发送完毕,且tcp
read buffer里面还有数据没有读,close()系统调用会导致客户端收到RST报文且不会拿到服务端发送过来的错误信息数据。那客户端肯定会想,这服务器好霸道,动不动就reset我的连接,连个错误信息都没有。
在上面这个场景中,我们可以看到,关键点是服务端给客户端发送了RST包,导致自己发送的数据在客户端忽略掉了。所以,解决问题的重点是,让服务端别发RST包。再想想,我们发送RST是因为我们关掉了连接,关掉连接是因为我们不想再处理此连接了,也不会有任何数据产生了。对于全双工的TCP连接来说,我们只需要关掉写就行了,读可以继续进行,我们只需要丢掉读到的任何数据就行了,这样的话,当我们关掉连接后,客户端再发过来的数据,就不会再收到RST了。当然最终我们还是需要关掉这个读端的,所以我们会设置一个超时时间,在这个时间过后,就关掉读,客户端再发送数据来就不管了,作为服务端我会认为,都这么长时间了,发给你的错误信息也应该读到了,再慢就不关我事了,要怪就怪你RP不好了。当然,正常的客户端,在读取到数据后,会关掉连接,此时服务端就会在超时时间内关掉读端。这些正是lingering_close所做的事情。协议栈提供
SO_LINGER 这个选项,它的一种配置情况就是来处理lingering_close的情况的,不过nginx是自己实现的lingering_close。lingering_close存在的意义就是来读取剩下的客户端发来的数据,所以nginx会有一个读超时时间,通过lingering_timeout选项来设置,如果在lingering_timeout时间内还没有收到数据,则直接关掉连接。nginx还支持设置一个总的读取时间,通过lingering_time来设置,这个时间也就是nginx在关闭写之后,保留socket的时间,客户端需要在这个时间内发送完所有的数据,否则nginx在这个时间过后,会直接关掉连接。当然,nginx是支持配置是否打开lingering_close选项的,通过lingering_close选项来配置。
那么,我们在实际应用中,是否应该打开lingering_close呢?这个就没有固定的推荐值了,如Maxim
Dounin所说,lingering_close的主要作用是保持更好的客户端兼容性,但是却需要消耗更多的额外资源(比如连接会一直占着)。
这节,我们介绍了nginx中,连接与请求的基本概念,下节,我们讲基本的数据结构。
基本数据结构(99%)
nginx的作者为追求极致的高效,自己实现了很多颇具特色的nginx风格的数据结构以及公共函数。比如,nginx提供了带长度的字符串,根据编译器选项优化过的字符串拷贝函数ngx_copy等。所以,在我们写nginx模块时,应该尽量调用nginx提供的api,尽管有些api只是对glibc的宏定义。本节,我们介绍string、list、buffer、chain等一系列最基本的数据结构及相关api的使用技巧以及注意事项。
ngx_str_t(100%)
在nginx源码目录的src/core下面的ngx_string.h|c里面,包含了字符串的封装以及字符串相关操作的api。nginx提供了一个带长度的字符串结构ngx_str_t,它的原型如下:
typedef struct {
size_t len;
u_char *data;
} ngx_str_t; |
在结构体当中,data指向字符串数据的第一个字符,字符串的结束用长度来表示,而不是由’\0’来表示结束。所以,在写nginx代码时,处理字符串的方法跟我们平时使用有很大的不一样,但要时刻记住,字符串不以’\0’结束,尽量使用nginx提供的字符串操作的api来操作字符串。
那么,nginx这样做有什么好处呢?首先,通过长度来表示字符串长度,减少计算字符串长度的次数。其次,nginx可以重复引用一段字符串内存,data可以指向任意内存,长度表示结束,而不用去copy一份自己的字符串(因为如果要以’\0’结束,而不能更改原字符串,所以势必要copy一段字符串)。我们在ngx_http_request_t结构体的成员中,可以找到很多字符串引用一段内存的例子,比如request_line、uri、args等等,这些字符串的data部分,都是指向在接收数据时创建buffer所指向的内存中,uri,args就没有必要copy一份出来。这样的话,减少了很多不必要的内存分配与拷贝。
正是基于此特性,在nginx中,必须谨慎的去修改一个字符串。在修改字符串时需要认真的去考虑:是否可以修改该字符串;字符串修改后,是否会对其它的引用造成影响。在后面介绍ngx_unescape_uri函数的时候,就会看到这一点。但是,使用nginx的字符串会产生一些问题,glibc提供的很多系统api函数大多是通过’\0’来表示字符串的结束,所以我们在调用系统api时,就不能直接传入str->data了。此时,通常的做法是创建一段str->len
+ 1大小的内存,然后copy字符串,最后一个字节置为’\0’。比较hack的做法是,将字符串最后一个字符的后一个字符backup一个,然后设置为’\0’,在做完调用后,再由backup改回来,但前提条件是,你得确定这个字符是可以修改的,而且是有内存分配,不会越界,但一般不建议这么做。
接下来,看看nginx提供的操作字符串相关的api。
#define ngx_string(str) { sizeof(str) - 1, (u_char *) str } |
ngx_string(str)是一个宏,它通过一个以’\0’结尾的普通字符串str构造一个nginx的字符串,鉴于其中采用sizeof操作符计算字符串长度,因此参数必须是一个常量字符串。
#define ngx_null_string { 0, NULL } |
定义变量时,使用ngx_null_string初始化字符串为空字符串,符串的长度为0,data为NULL。
#define ngx_str_set(str, text) \
(str)->len = sizeof(text) - 1; (str)->data = (u_char *) text
|
ngx_str_set用于设置字符串str为text,由于使用sizeof计算长度,故text必须为常量字符串。
#define ngx_str_null(str) (str)->len = 0; (str)->data = NULL
|
ngx_str_null用于设置字符串str为空串,长度为0,data为NULL。
上面这四个函数,使用时一定要小心,ngx_string与ngx_null_string是“{,}”格式的,故只能用于赋值时初始化,如:
ngx_str_t str = ngx_string("hello world");
ngx_str_t str1 = ngx_null_string; |
如果向下面这样使用,就会有问题,这里涉及到c语言中对结构体变量赋值操作的语法规则,在此不做介绍。
ngx_str_t str, str1;
str = ngx_string("hello world"); // 编译出错
str1 = ngx_null_string; // 编译出错
|
这种情况,可以调用ngx_str_set与ngx_str_null这两个函数来做:
ngx_str_t str, str1;
ngx_str_set(&str, "hello world");
ngx_str_null(&str1); |
按照C99标准,您也可以这么做:
ngx_str_t str, str1;
str = (ngx_str_t) ngx_string("hello world");
str1 = (ngx_str_t) ngx_null_string; |
另外要注意的是,ngx_string与ngx_str_set在调用时,传进去的字符串一定是常量字符串,否则会得到意想不到的错误(因为ngx_str_set内部使用了sizeof(),如果传入的是u_char*,那么计算的是这个指针的长度,而不是字符串的长度)。如:
ngx_str_t str;
u_char *a = "hello world";
ngx_str_set(&str, a); // 问题产生
|
此外,值得注意的是,由于ngx_str_set与ngx_str_null实际上是两行语句,故在if/for/while等语句中单独使用需要用花括号括起来,例如:
ngx_str_t str;
if (cond)
ngx_str_set(&str, "true"); // 问题产生
else
ngx_str_set(&str, "false"); // 问题产生
|
void ngx_strlow(u_char *dst, u_char *src, size_t n); |
将src的前n个字符转换成小写存放在dst字符串当中,调用者需要保证dst指向的空间大于等于n,且指向的空间必须可写。操作不会对原字符串产生变动。如要更改原字符串,可以:
ngx_strlow(str->data, str->data, str->len); |
区分大小写的字符串比较,只比较前n个字符。
区分大小写的不带长度的字符串比较。
ngx_int_t ngx_strcasecmp(u_char *s1, u_char *s2); |
不区分大小写的不带长度的字符串比较。
ngx_int_t ngx_strncasecmp(u_char *s1, u_char *s2, size_t n); |
不区分大小写的带长度的字符串比较,只比较前n个字符。
u_char * ngx_cdecl ngx_sprintf(u_char *buf, const char *fmt, ...);
u_char * ngx_cdecl ngx_snprintf(u_char *buf, size_t max, const char *fmt, ...);
u_char * ngx_cdecl ngx_slprintf(u_char *buf, u_char *last, const char *fmt, ...); |
上面这三个函数用于字符串格式化,ngx_snprintf的第二个参数max指明buf的空间大小,ngx_slprintf则通过last来指明buf空间的大小。推荐使用第二个或第三个函数来格式化字符串,ngx_sprintf函数还是比较危险的,容易产生缓冲区溢出漏洞。在这一系列函数中,nginx在兼容glibc中格式化字符串的形式之外,还添加了一些方便格式化nginx类型的一些转义字符,比如%V用于格式化ngx_str_t结构。在nginx源文件的ngx_string.c中有说明:
/*
* supported formats:
* %[0][width][x][X]O off_t
* %[0][width]T time_t
* %[0][width][u][x|X]z ssize_t/size_t
* %[0][width][u][x|X]d int/u_int
* %[0][width][u][x|X]l long
* %[0][width|m][u][x|X]i ngx_int_t/ngx_uint_t
* %[0][width][u][x|X]D int32_t/uint32_t
* %[0][width][u][x|X]L int64_t/uint64_t
* %[0][width|m][u][x|X]A ngx_atomic_int_t/ngx_atomic_uint_t
* %[0][width][.width]f double, max valid number fits to %18.15f
* %P ngx_pid_t
* %M ngx_msec_t
* %r rlim_t
* %p void *
* %V ngx_str_t *
* %v ngx_variable_value_t *
* %s null-terminated string
* %*s length and string
* %Z '\0'
* %N '\n'
* %c char
* %% %
*
* reserved:
* %t ptrdiff_t
* %S null-terminated wchar string
* %C wchar
*/ |
这里特别要提醒的是,我们最常用于格式化ngx_str_t结构,其对应的转义符是%V,传给函数的一定要是指针类型,否则程序就会coredump掉。这也是我们最容易犯的错。比如:
ngx_str_t str = ngx_string("hello world");
char buffer[1024];
ngx_snprintf(buffer, 1024, "%V", &str); // 注意,str取地址
|
这两个函数用于对str进行base64编码与解码,调用前,需要保证dst中有足够的空间来存放结果,如果不知道具体大小,可先调用ngx_base64_encoded_length与ngx_base64_decoded_length来预估最大占用空间。
void ngx_encode_base64(ngx_str_t *dst, ngx_str_t *src);
ngx_int_t ngx_decode_base64(ngx_str_t *dst, ngx_str_t *src); |
对src进行编码,根据type来按不同的方式进行编码,如果dst为NULL,则返回需要转义的字符的数量,由此可得到需要的空间大小。type的类型可以是:
uintptr_t ngx_escape_uri(u_char *dst, u_char *src, size_t size,
ngx_uint_t type); |
#define NGX_ESCAPE_URI 0
#define NGX_ESCAPE_ARGS 1
#define NGX_ESCAPE_HTML 2
#define NGX_ESCAPE_REFRESH 3
#define NGX_ESCAPE_MEMCACHED 4
#define NGX_ESCAPE_MAIL_AUTH 5
|
对src进行反编码,type可以是0、NGX_UNESCAPE_URI、NGX_UNESCAPE_REDIRECT这三个值。如果是0,则表示src中的所有字符都要进行转码。如果是NGX_UNESCAPE_URI与NGX_UNESCAPE_REDIRECT,则遇到’?’后就结束了,后面的字符就不管了。而NGX_UNESCAPE_URI与NGX_UNESCAPE_REDIRECT之间的区别是NGX_UNESCAPE_URI对于遇到的需要转码的字符,都会转码,而NGX_UNESCAPE_REDIRECT则只会对非可见字符进行转码。
void ngx_unescape_uri(u_char **dst, u_char **src, size_t size, ngx_uint_t type); |
对src进行反编码,type可以是0、NGX_UNESCAPE_URI、NGX_UNESCAPE_REDIRECT这三个值。如果是0,则表示src中的所有字符都要进行转码。如果是NGX_UNESCAPE_URI与NGX_UNESCAPE_REDIRECT,则遇到’?’后就结束了,后面的字符就不管了。而NGX_UNESCAPE_URI与NGX_UNESCAPE_REDIRECT之间的区别是NGX_UNESCAPE_URI对于遇到的需要转码的字符,都会转码,而NGX_UNESCAPE_REDIRECT则只会对非可见字符进行转码。
uintptr_t ngx_escape_html(u_char *dst, u_char *src, size_t size); |
对html标签进行编码。
当然,我这里只介绍了一些常用的api的使用,大家可以先熟悉一下,在实际使用过程中,遇到不明白的,最快最直接的方法就是去看源码,看api的实现或看nginx自身调用api的地方是怎么做的,代码就是最好的文档。
|






